



1. Introduction
In the novella Story of Your Life (adapted into the motion picture Arrival) the writer Ted Chiang (Reference Chiang2016) imagines a species of aliens with rather strange habits of communication. The aliens produce a variety of grunts and cries unintelligible to humans, but their main mode of expression seems to consist of images. They use their tentacles to produce large circular inkblots arranged into patterns. This language baffles the linguist sent to initiate contact with the aliens, because the inkblots do not resemble any known human communication system. Unlike spoken language, the aliens' inkblots engage vision, not hearing. Unlike sign language, they are static, allowing the linguist to store them as photographs. And unlike human writing, the inkblots can be deciphered on their own: They do not bear any relation with the aliens' grunts and cries. This, the linguist notices, is exceedingly rare. Permanent images can be used for communication in many human cultures, but they usually fail to reach the degree of sophistication of a full-blown language. Whenever they do reach it, that is because permanent images are being used to encode a spoken language. The way the aliens communicate visually is puzzling.
Most linguists today would agree. And yet the aliens' visual language, or at least the possibility of it, would not have seemed so odd to a linguist from a different era. The notion of a complete language consisting entirely of images referring directly to ideas without encoding words was until fairly recently a commonplace. Western philosophers such as Leibniz or Bacon were convinced that Chinese characters or Egyptian hieroglyphs were ideographic (Rossi, Reference Rossi2000). That is, the meanings they encoded were thought to be understood directly by anyone literate in these symbols, even without knowing the Egyptian or Chinese language. This misconception has long been dispelled. Egyptian, Chinese, and Mayan, among other writing systems formerly assumed to be ideographic, have been shown to encode a natural, spoken language (if only among other things). Parallel to this, numerous attempts at building a universal ideography have failed. These ideographic languages proved exceedingly difficult to use for anyone, including their makers. John Wilkins's “philosophical language,” Charles Bliss's Bliss symbolic, or Otto Neurath's picture language are the most famous examples (Lin & Biggs, Reference Lin and Biggs2006; Rossi, Reference Rossi2000). These multiple failures resulted in the widespread linguistic intuition, echoed in Chiang's short story, that full-blown ideographies are impossible.
Why? There would be, after all, many benefits to mastering an ideographic language. Such a system could exploit the iconicity of pictures to make the symbols' meanings more intuitive and easier to remember. It could transmit information across timespans and across space, which neither spoken nor signed language can do (unless backed by modern technology or by writing). It could break language barriers.
This is the puzzle of ideography: A uniquely rich mode of communication that most cultures seem to avoid.
In the evolution of communication, ideography is the road not traveled. If we can understand why, we will be in a better position to understand why writing evolved in the way that it did. Literacy is widely recognized as an epochal invention – arguably the most important technological innovation since stone tools (Coulmas, Reference Coulmas2003; Goody, Reference Goody1977; Morris, Reference Morris2014). With a powerful graphic code like writing, modes of communication that were hardly possible – direct communication with distant people, with entirely unknown strangers, with dead people – can become routine (Morin, Kelly, & Winters, Reference Morin, Kelly and Winters2020). No serious account of cultural evolution can bypass it. But the first thing we notice when studying writing is how peculiar it is. Here is a mode of communication that seems to work almost entirely by parasitizing another mode of communication – spoken language.
One might think entire fields of research would be fighting to explain the puzzle of ideography. Instead, more energy has been spent on explaining the puzzle away. The first way to do this is to trivialize the puzzle: Writing cannot be ideographic, but that is simply a matter of definition, or it is because of some basic and obvious inability to think or communicate with pictures. The second way is to deny there is a puzzle: Ideographic writing exists, in the shape of emojis, Chinese characters, Bliss symbolics, pictographic symbols, and so on. The puzzle, I will argue, will not disappear in either fashion. But progress on a number of issues will be thwarted as long as the puzzle stands in the way. Solving the puzzle can help us trace the boundaries of human communication: It is clear today that we can express ourselves in many ways that language, narrowly construed, does not capture: Gestures, art, music, and so on (Heintz & Scott-Phillips, Reference Heintz and Scott-Phillips2022; Schlenker, Reference Schlenker2018; Wharton, Reference Wharton2009). But how far can communication go without language? Studying ideography can answer this.
Ideography can also teach us about the human brain's difficulties in dealing with visual codes such as writing. Our brains' visual areas can be recycled to process letter shapes by repurposing hardwired circuits that evolved to treat other stimuli (Dehaene, Reference Dehaene2010; Dehaene & Cohen, Reference Dehaene and Cohen2007), helped by the fact that letter shapes are optimized to fit our visual brains' native constraints (Changizi, Zhang, Ye, & Shimojo, Reference Changizi, Zhang, Ye and Shimojo2006; Kelly, Winters, Miton, & Morin, Reference Kelly, Winters, Miton and Morin2021; Morin, Reference Morin2018). In spite of the flexibility of human neural and cultural resources, learning to read never became as natural as learning to speak, and remains a tall order for around 5% of the schooled population (Ramus, Reference Ramus and Gazzania2004; Wagner et al., Reference Wagner, Zirps, Edwards, Wood, Joyner, Becker and Beal2020). Even for proficient literates, spoken or signed conversation remains much easier than reading or writing (Garrod & Pickering, Reference Garrod and Pickering2004); the failure of ideography is another aspect of this struggle to master graphic codes.
Last but not least, understanding why ideography has not worked in the past may help us understand how technology could make it work in the future.
This paper pursues two related goals. It grounds and specifies the widespread intuition that ideographies, that is to say, general-purpose codes made of symbols that do not encode words, are extremely rare; and it explains this rarity.
Section 2 defines graphic codes, which are ways of encoding information with lasting inscriptions. It describes how these codes differ from spoken or signed languages, and argues that it is not helpful to think of graphic codes as languages. The next section (sect. 3) distinguishes writing, a graphic code that primarily encodes components of spoken languages, from ideography, which does not (graphic notations of sign languages do exist, but are culturally less significant). It has often been claimed that writing simply cannot be ideographic, either by definition or as a matter of fact.
Section 4 unpacks this widespread intuition and argues in favor of the “specialization hypothesis”: The view that any graphic code that can be used in a self-sufficient way (not just as a memory prop) happens to be, at heart, a narrowly specialized notation. This applies to writing itself which, under this account, rests on an encoding of language.
Why do we not find graphic codes that are both self-sufficient and generalist? Section 5 considers two answers. One, the “learning account,” is based on the notion that graphic codes are much harder to learn than spoken languages, because of a cognitive specialization for language acquisition. I argue against this account and I propose another solution in section 6. The “standardization account” considers that graphic codes may not be much harder to learn than spoken languages, but are instead considerably more difficult to standardize. To standardize a code is to ensure that all its users ascribe the same meanings to the same symbols. Spoken or signed languages are self-standardizing because they are based on cheap, fast, and transient signals, which allow for easy online repairing of miscommunication, and which constrain interlocutors to communicate in face-to-face interactions where the advantages of common ground are maximized. Being easier to standardize, spoken or signed languages have a “lock-in” effect on the evolution of other codes. This, I argue, solves the puzzle of ideography.
2. Languages are codes, but not every code is a language
This paper uses the words “code” and “language” in a rather restrictive way. There is a tendency, inherited from the semiotics research tradition, to use these two terms loosely and interchangeably, as referring to any means of expression that carries information: Paintings (Panofsky, Reference Panofsky1939), comic books (Cohn, Reference Cohn2013), and so on. For the sake of this argument, different terminological choices were made.
A code is a set of conventional associations between meaning and signals (de Saussure, Reference de Saussure2011; Scott-Phillips, Reference Scott-Phillips2014). Musical notations, road signs, writing systems, and so on are codes in this sense, and so are languages like Swahili, French, and so on. Means of expression that do not mostly rely on conventional signals do not qualify as codes. In particular those may be pictures, schemas, maps, and other forms of graphic communication that rely chiefly on the visual resemblance between graphic shapes and the things they refer to. Graphic communication interests us here only insofar as it relies on a code.
What is so special about codes? They make communication more efficient (Kirby, Tamariz, Cornish, & Smith, Reference Kirby, Tamariz, Cornish and Smith2015; Regier, Kemp, & Kay, Reference Regier, Kemp, Kay, MacWhinney and O'Grady2015; Scott-Phillips, Reference Scott-Phillips2014; Winters & Morin, Reference Winters and Morin2019). Codes allow us to compress a long or complex message into a small number of symbols. A code works by relying on memorized associations between symbols and their meanings. Once the association is in place in someone's mind, the meaning can simply be triggered with the relevant symbol. It does not have to be explained again. As a result, conventional graphic symbols can afford to be much simpler than nonconventionalized ones.
This was shown elegantly in a series of experiments by Garrod, Fay, Lee, Oberlander, and MacLeod (Reference Garrod, Fay, Lee, Oberlander and MacLeod2007), where participants engage in a Pictionary-style task repeatedly for the same referents. Two things happened. One is partial conventionalization: Drawings for referents such as “Opera” or “Brad Pitt” become standardized inside the group and increasingly difficult for outsiders to understand. The other is a clear simplification of the pictures. Of course, this process, taking an hour or so of experimental time, only approximates the history of real-life graphic conventions, but it captures their essential features: Graphic conventions are signal–meaning pairings that need to be learnt from the group that gave them their meaning. These can be used to compress complex messages into a few simpler shapes. Codification is the standardization of pairings between meanings and signals, making a mode of communication more efficient by making messages more compressible (Winters, Kirby, & Smith, Reference Winters, Kirby and Smith2018; Winters & Morin, Reference Winters and Morin2019).
2.1. Not all forms of expression are codified
In theory, codification is a matter of degree. In the experiments just cited, the pairings between signals and symbols progressively become simplified and conventional, so that the associated meanings become increasingly opaque to outsiders who have not had access to previous steps. This is a gradual process, and an incomplete one: Many signals retain an iconic resemblance with their referents and are sometimes still transparent enough that their meaning can be accessed directly by outsiders. Familiarity with the previous steps of the game is a facilitator, not a requirement (Caldwell & Smith, Reference Caldwell and Smith2012; Granito, Tehrani, Kendal, & Scott-Phillips, Reference Granito, Tehrani, Kendal and Scott-Phillips2019). In that sense, conventionality can be partial.
It would be tempting to go one step further and assert that conventionality is a smooth continuum, to such an extent that any sharp distinction between conventional graphic codes (like writing systems) and nonconventional graphic expression (like artistic drawings) is bound to be moot. Two main arguments support this view, neither of them as convincing as they appear to be.
The first argument rests on the view that the visual arts make use of codified cultural conventions. This is well established (Cohn, Reference Cohn2013; Panofsky, Reference Panofsky1939). An excellent case for the cultural conventionality of pictures was made by Neil Cohn in his study of comic books focusing on the contrast between Euro-American comics and Japanese manga (Cohn, Reference Cohn2013). Cohn shows convincingly that important aspects of Japanese graphic culture are akin to codes. One must learn them in order to understand mangas. In Cohn's view, the degree of codification of comics allows us to treat the distinct conventions of particular cultures as full-blown “visual languages.” The phrase makes sense in the context of Cohn's study, but there are good reasons to resist it in general. Comic book drawings are not a language in the same sense that spoken or written Japanese or English are languages. The degree of conventionality is vastly lower for comic book drawings compared to languages. To see why, consider the amount of effort and time required to learn Japanese or English compared to the amount of learning involved in understanding the visual language of manga, or simply the fact that manga drawings require no translation, while their written text does.Footnote 1
While the first argument emphasizes the conventionality of drawings, the second argument in favor of blurring the distinction between codes and noncodes highlights the iconic aspect of graphic codes and writing in particular. Iconicity is a multifaceted notion, but for the purposes of this argument, only one sense of it really matters: The capacity to know the meaning of a sign directly, without the preexisting knowledge of a code.
Iconicity in this sense should be distinguished from three related observations.
First, the fact that characters in some writing systems are figurative shapes – pictures of recognizable objects – does not make the system iconic. Indeed, figurative shapes may be quite unrelated to their coded meaning. Egyptian or Mayan hieroglyphics are a case in point. Even though many of these symbols are figurative depictions, their meaning is often quite different from what their iconic shape suggests. Their meaning is also coded: A naïve reader cannot make sense of them based on shape alone. No real progress was made in deciphering these writing systems as long as scholars assumed they could be read iconically (Pope, Reference Pope1999).
The second observation is different. In some writing systems, there are symbols that were originally iconic, lost this quality with time, but kept traces of it – traces that can be deciphered with a bit of erudition. This is, famously, the case for many Chinese characters. In most cases, however, the pictographic meaning has become unrecognizable to an untrained eye, and the sign has acquired phonetic or morphemic values that cannot be retrieved directly from a picture.
The third and last form of iconicity is suggested by recent work on sound symbolism in letters (Turoman & Styles, Reference Turoman and Styles2017). This work suggests that letter shapes are not unrelated to sound shapes (Jee, Tamariz, & Shillcock, Reference Jee, Tamariz and Shillcock2022), so that naïve subjects are better than chance at identifying which letters stand for the sounds /i/ or /u/, in unknown writing systems. If confirmed, such findings would show that the pairings between sounds and shapes that make up writing systems are not entirely arbitrary and possess limited iconicity. Still, there is a vast difference between the kind of above-chance guessing that these studies are interested in and the near-certain decoding that a fluent reader routinely achieves.
Thus, a few interesting boundary cases notwithstanding the distinction between graphic codes and noncoded means of expression (such as pictures) remains a crucial one. Codification is, in theory, a matter of degree: Some conventions are easily learnt with just a little familiarization, others cannot be deciphered without a hard-won knowledge of precise conventional pairings between symbols and meanings. In the case of graphic codes, the difference of degree between full-blown codes, like writing systems, and vaguely conventional graphic expression, like art, is vast enough to justify placing a clear boundary between codes and noncodes (Fig. 1).
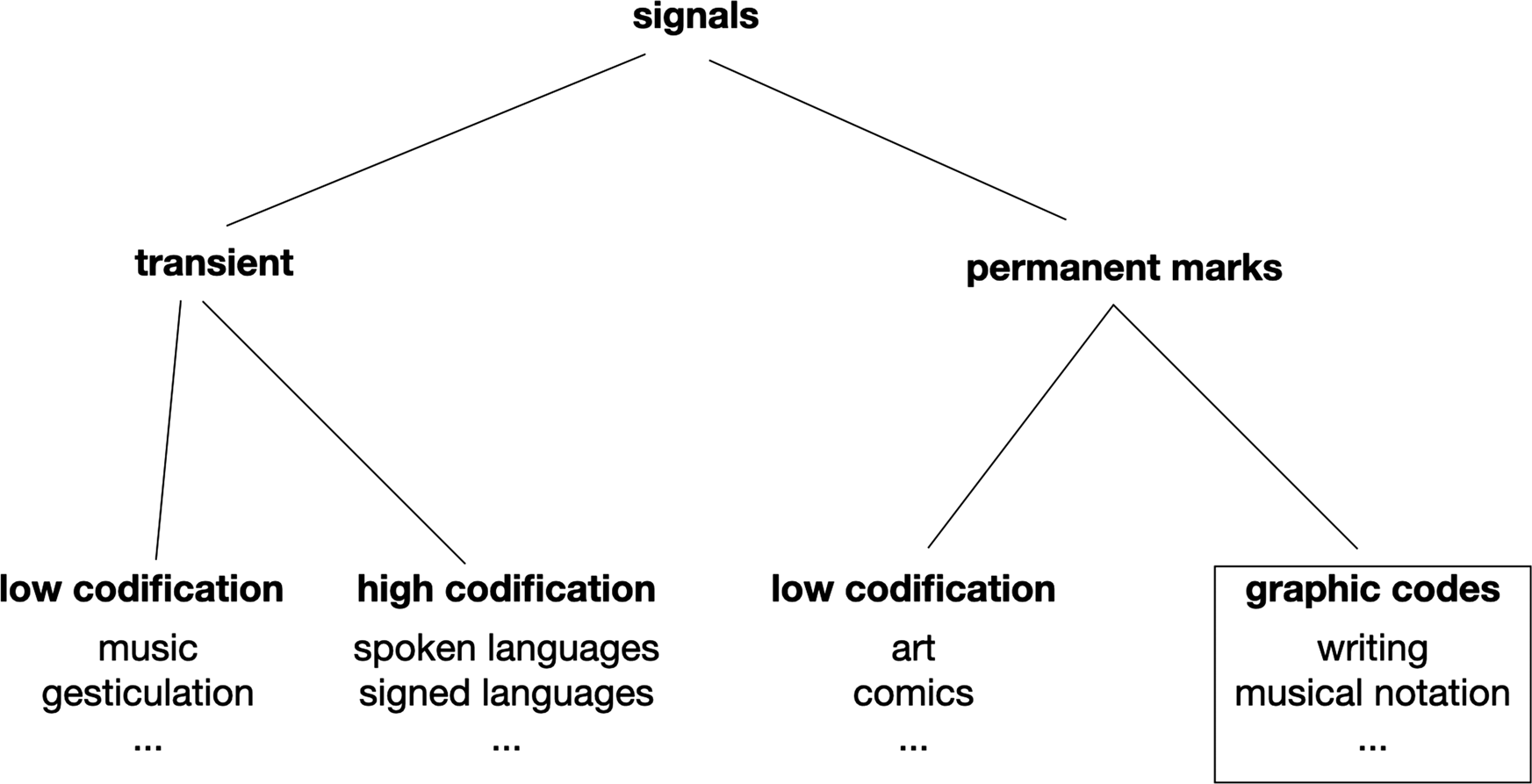
Figure 1. Place of graphic codes in human communication.
If schemas, maps, comics, or paintings are not full-blown codes in the sense used here, it makes even less sense to call them “visual languages.” In fact, the term “language” will be reserved here for spoken languages like Swahili, German, and so on, or signed languages like British Sign Language. Once again, this terminological choice is debatable. Some highly stimulating research is based on the premise that a wide variety of means of expression – diagrams, gestures, music, and so on – can be studied with the tools of the linguist (Schlenker, Reference Schlenker2018). Without disputing this point, I find it convenient to reserve the term “language” for means of expression that are clearly codified, generalist, and self-sufficient.Footnote 2 This section explained what I mean by codification; the next one turns to generality and self-sufficiency.
2.2. Languages are uniquely generalist and self-sufficient
Consider musical or mathematical notations. These are fully codified graphic codes: They pair conventional graphic symbols with precise concepts (musical or mathematical). It has been noted (e.g., by Casati, Reference Casati and Zaibert2016; McCawley, Reference McCawley, Downing, Lima and Noonan1992) that these codes resemble language in many ways: They carry meaning, they combine a small number of symbols to generate messages, combinations of symbols obey syntactic rules, and so on. Why not count them as languages?
For the same reasons that I resist an overly extensive understanding of codes, the word “language” will only be used here to refer to spoken or signed languages in the everyday sense. This stresses the fact that languages possess unique properties. They are rich and complex codes, understood as conventional pairings of signals and meanings. Other rich and complex codes exist, but languages deserve to be singled out, being uniquely strong on two dimensions: Self-sufficiency and generality.
2.2.1. Self-sufficiency
A code is self-sufficient if we can use it to communicate with one another, without recourse to another type of code. Many codes share this property, from smoke signals to musical notations. Self-sufficiency is about usage, not acquisition: A code usually needs to be learnt linguistically before it can be used; but once fluent in the use of musical notations or smoke signals, a user may communicate without the help of auxiliary codes. This is not possible with codes lacking self-sufficiency. Few people claim to master Bliss symbolics to the point where they could produce and decipher symbols without constantly referring to a dictionary (i.e., to a linguistic gloss of Bliss's code). The fact that Bliss symbolics found its only niche as a teaching tool for children with special educational needs underscores this point (Sevcik, Barton-Hulsey, Romski, & Hyatt Fonseca, Reference Sevcik, Barton-Hulsey, Romski and Hyatt Fonseca2018; Sevcik, Romski, & Wilkinson, Reference Sevcik, Romski and Wilkinson1991): The ideographic code is used to make better sense of written or spoken language.
Language is self-sufficient in the sense that two people can communicate using a linguistic code and nothing else. Linguistic communication does not work in a vacuum, to be sure. It is backed by the common ground that interlocutors share; it can be complemented with gestures (some codified, some not). Some forms of linguistic exchange gain in clarity with the help of specialized codes (think of a scientific presentation in physics or mathematics). But even if we block all the side channels we use to pass information across (gestures, pauses, sighs, etc.), the linguistic code suffices to communicate a great deal. This is clearly not because all linguistic expression is immediately obvious and transparent – we regularly encounter rare or novel phrases whose opaque meaning needs unpacking, or translating. But in such cases the gloss can be given in spoken language,Footnote 3 thanks to the reflexive nature of language – its capacity to talk about itself (Taylor, Reference Taylor2000). In that sense, language is both self-sufficient and self-decoding.
2.2.2. Generality
A code is general if it can be used to encode information across a wide range of domains. Mathematical or musical notations are not general in this sense, but language is. “Generality” here is equivalent to what Liberman (Reference Liberman, Frost and Katz1992) called “openness” (see also DeFrancis's, Reference DeFrancis1989, distinction between full and partial writing). I endorse his claim that languages are uniquely open:
Spoken language has the critically important property of “openness”: unlike nonhuman systems of communication, speech is capable of expressing and conveying an indefinitely numerous variety of messages. A script can share this property, but only to the extent that it somehow transcribes its spoken-language base. (Liberman, Reference Liberman, Frost and Katz1992, p. 120)
Liberman's second sentence considers the possibility that writing systems could also qualify as generalist (or “open”) codes. His answer, which I will endorse and develop, is that they can – but only to the extent that a writing system encodes a language. The generality of writing is vicarious, derived from the language that it encodes. This classical view (Aristotle, Reference Cajetan and Oesterle1962 (ed.)) considers writing to be a meta-code, a higher-level code that encodes another, more basic code. The first-level code is language, which associates meanings with spoken or signed symbols. Writing, made possible by the reflexive nature of language (Taylor, Reference Taylor2000), relies on our capacity to name and classify linguistic objects (and also improves upon it; Olson, Reference Olson, Olson and Torrance1991). It is the meta-level code that associates graphic symbols with the spoken or signed symbols of a language. It does not usually encode meanings directly, but does so by encoding spoken or signed symbols.
To say that writing encodes ideas only indirectly by encoding language is to oppose writing to ideography. But what exactly is ideography?
3. Ideography and writing, contrasted
3.1. What is ideography?
Ideographic symbols can be directly associated with a concept by a reader acquainted with the sign's meaning (following Coulmas, Reference Coulmas1996a, p. 309). Examples in use in English writing include Arabic numerals (1, 2, 3, 4,…), as well as conventional symbols such as £, ±, ☺, ℃, ©, &, and so on. These symbols can be verbalized differently in several entirely distinct languages, and they contain no clue to their pronunciation in any of these languages. They are “translinguistic” (Chrisomalis, Reference Chrisomalis2020). For this reason, such symbols can be said to encode ideas directly. Ideographic symbols are not necessarily pictographic or iconic. Some of them are (consider the Chinese numerals 一, 二, 三) but in general they need not resemble in any way the idea that they refer to, and their association with their referent can be entirely conventional (consider the signs “$” or “+”).
Most ideographs can be verbalized, but not read: They do not encode linguistic information. Although ideographic symbols do not tell readers how to verbalize them in a given language, a competent speaker can, of course, match them with the corresponding words in her language. A Spanish reader can verbalize “1, 2, 3” as “uno, dos, tres,” even though the ideographs do not provide her with any clue concerning the pronunciation of these words. The ![]() symbol can be verbalized as “love,” “heart,” “lots of love,” “I love you,” and so on, depending on context.
symbol can be verbalized as “love,” “heart,” “lots of love,” “I love you,” and so on, depending on context.
This property has been used to back the claim that ideographs indeed do encode words, but do so indirectly (Boltz, Reference Boltz1993; Taylor, Taylor, & Taylor, Reference Taylor, Taylor and Taylor1995). In an extreme version of this claim, Boltz argued that early Chinese pictographs (before the emergence of Chinese writing proper) were already representing the Chinese language of the time, because they could be verbalized in Chinese in various ways, even though they did not stand for specific individual words. This view should be resisted (Coulmas, Reference Coulmas, Gunther and Ludwig1996b; Hyman, Reference Hyman2006), because it blurs the distinction between those symbols that contain cues concerning the pronunciation of a word in a language and those that do not. A symbol like “9” that can be verbalized in a multitude of languages (as “nine,” “nueve,” “kilenc,” or possibly “ninth” or “noveno,” etc.) is not the same thing as a symbol that can be read (Hyman, Reference Hyman2006). The string of letters “nueve” can be read and it means /nweβe/, a specific spoken Spanish word. Unlike “9,” it cannot encode the words “nine,” “ninth,” “noveno,” or “kilenc.” Hence, ideographs as defined here do not encode language words simply because they can be verbalized.
Use of the rebus principle is not sufficient to make ideographic symbols glottographic. Many ideographs still intuitively match one or a few spoken words in most languages in relatively straightforward ways. This property is of no small historical importance. Thanks to the rebus principle (e.g., “![]() ” = eye/can/reed = “I can read”), ideographic symbols can be made to represent phonemes. Rebus-based encodings of words are not rare, and played a key role in the emergence of glottography (Valério & Ferrara, Reference Valério and Ferrara2019). Glottography will be defined later; it is, in short, the fact that writing, as a code, represents language. Is rebus sufficient to make a graphic code glottographic? Not if its use is neither systematic nor standardized. A series of haphazard rebus or visual puns does not amount to a systematic encoding of a language. European heraldry is a good example of a code that made frequent use of the rebus principle, but remained ideographic at heart (Pastoureau, Reference Pastoureau2007). Heraldic symbols (coats of arms), used as emblems by families or institutions, were purely ideographic most of the time, for instance symbolizing the Kingdom of Prussia with a black eagle. However, some arms (“canting arms”) used the rebus principle to encode proper names (or parts thereof): The arms of Castile and León feature a castle and a lion, the arms of Berlin, a bear. But this practice was neither systematic nor standardized: Depending on the country, the arms, or the viewer, a bear could encode the corresponding sound, but it could just as well be simply a picture of a bear devoid of phonetic meaning. Neither were rebus-based encodings standardized: The sound /beə(r)/ could be encoded by one bear or by three, or by another image with the same phonetic value.
” = eye/can/reed = “I can read”), ideographic symbols can be made to represent phonemes. Rebus-based encodings of words are not rare, and played a key role in the emergence of glottography (Valério & Ferrara, Reference Valério and Ferrara2019). Glottography will be defined later; it is, in short, the fact that writing, as a code, represents language. Is rebus sufficient to make a graphic code glottographic? Not if its use is neither systematic nor standardized. A series of haphazard rebus or visual puns does not amount to a systematic encoding of a language. European heraldry is a good example of a code that made frequent use of the rebus principle, but remained ideographic at heart (Pastoureau, Reference Pastoureau2007). Heraldic symbols (coats of arms), used as emblems by families or institutions, were purely ideographic most of the time, for instance symbolizing the Kingdom of Prussia with a black eagle. However, some arms (“canting arms”) used the rebus principle to encode proper names (or parts thereof): The arms of Castile and León feature a castle and a lion, the arms of Berlin, a bear. But this practice was neither systematic nor standardized: Depending on the country, the arms, or the viewer, a bear could encode the corresponding sound, but it could just as well be simply a picture of a bear devoid of phonetic meaning. Neither were rebus-based encodings standardized: The sound /beə(r)/ could be encoded by one bear or by three, or by another image with the same phonetic value.
Ideographic symbols thus can be defined as symbols whose standardized and coded meaning does not include linguistic information. They may be used to convey such information indirectly (for instance, through the rebus principle), but in order to get that information, recipients need to possess linguistic knowledge (e.g., the sound of the German word Bär) that is not encoded by the symbol.
An ideographic graphic code (also known as “semasiography” – Boone & Mignolo, Reference Boone and Mignolo1994; Croft, Reference Croft, Coupé, Pellegrino and Mufwene2017; Gelb, Reference Gelb1963) is simply a set of ideographic symbols used in conjunction with each other. Examples include mathematical or musical notations, some shamanistic pictographic notations (e.g., Severi, Reference Severi2012), heraldic emblems, commodity brands (Wengrow, Reference Wengrow2008), formal logic, among others. These systems of symbols may be used by people who do not share a common language. Contrary to what has sometimes been claimed (e.g., Boltz, Reference Boltz1993; du Ponceau, Reference du Ponceau1838; Hill, Reference Hill and Austin1967), such systems are neither impossible, nor are they contradictions in terms. Countless ideographic codes existed long before and after the rise of writing (Lock & Gers, Reference Lock, Gers, Grigorenko, Mambrino and Preiss2012), ranging from tallies, property marks, and tokens to pictographic stories like Winter Counts (Mallery, Reference Mallery1886) or Aztec codices (Boone, Reference Boone, Boone and Mignolo1994) that recounted sequences of events using images.
3.2. A generality/self-sufficiency trade-off
Section 2.2 argued that, of all the codes we can use for communication, languages (spoken or signed) stand out for being both self-sufficient (they can be used on their own without resorting to an auxiliary code to gloss each message) and generalist (they can be used to talk about an indefinite variety of topics). I argued that this combination of self-sufficiency and generality was unique to language, putting aside writing as a possible exception that nonetheless seems intricately tied to language. This section and the next detail this claim. This section explores the trade-off between generality and self-sufficiency: Very few graphic codes seem capable of combining these two properties. The main exception seems to be writing, which the next section introduces.
Figure 2 classifies the codes we use for communication (leaving out writing for the moment) along two dimensions: Self-sufficiency and specialization. Most of the graphic codes you and I are familiar with are specialized: This includes mathematical or musical symbols, counting tools, and so on. The symbols in specialized codes may (for some codes) be combined productively according to clear and well-standardized rules to yield vast numbers of possible messages.

Figure 2. Typology of graphic codes, illustrating the trade-off between specialization and self-sufficiency that graphic codes face. Writing has been left out: The question whether it is specialized or generalist is answered in section 4.
In spite of this, these codes remain limited in the range of topics they can tackle. Some serve but one narrow function and are strictly circumscribed to one domain: To record measurements, to encode music, to make a population census, to record a debt, to serve as emblems for families, and so on. Others are apparently more versatile – for instance the international airport signs for “toilets,” “wifi,” “luggage,” and so on – but the number of symbols they contain is too limited to allow them to serve as a generalist code. Graphic codes are not the only kind of code to be limited by specialization: Some gestured languages are similarly restricted in their use – for instance, the specialized sign languages used by hunters (Mohr, Reference Mohr, Bakken Jepsen, De Clerck, Lutalo-Kingii and McGregor2015) when they must be silent, or by workers in noisy environments (Meissner, Philpott, & Philpott, Reference Meissner, Philpott and Philpott1975).
Specialist codes differ in how self-sufficient they can be. If a code is self-sufficient, a proficient user does not need an oral gloss to understand every message. An oral gloss is usually needed to learn the code, but not to use it. Mathematical or musical notations may be read in the same way that one reads print; today's most important corporate brands are recognizable without intermediates (linguistic or otherwise). Heraldic emblems could be recognized without being glossed (although large gatherings required arms to be glossed by professional heralds, often with the help of specialized directories).
A clear example of a family of specialized codes lacking self-sufficiency is provided by the early history of musical notations, as studied by Croft (Reference Croft, Coupé, Pellegrino and Mufwene2017). The earliest known inscriptions that provide instructions for the performance of a musical piece (for instance, Babylonian lyre or harp notations) are exceedingly hard to interpret, because they require implicit knowledge of the musical piece that is not encoded – the tune's rhythm, for instance. The ancestors of modern Western notations, staffless neumes, were also lacunar, leading specialists to argue that they served as mnemonic tools for melodies that were orally transmitted. These early musical notations were neither self-sufficient nor generalist. In time, they evolved to become self-sufficient, but remained narrowly specialized.
If we switch to the second column of the table, to generalist codes, we find that the vast majority of generalist graphic codes rely on an oral gloss to function. Australian message sticks, for instance, were sophisticated ideographic messages that could communicate information on a wide range of topics, as long as the messenger stood by to translate the code. Although message sticks were occasionally sent through the mail with no accompanying gloss (Kelly, Reference Kelly2019), this was not at all their typical use. Message sticks, in other words, are not self-sufficient codes: Most of the information they impart is not entirely encoded in the graphic message, which serves instead as a mnemonic prop. The same has been said for the pictographs used in recitation of shamanistic chants, for instance those of Cuna shamans studied by Severi (Reference Severi2012, Reference Severi2019), or for sand drawings as used in several Pacific societies (Green, Reference Green2007; Zagala, Reference Zagala2004). Such codes are generalist, in the sense that the scope of all the things one may refer to using the code is rather broad; but they lack self-sufficiency.
Could we find an ideographic code that is both generalist and self-sufficient? At this stage of my argument, I have no theoretical reasons to deny this. In practice, however, examples do not come easily. One of the clearest cases (that I know of) is Nsibidi pictographs, a system of symbols in use in the Cross River region of Nigeria (Battestini, Reference Battestini and Battestini2006; Dayrell, Reference Dayrell1911; Griaule & Dieterlen, Reference Griaule and Dieterlen1951; Macgregor, Reference Macgregor1909). Nsibidi symbols, the preserve of a secret society (at least initially), can be gestured or inscribed; when inscribed, they can carry simple messages that recipients can understand without an oral gloss. How far the range of expression of these symbols goes is difficult to determine, given the secrecy that surrounds them. One clear limitation comes from the fact that many symbols are inaccessible below a certain level of initiation. Other examples are few and far between, with one obvious exception: Writing.
3.3. Defining writing
Writing is a versatile code, capable of encoding information on a broad range of content, and it can be used in a self-sufficient way – as you and I are using it now – to convey information across time and space without the help of an oral gloss. But how do we define writing? There are countless definitions. Some are so broad that they encompass anything that I call here a graphic code: That is what Gelb's definition does (writing is “a system of human intercommunication by means of conventional visible marks” – Gelb, Reference Gelb1963). But most definitions of writing oppose it to ideography (e.g., Coulmas, Reference Coulmas2003; Daniels & Bright, Reference Daniels and Bright1996; DeFrancis, Reference DeFrancis1989). For those authors, writing is at heart a notation of language, even if it is only partially a notation of language.
Should we care? Definitions are cheap: Saying that writing encodes language because that is how we define it cuts little ice. Yet in this case scholarly conventions harbor an empirical truth that is anything but trivial. In the next section, I will argue that most and perhaps all self-sufficient and general-purpose graphic codes used by humans are notations of a language. This empirical claim is part of what I call the specialization hypothesis.
4. The specialization hypothesis
This hypothesis, in its most general form, claims that all self-sufficient and well-standardized graphic codes, including writing systems, are highly specialized notations. Unlike languages, which can encode all sorts of thoughts, self-sufficient and standardized graphic codes specialize in one or a few specific types of information: Numbers, logical connectors, personal emblems, the sounds of a language, and so on. The most important consequence of the specialization hypothesis is that writing systems, the most powerful and widespread of graphic codes, are specialized notations in spite of the wide range of uses they can be put to. A writing system, in this view, is at heart a specialized notation of a language. The generalist scope of writing systems is derivative: They inherit their versatility from the language that they encode. As a code, writing is narrowly specialized: Merely a notation of morphemes, syllables, or phonemes. One proof that writing is not actually a generalist code is given by liturgical or religious texts, which can be learnt and read by people who do not understand the target language (see, e.g., the Quranic recitations described by Scribner & Cole, Reference Scribner and Cole1981). These reciters know the writing system and the phonology that it encodes, but not the underlying language.
The specialization hypothesis differs from standard language-centric views of writing in a number of ways. The view that writing is mainly an encoding of spoken language is quite commonplace, dating back to Aristotle at least (Aristotle, Reference Cajetan and Oesterle1962 (ed.); de Saussure, Reference de Saussure2011), but this classical formulation was only a definition, not a strong empirical claim. Saussure's position on this matter is representative: While treating writing exclusively as a representation of spoken language, he also believed that purely ideographic forms of writing existed (e.g., Chinese characters). The specialization hypothesis is stronger. It casts doubt on the existence of any self-sufficient, generalist ideography.
In this respect, the specialization hypothesis agrees with the language-centric views of writing put forward by critiques of the ideographic interpretation of Chinese or Egyptian writing (e.g., DeFrancis, Reference DeFrancis1989; du Ponceau, Reference du Ponceau1838; Unger, Reference Unger2003). This critique was spurred by three realizations. First, there was a growing awareness of the importance of morphemic and phonetic notations in scripts traditionally thought to be ideographic, like Chinese writing. The second trigger was the failure of attempts to build purely ideographic systems like Bliss symbolics. Lastly, critics like DeFrancis showed that ideographic systems used in mostly illiterate societies were not self-sufficient, but instead relied on an oral gloss. The locus classicus for this demonstration is the so-called “Yukaghir love letter,” which Sampson (Reference Sampson1985) presented as an ideographic message couched in a complex pictographic code. The letter was in fact no letter at all, but part of a parlor game whose participants had to guess the meaning of the cryptic message through a series of yes-or-no questions (DeFrancis, Reference DeFrancis1989; Unger, Reference Unger2003). A closer look at other instances of pictographic communication, once presented as ideographies (or “semasiographies” in Gelb's terminology) in classic works (e.g., Gelb, Reference Gelb1963; Sampson, Reference Sampson1985) reveals a similar picture: Ideographic notations are heavily reliant on oral glosses, calling into question their capacity to encode a lot of information on their own (DeFrancis, Reference DeFrancis1989). This new interpretation of pictographic messages came at the same time as a series of important anthropological studies stressing the role of orality in traditional pictographic communication (Boone & Mignolo, Reference Boone and Mignolo1994; Severi, Reference Severi2012). These landmark findings transformed our understanding of pictographic communication. They also widened the gap between writing and other graphic codes.
4.1. What glottography means
The glottographic principle (also known as phonography; Gelb, Reference Gelb1963; Hyman, Reference Hyman2006) is the use of symbols to indicate linguistic information at the phonological level: Phonemes, syllables, or morphemes. Unlike ideography, the glottographic principle does not allow the direct encoding of semantic information, bypassing language. As a result, a code that makes heavy use of the glottographic principle is useless to someone who does not know the particular language that it encodes, or at least a closely related one.
How much use should a system make of the glottographic principle to count as writing? No writing system is glottographic through and through. Many systems use ideographic symbols (as in “$1”). And written representations may be richer than the spoken linguistic representations that they encode: In English, “be” and “bee” are less ambiguous than the spoken sound /bi(ː)/. Because of this, writing will sometimes represent information through purely graphic cues that have no counterpart in language. Any writing system will occasionally carry information that is absent from the spoken form.
If glottography is but one aspect of writing, does this refute the specialization hypothesis? Not if the vast majority of written symbols (in contemporary systems at least) encode linguistic units (phonemes, syllables, or morphemes). Is this true?
Of the alleged counterexamples that come to mind, Chinese characters are the most famous. Chinese writing would refute the specialization hypothesis if it were true that most of them (and the most frequently used among them) primarily encode semantic information without the help of a phonetic notation. The debate on the nature of Chinese characters is not fully settled (Handel, Reference Handel2015; Lurie, Reference Lurie2006; Sampson, Reference Sampson2017; Unger & DeFrancis, Reference Unger, DeFrancis, Taylor and Olson1995). Yet there is a broad and robust consensus around the view that (in the words of a critic of phonocentric views), “the vast majority of Chinese characters contain phonetic elements” (Handel, Reference Handel2015, pp. 117–118); indeed, “nobody is disputing the role that phonological components play in the Chinese writing system or the role that phonological recoding plays in the reading of Chinese” (Handel, Reference Handel2015, p. 130 – see also Coulmas, Reference Coulmas1996a; DeFrancis, Reference DeFrancis1989; Sampson, Reference Sampson1985, Reference Sampson2017; Unger & DeFrancis, Reference Unger, DeFrancis, Taylor and Olson1995). Nor is this phonetic information inert: There is massive psychological and neuropsychological evidence that Chinese readers process writing using phonological cues (Dehaene, Reference Dehaene2010; Li, Peng, Liu, Booth, & Ding, Reference Li, Peng, Liu, Booth and Ding2014; Liu, Vermeylen, Wisniewski, & Brysbaert, Reference Liu, Vermeylen, Wisniewski and Brysbaert2020).
Having said that, it is still possible that Chinese characters encode language in a way that is quite different from alphabetic or syllabic systems, that is to say, mostly at the level of morphemes instead of phonemes or syllables (Handel, Reference Handel2015). If true, this would set Chinese writing apart in an interesting way, because morphemes do carry meaning, unlike syllables or phonemes that are semantically empty. Morphemic encoding makes some sense of the intuition that Chinese writing is somehow less phonetic or more ideographic than, say, an alphabet.
The morphemic encoding hypothesis is hard to evaluate, chiefly because no writing system ever sticks to one single organizing principle all the time. English orthography is occasionally logographic: Sometimes, it encodes language at the level of words (compare the written forms write, right, and rite), even though it is alphabetic at heart; Chinese writing presents many syllabic features (DeFrancis & Unger, Reference DeFrancis and Unger2009), even though it cannot be reduced to a syllabary.
The same reasoning applies to writing systems that adapt Chinese characters to encode another language (Coulmas, Reference Coulmas2003). Consider the case of kanjis in Japanese writing (Matsunaga, Reference Matsunaga1996): Only a minority (around 7%) is used in a properly ideographic way, that is, to refer to a unique concept that the two languages verbalize differently. (In the same way that English and French scripts use the character “9” to mean the number verbalized as “nine” or “neuf.”) Most kanjis either admit a variety of other readings in addition to their ideographic reading, or no such ideographic reading. Another possible reading is logographic. In those cases, the respective kanjis encode a word of a precise language (usually, Chinese as pronounced by the Japanese at the time and place when the character was introduced). Yet, here again, most Japanese words cannot be encoded by their own distinctive kanji. Writing them down either requires the use of a syllabary or the use of kanjis employed for their phonetic value. The same point is true of many literate cultures that adopt and adapt foreign scripts: Such adoption would not be possible without either literate bilingualism, or the use of special glosses to transcribe the new script into the vernacular (Whitman, Reference Whitman2011). With a few exceptions (like the numerical notations that Latin scripts borrowed from Arabic), it is rare for a script to use symbols from another script purely for their meaning, without learning the corresponding spoken form or glossing it in the local language.
Inside the Chinese language family, it is often claimed that Chinese writing enables speakers of mutually unintelligible languages to communicate, because it encodes morphemes in addition to sounds. This claim can be broken down into several notions, some true, others debatable. First, written standards are factors of linguistic unification, in China as elsewhere, because writing can be understood by speakers whose differing pronunciation would hinder mutual comprehension, and because the written standard helps in the diffusion of a unified vocabulary and grammar (Coulmas, Reference Coulmas2003). Second, mutual comprehension can be assured by a language that is quite different from most (or any) vernacular and is only ever used in a literate context – like Latin in Europe (“diglossia”). This second factor is arguably far more important than the first in a language family as diverse as the Chinese one. Written Chinese was a literate idiom, for at least some literate Chinese, for most of its history, until it was simplified and oralized, attaining its status as lingua franca (Li, Reference Li2006). Lastly, the morpho-syllabic nature of written Chinese does allow its users to read some characters correctly even when they would pronounce it quite differently. However, morphemic notation only goes so far in helping this. It works to the extent that the two languages have a closely overlapping grammar (at least), and many closely related cognates (Chen & Ping, Reference Chen and Ping1999; Li, Reference Li2006). Modern written Chinese cannot, for instance, encode Cantonese without modifications (Chen & Ping, Reference Chen and Ping1999). Cantonese is developing a writing system of its own, with specific conventions (Bauer, Reference Bauer2018; Snow, Reference Snow2008).
4.2. The limits of glottography
What matters, from the point of view of the glottographic principle, is the simple fact that written symbols encode linguistic information. Surprisingly, perhaps, the glottographic principle does not imply that writing systems encode sounds. Writing is not a record of speech or a phonography (contra DeFrancis, Reference DeFrancis1989), because writing systems encode morphemes, syllables, or phonemes, which are not sounds but contrastive categories. Of all the systems that we know, only Korean Hangul attempts to encode actual features (e.g., whether a consonant is palatal or not, etc.) (Coulmas, Reference Coulmas2003). Other systems encode language at the phonemic level, or above it. In hearing individuals, phonemic awareness is a predictor of literacy acquisition, in keeping with the glottographic principle (Mattingly, Reference Mattingly, Kavanagh and Mattingly1972), for a broad range of scripts, including Chinese (McBride-Chang et al., Reference McBride-Chang, Cho, Liu, Wagner, Shu, Zhou and Muse2005, Reference McBride-Chang, Tong, Shu, Wong, Leung and Tardif2008; Verhoeven & Perfetti, Reference Verhoeven and Perfetti2022). Having said that, the fact that writing encodes abstract linguistic categories as opposed to sounds opens the possibility that one could become literate in a language when one's only contact with that language is visual – through writing, fingerspelling, or lip reading (Hirshorn & Harris, Reference Hirshorn and Harris2022; Petitto et al., Reference Petitto, Langdon, Stone, Andriola, Kartheiser and Cochran2016). A close approximation of this case is provided by the minority of persons born with deep congenital deafness who nonetheless become literate (Hirshorn & Harris, Reference Hirshorn and Harris2022).
The glottographic principle, to qualify it further, is compatible with the view that reading in proficient readers rests on a broad variety of mental representations, mapping written signs onto phonemes, syllables, morphemes, or (occasionally, for frequent expressions) whole words (Perfetti & Harris, Reference Perfetti and Harris2013). Indeed, proficient readers follow two routes in accessing the meaning of a text: One that connects written words directly to their meanings through associated phonological representations, and one that connects written words to meanings without going through this phonological stage, with the two routes working in parallel, some writing systems relying more heavily on one or the other route (Harm & Seidenberg, Reference Harm and Seidenberg2004; Hirshorn & Harris, Reference Hirshorn and Harris2022; Ramus, Reference Ramus and Gazzania2004).
4.3. The case of early writing
The specialization hypothesis implies a straightforward prediction regarding the graphic codes that preceded the rise of writing: They should be lacking in self-sufficiency or generality, or both. Looking at the four civilizations that invented writing independently of one another (China, Egypt, Meso-America, Mesopotamia), it becomes clear that in three of these four cases the emergence of writing was preceded by sophisticated specialized codes. Sumer is the clearest case. Proto-cuneiform was a poorly standardized and narrowly specialized code that lacked most of the features of glottographic writing (Damerow, Reference Damerow2006), but was preceded and accompanied by sophisticated accounting tools (Schmandt-Besserat, Reference Schmandt-Besserat2007). Likewise, among ancient Egyptians writing was preceded by a rich system of signs, mostly used to mark goods or commodities (Baines, Reference Baines2007). The Maya also had sophisticated systems of symbols encoding proper nouns before the rise of any more fully glottographic writing (Houston, Reference Houston2004). As for the exception, ancient China, the lack of data before the period of oracle bone inscriptions, c. 1400 BCE, does not let us know much about the script's evolution (Wang, Reference Wang2014). Thus, inventing sophisticated special-purpose graphic codes appears to be a necessary but not sufficient condition for developing writing (with one intriguing exception where the evidence is inconclusive). Numeration systems, tallying and accounting tools more generally illustrate this most clearly, because they tend to develop in state societies before the rise of writing, or in its absence (Chrisomalis, Reference Chrisomalis2020).
5. One puzzle and two solutions
The specialization hypothesis implies that general-purpose ideographies are exceedingly difficult to use, and unlikely to gain currency. Because ideographies are conceptually possible, one may still invent a general-purpose ideography, just like George Bliss or Otto Neurath did. But these systems will not be used in an autonomous fashion, without the help of a written or oral gloss. In contrast, attempts to engineer a new spoken language (like Esperanto or Volapük) did not fail as languages, even though they did not become the universal languages their inventors hoped they would be (Okrent, Reference Okrent2010). They have (or had) communities of speakers (including native speakers) comparable in size to those of many regular languages.
Why can visual languages not be turned into self-sufficient and generalist communication devices? Graphic codes can be self-sufficient, like mathematical notations, or they can be generalist, like mnemonic pictographs. But the specialization hypothesis contends that they cannot be both at the same time: Mathematical notations are highly specialized, whereas mnemonic pictographs require an oral gloss. What the specialization hypothesis does not do is explain why this is so. This section reviews two possible reasons for the failure of general-purpose ideographies.
5.1. Unpacking the puzzle of ideography
A full ideography would combine four advantageous features: It would be generalist, language-independent, asynchronous, and visual. Each of these features is present in extant communication devices, but none combines them all.
Language-independent, visual, and generalist codes are communication devices that can be used by people having no language in common. The clearest (though poorly documented) cases are signed languages used in multilingual hearing populations, such as the “Plain Indians Signed Language” (Davis, Reference Davis, Bakken Jepsen, De Clerck, Lutalo-Kingii and McGregor2015; Mallery, Reference Mallery1879), said to have served as a visual communication tool crossing language barriers, all over the mid-Western area of the contemporary United States. The signed languages developed in silent monastic communities (Banham, Reference Banham, Bakken Jepsen, Lutalo-Kingii, De Clerck and McGregor2015; Quay, Reference Quay, Bakken Jepsen, Lutalo-Kingii, De Clerck and McGregor2015) belong to this category, although they were arguably less generalist and expressive, consisting in hundreds of symbols at the most, with little in the way of syntax or morphology. The potential of visual languages (gestured or visual) to bypass the barriers of language has long been recognized: People can use these codes without sharing a spoken idiom (Knowlson, Reference Knowlson1965; Rossi, Reference Rossi2000).
Such gestured codes (distinct from sign languages, among other things because their users can hear and speak) are rare in the historical record, probably because most of their functions can be filled by spoken pidgins. They also lack one feature that would make ideographies uniquely useful: Asynchronous use. The crucial advantage of graphic codes, compared to signed or spoken languages, is that, in our species' history, they were for a long time the only kind of code that allowed sending messages across time or space (Morin et al., Reference Morin, Kelly and Winters2020). Asynchronous messages are “temporally and spatially portable” (to use the terminology of Pickering & Garrod, Reference Pickering and Garrod2021), or “location and time independent” (to use that of Lee & Karmiloff-Smith, Reference Lee and Karmiloff-Smith1996). The impact of asynchronous communication on cultural evolution is twofold. First, it allows information to be transmitted in one single step across potentially unlimited temporal and spatial distances, without the need for long transmission chains, which tend to lose information (Bartlett, Reference Bartlett1932; Tamariz & Kirby, Reference Tamariz and Kirby2015). Second, it allows one single message to transmit the same piece of information multiple times, in contrast to spoken or signed messages, which do not endure and must be continuously reproduced.
So why, despite all these potential advantages, do we not communicate with ideographies? Two broad families of explanations will be reviewed. The first starts from potential cognitive difficulties raised by the learning and memorization of graphic codes (the “learning account”). Explanations of the second kind are based on the difficulty of standardizing the codes we use for communication, when communication is not face-to-face (the “standardization account”). Both explanations imply that graphic codes consisting of a small number of symbols and rules can be learnt, thus allowing for the possibility of highly specialized codes, but more generalist codes cannot (Fig. 3).
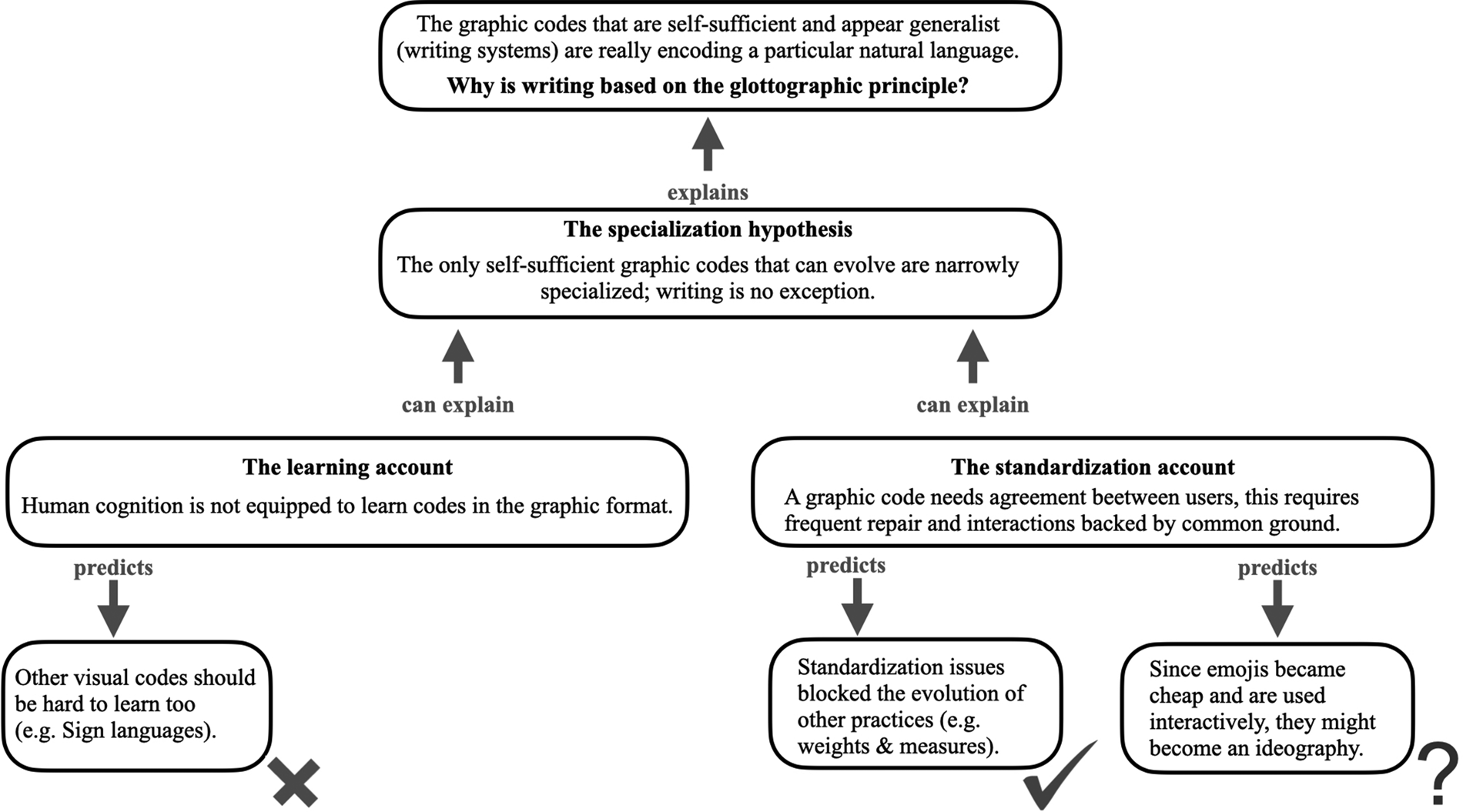
Figure 3. Argument of sections 5 and 6.
The learning account and the standardization account are both consistent with the specialization hypothesis. On both accounts, rich graphic codes using a number of symbols vast enough to rival the richness of languages cannot evolve. On the learning account, that is because graphic symbols are difficult to learn (compared to strings of phonemes, or bundles of gestures). On the standardization account, that is because of the difficulty of coordinating usage on a vast range of graphic conventions (as compared to the conventions that govern face-to-face communication: Spoken and signed languages). Under both accounts, graphic codes cannot encode a broad range of meanings, so there are only two ways for them to convey information: To rely on an oral gloss, or to be highly specialized. In other words, self-sufficient graphic codes that do not rely on oral glosses are necessarily highly specialized. Writing, an apparent exception to this rule, actually proves it. Writing is a specialized notation of language. Because languages are themselves general-purpose, writing benefits from this property of language vicariously.
The way that the two accounts solve the puzzle of ideography is broadly the same: Graphic codes are specialized because they are limited, and writing is glottographic because it is the only way for a graphic code to be both specialized and all-purpose. But the two accounts take quite different paths to reach this conclusion.
5.2. Graphic codes as a challenge for human cognition
The first family of explanations – the learning account – posits that human cognition has problems dealing with visual communication: Static images as opposed to gestures or strings of phonemes (Jakobson, Reference Jakobson1964; Liberman, Reference Liberman, Frost and Katz1992). Its best proponent was the linguist Alvin Liberman (Reference Liberman, Frost and Katz1992). Liberman was struck by the ease and naturalness with which we learn spoken languages, compared to the acquisition of reading and writing. Speech is universal; it is older than writing, phylogenetically and ontogenetically. Literacy, a localized and contingent cultural artifact, has no biological basis specifically evolved to support it (Dehaene, Reference Dehaene2010). But stopping there would beg the questions: Why does spoken language benefit from a specific biological adaptation? What is the biological adaptation that makes spoken language, but not its graphic counterpart, so easy to acquire? Obviously, humans have been speaking for much longer than they have been writing, but then again, we need to know why writing evolved much later, and much more rarely, compared to speech.
Liberman posited that speech relied on an adaptation for phoneme perception, which worked for phonemes and only for them. Letters are not phonemes, and that is why graphic codes are difficult to learn. Can this hypothesis solve the puzzle? Before answering, I will review the things that the learning account, in my view, gets right.
5.3. Self-sufficient graphic codes must use a small number of symbols
The learning account clearly points at an important problem that graphic codes encounter, and that Liberman noted: They do not seem to possess nearly as many signs as the number of words in spoken languages, suggesting difficulties in learning a large set of graphic symbols.
The graphic codes that can be used to communicate a great deal of information without the help of an oral gloss, such as mathematical notations or writing systems, are based on a relatively small number of conventions. These conventions specify which meanings are paired with each symbol, how symbols can be combined with one another, and how to derive the meaning of a string of symbols from the meanings of the individual symbols that compose it. In the most regular graphic codes, like mathematical notations, a small number of conventions fixing the meaning of symbols is sufficient to make a great variety of messages possible to produce and to comprehend. The meaning of a mathematical expression like “2 + 2 = 4” is entirely and unambiguously given by transparent and standardized rules codified by mathematicians. Graphic codes like mathematical or musical notations possess clear syntax-like properties (Casati, Reference Casati and Zaibert2016; Friederici, Reference Friederici2020; McCawley, Reference McCawley, Downing, Lima and Noonan1992).
The orthographies of most writing systems are not as transparent and regular as this (far from it) but, as we saw, when compared to spoken languages, the number of meaning–symbol mappings that must be learnt in order to master even a complex system like Chinese characters is small relative to that of spoken language, thanks to the glottographic principle. Self-sufficient graphic codes manage to make the most of a few learnt conventions.
Attempted generalist ideographies, like Bliss symbolics, struggle to express as broad a variety of meaning as language does, in part because of the large number of conventional symbols that one would need to learn in order to make the system work, and in part because the rules that are supposed to help compose complex expressions from simpler symbols are too ambiguous. Consider the last symbol in the Bliss sentence given in Figure 4. The arrow at the end modifies the symbol that means “camera,” to create a compound meaning “moving picture,” that is, “film.” But figuring this out requires a great deal of familiarity with Bliss. Why cannot we interpret the arrow as having a directional meaning, as in “I want to go see a picture,” where the arrow would encode “to”? The grammar of Bliss is often not systematic enough to answer questions like this univocally, resulting in sentences too ambiguous to be understood without an oral gloss.

Figure 4. Phrase “I want to go to the movies” in Bliss symbolics. The Bliss symbols are reproduced by the author, copying an image from Wikimedia commons (Blissymbols, 2022).
One way to understand the failure of general ideographies like Bliss symbolics is to frame it in terms of McNeill's demarcation criteria for language. According to McNeill (Reference McNeill1992), linguistic communication differs from gestural communication in four ways. Linguistic messages have a specific hierarchical structure (they can be broken down into parts following a specific arrangement); their units can be combined productively; they can be understood out of context; they obey standards of form. In theory, Bliss has rules for ordering words, but their proper application is difficult, hence unlikely to be consistent; the production of combinatorial messages through compositionality is problematic, as just seen; decontextualized understanding (absent a written or an oral gloss) is seldom achieved or even sought. Emojis fail to function as a general visual language for the same reason (Gawne & McCulloch, Reference Gawne and McCulloch2019).
One possible explanation could be that graphic codes, in general, are simply incapable of fulfilling McNeill's criteria; but this is clearly false. Many graphic codes obey strict rules for combining the symbols they are made of. Heraldic coats of arms, for instance, must be composed in ways that forbid the juxtaposition of certain colors (Morin & Miton, Reference Morin and Miton2018). Combinatorial structure and compositionality are evident in writing systems, mathematical or musical notations, formal logic (Zalta, Reference Zalta2022), and so on. As for context-independence and standardization, we encountered several examples of graphic codes exhibiting them. Nothing about graphic codes as such seems to prevent them from exhibiting all of McNeill's features. The problem, according to the specialization hypothesis, is that the only codes to achieve this are specialized. Enlarge the range of meanings that the code is to carry, and the system breaks down.
This suggests an obvious solution to the puzzle of ideography: The human mind cannot memorize large numbers of pairings between meanings and visual symbols. A self-sufficient code can be built on the basis of a few conventions, as long as it remains specialized and follows relatively strict rules of composition. But a more generalist code, to be usable without an oral gloss, would require users to learn an excessive number of conventions. If humans only have a large memory storing for codes and symbols when the symbols are made of phonemes, this would solve the puzzle of ideography.
5.4. Why the learning account fails
In Liberman's view, the speech faculty was specialized for processing and storing strings of phonemes. Phonemes, in his view, were quite distinct from sounds in general. His theory of the human phonetic capacity saw it essentially as a motor faculty rather than an auditory one: To represent phonemes is to represent gestures of the tongue and mouth. Because this definition excludes graphic shapes, it would explain why we can only learn a restricted number of graphic symbols.
The first issue with this account's solution to the puzzle of ideography is the fact that sign languages seem to be as easy to learn as spoken ones, even though their signs are not limited to mouth or tongue movements. A straightforward response would be to broaden the scope of Liberman's theory, so that speech includes signed speech as well as oral speech (a view considered in Lane, Reference Lane1991). This move would make sense for a motor theory of language, but raises two new issues. First, it makes it harder to defend the view that speech perception is narrowly specialized. Such a view is sensible as long as speech perception is confined to the analysis of mouth and lips movements, but the perception of whole-body gestures blends into more general mechanisms of action perception. The second issue is that graphic codes are gestural codes too. Graphic forms, generally, are traces of handwriting gestures. Even in the computer age, literate people learn their letters by inscribing them, affecting the way these graphic forms are represented. Even today, motor representations are involved in reading Latin-alphabet letters or Chinese characters (Schubert, Reilhac, & McCloskey, Reference Schubert, Reilhac and McCloskey2018; Yin & Zhang, Reference Yin and Zhang2021); and printed or computer-written fonts are modeled after handwritten symbols.
Thus, it seems that Liberman's motor theory of speech cannot have it both ways. If it posits a narrowly specific adaptation to process mouth and tongue gestures, it can explain why spoken language is easier to acquire compared to its graphic form, but it fails to explain why signed languages are easily and spontaneously acquired. Alternatively, it may assume that the speech faculty applies to gestures of the whole body, but in that case does not explain why traces of handwriting gestures would elude it.
5.5. The specialization constraint as a standardization problem
The learning account posits that the human mind is ill-equipped to memorize large numbers of pairings between meanings and visual symbols. This hypothesis is sufficient to derive the specialization hypothesis, but it also wrongly predicts that full-blown sign languages cannot evolve.
The standardization account focuses on the fact that any code used for communication is a standard: It serves its purpose only if a sufficient number of users share the same way of pairing symbols with meanings. Low standardization, I will argue, places the most serious limit on graphic codes' capacity to convey information. The kupesi symbols in use on the Tonga archipelago (Bell & Paegle, Reference Bell and Paegle2021) are ideographic symbols, often standing for clans, lineages, or mythical animals associated with them. Bell and Paegle's ethnographic work shows precisely how little shared meaning the symbols carry. Having sampled 15 kupesi from photographs of public spaces in Nuku'alofa, they show that none of these symbols could be named accurately by the majority of their interviewees, naming performance falling below 5% for 11 of the 15 symbols. This is what it means for a graphic code to be poorly standardized.
Building a shared standard raises a coordination problem (Lewis, Reference Lewis1969; Skyrms, Reference Skyrms2010): The benefits of learning to communicate with a specific code depend on the number of others fluent in that code. This coordination problem is quite distinct from the issues that graphic codes pose for individual learning. The difficulties of standardization are surmountable for the codes used for face-to-face communication (like spoken or signed languages) because these are self-standardizing: Any occasion to use them is an occasion to learn to align with someone else's use. Mnemonic codes, being limited to private use, do not need to be standardized across several users. But to use a graphic code to communicate, and thus unlock the tremendous potential of asynchronous communication (Morin et al., Reference Morin, Kelly and Winters2020), a high degree of standardization is required.
6. The case for the standardization account
The standardization account implies that whether or not graphic expression develops into a full-blown code is a matter of forming and maintaining conventions between users. This view chimes in with recent claims that standardization is a key property that demarcates linguistic from nonlinguistic signs (Goldin-Meadow & Brentari, Reference Goldin-Meadow and Brentari2017). In emerging sign languages such as Al-Sayyid Bedouin sign language, the standardization of gestures into shared signs is a precondition for the emergence of phonological regularities (Sandler, Reference Sandler and Enfield2009). More generally, standardization is an important point of demarcation between mere gestures or gesticulations, and full-blown signs (Goldin-Meadow & Brentari, Reference Goldin-Meadow and Brentari2017). I contend that difficulties linked to standardization are the reason why graphic codes remain underdeveloped compared to their spoken or signed counterparts.
6.1. Codes are standards, subject to lock-in dynamics
Many technologies benefit from the adoption of shared standards: Identical track gauges for railroads, compatible plug-in systems for electric appliances, shared coding languages for software design, and so on. The evolution and diffusion of technological standards is driven by several well-known effects: Positive feedback loops (successful standards tend to become even more successful), path-dependency, and lock-in dynamics (a small initial advantage solidifying into near-complete dominance) (Arthur, Reference Arthur1990; David, Reference David1985). This last effect can lead to economic inefficiencies: Once in place, a suboptimal standard can persist indefinitely simply by virtue of being widespread. The most well-known example of such a lock-in dynamic is linked to writing: David (Reference David1985) and David and Rothwell (Reference David and Rothwell1996) argued that the costs of learning to type on a particular type of keyboard incentivized alignment on one standard ordering of letters (the QWERTY keyboard in many countries), to the detriment of other orderings that may have been more efficient. A similar but more consequential example of the same dynamic is the stifled development of the electric car in the twentieth century (Cowan & Hultén, Reference Cowan and Hultén1996).
A very similar problem affects the codes that we use to communicate. Because codes are conventions, only users who have learnt the same code as other users can profit from them. If learning costs are reasonably high, this constraint can lead to a frequency-dependent advantage in favor of the codes that already have a high number of users, to the detriment of others – what Arthur calls a “positive feedback-loop” (Arthur, Reference Arthur1990), and Chrisomalis (Reference Chrisomalis2020) “networked frequency dependence.” Cultural evolutionists talk of frequency-dependent cultural transmission when an agent's choice to copy a cultural trait is biased by the number of other agents having copied the trait (Boyd & Richerson, Reference Boyd and Richerson1985). Networked frequency dependence is a special case of such dynamics, where network effects imply that it is advantageous for an agent to copy the most frequent behavior (Arthur, Reference Arthur1990, Reference Arthur2009; Chrisomalis, Reference Chrisomalis2020; David, Reference David1985; David & Rothwell, Reference David and Rothwell1996).
This dynamic is evident in the case of language extinction (Zhang & Mace, Reference Zhang and Mace2021). The benefits of learning a language that has few speakers become less likely to outweigh its costs as the number of speakers declines, leading to an extinction spiral in which minority languages increasingly struggle to attract learners. The same type of frequency-dependent evolution asserts itself at the level of individual words: The distribution of synonym use for many meanings in English is best modeled by assuming that each individual speaker is disproportionately more likely to use the words most frequently used by others (Pagel, Beaumont, Meade, Verkerk, & Calude, Reference Pagel, Beaumont, Meade, Verkerk and Calude2019). Frequency-dependent advantages are not confined to human codes but are a general feature of communication signals throughout the animal world: Threat signals like warning coloration are better heeded by predators when they are common, increasing their bearer's fitness (Chouteau, Arias, & Joron, Reference Chouteau, Arias and Joron2016). Standardization problems are, thus, not restricted to economics. They affect codes pervasively.
A code that is not standardized is useless as a communication system, although it may still be used privately as a memory prop. This issue was a roadblock in the evolution of basic information technologies. As Stephen Chrisomalis (Reference Chrisomalis2020) convincingly argues, standardization partly explains why it took so long for Roman numerals (I, II, III, IV, etc.) to be displaced by our current numeration system. Standardization can thus halt the displacement of a locked-in standard; it may also prevent the evolution of a useful one. This explains in part why the Romans failed to fully master tables, maps, or indexes (Riggsby, Reference Riggsby2019). These simple and intuitive technologies seem fairly easy to invent, but such inventions are useless outside of a population of users who master the tool, having learnt to use it in the same way as others. Weights and measures are another case in point. Weights and measure are not standardized in all societies: Standards arise through commercial activity (Cooperrider & Gentner, Reference Cooperrider and Gentner2019). Not all standards are equally likely to evolve: Ancient Romans possessed a refined system of relative weights and measures, based on fractions of an unspecified quantity: Halves, tenths, and so on. They did not manage to develop a consistent system of absolute weights and measures similar to the imperial or metric system. Such systems are harder to develop, because absolute units require standardization of measuring instruments to a much more precise degree than relative units (Riggsby, Reference Riggsby2019, p. 86–88). Even for a large state with an advanced bureaucracy and a sophisticated literate culture, the challenges raised by standardization were serious enough to block the development of communication devices.
The deservedly famous example of the QWERTY keyboard highlights one key property of standardization dynamics – lock-in effects –, but arguably obscures an important fact about standardization: Standards do not always compete for the exact same niche. All English-language keyboards allow you to do the same thing: Type English words, more or less rapidly. But take video game hardware. A broad range of technologies exists to support video-gaming, from Arcade machines to personal computers (PCs) to Nintendo to virtual reality. Some of these technologies are directly competing standards offering basically the same functionalities (like Nintendo/Sony consoles); but there are things that can be done on a console that a PC will not allow, things which arcade or virtual reality hardware makes possible that a console cannot, and so on. When different standards do not compete for the exact same niche, lock-in dynamics should be less likely to arise. A competing standard can make up for an initial lack of popularity by offering services that dominant standards lack. The success of Nintendo consoles does not directly threaten the spread and development of virtual reality headsets, although it arguably holds it back. However, when a lock-in effect does occur, its consequences are more serious, because the suppressed standards do not simply offer more efficient ways of doing the same thing, but entirely new functionalities.
This, I hypothesize, is what often happened during the development of graphic codes: Spoken or signed codes, being easier to standardize, install a lock-in situation where other types of codes are less likely to evolve, even though evolving them would be beneficial, because they can do things other codes cannot do.
6.2. Cheap and transient signals are self-standardizing
All the codes that we use to communicate, including spoken and signed languages, face a standardization problem. This challenge is less daunting for languages because they are based on cheap, fast, and transient symbols. Spoken or signed messages require little effort or time to produce and vanish soon once they are emitted (Galantucci, Kroos, & Rhodes, Reference Galantucci, Kroos and Rhodes2010; Hockett, Reference Hockett1960). Being cheap and fast, they form messages that can be modified or repaired multiple times, allowing interlocutors to converge on shared meanings (Fusaroli, Rączaszek-Leonardi, & Tylén, Reference Fusaroli, Rączaszek-Leonardi and Tylén2014; Pickering & Garrod, Reference Pickering and Garrod2004). Being transient (language's “rapidity of fading”; Hockett, Reference Hockett1960), they constrain interlocutors to face-to-face interactions, where the advantages of common ground are maximized. This leads to standardization not only at the level of the pair, but also at the level of entire populations, because turnover in conversation partners leads to convergence to broader standards that everyone can share (Guilbeault, Baronchelli, & Centola, Reference Guilbeault, Baronchelli and Centola2021).
Transient messages have one obvious drawback: They cannot travel far in time or space. Transient symbols can only be used by interlocutors who share the same time- and spaceframe in a face-to-face setting. (I am not considering here the changes brought about by electronic recording or transmission technologies – changes that are very recent in the long-term cultural evolution of our species.) In other words, they exclude asynchronous communication. But the drawback is also an advantage: Face-to-face communication maximizes common ground, the body of information that interlocutors share by virtue of being together (Clark, Reference Clark1996; Sperber & Wilson, Reference Sperber and Wilson1995). If two people are together in a room, this includes the environment that they are both aware of, information on the identity of other interlocutors and, crucially, the knowledge that the other interlocutors know some of what I know, know that I know it, and so on. Face-to-face communication makes a lot of common ground information available without the need to infer it or to encode it explicitly (Pickering & Garrod, Reference Pickering and Garrod2004). It also provides interlocutors with opportunities to enrich and update this common ground in real time, because any signal they exchange becomes part of this common ground (Clark, Reference Clark1996).
In asynchronous communication, interlocutors also have access to common ground information, but it must be either encoded or inferred. Take the identity of a message's author. In asynchronous communication, it can be inferred from various cues (e.g., the handwriting on a note, the fact that it's pasted on the fridge door, etc.) or it can be explicitly encoded through a signature, a seal, or some other identifying mark. Both inference and explicit encoding are fallible and costly processes. They may reach the wrong conclusion and require effort in any case.
Access to common ground provides interlocutors with the means to solidify the standards and conventions of spoken language (Clark & Wilkes-Gibbs, Reference Clark and Wilkes-Gibbs1986; Keysar, Barr, Balin, & Paek, Reference Keysar, Barr, Balin and Paek1998). Of course, interlocutors in most conversations can avail themselves of a shared language; but these conventions often need to be refined and tailored to immediate needs: Shorter, more precise ways to refer to things that matter to the conversation. A USB-A to HDMI adapter therefore becomes “the dongle” to the people frantically looking for it; the strange newcomer who just entered the bar becomes “blue hair” to the regulars; and so on. In Clark and Wilkes-Gibbs' classic experiment, ambiguous Tangram shapes get baptized in this way, long and variable descriptions swiftly morphing into short and shared conventional labels. Common ground is crucial to standardization process for two reasons. First, conventional meanings can be anchored to immediately perceptible referents: Alice points at “the thingy” on the table, and Bruno immediately knows that “the thingy” stands for his keychain. Second, the past history of a face-to-face conversation is part of the common ground that interlocutors share (Clark & Brennan, Reference Clark, Brennan, Resnick, Levine and Teasley1991). When Alice baptized “the thingy,” what she did was manifest to both Alice and Bruno, and they carry this shared memory into future stages of the conversation. These cues that a message has been attended to are much more difficult to get from graphic communication.
Face-to-face communication can take full advantage of this common ground because it is based on cheap-to-produce signals. Any spoken (or signed) message can be modified or repaired at a little cost, until interlocutors align on a shared understanding (Clark & Brennan, Reference Clark, Brennan, Resnick, Levine and Teasley1991; Clark & Wilkes-Gibbs, Reference Clark and Wilkes-Gibbs1986; Enfield, Reference Enfield2017). Cheap signals allow for a large amount of information to be exchanged, whereas face-to-face interaction prevents the flow of information from being one-sided, allowing for repair and quick turn-taking (Fusaroli et al., Reference Fusaroli, Rączaszek-Leonardi and Tylén2014; Levinson, Reference Levinson, Levinson and Enfield2006). High-bandwidth, two-sided communication prevents misunderstandings and ensures standardization through mechanisms such as repair (signaling misunderstandings by linguistic means); backchannel communication (subtle signals like grunts, nods, eyebrow flashes, etc.), which can function among other things to signal that repair is not needed (Schegloff, Reference Schegloff1982); and interactive alignment (repetition or imitation of speech at various levels) (Dideriksen, Christiansen, Tylén, Dingemanse, & Fusaroli, Reference Dideriksen, Christiansen, Tylén, Dingemanse and Fusaroli2023; Garrod & Pickering, Reference Garrod and Pickering2004; Pickering & Garrod, Reference Pickering and Garrod2004). None of those mechanisms work as efficiently in asynchronous communication as they do in face-to-face interaction – and often do not work at all. Asynchronous turn-taking (which can take place in letters exchange, for instance) is slow by definition, because interlocutors do not inhabit the same timeframe. In other cases it is simply absent: One cannot put an objection to Plato's arguments and get a reply. Compounding this problem, asynchronous repair signals need to be explicitly encoded: There is no nonverbal or paraverbal channel through which to convey them, whereas conversation has eyebrow flashes, humming, and so on (Bavelas & Gerwing, Reference Bavelas and Gerwing2011).
Access to common ground information and its exploitation through repair, backchannel communication, and interactive alignment reinforces the standardization of the codes used for communication. Spoken and signed languages are “self-standardizing” because they are based on cheap and transient symbols. Transience forces interlocutors to use symbols in face-to-face settings, where common ground is rich and repair is quick. Cheap and fast production allows interlocutors to take full advantage of the possibilities offered by repair. This is how spoken and signed languages solve the challenge of standardization.
6.3. Languages have a lock-in effect on the evolution of codes
The previous section explained why languages, adapted for face-to-face communication, should evolve more readily than other codes. This section explains why, conversely, the codes fit for asynchronous communication, like writing systems and other graphic codes, evolve more rarely. Because they lack the self-standardizing property of languages, they are less likely to appear in the first place. And once a spoken language is in place, it fulfills most of the functions that a graphic code is useful for, making graphic codes largely redundant. As an unfortunate consequence, asynchronous communication, the one function that graphic codes are uniquely fit for, remains underdeveloped (Morin et al., Reference Morin, Kelly and Winters2020).
This argument assumes that, once a code exists, it inhibits the development of other codes that fulfill similar but partially different functions. This point can be made with an analogy. Most languages are based on spoken words, not gestured signs. Sign languages, however, permit some forms of communication that are not possible with spoken languages, communication with the deaf, communication in noisy environments, and so on. Yet, for most people, they remain a latent possibility, because spoken language is already the default tool for communication, and the unique benefits of signed language are not sufficient to offset the costs of developing and learning a new code. The inhibiting effects that the availability of spoken language exert over the development of signed language is suggested by a series of studies by Goldin-Meadow and collaborators (Goldin-Meadow & Brentari, Reference Goldin-Meadow and Brentari2017; Goldin-Meadow, McNeill, & Singleton, Reference Goldin-Meadow, McNeill and Singleton1996; see also McNeill, Reference McNeill1992), who asked hearing participants to describe a scene using only gestures; compared to the cospeech gestures produced by the same participants while speaking, these “silent gestures” exhibit more discrete segmentation and a greater degree of hierarchical combination, two conditions that favor the emergence of a coherent code.
A lock-in occurs when a standard is so widespread that it hinders the rise of a different standard that would better accomplish the same task (like alternatives to the QWERTY keyboard, or the electric car), or that would fulfill different but overlapping functions (like virtual reality headsets compared to gaming consoles). The first type of lock-in can protect a deficient technology. The second type can inhibit the evolution of technologies that offer different but overlapping functionalities. Graphic codes face a lock-in of the second type. The availability of spoken or signed languages means that the benefits of developing graphic codes (including writing) do not, for most purposes, warrant the costs, because most of the things we could accomplish with them can also be performed with language.
In spite of language's inhibiting effects, graphic codes do emerge, but only for a few niche functionalities, and even then, they grow in the shadow of language. The availability of memorized oral messages means that the graphic code does not need to carry as much information as a self-standing code would; the availability of an oral gloss removes the need for spectators to understand the graphic code; misunderstandings can be repaired orally without changing or correcting the graphically encoded message. In all these ways, an oral crutch prevents graphic codes from learning to walk.
6.4. The future of ideography
This paper has so far deliberately neglected recent inventions that are too young to have left their mark on the long-term evolution of language or writing: Electronic communication, telephones, voicemail, and so on. But those have clearly started to transform human communication, graphic or oral. If the standardization account is on the right track, it opens a window for the evolution of ideographic communication in the digital age. Digital communication might overthrow the constraints that weigh on the evolution of graphic codes. Thanks to texting, graphic signals are becoming almost as fast and effortless to send as spoken words or gestures; the amount of information that participants in a digital interaction can have in common has exploded, to the point that it can rival the common ground shared by face-to-face interlocutors. The standardization account should thus predict that emojis, gifs, and other digital pictographs should become increasingly endowed with precise and shared meanings. There has been an explosion in emoji and emoticon use, concomitant with the rise of digital communication, but whether these are replacing writing or complementing it is a matter of debate. The prevalent view does not see emojis as genuine alternatives to verbal communication. Instead, they are viewed as filling some of the functions that paraverbal signals, such as intonation, facial expression, and hand gestures, would fulfill in face-to-face conversation (Derks, Bos, & von Grumbkow, Reference Derks, Bos and von Grumbkow2008; Gawne & McCulloch, Reference Gawne and McCulloch2019; Vandergriff, Reference Vandergriff2013).
Why are emojis not yet ready to replace writing? As the standardization account would predict, a lack of agreement over the symbols' meanings is partly to blame. Survey studies show substantial disagreement over the meaning of the Unicode-encoded emojis (Częstochowska et al., Reference Częstochowska, Gligorić, Peyrard, Mentha, Bień, Grütter and West2022; Miller et al., Reference Miller, Thebault-Spieker, Chang, Johnson, Terveen and Hecht2016; Tigwell & Flatla, Reference Tigwell and Flatla2016). Agreement is weak even for very frequent symbols like ![]() ,
, ![]() , or the seemingly obvious
, or the seemingly obvious ![]() (whose interpretation ranges from intense positivity to awkwardness). Even on basic dimensions such as valence (whether an emoji is associated with positive, negative, or neutral emotions), participants' ratings disagree 25% of the time (Miller et al., Reference Miller, Thebault-Spieker, Chang, Johnson, Terveen and Hecht2016; Tigwell & Flatla, Reference Tigwell and Flatla2016, find qualitatively similar results for valence and arousal). This limits the symbols' expressive power and forces users to rely on context.
(whose interpretation ranges from intense positivity to awkwardness). Even on basic dimensions such as valence (whether an emoji is associated with positive, negative, or neutral emotions), participants' ratings disagree 25% of the time (Miller et al., Reference Miller, Thebault-Spieker, Chang, Johnson, Terveen and Hecht2016; Tigwell & Flatla, Reference Tigwell and Flatla2016, find qualitatively similar results for valence and arousal). This limits the symbols' expressive power and forces users to rely on context.
The standardization account would, however, also predict that agreement over the meaning of emojis should grow over time, insofar as written digital communication approaches the conditions of synchronous face-to-face interaction. It is unclear whether digital communication can become cheap and fast enough for this; the pace of repair and turn-taking in normal conversation is so rapid (Stivers et al., Reference Stivers, Enfield, Brown, Englert, Hayashi, Heinemann and Levinson2009) that even sophisticated videoconferencing tools cannot always avoid disrupting it. Still there seems to be, for the first time ever, a possibility that digital communication breaks the chains that keep ideographic communication bound. Should this happen, the evolution of the online ideographic language should start with a consolidation of emojis that serve the restricted function of encoding paraverbal cues, such as the facial expressions of emotions. Their ambiguity should decrease over time, in keeping with experimental results showing increasing specificity for online signals in referential communication (Guilbeault et al., Reference Guilbeault, Baronchelli and Centola2021; Morin, Müller, Morisseau, & Winters, Reference Morin, Müller, Morisseau and Winters2022). Once this stage is passed the code could grow to include an expanding range functions, gradually becoming more generalist. This is based on the fact that complex graphic codes tend to grow on top of simpler ones, as we saw in the case of writing systems (pre-existed by numeration systems), or musical notations that grew increasingly generalist (Croft, Reference Croft, Coupé, Pellegrino and Mufwene2017).
7. Conclusion
Everyone knows writing has a special relationship with language, but that relation has often been minimized or trivialized in the scholarly literature. Minimized by showing that writing encodes much more than sounds, by casting doubt on the importance of phonemic or syllabic notations in writing systems like Chinese or Egyptian, by giving credence to the notion that some writing systems are ideographic. Trivialized too: If writing mainly encodes language, is that not merely because we chose to define it in this way? Do we not possess many graphic notations that do not encode language, but are just as powerful as writing?
Against these tendencies, this paper sought to show that the glottographic nature of writing is neither a falsity nor a platitude, but a puzzle. The puzzle is the absolute rarity, in the current or past record, of a fully ideographic code that can be used autonomously, not just as a mnemonic prop, to encode information on a broad range of topics. I have attempted to make the case for this claim – the specialization hypothesis – reviewing two possible answers to the puzzle that it raises, as well as some implications for the evolution of writing. I argued against one plausible explanation of the puzzle. Ideographies, if they existed, would not necessarily be overly difficult to learn: Sign languages demonstrate that visual codes can be just as easy to acquire as spoken ones. Ideographies are not hard to learn; they are hard to standardize. One can build an ideographic code and learn how to use it, but getting a sufficient number of people to go along with it is the real challenge. This problem is specific to graphic codes. It does not apply to the same degree to spoken or signed codes. Languages, spoken or signed, have been used in an exclusively synchronous fashion until very recently, and face-to-face interaction makes it easier for interlocutors to resolve any salient discrepancy between my code and your code. Words and gestures are quick and effortless to produce (compared to graphic symbols), making it easier to change codes and converge on shared symbols. Spoken or signed codes get a first-mover advantage from this. They are likely to be in place before graphic codes can evolve.
This answer to the puzzle requires testing, and the puzzle itself is an empirical claim. The nonexistence of generalist and self-sufficient ideographies is not a simple consequence of how we choose to define the word “writing.” The graphic codes in use before the rise of the glottographic principle, and during the long periods where the principle was known but scarcely used, should lack either generality or self-sufficiency, or both. This claim is exposed to empirical refutation – I contend it has not occurred yet.
In the history of writing, the nonevolution of ideography is the dog that did not bark: Its absence tells us much about the nature of graphic codes, their power, and their limitations. In evolutionary terms, a complete ideography could be seen as a peak in the design space of graphic codes (Acerbi, Tennie, & Mesoudi, Reference Acerbi, Tennie and Mesoudi2016; Dennett, Reference Dennett1995; Mesoudi & Thornton, Reference Mesoudi and Thornton2018). A design space (modeled on Sewall-Wright's fitness landscapes) is a representation of the quality of different solutions to a given problem, plotted against their similarity. A set of good solutions is represented as a peak in the design space, whereas a set of bad solutions will appear as a valley or a plain. Some peaks are easily accessible through a gradual evolutionary progress, because they are surrounded by similar solutions that are also relatively good. But some peaks are located in an area of the design space that can hardly be reached, because there is no smooth evolutionary path leading to them. In this view, writing is an isolated peak in the design landscape of graphic codes. The availability of spoken language kept most of human communication away from it. Future work could uncover interesting parallels with other domains of technology where the constraints of standardization kept good ideas from being realized.
Acknowledgments
I wish to thank Nicolas Baumard, Pascal Boyer, Roberto Casati, Paul Égré, Silvia Ferrara, David Gil, Yoolim Kim, Helena Miton, Thom Scott-Phillips, Oleg Sobchuk, Kristian Tylén, Mason Youngblood, and Elia Weber, for their helpful comments on an earlier draft. I thank the BBS reviewers, including Nick Enfield, for their input.
Financial support
The work leading to this paper has received funding from the “Frontiers in Cognition” EUR grant, ANR-17-EURE-0017 EUR and the Max Planck Society.
Competing interest
None.





Target article
The puzzle of ideography
Related commentaries (26)
A bigger problem for ideography: The pervasiveness of linguistic structure
A cognitive account of the puzzle of ideography
A source- and channel-coding approach to the analysis and design of languages and ideographies
Bypass language en route to meaning at your peril
Chinese offers a test for universal cognitive processes
Communication consistency, completeness, and complexity of digital ideography in trustworthy mobile extended reality
Emoji use validates the potential for meaning standardization among ideographic symbols
Fractals and artificial intelligence to decrypt ideography and understand the evolution of language
Functional ideographies are composite semiotic systems
Graphic codes, language, and the computational niche
How standardized must a code be to be useful?
Ideography in interaction
Ideography insight from facial recognition and neuroimaging
Ideography, Blissymbolics, standardization, and emergent conformity
Mind the gap: Why is there no general purpose ideographic system?
Notational systems are distinct cognitive systems with different material prehistories
On the semiotic and material constraints of ideographies
Pragmatic interpretation and the production of ideographic codes
The centrality of practice in ideographic communication, and the perennial puzzle of positivistic thinking
The design space of human communication and the nonevolution of ideography
The different paths to cultural convergence
The disadvantage of ideography
The feasibility of ideography as an empirical question for a science representational systems design
The stranding of the ideography: A nonnegligible role of the spoken language
Visual languages and the problems with ideographies: A commentary on Morin
Why the use of ideographic codes does not improve communicative skills in patients with severe aphasia?
Author response
Puzzling out graphic codes