



Introduction
Depression and anxiety are highly prevalent and associated with a substantial burden on both patients, their caregivers and society as a whole (Kessler, Reference Kessler2012; Whiteford et al., Reference Whiteford, Ferrari and Degenhardt2016; World Health Organization (WHO), 2016). The overlap between depressive and anxiety symptoms and disorders is the rule rather than the exception, and much of the same treatments are currently used for patients in both diagnostics categories (Nutt et al., Reference Nutt, Ballenger, Sheehan and Wittchen2002; Hettema, Reference Hettema2008; Goldberg, Reference Goldberg2011). Despite the many research efforts that have been made over the past decades, the etiological mechanisms underlying depressive and anxiety disorders are still poorly understood, which is partially due to the heterogeneous nature of the patient population (Kendler, Reference Kendler2014; Monroe and Anderson, Reference Monroe and Anderson2015), resulting in small to moderate observed treatments effects (Turner and Rosenthal, Reference Turner and Rosenthal2008; Cuijpers et al., Reference Cuijpers, van Straten, Bohlmeijer, Hollon and Andersson2010; Cooney, Reference Cooney2013; Roest et al., Reference Roest, de Jonge, Williams, de Vries, Schoevers and Turner2015). Scientific progress is more likely if the problem of diagnostic heterogeneity is effectively addressed. Unfortunately, more homogeneous clinical subtypes have been shown to be weakly associated with etiology, the course of illness, and treatment response (Baumeister and Parker, Reference Baumeister and Parker2012). Alternative data-driven subtype classifications based on cluster analyses (Lubke and Muthén, Reference Lubke and Muthén2005; Hastie et al., Reference Hastie, Tibshirani and Friedman2011; Van Loo et al., Reference Van Loo, De Jonge, Romeijn, Kessler and Schoevers2012), have also been shown to have limited associations with specific etiological mechanisms (Van Loo et al., Reference Van Loo, De Jonge, Romeijn, Kessler and Schoevers2012; Marquand et al., Reference Marquand, Wolfers, Mennes, Buitelaar and Beckmann2016). This limited association with etiology might be explained by the fact that these subtypes are primarily optimized to differentiate between symptom patterns and not between biological mechanisms (Hasler et al., Reference Hasler, Drevets, Manji and Charney2004). Subtypes might be more suitable to investigate etiological heterogeneity when biological profiles are used as the point of departure.
It has been acknowledged that theories assuming that there is a single biological disturbance underlying depression in all patients (e.g. monoamine deficiency) have limited validity (Kendell and Jablensky, Reference Kendell and Jablensky2003; Hasler, Reference Hasler2010; Kapur et al., Reference Kapur, Phillips and Insel2012). Rather, the specific disturbances are likely to differ between patients, even those with similar symptomatology and/or diagnoses (Insel et al., Reference Insel, Cuthbert, Garvey, Heinssen, Pine, Quinn, Sanislow and Wang2010). If we consider this, the low observed effect sizes in treatment trials could be explained by the fact that only in part of the patients treated with a certain compound (e.g. selective serotonin reuptake inhibitors), the treatment actually affects their individual biological disturbances (Tang et al., Reference Tang, Helmeste and Leonard2010). Identification of more homogeneous biomarker-based subtypes in the patient population could help to gain more insight into patient-specific etiological mechanisms and to better target treatments to those that are likely to benefit (Meyer and Ginsburg, Reference Meyer and Ginsburg2002; Bartova et al., Reference Bartova, Berger and Pezawas2010; Leuchter et al., Reference Leuchter, Cook, Hamilton, Narr, Toga, Hunter, Faull, Whitelegge, Andrews, Loo, Way, Nelson, Horvath and Lebowitz2010; Simon and Perlis, Reference Simon and Perlis2010; Simon, Reference Simon2011; e Silva, Reference e Silva2013; Miller and O'Callaghan, Reference Miller and O'Callaghan2013; Ozomaro et al., Reference Ozomaro, Wahlestedt and Nemeroff2013; Cuijpers et al., Reference Cuijpers, Ebert, Acarturk, Andersson and Cristea2016; Korte et al., Reference Korte, Prins, Krajnc, Hendriksen, Oosting, Westphal, Korte-Bouws and Olivier2015).
To our knowledge, the existence of depression/anxiety subtypes with different biological disturbance profiles and their manifest clinical characteristics have not been extensively studied before. Therefore, this study aimed to identify biomarker-based subtypes using latent class analysis (LCA) a large and well-phenotyped sample of depressive and/or anxiety patients (n = 1460). In this sample, 36 biomarkers were measured, representing different underlying mechanisms that have previously been found to be relevant to depression and anxiety disorders (e.g. hypothalamus-pituitary-adrenal axis function, inflammation). Next, in order to investigate the clinical relevance and utility of the identified biomarker-based subtypes, clinical characteristics and symptomatology were compared across the identified classes.
Methods and materials
Participants and procedures
The Netherlands Study of Depression and Anxiety (NESDA) is a multisite naturalistic cohort study that aims to examine the long-term course of depressive and anxiety disorders. A detailed description of the NESDA study design and sampling procedures can be found elsewhere (Penninx et al., Reference Penninx, Beekman, Smit, Zitman, Nolen, Spinhoven, Cuijpers, De Jong, Van Marwijk and Assendelft2008). In brief, the NESDA cohort consists of 2981 subjects, aged 18—65 years, with (a history of) anxiety and/or depressive disorder and healthy controls. The research protocol was approved by the Medical Ethical Committees of participating institutes, and after complete description of the study, all respondents provided written informed consent. For the present study, all 1460 subjects with a current (last month) diagnosis of a depressive or anxiety disorder according to the Composite International Diagnostic Interview (CIDI; WHO version 2.1) were selected. For additional analyses (see below), 634 healthy control subjects were added to the dataset.
Measurements
During a 4-hour baseline assessment including interviews, a medical examination, a cognitive computer task and collection of blood samples, extensive information was gathered about key (mental) health outcomes and demographic, psychosocial, clinical and biological determinants. Additional measures (written questionnaires and saliva samples) were carried out at home by the participants. Diagnostic and statistical manual of mental disorders-fourth edition (DSM-IV) diagnoses of depressive [minor depression, dysthymia and major depressive disorder (MDD)] and anxiety disorders (generalized anxiety disorder, social phobia, agoraphobia and panic disorder) were established using the Composite International Diagnostic Interview (CIDI) 2.1. Depression symptom severity was measured with the 30-item Inventory of Depressive Symptomatology Self Report (IDS-SR) (Rush et al., Reference Rush, Gullion, Basco, Jarrett and Trivedi1996). Anxiety symptom severity was measured with the Beck Anxiety Inventory (BAI) (Beck et al., Reference Beck, Epstein, Brown and Steer1988). Sociodemographic information included age, sex, number of chronic diseases, drinking and smoking behavior. The biological data consisted of waist circumference, body mass index (BMI), blood pressure (systolic/diastolic and the ankle-brachial index), heart rate variability and markers from blood and saliva samples. A summary of the biological methods is provided below. For more details, see online Supplementary Table S1.
Blood markers
Venous blood was drawn prior to the interview session (between 8:00 and 9:00 am) after an overnight fast. Venous blood samples were transferred to a local lab for routine assessments; serum and plasma were spun down within an hour and stored at −80 °C for later analyses. The routine assays included hematological variables (hemoglobin, hematocrit, and erythrocyte count), liver function (γ-glutamyltransferase, aspartate aminotransferase, alanine aminotransferase) and kidney function (creatinine), as well as markers related to the metabolic syndrome (MetS) and obesity (glucose, cholesterol, triglycerides, HDL- and LDL-cholesterol, thyroid-stimulating hormone, free thyroxine). Additional biomarkers are described below. Most of these markers’ associations with mental-health outcomes have previously been established (Chaves et al., Reference Chaves, Xue, Guralnik, Ferrucci, Volpato and Fried2004; Vancampfort et al., Reference Vancampfort, Correll, Wampers, Sienaert, Mitchell, De Herdt, Probst, Scheewe and De Hert2014; Hiles et al., Reference Hiles, Révész, Lamers, Giltay and Penninx2016).
Inflammation
C-reactive protein (hsCRP) was measured in duplicate by an in-house enzyme-linked immunosorbent assay (ELISA), based on purified protein and polyclonal anti-hsCRP antibodies (Dako, Glostrup, Denmark). Plasma IL-6 levels were measured in duplicate by a high sensitivity ELISA (PeliKine Compact TM ELISA, Sanquin, Amsterdam, The Netherlands). Plasma tumor necrosis factor alpha (TNF-α) levels were assayed in duplicate using a high-sensitivity solid phase ELISA (Quantikine® HS Human TNF- α Immunoassay, R&D systems Inc, Minneapolis, MN, USA). Tryptophan and (OH-)kynurenine concentrations were assayed by an automated online solid-phase extraction-liquid chromatographic-tandem mass spectrometric (XLC-MS/MS) method. Both inflammation and degradation of tryptophan along the kynurenine pathway have been found to be associated with depression in this sample (Lamers et al., Reference Lamers, Vogelzangs, Merikangas, De Jonge, Beekman and Penninx2013; Quak et al., Reference Quak, Doornbos, Roest, Duivis, Vogelzangs, Nolen, Penninx, Kema and de Jonge2014).
Neuroplasticity
Brain-derived neurotrophic factor (BDNF) protein levels were measured in serum samples using the Emax Immuno Assay system from Promega (Madison, WI, USA). IGF-I (nmol/l) was assayed centrally by chemiluminescence immunoassay of EDTA plasma on the Liaison autoanalyzer (DiaSorin, S.p.A., Italy). Both measures have previously been found to be associated with depression with melancholic features in this sample (Patas et al., Reference Patas, Penninx, Bus, Vogelzangs, Molendijk, Elzinga, Bosker and Voshaar2014).
Mineral balance
Measurements of parathyroid hormone (PTH) were performed at the Endocrine Laboratory of the VU University Medical Center. PTH levels were measured in EDTA plasma using an intact PTH assay. Intact PTH levels were measured using an immunometric assay (Architect, Abbott Diagnostics, Abbott Park, IL). Vitamin D was measured based on circulating levels of 25(OH)D, extracted and analysed by XLC-MS/MSa (Spark Holland, Emmen, the Netherlands) and coupled to a Quattro Premier XE tandem mass spectrometer (Waters Corp., Milford, MA, USA). Vitamin D has previously been found to be associated with depression in this sample (Milaneschi et al., Reference Milaneschi, Hoogendijk, Lips, Heijboer, Schoevers, van Hemert, Beekman, Smit and Penninx2014).
Steroid hormones
Dehydroepiandrosterone and its sulfate conjugate (DHEA/-S) were determined using a delayed one-step immunoassay with a chemiflex assay protocol. Sex Hormone Binding Globulin (SHBG) was determined using a two-step immunoassay with a chemiflex assay protocol. Total estradiol (E2) was determined using a delayed one-step immunoassay with a chemiflex assay protocol. Previously, steroid hormones were found to be associated with anxiety and depression in this sample (Giltay et al., Reference Giltay, Enter, Zitman, Penninx, van Pelt, Spinhoven and Roelofs2012; Morita et al., Reference Morita, Senzaki, Ishihara, Umeda, Iwata, Nagai, Hida, Nabeshima, Yukawa, Ozaki and Noda2014).
Leptin
Plasma leptin concentrations were measured in EDTA plasma using an ELISA kit (Human Leptin ELISA Kit; Linco Research, Inc, St. Charles, Missouri). Leptin has previously been found to be associated with depression (with atypical features) in this sample (Milaneschi et al., Reference Milaneschi, Lamers, Bot, Drent and Penninx2017).
Saliva markers
On a single day, prior to the first face-to-face assessment session, participants themselves collected saliva samples at home using Salivettes (Sarstedt AG and Co, Nürmbrecht, Germany). Measurements were taken at awakening [T1], 30 [T2], 45 [T3] and 60 [T4] minutes later, and in the evening (22:00 [T5] and 23:00 [T6]). Additionally, the dexamethasone suppression test (Carroll, Reference Carroll1982) was carried out by oral administration of a 0.5 mg dexamethasone pill directly after T6 and a final cortisol measurement the next morning at awakening (T7). The saliva samples were used to assess levels of cortisol, amylase and testosterone. These measures have previously been observed to be associated with depression and anxiety in this sample (van Santen et al., Reference van Santen, Vreeburg, Van der Does, Spinhoven, Zitman and Penninx2011; Giltay et al., Reference Giltay, Enter, Zitman, Penninx, van Pelt, Spinhoven and Roelofs2012; Veen et al., Reference Veen, Giltay, Licht, Vreeburg, Cobbaert, Penninx and Zitman2013).
Heart rate variability
A heart rate recording was performed with the Vrije Universiteit Ambulatory Monitoring System (Cuijpers et al., Reference Cuijpers, Berking, Andersson, Quigley, Kleiboer and Dobson2013) (VU-AMS). Subjects were wearing the VU-AMS device during a large part of the NESDA baseline assessment, while participating in different assessment parts (i.e. medical examination, interviewing, and a computer task). The start of the various assessment parts was marked with an event marker to divide the total recording into fixed periods. Movement registration through vertical accelerometry was used to excise periods where subjects were non-stationary. For this project, VU-AMS heart rate variability (HRV) during resting baseline, and HRV change from baseline to two stress conditions (interview and stressful computer task) were used. HRV has previously been found to be associated with depression in this sample (Licht et al., Reference Licht, de Geus, Zitman, Hoogendijk, van Dyck and Penninx2008).
Statistical analyses
LCA was used to identify data-driven subgroups with distinct biological profiles. LCA assumes that an unobserved, latent categorical variable explains the association among a set of observed variables. The input variables are listed in online Supplementary Table S1. Models with increasing numbers of classes were estimated and compared. The optimal model selection was based on the highest entropy and the lowest Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC). Relative entropy is a measure of classification accuracy (range: 0–1), with values closer to 1 indicating greater accuracy. Lower AIC and BIC values indicate that the model provides a better description of the data. Because these measures do not always agree, parsimony and interpretability were also taken into account. To avoid convergence on a solution at a local maximum (Nylund et al., Reference Nylund, Asparouhov and Muthén2007) LCA was run using up to 1000 random starting values and 250 final stage optimizations. LCA was conducted using Mplus version 5 (Muthen and Muthen, Reference Muthen and Muthen2007). To investigate the influence of the different variables on the model solution Cramer's V (Cramér, Reference Cramér1946) was calculated for each biomarker variable.
After the optimal model was identified, subjects were assigned to their most likely class based on their highest posterior class probability. Differences between classes (in biomarkers, sociodemographics, DSM-IV diagnoses and clinical characteristics) were investigated by using two-tailed χ2 statistics for categorical variables and one-way analysis of variance statistics for continuous variables, or by using the Kruskall–Wallis test if the outcomes were not normally distributed. The False Discovery Rate controlling procedure was used to counteract the problem of multiple comparisons (Benjamini and Hochberg, Reference Benjamini and Hochberg1995). All comparisons were conducted using SPSS for Windows, version 23 (IBM Inc., USA). To evaluate if the identified class structure was specifically informative about the biological heterogeneity in depressed/anxious patients or was more broadly reflective of normal biological variations in the population as a whole, all analyses were rerun in a dataset including both patients and healthy controls (n = 2094).
Data preprocessing
Clinically determined cut-off values to categorize the biomarker variables were available for some but not all biomarkers. Therefore, an alternative approach was taken, categorizing every variable based on percentiles, with the lowest and highest scoring 10th percentile of all subjects being coded as −1 and 1, respectively, and the middle 80% being coded 0. The 10th percentile cutoff was chosen to make sure that especially the more extreme, potentially clinically relevant variations in biomarker levels would be represented in the eventual LCA model. Setting the cut-offs at higher percentile values would lead to biomarker variables with more subjects in both the lower and upper category, but with a more within-category variation of biomarker levels. This makes the categorization potentially less useful for differentiation between subjects with distinct biomarker patterns as relevant interpersonal differences are eliminated by pooling patients with different biomarker levels in the same category. Indeed, exploratory analyses using 25th and 50th percentiles as cutoffs led models with many classes (i.e. the AIC and BIC kept decreasing with each class addition) that could not be easily distinguished from each other in terms of their specific biomarker patterns. In the final coding scheme, the number of subjects per decile varied between 8% and 12%, because in some cases a large number of subjects had the same score, and we chose to use the percentile closest to 10. The above-described coding was done separately for different sex/age (<30, 30–50, >50) strata, because the distributions of some biological variables are known to differ across sex and age (e.g. testosterone). Differences between classes on other potentially relevant covariates were investigated after identification of the optimal latent class model.
To ensure that the model solution would not be driven by the fact that some variables were essentially measuring the same thing, all variables with a correlation above 0.75 before recoding were summed after categorization (i.e. the hematological markers, the heart rate variability reactivity in both test conditions, systolic and diastolic blood pressure, aspartate and alanine aminotransferase). Subjects with a score of ⩽−1 got a value of −1, those with a score of 0 got a value of 0 and subjects with a score of ⩾1 got a value of 1 on a newly constructed compound variable. Recoding was done using SPSS for Windows, version 23 (IBM Inc., USA). The final dataset included 36 biological variables.
Results
The LCA results are shown in Table 1. The lowest BIC combined with adequate entropy indicated that the 3-class model best described the data. Although the AIC decreased for the more complex models up to six classes, these models were less optimal in terms of parsimony and showed only marginally higher entropy. For each class, Fig. 1 shows the probabilities of biomarker scores in the top or bottom 10th percentile. Table 2 shows the distribution of biomarkers across the three latent classes. Most biomarkers differed among classes, with the notable exception of the cortisol-related biomarkers. Waist circumference, BMI and leptin had the largest effect (Cramer's V > 0.5) on the model solution and were used to inform class labeling. Other variables (e.g. measures on inflammation and steroid hormones) showed smaller, but still meaningful, variation between classes (Cramer's V = 0.335–0.209, see Table 3).
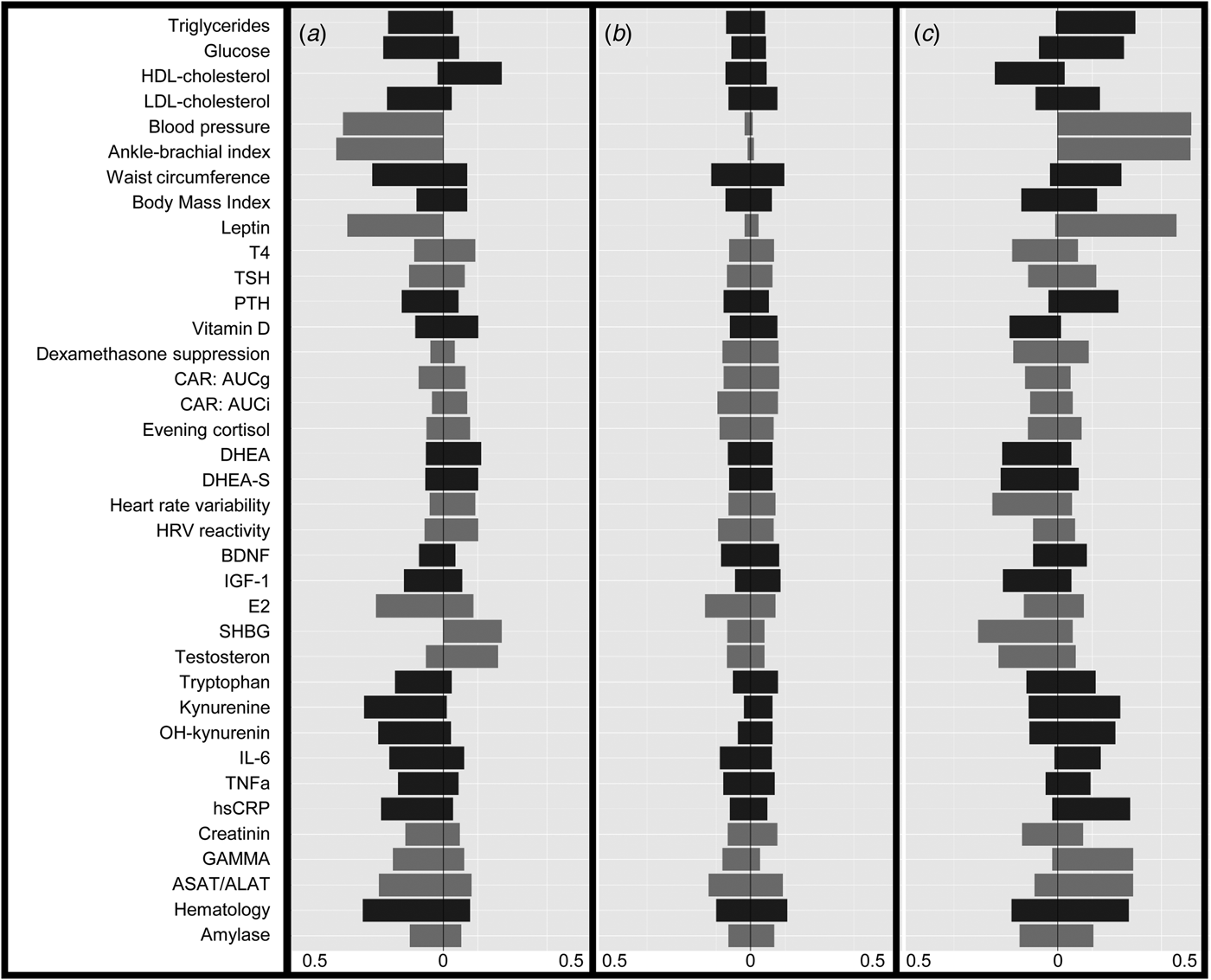
Fig. 1. Probabilities to score in the lowest (left) or highest (right) 10-th percentile of each variable for the different latent classes in the sample including subjects with current psychopathology. A = Lean (21.6%), B = Average (62.2%), C = Overweight (16.2%). Color groups consist of biomarkers with similar themes, as indicated in online Supplementary Table S1. Abbreviations: Blood pressure, combination of systolic and diastolic pressure; T4, free thyroxine; TSH, thyroid stimulating hormone; PTH, parathyroid hormone; CAR, cortisol awakening response; AUCg, area under the curve with respect to the ground, AUCi, area under the curve with respect to increase; DHEA(-S), dehydroepiandrosterone(-sulphate); HRV, heart rate variability; HRV reactivity, combination of HRV reactivity in both stress situations; BDNF, brain-derived neurotrophic factor, IGF-1 insulin-like growth factor 1; E2, estradiol; SHBG, sex hormone binding globulin; IL-6, interleukin 6; TNFa, tumor necrosis factor alpha; hsCRP, C-reactive protein; GAMMA, gamma-glutamyltransferase; ASAT/ALAT, combination of aspartate aminotransferase and, alanine aminotransferase; hematology, combination of hemoglobin, hematocrit, and erythrocyte values.
Table 1. Statistics for LCA models with different numbers of classes, based on the sample of subjects with current psychopathology (n = 1406)

a Most favorable score.
DF, Degrees of Freedom; AIC, Akaike Information Criterion; BIC, Bayesian Information Criterion; H, Entropy.
Table 2. Distribution of biomarkers across identified classes in the sample of subjects with current psychopathology

*Based on ANOVA for continuous variables (post-hoc = Tukey) and Kruskal–Wallis tests for non-normally distributed variables (post-hoc = Dunn test).
Significant differences by class (at α < 0.05 corrected using the False Discovery Rate controlling method):
a ‘lean’ v. ‘overweight’ class.
b ‘average’ v. ‘overweight’ class.
c ‘lean’ v. ‘average’ class.
Table 3. Cramer's V values for each biological variable in the 3-class model based on the sample of subjects with current psychopathology
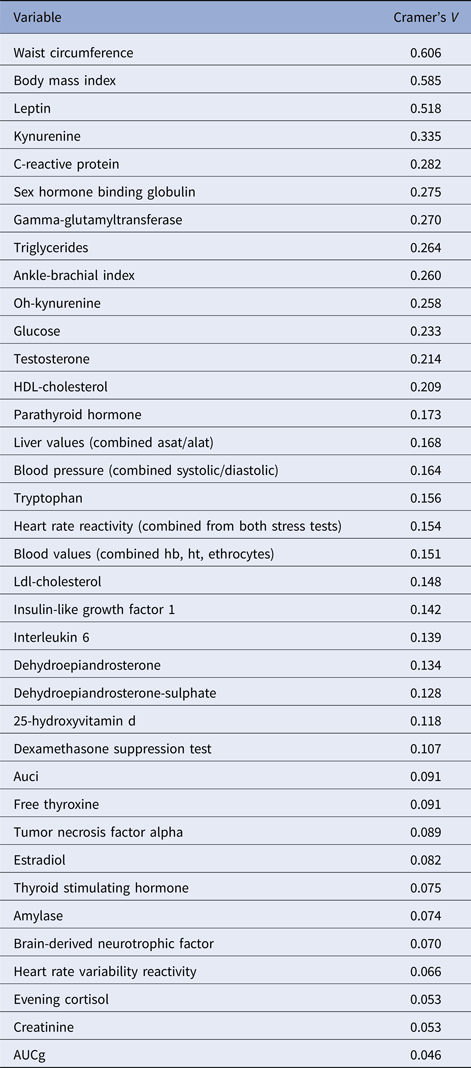
ASAT, aspartate aminotransferase; ALAT, alanine aminotransferase; Hb, hemoglobin; Ht, hematocrit; AUCi, area under the curve with respect to increase; AUCg, area under the curve with respect to the ground.
The first class was labeled ‘lean’ (n = 311) because it was associated with a healthy BMI and a comparatively high probability of being in the bottom 10th percentile for the obesity/MetS markers. The second class was labeled ‘average’ (n = 910) because it showed a low probability for extreme scores on any of the biomarkers. The third class was labeled ‘overweight’ (n = 239) and was characterized by a pattern of probabilities almost perpendicular to the lean class, with comparatively high probabilities to be in the upper 10% on obesity and MetS-related markers.
Table 4 shows the distribution of clinical characteristics across the three identified latent classes. As expected because of the pre-stratified processing of the data, the classes did not differ with respect to gender or age. The lean and average classes were similar in terms of diagnoses, whereas subjects in the overweight class were more likely to suffer from MDD. Persons in the overweight class were also more likely to endorse the atypical depressive subtype and to use psychotropic medication, specifically tricyclic antidepressants. Overweight subjects also had higher scores on both the IDS and the BAI. The lean class had a lower age of onset compared to the other classes (i.e. 18.1 v. 21.6 v. 22.6). There were no differences in course or diagnoses at 2 and 6 years follow-up (see online Supplementary Table S2). Individual symptoms of depression and anxiety did not differ between classes (data not shown).
Table 4. Distribution of characteristics across identified classes in the sample of subjects with current psychopathology
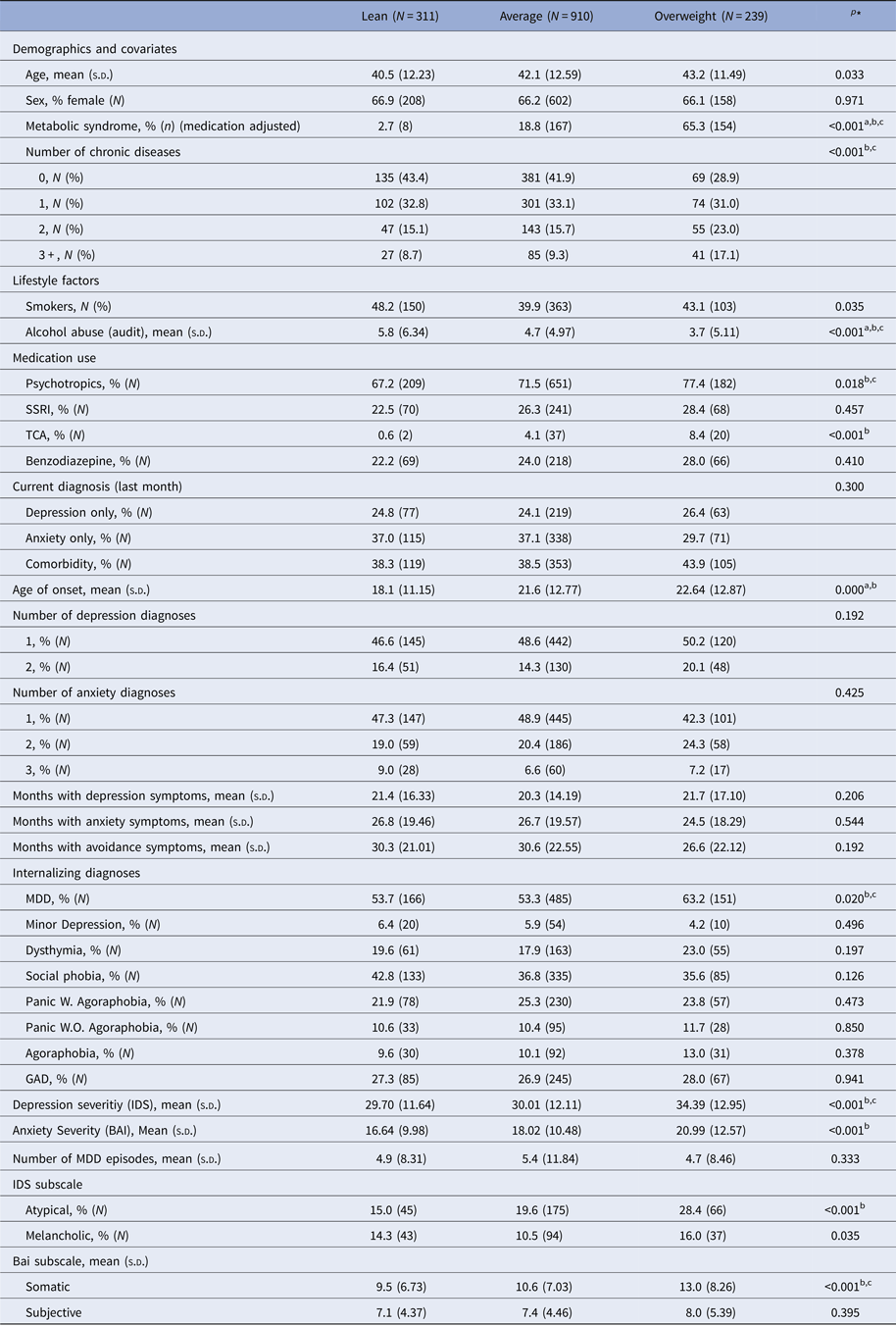
AUDIT, alcohol use disorder identification test; BAI, Beck Anxiety Inventory; BMI, body mass index; CIDI, Composite Interview Diagnostic Instrument; GAD, generalized anxiety disorder; IDS, Inventory of Depressive Symptomatology; MDD, major depression, NA, not applicable; SSRI, selective serotonin reuptake inhibitors; TCA, tricyclic antidepressants.
*Based on ANOVA for continuous variables (post-hoc = Tukey), Kruskal–Wallis tests for non-normally distributed variables (post-hoc = Dunn test) and chi-square test for categorical variables.
Significant differences by class (at α < 0.05 corrected using the False Discovery Rate controlling method):
a ‘lean’ v. ‘average’ class.
b ‘lean’ v. ‘overweight’ class.
c ‘average’ v. ‘overweight’ class.
LCA in the combined sample of patients and healthy controls (see online Supplementary Table S3) again showed a 3-class model to be optimal. The classes were very similar to the original model with regard to their respective biomarker profiles (see online Supplementary Fig. S1). When compared across the classes, the percentage of subjects with current psychopathology was higher in the overweight class, whereas the percentages of patients and controls in the lean class were equal (see online Supplementary Table S4).
Discussion
This study aimed to use LCA in to identify subgroups with different biomarker profiles in a large sample of patients with depressive and anxiety disorders. A lean (21.6%), an average (62.2%) and an overweight (16.2%) class were identified. Overall, the model seemed to reflect somatic health status, which was confirmed by the observation of similar classes when healthy controls were included in the sample. Still, the fact that the subjects with psychopathology were relatively likely to be in the ‘overweight’ class compared with healthy controls, indicates a possible connection between these disorders and the overweight biomarker profile. Furthermore, we found that the lean group had a significantly lower age of onset compared to the other two groups (see Table 4). Although the mean ages of onset are all in early adulthood and relatively close to each other, it cannot be excluded that there may be subtle differences in etiological mechanisms.
These bottom-up findings align with findings from research that used a more top-down approach and showed an association between depression and anxiety and obesity/MetS in this sample (van Reedt Dortland et al., Reference van Reedt Dortland, Giltay, van Veen, van Pelt, Zitman and Penninx2009; Van Reedt Dortland et al., Reference Van Reedt Dortland, Giltay, Van Veen, Zitman and Penninx2010), and with results from large-scale meta-analyses (Blaine, Reference Blaine2008; Luppino et al., Reference Luppino, de Wit, Bouvy, Stijnen, Cuijpers, Penninx and Zitman2010; Sardinha and Nardi, Reference Sardinha and Nardi2014; Vancampfort et al., Reference Vancampfort, Correll, Wampers, Sienaert, Mitchell, De Herdt, Probst, Scheewe and De Hert2014; Ghanei Gheshlagh et al., Reference Ghanei Gheshlagh, Parizad, Sayehmiri, Zamanian-Azodi and Rashidy-pour2015; Mannan et al., Reference Mannan, Mamun, Doi and Clavarino2016). The exact mechanisms behind these associations are unclear, partially because the (bi)directional nature of the association is still a point of discussion (Blaine, Reference Blaine2008; Ghanei Gheshlagh et al., Reference Ghanei Gheshlagh, Parizad, Sayehmiri, Zamanian-Azodi and Rashidy-pour2015; Hiles et al., Reference Hiles, Révész, Lamers, Giltay and Penninx2016; Mannan et al., Reference Mannan, Mamun, Doi and Clavarino2016). Obesity might cause depression and anxiety through social or biological mechanisms, but it might also be that the excessive weight gain is caused by the unhealthy lifestyle habits of patients. Medication use is another risk factor, as it is becoming apparent that many commonly used psychotropic medications such as antidepressants are associated with cardiometabolic risk factors such as insulin resistance, obesity, and dyslipidemia (Abosi et al. Reference Abosi, Lopes, Schmitz and Fiedorowicz2018). Evidence from the current sample supports this hypothesis. We found that psychotropic medication use is higher in the overweight subtype, and previous research in this sample showed a directional relationship between medication use and waist circumference and MetS (Hiles et al., Reference Hiles, Révész, Lamers, Giltay and Penninx2016). Another interesting hypothesis is that depression and the MetS share a common cause, for instance, genetic risk factors (Bornstein et al., Reference Bornstein, Schuppenies, Wong and Licinio2006). Indeed, some evidence indicates that MetS and depression are caused by similar alterations of the stress system, including the hypothalamus-pituitary-adrenal axis, the autonomic nervous system, the immune system, and platelet and endothelial function (Van Reedt Dortland et al., Reference Van Reedt Dortland, Giltay, Van Veen, Zitman and Penninx2010; Luppino et al., Reference Luppino, Bouvy, Giltay, Penninx and Zitman2014; Marazziti et al., Reference Marazziti, Rutigliano, Baroni, Landi and Dell'Osso2014; Vancampfort et al., Reference Vancampfort, Correll, Wampers, Sienaert, Mitchell, De Herdt, Probst, Scheewe and De Hert2014; Vogelzangs et al., Reference Vogelzangs, Beekman, van Reedt Dortland, Schoevers, Giltay, de Jonge and Penninx2014).
However, we found no association between the overweight subtype and course or diagnoses at 2- and 6-year follow-up. It is possible that no such association exists, but there are alternative explanations. It is possible that other causal factors (not shared between depression and the MetS) obfuscated the results. Furthermore, in this sample, it has been shown that especially MDD subjects (with and without comorbid anxiety) are more likely to change weight compared to controls (de Wit et al., Reference de Wit, van Straten, Lamers, Cuijpers and Penninx2015; Gibson-Smith et al., Reference Gibson-Smith, Bot, Milaneschi, Twisk, Visser, Brouwer and Penninx2016). If subsequent biomarker changes also occurred, these subjects might have switched subtypes, and it might be that this change in subtype would have been more informative with respect to course than baseline subtype membership. Unfortunately, the current data did not allow for investigation of subtype changes because biomarker data needed to do so was not available at follow-up.
In accordance with previous symptom-based subtyping research (Van Loo et al., Reference Van Loo, De Jonge, Romeijn, Kessler and Schoevers2012; Rhebergen et al., Reference Rhebergen, van der Steenstraten, Sunderland, de Graaf, Ten Have, Lamers, Penninx and Andrews2013; de Vos et al., Reference de Vos, Wardenaar, Bos, Wit and de Jonge2015; Wardenaar et al., Reference Wardenaar, Wanders, ten Have, de Graaf and de Jonge2017) this study does not provide a bottom-up validation for the DSM-diagnosis categories of depression and anxiety disorders as patients with different diagnoses did not cluster into distinct biological classes. Also, in contrast to previous research (Cizza et al., Reference Cizza, Ronsaville, Kleitz, Eskandari, Mistry, Torvik, Sonbolian, Reynolds, Blackman, Gold and Martinez2012; Lamers et al., Reference Lamers, Vogelzangs, Merikangas, De Jonge, Beekman and Penninx2013; Łojko et al., Reference Łojko, Buzuk, Owecki, Ruchała and Rybakowski2015; Milaneschi et al., Reference Milaneschi, Lamers, Bot, Drent and Penninx2017), we did not find an association between the latent classes and atypical v. melancholic features of depression. When comparing melancholic and atypical symptomatology on the IDS-SR (Rush et al., Reference Rush, Gullion, Basco, Jarrett and Trivedi1996) between classes, the only significant difference was that the overweight class showed a higher percentage of atypical specifiers compared to the lean class. However, in absolute terms, both atypical and melancholic IDS-SR counts were highest for the overweight class (although differences on the melancholic subscale were no longer significant after correction for multiple comparisons).
Overall, the results indicate that biomarker heterogeneity among depressive and/or anxiety patients mostly reflects variations in somatic health that extend into the part of the population without mental health problems. However, this does not mean that part of these biological variations is not also related to psychological health. As stated above, variations in somatic health are known to be strongly related to variations in psychopathology. Additionally, there may be smaller but still relevant associations between specific sets of biomarkers and depression/anxiety that were not detected in the current analyses but could be of strong interest for the development of more personalized etiological models. A future methodological challenge lies in better investigating if generic somatic-health-related biological effects can be separated from more specific psychopathology-related biological effects. Possibilities for this may lie in the use of more flexible clustering algorithms, but also in the combination of biomarker and clinical data in the identification of subtypes. With regard to the biomarkers that could be investigated deeper, the current results suggested that there were several biomarkers that had smaller effects in the LCA results than the MetS biomarkers, but could still be potentially interesting as targets for further research, such as inflammation-related markers (e.g. Kynurenine, hsCRP) or sex-related markers (e.g. SHGB, testosterone).
Strengths and limitations
Strengths of the current study included the large sample size, the broad range of available biomarkers, and the presence of thorough clinical assessments. However, the results should also be interpreted in the context of several limitations. First, the results apply to a group of outpatients and results cannot be directly translated to other groups (e.g. inpatients). Second, LCA makes very strong assumptions (e.g. local independence) that enable LCA to estimate interpretable but strongly simplified models. However, we believe that (the violation of) the assumption of local independence is not a driving force in our model, because we made sure not to include strongly correlated pairs of biomarkers and found classes that were not defined by specific clusters of correlated biomarkers but rather by a collection of biomarkers from different domains (see Table 2). Third, the possible negative influence of underweight could not be evaluated because people with a BMI < 18.5 were rare compared with overweight persons. Fourth, to facilitate the analyses, continuous biomarker measurements were coded to a discrete scale, possibly leading to a loss of information. Latent Profile Analysis (using continuous variables) usually provides a more nuanced representation of the data. Unfortunately, this technique could not be applied to our dataset because it is very sensitive to non-normal distributions (Morgan et al., Reference Morgan, Hodge and Baggett2016). Fifth, coding was stratified for sex and age groups, but other unknown/unmeasured factors were not considered. Finally, the biological data needed to estimate the subtypes was not available at follow-up, making it impossible to investigate subtype stability over time and the effects of subtype changes over time.
In conclusion, three biological subgroups were identified with LCA among depressive and/or anxiety patients. These subgroups showed classes that (1) were strongly tied to general (metabolic) health, (2) did not reflect any natural cutoffs along the lines of the traditional diagnostic classifications, and (3) showed that especially poor metabolic health had a strong relationship with depression and anxiety and could, therefore, be seen as a distal marker for these types of psychopathology.
Supplementary Material
The supplementary material for this article can be found at https://doi.org/10.1017/S0033291718001307
Acknowledgements
The infrastructure for the NESDA study (www.nesda.nl) is funded through the Geestkracht program of the Netherlands Organisation for Health Research and Development (ZonMw, grant number 10-000-1002) and financial contributions by participating universities and mental health care organizations (VU University Medical Center, GGZ inGeest, Leiden University Medical Center, Leiden University, GGZ Rivierduinen, University Medical Center Groningen, University of Groningen, Lentis, GGZ Friesland, GGZ Drenthe, Rob Giel Onderzoekscentrum). We would like to thank the Center for Information Technology of the University of Groningen for their support and for providing access to the Peregrine high performance computing cluster.
Financial support
Dr. Lamers has received funding from the European Union Seventh Framework Programme (FP7/2007-2013) under grant agreement n° PCIG12-GA-2012-334065.
Conflict of interest
All authors declare that they have no conflicts of interest.








 Open access
Open access