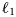Introduction
The through-the-wall radar imaging (TWRI) technique has been widely used in a variety of applications such as counter-terrorism, life detection in calamity rescuing, and security check for its non-destructive and non-contactable characteristics [Reference Muqaibel1–Reference Laviada, Arboleya, Lopez-Gayarre and Las-Heras3]. These applications must be guaranteed with high-resolution and high-sensitivity detection properties. However, satisfying these properties is considerably challenging due to the factors such as strong wall clutter reflection, radar echo signal sparseness characteristics, and prolonged data collection [Reference Tang, Bouzerdoum and Phung4]. To suppress the wall clutter reflection, numerous research studies have been exploited such as low-rank and sparse representation (LRSR), spatial filtering, and subspace projection [Reference Tivive, Bouzerdoum and Amin5–Reference Zhang and Xia7]. To reconstruct the target image, back projection (BP), and compressed sensing (CS) can be implemented. Compared to BP, CS can recover a sparse signal from a small number of data sets, whose sampling rate is far lower than what the Nyquist sampling theory claims, by exploiting signal sparsity [Reference Zhang, Chen, Chen, Chi and Wu8]. Hence, a CS-based method is possible to reconstruct target image with fewer data collection, which alleviates the burden of prolonged data collection and computational cost [Reference Lei, Huang and Sun9, Reference Yan, Xu and Zhang10]. In general, CS-based microwave imaging methods can be regarded as linear imaging under the born approximation. It can provide an accurate reconstruction scheme when the target dielectric constant is small and the target size is appropriate.
Since the TWRI is an ill-posed and inverse problem, it can be solved by using a minimum iterative optimization method enforced by regularization term. There are various regularization terms that can fit different scenarios. The $\ell _{2}$ (or Tikhonov) regularization yields linear reconstruction algorithms so that it can be applied to smooth scenarios [Reference Unser, Fageot and Gupta11]. Total-variation (TV) regularization preserves the rapid transitions and discontinuities in the signal to impose stability to signal recovery so that it is more suitable for piecewise smooth scenarios [Reference Hosseini and Plataniotis12]. Low-rank and joint sparsity regularization in CS methodology implement wall clutter estimation with discrete prolate spheroidal sequence basis before estimating the target image so that it is suitable for handling the nonlinear inverse problem [Reference Tang, Bouzerdoum and Phung4]. An autofocus CS algorithm is proposed to construct the imagery under the condition of unknown wall parameters. In the autofocus CS algorithm, the nonlinear conjugate gradient method is used to estimate the hyperparameters during the iterative framework [Reference Jin13]. Unfortunately, the traditional regularization term is not always optimal since they are not omni-knowledge to all types of scenarios.
(or Tikhonov) regularization yields linear reconstruction algorithms so that it can be applied to smooth scenarios [Reference Unser, Fageot and Gupta11]. Total-variation (TV) regularization preserves the rapid transitions and discontinuities in the signal to impose stability to signal recovery so that it is more suitable for piecewise smooth scenarios [Reference Hosseini and Plataniotis12]. Low-rank and joint sparsity regularization in CS methodology implement wall clutter estimation with discrete prolate spheroidal sequence basis before estimating the target image so that it is suitable for handling the nonlinear inverse problem [Reference Tang, Bouzerdoum and Phung4]. An autofocus CS algorithm is proposed to construct the imagery under the condition of unknown wall parameters. In the autofocus CS algorithm, the nonlinear conjugate gradient method is used to estimate the hyperparameters during the iterative framework [Reference Jin13]. Unfortunately, the traditional regularization term is not always optimal since they are not omni-knowledge to all types of scenarios.
In order to tackle these issues, deep learning has attracted much attention in handling the signal recovery problem in recent years [Reference Aggarwal, Mani and Jacob14–Reference Zheng, Pan, Ni, Shi, Ye and Fang17, Reference Li, Cui, Guo, Kong and Yang19]. In [Reference Aggarwal, Mani and Jacob14], a model-based deep learning network was proposed to recover the target image from noisy and sparse measurements based on an alternating recursive algorithm with the physical model. In [Reference Sanghvi, Kalepu and Khankhoje15], a framework based on deep learning is proposed for solving the electromagnetic (EM)inverse scattering problem, which constructs and expands the functions of existing physics-based inversion algorithms. In [Reference Chen, Wei, Li and Rocca16], there are also related physics-based deep learning methods for solving the inverse scattering problem. In [Reference Zheng, Pan, Ni, Shi, Ye and Fang17], a convolutional neural network (CNN)-based human posture reconstruction method for TWRI is proposed to reconstruct accurate human posture behind walls. The training process follows a supervision-prediction learning pipeline inspired by the cross-modal learning technique. In [Reference Zhang, Song, Chen, Wang, Jia and Yan18], an approach based on generative adversarial nets is proposed to suppress multi-path ghosts, side/grating lobe artifacts, and wall penetration effect suppression in MIMO TWRI. In [Reference Li, Cui, Guo, Kong and Yang19], the authors proposed a fully convolutional network (FCN) to extract multi-scale features to implement target imaging in TWRI. However, the lack of physical model in the pure FCN in [Reference Li, Cui, Guo, Kong and Yang19] causes the network to depend heavily on a large amount of training data and is hard to converge.
Motivated by the analysis mentioned above, a TWRI scheme is proposed based on a physical model-driven deep learning network prior, termed CS-Net, which is unrolled from the iterative CS optimization. Compared with the pure data-driven deep learning method in TWRI, CS-Net can achieve faster convergence speed with less training data. Our main contributions are summarized as follows:
(i) A physical model of the radar signal is considered in our proposed deep network to reduce the number of network parameters and avoid the network to be a black-box solver.
(ii) We propose a deep network unrolled from the iterative CS optimization. Compared with the traditional CS method, it greatly improves the performance of texture detail reconstruction and the reconstructed image has a higher resolution.
(iii) The performance of the target image reconstruction in TWRI using CS-Net is evaluated and compared with those traditional CS, BP, and LRSR schemes. Simulation results demonstrate that the performance of the proposed method is better than the traditional methods in terms of minimum square error (MSE) and target texture details.
The rest of this paper is organized as follows. Section “Signal model and compressed sensing” briefly introduces the radar signal physical model and reviews the CS model for target image reconstruction in TWRI. Section “CS-NET architecture” introduces the architecture of the model-driven deep learning network and loss function. Section “Simulation results” presents the experimental results and analysis. The final section concludes.
Notations: Boldface capital letters denote matrices and boldface lower case letters denotevectors. ${({\cdot}) ^{\rm {H}}}$ denotes the conjugate transpose operator. ${\left \Vert {{\rm { }} \cdot {\rm { }}} \right \Vert _2}$
denotes the conjugate transpose operator. ${\left \Vert {{\rm { }} \cdot {\rm { }}} \right \Vert _2}$ denotes the Euclidean norm of a vector, respectively. ${\mathbb C}$
denotes the Euclidean norm of a vector, respectively. ${\mathbb C}$ denotes the set of all the complex number, and ${\mathbb R}$
denotes the set of all the complex number, and ${\mathbb R}$ denotes the set of all the real number. $\ast$
denotes the set of all the real number. $\ast$ denotes the convolution operation. ${\bf 0}$
denotes the convolution operation. ${\bf 0}$ denotes the zero vector.
denotes the zero vector.
Signal model and compressed sensing
System scenario and signal model
The TWRI system in this study is considered in a two-dimensional (2-D) domain consisting of a pair of signal transmitter and receiver, a front wall, and a target. As depicted in Fig. 1, the signal transmitter and the receiver move against the wall with each step forms an antenna pair, which is equivalent to a multi-input-multi-output scanning array. In order to better illustrate the TWRI problem, the polarization of the antenna of the signal transmitter and receiver pair is along the $z$ -axis. Also, a 2-D EM wave with the longitude direction along the $z$
-axis. Also, a 2-D EM wave with the longitude direction along the $z$ -axis is considered. Moreover, to investigate the performance limitation of our proposed method, the TWRI scenario is assumed to be surrounded by a perfect match area (PMA), which absorbs all the EM waves without reflection to form a free-space setting.
-axis is considered. Moreover, to investigate the performance limitation of our proposed method, the TWRI scenario is assumed to be surrounded by a perfect match area (PMA), which absorbs all the EM waves without reflection to form a free-space setting.

Fig. 1. TWRI system scenario consists of a pair of transmitter and receiver, a front wall, a target, and a PMA. The transmitter and receiver pair move against the wall to form a B-scan.
Hence, the radar echo signal $s_{r}( t)$ is given by the convolution of the transmitted signal $s_{t}( t)$
is given by the convolution of the transmitted signal $s_{t}( t)$ and the system function $h( t)$
and the system function $h( t)$ , which describes the pulse response of the imaging area:
, which describes the pulse response of the imaging area:

Assuming the material of the wall and the target is non-dispersive and homogeneous, the signal channel can only influence the magnitude and the phase of the signal [Reference Tivive and Bouzerdoum20]. $h( t)$ can be written as:
can be written as:

where $\alpha _{i, j}$ and $\sigma _{i, j}$
and $\sigma _{i, j}$ , respectively, denote the complex reflectivity coefficient and the path loss factor of a single point located at ${\bf x}_{i, j} = ( x_{i},\; \, y_{j})$
, respectively, denote the complex reflectivity coefficient and the path loss factor of a single point located at ${\bf x}_{i, j} = ( x_{i},\; \, y_{j})$ . $\delta ( t-\tau _{i j})$
. $\delta ( t-\tau _{i j})$ denotes the impulse response of a single point located at ${\bf x}_{i, j}$
denotes the impulse response of a single point located at ${\bf x}_{i, j}$ with a propagation delay from transmitter to the single point, and back to the receiver. $L$
with a propagation delay from transmitter to the single point, and back to the receiver. $L$ and $W$
and $W$ denote the number of pixels along the length and width of the imaging area, respectively.
denote the number of pixels along the length and width of the imaging area, respectively.
Here, we use matrix ${\bf X}$ to represent the complex reflectivity coefficient distribution of the imaging area:
to represent the complex reflectivity coefficient distribution of the imaging area:

Since the radar echo signal is affected by the complex reflectivity coefficient distribution of the imaging area, matrix ${\bf X}$ can be calculated by solving the inverse problem using the CS methodology based on the physical model of the signal in the next subsection.
can be calculated by solving the inverse problem using the CS methodology based on the physical model of the signal in the next subsection.
Compressed sensing and physical model
The TWRI system can be thought of as an operator ${\bf A}$ that acts on an imaging domain vector ${\bf x}$
that acts on an imaging domain vector ${\bf x}$ to yield a vector of measurement ${\bf b}$
to yield a vector of measurement ${\bf b}$ [Reference Zhang and Xia7]. The goal of the CS imaging scheme is to recover vector ${\bf x}$
[Reference Zhang and Xia7]. The goal of the CS imaging scheme is to recover vector ${\bf x}$ from the measurement vector ${\bf b}$
from the measurement vector ${\bf b}$ , which is given by:
, which is given by:

where ${\bf A} = {\bf M}{\bf P}$ denotes the sensing matrix. ${\bf M} \in {{\mathbb R}^{Q \times ( {K} \times {N_a}) }}$
denotes the sensing matrix. ${\bf M} \in {{\mathbb R}^{Q \times ( {K} \times {N_a}) }}$ and ${\bf P} \in {{\mathbb C}^{( {K} \times {N_a}) \times {J} }}$
and ${\bf P} \in {{\mathbb C}^{( {K} \times {N_a}) \times {J} }}$ denote the Gaussian random measurement matrix and the dictionary matrix, respectively [Reference Li, Xi, Zhang and Liu21]. $Q$
denote the Gaussian random measurement matrix and the dictionary matrix, respectively [Reference Li, Xi, Zhang and Liu21]. $Q$ is the number of rows of matrix ${\bf M}$
is the number of rows of matrix ${\bf M}$ , $K$
, $K$ is the number of frequencies point, ${N_a}$
is the number of frequencies point, ${N_a}$ represents the number of antenna pairs and ${J} = {L}\times {W}$
represents the number of antenna pairs and ${J} = {L}\times {W}$ represents the image pixels. ${\bf x} \in {\mathbb C}^{ {J} \times 1}$
represents the image pixels. ${\bf x} \in {\mathbb C}^{ {J} \times 1}$ denotes the image of complex reflectivity coefficient vector, which is obtained by resizing ${\bf X}$
denotes the image of complex reflectivity coefficient vector, which is obtained by resizing ${\bf X}$ into a column vector. In the TWRI system, the dictionary matrix ${\bf P}$
into a column vector. In the TWRI system, the dictionary matrix ${\bf P}$ is given by:
is given by:


where ${\bf f} = ( f_{1},\; \, f_{2},\; \, \ldots ,\; \, f_{k},\; \, \ldots ,\; \, f_{K}) ^{{\rm H}}$ denotes the frequencies point of the echo signal from the receiver with number of frequencies point $K$
denotes the frequencies point of the echo signal from the receiver with number of frequencies point $K$ , where $f_{k}$
, where $f_{k}$ denotes the $k$
denotes the $k$ -th frequency point. ${\bf t}_{ij}$
-th frequency point. ${\bf t}_{ij}$ denotes the round-trip delay between the $i$
denotes the round-trip delay between the $i$ -th antenna position and the $j$
-th antenna position and the $j$ -th image pixel. Since ${\bf A}$
-th image pixel. Since ${\bf A}$ represents the mapping from the imaging field to measurement field, measurement vector ${\bf b} \in {\mathbb C}^{ {Q} \times 1}$
represents the mapping from the imaging field to measurement field, measurement vector ${\bf b} \in {\mathbb C}^{ {Q} \times 1}$ can be obtained by down-sampling radar echo signal matrix ${\bf Y}$
can be obtained by down-sampling radar echo signal matrix ${\bf Y}$ in frequency domain and vector ${\bf b}$
in frequency domain and vector ${\bf b}$ is given by:
is given by:


where ${\bf R} \in {{\mathbb C}^{ {T_i} \times {N_a}}}$ denotes the echo signal matrix from the receiver in time domain and ${\bf F} \in {{\mathbb C}^{ {K} \times {T_i}}}$
denotes the echo signal matrix from the receiver in time domain and ${\bf F} \in {{\mathbb C}^{ {K} \times {T_i}}}$ denotes the 2-D discrete Fourier transform base matrix that acting on ${\bf R}$
denotes the 2-D discrete Fourier transform base matrix that acting on ${\bf R}$ . Here, ${T_i}$
. Here, ${T_i}$ represents the index of traveling time in time domain and $vec( {\bf Y})$
represents the index of traveling time in time domain and $vec( {\bf Y})$ represents resize matrix ${\bf Y}$
represents resize matrix ${\bf Y}$ into a column vector. Then, a high-resolution image vector ${\bf x}_{\text {rec}}$
into a column vector. Then, a high-resolution image vector ${\bf x}_{\text {rec}}$ can be recovered from the under determined equations ${\bf b} = {\bf A}{\bf x}$
can be recovered from the under determined equations ${\bf b} = {\bf A}{\bf x}$ by solving the problem of the following minimization:
by solving the problem of the following minimization:

where $\lambda$ is a regularization parameter that adjusts the weights of data consistency (DC) term and the regularization term. $R( {\bf x})$
is a regularization parameter that adjusts the weights of data consistency (DC) term and the regularization term. $R( {\bf x})$ is an regularization prior. $R( {\bf x})$
is an regularization prior. $R( {\bf x})$ is a small scalar when ${\bf x}$
is a small scalar when ${\bf x}$ is a noise-free image, while its value is high for noisy and artifact image [Reference Aggarwal, Mani and Jacob14]. Traditional choices include Tikhonov [Reference Unser, Fageot and Gupta11], TV [Reference Hosseini and Plataniotis12], as well as their combinations. Nevertheless, the method mentioned above is not always optimum due to the following reasons:
is a noise-free image, while its value is high for noisy and artifact image [Reference Aggarwal, Mani and Jacob14]. Traditional choices include Tikhonov [Reference Unser, Fageot and Gupta11], TV [Reference Hosseini and Plataniotis12], as well as their combinations. Nevertheless, the method mentioned above is not always optimum due to the following reasons:
(i) The reconstruction result can be affected by the initiative value ${\bf x}_{0}$
 , but there is no theoretical instruction on how to choose a suitable initiative value.
, but there is no theoretical instruction on how to choose a suitable initiative value.(ii) The $\lambda$
plays a vital role in the reconstruction. But it is challenging to choose the most suitable $\lambda$ value.



In order to tackle these issues, we will introduce a deep learning network to yield a physical model-driven deep network (CS-Net) in the next subsection.
CS-Net architecture
To overcome the limitations mentioned above, we propose an efficient and flexible iterative CNN-based framework CS-Net based on the physical model to reconstruct the target image. The structure of the CS-Net is shown in Fig. 2. The iterative network alternates between a CNN-based estimator sub-network $E( {\bf x})$ and a DC sub-network based on the conjugate gradient (CG) method. In order to enhance the network performance and effectively speed up the convergence rate, each layer in $E( {\bf x})$
and a DC sub-network based on the conjugate gradient (CG) method. In order to enhance the network performance and effectively speed up the convergence rate, each layer in $E( {\bf x})$ is composed of three types of operations: convolution (Conv), batch normalizing (BN), and rectified linear units (ReLU). The first and the middle layers “CNN + BN + ReLU” use 64 filters with size $3 \times 3 \times 64$
is composed of three types of operations: convolution (Conv), batch normalizing (BN), and rectified linear units (ReLU). The first and the middle layers “CNN + BN + ReLU” use 64 filters with size $3 \times 3 \times 64$ . The last layer “CNN + BN” adopts 64 filters with size $3 \times 3 \times 64$
. The last layer “CNN + BN” adopts 64 filters with size $3 \times 3 \times 64$ to reconstruct the output image.
to reconstruct the output image.

Fig. 2. Flowchart of the CS-Net architecture. The network consists of a cascade of iteration block, with each block consisting of a CNN-based estimator $E( {\bf x})$ and a DC sub-network ${\rm DC}$
and a DC sub-network ${\rm DC}$ . Each layer in $E( {\bf x})$
. Each layer in $E( {\bf x})$ is composed of three types of operations: convolution (Conv), batch normalizing (BN), and rectified linear units (ReLU).
is composed of three types of operations: convolution (Conv), batch normalizing (BN), and rectified linear units (ReLU).
In Section “Signal model and compressed sensing,” we have introduced that solving the problem of TWRI is to recover high-resolution image vector ${\bf x}_{\text {rec}}$ by (7). Here, we will solve the problem efficiently by introducing a CNN-based regularization prior, and the problem (7) can be reformulated as:
by (7). Here, we will solve the problem efficiently by introducing a CNN-based regularization prior, and the problem (7) can be reformulated as:


where ${N_w}$ is a learned CNN estimator of noise and alias patterns, which depends on the learned parameters ${w}$
is a learned CNN estimator of noise and alias patterns, which depends on the learned parameters ${w}$ . $\lambda$
. $\lambda$ is a trainable regularization parameter. $E( {\bf x})$
is a trainable regularization parameter. $E( {\bf x})$ is a CNN-based estimator sub-network of CS-Net. It can be regarded as a denoising part of ${\bf x }$
is a CNN-based estimator sub-network of CS-Net. It can be regarded as a denoising part of ${\bf x }$ to learn the redundancies radar echo signals and remove ghosts and noises.
to learn the redundancies radar echo signals and remove ghosts and noises.
Then, by introducing an auxiliary intermediate variable $e_{n}$ , we can obtain an alternating iterative formulation to unroll the recursive network:
, we can obtain an alternating iterative formulation to unroll the recursive network:


By calculating the gradient of problem (9a) and setting it to be zero, then we can obtain the following equation:

Then problem (9a) can be solved by:

Problem (11) can be solved by using CG method. Furthermore, by regarding each iteration in CG scheme as a layer, it forms the DC sub-network in the whole network.
Taking each iteration as one layer, the above update rule can be regarded as an unrolled deep CNN called CS-Net. After initializing with ${\bf x}_{0} = {{\bf A}^{{\rm H}} {\bf b}}$ , it alternatively updates $e_{n}$
, it alternatively updates $e_{n}$ and $x_{n + 1}$
and $x_{n + 1}$ by CNN-based estimator step (9b) and CG step (11). The sub-network $E( {\bf x})$
by CNN-based estimator step (9b) and CG step (11). The sub-network $E( {\bf x})$ learns the redundancies of the radar echo signal and remove ghosts and noises. Then, the DC sub-network, which encourages consistency with the measurements, fetches the input of $E( {\bf x})$
learns the redundancies of the radar echo signal and remove ghosts and noises. Then, the DC sub-network, which encourages consistency with the measurements, fetches the input of $E( {\bf x})$ and the output of $E( {\bf x})$
and the output of $E( {\bf x})$ to implement CG algorithm. We can obtain the radar targets reconstruction image after several iterations.
to implement CG algorithm. We can obtain the radar targets reconstruction image after several iterations.
In the general compressive sensing problem model, matrix ${\bf A}$ is usually a measurement matrix without physical meaning. In our physical model driven CS-Net, matrix ${\bf A}$
is usually a measurement matrix without physical meaning. In our physical model driven CS-Net, matrix ${\bf A}$ represents the mapping from the imaging field to the measurement field in the radar detection scene. Since the choice of $\lambda$
represents the mapping from the imaging field to the measurement field in the radar detection scene. Since the choice of $\lambda$ is affected by the spectrum of ${\bf A}$
is affected by the spectrum of ${\bf A}$ , in this study, $\lambda$
, in this study, $\lambda$ is seen as one of the training parameters in the CS-Net. CS-Net learns the spectrum of ${\bf A}$
is seen as one of the training parameters in the CS-Net. CS-Net learns the spectrum of ${\bf A}$ and update the $\lambda$
and update the $\lambda$ and ${e}_{n}$
and ${e}_{n}$ to a suitable value during the training process. Hence, we set the initial value of ${e}_{n} = {\bf 0}$
to a suitable value during the training process. Hence, we set the initial value of ${e}_{n} = {\bf 0}$ and $\lambda = 0.5$
and $\lambda = 0.5$ . The input of CS-Net is initialized to be ${\bf x}_{0} = {{\bf A}^{{\rm H}} {\bf b}}$
. The input of CS-Net is initialized to be ${\bf x}_{0} = {{\bf A}^{{\rm H}} {\bf b}}$ , and vector ${\bf b}$
, and vector ${\bf b}$ represents the radar echo signal data after down-sampling in frequency domain. Once the network depth $D_{e}$
represents the radar echo signal data after down-sampling in frequency domain. Once the network depth $D_{e}$ and iteration number $N_{i}$
and iteration number $N_{i}$ is fixed, the update step in (9) and (11) and be viewed as an unrolled deep network in Fig. 2. Since each iteration uses the same solving structure, we use weight sharing mechanism at different iterations to reduce the number of network parameters and speed up the training time. Moreover, we use the same regularization parameter $\lambda$
is fixed, the update step in (9) and (11) and be viewed as an unrolled deep network in Fig. 2. Since each iteration uses the same solving structure, we use weight sharing mechanism at different iterations to reduce the number of network parameters and speed up the training time. Moreover, we use the same regularization parameter $\lambda$ in each iteration to ensure the consistency of each iteration.
in each iteration to ensure the consistency of each iteration.
In order to balance the network performance and computational cost, similar to the parameter settings in [Reference Aggarwal, Mani and Jacob14], the depth of the network is set as 5 and the number of iterations is set as 6. After that, the network is trained by minimizing the loss function, which is specified as the MSE between ${\bf x}$ and the training label ${\bf l}$
and the training label ${\bf l}$ :
:

where ${N_{p}}$ is the number of training data sets. ${\bf x}( i)$
is the number of training data sets. ${\bf x}( i)$ and ${\bf l}( i)$
and ${\bf l}( i)$ denote the $i$
denote the $i$ -th output and the $i$
-th output and the $i$ -th label, respectively.
-th label, respectively.
Simulation results
This section mainly shows the experimental details of CS-Net, the training process evaluation, and the comparison with the reconstruction results of other methods.
In the simulation experiments, we set the imaging area as a rectangle and the target as two cylinders. In order to obtain diversified sample data, the position is randomly distributed. Some specific simulation parameters about radar detection are given in Table 1. The radar echo signal data ${\bf R}$ is obtained by simulating the EM wave propagation in the set scene, and the ground truth of the target is obtained by simulating the distribution of the detected target as the label data of the CS-Net. After the transformation of radar echo data ${\bf R}$
is obtained by simulating the EM wave propagation in the set scene, and the ground truth of the target is obtained by simulating the distribution of the detected target as the label data of the CS-Net. After the transformation of radar echo data ${\bf R}$ in (6), the down-sampled frequency domain data ${\bf b}$
in (6), the down-sampled frequency domain data ${\bf b}$ is obtained as the data set needed by the network. The network training data set is 200, and the test data set is 100. After the network training is completed, the down-sampled frequency domain data ${\bf b}$
is obtained as the data set needed by the network. The network training data set is 200, and the test data set is 100. After the network training is completed, the down-sampled frequency domain data ${\bf b}$ in the test data is input into the network model to obtain the target reconstruction image in the corresponding scene.
in the test data is input into the network model to obtain the target reconstruction image in the corresponding scene.
Table 1. Basic simulation parameters

In order to explore the performance limitation of the CS-Net, we implement wall signal elimination (WSE) to remove the echo signal from the wall by using time-gate method. Figure 3 depicts the reconstructed target images by the CS-Net with WSE and two traditional representative schemes. As shown in Fig. 3, CS-Net can recover most of the target texture. Reconstructed image with the BP method in T(a) can present the target position. However, the larger target in the reconstructed image with the BP method in T(b) is immersed by the echo signal from the smaller one. The reconstructed image with the CS method can reveal the target position. Nevertheless, similar to the BP method, the larger target in T(b) is immersed in the echo signal from the smaller one.

Fig. 3. Target texture detail recovery performance of the reconstructed target images achieved by CS-Net with WSE and CS, BP schemes. The first column shows the ground truth images for two representative scenarios and the other columns are the echo signal and the reconstruction results, respectively.
In order to reflect the anti-interference performance to the front wall of the CS-Net, we test the network with the echo signal without implementing WSE and compare the reconstructed result with those obtained by three traditional representative schemes. Based on the same setting in Fig. 3, the experimental data in Fig. 4 is the echo signal that do not implement WSE by using the time-gate method, and is marked as without WSE. Specifically, under the same scenario and parameter settings, T(a) in Fig. 3 includes the ground truth, echo signal, and the reconstructed target images of different methods after implementing WSE, while T(b) in Fig. 4 do not implement WSE, and obtained the corresponding results. The reconstructed images with the CS-Net still can present the target position and some of the related texture details with the wall eliminated. Meanwhile, the results with the LRSR method show the target position and number without the target texture details, since it reconstructs the target image based on the echo signal from the front wall and targets. Comparatively, the results with the BP and CS methods even cannot reflect the target position due to the interference from the front wall.

Fig. 4. Target texture detail recovery performance of the reconstructed target images achieved by CS-Net without WSE and CS, BP, LRSR schemes. The first column shows the ground truth images for two representative scenarios and the other columns are the echo signal and the reconstruction results, respectively.
To better reflect the performance of the reconstructed image with CS-Net in the TWRI system, without generality, we use MSE and program running time (PRT) as an evaluation index. MSE is used to evaluate the error between the ground truth and the reconstruction result, and PRT is used to reflect imaging time. Since the output vector from each method is in different value scales, we normalize the $i$ -th value $x_{i}$
-th value $x_{i}$ in the output vector ${\bf x} = ( x_{1},\; \, x_{2},\; \, \ldots ,\; \, x_{i},\; \, \ldots x_{N}) ^{{\rm T}}$
in the output vector ${\bf x} = ( x_{1},\; \, x_{2},\; \, \ldots ,\; \, x_{i},\; \, \ldots x_{N}) ^{{\rm T}}$ to $x_{i} \in [ 0,\; \, 1]$
to $x_{i} \in [ 0,\; \, 1]$ as shown below:
as shown below:

where ${\bf x}_{\max }$ and ${\bf x}_{\min }$
and ${\bf x}_{\min }$ denote the maximum and minimum value of the vector ${\bf x}$
denote the maximum and minimum value of the vector ${\bf x}$ , respectively.
, respectively.
Table 2 compares the performance achieved by CS-Net with those obtained by the traditional method based on CS, BP, and LRSR schemes. Table 2 shows that the MSE of the CS-Net is smaller than those with CS, BP, and LRSR schemes, both in with WSE and without WSE configurations. It validates that the quality of the reconstructed image with the proposed CS-Net is better than those with the traditional scheme. Moreover, the MSE of those with WSE configuration in T(a) and T(b) is smaller than those without WSE in T(c) and T(d). Thus, the echo signal from the wall can largely affect the quality of the reconstructed image and it is necessary to eliminate the echo signal from the wall before implementing the reconstruction method.
Table 2. MSE performance of target image reconstruction achieved by CS-Net and those obtained by CS, BP, and LRSR schemes

Table 3 compares the imaging time achieved by CS-Net with those obtained by the traditional method based on CS, BP, and LRSR schemes. Table 3 shows that the PRT of the CS-Net is shorter than those with CS, BP, and LRSR schemes, both in with WSE and without WSE configurations. It validates that CS-Net can reconstruct the target image faster than the traditional algorithm, and has great advantages in imaging time.
Table 3. PRT target image reconstruction achieved by CS-Net and those obtained by CS, BP, and LRSR schemes

Figures 5 and 6 show the evaluation in the network training process. Figure 5 displays the influence of the number of alternating iterations of $E( {\bf x})$ and DC on MSE. It can be observed that as the increase of network iterations, MSE gradually decreases to around six iterations to reach a stable value. Figure 6 indicates the impact of the number of network training sets on MSE. It can be observed that MSE tends to be stable when the training data set is around 200. This shows that CS-Net can use less training data to achieve faster network convergence speed.
and DC on MSE. It can be observed that as the increase of network iterations, MSE gradually decreases to around six iterations to reach a stable value. Figure 6 indicates the impact of the number of network training sets on MSE. It can be observed that MSE tends to be stable when the training data set is around 200. This shows that CS-Net can use less training data to achieve faster network convergence speed.

Fig. 5. MSE as a function of number of iterations. As the number of iterations of the network increases during training, the average MSE of 100 sets of test data changes. It shows that MSE stabilizes around six iterations.

Fig. 6. MSE as a function of number of training set. As the number of training set increases during training, the average MSE of test data changes. It shows that MSE stabilizes around 200 sets of test data.
Conclusion
In this paper, a physical model-driven deep network, termed CS-Net, was proposed to estimate the target image of a TWRI system. The proposed method introduced a regularization prior based on CNN and alternately iterates with the DC layer to form a physical model-driven network solution model, without manually adjusting algorithm parameters. Simulation results have shown the superiority of our proposed CS-Net estimation scheme in comparison with the existing traditional schemes. Compared with the traditional iterative solution method, the deep learning method proposed in this study can significantly improve the speed of reconstructing the target image and accurately reconstruct the target image and show excellent computational performance in TWRI.
 Yuhao Wang received his Ph.D. degree from Wuhan University, Wuhan, China, in 2006. He is currently a Professor with the Cognition Sensor Network Laboratory, School of Information Engineering, Nanchang University (NCU), Nanchang, China. He is the Dean of the Artificial Intelligence Industry Institute, NCU, and also is the Head of Jiangxi Embedded Systems Engineering Research Center. His current research interests include wideband wireless communication and radar sensing fusion systems, channel measurement and modeling, nonlinear signal processing, smart sensors, image and video processing, and machine learning, and visible light communication.
Yuhao Wang received his Ph.D. degree from Wuhan University, Wuhan, China, in 2006. He is currently a Professor with the Cognition Sensor Network Laboratory, School of Information Engineering, Nanchang University (NCU), Nanchang, China. He is the Dean of the Artificial Intelligence Industry Institute, NCU, and also is the Head of Jiangxi Embedded Systems Engineering Research Center. His current research interests include wideband wireless communication and radar sensing fusion systems, channel measurement and modeling, nonlinear signal processing, smart sensors, image and video processing, and machine learning, and visible light communication.
 Yue Zhang received her bachelor's degree from the East China University of Technology, Nanchang, China. She is currently pursuing her master's degree with the School of Information Engineering, Nanchang University, Nanchang, China. Her research interests include radar sensor signal processing, through-the-wall radar imaging methods, and deep learning.
Yue Zhang received her bachelor's degree from the East China University of Technology, Nanchang, China. She is currently pursuing her master's degree with the School of Information Engineering, Nanchang University, Nanchang, China. Her research interests include radar sensor signal processing, through-the-wall radar imaging methods, and deep learning.
 Mingcheng Xiao received his bachelor's degree and his master's degree from the School of Information Engineering, Nanchang University, Nanchang, China. His research interests include through-the-wall radar, MIMO radar imaging, and cognitive radio sensor networks.
Mingcheng Xiao received his bachelor's degree and his master's degree from the School of Information Engineering, Nanchang University, Nanchang, China. His research interests include through-the-wall radar, MIMO radar imaging, and cognitive radio sensor networks.
 Huilin Zhou received his Ph.D. degree in information engineering from Wuhan University, Wuhan, China. He is currently a Professor with the School of Information Engineering, Nanchang University, Nanchang, China. His research interests include radar systems, radar signal processing, and radar imaging.
Huilin Zhou received his Ph.D. degree in information engineering from Wuhan University, Wuhan, China. He is currently a Professor with the School of Information Engineering, Nanchang University, Nanchang, China. His research interests include radar systems, radar signal processing, and radar imaging.
 Qiegen Liu received his B.S. degree in applied mathematics from Gannan Normal University, Ganzhou, China, his M.S. degree in computation mathematics, and his Ph.D. degree in biomedical engineering from Shanghai Jiaotong University, Shanghai, China. Since 2012, he has been with the School of Information Engineering, Nanchang University, Nanchang, China, where he is currently a Professor. During 2015–2017, he was also a Postdoc with UIUC and University of Calgary, Calgary, AB, Canada. His current research interests include sparse representations, deep learning and their applications in image processing, computer vision, and MRI reconstruction.
Qiegen Liu received his B.S. degree in applied mathematics from Gannan Normal University, Ganzhou, China, his M.S. degree in computation mathematics, and his Ph.D. degree in biomedical engineering from Shanghai Jiaotong University, Shanghai, China. Since 2012, he has been with the School of Information Engineering, Nanchang University, Nanchang, China, where he is currently a Professor. During 2015–2017, he was also a Postdoc with UIUC and University of Calgary, Calgary, AB, Canada. His current research interests include sparse representations, deep learning and their applications in image processing, computer vision, and MRI reconstruction.
 Jianfei Gao received his bachelor's degree from the College of Applied Science, Jiangxi University of Technology, Ganzhou, China. He is currently pursuing his master's degree with the School of Information Engineering, Nanchang University, Nanchang, China. His research interests include radar imaging, clutter suppression, and deep learning.
Jianfei Gao received his bachelor's degree from the College of Applied Science, Jiangxi University of Technology, Ganzhou, China. He is currently pursuing his master's degree with the School of Information Engineering, Nanchang University, Nanchang, China. His research interests include radar imaging, clutter suppression, and deep learning.