



Introduction
Automated text analysis is like a gold rush. Many researchers have noticed its potential and are now using methods such as topic modeling, scaling and sentiment analysis to analyze political texts (for an overview see Grimmer and Stewart Reference Grimmer and Stewart2013). But researchers interested in cross-country comparisons face a problem: people speak different languages. In order to make comparisons across countries, researchers first need to translate texts from several languages into one. On the plus side, nowadays this can be automated by using machine translation, such as Google Translate. But does the meaning of these texts get lost in Google translation? That is, do we lose (too much) information if we Google Translate texts before we analyze them? Or does doing so leave us like the poor souls who journeyed west for gold but were left with nothing?
This paper evaluates the usefulness of machine translation for automated bag-of-words models.Footnote 1 We identify and evaluate four reasons why the meaning of a text may get lost in translation. First, a general problem occurs when words or stems in machine-translated documents are translated differently than those in gold standard documents, leading to different term-document matrices (TDMs).Footnote 2 We evaluate this issue by comparing the overlap between gold standard and machine-translated TDMs. Other translation problems relate more specifically to LDA topic modeling, a popular bag-of-words model that identifies the topics in a corpus, and assigns documents and words to these topics. In this case, translation issues may arise because (1) topics might be distributed differently in the machine-translated corpus than in the gold standard corpus, (2) machine-translated documents are assigned to different topics than gold standard documents and (3) a topic in the machine-translated corpus consists of different words than the same topic in the gold standard corpus. We evaluate each issue by systematically comparing topic models estimated using machine-translated documents with those estimated using human-translated (gold standard) documents.
To set up our comparisons, we use the europarl dataset (Koehn Reference Koehn2005), which contains the official transcriptions of debates in the European Parliament both in English and in most other official languages of the EU. From this dataset we take debate transcriptions in Danish, German, Spanish, French and Polish for the period of January 2007 to November 2011. Delivered by professional translators, these official transcriptions serve as our gold standard.Footnote 3 We first compare the bag-of-words vectors of each document in the machine translation and the gold standard translation. We then compare the output of the LDA topic models in three ways: topical prevalence at the document level, topical prevalence at the corpus level and topical content at the corpus level.Footnote 4
We find that TDMs for both sets of data are highly similar, with significant but minor differences across languages. What is more, we find considerable overlap in the set of features (stems) appearing in human- and machine-translated texts. With regards to LDA topic models, at both the document and the corpus levels we find topical prevalence to be similar with only small differences across languages, and we find topical content to strongly overlap as well. These findings suggest that Google Translate does in fact generate useful TDMs, and, what is more, it deals successfully with the above-mentioned risks of machine translation when estimating topic models. We conclude that Google Translate is a useful tool for researchers who use or want to use bag-of-words text models for comparative questions.
Background
Numerous bag-of-words based studies have analyzed machine-translated texts, yet little is known about the quality of machine translations and its impact on subsequent analyses. Generally, authors either assume machine-translated text to be suitable for their purposes or they do not pay attention to the issue at all. For example, Agarwal et al. (Reference Agarwal, Xie, Vovsha, Rambow and Passonneau2011) use Twitter data which was machine-translated by an unidentified commercial source, but they do not address the possibility that machine translation may have influenced their results. Schwarz, Traber, and Benoit (Reference Schwarz, Traber and Benoit2017) use Google Translate in the multilingual Swiss context. While these authors describe the machine-translation process in more detail, they do not discuss comparisons between different machine-translation strategies, or the quality of their translations.
To be clear, we do not imply that machine translation is not useful for analyzing texts in multiple languages. As Lotz and Van Rensburg (Reference Lotz and Van Rensburg2014) show, developments in machine-translation systems are moving fast and their quality is clearly increasing with time. Balahur and Turchi (Reference Balahur and Turchi2014) give a comprehensive account of using machine-translated text for automated analyses in the context of sentiment analysis, and Courtney et al. (Reference Courtney, Breen, McMenamin and McNulty2017) find that machine-translated newspaper articles can be reliably categorized by human coders. But while these contributions are highly relevant, they do not evaluate the implications of machine translation for bag-of-words methods more generally. The same is true for Lucas et al. (Reference Lucas, Nielsen, Roberts, Stewart, Storer and Tingley2015), who write extensively about the possible pitfalls of analyzing machine-translated text but do not evaluate its quality empirically. Adding to this line of research, this paper systematically evaluates both the bag-of-words approach in general and topic modeling in particular.
Another issue relevant to this study concerns the impact of specific languages and language groups on machine-translation quality. For example, machine-translated texts may be of better quality when translated from French to English than when translated from Polish to English. There are two reasons for this. First, some language pairs are simply more easily translated than others (Koehn and Monz Reference Koehn and Monz2006). Furthermore, larger parallel corpora are available to train machine-translation models for some language pairs than for others (e.g., there is more parallel data available for French and English than there is for Polish and English). To examine this possibility we include in our analysis languages from different language groups: French and Spanish (belonging to the Italic language group), German and Danish (belonging to the Germanic language group), and Polish (belonging to the Balto-Slavic language group).Footnote 5
Data and Measurement
To evaluate the quality of machine translation, we need to compare its output to gold standard translations of identical documents.Footnote 6 The europarl dataset (Koehn Reference Koehn2005) contains parallel corpora which allow us to set up such comparisons. The dataset consists of official European Parliament debate transcriptions in most of the official EU languages.Footnote 7 The europarl dataset ranges from April 1996 until November 2011, but some Slavic language translations were included only since January 2007. Because of that, we focus our analysis on translations between 2007 and 2011.
The primary purpose of the europarl dataset is to train, test and improve machine-translation algorithms (e.g. Koehn Reference Koehn2005; Popescu-Belis et al. Reference Popescu-Belis, Meyer, Liyanapathirana, Cartoni and Zufferey2012; Loaiciga, Meyer, and Popescu-Belis Reference Loaiciga, Meyer and Popescu-Belis2014). The data is available in both the raw form and as text files with sentence-aligned language pairs. We use the raw data, because the sentence-aligned text files do not distinguish between different dates and debate chapters. The raw data files are organized per session (typically one day) and chapter. Each chapter is a different item on the agenda (e.g a debate, questioning of EU official or vote) of a session.Footnote 8 When estimating topic models, we consider each chapter to be a single document, because each chapter in a session concerns a specific agenda item. Each agenda item may in turn consist of multiple topics.
Methods
Figure 1 shows the steps we take to compare machine-translated and gold standard documents. In both cases we start with identical non-English texts, which have been translated into English, either through Google Translate or through EU-employed expert translators (Step 1). These translations are preprocessed and turned into TDMs (Step 2) on which we then estimate a topic model (Step 3). We then compare the similarities of the TDMs, the topical prevalence at the level of individual documents and the corpus at large, and the topical content (Step 4). In what follows we discuss each step in more detail.

Figure 1. Research design.Note: This figure shows the different steps of our research design. In both cases we start with non-English texts, which have been translated into English, either through Google Scholar or through EU-employed expert translators (Step 1). The English translations are then preprocessed and turned into TDMs (Step 2), on which we then estimate a topic model (Step 3). We then compare our four different outcome variables (Step 4). The comparisons are the following: Comparison 1: document-to-document comparison TDM similarity; Comparison 2: document-to-document comparison of topic distributions (topical prevalence); Comparison 3: topic-to-topic comparison of stem weights (topical content); Comparison 4: topic-to-topic comparison of topic distribution (topical prevalence).
Step 1. Machine translation and Google Translate
We use Google Translate as the specific machine-translation service to evaluate the performance of machine-translated texts in bag-of-words analyses. We chose Google Translate because of its translation quality, which is top-tier when compared to other online machine translating services (Hampshire and Salvia Reference Hampshire and Salvia2010). We translated the texts using the Google Website Translator plugin which can translate web pages. To be able to use this plugin we converted the raw text data to bare html web pages. The translation process took place in August and September 2016.Footnote 9 We have translated the texts into English, because machine-translation algorithms are expected to perform best when translating to and from English.Footnote 10
Step 2. Preprocessing and generating TDMs
When using bag-of-words models, it is common to preprocess the data in order to remove noise. In our case we have removed punctuation, numbers and general stopwords, and all remaining words have been lowercased and stemmed. The preprocessing steps on both the gold standard and machine-translated texts are identical, and were applied to the translated texts.Footnote 11 To perform these preprocessing steps, we used both Python and R libraries. For stemming, stopword removal, number removal, lowercasing, and punctuation removal, we used regular expressions in Python and the NLTK package (Bird, Klein, and Loper Reference Bird, Klein and Loper2009). To create the TDMs we switched to R and the quanteda package (Benoit and Nulty Reference Benoit and Nulty2013).Footnote 12 We compare the TDMs of the machine-translated and gold standard documents and we also use them as input for the topics models described below. Readers primarily interested in our analysis of the TDMs may decide to skip the next section, which contains more technical details regarding the specification of our topic models.
Step 3. Fitting topic models
To assess the quality of machine-translated texts, we estimated topic models on the gold standard and machine-translated texts separately using the LDA algorithm (Blei, Ng, and Jordan Reference Blei, Ng and Jordan2003) and Gibbs sampling. For this we used the LDA function in the R topicmodels package (Hornik and Grün Reference Hornik and Grün2011). LDA is a generative model. It takes the words in each text as input and then estimates the topical prevalence and topical content in the corpus. To run the model researchers need to set a few parameters: the number of topics in the corpus, the model seed, burn-in time, the number of iterations and which and how many iterations to keep for use in the final model. To ensure that differences between a model based on the gold standard corpus and a model based on the machine-translated corpus are solely the result of language differences between these corpora, the parameters for the topic models based on gold standard translations and machine translations were kept identical. This means that the number of topics was kept constant, and a fixed seed was used—based on the sys.time variable—as suggested by Hornik and Grün (Reference Hornik and Grün2011). This seed (1473943969) has been used for all models described below. Furthermore, the burn-in (1000) and number of iterations (300) were also kept constant. The algorithm keeps every 100th model and returns the model with the highest posterior likelihood (the best-fitting model). Consequently, all variation between the models—when the model parameters are kept the same—results from differences caused by the translation process.
The most important parameter to set is the number of topics in the topic model. This is crucial because the number of topics affects the distribution of words over topics (topical content) and the distribution of topics over documents (topical prevalence). When the number of topics changes so do these distributions. It was practically infeasible to run and optimize the number of topics for each language pair. Also, all language pairs are based on roughly similar data from the same time period. Therefore the optimum number of topics for all models was determined based on the French dataset. This is the largest gold standard and machine-translated dataset. We estimated the best-fitting number of topics by evaluating the model harmonic mean of models that contain between 10 and 150 topics, in increments of 10. The model harmonic mean indicates the extent to which word counts in the documents used to construct the model match the word distributions in the model itself. Put differently, it indicates the extent to which the model accurately describes the distribution of words in the documents. In this case, a larger harmonic mean indicates that the model fits the data better. The results of the optimization runs are displayed in Figure 2. The gold standard model has an optimum of 90 topics. After 90 topics adding more topics does not improve model fit. The machine-translated model peaks at 100 topics. To isolate the effect of language differences between gold standard and machine-translated texts it is important to choose the same number of topics for both models. Therefore, we settled for 90 topics. That said, we also evaluated comparisons of models with 90 topics for the gold standard models and 100 topics for the machine-translated models. This produced results almost identical to the topic model comparisons with 90 topics. These results are available in the Supplementary Appendix.

Figure 2. Model harmonic mean.
Our next challenge is to match the topics generated by the gold standard and machine-translated models. This is because the topic order in both models may differ (i.e., topic 1 in the machine-translated model may match best with, for example, topic 2 in the gold standard model). Our matching procedure is as follows: for each stem we find the highest loading in the machine-translated topic model and the gold standard topic model. For example, take the stem “agricultur”. This stem loads highest on (is most important in) topic 12 of the machine-translated model, and topic 45 in the gold standard model. This results in a 12–45 topic pairing for that specific stem. We subsequently count the topic pairings of all shared stems. We match topics based on the highest count of topic pairings. For example, we pair topic 12 of the machine-translated model with topic 45 in the gold standard model because they have the highest number of important, shared stems like the stem “agricultur” (see the Supplementary Appendix for a numerical example of our topic matching procedure). Footnote
13
Using this procedure we matched 90 topics for the German corpus and 89 topics for all other languages.Footnote
14
 $^{,}$
Footnote
15
$^{,}$
Footnote
15
Step 4. Comparing term-document matrices and topic models
We make four different comparisons, which vary on two dimensions: stems versus topics and documents versus corpora (see Table 1). The comparison of TDMs takes place at the level of stems and documents (Comparison 1 in Figure 1). Furthermore, we report three comparisons based on our topic models, all of which give us evidence on how much the matched topics in the machine-translated and the gold standard topics overlap in content and prevalence. We evaluate topical content by means of stem loadings per topic pair (Comparison 3 in Figure 1). We evaluate topical prevalence by means of topic distributions over document pairs (Comparison 2 in Figure 1), and topic distributions across the corpus at large (Comparison 4 in Figure 1).
Table 1. Comparisons between gold standard and machine-translated data.

It is important to evaluate results at both the document and the corpus level because the former only speak to how similar individual documents are being characterized by the topic model (i.e., the extent to which topical prevalence for gold standard and machine-translated documents is similar). However, such a comparison does not tell us how similar the fitted topics themselves are. For example, both the gold standard and machine-translated document might have a high topic loading on topic 1, making them highly similar on the document level, but if topic 1 is about cars in the gold standard topic model and about trees in the machine-translated model, then document-level similarity does not tell us much. While the chances of this happening are slim, structural and consistent translation errors by Google Translate might cause such differences. As a consequence, the level of topical similarity does say something about the quality of the translation. We thus need comparisons on both the document and corpus level.
Our outcome measure for the TDM comparisons is different from that of the topic model comparisons. For the TDM comparisons, we use cosine similarity because—in contrast to correlation—it takes into account the absolute differences in values. This is relevant for comparing TDMs because of our goal of knowing how similar the counts of all TDM features per document pair are to each other. Cosine similarity varies between 0 and 1, with the latter indicating a perfect match (i.e., two identical vectors). For the topic model comparisons, correlations are a more suitable similarity measure because they detect trends rather than absolute values. This is important because we make comparisons between different models.Footnote
16
Correlations vary between
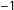 $-1$
and 1, with the latter indicating a perfect linear positive relationship, and the former indicating a perfect linear negative relationship.
$-1$
and 1, with the latter indicating a perfect linear positive relationship, and the former indicating a perfect linear negative relationship.
Results
This section contains the results of our four comparisons, starting with the TDM analysis, and continuing with the topic model analyses.
Comparing TDMs
We first compare—at the document level—machine-translated and gold standard bags of words to each other, using the built-in similarity function in the quanteda R package (Benoit and Nulty Reference Benoit and Nulty2013). Figure 3 displays the distribution of the cosine similarity scores for each language. Most notably, the average similarity between the gold standard documents and their machine-translated counterparts is very high (
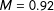 $M=0.92$
,
$M=0.92$
,
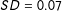 $SD=0.07$
). Furthermore, more than 92% of all document pairs achieve a cosine similarity score of 0.80 or higher. These results show that the TDMs of machine-translated and gold standard documents are very similar. Very often the stems in the machine-translated and gold standard documents occur with (approximately) the same frequency.
$SD=0.07$
). Furthermore, more than 92% of all document pairs achieve a cosine similarity score of 0.80 or higher. These results show that the TDMs of machine-translated and gold standard documents are very similar. Very often the stems in the machine-translated and gold standard documents occur with (approximately) the same frequency.

Figure 3. Distribution of cosine similarity per language pair.
Table 2 shows the means and standard deviations for document cosine similarity scores per language. The differences between languages are tiny: the lowest mean cosine similarity (Polish
 $=$
0.913) is only 0.016 smaller than the highest mean cosine similarity (Spanish
$=$
0.913) is only 0.016 smaller than the highest mean cosine similarity (Spanish
 $=$
0.929). The French and Spanish documents have significantly higher average cosine similarities than the overall mean (French:
$=$
0.929). The French and Spanish documents have significantly higher average cosine similarities than the overall mean (French:
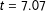 $t=7.07$
,
$t=7.07$
,
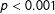 $p<0.001$
; Spanish:
$p<0.001$
; Spanish:
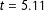 $t=5.11$
,
$t=5.11$
,
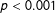 $p<0.001$
), but the size of these differences is, again, very small (French: 0.005 and Spanish: 0.009). The Danish, Polish and German cosine similarities between document pairs are not significantly different from the overall mean.
$p<0.001$
), but the size of these differences is, again, very small (French: 0.005 and Spanish: 0.009). The Danish, Polish and German cosine similarities between document pairs are not significantly different from the overall mean.
Table 2. Cosine similarity distribution per language.
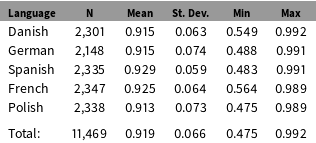
Note: Statistically significant but substantively small difference between languages (ANOVA results: F(4, 11464)
 $=$
27.855,
$=$
27.855,
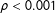 $\unicode[STIX]{x1D70C}<0.001$
,
$\unicode[STIX]{x1D70C}<0.001$
,
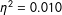 $\unicode[STIX]{x1D702}^{2}=0.010$
).
$\unicode[STIX]{x1D702}^{2}=0.010$
).
We also consider the total number of unique stems (features), as well as the number of shared stems between the gold standard and machine-translated TDMs. The higher the number of shared stems, the more overlap there is. Figure 4 shows that the shared features of the TDMs of the gold standard and machine-translated documents overlap to a large degree (about 75% or higher). The number of shared features is also quite similar for each language (DA, 28431; DE, 27732; ES, 28578; FR, 28162; PL, 26916). The same goes for the features that are unique to either the gold standard or machine-translated TDMs.

Figure 4. Unique TDM features for gold standard and machine-translated corpora. Reading example: for the French language, the amount of overlapping features is around 28,000, while the total number of features is around 33,000 for the machine-translated documents and around 38,000 for the gold standard documents.
The exception is French, and to a lesser extent Spanish. In the Spanish case, more unique features are present in the machine-translated than in the gold standard texts, which indicates that Google Translate adds new features to the texts (by using different English translations for the same Spanish word). Similarly, French translations are simplified (different French words are translated as the same English word).Footnote 17 However, regardless of these differences, both the substantial overlap among features and the high cosine similarity scores for both Spanish and French show that their machine-translated and gold standard TDMs are highly similar.
Comparing topic models
Each document in our corpus is about one or more topics. Do the topic models with the machine-translated text as input assign the same topics to a document as the topic models with the gold standard translated texts? Figure 5 displays for each language how similar topical prevalence is for each pair of gold standard and machine-translated documents (based on an equal number of topics; for the comparison between unequal number of topics, see the Appendix). These correlations denote the extent to which topical prevalence in individual gold standard and machine-translated documents overlaps. The higher the correlation the more the overlap.Footnote 18 It shows that document-level topical prevalence is similar for gold standard and machine-translated corpora, with on average—across all languages—65% of document pairs having a topic distribution correlation of 0.8 or higher. Put differently, a particular document is likely to be assigned to identical topics regardless of whether it was machine-translated or gold standard translated.

Figure 5. Similarity of document-level topical prevalence with equal number of topics.
That said, there are statistically significant differences between languages (see Table 3).Footnote 19 Table 3 breaks down mean topical prevalence for each language, as well as their standard deviations. The highest mean topic distribution per document pair is obtained for Spanish (0.83), and the lowest for French (0.75). Again, the absolute differences are small, and across languages it appears that topical prevalence at the level of individual documents is similar.
Table 3. Similarity of document-level topical prevalence with equal number of topics.

Note: ANOVA results: F(4, 11464)
 $=$
56.414,
$=$
56.414,
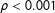 $\unicode[STIX]{x1D70C}<0.001$
,
$\unicode[STIX]{x1D70C}<0.001$
,
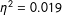 $\unicode[STIX]{x1D702}^{2}=0.019$
.
$\unicode[STIX]{x1D702}^{2}=0.019$
.
Each topic in our data is discussed in several documents. Are these the same documents in the topic models of the machine-translated text and the gold standard translations? To evaluate this we calculate the correlations between the topical prevalence of each topic in the gold standard and the machine-translated documents (Figure 6 show the results of 446 topic distribution comparisons).Footnote 20 As in the case of document-level topic distributions, these corpus-level correlations are generally quite similar, having a mean of 0.69. This indicates that on average topics are similarly distributed across all documents in the corpus. This indicates that a topic is likely to be distributed similarly across documents, regardless of whether these documents where machine translations or gold standard translations of the same source.

Figure 6. Similarity of corpus-level topical prevalence with equal number of topics. Overall descriptives:
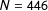 $N=446$
,
$N=446$
,
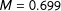 $M=0.699$
,
$M=0.699$
,
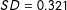 $SD=0.321$
.
$SD=0.321$
.
Finally, we also compare the similarity in the content of paired topics. To do so, we analyze for each topic pair the stem loadings of all shared features in the gold standard and machine-translated TDMs. The results are presented in Figure 7. Again, the average correlation is about 0.70 across languages indicating that topical content, as measured by the distribution of stem loadings, is similar for both the machine-translated and the gold standard corpora.Footnote 21 That implies that topics are discussed using the same terms in both the machine-translation and gold standard translation documents.

Figure 7. Similarity of topical content with equal number of topics. Overall descriptives:
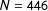 $N=446$
,
$N=446$
,
 $M=0.708$
,
$M=0.708$
,
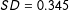 $SD=0.345$
.
$SD=0.345$
.
Conclusion
The results in this paper support the claim that Google Translate is a useful tool for researchers using bag-of-words text models for comparative questions. We first found TDMs for machine translations and gold standard translations to be highly similar, with substantively small differences across languages. What is more, we found considerable overlap in the set of features (stems) generated from both corpora. With regards to LDA topic models, at both the document and the corpus levels we found topical prevalence to be generally similar with only small differences across languages. Furthermore, we found topical content to be highly similar.
Do our findings extend to other bag-of-words approaches such as position scaling or sentiment analysis? If a topic model with 90 models using machine-translated documents is highly similar to the topic model with the gold standard documents, we believe it to be very likely that a 2-dimensional or 3-dimensional scaling model can be similarly reproduced. In addition, for sentiment analysis machine-translation is already used. Sentiment dictionaries are sometimes translated from English to other languages without validation. This is problematic since the specific meaning of words is more relevant. Some words may be translated in such a way that they lack emotional content, while other words may gain emotional content in translation. As long as these translation issues are random, the problem of the identification of false positives or false negatives is reduced when sentiment scores are aggregated over entire documents. Then again, we do not quite know whether these translation issues are random or not. We leave these issues for future work.
Supplementary material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2018.26.














 Open access
Open access