



Introduction
Prediction provides a better understanding and quantitative assessment for infectious disease control and risk evaluation. Accurate and explainable predictions also provide useful information for health administration and policymakers. Therefore, accuracy and interpretability are among the most important objectives of prediction research. With the establishment and development of the biopsychosocial model, most researchers pay attention not only to the infectious disease itself, but also to the impact of environmental factors, socio-economic factors, human behaviour and other factors on infectious disease prediction. In the past decade, due to climate change and environmental pollution, people have become increasingly concerned about the health effects of external environmental factors, such as temperature, relative humidity and air pollutants. Many of these factors have been found to have health effects and have become potential predictors in infectious disease prediction [Reference Kelly and Fussell1–Reference Maes and De Meyer3]. Introducing such external environmental factors into prediction models also improves the performance of the models. Basile et al. used meteorological data to predict the incidence rate of influenza and the accuracy of prediction was above 80% [Reference Basile4]. Additionally, Guo et al. used climate data to predict cases of dengue more accurately [Reference Guo5].
However, most external environmental factors affect infectious disease simultaneously and are thus usually correlated (e.g. temperature, humidity and rainfall). These correlation factors can cause multiple collinearities, hide the real relationship between the factors, even generate confounding correlation paths, thereby jeopardising the performance of the prediction model [Reference Allen and Morzuch6, Reference De Gooijer and Hyndman7]. Therefore, when using multiple correlated environmental factors (or multivariate time series, MTS) for prediction, how to introduce these factors into the model remains a major challenge.
Traditionally, the autoregressive integrated moving average model with external variables (ARIMAX) is commonly used to predict MTS data. However, the ARIMAX model often encounters various problems, such as variable selection and model interpretation. In this study, we proposed a novel ensemble analysis strategy to solve these problems and establish a prediction model within a unified framework. The ensemble analysis strategy started by establishing a vector autoregressive model (VAR) with all the external environment variables. Then, the VAR model was equivalently transformed into a dynamic Bayesian networks (DBN) model [Reference Opgen-Rhein and Strimmer8], and the latter was used to select the variables, which could be considered as a constraint condition. Finally, the VAR model with the constraint condition (CVAR) was established for prediction. Our previous studies proved that the VAR model can accurately predict MTS data and can be interpreted by impulse response analysis [Reference Zhang9]. Moreover, DBN can identify the correlation among multiple variables simultaneously [Reference Zhang10], while common correlation analysis can only identify two variables at a time. The variable selection process of DBN can simulate the real-world context in which influencing factors impact diseases. Based on these advantages, this study combined the two models under a unified mathematical framework to construct CVAR and improve the accuracy and interpretability of the prediction model.
In this study, hand, foot and mouth disease (HFMD) was used as an example to illustrate this ensemble analysis strategy, and the prediction performance was compared with that of a commonly used prediction model, the ARIMAX model, to evaluate the prediction accuracy and interpretability of the proposed strategy. HFMD is a major public health problem in China that is caused mainly by enterovirus 71 (EV71) and coxsackievirus A16 (CVA16) [Reference Jiang11]. Many studies have found that environmental factors are related to HFMD incidence. For example, the relationship of temperature and relative humidity with HFMD approximated a positive linear association, while that of air pressure approximated a negative linear association [Reference Koh12, Reference Xing13]. In the following section, the step-by-step application of our proposed ensemble analysis strategy was presented in the context of HFMD incidence prediction.
Material and methods
Study area and data sources
Our previous studies in Chengdu city found that temperature, diurnal temperature range and particulate matter under 10 μm (PM10) are related to HFMD [Reference Yin14–Reference Yin16]. Therefore, this study selected Chengdu city as the study area and included more environmental factors to conduct prediction research. Chengdu is the capital city of Sichuan Province, which lies in the west of the Sichuan Basin and at the centre of the Chengdu Plains. Air pollution in Chengdu is relatively serious because of the basin terrain. Chengdu lies in the subtropical humid climate subzone under the eastern-monsoonal region. The annual average temperature is 16.5 − 18.0°C, the annual maximum and minimum temperatures are 35.2 − 37.4°C and −5.3 ~ −1.4°C, respectively, and the annual average precipitation is 800 − 1400 mm. According to our previous studies and a meta-analysis, these climatic features could increase the risk of HFMD [Reference Yin14–Reference Duan17].
This study collected HFMD surveillance data and 10 environmental factors to develop prediction models. Daily HFMD data among children aged 0–14 years, from 1 January 2011 to 31 December 2017, were obtained from the Sichuan Center for Disease Control and Prevention (https://www.sccdc.cn/). All HFMD cases were confirmed by clinical diagnosis and met the National Guideline on Diagnosis and Treatment of Hand Foot Mouth Disease.
Environmental factors included meteorological factors and air pollutants. Daily meteorological data from 2011 to 2017 were obtained from the China National Weather Data Sharing System (http://data.cma.cn/). Daily air pollutant data during the same period were obtained from the Sichuan Environmental Monitoring Center (http://sthjt.sc.gov.cn/sthjt/c104334/scemc.shtml). The names and abbreviations of the variables are shown in Table 1.
Table 1. Variable names, abbreviations and units in this study

Note. All the mean of environmental variables is a daily mean.
Steps of the ensemble analysis strategy
Step 1. Data preparation
Figure 1 shows the process of the novel ensemble analysis strategy. Before fitting the VAR model, the trace statistic of the Johansen cointegration test was used to test a long-term equilibrium relationship of the MTS to avoid spurious regression (i.e. the random trend of several time series is the same). In addition, according to the stationary data requirement in time-series analysis and prediction [Reference Tsay18], the augmented Dickey−Fuller (ADF) test was used to estimate the stationarity of the MTS: non-stationary MTS should be transformed by differencing to induce stationarity.

Fig. 1. Process of the novel ensemble analysis strategy.
Step 2. The incorporation of environmental variables
The ensemble analysis strategy started by establishing a VAR model with all the external environment variables as follows:

In equation (1), $\nabla {\bi X}_{\bi t}$ is the first-order differenced series of ${\bi X}_{\bi t}{\bi \;}\lpar {\nabla {\bi X}_{\bi t} = {\bi X}_{\bi t}-{\bi X}_{{\bi t}-1}} \rpar$
is the first-order differenced series of ${\bi X}_{\bi t}{\bi \;}\lpar {\nabla {\bi X}_{\bi t} = {\bi X}_{\bi t}-{\bi X}_{{\bi t}-1}} \rpar$ , which represents environmental factors and HFMD incidence, and Ap represents the coefficient matrix of the variables. Maximum likelihood estimation (MLE) was used to estimate the VAR parameters. B represents the baseline measurement for each variable; ɛt is the residual series; p (1 ≤ p < t) is the maximum lag order, which represents the delayed effects of factors on HFMD and was determined by the Schwarz criterion (SC) via the ‘VARselect()’ function in the ‘vars’ package in R3.6.3. This maximum lag order was also used in the DBN.
, which represents environmental factors and HFMD incidence, and Ap represents the coefficient matrix of the variables. Maximum likelihood estimation (MLE) was used to estimate the VAR parameters. B represents the baseline measurement for each variable; ɛt is the residual series; p (1 ≤ p < t) is the maximum lag order, which represents the delayed effects of factors on HFMD and was determined by the Schwarz criterion (SC) via the ‘VARselect()’ function in the ‘vars’ package in R3.6.3. This maximum lag order was also used in the DBN.
Step 3. The selection of variables and the constraints on the VAR model
The DBN, which was used to select variables, is a directed acyclic graph that uses nodes and arcs to express the joint probability distribution function between variables. Nodes represent candidate variables in this study, and arcs (or arrows) represent the correlation between variables. For example, the correlation between nodes i and j could be measured by the coefficient aij in Ap (Eq. 1), where a larger aij indicated a stronger correlation. Under such circumstances, the aim of variable selection via DBN is to identify whether aij is non-zero for any two nodes i and j in the candidate set. In other words, if aij is non-zero, then the network includes an arc between nodes i and j. The coefficients of DBN can be estimated by the least absolute shrinkage and selection operator (lasso), which uses a penalty term to constrain the sum of absolute parameter coefficients and shrink some coefficients to zero. In addition, variables selected by DBN usually have different lag orders, in contrast to Pearson's correlation analysis and other variable selection methods. However, the VAR model requires the same lag order for all variables; therefore, we propose the constrained VAR model (CVAR). In this model, the coefficients of unrelated variables in matrix Ap (Eq. 1) were set to 0 by means of constraints that were obtained from DBN by the lasso method. The CVAR model is defined as follows:

where ${\bi A}_{{\bi p} + {\bi h}\vert {\bi t}}^{\bi \ast }$ is the coefficient matrix with DBN constraints and h is the step of prediction, h ≥ 0. The other terms are the same as in equation (1). We used the ‘VAR()’ function in the ‘var’ package to fit the VAR models. After fitting the VAR models, we used the DBN and prior knowledge to impose constraints on the coefficient matrices and then used MLE to estimate the CVAR models. The OLS-CUSUM test was used to verify the stability over time of the coefficients of a linear regression model (i.e., CVAR) [Reference Ploberger and Kramer19]. If the coefficients were within the confidence intervals, the models were considered effective and could be used for prediction.
is the coefficient matrix with DBN constraints and h is the step of prediction, h ≥ 0. The other terms are the same as in equation (1). We used the ‘VAR()’ function in the ‘var’ package to fit the VAR models. After fitting the VAR models, we used the DBN and prior knowledge to impose constraints on the coefficient matrices and then used MLE to estimate the CVAR models. The OLS-CUSUM test was used to verify the stability over time of the coefficients of a linear regression model (i.e., CVAR) [Reference Ploberger and Kramer19]. If the coefficients were within the confidence intervals, the models were considered effective and could be used for prediction.
Step 4. Model fitting and prediction
To make full use of the daily data, we conducted rolling training on the time-series data; that is, we took the three-year differenced data as a sample set (1094 days), analysed them in days and divided them into an integer training set (985 days) and test set (109 days) in a ratio of 9:1. Then, we scrolled forward the sample set in half a year until the end of the data. For example, the data from 1 January 2011 to 31 December 2013 were the first sample set. We divided this sample set into a training set and test set at a ratio of 9:1. The data from 1 July 2011 to 30 June 2014 were the second sample set and were also divided by a ratio of 9:1. In this way, we obtained nine sample sets and fitted nine VAR models (referred to as VAR_①−⑨). The nine sample sets were also used to fit the DBN, CVAR and ARIMAX models (referred to as DBN_①−⑨, CVAR_①−⑨ and ARIMAX_①−⑨). The coefficient of determination (R 2) was used to evaluate the proportion of the variance explained and the goodness of fit for these models.
In addition, we summarised the graphs of the DBN_①−⑨ in one graph to show the results briefly. Based on the voting principle, the arcs of each variable within the DBN_①−⑨ appearing at least six times (more than half the times) were included in the summarised DBN graph. The corresponding coefficients were the average coefficients of these arcs.
The HFMD surveillance data can be updated within 24 h, thus, a dynamic prediction method was used to predict the incidence of HFMD 1-day ahead [Reference Luz20]. In addition, the results of 2-, 3-, 7-, 10-days ahead dynamic prediction and direct prediction without updating the data (109-days ahead) can be referred to Supplementary File, Tables S7 and S8. The dynamic prediction with 1-day ahead is that after one day of out-of-sample prediction, the training set was updated with observed data, the prediction model was re-fitted, and the re-fitted model was used to make the next 1-day ahead out-of-sample prediction. This process was repeated until the complete test set was predicted. The root mean-squared error (RMSE) and mean absolute percentage error (MAPE), which quantified the error between the actual and predicted values, were used to evaluate the prediction accuracy. A confusion matrix was used to summarise the ability of the CVAR model to predict increases and decreases in nine subsets [Reference Kane21]. Then, we averaged the results of the subsets and estimated the average accuracy.
Step 5. The enhancement of interpretability
Step 5.1 Sensitivity analysis: The sensitivity analysis was used to evaluate the importance of related variables selected by the summarised DBN graph in predicting the incidence of HFMD. This analysis was conducted based on the deletion of an environmental factor from the full CVAR model, and then the RMSE was calculated to check whether this factor could affect the prediction of HFMD incidence.
Step 5.2 Impulse response analysis: After establishing the CVAR model, the interpretability of the model was enhanced by the impulse response analysis, which is based on the Wold moving average function [Reference Tsay18], and the model structure is as follows:

where Ψp is the coefficient matrix of the impulse response. The ‘irf()’ function in the ‘var’ package was used to conduct the impulse response analysis to evaluate the response of a dependent variable in the next 10 days when an independent variable was subject to an impulse (changed by a unit). Because the average incubation period of HFMD is three to seven days, the period of 10 days could reflect the effects of environmental variables on HFMD. This analysis helped to explain the dynamic effects of predictors on response variables; therefore, we used it to enhance the interpretability of the CVAR model. The impulse response analysis was performed on each CVAR_①−⑨ model, and the variables that appeared in the summarised DBN graph were extracted. The impulse response results of these variables were averaged to construct a summarised impulse response analysis.
Step 6. Model comparison
To verify the performance of the CVAR model, we compared it with the ARIMAX model. The ARIMAX model is a classic method in prediction research, which provides a general analysis framework for predicting infectious disease [Reference Chadsuthi22]. Since exogenous variables need to be introduced and ARIMAX is a linear model, researchers usually use Pearson's correlation analysis to select variables and then fit the prediction model [Reference Liu23]. MLE was used to estimate the parameters of ARIMAX, and the optimal ARIMAX models were selected based on the Akaike information criterion (AIC) via the ‘auto.arima()’ function in the ‘forecast’ package in R3.6.3. The Ljung−Box test was used to verify the stability of ARIMAX models. When P Ljung−Box > 0.05, indicating that the residual is white noise and the model is effective for prediction.
The R 2, RMSE, MAPE and averaged confusion matrix of the ARIMAX models were estimated and compared with those of the CVAR models. A two-tailed paired t-test was used to test whether the R 2, RMSE and MAPE of the two models were different. The ranges of R 2, RMSE and MAPE were calculated to reflect the stability of the two models.
All the above statistical analyses were performed in R 3.6.3 using packages such as ‘bnlearn’, ‘lars’, ‘vars’, ‘tseries’ and ‘forecast’.
Results
From 1 January 2011 to 31 December 2017, a total of 184 210 cases of HFMD were reported among children aged 0−14 years in Chengdu. The incidence rates were about 5 cases per 10 00 000-person day in Chengdu. Figure 2 shows the time-series plots of all the variables and Table 2 shows the statistical descriptions.

Fig. 2. Time-series plots of variables in this study.
Table 2. Descriptions of daily HFMD incidence, meteorological and air pollution variables in Chengdu from 2011 to 2017

This study included 11 time series, and we conducted the Johansen cointegration test on the original data first. For all the r values tested, there were at least 11 cointegration ranks (Supplementary File, Table S1). Thus, the original data have a long-term equilibrium relationship and would not undergo spurious regression. The ADF statistic values showed that TM and HFMD were non-stationary, which might be related to the long-term time variation of these variables, thus we performed a first-order differencing for all the data (Supplementary File, Table S2). Then, we used the differenced data to establish the VAR, DBN, CVAR and ARIMAX models. Finally, the data were converted to the original scale.
The parameter estimates of the DBN and CVAR models
We performed rolling training on the MTS data. According to the Schwarz criterion (SC) values of the nine different training sets, the optimal maximum lag orders were two (Supplementary File, Table S3), and VAR_①−⑨ models were fitted with maximum lag = 2 (Supplementary File, VAR_①−⑨ Equations). Then, DBN_①−⑨ models were used to select the variables of the VAR_①−⑨ models. The parameters of the DBN_①−⑨ models are shown in the Supplementary File, Table S4 and Figure S1. In the nine DBN graphs, arcs appearing at least six times (more than half the times) were included in the summarised DBN graph (Fig. 3). The corresponding coefficients are shown in the Supplementary File, Table S5. The factors' coefficients ≠ 0 had arc connections, indicating correlations to HFMD, while coefficients = 0 would not show in the summarised DBN graph and were not related to HFMD. TM was related to HFMD at both lag 1 and lag 2, indicating that TM was an important factor for HFMD.

Fig. 3. Summarised DBN graph of the DBN_①−⑨ models.
HFMD has no impact on environmental factors. Therefore, in the VAR models with environmental factors as dependent variables and HFMD as an independent variable, the coefficient of HFMD was zero. Combined with the variables selected by DBN, we imposed two types of constraints on the VAR models (DBN variable selection and common knowledge). We followed this approach to fit the CVAR_①−⑨ models. The coefficients of the CVAR models can be found in the Supplementary File, CVAR_①−⑨ Equations. The results of the OLS-CUSUM test indicated that all the coefficients were within the confidence intervals, and the CVAR_①−⑨ models were stable and effective (Supplementary File, Fig. S2).
The interpretation of the CVAR model
Sensitivity analysis
According to the summarised DBN graph, we deleted a related factor from the full CVAR model once a time and compared the increased RMSE of each model (Table 3). The sensitivity analysis results showed that temperature, wind speed and humidity had great effects on the HFMD prediction. NO2 and PM10 were important predictors among the air pollutants.
Table 3. The sensitivity analysis of the CVAR_①−⑨ models

Note. ‘-’ represents the deletion of this variable from the full model.
Impulse response analysis
After establishing CVAR_①−⑨ models, we estimated the effects of environmental variables on HFMD through the impulse response analysis. Figure 4 shows a summary of the impulse response analysis. Wind speed was positively related to HFMD during the first five days, negatively related to HFMD on days five to seven and then tended to be zero. Sunshine was negatively related to HFMD during the first five days, positively related on days five to seven and finally tended to be zero. Temperature was negatively related to HFMD during the first three days, positively related to HFMD on day four and day five and then tended to be zero. Humidity was negatively related to HFMD during the first four days, positively related to HFMD on the next several days, and then tended to be zero. PM10, SO2 and NO2 were negatively related to HFMD during the first three or four days and then had a positive impact, eventually tending to zero.

Fig. 4. Summarised impulse response analysis of the CVAR_①−⑨ models.
The results of model comparison
On the basis of the Pearson correlation analysis conducted on the nine training sets (Supplementary File, Table S6), we selected the relevant environmental variables and used them to fit ARIMAX_①−⑨ models (Table 4). The Ljung−Box test showed that the residuals of each model were white noise; therefore, the ARIMAX_①−⑨ models were stable and could be used for prediction.
Table 4. Results of the ARIMAX_①−⑨ models

In the training sets, the coefficients of determination (R 2) were calculated for CVAR_①−⑨ and ARIMAX_①−⑨ models. In the test set, the CVAR and ARIMAX models were used to predict the incidence of HFMD 1-day ahead (Table 5). The results of 2, 3, 7, 10-days ahead dynamic prediction and direct prediction (109-days ahead) can be referred to Supplementary File, Tables S7 and S8. Compared with the ARIMAX model, the CVAR model showed a significantly higher R 2 (average difference: +2.11%; two-tailed paired t-test: t = 6.2051, P = 0.0003 < 0.05), a lower RMSE (−24.88%; t = −5.2898, P = 0.0007 < 0.05) and a lower MAPE (−16.69%; t = −4.3647, P = 0.0024 < 0.05). These indicated that the CVAR models performed better than the ARIMAX models. The ranges of R 2, RMSE and MAPE of the CVAR models were always narrower than those of the ARIMAX models, indicating that the performance of the CVAR model was more stable. Figures 5 and 6 show the prediction and fitting plots, respectively. Comparison of the averaged confusion matrices of the two models (Tables 6 and 7) indicated that the accuracy of the CVAR models was 88.16% ((50.26 + 45.84)/109) and that of the ARIMAX models was 86.41% ((48.56 + 45.63)/109). Thus, the CVAR models were more accurate in predicting the time-series shape.

Fig. 5. Incidence of HFMD predicted by the CVAR_①−⑨ and ARIMAX_①−⑨ models in the test set.

Fig. 6. Incidence of HFMD fitted by the CVAR_①−⑨ and ARIMAX_①−⑨ models in the training set.
Table 5. Comparisons of R 2, RMSE, MAPE, ranges and means between the CVAR_①−⑨ and ARIMAX_①−⑨ models for 1-day ahead dynamic prediction
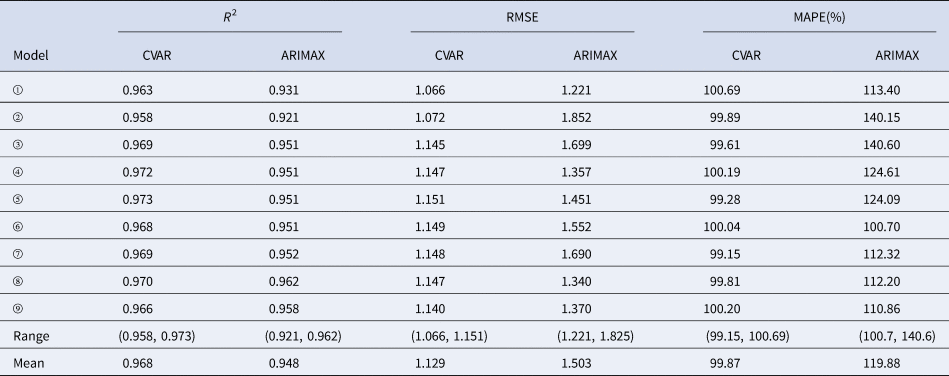
Table 6. The averaged confusion matrix of the CVAR models

Table 7. The averaged confusion matrix of the ARIMAX models

Discussion
Accuracy and interpretability have always been among the most important objectives of infectious disease prediction. In this study, data on environmental factors and HFMD incidence in Chengdu city from 2011 to 2017 were used to establish CVAR models using an ensemble analysis strategy, and the prediction accuracy and interpretability of the models were evaluated. In this ensemble analysis strategy, we first established the VAR model, then used the DBN model to select variables under the unified framework and finally established the CVAR model. We found that the ensemble analysis strategy had advantages in terms of variable selection, model interpretation and prediction.
The DBN used in this strategy had advantages in variable selection and results display. The variables selected by the DBN (Fig. 3) included temperature, which was related to HFMD at lag 1 and lag 2, as well as relative humidity, wind speed, sunshine, PM10, SO2 and NO2, which were related to HFMD at lag 2. Previous work in Sichuan province showed that the meteorological factors, including temperature, humidity, sunshine, air pressure and wind speed, were related to HFMD [Reference Song24], which is consistent with the results of our study. Many other works have provided several postulations to explain the pathways through which meteorological factors affect HFMD [Reference Hagiwara and Hashimoto25, Reference Altizer26]. One possible explanation is that meteorological factors could influence the transmission and the survival of the HFMD virus, as well as human behaviours, thereby influencing infection transmission. Several studies have found that air pollutants can increase the risk of respiratory diseases [Reference Devalia27, Reference Nel28]. One of the infection pathways of HFMD is the respiratory transmission. This might provide a possible explanation for why pollutants affect HFMD; however, more studies are needed to evaluate the mechanisms. A recent analysis of ours in Chengdu found that PM10 in air pollutants increased the risk of HFMD [Reference Yin16], and another study in Hefei found a significant statistical correlation between SO2 and HFMD [Reference Wei29], which could support the results of our present study. In addition, this study first found that NO2 had an impact on HFMD. This impact may be related to the high concentration of NO2 in Chengdu city and more studies are needed to test this finding. By contrast, other studies have found that wind speed, air pressure, SO2 and NO2 were not related to HFMD [Reference Kim30, Reference Yu31]. Possible explanations for these discrepancies could be the different analysis methods and the differences in climatic and geographic conditions of the study areas.
This ensemble analysis strategy applied sensitivity analysis and impulse response analysis to enhance the interpretability of CVAR models. We found that temperature, wind speed and humidity had great effects on the HFMD prediction. NO2 and PM10 were more important among the air pollutant predictors. Temperature, humidity, sunshine, PM10, SO2 and NO2 were negatively related to HFMD during the first three or four days and then had a positive impact on the next three days, with the effect eventually tending to zero. This process is very similar to the clinical course of HFMD, which has an average incubation period of 3–7 days. This phenomenon may be attributed to the delayed effect of environmental factors on health [Reference Wei32]. Other studies found similar effects of temperature, humidity and air pollutants on HFMD [Reference Zhang33, Reference Huang34]. Wind speed was positively related to HFMD during the first several days, negatively related during the next few days, then positively related and finally unrelated, but the general effects were positive. These findings are supported by previous studies, which indicated that wind speed could increase the risk of HFMD [Reference Zhang33]. However, our findings differ from other studies, which found that wind speed and sunshine have no statistically significant effect on HFMD [Reference Kim30]. Possible explanations for the discrepancies could be the differences in the environmental and socio-economic profiles of these study areas.
Compared with that of the VAR model, the structure of the CVAR model was more reasonable, which further improved the interpretability of the CVAR model. The VAR model allows all variables to be either explanatory or response variables, which often leads to unreasonable relationships in the model. Take the dengue VAR model established by Goto et al. as an example [Reference Goto35]. When temperature was taken as a response variable and dengue incidence as an explanatory variable, the model indicated that the incidence of dengue impacted temperature. This result is clearly not consistent with an epidemiological causal relationship. In our ensemble analysis strategy, the CVAR model could use DBN and prior information to adjust unreasonable correlations between variables and optimise the model structure.
In addition, the ensemble analysis strategy also had advantages in prediction. We compared the performance of the CVAR model with that of the ARIMAX model, which is a traditional model for the prediction of MTS data. The CVAR model had a higher R 2 (+2.11%; t = 6.2051, P = 0.0003 < 0.05), a lower RMSE (−24.88%; t = −5.2898, P = 0.0007 < 0.05) and a lower MAPE (−16.69%; t = −4.3647, P = 0.0024 < 0.05). The ranges of R 2, RMSE and MAPE of the CVAR models were always narrower than those of the ARIMAX models. These results suggested that the CVAR models could predict HFMD more accurately and stably. Comparing the confusion matrices of the two type models (Tables 6 and 7), the accuracy of the CVAR models was 88.16%, while the accuracy of the ARIMAX models was 86.41%, indicating that the CVAR models were more accurate in predicting the time-series shape. Besides, comparing the results of 1-, 2-, 3-, 7-, 10-days ahead dynamic prediction and direct prediction (109-days ahead), we found that the RMSE increased significantly after 7-days ahead and then reached a steady state. Therefore, it is better to set the prediction step within 7-days for HFMD prediction.
Based on this information, researchers can provide recommendations for health and related authorities to prevent and control HFMD. For example, according to the relationship between temperature, humidity, wind speed, sunshine, PM10, SO2, NO2 and HFMD, we recommend that the health sector establish a disease warning system based on meteorological variables. Furthermore, the meteorological department should warn of bad weather, especially when it is hot, stormy or hazy weather. The public should be reminded to take protective measures to reduce exposure to bad weather. Moreover, the government can reduce air pollution in the basin region by increasing green areas, promoting clean energy vehicles or encouraging citizens to install gas purification devices.
Under this novel framework, we used the VAR and DBN models to establish the CVAR models. This ensemble analysis strategy has some benefits. By using the DBN model to select variables, we can identify the complex correlation pattern and delayed effect among MTS data simultaneously, and the DBN can use the network graph to represent the relationship between variables by lag order, which is difficult to achieve in the ordinary correlation analysis. The characteristics of the DBN model make it applicable not only to HFMD prediction, but also to the prediction of other infectious diseases. Besides, common knowledge constraints made the structures of the CVAR models more reasonable, and the impulse response analysis enhanced the interpretability of the CVAR models. Furthermore, the t-tests of the R 2, RMSE and MAPE showed that the CVAR models had a higher prediction accuracy. Additionally, the ranges of R 2, RMSE and MAPE indicated that the CVAR models were more stable, and the averaged confusion matrix indicated that CVAR models could predict increases and decreases in the time series more accurately. The results of our study can provide useful recommendations for HFMD prevention and have a certain application value. Both the DBN and the ensemble analysis strategy have the potential to be applied in other infectious disease predictions.
However, some limitations require mentioning. First, our previous work suggested that at least three years of weekly HFMD data are required to fit the DBN model, as well as the CVAR model [Reference Zhang10], while the ARIMAX model required four to seven seasonal cycles of data [Reference Tsay18]. When the available HFMD surveillance data are insufficient, the parameters of these models might be unstable. Second, since the short-term dynamic prediction of a CVAR model is more accurate, surveillance data and prediction models must be updated constantly to ensure the accuracy of prediction. Third, the CVAR models analysed only environmental factors and did not include other field factors, such as socio-economic factors. Thus, more studies are needed to identify whether other factors could improve the prediction accuracy of CVAR models.
Conclusion
In conclusion, the ensemble analysis strategy could accurately select variables and display the correlation pattern via a network graph. The interpretability and prediction accuracy of the CVAR models were better than those of the ARIMAX models. Health authorities can use the ensemble analysis strategy to identify potential HFMD outbreaks and apply this information to develop disease prevention and control measures.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0950268821000091
Acknowledgements
Not applicable.
Author contributions
FY, YM and TZ designed the study. QL and YL collected the data. JT and XZ contributed to the data analysis. JT wrote the original draft. All authors contributed to writing the paper and revising the final version.
Financial support
This work was supported by the National Natural Science Foundation of China (Grant Nos. 81872713, 81602935 and 81803332) and the Sichuan Science and Technology Program (Grant Nos. 2019YFS0471, 2020YFS0015 and 2021YFS0181).
Conflict of interest
The authors declare no competing interests.
Ethical standards
This effort related to disease prediction was part of the CDC's routine responsibility in Chengdu City, China. Therefore, institutional review and informed consent were not required for this study. All analysed data were anonymised.
Consent for publication
Not applicable.
Data availability statement
HFMD surveillance data were obtained from the Sichuan Center for Disease Control and Prevention (https://www.sccdc.cn/). Daily meteorological data were obtained from the China Meteorological Data Sharing Service System (http://data.cma.cn/). Daily air pollutant data were obtained from the Sichuan Environmental Monitoring Center (http://sthjt.sc.gov.cn/sthjt/c104334/scemc.shtml). Researchers who need these data can apply to these sectors on their websites and obtain the data after approval. Raw data will not be shared because the authors are not authorised to distribute the data.















 Open access
Open access