


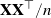
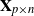
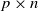
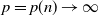
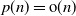
1. Introduction
For any two integers
 $p,n\geq2$
, let
$p,n\geq2$
, let
 $\mathbf{X}_{p\times n}$
be a
$\mathbf{X}_{p\times n}$
be a
 $p\times n$
random matrix with independent and identically distributed (i.i.d.) real entries. The matrix
$p\times n$
random matrix with independent and identically distributed (i.i.d.) real entries. The matrix
 $\mathbf{W}$
defined by
$\mathbf{W}$
defined by
 $\mathbf{W} = \mathbf{X}\mathbf{X}^\top/n$
(with
$\mathbf{W} = \mathbf{X}\mathbf{X}^\top/n$
(with
 $^\top$
standing for matrix transpose) is usually called a sample covariance matrix (see [Reference Bai and Yin1] and [Reference Yin, Bai and Krishnaiah11]), where p and n can be understood as dimension size and sample size respectively. When the entries are i.i.d. centered normal random variables, then
$^\top$
standing for matrix transpose) is usually called a sample covariance matrix (see [Reference Bai and Yin1] and [Reference Yin, Bai and Krishnaiah11]), where p and n can be understood as dimension size and sample size respectively. When the entries are i.i.d. centered normal random variables, then
 $n\mathbf{W}$
is called a Wishart matrix. Sample covariance matrices appear naturally in many situations of multivariate statistical inference; in particular, many test statistics involve the extremal eigenvalues of
$n\mathbf{W}$
is called a Wishart matrix. Sample covariance matrices appear naturally in many situations of multivariate statistical inference; in particular, many test statistics involve the extremal eigenvalues of
 $\mathbf{W}$
. For instance, the union-intersection principle proposed in [Reference Roy8] suggests that one can use the largest eigenvalue of the sample covariance matrix to test whether or not the population covariance is identity. In the literature, weak convergence and law of large numbers of the extremal eigenvalues of
$\mathbf{W}$
. For instance, the union-intersection principle proposed in [Reference Roy8] suggests that one can use the largest eigenvalue of the sample covariance matrix to test whether or not the population covariance is identity. In the literature, weak convergence and law of large numbers of the extremal eigenvalues of
 $\mathbf{W}$
have been well studied; see [Reference Bai and Yin1], [Reference Johansson5], [Reference Johnstone6], [Reference Yin, Bai and Krishnaiah11], and the references therein. In this note we study large deviations of the extremal eigenvalues of
$\mathbf{W}$
have been well studied; see [Reference Bai and Yin1], [Reference Johansson5], [Reference Johnstone6], [Reference Yin, Bai and Krishnaiah11], and the references therein. In this note we study large deviations of the extremal eigenvalues of
 $\mathbf{W}$
as both p and n tend to infinity.
$\mathbf{W}$
as both p and n tend to infinity.
As the non-zero eigenvalues of
 $\mathbf{X}\mathbf{X}^\top$
are the same as those of
$\mathbf{X}\mathbf{X}^\top$
are the same as those of
 $\mathbf{X}^\top\mathbf{X}$
, it is without loss of generality to assume that
$\mathbf{X}^\top\mathbf{X}$
, it is without loss of generality to assume that
 $p\leq n$
. Let
$p\leq n$
. Let
 $\lambda_{\min}$
and
$\lambda_{\min}$
and
 $\lambda_{\max}$
denote the smallest and largest eigenvalue of
$\lambda_{\max}$
denote the smallest and largest eigenvalue of
 $\mathbf{W}$
respectively. It is assumed throughout the note that the i.i.d. entries
$\mathbf{W}$
respectively. It is assumed throughout the note that the i.i.d. entries
 $\{X_{ij}\}_{1\leq i\leq p,1\leq j\leq n}$
of
$\{X_{ij}\}_{1\leq i\leq p,1\leq j\leq n}$
of
 $\mathbf{X}$
have zero mean
$\mathbf{X}$
have zero mean
 $\mathbb{E}(X_{ij})=0$
and unit variance
$\mathbb{E}(X_{ij})=0$
and unit variance
 $\mathbb{V}(X_{ij})=1$
. Under the fourth finite moment assumption
$\mathbb{V}(X_{ij})=1$
. Under the fourth finite moment assumption
 $EX_{ij}^4<\infty$
, Bai and Yin [Reference Bai and Yin1] proved that
$EX_{ij}^4<\infty$
, Bai and Yin [Reference Bai and Yin1] proved that
 $\lambda_{\min}\rightarrow (1-\kappa^{1/2})^2$
and
$\lambda_{\min}\rightarrow (1-\kappa^{1/2})^2$
and
 $\lambda_{\max}\rightarrow (1+\kappa^{1/2})^2$
almost surely as
$\lambda_{\max}\rightarrow (1+\kappa^{1/2})^2$
almost surely as
 $n\rightarrow\infty$
and
$n\rightarrow\infty$
and
 $p=p(n)\rightarrow\infty$
with
$p=p(n)\rightarrow\infty$
with
 $p(n)/n\rightarrow \kappa$
. When
$p(n)/n\rightarrow \kappa$
. When
 $\kappa=0$
, the above results indicate that for large p and n the majority of
$\kappa=0$
, the above results indicate that for large p and n the majority of
 $\lambda_{\min}$
lies in the region close to 1 from the left, and the majority of
$\lambda_{\min}$
lies in the region close to 1 from the left, and the majority of
 $\lambda_{\max}$
lies in the region close to 1 from the right. Therefore Fey et al. [Reference Fey, van der Hofstad and Klok3, Theorem 3.1] studied asymptotics on large deviation probabilities in the forms
$\lambda_{\max}$
lies in the region close to 1 from the right. Therefore Fey et al. [Reference Fey, van der Hofstad and Klok3, Theorem 3.1] studied asymptotics on large deviation probabilities in the forms
 $\mathbb{P}(\lambda_{\min}\leq c)$
with
$\mathbb{P}(\lambda_{\min}\leq c)$
with
 $0\leq c\leq 1$
and
$0\leq c\leq 1$
and
 $\mathbb{P}(\lambda_{\max}\geq c)$
with
$\mathbb{P}(\lambda_{\max}\geq c)$
with
 $c\geq 1$
for large p and n satisfying
$c\geq 1$
for large p and n satisfying
 $p={\mathrm{o}}(n/{\ln}\ln n)$
. They also noted [Reference Fey, van der Hofstad and Klok3, p. 1061] that the technical assumption
$p={\mathrm{o}}(n/{\ln}\ln n)$
. They also noted [Reference Fey, van der Hofstad and Klok3, p. 1061] that the technical assumption
 $p={\mathrm{o}}(n/{\ln}\ln n)$
might be extended further by refining the arguments; however, this does not seem to be able to get rid of the logarithmic term.
$p={\mathrm{o}}(n/{\ln}\ln n)$
might be extended further by refining the arguments; however, this does not seem to be able to get rid of the logarithmic term.
The main result of this note (see Theorem 1 below) is an extension of [Reference Fey, van der Hofstad and Klok3, Theorem 3.1] in two respects: (a) the technical assumption is extended to
 $p={\mathrm{o}}(n)$
, and (b) the i.i.d. entries are more general. To state our main result, let us recall the definition of sub-Gaussian distribution. A random variable X is said to be sub-Gaussian if it satisfies one of the following three equivalent properties, with parameters
$p={\mathrm{o}}(n)$
, and (b) the i.i.d. entries are more general. To state our main result, let us recall the definition of sub-Gaussian distribution. A random variable X is said to be sub-Gaussian if it satisfies one of the following three equivalent properties, with parameters
 $K_i, 1\leq i\leq 3$
differing from each other by at most an absolute constant factor (see [Reference Vershynin10, Lemma 5.5]).
$K_i, 1\leq i\leq 3$
differing from each other by at most an absolute constant factor (see [Reference Vershynin10, Lemma 5.5]).
-
(i) Tails:
 $\mathbb{P}(|X|>t)\leq \exp\big\{1-t^2/K_1^2\big\}$
for all
$t\geq0$
.
$\mathbb{P}(|X|>t)\leq \exp\big\{1-t^2/K_1^2\big\}$
for all
$t\geq0$
. -
(ii) Moments:
$(\mathbb{E}|X|^p)^{1/p}\leq K_2\sqrt{p}$
for all
$p\geq1$
. -
(iii) Super-exponential moment:
$\mathbb{E}\exp\big\{X^2/K_3^2\big\}\leq e$
.





If moreover
 $\mathbb{E}(X)=0$
, then (i)–(iii) are also equivalent to the following.
$\mathbb{E}(X)=0$
, then (i)–(iii) are also equivalent to the following.
-
(iv) Moment generating function:
$\mathbb{E}\exp\{tX\}\leq \exp\big\{t^2K_4^2\big\}$
for all
$t\in \mathbb{R}$
for some constant
$K_4$
.



Furthermore, the sub-Gaussian norm of X is defined as
 $\sup_{p\geq1}p^{-1/2}(\mathbb{E}|X|^p)^{1/p}$
, namely the smallest
$\sup_{p\geq1}p^{-1/2}(\mathbb{E}|X|^p)^{1/p}$
, namely the smallest
 $K_2$
in (ii).
$K_2$
in (ii).
Theorem 1.
Suppose that the entries
 $\{X_{ij}\}_{1\leq i\leq p,1\leq j\leq n}$
of
$\{X_{ij}\}_{1\leq i\leq p,1\leq j\leq n}$
of
 $\mathbf{X}$
are i.i.d. sub-Gaussian with zero mean and unit variance. Then, for
$\mathbf{X}$
are i.i.d. sub-Gaussian with zero mean and unit variance. Then, for
 $p = p(n)\rightarrow\infty$
with
$p = p(n)\rightarrow\infty$
with
 $p(n)={\mathrm{o}}(n)$
as
$p(n)={\mathrm{o}}(n)$
as
 $n\rightarrow\infty$
, we have the following.
$n\rightarrow\infty$
, we have the following.
-
(i) For any
$c\geq 1$
,(1)
\begin{align}\liminf_{n\rightarrow\infty}n^{-1}\ln \mathbb{P}(\lambda_{\max}\geq c) \geq -I(c),\qquad\quad\end{align}
(2)
\begin{align}\limsup_{n\rightarrow\infty}n^{-1}\ln \mathbb{P}(\lambda_{\max}\geq c) \leq -\lim_{\epsilon\rightarrow 0}I(c - \epsilon).\end{align}
-
(ii) For any
$0\leq c\leq 1$
,(3)
\begin{align}\liminf_{n\rightarrow\infty}n^{-1}\ln \mathbb{P}(\lambda_{\min}\leq c) \geq -I(c),\qquad\qquad\end{align}
(4)
\begin{align}\limsup_{n\rightarrow\infty}n^{-1}\ln \mathbb{P}(\lambda_{\min}\leq c) \leq -\lim_{\epsilon\rightarrow 0}I(c + \epsilon).\end{align}






Here
 $I(c)\,:\!=\, \lim_{p\rightarrow\infty}I_{p}(c)$
with
$I(c)\,:\!=\, \lim_{p\rightarrow\infty}I_{p}(c)$
with
 \[I_{p}(c)=\inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{\theta\in\mathbb{R}}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr],\]
\[I_{p}(c)=\inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{\theta\in\mathbb{R}}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr],\]
 $\|x\|$
being the Euclidean norm, and
$\|x\|$
being the Euclidean norm, and
 \[S_{x,i}=\sum_{k=1}^px_k X_{ki}\quad{for}\ x=(x_1,\ldots, x_p)\in \mathbb{R}^p,\ 1\leq i\leq n.\]
\[S_{x,i}=\sum_{k=1}^px_k X_{ki}\quad{for}\ x=(x_1,\ldots, x_p)\in \mathbb{R}^p,\ 1\leq i\leq n.\]
For standard normal entries, the results of Theorem 1 were proved in [Reference Fey, van der Hofstad and Klok3, Theorem 3.1] (assuming
 $p={\mathrm{o}}(n/{\ln}\ln n)$
), and in [Reference Jiang and Li4, Theorems 2 and 3] (under the assumption
$p={\mathrm{o}}(n/{\ln}\ln n)$
), and in [Reference Jiang and Li4, Theorems 2 and 3] (under the assumption
 $p(n)={\mathrm{o}}(n)$
) where general
$p(n)={\mathrm{o}}(n)$
) where general
 $\beta$
-Laguerre ensembles were considered (with
$\beta$
-Laguerre ensembles were considered (with
 $\beta=1$
corresponding to entries being standard normal). From this point of view, Theorem 1 can also be regarded as an extension of [Reference Jiang and Li4, Theorems 2 and 3] from
$\beta=1$
corresponding to entries being standard normal). From this point of view, Theorem 1 can also be regarded as an extension of [Reference Jiang and Li4, Theorems 2 and 3] from
 $\beta$
-Laguerre ensembles to sub-Gaussian entries. The continuity of I(c) is still largely unknown, as pointed out in [Reference Fey, van der Hofstad and Klok3]. However, with the arguments in [Reference Fey, van der Hofstad and Klok3, Theorem 3.2], I(c) can be shown to be continuous on
$\beta$
-Laguerre ensembles to sub-Gaussian entries. The continuity of I(c) is still largely unknown, as pointed out in [Reference Fey, van der Hofstad and Klok3]. However, with the arguments in [Reference Fey, van der Hofstad and Klok3, Theorem 3.2], I(c) can be shown to be continuous on
 $[1,\infty)$
for some special sub-Gaussian entries; see Section 2.3 for more details. The proof of Theorem 1 makes use of a concentration inequality of the largest eigenvalue
$[1,\infty)$
for some special sub-Gaussian entries; see Section 2.3 for more details. The proof of Theorem 1 makes use of a concentration inequality of the largest eigenvalue
 $\lambda_{\max}$
(see Section 2.1), which helps us to avoid refining the arguments in [Reference Fey, van der Hofstad and Klok3]. The same idea was employed in [Reference Singull, Uwamariya and Yang9] for the study of condition numbers of sample covariance matrices.
$\lambda_{\max}$
(see Section 2.1), which helps us to avoid refining the arguments in [Reference Fey, van der Hofstad and Klok3]. The same idea was employed in [Reference Singull, Uwamariya and Yang9] for the study of condition numbers of sample covariance matrices.
2. Proof of Theorem 1
2.1. Concentration inequality for the largest eigenvalue
Vershynin [Reference Vershynin10, Theorem 5.39] considered a random matrix
 $A_{p\times n}$
whose columns
$A_{p\times n}$
whose columns
 $A_j$
,
$A_j$
,
 $1\leq j\leq n$
are independent sub-Gaussian isotropic random vectors in
$1\leq j\leq n$
are independent sub-Gaussian isotropic random vectors in
 $\mathbb{R}^p$
. Here we switched ‘rows’, which was originally written in [Reference Vershynin10, Theorem 5.39], to ‘columns’, as therein the largest singular value
$\mathbb{R}^p$
. Here we switched ‘rows’, which was originally written in [Reference Vershynin10, Theorem 5.39], to ‘columns’, as therein the largest singular value
 $s_{\max}(A)$
of A is defined as the largest eigenvalue of
$s_{\max}(A)$
of A is defined as the largest eigenvalue of
 $(A^\top A)^{1/2}$
, while in the current note we always consider the form
$(A^\top A)^{1/2}$
, while in the current note we always consider the form
 $\mathbf{X}\mathbf{X}^\top $
because of the assumption
$\mathbf{X}\mathbf{X}^\top $
because of the assumption
 $p\leq n$
. If we now take
$p\leq n$
. If we now take
 $A=\mathbf{X}$
, then the elements in each column are i.i.d. sub-Gaussian random variables, implying (based on [Reference Vershynin10, Lemma 5.24]) that the sub-Gaussian norm
$A=\mathbf{X}$
, then the elements in each column are i.i.d. sub-Gaussian random variables, implying (based on [Reference Vershynin10, Lemma 5.24]) that the sub-Gaussian norm
 $\|A_j\|_{\psi_2}$
of each column
$\|A_j\|_{\psi_2}$
of each column
 $A_j$
is finite, which is independent of p and n. As columns have the same distribution, it holds that
$A_j$
is finite, which is independent of p and n. As columns have the same distribution, it holds that
 $K\,:\!=\, \|A_1\|_{\psi_2}=\cdots=\|A_n\|_{\psi_2}$
. The concentration inequality in [Reference Vershynin10, Theorem 5.39] says that for any
$K\,:\!=\, \|A_1\|_{\psi_2}=\cdots=\|A_n\|_{\psi_2}$
. The concentration inequality in [Reference Vershynin10, Theorem 5.39] says that for any
 $t\geq0$
, and two absolute constants
$t\geq0$
, and two absolute constants
 $\kappa_1,\kappa_2>0$
only dependent on K,
$\kappa_1,\kappa_2>0$
only dependent on K,
 \[\mathbb{P}\big(s_{\max}(A)>\sqrt{n}+\kappa_1\sqrt{p}+t\big)\leq 2 {\mathrm{e}}^{-\kappa_2 t^2}.\]
\[\mathbb{P}\big(s_{\max}(A)>\sqrt{n}+\kappa_1\sqrt{p}+t\big)\leq 2 {\mathrm{e}}^{-\kappa_2 t^2}.\]
Note that
 $s_{\max}^2(A)=n\lambda_{\max}$
in the case
$s_{\max}^2(A)=n\lambda_{\max}$
in the case
 $A=\mathbf{X}$
, so the above non-asymptotic inequality reads
$A=\mathbf{X}$
, so the above non-asymptotic inequality reads
 \[\mathbb{P}\bigl(\lambda_{\max}>\bigl(1+\kappa_1\sqrt{p/n}+t/\sqrt{n}\bigr)^2\bigr)\leq 2 {\mathrm{e}}^{-\kappa_2t^2}.\]
\[\mathbb{P}\bigl(\lambda_{\max}>\bigl(1+\kappa_1\sqrt{p/n}+t/\sqrt{n}\bigr)^2\bigr)\leq 2 {\mathrm{e}}^{-\kappa_2t^2}.\]
With
 $\gamma\,:\!=\, t/\sqrt{n}$
and the fact
$\gamma\,:\!=\, t/\sqrt{n}$
and the fact
 $p\leq n$
, for any
$p\leq n$
, for any
 $\gamma\geq0$
it becomes
$\gamma\geq0$
it becomes
 \begin{align}\mathbb{P}\bigl(\lambda_{\max}>(1+\kappa_1+\gamma)^2\bigr)\leq 2 {\mathrm{e}}^{-\kappa_2\gamma^2n}.\end{align}
\begin{align}\mathbb{P}\bigl(\lambda_{\max}>(1+\kappa_1+\gamma)^2\bigr)\leq 2 {\mathrm{e}}^{-\kappa_2\gamma^2n}.\end{align}
2.2. Proof of the upper bounds
As suggested in [Reference Fey, van der Hofstad and Klok3], the fundamental first step of the proof is as follows:
 \begin{align}\mathbb{P}(\lambda_{\max}\geq c) &= \mathbb{P}( \exists x\in\mathbb{R}^p \text{ with $ \|x\|=1$ and $ (x\cdot\mathbf{W}x)\geq c$}) \notag \\&=\mathbb{P}\Biggl( \exists x \in\mathbb{R}^p \text{ with $ \|x\|=1$ such that } \sum_{i=1}^nS_{x,i}^2/n\geq c \Biggr),\end{align}
\begin{align}\mathbb{P}(\lambda_{\max}\geq c) &= \mathbb{P}( \exists x\in\mathbb{R}^p \text{ with $ \|x\|=1$ and $ (x\cdot\mathbf{W}x)\geq c$}) \notag \\&=\mathbb{P}\Biggl( \exists x \in\mathbb{R}^p \text{ with $ \|x\|=1$ such that } \sum_{i=1}^nS_{x,i}^2/n\geq c \Biggr),\end{align}
 \begin{align}\mathbb{P}(\lambda_{\min}\leq c) &= \mathbb{P}( \exists x \in\mathbb{R}^p \text{ with $ \|x\|=1 $ and $ (x\cdot\mathbf {W}x) \leq c$}) \notag \\&=\mathbb{P}\Biggl(\exists x \in\mathbb{R}^p \text{ with $ \|x\|=1$ such that } \sum_{i=1}^nS_{x,i}^2/n\leq c \Biggr).\end{align}
\begin{align}\mathbb{P}(\lambda_{\min}\leq c) &= \mathbb{P}( \exists x \in\mathbb{R}^p \text{ with $ \|x\|=1 $ and $ (x\cdot\mathbf {W}x) \leq c$}) \notag \\&=\mathbb{P}\Biggl(\exists x \in\mathbb{R}^p \text{ with $ \|x\|=1$ such that } \sum_{i=1}^nS_{x,i}^2/n\leq c \Biggr).\end{align}
Then the lower bounds (1) and (3) (for any
 $p\leq n$
) follow directly from Cramér’s theorem for i.i.d. random variables
$p\leq n$
) follow directly from Cramér’s theorem for i.i.d. random variables
 $S_{x,i}$
,
$S_{x,i}$
,
 $1\leq i\leq n$
. More specifically, we first fix an integer p and choose an x such that only the first p components are non-zero, then apply Cramér’s theorem, and finally send p to infinity; see also the detailed arguments in [Reference Fey, van der Hofstad and Klok3, Section 3.2] leading to (3.8) therein. To prove the upper bounds in (2) and (4), as explained in [Reference Fey, van der Hofstad and Klok3] and [Reference Singull, Uwamariya and Yang9], we shall use a finite number
$1\leq i\leq n$
. More specifically, we first fix an integer p and choose an x such that only the first p components are non-zero, then apply Cramér’s theorem, and finally send p to infinity; see also the detailed arguments in [Reference Fey, van der Hofstad and Klok3, Section 3.2] leading to (3.8) therein. To prove the upper bounds in (2) and (4), as explained in [Reference Fey, van der Hofstad and Klok3] and [Reference Singull, Uwamariya and Yang9], we shall use a finite number
 $N_d$
of spherical caps of chord
$N_d$
of spherical caps of chord
 $2\,\tilde{\!d}\,:\!=\, 2d\sqrt{1-d^2/4}$
with centers
$2\,\tilde{\!d}\,:\!=\, 2d\sqrt{1-d^2/4}$
with centers
 $x^{(j)}$
to cover the entire unit sphere S defined as
$x^{(j)}$
to cover the entire unit sphere S defined as
 $\|x\|=1$
, such that for any
$\|x\|=1$
, such that for any
 $x\in S$
there is some
$x\in S$
there is some
 $x^{(j)}\in S$
close to x with
$x^{(j)}\in S$
close to x with
 $\|x-x^{(j)}\|\leq d$
. In this case,
$\|x-x^{(j)}\|\leq d$
. In this case,
 \[|x\cdot\mathbf{W}x-x^{(j)}\cdot\mathbf{W}x^{(j)}|\leq \bigl(\|x\|+\|x^{(j)}\|\bigr)\|\mathbf{W}\|\|x-x^{(j)}\|\leq 2 \lambda_{\max}d\]
\[|x\cdot\mathbf{W}x-x^{(j)}\cdot\mathbf{W}x^{(j)}|\leq \bigl(\|x\|+\|x^{(j)}\|\bigr)\|\mathbf{W}\|\|x-x^{(j)}\|\leq 2 \lambda_{\max}d\]
(see [Reference Fey, van der Hofstad and Klok3, p. 1054]). For
 $p=p(n)\rightarrow\infty$
as
$p=p(n)\rightarrow\infty$
as
 $n\rightarrow\infty$
, we need an explicit expression of
$n\rightarrow\infty$
, we need an explicit expression of
 $N_d$
, which can be borrowed from [Reference Singull, Uwamariya and Yang9] (see also [Reference Fey, van der Hofstad and Klok3] and [Reference Rogers7]) as
$N_d$
, which can be borrowed from [Reference Singull, Uwamariya and Yang9] (see also [Reference Fey, van der Hofstad and Klok3] and [Reference Rogers7]) as
 \[N_d=4\tilde{p}(n)^{3/2}\,\tilde{\!d}^{-\tilde{p}(n)}(\!\ln \tilde{p}(n)+\ln\ln \tilde{p}(n)-\ln \,\tilde{\!d})(1+{\mathrm{O}}(1/{\ln} \tilde{p}(n)))\]
\[N_d=4\tilde{p}(n)^{3/2}\,\tilde{\!d}^{-\tilde{p}(n)}(\!\ln \tilde{p}(n)+\ln\ln \tilde{p}(n)-\ln \,\tilde{\!d})(1+{\mathrm{O}}(1/{\ln} \tilde{p}(n)))\]
for all
 $d<1/2$
and large
$d<1/2$
and large
 $\tilde{p}(n)\,:\!=\, p(n)-1$
. Then it is clear that for any fixed d, we have the limit
$\tilde{p}(n)\,:\!=\, p(n)-1$
. Then it is clear that for any fixed d, we have the limit
 $\lim_{n\rightarrow\infty}n^{-1}\ln N_d=0$
with
$\lim_{n\rightarrow\infty}n^{-1}\ln N_d=0$
with
 $p(n)={\mathrm{o}}(n)$
.
$p(n)={\mathrm{o}}(n)$
.
Thanks to the concentration inequality (5), the following upper estimates are used:
 \begin{align}\mathbb{P}(\lambda_{\max}\geq c) \leq \mathbb{P}\bigl( c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr) + \mathbb{P}\bigl( \lambda_{\max} > (1+\kappa_1+\gamma)^2 \bigr),\ \qquad\end{align}
\begin{align}\mathbb{P}(\lambda_{\max}\geq c) \leq \mathbb{P}\bigl( c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr) + \mathbb{P}\bigl( \lambda_{\max} > (1+\kappa_1+\gamma)^2 \bigr),\ \qquad\end{align}
 \begin{align}\mathbb{P}(\lambda_{\min}\leq c) \leq \mathbb{P}\bigl(\lambda_{\min}\leq c, \lambda_{\max}\leq (1+\kappa_1+\gamma)^2\bigr) + \mathbb{P}\bigl( \lambda_{\max} > (1+\kappa_1+\gamma)^2 \bigr).\end{align}
\begin{align}\mathbb{P}(\lambda_{\min}\leq c) \leq \mathbb{P}\bigl(\lambda_{\min}\leq c, \lambda_{\max}\leq (1+\kappa_1+\gamma)^2\bigr) + \mathbb{P}\bigl( \lambda_{\max} > (1+\kappa_1+\gamma)^2 \bigr).\end{align}
To prove (2), applying (6) to (8) gives
 \begin{align*}\mathbb{P}\bigl(c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr) &\leq \mathbb{P}\bigl(\exists x^{(j)} \,:\, \bigl(x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr)\geq c-2d(1+\kappa_1+\gamma)^2\bigr)\\&\leq \sum_{1\leq j\leq N_d} \mathbb{P}\bigl(\bigl(x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr)\geq c - 2d(1+\kappa_1+\gamma)^2\bigr)\\&\leq N_d\max_{1\leq j\leq N_d} \mathbb{P}\bigl(\bigl(x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr)\geq c - 2d(1+\kappa_1+\gamma)^2\bigr)\\&\leq N_d\max_{1\leq j\leq N_d}\mathbb{P}\Biggl(\sum_{i=1}^nS_{x^{(j)},i}^2/n\geq c - 2d(1+\kappa_1+\gamma)^2\Biggr),\end{align*}
\begin{align*}\mathbb{P}\bigl(c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr) &\leq \mathbb{P}\bigl(\exists x^{(j)} \,:\, \bigl(x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr)\geq c-2d(1+\kappa_1+\gamma)^2\bigr)\\&\leq \sum_{1\leq j\leq N_d} \mathbb{P}\bigl(\bigl(x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr)\geq c - 2d(1+\kappa_1+\gamma)^2\bigr)\\&\leq N_d\max_{1\leq j\leq N_d} \mathbb{P}\bigl(\bigl(x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr)\geq c - 2d(1+\kappa_1+\gamma)^2\bigr)\\&\leq N_d\max_{1\leq j\leq N_d}\mathbb{P}\Biggl(\sum_{i=1}^nS_{x^{(j)},i}^2/n\geq c - 2d(1+\kappa_1+\gamma)^2\Biggr),\end{align*}
where the first inequality comes from the facts
 \[\bigl|x\cdot\mathbf{W}x-x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr|\leq \bigl(\|x\|+\|x^{(j)}\|\bigr)\|\mathbf{W}\|\|x-x^{(j)}\|\leq 2 \lambda_{\max}d\]
\[\bigl|x\cdot\mathbf{W}x-x^{(j)}\cdot\mathbf{W}x^{(j)}\bigr|\leq \bigl(\|x\|+\|x^{(j)}\|\bigr)\|\mathbf{W}\|\|x-x^{(j)}\|\leq 2 \lambda_{\max}d\]
and
 $\lambda_{\max}<(1+\kappa_1+\gamma)^2$
. With
$\lambda_{\max}<(1+\kappa_1+\gamma)^2$
. With
 $\epsilon\,:\!=\, 2d(1+\kappa_1+\gamma)^2$
, the Chernoff upper bound (see [Reference Dembo and Zeitouni2, remark (c) of Theorem 2.2.3]) implies
$\epsilon\,:\!=\, 2d(1+\kappa_1+\gamma)^2$
, the Chernoff upper bound (see [Reference Dembo and Zeitouni2, remark (c) of Theorem 2.2.3]) implies
 \begin{align*} & n^{-1}\ln \mathbb{P}\bigl(c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr) \\ &\quad \leq n^{-1}\ln N_d - \min_{1\leq j\leq N_d}\sup_{\theta\in\mathbb{R}}\bigl[\theta (c - \epsilon)-\ln \mathbb{E}\exp\bigl\{\theta\bigl(S_{x^{(j)},1}^2\bigr)\bigr\}\bigr]\\ &\quad \leq n^{-1}\ln N_d - I_{p(n)}(c - \epsilon)+{\mathrm{o}}(1).\end{align*}
\begin{align*} & n^{-1}\ln \mathbb{P}\bigl(c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr) \\ &\quad \leq n^{-1}\ln N_d - \min_{1\leq j\leq N_d}\sup_{\theta\in\mathbb{R}}\bigl[\theta (c - \epsilon)-\ln \mathbb{E}\exp\bigl\{\theta\bigl(S_{x^{(j)},1}^2\bigr)\bigr\}\bigr]\\ &\quad \leq n^{-1}\ln N_d - I_{p(n)}(c - \epsilon)+{\mathrm{o}}(1).\end{align*}
With
 $p(n)={\mathrm{o}}(n)$
and the fact
$p(n)={\mathrm{o}}(n)$
and the fact
 $\lim_{n\rightarrow\infty}n^{-1}\ln N_d = 0$
, it follows that
$\lim_{n\rightarrow\infty}n^{-1}\ln N_d = 0$
, it follows that
 \[\limsup_{n\rightarrow\infty}n^{-1}\ln \mathbb{P}\bigl(c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr)\leq - I(c - \epsilon).\]
\[\limsup_{n\rightarrow\infty}n^{-1}\ln \mathbb{P}\bigl(c\leq \lambda_{\max} \leq (1+\kappa_1+\gamma)^2\bigr)\leq - I(c - \epsilon).\]
Taking into account the concentration inequality (5), we obtain
 \[\limsup_{n\rightarrow\infty}n^{-1} \mathbb{P}(\lambda_{\max}\geq c) \leq \max\bigl\{- I(c - \epsilon),-\kappa_2 \gamma^2\bigr\}.\]
\[\limsup_{n\rightarrow\infty}n^{-1} \mathbb{P}(\lambda_{\max}\geq c) \leq \max\bigl\{- I(c - \epsilon),-\kappa_2 \gamma^2\bigr\}.\]
Thus (2) is proved by first taking
 $d\rightarrow0^+$
(implying that
$d\rightarrow0^+$
(implying that
 $\epsilon \rightarrow0^+$
) and then sending
$\epsilon \rightarrow0^+$
) and then sending
 $\gamma\rightarrow\infty$
.
$\gamma\rightarrow\infty$
.
In a very similar way (4) can be proved by applying (7) to (9) as follows:
 \begin{align*}\mathbb{P}\bigl(\lambda_{\min}\leq c, \lambda_{\max}\leq (1+\kappa_1+\gamma)^2\bigr) \leq N_d\max_{1\leq j\leq N_d}\mathbb{P}\Biggl(\sum_{i=1}^nS_{x^{(j)},i}^2/n\leq c + 2d(1+\kappa_1+\gamma)^2\Biggr).\end{align*}
\begin{align*}\mathbb{P}\bigl(\lambda_{\min}\leq c, \lambda_{\max}\leq (1+\kappa_1+\gamma)^2\bigr) \leq N_d\max_{1\leq j\leq N_d}\mathbb{P}\Biggl(\sum_{i=1}^nS_{x^{(j)},i}^2/n\leq c + 2d(1+\kappa_1+\gamma)^2\Biggr).\end{align*}
Here we remark that the original proof in [Reference Fey, van der Hofstad and Klok3] is based on splitting the values of
 $\lambda_{\max}$
into two (or more) parts with the length of each part depending on n, which leads to the restrictive assumption
$\lambda_{\max}$
into two (or more) parts with the length of each part depending on n, which leads to the restrictive assumption
 $p={\mathrm{o}}(n/{\ln}\ln n)$
. Because of the uniform constant
$p={\mathrm{o}}(n/{\ln}\ln n)$
. Because of the uniform constant
 $\gamma$
in the concentration inequality (5), it is thus possible to improve it as
$\gamma$
in the concentration inequality (5), it is thus possible to improve it as
 $p={\mathrm{o}}(n)$
.
$p={\mathrm{o}}(n)$
.
2.3. Continuity of I(c)
It was remarked in [Reference Fey, van der Hofstad and Klok3] that the continuity of I(c) is still largely unknown. Here we derive bounds for I(c) using the ideas of [Reference Fey, van der Hofstad and Klok3, Theorem 3.2], and show that I(c) is continuous on
 $[1,\infty)$
for sub-Gaussian entries satisfying the conditions in Theorem 1 and
$[1,\infty)$
for sub-Gaussian entries satisfying the conditions in Theorem 1 and
 $K_4^2=1/2$
(recall that
$K_4^2=1/2$
(recall that
 $K_4^2$
is given in the definition of sub-Gaussian distributions in Section 1).
$K_4^2$
is given in the definition of sub-Gaussian distributions in Section 1).
Recall that
 $I(c)=\lim_{p\rightarrow\infty}I_{p}(c)$
, where
$I(c)=\lim_{p\rightarrow\infty}I_{p}(c)$
, where
 \[ I_{p}(c)=\inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{\theta\in\mathbb{R}}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]. \]
\[ I_{p}(c)=\inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{\theta\in\mathbb{R}}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]. \]
For
 $c\geq1$
, we have
$c\geq1$
, we have
 \[ \sup_{\theta\in\mathbb{R}}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]=\sup_{\theta\geq0}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]{,} \]
\[ \sup_{\theta\in\mathbb{R}}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]=\sup_{\theta\geq0}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]{,} \]
since
 \[ \theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\leq \theta c-\mathbb{E}\bigl(\theta S_{x,1}^2\bigr)=\theta (c-1)\leq 0\quad\text{for $\theta<0$.} \]
\[ \theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\leq \theta c-\mathbb{E}\bigl(\theta S_{x,1}^2\bigr)=\theta (c-1)\leq 0\quad\text{for $\theta<0$.} \]
It was shown in [Reference Singull, Uwamariya and Yang9] that
 \[ \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\leq \bigl(1-4\theta K_4^2\bigr)^{-1/2}\quad\text{for $\theta<1/\bigl(4K_4^2\bigr)$.} \]
\[ \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\leq \bigl(1-4\theta K_4^2\bigr)^{-1/2}\quad\text{for $\theta<1/\bigl(4K_4^2\bigr)$.} \]
Therefore, for
 $c\geq1$
,
$c\geq1$
,
 \begin{align*}I_{p}(c)&\geq \inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{0\leq \theta<1/(4K_4^2)}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]\\&\geq \inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{0\leq \theta<1/(4K_4^2)}\bigl[\theta c-\ln \bigl(\bigl(1-4\theta K_4^2\bigr)^{-1/2}\bigr)\bigr]\\&=\sup_{0\leq \theta<1/(4K_4^2)}\bigl[\theta c-\ln \bigl(\bigl(1-4\theta K_4^2\bigr)^{-1/2}\bigr)\bigr]\\&=c/\bigl(4K_4^2\bigr)-1/2+\bigl[\ln\bigl(2K_4^2/c\bigr)\bigr]/2\quad \text{for $1/2\leq K_4^2\leq c/2$.}\end{align*}
\begin{align*}I_{p}(c)&\geq \inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{0\leq \theta<1/(4K_4^2)}\bigl[\theta c-\ln \mathbb{E}\exp\bigl\{\theta S_{x,1}^2\bigr\}\bigr]\\&\geq \inf_{x\in \mathbb{R}^p,\|x\|=1}\sup_{0\leq \theta<1/(4K_4^2)}\bigl[\theta c-\ln \bigl(\bigl(1-4\theta K_4^2\bigr)^{-1/2}\bigr)\bigr]\\&=\sup_{0\leq \theta<1/(4K_4^2)}\bigl[\theta c-\ln \bigl(\bigl(1-4\theta K_4^2\bigr)^{-1/2}\bigr)\bigr]\\&=c/\bigl(4K_4^2\bigr)-1/2+\bigl[\ln\bigl(2K_4^2/c\bigr)\bigr]/2\quad \text{for $1/2\leq K_4^2\leq c/2$.}\end{align*}
The restriction
 $1/2\leq K_4^2$
is from the assumptions that the entries
$1/2\leq K_4^2$
is from the assumptions that the entries
 $X_{ij}$
have zero mean, unit variance, and
$X_{ij}$
have zero mean, unit variance, and
 \[\mathbb{E}\exp\{tX_{ij}\}\leq \exp\bigl\{t^2K_4^2\bigr\} \quad\text{for all $t\in \mathbb{R}$.}\]
\[\mathbb{E}\exp\{tX_{ij}\}\leq \exp\bigl\{t^2K_4^2\bigr\} \quad\text{for all $t\in \mathbb{R}$.}\]
The other restriction
 $K_4^2\leq c/2$
is from searching for the supremum. Therefore
$K_4^2\leq c/2$
is from searching for the supremum. Therefore
 \[I(c)\geq c/\bigl(4K_4^2\bigr)-1/2+\bigl[\ln\bigl(2K_4^2/c\bigr)\bigr]/2\quad\text{for $1/2\leq K_4^2\leq c/2$.}\]
\[I(c)\geq c/\bigl(4K_4^2\bigr)-1/2+\bigl[\ln\bigl(2K_4^2/c\bigr)\bigr]/2\quad\text{for $1/2\leq K_4^2\leq c/2$.}\]
On the other hand, Fey et al. [Reference Fey, van der Hofstad and Klok3, Theorem 3.2] proved that
 $I(c)\leq (c-1-\ln c)/2$
for
$I(c)\leq (c-1-\ln c)/2$
for
 $c\geq1$
. In summary, if one takes the entries
$c\geq1$
. In summary, if one takes the entries
 $X_{ij}$
as sub-Gaussian random variables satisfying the conditions in Theorem 1 and
$X_{ij}$
as sub-Gaussian random variables satisfying the conditions in Theorem 1 and
 $K_4^2=1/2$
, then
$K_4^2=1/2$
, then
 $I(c)=(c-1-\ln c)/2$
for
$I(c)=(c-1-\ln c)/2$
for
 $c\geq1$
. As mentioned in [Reference Fey, van der Hofstad and Klok3], this is a kind of universality result as
$c\geq1$
. As mentioned in [Reference Fey, van der Hofstad and Klok3], this is a kind of universality result as
 $(c-1-\ln c)/2$
is the corresponding rate function with i.i.d. standard normal entries. Furthermore, the condition
$(c-1-\ln c)/2$
is the corresponding rate function with i.i.d. standard normal entries. Furthermore, the condition
 $K_4^2=1/2$
is satisfied for at least three distributions: standard normal, Bernoulli
$K_4^2=1/2$
is satisfied for at least three distributions: standard normal, Bernoulli
 $\mp1$
with equal probabilities, and uniform distribution on
$\mp1$
with equal probabilities, and uniform distribution on
 $[{-}\sqrt{3},\sqrt{3}]$
.
$[{-}\sqrt{3},\sqrt{3}]$
.
Acknowledgements
The authors are grateful to the referee and Editor for several constructive comments which have led to an improved version of the paper.
Funding information
There are no funding bodies to thank relating to this creation of this article.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
