



1 Introduction
Defects on the surface of optics are among the earliest indications of degradation which are critical for the maintenance of optical systems. Early detection of the defects allows preventive measures to be taken to prevent the defects from growing to an unrepairable size. Large laser facilities, such as the National Ignition Facility (NIF)[Reference Spaeth, Manes, Kalantar, Miller, Heebner, Bliss, Speck, Parham, Whitman, Wegner, Baisden, Menapace, Bowers, Cohen, Suratwala, Di Nicola, Newton, Adams, Trenholme, Finucane, Bonanno, Rardin, Arnold, Dixit, Erbert, Erlandson, Fair, Feigenbaum, Gourdin, Hawley, Honig, House, Jancaitis, LaFortune, Larson, Le Galloudec, Lindl, MacGowan, Marshall, McCandless, McCracken, Montesanti, Moses, Nostrand, Pryatel, Roberts, Rodriguez, Rowe, Sacks, Salmon, Shaw, Sommer, Stolz, Tietbohl, Widmayer and Zacharias1] and the Laser Megajoule (LMJ)[Reference Casner, Caillaud, Darbon, Duval, Thfouin, Jadaud, LeBreton, Reverdin, Rosse, Rosch, Blanchot, Villette, Wrobel and Miquel2], routinely operate at high ultraviolet fluences above the damage threshold of optical components. The laser-induced defects on optics, once initiated, will grow rapidly in subsequent exposure to high fluence, until to the point at which the entire optical component needs to be replaced. Therefore, it is critical for sustainable operation to detect and monitor defects in the early stage.
Various image processing techniques, such as the threshold method, Otsu’s method and Fourier transform[Reference He and Sun3–Reference Zhu, Chen, Liu, Ma, Zheng, Han and Li5], have been implemented for defect detection to replace the time-consuming and error-prone manual inspection. Scientists at the Lawrence Livermore National Laboratory (LLNL) have conducted a lot of valuable researches in the field of damage online inspection. Using linescan phase-differential imaging, LLNL developed a process for rapid detection of phase defects in the bulk or surface of large-aperture optics[Reference Ravizza, Nostrand, Kegelmeyer, Hawley and Johnson6]. A threshold is set on the brightest pixel value to select candidates for further assessment of their fratricidal threat. LLNL also designed the local area signal-to-noise ratio (LASNR) algorithm[Reference Kegelmeyer, Fong, Glenn and Liebman7] for accurate and rapid inspection of the optics from the NIF. The algorithm estimates the strength of signal within an object versus the noise in its local neighborhood. However, the accuracy and robustness of these image processing techniques are largely affected by varying situations like illumination conditions, shading and noises.
Machine-learning-based models outperform the image processing techniques in accuracy and robustness, and have been successfully applied in computer vision tasks such as object detection and classification. LLNL extracted various features from each damage site and employed ensemble of decision trees to identify false damage sites from hardware reflections[Reference Abdulla, Kegelmeyer, Liao and Carr8]. Harbin Institute of Technology (HIT) developed the final optics damage inspection (FODI) system for the laser facility at the China Academy of Engineering Physics (CAEP)[Reference Liu, Wei, Chen, Peng and Tang9, Reference Wei, Chen, Liu, Peng, Tang, Zhu, Hu, Xiang, Liu, Sun and Liu10]. HIT manually extracted features associated with each damage site, and then used extreme learning machine to distinguish true and false damage sites and predict the damage size. The success of the machine learning models above relies on the manually custom-built features based on the experience of domain experts. Nathan et al. [Reference Mundhenk, Kegelmeyer and Trummer11] built convolutional neural network (CNN) with features auto-generated from data, and found that it outperforms the method using custom-built features in finding the subtle, rare, incomplete repairs of damage. However, typical CNNs rely heavily on the availability of a large labeled training sample. The label for each potential damage site is identified by a microscope. It is difficult and time-consuming to obtain a large labeled sample in practice for training the models.
In recent years, fully convolutional networks with U-shaped architecture (U-Net) have been lauded for precise segmentation and efficient use of available samples. Models based on U-Net are commonly used in image analysis tasks in medical diagnosis, biological science and cosmology[Reference Ronneberger, Fischer and Brox12–Reference Berger and Stein15]. Dong et al. [Reference Dong, Taylor and Cootes16] used features sampled from the earlier U-Net layers to identify defects in radiographs of aerospace welds. Inspired by these works, we present our approach to detection of optical defects that leverages the power of U-Net. We trained the network end to end on paired sets of online and offline images of optics from a large laser facility. The main advantage of the proposed method is that the network can be trained from very few images without manual labeling or manual feature extraction.
The paper is outlined as follows. First, we introduce the structure of the detection model based on U-Net. Then, we explain in detail about the methodology used in building the model, including the overall architecture, the preparation of the training set, the specifics of its implementation and training procedure. Finally, we show the robustness and adaptability of the model for online detection on the laser facility using novel optical images never seen by the network.
2 U-Net for defect detection
Convolutional neural networks serve as the network backbones for image segmentation due to the high representation power and filter sharing properties. The U-Net architecture is built upon the fully convolutional networks. It consists of a contracting path to capture context and a symmetric expanding path that enables precise localization. The schematic representation of our model used for defect detection is shown in Figure 1, which follows the original architecture proposed by Ronneberger et al. in 2015[Reference Ronneberger, Fischer and Brox12]. The dimensions, padding method and other parameters of the model are adjusted to make the model better suited to our task.
The network consists of four major operations, convolution, up-convolution, max pooling and feature forwarding, as shown by the arrows in Figure 1. The operation of convolution processes an image using a receptive field that detects specific attributes like lines and edges. More complex attributes are detected as the layers go deeper. An up-convolution is the transpose matrix operation of the normal convolution, which remaps the detected attributes into the image space. Pooling layers are inserted between the successive convolutional layers to reduce the amount of parameters and computational cost. The high-resolution features from the contracting path on the left are forwarded to the expanding path by combining with the up-sampled output. In addition, dropout layers are added at the end of the contracting path to prevent the model from over-fitting. The final convolutional layer’s output has the same dimension as the input. A sigmoid function is applied to convert the output to the probability of real laser-induced defects.

Figure 1. Schematic representation of the proposed U-Net model for defect detection. The boxes correspond to multi-channel feature maps, connected by different operations (denoted by arrows). The length and height of each box represent the number of filters (
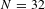 $N=32$
) and the
$N=32$
) and the
 $x$
–
$x$
–
 $y$
size, respectively.
$y$
size, respectively.

Figure 2. The overall architecture to train the model for detection of optical defects in real time.
3 Methodology
3.1 Overall architecture
Figure 2 shows the overall architecture of our method to train the model for online detection of optical defects. Raw images of optics were taken from the monitoring system of a large laser facility, as described in detail in Ref. [Reference Liu, Wei, Chen, Peng and Tang9]. The training set consists of pairs of online regions and corresponding masks of real defects (Figure 2(a)). The masks were created by the images of optics taken offline. Figure 2(b) is the unfitted U-Net model with untrained parameters. The structure of the model has been shown in Section 2. We trained the model using the training set to learn the mapping from the online optics to the masks of real defects. To test whether the system could make accurate predictions for novel online images, the trained U-Net (Figure 2(d)) was used to locate defects for images from different beamlines. The input (Figure 2(c)) of the trained U-Net is thus the online image of the optic. The output (Figure 2(e)) is a mask whose value is the network’s certainty that an input element is a part of real defects.
3.2 Training set preparation
To train the U-Net to detect defects from online images, we first prepared a dataset of training samples, consisting of pairs of regions from online images and corresponding masks created by the offline images. The online images of the optics were acquired using the camera system placed at the center of the target chamber between the laser shots. Defects on the optics scatter light into the CCD yielding bright signals against dark backgrounds. However, a potential defect site on the online image can fall into one of several categories, such as real laser-induced defect, hardware reflection, light spot, reflection from the exit surface or damaged CCD pixels. Figure 3 shows examples of some categories to illustrate the difficulty in distinguishing between them.
Most of the optics on site are under daily maintenance. It will take long to accumulate sufficient number of defects for training the network. We selected two badly damaged optics after high exposure to the laser, which contained several hundreds of real laser-induced defects. After the online images were taken, the optics were disassembled from the frame and passed through a cleaning system. Then the offline images were collected by scanning the cleaned optic in a non-disturbing light environment. The offline images only contained laser-induced defects, without reflections, light spots and other on-site noises; hence, it can be used as the mask of real laser-induced defects for the online image. Figure 4 is the schematic of the experimental setup to illustrate the methodology in obtaining the online and offline images.
To determine the mapping between the online and offline images, a frame of reference was established by applying fiducials making up groups of small dots at the four corners of each optic. The circle Hough transform (CHT)[Reference Hough17], as a feature-extraction technique for detecting circles, was further applied to add additional obvious matching points between the online and offline images of the inspected optic. A
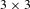 $3\times 3$
matrix, called homography[Reference Szeliski18], was then calculated based on these matching points that warped the offline image to the online image.
$3\times 3$
matrix, called homography[Reference Szeliski18], was then calculated based on these matching points that warped the offline image to the online image.
The resolution of the online and transformed offline images was around
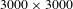 $3000\times 3000$
, which was too large for the input of the neural network. The online images were cropped into small images of
$3000\times 3000$
, which was too large for the input of the neural network. The online images were cropped into small images of
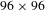 $96\times 96$
pixel resolutions with a stride of 48. Considering the pixel-level distortion and shift between the online and offline images, we obtained the matched offline region by searching the corresponding neighborhood for each cropped region using the template matching algorithm[Reference Brunelli19]. We compared the online regions
$96\times 96$
pixel resolutions with a stride of 48. Considering the pixel-level distortion and shift between the online and offline images, we obtained the matched offline region by searching the corresponding neighborhood for each cropped region using the template matching algorithm[Reference Brunelli19]. We compared the online regions
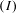 $(I)$
against the offline regions
$(I)$
against the offline regions
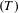 $(T)$
of
$(T)$
of
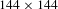 $144\times 144$
by sliding and computed a metric for each location[20]. The location with the highest match value and the corresponding region of
$144\times 144$
by sliding and computed a metric for each location[20]. The location with the highest match value and the corresponding region of
 $T$
were selected to get the matched offline region.
$T$
were selected to get the matched offline region.
The LASNR algorithm was applied to mark the position of defects on the offline images and find the full extent of each defect. All the marked sites on the offline image could be considered as real defects; hence, 0–1 mask was given for each pixel, with 1 for real defect and 0 for background. Figure 5 shows an example of the prepared dataset for illustration. The inputs to the network were the cropped online images with
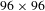 $96\times 96$
pixel resolutions, and the target outputs were the corresponding masks of the same dimension.
$96\times 96$
pixel resolutions, and the target outputs were the corresponding masks of the same dimension.

Figure 3. Examples of a potential damage site classified as: (a) real defect; (b) hardware reflection; (c) reflection from the exit surface (marked in the box); (d) light spot.

Figure 4. Schematic diagram of the methodology in obtaining the online and offline images of the final optics.

Figure 5. An example of the prepared training dataset: (a) the cropped region from the online image; (b) the matched region of (a) in the offline image; (c) the 0–1 mask created by (b), with 1 for real defect and 0 for background.
3.3 Implementation and training
Our implementation was realized in Python 3.6, using the Keras[Reference Chollet21] framework with TensorFlow backend. TensorFlow[Reference Abadi, Agarwal, Barham, Brevdo, Chen, Citro, Corrado, Davis, Dean, Devin, Ghemawat, Goodfellow, Harp, Irving, Isard, Jia, Jozefowicz, Kaiser, Kudlur, Levenberg, Mane, Monga, Moore, Murray, Olah, Schuster, Shlens, Steiner, Sutskever, Talwar, Tucker, Vanhoucke, Vasudevan, Viegas, Vinyals, Warden, Wattenberg, Wicke, Yu and Zheng22] is a popular open-source library for deep learning, and Keras is a high-level neural networks library with a focus on enabling fast experimentation. All the training and experiments were run on a standard workstation with the Nvidia Tesla P100 GPU.
The total number of paired images for training the network was 550 (with
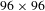 $96\times 96$
pixel resolutions for both the online samples and masks), after removal of images with all dark backgrounds. The samples were split randomly with a ratio of 4:1, yielding 440 training samples and 110 validation samples. The validation samples were used for early stopping to prevent the network from over-fitting when the network started to model the noise in the training samples.
$96\times 96$
pixel resolutions for both the online samples and masks), after removal of images with all dark backgrounds. The samples were split randomly with a ratio of 4:1, yielding 440 training samples and 110 validation samples. The validation samples were used for early stopping to prevent the network from over-fitting when the network started to model the noise in the training samples.
For our task, the available training sample was quite small. Data augmentation was essential to teach the network the desired invariance. Morphology transformations like rotation, shift in width and height, horizontal and vertical flips, and variation in gray values were applied to images and masks at the same time. The data samples and parameters for augmentation were wrapped in a data generator, which generated batches of tensor image data for each training epoch.
The intensity distribution of the images was highly imbalanced, as shown in Figure 6. The dark backgrounds converged near 0 while the potential defects spread from 0 to 1.0 with a fraction of less than 3%. The bin near 1.0 was caused by over-exposure of some of the potential defects. The learning process was prone to get trapped in local minima of the loss function with predictions strongly biased toward 0. To solve the problem, we implemented a dice loss function in Keras following Milletari et al. (2016)[Reference Milletari, Navab and Ahmadi23]. The dice coefficient (DCE) between two regions is defined as
 $$\begin{eqnarray}\text{DCE}=\frac{2\overrightarrow{p}\overrightarrow{g}}{\overrightarrow{p}+\overrightarrow{g}},\end{eqnarray}$$
$$\begin{eqnarray}\text{DCE}=\frac{2\overrightarrow{p}\overrightarrow{g}}{\overrightarrow{p}+\overrightarrow{g}},\end{eqnarray}$$
where
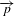 $\overrightarrow{p}$
and
$\overrightarrow{p}$
and
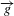 $\overrightarrow{g}$
are vectors of the predicted results and the ground truth, respectively. We trained the network by minimizing the dice loss, which is defined as
$\overrightarrow{g}$
are vectors of the predicted results and the ground truth, respectively. We trained the network by minimizing the dice loss, which is defined as
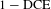 $1-\text{DCE}$
. Alternatively, we trained the network using the binary cross-entropy loss and assigned more weights to the foreground. It was found that training with the dice loss outperforms the re-weighting method and the training process could quickly pass the local minimum.
$1-\text{DCE}$
. Alternatively, we trained the network using the binary cross-entropy loss and assigned more weights to the foreground. It was found that training with the dice loss outperforms the re-weighting method and the training process could quickly pass the local minimum.

Figure 6. Intensity distribution of the training samples (in log scale).
We trained the network using the Adam optimizer. The Adam optimization is an extension to stochastic gradient descent that can be used to update the network weights. The initial learning rate was
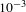 $10^{-3}$
, which allowed the network to converge fast. The network was trained iteratively with a mini-batch of size 50 until the loss of the validation samples did not decrease. For each iteration, we fed randomly augmented samples as input to the network. Then, we changed the learning rate to
$10^{-3}$
, which allowed the network to converge fast. The network was trained iteratively with a mini-batch of size 50 until the loss of the validation samples did not decrease. For each iteration, we fed randomly augmented samples as input to the network. Then, we changed the learning rate to
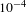 $10^{-4}$
and iterated the above process for fine-tuning of the model. Figure 7 shows the curves of training and validation loss with respect to the number of iterations.
$10^{-4}$
and iterated the above process for fine-tuning of the model. Figure 7 shows the curves of training and validation loss with respect to the number of iterations.

Figure 7. The curves of training and validation loss with respect to the number of iterations. We used a learning rate of
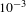 $10^{-3}$
for the first 500 iterations and changed the learning rate to
$10^{-3}$
for the first 500 iterations and changed the learning rate to
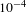 $10^{-4}$
for later iterations.
$10^{-4}$
for later iterations.
4 Results
To test the robustness and adaptability of the model for online detection, we took images of optics from different beamlines and prepared the testing set following the same method used to produce the training set. The online images were cropped into small regions of
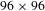 $96\times 96$
pixel resolutions and fed as input to the trained U-Net model. Then the predictions by the model were used to locate the real laser-induced defects on the online image and get the predicted mask. The total number of testing samples was 636 (with
$96\times 96$
pixel resolutions and fed as input to the trained U-Net model. Then the predictions by the model were used to locate the real laser-induced defects on the online image and get the predicted mask. The total number of testing samples was 636 (with
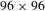 $96\times 96$
pixel resolutions). The sample contained 415 real laser-induced defects. The trained U-Net model achieved a DCE of 86.2% on the testing set. Figure 8 shows the predictions of defects by the trained model (Figure 8(c)), compared with the mask of real defects created by the offline image (Figure 8(b)), on one of the inspected optics (Figure 8(a)) as an example. As shown by the bottom panels of the figure, the trained model could separate real defects from backgrounds such as hardware reflections and light spots.
$96\times 96$
pixel resolutions). The sample contained 415 real laser-induced defects. The trained U-Net model achieved a DCE of 86.2% on the testing set. Figure 8 shows the predictions of defects by the trained model (Figure 8(c)), compared with the mask of real defects created by the offline image (Figure 8(b)), on one of the inspected optics (Figure 8(a)) as an example. As shown by the bottom panels of the figure, the trained model could separate real defects from backgrounds such as hardware reflections and light spots.

Figure 8. Predictions of real defects by the trained model on the test images. (a) The online image of an inspected optic. (b) 0–1 mask created by the offline images of the same inspected optic. (c) Predicted mask by the trained U-Net model. Bottom panels show a zoom-in on a highly contaminated region.
To further characterize the performance of the trained U-Net model, we calculated the precision
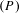 $(P)$
and recall
$(P)$
and recall
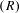 $(R)$
in object level, as given in terms of the number of true positives (TP), false positives (FP) and false negatives (FN):
$(R)$
in object level, as given in terms of the number of true positives (TP), false positives (FP) and false negatives (FN):
 $$\begin{eqnarray}\displaystyle P & = & \displaystyle \text{TP}/(\text{TP}+\text{FP}),\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle P & = & \displaystyle \text{TP}/(\text{TP}+\text{FP}),\end{eqnarray}$$
 $$\begin{eqnarray}\displaystyle R & = & \displaystyle \text{TP}/(\text{TP}+\text{FN}),\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle R & = & \displaystyle \text{TP}/(\text{TP}+\text{FN}),\end{eqnarray}$$
where
 $\text{TP}$
in our case corresponds to real defects correctly marked by the prediction of the model,
$\text{TP}$
in our case corresponds to real defects correctly marked by the prediction of the model,
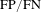 $\text{FP}/\text{FN}$
corresponds to false/real defects incorrectly marked as real/false defects by the model. The recall was 95.7% and the precision was 92.5% for the trained U-Net on the testing set. The
$\text{FP}/\text{FN}$
corresponds to false/real defects incorrectly marked as real/false defects by the model. The recall was 95.7% and the precision was 92.5% for the trained U-Net on the testing set. The
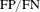 $\text{FP}/\text{FN}$
mainly came from some tiny defects of several pixels contaminated with backgrounds. And the
$\text{FP}/\text{FN}$
mainly came from some tiny defects of several pixels contaminated with backgrounds. And the
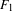 $F_{1}$
score, defined as
$F_{1}$
score, defined as
 $$\begin{eqnarray}F_{1}=2\mathit{PR}/(P+R),\end{eqnarray}$$
$$\begin{eqnarray}F_{1}=2\mathit{PR}/(P+R),\end{eqnarray}$$
was 0.94. We implemented the algorithm on a platform with user interface. It took less than 30 s to process an entire online image of
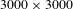 $3000\times 3000$
pixels on the platform, which met the system’s requirement for online detection between the laser shots on the laser facility.
$3000\times 3000$
pixels on the platform, which met the system’s requirement for online detection between the laser shots on the laser facility.
5 Conclusion
In this paper, a vision-based approach for detecting optical defects has been proposed based on image segmentation. The proposed deep learning system can accurately locate laser-induced defects on the optics in real time. Unlike typical classification models where the output to an image is a single label, the U-Net model is able to assign a class label to each pixel. Moreover, the detection model can be trained end to end on small samples without the requirement for manual labeling or manual feature extraction. The proposed method is especially strong at detecting defects when each sample may contain multiple adjacent objects. In our case, the model removes the fake defects from reflections by learning the relative spatial and intensity information, where we had limited success with typical classification models in previous studies. The proposed approach may have wide applications in the online detection and maintenance of large laser facilities where a large number of labeled samples are not available.
Nevertheless, we encountered some limitations of the current method. First, it is assumed that the object inspected does not have complicated structures. Hence, the offline images can be used as the mask of real defects. Second, the network’s predictive ability relies on the quality of the imaging system. In our study, the detailed information of the defects was lost due to exposure. Third, the method did not make use of the successive online images taken per week in discriminating the tiny defects from backgrounds. Tracking and predicting the growth of each defect in successive online images will be an important topic for future research.









 Open access
Open access