


1 Introduction
Community detection is the task of dividing a network — typically one which is large — into many smaller groups of nodes that have a similar contribution to the overall network structure. With such a division, we can better summarize the large-scale structure of a network by describing how these groups are connected, rather than describing each individual node. This simplified description can be used to digest an otherwise intractable representation of a large system, providing insight into its most important patterns, how these patterns relate to its function, and the underlying mechanisms responsible for its formation.
Because of its important role in network science, community detection has attracted substantial attention from researchers, specially in the last 20 years, culminating in an abundant literature (see Refs. [Reference Fortunato1, Reference Fortunato and Hric2] for a review). This field has developed significantly from its early days, specially over the last 10 years, during which the focus has been shifting towards methods that are based on statistical inference (see e.g. Refs. [Reference Moore3–Reference Peixoto, Doreian, Batagelj and Ferligoj5]).
Despite this shift in the state-of-the-art, there remains a significant gap between the best practices and the adopted practices in the use of community detection for the analysis of network data. It is still the case that some of the earliest methods proposed remain in widespread use, despite their many serious shortcomings that have been uncovered over the years. Most of these problems have been addressed with more recent methods, that also contributed to a much deeper theoretical understanding of the problem of community detection [Reference Moore3, Reference Abbe4, Reference Decelle, Krzakala, Moore and Zdeborová6, Reference Krzakala7].
Nevertheless, some misconceptions remain and are still promoted. Here we address some of the more salient ones, in an effort to dispel them. These misconceptions are not uniformly shared; and those that pay close attention to the literature will likely find few surprises here. However, it is possible that many researchers employing community detection are simply unaware of the issues with the methods being used. Perhaps even more commonly, there are those that are in fact aware of them, but not of their actual solutions, or the fact that some supposed countermeasures are ineffective.
Throughout the following we will avoid providing “black box” recipes to be followed uncritically, and instead try as much as possible to frame the issues within a theoretical framework, such that the criticisms and solutions can be justified in a principled manner.
We will set the stage by making a fundamental distinction between “descriptive” and “inferential” community detection approaches. As others have emphasized before [Reference Schaub, Delvenne, Rosvall and Lambiotte8], community detection can be performed with many goals in mind, and this will dictate which methods are most appropriate. We will provide a simple “litmus test” that can be used to determine which overall approach is more adequate, based on whether our goal is to seek inferential interpretations. We will then move to a more focused critique of the method that is arguably the most widely employed — modularity maximization. This method has an exemplary character, since it contains all possible pitfalls of using descriptive methods for inferential aims. We will then follow with a discussion of myths, pitfalls, and half-truths that obstruct a more effective analysis of community structure in networks.
(We will not give a throughout technical introduction to inferential community detection methods, which can be obtained instead in Ref. [Reference Peixoto, Doreian, Batagelj and Ferligoj5]. For a practical guide on how to use various inferential methods, readers are referred to the detailed HOWTOFootnote 1 available as part of the graph-tool Python library [Reference Peixoto9].)
2 Descriptive vs. inferential community detection
At a very fundamental level, community detection methods can be divided into two main categories: “descriptive” and “inferential.”
Descriptive methods attempt to find communities according to some context-dependent notion of a good division of the network into groups. These notions are based on the patterns that can be identified in the network via an exhaustive algorithm, but without taking into consideration the possible rules that were used to create the patterns uncovered. These patterns are used only to describe the network, not to explain it. Usually, these approaches do not articulate precisely what constitutes community structure to begin with, and focus instead only on how to detect such patterns. For this kind of method, concepts of statistical significance, parsimony, and generalizability are usually not evoked.
Inferential methods, on the other hand, start with an explicit definition of what constitutes community structure, via a generative model for the network. This model describes how a latent (i.e. not observed) partition of the nodes would affect the placement of the edges. The inference consists on reversing this procedure to determine which node partitions are more likely to have been responsible for the observed network. The result of this is a “fit” of a model to data, that can be used as a tentative explanation of how the network came to be. The concepts of statistical significance, parsimony, and generalizability arise naturally and can be quantitatively assessed in this context.
Descriptive community detection methods are by far the most numerous, and those that are in most widespread use. However, this contrasts with the current state-of-the-art, which is composed in large part of inferential approaches. Here we point out the major differences between them and discuss how to decide which is more appropriate, and also why one should in general favor the inferential varieties whenever the objective is to derive generative interpretations from data.
2.1 Describing vs. explaining
We begin by observing that descriptive clustering approaches are the methods of choice in certain contexts. For instance, such approaches arise naturally when the objective is to divide a network into two or more parts as a means to solve a variety of optimization problems. Arguably, the most classic example of this is the design of very large scale integrated (VLSI) circuits [Reference Jacob Baker10]. The task is to combine from up to billions of transistors into a single physical microprocessor chip. Transistors that connect to each other must be placed together to take less space, consume less power, reduce latency, and reduce the risk of cross-talk with other nearby connections. To achieve this, the initial stage of a VLSI process involves the partitioning of the circuit into many smaller modules with few connections between them, in a manner that enables their efficient spatial placement, i.e. by positioning the transistors in each module close together and those in different modules farther apart.
Another notable example is parallel task scheduling, a problem that appears in computer science and operations research. The objective is to distribute processes (i.e. programs, or tasks in general) between different processors, so they can run at the same time. Since processes depend on the partial results of other processes, this forms a dependency network, which then needs to be divided such that the number of dependencies across processors is minimized. The optimal division is the one where all tasks are able to finish in the shortest time possible.
Both examples above, and others, have motivated a large literature on “graph partitioning” dating back to the 70s [Reference Kernighan11–Reference Bichot and Siarry13], which covers a family of problems that play an important role in computer science and algorithmic complexity theory.
Although reminiscent of graph partitioning, and sharing with it many algorithmic similarities, community detection is used more broadly with a different goal [Reference Fortunato1, Reference Fortunato and Hric2]. Namely, the objective is to perform data analysis, where one wants to extract scientific understanding from empirical observations. The communities identified are usually directly used for representation and/or interpretation of the data, rather than as a mere device to solve a particular optimization problem. In this context, a merely descriptive approach will fail at giving us a meaningful insight into the data, and can be misleading, as we will discuss in the following.
We illustrate the difference between descriptive and inferential approaches in Fig. 1. We first make an analogy with the famous “face” seen on images of the Cydonia Mensae region of the planet Mars. A merely descriptive account of the image can be made by identifying the facial features seen, which most people immediately recognize. However, an inferential description of the same image would seek instead to explain what is being seen. The process of explanation must invariably involve at its core an application of the law of parsimony, or Occam’s razor. This principle predicates that when considering two hypotheses compatible with an observation, the simplest one must prevail. Employing this logic results in the conclusion that what we are seeing is in fact a regular mountain, without denying that it looks like a face in that picture and instead acknowledging that it does so accidentally. In other words, the “facial” description is not useful as an explanation, as it emerges out of random features rather than exposing any underlying mechanism.
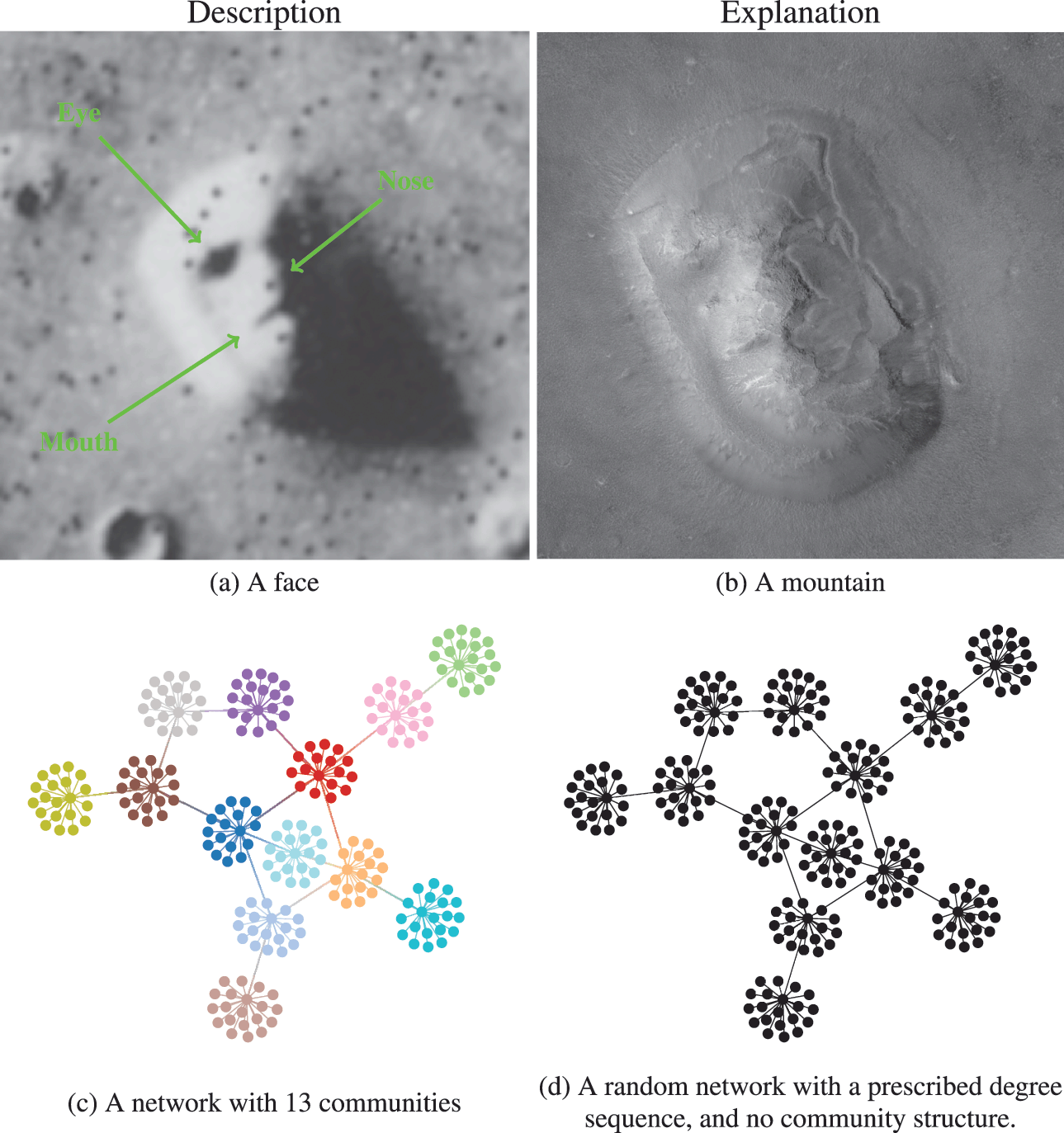
Figure 1 Difference between descriptive and inferential approaches to data analysis. As an analogy, in panels (a) and (b) we see two representations of the Cydonia Mensae region on Mars. Panel (a) is a descriptive account of what we see in the picture, namely a face. Panel (b) is an inferential representation of what lies behind it, namely a mountain (this is a more recent image of the same region with a higher resolution to represent an inferential interpretation of the figure in panel (a)). More concretely for the problem of community detection, in panels (c) and (d) we see two representations of the same network. Panel (c) shows a descriptive division into 13 assortative communities. In panel (d) we see an inferential representation as a degree-constrained random network, with no communities, since this is a more likely model of how this network was formed (see Fig. 2).

Figure 2 Descriptive community detection finds a partition of the network according to an arbitrary criterion that bears in general no relation to the rules that were used to generate it. In (a) is shown the generative model we consider, where first a degree sequence is given to the nodes (forming “stubs”, or “half-edges”) which then are paired uniformly at random, forming a graph. In (b) is shown a realization of this model. The node colors show the partition found with virtually any descriptive community detection method. In (c) is shown another network sampled from the same model, together with the same partition found in (b), which is completely uncorrelated with the new apparent communities seen, since they are the mere byproduct of the random placement of the edges. An inferential approach would find only a single community in both (b) and (c), since no partition of the nodes is relevant for the underlying generative model.
Going out of the analogy and back to the problem of community detection, in Fig. 1(c) and (d) we see a descriptive and an inferential account of an example network, respectively. The descriptive one is a division of the nodes into 13 assortative communities, which would be identified with many descriptive community detection methods available in the literature. Indeed, we can inspect visually that these groups form assortative communities,Footnote 2 and most people would agree that these communities are really there, according to most definitions in use: these are groups of nodes with many more internal edges than external ones. However, an inferential account of the same network would reveal something else altogether. Specifically, it would explain this network as the outcome of a process where the edges are placed at random, without the existence of any communities. The communities that we see in Fig. 1(c) are just a byproduct of this random process, and therefore carry no explanatory power. In fact, this is exactly how the network in this example was generated, i.e. by choosing a specific degree sequence and connecting the edges uniformly at random.
In Fig. 2(a) we illustrate in more detail how the network in Fig. 1 was generated: The degrees of the nodes are fixed, forming “stubs” or “half-edges,” which are then paired uniformly at random forming the edges of the network.Footnote 3 In Fig. 2(b), like in Fig. 1, the node colors show the partition found with descriptive community detection methods. However, this network division carries no explanatory power beyond what is contained in the degree sequence of the network, since it is generated otherwise uniformly at random. This becomes evident in Fig. 2(c), where we show another network sampled from the same generative process, i.e. another random pairing, but partitioned according to the same division as in Fig. 2(b). Since the nodes are paired uniformly at random, constrained only by their degree, this will create new apparent “communities” that are always uncorrelated with one another. Like the “face” on Mars, they can be seen and described, but they cannot (plausibly) explain how the network came to be.
We emphasize that the communities found in Fig. 2(b) are indeed really there from a descriptive point of view, and they can in fact be useful for a variety of tasks. For example, the cut given by the partition, i.e. the number of edges that go between different groups, is only 13, which means that we need only to remove this number of edges to break the network into (in this case) 13 smaller components. Depending on context, this kind of information can be used to prevent a widespread epidemic, hinder undesired communication, or, as we have already discussed, distribute tasks among processors and design a microchip. However, what these communities cannot be used for is to explain the data. In particular, a conclusion that would be completely incorrect is that the nodes that belong to the same group would have a larger probability of being connected between themselves. As shown in Fig. 2(a), this is clearly not the case, as the observed “communities” arise by pure chance, without any preference between the nodes.
2.2 To infer or to describe? A litmus test
Given the above differences, and the fact that both inferential and descriptive approaches have their uses depending on context, we are left with the question: Which approach is more appropriate for a given task at hand? In order to help answering this question, for any given context, it is useful to consider the following “litmus test”:
Litmus test: to infer or to describe?
Q: “Would the usefulness of our conclusions change if we learn, after obtaining the communities, that the network being analyzed is maximally random?”
If the answer is “yes,” then an inferential approach is needed.
If the answer is “no,” then an inferential approach is not required.
If the answer to the above question is “yes,” then an inferential approach is warranted, since the conclusions depend on an interpretation of how the data were generated. Otherwise, a purely descriptive approach may be appropriate since considerations about generative processes are not relevant.
It is important to understand that the relevant question in this context is not whether the network being analyzed is actually maximally random,Footnote 4 since this is rarely the case for empirical networks. Instead, considering this hypothetical scenario serves as a test to evaluate if our task requires us to separate between actual latent community structures (i.e. those that are responsible for the network formation), from those that arise completely out of random fluctuations, and hence carry no explanatory power. Furthermore, most empirical networks, even if not maximally random, like most interesting data, are better explained by a mixture of structure and randomness, and a method that cannot tell those apart cannot be used for inferential purposes.
Returning to the VLSI and task scheduling examples we considered in the previous section, it is clear that the answer to the litmus test above would be “no,” since it hardly matters how the network was generated and how we should interpret the partition found, as long as the integrated circuit can be manufactured and function efficiently, or the tasks finish in the minimal time. Interpretation and explanations are simply not the primary goals in these cases.Footnote 5
However, it is safe to say that in network data analyses very often the answer to the question above question would be “yes.” Typically, community detection methods are used to try to understand the overall large-scale network structure, determine the prevalent mixing patterns, make simplifications and generalizations, all in a manner that relies on statements about what lies behind the data, e.g. whether nodes were more or less likely to be connected to begin with. A majority of conclusions reached would be severely undermined if one would discover that the underlying network is in fact completely random. This means that these analyses suffer the substantial risk of yielding misleading answers when using purely descriptive methods, since they are likely to be overfitting the data — i.e. confusing randomness with underlying generative structure.Footnote 6
2.3 Inferring, explaining, and compressing
Inferential approaches to community detection (see Ref. [Reference Peixoto, Doreian, Batagelj and Ferligoj5] for a detailed introduction) are designed to provide explanations for network data in a principled manner. They are based on the formulation of generative models that include the notion of community structure in the rules of how the edges are placed. More formally, they are based on the definition of a likelihood
 for the network
for the network
 conditioned on a partition
conditioned on a partition
 , which describes how the network could have been generated, and the inference is obtained via the posterior distribution, according to Bayes’ rule, i.e.
, which describes how the network could have been generated, and the inference is obtained via the posterior distribution, according to Bayes’ rule, i.e.
 (1)
(1)
where
 is the prior probability for a partition
is the prior probability for a partition
 . The inference procedure consists in sampling from or maximizing this distribution, which yields the most likely division(s) of the network into groups, according to the statistical evidence available in the data (see Fig. 3).
. The inference procedure consists in sampling from or maximizing this distribution, which yields the most likely division(s) of the network into groups, according to the statistical evidence available in the data (see Fig. 3).
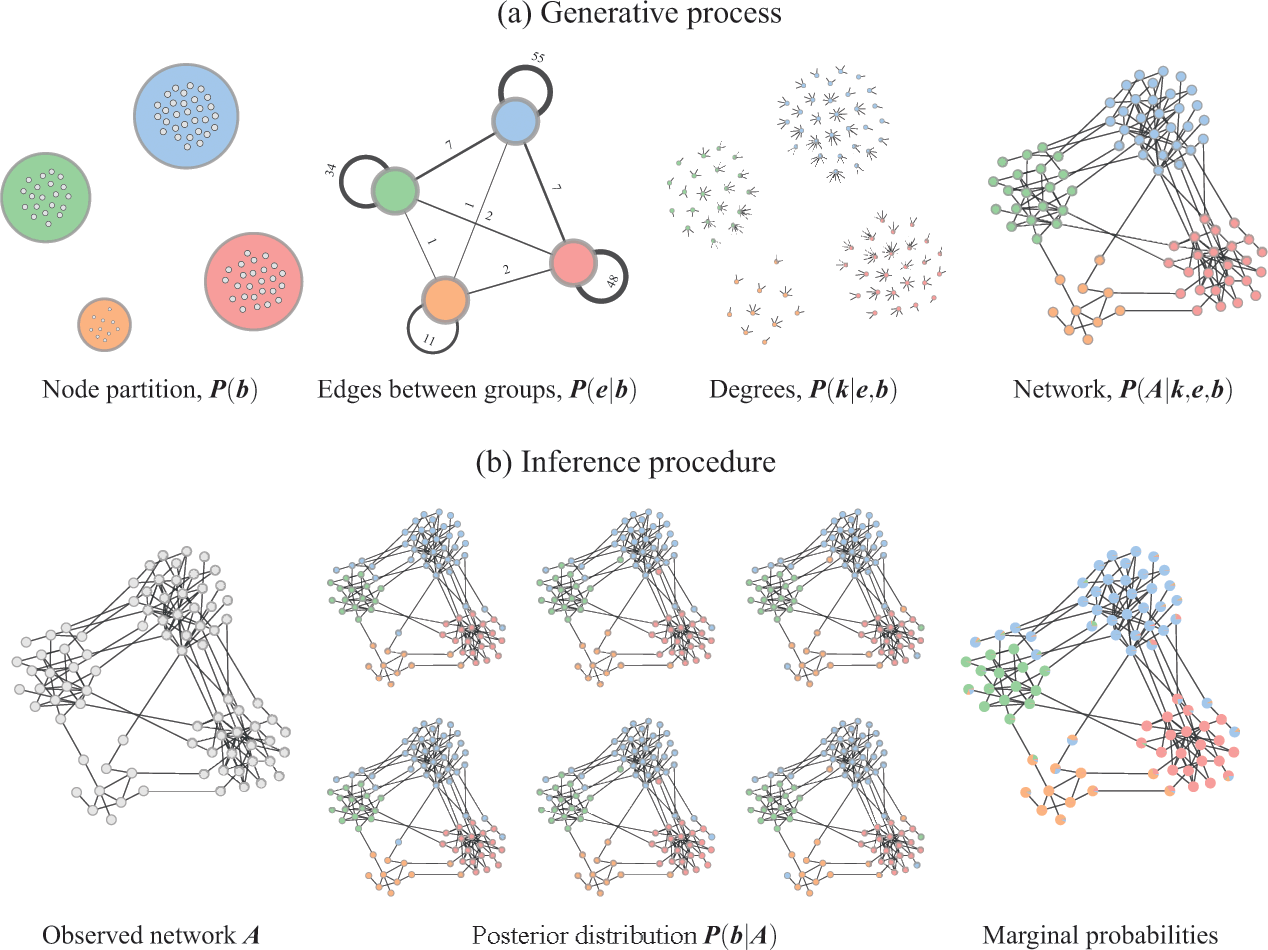
Figure 3 Inferential community detection considers a generative process (a), where the unobserved model parameters are sampled from prior distributions. In the case of the DC-SBM, these are the priors for the partition
 , the number of edges between groups
, the number of edges between groups
 , and the node degrees,
, and the node degrees,
 . Finally, the network itself is sampled from its model,
. Finally, the network itself is sampled from its model,
 . The inference procedure (b) consists on inverting the generative process given an observed network
. The inference procedure (b) consists on inverting the generative process given an observed network
 , corresponding to a posterior distribution
, corresponding to a posterior distribution
 , which then can be summarized by a marginal probability that a node belongs to a given group (represented as pie charts on the nodes).
, which then can be summarized by a marginal probability that a node belongs to a given group (represented as pie charts on the nodes).
Overwhelmingly, the models used to infer communities are variations of the stochastic block model (SBM) [Reference Holland, Laskey and Leinhardt14], where in addition to the node partition, it takes the probability of edges being placed between the different groups as an additional set of parameters. A particularly expressive variation is the degree-corrected SBM (DC-SBM) [Reference Karrer and Newman15], with a marginal likelihood given by [Reference Peixoto16]
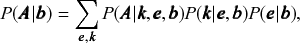 (2)
(2)
where
 is a matrix with elements
is a matrix with elements
 specifying how many edges go between groups
specifying how many edges go between groups
 and
and
 , and
, and
 are the degrees of the nodes. Therefore, this model specifies that, conditioned on a partition
are the degrees of the nodes. Therefore, this model specifies that, conditioned on a partition
 , first the edge counts
, first the edge counts
 are sampled from a prior distribution
are sampled from a prior distribution
 , followed by the degrees from the prior
, followed by the degrees from the prior
 , and finally the network is wired together according to the probability
, and finally the network is wired together according to the probability
 , which respects the constraints given by
, which respects the constraints given by
 ,
,
 , and
, and
 . See Fig. 3(a) for a illustration of this process.
. See Fig. 3(a) for a illustration of this process.
This model formulation includes maximally random networks as special cases — indeed the model we considered in Fig. 2 corresponds exactly to the DC-SBM with a single group. Together with the Bayesian approach, the use of this model will inherently favor a more parsimonious account of the data, whenever it does not warrant a more complex description — amounting to a formal implementation of Occam’s razor. This is best seen by making a formal connection with information theory, and noticing that we can write the numerator of Eq. 1 as
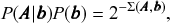 (3)
(3)
where the quantity
 is known as the description length [Reference Rissanen17–Reference Rissanen19] of the network. It is computed asFootnote 7
is known as the description length [Reference Rissanen17–Reference Rissanen19] of the network. It is computed asFootnote 7
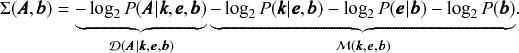
The second set of terms
 in the above equation quantifies the amount of information in bits necessary to encode the parameters of the model.Footnote 8 The first term
in the above equation quantifies the amount of information in bits necessary to encode the parameters of the model.Footnote 8 The first term
 determines how many bits are necessary to encode the network itself, once the model parameters are known. This means that if Bob wants to communicate to Alice the structure of a network
determines how many bits are necessary to encode the network itself, once the model parameters are known. This means that if Bob wants to communicate to Alice the structure of a network
 , he first needs to transmit
, he first needs to transmit
 bits of information to describe the parameters
bits of information to describe the parameters
 ,
,
 , and
, and
 , and then finally transmit the remaining
, and then finally transmit the remaining
 bits to describe the network itself. Then, Alice will be able to understand the message by first decoding the parameters
bits to describe the network itself. Then, Alice will be able to understand the message by first decoding the parameters
 from the first part of the message, and using that knowledge to obtain the network
from the first part of the message, and using that knowledge to obtain the network
 from the second part, without any errors.
from the second part, without any errors.
What the above connection shows is that there is a formal equivalence between inferring the communities of a network and compressing it. This happens because finding the most likely partition
 from the posterior
from the posterior
 is equivalent to minimizing the description length
is equivalent to minimizing the description length
 used by Bob to transmit a message to Alice containing the whole network.
used by Bob to transmit a message to Alice containing the whole network.
Data compression amounts to a formal implementation of Occam’s razor because it penalizes models that are too complicated: if we want to describe a network using many communities, then the model part of the description length
 will be large, and Bob will need many bits to transmit the model parameters to Alice. However, increasing the complexity of the model will also reduce the first term
will be large, and Bob will need many bits to transmit the model parameters to Alice. However, increasing the complexity of the model will also reduce the first term
 , since there are fewer networks that are compatible with the bigger set of constraints, and hence the second part of Bob’s message will need to be shorter to convey the network itself once the parameters are known. Compression (and hence inference), therefore, is a balancing act between model complexity and quality of fit, where an increase in the former is only justified when it results in an even larger increase of the second, such that the total description length is minimized.
, since there are fewer networks that are compatible with the bigger set of constraints, and hence the second part of Bob’s message will need to be shorter to convey the network itself once the parameters are known. Compression (and hence inference), therefore, is a balancing act between model complexity and quality of fit, where an increase in the former is only justified when it results in an even larger increase of the second, such that the total description length is minimized.
The reason why the compression approach avoids overfitting the data is due to a powerful fact from information theory, known as Shannon’s source coding theorem [Reference Shannon21], which states that it is impossible to compress data sampled from a distribution
 using fewer bits per symbol than the entropy of the distribution,
using fewer bits per symbol than the entropy of the distribution,
 — indeed, it’s a remarkable fact from Shannon’s theory that a statement about a single sample (how many bits we need to describe it) is intrinsically connected to the distribution from which it came. Therefore, as the dataset becomes large, it also becomes impossible to compress the data more than can be achieved by using a code that is optimal according to its true distribution. In our context, this means that it is impossible, for example, to compress a maximally random network using a SBM with more than one group.Footnote 9 This means, for example, that when encountering an example like in Fig. 2, inferential methods will detect a single community comprising all nodes in the network, since any further division does not provide any increased compression, or equivalently, no augmented explanatory power. From the inferential point of view, a partition like Fig. 2(b) overfits the data, since it incorporates irrelevant random features — a.k.a. “noise” — into its description.
— indeed, it’s a remarkable fact from Shannon’s theory that a statement about a single sample (how many bits we need to describe it) is intrinsically connected to the distribution from which it came. Therefore, as the dataset becomes large, it also becomes impossible to compress the data more than can be achieved by using a code that is optimal according to its true distribution. In our context, this means that it is impossible, for example, to compress a maximally random network using a SBM with more than one group.Footnote 9 This means, for example, that when encountering an example like in Fig. 2, inferential methods will detect a single community comprising all nodes in the network, since any further division does not provide any increased compression, or equivalently, no augmented explanatory power. From the inferential point of view, a partition like Fig. 2(b) overfits the data, since it incorporates irrelevant random features — a.k.a. “noise” — into its description.
In Fig. 4(a) is shown an example of the results obtained with an inferential community detection algorithm, for a network sampled from the SBM. As shown in Fig. 4(b), the obtained partitions are still valid when carried over to an independent sample of the model, because the algorithm is capable of separating the general underlying pattern from the random fluctuations. As a consequence of this separability, this kind of algorithm does not find communities in maximally random networks, which are composed only of “noise.”
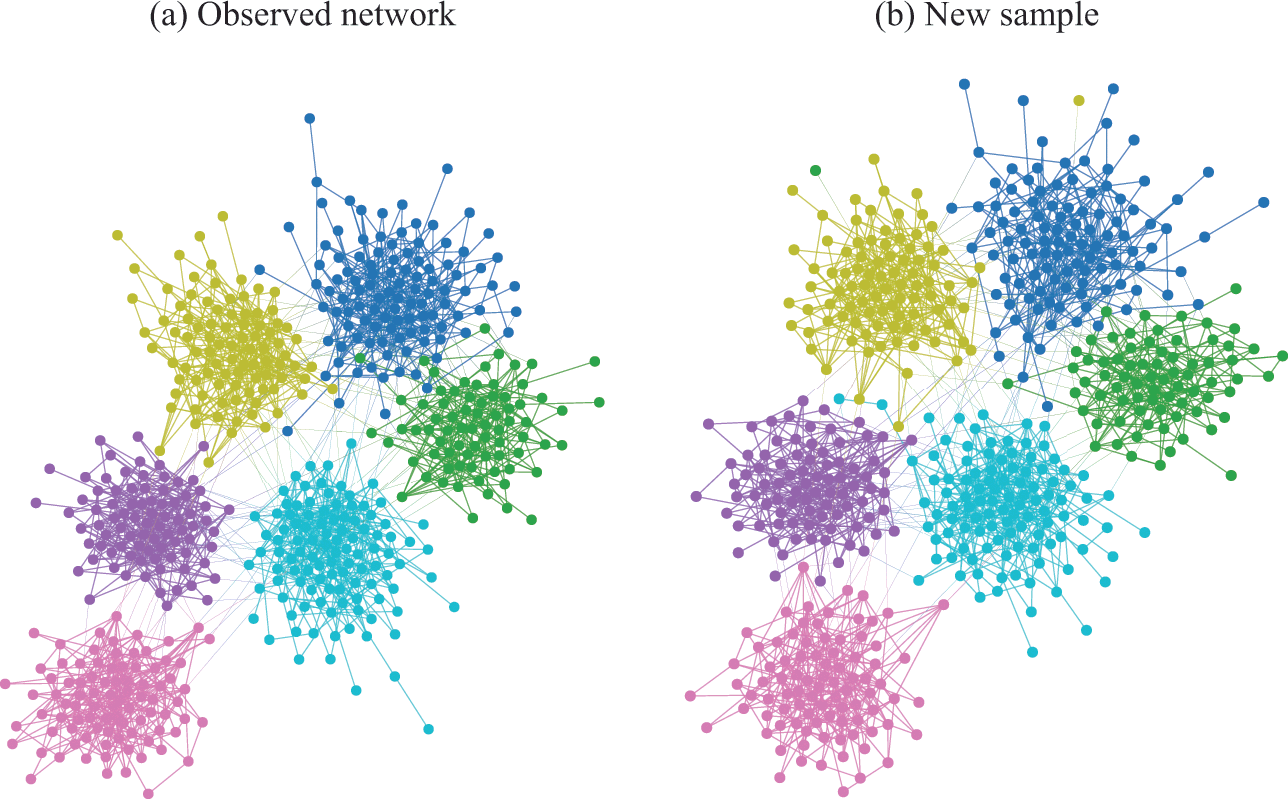
Figure 4 Inferential community detection aims to find a partition of the network according to a fit of a generative model that can explain its structure. In (a) is shown a network sampled from a stochastic block model (SBM) with 6 groups, and where the group assignments were hidden from view. The node colors show the groups found via Bayesian inference of the SBM. In (b) is shown another network sampled from same SBM, together with the same partition found in (a), showing that it carries a substantial explanatory power — very differently from the example in Fig. 2 (c).
The concept of compression is more generally useful than just avoiding overfitting within a class of models. In fact, the description length gives us a model-agnostic objective criterion to compare different hypotheses for the data generating process according to their plausibility. Namely, since Shannon’s theorem tells us that the best compression can be achieved asymptotically only with the true model, then if we are able to find a description length for a network using a particular model, regardless of how it is parametrized, this also means that we have automatically found an upper bound on the optimal compression achievable. By formulating different generative models and computing their description length, we have not only an objective criterion to compare them against each other, but we also have a way to limit further what can be obtained with any other model. The result is an overall scale on which different models can be compared, as we move closer to the limit of what can be uncovered for a particular network at hand.
As an example, in Fig. 5 we show the description length values with some models obtained for a protein-protein interaction network for the organism Meleagris gallopavo (wild turkey) [Reference Zitnik, Sosič, Feldman and Leskovec22]. In particular, we can see that with the DC-SBM/TC (a version of the model with the addition of triadic closure edges [Reference Peixoto23]) we can achieve a description length that is far smaller than what would be possible with networks sampled from either the Erdős-Rényi, configuration, or planted partition (a SBM with strictly assortative communities [Reference Zhang and Peixoto24]) models, meaning that the inferred model is much closer to the true process that actually generated this network than the alternatives. Naturally, the actual process that generated this network is different from the DC-SBM/TC, and it likely involves, for example, mechanisms of node duplication which are not incorporated into this rather simple model [Reference Pastor-Satorras, Smith and Solé25]. However, to the extent that the true process leaves statistically significant traces in the network structure,Footnote 10 computing the description length according to it should provide further compression when compared to the alternatives.Footnote 11 Therefore, we can try to extend or reformulate our models to incorporate features that we hypothesize to be more realistic, and then verify if this in fact the case, knowing that whenever we find a more compressive model, it is moving closer to the true model — or at least to what remains detectable from it for the finite data.
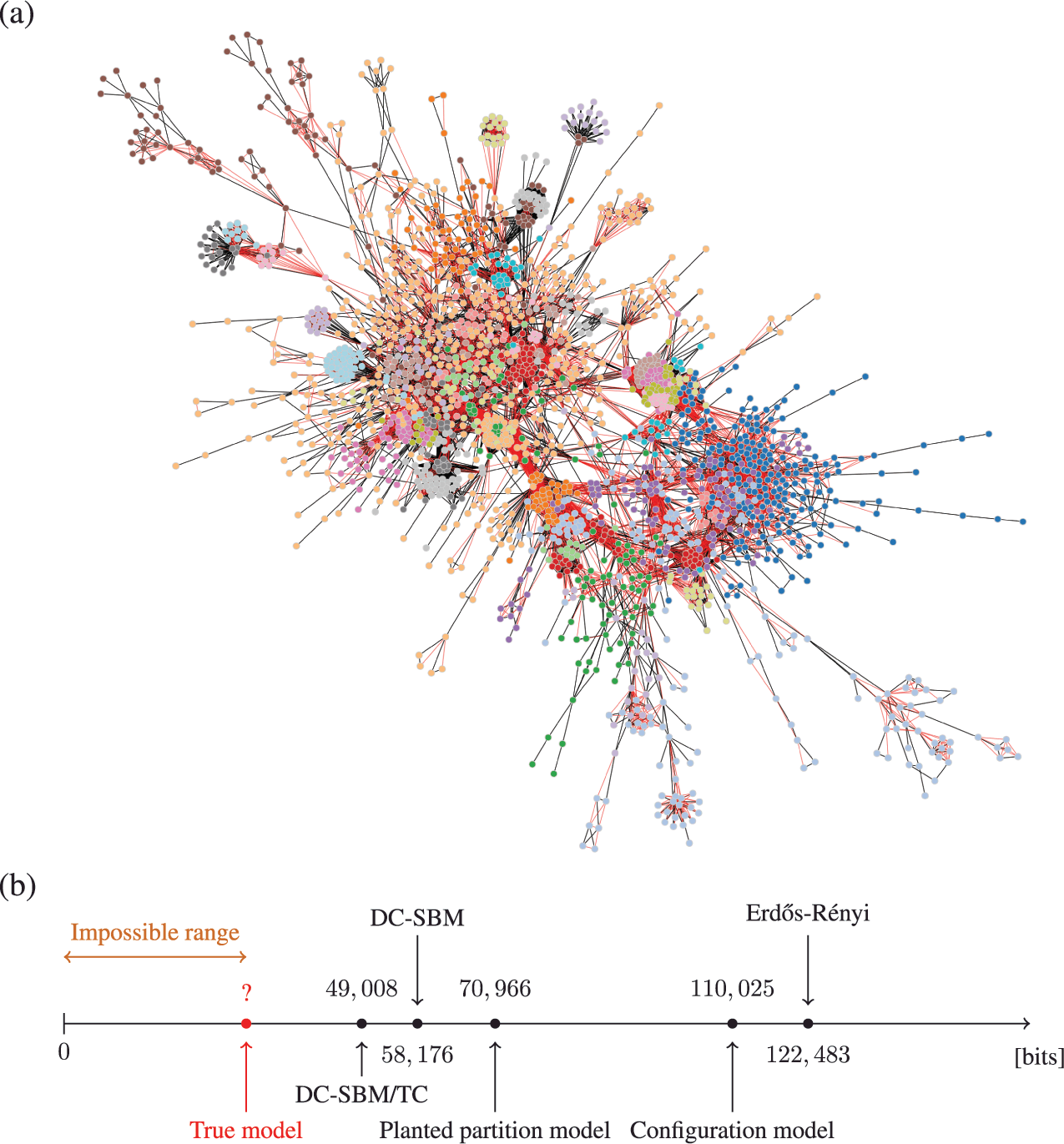
Figure 5 Compression points towards the true model. (a) Protein-protein interaction network for the organism Meleagris gallopavo [Reference Zitnik, Sosič, Feldman and Leskovec22]. The node colors indicate the best partition found with the DC-SBM/TC [Reference Peixoto23] (there are more groups than colors, so some colors are repeated), and the edge colors indicate whether they are attributed to triadic closure (red) or the DC-SBM (black). (b) Description length values according to different models. The unknown true model must yield a description length value smaller than the DC-SBM/TC, and no other model should be able to provide a superior compression that is statistically significant.
The discussion above glosses over some important technical aspects. For example, it is possible for two (or, in fact, many) models to have the same or very similar description length values. In this case, Occam’s razor fails as a criterion to select between them, and we need to consider them collectively as equally valid hypotheses. This means, for example, that we would need to average over them when making specific inferential statements [Reference Peixoto26] — selecting between them arbitrarily can be interpreted as a form of overfitting. Furthermore, there is obviously no guarantee that the true model can actually be found for any particular data. This is only possible in the asymptotic limit of “sufficient data,” which will vary depending on the actual model. Outside of this limit (which is the typical case in empirical settings, in particular when dealing with sparse networks [Reference Yan, Shalizi, Jensen, Krzakala, Moore, Zdeborová, Zhang and Zhu27]), fundamental limits to inference are unavoidable,Footnote 12 which means in practice that we will always have limited accuracy and some amount of error in our conclusions. However, when employing compression, these potential errors tend towards overly simple explanations, rather than overly complex ones. Whenever perfect accuracy is not possible, it is difficult to argue in favor of a bias in the opposite direction.
We emphasize that it is not possible to “cheat” when doing compression. For any particular model, the description length will have the same form
 (5)
(5)
where
 is some arbitrary set of parameters. If we constrain the model such that it becomes possible to describe the data with a number of bits
is some arbitrary set of parameters. If we constrain the model such that it becomes possible to describe the data with a number of bits
 that is very small, this can only be achieved, in general, by increasing the number of parameters
that is very small, this can only be achieved, in general, by increasing the number of parameters
 , such that the number of bits
, such that the number of bits
 required to describe them will also increase. Therefore, there is no generic way to achieve compression that bypasses actually formulating a meaningful hypothesis that matches statistically significant patterns seen in the data. One may wonder, therefore, if there is an automatized way of searching for hypotheses in a manner that guarantees optimal compression. The most fundamental way to formulate this question is to generalize the concept of minimum description length as follows: for any binary string
required to describe them will also increase. Therefore, there is no generic way to achieve compression that bypasses actually formulating a meaningful hypothesis that matches statistically significant patterns seen in the data. One may wonder, therefore, if there is an automatized way of searching for hypotheses in a manner that guarantees optimal compression. The most fundamental way to formulate this question is to generalize the concept of minimum description length as follows: for any binary string
 (representing any measurable data), we define
(representing any measurable data), we define
 as the length in bits of the shortest computer program that yields
as the length in bits of the shortest computer program that yields
 as an output. The quantity
as an output. The quantity
 is known as Kolmogorov complexity [Reference Cover and Thomas29, Reference Ming and Vitányi30], and if we would be able to compute it for a binary string representing an observed network, we would be able to determine the “true model” value in Fig. 5, and hence know how far we are from the optimum.Footnote 13
is known as Kolmogorov complexity [Reference Cover and Thomas29, Reference Ming and Vitányi30], and if we would be able to compute it for a binary string representing an observed network, we would be able to determine the “true model” value in Fig. 5, and hence know how far we are from the optimum.Footnote 13
Unfortunately, an important result in information theory is that
 is not computable [Reference Ming and Vitányi30]. This means that it is strictly impossible to write a computer program that computes
is not computable [Reference Ming and Vitányi30]. This means that it is strictly impossible to write a computer program that computes
 for any string
for any string
 .Footnote 14 This does not invalidate using the description length as a criterion to select among alternative models, but it dashes any hope of fully automatizing the discovery of optimal hypotheses.
.Footnote 14 This does not invalidate using the description length as a criterion to select among alternative models, but it dashes any hope of fully automatizing the discovery of optimal hypotheses.
2.4 Role of inferential approaches in community detection
Inferential approaches based on the SBM have an old history, and were introduced for the study of social networks in the early 80’s [Reference Holland, Laskey and Leinhardt14]. But despite such an old age, and having appeared repeatedly in the literature over the years [Reference Snijders and Nowicki31–Reference Mørup and Hansen39] (also under different names in other contexts e.g. [Reference Boguñá and Pastor-Satorras40, Reference Bollobás, Janson and Riordan41]), they entered the mainstream community detection literature rather late, arguably after the influential paper by Karrer and Newman that introduced the DC-SBM [Reference Karrer and Newman15] in 2011, at a point where descriptive approaches were already dominating. However, despite the dominance of descriptive methods, the existence of inferential criteria was already long noticeable. In fact, in a well-known attempt to systematically compare the quality of a variety of descriptive community detection methods, the authors of Ref. [Reference Lancichinetti, Fortunato and Radicchi42] proposed the now so-called Lancichinetti–Fortunato–Radicchi (LFR) benchmark, offered as a more realistic alternative to the simpler Newman-Girvan benchmark [Reference Girvan and Newman43] introduced earlier. Both are in fact generative models, essentially particular cases of the DC-SBM, containing a “ground truth” community label assignment, against which the results of various algorithms are supposed to be compared. Clearly, this is an inferential evaluation criterion, although, historically, virtually all of the methods compared against that benchmark are descriptive in nature [Reference Lancichinetti and Fortunato44] (these studies were conducted mostly before inferential approaches had gained more traction). The use of such a criterion already betrays that the answer to the litmus test considered previously would be “yes,” and therefore descriptive approaches are fundamentally unsuitable for the task. In contrast, methods based on statistical inference are not only more principled, but in fact provably optimal in the inferential scenario: an estimation based on the posterior distribution obtained from the true generative model is called “Bayes optimal,” since there is no procedure that can, on average, produce results with higher accuracy. The use of this inferential formalism has led to the development of asymptotically optimal algorithms and the identification of sharp transitions in the detectability of planted community structure [Reference Decelle, Krzakala, Moore and Zdeborová6, Reference Decelle, Krzakala, Moore and Zdeborová45].
The conflation one often finds between descriptive and inferential goals in the literature of community detection likely stems from the fact that while it is easy to define benchmarks in the inferential setting, it is substantially more difficult to do so in a descriptive setting. Given any descriptive method (modularity maximization [Reference Newman46], Infomap [Reference Rosvall and Bergstrom47], Markov stability [Reference Lambiotte, Delvenne and Barahona48], etc.) it is usually problematic to determine for which network these methods are optimal (or even if one exists), and what would be a canonical output that would be unambiguously correct. In fact, the difficulty with establishing these fundamental references already serve as evidence that the task itself is ill-defined. On the other hand, taking an inferential route forces one to start with the right answer, via a well-specified generative model that articulates what the communities actually mean with respect to the network structure. Based on this precise definition, one then derives the optimal detection method by employing Bayes’ rule.
It is also useful to observe that inferential analyses of aspects of the network other than directly its structure might still be only descriptive of the structure itself. A good example of this is the modelling of dynamics that take place on a network, such as a random walk. This is precisely the case of the Infomap method [Reference Rosvall and Bergstrom47], which models a simulated random walk on a network in an inferential manner, using for that a division of the network into groups. While this approach can be considered inferential with respect to an artificial dynamics, it is still only descriptive when it comes to the actual network structure (and will suffer the same problems, such a finding communities in maximally random networks). Communities found in this way could be useful for particular tasks, such as to identify groups of nodes that would be similarly affected by a diffusion process. This could be used, for example, to prevent or facilitate the diffusion by removing or adding edges between the identified groups. In this setting, the answer to the litmus test above would also be “no,” since what is important is how the network “is” (i.e. how a random walk behaves on it), not how it came to be, or if its features are there by chance alone. Once more, the important issue to remember is that the groups identified in this manner cannot be interpreted as having any explanatory power about the network structure itself, and cannot be used reliably to extract inferential conclusions about it. We are firmly in a descriptive, not inferential setting with respect to the network structure.
Another important difference between inferential and descriptive approaches is worth mentioning. Descriptive approaches are often tied to very particular contexts, and cannot be directly compared to one another. This has caused great consternation in the literature, since there is a vast number of such methods, and little robust methodology on how to compare them. Indeed, why should we expect that the modules found by optimizing task scheduling should be comparable to those that optimize the description of a dynamics? In contrast, inferential approaches all share the same underlying context: they attempt to explain the network structure; they vary only in how this is done. They are, therefore, amenable to principled model selection procedures [Reference MacKay20, Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin49, Reference Bishop50], designed to evaluate which is the most appropriate fit for any particular network, even if the models used operate with very different parametrizations, as we discussed already in Sec. 2.3. In this situation, the multiplicity of different models available becomes a boon rather than a hindrance, since they all contribute to a bigger toolbox we have at our disposal when trying to understand empirical observations.
Finally, inferential approaches offer additional advantages that make them more suitable as part of a scientific pipeline. In particular, they can be naturally extended to accommodate measurement uncertainties [Reference Newman51–Reference Peixoto53] — an unavoidable property of empirical data, which descriptive methods almost universally fail to consider. This information can be used not only to propagate the uncertainties to the community assignments [Reference Peixoto26] but also to reconstruct the missing or noisy measurements of the network itself [Reference Clauset, Moore and Newman37, Reference Guimerà and Sales-Pardo54]. Furthermore, inferential approaches can be coupled with even more indirect observations such as time-series on the nodes [Reference Hoffmann, Peel, Lambiotte and Jones55], instead of a direct measurement of the edges of the network, such that the network itself is reconstructed, not only the community structure [Reference Peixoto56]. All these extensions are possible because inferential approaches give us more than just a division of the network into groups; they give us a model estimate of the network, containing insights about its formation mechanism.
2.5 Behind every description there is an implicit generative model
Descriptive methods of community detection — such as graph partitioning for VLSI [Reference Kernighan11] or Infomap [Reference Rosvall and Bergstrom47] — are not designed to produce inferential statements about the network structure. They do not need to explicitly articulate a generative model, and the quality of their results should be judged solely against their manifestly noninferential goals, e.g. whether a chip design can be efficiently manufactured in the case of graph partitioning.
Nevertheless, descriptive methods are often employed with inferential aims in practice. This happens, for example, when modularity maximization is used to discover homophilic patterns in a social network, or when Infomap is used to uncover latent communities generated by the LFR benchmark. In these situations, it is useful to consider to what extent can we expect any of these methods reveal meaningful inferential results, despite their intended use.
From a purely mathematical perspective, there is actually no formal distinction between descriptive and inferential methods, because every descriptive method can be mapped to an inferential one, according to some implicit model. Therefore, whenever we are attempting to interpret the results of a descriptive community detection method in an inferential way — i.e. make a statement about how the network came to be — we cannot in fact avoid making implicit assumptions about the data generating process that lies behind it. (At first this statement seems to undermine the distinction we have been making between descriptive and inferential methods, but in fact this is not the case, as we will see below.)
It is not difficult to demonstrate that it is possible to formulate any conceivable community detection method as a particular inferential method. Let us consider an arbitrary quality function
 (6)
(6)
which is used to perform community detection via the optimization
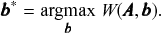 (7)
(7)
We can then interpret the quality function
 as the “Hamiltonian” of a posterior distribution
as the “Hamiltonian” of a posterior distribution
 (8)
(8)
with normalization
 . By making
. By making
 we recover the optimization of Eq. 7, or we may simply try to find the most likely partition according to the posterior, in which case
we recover the optimization of Eq. 7, or we may simply try to find the most likely partition according to the posterior, in which case
 remains an arbitrary parameter. Therefore, employing Bayes’ rule in the opposite direction, we obtain the following effective generative model:
remains an arbitrary parameter. Therefore, employing Bayes’ rule in the opposite direction, we obtain the following effective generative model:
 (9)
(9)
 (10)
(10)
where
 is the marginal distribution over networks, and
is the marginal distribution over networks, and
 is the prior distribution for the partition. Due to the normalization of
is the prior distribution for the partition. Due to the normalization of
 we have the following constraint that needs to be fulfilled:
we have the following constraint that needs to be fulfilled:
 (11)
(11)
Therefore, not all choices of
 and
and
 are compatible with the posterior distribution and the exact possibilities will depend on the actual shape of
are compatible with the posterior distribution and the exact possibilities will depend on the actual shape of
 . However, one choice that is always possible is a maximum-entropy one,
. However, one choice that is always possible is a maximum-entropy one,
 (12)
(12)
with
 and
and
 . Taking this choice leads to the effective generative model
. Taking this choice leads to the effective generative model
 (13)
(13)
Therefore, inferentially interpreting a community detection algorithm with a quality function
 is equivalent to assuming the generative model
is equivalent to assuming the generative model
 and prior
and prior
 of Eqs. 13 and 12 above. Furthermore, this also means that any arbitrary community detection algorithm implies a description length given (in nats) byFootnote 15
of Eqs. 13 and 12 above. Furthermore, this also means that any arbitrary community detection algorithm implies a description length given (in nats) byFootnote 15
 (14)
(14)
What the preceding results show is that there is no such thing as a “model-free” community detection method, since they are all equivalent to the inference of some generative model. The only difference to a direct inferential method is that in that case the modelling assumptions are made explicitly, inviting rather than preventing scrutiny. Most often, the effective model and prior that are equivalent to an ad hoc community detection method will be difficult to interpret, justify, or even compute (in general, Eq. 14 cannot be written in closed form).
Furthermore there is no guarantee that the obtained description length of Eq. 14 will yield a competitive or even meaningful compression. In particular, there is no guarantee that this effective inference will not overfit the data. Although we mentioned in Section 2.3 that inference and compression are equivalent, the compression achieved when considering a particular generative model is constrained by the assumptions encoded in its likelihood and prior. If these are poorly chosen, no actual compression might be achieved, for example when comparing to the one obtained with a maximally random model. This is precisely what happens with descriptive community detection methods: they overfit because their implicit modelling assumptions do not accommodate the possibility that a network may be maximally random, or contain a balanced mixture of structure and randomness.
Since we can always interpret any community detection method as inferential, is it still meaningful to categorize some methods as descriptive? Arguably yes, because directly inferential approaches make their generative models and priors explicit, while for a descriptive method we need to extract them from reverse engineering. Explicit modelling allows us to make judicious choices about the model and prior that reflect the kinds of structures we want to detect, relevant scales or lack thereof, and many other aspects that improve their performance in practice, and our understanding of the results. With implicit assumptions we are “flying blind,” relying substantially on serendipity and trial-and-error — not always with great success.
It is not uncommon to find criticisms of inferential methods due to a perceived implausibility of the generative models used — such as the conditional independence of the placement of the edges present in the SBM [Reference Schaub, Delvenne, Rosvall and Lambiotte8] — although these assumptions are also present, but only implicitly, in other methods, like modularity maximization (see Sec. 4.1). We discuss this issue further in Sec. 4.8.
The above inferential interpretation is not specific to community detection, but is in fact valid for any learning problem. The set of explicit or implicit assumptions that must come with any learning algorithm is called an “inductive bias.” An algorithm is expected to function optimally only if its inductive bias agrees with the actual instances of the problems encountered. It is important to emphasize that no algorithm can be free of an inductive bias, we can only chose which intrinsic assumptions we make about how likely we are to encounter a particular kind of data, not whether we are making an assumption. Therefore, it is particularly problematic when a method does not articulate explicitly what these assumptions are, since even if they are hidden from view, they exist nonetheless, and still need to be scrutinized and justified. This means we should be particularly skeptical of the impossible claim that a learning method is “model-free,” since this denomination is more likely to signal an inability or unwillingness to expose the underlying modelling assumptions, which could potentially be revealed as unappealing and fragile when eventually forced to come under scrutiny.
2.6 Caveats and challenges with inferential methods
Inferential community detection is a challenging task, and is not without its caveats. One aspect they share with descriptive approaches is algorithmic complexity (see Sec. 4.9), and the fact that they in general try to solve NP-hard problems. This means that there is no known algorithm that is guaranteed to produce exact results in a reasonable amount of time, except for very small networks. That does not mean that every instance of the problem is hard to answer, in fact it can be shown that in key cases robust answers can be obtained [Reference Decelle, Krzakala, Moore and Zdeborová45], but in general all existing methods are approximative, with the usual trade-off between accuracy and speed. The quest for general approaches that behave well while being efficient is still ongoing and is unlikely to exhausted soon.
Furthermore, employing statistical inference is not a “silver bullet” that automatically solves every problem. If our models are “misspecified,” i.e. represent very poorly the structure present in the data, then our inferences using them will be very limited and potentially misleading (see Sec. 4.8) — the most we can expect from our methodology in this case is to obtain good diagnostics of when this is happening [Reference Peixoto26]. There is also a typical trade-off between realism and simplicity, such that models that more closely match reality are more difficult to express in simple terms with tractable models. Usually, the more complex a model is, the more difficult becomes its inference. The technical task of using algorithms such as Markov chain Monte Carlo (MCMC) to produce reliable inferences for a complex model is nontrivial and requires substantial expertise, and is likely to be a long-living field of research.
In general it can be said that, although statistical inference does not provide automatic answers, it gives us an invaluable platform where the questions can be formulated more clearly, and allows us to navigate the space of answers using more robust methods and theory.
3 Modularity maximization considered harmful
The most widespread method for community detection is modularity maximization [Reference Newman46], which happens also to be one the most problematic. This method is based on the modularity function,
 (15)
(15)
where
 is an entry of the adjacency matrix,
is an entry of the adjacency matrix,
 is the degree of node
is the degree of node
 ,
,
 is the group membership of node
is the group membership of node
 , and
, and
 is the total number of edges. The method consists in finding the partition
is the total number of edges. The method consists in finding the partition
 that maximizes
that maximizes
 ,
,
 (16)
(16)
The motivation behind the modularity function is that it compares the existence of an edge
 to the probability of it existing according to a null model,
to the probability of it existing according to a null model,
 , namely that of the configuration model [Reference Fosdick, Larremore, Nishimura and Ugander57] (or more precisely, the Chung-Lu model [Reference Chung and Linyuan58]). The motivation for this method is that we should consider a partition of the network meaningful if the occurrence of edges between nodes of the same group exceeds what we would expect with a random null model without communities.
, namely that of the configuration model [Reference Fosdick, Larremore, Nishimura and Ugander57] (or more precisely, the Chung-Lu model [Reference Chung and Linyuan58]). The motivation for this method is that we should consider a partition of the network meaningful if the occurrence of edges between nodes of the same group exceeds what we would expect with a random null model without communities.
Despite its widespread adoption, this approach suffers from a variety of serious conceptual and practical flaws, which have been documented extensively [Reference Fortunato1, Reference Fortunato and Hric2, Reference Guimerà, Sales-Pardo and Nunes Amaral59–Reference Good, Yves-Alexandre and Clauset61]. The most problematic one is that it purports to use an inferential criterion — a deviation from a null generative model — but is in fact merely descriptive. As has been recognized very early, this method categorically fails in its own stated goal, since it always finds high-scoring partitions in networks sampled from its own null model [Reference Guimerà, Sales-Pardo and Nunes Amaral59]. Indeed, the generative model we used in Fig. 2(a) is exactly the null model considered in the modularity function, which if maximized yields the partition seen in Fig. 2(a). As we already discussed, this result bears no relevance to the underlying generative process, and overfits the data.
The reason for this failure is that the method does not take into account the deviation from the null model in a statistically consistent manner. The modularity function is just a re-scaled version of the assortativity coefficient [Reference Newman62], a correlation measure of the community assignments seen at the endpoints of edges in the network. We should expect such a correlation value to be close to zero for a partition that is determined before the edges of the network are placed according to the null model, or equivalently, for a partition chosen at random. However, it is quite a different matter to find a partition that optimizes the value of
 , after the network is observed. The deviation from a null model computed in Eq. 15 completely ignores the optimization step of Eq. 16, although it is a crucial part of the algorithm. As a result, the method of modularity maximization tends to massively overfit, and find spurious communities even in networks sampled from its null model. If we search for patterns of correlations in a random graph, most of the time we will find them. This is a pitfall known as “data dredging” or “
, after the network is observed. The deviation from a null model computed in Eq. 15 completely ignores the optimization step of Eq. 16, although it is a crucial part of the algorithm. As a result, the method of modularity maximization tends to massively overfit, and find spurious communities even in networks sampled from its null model. If we search for patterns of correlations in a random graph, most of the time we will find them. This is a pitfall known as “data dredging” or “
 -hacking,” where one searches exhaustively for different patterns in the same data and reports only those that are deemed significant, according to a criterion that does not take into account the fact that we are doing this search in the first place.
-hacking,” where one searches exhaustively for different patterns in the same data and reports only those that are deemed significant, according to a criterion that does not take into account the fact that we are doing this search in the first place.
We demonstrate this problem in Fig. 6, where we show the distribution of modularity values obtained with a uniform configuration model with
 for every node
for every node
 , considering both a random partition and the one that maximizes
, considering both a random partition and the one that maximizes
 . While for a random partition we find what we would expect, i.e. a value of
. While for a random partition we find what we would expect, i.e. a value of
 close to zero, for the optimized partition the value is substantially larger. Inspecting the optimized partition in Fig. 6(c), we see that it corresponds indeed to 15 seemingly clear assortative communities — which by construction bear no relevance to how the network was generated. They have been dredged out of randomness by the optimization procedure.
close to zero, for the optimized partition the value is substantially larger. Inspecting the optimized partition in Fig. 6(c), we see that it corresponds indeed to 15 seemingly clear assortative communities — which by construction bear no relevance to how the network was generated. They have been dredged out of randomness by the optimization procedure.
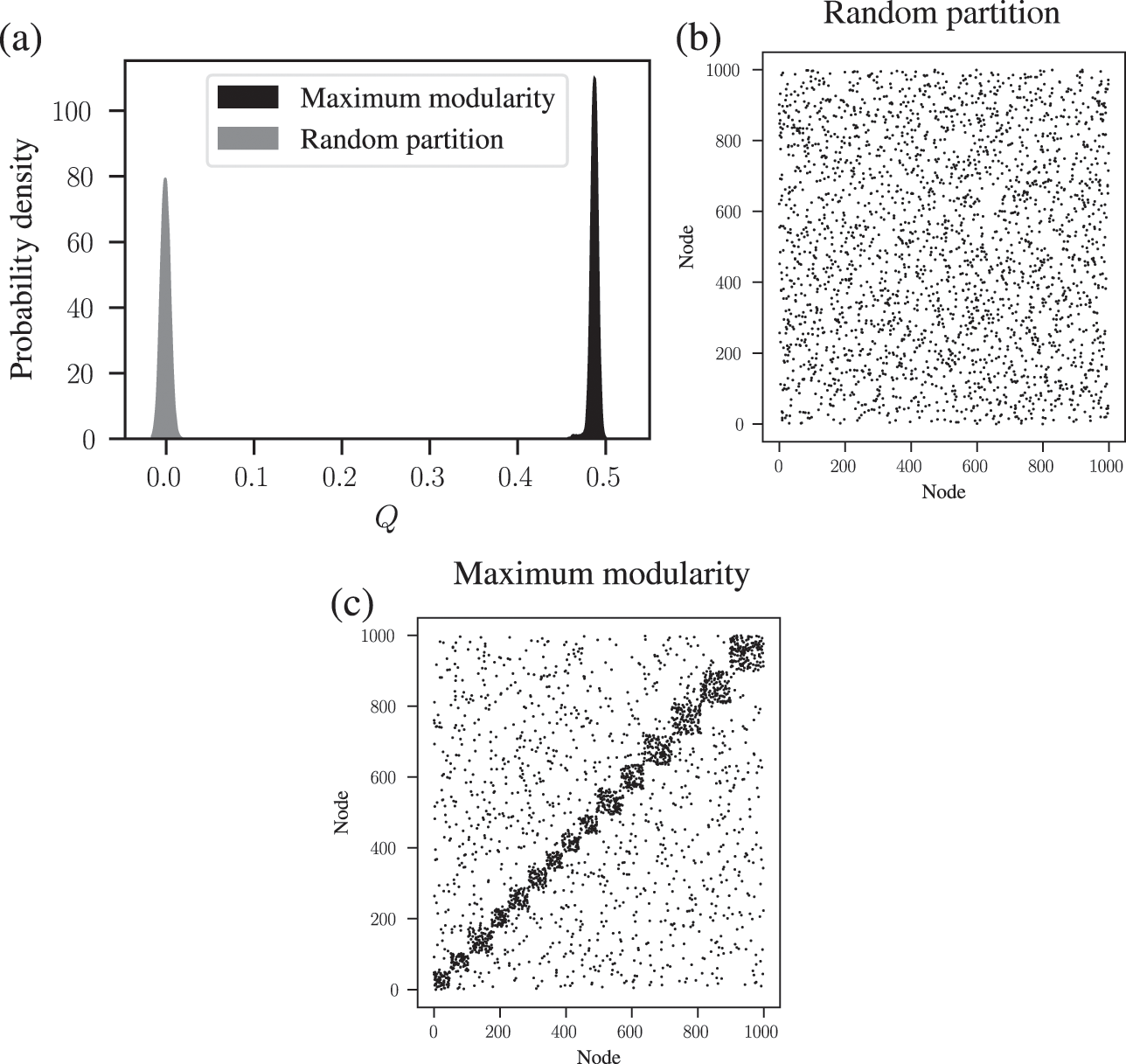
Figure 6 Modularity maximization systematically overfits, and finds spurious structures even its own null model. In this example we consider a random network model with
 nodes, with every node having degree
nodes, with every node having degree
 . (a) Distribution of modularity values for a partition into 15 groups chosen at random, and for the optimized value of modularity, for
. (a) Distribution of modularity values for a partition into 15 groups chosen at random, and for the optimized value of modularity, for
 networks sampled from the same model. (b) Adjacency matrix of a sample from the model, with the nodes ordered according to a random partition. (c) Same as (b), but with the nodes ordered according to the partition that maximizes modularity.
networks sampled from the same model. (b) Adjacency matrix of a sample from the model, with the nodes ordered according to a random partition. (c) Same as (b), but with the nodes ordered according to the partition that maximizes modularity.
Somewhat paradoxically, another problem with modularity maximization is that in addition to systematically overfitting, it also systematically underfits. This occurs via the so-called resolution limit: in a connected networkFootnote 16 the method cannot find more than
 communities [Reference Fortunato and Barthélemy60], even if they seem intuitive or can be found by other methods. An example of this is shown in Fig. 7, where for a network generated with the SBM containing 30 communities, modularity maximization finds only 18, while an inferential approach has no problems finding the true structure. There are attempts to counteract the resolution limit by introducing a “resolution parameter” to the modularity function, but as we discuss in Sec. 4.4 they are in general ineffective.
communities [Reference Fortunato and Barthélemy60], even if they seem intuitive or can be found by other methods. An example of this is shown in Fig. 7, where for a network generated with the SBM containing 30 communities, modularity maximization finds only 18, while an inferential approach has no problems finding the true structure. There are attempts to counteract the resolution limit by introducing a “resolution parameter” to the modularity function, but as we discuss in Sec. 4.4 they are in general ineffective.
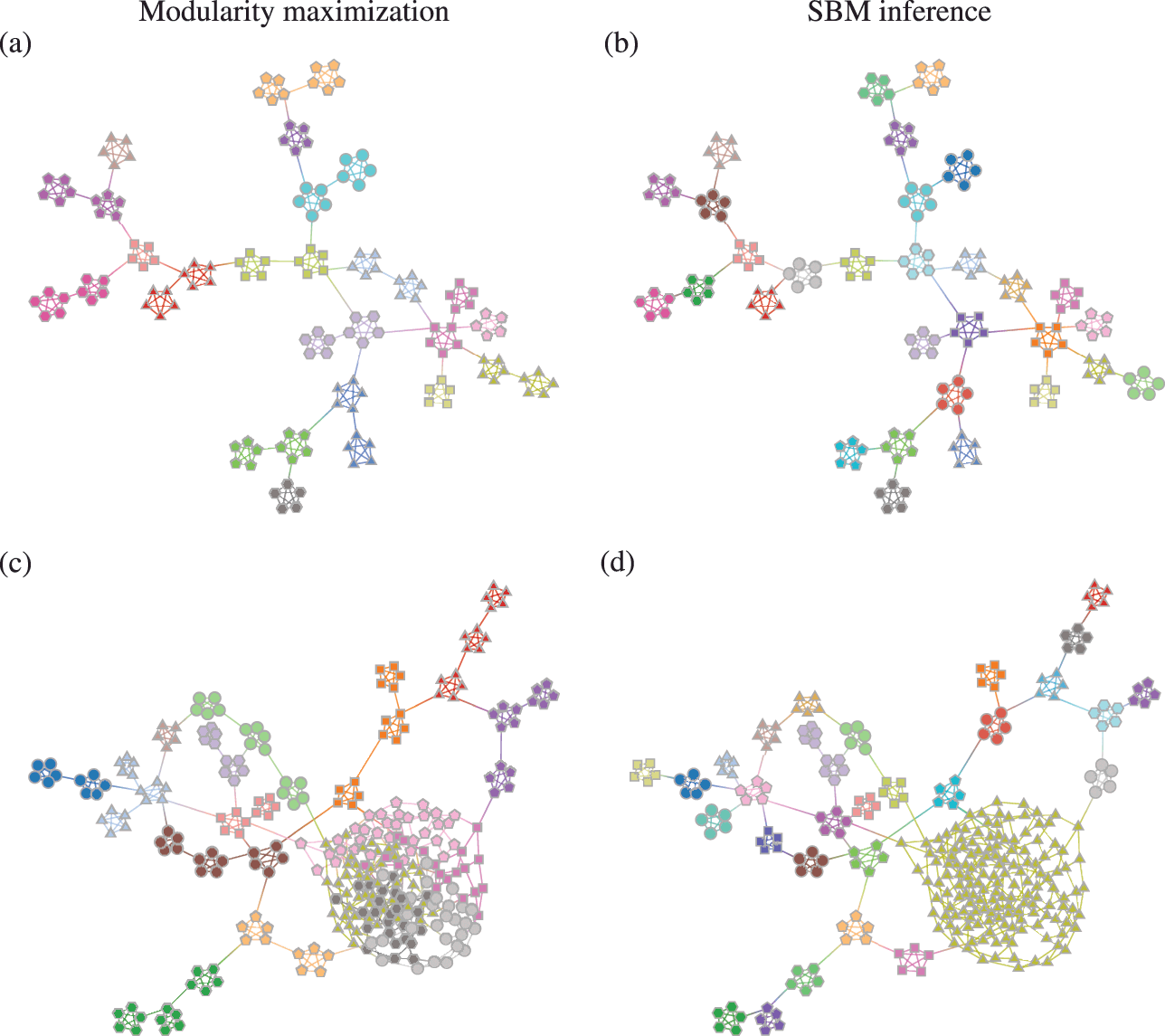
Figure 7 The resolution limit of modularity maximization prevents small communities from being identified, even if there is sufficient statistical evidence to support them. Panel (a) shows a network with
 communities sampled from an assortative SBM parametrization. The colors indicate the
communities sampled from an assortative SBM parametrization. The colors indicate the
 communities found with modularity maximization, where several pairs of true communities are merged together. Panel (b) shows the inference result of an assortative SBM [Reference Zhang and Peixoto24], recovering the true communities with perfect accuracy. Panels (c) and (d) show the results for a similar model where a larger community has been introduced. In (c) we see the results of modularity maximization, which not only merges the smaller communities together, but also splits the larger community into several spurious ones — thus both underfitting and overfitting different parts of the network at the same time. In (d) we see the result obtained by inferring the SBM, which once again finds the correct answer.
communities found with modularity maximization, where several pairs of true communities are merged together. Panel (b) shows the inference result of an assortative SBM [Reference Zhang and Peixoto24], recovering the true communities with perfect accuracy. Panels (c) and (d) show the results for a similar model where a larger community has been introduced. In (c) we see the results of modularity maximization, which not only merges the smaller communities together, but also splits the larger community into several spurious ones — thus both underfitting and overfitting different parts of the network at the same time. In (d) we see the result obtained by inferring the SBM, which once again finds the correct answer.
These two problems — overfitting and underfitting — can occur in tandem, such that portions of the network dominated by randomness are spuriously revealed to contain communities, whereas other portions with clear modular structure can have those obstructed. The result is a very unreliable method to capture the structure of heterogeneous networks. We demonstrate this in Fig. 7(c) and (d).
In addition to these major problems, modularity maximization also often possesses a degenerate landscape of solutions, with very different partitions having similar values of
 [Reference Good, Yves-Alexandre and Clauset61]. In these situations the partition with maximum value of modularity can be a poor representative of the entire set of high-scoring solutions and depend on idiosyncratic details of the data rather than general patterns — which can be interpreted as a different kind of overfitting.Footnote 17
[Reference Good, Yves-Alexandre and Clauset61]. In these situations the partition with maximum value of modularity can be a poor representative of the entire set of high-scoring solutions and depend on idiosyncratic details of the data rather than general patterns — which can be interpreted as a different kind of overfitting.Footnote 17
The combined effects of underfitting and overfitting can make the results obtained with the method unreliable and difficult to interpret. As a demonstration of the systematic nature of the problem, in Fig. 8(a) we show the number of communities obtained using modularity maximization for 263 empirical networks of various sizes and belonging to different domains [Reference Zhang and Peixoto64], obtained from the Netzschleuder catalogue [Reference Peixoto65]. Since the networks considered are all connected, the values are always below
 , due to the resolution limit; but otherwise they are well distributed over the allowed range. However, in Fig. 8(b) we show the same analysis, but for a version of each network that is fully randomized, while preserving the degree sequence. In this case, the number of groups remains distributed in the same range (sometimes even exceeding the resolution limit, because the randomized versions can end up disconnected). As Fig. 8(c) shows, the number of groups found for the randomized networks is strongly correlated with the original ones, despite the fact that the former have no latent community structure. This is a strong indication of the substantial amount of noise that is incorporated into the partitions found with the method.
, due to the resolution limit; but otherwise they are well distributed over the allowed range. However, in Fig. 8(b) we show the same analysis, but for a version of each network that is fully randomized, while preserving the degree sequence. In this case, the number of groups remains distributed in the same range (sometimes even exceeding the resolution limit, because the randomized versions can end up disconnected). As Fig. 8(c) shows, the number of groups found for the randomized networks is strongly correlated with the original ones, despite the fact that the former have no latent community structure. This is a strong indication of the substantial amount of noise that is incorporated into the partitions found with the method.
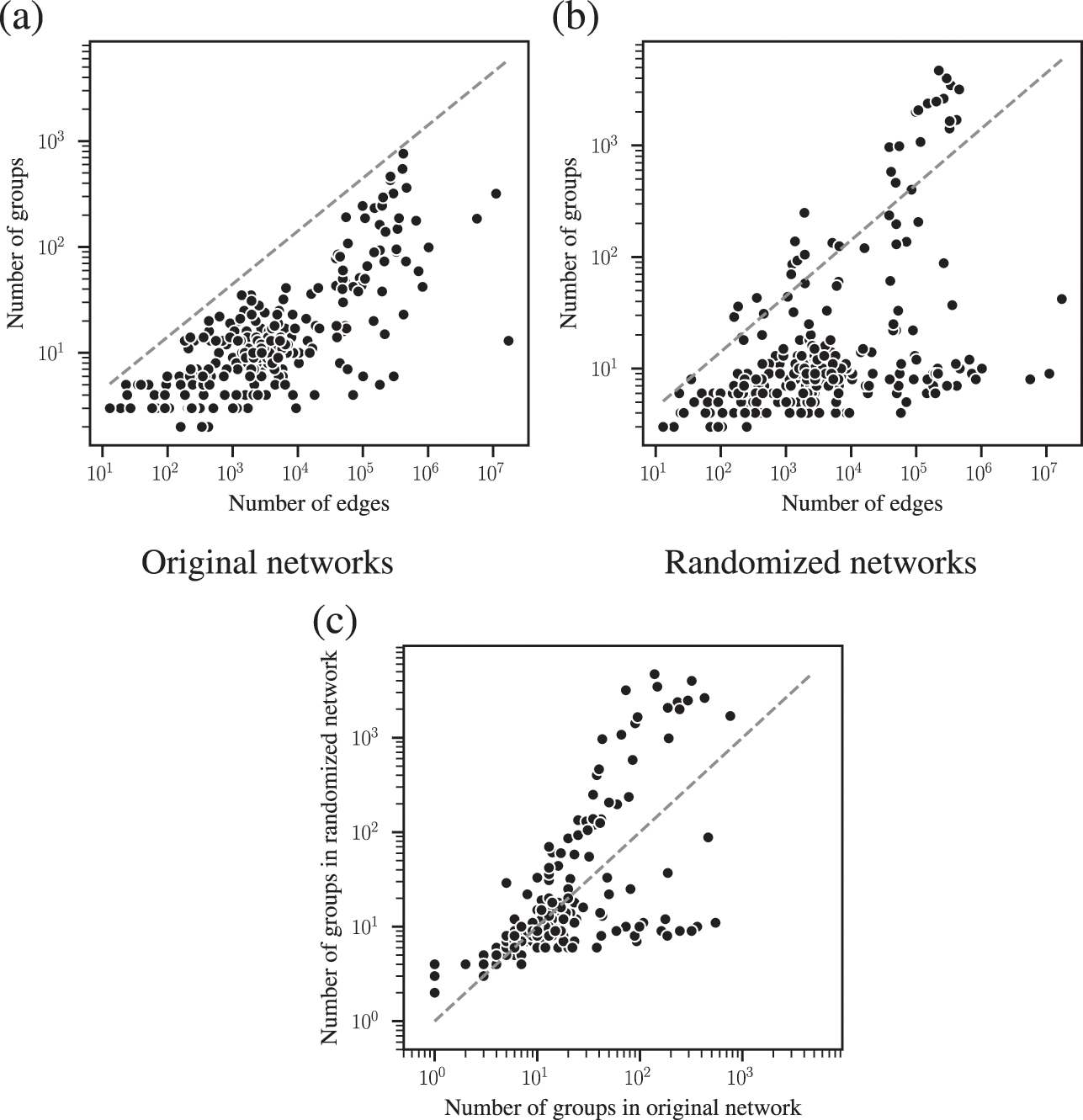
Figure 8 Modularity maximization incorporates a substantial amount of noise into its results. (a) Number of groups found using modularity maximization for 263 empirical networks as a function of the number of edges. The dashed line corresponds to the
 upper bound due to the resolution limit. (b) The same as in (a) but with randomized versions of each network. (c) Correspondence between the number of groups of the original and randomized network. The dashed line shows the diagonal.
upper bound due to the resolution limit. (b) The same as in (a) but with randomized versions of each network. (c) Correspondence between the number of groups of the original and randomized network. The dashed line shows the diagonal.
The systematic overfitting of modularity maximization — as well as other descriptive methods such as Infomap — has been also demonstrated recently in Ref. [Reference Ghasemian, Hosseinmardi and Clauset66], from the point of view of edge prediction, on a separate empirical dataset of 572 networks from various domains.
Although many of the problems with modularity maximization were long known, for some time there were no principled solutions to them, but this is no longer the case. In the table below we summarize some of the main problems with modularity and how they are solved with inferential approaches.
| Problem | Principled solution via inference |
|---|---|
Modularity maximization overfits, and finds modules in maximally random networks. [Reference Guimerà, Sales-Pardo and Nunes Amaral59] | Bayesian inference of the SBM is designed from the ground up to avoid this problem in a principled way and systematically succeeds [Reference Peixoto, Doreian, Batagelj and Ferligoj5]. |
Modularity maximization has a resolution limit, and finds at most
| Inferential approaches with hierarchical priors [Reference Peixoto16, Reference Peixoto67] or strictly assortative structures [Reference Zhang and Peixoto24] do not have any appreciable resolution limit, and can find a maximum number of groups that scales as
|
Modularity maximization has a characteristic scale, and tends to find communities of similar size; in particular with the same sum of degrees (see Sec. 4.4). | Hierarchical priors can be specifically chosen to be a priori agnostic about characteristic sizes, densities of groups and degree sequences [Reference Peixoto16], such that these are not imposed, but instead obtained from inference, in an unbiased way. |
Modularity maximization can only find strictly assortative communities. | Inferential approaches can be based on any generative model. The general SBM will find any kind of mixing pattern in an unbiased way, and has no problems identifying modular structure in bipartite networks, core-periphery networks, and any mixture of these or other patterns. There are also specialized versions for bipartite [Reference Larremore, Clauset and Jacobs68], core-periphery [Reference Zhang, Martin and Newman69], and assortative patterns [Reference Zhang and Peixoto24], if these are being searched exclusively. |
The solution landscape of modularity maximization is often degenerate, with many different solutions with close to the same modularity value [Reference Good, Yves-Alexandre and Clauset61], and with no clear way of how to select between them. | Inferential methods are characterized by a posterior distribution of partitions. The consensus or dissensus between the different solutions [Reference Peixoto26] can be used to determine how many cohesive hypotheses can be extracted from inference, and to what extent is the model being used a poor or a good fit for the network. |


Because of the above problems, the use of modularity maximization should be discouraged, since it is demonstrably not fit for purpose as an inferential method. As a consequence, the use of modularity maximization in any recent network analysis that relies on inferential conclusions can be arguably considered a “red flag” that strongly indicates methodological inappropriateness. In the absence of secondary evidence supporting the alleged community structures found, or extreme care to counteract the several limitations of the method (see Secs. 4.2, 4.3 and 4.4 for how typical attempts usually fail), the safest assumption is that the results obtained with that method tend to contain a substantial amount of noise, rendering any inferential conclusion derived from them highly suspicious.
As a final note, we focus on modularity here not only for its widespread adoption but also because of its exemplary character. At a fundamental level, all of its shortcoming are shared with any descriptive method in the literature — to varied but always non-negligible degrees.
4 Myths, pitfalls, and half-truths
In this section we focus on assumed or asserted statements about how to circumvent pitfalls in community detection, which are in fact better characterized as myths or half-truths, since they are either misleading, or obstruct a more careful assessment of the true underlying nature of the problem. The following subsections each deal with one of these pitfalls.
4.1 “Modularity maximization and SBM inference are equivalent methods.”
As we have discussed in Sec. 2.5, it is possible to interpret any community detection algorithm as the inference of some generative model. Because of this, the mere fact that an equivalence with an inferential approach exists cannot be used to justify the inferential use of a descriptive method, or to use it as a criterion to distinguish between approaches that are statistically principled or not. To this aim, we need to ask instead whether the modelling assumptions that are implicit in the descriptive approach can be meaningfully justified, and whether they can be used to consistently infer structures from networks.
Some recent works have detailed some specific equivalences of modularity maximization with statistical inference [Reference Zhang and Moore70, Reference Newman71]. As we will discuss in this section, these equivalences are far more limited than commonly interpreted. They serve mostly to understand in more detail the reasons why modularity maximization fails as a reliable method, but do not prevent it from failing — they expose more clearly its sins, but offer no redemption.
We start with a very interesting connection revealed by Zhang and Moore [Reference Zhang and Moore70] between the effective posterior distribution we obtain when using the modularity function as a Hamiltonian,
 (17)
(17)
and the posterior distribution of the strictly assortative DC-SBM, which we refer here as the degree-corrected planted partition model (DC-PP),
 (18)
(18)
which has a likelihood given by
 (19)
(19)
where
 (20)
(20)
This model assumes that there are constant rates
 and
and
 controlling the number of edges that connect to nodes of the same and different communities, respectively. In addition, each node has its own propensity
controlling the number of edges that connect to nodes of the same and different communities, respectively. In addition, each node has its own propensity
 , which determines the relative probability it has of receiving an edge, such that nodes inside the same community are allowed to have very different degrees. This is a far more restrictive version of the full DC-SBM we considered before, since it not only assumes assortativity as the only mixing pattern, but also that all communities share the same rate
, which determines the relative probability it has of receiving an edge, such that nodes inside the same community are allowed to have very different degrees. This is a far more restrictive version of the full DC-SBM we considered before, since it not only assumes assortativity as the only mixing pattern, but also that all communities share the same rate
 , which imposes a rather unrealistic similarity between the different groups.
, which imposes a rather unrealistic similarity between the different groups.
Before continuing, it is important to emphasize that the posterior of Eq. 18 corresponds to the situation where the number of communities and all parameters of the model, except the partition itself, are known a priori. This does not correspond to any typical empirical setting where community detection is employed, since we do not often have such detailed information about the community structure, and in fact no good reason to even use this particular parametrization to begin with. The equivalences that we are about to consider apply only in very idealized scenarios, and are not expected to hold in practice.
Taking the logarithm of both sides of Eq. 19, and ignoring constant terms with respect to the model parameters we have
 (21)
(21)
Therefore, ignoring additive terms that do not depend on
 (since they become irrelevant after normalization in Eq. 17) and making the arbitrary choices (we will inspect these in detail soon),
(since they become irrelevant after normalization in Eq. 17) and making the arbitrary choices (we will inspect these in detail soon),
 (22)
(22)
we obtain the equivalence,
 (23)
(23)
allowing us to equate Eqs. 17 and 18 (there is a methodological problem with the choice
 , as we will see later, but we will ignore this for the time being). Therefore, for particular choices of the model parameters, one recovers modularity optimization from the maximum likelihood estimation of the DC-PP model with respect to
, as we will see later, but we will ignore this for the time being). Therefore, for particular choices of the model parameters, one recovers modularity optimization from the maximum likelihood estimation of the DC-PP model with respect to
 . Indeed, this allows us to understand more clearly what implicit assumptions go behind using modularity for inferential aims. For example, besides making very specific prior assumptions about the model parameters
. Indeed, this allows us to understand more clearly what implicit assumptions go behind using modularity for inferential aims. For example, besides making very specific prior assumptions about the model parameters
 ,
,
 and
and
 , this posterior also assumes that all partitions are equally likely a priori,
, this posterior also assumes that all partitions are equally likely a priori,
 (24)
(24)
We can in fact write this uniform prior more precisely as
 (25)
(25)
where
 is the number of labelled partitions of a set
is the number of labelled partitions of a set
 into
into
 groups. This number reaches a maximum at
groups. This number reaches a maximum at
 , and decays fast from there, meaning that such a uniform prior is in fact very concentrated on a very large number of groups — partially explaining the tendency of the modularity posterior to overfit. Let us examine now the prior assumption
, and decays fast from there, meaning that such a uniform prior is in fact very concentrated on a very large number of groups — partially explaining the tendency of the modularity posterior to overfit. Let us examine now the prior assumption
 (26)
(26)
For any value of
 , Eq. (26) admits many solutions. However, not all of them are consistent with the expected number of edges in the network according to the DC-PP model. Assuming, for simplicity, that all
, Eq. (26) admits many solutions. However, not all of them are consistent with the expected number of edges in the network according to the DC-PP model. Assuming, for simplicity, that all
 groups have the same size
groups have the same size
 , and that all nodes have the same degree
, and that all nodes have the same degree
 , then the expected number of edges according to the assumed DC-PP model is given by
, then the expected number of edges according to the assumed DC-PP model is given by
 (27)
(27)
Equating the expected with the observed value,
 , leads to
, leads to
 (28)
(28)
Combining Eqs. 26 and 28 gives us at most only two values of
 and
and
 that are compatible with the expected density of the network and the modularity interpretation of the likelihood, as seen in Fig. 9(a), and therefore only two possible values for the expected modularity, computed as
that are compatible with the expected density of the network and the modularity interpretation of the likelihood, as seen in Fig. 9(a), and therefore only two possible values for the expected modularity, computed as
Figure 9 Using modularity maximization is equivalent to performing a maximum likelihood estimate of the DC-PP model with very specific parameter choices, that depend on the number of edges
 in the network and the number of communities
in the network and the number of communities
 . In (a) we show the valid choices of
. In (a) we show the valid choices of
 and
and
 obtained when the solid and dashed lines cross, corresponding respectively to Eqs. 26 and 28, where we can see that for
obtained when the solid and dashed lines cross, corresponding respectively to Eqs. 26 and 28, where we can see that for
 no solution is possible where the expected modularity is positive. In (b) we show the two possible values for the expected modularity that are consistent with the implicit model assumptions, as a function of the number of groups.
no solution is possible where the expected modularity is positive. In (b) we show the two possible values for the expected modularity that are consistent with the implicit model assumptions, as a function of the number of groups.
 (29)
(29)
One possible solution is always
 , which leads to
, which leads to
 . The other solution is only possible for
. The other solution is only possible for
 , and yields a specific expected value of modularity which approaches
, and yields a specific expected value of modularity which approaches
 as
as
 increases (see Fig. 9(b)). This yields an implausibly narrow range for the consistency of modularity maximization with the inference of the DC-PP model. The bias towards larger values of
increases (see Fig. 9(b)). This yields an implausibly narrow range for the consistency of modularity maximization with the inference of the DC-PP model. The bias towards larger values of
 as the number of groups increases is not an inherent property of the DC-PP model, as it accommodates any expected value of modularity by properly choosing its parameters. Instead, this is an arbitrary implicit assumption baked in
as the number of groups increases is not an inherent property of the DC-PP model, as it accommodates any expected value of modularity by properly choosing its parameters. Instead, this is an arbitrary implicit assumption baked in
 , which further explains why maximizing it will tend to find many groups even on random networks.
, which further explains why maximizing it will tend to find many groups even on random networks.
In a later work [Reference Newman71], Newman relaxed the above connection with modularity by using instead its generalized version [Reference Reichardt and Bornholdt72, Reference Arenas, Fernández and Gómez73],
 (30)
(30)
where
 is the so-called “resolution” parameter. With this additional parameter, we have more freedom about the implicit assumptions of the DC-PP model. Newman in fact showed that if we make the choices,
is the so-called “resolution” parameter. With this additional parameter, we have more freedom about the implicit assumptions of the DC-PP model. Newman in fact showed that if we make the choices,
 (31)
(31)
then we recover the Gibbs distribution with the generalized modularity from the DC-PP likelihood of Eq. 19. Due to the independent parameter
 , now the assumed values of
, now the assumed values of
 and
and
 are no longer constrained by
are no longer constrained by
 alone, and can take any value. Therefore, if we knew the correct value of the model parameters, we could use them to choose the appropriate value of
alone, and can take any value. Therefore, if we knew the correct value of the model parameters, we could use them to choose the appropriate value of
 and hence maximize
and hence maximize
 , yielding the same answer as maximizing
, yielding the same answer as maximizing
 with the same parameters.
with the same parameters.
There are, however, serious problems remaining that prevent this equivalence from being true in general, or in fact even typically. For the equivalence to hold, we need the number of groups
 and all parameters to be known a priori and to be equal to Eq. 31. However, the choice
and all parameters to be known a priori and to be equal to Eq. 31. However, the choice
 involves information about the observed network, namely the actual degrees seen — and therefore is not just a prior assumption, but one done a posteriori, and hence needs to be justified via a consistent estimation that respects the likelihood principle. When we perform a maximum likelihood estimate of the parameters
involves information about the observed network, namely the actual degrees seen — and therefore is not just a prior assumption, but one done a posteriori, and hence needs to be justified via a consistent estimation that respects the likelihood principle. When we perform a maximum likelihood estimate of the parameters
 ,
,
 , and
, and
 , we obtain the following system of nonlinear equations [Reference Zhang and Peixoto24],
, we obtain the following system of nonlinear equations [Reference Zhang and Peixoto24],
 (32)
(32)
 (33)
(33)
 (34)
(34)
where
 ,
,
 , and
, and
 . This system (Eqs. (32), (33), and (34)) admits
. This system (Eqs. (32), (33), and (34)) admits
 as a solution only if the following condition is met for every group
as a solution only if the following condition is met for every group
 :
:
 (35)
(35)
In other words, the sum of degrees inside each group must be the same for every group. Note also that the expected degrees according to the DC-PP model will be inconsistent with Eq. 31 if the condition in Eq. (35) is not met, i.e.
 (36)
(36)
Substituting
 in the above equation will yield in general
in the above equation will yield in general
 , as long as Eq. 35 is not fulfilled, regardless of how we choose
, as long as Eq. 35 is not fulfilled, regardless of how we choose
 and
and
 .
.
Framing it differently, for any choice of
 ,
,
 and
and
 such that the sums
such that the sums
 are not identical for every group
are not identical for every group
 , the DC-SBM likelihood
, the DC-SBM likelihood
 is not captured by
is not captured by
 for any value of
for any value of
 , and therefore maximizing both functions will not yield the same results. That is, the equivalence is only valid for special cases of the model and data. We show in Fig. 10 an example of an instance of the DC-PP model where the generalized modularity yields results which are inconsistent with using likelihood of the DC-PP model directly.
, and therefore maximizing both functions will not yield the same results. That is, the equivalence is only valid for special cases of the model and data. We show in Fig. 10 an example of an instance of the DC-PP model where the generalized modularity yields results which are inconsistent with using likelihood of the DC-PP model directly.
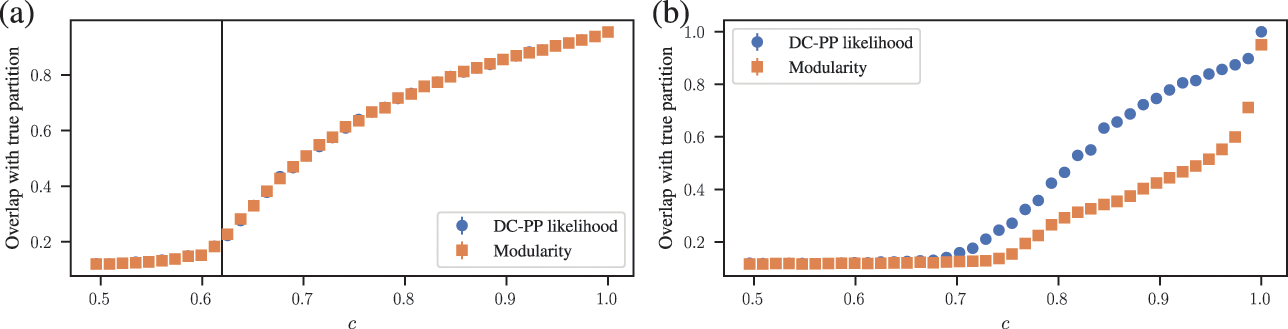
Figure 10 Generalized modularity and the DC-PP model are only equivalent if the symmetry of Eq. 35 is preserved. Here we consider an instance of the DC-PP model with
 ,
,
 , and
, and
 , where
, where
 is the number of nodes in group
is the number of nodes in group
 . The parameter
. The parameter
 controls the degree of assortativity. For non-uniform group sizes, the symmetry of Eq. 35 is not preserved with this choice of parameters. We use the parametrization
controls the degree of assortativity. For non-uniform group sizes, the symmetry of Eq. 35 is not preserved with this choice of parameters. We use the parametrization
 , where
, where
 controls the group size heterogeneity. When employing generalized modularity, we choose the closest possible parameter choice with
controls the group size heterogeneity. When employing generalized modularity, we choose the closest possible parameter choice with
 and
and
 , where
, where
 . In (a) we show the inference results for the uniform case with
. In (a) we show the inference results for the uniform case with
 , where both approaches are identical, performing equally well all the way down to the detectability threshold [Reference Decelle, Krzakala, Moore and Zdeborová6] (vertical line). In (b) we show the result with
, where both approaches are identical, performing equally well all the way down to the detectability threshold [Reference Decelle, Krzakala, Moore and Zdeborová6] (vertical line). In (b) we show the result with
 , which leads to unequal group sizes, causing the behavior between both approaches to diverge. In all cases we consider averages over 5 networks with
, which leads to unequal group sizes, causing the behavior between both approaches to diverge. In all cases we consider averages over 5 networks with
 nodes, average degree
nodes, average degree
 , and
, and
 groups.
groups.
Because of the above caveats, we have to treat the claimed equivalence with a grain of salt. In general there are only three scenarios we may consider when analysing a network:
1. We know that the network has been sampled from the DC-PP model, as well as the correct number of groups
 and the values of the parameters
,
, and
, and the following symmetry exists:
where(37)
is a constant.
and the values of the parameters
,
, and
, and the following symmetry exists:
where(37)
is a constant.2. Like the first case, but where the symmetry of Eq. 37 does not exist.
3. Every other situation.






Cases 1 and 2 are highly idealized and are not expected to be encountered in practice, which almost always falls in case 3. Nevertheless, the equivalence between the DC-PP model and generalized modularity is only valid in case 1. In case 2, as we already discussed, the use of generalized modularity will be equivalent to some generative model — as all methods are — but which cannot be expressed within the DC-PP parametrization.
Because of the above problems, the relevance of this partial equivalence between these approaches in practical scenarios is arguably dubious. It serves only to demonstrate how the implicit assumptions behind modularity maximization are hard to justify.
We emphasize also the obvious fact that even if the equivalence with the DC-PP model were to hold more broadly, this would not make the pathological behavior of modularity described in Sec. 3 disappear. Instead, it would only show that this particular inferential method would also be pathological. In fact, it is well understood that maximum likelihood is not in general an appropriate inferential approach for models with an arbitrarily large number of degrees of freedom, since it lacks the regularization properties of Bayesian methods [Reference Peixoto, Doreian, Batagelj and Ferligoj5], such as the one we described in Sec. 2.2, where instead of considering point estimates of the parameters, we integrate over all possibilities, weighted according to their prior probability. In this way, it is possible to infer the number of communities, instead of assuming it a priori, together with all other model parameters. In fact, when such a Bayesian approach is employed for the DC-PP model, one obtains the following marginal likelihood [Reference Zhang and Peixoto24],
 (38)
(38)
 (39)
(39)
where
 and
and
 . As demonstrated in Ref. [Reference Zhang and Peixoto24], this approach allows us to detect purely assortative community structures in a nonparametric way, in a manner that prevents both overfitting and underfitting — i.e. the resolution limit vanishes since we inherently consider every possible value of the parameters
. As demonstrated in Ref. [Reference Zhang and Peixoto24], this approach allows us to detect purely assortative community structures in a nonparametric way, in a manner that prevents both overfitting and underfitting — i.e. the resolution limit vanishes since we inherently consider every possible value of the parameters
 and
and
 — thus lifting two major limitations of modularity. Note also that Eq. 39 (or its logarithm) does not bear any direct resemblance to the modularity function, and therefore it does not seem possible to reproduce its behavior via a simple modification of the latter.Footnote 18
— thus lifting two major limitations of modularity. Note also that Eq. 39 (or its logarithm) does not bear any direct resemblance to the modularity function, and therefore it does not seem possible to reproduce its behavior via a simple modification of the latter.Footnote 18
We also mention briefly a result obtained by Bickel and Chen [Reference Bickel and Chen74], which states that modularity maximization can consistently identify the community assignments of networks generated by the SBM in the dense limit. This limit corresponds to networks where the average number of neighbors is comparable to the total number of nodes. In this situation, the community detection problem becomes substantially easier, and many algorithms, including e.g. unregularized spectral clustering, can do just as well as modularity maximization. This result tells us more about how easy it is to find communities in dense networks than about the quality of the algorithms compared. The dense scenario does not represent well the difficulty of finding communities in real networks, which are overwhelmingly sparse, with an average degree much smaller than the total number of nodes. In the sparse case, likelihood-based inferential approaches are optimal and outperform modularity [Reference Decelle, Krzakala, Moore and Zdeborová6, Reference Bickel and Chen74]. Comparable equivalences have also been encountered with spectral methods [Reference Newman75], but they also rely on particular realizations of the community detection problem, and do not hold in general.
In short, if the objective is to infer the DC-PP model, there is no reason to do it via the maximization of
 , nor is it in general equivalent to any consistent inference approach such as maximum likelihood or Bayesian posterior inference. Even in the unlikely case where the true number of communities is known, the implicit assumptions of modularity correspond to the DC-PP model not only with uniform probabilities between communities but also uniform sums of degrees for every community. If these properties are not present in the network, the method offers no inherent diagnostic, and will find spurious structures that tend to match it, regardless of their statistical significance. Combined with the overall lack of regularization, these features render the method substantially prone to distortion and overfitting. Ultimately, the use of any form of modularity maximization fails the litmus test we considered earlier, and should be considered a purely descriptive community detection method. Whenever the objective is to understand network structure, it needs to be replaced with a flexible and robust inferential procedure.
, nor is it in general equivalent to any consistent inference approach such as maximum likelihood or Bayesian posterior inference. Even in the unlikely case where the true number of communities is known, the implicit assumptions of modularity correspond to the DC-PP model not only with uniform probabilities between communities but also uniform sums of degrees for every community. If these properties are not present in the network, the method offers no inherent diagnostic, and will find spurious structures that tend to match it, regardless of their statistical significance. Combined with the overall lack of regularization, these features render the method substantially prone to distortion and overfitting. Ultimately, the use of any form of modularity maximization fails the litmus test we considered earlier, and should be considered a purely descriptive community detection method. Whenever the objective is to understand network structure, it needs to be replaced with a flexible and robust inferential procedure.
4.2 “Consensus clustering can eliminate overfitting.”
As mentioned in Sec. 3, methods like modularity maximization tend to have a degenerate solution landscape. One strategy proposed to tackle this problem is to obtain a consensus clustering, i.e. leverage the entire landscape of solutions to produce a single partition that points in a cohesive direction, representative of the whole ensemble [Reference Riolo and Newman63, Reference Massen and Doye76, Reference Lancichinetti and Fortunato77]. If no cohesive direction exists, one could then conclude that no actual community structure exists, and therefore solve the overfitting problem of finding communities in maximally random networks. In reality, however, a descriptive community detection method can in fact display a cohesive set of solutions on a maximally random network. We demonstrate this in Fig. 11 which shows the consensus between
 different maximum modularity solutions for a small random network, using the method of Ref. [Reference Peixoto26] to obtain the consensus. Although we can notice a significant variability between the different partitions, there is also substantial agreement. In particular, there is no clear indication from the consensus that the underlying network is maximally random. The reason for this that the randomness of the network is quenched, and does indeed point to a specific community structure with the highest modularity. The ideas of solution heterogeneity and overfitting are, in general, orthogonal concepts.
different maximum modularity solutions for a small random network, using the method of Ref. [Reference Peixoto26] to obtain the consensus. Although we can notice a significant variability between the different partitions, there is also substantial agreement. In particular, there is no clear indication from the consensus that the underlying network is maximally random. The reason for this that the randomness of the network is quenched, and does indeed point to a specific community structure with the highest modularity. The ideas of solution heterogeneity and overfitting are, in general, orthogonal concepts.
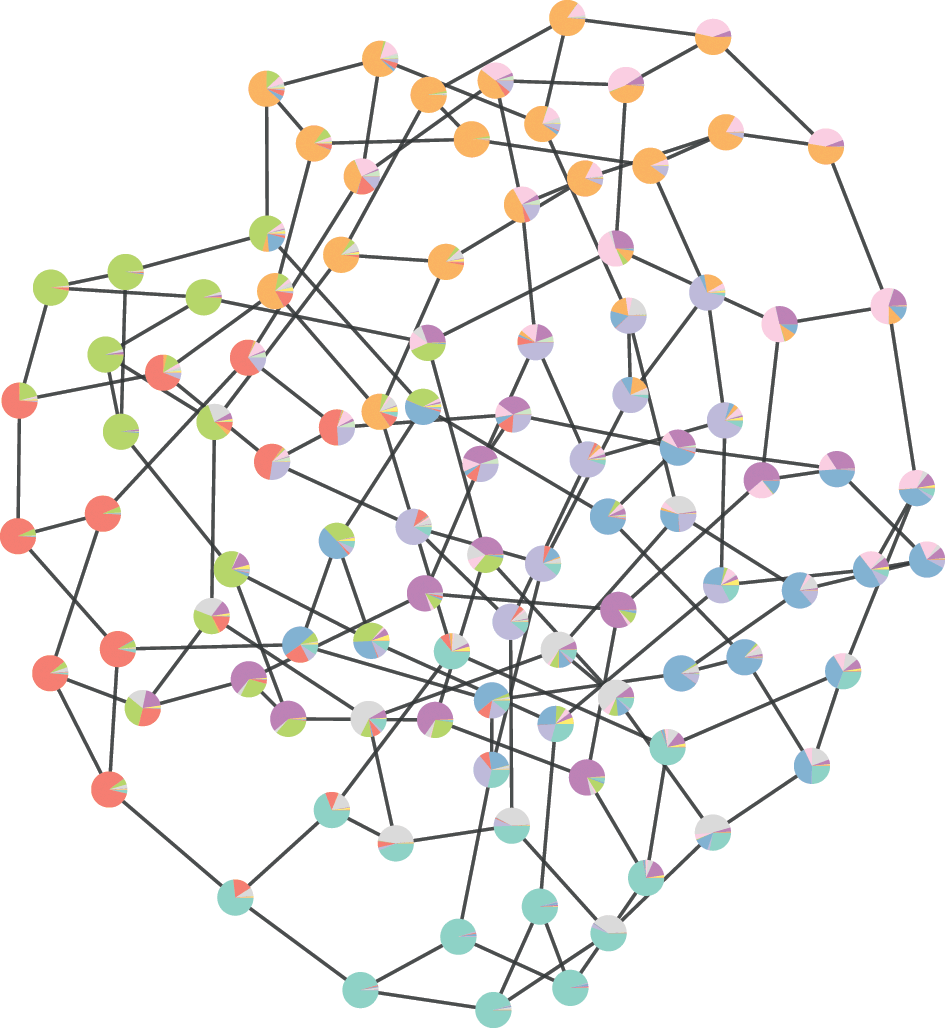
Figure 11 Consensus clustering of a maximally random network, sampled from the Erdős-Rényi model, that combines
 solutions of the maximum modularity method. On each node there is a pie chart describing the frequencies with which it was observed in a given community, obtained using the approach described in Ref. [Reference Peixoto26]. Despite the lack of latent communities, there is a substantial agreement between the different answers.
solutions of the maximum modularity method. On each node there is a pie chart describing the frequencies with which it was observed in a given community, obtained using the approach described in Ref. [Reference Peixoto26]. Despite the lack of latent communities, there is a substantial agreement between the different answers.
With care, it is possible to probe the solution landscape in a manner that reveals a signal of the randomness of the underlying network. For this purpose, some authors have proposed that instead of finding the maximum modularity partition, one instead samples them from the Gibbs distribution [Reference Zhang and Moore70, Reference Massen and Doye76, Reference Reichardt and Bornholdt78, Reference Dandan, Ronhovde and Nussinov79],
 (40)
(40)
with normalization
 , effectively considering
, effectively considering
 as the Hamiltonian of a spin system with an inverse temperature parameter
as the Hamiltonian of a spin system with an inverse temperature parameter
 . For a sufficiently large random network, there is a particular value
. For a sufficiently large random network, there is a particular value
 , below which samples from the distribution become uncorrelated, forming a lack of consensus [Reference Zhang and Moore70]. There is a problem, however: there is no guarantee that if a lack of consensus exists for
, below which samples from the distribution become uncorrelated, forming a lack of consensus [Reference Zhang and Moore70]. There is a problem, however: there is no guarantee that if a lack of consensus exists for
 , then the network must be random; only the reverse is true. In general, while statements can be made about the behavior of the modularity landscape for maximally random and sufficiently large networks, or even for networks sampled from a SBM, very little can be said about its behavior on real, finite networks. Since real networks are likely to contain a heterogeneous mixture of randomness and structure (e.g. as illustrated in Fig. 7(c)) this kind of approach becomes ultimately unreliable. One fundamental problem here is that these approaches attempt to reach an inferential conclusion (“is the network sampled from a random model?”) without fully going through Bayes’ formula of Eq. 1, and reasoning about model assumptions, prior information and compressibility. We currently lack a principled methodology to reach such a conclusion while avoiding these crucial steps.
, then the network must be random; only the reverse is true. In general, while statements can be made about the behavior of the modularity landscape for maximally random and sufficiently large networks, or even for networks sampled from a SBM, very little can be said about its behavior on real, finite networks. Since real networks are likely to contain a heterogeneous mixture of randomness and structure (e.g. as illustrated in Fig. 7(c)) this kind of approach becomes ultimately unreliable. One fundamental problem here is that these approaches attempt to reach an inferential conclusion (“is the network sampled from a random model?”) without fully going through Bayes’ formula of Eq. 1, and reasoning about model assumptions, prior information and compressibility. We currently lack a principled methodology to reach such a conclusion while avoiding these crucial steps.
Another aspect of the relationship between consensus clustering and overfitting is worth mentioning. In an inferential setting, if we wish to obtain an estimator for the true partition
 , this will in general depend on how we evaluate its accuracy. In other words, we must define an error function
, this will in general depend on how we evaluate its accuracy. In other words, we must define an error function
 such that
such that
 (41)
(41)
Based on this, our best possible estimate is the one which minimizes the average error over the entire posterior distribution,
 (42)
(42)
Note that in general this estimator will be different from the most likely partition, i.e.
 (43)
(43)
The optimal estimator
 will indeed correspond to a consensus over all possible partitions, weighted according to their plausibility. In situations where the posterior distribution is concentrated on a single partition, both estimators will coincide. Otherwise, the most likely partition might in fact be less accurate and incorporate more noise than the consensus estimator, which might be seen as a form of overfitting. This kind of overfitting is of a different nature than the one we have considered so far, since it amounts to a residual loss of accuracy, where an (often small) fraction of the nodes end up incorrectly classified, instead of spurious groups being identified. However, there are many caveats to this kind of analysis. First, it will be sensitive to the error function chosen, which needs to be carefully justified. Second, there might be no cohesive consensus, in situations where the posterior distribution is composed of several distinct “modes,” each corresponding to a different hypothesis for the network. In such a situation the consensus between them might be unrepresentative of the ensemble of solutions. There are principled approaches to deal with this problem, as described in Refs. [Reference Peixoto26, Reference Kirkley and Newman80].
will indeed correspond to a consensus over all possible partitions, weighted according to their plausibility. In situations where the posterior distribution is concentrated on a single partition, both estimators will coincide. Otherwise, the most likely partition might in fact be less accurate and incorporate more noise than the consensus estimator, which might be seen as a form of overfitting. This kind of overfitting is of a different nature than the one we have considered so far, since it amounts to a residual loss of accuracy, where an (often small) fraction of the nodes end up incorrectly classified, instead of spurious groups being identified. However, there are many caveats to this kind of analysis. First, it will be sensitive to the error function chosen, which needs to be carefully justified. Second, there might be no cohesive consensus, in situations where the posterior distribution is composed of several distinct “modes,” each corresponding to a different hypothesis for the network. In such a situation the consensus between them might be unrepresentative of the ensemble of solutions. There are principled approaches to deal with this problem, as described in Refs. [Reference Peixoto26, Reference Kirkley and Newman80].
4.3 “Overfitting can be tackled by doing a statistical significance test of the quality function.”
Sometimes practitioners are aware that non-inferential methods like modularity maximization can find communities in random networks. In an attempt to extract an inferential conclusion from their results, they compare the value of the quality function with a randomized version of the network — and if a significant discrepancy is found, they conclude that the community structure is statistically meaningful [Reference Reichardt and Bornholdt78]. Unfortunately, this approach is as fundamentally flawed as it is straightforward to implement.
The reason why the test fails is because in reality it answers a question that is different from the one intended. When we compare the value of the quality function obtained from a network and its randomized counterpart, we can use this information to answer only the following question: “Can we reject the hypothesis that the observed network was sampled from a random null model?” No other information can be obtained from this test, including whether the network partition we obtained is significant. All we can determine is if the optimized value of the quality function is significant or not. The distinction between the significance of the quality function value and the network partition itself is subtle but crucial.
We illustrate the above difference with an example in Fig. 12(b). This network is created by starting with a maximally random Erdős-Rényi (ER) network, and adding to it a few more edges so that it has an embedded clique of six nodes. The occurrence of such a clique from an ER model is very unlikely, so if we perform a statistical test on this network that is powerful enough, we should be able to rule out that it came from the ER model with good confidence. Indeed, if we use the value of maximum modularity for this test, and compare with the values obtained for the ER model with the name number of nodes and edges (see Fig. 12(a)), we are able to reach the correct conclusion that the null model should be rejected, since the optimized value of modularity is significantly higher for the observed network. Should we conclude therefore that the communities found in the network are significant? If we inspect Fig. 12(b), we see that the maximum value of modularity indeed corresponds to a more-or-less decent detection of the planted clique. However, it also finds another seven completely spurious communities in the random part of the network. What is happening is clear — the planted clique is enough to increase the value of
 such that it becomes a suitable test to reject the null model,Footnote 19 but the test is not able to determine that the communities themselves are statistically meaningful. In short, the statement “the value of
such that it becomes a suitable test to reject the null model,Footnote 19 but the test is not able to determine that the communities themselves are statistically meaningful. In short, the statement “the value of
 is significant” is not synonymous with “the network partition is significant.” Conflating the two will lead to the wrong conclusion about the significance of the communities uncovered.
is significant” is not synonymous with “the network partition is significant.” Conflating the two will lead to the wrong conclusion about the significance of the communities uncovered.
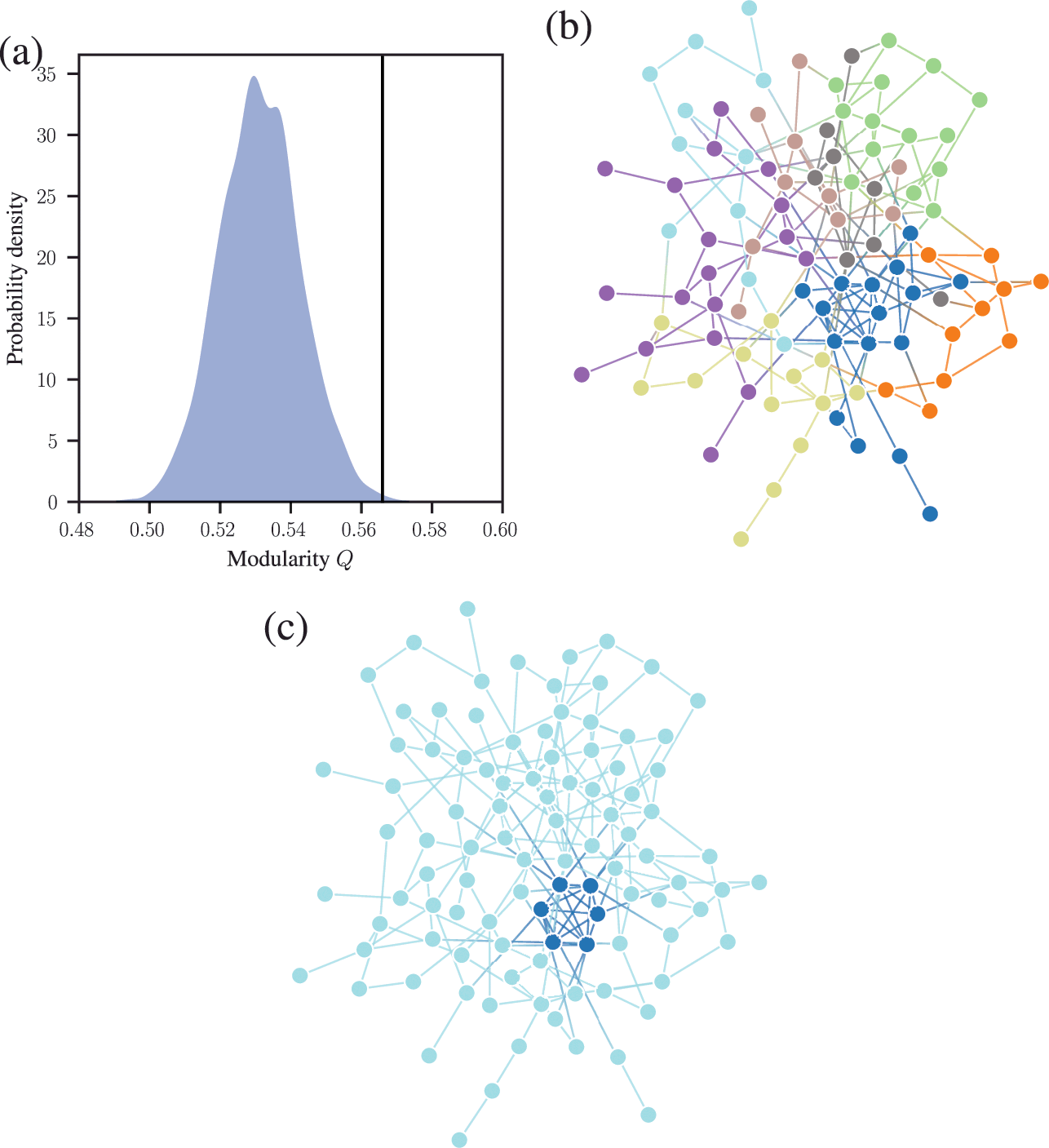
Figure 12 The statistical significance of the maximum modularity value is not informative of the significance of the community structure. In (a) we show the distribution of optimized values of modularity for networks sampled from the Erdős-Rényi (ER) model with the same number of nodes and edges as the network shown in (b) and (c). The vertical line shows the value obtained for the partition shown in (b), indicating that the network is very unlikely to have been sampled from the ER model (
 ). However, what sets this network apart from typical samples is the existence of a small clique of six nodes that would not occur in the ER model. The remaining communities found in (b) are entirely meaningless. In (c) we show the result of inferring the SBM on this network, which perfectly identifies the planted clique without overfitting the rest of the network.
). However, what sets this network apart from typical samples is the existence of a small clique of six nodes that would not occur in the ER model. The remaining communities found in (b) are entirely meaningless. In (c) we show the result of inferring the SBM on this network, which perfectly identifies the planted clique without overfitting the rest of the network.
In Fig. 12(c) we show the result of a more appropriate inferential approach, based on the SBM as described in Sec. 2.3, that attempts to answer a much more relevant question: “which partition of the network into groups is more likely?” The result is able to cleanly separate the planted clique from the rest of the network, which is grouped into a single community.
This example also shows how the task of rejecting a null model is very oblique to Bayesian inference of generative models. The former attempts to determine what the network is not, while the latter what it is. The first task tends to be easy — we usually do not need very sophisticated approaches to determine that our data did not come from a null model, specially if our data is complex. On the other hand, the second task is far more revealing, constructive, and arguably more useful in general.
4.4 “Setting the resolution parameter of modularity maximization can remove the resolution limit.”
The resolution limit of the generalized modularity of Eq. 30 is such that, in a connected network, no more than
 communities can be found, with
communities can be found, with
 being the resolution parameter [Reference Reichardt and Bornholdt72, Reference Arenas, Fernández and Gómez73]. Therefore, by changing the value of
being the resolution parameter [Reference Reichardt and Bornholdt72, Reference Arenas, Fernández and Gómez73]. Therefore, by changing the value of
 , we can induce the discovery of modules of arbitrary size, at least in principle. However, there are several underlying problems with tuning the value of
, we can induce the discovery of modules of arbitrary size, at least in principle. However, there are several underlying problems with tuning the value of
 for the purpose of counter-acting the resolution limit. The first is that it requires a specific prior knowledge about what would be the relevant scale for a particular network — which is typically unavailable — turning an otherwise nonparametric approach into one which is parametric.Footnote 20 The second problem is even more serious: In many cases no single value of
for the purpose of counter-acting the resolution limit. The first is that it requires a specific prior knowledge about what would be the relevant scale for a particular network — which is typically unavailable — turning an otherwise nonparametric approach into one which is parametric.Footnote 20 The second problem is even more serious: In many cases no single value of
 is appropriate. This happens because, as we have seen in Sec. 4.1, generalized modularity comes with the built-in assumption that the sum of degrees of every group should be the same. The preservation of this homogeneity means that when the network is composed of communities of different sizes, either the smaller ones will be merged together or the bigger ones will be split into smaller ones, regardless of the statistical evidence [Reference Lancichinetti and Fortunato82]. We show a simple example of this in Fig. 13, where no value of
is appropriate. This happens because, as we have seen in Sec. 4.1, generalized modularity comes with the built-in assumption that the sum of degrees of every group should be the same. The preservation of this homogeneity means that when the network is composed of communities of different sizes, either the smaller ones will be merged together or the bigger ones will be split into smaller ones, regardless of the statistical evidence [Reference Lancichinetti and Fortunato82]. We show a simple example of this in Fig. 13, where no value of
 can be used to recover the correct partition.
can be used to recover the correct partition.
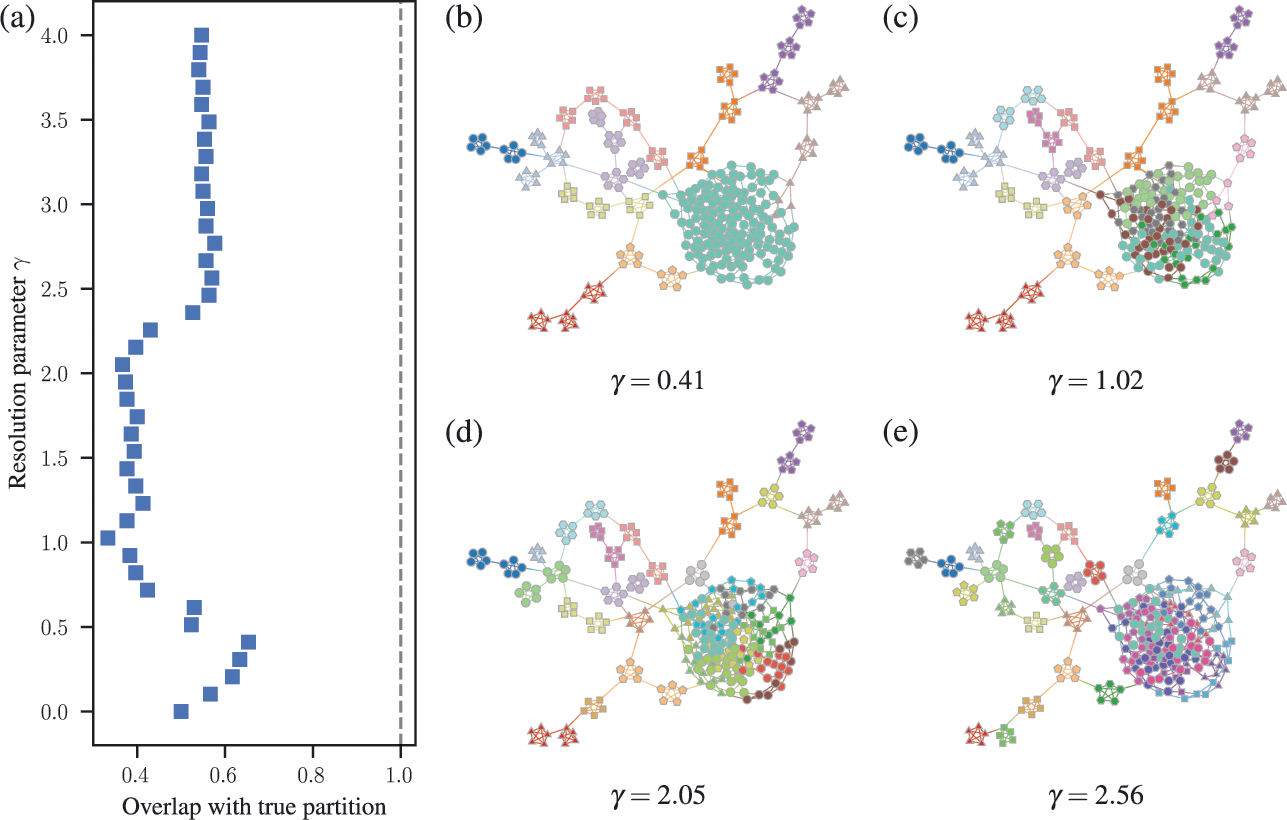
Figure 13 Modularity maximization imposes characteristic community sizes in a manner that hides heterogeneity. Panel (a) shows the overlap between the true and obtained partition for the network described in Fig. 7, as a function of the resolution parameter
 . Panels (b) to (e) show the partitions found for different values of
. Panels (b) to (e) show the partitions found for different values of
 , where we see that as smaller groups are uncovered, bigger ones are spuriously split. The result is that no value of
, where we see that as smaller groups are uncovered, bigger ones are spuriously split. The result is that no value of
 allows the true communities to be uncovered.
allows the true communities to be uncovered.
However, the most important problem with the analysis of the resolution limit in the context of modularity maximization is that it is often discussed in a manner that is largely decoupled from the issue of statistical significance. Since we can interpret a limit on the maximum number of groups as type of systematic underfitting, we can only meaningfully discuss the removal of this limitation if we also do not introduce a tendency to overfit, i.e. find more groups than justifiable by statistical evidence. This is precisely the problem with “mutliresolution” approaches [Reference Granell, Gómez and Arenas83], or analyses of quality functions other than modularity [Reference Kawamoto and Rosvall84], that claim a reduced or a lack of resolution limit, but without providing a robustness against overfitting. This one-sided evaluation is fundamentally incomplete, as we may end up trading one serious limitation for another.
Methods based on the Bayesian inference of the SBM can tackle the issue of over- and underfitting, as well as preferred sizes of communities at the source. As was shown in Ref. [Reference Peixoto85], a uninformative assumption about the mixing patterns between groups leads naturally to a resolution limit similar to the one existing for modularity, where no more than
 groups can be inferred for sparse networks. However, since in an inferential context our assumptions are made explicitly, we can analyse them more easily and come up with more appropriate choices. In Ref. [Reference Peixoto67] it was shown how replacing the noninformative assumption by a Bayesian hierarchical model can essentially remove the resolution limit, with a maximum number of groups scaling as
groups can be inferred for sparse networks. However, since in an inferential context our assumptions are made explicitly, we can analyse them more easily and come up with more appropriate choices. In Ref. [Reference Peixoto67] it was shown how replacing the noninformative assumption by a Bayesian hierarchical model can essentially remove the resolution limit, with a maximum number of groups scaling as
 . That model is still unbiased with respect to the expected mixing patterns, and incorporates only the assumption that the patterns themselves are generated by another SBM, with its own patterns generated by yet another SBM, and so on recursively. Another model that has also been shown to be free of the resolution limit is the assortative SBM of Ref. [Reference Zhang and Peixoto24]. Importantly, in both these cases the removal of the resolution limit is achieved without sacrificing the capacity of the method to avoid overfitting — e.g. none of these approaches will find spurious groups in random networks.
. That model is still unbiased with respect to the expected mixing patterns, and incorporates only the assumption that the patterns themselves are generated by another SBM, with its own patterns generated by yet another SBM, and so on recursively. Another model that has also been shown to be free of the resolution limit is the assortative SBM of Ref. [Reference Zhang and Peixoto24]. Importantly, in both these cases the removal of the resolution limit is achieved without sacrificing the capacity of the method to avoid overfitting — e.g. none of these approaches will find spurious groups in random networks.
The issue with preferred group sizes can also be tackled in a principled way in an inferential setting. As demonstrated in Ref. [Reference Peixoto16], we can also design Bayesian prior hierarchies where the group size distribution is chosen in a non-informative manner, before the partition itself is determined. This results in an inference method that is by design agnostic with respect to the distribution of group sizes, and will not prefer any of them in particular. Such a method can then be safely employed on networks with heterogeneous group sizes in an unbiased manner. In Fig. 7(d) we show how such an approach can easily infer groups of different sizes for the same example of Fig. 13, in a completely nonparametric manner.
4.5 “Modularity maximization can be fixed by replacing the null model.”
Several variations of the method of modularity maximization have been proposed, where instead of the configuration model, another null model is used, in a manner that makes the method applicable in various scenarios, e.g. with bipartite networks [Reference Barber86], correlation matrices [Reference MacMahon and Garlaschelli87], signed edge weights [Reference Traag and Bruggeman88], networks embedded in euclidean spaces [Reference Expert, Evans, Blondel and Lambiotte89], to name a few. While the choice of null model has an important effect on what kind of structures are uncovered, its choice does not address any of the statistical shortcomings of modularity that we consider here. In general, just like it happens for the configuration model, the approach will find spurious communities in networks sampled from its null model, regardless of how it is chosen. As as discussed in Sec. 3, this happens because the measured deviation does not account for the optimization procedure employed. Any method based on optimizing the modularity score will amount to a data dredging procedure, independently of the null model chosen, and are thus unsuitable for inferential aims.
4.6 “Descriptive approaches are good enough when the community structure is obvious.”
A common argument goes that, sometimes, the community structure of a network is so “obvious” that it will survive whatever abuse we direct at it, and it will be uncovered by a majority of community detection methods that we employ. Therefore, if we are confident that our network contains a clear signal of its community structure, specially if several algorithms substantially agree with each other, or they agree with metadata, then it does not matter very much which algorithm we use.
There are several problems with this argument. First, if an “obvious” structure exists, it does not necessarily mean that it is really meaningful, or statistically significant. If ten algorithms overfit, and one does not, the majority vote is incorrect, and we should prefer the minority opinion. This is precisely the case we considered in Fig. 2, where virtually any descriptive method would uncover the same 13 communities — thus overfitting the network — while an inferential approach would not. And if a method agrees with metadata, while another finds further structure not in agreement, what is to say that this structure is not really there? (Metadata are not “ground truth,” they are only more data [Reference Hric, Peixoto and Fortunato90–Reference Peel, Larremore and Clauset92], and hence can have its own complex, incomplete, noisy, or even irrelevant relationship with the network.)
Secondly, and even more importantly, how do we even define what is an “obvious” community structure? In general, networks are not low dimensional objects, and we lack methods to inspect their structure directly, a fact which largely motivates community detection in the first place. Positing that we can just immediately determine community structure largely undermines this fact. Often, structure which is deemed “obvious” at first glance, ceases to be so upon closer inspection. For example, one can find claims in the literature that different connected components must “obviously” correspond to different communities. However, maximally random graphs can end up disconnected if they are sufficiently sparse, which means that from an inferential point of view different components can belong to the same community.
Another problem is that analyses of community detection results rely frequently on visual inspections of graphical network layouts, where one tries to evaluate if the community labels agree with the position of the nodes. However, the positioning of the nodes and edges is not inherent to the network itself, and needs to be obtained with some graph drawing algorithm. A typical example are the so-called “spring-block” or “force-directed” layouts, where one considers attractive forces between nodes connected by an edge (like a spring) and an overall repulsive force between all nodes [Reference Hu93]. The final layout is then obtained by minimizing the energy of the system, resulting in edges that have similar length and as few crossings between edges as possible (e.g. in Fig. 1 we used the algorithm of Ref. [Reference Hu93]). This kind of drawing in itself can be seen as a type of indirect descriptive community detection method, since nodes belonging to the same assortative community will tend to be placed close to each other [Reference Noack94]. Based on this observation, when we say that we “see” the communities in a drawing like in Fig. 1, we are in reality only seeing what the layout algorithm is telling us. Therefore, we should always be careful when comparing the results we get with a community detection algorithm to the structure we see in these layouts, because there is no reason to assume that the layout algorithm itself is doing a better job than the clustering algorithm we are evaluating.Footnote 21 In fact, this is often not the case, since the actual community structures in many networks do not necessarily have a sufficiently low-dimensional representation that is required for this kind of visualization to be effective.
4.7 “The no-free-lunch theorem means that every community detection method is equally good.”
For a wide class of optimization and learning problems there exist so-called “no-free-lunch” (NFL) theorems, which broadly state that when averaged over all possible problem instances, all algorithms show equivalent performance [Reference Wolpert and Macready95–Reference Wolpert and Macready97]. Peel et al [Reference Peel, Larremore and Clauset92] have proved that this is also valid for the problem of community detection, meaning that no single method can perform systematically better than any other, when averaged over all community detection problems. This has been occasionally interpreted as a reason to reject the claim that we should systematically prefer certain classes of algorithms over others. This is, however, a misinterpretation of the theorem, as we will now discuss.
The NFL theorem for community detection is easy to state. Let us consider a generic deterministic community detection algorithm indexed by
 , defined by the function
, defined by the function
 , which ascribes a single partition to a network
, which ascribes a single partition to a network
 . Peel et al [Reference Peel, Larremore and Clauset92] consider an instance of the community detection problem to be an arbitrary pair
. Peel et al [Reference Peel, Larremore and Clauset92] consider an instance of the community detection problem to be an arbitrary pair
 composed of a network
composed of a network
 and the correct partition
and the correct partition
 that one wants to find from
that one wants to find from
 . We can evaluate the accuracy of the algorithm
. We can evaluate the accuracy of the algorithm
 via an error (or “loss”) function
via an error (or “loss”) function
 (44)
(44)
which should take the smallest possible value if
 . If the error function does not have an inherent preference for any partition (it’s “homogeneous”), then the NFL theorem states [Reference Wolpert96, Reference Peel, Larremore and Clauset92]
. If the error function does not have an inherent preference for any partition (it’s “homogeneous”), then the NFL theorem states [Reference Wolpert96, Reference Peel, Larremore and Clauset92]
 (45)
(45)
where
 is a value that depends only on the error function chosen, but not on the community detection algorithm
is a value that depends only on the error function chosen, but not on the community detection algorithm
 . In other words, when averaged over all problem instances, all algorithms have the same accuracy. This implies, therefore, that in order for one class of algorithms to perform systematically better than another, we need to restrict the universe of problems to a particular subset. This is a seemingly straightforward result, but which is unfortunately very susceptible to misinterpretation and overstatement.
. In other words, when averaged over all problem instances, all algorithms have the same accuracy. This implies, therefore, that in order for one class of algorithms to perform systematically better than another, we need to restrict the universe of problems to a particular subset. This is a seemingly straightforward result, but which is unfortunately very susceptible to misinterpretation and overstatement.
A common criticism of this kind of NFL theorem is that it is a poor representation of the typical problems we may encounter in real domains of application, which are unlikely to be uniformly distributed across the entire problem space. Therefore, as soon as we constrain ourselves to a subset of problems that are relevant to a particular domain, then this will favor some algorithms over others — but then no algorithm will be superior for all domains. But since we are typically only interested in some domains, the NFL theorem is then arguably “theoretically sound, but practically irrelevant” [Reference Schaffer, Cohen and Hirsh98]. Although indeed correct, in the case of community detection this logic is arguably an understatement. This is because as soon as we restrict our domain to community detection problems that reveal something informative about the network structure, then we are out of reach of the NFL theorem, and some algorithms will do better than others, without evoking any particular domain of application. We demonstrate this in the following.
The framework of the NFL theorem of Ref. [Reference Peel, Larremore and Clauset92] operates on a liberal notion of what constitutes a community detection problem and its solution, which means for an arbitrary pair
 choosing the right
choosing the right
 such that
such that
 . Under this framework, algorithms are just arbitrary mappings from network to partition, and there is no necessity to articulate more specifically how they relate to the structure of the network — community detection just becomes an arbitrary game of “guess the hidden node labels.” This contrasts with how actual community detection algorithms are proposed, which attempt to match the node partitions to patterns in the network, e.g. assortativity, general connection preferences between groups, etc. Although the large variety of algorithms proposed for this task already reveal a lack of consensus on how to precisely define it, few would consider it meaningful to leave the class of community detection problems so wide open as to accept any matching between an arbitrary network and an arbitrary partition as a valid instance.
. Under this framework, algorithms are just arbitrary mappings from network to partition, and there is no necessity to articulate more specifically how they relate to the structure of the network — community detection just becomes an arbitrary game of “guess the hidden node labels.” This contrasts with how actual community detection algorithms are proposed, which attempt to match the node partitions to patterns in the network, e.g. assortativity, general connection preferences between groups, etc. Although the large variety of algorithms proposed for this task already reveal a lack of consensus on how to precisely define it, few would consider it meaningful to leave the class of community detection problems so wide open as to accept any matching between an arbitrary network and an arbitrary partition as a valid instance.
Even though we can accommodate any (deterministic) algorithm deemed valid according to any criterion under the NFL framework, most algorithms in this broader class do something else altogether. In fact, the absolute vast majority of them correspond to a maximally random matching between network and partition, which amounts to little more than just randomly guessing a partition for any given network, i.e. they return widely different partitions for inputs that are very similar, and overall point to no correlation between input and output.Footnote 22 It is not difficult to accept that these random algorithms perform equally “well” for any particular problem, or even all problems, but the NFL theorem says that they have equivalent performance even to algorithms that we may deem more meaningful. How do we make a formal distinction between algorithms that are just randomly guessing from those that are doing something coherent and trying to discover actual network patterns? As it turns out, there is an answer to this question that does not depend on particular domains of application: we require the solutions found to be structured and compressive of the network.
In order to interpret the statement of the NFL theorem in this vein, it is useful to re-write Eq. 45 using an equivalent probabilistic language,
 (46)
(46)
where
 , and
, and
 is the uniform probability of encountering a problem instance. When writing the theorem statement in this way, we notice immediately that instead of being agnostic about problem instances, it implies a very specific network generative model, which assumes a complete independence between network and partition. Namely, if we restrict ourselves to networks of
is the uniform probability of encountering a problem instance. When writing the theorem statement in this way, we notice immediately that instead of being agnostic about problem instances, it implies a very specific network generative model, which assumes a complete independence between network and partition. Namely, if we restrict ourselves to networks of
 nodes, we have then:Footnote 23
nodes, we have then:Footnote 23
 (47)
(47)
 (48)
(48)
 (49)
(49)
Therefore, the NFL theorem states simply that if we sample networks and partitions from a maximally random generative model, then all algorithms will have the same average accuracy at inferring the partition from the network. This is hardly a spectacular result — indeed the Bayes-optimal algorithm in this case, i.e. the one derived from the posterior distribution of the true generative model and which guarantees the best accuracy on average, consists of simply guessing partitions uniformly at random, ignoring the network structure altogether.
The probabilistic interpretation reveals that the NFL theorem involves a very specific assumption about what kind of community detection problem we are expecting. It is important to remember that it is not possible to make “no assumption” about a problem; we are always forced to make some assumption, which even if implicit is not exempted from justification, and the uniform assumption of Eqs. 47 to 49 is no exception. In Fig. 14(a) we show a typical sample from this ensemble of community detection problems. In a very concrete sense, we can state that such problem instances are unstructured and contain no learnable community structure, or in fact no learnable network structure at all. We say that a community structure is (in principle) learnable if the knowledge of the partition
 can be used to compress the network
can be used to compress the network
 , i.e. there exists an encoding
, i.e. there exists an encoding
 (i.e. a generative model) such that
(i.e. a generative model) such that
Figure 14 The NFL theorem involves predominantly instances of the community detection problem that are strictly incompressible, i.e. the true partitions cannot be used to explain the network. In (a) we show a typical sample of the uniform problem space given by Eq. 47, for
 nodes, which yields a dense maximally random network, randomly divided into
nodes, which yields a dense maximally random network, randomly divided into
 groups. It is asymptotically impossible to use this partition to compress this network into fewer than
groups. It is asymptotically impossible to use this partition to compress this network into fewer than
 bits, and therefore the partition is not learnable from the network alone with any inferential algorithm. We show also the description length of the SBM conditioned on the true partition,
bits, and therefore the partition is not learnable from the network alone with any inferential algorithm. We show also the description length of the SBM conditioned on the true partition,
 , as a reference. In (b) we show an example of a community detection problem that is solvable, at least in principle, since
, as a reference. In (b) we show an example of a community detection problem that is solvable, at least in principle, since
 . In this case, the partition can be used to inform the network structure, and potentially vice-versa. This class of problem instance has a negligible contribution to the sum in the NFL theorem in Eq. 45, since it occurs only with an extremely small probability when sampled from the uniform model of Eq. 47. It is therefore more reasonable to state that the network in example (b) has an actual community structure, while the one in (a) does not.
. In this case, the partition can be used to inform the network structure, and potentially vice-versa. This class of problem instance has a negligible contribution to the sum in the NFL theorem in Eq. 45, since it occurs only with an extremely small probability when sampled from the uniform model of Eq. 47. It is therefore more reasonable to state that the network in example (b) has an actual community structure, while the one in (a) does not.
 (50)
(50)
 (51)
(51)
where
 is the description length of
is the description length of
 according to model
according to model
 , conditioned on the partition being known. However, it is a direct consequence of Shannon’s source coding theorem [Reference Shannon21, Reference Cover and Thomas29], that for the vast majority of networks sampled from the model of Eq. 47 the inequality in Eqs. (50) and (51) cannot be fulfilled as
, conditioned on the partition being known. However, it is a direct consequence of Shannon’s source coding theorem [Reference Shannon21, Reference Cover and Thomas29], that for the vast majority of networks sampled from the model of Eq. 47 the inequality in Eqs. (50) and (51) cannot be fulfilled as
 , i.e. the networks are incompressible.Footnote 24 This means that the true partition
, i.e. the networks are incompressible.Footnote 24 This means that the true partition
 carries no information about the network structure, and vice versa, i.e. the partition is not learnable from the network. In view of this, the common interpretation of the NFL theorem as “all algorithms perform equally well” is in fact quite misleading, and should be more accurately phrased as “all algorithms perform equally poorly,” since no inferential algorithm can uncover the true community structure in most cases, at least no better than by chance alone. In other words, the universe of community detection problems considered in the NFL theorem is composed overwhelmingly of instances for which compression and explanation are not possible.Footnote 25 This uniformity between instances also reveals that there is no meaningful trade-off between algorithms for most instances, since all algorithms will yield the same negligible asymptotic performance, with an accuracy tending towards zero as the number of nodes increases. In this setting, there is not only no free lunch, but in fact there is no lunch at all (see Fig. 15).
carries no information about the network structure, and vice versa, i.e. the partition is not learnable from the network. In view of this, the common interpretation of the NFL theorem as “all algorithms perform equally well” is in fact quite misleading, and should be more accurately phrased as “all algorithms perform equally poorly,” since no inferential algorithm can uncover the true community structure in most cases, at least no better than by chance alone. In other words, the universe of community detection problems considered in the NFL theorem is composed overwhelmingly of instances for which compression and explanation are not possible.Footnote 25 This uniformity between instances also reveals that there is no meaningful trade-off between algorithms for most instances, since all algorithms will yield the same negligible asymptotic performance, with an accuracy tending towards zero as the number of nodes increases. In this setting, there is not only no free lunch, but in fact there is no lunch at all (see Fig. 15).
Figure 15 A common interpretation of the NFL theorem for community detection is that it reveals a necessary trade-off between algorithms: since they all have the same average performance, if one algorithm does better than another in one set of instances, it must do worse on a equal number of different instances, as depicted in panel (a). However, in the actual setting considered by the NFL theorem there is no meaningful trade-off: asymptotically, all algorithms perform maximally poorly for the vast majority of instances, as depicted in panel (b), since in these cases the network structure is uninformative of the partition. If we constrain ourselves to informative problem instances (which compose only an infinitesimal fraction of all instances), the NFL theorem is no longer applicable.
If we were to restrict the space of possible community detection algorithms to those that provide actual explanations, then by definition this would imply a positive correlation between network and partition,Footnote 26 i.e.
 (52)
(52)
 (53)
(53)
Not only this implies a specific generative model but, as a consequence, also an optimal community detection algorithm, that operates based on the posterior distribution
 (54)
(54)
Therefore, learnable community detection problems are invariably tied to an optimal class of algorithms, undermining to a substantial degree the relevance of the NFL theorem in practice. In other words, whenever there is an actual community structure in the network being considered — i.e. due to a systematic correlation between
 and
and
 , such that
, such that
 — there will be algorithms that can exploit this correlation better than others (see Fig. 14(b) for an example of a learnable community detection problem). Importantly, the set of learnable problems form only an infinitesimal fraction of all problem instances, with a measure that tends to zero as the number of nodes increases, and hence remain firmly out of scope of the NFL theorem. This observation has been made before, and is equally valid, in the wider context of NFL theorems beyond community detection [Reference Streeter, Erick Cantú-Paz, Foster, Davis, Roy, O’Reilly, Beyer, Standish, Kendall, Wilson, Harman, Wegener, Dipankar Dasgupta, Potter, Schultz, Dowsland, Miller and (Springer99–Reference Schurz103].
— there will be algorithms that can exploit this correlation better than others (see Fig. 14(b) for an example of a learnable community detection problem). Importantly, the set of learnable problems form only an infinitesimal fraction of all problem instances, with a measure that tends to zero as the number of nodes increases, and hence remain firmly out of scope of the NFL theorem. This observation has been made before, and is equally valid, in the wider context of NFL theorems beyond community detection [Reference Streeter, Erick Cantú-Paz, Foster, Davis, Roy, O’Reilly, Beyer, Standish, Kendall, Wilson, Harman, Wegener, Dipankar Dasgupta, Potter, Schultz, Dowsland, Miller and (Springer99–Reference Schurz103].
Note that since there are many ways to choose a nonuniform model according to Eq. 53, the optimal algorithms will still depend on the particular assumptions made via the choice of
 and how it relates to the true distribution. However, this does not imply that all algorithms have equal performance on compressible problem instances. If we sample a problem from the universe
and how it relates to the true distribution. However, this does not imply that all algorithms have equal performance on compressible problem instances. If we sample a problem from the universe
 , with
, with
 , but use instead two algorithms optimal in
, but use instead two algorithms optimal in
 and
and
 , respectively, their relative performances will depend on how close each of these universes is to
, respectively, their relative performances will depend on how close each of these universes is to
 , and hence will not be in general the same. In fact, if our space of universes is finite, we can compose them into a single unified universe [Reference Jaynes and Larry Bretthorst104] according to
, and hence will not be in general the same. In fact, if our space of universes is finite, we can compose them into a single unified universe [Reference Jaynes and Larry Bretthorst104] according to
 (55)
(55)
which will incur a compression penalty of at most
 bits added to the description length of the optimal algorithm. This gives us a path, based on hierarchical Bayesian models and minimum description length, to achieve optimal or near-optimal performance on instances of the community detection problem that are actually solvable, simply by progressively expanding our set of hypotheses.
bits added to the description length of the optimal algorithm. This gives us a path, based on hierarchical Bayesian models and minimum description length, to achieve optimal or near-optimal performance on instances of the community detection problem that are actually solvable, simply by progressively expanding our set of hypotheses.
The idea that we can use compression as an inference criterion has been formalized by Solomonoff’s theory of inductive inference [Reference Solomonoff105], which forms a rigorous induction framework based on the principle of Occam’s razor. Importantly, the expected errors of predictions achieved under this framework are provably upper-bounded by the Kolmogorov complexity of the data generating process [Reference Hutter106], making the induction framework consistent. As we mentioned already in Sec. 2.3, the Kolmogorov complexity is a generalization of the description length we have been using, and it is defined by the length of the shortest binary program that generates the data. The only major limitation of Solomonoff’s framework is its uncomputability, i.e. the impossibility of determining Kolmogorov’s complexity with any algorithm [Reference Ming and Vitányi30]. However, this impossibility does not invalidate the framework, it only means that induction cannot be fully automatized: we have a consistent criterion to compare hypotheses, but no deterministic mechanism to produce directly the best hypothesis. There are open philosophical questions regarding the universality of this inductive framework [Reference Hutter107, Reference Montanez108], but whatever fundamental limitations it may have do not follow directly from NFL theorems such as the one from Ref. [Reference Peel, Larremore and Clauset92]. In fact, as mentioned in footnote 25, it is a rather simple task to use compression to reject the uniform hypothesis forming the basis of the NFL theorem for almost any network data.
Since compressive community detection problems are out of the scope of the NFL theorem, it is not meaningful to use it to justify avoiding comparisons between algorithms, on the grounds that all choices must be equally “good” in a fundamental sense. In fact, we do not need much sophistication to reject this line of argument, since the NFL theorem applies also when we are considering trivially inane algorithms, e.g. one that always returns the same partition for every network. The only domain where such an algorithm is as good as any other is when we have no community structure to begin with, which is precisely what the NFL theorem relies on.
Nevertheless, there are some lessons we can draw from the NFL theorem. It makes it clear that the performances of algorithms are tied directly to the inductive bias adopted, which should always be made explicit. The superficial interpretation of the NFL theorem as an inherent equity between all algorithms stems from the assumption that considering all problem instances uniformly is equivalent to being free of an inductive bias, but that is not possible. The uniform assumption is itself an inductive bias, and one that it is hard to justify in virtually any context, since it involves almost exclusively unsolvable problems (from the point of view of compressibility). In contrast, considering only compressible problem instances is also an inductive bias, but one that relies only on Occam’s razor as a guiding principle. The advantage of the latter is that it is independent of domain of application, i.e. we are requiring only that an inferred partition can help explaining the network in some manner, without having to specify exactly how a priori.
In view of the above observations, it becomes easier to understand results such as of Ghasemian et al [Reference Ghasemian, Hosseinmardi and Clauset66] who found that compressive inferential community detection methods tend to systematically outperform descriptive methods in empirical settings, when these are employed for the task of edge prediction. Even though edge prediction and community detection are not the same task, and using the former to evaluate the latter can lead in some cases to overfitting [Reference Vallès-Català, Peixoto, Sales-Pardo and Guimerà109], typically the most compressive models will also lead to the best generalization. Therefore, the superior performance of the inferential methods is understandable, even though Ghasemian et al also found a minority of instances where some descriptive methods can outperform inferential ones. To the extent that these minority results cannot be attributed to overfitting, or technical issues such as insufficient MCMC equilibration, it could simply mean that the structure of these networks fall sufficiently outside of what is assumed by the inferential methods, but without it being a necessary trade-off that comes as a consequence of the NFL theorem — after all, under the uniform assumption, edge prediction is also strictly impossible, just like community detection. In other words, these results do not rule out the existence of an algorithm that works better in all cases considered, at least if their number is not too large.Footnote 27 In fact, this is precisely what is achieved in Ref. [Reference Ghasemian, Hosseinmardi, Galstyan, Airoldi and Clauset110] via model stacking, i.e. a combination of several predictors into a meta-predictor that achieves systematically superior performance. This points indeed to the possibility of using universal methods to discover the latent compressive modular structure of networks, without any tension with the NFL theorem.
4.8 “Statistical inference requires us to believe the generative model being used.”
We have been advocating for the use of statistical inference for community detection in networks whenever our objective is of an inferential nature.
One possible objection to the use of statistical inference is when the generative models on which they are based are considered unrealistic for a particular kind of network. Although this type of consideration is ultimately important, it is not necessarily an obstacle. First we need to remember that realism is a matter of degree, not kind, since no model can be fully realistic, and therefore we should never be fully committed to “believe” any particular model. Because of this, an inferential approach can be used to target a particular kind of structure, and the corresponding model is formulated with this in mind, but without the need to describe other properties of the data. The SBM is a good example of this, since it is often used with the objective of finding communities, rather than any kind of network structure. A model like the SBM is a good way to offset the regularities that relate to the community structure with the irregularities present in real networks, without requiring us to believe that in fact it generated the network.
Furthermore, certain kinds of models are flexible enough so that they can approximate other models. For example, a good analogy with fitting the SBM to network data is to fit a histogram to numerical data, with the node partitioning being analogous to the data binning. Although a piecewise constant model is almost never the true underlying distribution, it provides a reasonable approximation in a tractable, nonparametric manner. Because of its capacity to approximate a wide class of distributions, we certainly do not need to believe that a histogram is the true data-generating process to extract meaningful inferences from it. In fact, the same can be said of the SBM in its capacity to approximate a wide class of network models [Reference Olhede and Wolfe111, Reference Young, St-Onge, Desrosiers and Dubé112].
The above means that we can extract useful, statistically meaningful information from data even if the models we use are misspecified. For example, if a network is generated by a latent space model [Reference Hoff, Raftery and Handcock113], and we fit a SBM to it, the communities that are obtained in this manner are not quite meaningless: they will correspond to discrete spatial regions. Hence, the inference would yield a caricature of the underlying latent space, amounting to a discretization of the true model — indeed, much like a histogram. This is very different from, say, finding communities in an Erdős-Rényi graph, which bear no relation to the true underlying model, and would be just overfitting the data. In contrast, the SBM fit to a spatial network would be approximately capturing the true model structure, in a manner that could be used to compress the data and make predictions (although not optimally).
Furthermore, the associated description length of a network model is a good criterion to tell whether the patterns we have found are actually simplifying our network description, without requiring the underlying model to be perfect. This happens in the same way as using a software like gzip makes our files smaller, without requiring us to believe that they are in fact generated by the Markov chain underlying the Lempel-Ziv algorithm [Reference Ziv and Lempel114].
Of course, realism becomes important as soon as we demand more from the point of view of interpretation and prediction. Are the observed community structures due to homophily or triadic clusure [Reference Peixoto23]? Or are they due to spatial embedding [Reference Hoff, Raftery and Handcock113]? What models are capable of reproducing other network descriptors, together with the community structure? Which models can better reconstruct incomplete networks [Reference Peixoto53, Reference Guimerà and Sales-Pardo54]? When answering these questions, we are forced to consider more detailed generative processes, and compare them. However, we are never required to believe them — models are always tentative, and should always be replaced by superior alternatives when these are found. Indeed, criteria such as MDL serve precisely to implement such a comparison between models, following the principle of Occam’s razor. Therefore, the lack of realism of any particular model cannot be used to dismiss statistical inference as an underlying methodology. On the contrary, the Bayesian workflow [Reference Gelman, Vehtari, Daniel Simpson, Margossian, Yao, Kennedy, Gabry, Bürkner and Modrák115] enables a continuous improvement of our modelling apparatus, via iterative model building, model checking, and validation, all within a principled and consistent framework.
It should be emphasized that, fundamentally, there is no alternative. Rejecting an inferential approach based on the SBM on the grounds that it is an unrealistic model (e.g. because of the conditional independence of the edges being placed, or some other unpalatable assumption), but instead preferring some other non-inferential community detection method is incoherent: As we discussed in Sec. 2.5, every descriptive method can be mapped to an inferential analogue, with implicit assumptions that are hidden from view. Unless one can establish that the implicit assumptions are in fact more realistic, then the comparison cannot be justified. Unrealistic assumptions should be replaced by more realistic ones, not by burying one’s head in the sand.
4.9 “Inferential approaches are prohibitively expensive.”
One of the reasons why descriptive methods such as modularity maximization are widely used is because of very efficient heuristics that enable their application for very large networks. The most famous of which is the Louvain algorithm [Reference Blondel, Guillaume, Lambiotte and Lefebvre116], touted for its speed and good ability to find high-scoring partitions. A more recent variation of this method is the Leiden algorithm [Reference Traag, Waltman and van Eck117], which is a refinement of the Louvain approach, designed to achieve even more high-scoring partitions, without sacrificing speed. None of these methods were developed with the purpose of assessing the statistical evidence of the partitions found, and since they are most often employed as modularity maximization techniques, they suffer from all the shortcomings that come with it.
It is often perceived that principled inferential approaches based on the SBM, designed to overcome all of the shortcomings of descriptive methods including modularity maximization, are comparatively much slower, often prohibitively so. However, we show here that this perception is quite inaccurate, since modern inferential approaches can be quite competitive. From the point of view of algorithmic complexity, agglomerative [Reference Peixoto118] or merge-split MCMC [Reference Peixoto119] have at most a log-linear complexity
 , where
, where
 and
and
 are the number of nodes and edges, respectively, when employed to find the most likely partition. This means they belong to the same complexity class as the Louvain and Leiden algorithms, despite the fact the SBM-based algorithms are in fact more general, and do not attempt to find strictly assortative structures — and hence cannot make any optimizations that are only applicable in this case, as done by Louvain and Leiden. In practice, all these algorithms return results in comparable times.
are the number of nodes and edges, respectively, when employed to find the most likely partition. This means they belong to the same complexity class as the Louvain and Leiden algorithms, despite the fact the SBM-based algorithms are in fact more general, and do not attempt to find strictly assortative structures — and hence cannot make any optimizations that are only applicable in this case, as done by Louvain and Leiden. In practice, all these algorithms return results in comparable times.
In Fig. 16 we show a performance comparison between various algorithms on 38 empirical networks of various domains and number of edges spanning six orders of magnitude, obtained from the Netzschleuder repository [Reference Peixoto65]. We used the Leiden implementation provided by its authors,Footnote 28 and compared with various SBM parametrizations implemented in the graph-tool library [Reference Peixoto9]. In particular we consider the agglomerative MCMC of Ref. [Reference Peixoto118] employed for modularity maximization, the Bayesian planted partition (PP) model [Reference Zhang and Peixoto24], the degree-corrected SBM with uniform priors [Reference Peixoto16] and the nested SBM [Reference Peixoto16, Reference Peixoto67]. As seen in Fig. 16(a), all algorithms display the same scaling with the number of edges, and differ only by an approximately constant factor. This difference is speed is due to the more complex likelihoods used by the SBM and additional data structures that are needed for its computation. When the agglomerative MCMC [Reference Peixoto118] is used with the simpler modularity function, it comes very close to the Leiden algorithm, despite not taking advantage of any custom optimization for that particular quality function. When used with the strictly assortative PP model, the algorithm slows down by a larger factor when compared to Leiden — most of which can be attributed to the increased complexity of the quality function. For the general SBM and nested SBM the algorithm slows down further, since now it is searching for arbitrary mixing patterns (not only assortative ones) and entire modular hierarchies. Indeed the performance difference between the most complex SBM and Leiden can be substantial, but at this point it also becomes an apples-and-oranges comparison, since the inferential method not only is not restricted to assortative communities, but it also uncovers an entire hierarchy of partitions in a nonparametric manner, while being unhindered by the resolution limit and with protection against overfitting. Overall, if a practitioner is considering modularity maximization, they should prefer instead at least the Bayesian PP model, which solves the same kind of problem but it is not marred by all the shortcomings of modularity, including the resolution limit and systematic overfitting, while still being comparatively fast. The more advanced SBM formulations allow the researcher to probe a wider array of mixing patterns, without abdicating from statistical robustness, at the expense of increased computation time. As this analysis shows, all algorithms are accessible for fairly large networks of up to
 edges on a laptop, but in fact can scale to
edges on a laptop, but in fact can scale to
 or more on high-performance computing (HPC) systems.
or more on high-performance computing (HPC) systems.
Figure 16 Inferential algorithms show competitive performance with descriptive ones. In panel (a) is shown the run-time of the Leiden algorithm [Reference Traag, Waltman and van Eck117] and the agglomerative MCMC [Reference Peixoto118] for modularity, and three SBM parametrizations: planted partition (PP), degree-corrected SBM, and nested degree-corrected SBM (NSBM), for 38 empirical networks [Reference Peixoto65]. All experiments were done on a laptop with an i9-9980HK Intel CPU, and averaged over at least 10 realizations. The dashed line shows an
 scaling. In (b) are shown the same run times, but relative to the Leiden algorithm. The horizontal dashed lines show the median values.
scaling. In (b) are shown the same run times, but relative to the Leiden algorithm. The horizontal dashed lines show the median values.
Based on the above, it becomes difficult to justify the use modularity maximization based solely on performance concerns, even on very large networks, since there are superior inferential approaches available with comparable speed, and which achieve more meaningful results in general.Footnote 29
4.10 “Belief propagation outperforms MCMC.”
The method of belief propagation (BP) [Reference Decelle, Krzakala, Moore and Zdeborová6] is an alternative algorithm to MCMC for inferring the partitions from the posterior distribution of the SBM in the semi-parametric case where the model parameters controlling the probability of connections between groups and the expected sizes of the groups are known a priori. It relies on the assumption that the network analyzed was truly sampled from the SBM, that the number of groups is much smaller than the number of nodes,
 , and the network is sufficiently large,
, and the network is sufficiently large,
 . Even though none of these assumptions are likely to hold in practice, BP is an extremely useful and powerful algorithm since it returns an estimate of the marginal posterior probability that is not stochastic, unlike MCMC. Furthermore, it is amenable to analytical investigations, which was used to uncover the detectability threshold of the SBM [Reference Decelle, Krzakala, Moore and Zdeborová6, Reference Decelle, Krzakala, Moore and Zdeborová45], and important connections with spectral clustering [Reference Krzakala, Moore, Mossel, Neeman, Sly, Zdeborová and Zhang120]. It is often claimed, however, that it is also faster than MCMC when employed for the same task. This is, however, not quite true in general, as we now discuss. The complexity of BP is
. Even though none of these assumptions are likely to hold in practice, BP is an extremely useful and powerful algorithm since it returns an estimate of the marginal posterior probability that is not stochastic, unlike MCMC. Furthermore, it is amenable to analytical investigations, which was used to uncover the detectability threshold of the SBM [Reference Decelle, Krzakala, Moore and Zdeborová6, Reference Decelle, Krzakala, Moore and Zdeborová45], and important connections with spectral clustering [Reference Krzakala, Moore, Mossel, Neeman, Sly, Zdeborová and Zhang120]. It is often claimed, however, that it is also faster than MCMC when employed for the same task. This is, however, not quite true in general, as we now discuss. The complexity of BP is
 , where
, where
 is the convergence time, which is typically small compared to the other quantities [for the DC-SBM the complexity becomes
is the convergence time, which is typically small compared to the other quantities [for the DC-SBM the complexity becomes
 , where
, where
 is the number of distinct degrees in the network [Reference Yan, Shalizi, Jensen, Krzakala, Moore, Zdeborová, Zhang and Zhu27]]. A MCMC sweep of the SBM, i.e. the number of operations required to give a chance of each node to be moved once from its current node membership, can be implemented in time
is the number of distinct degrees in the network [Reference Yan, Shalizi, Jensen, Krzakala, Moore, Zdeborová, Zhang and Zhu27]]. A MCMC sweep of the SBM, i.e. the number of operations required to give a chance of each node to be moved once from its current node membership, can be implemented in time
 , independent of the number of groups
, independent of the number of groups
 [Reference Peixoto118, Reference Peixoto119], when using the parametrization of Refs. [Reference Peixoto85, Reference Peixoto16]. This means that the performance difference between both approaches can be substantial when the number of groups is large. In fact, if
[Reference Peixoto118, Reference Peixoto119], when using the parametrization of Refs. [Reference Peixoto85, Reference Peixoto16]. This means that the performance difference between both approaches can be substantial when the number of groups is large. In fact, if
 which a reasonable reference for empirical networks, BP becomes
which a reasonable reference for empirical networks, BP becomes
 while MCMC remains
while MCMC remains
 . Agglomerative MCMC initialization schemes, which can significantly improve the mixing time, have themselves a complexity
. Agglomerative MCMC initialization schemes, which can significantly improve the mixing time, have themselves a complexity
 [Reference Peixoto118], still significantly faster than BP for large
[Reference Peixoto118], still significantly faster than BP for large
 .
.
In Fig. 17 we show a run-time comparison between BP and MCMC for an empirical network of flights between airports.Footnote 30 As the number of groups increases, the run-time of BP grows quadratically, as expected, while for MCMC it remains constant. There are several caveats in this comparison, which is somewhat apples-to-oranges: BP outputs a full marginal distribution for every node, containing even probabilities that are very low, while for MCMC we obtain anything from a point estimate to full marginal or joint probabilities, at the expense of longer running times, which is not revealed by the comparison in Fig. 17, which corresponds only to a point estimate. On the other hand, BP requires a value of the model parameters besides the partition itself, which can in principle be obtained together with the marginals via expectation-maximization (EM) [Reference Decelle, Krzakala, Moore and Zdeborová6], although a meaningful convergence for complex problems cannot be guaranteed with this algorithm [Reference Kawamoto121]. Overall, we can state that some answers can be achieved in log-linear time with MCMC independently from the number of groups (and requiring no particular assumptions on the data), while with BP we can never escape the quadratic dependence on
 .
.
Figure 17 Comparison of run times between MCMC and BP on laptop with an i9-9980HK Intel CPU, for a network of flights between airports, with
 nodes and
nodes and
 . We used the agglomerative algorithm of Ref. [Reference Peixoto118], and initialized BP with the model parameters found with MCMC. The dashes line shows a
. We used the agglomerative algorithm of Ref. [Reference Peixoto118], and initialized BP with the model parameters found with MCMC. The dashes line shows a
 slope.
slope.
We emphasize that BP is only applicable in the semiparametric case, where the number of groups and model parameters are known. The nonparametric case considered in Sec. 2.3, which is arguably more relevant in practice, cannot be tackled using BP, leaving MCMC as the only game in town, at least with the current state-of-the-art.
4.11 “Spectral clustering outperforms likelihood-based methods.”
Spectral clustering methods divide a network into groups based on the leading eigenvectors of a linear operator associated with the network structure [Reference Spielman and Teng122, Reference Ulrike123]. There are important connections between spectral methods and statistical inference, in particular there are certain linear operators that can be shown to provide a consistent estimation of the SBM [Reference Krzakala, Moore, Mossel, Neeman, Sly, Zdeborová and Zhang120, Reference Rohe124]. However, when compared to likelihood-based methods, spectral methods are only approximations, as they amount to a simplification of the problem. Nevertheless, one of the touted advantages of this class of methods is that they tend to be significantly faster than likelihood based methods using MCMC. But like in the case of BP considered in the previous section, the run-time of spectral methods is intimately related to the number of groups one wishes to infer, unlike MCMC. Independently of the operator being used, the clustering into
 groups requires the computation of the first
groups requires the computation of the first
 leading eigenvectors. The most efficient algorithms for this purpose are based on the implicitly restarted Arnoldi method [Reference Lehoucq and Sorensen125], which has a worse-case time complexity
leading eigenvectors. The most efficient algorithms for this purpose are based on the implicitly restarted Arnoldi method [Reference Lehoucq and Sorensen125], which has a worse-case time complexity
 for sparse matrices. Therefore, for sufficiently large number of groups they can cease to be faster than MCMC, which has a run-time complexity independent of the number of groups [Reference Peixoto118, Reference Peixoto119].
for sparse matrices. Therefore, for sufficiently large number of groups they can cease to be faster than MCMC, which has a run-time complexity independent of the number of groups [Reference Peixoto118, Reference Peixoto119].
In Fig. 18 we show a comparison of spectral clustering and MCMC inference for the Anybeat social network [Reference Fire, Puzis, Elovici and Subrahmanian126]. Indeed, for small number of groups spectral clustering can be significantly faster, but eventually becomes slower as the number of groups increases. The complexity of the spectral algorithm does not scale exactly like the worse case
 in practice, and the actual times will depend on the details of the particular operator. The MCMC algorithm becomes slightly faster, on the other hand, since the agglomerative initialization heuristic used terminates sooner when more groups are imposed [Reference Peixoto118]. As usual, there are caveats with this comparison. First, the eigenvectors by themselves do not provide a clustering of the network. Usually, these are given as input to a general-purpose clustering algorithm, typically
in practice, and the actual times will depend on the details of the particular operator. The MCMC algorithm becomes slightly faster, on the other hand, since the agglomerative initialization heuristic used terminates sooner when more groups are imposed [Reference Peixoto118]. As usual, there are caveats with this comparison. First, the eigenvectors by themselves do not provide a clustering of the network. Usually, these are given as input to a general-purpose clustering algorithm, typically
 -means, which itself also has a complexity
-means, which itself also has a complexity
 , not included in the comparison of Fig. 18. Furthermore, spectral clustering usually requires the number of groups itself to be known in advance — although heuristics exist for spectral algorithms, but which usually require a significant part of the entire spectrum to be determined [Reference Krzakala, Moore, Mossel, Neeman, Sly, Zdeborová and Zhang120]. Likelihood-based methods, if implemented as a nonparametric Bayesian posterior like done in Sec. 2.3, do not require this prior information. On the other hand, spectral methods can be parallelized rather easily, unlike MCMC, and hence can take advantage of multicore processors.
, not included in the comparison of Fig. 18. Furthermore, spectral clustering usually requires the number of groups itself to be known in advance — although heuristics exist for spectral algorithms, but which usually require a significant part of the entire spectrum to be determined [Reference Krzakala, Moore, Mossel, Neeman, Sly, Zdeborová and Zhang120]. Likelihood-based methods, if implemented as a nonparametric Bayesian posterior like done in Sec. 2.3, do not require this prior information. On the other hand, spectral methods can be parallelized rather easily, unlike MCMC, and hence can take advantage of multicore processors.
Figure 18 Comparison of run times between MCMC and spectral clustering using the Laplacian matrix, on a laptop with an i9-9980HK Intel CPU, for the Anybeat social network [Reference Fire, Puzis, Elovici and Subrahmanian126], with
 vertices and
vertices and
 edges. We used the agglomerative algorithm of Ref. [Reference Peixoto118] and the ARPACK eigenvector solver [Reference Lehoucq, Sorensen and Yang127].
edges. We used the agglomerative algorithm of Ref. [Reference Peixoto118] and the ARPACK eigenvector solver [Reference Lehoucq, Sorensen and Yang127].
4.12 “Bayesian posterior, MDL, BIC and AIC are different but equally valid model selection criteria.”
One outstanding problem with using inferential community detection is that the likelihood of a model like the SBM does not, by itself, offer a principled way to determine the appropriate number of groups. This is because if we maximize the likelihood directly, it will favor a number of groups that is equal to the number of nodes, i.e. an extreme overfitting. This is similar to what happens when we fit a polynomial to a set of one-dimensional data points by varying its degree: for a degree equal to the number of points we can fit any set of points perfectly, but we are guaranteed to be overfitting the data. In other words, if we do not account for model complexity explicitly, we cannot separate randomness from structure.
In the literature we often see mentions of Bayesian posterior inference, minimum description length (MDL) [Reference Rissanen17, Reference Grünwald18], as well as likelihood penalty schemes such as Bayesian Information Criterion (BIC) [Reference Schwarz128] and Akaike’s Information Criterion (AIC)[Reference Akaike129], as being equally valid alternatives that can be used to solve this problem. It is sometimes said that the choice between them is philosophical and often simply reflects the culture that a researcher stems from. As we show here, this is demonstrably incorrect, since Bayes, MDL, and BIC are in fact the same criterion, where BIC is simply an (arguably crude) approximation of the first two, which are in fact identical. AIC is indeed a different criterion, but, like BIC, it involves approximations that are known to be invalid for community detection.
The exact equivalence between MDL and Bayesian inference is easy to demonstrate [Reference Peixoto16, Reference Peixoto67], as we have already done already in Sec. 2.3. Namely, the posterior distribution of the community detection problem is given by
 (56)
(56)
 (57)
(57)
where the numerator of Eq. 56 is related to the description length
 via
via
 (58)
(58)
Therefore, maximizing Eq. 56 is identical to minimizing Eq. 58. Although this is already sufficient to demonstrate their equivalence, we can go in even more detail and show that the marginal integrated likelihood,
 (59)
(59)
where
 and
and
 are the parameters of the canonical DC-SBM [Reference Karrer and Newman15], is identical to the marginal likelihood of the microcanonical SBM we have used in Eq. 2. This is proved in Ref. [Reference Peixoto16]. Therefore, the MDL criterion is simply an information-theoretical interpretation of the Bayesian approach, and the two methods coincide in their implementation.Footnote 31
are the parameters of the canonical DC-SBM [Reference Karrer and Newman15], is identical to the marginal likelihood of the microcanonical SBM we have used in Eq. 2. This is proved in Ref. [Reference Peixoto16]. Therefore, the MDL criterion is simply an information-theoretical interpretation of the Bayesian approach, and the two methods coincide in their implementation.Footnote 31
The BIC criterion is based on the exact same framework, but it amounts to an approximation of the integrated marginal likelihood of a generic model
 ,
,
 , where
, where
 is a data vector of size
is a data vector of size
 and
and
 is a parameter vector of size
is a parameter vector of size
 , given by
, given by
 (60)
(60)
 (61)
(61)
 (62)
(62)
where
 is the Fisher information matrix, and the values of the likelihood and parameters are obtained at the maximum,
is the Fisher information matrix, and the values of the likelihood and parameters are obtained at the maximum,
 (63)
(63)
and finally the BIC score is obtained from Eq. 61 by assuming
 ,
,
 (64)
(64)
The BIC method consists of employing the equation above as criterion to decide which model to select, applicable even if they have different number of parameters
 , with the first term functioning as penalty for larger models. Eq. 61 corresponds to an approximation of the likelihood obtained via Laplace’s method, which involves a second-order Taylor expansion of the log-likelihood. Therefore, it requires the likelihood function to be well approximated by a multivariate Gaussian distribution with respect to the parameters at the vicinity of its maximum. However, as demonstrated by Yan et al. [Reference Yan, Shalizi, Jensen, Krzakala, Moore, Zdeborová, Zhang and Zhu27], this assumption is invalid for SBMs, however large the networks are, as long as they are sparse, i.e. with an average degree much smaller than the number of nodes. This is because for sparse SBMs we have both the number of parameters
, with the first term functioning as penalty for larger models. Eq. 61 corresponds to an approximation of the likelihood obtained via Laplace’s method, which involves a second-order Taylor expansion of the log-likelihood. Therefore, it requires the likelihood function to be well approximated by a multivariate Gaussian distribution with respect to the parameters at the vicinity of its maximum. However, as demonstrated by Yan et al. [Reference Yan, Shalizi, Jensen, Krzakala, Moore, Zdeborová, Zhang and Zhu27], this assumption is invalid for SBMs, however large the networks are, as long as they are sparse, i.e. with an average degree much smaller than the number of nodes. This is because for sparse SBMs we have both the number of parameters
 [or even larger, since for
[or even larger, since for
 groups we a matrix
groups we a matrix
 of size
of size
 , and in principle we could have
, and in principle we could have
 ] and effective data size
] and effective data size
 where
where
 is the number of nodes, therefore the “sufficient data” limit required for the approximation to hold is never realized for any
is the number of nodes, therefore the “sufficient data” limit required for the approximation to hold is never realized for any
 . Furthermore, the BIC penalty completely neglects the contribution of the prior
. Furthermore, the BIC penalty completely neglects the contribution of the prior
 in the regularization, which cannot be ignored outside of this limit. Since the vast majority of empirical networks of interest are sparse, this renders this method unreliable, and in fact it will tend to overfit in most cases when employed with the SBM. We emphasize that the approximation of Eq. 61 is unnecessary, since we can compute the marginal likelihood of Eq. 59 exactly for most versions of the SBM [Reference Peixoto16, Reference Guimerà and Sales-Pardo54, Reference Peixoto67, Reference Côme and Latouche130, Reference Newman and Reinert131]. When we compare the BIC penalty with the exact values of the integrated likelihoods we see that they in general produce significantly different regularizations, even asymptotically, and also even if we add ad hoc parameters, e.g.
in the regularization, which cannot be ignored outside of this limit. Since the vast majority of empirical networks of interest are sparse, this renders this method unreliable, and in fact it will tend to overfit in most cases when employed with the SBM. We emphasize that the approximation of Eq. 61 is unnecessary, since we can compute the marginal likelihood of Eq. 59 exactly for most versions of the SBM [Reference Peixoto16, Reference Guimerà and Sales-Pardo54, Reference Peixoto67, Reference Côme and Latouche130, Reference Newman and Reinert131]. When we compare the BIC penalty with the exact values of the integrated likelihoods we see that they in general produce significantly different regularizations, even asymptotically, and also even if we add ad hoc parameters, e.g.
 . This is because simply counting the number of parameters is too crude an estimation of the model complexity, since it is composed of different classes of parameters occupying different volumes which need (and can) be more carefully computed. Therefore the use of BIC for model selection in community detection should be in general avoided.
. This is because simply counting the number of parameters is too crude an estimation of the model complexity, since it is composed of different classes of parameters occupying different volumes which need (and can) be more carefully computed. Therefore the use of BIC for model selection in community detection should be in general avoided.
Akaike’s Information Criterion (AIC) [Reference Akaike129], on the other hand, actually starts out from a different framework. The idea is assume that the data are sampled from a true generative model
 , and a candidate model
, and a candidate model
 with its parameter estimates
with its parameter estimates
 is evaluated according to its Kullback-Leibler (KL) divergence with respect to the true model,
is evaluated according to its Kullback-Leibler (KL) divergence with respect to the true model,
 (65)
(65)
Of course, whenever it is relevant to employ model selection criteria we do not have access to the true model, which means we cannot compute the quantity in Eq. (65). We can, however, estimate the following upper bound, corresponding to the average over all data
 ,
,
 (66)
(66)
In this case, for sufficiently large data
 , the quantity in Eq. (66) can be estimated making use of a series of Laplace approximations [Reference Burnham and Anderson132], resulting in
, the quantity in Eq. (66) can be estimated making use of a series of Laplace approximations [Reference Burnham and Anderson132], resulting in
 (67)
(67)
where
 is the point around which we compute the quadratic approximation in Laplace’s method, and
is the point around which we compute the quadratic approximation in Laplace’s method, and
 ,
,
 , with
, with
 (68)
(68)
The AIC criterion is finally obtained by heuristically assuming
 , yielding
, yielding
 (69)
(69)
where the overall sign and multiplicative factor is a matter of convention. It is also possible to recover AIC from BIC by making a choice of prior
 [Reference Burnham and Anderson132], which makes it clear that it favors more complex models over BIC. Independently of how one judges the suitability of the fundamental criterion of Eq. 66, just like BIC, AIC involves several approximations that are known to be invalid for sparse networks. Together with its heuristic nature and crude counting of parameters, it is safe to conclude that the use of AIC is ill-advised for community detection, specially considering the more principled and exact alternatives of Bayes/MDL.
[Reference Burnham and Anderson132], which makes it clear that it favors more complex models over BIC. Independently of how one judges the suitability of the fundamental criterion of Eq. 66, just like BIC, AIC involves several approximations that are known to be invalid for sparse networks. Together with its heuristic nature and crude counting of parameters, it is safe to conclude that the use of AIC is ill-advised for community detection, specially considering the more principled and exact alternatives of Bayes/MDL.
5 Conclusion
We have framed the problem of community detection under two different paradigms, namely that of “inference” and “description.” We argued that statistical inference is unavoidable when the objective is to draw inferential interpretations from the communities found, and we provided a simple “litmus test” to help deciding when this is indeed the case. Under this framing, we showed that descriptive methods always come with hidden inferential assumptions, and reviewed the dangers of employing descriptive methods with inferential aims, focusing on modularity maximization as a representative (and hence not unique) case.
We covered a series of pitfalls encountered in community detection, as well as myths and half-truths commonly believed, and attempted to clarify them under the same lenses, focusing on simple examples and conceptual arguments.
Although it is true that community detection in general involves diverse aims, and hence it is difficult to argue for an one-size-fits-all approach, here we have taken a more opinionated stance, since it is also not true that all approaches are used in a manner consistent with their intended aims. We have clearly favored inferential methods, since they are more theoretically grounded, are better aligned with well-defined scientific questions (whenever those involve inferential queries), are more widely applicable, and can be used to develop more robust algorithms.
Inferential methodology for community detection has reached a level of maturity, both in our understanding of them and in the efficiency of available implementations, that should make it the preferred choice when analysing network data, whenever the ultimate goal has an inferential nature.
Guido Caldarelli
Ca’ Foscari University of Venice
Guido Caldarelli is Full Professor of Theoretical Physics at Ca’ Foscari University of Venice. Guido Caldarelli received his Ph.D. from SISSA, after which he held postdoctoral positions in the Department of Physics and School of Biology, University of Manchester, and the Theory of Condensed Matter Group, University of Cambridge. He also spent some time at the University of Fribourg in Switzerland, at École Normale Supérieure in Paris, and at the University of Barcelona. His main scientific activity (interest?) is the study of networks, mostly analysis and modelling, with applications from financial networks to social systems as in the case of disinformation. He is the author of more than 200 journal publications on the subject, and three books, and is the current President of the Complex Systems Society (2018 to 2021).
About the Series
This cutting-edge series provides authoritative and detailed coverage of the underlying theory of complex networks, specifically their structure and dynamical properties. Each Element within the series will focus upon one of three primary topics: static networks, dynamical networks, and numerical/computing network resources.















































 Open access
Open access