



Introduction
Requirement elicitation is one of the important processes of product development. Several conventional requirement elicitation techniques, such as interviews, meetings, and brainstorming, are used to collect precise and individualized requirements. However, due to the ever-growing demands of end-users and the rapid pace of product iterations, the use of only traditional methods to elicit requirements would be quite insufficient.
The fourth industrial revolution is triggering a pervasive digital transformation in many fields of human activities. Particularly, engineering is being transformed into “Digital Engineering” (Zimmerman, Reference Zimmerman2017; US DoD, 2018). In digital engineering, digital data and models will be shared in the engineering life cycle (US DoD, 2018); engineering artifacts and processes will be digitalized with standardized digital representation, unique identifier, and the augmented metadata about their attributes, including provenance, thus making those digital artifacts machine-processible, uniquely identifiable, traceable, and accountable (Huang et al., Reference Huang, Gheorghe, Handley, Pazos, Pinto, Kovacic, Collins, Keating, Sousa-Poza, Rabadi, Unal, Cotter, Landaeta and Daniels2020). The digital engineering transformation brings both opportunities and challenges for requirements elicitation.
The evolution of digital transformation has led to improved productivity, quality, and customer satisfaction through agile and robust big data collection, analysis, learning, and decision-making processes. Success stories, advancing technologies, and growing customer demands are why digitalization has become necessary for various fields. For example, in recent years, there has been a growing number of studies involving a digital transformation in requirement engineering, such as identifying requirements from documents (Wang et al., Reference Wang, Chen, Zheng, Li and Khoo2019), automatically classifying the requirements (Casamayor et al., Reference Casamayor, Godoy and Campo2012), and prioritizing the requirements (Maiti and Mitropoulos, Reference Maiti and Mitropoulos2017). By applying advanced technologies and shifting the existing process to a new digitized paradigm, it may be possible to solve the problem.
Traditionally, expert experience or intuition has been used to direct requirement elicitation activities. Each decision is based on a combination of implicit and explicit domain expertise (Maalej and Thurimella, Reference Maalej and Thurimella2013). Developing a computer model that mimics expert reasoning with knowledge is expensive to construct and maintain. A data-driven strategy, unlike knowledge-based systems, does not require codifying the rules and knowledge for decision-making. The term data-driven refers to a decision-making strategy based on data analytics, interpretation, and prediction rather than pure intuition (Provost and Fawcett, Reference Provost and Fawcett2013). Over the past 15 years, several studies have been published on the application of machine learning (ML) to requirements engineering, followed by reviews that summarize these studies (Meth et al., Reference Meth, Brhel and Maedche2013; Wong et al., Reference Wong, Mauricio and Rodriguez2017; Lim et al., Reference Lim, Henriksson and Zdravkovic2021). Different from those existing studies, this literature review includes 86 studies from 2007 to the present, and categorizes the included works from 7 perspectives, including tasks, data collection, data cleansing and preprocessing, textual feature extraction, learning, evaluation, and the open-source tools.
The rest of this paper is structured as follows. In Section “Related works”, literature reviews related to the proposed review are summarized; and Section “Review methodology”, the scope and methodology of the literature review, as well as search strategies, criteria for inclusion and exclusion, and the data extraction template, are presented. Section “Results” shows the primary results of the literature review. Section “Findings” summarizes the major findings from the review by analyzing the included works and categorizing them into various categories from seven different research concerns. In Section “Open issues and future works”, the current role of ML in requirement elicitation and its limitations are discussed. In addition, the open issues and potential future works in this field are discussed. In Section “Limitation of this review”, we discuss the potential threat to validity of the review and the measures we took to address these limitations. Finally, Section “Conclusion” concludes the paper.
Related works
To our knowledge, eight existing review articles, as shown in Table 1, are relevant to our study. Meth et al. (Reference Meth, Brhel and Maedche2013) conducted a review mainly focused on the automated approach applied for requirements elicitation, mainly focusing on the degree of the automation of proposed approaches. Binkhonain and Zhao (Reference Binkhonain and Zhao2019) introduced ML algorithms in the requirements elicitation domain by dividing the 24 related articles into 3 sections: NLP techniques, ML algorithms, and evaluation. Perez-Verdejo et al. (Reference Perez-Verdejo, Sanchez-Garcia and Ocharan-Hernandez2020) applied topic models and visualization techniques to analyze ML-based requirement classification articles. Wong et al. (Reference Wong, Mauricio and Rodriguez2017) identified various software requirements elicitation methods, including manual, rule-based, and ML-based approaches. Shabestari et al. (Reference Shabestari, Herzog and Bender2019) proposed a systematic literature review that covers early product development phases, including various activities such as requirements elicitation, requirement identification, and requirement categorization. Similarly, Sampada et al. (Reference Sampada, Sake and Chhabra2020) focus on the early requirement phases but are more concerned with requirements elicitation and documentation. Ahmad et al. (Reference Ahmad, Feng, Khan, Khan, Ullah, Nazir and Tahir2020) reviewed a collection of articles for identifying requirements for Q&A platforms.
Table 1. Related works
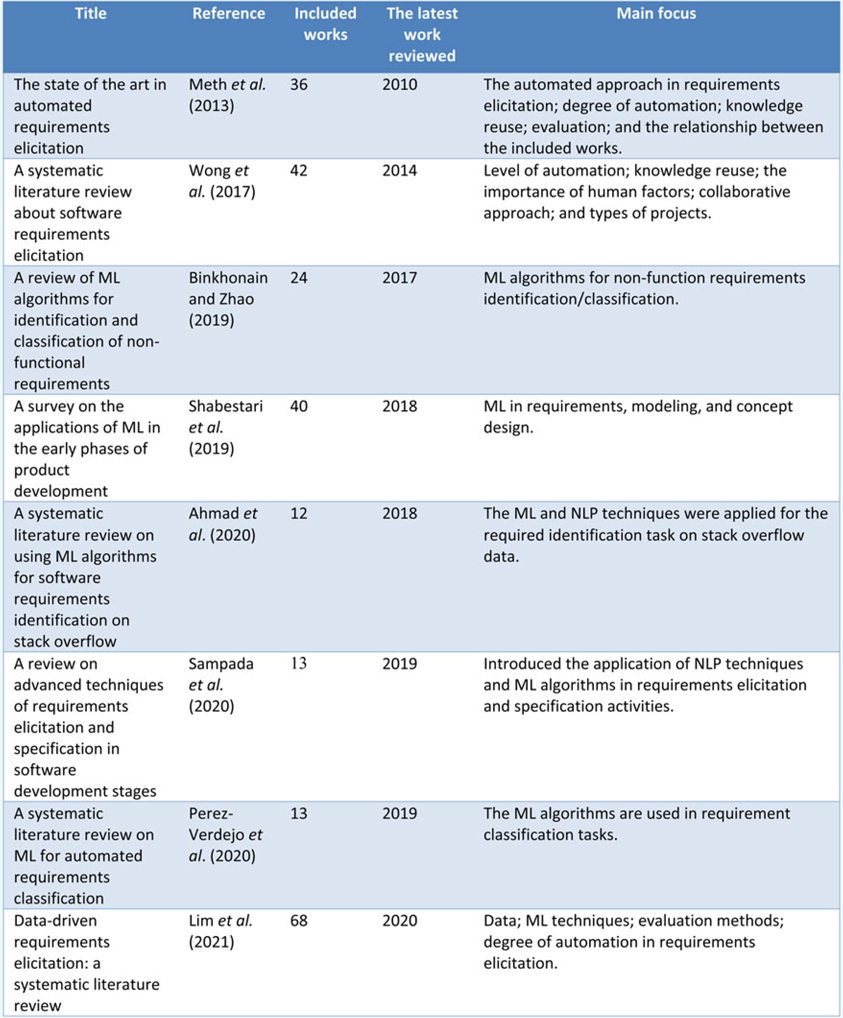
Among the existing studies, one existing work proposed by Lim et al. (Reference Lim, Henriksson and Zdravkovic2021) is the closest to our research, which was conducted almost concurrently with ours. Both works aim to introduce the current state of the works in data-driven requirements elicitation; however, the focuses of the two works are different. Lim et al. (Reference Lim, Henriksson and Zdravkovic2021) focus more on data sources, data types, learning techniques, and degree of automation. In comparison, the present review focuses more on technical details, such as text features. Our work aims to provide a comprehensive overview of current work and include a more detailed investigation into the types of requirement elicitation tasks, existing methods, algorithms, and tools. This review could provide a more practical guide to requirements elicitation researchers, and engineers to leverage the existing techniques in their projects.
Review methodology
Review scope
The review adheres to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) reporting structure, aiming to answer the five research questions below:
-
RQ1. What requirement elicitation activities are supported by ML?
-
RQ2. What data sources are used to build ML-based requirement solutions?
-
RQ3. What technologies and algorithms are used to build ML-based requirement elicitation?
-
RQ4. What are the available tools to support ML-based requirements elicitation methodology?
-
RQ5. How to construct an ML-based requirements elicitation method?
The review scope is defined in Table 2 according to Cooper's taxonomy for literature review, including focus, goal perspective, coverage, organization, and audience (Cooper, Reference Cooper1988; Cooper et al., Reference Cooper, Hedges and Valentine2019). First, in this work, the emphasis is on practical solutions that can be applied; therefore, the theoretical works are not our focus. Second, this study aims to synthesize and integrate existing studies to identify the specific requirement elicitation tasks supported by ML; thus, criticism of the field or related works is not a goal of this article. Third, this paper does not take an espousal perspective to advocate for or against ML-based requirements elicitation. Instead, it demonstrates how the existing work would convert requirements elicitation challenges into ML problems. Fourth, the coverage of the literature is a non-exhaustive set of research articles that are retrieved by search queries and filtered by inclusion and exclusion criteria. Fifth, the work applies a methodological organization that group and organize similar methodologies or tools together, presenting a modular organization to the target audience. Finally, the targeted audiences are mainly requirements analysts, engineers, and scholars.
Table 2. The research scope under Cooper's literature review taxonomy

Databases and search strategies
Seven bibliographic databases, including Scopus, Web of Science, Google Scholar, IEEE Xplore, Springer Link, ACM digital library, and ASME digital library are adopted to guarantee the coverage of the review. Three search strategies are applied: (1) the query expanding strategy is used to add synonyms, inflectional, and derivational morphological forms to the original term; (2) a wildcard character is used to capture multiple forms of a keyword by replacing one or more characters with a star symbol (*) or question marks (?); and (3) a query scoping strategy is applied when the search term is too general to retrieve a related result, such as adding terms “system engineering” or “requirement engineering” in addition to the search string.
Based on the above consideration, the search strings are defined as follows:
(“Requirement” OR “Demand” OR “Need”) AND (“Elicit” OR “Collect” OR “Gather” OR “Detect” OR “Identify” OR “Classify”) AND (“ML” OR “Machine Learning” OR “Deep Learning” OR “Text Mining” OR “Data Mining” OR “NLP” OR “Natural Language Processing” OR “Neural Network” OR “Automated” OR “Data-driven” OR “Decision Support”).
Due to search functions being different across the seven academic search engines, in the actual search pattern certain differences may exist. For example, the Web of Science engine supports additional Boolean operators, such as the “NEAR” operator that provides additional restrictions on the “AND” operator by considering a fixed-size context window.
Inclusion exclusion criteria and paper screening
The next step of the literature review is selecting studies by screening the title, abstract, and full text of the works found in the previous steps. We applied the inclusion/exclusion criteria in Table 3.
Table 3. Inclusion/exclusion criteria

Data extraction table
Research information was collected from each included article with a data extraction form. Basic information about the study (author, title, year of publication, etc.) and content related to research interests (data source, preprocess, feature extraction, etc.) was collected. This includes 14 data elements described in Table 4. The required data fields are designed as open questions, which require reviewers to collect, summarize, and categorize data from the collect works.
Table 4. Elements of data extraction table

Based on the search strategies applied on the 7 included scientific search engines, 975 papers were retrieved. Upon initial screening and the title screening, 915 works were forwarded to the title-abstract screening. A subset of 774 was irrelevant and thus discarded. As a result, 129 papers are retained for the full-text screening. In accordance with the inclusion–exclusion criteria, 43 articles were excluded, and finally, 86 articles were selected. The complete process of study selection is shown in Figure 1.

Fig. 1. PRISMA flowchart.
Results
Tendencies of the publications
The overall trend for the 86 articles is shown in Figure 2, and an increasing trend can be observed. The reviewed studies came from 30 different countries, and 17 of them were conducted in more than one country. The average number of publications in each country is 3.8, with seven countries having more publications than the average, which are the United States (n = 28, 25.0%), China (n = 14, 12.5%), Germany (n = 13, 11.6%), Canada (n = 8, 7.1%), Singapore (n = 5, 4.5%), South Korea (n = 5, 4.5%), and the United Kingdom (n = 5, 4.5%).

Fig. 2. The number of included papers by year.
Thirty-nine of the studies are conference papers (n = 39, 45.3%) and 31 are journal papers (n = 31, 36.0%). In addition, eight workshop papers (n = 8, 9.3%) and eight book sections (n = 8, 9.3%) are included, respectively. The included conference papers are collected in 23 unique conference proceedings, with 16 works appearing in the Proceedings of the IEEE International Conference on Requirements Engineering. The majority of the journal publications in this collection are from the Journal of Mechanical Design, Information and Software Technology, and Requirement Engineering.
The data source for ML-based requirement elicitation
The requirement specification (RS) is a textual document that systematically stores system definition and system requirements (Bourque and Fairley, Reference Bourque and Fairley2014). In the reviewed articles, 17 works applied available requirement specifications to build ML-based solutions to support requirement elicitation. The majority (n = 12) of the requirements specifications in the selected studies are written in English, and two of the requirement specification are bilingual (Ko et al., Reference Ko, Park, Seo and Choi2007; Lyutov et al., Reference Lyutov, Uygun and Hütt2019), three are written in the non-English language (Falessi et al., Reference Falessi, Cantone and Canfora2010; Ott, Reference Ott2013; Gulle et al., Reference Gulle, Ford, Ebel, Brokhausen and Vogelsang2020).
A total of 27 works are based on already existing corpora, mainly DePaul's NFR corpus (Cleland-Huang et al., Reference Cleland-Huang, Settimi, Zou and Solc2007), SecReq dataset (Knauss et al., Reference Knauss, Houmb, Schneider, Islam and Jürjens2011), and PURE dataset (Ferrari et al., Reference Ferrari, Spagnolo and Gnesi2017). The DePaul's NFR corpus and SecReq dataset are labeled datasets for specified tasks and the PURE corpus is unlabeled that contains multiple raw requirement documents.
About half of the included works applied available data from user-generated content (UGC) to aid requirement elicitation. The UGC includes textual data from e-commerce websites (n = 16), mobile app marketplace (n = 13), microblogs and social media (n = 5), organizational internal forum (Lange, Reference Lange2008), GitHub repository (Nyamawe et al., Reference Nyamawe, Liu, Niu, Umer and Niu2019), and crowdsourcing platforms (Jones and Kim, Reference Jones and Kim2015).
Requirement data preprocessing
On average, most papers described at least one preprocessing methodology. The preprocessing techniques referred to in the reviewed articles including stop words removal (n = 50), case folding (n = 31), stemming (n = 26), lemmatization (n = 16), punctuation and special character removal (n = 14), URL removal (n = 5), non-English word removing (n = 3), emoticon handling (n = 3), slang translation (n = 3), abbreviation replacement (n = 3), typo correction (n = 2), and acronym replacement (n = 1).
Requirement representations and features
The most frequently applied textual feature in the included works is the Bag-of-Word language model (n = 49), which is an effective and efficient method to convert text into the numerical format. Apart from the BOW model, various grammatical features are introduced by the selected papers, including POS n-gram (Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017b), the frequencies of POS (Noun/Verb/Adj/Adv/Modal) (Hussain et al., Reference Hussain, Kosseim and Ormandjieva2008; Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013; Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017a), the frequency of keywords (Halim and Siahaan, Reference Halim and Siahaan2019), and the number of syntax sub-tree (Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017a, Reference Kurtanovic and Maalej2017b; Dalpiaz et al., Reference Dalpiaz, Dell'Anna, Aydemir and Çevikol2019).
Some statistics of sentences are applied to represent text, such as the number of characters (Abualhaija et al., Reference Abualhaija, Arora, Sabetzadeh, Briand and Vaz2019), the number of words (Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017b), the number of sentences (Qi et al., Reference Qi, Zhang, Jeon and Zhou2016), the number of paragraphs (Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015), and the number of words per sentence (Ormandjieva et al., Reference Ormandjieva, Hussain and Kosseim2007).
Metadata of UGC data is applied by several works to make requirement representation more informative. A few articles have utilized metadata to provide supplementary information on requirement representations, such as the average star ratings (Maalej et al., Reference Maalej, Kurtanović, Nabil and Stanik2016) and the total number of reviews (Martens and Maalej, Reference Martens and Maalej2019). In addition, platforms contain metadata about users, such as the total number of reviews/ratings of the user performed (Martens and Maalej, Reference Martens and Maalej2019) and the platform level of the user (Qi et al., Reference Qi, Zhang, Jeon and Zhou2016), are also included in the feature construction.
Domain knowledge is one of the supportive information to represent requirements. The domain knowledge is reflected by domain-specific terms, for example, the number of design terms (Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015) and the number of keywords from the domain (Hussain et al., Reference Hussain, Kosseim and Ormandjieva2008; Stanik et al., Reference Stanik, Haering and Maalej2019).
Among included works, a large proportion of recent works have used word embedding techniques to represent requirements. Word2vec (Mikolov et al., Reference Mikolov, Chen, Corrado and Dean2013), FastText (Joulin et al., Reference Joulin, Grave, Bojanowski and Mikolov2017), and BERT (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019) are the most widely applied embedding models across the included works (n = 14, 16%).
Several other features, such as the verb tense (Stanik et al., Reference Stanik, Haering and Maalej2019), the elapsed days (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013), the temporal tags (Abad et al., Reference Abad, Karras, Ghazi, Glinz, Ruhe and Schneider2017), the number of subjective/objective sentences in a user review (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013), the number of ambiguous expressions in requirements (Ormandjieva et al., Reference Ormandjieva, Hussain and Kosseim2007; Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015), the number of the sentence referring product characteristics (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013; Qi et al., Reference Qi, Zhang, Jeon and Zhou2016), smoothed probability measure (SPM) and unsmoothed probability measure (UPM) (Hussain et al., Reference Hussain, Kosseim and Ormandjieva2008), and named entities (Abad et al., Reference Abad, Karras, Ghazi, Glinz, Ruhe and Schneider2017), are also observed from the reviewed articles.
Machine learning techniques
Most of the selected works (n = 67) applied classification algorithms for classifying textual documents. Naïve Bayes (n = 33), Support Vector Machine (SVM) (n = 29), Decision Tree (DT) (n = 22), and neural networks (n = 26) are the most widely applied algorithms among the studies. In addition, several specific neural network frameworks are mentioned in the included papers, which are Convolutional Neural Networks (CNNs) (n = 12), Feedforward Neural Networks (FNNs) (n = 9), and Recurrent Neural Networks (RNNs) (n = 5). Besides, the reviewed articles present a variety of other supervised machine learning algorithms including logistic regression (n = 14), K-nearest neighbors (n = 8), and random forest (n = 5).
In the included studies, two types of unsupervised algorithms were applied: text clustering techniques (n = 4) and topic models (n = 13). Clustering algorithms such as Hierarchical Agglomerative Clustering (Mahmoud, Reference Mahmoud2015; Al-Subaihin et al., Reference Al-Subaihin, Sarro, Black, Capra, Harman, Jia and Zhang2016), K-medoids (Barbosa et al., Reference Barbosa, Januario, Silva, Moraes and Martins2015), and X-means (Suryadi and Kim, Reference Suryadi and Kim2019) were utilized in the selected papers. Topic models are applied to extract main topics from the textual documents, including the Latent Dirichlet Allocation (LDA) algorithm (Blei et al., Reference Blei, Ng and Jordan2003) (n = 6), aspect and sentiment unification model (Jo and Oh, Reference Jo and Oh2011) (n = 3), Bi-term Topic Model (Yan et al., Reference Yan, Guo, Lan and Cheng2013) (n = 3), and Tag Sentiment Aspect (Tang et al., Reference Tang, Jin, Liu, Li and Zhang2019) (n = 1).
Model evaluation methods
The evaluation metrics are employed differently in supervised and unsupervised approaches due to the mechanical differences between their learning methods. Manually annotated data corpus for supervised ML algorithms is applied for training and validation purposes. Hence, comparing machine predictions with actual values on a labeled dataset is a simple, straightforward way to evaluate a learning algorithm. For regression models, metrics Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) are common error functions to reflect the accuracy of regression methods (Chai and Draxler, Reference Chai and Draxler2014). Common metrics for classification tasks are precision, recall, accuracy, f-score, and area-under-curve (AUC) (Chai and Draxler, Reference Chai and Draxler2014). The precision (n = 58), recall (n = 56), and F1 score (n = 49) are the most applied metrics to evaluate a supervised classifier by the included works. Due to the differences in data and research questions, it is difficult to compare the included works.
To evaluate the performance of the unsupervised methods, the Silhouette score was used by the included studies (n = 4) to assess clustering outcomes (Barbosa et al., Reference Barbosa, Januario, Silva, Moraes and Martins2015; Mahmoud, Reference Mahmoud2015; Al-Subaihin et al., Reference Al-Subaihin, Sarro, Black, Capra, Harman, Jia and Zhang2016; Abad et al., Reference Abad, Karras, Ghazi, Glinz, Ruhe and Schneider2017). Furthermore, five papers applied perplexity to analyze the goodness of unsupervised categorization (Massey et al., Reference Massey, Eisenstein, Anton and Swire2013; Chen et al., Reference Chen, Lin, Hoi, Xiao and Zhang2014; Wang et al., Reference Wang, Feng and Dai2018b; Zhou et al., Reference Zhou, Ayoub, Xu and Yang2020; Joung and Kim, Reference Joung and Kim2021). Similar to the supervised method, some works manually built a golden standard to evaluate unsupervised methods with precision, recall, and F1 score (Carreno and Winbladh, Reference Carreno and Winbladh2013; Chen et al., Reference Chen, Lin, Hoi, Xiao and Zhang2014; Guzman and Maalej, Reference Guzman and Maalej2014; Abad et al., Reference Abad, Karras, Ghazi, Glinz, Ruhe and Schneider2017). In addition, several reviewed articles examine the performance with manual inspection (Massey et al., Reference Massey, Eisenstein, Anton and Swire2013; Al-Subaihin et al., Reference Al-Subaihin, Sarro, Black, Capra, Harman, Jia and Zhang2016; Guzman et al., Reference Guzman, Ibrahim and Glinz2017; Gulle et al., Reference Gulle, Ford, Ebel, Brokhausen and Vogelsang2020).
Tools
Most of the included works are built upon existing open-access tools and libraries. Scikit-learn Footnote 1 and Waikato Environment for Knowledge Analysis Footnote 2 (Weka) are the two most popular ML tools mentioned in the included articles (Hall et al., Reference Hall, Frank, Holmes, Pfahringer, Reutemann and Witten2009; Pedregosa et al., Reference Pedregosa, Varoquaux, Alexandre and Thirion2011). Seventeen works applied Scikit-learn to build different kinds of algorithms such as Naïve Bayes, Support Vector Machine, and Random Forest. Another popular tool in the reviewed articles is the Weka, with 19 articles reporting that they applied Weka for building their solutions. Both Scikit-learn and Weka provide ready-to-use learning algorithms and have numerous tricks for preprocessing and feature extraction. For example, Wang et al. (Reference Wang, Zhang, Liang, Daneva and Van Sinderen2018a) used the StringToWordVector package from Weka to produce TF-IDF word vectors. In contrast, Dekhtyar and Fong (Reference Dekhtyar and Fong2017) applied TfidfVectorizer from the Scikit-learn library for the same purpose.
For natural language processing (NLP), the most popular tool is the Natural Language Toolkit (NLTK),Footnote 3 a Python library designed specifically for human language processing (Loper and Bird, Reference Loper and Bird2002). The NLTK library is applied in selected papers for numerous preprocessing and feature extraction tasks, such as tokenization (Rahman et al., Reference Rahman, Haque, Tawhid and Siddik2019), sentiment analysis (Noei et al., Reference Noei, Zhang and Zou2021), part-of-speech tagging (Halim and Siahaan, Reference Halim and Siahaan2019), lemmatization (Guzman and Maalej, Reference Guzman and Maalej2014), and stemming (Jha and Mahmoud, Reference Jha and Mahmoud2019). For POS and dependency parsing tasks, tools from the Stanford NLP group are mentioned, such as Stanford parser, CoreNLP, and POS tagger. TensorFlow and its high-level wrapper Keras are the most often used neural network libraries in the listed studies.
Findings
The purposed work is a literature review paper, which collect, review, analysis, synthesis, and report existing works based on PRISMA methodology, which aim to provide audience a summarized knowledge in ML-based requirement eliciation. The findings from the literature review will be discussed in this section. The section is organized according to the order of our research questions. In addition, the articles included in this review are categorized according to the different perspectives on the research questions. The summarization of our categorization is illustrated in Figure 3.

Fig. 3. An illustration of the categorization schema of the collected studies.
What requirements elicitation activities are supported by ML?
After analyzing the selected 86 papers in-depth, 15 different ML-based requirement elicitation tasks are identified (as shown in Figure 4). The identified tasks can be categorized into four main categories, which are Preparation, Collection, Inspection, and Negotiation.
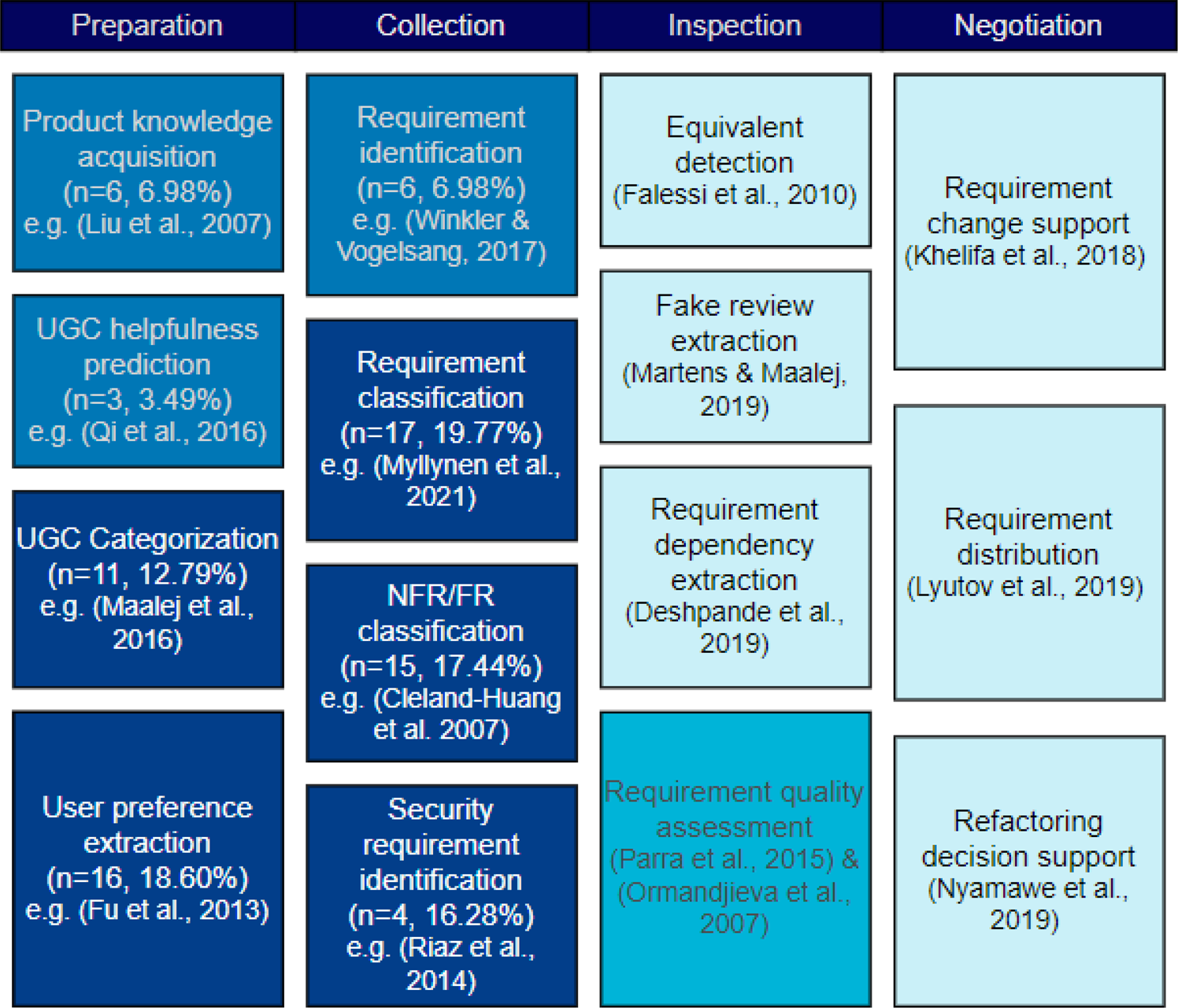
Fig. 4. ML-based requirement elicitation tasks.
Preparation refers to a set of activities that engineers must undertake before the elicitation of requirements to ensure that the process is supported by sufficient knowledge. A total of five articles are proposed to extract knowledge about the design from textual documents. For example, Liu et al. (Reference Liu, Lu and Loh2007) proposed an SVM-based design knowledge acquisition framework that can collect research articles according to organizational design knowledge taxonomy.
In addition, extracting user preferences, requests, and complaints from massive UGC is also considered a Preparation task. The ML-based text mining algorithms would be used to extract useful information from UGC, providing engineers with insights and knowledge about the target product. For example, Maalej et al. (Reference Maalej, Kurtanović, Nabil and Stanik2016) proposed a supervised method to automatically classify user app reviews into four predefined categories: user experience, bug report, feature quest, and ratings.
Liu et al. (Reference Liu, Jin, Ji, Harding and Fung2013) present a regression model which enables engineers to estimate the usefulness of customer reviews. UGC helpfulness analysis helps determine whether users’ feedback is constructive. However, evaluating usefulness is a subjective activity that often entails a viewpoint. In a data-driven approach, the annotators represent the viewpoint. This review identifies two perspectives including designer-perspective (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013; Qi et al., Reference Qi, Zhang, Jeon and Zhou2016) and consumer-perspective (Chen et al., Reference Chen, Zhang and Niu2016).
Stakeholder preference (or tendency, rationale) is another activity categorized as Preparation. Since UGC is the cumulative contribution of users over some time, it incorporates their preferences and emotions about the product, product functions, and product features. For example, combining the LDA and sentiment analysis techniques can help engineers to explain which features of the product are loved by users (Guzman and Maalej, Reference Guzman and Maalej2014; Zhou et al., Reference Zhou, Ayoub, Xu and Yang2020), and which are the most dissatisfied product characteristics (Fu et al., Reference Fu, Lin, Liy, Faloutsos, Hong and Sadeh2013).
The second group of tasks is Collection, which includes tasks related to directly extracting requirements or identifying specific types of requirements from a given collection of documents. In selected articles, all ML-based solutions in this category are supervised methods. The first type of collection task is requirement identification, which refers to the activity to determine whether a given sentence or paragraph is a user requirement. For example, Kengphanphanit and Muenchaisri (Reference Kengphanphanit and Muenchaisri2020) proposed a requirement identification framework named ARESM, which can distinguish whether a given text is a requirement or non-requirement.
Requirement classification is another task in the Collection category. The objective of this task is to categorize the given requirements based on a certain concern. For example, Hussain et al. (Reference Hussain, Kosseim and Ormandjieva2008) proposed a decision tree algorithm that can classify natural language requirements into functional requirements (FRs) and non-functional requirements (NFRs). The NFRs/FRs classification task takes NFRs or FRs as input and classifies them further into fine-grained subcategories. Cleland-Huang et al. (Reference Cleland-Huang, Settimi, Zou and Solc2007) proposed a TF-IDF-based classification algorithm that is capable of classifying textual requirements into predefined NFR subcategories. For this purpose, Cleland-Huang et al. (Reference Cleland-Huang, Settimi, Zou and Solc2007) established a manually labeled dataset for NFR classification.
The last type of task identified in the Collection is security requirement identification. Riaz et al. (Reference Riaz, King, Slankas and Williams2014) trained a K-NN classifier that can automatically detect six predefined security requirement types from natural text documents. Two articles introduce binary classifiers for identifying security requirements from written requirements (Li, Reference Li2018; Kobilica et al., Reference Kobilica, Ayub and Hassine2020). Jindal et al. (Reference Jindal, Malhotra and Jain2016) trained a decision tree to further categorize security requirements into four specific categories, which are authentication-authorization, access control, cryptograph-encryption, and data integrity.
The Inspection and Negotiation could happen at any stage during a requirement engineering process. Inspection refers to the ML-based methods applied to inspect and assure the quality and validity of the requirements. The Inspection category includes equivalent requirement detection (Falessi et al., Reference Falessi, Cantone and Canfora2010), requirement quality support (Ormandjieva et al., Reference Ormandjieva, Hussain and Kosseim2007; Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015), and requirement dependency analysis (Deshpande et al., Reference Deshpande, Arora and Ruhe2019), and fake review detection (Martens and Maalej, Reference Martens and Maalej2019). The Negotiation category includes activities to support resolving requirement-related conflicts, and there are three types of tasks were identified under this category. An SVM classifier was used by Khelifa et al. (Reference Khelifa, Haoues and Sellami2018) to automatically classify users’ change requests into functional change and technical change, thereby assisting project managers to negotiate requirements and make appropriate decisions. In a recent paper, Lyutov et al. (Reference Lyutov, Uygun and Hütt2019) presented a supervised learning-enabled workflow that facilitates the automatic transmission of customer requirements to the corresponding department to facilitate the process of requirement negotiation. Moreover, an ML-based software refactoring recommendation method is proposed to assist decision-makers in deciding which major update should be applied according to customers’ requests (Nyamawe et al., Reference Nyamawe, Liu, Niu, Umer and Niu2019).
What data sources are used to build ML-based requirement elicitation solutions?
Based on an in-depth analysis of included studies, we found that current studies heavily rely on three types of data sources: Textual Documents, UGC, and Existing Requirement Datasets (Fig. 5). The category Textual Documents includes product requirement specification (RS) from actual projects (n = 9), RS from open-access online resources (n = 8), user stories (Barbosa et al., Reference Barbosa, Januario, Silva, Moraes and Martins2015; Rodeghero et al., Reference Rodeghero, Jiang, Armaly and McMillan2017), policy documents (Massey et al., Reference Massey, Eisenstein, Anton and Swire2013), and research publications (Liu et al., Reference Liu, Lu and Loh2007).

Fig. 5. The data source for building ML-based requirement elicitation solutions.
DePaul's NFRs corpus is the most extensively used Existing Requirement Datasets, which was originally introduced by Cleland-Huang et al. (Reference Cleland-Huang, Settimi, Zou and Sole2006). The dataset is manually labeled by graduate students from DePaul University into 10 NFR subcategories and one functional requirements category including Availability, Look and Feel, Legal, Maintainability, Operational, Performance, Scalability, Security, Usability, and FRs. In total, the dataset contains 358 FRs and 326 NFRs from 15 different RS. Follow-up studies applied the DePaul NFR dataset to build binary classifiers to distinguish between FR and NFR (Hussain et al., Reference Hussain, Kosseim and Ormandjieva2008; Canedo and Mendes, Reference Canedo and Mendes2020), or multi-class classifiers to assign requirements to finer categories (Abad et al., Reference Abad, Karras, Ghazi, Glinz, Ruhe and Schneider2017; Rahman et al., Reference Rahman, Haque, Tawhid and Siddik2019).
SecReq is another publicly available requirement dataset, which was created to assist in the early stages of security requirement elicitation (Houmb et al., Reference Houmb, Islam, Knauss, Jürjens and Schneider2010). The dataset contains three projects, which are Electronic Purse, Customer Premises Network, and Global Platform Specification. Three projects contain 511 requirements that are tagged as security-related requirements (sec) and non-security-related requirements (non-sec). Three works trained and tested their data-driven requirement elicitation methods with SecReq corpus (Dekhtyar and Fong, Reference Dekhtyar and Fong2017; Li, Reference Li2018; Kobilica et al., Reference Kobilica, Ayub and Hassine2020).
The PURE dataset has 79 requirement specifications including about 35,000 sentences with an average length of 15 words (Ferrari et al., Reference Ferrari, Spagnolo and Gnesi2017). Unlike the previously described two datasets, the PURE is not labeled; rather, the authors made it open for a variety of applications. Deshpande et al. (Reference Deshpande, Arora and Ruhe2019) studied requirement dependencies with the PURE corpus, and EzzatiKarami and Madhavji (Reference EzzatiKarami and Madhavji2021) merged both DePaul NFR and PRUE datasets for constructing a bigger training set for their study.
User-generated data (UGC) is another important source for data-driven requirements elicitation. Research shows that the needs of system users are hidden in rich UGC, such as user feedback, social networks, online software markets review, and product discussion forums (Maalej et al., Reference Maalej, Nayebi, Johann and Ruhe2015, Reference Maalej, Kurtanović, Nabil and Stanik2016; Lu and Liang, Reference Lu and Liang2017; Perini, Reference Perini2018). UGC contains any form of data generated by users, like numerical ratings, textual product reviews, and videos. In total, half of the included studies (n = 43) applied UGC to build their ML-based solutions. The UGC source includes mobile application platform user reviews (Apple App Store and Google Play Store), e-commerce user reviews (Amazon and other online retailers), social media (Twitter and Facebook), and crowdsourcing platforms.
What technologies, algorithms, and tools are used to build ML-based requirement elicitation?
This subsection answers RQ3 and RQ4. Our study identified the technical approaches and algorithms used by the included studies and divided them into three categories: Textual Data Cleansing and Preprocessing, Textual Features Extraction, and Machine Learning (ML) (Fig. 6). The ML models are evaluated by two strategies, which are Manual evaluation and Metrics-based evaluation. In addition, we categorized many open-source tools identified from the reviewed articles into two categories: ML tools and NLP tools.

Fig. 6. Technologies and algorithms.
Textual data cleansing and preprocessing
Twenty different techniques were identified from the included papers specifically for cleaning and preparing data, which we categorized under the Textual Data Cleansing and Preprocessing category. In addition, due to the functional features of these techniques, we further grouped these techniques into three parts: tokenization, text chunking, and text normalization.
Tokenization is a procedure to break a given sequence of text down into smaller parts, such as breaking a document into sentences (sentence tokenization) or breaking a sentence into individual words (word tokenization). Text filtering is a group of preprocessing methods, which aim to eliminate redundant, erroneous, non-representative, inconsistent, and ineligible data from a text document. In the reviewed articles techniques include stopwords removal, rare word filtering, non-English word removing, URL removing, special character handling, empty value handling, punctuation removal, emoticon handling, non-informative/irrelevant word removing, and inconsistent information removal are considered under this classification. Text normalization aims to transform a text sequence into a standard form to reduce its randomness. Stemming and lemmatization are the most common text normalization methods. In a document, a word has various forms, and some of these forms can be converted to one another by adding or removing the prefix or suffix (Manning et al., Reference Manning, Raghavan and Schütze2008). Stemming is a crude heuristic procedure that removes the tails from words to get word stems, which are the fundamental word units, such as for word requirements, the word stem is required (Manning et al., Reference Manning, Raghavan and Schütze2008). In comparison, lemmatization yields a basic dictionary form of a word. For example, the lemmatization of requirements will yield requirements. Case folding is another popular text normalization approach that changes all letters in a word into lower cases (Manning et al., Reference Manning, Raghavan and Schütze2008). In addition, slang translations, abbreviation translations, typo corrections, and acronym substitutes are considered text normalization procedures since they convert text into a more generic form.
Textual features extraction
Textual Features Extraction includes a set of techniques to convert natural text into numbers. We found three major textual data representation strategies from the reviewed articles: Bag-of-word, Rule-based, and Embedding features. The Bag-of-word considers a sequence of text as a set (or multi-set) of the word regardless of word order and grammar (Manning and Schütze, Reference Manning and Schütze1999). Various BOW representation strategies can be found in the included works, such as using simple raw counts for words, a bag of bigram or trigram (Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017a), and BOW with TF-IDF weighting (Li et al., Reference Li, Huang, Ge, Luo and Ng2018).
In addition to BOW features, studies included in this review also applied rule-based handcraft features, such as POS n-gram (Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017b), the number of Noun/Verb/Adj/Adv/Modal (Hussain et al., Reference Hussain, Kosseim and Ormandjieva2008; Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013; Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017a), frequency of POS of the keywords (Halim and Siahaan, Reference Halim and Siahaan2019), and the count of syntax sub-tree (Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017a, Reference Kurtanovic and Maalej2017b; Dalpiaz et al., Reference Dalpiaz, Dell'Anna, Aydemir and Çevikol2019). In addition, textual descriptive statistics are also applied to represent requirements, including the number of characters (Abualhaija et al., Reference Abualhaija, Arora, Sabetzadeh, Briand and Vaz2019), word count (Kurtanovic and Maalej, Reference Kurtanovic and Maalej2017b), sentence count (Qi et al., Reference Qi, Zhang, Jeon and Zhou2016), paragraphs count (Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015), and the number of words per sentence (Ormandjieva et al., Reference Ormandjieva, Hussain and Kosseim2007). Furthermore, temporal features including verb tense (Stanik et al., Reference Stanik, Haering and Maalej2019), the number of elapsed days (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013), and temporal tags, such as time, duration, and time set (Abad et al., Reference Abad, Karras, Ghazi, Glinz, Ruhe and Schneider2017), were used to represent the temporal information of the requirements. For UGC-based research, some platforms provide metadata that can be extracted to represent user comments. Metadata features include star ratings (Maalej et al., Reference Maalej, Kurtanović, Nabil and Stanik2016), review count (Martens and Maalej, Reference Martens and Maalej2019), and the number of links (Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015).
Moreover, some studies applied document quality features to represent textual requirements, including the number of subjective/objective sentences in a review (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013), the number of ambiguous expressions in a requirement (Ormandjieva et al., Reference Ormandjieva, Hussain and Kosseim2007; Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015), and the number of the sentence referring product feature appeared in a user review (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013; Qi et al., Reference Qi, Zhang, Jeon and Zhou2016). Additionally, some articles introduce domain-specific features, such as the number of design terms (Parra et al., Reference Parra, Dimou, Llorens, Moreno and Fraga2015) and the number of keywords from the input text (Hussain et al., Reference Hussain, Kosseim and Ormandjieva2008; Stanik et al., Reference Stanik, Haering and Maalej2019).
In recent years, word embedding has gained popularity in a range of NLP applications. The selected articles used a range of embedding techniques, including Word2vec (Mikolov et al., Reference Mikolov, Chen, Corrado and Dean2013), FastText (Joulin et al., Reference Joulin, Grave, Bojanowski and Mikolov2017), Glove (Pennington et al., Reference Pennington, Socher and Manning2014), and BERT (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019) to represent words. Three strategies associated with embedding features are identified in the included studies: training the embedding from scratch using a pre-trained embedding and fine-tuning the previously trained language models.
Machine learning
In this review, the learning algorithms applied by the included studies are categorized into two categories: supervised and unsupervised learning. Under supervised learning categories, only three studies applied regression models (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013; Chen et al., Reference Chen, Zhang and Niu2016; Qi et al., Reference Qi, Zhang, Jeon and Zhou2016). The regression methods can help engineers to predict a numerical value to reflect the helpfulness of a given user review. The rest of the methods in supervised learning are all classification algorithms. Topic modeling and clustering techniques are two frequently applied Unsupervised Learning methods and the LDA is the most widely applied unsupervised method in the papers included.
Evaluation methods
The quality of models can be reflected in the evaluation metrics, which are a set of formulas and units of measurement that reflect how well the learning algorithm could perform (Hossin and Sulaiman, Reference Hossin and Sulaiman2015). For different types of learning tasks, the evaluation methods are used differently. In the included studies, the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) are employed for regression models. Both MAE and RMSE are negatively oriented, which means the better the model, the lower the errors. Precision, Recall, and F1 score are most frequently applied for classification models. On the other hand, the unsupervised method is evaluated by two strategies: internal and external evaluation. The included works applied intra and inter-cluster similarity (or distance), Silhouette score, and perplexity to assess the clustering results for internal evaluation. In the case of external evaluation, domain experts are asked to evaluate the models’ results manually. Additionally, a truth set can be built to evaluate the clustering results, similar to a supervised classifier.
Available tools
The included studies widely mentioned two types of tools: ML tools and NLP tools. The NLP tools such as NLTK and CoreNLP are applied to preprocess and extract the features from the textual data. The most widely mentioned ML tools are Weka and Scikit-learn, which integrate multiple ML algorithms and quickly build a data-driven solution. Keras is a popular deep learning library among the included studies, which contains the most popular neural network architectures with compact and straightforward APIs.
Table 5 lists the tools mentioned in the reviewed articles, arranged by their uses. In total, seven types of tools are extracted: ML tools (conventional), deep learning tools, language, and topic model tools, multi-purpose NLP tools, sentiment analysis tools, parsing tools, and single-purpose tools.
Table 5. Tools mentioned by included works

How to construct an ML-based requirements elicitation method?
According to the included studies, building an ML-based requirements elicitation method contains four major steps: study design, data preparation, model construction, and model implementation. The first step is to design the ML-based requirements elicitation study by considering two fundamental elements: identifying the requirements elicitation subtasks and available datasets. In this literature review, we identify four major tasks and three types of data sources that support requirements elicitation from the reviewed articles.
Different ML-based requirement elicitation tasks require different datasets and data annotation strategies. Hence, studies should be designed differently accordingly. Both requirement documents and UGC data were applied in the selected research. Through the detailed review of the included papers, we identified that the requirements are usually stored in plain text format, and the corresponding tasks are mostly focusing on requirement text classification. However, the UGC data contains additional metadata that describes the data in many aspects, such as ratings and timestamps. With these additional data, researchers can design studies such as the prediction of usefulness associated with user reviews (Liu et al., Reference Liu, Jin, Ji, Harding and Fung2013), and analysis of user preferences on a timely basis (Fu et al., Reference Fu, Lin, Liy, Faloutsos, Hong and Sadeh2013).
In addition, sentiment is another reason that causes differences in requirement document analysis and UGC analysis. Documents describing the requirements are usually written with neutral language; therefore, analyzing the sentiment of each requirement may not be as significant as analyzing the sentiment of UGC. As a result, sentiment analysis does not appear in the requirement document analysis tasks but is commonly used in UGC-based research.
With the defined task and dataset, the next step is to construct an ML pipeline, which relies heavily on the understanding of machine learning and NLP techniques. Data cleansing, data preprocessing, feature extraction, model training, and model evaluation are part of this phase. Though the model construction pipeline can be independent of domain knowledge for unsupervised learning, domain expertise is still necessary to validate and evaluate the models. Finally, the model implementation is an important final step to build an ML-based requirements elicitation. Multiple aspects must be considered, such as organizational culture, management, security, development, and operation procedure.
Open issues and future works
It is important to note that eliciting requirements is not one single activity, rather it comprises multiple sessions and operations that work together as a whole. However, there is no very detailed definition or uniform approach to this stage in academia and industry. For example, Young (Reference Young2004) suggested a twenty-eight-step requirement gathering activities checklist including planning, managing, collecting, reviewing, tracing, etc. Wiegers and Beatty (Reference Wiegers and Beatty2013) summarizes 21 best practices for requirements elicitation, including defining scope, identifying stakeholders, reusing existing requirements, modeling the application environment, and analyzing requirements feasibility. Using a single ML model cannot accomplish so many different tasks. Therefore, ML techniques are only able to accomplish partial tasks involved in requirement elicitation. Furthermore, most of the included studies are all focusing on resolving a particular task with ML, rather than designing a complete system that supports requirement elicitation. In this regard, most of the ML-based methods developed so far have a supporting or complementary role to traditional methods. For example, in an ML-aided requirement elicitation system, conventional methods, such as interviews, questionnaires, and brainstorming, are responsible for producing and collecting requirement-related data. ML algorithms, however, are responsible for analyzing data or supporting follow-up data-related activities.
In Section “What requirements elicitation activities are supported by ML?”, we summarized 15 ML-based requirements elicitation subtasks from included studies and categorize them into four groups. Most works were classified as Preparation (n = 37) and Collection (n = 41) tasks, and only eight articles were identified as Validation (n = 5) and Negotiation (n = 3) tasks. One reason for this is that the validation and negotiation are hard to articulate due to the high complexity of the tasks. For example, tasks from Negotiations require collaboration, discussion, and trade-offs between stakeholders from many aspects. Therefore, most of the challenges related to these tasks are related to background knowledge, communication, budgets, or other limitations imposed by the real world. As a result, it is difficult to model these tasks correctly.
It is still challenging to build an ML-based solution to fully automate requirement elicitation. First, since requirement elicitation is a comprehensive process composed of a variety of tasks and goals, it is difficult to develop an end-to-end ML model to fully automate the requirement elicitation process. Second, requirements could come from a large variety of sources, particularly in the big data era. In terms of data type and format, the datasets included in the study were highly heterogeneous. For example, sentiment analysis may be useful when analyzing UGC data, but it is not valuable when analyzing neutral document data. Hence, using the model specifically designed for UGC, such as ASUM (Jo and Oh, Reference Jo and Oh2011), cannot perform as expected on document data, and vice versa. Third, the ML-based requirement elicitation approach is automatic but easily affected by errors and failure. Unlike rule-based systems that can be debugged and fixed locally in the coded knowledge body, it is difficult to directly tune the ML model when dealing with known errors. In addition, the interpretation of ML models is still an open challenge in academia and industry. For example, deep neural networks learn features automatically, which makes it more challenging to analyze the reasons behind ML-based solutions. Furthermore, only a few research considered the changing nature of the requirements. Due to the dynamic nature of the requirements, in practice, requirement elicitation requires engineers to identify and modify requirements based on the unpredictable nature of user needs (Xie et al., Reference Xie, Yang, Chang and Liu2017). Besides, in terms of both content and type of task, the current research is monotonous. The vast majority of studies still focus on classification and clustering.
To tackle these challenges, the following future research directions are suggested by the authors. First, although there are growing interests and works in building ML-based requirement elicitation methods, there is still a vacancy for a systematic guide on how to integrate the ML-based components into the requirement elicitation framework. Multiple aspects of the integrated system should be considered, such as how humans and machines interact in requirements elicitation, what is the input–output of the system and each subsystem, and what specific tasks should be performed by machines when expert involvement is required, among others. Hence, a systematic study and guidance of AI system design, engineering, implementation, and management are required.
Second, there is a lack of in-depth analysis of ML-based requirement elicitation failure and errors. For example, research papers and projects typically rely on statistical metrics for ML model validation and evaluation. This type of evaluation can tell us how good or bad a model is, but neglects to address the question of what leads a model to perform unexpectedly. Future studies should address this issue by introducing methods and techniques to explore the factors that affect the performance of ML-based requirement elicitation.
Third, the ML-based methods, especially deep learning models are lacking transparency. Because deep neural networks derive their features not from experience and knowledge, but from data, which is more effective but less intuitive. Since requirement elicitation is knowledge-intensive human-involved activity, the engineers not only expect models to solve the problems but also to explain them. The significance of Explainable AI (XAI) is increased along with the widespread adoption of deep learning methods in recent years (Xu et al., Reference Xu, Uszkoreit, Du, Fan and Zhao2019). In the future, research in ML-based engineering of requirements will also need to leverage XAI techniques and methods to investigate the nature of decision-related requirements.
Forth, a broad range of NLP tasks could be incorporated into the requirements elicitation. Apart from text classification, many other NLP techniques can be utilized to support requirements elicitation, such as neural summarization, text generation, neural conversational bots, question asking, question answering, and text to speech. Due to its wide range of tasks, requirements elicitation provides an excellent opportunity to practice cutting-edge NLP methods. Future research works should try more to incorporate these methods into requirement elicitation. As an example, neural text generation technologies such as Seq2Seq (Sutskever et al., Reference Sutskever, Vinyals and Le2014), GAN (Goodfellow et al., Reference Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville and Bengio2014), and T5 Text-to-Text transformers (Matena et al., Reference Matena, Lee and Liu2019) have the potential to produce new mock requirements based on a particular context, which may provide innovative data-driven ideas from a new perspective.
Fifth, aside from natural text, user needs also can be mined from other data formats. E-commerce platforms, for instance, allow individuals to upload videos and pictures to share usage experiences, complaints, and feedback. Although techniques such as neural image description (Vinyals et al., Reference Vinyals, Toshev, Bengio and Erhan2015; Karpathy and Li, Reference Karpathy and Li2017) and neural video description (Yao et al., Reference Yao, Torabi, Cho, Ballas, Pal, Larochelle and Courville2015) are not as mature as text classification techniques, they are also of great research value and can play a major role in requirement engineering as well.
Sixth, due to the data-intensive nature of ML methods, more requirements related to high-quality text data should also be introduced. However, some interest-related requirements are requested to be kept confidential by the relevant stakeholders. Hence, sharing high-quality requirement data with the requirement engineering community is challenging. Masking sensitive data or substituting entities can be effective means of modifying sensitive requirements, which can facilitate the sharing of information within the requirement engineering community. Another strategy to address insufficient training data is to develop a language model specifically for requirements engineering. Research shows that transfer learning techniques can overcome the limitations of insufficient data (Howard and Ruder, Reference Howard and Ruder2018). Future works could also consider building neural language models that are specifically trained with requirement specifications.
Seventh, since user-requirement elicitation is a human-centric activity, analyzing user behavior may provide valuable insight into understanding and eliciting requirements. As the study of representation learning, such as user embedding, is being applied to a variety of different domains, including recommendation and healthcare systems (Miotto et al., Reference Miotto, Li, Kidd and Dudley2016; Pan and Ding, Reference Pan and Ding2019). Analyzing user behavior can help to predict user preference and explore potential requirements change.
Last, future work should address the issues caused by the dynamic nature of user requirements. In practice, stakeholder requirements are not always static; however, in the studies reviewed, ML algorithms were used to read the static text to identify requirements. Further research on ML-based methods should be focusing on changing requirements and reducing their impact are urgently needed.
Limitation of this review
We used PRISMA as the research framework to identify the primary research studies in this review. Unlike other popular methods, such as snowballing approach, in this study, we did not exhaustively identify further relevant studies by iterating through the reference lists. This review chose to use minimum evidence to reflect the current state of ML-based requirements elicitation rather than providing an exhaustive result. Thus, some relevant studies may have been omitted from this review. In addition, there is a paradox between literature review and search query generation. Before a literature review is completed, it is not easy to define a set of exact keywords to represent the topic. Simultaneously, the absence of good search queries and keywords could defy the effort to retrieve relevant papers effectively. Hence, it is challenging to develop a perfect set of search queries at the initial stage that covers all of the aspects related to the field. To deal with these issues, we dynamically adjusted the search queries for seven academic databases to reduce bias and loss in the search results.
Numerous publications are excluded due to a lack of technical details; this does not imply that those articles are unimportant to this field. Various ideas and concepts may still be derived from these works. Moreover, only one of the similar works by the same author has been retained in the study; however, it is difficult to define a clear boundary to decide which work to keep. As a precaution to minimize the risks associated with inclusion–exclusion criteria, the authors discussed and evaluated the articles through meetings in cases wherever it was challenging to decide individually.
Additionally, human errors could not be avoided in the data extraction phase due to its nature of subjectivity. As data extraction table in Table 4 illustrated, the reviewer needs to enter two types of data manually. The first type of data is the descriptive data, which can be accessed from the academic research databases and the websites of journals. However, the second type of data requires reviewers to assess and extract information based on personal understanding. Therefore, the data extraction process inevitably contains a certain amount of bias and subjectivity. In addition, since the requirement elicitation is an interdisciplinary problem, many definitions are disputed. For example, the definition of the requirement and requirement elicitation are all defined differently by various researchers. Besides, some information was not explicitly stated in the reviewed articles, which led to difficulties in corresponding information retrieval. To overcome this limitation, the author team iterated and adjusted the data extraction table before reaching a final agreement.
Conclusion
The review provides an overview of the current research on ML-based requirements elicitation. First, we categorized the included studies into four ML-based requirement elicitation tasks: Preparation, Collection, Validation, and Negotiation. Second, we examined the data sources and corpora used by the included studies to develop the machine learning models for requirements elicitation. As a result, we identified three types of data sources for building ML solutions, which are Textual Documents, UGC, and Existing Requirement Datasets. Third, in this review, general ML pipelines are extracted from the included studies: text cleansing and preprocessing, textual feature extraction, machine learning, and evaluation. Furthermore, we identified 19 tasks among the selected works and assigned them to three types of text cleaning and preprocessing groups: filtering, normalizing, and tokenizing. For the text feature extraction part, we classified the included works into three groups according to the technique used to extract the features. BOW language models and handcrafted features are frequently found in reviewed publications, but in recent years, an increasing trend towards using embedding features has been observed. In addition, we discovered the most popular algorithms, such as Naive Bayes, Support Vector Machines, Decision Trees, and Neural Networks in this review. Precision, Recall, and F1 score are the most prevalent evaluation metrics applied to assess model performance. Finally, we listed the most popular NLP tools, which are NLTK and CoreNLP, and the most commonly applied machine learning tools, Weka and Scikit-learn.
Apart from the main findings, one major observation is that most research focuses on requirements categorization tasks. There is a notable majority of papers in the collection that are focused on supervised text classification, followed by topic modeling and clustering techniques. Second, we noticed that the existing articles are more focused on using machine learning to solve specific and fine-grained problems in requirements elicitation, such as classifying NFRs and extracting main topics from massive user reviews. It has, however, been relatively rare for research to examine how to integrate machine learning-based requirements acquisition methods into existing requirements elicitation workflows. Hence, the lack of expertise in designing, engineering, implementing, and configuring ML-based requirement elicitation systems calls for further research. Furthermore, most studies lack concrete evidence that machine learning can assist designers and engineers in reducing time and effort in requirement extraction. Last, although supervised learning is prevalent in this field, we have found only two publicly accessible labeled datasets from the 86 reviewed papers: DePaul's NFRs dataset (Cleland-Huang et al., Reference Cleland-Huang, Settimi, Zou and Sole2006) and SecReq (Knauss et al., Reference Knauss, Houmb, Schneider, Islam and Jürjens2011).
Thus far, ML-based solutions have been monolithic in eliciting requirements; however, the publications in this field provide sufficient evidence that ML can support requirements activities both theoretically and practically. A number of labor-intensive, error-prone activities from requirement engineering are waiting to be supported by ML. Despite what has already been accomplished, the best is yet to come.
Acknowledgments
This reported research is supported by NSERC Discovery Grant and NSERC Collaborative Research and Development Grant. In addition, we wish to express our gratitude to anonymous reviewers for their valuable comments and suggestions.
Cheligeer Cheligeer completed his Ph.D. program at Concordia University's Institute for Information Systems Engineering (CIISE) in 2022. He received his Master of Information Technology and Master of Business Information System from Monash University, Australia in 2015. His research interests include artificial intelligence, natural language processing, system design, software engineering, and health data science.
Jingwei Huang is a Ph.D. in Information Engineering (University of Toronto, 2008) and an Associate Professor of Systems Engineering at Old Dominion University. He has extensive research experience applying artificial intelligence in systems engineering and digital trust. His previous work includes using a logic-based AI approach for Knowledge Provenance ontologies, formal semantics of trust, trust calculus, trust mechanisms, trust models in PKIs, security policies integrating role-based and attribute-based access control models, and their applications in industry. Dr. Huang's current research focuses on Digital Systems Engineering to develop trustworthy AI/ML & Big Data solutions for Digital Engineering Transformation.
Guosong Wu is a postdoc fellow at the Centre for Health Informatics, Cumming School of Medicine, University of Calgary and Institute of Health Economics, University of Alberta. He received his Ph.D. in Health Services Research at the Department of Critical Care Medicine, University of Calgary, focused on the healthcare system performance evaluation by developing indicators to measure the quality and safety of care. His research interests focus on the improvement of healthcare quality through machine learning driven analytics of structured and unstructured Electronic Medical Records and administrative databases.
Nadia Bhuiyan obtained her bachelor's degree in Industrial Engineering from Concordia University and her M.Sc. and Ph.D. in Mechanical Engineering from McGill University. Her research focuses on product development processes, dealing with the design, development, production, and distribution of goods and services. Dr. Bhuiyan served as Associate Director and Director of Education of the Concordia Institute of Aerospace Design and Innovation, and Director of the Master of Aerospace Engineering program. She currently serves as Vice-Provost of Partnerships and Experiential Learning.
Yuan Xu is an Assistant Professor in Departments of Oncology, Community Health Science, and Surgery at University of Calgary. He obtained his M.D. and M.Sc. degrees and general surgery residency at Capital Medical University in Beijing, China. Subsequently, he received trainings on epidemiology and health services research as Ph.D. and Postdoctoral fellow at University of Calgary. Dr. Xu's main interest lies in developing methods to leverage multidimensional health data including electronic health data and administrative data to boost the outcome of health service studies, and to generate real-world evidence to support medical decision making at the health-system and point-care levels in cancer care.
Yong Zeng is a Professor in Information Systems Engineering at Concordia University. He is the President of the Society for Design and Process Science. He was NSERC Chair in aerospace design engineering (2015–2019) and Canada Research Chair in design science (2004–2014). Zeng researches into creative design by developing and employing mathematical and neurocognitive approaches. He has proposed Environment-Based Design (EBD) addressing the recursive nature of design and the role of mental stress in designer creativity. He applies the EBD to aerospace industry, medical device design, human resource management, municipality, teaching and learning design, and health.






















 Open access
Open access