


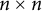
1 Introduction
This paper introduces norms on the space
 $\mathrm {M}_n$
of
$\mathrm {M}_n$
of
 $n\times n$
complex matrices that are induced by random vectors in
$n\times n$
complex matrices that are induced by random vectors in
 $\mathbb {R}^n$
. Specifically, we construct a family of norms for each random vector
$\mathbb {R}^n$
. Specifically, we construct a family of norms for each random vector
 $\boldsymbol {X}$
whose entries are independent and identically distributed (iid) random variables with sufficiently many moments . Initially, these norms are defined on complex Hermitian matrices as symmetric functions of their (necessarily real) eigenvalues. This contrasts with Schatten and Ky-Fan norms, which are defined in terms of singular values. To be more specific, our norms do not arise from the machinery of symmetric gauge functions [Reference Horn and Johnson13, Section 7.4.7]. The random vector norms we construct are actually generalizations of the complete homogeneous symmetric (CHS) polynomial norms introduced in [Reference Aguilar, Chávez, Garcia and Volčič1].
$\boldsymbol {X}$
whose entries are independent and identically distributed (iid) random variables with sufficiently many moments . Initially, these norms are defined on complex Hermitian matrices as symmetric functions of their (necessarily real) eigenvalues. This contrasts with Schatten and Ky-Fan norms, which are defined in terms of singular values. To be more specific, our norms do not arise from the machinery of symmetric gauge functions [Reference Horn and Johnson13, Section 7.4.7]. The random vector norms we construct are actually generalizations of the complete homogeneous symmetric (CHS) polynomial norms introduced in [Reference Aguilar, Chávez, Garcia and Volčič1].
1.1 Preliminaries
Our main result (Theorem 1.1 on page 4) connects a wide range of topics, such as cumulants, Bell polynomials, partitions, and Schur convexity. We briefly cover the preliminary concepts and notation necessary to state our main results.
1.1.1 Numbers and matrices
In what follows,
 $\mathbb {N} = \{1,2,\ldots \}$
; the symbols
$\mathbb {N} = \{1,2,\ldots \}$
; the symbols
 $\mathbb {R}$
and
$\mathbb {R}$
and
 $\mathbb {C}$
denote the real and complex number systems, respectively. Let
$\mathbb {C}$
denote the real and complex number systems, respectively. Let
 $\mathrm {M}_n$
denote the set of
$\mathrm {M}_n$
denote the set of
 $n \times n$
complex matrices and
$n \times n$
complex matrices and
 $\mathrm {H}_n \subset \mathrm {M}_n$
the subset of
$\mathrm {H}_n \subset \mathrm {M}_n$
the subset of
 $n\times n$
Hermitian complex matrices. We reserve the letter A for Hermitian matrices (so
$n\times n$
Hermitian complex matrices. We reserve the letter A for Hermitian matrices (so
 $A=A^*$
) and Z for arbitrary square complex matrices. The eigenvalues of each
$A=A^*$
) and Z for arbitrary square complex matrices. The eigenvalues of each
 $A\in \mathrm {H}_n$
are real and denoted
$A\in \mathrm {H}_n$
are real and denoted
 $\lambda _1(A)\geq \lambda _2(A)\geq \cdots \geq \lambda _n(A)$
. We may write
$\lambda _1(A)\geq \lambda _2(A)\geq \cdots \geq \lambda _n(A)$
. We may write
 $\boldsymbol {\lambda }=(\lambda _1, \lambda _2, \ldots , \lambda _n)$
if A is understood.
$\boldsymbol {\lambda }=(\lambda _1, \lambda _2, \ldots , \lambda _n)$
if A is understood.
1.1.2 Probability theory
A probability space is a measure space
 $(\Omega , \mathcal {F}, \mathbf {P}),$
in which
$(\Omega , \mathcal {F}, \mathbf {P}),$
in which
 $\mathcal {F}$
is a
$\mathcal {F}$
is a
 $\sigma $
-algebra on
$\sigma $
-algebra on
 $\Omega $
,
$\Omega $
,
 $\mathbf {P}$
is nonnegative, and
$\mathbf {P}$
is nonnegative, and
 $\mathbf {P}(\Omega )=1$
. A random variable is a measurable function
$\mathbf {P}(\Omega )=1$
. A random variable is a measurable function
 $X: \Omega \to \mathbb {R}$
. We assume that
$X: \Omega \to \mathbb {R}$
. We assume that
 $\Omega \subseteq \mathbb {R}$
and X is nondegenerate, that is, nonconstant. The expectation of X is
$\Omega \subseteq \mathbb {R}$
and X is nondegenerate, that is, nonconstant. The expectation of X is
 $\mathbf {E} [X]=\int _{\Omega } X \,d\mathbf {P},$
often written as
$\mathbf {E} [X]=\int _{\Omega } X \,d\mathbf {P},$
often written as
 $\mathbf {E} X$
. For
$\mathbf {E} X$
. For
 $p\geq 1,$
let
$p\geq 1,$
let
 $L^p(\Omega , \mathcal {F}, \mathbf {P})$
denote the vector space of random variables such that
$L^p(\Omega , \mathcal {F}, \mathbf {P})$
denote the vector space of random variables such that
 $\| X \|_{L^p}=(\mathbf {E} |X|^p)^{1/p} < \infty $
. The pushforward measure
$\| X \|_{L^p}=(\mathbf {E} |X|^p)^{1/p} < \infty $
. The pushforward measure
 $X_*\mathbf {P}$
of X is the probability distribution of X. The cumulative distribution of X is
$X_*\mathbf {P}$
of X is the probability distribution of X. The cumulative distribution of X is
 $F_X(x)=\mathbf {P}(X\leq x),$
which is the pushforward measure of
$F_X(x)=\mathbf {P}(X\leq x),$
which is the pushforward measure of
 $(-\infty , x]$
. If
$(-\infty , x]$
. If
 $X_{*}\mathbf {P}$
is absolutely continuous with respect to Lebesgue measure
$X_{*}\mathbf {P}$
is absolutely continuous with respect to Lebesgue measure
 $m,$
the Radon–Nikodym derivative
$m,$
the Radon–Nikodym derivative
 $f_X= dX_* P/dm$
is the probability density function (PDF) of X [Reference Billingsley5, Chapter 1].
$f_X= dX_* P/dm$
is the probability density function (PDF) of X [Reference Billingsley5, Chapter 1].
1.1.3 Random vectors
A random vector is a tuple
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which
 $X_1, X_2, \ldots , X_n$
are real-valued random variables on a common probability space
$X_1, X_2, \ldots , X_n$
are real-valued random variables on a common probability space
 $(\Omega ,\mathcal {F},\mathbf {P})$
; we assume
$(\Omega ,\mathcal {F},\mathbf {P})$
; we assume
 $\Omega \subseteq \mathbb {R}$
. A random vector
$\Omega \subseteq \mathbb {R}$
. A random vector
 $\boldsymbol {X}$
is positive definite if its second-moment matrix
$\boldsymbol {X}$
is positive definite if its second-moment matrix
 $\Sigma (\boldsymbol {X}) = [\mathbf {E} X_iX_j ]_{i,j=1}^n$
exists and is positive definite. This occurs if the
$\Sigma (\boldsymbol {X}) = [\mathbf {E} X_iX_j ]_{i,j=1}^n$
exists and is positive definite. This occurs if the
 $X_i$
are iid and belong to
$X_i$
are iid and belong to
 $L^2(\Omega ,\mathcal {F},\mathbf {P})$
(see Lemma 3.1).
$L^2(\Omega ,\mathcal {F},\mathbf {P})$
(see Lemma 3.1).
1.1.4 Moments
For
 $k \in \mathbb {N},$
the kth moment of X is
$k \in \mathbb {N},$
the kth moment of X is
 $\mu _k = \mathbf {E}[X^k],$
if it exists. If X has PDF
$\mu _k = \mathbf {E}[X^k],$
if it exists. If X has PDF
 $f_X,$
then
$f_X,$
then
 $\mu _k = \int _{-\infty }^{\infty } x^k f_X(x)\,dm(x)$
. The mean of X is
$\mu _k = \int _{-\infty }^{\infty } x^k f_X(x)\,dm(x)$
. The mean of X is
 $\mu _1$
and the variance of X is
$\mu _1$
and the variance of X is
 $\mu _2 - \mu _1^2$
; Jensen’s inequality ensures that the variance is positive since X is nondegenerate. The moment generating function (if it exists) of X is
$\mu _2 - \mu _1^2$
; Jensen’s inequality ensures that the variance is positive since X is nondegenerate. The moment generating function (if it exists) of X is
 $$ \begin{align} M(t)=\mathbf{E} [e^{tX}]=\sum_{k=0}^{\infty} \mathbf{E} [X^k] \frac{t^k}{k!} = \sum_{k=0}^{\infty} \mu_k\frac{t^k}{k!}. \end{align} $$
$$ \begin{align} M(t)=\mathbf{E} [e^{tX}]=\sum_{k=0}^{\infty} \mathbf{E} [X^k] \frac{t^k}{k!} = \sum_{k=0}^{\infty} \mu_k\frac{t^k}{k!}. \end{align} $$
If
 $X_1, X_2, \ldots , X_n$
are independent, then
$X_1, X_2, \ldots , X_n$
are independent, then
 $\mathbf {E} [X_1^{i_1} X_2^{i_2}\cdots X_n^{i_n}]=\prod _{k=1}^n\mathbf {E} [X_k^{i_k}],$
for all
$\mathbf {E} [X_1^{i_1} X_2^{i_2}\cdots X_n^{i_n}]=\prod _{k=1}^n\mathbf {E} [X_k^{i_k}],$
for all
 $i_1, i_2, \ldots , i_n \in \mathbb {N}$
whenever both sides exist.
$i_1, i_2, \ldots , i_n \in \mathbb {N}$
whenever both sides exist.
1.1.5 Cumulants
If X admits a moment generating function
 $M(t),$
then the rth cumulant
$M(t),$
then the rth cumulant
 $\kappa _r$
of X is defined by the cumulant generating function
$\kappa _r$
of X is defined by the cumulant generating function
 $$ \begin{align} K(t)=\log M(t)=\sum_{r=1}^{\infty} \kappa_r \frac{t^r}{r!}. \end{align} $$
$$ \begin{align} K(t)=\log M(t)=\sum_{r=1}^{\infty} \kappa_r \frac{t^r}{r!}. \end{align} $$
The first two cumulants are
 $\kappa _1 = \mu _1$
and
$\kappa _1 = \mu _1$
and
 $\kappa _2 = \mu _2 - \mu _1^2$
. If X does not admit a moment generating function but
$\kappa _2 = \mu _2 - \mu _1^2$
. If X does not admit a moment generating function but
 $X\in L^d(\Omega , \mathcal {F}, \mathbf {P})$
for some
$X\in L^d(\Omega , \mathcal {F}, \mathbf {P})$
for some
 $d\in \mathbb {N},$
we can define
$d\in \mathbb {N},$
we can define
 $\kappa _1, \kappa _2, \ldots , \kappa _d$
by the recursion
$\kappa _1, \kappa _2, \ldots , \kappa _d$
by the recursion
 $\mu _r=\sum _{\ell =0}^{r-1}{r-1\choose \ell } \mu _{\ell }\kappa _{r-\ell }$
for
$\mu _r=\sum _{\ell =0}^{r-1}{r-1\choose \ell } \mu _{\ell }\kappa _{r-\ell }$
for
 $1 \leq r \leq d$
(see [Reference Billingsley5, Section 9]).
$1 \leq r \leq d$
(see [Reference Billingsley5, Section 9]).
1.1.6 Power-series coefficients
The coefficient
 $c_k$
of
$c_k$
of
 $t^k$
in
$t^k$
in
 $f(t) = \sum _{r=0}^{\infty } c_r t^r$
is denoted
$f(t) = \sum _{r=0}^{\infty } c_r t^r$
is denoted
 $[t^k]f(t),$
as is standard in combinatorics and the study of generating functions.
$[t^k]f(t),$
as is standard in combinatorics and the study of generating functions.
1.1.7 Complete Bell polynomials
The complete Bell polynomials of degree
 $\ell $
[Reference Bell4, Section II] are the polynomials
$\ell $
[Reference Bell4, Section II] are the polynomials
 $B_{\ell }(x_1, x_2, \ldots , x_{\ell })$
defined by
$B_{\ell }(x_1, x_2, \ldots , x_{\ell })$
defined by
 $$ \begin{align} \sum_{\ell=0}^{\infty} B_{\ell}(x_1, x_2, \ldots, x_{\ell}) \frac{t^{\ell}}{\ell !}=\exp\bigg( \sum_{j=1}^{\infty} x_j \frac{t^j}{j!}\bigg). \end{align} $$
$$ \begin{align} \sum_{\ell=0}^{\infty} B_{\ell}(x_1, x_2, \ldots, x_{\ell}) \frac{t^{\ell}}{\ell !}=\exp\bigg( \sum_{j=1}^{\infty} x_j \frac{t^j}{j!}\bigg). \end{align} $$
For example,
 $B_0 = 1$
,
$B_0 = 1$
,
 $B_2(x_1,x_2)=x_1^2+x_2$
, and
$B_2(x_1,x_2)=x_1^2+x_2$
, and
 $$ \begin{align} B_4(x_1, x_2, x_3, x_4)=x_1^4+6x_1^2x_2+4x_1x_3+3x_2^2+x_4. \end{align} $$
$$ \begin{align} B_4(x_1, x_2, x_3, x_4)=x_1^4+6x_1^2x_2+4x_1x_3+3x_2^2+x_4. \end{align} $$
1.1.8 Symmetric and positive functions
A function is symmetric if it is invariant under all permutations of its arguments. A continuous real-valued function on
 $\mathrm {M}_n$
or
$\mathrm {M}_n$
or
 $\mathrm {H}_n$
is positive definite if it is everywhere positive, except perhaps at
$\mathrm {H}_n$
is positive definite if it is everywhere positive, except perhaps at
 $0$
.
$0$
.
1.1.9 Partitions
A partition of
 $d\in \mathbb {N}$
is a tuple
$d\in \mathbb {N}$
is a tuple
 $\boldsymbol {\pi }=(\pi _1, \pi _2, \ldots , \pi _r) \in \mathbb {N}^r$
such that
$\boldsymbol {\pi }=(\pi _1, \pi _2, \ldots , \pi _r) \in \mathbb {N}^r$
such that
 $\pi _1 \geq \pi _2 \geq \cdots \geq \pi _r$
and
$\pi _1 \geq \pi _2 \geq \cdots \geq \pi _r$
and
 $\pi _1+ \pi _2 + \cdots + \pi _r = d$
[Reference Stanley20, Section 1.7]. We denote this
$\pi _1+ \pi _2 + \cdots + \pi _r = d$
[Reference Stanley20, Section 1.7]. We denote this
 $\boldsymbol {\pi } \vdash d$
and write
$\boldsymbol {\pi } \vdash d$
and write
 $| \boldsymbol {\pi }| = r$
for the number of parts in the partition. Define
$| \boldsymbol {\pi }| = r$
for the number of parts in the partition. Define
 $$ \begin{align} \kappa_{\boldsymbol{\pi}} = \kappa_{\pi_1} \kappa_{\pi_2} \cdots \kappa_{\pi_{r}} \quad \text{and} \quad y_{\boldsymbol{\pi}}=\prod_{i\geq 1}(i!)^{m_i}m_i!, \end{align} $$
$$ \begin{align} \kappa_{\boldsymbol{\pi}} = \kappa_{\pi_1} \kappa_{\pi_2} \cdots \kappa_{\pi_{r}} \quad \text{and} \quad y_{\boldsymbol{\pi}}=\prod_{i\geq 1}(i!)^{m_i}m_i!, \end{align} $$
in which
 $m_i=m_i(\boldsymbol {\pi })$
is the multiplicity of i in
$m_i=m_i(\boldsymbol {\pi })$
is the multiplicity of i in
 $\boldsymbol {\pi }$
. For example,
$\boldsymbol {\pi }$
. For example,
 $\boldsymbol {\pi } = (4,4,2,1,1,1)$
yields
$\boldsymbol {\pi } = (4,4,2,1,1,1)$
yields
 $\kappa _{\boldsymbol {\pi }} = \kappa _4^2 \kappa _2 \kappa _1^3$
and
$\kappa _{\boldsymbol {\pi }} = \kappa _4^2 \kappa _2 \kappa _1^3$
and
 $y_{\boldsymbol {\pi }}= (1!^3 3!) (2!^1 1!) (4!^2 2!) = 13{,}824$
. Note that
$y_{\boldsymbol {\pi }}= (1!^3 3!) (2!^1 1!) (4!^2 2!) = 13{,}824$
. Note that
 $y_{\boldsymbol {\pi }}$
is not the quantity
$y_{\boldsymbol {\pi }}$
is not the quantity
 $z_{\boldsymbol {\pi }} = \prod _{i \geq 1} i^{m_i} m_i!$
from symmetric function theory [Reference Stanley21, Proposition 7.7.6].
$z_{\boldsymbol {\pi }} = \prod _{i \geq 1} i^{m_i} m_i!$
from symmetric function theory [Reference Stanley21, Proposition 7.7.6].
1.1.10 Power sums
For
 $\boldsymbol {\pi } \vdash d,$
let
$\boldsymbol {\pi } \vdash d,$
let
 $p_{\boldsymbol {\pi }}(x_1, x_2, \ldots , x_n)=p_{\pi _1}p_{\pi _1}\cdots p_{\pi _r},$
where
$p_{\boldsymbol {\pi }}(x_1, x_2, \ldots , x_n)=p_{\pi _1}p_{\pi _1}\cdots p_{\pi _r},$
where
 $p_k(x_1,x_2, \ldots , x_n)=x_1^k+x_2^k+\cdots +x_n^k$
is a power-sum symmetric polynomial; we often simply write
$p_k(x_1,x_2, \ldots , x_n)=x_1^k+x_2^k+\cdots +x_n^k$
is a power-sum symmetric polynomial; we often simply write
 $p_k$
. If
$p_k$
. If
 $A \in \mathrm {H}_n$
has eigenvalues
$A \in \mathrm {H}_n$
has eigenvalues
 $\boldsymbol {\lambda } = (\lambda _1,\lambda _2,\ldots ,\lambda _n),$
we write
$\boldsymbol {\lambda } = (\lambda _1,\lambda _2,\ldots ,\lambda _n),$
we write
 $$ \begin{align} p_{\boldsymbol{\pi}}(\boldsymbol{\lambda}) =p_{\pi_1}(\boldsymbol{\lambda})p_{\pi_2}(\boldsymbol{\lambda})\cdots p_{\pi_r}(\boldsymbol{\lambda}) =(\operatorname{tr} A^{\pi_1})(\operatorname{tr} A^{\pi_2})\cdots (\operatorname{tr} A^{\pi_{r}}). \end{align} $$
$$ \begin{align} p_{\boldsymbol{\pi}}(\boldsymbol{\lambda}) =p_{\pi_1}(\boldsymbol{\lambda})p_{\pi_2}(\boldsymbol{\lambda})\cdots p_{\pi_r}(\boldsymbol{\lambda}) =(\operatorname{tr} A^{\pi_1})(\operatorname{tr} A^{\pi_2})\cdots (\operatorname{tr} A^{\pi_{r}}). \end{align} $$
1.1.11 Complete homogeneous symmetric polynomials
The CHS polynomial of degree d in
 $x_1, x_2, \ldots x_n$
is
$x_1, x_2, \ldots x_n$
is
 $$ \begin{align} h_d(x_1,x_2,\ldots,x_n) = \sum_{1 \leq i_1 \leq \cdots \leq i_{d} \leq n} x_{i_1} x_{i_2}\cdots x_{i_d}, \end{align} $$
$$ \begin{align} h_d(x_1,x_2,\ldots,x_n) = \sum_{1 \leq i_1 \leq \cdots \leq i_{d} \leq n} x_{i_1} x_{i_2}\cdots x_{i_d}, \end{align} $$
the sum of all monomials of degree d in
 $x_1,x_2,\ldots ,x_n$
(see [Reference Stanley21, Section 7.5]). For example,
$x_1,x_2,\ldots ,x_n$
(see [Reference Stanley21, Section 7.5]). For example,
 $h_0(x_1,x_2) =1$
,
$h_0(x_1,x_2) =1$
,
 $h_2(x_1,x_2)= x_1^2+x_1 x_2+x_2^2$
, and
$h_2(x_1,x_2)= x_1^2+x_1 x_2+x_2^2$
, and
 $h_4(x_1,x_2)= x_1^4 + x_1^3 x_2 + x_1^2 x_2^2 + x_1 x_2^3 + x_2^4$
. Hunter proved that the even-degree CHS polynomials are positive definite [Reference Hunter14]. This has been rediscovered many times [Reference Aguilar, Chávez, Garcia and Volčič1, Theorem 1], [Reference Barvinok2, Lemma 3.1], [Reference Baston3], [Reference Böttcher, Garcia, Omar and O’Neill6, Theorem 2], [Reference Garcia, Omar, O’Neill and Yih9, Corollary 17], [Reference Rovenţa and Temereancă19, Theorem 2.3], [Reference Tao22, Theorem 1].
$h_4(x_1,x_2)= x_1^4 + x_1^3 x_2 + x_1^2 x_2^2 + x_1 x_2^3 + x_2^4$
. Hunter proved that the even-degree CHS polynomials are positive definite [Reference Hunter14]. This has been rediscovered many times [Reference Aguilar, Chávez, Garcia and Volčič1, Theorem 1], [Reference Barvinok2, Lemma 3.1], [Reference Baston3], [Reference Böttcher, Garcia, Omar and O’Neill6, Theorem 2], [Reference Garcia, Omar, O’Neill and Yih9, Corollary 17], [Reference Rovenţa and Temereancă19, Theorem 2.3], [Reference Tao22, Theorem 1].
1.1.12 Schur convexity
Let
 $\widetilde {\boldsymbol {x}}=(\widetilde {x}_1, \widetilde {x}_2, \ldots , \widetilde {x}_n)$
be the nondecreasing rearrangement of
$\widetilde {\boldsymbol {x}}=(\widetilde {x}_1, \widetilde {x}_2, \ldots , \widetilde {x}_n)$
be the nondecreasing rearrangement of
 $\boldsymbol {x}=(x_1,x_2, \ldots , x_n) \in \mathbb {R}^n$
. Then
$\boldsymbol {x}=(x_1,x_2, \ldots , x_n) \in \mathbb {R}^n$
. Then
 $\boldsymbol {y}$
majorizes
$\boldsymbol {y}$
majorizes
 $\boldsymbol {x},$
denoted
$\boldsymbol {x},$
denoted
 $\boldsymbol {x}\prec \boldsymbol {y},$
if
$\boldsymbol {x}\prec \boldsymbol {y},$
if
 $\sum _{i=1}^n \widetilde {x}_i = \sum _{i=1}^n \widetilde {y}_i$
and
$\sum _{i=1}^n \widetilde {x}_i = \sum _{i=1}^n \widetilde {y}_i$
and
 $\sum _{i=1}^k \widetilde {x}_i \leq \sum _{i=1}^k \widetilde {y}_i$
for
$\sum _{i=1}^k \widetilde {x}_i \leq \sum _{i=1}^k \widetilde {y}_i$
for
 $1 \leq k \leq n$
. A function
$1 \leq k \leq n$
. A function
 $f:\mathbb {R}^n\to \mathbb {R}$
is Schur convex if
$f:\mathbb {R}^n\to \mathbb {R}$
is Schur convex if
 $f(\boldsymbol {x})\leq f(\boldsymbol {y})$
whenever
$f(\boldsymbol {x})\leq f(\boldsymbol {y})$
whenever
 $\boldsymbol {x}\prec \boldsymbol {y}$
. This occurs if and only if
$\boldsymbol {x}\prec \boldsymbol {y}$
. This occurs if and only if
 $(x_i-x_j)( \frac {\partial }{\partial x_i}-\frac {\partial }{\partial x_j} )f(x_1, x_2, \ldots , x_n)\geq 0$
for all
$(x_i-x_j)( \frac {\partial }{\partial x_i}-\frac {\partial }{\partial x_j} )f(x_1, x_2, \ldots , x_n)\geq 0$
for all
 $1\leq i<j\leq n$
, with equality if and only if
$1\leq i<j\leq n$
, with equality if and only if
 $x_i=x_j$
[Reference Roberts and Varberg18, p. 259].
$x_i=x_j$
[Reference Roberts and Varberg18, p. 259].
1.2 Statement of main results
With the preliminary concepts and notation covered, we can state our main theorem. In what follows,
 $\Gamma $
is the gamma function and
$\Gamma $
is the gamma function and
 $\langle \cdot , \cdot \rangle $
is the Euclidean inner product on
$\langle \cdot , \cdot \rangle $
is the Euclidean inner product on
 $\mathbb {R}^n$
.
$\mathbb {R}^n$
.
Theorem 1.1 Let
 $d\geq 2$
and
$d\geq 2$
and
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which
 $X_1, X_2, \ldots , X_n \in L^d(\Omega ,\mathcal {F},\mathbf {P})$
are nondegenerate iid random variables.
$X_1, X_2, \ldots , X_n \in L^d(\Omega ,\mathcal {F},\mathbf {P})$
are nondegenerate iid random variables.
-
(a)
 $|\!|\!| A |\!|\!|_{\boldsymbol {X},d}= \bigg (\dfrac { \mathbf {E} |\langle \boldsymbol {X}, \boldsymbol {\lambda }\rangle |^d}{\Gamma (d+1)} \bigg )^{1/d}$
is a norm on
$\mathrm {H}_n$
.
$|\!|\!| A |\!|\!|_{\boldsymbol {X},d}= \bigg (\dfrac { \mathbf {E} |\langle \boldsymbol {X}, \boldsymbol {\lambda }\rangle |^d}{\Gamma (d+1)} \bigg )^{1/d}$
is a norm on
$\mathrm {H}_n$
. -
(b) If the
$X_i$
admit a moment generating function
$M(t)$
and
$d \geq 2$
is even, then (1.8)
$$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d = [t^d] M_{\Lambda}(t) \quad \text{for all } A \in \mathrm{H}_n, \end{align} $$
in which
$M_{\Lambda }(t) = \prod _{i=1}^n M(\lambda _i t)$
is the moment generating function for the random variable
$\Lambda =\langle \boldsymbol {X}, \boldsymbol {\lambda }(A) \rangle =\lambda _1X_1+\lambda _2X_2+\cdots +\lambda _n X_n$
. In particular,
$|\!|\!| A |\!|\!|_{\boldsymbol {X},d}$
is a positive definite, homogeneous, symmetric polynomial in the eigenvalues of A. -
(c) If the first d moments of
$X_i$
exist, then (1.9)
$$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d &= \frac{1}{d!} B_{d}(\kappa_1\operatorname{tr} A, \kappa_2\operatorname{tr} A^2, \ldots, \kappa_d\operatorname{tr} A^d) \end{align} $$
(1.10)
$$ \begin{align} &\!\!\!\!\!\kern-1pt= \sum_{\boldsymbol{\pi}\vdash d}\frac{\kappa_{\boldsymbol{\pi}}p_{\boldsymbol{\pi}} (\boldsymbol{\lambda})}{y_{\boldsymbol{\pi}}} \quad \text{for } A \in \mathrm{H}_n, \end{align} $$
in which
$B_d$
is given by (1.3), and in which
$\kappa _{\boldsymbol {\pi }}$
and
$y_{\boldsymbol {\pi }}$
are defined in (1.5),
$p_{\boldsymbol {\pi }} (\boldsymbol {\lambda })$
is defined in (1.6), and the second sum runs over all partitions
$\boldsymbol {\pi }$
of d. -
(d) The function
$\boldsymbol {\lambda }(A) \mapsto |\!|\!| A |\!|\!|_{\boldsymbol {X},d}$
is Schur convex. -
(e) Let
$\boldsymbol {\pi }=(\pi _1, \pi _2, \ldots ,\pi _r)$
be a partition of d. Define
$\mathrm {T}_{\boldsymbol {\boldsymbol {\pi }}} : \mathrm {M}_{n}\to \mathbb {R}$
by setting
$\mathrm {T}_{\boldsymbol {\pi }}(Z)$
to be
$1/{d\choose d/2}$
times the sum over the
$\binom {d}{d/2}$
possible locations to place
$d/2$
adjoints
${}^*$
among the d copies of Z in
$(\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _1}) (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _2}) \cdots (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _r})$
. Then (1.11)
$$ \begin{align} |\!|\!| Z |\!|\!|_{\boldsymbol{X},d}= \bigg( \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{ \kappa_{\boldsymbol{\pi}}\mathrm{T}_{\boldsymbol{\pi}}(Z)}{y_{\boldsymbol{\pi}}}\bigg)^{1/d} \quad \text{for } Z \in \mathrm{M}_n, \end{align} $$
in which
$\kappa _{\boldsymbol {\pi }}$
and
$y_{\boldsymbol {\pi }}$
are defined in (1.5) and the sum runs over all partitions
$\boldsymbol {\pi }$
of
$d,$
is a norm on
$\mathrm {M}_n$
that restricts to the norm on
$\mathrm {H}_n$
above. In particular,
$|\!|\!| Z |\!|\!|_{\boldsymbol {X},d}^d$
is a positive definite trace polynomial in Z and
$Z^*$
.



































The independence of the
 $X_i$
is not needed in (a) and (d) (see Remarks 3.4 and 3.5, respectively). A more precise definition of
$X_i$
is not needed in (a) and (d) (see Remarks 3.4 and 3.5, respectively). A more precise definition of
 $\mathrm {T}_{\boldsymbol {\pi }}(Z)$
is in Section 3.5, although the examples in the next section better illustrate how to compute (1.11).
$\mathrm {T}_{\boldsymbol {\pi }}(Z)$
is in Section 3.5, although the examples in the next section better illustrate how to compute (1.11).
The positive definiteness of (1.8), (1.9), and (1.11) is guaranteed by Theorem 1.1; the triangle inequality is difficult to verify directly. Positivity is not obvious since we consider the eigenvalues of
 $A \in \mathrm {H}_n$
and not their absolute values in (a) and (b). Thus, these norms on
$A \in \mathrm {H}_n$
and not their absolute values in (a) and (b). Thus, these norms on
 $\mathrm {H}_n$
do not arise from singular values or symmetric gauge functions [Reference Horn and Johnson13, Section 7.4.7]. Norms like ours can distinguish singularly cospectral graphs, unlike the operator, Frobenius, Schatten–von Neumann, and Ky Fan norms (see [Reference Aguilar, Chávez, Garcia and Volčič1, Example 2]).
$\mathrm {H}_n$
do not arise from singular values or symmetric gauge functions [Reference Horn and Johnson13, Section 7.4.7]. Norms like ours can distinguish singularly cospectral graphs, unlike the operator, Frobenius, Schatten–von Neumann, and Ky Fan norms (see [Reference Aguilar, Chávez, Garcia and Volčič1, Example 2]).
1.3 Organization
This paper is organized as follows: We first cover examples and applications in Section 2, including a generalization of Hunter’s positivity theorem. The proof of Theorem 1.1, which is lengthy and involves a variety of ingredients, is contained in Section 3. We end this paper in Section 4 with a list of open questions that demand further exploration.
2 Examples and applications
We begin with computations for small d (Section 2.1). Gamma random variables (Section 2.2) lead to a generalization of Hunter’s positivity theorem (Section 2.3). We examine norms arising from familiar distributions in Sections 2.4–2.10.
2.1 Generic computations
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
where the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
where the
 $X_i$
are nondegenerate iid random variables such that the stated cumulants and moments exist. For
$X_i$
are nondegenerate iid random variables such that the stated cumulants and moments exist. For
 $d=2$
and
$d=2$
and
 $4,$
we obtain trace-polynomial representations of
$4,$
we obtain trace-polynomial representations of
 $|\!|\!| Z |\!|\!|_{d}$
in terms of cumulants or moments. This can also be done for
$|\!|\!| Z |\!|\!|_{d}$
in terms of cumulants or moments. This can also be done for
 $d=6,8,\ldots ,$
but we refrain from the exercise.
$d=6,8,\ldots ,$
but we refrain from the exercise.
Example 2.1 The two partitions of
 $d=2$
satisfy
$d=2$
satisfy
 $\kappa _{(2)} = \kappa _2= \mu _2 - \mu _1^2,$
$\kappa _{(2)} = \kappa _2= \mu _2 - \mu _1^2,$
 $\kappa _{(1,1)} = \kappa _1^2 = \mu _1^2,$
and
$\kappa _{(1,1)} = \kappa _1^2 = \mu _1^2,$
and
 $y_{(2)} = y_{(1,1)} = 2$
. There are
$y_{(2)} = y_{(1,1)} = 2$
. There are
 $\binom {2}{1} = 2$
ways to place two adjoints
$\binom {2}{1} = 2$
ways to place two adjoints
 ${}^*$
in a string of two Zs. Thus,
${}^*$
in a string of two Zs. Thus,
 $\mathrm {T}_{(2)}(Z) = \frac {1}{2} (\operatorname {tr}(Z^*Z)+\operatorname {tr}(ZZ^*) ) = \operatorname {tr}(Z^*Z)$
and
$\mathrm {T}_{(2)}(Z) = \frac {1}{2} (\operatorname {tr}(Z^*Z)+\operatorname {tr}(ZZ^*) ) = \operatorname {tr}(Z^*Z)$
and
 $\mathrm {T}_{(1,1)}(Z) = \frac {1}{2}( (\operatorname {tr} Z^*)(\operatorname {tr} Z) +(\operatorname {tr} Z)(\operatorname {tr} Z^*) ) =(\operatorname {tr} Z^*)(\operatorname {tr} Z)$
, so
$\mathrm {T}_{(1,1)}(Z) = \frac {1}{2}( (\operatorname {tr} Z^*)(\operatorname {tr} Z) +(\operatorname {tr} Z)(\operatorname {tr} Z^*) ) =(\operatorname {tr} Z^*)(\operatorname {tr} Z)$
, so
 $$ \begin{align} |\!|\!| Z |\!|\!|_{\boldsymbol{X},2}^2 = \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{ \kappa_{\boldsymbol{\pi}}\mathrm{T}_{\boldsymbol{\pi}}(A) }{y_{\boldsymbol{\pi}}} = \frac{\mu_2-\mu_1^2}{2} \operatorname{tr}(Z^*Z) + \frac{\mu_1^2}{2} (\operatorname{tr} Z^*)(\operatorname{tr} Z). \end{align} $$
$$ \begin{align} |\!|\!| Z |\!|\!|_{\boldsymbol{X},2}^2 = \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{ \kappa_{\boldsymbol{\pi}}\mathrm{T}_{\boldsymbol{\pi}}(A) }{y_{\boldsymbol{\pi}}} = \frac{\mu_2-\mu_1^2}{2} \operatorname{tr}(Z^*Z) + \frac{\mu_1^2}{2} (\operatorname{tr} Z^*)(\operatorname{tr} Z). \end{align} $$
If
 $\mu _1 = 0$
(mean zero), then
$\mu _1 = 0$
(mean zero), then
 $|\!|\!| \cdot |\!|\!|_2$
is a nonzero multiple of the Frobenius norm since the variance
$|\!|\!| \cdot |\!|\!|_2$
is a nonzero multiple of the Frobenius norm since the variance
 $\mu _2-\mu _1^2$
is positive by nondegeneracy. As predicted by Theorem 1.1, the norm (2.1) on
$\mu _2-\mu _1^2$
is positive by nondegeneracy. As predicted by Theorem 1.1, the norm (2.1) on
 $\mathrm {M}_n$
reduces to (1.9) on
$\mathrm {M}_n$
reduces to (1.9) on
 $\mathrm {H}_n$
since
$\mathrm {H}_n$
since
 $B_2(x_1,x_2)=x_1^2+x_2$
and
$B_2(x_1,x_2)=x_1^2+x_2$
and
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},2}^2 &=\frac{1}{2}B_2( \kappa_1 \operatorname{tr} A, \kappa_2 \operatorname{tr} A^2)\\& = \frac{1}{2}\big[ (\kappa_1 \operatorname{tr} A)^2 + \kappa_2 \operatorname{tr} (A^2) \big] = \frac{\mu_2 - \mu_1^2}{2} \operatorname{tr}(A^2) + \frac{\mu_1^2}{2} (\operatorname{tr} A)^2, \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},2}^2 &=\frac{1}{2}B_2( \kappa_1 \operatorname{tr} A, \kappa_2 \operatorname{tr} A^2)\\& = \frac{1}{2}\big[ (\kappa_1 \operatorname{tr} A)^2 + \kappa_2 \operatorname{tr} (A^2) \big] = \frac{\mu_2 - \mu_1^2}{2} \operatorname{tr}(A^2) + \frac{\mu_1^2}{2} (\operatorname{tr} A)^2, \end{align*} $$
which agrees with (2.1) if
 $Z = A = A^*$
.
$Z = A = A^*$
.
Example 2.2 The five partitions of
 $d=4$
satisfy
$d=4$
satisfy
 $$ \begin{align*} \begin{array}{r@{\ }c@{\ }lr@{\ }c@{\ }lr@{\ }c@{\ }lr@{\ }c@{\ }lr@{\ }c@{\ }l} \kappa_{(4)} &=& \kappa_4,\quad &\kappa_{(3,1)} &=& \kappa_1 \kappa_3,\quad &\kappa_{(2,2)} &=& \kappa_2^2,\quad &\kappa_{(2,1,1)} &=& \kappa_2 \kappa_1^2,\quad &\kappa_{(1,1,1,1)} &=& \kappa_1^4, \\ y_{(4)} &=& 24,\quad &y_{(3,1)} &=& 6,\quad &y_{(2,2)} &=& 8,\quad &y_{(2,1,1)} &=& 4,\quad &y_{(1,1,1,1)} &=& 24. \end{array} \end{align*} $$
$$ \begin{align*} \begin{array}{r@{\ }c@{\ }lr@{\ }c@{\ }lr@{\ }c@{\ }lr@{\ }c@{\ }lr@{\ }c@{\ }l} \kappa_{(4)} &=& \kappa_4,\quad &\kappa_{(3,1)} &=& \kappa_1 \kappa_3,\quad &\kappa_{(2,2)} &=& \kappa_2^2,\quad &\kappa_{(2,1,1)} &=& \kappa_2 \kappa_1^2,\quad &\kappa_{(1,1,1,1)} &=& \kappa_1^4, \\ y_{(4)} &=& 24,\quad &y_{(3,1)} &=& 6,\quad &y_{(2,2)} &=& 8,\quad &y_{(2,1,1)} &=& 4,\quad &y_{(1,1,1,1)} &=& 24. \end{array} \end{align*} $$
There are
 $\binom {4}{2} = 6$
ways to place two adjoints
$\binom {4}{2} = 6$
ways to place two adjoints
 ${}^*$
in a string of four Zs. For example,
${}^*$
in a string of four Zs. For example,
 $$ \begin{align*} 6\mathrm{T}_{(3,1)}(Z) &= (\operatorname{tr} Z^*Z^*Z)(\operatorname{tr} Z) + (\operatorname{tr} Z^*ZZ^*)(\operatorname{tr} Z) + (\operatorname{tr} Z^*ZZ)(\operatorname{tr} Z^*) \\ &\quad + (\operatorname{tr} ZZ^*Z^*)(\operatorname{tr} Z) +(\operatorname{tr} ZZ^*Z)(\operatorname{tr} Z^*) +(\operatorname{tr} ZZZ^*)(\operatorname{tr} Z^*)\\ &=3 \operatorname{tr} (Z^{*2}Z)(\operatorname{tr} Z) +3 (\operatorname{tr} Z^2 Z^*)(\operatorname{tr} Z^*). \end{align*} $$
$$ \begin{align*} 6\mathrm{T}_{(3,1)}(Z) &= (\operatorname{tr} Z^*Z^*Z)(\operatorname{tr} Z) + (\operatorname{tr} Z^*ZZ^*)(\operatorname{tr} Z) + (\operatorname{tr} Z^*ZZ)(\operatorname{tr} Z^*) \\ &\quad + (\operatorname{tr} ZZ^*Z^*)(\operatorname{tr} Z) +(\operatorname{tr} ZZ^*Z)(\operatorname{tr} Z^*) +(\operatorname{tr} ZZZ^*)(\operatorname{tr} Z^*)\\ &=3 \operatorname{tr} (Z^{*2}Z)(\operatorname{tr} Z) +3 (\operatorname{tr} Z^2 Z^*)(\operatorname{tr} Z^*). \end{align*} $$
Summing over all five partitions yields the following norm on
 $\mathrm {M}_n$
:
$\mathrm {M}_n$
:
 $$ \begin{align} |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{72}\big( 3 \kappa_1^4 (\operatorname{tr} Z^*)^2 (\operatorname{tr} Z)^2 +3 \kappa_2 \kappa_1^2 (\operatorname{tr} Z^*)^2 \operatorname{tr} (Z^2) +3 \kappa_2 \kappa_1^2 \operatorname{tr} (Z^{*2})(\operatorname{tr} Z)^2 \nonumber \\ &\qquad +12 \kappa_2 \kappa_1^2 (\operatorname{tr} Z^*) (\operatorname{tr} Z^*Z) (\operatorname{tr} Z) +6 \kappa_3 \kappa_1 \operatorname{tr} ( Z^{*2}Z)(\operatorname{tr} Z) \nonumber \\ &\qquad +6 \kappa_3 \kappa_1 \operatorname{tr} (Z^*) \operatorname{tr} (Z^* Z^2 ) +6 \kappa_2^2 (\operatorname{tr} Z^*Z)^2 +3 \kappa_2^2 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2}) \nonumber \\ &\qquad +2 \kappa_4 \operatorname{tr} (Z^2 Z^{*2})+\kappa_4 \operatorname{tr} (Z Z^* Z Z^*) \big). \end{align} $$
$$ \begin{align} |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{72}\big( 3 \kappa_1^4 (\operatorname{tr} Z^*)^2 (\operatorname{tr} Z)^2 +3 \kappa_2 \kappa_1^2 (\operatorname{tr} Z^*)^2 \operatorname{tr} (Z^2) +3 \kappa_2 \kappa_1^2 \operatorname{tr} (Z^{*2})(\operatorname{tr} Z)^2 \nonumber \\ &\qquad +12 \kappa_2 \kappa_1^2 (\operatorname{tr} Z^*) (\operatorname{tr} Z^*Z) (\operatorname{tr} Z) +6 \kappa_3 \kappa_1 \operatorname{tr} ( Z^{*2}Z)(\operatorname{tr} Z) \nonumber \\ &\qquad +6 \kappa_3 \kappa_1 \operatorname{tr} (Z^*) \operatorname{tr} (Z^* Z^2 ) +6 \kappa_2^2 (\operatorname{tr} Z^*Z)^2 +3 \kappa_2^2 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2}) \nonumber \\ &\qquad +2 \kappa_4 \operatorname{tr} (Z^2 Z^{*2})+\kappa_4 \operatorname{tr} (Z Z^* Z Z^*) \big). \end{align} $$
If
 $Z = A\in \mathrm {H}_n,$
Theorem 1.1.c and (1.4) ensure that the above reduces to
$Z = A\in \mathrm {H}_n,$
Theorem 1.1.c and (1.4) ensure that the above reduces to
 $$ \begin{align*} \tfrac{1}{24}\big( \kappa _1^4 (\operatorname{tr} A)^4\kern1.3pt{+}\kern1.3pt6 \kappa _1^2 \kappa _2 \operatorname{tr}(A^2) (\operatorname{tr} A)^2 \kern1.3pt{+}\kern1.3pt 4 \kappa _1 \kappa _3 \operatorname{tr} (A^3) \operatorname{tr} (A) \kern1.3pt{+}\kern1.3pt 3 \kappa _2^2 \operatorname{tr} (A^2)^2\kern1.3pt{+}\kern1.3pt\kappa _4 \operatorname{tr} (A^4) \kern-1pt\big). \end{align*} $$
$$ \begin{align*} \tfrac{1}{24}\big( \kappa _1^4 (\operatorname{tr} A)^4\kern1.3pt{+}\kern1.3pt6 \kappa _1^2 \kappa _2 \operatorname{tr}(A^2) (\operatorname{tr} A)^2 \kern1.3pt{+}\kern1.3pt 4 \kappa _1 \kappa _3 \operatorname{tr} (A^3) \operatorname{tr} (A) \kern1.3pt{+}\kern1.3pt 3 \kappa _2^2 \operatorname{tr} (A^2)^2\kern1.3pt{+}\kern1.3pt\kappa _4 \operatorname{tr} (A^4) \kern-1pt\big). \end{align*} $$
2.2 Gamma random variables
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
 $X_i$
are independent with probability density
$X_i$
are independent with probability density
 $$ \begin{align} f(t)=\begin{cases} \frac{1}{\beta^{\alpha} \Gamma(\alpha)} t^{\alpha - 1} e^{-t/\beta}, & \text{if } t> 0,\\ 0, & \text{if } t\leq 0. \end{cases} \end{align} $$
$$ \begin{align} f(t)=\begin{cases} \frac{1}{\beta^{\alpha} \Gamma(\alpha)} t^{\alpha - 1} e^{-t/\beta}, & \text{if } t> 0,\\ 0, & \text{if } t\leq 0. \end{cases} \end{align} $$
Here,
 $\alpha , \beta>0$
(note that
$\alpha , \beta>0$
(note that
 $\alpha = k/2$
and
$\alpha = k/2$
and
 $\beta = 2$
yield a chi-squared random variable with k degrees of freedom, and
$\beta = 2$
yield a chi-squared random variable with k degrees of freedom, and
 $\alpha =\beta =1$
is the standard exponential distribution). Then
$\alpha =\beta =1$
is the standard exponential distribution). Then
 $M(t) = (1 - \beta t)^{-\alpha }$
and
$M(t) = (1 - \beta t)^{-\alpha }$
and
 $K(t) = - \alpha \log (1 - \beta t)$
, so
$K(t) = - \alpha \log (1 - \beta t)$
, so
 $$ \begin{align} \kappa_r = \alpha \beta^r(r-1)! \quad \text{for } r \in \mathbb{N}. \end{align} $$
$$ \begin{align} \kappa_r = \alpha \beta^r(r-1)! \quad \text{for } r \in \mathbb{N}. \end{align} $$
For even
 $d\geq 2,$
$d\geq 2,$
 $$ \begin{align}\ \qquad |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d = [t^d] \prod_{i=1}^n \frac{1}{(1-\beta \lambda_i t)^{\alpha}} =[t^d] \Bigg(\frac{1}{\beta^n t^n p_A(\beta^{-1}t^{-1})}\Bigg)^{\alpha} \quad \text{for } A \in \mathrm{H}_n, \end{align} $$
$$ \begin{align}\ \qquad |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d = [t^d] \prod_{i=1}^n \frac{1}{(1-\beta \lambda_i t)^{\alpha}} =[t^d] \Bigg(\frac{1}{\beta^n t^n p_A(\beta^{-1}t^{-1})}\Bigg)^{\alpha} \quad \text{for } A \in \mathrm{H}_n, \end{align} $$
in which
 $p_A(t) = \det (tI-A)$
denotes the characteristic polynomial of A.
$p_A(t) = \det (tI-A)$
denotes the characteristic polynomial of A.
Example 2.3 Since
 $\kappa _1 = \alpha \beta $
and
$\kappa _1 = \alpha \beta $
and
 $\kappa _2 = \alpha \beta ^2,$
(2.1) becomes
$\kappa _2 = \alpha \beta ^2,$
(2.1) becomes
 $|\!|\!| Z |\!|\!|_{\boldsymbol {X},2}^2 = \tfrac {1}{2} \alpha \beta ^2 \operatorname {tr} (Z^*Z) + \tfrac {1}{2} \alpha ^2 \beta ^2 (\operatorname {tr} Z^*)(\operatorname {tr} Z) $
for
$|\!|\!| Z |\!|\!|_{\boldsymbol {X},2}^2 = \tfrac {1}{2} \alpha \beta ^2 \operatorname {tr} (Z^*Z) + \tfrac {1}{2} \alpha ^2 \beta ^2 (\operatorname {tr} Z^*)(\operatorname {tr} Z) $
for
 $Z\in \mathrm {M}_n$
. Similarly, (2.2) yields generalizations of [Reference Aguilar, Chávez, Garcia and Volčič1, equations (8) and (9)] (which correspond to
$Z\in \mathrm {M}_n$
. Similarly, (2.2) yields generalizations of [Reference Aguilar, Chávez, Garcia and Volčič1, equations (8) and (9)] (which correspond to
 $\alpha = \beta = 1$
):
$\alpha = \beta = 1$
):
 $$ \begin{align*} |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{24}\big( \alpha^4 \beta^4 (\operatorname{tr} Z)^2 (\operatorname{tr} Z^*)^2 +\alpha^3 \beta^4 (\operatorname{tr} Z^*)^2 \operatorname{tr}(Z^2) \\ &\quad +4 \alpha^3 \beta^4 (\operatorname{tr} Z)(\operatorname{tr} Z^*)(\operatorname{tr} Z^* Z) +2 \alpha^2 \beta^4 (\operatorname{tr} Z^* Z)^2 \\ &\quad +\alpha^3 \beta^4 (\operatorname{tr} Z)^2 \operatorname{tr}(Z^{*2}) +\alpha^2 \beta^4 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2}) \\ &\quad +4 \alpha^2 \beta^4 \operatorname{tr}(Z^*)\operatorname{tr} (Z^* Z^2) +4 \alpha^2 \beta^4 \operatorname{tr} (Z) \operatorname{tr} (Z^{*2} Z) \\ &\quad +2 \alpha \beta^4 \operatorname{tr} (Z^* Z Z^* Z) +4 \alpha \beta^4 \operatorname{tr} (Z^{*2} Z^2) \big). \end{align*} $$
$$ \begin{align*} |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{24}\big( \alpha^4 \beta^4 (\operatorname{tr} Z)^2 (\operatorname{tr} Z^*)^2 +\alpha^3 \beta^4 (\operatorname{tr} Z^*)^2 \operatorname{tr}(Z^2) \\ &\quad +4 \alpha^3 \beta^4 (\operatorname{tr} Z)(\operatorname{tr} Z^*)(\operatorname{tr} Z^* Z) +2 \alpha^2 \beta^4 (\operatorname{tr} Z^* Z)^2 \\ &\quad +\alpha^3 \beta^4 (\operatorname{tr} Z)^2 \operatorname{tr}(Z^{*2}) +\alpha^2 \beta^4 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2}) \\ &\quad +4 \alpha^2 \beta^4 \operatorname{tr}(Z^*)\operatorname{tr} (Z^* Z^2) +4 \alpha^2 \beta^4 \operatorname{tr} (Z) \operatorname{tr} (Z^{*2} Z) \\ &\quad +2 \alpha \beta^4 \operatorname{tr} (Z^* Z Z^* Z) +4 \alpha \beta^4 \operatorname{tr} (Z^{*2} Z^2) \big). \end{align*} $$
2.3 A generalization of Hunter’s positivity theorem
Examining the gamma distribution (Section 2.2) recovers Hunter’s theorem [Reference Hunter14] (Corollary 2.6) and establishes a powerful generalization (Theorem 2.5).
Example 2.4 Let
 $\alpha =\beta =1$
in (2.3) and (2.5). Then
$\alpha =\beta =1$
in (2.3) and (2.5). Then
 $$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^2 = [t^d] \prod_{i=1}^n\frac{1}{1-\lambda_it}=[t^d] \frac{1}{t^np_A(t^{-1})} \quad \text{for } A \in \mathrm{H}_n, \end{align} $$
$$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^2 = [t^d] \prod_{i=1}^n\frac{1}{1-\lambda_it}=[t^d] \frac{1}{t^np_A(t^{-1})} \quad \text{for } A \in \mathrm{H}_n, \end{align} $$
which is [Reference Aguilar, Chávez, Garcia and Volčič1, Theorem 20]. Expand each factor
 $(1 - \lambda _i t)^{-1}$
as a geometric series, multiply out the result, and deduce that for
$(1 - \lambda _i t)^{-1}$
as a geometric series, multiply out the result, and deduce that for
 $d \geq 2$
even,
$d \geq 2$
even,
 $$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d =[t^d] \prod_{i=1}^n\frac{1}{1-\lambda_it} =[t^d] \sum_{r=0}^{\infty} h_r(\lambda_1, \lambda_2, \ldots, \lambda_n) t^r. \end{align} $$
$$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d =[t^d] \prod_{i=1}^n\frac{1}{1-\lambda_it} =[t^d] \sum_{r=0}^{\infty} h_r(\lambda_1, \lambda_2, \ldots, \lambda_n) t^r. \end{align} $$
From (2.4), we have
 $\kappa _i=(i-1)!$
. Therefore,
$\kappa _i=(i-1)!$
. Therefore,
 $$ \begin{align*} \frac{\kappa_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}}=\frac{\prod_{i\geq 1} \big[(i-1)!\big]^{m_i}}{\prod_{i\geq 1} (i!)^{m_i} m_i!}=\frac{1}{\prod_{i\geq 1}i^{m_i}m_i!} \end{align*} $$
$$ \begin{align*} \frac{\kappa_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}}=\frac{\prod_{i\geq 1} \big[(i-1)!\big]^{m_i}}{\prod_{i\geq 1} (i!)^{m_i} m_i!}=\frac{1}{\prod_{i\geq 1}i^{m_i}m_i!} \end{align*} $$
for any partition
 $\boldsymbol {\pi }$
. Theorem 1.1 and (1.5) imply that for even
$\boldsymbol {\pi }$
. Theorem 1.1 and (1.5) imply that for even
 $d\geq 2$
and
$d\geq 2$
and
 $A \in \mathrm {H}_n,$
$A \in \mathrm {H}_n,$
 $$ \begin{align} h_d(\lambda_1, \lambda_2, \ldots, \lambda_n) = |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=\sum_{\boldsymbol{\pi}\vdash d}\frac{\kappa_{\boldsymbol{\pi}}p_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}} =\sum_{\boldsymbol{\pi}\vdash d}\frac{p_{\boldsymbol{\pi}}}{z_{\boldsymbol{\pi}}} , \end{align} $$
$$ \begin{align} h_d(\lambda_1, \lambda_2, \ldots, \lambda_n) = |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=\sum_{\boldsymbol{\pi}\vdash d}\frac{\kappa_{\boldsymbol{\pi}}p_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}} =\sum_{\boldsymbol{\pi}\vdash d}\frac{p_{\boldsymbol{\pi}}}{z_{\boldsymbol{\pi}}} , \end{align} $$
in which
 $z_{\boldsymbol {\pi }}=\prod _{i\geq 1}i^{m_i}m_i!$
and
$z_{\boldsymbol {\pi }}=\prod _{i\geq 1}i^{m_i}m_i!$
and
 $p_{\boldsymbol {\pi }}$
is given by (1.6). This recovers the combinatorial representation of even-degree CHS polynomials [Reference Stanley21, Proposition 7.7.6] and establishes Hunter’s positivity theorem since
$p_{\boldsymbol {\pi }}$
is given by (1.6). This recovers the combinatorial representation of even-degree CHS polynomials [Reference Stanley21, Proposition 7.7.6] and establishes Hunter’s positivity theorem since
 $|\!|\!| \cdot |\!|\!|_{\boldsymbol {X},d}^d$
is positive definite.
$|\!|\!| \cdot |\!|\!|_{\boldsymbol {X},d}^d$
is positive definite.
The next theorem generalizes Hunter’s theorem [Reference Hunter14], which is the case
 $\alpha = 1$
.
$\alpha = 1$
.
Theorem 2.5 For even
 $d\geq 2$
and
$d\geq 2$
and
 $\alpha \in \mathbb {N},$
$\alpha \in \mathbb {N},$
 $$ \begin{align*} H_{d,\alpha}(x_1,x_2, \ldots, x_n)= \sum_{\substack{\boldsymbol{\pi}\vdash d\\ |\boldsymbol{\pi}|\leq\alpha}} c_{\boldsymbol{\pi}} h_{\boldsymbol{\pi}}(x_1,x_2,\ldots,x_n) \end{align*} $$
$$ \begin{align*} H_{d,\alpha}(x_1,x_2, \ldots, x_n)= \sum_{\substack{\boldsymbol{\pi}\vdash d\\ |\boldsymbol{\pi}|\leq\alpha}} c_{\boldsymbol{\pi}} h_{\boldsymbol{\pi}}(x_1,x_2,\ldots,x_n) \end{align*} $$
is positive definite on
 $\mathbb {R}^n,$
in which the sum runs over all partitions
$\mathbb {R}^n,$
in which the sum runs over all partitions
 $\boldsymbol {\pi }=(\pi _1,\pi _2,\ldots ,\pi _r)$
of d. Here,
$\boldsymbol {\pi }=(\pi _1,\pi _2,\ldots ,\pi _r)$
of d. Here,
 $h_{\boldsymbol {\pi }}=h_{\pi _1}h_{\pi _2}\cdots h_{\pi _r}$
is a product of CHS polynomials and
$h_{\boldsymbol {\pi }}=h_{\pi _1}h_{\pi _2}\cdots h_{\pi _r}$
is a product of CHS polynomials and
 $$ \begin{align*} c_{\boldsymbol{\pi}} = \frac{\alpha !}{ (\alpha-|\boldsymbol{\pi}|)! \prod_{i=1}^r m_i!}, \end{align*} $$
$$ \begin{align*} c_{\boldsymbol{\pi}} = \frac{\alpha !}{ (\alpha-|\boldsymbol{\pi}|)! \prod_{i=1}^r m_i!}, \end{align*} $$
where
 $|\boldsymbol {\pi }|$
denotes the number of parts in
$|\boldsymbol {\pi }|$
denotes the number of parts in
 $\boldsymbol {\pi }$
and
$\boldsymbol {\pi }$
and
 $m_i$
is the multiplicity of i in
$m_i$
is the multiplicity of i in
 $\boldsymbol {\pi }$
.
$\boldsymbol {\pi }$
.
Proof Let
 $\alpha \in \mathbb {N}$
and define polynomials
$\alpha \in \mathbb {N}$
and define polynomials
 $P_{\ell }^{(\alpha )}(x_1, x_2, \ldots , x_{\ell })$
by
$P_{\ell }^{(\alpha )}(x_1, x_2, \ldots , x_{\ell })$
by
 $$ \begin{align} P_0^{(\alpha)}=x_0=1 \quad \text{and} \quad \Big(1+ \sum_{r=1}^{\infty} x_r t^r \Big)^{\alpha} =\sum_{\ell=0}^{\infty}P_{\ell}^{(\alpha)}(x_1, x_2, \ldots, x_{\ell})t^{\ell}. \end{align} $$
$$ \begin{align} P_0^{(\alpha)}=x_0=1 \quad \text{and} \quad \Big(1+ \sum_{r=1}^{\infty} x_r t^r \Big)^{\alpha} =\sum_{\ell=0}^{\infty}P_{\ell}^{(\alpha)}(x_1, x_2, \ldots, x_{\ell})t^{\ell}. \end{align} $$
Then
 $$ \begin{align} P_{\ell}^{(\alpha)}( x_1,x_2, \ldots, x_{\ell}) \,\,=\!\! \sum_{\substack{ i_1, i_2, \ldots, i_{\alpha}\leq \ell \\ i_1+i_2+\cdots+i_{\alpha}=\ell}} x_{i_1}x_{i_2}\cdots x_{i_{\alpha}} =\sum_{\substack{\boldsymbol{\pi}\vdash \ell \\ |\boldsymbol{\pi}|\leq\alpha}} c_{\boldsymbol{\pi}} x_{\boldsymbol{\pi}}. \end{align} $$
$$ \begin{align} P_{\ell}^{(\alpha)}( x_1,x_2, \ldots, x_{\ell}) \,\,=\!\! \sum_{\substack{ i_1, i_2, \ldots, i_{\alpha}\leq \ell \\ i_1+i_2+\cdots+i_{\alpha}=\ell}} x_{i_1}x_{i_2}\cdots x_{i_{\alpha}} =\sum_{\substack{\boldsymbol{\pi}\vdash \ell \\ |\boldsymbol{\pi}|\leq\alpha}} c_{\boldsymbol{\pi}} x_{\boldsymbol{\pi}}. \end{align} $$
Let
 $\boldsymbol {X}$
be a random vector whose n components are iid and distributed according to (2.3) with
$\boldsymbol {X}$
be a random vector whose n components are iid and distributed according to (2.3) with
 $\beta = 1$
. Let
$\beta = 1$
. Let
 $A\in \mathrm {H}_n$
have eigenvalues
$A\in \mathrm {H}_n$
have eigenvalues
 $x_1,x_2,\ldots ,x_n$
. For even
$x_1,x_2,\ldots ,x_n$
. For even
 $d \geq 2,$
$d \geq 2,$
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d &\overset{(2.5)}{=} [t^d] \bigg( \prod_{i=1}^k \frac{1}{1-x_i t} \bigg)^{\alpha} \overset{(2.7)}{=} [t^d] \bigg(1+\sum_{r=1}^{\infty} h_{r}(x_1, x_2, \ldots, x_n) t^{r} \bigg)^{\alpha} \\ &\overset{(2.9)}{=} [t^d] \sum_{\ell=0}^{\infty} P_{\ell}^{(\alpha)}(h_1, h_2, \ldots, h_{\ell})t^{\ell} \\ &\overset{(2.10)}{=} [t^d]\sum_{\ell=0}^{\infty} \bigg( \sum_{\substack{\boldsymbol{\pi}\vdash \ell \\ |\boldsymbol{\pi}|\leq\alpha}} c_{\boldsymbol{\pi}} h_{\boldsymbol{\pi}}(x_1, x_2, \ldots, x_n) \bigg)t^{\ell}. \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d &\overset{(2.5)}{=} [t^d] \bigg( \prod_{i=1}^k \frac{1}{1-x_i t} \bigg)^{\alpha} \overset{(2.7)}{=} [t^d] \bigg(1+\sum_{r=1}^{\infty} h_{r}(x_1, x_2, \ldots, x_n) t^{r} \bigg)^{\alpha} \\ &\overset{(2.9)}{=} [t^d] \sum_{\ell=0}^{\infty} P_{\ell}^{(\alpha)}(h_1, h_2, \ldots, h_{\ell})t^{\ell} \\ &\overset{(2.10)}{=} [t^d]\sum_{\ell=0}^{\infty} \bigg( \sum_{\substack{\boldsymbol{\pi}\vdash \ell \\ |\boldsymbol{\pi}|\leq\alpha}} c_{\boldsymbol{\pi}} h_{\boldsymbol{\pi}}(x_1, x_2, \ldots, x_n) \bigg)t^{\ell}. \end{align*} $$
Consequently,
 $ \sum _{\!\!\substack {\boldsymbol {\pi }\vdash d \\ |\boldsymbol {\pi }|\leq \alpha }} c_{\boldsymbol {\pi }} h_{\boldsymbol {\pi }}(x_1, x_2, \ldots , x_n) = |\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d,$
which is positive definite.
$ \sum _{\!\!\substack {\boldsymbol {\pi }\vdash d \\ |\boldsymbol {\pi }|\leq \alpha }} c_{\boldsymbol {\pi }} h_{\boldsymbol {\pi }}(x_1, x_2, \ldots , x_n) = |\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d,$
which is positive definite.
Corollary 2.6 (Hunter [Reference Hunter14])
For even
 $d \geq 2,$
the complete symmetric homogeneous polynomial
$d \geq 2,$
the complete symmetric homogeneous polynomial
 $h_d(x_1,x_2,\ldots ,x_n)$
is positive definite.
$h_d(x_1,x_2,\ldots ,x_n)$
is positive definite.
Example 2.7 If
 $\alpha = 2,$
then we obtain the positive definite symmetric polynomial
$\alpha = 2,$
then we obtain the positive definite symmetric polynomial
 $H_{d,2}(x_1,x_2, \ldots , x_n)= \sum _{i=0}^d h_i (x_1,x_2, \ldots , x_n) h_{d-i}(x_1,x_2, \ldots , x_n)$
.
$H_{d,2}(x_1,x_2, \ldots , x_n)= \sum _{i=0}^d h_i (x_1,x_2, \ldots , x_n) h_{d-i}(x_1,x_2, \ldots , x_n)$
.
Example 2.8 The relation
 $ \sum _{\ell =0}^{\infty } H_{\ell , \alpha }t^{\ell }=(\sum _{\ell =0}^{\infty } h_{\ell }t^{\ell })(\sum _{\ell =0}^{\infty } H_{\ell , \alpha -1}t^{\ell }) $
implies that the sequence
$ \sum _{\ell =0}^{\infty } H_{\ell , \alpha }t^{\ell }=(\sum _{\ell =0}^{\infty } h_{\ell }t^{\ell })(\sum _{\ell =0}^{\infty } H_{\ell , \alpha -1}t^{\ell }) $
implies that the sequence
 $\{H_{d,\alpha }\}_{\alpha \geq 1}$
satisfies the recursion
$\{H_{d,\alpha }\}_{\alpha \geq 1}$
satisfies the recursion
 $$ \begin{align} H_{d,\alpha}=\sum_{i=0}^d h_i H_{d-i, \alpha-1}. \end{align} $$
$$ \begin{align} H_{d,\alpha}=\sum_{i=0}^d h_i H_{d-i, \alpha-1}. \end{align} $$
For example, let
 $j=4$
and
$j=4$
and
 $\alpha =3$
. There are four partitions
$\alpha =3$
. There are four partitions
 $\boldsymbol {\pi }$
of j with
$\boldsymbol {\pi }$
of j with
 $|\boldsymbol {\pi }|\leq 3$
. These are
$|\boldsymbol {\pi }|\leq 3$
. These are
 $(1,1,2)$
,
$(1,1,2)$
,
 $(1,3)$
,
$(1,3)$
,
 $(2,2),$
and
$(2,2),$
and
 $(4)$
. Therefore,
$(4)$
. Therefore,
 $$ \begin{align*} H_{4,3}(x_1, x_2, x_3,x_4)&=c(1,1,2)h_1^2h_2+c(1,3)h_1h_3+c(2,2)h_2^2+c(4)h_4\\ &=\frac{3!}{0! 2! 1!}h_1^2h_2+\frac{3!}{1! 1! 1!}h_1h_3+\frac{3!}{1! 2!}h_2^2+\frac{3!}{2!1!}h_4\\[2pt] &=3h_1^2h_2+6h_1h_3+3h_2^2+3h_4 \end{align*} $$
$$ \begin{align*} H_{4,3}(x_1, x_2, x_3,x_4)&=c(1,1,2)h_1^2h_2+c(1,3)h_1h_3+c(2,2)h_2^2+c(4)h_4\\ &=\frac{3!}{0! 2! 1!}h_1^2h_2+\frac{3!}{1! 1! 1!}h_1h_3+\frac{3!}{1! 2!}h_2^2+\frac{3!}{2!1!}h_4\\[2pt] &=3h_1^2h_2+6h_1h_3+3h_2^2+3h_4 \end{align*} $$
is a positive definite symmetric polynomial. In light of (2.11), we can also write
 $H_{4,3}(x_1, x_2, x_3,x_4)=\sum _{i=0}^4 h_i H_{4-i, 2}=H_{4,2}+h_1H_{3,2}+h_2H_{2,2}+h_3H_{1,2}+h_4$
.
$H_{4,3}(x_1, x_2, x_3,x_4)=\sum _{i=0}^4 h_i H_{4-i, 2}=H_{4,2}+h_1H_{3,2}+h_2H_{2,2}+h_3H_{1,2}+h_4$
.
2.4 Normal random variables
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
 $X_i$
are independent normal random variables with mean
$X_i$
are independent normal random variables with mean
 $\mu $
and variance
$\mu $
and variance
 $\sigma ^2>0$
. Then
$\sigma ^2>0$
. Then
 $M(t)=\exp (t\mu +\frac {\sigma ^2t^2}{2} )$
and
$M(t)=\exp (t\mu +\frac {\sigma ^2t^2}{2} )$
and
 $K(t) = \frac {\sigma ^2 t^2}{2}+\mu t$
; in particular,
$K(t) = \frac {\sigma ^2 t^2}{2}+\mu t$
; in particular,
 $\kappa _1 = \mu $
and
$\kappa _1 = \mu $
and
 $\kappa _2 = \sigma ^2$
and all higher cumulants are zero. Then
$\kappa _2 = \sigma ^2$
and all higher cumulants are zero. Then
 $$ \begin{align*} M_{\boldsymbol{X},\boldsymbol{\lambda}}(t) = \prod_{i=1}^n \exp\!\Big(\lambda_i t\mu+\frac{\sigma^2 \lambda_i^2 t^2}{2} \Big) =\exp\! \Big( t\mu\operatorname{tr} A+\frac{\sigma^2\operatorname{tr}(A^2)t^2}{2} \Big). \end{align*} $$
$$ \begin{align*} M_{\boldsymbol{X},\boldsymbol{\lambda}}(t) = \prod_{i=1}^n \exp\!\Big(\lambda_i t\mu+\frac{\sigma^2 \lambda_i^2 t^2}{2} \Big) =\exp\! \Big( t\mu\operatorname{tr} A+\frac{\sigma^2\operatorname{tr}(A^2)t^2}{2} \Big). \end{align*} $$
Theorem 1.1 and the above tell us that
 $$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=\sum_{k=0}^{\frac{d}{2}} \frac{\mu^{2k} (\operatorname{tr} A)^{2k}}{(2k)!} \cdot \frac{\sigma^{d-2k} \| A \|_{\operatorname{F}}^{d-2k}}{2^{\frac{d}{2}-k} (\frac{d}{2}-k)!} \quad \text{for } A \in \mathrm{H}_n, \end{align} $$
$$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=\sum_{k=0}^{\frac{d}{2}} \frac{\mu^{2k} (\operatorname{tr} A)^{2k}}{(2k)!} \cdot \frac{\sigma^{d-2k} \| A \|_{\operatorname{F}}^{d-2k}}{2^{\frac{d}{2}-k} (\frac{d}{2}-k)!} \quad \text{for } A \in \mathrm{H}_n, \end{align} $$
in which
 $\| A \|_{\operatorname {F}}$
is the Frobenius norm of A. For
$\| A \|_{\operatorname {F}}$
is the Frobenius norm of A. For
 $d\geq 2$
even, Theorem 1.1 yields
$d\geq 2$
even, Theorem 1.1 yields
 $$ \begin{align*} |\!|\!| Z |\!|\!|_{\boldsymbol{X},2}^2 &= \tfrac{1}{2} \sigma^2 \operatorname{tr}(Z^*\!Z) + \tfrac{1}{2} \mu^2 (\operatorname{tr} Z^*)(\operatorname{tr} Z), \\ |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{24} \big( \mu^4 (\operatorname{tr} Z)^2 (\operatorname{tr} Z^*)^2 +\mu^2 \sigma^2 \operatorname{tr} (Z^*)^2\operatorname{tr} (Z^2) \\ &\quad +4 \mu^2 \sigma^2 (\operatorname{tr} Z) (\operatorname{tr} Z^*) (\operatorname{tr} Z^* Z) +2 \sigma^4 (\operatorname{tr} Z^* Z)^2 \\ &\quad +\mu^2 \sigma^2 (\operatorname{tr} Z)^2 \operatorname{tr} (Z^{*2}) +\sigma^4 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2}) \big). \end{align*} $$
$$ \begin{align*} |\!|\!| Z |\!|\!|_{\boldsymbol{X},2}^2 &= \tfrac{1}{2} \sigma^2 \operatorname{tr}(Z^*\!Z) + \tfrac{1}{2} \mu^2 (\operatorname{tr} Z^*)(\operatorname{tr} Z), \\ |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{24} \big( \mu^4 (\operatorname{tr} Z)^2 (\operatorname{tr} Z^*)^2 +\mu^2 \sigma^2 \operatorname{tr} (Z^*)^2\operatorname{tr} (Z^2) \\ &\quad +4 \mu^2 \sigma^2 (\operatorname{tr} Z) (\operatorname{tr} Z^*) (\operatorname{tr} Z^* Z) +2 \sigma^4 (\operatorname{tr} Z^* Z)^2 \\ &\quad +\mu^2 \sigma^2 (\operatorname{tr} Z)^2 \operatorname{tr} (Z^{*2}) +\sigma^4 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2}) \big). \end{align*} $$
Since
 $\kappa _r=0$
for
$\kappa _r=0$
for
 $r \geq 3,$
we see that
$r \geq 3,$
we see that
 $|\!|\!| Z |\!|\!|_{\boldsymbol {X},4}^4$
does not contain summands like
$|\!|\!| Z |\!|\!|_{\boldsymbol {X},4}^4$
does not contain summands like
 $\operatorname {tr}(Z^*)\operatorname {tr} (Z^* Z^2)$
and
$\operatorname {tr}(Z^*)\operatorname {tr} (Z^* Z^2)$
and
 $\operatorname {tr} (Z^{*2} Z^2),$
in contrast to the formula in Example 2.3.
$\operatorname {tr} (Z^{*2} Z^2),$
in contrast to the formula in Example 2.3.
2.5 Uniform random variables
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
where the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
where the
 $X_i$
are independent and uniformly distributed on
$X_i$
are independent and uniformly distributed on
 $[a,b]$
. Each
$[a,b]$
. Each
 $X_i$
has probability density
$X_i$
has probability density
![]() where
where
![]() is the indicator function of
is the indicator function of
 $[a,b]$
. Then
$[a,b]$
. Then
 $$ \begin{align} \mu_k = \mathbf{E} [X_i^k] = \int_{-\infty}^{\infty} x^k f(x)\,dx= \frac{h_k(a,b)}{k+1}, \end{align} $$
$$ \begin{align} \mu_k = \mathbf{E} [X_i^k] = \int_{-\infty}^{\infty} x^k f(x)\,dx= \frac{h_k(a,b)}{k+1}, \end{align} $$
in which
 $h_k(a,b)$
is the CHS polynomial of degree k in the variables
$h_k(a,b)$
is the CHS polynomial of degree k in the variables
 $a,b$
. The moment and cumulant generating functions of each
$a,b$
. The moment and cumulant generating functions of each
 $X_i$
are
$X_i$
are
 $M(t)=\frac {e^{bt}-e^{at}}{t(b-a)}$
and
$M(t)=\frac {e^{bt}-e^{at}}{t(b-a)}$
and
 $K(t) = \log (\frac {e^{t (b-a)}-1}{t (b-a)})+a t$
. The cumulants are
$K(t) = \log (\frac {e^{t (b-a)}-1}{t (b-a)})+a t$
. The cumulants are
 $$ \begin{align*} \kappa_r = \begin{cases} \frac{a+b}{2}, & \text{if } r=1,\\[2pt] \frac{B_r}{r}(b-a)^r, & \text{if } r \text{ is even},\\[2pt] 0, & \text{otherwise}, \end{cases} \end{align*} $$
$$ \begin{align*} \kappa_r = \begin{cases} \frac{a+b}{2}, & \text{if } r=1,\\[2pt] \frac{B_r}{r}(b-a)^r, & \text{if } r \text{ is even},\\[2pt] 0, & \text{otherwise}, \end{cases} \end{align*} $$
in which
 $B_r$
is the rth Bernoulli number [Reference Gould10]. Theorem 1.1 ensures that
$B_r$
is the rth Bernoulli number [Reference Gould10]. Theorem 1.1 ensures that
 $$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d = [t^d]\prod_{i=1}^n\frac{ e^{b\lambda_i t}-e^{a\lambda_i t}}{\lambda_it(b-a)} \quad \text{for } A \in \mathrm{H}_n. \end{align} $$
$$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d = [t^d]\prod_{i=1}^n\frac{ e^{b\lambda_i t}-e^{a\lambda_i t}}{\lambda_it(b-a)} \quad \text{for } A \in \mathrm{H}_n. \end{align} $$
Example 2.9 If
 $[a,b]=[-1,1],$
then
$[a,b]=[-1,1],$
then
 $$ \begin{align*} |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4= \tfrac{1}{1,080}\big( 10 (\operatorname{tr} Z^*Z)^2+5 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2})-4 (\operatorname{tr} Z^2Z^{*2})-2 \operatorname{tr} (ZZ^*ZZ^*)\big) \end{align*} $$
$$ \begin{align*} |\!|\!| Z |\!|\!|_{\boldsymbol{X},4}^4= \tfrac{1}{1,080}\big( 10 (\operatorname{tr} Z^*Z)^2+5 \operatorname{tr} (Z^2) \operatorname{tr} (Z^{*2})-4 (\operatorname{tr} Z^2Z^{*2})-2 \operatorname{tr} (ZZ^*ZZ^*)\big) \end{align*} $$
for
 $Z \in \mathrm {M}_n,$
which is not obviously positive, let alone a norm. Indeed,
$Z \in \mathrm {M}_n,$
which is not obviously positive, let alone a norm. Indeed,
 $\operatorname {tr} Z^2Z^{*2}$
and
$\operatorname {tr} Z^2Z^{*2}$
and
 $\operatorname {tr} (ZZ^*ZZ^*)$
appear with negative scalars in front of them! Similarly,
$\operatorname {tr} (ZZ^*ZZ^*)$
appear with negative scalars in front of them! Similarly,
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},6}^6 = \tfrac{1}{45,360} \big(35 (\operatorname{tr} A^2)^3-42 \operatorname{tr}(A^4) \operatorname{tr} (A^2)+16 \operatorname{tr}(A^6) \big) \quad \text{for } A \in \mathrm{H}_6 \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},6}^6 = \tfrac{1}{45,360} \big(35 (\operatorname{tr} A^2)^3-42 \operatorname{tr}(A^4) \operatorname{tr} (A^2)+16 \operatorname{tr}(A^6) \big) \quad \text{for } A \in \mathrm{H}_6 \end{align*} $$
has a nonpositive summand. Since
 $ M_{\boldsymbol {X},\boldsymbol {\lambda }}(t)= \prod _{i=1}^n\frac {\sinh (\lambda _it)}{\lambda _i t} $
is an even function of each
$ M_{\boldsymbol {X},\boldsymbol {\lambda }}(t)= \prod _{i=1}^n\frac {\sinh (\lambda _it)}{\lambda _i t} $
is an even function of each
 $\lambda _i$
, the corresponding norms are polynomials in even powers of the eigenvalues (so positive definiteness is no surprise, although the triangle inequality is nontrivial).
$\lambda _i$
, the corresponding norms are polynomials in even powers of the eigenvalues (so positive definiteness is no surprise, although the triangle inequality is nontrivial).
Example 2.10 If
 $[a,b]=[0,1],$
then
$[a,b]=[0,1],$
then
 $M_{\boldsymbol {X},\boldsymbol {\lambda }}(t) = \prod _{i=1}^n \frac {e^{\lambda _i t}-1}{\lambda _i t}$
, and hence for
$M_{\boldsymbol {X},\boldsymbol {\lambda }}(t) = \prod _{i=1}^n \frac {e^{\lambda _i t}-1}{\lambda _i t}$
, and hence for
 $A \in \mathrm {H}_n,$
$A \in \mathrm {H}_n,$
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},2}^2 &= \tfrac{1}{12}(2 \lambda_1^2+3 \lambda_1 \lambda_2+2 \lambda_2^2), \\ |\!|\!| A |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{720}( 6 \lambda_1^4 +15 \lambda_1^3 \lambda_2 +20 \lambda_1^2 \lambda_2^2 +15 \lambda_1 \lambda_2^3 +6 \lambda_2^4 ). \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},2}^2 &= \tfrac{1}{12}(2 \lambda_1^2+3 \lambda_1 \lambda_2+2 \lambda_2^2), \\ |\!|\!| A |\!|\!|_{\boldsymbol{X},4}^4 &= \tfrac{1}{720}( 6 \lambda_1^4 +15 \lambda_1^3 \lambda_2 +20 \lambda_1^2 \lambda_2^2 +15 \lambda_1 \lambda_2^3 +6 \lambda_2^4 ). \end{align*} $$
Unlike the previous example, these symmetric polynomials are not obviously positive definite since
 $\lambda _1^3 \lambda _2$
and
$\lambda _1^3 \lambda _2$
and
 $\lambda _1 \lambda _2^3$
need not be nonnegative.
$\lambda _1 \lambda _2^3$
need not be nonnegative.
2.6 Laplace random variables
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
where the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
where the
 $X_i$
are independent random variables distributed according to the probability density
$X_i$
are independent random variables distributed according to the probability density
 $f(x)=\frac {1}{2\beta } e^{-\frac {|x-\mu |}{\beta }}$
, in which
$f(x)=\frac {1}{2\beta } e^{-\frac {|x-\mu |}{\beta }}$
, in which
 $\mu \in \mathbb {R}$
and
$\mu \in \mathbb {R}$
and
 $\beta>0$
. The moment and cumulant generating functions of the
$\beta>0$
. The moment and cumulant generating functions of the
 $X_i$
are
$X_i$
are
 $M(t)=\frac {e^{\mu t}}{1-\beta ^2t^2}$
and
$M(t)=\frac {e^{\mu t}}{1-\beta ^2t^2}$
and
 $K(t) = \mu t-\log (1-\beta ^2 t^2)$
, respectively. The cumulants are
$K(t) = \mu t-\log (1-\beta ^2 t^2)$
, respectively. The cumulants are
 $$ \begin{align*} \kappa_r = \begin{cases} \mu, & \text{if } r=1,\\ 2 \beta^r (r-1)!, & \text{if } r \text{ is even},\\ 0, & \text{otherwise}. \end{cases} \end{align*} $$
$$ \begin{align*} \kappa_r = \begin{cases} \mu, & \text{if } r=1,\\ 2 \beta^r (r-1)!, & \text{if } r \text{ is even},\\ 0, & \text{otherwise}. \end{cases} \end{align*} $$
For even
 $d\geq 2,$
it follows that
$d\geq 2,$
it follows that
 $|\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d$
is the dth term in the Taylor expansion of
$|\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d$
is the dth term in the Taylor expansion of
 $$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d = [t^d] \prod_{i=1}^n\frac{ e^{\mu t}}{1-\beta^2\lambda_i^2t^2}. = e^{\mu \operatorname{tr} A t} [t^d]\prod_{i=1}^n\frac{ 1}{1-\beta^2\lambda_i^2t^2}. \end{align} $$
$$ \begin{align} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d = [t^d] \prod_{i=1}^n\frac{ e^{\mu t}}{1-\beta^2\lambda_i^2t^2}. = e^{\mu \operatorname{tr} A t} [t^d]\prod_{i=1}^n\frac{ 1}{1-\beta^2\lambda_i^2t^2}. \end{align} $$
Example 2.11 Let
 $\mu =\beta =1$
. Expanding the terms in (2.15) gives
$\mu =\beta =1$
. Expanding the terms in (2.15) gives
 $$ \begin{align*} M_{\boldsymbol{X},\boldsymbol{\lambda}}(t)=e^{ \operatorname{tr} A t}\prod_{i=1}^n\frac{ 1}{1-\lambda_i^2t^2}=\Big(\sum_{k=0}^{\infty} (\operatorname{tr} A)^k\frac{t^k}{k!} \Big)\Big(\sum_{k=0}^{\infty} h_k(\lambda_1^2, \lambda_2^2, \ldots, \lambda_n^2)t^{2k} \Big), \end{align*} $$
$$ \begin{align*} M_{\boldsymbol{X},\boldsymbol{\lambda}}(t)=e^{ \operatorname{tr} A t}\prod_{i=1}^n\frac{ 1}{1-\lambda_i^2t^2}=\Big(\sum_{k=0}^{\infty} (\operatorname{tr} A)^k\frac{t^k}{k!} \Big)\Big(\sum_{k=0}^{\infty} h_k(\lambda_1^2, \lambda_2^2, \ldots, \lambda_n^2)t^{2k} \Big), \end{align*} $$
which implies
 $ |\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d=\sum _{k=0}^{d/2} \frac {(\operatorname {tr} A)^{2k}}{(2k)!} h_{\frac {d}{2}-k}(\lambda _1^2, \lambda _2^2, \ldots , \lambda _n^2) $
.
$ |\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d=\sum _{k=0}^{d/2} \frac {(\operatorname {tr} A)^{2k}}{(2k)!} h_{\frac {d}{2}-k}(\lambda _1^2, \lambda _2^2, \ldots , \lambda _n^2) $
.
2.7 Bernoulli random variables
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
 $X_i$
are independent Bernoulli random variables. Each
$X_i$
are independent Bernoulli random variables. Each
 $X_i$
takes values in
$X_i$
takes values in
 $\{0,1\}$
with
$\{0,1\}$
with
 $\mathbf {P}(X_i=1)=q$
and
$\mathbf {P}(X_i=1)=q$
and
 $\mathbf {P}(X_i=0)=1-q$
for some fixed
$\mathbf {P}(X_i=0)=1-q$
for some fixed
 $0<q<1$
. Each
$0<q<1$
. Each
 $X_i$
satisfies
$X_i$
satisfies
 $\mathbf {E} [X_i^k]=\sum _{j\in \{0,1\}} j^k\mathbf {P}(X_i=j)=q$
for
$\mathbf {E} [X_i^k]=\sum _{j\in \{0,1\}} j^k\mathbf {P}(X_i=j)=q$
for
 $k \in \mathbb {N}$
. We have
$k \in \mathbb {N}$
. We have
 $M(t) = 1-q + qe^t$
and
$M(t) = 1-q + qe^t$
and
 $K(t) = \log (1-q+qe^t)$
. The first few cumulants are
$K(t) = \log (1-q+qe^t)$
. The first few cumulants are
 $$ \begin{align*} q, \qquad q-q^2, \qquad 2 q^3-3 q^2+q, \qquad -6 q^4+12 q^3-7 q^2+q,\ldots. \end{align*} $$
$$ \begin{align*} q, \qquad q-q^2, \qquad 2 q^3-3 q^2+q, \qquad -6 q^4+12 q^3-7 q^2+q,\ldots. \end{align*} $$
For even
 $d\geq 2,$
the multinomial theorem and independence imply that
$d\geq 2,$
the multinomial theorem and independence imply that
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d =\frac{1}{d!} \sum_{i_1+ i_2+\cdots + i_n=d} q^{|I|} \lambda_1^{i_1}\lambda_2^{i_2}\cdots \lambda_n^{i_n}, \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d =\frac{1}{d!} \sum_{i_1+ i_2+\cdots + i_n=d} q^{|I|} \lambda_1^{i_1}\lambda_2^{i_2}\cdots \lambda_n^{i_n}, \end{align*} $$
in which
 $|I|$
denotes the cardinality of
$|I|$
denotes the cardinality of
 $I=\{i_1, i_2, \ldots , i_n\}$
. We can write this as
$I=\{i_1, i_2, \ldots , i_n\}$
. We can write this as
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=\sum_{\boldsymbol{\pi}\, \vdash \, d} \frac{|\boldsymbol{\pi}|!}{d!}q^{| \boldsymbol{\pi}|} m_{\boldsymbol{\pi}}(\boldsymbol{\lambda}), \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=\sum_{\boldsymbol{\pi}\, \vdash \, d} \frac{|\boldsymbol{\pi}|!}{d!}q^{| \boldsymbol{\pi}|} m_{\boldsymbol{\pi}}(\boldsymbol{\lambda}), \end{align*} $$
in which
 $m_{\boldsymbol {\pi }}$
denotes the monomial symmetric polynomial corresponding to the partition
$m_{\boldsymbol {\pi }}$
denotes the monomial symmetric polynomial corresponding to the partition
 $\boldsymbol {\pi }$
of d [Reference Stanley21, Section 7.3]. To be more specific,
$\boldsymbol {\pi }$
of d [Reference Stanley21, Section 7.3]. To be more specific,
 $$ \begin{align*} m_{\boldsymbol{\pi}}(\boldsymbol{x})=\sum_{\boldsymbol{\alpha}} x^{\boldsymbol{\alpha}}, \end{align*} $$
$$ \begin{align*} m_{\boldsymbol{\pi}}(\boldsymbol{x})=\sum_{\boldsymbol{\alpha}} x^{\boldsymbol{\alpha}}, \end{align*} $$
in which the sum is taken over all distinct permutations
 $\boldsymbol {\alpha }=(\alpha _1, \alpha _2, \ldots , \alpha _r)$
of the entries of
$\boldsymbol {\alpha }=(\alpha _1, \alpha _2, \ldots , \alpha _r)$
of the entries of
 $\boldsymbol {\pi }=(i_1, i_2, \ldots , i_r)$
and
$\boldsymbol {\pi }=(i_1, i_2, \ldots , i_r)$
and
 $x^{\boldsymbol {\alpha }}=x_1^{\alpha _1}x_2^{\alpha _2}\cdots x_r^{\alpha _r}$
. For example,
$x^{\boldsymbol {\alpha }}=x_1^{\alpha _1}x_2^{\alpha _2}\cdots x_r^{\alpha _r}$
. For example,
 $m_{(1)} =\sum _i x_i$
,
$m_{(1)} =\sum _i x_i$
,
 $m_{(2)} =\sum _i x_i^2$
, and
$m_{(2)} =\sum _i x_i^2$
, and
 $m_{(1,1)}=\sum _{i<j}x_ix_j$
.
$m_{(1,1)}=\sum _{i<j}x_ix_j$
.
2.8 Finite discrete random variables
Let X be supported on
 $\{a_1, a_2, \ldots , a_{\ell }\} \subset \mathbb {R},$
with
$\{a_1, a_2, \ldots , a_{\ell }\} \subset \mathbb {R},$
with
 $\mathbf {P}(X=a_j)=q_j>0$
for
$\mathbf {P}(X=a_j)=q_j>0$
for
 $1\leq j \leq \ell $
and
$1\leq j \leq \ell $
and
 $q_1+q_2+\cdots +q_{\ell }=1$
. Then
$q_1+q_2+\cdots +q_{\ell }=1$
. Then
 $\mathbf {E}[X^k]=\sum _{i=1}^{\ell } a_i^k q_i$
, and hence
$\mathbf {E}[X^k]=\sum _{i=1}^{\ell } a_i^k q_i$
, and hence
 $$ \begin{align} M(t)=\sum_{j=1}^{\ell}q_j\bigg(\sum_{k=0}^{\infty} a_j^k \frac{t^k}{k!}\bigg)=\sum_{j=1}^{\ell} q_j e^{a_jt}. \end{align} $$
$$ \begin{align} M(t)=\sum_{j=1}^{\ell}q_j\bigg(\sum_{k=0}^{\infty} a_j^k \frac{t^k}{k!}\bigg)=\sum_{j=1}^{\ell} q_j e^{a_jt}. \end{align} $$
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which
 $X_1, X_2, \ldots , X_n\sim X$
are iid random variables.
$X_1, X_2, \ldots , X_n\sim X$
are iid random variables.
Example 2.12 Let
 $\ell =2$
and
$\ell =2$
and
 $a_1=-a_2=1$
with
$a_1=-a_2=1$
with
 $q_1=q_2=\frac {1}{2}$
. The
$q_1=q_2=\frac {1}{2}$
. The
 $X_i$
are Rademacher random variables. Identity (2.16) yields
$X_i$
are Rademacher random variables. Identity (2.16) yields
 $M(t)=\cosh t,$
so
$M(t)=\cosh t,$
so
 $M_{\boldsymbol {X},\boldsymbol {\lambda }}(t) = \prod _{i=1}^n\cosh (\lambda _it)$
. For
$M_{\boldsymbol {X},\boldsymbol {\lambda }}(t) = \prod _{i=1}^n\cosh (\lambda _it)$
. For
 $n=2$
, we have
$n=2$
, we have
 $|\!|\!| A |\!|\!|_{\boldsymbol {X},2}^2 = \tfrac {1}{2} (\lambda _1^2+\lambda _2^2)$
,
$|\!|\!| A |\!|\!|_{\boldsymbol {X},2}^2 = \tfrac {1}{2} (\lambda _1^2+\lambda _2^2)$
,
 $|\!|\!| A |\!|\!|_{\boldsymbol {X},4}^4 = \tfrac {1}{24} (\lambda _1^4+6 \lambda _2^2 \lambda _1^2+\lambda _2^4)$
, and
$|\!|\!| A |\!|\!|_{\boldsymbol {X},4}^4 = \tfrac {1}{24} (\lambda _1^4+6 \lambda _2^2 \lambda _1^2+\lambda _2^4)$
, and
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},6}^6 =\tfrac{1}{720} (\lambda_1^6+15 \lambda_2^2 \lambda_1^4+15 \lambda_2^4 \lambda_1^2+\lambda_2^6). \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X},6}^6 =\tfrac{1}{720} (\lambda_1^6+15 \lambda_2^2 \lambda_1^4+15 \lambda_2^4 \lambda_1^2+\lambda_2^6). \end{align*} $$
Let
 $\gamma _p=\sqrt {2} (\sqrt {\pi })^{-1/p }\Gamma (\frac {p+1}{2})^{1/p}$
denote the pth moment of a standard normal random variable. Let
$\gamma _p=\sqrt {2} (\sqrt {\pi })^{-1/p }\Gamma (\frac {p+1}{2})^{1/p}$
denote the pth moment of a standard normal random variable. Let
 $X_1, X_2, \ldots , X_n$
be independent Rademacher random variables (see Example 2.12). The classic Khintchine inequality asserts that
$X_1, X_2, \ldots , X_n$
be independent Rademacher random variables (see Example 2.12). The classic Khintchine inequality asserts that
 $$ \begin{align} \Big(\mathbf{E} \Big|\sum_{i=1}^n \lambda_iX_i \Big|^2\Big)^{1/2}\leq \Big(\mathbf{E} \Big|\sum_{i=1}^n \lambda_iX_i\Big|^p\Big)^{1/p}\leq a_p\Big(\mathbf{E} \Big|\sum_{i=1}^n \lambda_iX_i\Big|^2\Big)^{1/2}, \end{align} $$
$$ \begin{align} \Big(\mathbf{E} \Big|\sum_{i=1}^n \lambda_iX_i \Big|^2\Big)^{1/2}\leq \Big(\mathbf{E} \Big|\sum_{i=1}^n \lambda_iX_i\Big|^p\Big)^{1/p}\leq a_p\Big(\mathbf{E} \Big|\sum_{i=1}^n \lambda_iX_i\Big|^2\Big)^{1/2}, \end{align} $$
for all
 $\lambda _1, \lambda _2, \ldots , \lambda _n\in \mathbb {R}$
and
$\lambda _1, \lambda _2, \ldots , \lambda _n\in \mathbb {R}$
and
 $p\geq 2,$
with
$p\geq 2,$
with
 $a_2=1$
and
$a_2=1$
and
 $a_p=\gamma _p$
for
$a_p=\gamma _p$
for
 $p>2$
. Moreover, these constants are optimal [Reference Haagerup11]. Immediately, we obtain the equivalence of norms
$p>2$
. Moreover, these constants are optimal [Reference Haagerup11]. Immediately, we obtain the equivalence of norms
 $$ \begin{align} \| A \|_{\mathrm{F}}\leq \Gamma(p+1)^{1/p}|\!|\!| A |\!|\!|_{\boldsymbol{X},p}\leq a_p\| A \|_{\mathrm{F}}, \end{align} $$
$$ \begin{align} \| A \|_{\mathrm{F}}\leq \Gamma(p+1)^{1/p}|\!|\!| A |\!|\!|_{\boldsymbol{X},p}\leq a_p\| A \|_{\mathrm{F}}, \end{align} $$
for all
 $A\in \mathrm {H}_n(\mathbb {C})$
and
$A\in \mathrm {H}_n(\mathbb {C})$
and
 $p\geq 2$
. The proof of Theorem 1.e implies that
$p\geq 2$
. The proof of Theorem 1.e implies that
 $\| Z \|_{\mathrm {F}}\leq \Gamma (p+1)^{1/p}|\!|\!| Z |\!|\!|_{\boldsymbol {X},p}\leq a_p\| Z \|_{\mathrm {F}}$
for all
$\| Z \|_{\mathrm {F}}\leq \Gamma (p+1)^{1/p}|\!|\!| Z |\!|\!|_{\boldsymbol {X},p}\leq a_p\| Z \|_{\mathrm {F}}$
for all
 $Z\in \mathrm {M}_n$
and
$Z\in \mathrm {M}_n$
and
 $p\geq 2$
.
$p\geq 2$
.
In general, suppose that
 $X_1, X_2, \ldots , X_n$
are iid random variables. A comparison of the form (2.17) is a Khintchine-type inequality. Establishing a Khintchine-type inequality here is equivalent to establishing an equivalence of norms as in (2.18). This is always possible since
$X_1, X_2, \ldots , X_n$
are iid random variables. A comparison of the form (2.17) is a Khintchine-type inequality. Establishing a Khintchine-type inequality here is equivalent to establishing an equivalence of norms as in (2.18). This is always possible since
 $\mathrm {H}_n(\mathbb {C})$
is finite dimensional. However, establishing Khintchine-type inequalities is, in general, a nontrivial task (see [Reference Eskenazis, Nayar and Tkocz7, Reference Eskenazis, Nayar and Tkocz8, Reference Havrilla and Tkocz12, Reference Latała and Oleszkiewicz15]).
$\mathrm {H}_n(\mathbb {C})$
is finite dimensional. However, establishing Khintchine-type inequalities is, in general, a nontrivial task (see [Reference Eskenazis, Nayar and Tkocz7, Reference Eskenazis, Nayar and Tkocz8, Reference Havrilla and Tkocz12, Reference Latała and Oleszkiewicz15]).
2.9 Poisson random variables
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
 $X_i$
are independent random variables on
$X_i$
are independent random variables on
 $\{0,1,2,\ldots \}$
distributed according to
$\{0,1,2,\ldots \}$
distributed according to
 $f(t)= \frac {e^{-\alpha } \alpha ^t}{t!}$
, in which
$f(t)= \frac {e^{-\alpha } \alpha ^t}{t!}$
, in which
 $\alpha>0$
. The moment and cumulant generating functions of the
$\alpha>0$
. The moment and cumulant generating functions of the
 $X_i$
are
$X_i$
are
 $M(t)= e^{\alpha (e^t-1)}$
and
$M(t)= e^{\alpha (e^t-1)}$
and
 $K(t) = \alpha (e^t-1)$
, respectively. Therefore,
$K(t) = \alpha (e^t-1)$
, respectively. Therefore,
 $\kappa _i = \alpha $
for all
$\kappa _i = \alpha $
for all
 $i \in \mathbb {N}$
and hence
$i \in \mathbb {N}$
and hence
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X}, d}^d=\sum_{\boldsymbol{\pi}\vdash d} \frac{ \alpha^{|\boldsymbol{\pi}|} p_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}}. \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X}, d}^d=\sum_{\boldsymbol{\pi}\vdash d} \frac{ \alpha^{|\boldsymbol{\pi}|} p_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}}. \end{align*} $$
For example, if
 $A \in \mathrm {H}_n$
we have
$A \in \mathrm {H}_n$
we have
 $$ \begin{align*} 4!|\!|\!| A |\!|\!|_{\boldsymbol{X},4}^4 =\alpha^4(\operatorname{tr} A)^4+6\alpha^3(\operatorname{tr} A)^2\operatorname{tr} A^2+4\alpha^2\operatorname{tr} A\operatorname{tr} A^3+3\alpha^2(\operatorname{tr} A^2)^2+\alpha \operatorname{tr} A^4. \end{align*} $$
$$ \begin{align*} 4!|\!|\!| A |\!|\!|_{\boldsymbol{X},4}^4 =\alpha^4(\operatorname{tr} A)^4+6\alpha^3(\operatorname{tr} A)^2\operatorname{tr} A^2+4\alpha^2\operatorname{tr} A\operatorname{tr} A^3+3\alpha^2(\operatorname{tr} A^2)^2+\alpha \operatorname{tr} A^4. \end{align*} $$
2.10 Pareto random variables
Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n),$
in which the
 $X_i$
are independent random variables distributed according to the probability density
$X_i$
are independent random variables distributed according to the probability density
 $$ \begin{align*} f(x) = \begin{cases} \frac{\alpha}{x^{\alpha+1}}, & x\geq 1, \\ 0, & x < 1. \end{cases} \end{align*} $$
$$ \begin{align*} f(x) = \begin{cases} \frac{\alpha}{x^{\alpha+1}}, & x\geq 1, \\ 0, & x < 1. \end{cases} \end{align*} $$
The moments that exist are
 $\mu _k = \frac {\alpha }{\alpha - k}$
for
$\mu _k = \frac {\alpha }{\alpha - k}$
for
 $k < \alpha $
. For even
$k < \alpha $
. For even
 $d\geq 2$
with
$d\geq 2$
with
 $d < \alpha ,$
the multinomial theorem and independence yield
$d < \alpha ,$
the multinomial theorem and independence yield
 $$ \begin{align*} d!|\!|\!| A |\!|\!|_{\boldsymbol{X} ,d}^d &= \mathbf{E}[ \langle \boldsymbol{X} , \boldsymbol{\lambda}\rangle^d ] = \mathbf{E}\big[(\lambda_1 X_1 + \lambda_2 X_2 + \cdots + \lambda_n X_n)^d \big] \\ &= \mathbf{E} \left[ \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n (\lambda_i X_i)^{k_i} \right] \\ &= \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n \lambda_i^{k_i} \mathbf{E}\big[X_i^{k_i}\big] \\ &= \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n \frac{\alpha \lambda_i^{k_i}}{\alpha - k_i}. \end{align*} $$
$$ \begin{align*} d!|\!|\!| A |\!|\!|_{\boldsymbol{X} ,d}^d &= \mathbf{E}[ \langle \boldsymbol{X} , \boldsymbol{\lambda}\rangle^d ] = \mathbf{E}\big[(\lambda_1 X_1 + \lambda_2 X_2 + \cdots + \lambda_n X_n)^d \big] \\ &= \mathbf{E} \left[ \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n (\lambda_i X_i)^{k_i} \right] \\ &= \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n \lambda_i^{k_i} \mathbf{E}\big[X_i^{k_i}\big] \\ &= \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n \frac{\alpha \lambda_i^{k_i}}{\alpha - k_i}. \end{align*} $$
In particular,
 $\lim _{\alpha \to \infty }d!|\!|\!| A |\!|\!|_{\boldsymbol {X}_{\alpha },d}^d = (\operatorname {tr} A)^d$
and
$\lim _{\alpha \to \infty }d!|\!|\!| A |\!|\!|_{\boldsymbol {X}_{\alpha },d}^d = (\operatorname {tr} A)^d$
and
 $$ \begin{align*}\lim_{\alpha \to d^{+}} (\alpha-d)d!|\!|\!| A |\!|\!|_{\boldsymbol{X}_{\alpha},d}^d &= \lim_{\alpha \to d^{+}} (\alpha-d) \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n \frac{\alpha \lambda_i^{k_i}}{\alpha - k_i} \\ &= \lim_{\alpha \to d^{+}}(\alpha-d) \sum_{i=1}^n \binom{d}{d}\frac{d\lambda_i^{d}}{\alpha-d} = d \sum_{i=1}^n \lambda_i^{d} = d\| A \|_d^d, \end{align*} $$
$$ \begin{align*}\lim_{\alpha \to d^{+}} (\alpha-d)d!|\!|\!| A |\!|\!|_{\boldsymbol{X}_{\alpha},d}^d &= \lim_{\alpha \to d^{+}} (\alpha-d) \sum_{ \substack{k_1+k_2+\cdots+k_n=d \\ k_1,k_2,\ldots,k_n \geq 0}} \binom{d}{k_1,k_2,\ldots,k_n} \prod_{i=1}^n \frac{\alpha \lambda_i^{k_i}}{\alpha - k_i} \\ &= \lim_{\alpha \to d^{+}}(\alpha-d) \sum_{i=1}^n \binom{d}{d}\frac{d\lambda_i^{d}}{\alpha-d} = d \sum_{i=1}^n \lambda_i^{d} = d\| A \|_d^d, \end{align*} $$
in which
 $\| A \|_d$
is the Schatten d-norm on
$\| A \|_d$
is the Schatten d-norm on
 $\mathrm {H}_n$
.
$\mathrm {H}_n$
.
Example 2.13 For
 $n=2,$
$n=2,$
 $$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X} ,2}^2 &=\frac{1}{2}\alpha\left(\frac{\lambda_1^2}{\alpha-2}+ \frac{2\alpha\lambda_1\lambda_2}{(\alpha-1)^2}+\frac{\lambda_2^2}{\alpha-2} \right) \quad \text{and}\\ |\!|\!| A |\!|\!|_{\boldsymbol{X} ,4}^4 &= \frac{1}{24}\alpha \left(\frac{\lambda_1^4}{\alpha-4} + \frac{4\alpha\lambda_1^3\lambda_2}{\alpha^2-4\alpha+3} + \frac{6\alpha\lambda_2^2\lambda_1^2}{(\alpha-2)^2} + \frac{4\alpha\lambda_1\lambda_2^3}{\alpha^2-4\alpha+3} + \frac{\lambda_2^4}{\alpha-4}\right). \end{align*} $$
$$ \begin{align*} |\!|\!| A |\!|\!|_{\boldsymbol{X} ,2}^2 &=\frac{1}{2}\alpha\left(\frac{\lambda_1^2}{\alpha-2}+ \frac{2\alpha\lambda_1\lambda_2}{(\alpha-1)^2}+\frac{\lambda_2^2}{\alpha-2} \right) \quad \text{and}\\ |\!|\!| A |\!|\!|_{\boldsymbol{X} ,4}^4 &= \frac{1}{24}\alpha \left(\frac{\lambda_1^4}{\alpha-4} + \frac{4\alpha\lambda_1^3\lambda_2}{\alpha^2-4\alpha+3} + \frac{6\alpha\lambda_2^2\lambda_1^2}{(\alpha-2)^2} + \frac{4\alpha\lambda_1\lambda_2^3}{\alpha^2-4\alpha+3} + \frac{\lambda_2^4}{\alpha-4}\right). \end{align*} $$
3 Proof of Theorem 1.1
Let
 $d\geq 2$
be arbitrary, and let
$d\geq 2$
be arbitrary, and let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n)$
be a random vector in
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n)$
be a random vector in
 $\mathbb {R}^n,$
in which
$\mathbb {R}^n,$
in which
 $X_1, X_2, \ldots , X_n\in L^d(\Omega , \mathcal {F}, \mathbf {P})$
are iid random variables. Independence is not needed for (a) (see Remark 3.4). We let
$X_1, X_2, \ldots , X_n\in L^d(\Omega , \mathcal {F}, \mathbf {P})$
are iid random variables. Independence is not needed for (a) (see Remark 3.4). We let
 $\boldsymbol {\lambda }=(\lambda _1, \lambda _2, \ldots , \lambda _n)$
denote the vector of eigenvalues of
$\boldsymbol {\lambda }=(\lambda _1, \lambda _2, \ldots , \lambda _n)$
denote the vector of eigenvalues of
 $A \in \mathrm {H}_n$
. As before, A denotes a typical Hermitian matrix and
$A \in \mathrm {H}_n$
. As before, A denotes a typical Hermitian matrix and
 $Z \in \mathrm {M}_n$
an arbitrary square matrix.
$Z \in \mathrm {M}_n$
an arbitrary square matrix.
The proofs of (a)–(e) of Theorem 1.1 are placed in separate subsections below. Before we proceed, we require an important lemma.
Lemma 3.1
 $\boldsymbol {X}$
is positive definite.
$\boldsymbol {X}$
is positive definite.
Proof Hölder’s inequality shows that each
 $X_i \in L^2(\Omega , \mathcal {F}, \mathbf {P}),$
so
$X_i \in L^2(\Omega , \mathcal {F}, \mathbf {P}),$
so
 $\mu _1$
and
$\mu _1$
and
 $\mu _2$
are finite. Jensen’s inequality yields
$\mu _2$
are finite. Jensen’s inequality yields
 $\mu _1^2\leq \mu _2$
; nondegeneracy of the
$\mu _1^2\leq \mu _2$
; nondegeneracy of the
 $X_i$
ensures the inequality is strict. Independence implies that
$X_i$
ensures the inequality is strict. Independence implies that
 $\mathbf {E}[X_i X_j] = \mathbf {E}[X_i]\mathbf {E}[X_j]$
for
$\mathbf {E}[X_i X_j] = \mathbf {E}[X_i]\mathbf {E}[X_j]$
for
 $i\neq j,$
so
$i\neq j,$
so
 $$ \begin{align*} \Sigma(\boldsymbol{X}) = [\mathbf{E} X_iX_j ]= \begin{bmatrix} \mu_2 & \mu_1^2 & \cdots & \mu_1^2 \\[2pt] \mu_1^2 & \mu_2 & \cdots & \mu_1^2 \\ \vdots & \vdots & \ddots & \vdots \\ \mu_1^2 & \mu_1^2 & \cdots & \mu_2 \\ \end{bmatrix} =(\mu_2-\mu_1^2)I+\mu_1^2J, \end{align*} $$
$$ \begin{align*} \Sigma(\boldsymbol{X}) = [\mathbf{E} X_iX_j ]= \begin{bmatrix} \mu_2 & \mu_1^2 & \cdots & \mu_1^2 \\[2pt] \mu_1^2 & \mu_2 & \cdots & \mu_1^2 \\ \vdots & \vdots & \ddots & \vdots \\ \mu_1^2 & \mu_1^2 & \cdots & \mu_2 \\ \end{bmatrix} =(\mu_2-\mu_1^2)I+\mu_1^2J, \end{align*} $$
in which
 $\mu _2-\mu _1^2>0$
and J is the all-ones matrix. Thus,
$\mu _2-\mu _1^2>0$
and J is the all-ones matrix. Thus,
 $\Sigma (\boldsymbol {X})$
is the sum of a positive definite and a positive semidefinite matrix, so it is positive definite.
$\Sigma (\boldsymbol {X})$
is the sum of a positive definite and a positive semidefinite matrix, so it is positive definite.
3.1 Proof of Theorem 1.1.a
Since
 $X_1, X_2, \ldots , X_n\in L^d(\Omega , \mathcal {F}, \mathbf {P})$
for some
$X_1, X_2, \ldots , X_n\in L^d(\Omega , \mathcal {F}, \mathbf {P})$
for some
 $d\geq 2,$
Hölder’s inequality implies the random variable
$d\geq 2,$
Hölder’s inequality implies the random variable
 $\Lambda =\langle \boldsymbol {X}, \boldsymbol {\lambda }\rangle $
satisfies
$\Lambda =\langle \boldsymbol {X}, \boldsymbol {\lambda }\rangle $
satisfies
 $$ \begin{align} \langle \boldsymbol{\lambda}, \Sigma(\boldsymbol{X})\boldsymbol{\lambda}\rangle = \mathbf{E} [| \Lambda |^2] \leq (\mathbf{E} | \Lambda |^d)^{2/d}. \end{align} $$
$$ \begin{align} \langle \boldsymbol{\lambda}, \Sigma(\boldsymbol{X})\boldsymbol{\lambda}\rangle = \mathbf{E} [| \Lambda |^2] \leq (\mathbf{E} | \Lambda |^d)^{2/d}. \end{align} $$
For
 $A\in \mathrm {H}_n,$
consider the nonnegative function
$A\in \mathrm {H}_n,$
consider the nonnegative function
 $$ \begin{align} \mathfrak{N}(A)=\bigg(\,\frac{ \mathbf{E} |\langle \boldsymbol{X}, \boldsymbol{\lambda}\rangle|^d}{\Gamma(d+1)}\, \bigg)^{1/d}. \end{align} $$
$$ \begin{align} \mathfrak{N}(A)=\bigg(\,\frac{ \mathbf{E} |\langle \boldsymbol{X}, \boldsymbol{\lambda}\rangle|^d}{\Gamma(d+1)}\, \bigg)^{1/d}. \end{align} $$
It is clearly homogeneous:
 $\mathfrak {N}(\alpha A)=|\alpha | \mathfrak {N}(A)$
for all
$\mathfrak {N}(\alpha A)=|\alpha | \mathfrak {N}(A)$
for all
 $\alpha \in \mathbb {R}$
. Lemma 3.1 ensures that
$\alpha \in \mathbb {R}$
. Lemma 3.1 ensures that
 $\Sigma (\boldsymbol {X})$
is positive definite, so (3.1) implies
$\Sigma (\boldsymbol {X})$
is positive definite, so (3.1) implies
 $\mathfrak {N}(A) = 0$
if and only if
$\mathfrak {N}(A) = 0$
if and only if
 $A = 0$
.
$A = 0$
.
We must show that
 $\mathfrak {N}$
satisfies the triangle inequality. Our approach parallels that of [Reference Aguilar, Chávez, Garcia and Volčič1, Theorem 1]. We first show that
$\mathfrak {N}$
satisfies the triangle inequality. Our approach parallels that of [Reference Aguilar, Chávez, Garcia and Volčič1, Theorem 1]. We first show that
 $\mathfrak {N}$
satisfies the triangle inequality on
$\mathfrak {N}$
satisfies the triangle inequality on
 $\mathrm {D}_n(\mathbb {R}),$
the space of real diagonal matrices. Then, we use Lewis’ framework for convex matrix analysis [Reference Lewis17] to establish the triangle inequality on
$\mathrm {D}_n(\mathbb {R}),$
the space of real diagonal matrices. Then, we use Lewis’ framework for convex matrix analysis [Reference Lewis17] to establish the triangle inequality on
 $\mathrm {H}_n$
.
$\mathrm {H}_n$
.
Let
 $\mathcal {V}$
be a finite-dimensional real vector space with inner product
$\mathcal {V}$
be a finite-dimensional real vector space with inner product
 $\langle \cdot , \cdot \rangle _{\mathcal {V}}$
. The adjoint
$\langle \cdot , \cdot \rangle _{\mathcal {V}}$
. The adjoint
 $\phi ^*$
of a linear map
$\phi ^*$
of a linear map
 $\phi : \mathcal {V}\to \mathcal {V}$
satisfies
$\phi : \mathcal {V}\to \mathcal {V}$
satisfies
 $\langle \phi ^*(A), B \rangle = \langle A, \phi (B) \rangle $
for all
$\langle \phi ^*(A), B \rangle = \langle A, \phi (B) \rangle $
for all
 $A,B \in \mathcal {V}$
. We say that
$A,B \in \mathcal {V}$
. We say that
 $\phi $
is orthogonal if
$\phi $
is orthogonal if
 $\phi ^*\circ \phi $
is the identity. Let
$\phi ^*\circ \phi $
is the identity. Let
 $\mathrm {O}(\mathcal {V})$
denote the set of orthogonal linear maps on
$\mathrm {O}(\mathcal {V})$
denote the set of orthogonal linear maps on
 $\mathcal {V}$
. If
$\mathcal {V}$
. If
 $\mathcal {G} \subset \mathrm {O}(\mathcal {V})$
is a subgroup, then
$\mathcal {G} \subset \mathrm {O}(\mathcal {V})$
is a subgroup, then
 $f: \mathcal {V}\to \mathbb {R}$
is
$f: \mathcal {V}\to \mathbb {R}$
is
 $\mathcal {G}$
-invariant if
$\mathcal {G}$
-invariant if
 $f( \phi (A))=f(A)$
for all
$f( \phi (A))=f(A)$
for all
 $\phi \in \mathcal {G}$
and
$\phi \in \mathcal {G}$
and
 $A\in V$
.
$A\in V$
.
Definition 3.1 (Definition 2.1 of [Reference Lewis17])
 $\delta : \mathcal {V}\to \mathcal {V}$
is a G-invariant normal form if
$\delta : \mathcal {V}\to \mathcal {V}$
is a G-invariant normal form if
-
(a)
$\delta $
is
$\mathcal {G}$
-invariant. -
(b) For each
$A\in \mathcal {V},$
there is an
$\phi \in \mathrm {O}(\mathcal {V})$
such that
$A=\phi ( \delta (A)).$
-
(c)
$\langle A, B\rangle _{\mathcal {V}} \leq \langle \delta (A), \delta (B) \rangle _{\mathcal {V}}$
for all
$A,B\in \mathcal {V}$
.







Such a triple
 $(\mathcal {V}, G, \delta )$
is a normal decomposition system (NDS). Let
$(\mathcal {V}, G, \delta )$
is a normal decomposition system (NDS). Let
 $(\mathcal {V}, \mathcal {G}, \delta )$
be an NDS and
$(\mathcal {V}, \mathcal {G}, \delta )$
be an NDS and
 $\mathcal {W} \subseteq \mathcal {V}$
a subspace. The stabilizer of
$\mathcal {W} \subseteq \mathcal {V}$
a subspace. The stabilizer of
 $\mathcal {W}$
in
$\mathcal {W}$
in
 $\mathcal {G}$
is
$\mathcal {G}$
is
 $\mathcal {G}_{\mathcal {W}} = \{ \phi \in \mathcal {G} : \phi (\mathcal {W})=\mathcal {W}\}$
. We restrict the domain of
$\mathcal {G}_{\mathcal {W}} = \{ \phi \in \mathcal {G} : \phi (\mathcal {W})=\mathcal {W}\}$
. We restrict the domain of
 $\phi \in \mathcal {G}_{\mathcal {W}}$
and consider
$\phi \in \mathcal {G}_{\mathcal {W}}$
and consider
 $\mathcal {G}_{\mathcal {W}}$
as a subset of
$\mathcal {G}_{\mathcal {W}}$
as a subset of
 $\mathrm {O}(\mathcal {W})$
.
$\mathrm {O}(\mathcal {W})$
.
Lemma 3.2 (Theorem 4.3 of [Reference Lewis17])
Let
 $(\mathcal {V}, \mathcal {G}, \delta )$
and
$(\mathcal {V}, \mathcal {G}, \delta )$
and
 $(\mathcal {W}, \mathcal {G}_{\mathcal {W}}, \delta |_{\mathcal {W}})$
be NDSs with
$(\mathcal {W}, \mathcal {G}_{\mathcal {W}}, \delta |_{\mathcal {W}})$
be NDSs with
 $\operatorname {ran} \delta \subset \mathcal {W}$
. Then a
$\operatorname {ran} \delta \subset \mathcal {W}$
. Then a
 $\mathcal {G}$
-invariant function
$\mathcal {G}$
-invariant function
 $f:\mathcal {V}\to \mathbb {R}$
is convex if and only if its restriction to
$f:\mathcal {V}\to \mathbb {R}$
is convex if and only if its restriction to
 $\mathcal {W}$
is convex.
$\mathcal {W}$
is convex.
Let
 $\mathcal {V}=\mathrm {H}_n$
be the
$\mathcal {V}=\mathrm {H}_n$
be the
 $\mathbb {R}$
-vector space of complex Hermitian
$\mathbb {R}$
-vector space of complex Hermitian
 $(A=A^*$
) matrices equipped with the Frobenius inner product
$(A=A^*$
) matrices equipped with the Frobenius inner product
 $(A,B) \mapsto \operatorname {tr} AB$
. Let
$(A,B) \mapsto \operatorname {tr} AB$
. Let
 $\operatorname {U}_n$
denote the group of
$\operatorname {U}_n$
denote the group of
 $n \times n$
complex unitary matrices. For
$n \times n$
complex unitary matrices. For
 $U \in \operatorname {U}_n,$
define
$U \in \operatorname {U}_n,$
define
 $\phi _U: \mathcal {V}\to \mathcal {V}$
by
$\phi _U: \mathcal {V}\to \mathcal {V}$
by
 $\phi _U(A)=UAU^*$
. Then
$\phi _U(A)=UAU^*$
. Then
 $\mathcal {G}=\{\phi _U : U\in \operatorname {U}_n\}$
is a group under composition. We may regard it is a subgroup of
$\mathcal {G}=\{\phi _U : U\in \operatorname {U}_n\}$
is a group under composition. We may regard it is a subgroup of
 $\mathrm {O}(\mathcal {V})$
since
$\mathrm {O}(\mathcal {V})$
since
 $\phi _U^*=\phi _{U^*}$
.
$\phi _U^*=\phi _{U^*}$
.
Let
 $\mathcal {W}=\mathrm {D}_n(\mathbb {R}) \subset \mathcal {V}$
denote the set of real diagonal matrices. Then
$\mathcal {W}=\mathrm {D}_n(\mathbb {R}) \subset \mathcal {V}$
denote the set of real diagonal matrices. Then
 $\mathcal {G}_{\mathcal {W}} = \{ \phi _P : P \in \mathcal {P}_n\},$
in which
$\mathcal {G}_{\mathcal {W}} = \{ \phi _P : P \in \mathcal {P}_n\},$
in which
 $\mathcal {P}_n$
is the group of
$\mathcal {P}_n$
is the group of
 $n \times n$
permutation matrices. Define
$n \times n$
permutation matrices. Define
 $\delta : \mathcal {V}\to \mathcal {V}$
by
$\delta : \mathcal {V}\to \mathcal {V}$
by
 $\delta (A)=\operatorname {diag} (\lambda _1(A), \lambda _2(A), \ldots , \lambda _n(A)),$
the
$\delta (A)=\operatorname {diag} (\lambda _1(A), \lambda _2(A), \ldots , \lambda _n(A)),$
the
 $n \times n$
diagonal matrix with
$n \times n$
diagonal matrix with
 $\lambda _1(A), \lambda _2(A), \ldots , \lambda _n(A)$
on its diagonal. Observe that
$\lambda _1(A), \lambda _2(A), \ldots , \lambda _n(A)$
on its diagonal. Observe that
 $\operatorname {ran} \delta \subset \mathcal {W}$
since the eigenvalues of a Hermitian matrix are real. We maintain this notation below.
$\operatorname {ran} \delta \subset \mathcal {W}$
since the eigenvalues of a Hermitian matrix are real. We maintain this notation below.
Lemma 3.3
 $(\mathcal {V}, \mathcal {G},\delta )$
and
$(\mathcal {V}, \mathcal {G},\delta )$
and
 $(\mathcal {W}, \mathcal {G}_{\mathcal {W}}, \delta |_{\mathcal {W}})$
are NDSs.
$(\mathcal {W}, \mathcal {G}_{\mathcal {W}}, \delta |_{\mathcal {W}})$
are NDSs.
Proof We claim that
 $(\mathcal {V}, \mathcal {G},\delta )$
is an NDS. (a) Eigenvalues are similarity invariant, so
$(\mathcal {V}, \mathcal {G},\delta )$
is an NDS. (a) Eigenvalues are similarity invariant, so
 $\delta $
is
$\delta $
is
 $\mathcal {G}$
-invariant. (b) For
$\mathcal {G}$
-invariant. (b) For
 $A \in \mathcal {V},$
the spectral theorem gives a
$A \in \mathcal {V},$
the spectral theorem gives a
 $U \in \operatorname {U}_n$
such that
$U \in \operatorname {U}_n$
such that
 $A = U\delta (A)U^* = \phi _U( \delta (A) )$
. (c) For
$A = U\delta (A)U^* = \phi _U( \delta (A) )$
. (c) For
 $A,B \in \mathcal {V},$
note that
$A,B \in \mathcal {V},$
note that
 $\operatorname {tr} AB\leq \operatorname {tr} \delta (A)\delta (B)$
[Reference Lewis16, Theorem 2.2] (see [Reference Aguilar, Chávez, Garcia and Volčič1, Remark 10] for further references).
$\operatorname {tr} AB\leq \operatorname {tr} \delta (A)\delta (B)$
[Reference Lewis16, Theorem 2.2] (see [Reference Aguilar, Chávez, Garcia and Volčič1, Remark 10] for further references).
We claim that
 $(\mathcal {W},\mathcal {G}_{\mathcal {W}}, \delta |_{\mathcal {W}})$
is an NDS. (a)
$(\mathcal {W},\mathcal {G}_{\mathcal {W}}, \delta |_{\mathcal {W}})$
is an NDS. (a)
 $\delta |_{\mathcal {W}}$
is
$\delta |_{\mathcal {W}}$
is
 $\mathcal {G}_{\mathcal {W}}$
-invariant since
$\mathcal {G}_{\mathcal {W}}$
-invariant since
 $\delta (\phi _P(A))=\delta (PAP^*) = \delta (A)$
for all
$\delta (\phi _P(A))=\delta (PAP^*) = \delta (A)$
for all
 $A \in \mathcal {W}$
and
$A \in \mathcal {W}$
and
 $P \in \mathcal {P}_n$
. (b) If
$P \in \mathcal {P}_n$
. (b) If
 $A \in \mathcal {W},$
then there is a
$A \in \mathcal {W},$
then there is a
 $P \in \mathcal {P}_n$
such that
$P \in \mathcal {P}_n$
such that
 $A = P\delta (A)P^* = \phi _P(\delta (A))$
. (c) The diagonal elements of a diagonal matrix are its eigenvalues. Thus, this property is inherited from
$A = P\delta (A)P^* = \phi _P(\delta (A))$
. (c) The diagonal elements of a diagonal matrix are its eigenvalues. Thus, this property is inherited from
 $\mathcal {V}$
.
$\mathcal {V}$
.
The function
 $\mathfrak {N}: \mathcal {V}\to \mathbb {R}$
is
$\mathfrak {N}: \mathcal {V}\to \mathbb {R}$
is
 $\mathcal {G}$
-invariant since it is a symmetric function of
$\mathcal {G}$
-invariant since it is a symmetric function of
 $\lambda _1(A), \lambda _2(A), \ldots , \lambda _n(A)$
(see Remark 3.4). If
$\lambda _1(A), \lambda _2(A), \ldots , \lambda _n(A)$
(see Remark 3.4). If
 $A,B\in \mathcal {W},$
define random variables
$A,B\in \mathcal {W},$
define random variables
 $X=\langle \boldsymbol {X}, \boldsymbol {\lambda }(A)\rangle $
and
$X=\langle \boldsymbol {X}, \boldsymbol {\lambda }(A)\rangle $
and
 $Y=\langle \boldsymbol {X}, \boldsymbol {\lambda }(B)\rangle $
. Since A and B are diagonal,
$Y=\langle \boldsymbol {X}, \boldsymbol {\lambda }(B)\rangle $
. Since A and B are diagonal,
 $\boldsymbol {\lambda }(A+B)=\boldsymbol {\lambda }(A)+\boldsymbol {\lambda }(B)$
and hence Minkowski’s inequality for
$\boldsymbol {\lambda }(A+B)=\boldsymbol {\lambda }(A)+\boldsymbol {\lambda }(B)$
and hence Minkowski’s inequality for
 $L^d(\Omega , \mathcal {F}, \mathbf {P})$
yields
$L^d(\Omega , \mathcal {F}, \mathbf {P})$
yields
 $$ \begin{align*} \big(\mathbf{E} \big|\langle \boldsymbol{X},\boldsymbol{\lambda}(A+B)\rangle\big|^d\big)^{1/d} =\big(\mathbf{E} |X+Y|^d\big)^{1/d} \leq \big(\mathbf{E} |X|^d\big)^{1/d}+\big(\mathbf{E} |Y|^d\big)^{1/d}. \end{align*} $$
$$ \begin{align*} \big(\mathbf{E} \big|\langle \boldsymbol{X},\boldsymbol{\lambda}(A+B)\rangle\big|^d\big)^{1/d} =\big(\mathbf{E} |X+Y|^d\big)^{1/d} \leq \big(\mathbf{E} |X|^d\big)^{1/d}+\big(\mathbf{E} |Y|^d\big)^{1/d}. \end{align*} $$
Thus,
 $\mathfrak {N}(A+B) \leq \mathfrak {N}(A) + \mathfrak {N}(B)$
for all
$\mathfrak {N}(A+B) \leq \mathfrak {N}(A) + \mathfrak {N}(B)$
for all
 $A,B\in \mathcal {W},$
and hence
$A,B\in \mathcal {W},$
and hence
 $\mathfrak {N}$
is convex on
$\mathfrak {N}$
is convex on
 $\mathcal {W}$
. Lemma 3.2 implies that
$\mathcal {W}$
. Lemma 3.2 implies that
 $\mathfrak {N}$
is convex on
$\mathfrak {N}$
is convex on
 $\mathcal {V}$
. Therefore,
$\mathcal {V}$
. Therefore,
 $\tfrac {1}{2} \mathfrak {N}(A+B)=\mathfrak {N}( \tfrac {1}{2}A+\tfrac {1}{2}B)\leq \tfrac {1}{2}\mathfrak {N}(A) +\tfrac {1}{2}\mathfrak {N}(B)$
for all
$\tfrac {1}{2} \mathfrak {N}(A+B)=\mathfrak {N}( \tfrac {1}{2}A+\tfrac {1}{2}B)\leq \tfrac {1}{2}\mathfrak {N}(A) +\tfrac {1}{2}\mathfrak {N}(B)$
for all
 $A,B\in \mathcal {V},$
so (3.2) defines a norm on
$A,B\in \mathcal {V},$
so (3.2) defines a norm on
 $\mathcal {V}=\mathrm {H}_n$
.
$\mathcal {V}=\mathrm {H}_n$
.
Remark 3.4 Independence is not used in the proof of (a). Our proof only requires that the function
 $|\!|\!| A |\!|\!|_{\boldsymbol {X},d}$
be invariant with respect to unitary conjugation. If the
$|\!|\!| A |\!|\!|_{\boldsymbol {X},d}$
be invariant with respect to unitary conjugation. If the
 $X_i$
are assumed to be iid, but not necessarily independent, then
$X_i$
are assumed to be iid, but not necessarily independent, then
 $|\!|\!| A |\!|\!|_{\boldsymbol {X},d}$
is a homogeneous symmetric function of the eigenvalues of A. Any such function is invariant with respect to unitary conjugation.
$|\!|\!| A |\!|\!|_{\boldsymbol {X},d}$
is a homogeneous symmetric function of the eigenvalues of A. Any such function is invariant with respect to unitary conjugation.
3.2 Proof of Theorem 1.1.b
Let
 $d \geq 2$
be even, and let
$d \geq 2$
be even, and let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n)$
be a random vector, in which
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n)$
be a random vector, in which
 $X_1, X_2, \ldots , X_n$
are iid random variables which admit a moment generating function
$X_1, X_2, \ldots , X_n$
are iid random variables which admit a moment generating function
 $M(t)$
. Let
$M(t)$
. Let
 $A \in \mathrm {H}_n$
have eigenvalues
$A \in \mathrm {H}_n$
have eigenvalues
 $\lambda _1 \geq \lambda _2 \geq \cdots \geq \lambda _n$
. If
$\lambda _1 \geq \lambda _2 \geq \cdots \geq \lambda _n$
. If
 $\Lambda =\langle \boldsymbol {X}, \boldsymbol {\lambda } \rangle =\lambda _1X_1+\lambda _2X_2+\cdots +\lambda _n X_n,$
then independence ensures that
$\Lambda =\langle \boldsymbol {X}, \boldsymbol {\lambda } \rangle =\lambda _1X_1+\lambda _2X_2+\cdots +\lambda _n X_n,$
then independence ensures that
 $M_{\Lambda }(t) = \prod _{i=1}^n M(\lambda _i t)$
. Thus,
$M_{\Lambda }(t) = \prod _{i=1}^n M(\lambda _i t)$
. Thus,
 $|\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d=\mathbf {E} [\Lambda ^d]/d! = [t^d] M_{\Lambda }(t)$
.
$|\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d=\mathbf {E} [\Lambda ^d]/d! = [t^d] M_{\Lambda }(t)$
.
3.3 Proof of Theorem 1.1.c
Maintain the same notation as in the proof of (b). However, we only assume existence of the first d moments of the
 $X_i$
. In this case,
$X_i$
. In this case,
 $M_{\Lambda }(t)$
is a formal series with
$M_{\Lambda }(t)$
is a formal series with
 $\kappa _1,\kappa _2,\ldots ,\kappa _d$
determined and the remaining cumulants treated as formal variables. Then
$\kappa _1,\kappa _2,\ldots ,\kappa _d$
determined and the remaining cumulants treated as formal variables. Then
 $$ \begin{align*} M_{\Lambda}(t) &= \prod_{i=1}^n M(\lambda_i t) \overset{(1.2)}{=} \exp\bigg( \sum_{i=1}^n K(\lambda_i t) \bigg) \overset{(1.2)}{=} \exp\bigg( \sum_{j=1}^{\infty} \kappa_j (\lambda_1^j +\lambda_2^j+\cdots +\lambda_n^j)\frac{t^j}{j!}\bigg) \\ &=\exp \bigg( \sum_{j=1}^{\infty} \kappa_j \operatorname{tr} (A^j)\frac{t^j}{j!}\bigg) \overset{(1.3)}{=}\sum_{\ell=0}^{\infty} B_{\ell}(\kappa_1\operatorname{tr} A, \kappa_2\operatorname{tr} A^2, \ldots, \kappa_{\ell}\operatorname{tr} A^{\ell})\frac{t^{\ell}}{\ell !}. \end{align*} $$
$$ \begin{align*} M_{\Lambda}(t) &= \prod_{i=1}^n M(\lambda_i t) \overset{(1.2)}{=} \exp\bigg( \sum_{i=1}^n K(\lambda_i t) \bigg) \overset{(1.2)}{=} \exp\bigg( \sum_{j=1}^{\infty} \kappa_j (\lambda_1^j +\lambda_2^j+\cdots +\lambda_n^j)\frac{t^j}{j!}\bigg) \\ &=\exp \bigg( \sum_{j=1}^{\infty} \kappa_j \operatorname{tr} (A^j)\frac{t^j}{j!}\bigg) \overset{(1.3)}{=}\sum_{\ell=0}^{\infty} B_{\ell}(\kappa_1\operatorname{tr} A, \kappa_2\operatorname{tr} A^2, \ldots, \kappa_{\ell}\operatorname{tr} A^{\ell})\frac{t^{\ell}}{\ell !}. \end{align*} $$
Expanding the right side of (1.3) yields
 $$ \begin{align} B_{\ell}(x_1,x_2, \ldots, x_{\ell})=\ell !\sum_{\substack{j_1,j_2, \ldots, j_{\ell}\geq 0\\ j_1+2j_2+\cdots +\ell j_{\ell}=\ell }}\prod_{r=1}^{\ell} \frac{x_r^{j_r}}{(r!)^{j_r} j_r!}=\ell !\sum_{\boldsymbol{\pi}\vdash \ell}\frac{x_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}}, \end{align} $$
$$ \begin{align} B_{\ell}(x_1,x_2, \ldots, x_{\ell})=\ell !\sum_{\substack{j_1,j_2, \ldots, j_{\ell}\geq 0\\ j_1+2j_2+\cdots +\ell j_{\ell}=\ell }}\prod_{r=1}^{\ell} \frac{x_r^{j_r}}{(r!)^{j_r} j_r!}=\ell !\sum_{\boldsymbol{\pi}\vdash \ell}\frac{x_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}}, \end{align} $$
in which
 $x_{\boldsymbol {\pi }}=x_{i_1}x_{i_2}\cdots x_{i_j}$
for a each partition
$x_{\boldsymbol {\pi }}=x_{i_1}x_{i_2}\cdots x_{i_j}$
for a each partition
 $\boldsymbol {\pi }=(i_1, i_2, \ldots , i_j)$
of
$\boldsymbol {\pi }=(i_1, i_2, \ldots , i_j)$
of
 $\ell $
. Substitute
$\ell $
. Substitute
 $x_i= \kappa _i \operatorname {tr} (A^i)$
above and obtain
$x_i= \kappa _i \operatorname {tr} (A^i)$
above and obtain
 $$ \begin{align*} d!|\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=[t^d] M_{\Lambda}(t) = B_{d}(\kappa_1\operatorname{tr} A, \kappa_2\operatorname{tr} A^2, \ldots, \kappa_d\operatorname{tr} A^d). \end{align*} $$
$$ \begin{align*} d!|\!|\!| A |\!|\!|_{\boldsymbol{X},d}^d=[t^d] M_{\Lambda}(t) = B_{d}(\kappa_1\operatorname{tr} A, \kappa_2\operatorname{tr} A^2, \ldots, \kappa_d\operatorname{tr} A^d). \end{align*} $$
Finally, (3.3) and the above ensure that
 $ |\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d = \sum _{\boldsymbol {\pi }\vdash d}\frac {\kappa _{\boldsymbol {\pi }}p_{\boldsymbol {\pi }}}{y_{\boldsymbol {\pi }}} $
for
$ |\!|\!| A |\!|\!|_{\boldsymbol {X},d}^d = \sum _{\boldsymbol {\pi }\vdash d}\frac {\kappa _{\boldsymbol {\pi }}p_{\boldsymbol {\pi }}}{y_{\boldsymbol {\pi }}} $
for
 $A \in \mathrm {H}_n$
.
$A \in \mathrm {H}_n$
.
3.4 Proof of Theorem 1.1.d
Recall that a convex function
 $f:\mathbb {R}^n\to \mathbb {R}$
is Schur convex if and only if it is symmetric [Reference Roberts and Varberg18, p. 258]. Suppose that
$f:\mathbb {R}^n\to \mathbb {R}$
is Schur convex if and only if it is symmetric [Reference Roberts and Varberg18, p. 258]. Suppose that
 $\boldsymbol {x},\boldsymbol {y}\in \mathbb {R}^n$
. Let
$\boldsymbol {x},\boldsymbol {y}\in \mathbb {R}^n$
. Let
 $\boldsymbol {X}=(X_1, X_2, \ldots , X_n)$
be a random vector, in which
$\boldsymbol {X}=(X_1, X_2, \ldots , X_n)$
be a random vector, in which
 $X_1, X_2, \ldots , X_n \in L^d(\Omega , \mathcal {F}, \mathbf {P})$
are iid. Define random variables
$X_1, X_2, \ldots , X_n \in L^d(\Omega , \mathcal {F}, \mathbf {P})$
are iid. Define random variables
 $X=\langle \boldsymbol {X}, \boldsymbol {x}\rangle $
and
$X=\langle \boldsymbol {X}, \boldsymbol {x}\rangle $
and
 $Y=\langle \boldsymbol {X}, \boldsymbol {y}\rangle $
.
$Y=\langle \boldsymbol {X}, \boldsymbol {y}\rangle $
.
Define
 $\mathfrak {N}:\mathbb {R}^n\to \mathbb {R}_{\geq 0}$
by
$\mathfrak {N}:\mathbb {R}^n\to \mathbb {R}_{\geq 0}$
by
 $\mathfrak {N}(\boldsymbol {x})=\Big (\frac {\mathbf {E} |\langle \boldsymbol {X}, \boldsymbol {x}\rangle |^d}{\Gamma (d+1)}\Big )^{1/d}$
. This function satisfies
$\mathfrak {N}(\boldsymbol {x})=\Big (\frac {\mathbf {E} |\langle \boldsymbol {X}, \boldsymbol {x}\rangle |^d}{\Gamma (d+1)}\Big )^{1/d}$
. This function satisfies
 $$ \begin{align*} \mathfrak{N}(\boldsymbol{x}+\boldsymbol{y})=\bigg(\frac{\mathbf{E} |\langle \boldsymbol{X}, \boldsymbol{x}+\boldsymbol{y}\rangle|^d}{\Gamma(d+1)}\bigg)^{1/d}=\bigg(\frac{\mathbf{E} |X+Y|^d}{\Gamma(d+1)}\bigg)^{1/d}\leq \mathfrak{N}(\boldsymbol{x}) +\mathfrak{N}(\boldsymbol{y}) \end{align*} $$
$$ \begin{align*} \mathfrak{N}(\boldsymbol{x}+\boldsymbol{y})=\bigg(\frac{\mathbf{E} |\langle \boldsymbol{X}, \boldsymbol{x}+\boldsymbol{y}\rangle|^d}{\Gamma(d+1)}\bigg)^{1/d}=\bigg(\frac{\mathbf{E} |X+Y|^d}{\Gamma(d+1)}\bigg)^{1/d}\leq \mathfrak{N}(\boldsymbol{x}) +\mathfrak{N}(\boldsymbol{y}) \end{align*} $$
as seen in the proof of Theorem 1.1.a. Homogeneity implies that
 $\mathfrak {N}$
is convex on
$\mathfrak {N}$
is convex on
 $\mathbb {R}^n$
. Finally,
$\mathbb {R}^n$
. Finally,
 $\mathfrak {N}$
is symmetric since
$\mathfrak {N}$
is symmetric since
 $X_1, X_2, \ldots , X_n$
are iid. It follows that
$X_1, X_2, \ldots , X_n$
are iid. It follows that
 $\mathfrak {N}$
is Schur convex. Thus,
$\mathfrak {N}$
is Schur convex. Thus,
 $\boldsymbol {\lambda }(A)\mapsto \mathfrak {N}(\lambda _1, \lambda _2, \ldots , \lambda _n)=|\!|\!| A |\!|\!|_{X,d}$
is Schur convex.
$\boldsymbol {\lambda }(A)\mapsto \mathfrak {N}(\lambda _1, \lambda _2, \ldots , \lambda _n)=|\!|\!| A |\!|\!|_{X,d}$
is Schur convex.
Remark 3.5 Note that independence is not required in the previous argument.
3.5 Proof of Theorem 1.1.e
The initial details parallel those of [Reference Aguilar, Chávez, Garcia and Volčič1, Theorem 3]. Let
 $\mathcal {V}$
be a
$\mathcal {V}$
be a
 $\mathbb {C}$
-vector space with conjugate-linear involution
$\mathbb {C}$
-vector space with conjugate-linear involution
 $*$
and suppose that the real-linear subspace
$*$
and suppose that the real-linear subspace
 $\mathcal {V}_{\mathbb {R}}=\{v\in \mathcal {V}:v=v^*\}$
of
$\mathcal {V}_{\mathbb {R}}=\{v\in \mathcal {V}:v=v^*\}$
of
 $*$
-fixed points has the norm
$*$
-fixed points has the norm
 $\| \cdot \|$
. Then
$\| \cdot \|$
. Then
 $e^{it}v+e^{-it}v^* \in \mathcal {V}_{\mathbb {R}}$
for each
$e^{it}v+e^{-it}v^* \in \mathcal {V}_{\mathbb {R}}$
for each
 $v \in \mathcal {V}$
and
$v \in \mathcal {V}$
and
 $t \in \mathbb {R},$
and
$t \in \mathbb {R},$
and
 $t\mapsto \|e^{it}v+e^{-it}v^*\|$
is continuous for each
$t\mapsto \|e^{it}v+e^{-it}v^*\|$
is continuous for each
 $v\in \mathcal {V}$
. The following is [Reference Aguilar, Chávez, Garcia and Volčič1, Proposition 15].
$v\in \mathcal {V}$
. The following is [Reference Aguilar, Chávez, Garcia and Volčič1, Proposition 15].
Lemma 3.6 For even
 $d \geq 2,$
the following is a norm on
$d \geq 2,$
the following is a norm on
 $\mathcal {V}$
that extends
$\mathcal {V}$
that extends
 $\|\cdot \|$
:
$\|\cdot \|$
:
 $$ \begin{align} \mathfrak{N}_d(v)= \bigg( \frac{1}{2\pi \binom{d}{d/2}}\int_0^{2\pi}\|e^{it}v+e^{-it}v^*\|^d\,dt \bigg)^{1/d}. \end{align} $$
$$ \begin{align} \mathfrak{N}_d(v)= \bigg( \frac{1}{2\pi \binom{d}{d/2}}\int_0^{2\pi}\|e^{it}v+e^{-it}v^*\|^d\,dt \bigg)^{1/d}. \end{align} $$
Let
 $\langle x,x^*\rangle $
be the free monoid generated by x and
$\langle x,x^*\rangle $
be the free monoid generated by x and
 $x^*$
. Let
$x^*$
. Let
 $|w|$
denote the length of a word
$|w|$
denote the length of a word
 $w\in \langle x,x^*\rangle ,$
and let
$w\in \langle x,x^*\rangle ,$
and let
 $|w|_x$
count the occurrences of x in w. For
$|w|_x$
count the occurrences of x in w. For
 $Z\in \mathrm {M}_n,$
let
$Z\in \mathrm {M}_n,$
let
 $w(Z)\in \mathrm {M}_n$
be the natural evaluation of w at Z. For example, if
$w(Z)\in \mathrm {M}_n$
be the natural evaluation of w at Z. For example, if
 $w = xx^*x^2,$
then
$w = xx^*x^2,$
then
 $|w| = 4$
,
$|w| = 4$
,
 $|w|_x = 3,$
and
$|w|_x = 3,$
and
 $w(Z) = Z Z^* Z^2$
. The next lemma is [Reference Aguilar, Chávez, Garcia and Volčič1, Lemma 16].
$w(Z) = Z Z^* Z^2$
. The next lemma is [Reference Aguilar, Chávez, Garcia and Volčič1, Lemma 16].
Lemma 3.7 Let
 $d\geq 2$
be even and
$d\geq 2$
be even and
 $\boldsymbol {\pi }=(\pi _1,\pi _2,\ldots ,\pi _r)$
be a partition of d. For
$\boldsymbol {\pi }=(\pi _1,\pi _2,\ldots ,\pi _r)$
be a partition of d. For
 $Z\in \mathrm {M}_n$
,
$Z\in \mathrm {M}_n$
,
 $$ \begin{align} \begin{aligned} &\frac{1}{2\pi} \int_0^{2\pi}\operatorname{tr}(e^{it} Z+e^{-it} Z^*)^{\pi_1}\cdots \operatorname{tr}(e^{it}Z+e^{-it}Z^*)^{\pi_r}\,dt \\ &\qquad\qquad = \sum_{\substack{ w_1,\ldots,w_r \in \langle x,x^*\rangle \colon \\ |w_j|=\pi_j\ \forall j \\ |w_1\cdots w_r|_x = \frac{d}{2} }} \operatorname{tr} w_1(Z)\cdots\operatorname{tr} w_r(Z). \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} &\frac{1}{2\pi} \int_0^{2\pi}\operatorname{tr}(e^{it} Z+e^{-it} Z^*)^{\pi_1}\cdots \operatorname{tr}(e^{it}Z+e^{-it}Z^*)^{\pi_r}\,dt \\ &\qquad\qquad = \sum_{\substack{ w_1,\ldots,w_r \in \langle x,x^*\rangle \colon \\ |w_j|=\pi_j\ \forall j \\ |w_1\cdots w_r|_x = \frac{d}{2} }} \operatorname{tr} w_1(Z)\cdots\operatorname{tr} w_r(Z). \end{aligned} \end{align} $$
Given a partition
 $\boldsymbol {\pi }=(\pi _1,\pi _2,\ldots ,\pi _r)$
of d and
$\boldsymbol {\pi }=(\pi _1,\pi _2,\ldots ,\pi _r)$
of d and
 $Z\in \mathrm {M}_n,$
let
$Z\in \mathrm {M}_n,$
let
 $$ \begin{align} \mathrm{T}_{\boldsymbol{\pi}}(Z)=\frac{1}{\binom{d}{d/2}}\sum_{\substack{ w_1,\ldots,w_r \in \langle x,x^*\rangle \colon \\ |w_j|=\pi_j\ \forall j \\ |w_1\cdots w_r|_x = \frac{d}{2} }} \operatorname{tr} w_1(Z)\cdots\operatorname{tr} w_r(Z), \end{align} $$
$$ \begin{align} \mathrm{T}_{\boldsymbol{\pi}}(Z)=\frac{1}{\binom{d}{d/2}}\sum_{\substack{ w_1,\ldots,w_r \in \langle x,x^*\rangle \colon \\ |w_j|=\pi_j\ \forall j \\ |w_1\cdots w_r|_x = \frac{d}{2} }} \operatorname{tr} w_1(Z)\cdots\operatorname{tr} w_r(Z), \end{align} $$
that is,
 $\mathrm {T}_{\boldsymbol {\pi }}(Z)$
is
$\mathrm {T}_{\boldsymbol {\pi }}(Z)$
is
 $1/{d\choose d/2}$
times the sum over the
$1/{d\choose d/2}$
times the sum over the
 $\binom {d}{d/2}$
possible locations to place
$\binom {d}{d/2}$
possible locations to place
 $d/2$
adjoints
$d/2$
adjoints
 ${}^*$
among the d copies of Z in
${}^*$
among the d copies of Z in
 $ (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _1}) (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _2}) \cdots (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _r}) $
.
$ (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _1}) (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _2}) \cdots (\operatorname {tr} \underbrace {ZZ\cdots Z}_{\pi _r}) $
.
Consider the conjugate transpose
 $*$
on
$*$
on
 $\mathcal {V}=\mathrm {M}_n$
. The corresponding real subspace of
$\mathcal {V}=\mathrm {M}_n$
. The corresponding real subspace of
 $*$
-fixed points is
$*$
-fixed points is
 $\mathcal {V}_{\mathbb {R}} = \mathrm {H}_n$
. Apply Proposition 3.6 to the norm
$\mathcal {V}_{\mathbb {R}} = \mathrm {H}_n$
. Apply Proposition 3.6 to the norm
 $|\!|\!| \cdot |\!|\!|_d$
on
$|\!|\!| \cdot |\!|\!|_d$
on
 $\mathrm {H}_n$
and obtain the extension
$\mathrm {H}_n$
and obtain the extension
 $\mathfrak {N}_d(\cdot )$
to
$\mathfrak {N}_d(\cdot )$
to
 $\mathrm {M}_n$
defined by (3.4).
$\mathrm {M}_n$
defined by (3.4).
If
 $Z \in \mathrm {M}_n$
and
$Z \in \mathrm {M}_n$
and
 $\mathfrak {N}_d(A) = \|A\|_d$
is the norm for
$\mathfrak {N}_d(A) = \|A\|_d$
is the norm for
 $A \in \mathrm {H}_n,$
then Proposition 3.6 ensures that the following is a norm on
$A \in \mathrm {H}_n,$
then Proposition 3.6 ensures that the following is a norm on
 $\mathrm {M}_n$
:
$\mathrm {M}_n$
:
 $$ \begin{align*} \mathfrak{N}_d(Z) &\overset{(3.4)}{=} \bigg( \frac{1}{2\pi \binom{d}{d/2}} \int_0^{2 \pi} |\!|\!| e^{it} Z + e^{-it}Z |\!|\!|_{\boldsymbol{X},d}^d \,dt\bigg)^{1/d} \\ &\overset{(1.10)}{=} \bigg( \frac{1}{2\pi \binom{d}{d/2}} \int_0^{2 \pi} \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{\kappa_{\boldsymbol{\pi}}p_{\boldsymbol{\pi}}( \boldsymbol{\lambda}(e^{it} Z + e^{-it}Z^*))}{y_{\pi}}\,dt \bigg)^{1/d} \\ &\overset{(1.6)}{=} \bigg( \frac{1}{\binom{d}{d/2}} \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{\kappa_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}} \cdot\frac{1}{2\pi} \int_0^{2\pi} \operatorname{tr}(e^{it} Z + e^{-it}Z^*)^{\pi_1} \cdots \operatorname{tr} (e^{it} Z + e^{-it} Z^*)^{\pi_r} \,dt \bigg)^{1/d} \\ &\overset{(3.5)}{=} \bigg( \frac{1}{\binom{d}{d/2}} \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{ \kappa_{\boldsymbol{\pi}} }{y_{\boldsymbol{\pi}}} \sum_{\substack{ w_1,\ldots,w_r \in \langle x,x^*\rangle \colon \\ |w_j|=\pi_j\ \forall j \\ |w_1\cdots w_r|_x = \frac{d}{2} }} \operatorname{tr} w_1(Z)\cdots\operatorname{tr} w_r(Z)\bigg)^{1/d} \\ &\overset{(3.6)}{=} \bigg( \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{ \kappa_{\boldsymbol{\pi}}\mathrm{T}_{\boldsymbol{\pi}}(Z) }{y_{\boldsymbol{\pi}}} \bigg)^{1/d}. \end{align*} $$
$$ \begin{align*} \mathfrak{N}_d(Z) &\overset{(3.4)}{=} \bigg( \frac{1}{2\pi \binom{d}{d/2}} \int_0^{2 \pi} |\!|\!| e^{it} Z + e^{-it}Z |\!|\!|_{\boldsymbol{X},d}^d \,dt\bigg)^{1/d} \\ &\overset{(1.10)}{=} \bigg( \frac{1}{2\pi \binom{d}{d/2}} \int_0^{2 \pi} \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{\kappa_{\boldsymbol{\pi}}p_{\boldsymbol{\pi}}( \boldsymbol{\lambda}(e^{it} Z + e^{-it}Z^*))}{y_{\pi}}\,dt \bigg)^{1/d} \\ &\overset{(1.6)}{=} \bigg( \frac{1}{\binom{d}{d/2}} \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{\kappa_{\boldsymbol{\pi}}}{y_{\boldsymbol{\pi}}} \cdot\frac{1}{2\pi} \int_0^{2\pi} \operatorname{tr}(e^{it} Z + e^{-it}Z^*)^{\pi_1} \cdots \operatorname{tr} (e^{it} Z + e^{-it} Z^*)^{\pi_r} \,dt \bigg)^{1/d} \\ &\overset{(3.5)}{=} \bigg( \frac{1}{\binom{d}{d/2}} \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{ \kappa_{\boldsymbol{\pi}} }{y_{\boldsymbol{\pi}}} \sum_{\substack{ w_1,\ldots,w_r \in \langle x,x^*\rangle \colon \\ |w_j|=\pi_j\ \forall j \\ |w_1\cdots w_r|_x = \frac{d}{2} }} \operatorname{tr} w_1(Z)\cdots\operatorname{tr} w_r(Z)\bigg)^{1/d} \\ &\overset{(3.6)}{=} \bigg( \sum_{\boldsymbol{\pi} \,\vdash\, d} \frac{ \kappa_{\boldsymbol{\pi}}\mathrm{T}_{\boldsymbol{\pi}}(Z) }{y_{\boldsymbol{\pi}}} \bigg)^{1/d}. \end{align*} $$
4 Open questions
If
 $\| \cdot \|$
is a norm on
$\| \cdot \|$
is a norm on
 $\mathrm {M}_n,$
then there is a scalar multiple of it (which may depend upon n) that is submultiplicative. One wonders which of the norms
$\mathrm {M}_n,$
then there is a scalar multiple of it (which may depend upon n) that is submultiplicative. One wonders which of the norms
 $|\!|\!| \cdot |\!|\!|_{\boldsymbol {X},d}$
are submultiplicative, or perhaps are when multiplied by a constant independent of n. For example, (2.1) ensures that for
$|\!|\!| \cdot |\!|\!|_{\boldsymbol {X},d}$
are submultiplicative, or perhaps are when multiplied by a constant independent of n. For example, (2.1) ensures that for
 $d=2,$
a mean-zero distribution leads to a multiple of the Frobenius norm. If
$d=2,$
a mean-zero distribution leads to a multiple of the Frobenius norm. If
 $\mu _2 = 2,$
then the norm is submultiplicative.
$\mu _2 = 2,$
then the norm is submultiplicative.
Problem 1 Characterize those
 $\boldsymbol {X}$
that give rise to submultiplicative norms.
$\boldsymbol {X}$
that give rise to submultiplicative norms.
For the standard exponential distribution, [Reference Aguilar, Chávez, Garcia and Volčič1, Theorem 31] provides an answer to the next question. An answer to the question in the general setting eludes us.
Problem 2 Characterize the norms
 $|\!|\!| \cdot |\!|\!|_{\boldsymbol {X},d}$
that arise from an inner product.
$|\!|\!| \cdot |\!|\!|_{\boldsymbol {X},d}$
that arise from an inner product.
Several other unsolved questions come to mind.
Problem 3 Identify the extreme points with respect to random vector norms.
Problem 4 Characterize norms on
 $\mathrm {M}_n$
or
$\mathrm {M}_n$
or
 $\mathrm {H}_n$
that arise from random vectors.
$\mathrm {H}_n$
that arise from random vectors.
Acknowledgment
We thank Bruce Sagan for remarks about symmetric functions.
