



No CrossRef data available.
Published online by Cambridge University Press: 29 August 2023
The move towards unlimited financial penalties in the UK for sewerage systems that do not operate in line with their discharge permits (and the even more extreme suggestion that there should be a financial penalty every time an overflow spills) sets a challenge to whether our existing sewerage models are accurate enough to provide certainty of avoiding those penalties. This article sets out proposed improved practice in the preparation of urban drainage models to improve their accuracy and usefulness and identifies areas where research, particularly into machine learning techniques, could deliver further improvements.
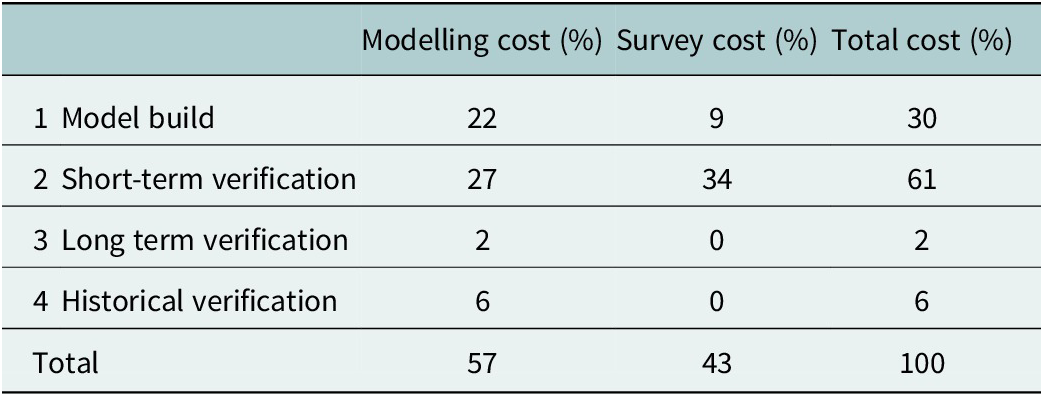
Table 1. Modelling cost for each stage of model preparation (Osborne, 2015)
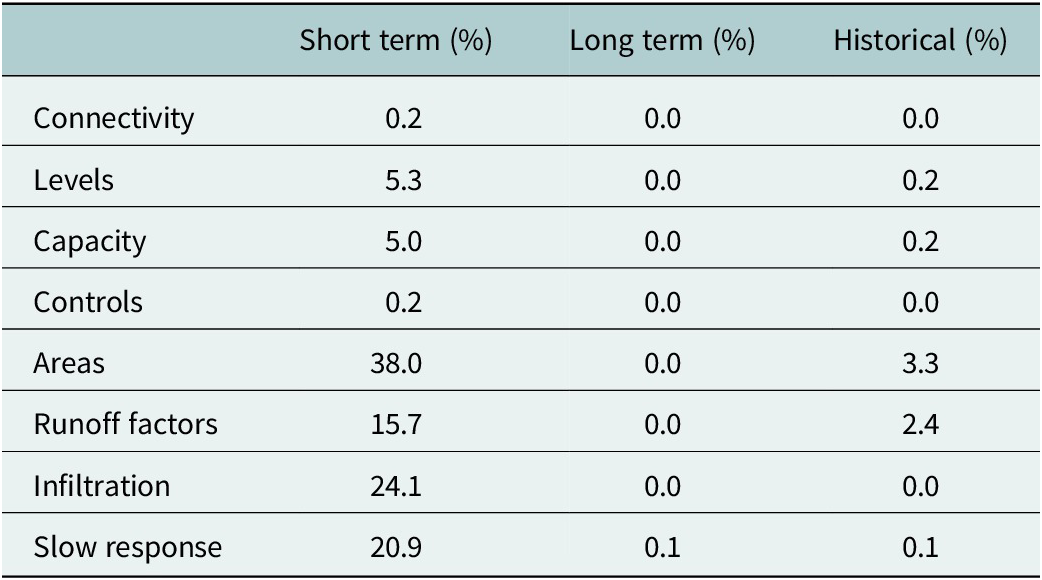
Table 2. Changes made to model data at each stage of model preparation (Osborne, 2015)
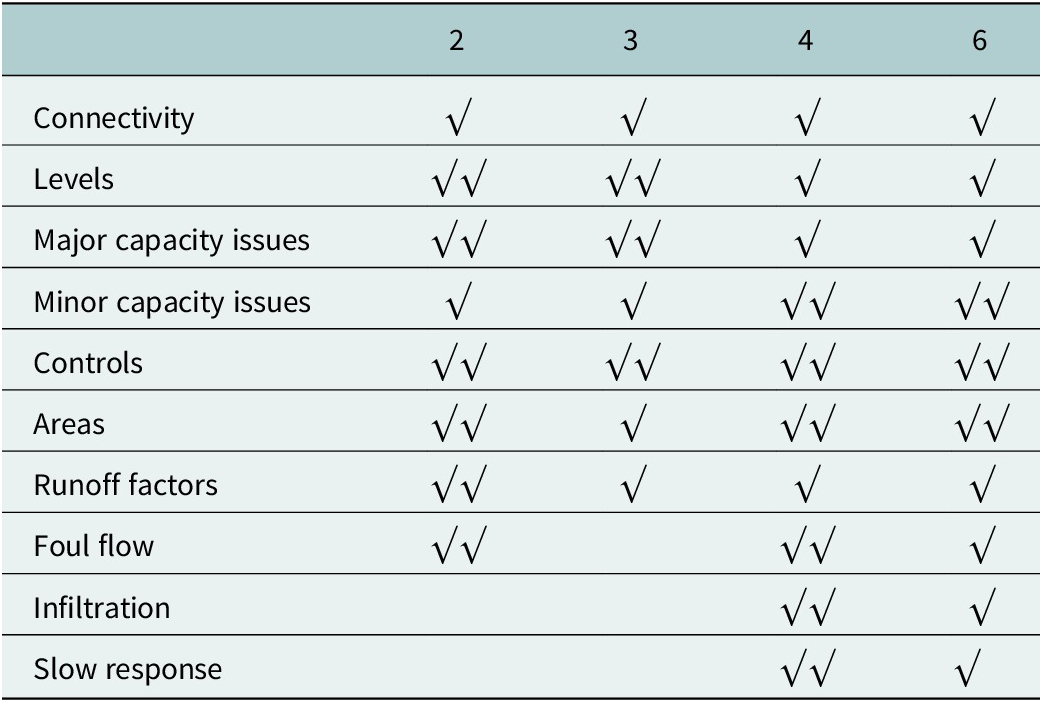
Table 3. Potential improvements at each stage of model preparation (Osborne, 2015)
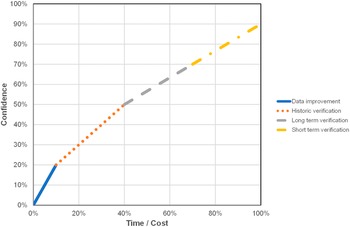
Figure 1. Cost of improving confidence for each stage of model preparation (Osborne, 2015).
No accompanying comment.
The manuscript is a collection of Author’s thoughts on some aspects of modelling of sewer systems. The Author is an experienced modelling practitioner, whose views are certainly well worth considering by the community of water professionals. Therefore the manuscript has a potential to be a valuable contribution to the discussion on this subject. The comments below aim to improve the clarity of statements and overall quality of this contribution. Some of my comments may be a matter of taste and style, but I hope that they will be seen as constructive criticism.
The title is bit misleading because it is unclear what is meant by “turning modelling on its head”. Offered suggestions for changes in practice related to calibration/verification procedures to some extent imply that everyone out there is using steps 1-4 (given on page 3) as a standard procedure, and now the Author is proposing steps 1-7 shown on page 6 (page numbering refers to numeration in the text, not PDF page numbers). The fact is that – in the UK, and much more so globally – engineers are applying different procedures based on current guidelines in their companies, communities or countries. Those are mostly chosen and driven by data availability, modeller’s experience and time and budget set for the project. All of this varies a lot, geographically and over time. So, whilst proposing a novel and improved practice and more precise guidelines is always welcome, the sense of universal applicability – that the manuscript seems to aspire to – is perhaps too optimistic. Back to the title, even if all suggestions by the Author are accepted, that would only mean a somewhat different order of doing things and different way of handling the data, but not really turning modelling on its head. Therefore, the title as it stands serves the purpose of turning readers’ attention to it, but may lead to disappointment.
Page 2 Lines 47-51 are too negative and pessimistic. Fair enough, yes, there are lot of uncertainties involved in modelling, but it is not all as bad as implied in that paragraph.
With all due respect for Huber and the Author, the distinction between “short term” and “long term” calibration/verification is bit arbitrary – because there is no clear distinction between the two. If there is one, it should be offered. Is a two-month survey short and a nine-month one is long, or what structures monitoring need to be included to count as long term survey – where do we draw the line?
The important element of verification is that it should be based on unseen data i.e. data not used in calibration – that should be mentioned somewhere in the text.
The manuscript is mostly based on the Author’s 2015 UKWIR report (no report number provided). Since this is not in public domain (my request to UKWIR resulted in “sorry I cannot find anything with that title”), it would be necessary to provide bit more information about how the data presented in the Tables 1-3 were obtained, most importantly how comprehensive the “survey of current practice” was, i.e. if “average results” were based on averaging ten or hundred responses, what the profile of respondents was etc.
Further, the method applied in the assessment of “the potential for … steps to improve each aspect of the model shown in Table 3” – as zero, one or two ticks – should be justified. What was that based upon?
Similarly, what were the costs estimates shown in Figure 1 based on? And, what does “confidence” percentages on this diagram actually mean? NB: I am not claiming that these are not valid, I just feel that a description of the assessment method should be provided, albeit in a short form.
Checking and improving the model data before we start verification is not really a step missing in our current practice (as indicated on page 6). That is recommended e.g. in the “Setting up and validating a system model” section in the standard Urban Drainage textbook by Butler et al.
In “Levels” section the statement that “Errors in sewer levels have little impact on depths”, if retained, should distinguish between errors in elevation of one (upstream or downstream) sewer level, and cases when the sewer slope is correct but both ends have the same level error. In addition, for both cases it should be reconsidered if errors have little impact on water depth or water level.
Statements in the section on “GIS data sources” are not quite up to date. Estimation of the size of catchments does not necessarily have to be uncertain because GIS tools for automatic DEM-based catchment delineation have been around for decades, and the cost of high resolution LIDaR data is ever decreasing. In addition, the research on methodologies for recognition and classification of catchment cover into impermeable and different permeable surfaces (from various types of digital maps) has also made lot of advances (even though not all of that found its implementation in standard industry software packages). In this context, what would be worth throwing in as an issue is how to classify various SuDS (and how to treat SuDS in modelling) – that is more of a hot topic than delineation of contributing areas.
Similarly, the section on “Sewer condition classification” does not appreciate recent development when it says that CCTV-based rapid classification of sewer defects is still experimental. This is in fact a fairly mature technology.
The first two bullet points on Page 7 are written in a rather casual style (“not much fun”, “infallible beings”). I would be surprised if that meets CUP standards.
The manuscript would benefit from a more precise structuring – instead of using mildly different size and colour of section/sub-section titles, those better be numbered, which would make the paper more readable.
I do understand that this is a “practice paper”, not a “research paper”, and in that respect it may not be a requirement that all statements in it are supported by citing relevant literature, otherwise it would have been useful to have few more references.
In summary, I would recommend that the Author is encouraged to revise the manuscript by addressing the above comments – or rather, those that he does not strongly disagree with – and resubmit the manuscript.
No accompanying comment.
No accompanying comment.
No accompanying comment.
No accompanying comment.
No accompanying comment.
 You have
Access
You have
Access
 Open access
Open access
Impact statement
Modelling the performance of sewerage systems is becoming increasingly important worldwide to identify the best value responses to current impacts and future challenges of population growth and climate change. The improved practice set out in this paper could reduce the cost and improve the effectiveness of that modelling so delivering better investment decisions.
Current practice
There is a famous aphorism that “all models are wrong but some of them are useful” (Box, Reference Box1976). This was recently explored in the context of urban drainage models (Pedersen et al., Reference Pedersen, Brink-Kjær and Mikkelsen2022). Comparing the results of a model to measured data will always show a discrepancy as we are comparing inaccurately measured flows caused by uncertain rainfall on a catchment of unknown condition. However, the purpose of the model is to be useful in understanding other conditions that have not yet occurred or cannot readily be measured.
The way that a model is prepared should therefore focus on making it useful rather than necessarily accurate in individual events. In current practice, the stages in preparing a model are generally as set out by Huber et al. (Reference Huber, Rossman and Dickinson2005):
1. Model build – pull together asset data and catchment data to represent the system with limited surveys to fill data gaps.
2. Short-term verification/calibration – compare the model to measured data from a short-term flow survey, covering only one season, and make corrections and adjustments.
3. (Long-term verification/calibration – compare the model to long-term measured data from treatment works, pumping stations or long-term monitors, covering multiple seasons and make corrections and adjustments.)
4. Validation/testing – compare the known performance of the system with model results from significant historical events or “design storms.”
Note that verification and calibration are not generally treated as separate processes using separate data sets.
Step 3 is optional and is not always carried out.
Steps 1–3 are to check that the model is accurate and step 4 is to check that it is useful (step 4 is often called “historical verification” in the UK).
A UK Water Industry Research (UKWIR) project from 2015 questioned the reliance placed on short-term flow surveys to verify models (Osborne, Reference Osborne2015). Industry’s current use of short-term flow data is flawed, being used to support the modellers claims of model confidence rather than to illuminate the understanding of the system performance. The UKWIR project started out with the objective of considering the use of long-term flow data instead, but this may also have similar shortcomings that the water industry must recognise.
The UKWIR project included a survey of current practice by 20 experienced UK sewerage modellers to identify the percentage of project cost spent on each of these steps. The average results are shown in Table 1.
Table 1. Modelling cost for each stage of model preparation (Osborne, Reference Osborne2015)
The typical cost of short-term verification is typically 61% of the project cost. Is this delivering good value?
The original WaPUG Code of practice for the hydraulic modelling of sewer systems (WaPUG, 2002) suggested that verification against short-term flow surveys is the first and most important step. However short-term flow surveys have some important limitations:
1. It is unlikely to record extreme or larger return period events, leading to uncertainty over extrapolating the model’s results for more significant events.
2. It does not show the seasonal variation in groundwater infiltration that can be a significant factor in system performance.
Short-term flow surveys therefore need to be supplemented with long-term data and historical verification.
The more recent update of the WaPUG code as the CIWEM UDG “Code of Practice for the Hydraulic Modelling of Urban Drainage Systems” (Titterington et al., Reference Titterington, Squibbs, Digman, Allitt, Osborne, Eccleston and Wisdish2017) does allow for an initial validation of the model against known performance before carrying out verification against short term flow data but states: “There is no definitive sequence of working through the stages of verification.”
As there is a presumption that verification will be carried out using a short-term flow survey and an awareness that planning and carrying out such a survey takes a long time, it is normal to commission the flow survey at the start of the project, before the model has been built or assessed.
As the performance of the system and the model is largely unknown at this stage it is not possible to focus the flow survey on those areas with the greatest uncertainty. The survey is therefore planned to cover the whole catchment with a focus on those areas with reported performance problems.
The focus on verification against short-term flow surveys can mean that there is inadequate focus on getting the data correct for a model as, “the errors will be found during verification.”
Changes to model data
The survey of current practice also identified the types and numbers of changes made to a model during verification (Table 2). The average results are shown in the table below expressed as the percentage of model nodes that were changed for asset data and the percentage of sub-catchments for contributing area data.
Table 2. Changes made to model data at each stage of model preparation (Osborne, Reference Osborne2015)
The results of this survey are discussed below.
Connectivity
Issues of incorrect connectivity can be identified from short-term flow survey data but are resolved by inspection of sewer asset data. They could potentially be identified by historical verification if this was carried out first.
Levels
Errors in sewer levels often have little impact on flow patterns in the sewerage system but the relative levels of sewers and ground levels have a big impact on the accuracy of the model in predicting the onset of flooding. My experience is therefore that these are more likely to be picked up by thorough historical verification than from short-term flow survey results.
However, these errors could potentially be identified earlier through close scrutiny of long sections of the sewerage system.
Capacity
Major errors of sewer capacity due to incorrect pipe sizes could often be identified from inspection of sewer records and are also likely to show up during historical verification. Minor differences of capacity due to differences in roughness and sediment deposits are more readily identified in short-term verification but could be identified by more widespread use of CCTV inspection perhaps driven by modelling of likely sediment deposition.
Controls
The correct representation of control structures (including pumps) can be achieved through a thorough site survey and detailed consideration of the hydraulics of the structure. However physical survey data is often incomplete or not sufficiently accurate. Pump capacities are often re-set using short-term flow survey data as the drop tests for capacity carried out during asset surveys are not sufficiently reliable because of poor site practice. Better asset surveys would reduce the need for short-term flow surveys.
Areas and runoff
Widespread changes to contributing areas and runoff factors driven by short-term flow surveys is a concern as this is effectively force-fitting the model to runoff conditions in generally low intensity and low volume rainfall events. Adjustment of runoff factors is a particular concern without evidence of the uniqueness of the runoff surfaces in the catchment that makes the standard factors inapplicable. Changes to the runoff areas are often because a review of the existing data shows that the area has been incorrectly classified as combined or separate and that this should have been evident when the model was built and could be confirmed through site visits or impermeable area surveys.
Infiltration and slow response
In current practice, infiltration and slow response are generally picked up from short-term flow survey data as this is carried out first, but could often be identified as easily from long-term flow data and pump station operation.
Improved practice
The discussion above also suggests that historical and long-term verification could be carried out earlier before short-term verification. So can we improve model preparation by changing the order in which we do things, by turning modelling on its head?
Also, there seems to be a step missing in our current practice – checking and improving the model data before we start verification.
So an alternative set of steps for preparing a model could be:
1. Model build – pull together asset data and catchment data to represent the system.
2. Data improvement – a detailed review of all model data to correct errors and identify uncertainties with additional site surveys where required.
3. Validation/testing – compare the known performance of the system with model results from significant historical events or “design storms.”
4. Long-term verification/calibration – compare the model to long-term measured data from treatment works, pumping stations or long-term monitors and make corrections and adjustments.
5. Plan short term flow survey to address uncertainties.
6. Short-term verification/calibration – compare the model to measured data from a short-term flow survey and make corrections and adjustments.
7. Validation/testing – compare the known performance of the system with model results from significant historical events or “design storms.”
The potential for each of these steps to improve each aspect of the model is shown in Table 3. This was assessed at a workshop of 60 experienced sewerage modellers.
Table 3. Potential improvements at each stage of model preparation (Osborne, Reference Osborne2015)
Estimates for the cost of each step are shown in Figure 1. The data improvement step is in addition to the current model build step. The short-term flow survey can be focussed on those areas where there is still uncertainty and so would be cheaper.
Figure 1. Cost of improving confidence for each stage of model preparation (Osborne, Reference Osborne2015).
There are challenges in adopting a new approach.
1. Checking asset data is boring and not as much fun as verification.
2. Some water companies allocate data quality scores with asset survey data as highest quality and expert judgement as the lowest. I assume because survey teams are believed to be infallible beings who never make mistakes.
3. Short-term flow surveys are seen as delivering greater confidence than they really deliver.
The future
A few things have changed in the years since the UKWIR report was produced and set out these ideas and the pace of change is getting faster. This section sets out some potential future changes and the research needed to allow them to happen.
GIS data sources
One of the big uncertainties of models is the estimation of how much of the impermeable surface in each sub-catchment contributes to each drainage system. This has traditionally been based on inspection of system data to identify separate surface water sewers. However, this may not identify Sustainable Drainage Systems including soakaways.
The increasing amounts of open GIS data can bring in extra components to this analysis. Matching soil type, age of development, system type, ground slope, and so forth can give a more reliable estimate of contributing areas. The process could be made quicker and more consistent using machine learning to learn from the classification of test catchments and apply this to new catchments with varied characteristics.
This will require research on how to combine data sets of different ages, pattern recognition of map features and potentially flow data to provide robust algorithms for classification.
Correction of asset data
Modelling software has an increasing capability to use automated scripting to check and correct data. This can take much of the drudgery out of the step to check and improve model data. Scripting based on expert knowledge can look for unexpected changes in sewer gradient, diameter, material and errors in connectivity.
There is the potential to improve on this even more using machine learning to learn from modellers what corrections to make to a model. The rules would be derived from past practice and embedded into algorithms that can make the correct change when there is confidence in the issue or flag for user intervention when the required change is uncertain.
Research is needed into how to derive and apply machine learning algorithms when there is so much uncertainty in the appropriate action.
Sewer condition classification
There are already tools to use image recognition to rapidly classify sewer pipe structural defects from CCTV images. These are still not widely used and more research is needed to demonstrate their reliability and increase their use. This could also be extended to assessing no defect factors such as sediment depths and effective pipe roughness to assist modellers to move away from the use of generic default values.
Cloud computing
There is an increasing move to have model data and models in the cloud with Software As A Service to run the models. Bring this together with machine learning and with the right checks and data access agreements the data improvement algorithms can learn good practice from modellers all over the world. They could deliver better models than any individual modeller could.
Conclusions
Current practice in preparing urban drainage model focusses on them accurately reproducing measured conditions in a few events rather than on ensuring that they are useful to predict conditions in a wide range of unmeasured events.
The modified approach set out here could improve the usefulness of models and potentially save money and time in their preparation.
Future developments of automation and machine learning could give even greater cost and time savings and improved consistency and usefulness of models.
This would free modellers from the drudgery of preparing models to have more time for the important tasks of understanding and solving the problems with the sewerage systems that the models illuminate.
Open peer review
To view the open peer review materials for this article, please visit http://doi.org/10.1017/wat.2023.8.