



Introduction
Depression affects ~320 million people worldwide every year (Thornicroft et al., Reference Thornicroft, Chatterji, Evans-Lacko, Gruber, Sampson, Aguilar-Gaxiola and Kessler2017; Vos et al., Reference Vos, Allen, Arora, Barber, Bhutta, Brown and Coggeshall2016). Despite the existence of effective treatments, roughly half of depressed patients do not recover with the first treatment they are given. This can lead to disengagement and poor long-term prognoses (Buckman et al., Reference Buckman, Underwood, Clarke, Saunders, Hollon, Fearon and Pilling2018; Judd et al., Reference Judd, Akiskal, Maser, Zeller, Endicott, Coryell and Keller1998). Providing accurate predictions about the likelihood of treatment response for patients would be of great value, informing clinical management and giving patients and clinicians desired information (Hayden, Windt Van Der, Cartwright, Côté, & Bombardier, Reference Hayden, Windt Van Der, Cartwright, Côté and Bombardier2013; Morgan, Reavley, & Jorm, Reference Morgan, Reavley and Jorm2014). However, there are a lack of accurate, validated prognostic models for adults in treatment for depression (Cohen & DeRubeis, Reference Cohen and DeRubeis2018). Central to this vacancy in the literature are methodological inconsistencies, debates about how best to develop predictive models, and what variables to include in such models. Recently, the field has begun to reach consensus on how to best test the utility of predictive models, for example, by evaluating them in datasets that are separate from those used for model development (Adibi, Sadatsafavi, & Ioannidis, Reference Adibi, Sadatsafavi and Ioannidis2020; Dwyer, Falkai, & Koutsouleris, Reference Dwyer, Falkai and Koutsouleris2018; Harrell, Lee, & Mark, Reference Harrell, Lee and Mark2004; Moons et al., Reference Moons, Altman, Reitsma, Ioannidis, Macaskill, Steyerberg and Collins2015; Steyerberg et al., Reference Steyerberg, Vickers, Cook, Gerds, Gonen, Obuchowski and Kattan2010).
One factor consistently found to be associated with prognosis of depression is the severity of depressive symptoms pre-treatment (Bower et al., Reference Bower, Kontopantelis, Sutton, Kendrick, Richards, Gilbody and Liu2013; Driessen, Cuijpers, Hollon, & Dekker, Reference Driessen, Cuijpers, Hollon and Dekker2010; Fournier, Derubeis, Hollon, Shelton, & Fawcett, Reference Fournier, Derubeis, Hollon, Shelton and Fawcett2010; Weitz et al., Reference Weitz, Hollon, Twisk, Van Straten, Huibers, David and Cuijpers2015). This is often captured with sum scores on depressive symptom scales. However, depression is heterogeneous (Fried & Nesse, Reference Fried and Nesse2015a) so utilising symptom level data might provide more nuanced information on patients experiences of depression, and consequently improve the accuracy of prognostic predictions (Boschloo, van Borkulo, Borsboom, & Schoevers, Reference Boschloo, van Borkulo, Borsboom and Schoevers2016; Fava, Ruini, & Belaise, Reference Fava, Ruini and Belaise2007; Fried & Nesse, Reference Fried and Nesse2014, Reference Fried and Nesse2015b). Network theory (Borsboom & Cramer, Reference Borsboom and Cramer2013; Fried & Cramer, Reference Fried and Cramer2017) has given rise to an approach that can capture the relationships between individual symptoms. These relationships could reflect potential causal pathways, thereby elucidating maintenance mechanisms that could be targeted with treatment, and might therefore inform prognosis (Borsboom, Reference Borsboom2017). The arrangement and inter-relationships of symptoms within networks have most often been captured with one or more measures of centrality – i.e. the interconnectedness of each symptom with other symptoms in the network (Bringmann et al., Reference Bringmann, Elmer, Epskamp, Krause, Schoch, Wichers and Snippe2019; Fried, Epskamp, Nesse, Tuerlinckx, & Borsboom, Reference Fried, Epskamp, Nesse, Tuerlinckx and Borsboom2016).
A recent study used centrality metrics to weight individual items of a depressive symptom questionnaire, which when summed together created a new, or weighted, sum score. A regression model using this weighted sum score was found to outperform a model containing the original sum score in an exploratory analysis (Boschloo et al., Reference Boschloo, van Borkulo, Borsboom and Schoevers2016). Other studies have utilised centrality metrics to predict changes in particular symptoms over time (Boschloo et al., Reference Boschloo, van Borkulo, Borsboom and Schoevers2016; Koenders et al., Reference Koenders, De Kleijn, Giltay, Elzinga, Spinhoven and Spijker2015; van Borkulo et al., Reference van Borkulo, Boschloo, Borsboom, Penninx, Waldorp and Schoevers2015; Wichers & Groot, Reference Wichers and Groot2016), or predict post-treatment outcomes (Berlim, Richard-Devantoy, Dos Santos, & Turecki, Reference Berlim, Richard-Devantoy, Dos Santos and Turecki2020; Elliott, Jones, & Schmidt, Reference Elliott, Jones and Schmidt2020). However, such studies have not tested the developed models against simpler comparative models, nor have they tested the predictive utility of the models in completely external data (Dwyer et al., Reference Dwyer, Falkai and Koutsouleris2018; Harrell et al., Reference Harrell, Lee and Mark2004; Webb et al., Reference Webb, Cohen, Beard, Forgeard, Peckham and Björgvinsson2020), or adhered to recent conventions for the transparency of conducting such research by following pre-registered analysis plans or protocols (Collins, Reitsma, Altman, & Moons, Reference Collins, Reitsma, Altman and Moons2015). Therefore, the extent to which the use of centrality metrics can add incremental value in prognostic models remains unclear. The present paper aims to fill this gap and further the consideration of the development of models that can be translated into clinical settings.
There are several potentially equally valid ways to estimate item centrality in network models. We will therefore investigate several methods that have been used in the recent network modelling literature. One method uses the estimated arrangement of items into communities of highly partially correlated items, we will compare this to a model in which it is assumed that there is a single latent factor. We will use these methods to investigate the benefit of using item centrality scores and factor loadings to create weighted sum scores, and compare these to an unweighted regression model, and to a penalised regression model, as these are typical methods used to develop predictive models. We will then compare all of these methods against models that use all the individual items rather than sum scores, and to a simple null model (Boschloo et al., Reference Boschloo, van Borkulo, Borsboom and Schoevers2016). In this way, this study aims to develop, validate and compare the predictive performance of prognostic models for depressed adults in primary care, based on pre-treatment data including individual symptoms of depression.
Methods
The methods for the present study were pre-registered (https://osf.io/vzk65/). We have reported the details in accordance with TRIPOD, brief details are given below, and further information including a TRIPOD checklist is available in the online Supplementary materials.
Ethical considerations and trial registrations
All included studies were granted ethical approvals and all participants gave informed consent (online Supplementary Table S5). No additional NHS ethical approval was required for this study: HRA reference 712/86/32/81.
Participants
The dataset for this study comes from a larger project investigating prognosis for adults with depression in primary care, the project involved systematic literature searches to form an individual patient dataset (IPD) from eligible randomised controlled trials (RCTs; Buckman et al., Reference Buckman, Saunders, Cohen, Clarke, Ambler, DeRubeis and Pilling2020). The final searches were conducted on 1 December 2020 (Buckman et al., Reference Buckman, Saunders, O'Driscoll, Cohen, Stott, Ambler and Pilling2021b). Studies were included if they were RCTs that recruited adults with depression in primary care, and used the Revised Clinical Interview Schedule (CIS-R) (Lewis, Pelosi, Araya, & Dunn, Reference Lewis, Pelosi, Araya and Dunn1992) to collect depressive and anxiety symptom data and determine diagnoses. This was to ensure uniformity across the studies in the items available for the predictive models. From our previous work we found that the CIS-R is the most commonly used comprehensive measure of this kind in studies of depression in primary care (Buckman et al., Reference Buckman, Saunders, Cohen, Barnett, Clarke, Ambler and Pilling2021a). Studies also had to use the Beck Depression Inventory Second Edition (BDI-II) (Beck, Steer, & Brown, Reference Beck, Steer and Brown1996) to collect individual symptoms of depression. Six RCTs met inclusion criteria and were split such that half (k = 3, n = 1722) would form a dataset to develop the predictive models (the ‘training set’) and half (k = 3, n = 1136, of which 918 had outcome data and were used to evaluate the models as detailed below) would form a separate dataset to test the models (the ‘test set’). See online Supplementary Table S1 and Supplementary Fig. S1, for details of each study. It was decided that studies with similar types of treatments would be split across the training and test sets (with all data from one study going into the training set and all data from the other study going into the test set), and where this was the case, those with the larger sample sizes would go into the training data.
Predictors and measures
Predictors varied depending on the model used, as detailed below (Table 1). Models either included total scores (with items either weighted or unweighted) or individual items from the BDI-II. All models used total scores for the eight anxiety subscales from CIS-R (generalised anxiety, worry, compulsions, obsessions, phobic anxiety, health anxiety, somatic concerns, and panic; with items either weighted or unweighted), and total scores for alcohol use, social support and life events. In previous studies using similar data it has been found that these factors are independently associated with poorer prognoses, and may have utility in predicting treatment outcomes (Buckman et al., Reference Buckman, Saunders, Cohen, Barnett, Clarke, Ambler and Pilling2021a; Buckman et al., Reference Buckman, Saunders, O'Driscoll, Cohen, Stott, Ambler and Pilling2021b; O'Driscoll et al., Reference O'Driscoll, Buckman, Fried, Saunders, Cohen, Ambler and Pilling2021). The total scores for the social support, life events and alcohol measures were required instead of the individual items. There was strong topological overlap between the social support items, and all eight items were highly correlated with one another, which would have led to inflated centrality scores were the individual items included in the network models. Further, the level of multi-collinearity went beyond pairs of items, so instead of removing those leading to high multi-collinearity, it was necessary to use the sum score as the best measure of this construct. Modelling binary items into a network is possible but not when using the fused graphical least absolute shrinkage and selection operator (LASSO) (FGL) method adopted here to deal with between-study heterogeneity, so the total score from the life events scale was used. As alcohol misuse was an exclusion criterion for some of the eligible RCTs, there was near zero variability for many of the items. The sum score therefore represented the best measure of alcohol use.
Table 1. Description of the modelling approaches for the primary outcome
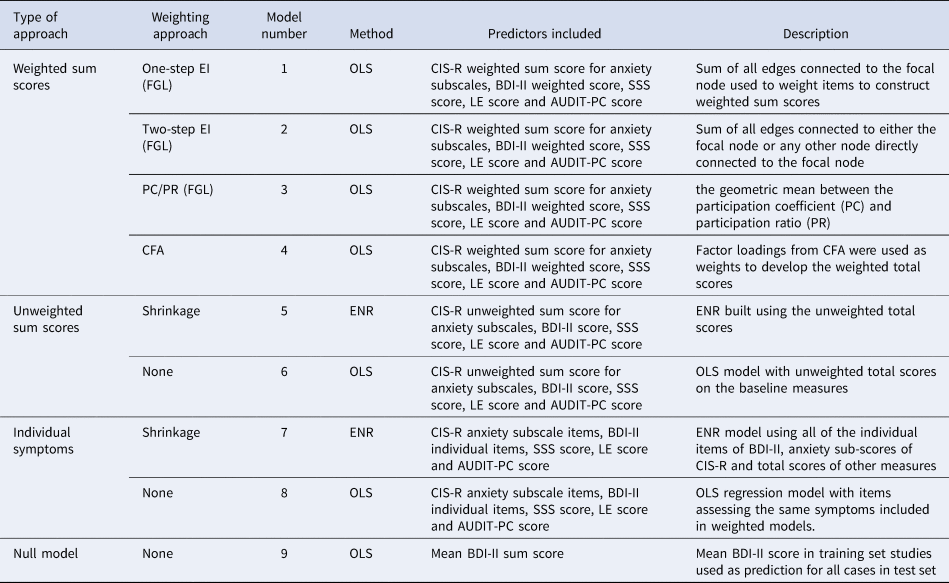
BDI-II, Beck Depression Inventory Second Edition; CFA, confirmatory factor analysis; CIS-R, Revised Clinical Interview Schedule; EI, expected influence; ENR, elastic net regularised regression; FGL, fused graphical LASSO; LE, life events; OLS, ordinary least squares; PC/PR, geometric mean between the participation ratio and participation coefficient; SSS, social support scale.
The null models used the BDI-II total score only. See online Supplementary Table S2 for details of the measures.
Outcomes
The primary outcome was the BDI-II score at 3–4 months post-baseline. The secondary outcome was remission at 3–4 months post-baseline, defined as a score of ⩽10 on the BDI-II. In all but one of the six studies, assessors and analysts were blind to treatment allocation when collecting these data.
Data analysis
Missing data were imputed in the training set for all variables with <30% missing, using the ‘missForest’ package in R (Stekhoven & Bühlmann, Reference Stekhoven and Bühlmann2012). In the test set, the same approach was used but outcome data were not imputed. The maximum amount of missing data of any of the variables used in the predictive models here, at baseline in any of the six studies was 0.83%. In the test set, 218 participants were missing outcome data and were excluded from the analyses. For one study whose data were included in the training set, ‘COBALT’, BDI-II was not collected at 3–4 months. These scores were imputed using the methods above based on all available variables in that study including baseline BDI-II scores and patient health questionnaire-9 (PHQ-9) scores, 3-month PHQ-9 scores, 6-month BDI-II and PHQ-9 scores, and 12-month BDI-II and PHQ-9 scores (see online Supplementary for additional details).
Model building
Nine models were constructed in the training set (Table 1) for both primary and secondary outcomes, so 18 models were fitted overall.
For the first four models, we developed separate weighted sum scores for the CIS-R anxiety subscales by summing together coefficient weights for each of the eight subscales, and for the BDI-II by summing together coefficient weights for each of the 21 BDI-II items. Weighted sum scores for the CIS-R anxiety subscales and BDI-II, and coefficient weights for the total scores for social support, life events, and alcohol were used as predictors by entering them into regression models (ordinary least squares (OLS) for the primary outcome and logistic regression for the secondary outcome). This follows a method used by others to develop predictive models from networks (Boschloo et al., Reference Boschloo, van Borkulo, Borsboom and Schoevers2016). As described below, models 5 and 7 were based on a method that develops model weights internally (elastic net regularised regression (ENR)). Models 6 and 8 used the original, unweighted scores as a means of comparison. Model 9 was a null model, detailed further below.
Network analyses
There are two established ways to estimate a network model across several datasets. First, pool the data and estimate a model. Second, a recent innovation in network methods, the FGL (Costantini & Epskamp, Reference Costantini and Epskamp2017b; Fried et al., Reference Fried, Eidhof, Palic, Costantini, Huisman-van Dijk, Bockting and Karstoft2018), which estimates a model on several datasets and obtains one network. The FGL uses extended Bayesian information criterion, LASSO regularised regression models run separately for each study, and the models are then fused together to get a single network penalising differences among corresponding edge weights in the study networks. It is therefore considered better suited to deal with between-study heterogeneity (Costantini et al., Reference Costantini, Richetin, Preti, Casini, Epskamp and Perugini2019), and so was the method used here. For further details on how to estimate and interpret network structures and a comprehensive review of the network literature (see Epskamp & Fried, Reference Epskamp and Fried2018; Robinaugh, Hoekstra, Toner, & Borsboom, Reference Robinaugh, Hoekstra, Toner and Borsboom2020). For models 1–3, the FGL model was estimated using item-level data from CIS-R anxiety subscales and the BDI-II with tuning parameters selected through 10-fold cross validation (Costantini & Epskamp, Reference Costantini and Epskamp2017a; Danaher, Wang, & Witten, Reference Danaher, Wang and Witten2014). Centrality metrics derived from the FGL were used to construct weights after re-scaling these to be between 0 and 1. The three methods for determining coefficient weights from the estimated networks were: model (1) one-step expected influence (EI: sum of all edges connected to the focal node); model (2) two-step EI (sum of all edges connected to either the focal node or any other node directly connected to the focal node) (Robinaugh, Millner, & McNally, Reference Robinaugh, Millner and McNally2016); and model (3) the geometric mean of the participation coefficient (PC) and participation ratio (PR) (Letina, Blanken, Deserno, & Borsboom, Reference Letina, Blanken, Deserno and Borsboom2019). See online Supplementary materials for details. The EI metrics are widely used and have recently been proposed to be informative for predicting treatment outcomes (Berlim et al., Reference Berlim, Richard-Devantoy, Dos Santos and Turecki2020; Elliott et al., Reference Elliott, Jones and Schmidt2020). PC/PR is a newer approach, which is thought to be more sensitive to the use of different scale measures within the same network as it takes the community structure (multidimensionality) into account (Letina et al., Reference Letina, Blanken, Deserno and Borsboom2019). This is important here as we used measures of severity beyond depressive symptoms, given their importance for prognosis (Buckman et al., Reference Buckman, Saunders, Cohen, Barnett, Clarke, Ambler and Pilling2021a; Lorenzo-Luaces, Rodriguez-Quintana, & Bailey, Reference Lorenzo-Luaces, Rodriguez-Quintana and Bailey2020).
Confirmatory factor analyses
Model 4 was a unidimensional confirmatory factor analytic (CFA) model that assumes the data come from a single dimensional latent construct (in contrast to model 3, which is based on a Walktrap algorithm that identifies densely connected communities of items via random walks). Factor loadings were rescaled to be between 0 and 1 and summed to develop the weighted total scores.
Penalised regression analyses
Model 5 was an ENR model built using the unweighted total scores on the same scales that were used for models 1–4. In ENR, variables are selected and model weights are assigned through the use of LASSO and ridge penalisations. Parameter space was searched using 10-fold cross-validation to identify the optimal settings for these parameters before building the final model (Friedman, Hastie, & Tibshirani, Reference Friedman, Hastie and Tibshirani2010; Webb et al., Reference Webb, Cohen, Beard, Forgeard, Peckham and Björgvinsson2020). Model 7 was an ENR using all of the individual items from the BDI-II and the CIS-R anxiety subscales, and total scores for life events, social support and alcohol use.
Non-penalised regression analyses
Two simple comparison models were constructed using non-penalised regression (OLS regression for continuous outcomes and logistic regression for binary outcomes). Model 6 used the unweighted total scores on the five baseline measures, and model 8 used the same items as model 7.
Null models
A null model was built for each outcome for the purpose of comparison. For the primary outcome, this used the mean 3–4-month BDI-II score in the training set as the prediction for all patients in the test set, and for the secondary outcome the proportion of participants in remission in the training set was used as the prediction for all patients in the test set.
Sensitivity analyses
In order to assess the impact of having to impute the 3–4-month BDI-II outcomes for the COBALT study, we conducted two sensitivity analyses. All analyses using BDI-II as the outcome were re-done excluding COBALT from the training dataset. Then, a different way of capturing depressive symptoms at 3–4 months was calculated based on a method of converting scores from different depressive symptom measures to a single comparable score; the PROMIS T-score (Choi, Schalet, Cook, & Cella, Reference Choi, Schalet, Cook and Cella2014), using a multidimensional item-response theory-based conversion tool (Fischer & Rose, Reference Fischer and Rose2016), see online Supplementary for further details.
Model evaluation
Models were first evaluated in the full test set comprising three studies (TREAD, IPCRESS and MIR), and then separately in each of the three study samples. They were also evaluated in a 10-fold internal cross-validation of the full training set data.
For the continuous outcomes, there were three metrics used to evaluate the models: the amount of variance explained (R 2), the root mean-squared error (RMSE), and the mean absolute error (MAE). For the binary outcome, there were two metrics used to evaluate the models: the area under the receiver operating characteristic curve, and Brier scores. Since the R 2 in this study is a comparison of the predicted BDI-II score values to the mean BDI-II score at 3–4 months in the test set, and the training and test set BDI-II score means at 3–4 months differed, it was expected that some models might have R 2 values less than zero. There are limits to the inferences that can be drawn from the above metrics due to the variability in the modelling schemes that were applied (e.g. in which variables were made available; the number of variables made available; whether or not network analysis or factor analysis was used to create weighted sum scores; and whether or not penalised regression was applied to the variables that were made available). To make these performance metrics more accessible, we have provided three visualisations that demonstrate the potential clinical relevance of each model. For each of the eight models (excluding the null model) the predicted BDI-II scores at 3–4 months were arrayed from the lowest to the highest, then: (1) we plotted the observed BDI-II score at 3–4 months against the predicted score in groups (‘bins’) of n = 50; (2) predicted scores were split into categories of severity in line with delineations made by the originators of the scale (Beck et al., Reference Beck, Steer and Brown1996) (i.e. scores between 0 and 13 were considered minimal, 14 and 19 mild, 20 and 28 moderate, and 29 and 63 severe), and the rate of remission observed in the test set samples was calculated for each category; and (3) to provide a more granular visualisation of remission we plotted the observed percentage of participants in remission against BDI-II predicted scores at 3–4 months, again in bins of n = 50.
Results
Characteristics of the included studies
Six RCTs met inclusion criteria, three formed the training dataset (n = 1772) and three formed the test dataset (n = 1136, of which n = 918 had outcome data available for analyses), see online Supplementary Fig. S1 for flow of studies and online Supplementary Table S1 for details of each study.
Descriptive statistics
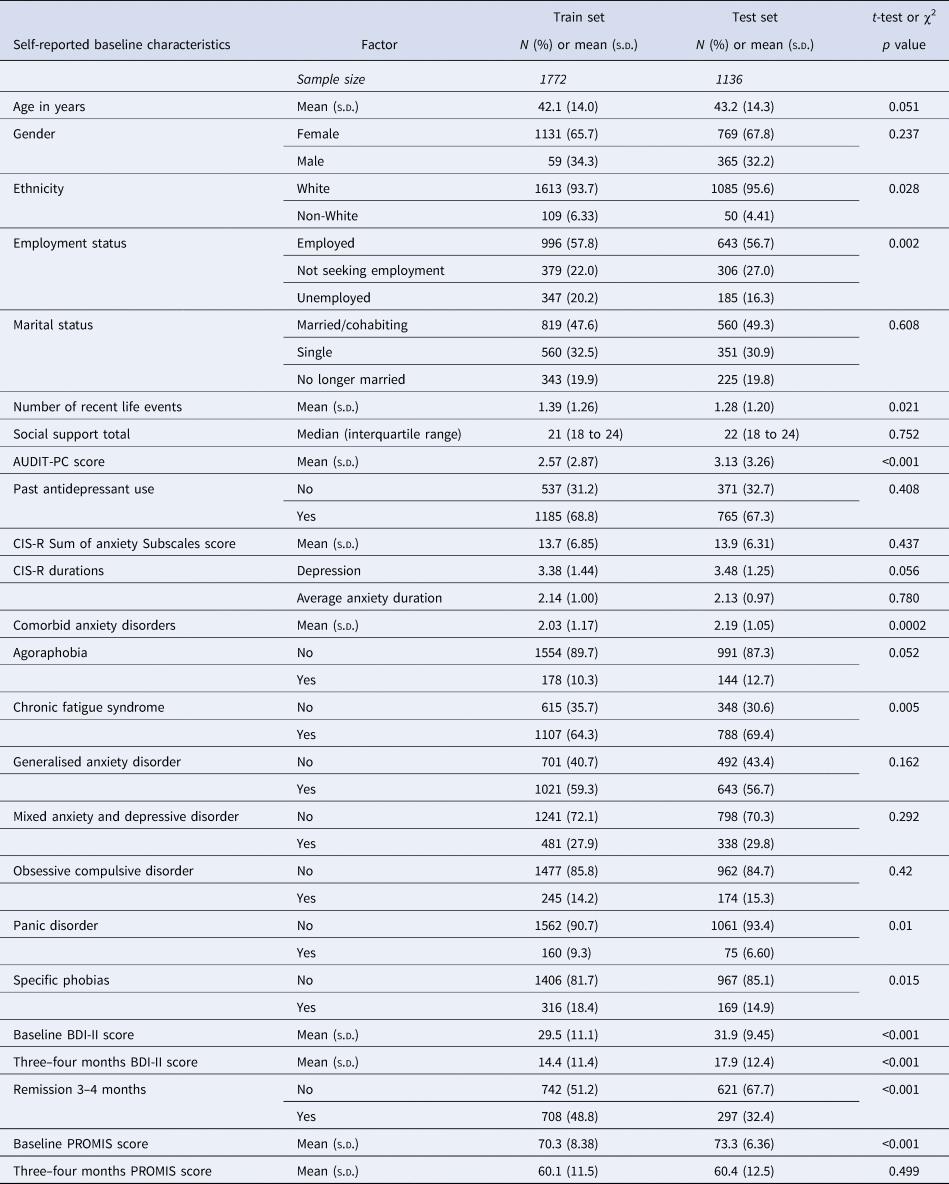
Descriptive statistics and comparisons of the distributions of socio-demographics and markers of severity across the training set and test set samples are provided in Table 2. There were some differences between the training and test datasets: fewer people of non-White ethnicities were in the test set, and more of the training sample were unemployed. On average the test set participants had more comorbid disorders although a higher proportion of the training set sample had comorbid panic disorder, specific phobias, or chronic fatigue syndrome. The mean score on the AUDIT-PC was higher in the test set. In addition, the mean BDI-II scores were higher in the test set (by 2.47 points at baseline and 3.53 points at 3–4 months). This corresponded with a large difference in the proportions of each sample reaching remission: 48.83% in the training set and 32.53% in the test set.
Table 2. Descriptive statistics for training and test set samples, and comparison of the two datasets
Formation of the models
The weights given to the individual items for models 1–4 are shown in online Supplementary Table S6. Final model coefficients are presented in online Supplementary Tables S7 and S8.
Comparison of model performance
After the models were developed they were evaluated using the test dataset. Despite slight differences in the formation of some of the models, they made very similar predictions of who would get better (remit) and by what magnitude (BDI-II score) at 3–4 months. To illustrate this, the predictions produced for the primary outcome by the models were highly correlated (all correlation coefficients above r = 0.90 for models 1–6 and above r = 0.75 for models 7–8) see online Supplementary Fig. S2.
For the primary outcome (BDI-II score at 3–4 months post-baseline) in the combined test sets, the RMSE was similar for models 1–6 (the largest difference was between model 2 which had the lowest RMSE and model 4, =0.057) with a slightly higher RMSE for the OLS individual-item model (model 8) (difference between model 2 and model 8 = 0.214). Models 1–8 made similar predictions for those with BDI-II scores at 3–4 months that were <18 or >25, but diverged more in the predictions for those with scores between 18 and 24, see Fig. 1 (for ease of presentation, results are displayed for groups of 50 participants, each point shows the mean predicted and observed score for the 50 participants closest to that point on the graph). All models (1–8) had lower RMSE scores than the null model (ranging from 0.944 for the difference between models 8 and 9 to 1.158 for the difference between models 2 and 9), see Table 3. The amount of variance explained by models 1–7 was again very similar with R 2 values between 0.157 and 0.169. Model 8 (R 2 = 0.109) explained less variance, but all models had R 2 values well above the null model (R 2 = −0.01). MAE values were similar for models 1–7 (ranging between 9.089 for model 5 and 9.173 for model 7). MAE was slightly higher in model 8 (=9.279) and higher again in the null model (9.935), see Table 3. For the secondary outcome there was a similar pattern to the results, although the null model (9) had a similar Brier score to models 1–7 and this was slightly lower than that of model 8 (=0.246), see online Supplementary Table S3. There were greater variations between the models in the separate test set studies than in the overall test set and for all models (1–9). Additionally, the RMSE and MAE scores were lower, and R 2s were higher, in the internal cross-validation than in the external test set data.
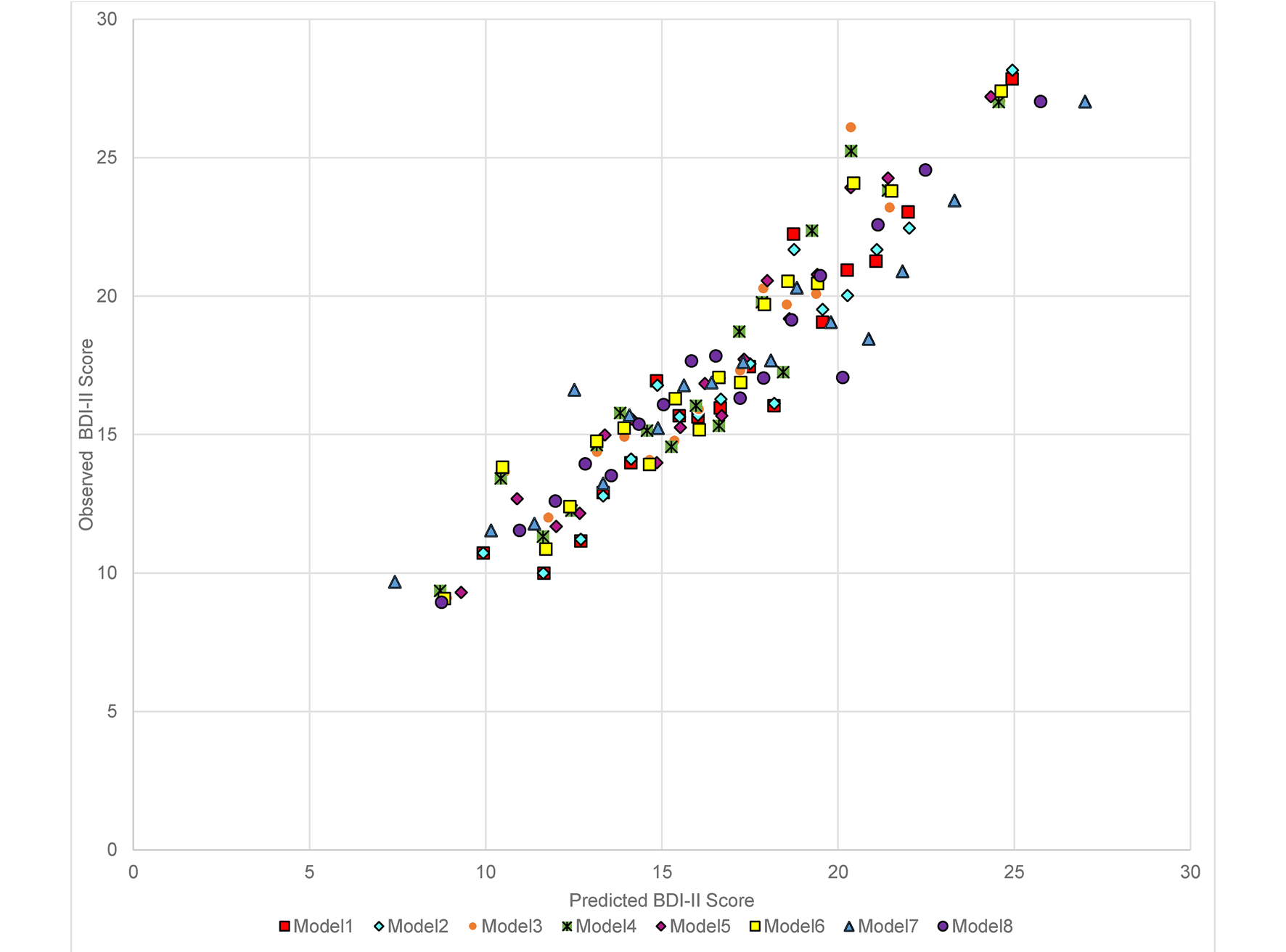
Fig. 1. Predicted and observed BDI-II score at 3–4 months in combined test set data (n = 918) by the eight models (excluding the null model) built in the Training set data.
Table 3. Performance of the models predicting BDI-II scores at 3–4 months post-baseline in the test datasets individually and combined
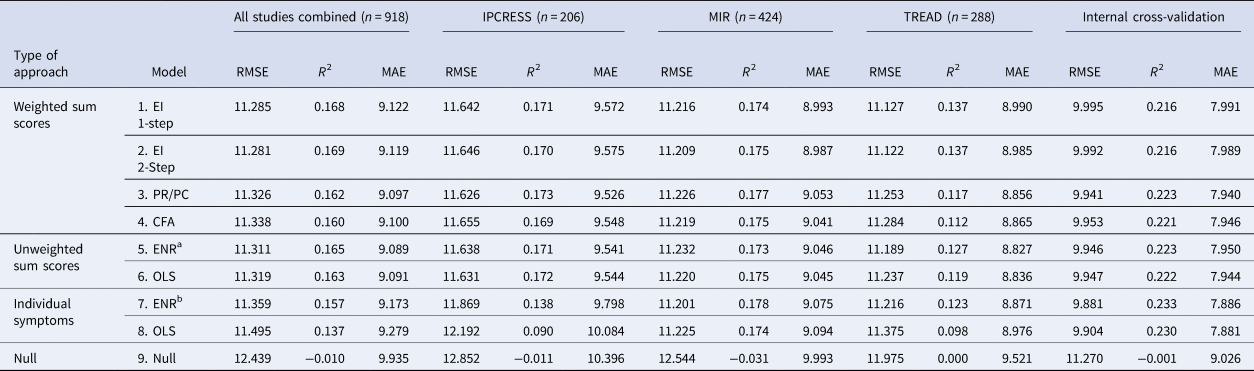
CFA, confirmatory factor analysis; EI, expected influence; ENR, elastic net regularised regression; MAE, mean absolute error; OLS, ordinary least squares; PC, participation coefficient; PR, participation ratio; RMSE, root mean-squared error.
Note there is no calculation of r2 for the null model as all there was no variability in prediction.
a Parameters were set at (ᾳ = 0.82 and λ = 0.20).
b Parameters were set at (ᾳ = 0.05 and λ = 2.0).
In order to evaluate the potential clinical relevance of the models we determined the observed proportion of participants in remission at 3–4 months based on the predicted score made by each model (online Supplementary Fig. S3), and the same based on categories of severity of symptoms taken from the predicted scores (see Fig. 2). From these figures we can see that when the models predicted high BDI-II scores at 3–4 months the chances of being in remission were very low. Models 7 and 8 predicted more participants would have severe depression at 3–4 months than the other models. When the models predicted minimal symptoms (BDI-II scores <10) the observed rate of remission was around 50%. There were few differences between the models overall, although greater variations in the observed rates of remission between the models for patients predicted to have mild to moderate BDI-II scores at 3–4 months.
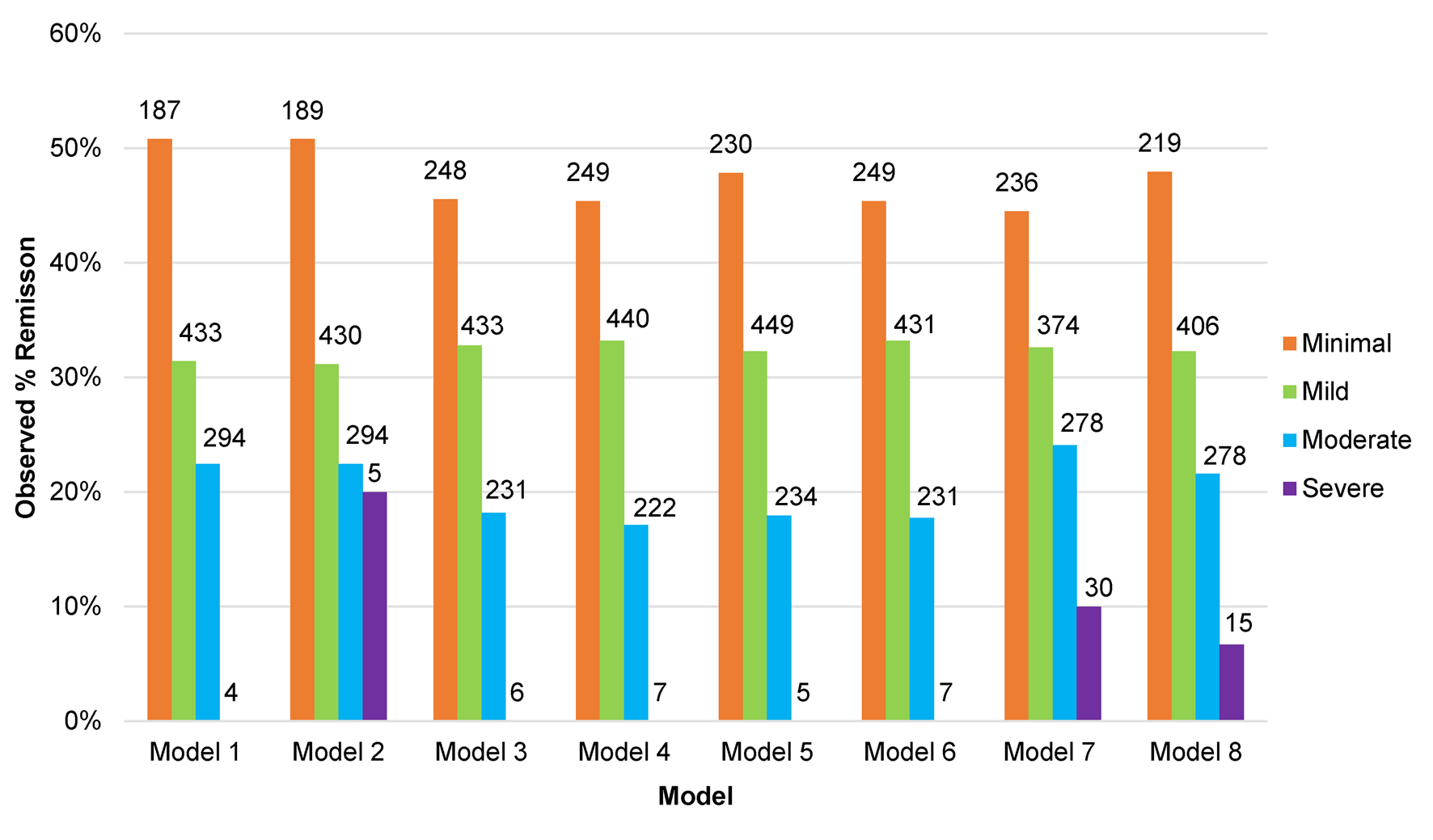
Fig. 2. Proportion of participants in remission at 3–4 months post-baseline in the test set studies (n = 918) by predicted category of depressive severity at 3–4 months, for each of the eight models.
Sensitivity analyses did not lead to any substantive differences in our findings, see online Supplementary Tables S2 and S3.
Discussion
There were few differences in the performance of the majority of the predictive models. The first seven models all outperformed the null models on all metrics for primary and secondary outcomes. Those using weighted or unweighted sum scores (the first six models) performed better in the held-out test data than the individual-item models did, particularly model 8 (the OLS regression model using all of the individual BDI-II score items and eight CIS-R anxiety subscale scores instead of the sum scores for each). Any of the eight models could be used to predict the severity of depressive symptoms at 3–4 months after starting treatment based on pre-treatment data. The large difference in observed remission rates between those predicted to have high compared to low BDI-II scores at 3–4 months informs the potential clinical relevance of these models.
Strengths and limitations
This study was the first to provide robust tests of the ability of centrality statistics from FGL networks and factor loadings from a factor analytic model to develop weighted total scale scores to inform predictive models of treatment outcomes. This is something that has been proposed as a promising method for using individual symptom data to build informative predictive models (Boschloo et al., Reference Boschloo, van Borkulo, Borsboom and Schoevers2016). We tested these methods against bone fide predictive models and simple comparison models, and in entirely held-out (test) data, and found there to be little evidence of any advantage to the above approaches. We used a large individual patient data dataset comprising six RCTs with a variety of widely available treatments for depression, all of the RCTs were situated in primary care, and five were pragmatic trials, increasing the generalisability of these results (Rothwell, Reference Rothwell2005). However, the variability in the samples between the studies may have limited the overall performance of the models. We included a range of psychopathology measures at baseline, not just depression symptoms from a single measure, as there is good evidence that such factors are associated with prognosis for depressed adults (Buckman et al., Reference Buckman, Saunders, Cohen, Barnett, Clarke, Ambler and Pilling2021a; Buckman et al., Reference Buckman, Saunders, O'Driscoll, Cohen, Stott, Ambler and Pilling2021b). We also used the most commonly utilised comprehensive measure of depressive and anxiety symptoms and diagnoses from RCTs of depression in primary care, to minimise bias in harmonising data, and ensure a broad range of depressive and anxiety based symptoms could be included in the models we developed.
However, there were a number of limitations. Not all important covariates were controlled for: we did not include data on durations of depression or anxiety despite their associations with prognosis for adults with depression (Buckman et al., Reference Buckman, Saunders, Cohen, Barnett, Clarke, Ambler and Pilling2021a; Lorenzo-Luaces et al., Reference Lorenzo-Luaces, Rodriguez-Quintana and Bailey2020). Including such data would have led to problems of multi-collinearity with the symptoms of the individual comorbid anxiety disorders experienced by each participant, and across durations of anxiety disorders and depression, biasing centrality estimates and factor loadings for models 1–4. The intercepts and coefficient weights provided in the online Supplementary materials could be used to derive prognostic predictions for future depressed patients using models developed here. However, there were large amounts of variance in the outcome that could not be explained by any of the models. This is consistent with other studies that developed and validated predictive models for patients with depression (Delgadillo, Huey, Bennett, & McMillan, Reference Delgadillo, Huey, Bennett and McMillan2017; Webb et al., Reference Webb, Cohen, Beard, Forgeard, Peckham and Björgvinsson2020). Some of the unexplained variance is likely due to measurement error and other factors, including those that better capture the biopsychosocial complexity of depression. We speculate that such factors would need to be included before the predictive models could more accurately predict prognosis for any individual patient (Fried & Robinaugh, Reference Fried and Robinaugh2020). Crucially, for this study, such improvements in accuracy may also have been required for us to find substantial differences in the performance of the modelling schemes.
In this study, predictions of prognosis were made regardless of the type of treatment given, as this may have most utility at the point when patients are seeking treatment, i.e. before a decision on the type of treatment has been made (Buckman et al., Reference Buckman, Saunders, Cohen, Barnett, Clarke, Ambler and Pilling2021a; Marwood, Wise, Perkins, & Cleare, Reference Marwood, Wise, Perkins and Cleare2018). Although the train and test set studies were split such that where possible, there was a balance of treatment types across the datasets, it may be the case that the models would perform differently between types of treatments. Future studies might address differential model performance by treatment type but adequate data to do so were not available here (Fisher, Carpenter, Morris, Freeman, & Tierney, Reference Fisher, Carpenter, Morris, Freeman and Tierney2017b).
The present study used prognostic outcomes including depressive symptom severity at 3–4 months and remission, but both of these relied on sum scores from the BDI-II. As the BDI-II items or sum score were used in the development of the predictive models it might have been informative to consider model performance with an entirely separate but clinically meaningful outcome such as functioning, quality of life, or mental pain (Fava et al., Reference Fava, Tomba, Brakemeier, Carrozzino, Cosci, Eöry and Guidi2019); data on such outcomes were not available here. In addition, models here used IPD but the networks were estimated based on aggregated data, a number of studies have shown the potential utility of using idiographic networks to predict outcomes for individual patients (Fisher & Boswell, Reference Fisher and Boswell2016; Fisher, Medaglia, & Jeronimus, Reference Fisher, Medaglia and Jeronimus2018; Fisher, Reeves, Lawyer, Medaglia, & Rubel, Reference Fisher, Reeves, Lawyer, Medaglia and Rubel2017a), this may yet prove the most fruitful avenue for using networks to inform prognostic models which are able to outperform classic regression models of the same factors.
Implications and conclusions
Prognoses generated by the models developed here could be informative for depressed patients seeking treatment in primary care. However, there were few differences between the models, with no clear advantage in using individual items over sum scores, or in using network models or factor analytic models to weight individual items, in order to derive prognostic predictions. This may represent a limitation of the available data, or of the modelling approaches (that e.g. rely on estimating linear relations). In all of the models, the degree of inaccuracy in their predictions might be unacceptable to any individual patient. There were clear differences in the number of people reaching remission when the models predicted patients would have particularly low or high scores, but the models performed less well with BDI-II scores between 18 and 25. It may be informative for future studies to test the utility in giving more intensive treatments or more regular clinical reviews for patients with these mid-range scores, particularly if there is uncertainty about the value of doing so based on clinical severity. It is noteworthy that all of the models utilised both depressive and anxiety symptom data, and all but one included the total score from the life events scale, and six of the eight included the social support scale score. It might therefore be informative for prognosis to assess for these factors routinely in clinic. The individual-item models outperformed the others in the internal cross-validation data suggesting that narrow constructs (e.g. anhedonia) might be more informative for prognosis than broad constructs (e.g. depression), but issues of measurement error arise, particularly with the validity of the single items to measure each narrow construct. The findings presented here also highlight the importance of external validation in accounting for issues of overfitting.
Authors contributions
JEJB, CO'D, ZDC and EF conceived of the original project, JEJB along with SP, GL, RJD, SDH, SG, TK, EW and GA applied for and received funding to support this work. All ten of the above and RS wrote the initial protocol document and plan for the current study. ZDC, NW, DK, TK, SG and GL provided data and liaison to resolve issues and discrepancies between received datasets and publications about those studies. JEJB, RS, GL and SP were responsible for the screening of studies, data extraction, and additional data cleaning. JB, CO'D and ZDC conducted the data analyses with support from EF, GA, RS, GL and SP, and consultation from all other authors. JEJB wrote the original manuscript will support from ZDC, RS, CO'D, EF, GA, GL and SP. All authors contributed to consecutive drafts and approved the final manuscript. The corresponding author attests that all listed authors meet authorship criteria and that no others meeting the criteria have been omitted.
Financial support
This work was supported by the Wellcome Trust through a Clinical Research Fellowship to JEJB (201292/Z/16/Z), MQ Foundation (for ZDC: MQDS16/72), the Higher Education Funding Council for England, the National Institute of Health Research (NIHR), NIHR University College London Hospitals Biomedical Research Centre (CO'D, RS, GL and SP), NIHR Biomedical Research Centre at the University Hospitals Bristol and Weston NHS Foundation Trust and the University of Bristol (NW and DK), University College London (GA, GL), University of Pennsylvania (RJD), Vanderbilt University (SDH), University of Southampton (TK), University of Exeter (EW), and University of York (SG), National Institute for Health Research (NIHR) Biomedical Research Centre at South London and Maudsley NHS Foundation Trust and King's College London (TE, AP and CR). The views expressed are those of the authors and not necessarily those of the NIHR or the Department of Health and Social Care.
The included studies that make up the Dep-GP IPD database were funded by:
(1) COBALT: The National Institute for Health Research Health Technology Assessment (NIHR HTA) programme (project number 06/404/02).
(2) GENPOD: Medical Research Council and supported by the Mental Health Research Network.
(3) IPCRESS: BUPA Foundation.
(4) MIR: NIHR HTA programme (project 11/129/76) and supported by the NIHR Biomedical Research Centre at University Hospitals Bristol NHS Foundation Trust and the University of Bristol.
(5) PANDA: NIHR Programme Grant for Applied Research (RP-PG-0610-10048).
(6) TREAD: NIHR HTA programme.
The funders of the study had no role in study design, data collection, data analysis, data interpretation, or writing of the report. All authors were fully independent of their respective funders and had responsibility for the decision to submit for this manuscript for publication.
Conflict of interest
None.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0033291721001616.








 Open access
Open access