Accurate disparity prediction is a hot spot in computer vision, and how to efficiently exploit contextual information is the key to improve the performance. In this paper, we propose a simple yet effective non-local context attention network to exploit the global context information by using attention mechanisms and semantic information for stereo matching. First, we develop a 2D geometry feature learning module to get a more discriminative representation by taking advantage of multi-scale features and form them into the variance-based cost volume. Then, we construct a non-local attention matching module by using the non-local block and hierarchical 3D convolutions, which can effectively regularize the cost volume and capture the global contextual information. Finally, we adopt a geometry refinement module to refine the disparity map to further improve the performance. Moreover, we add the warping loss function to help the model learn the matching rule of the non-occluded region. Our experiments show that (1) our approach achieves competitive results on KITTI and SceneFlow datasets in the end-point error and the fraction of erroneous pixels $({D_1})$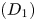 ; (2) our proposed method particularly has superior performance in the reflective regions and occluded areas.
; (2) our proposed method particularly has superior performance in the reflective regions and occluded areas.

