1 results
Describe the house and I will tell you the price: House price prediction with textual description data
-
- Journal:
- Natural Language Engineering / Volume 30 / Issue 4 / July 2024
- Published online by Cambridge University Press:
- 18 July 2023, pp. 661-695
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
House price prediction is an important problem that could benefit home buyers and sellers. Traditional models for house price prediction use numerical attributes such as the number of rooms but disregard the house description text. The recent developments in text processing suggest these can be valuable attributes, which motivated us to use house descriptions. This paper focuses on the house asking/advertising price and studies the impact of using house description texts to predict the final house price. To achieve this, we collected a large and diverse set of attributes on house postings, including the house advertising price. Then, we compare the performance of three scenarios: using only the house description, only numeric attributes, or both. We processed the description text through three word embedding techniques: TF-IDF, Word2Vec, and BERT. Four regression algorithms are trained using only textual data, non-textual data, or both. Our results show that by using exclusively the description data with Word2Vec and a Deep Learning model, we can achieve good performance. However, the best overall performance is obtained when using both textual and non-textual features. An
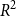 $R^2$ of 0.7904 is achieved by the deep learning model using only description data on the testing data. This clearly indicates that using the house description text alone is a strong predictor for the house price. However, when observing the RMSE on the test data, the best model was gradient boosting using both numeric and description data. Overall, we observe that combining the textual and non-textual features improves the learned model and provides performance benefits when compared against using only one of the feature types. We also provide a freely available application for house price prediction, which is solely based on a house text description and uses our final developed model with Word2Vec and Deep Learning to predict the house price.
$R^2$ of 0.7904 is achieved by the deep learning model using only description data on the testing data. This clearly indicates that using the house description text alone is a strong predictor for the house price. However, when observing the RMSE on the test data, the best model was gradient boosting using both numeric and description data. Overall, we observe that combining the textual and non-textual features improves the learned model and provides performance benefits when compared against using only one of the feature types. We also provide a freely available application for house price prediction, which is solely based on a house text description and uses our final developed model with Word2Vec and Deep Learning to predict the house price.