Diagnostic classification models (DCMs) are widely used for providing fine-grained classification of a multidimensional collection of discrete attributes. The application of DCMs requires the specification of the latent structure in what is known as the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} matrix. Expert-specified \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrix. Expert-specified \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} matrices might be biased and result in incorrect diagnostic classifications, so a critical issue is developing methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrices might be biased and result in incorrect diagnostic classifications, so a critical issue is developing methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} in order to infer the relationship between latent attributes and items. Existing exploratory methods for estimating \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
in order to infer the relationship between latent attributes and items. Existing exploratory methods for estimating \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} must pre-specify the number of attributes, K. We present a Bayesian framework to jointly infer the number of attributes K and the elements of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
must pre-specify the number of attributes, K. We present a Bayesian framework to jointly infer the number of attributes K and the elements of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} . We propose the crimp sampling algorithm to transit between different dimensions of K and estimate the underlying \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
. We propose the crimp sampling algorithm to transit between different dimensions of K and estimate the underlying \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} and model parameters while enforcing model identifiability constraints. We also adapt the Indian buffet process and reversible-jump Markov chain Monte Carlo methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
and model parameters while enforcing model identifiability constraints. We also adapt the Indian buffet process and reversible-jump Markov chain Monte Carlo methods to estimate \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document} . We report evidence that the crimp sampler performs the best among the three methods. We apply the developed methodology to two data sets and discuss the implications of the findings for future research.
. We report evidence that the crimp sampler performs the best among the three methods. We apply the developed methodology to two data sets and discuss the implications of the findings for future research.
The specification of the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}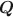 matrix in cognitive diagnosis models is important for correct classification of attribute profiles. Researchers have proposed many methods for estimation and validation of the data-driven \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrix in cognitive diagnosis models is important for correct classification of attribute profiles. Researchers have proposed many methods for estimation and validation of the data-driven \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}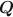 matrices. However, inference of the number of attributes in the general restricted latent class model remains an open question. We propose a Bayesian framework for general restricted latent class models and use the spike-and-slab prior to avoid the computation issues caused by the varying dimensions of model parameters associated with the number of attributes, K. We develop an efficient Metropolis-within-Gibbs algorithm to estimate K and the corresponding \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}
matrices. However, inference of the number of attributes in the general restricted latent class model remains an open question. We propose a Bayesian framework for general restricted latent class models and use the spike-and-slab prior to avoid the computation issues caused by the varying dimensions of model parameters associated with the number of attributes, K. We develop an efficient Metropolis-within-Gibbs algorithm to estimate K and the corresponding \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$${\varvec{Q}}$$\end{document}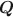 matrix simultaneously. The proposed algorithm uses the stick-breaking construction to mimic an Indian buffet process and employs a novel Metropolis–Hastings transition step to encourage exploring the sample space associated with different values of K. We evaluate the performance of the proposed method through a simulation study under different model specifications and apply the method to a real data set related to a fluid intelligence matrix reasoning test.
matrix simultaneously. The proposed algorithm uses the stick-breaking construction to mimic an Indian buffet process and employs a novel Metropolis–Hastings transition step to encourage exploring the sample space associated with different values of K. We evaluate the performance of the proposed method through a simulation study under different model specifications and apply the method to a real data set related to a fluid intelligence matrix reasoning test.

