When humans solve complex problems, they typically construct, reflect, and revise sequences of ideas, hypotheses, and beliefs until a final decision or conclusion is reached. Contrary to this, current machine learning models are mostly trained to map an input to one single and fixed output. In this paper, we investigate how we can equip models with the ability to represent, construct, and evaluate a second, third, and 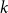 $k$-th thought within their prediction process. Drawing inspiration from Hegel’s dialectics, we propose and evaluate the thought flow concept which constructs a sequence of predictions. We present a self-correction mechanism which (a) is trained to estimate the model’s correctness and which (b) performs iterative prediction updates based on the gradient of the correctness prediction. We introduce our method focusing initially on question answering (QA) and carry out extensive experiments which demonstrate that (i) our method is able to correct its own predictions and that (ii) it can improve model performance by a large margin. In addition, we conduct a qualitative analysis of thought flow correction patterns and explore how thought flow predictions affect users’ human-AI collaboration in a crowdsourcing study. We find that (iii) thought flows improve user performance and are perceived as more natural, correct, and intelligent regarding single and/or top-3 predictions.
$k$-th thought within their prediction process. Drawing inspiration from Hegel’s dialectics, we propose and evaluate the thought flow concept which constructs a sequence of predictions. We present a self-correction mechanism which (a) is trained to estimate the model’s correctness and which (b) performs iterative prediction updates based on the gradient of the correctness prediction. We introduce our method focusing initially on question answering (QA) and carry out extensive experiments which demonstrate that (i) our method is able to correct its own predictions and that (ii) it can improve model performance by a large margin. In addition, we conduct a qualitative analysis of thought flow correction patterns and explore how thought flow predictions affect users’ human-AI collaboration in a crowdsourcing study. We find that (iii) thought flows improve user performance and are perceived as more natural, correct, and intelligent regarding single and/or top-3 predictions.

