





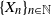
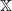
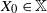
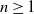
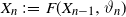
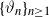
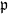
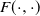
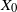
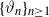
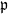
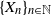
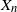
1. Introduction
Let
 $({\mathbb{X}},d)$
be a Polish space equipped with its Borel
$({\mathbb{X}},d)$
be a Polish space equipped with its Borel
 $\sigma$
-algebra
$\sigma$
-algebra
 ${\mathcal{X}}$
. The random variables are assumed to be defined on a probability space
${\mathcal{X}}$
. The random variables are assumed to be defined on a probability space
 $(\Omega,{\mathcal{F}},\mathbb{P})$
. Throughout the paper we are concerned with iterated function systems (IFSs) of Lipschitz maps according to the following definition.
$(\Omega,{\mathcal{F}},\mathbb{P})$
. Throughout the paper we are concerned with iterated function systems (IFSs) of Lipschitz maps according to the following definition.
Definition 1.1. (IFS of Lipschitz maps.) Let
 $({\mathbb{V}},{\mathcal{V}})$
be a measurable space, and let
$({\mathbb{V}},{\mathcal{V}})$
be a measurable space, and let
 $\{\vartheta_n\}_{n\geq 1}$
be a sequence of
$\{\vartheta_n\}_{n\geq 1}$
be a sequence of
 ${\mathbb{V}}$
-valued independent and identically distributed (i.i.d.) random variables with common distribution denoted by
${\mathbb{V}}$
-valued independent and identically distributed (i.i.d.) random variables with common distribution denoted by
 $\mathfrak{p}$
. Let
$\mathfrak{p}$
. Let
 $X_0$
be an
$X_0$
be an
 ${\mathbb{X}}$
-valued random variable that is assumed to be independent of the sequence
${\mathbb{X}}$
-valued random variable that is assumed to be independent of the sequence
 $\{\vartheta_n\}_{n\geq 1}$
. Finally, let
$\{\vartheta_n\}_{n\geq 1}$
. Finally, let
 $F \;:\; ({\mathbb{X}}\times {\mathbb{V}},{\mathcal{X}}\otimes {\mathcal{V}})\rightarrow ({\mathbb{X}},{\mathcal{X}})$
be jointly measurable and Lipschitz continuous in the first variable. The associated IFS is the sequence of random variables
$F \;:\; ({\mathbb{X}}\times {\mathbb{V}},{\mathcal{X}}\otimes {\mathcal{V}})\rightarrow ({\mathbb{X}},{\mathcal{X}})$
be jointly measurable and Lipschitz continuous in the first variable. The associated IFS is the sequence of random variables
 $\{X_n\}_{n\in{\mathbb{N}}}$
recursively defined, starting from
$\{X_n\}_{n\in{\mathbb{N}}}$
recursively defined, starting from
 $X_0$
, as follows:
$X_0$
, as follows:
 \begin{equation} \textrm{for all } n \geq 1, \quad X_n \;:\!=\; F(X_{n-1},\vartheta_n). \end{equation}
\begin{equation} \textrm{for all } n \geq 1, \quad X_n \;:\!=\; F(X_{n-1},\vartheta_n). \end{equation}
Let
 $x_0\in{\mathbb{X}}$
be fixed. For any
$x_0\in{\mathbb{X}}$
be fixed. For any
 $a\in [0,+\infty)$
, we set
$a\in [0,+\infty)$
, we set
 $V_a(x) \;:\!=\; (1+\, d(x,x_0))^a$
, and we denote by
$V_a(x) \;:\!=\; (1+\, d(x,x_0))^a$
, and we denote by
 $({\mathcal{B}}_a,|\cdot|_a)$
the weighted-supremum Banach space associated with
$({\mathcal{B}}_a,|\cdot|_a)$
the weighted-supremum Banach space associated with
 $V_a(\!\cdot\!)$
, i.e.
$V_a(\!\cdot\!)$
, i.e.
 \begin{equation*} \mathcal{B}_a \;:\!=\; \bigg\{f \;:\; {\mathbb{X}}\rightarrow{\mathbb{C}} \textrm{ measurable such that } |f|_a \;:\!=\; \sup_{x\in {\mathbb{X}}} \frac{|f(x)|}{V_a(x)} < \infty \bigg\}.\end{equation*}
\begin{equation*} \mathcal{B}_a \;:\!=\; \bigg\{f \;:\; {\mathbb{X}}\rightarrow{\mathbb{C}} \textrm{ measurable such that } |f|_a \;:\!=\; \sup_{x\in {\mathbb{X}}} \frac{|f(x)|}{V_a(x)} < \infty \bigg\}.\end{equation*}
Note that
 $({\mathcal{B}}_0,|\cdot|_0)$
is the Banach space of complex-valued bounded measurable functions on
$({\mathcal{B}}_0,|\cdot|_0)$
is the Banach space of complex-valued bounded measurable functions on
 ${\mathbb{X}}$
equipped with the supremum norm. The total variation distance between two probability distributions
${\mathbb{X}}$
equipped with the supremum norm. The total variation distance between two probability distributions
 $\mu_0$
and
$\mu_0$
and
 $\mu_1$
on
$\mu_1$
on
 ${\mathbb{X}}$
is defined by
${\mathbb{X}}$
is defined by
 $\| \mu_0 - \mu_1 \|_{\textrm{TV}} \;:\!=\; \sup_{ |f|_0 \le 1} | \mu_0(f) - \mu_1(f)|$
, where
$\| \mu_0 - \mu_1 \|_{\textrm{TV}} \;:\!=\; \sup_{ |f|_0 \le 1} | \mu_0(f) - \mu_1(f)|$
, where
 $\mu_i(f) \;:\!=\; \int_{{\mathbb{X}}} f(x) \, {\textrm{d}}\mu_i(x)$
,
$\mu_i(f) \;:\!=\; \int_{{\mathbb{X}}} f(x) \, {\textrm{d}}\mu_i(x)$
,
 $i=0,1$
.
$i=0,1$
.
Let
 $\{X_n\}_{n\in{\mathbb{N}}}$
be an IFS of Lipschitz maps. This is a Markov chain on
$\{X_n\}_{n\in{\mathbb{N}}}$
be an IFS of Lipschitz maps. This is a Markov chain on
 ${\mathbb{X}}$
with transition kernel P given by:
${\mathbb{X}}$
with transition kernel P given by:
 \begin{equation} \textrm{for all } x\in{\mathbb{X}} \textrm{ and } A\in{\mathcal{X}}, \quad P(x,A) = \mathbb{E}[\textbf{1}_A(F(x,\vartheta_1))] = \int_{{\mathbb{V}}} \textbf{1}_A(F(x,v))\, {\textrm{d}}\mathfrak{p}(v). \end{equation}
\begin{equation} \textrm{for all } x\in{\mathbb{X}} \textrm{ and } A\in{\mathcal{X}}, \quad P(x,A) = \mathbb{E}[\textbf{1}_A(F(x,\vartheta_1))] = \int_{{\mathbb{V}}} \textbf{1}_A(F(x,v))\, {\textrm{d}}\mathfrak{p}(v). \end{equation}
Recall that
 $\{X_n\}_{n\in{\mathbb{N}}}$
is
$\{X_n\}_{n\in{\mathbb{N}}}$
is
 $V_a$
-geometrically ergodic if P has an invariant probability measure
$V_a$
-geometrically ergodic if P has an invariant probability measure
 $\pi$
such that
$\pi$
such that
 $\pi(V_a)<\infty$
and if there exists
$\pi(V_a)<\infty$
and if there exists
 $\rho_a \in(0,1)$
and
$\rho_a \in(0,1)$
and
 $C_a\in(0,+\infty)$
such that
$C_a\in(0,+\infty)$
such that
 \begin{equation} \textrm{for all } n\geq 1 \textrm{ and } f\in{\mathcal{B}}_a, \quad |P^nf - \pi(f)\textbf{1}_{{\mathbb{X}}}|_a \leq C_a \rho_a^{n} |f|_a. \end{equation}
\begin{equation} \textrm{for all } n\geq 1 \textrm{ and } f\in{\mathcal{B}}_a, \quad |P^nf - \pi(f)\textbf{1}_{{\mathbb{X}}}|_a \leq C_a \rho_a^{n} |f|_a. \end{equation}
The
 $V_a$
-geometric ergodicity of IFSs has been extensively studied (see, e.g., [Reference Alsmeyer2, Reference Douc, Moulines, Priouret and Soulier12, Reference Guibourg, Hervé and Ledoux18, Reference Meyn and Tweedie36, Reference Wu47] and references therein). The common starting point in most of these works is that P satisfies the so-called drift condition under the moment/contractive Condition 1.1 below (see, e.g., [Reference Duflo13]), for which we introduce the following notation. If
$V_a$
-geometric ergodicity of IFSs has been extensively studied (see, e.g., [Reference Alsmeyer2, Reference Douc, Moulines, Priouret and Soulier12, Reference Guibourg, Hervé and Ledoux18, Reference Meyn and Tweedie36, Reference Wu47] and references therein). The common starting point in most of these works is that P satisfies the so-called drift condition under the moment/contractive Condition 1.1 below (see, e.g., [Reference Duflo13]), for which we introduce the following notation. If
 $\psi \;:\; ({\mathbb{X}},d)\rightarrow({\mathbb{X}},d)$
is a Lipschitz continuous function, we define
$\psi \;:\; ({\mathbb{X}},d)\rightarrow({\mathbb{X}},d)$
is a Lipschitz continuous function, we define
 \begin{equation*} L(\psi) \;:\!=\; \sup\bigg\{\frac{d\big(\psi(x),\psi(y)\big)}{d(x,y)},\, (x,y)\in {\mathbb{X}}^2,\ x\neq y\bigg\}.\end{equation*}
\begin{equation*} L(\psi) \;:\!=\; \sup\bigg\{\frac{d\big(\psi(x),\psi(y)\big)}{d(x,y)},\, (x,y)\in {\mathbb{X}}^2,\ x\neq y\bigg\}.\end{equation*}
For all
 $v\in {\mathbb{V}}$
, set
$v\in {\mathbb{V}}$
, set
 $L_F(v) \;:\!=\; L\big(F(\cdot,v)\big)$
to simplify. The Lipschitz continuity in the first variable in Definition 1.1 reads: for all
$L_F(v) \;:\!=\; L\big(F(\cdot,v)\big)$
to simplify. The Lipschitz continuity in the first variable in Definition 1.1 reads: for all
 $v\in {\mathbb{V}}$
,
$v\in {\mathbb{V}}$
,
 $L_F(v)<\infty$
. Then, for every
$L_F(v)<\infty$
. Then, for every
 $a\in [1,+\infty)$
, Condition 1.1 is written as follows.
$a\in [1,+\infty)$
, Condition 1.1 is written as follows.
Condition 1.1. The function
 $F(\cdot,\cdot)$
and the sequence
$F(\cdot,\cdot)$
and the sequence
 $\{\vartheta_n\}_{n\geq 1}$
satisfy
$\{\vartheta_n\}_{n\geq 1}$
satisfy
 \begin{align} \mathbb{E}\left[d\big(x_0, F(x_0,\vartheta_1)\big)^{{a}}\right] < \infty , \end{align}
\begin{align} \mathbb{E}\left[d\big(x_0, F(x_0,\vartheta_1)\big)^{{a}}\right] < \infty , \end{align}
 \begin{align} \mathbb{E}\left[L_F(\vartheta_1)^{{a}}\right] < 1. \end{align}
\begin{align} \mathbb{E}\left[L_F(\vartheta_1)^{{a}}\right] < 1. \end{align}
The condition
 $a\geq 1$
in Condition 1.1 is just a technical assumption for applying the Hölder inequality, for instance. In fact, Condition 1.1 can be considered with
$a\geq 1$
in Condition 1.1 is just a technical assumption for applying the Hölder inequality, for instance. In fact, Condition 1.1 can be considered with
 $a>0$
by replacing the initial distance d with
$a>0$
by replacing the initial distance d with
 $d^\alpha$
for some
$d^\alpha$
for some
 $\alpha\in(0,1)$
. Let us specify Condition 1.1 for the so-called vector autoregressive model.
$\alpha\in(0,1)$
. Let us specify Condition 1.1 for the so-called vector autoregressive model.
Example 1.1. (Vector autoregressive model (VAR).) Assume that
 ${\mathbb{X}}\;:\!=\;{\mathbb{R}}^q$
for some
${\mathbb{X}}\;:\!=\;{\mathbb{R}}^q$
for some
 $q\geq 1$
. Let
$q\geq 1$
. Let
 $\|\!\cdot\!\|$
be any norm of
$\|\!\cdot\!\|$
be any norm of
 ${\mathbb{R}}^q$
, and define
${\mathbb{R}}^q$
, and define
 $d(x,y)\;:\!=\;\|x-y\|$
as the associated distance. Consider
$d(x,y)\;:\!=\;\|x-y\|$
as the associated distance. Consider
 $V_a(x) \;:\!=\; (1+\|x\|)^a$
with
$V_a(x) \;:\!=\; (1+\|x\|)^a$
with
 $a\in[1,+\infty)$
(here
$a\in[1,+\infty)$
(here
 $x_0\;:\!=\;0$
), and let
$x_0\;:\!=\;0$
), and let
 $\{X_n\}_{n\in{\mathbb{N}}}$
be the IFS
$\{X_n\}_{n\in{\mathbb{N}}}$
be the IFS
 $X_0\in{\mathbb{R}}^q$
, for all
$X_0\in{\mathbb{R}}^q$
, for all
 $n\geq 1$
,
$n\geq 1$
,
 $X_n \;:\!=\; AX_{n-1} + \vartheta_n$
. Here,
$X_n \;:\!=\; AX_{n-1} + \vartheta_n$
. Here,
 $F(x,v) \;:\!=\; Ax +v$
, where
$F(x,v) \;:\!=\; Ax +v$
, where
 $A=(a_{ij})$
is a fixed real
$A=(a_{ij})$
is a fixed real
 $q\times q$
matrix. This is called a vector or multivariate autoregressive model. We have
$q\times q$
matrix. This is called a vector or multivariate autoregressive model. We have
 $L_F(v) = \|A\|$
, where
$L_F(v) = \|A\|$
, where
 $\|A\|$
denotes the induced norm of A corresponding to
$\|A\|$
denotes the induced norm of A corresponding to
 $\|\!\cdot\!\|$
, and
$\|\!\cdot\!\|$
, and
 $d(0,F(0,v)) = \|v\|$
. Consequently, Condition 1.1 holds for some
$d(0,F(0,v)) = \|v\|$
. Consequently, Condition 1.1 holds for some
 $a\in[1,+\infty)$
provided that
$a\in[1,+\infty)$
provided that
 $\mathbb{E}[\|\vartheta_1\|^a] < \infty$
and
$\mathbb{E}[\|\vartheta_1\|^a] < \infty$
and
 $\|A\| < 1$
. Moreover, if
$\|A\| < 1$
. Moreover, if
 $\vartheta_1$
has a probability density function (PDF) on
$\vartheta_1$
has a probability density function (PDF) on
 ${\mathbb{R}}^q$
, then P is
${\mathbb{R}}^q$
, then P is
 $V_a$
-geometrically ergodic. More precisely, inequality in (1.3) holds for any
$V_a$
-geometrically ergodic. More precisely, inequality in (1.3) holds for any
 $\rho_a\in (\|A\|,1)$
; see Remark 4.2.
$\rho_a\in (\|A\|,1)$
; see Remark 4.2.
The aim of this work is to use the results of [Reference Ferré, Hervé and Ledoux14, Reference Hervé and Ledoux23, Reference Rudolf and Schweizer43] to investigate the robustness first of the
 $V_a$
-geometrical ergodicity property (1.3), second of the stationary distribution
$V_a$
-geometrical ergodicity property (1.3), second of the stationary distribution
 $\pi$
, and third of the probability distribution of
$\pi$
, and third of the probability distribution of
 $X_n$
. This study is made with respect to parametric variations of both the function F and the probability distribution of the noise random variable
$X_n$
. This study is made with respect to parametric variations of both the function F and the probability distribution of the noise random variable
 $\vartheta_n$
in (1.1). For this purpose, let us introduce the following definition.
$\vartheta_n$
in (1.1). For this purpose, let us introduce the following definition.
Definition 1.2. (Parametric perturbation of IFS.) Let us introduce the parameter
 $\theta\;:\!=\;(\xi,\gamma)$
taking values in a subset
$\theta\;:\!=\;(\xi,\gamma)$
taking values in a subset
 $\Theta$
of some metric space. Let
$\Theta$
of some metric space. Let
 $F_{\xi} \;:\; ({\mathbb{X}}\times {\mathbb{V}},{\mathcal{X}}\otimes {\mathcal{V}})\rightarrow ({\mathbb{X}},{\mathcal{X}})$
and let
$F_{\xi} \;:\; ({\mathbb{X}}\times {\mathbb{V}},{\mathcal{X}}\otimes {\mathcal{V}})\rightarrow ({\mathbb{X}},{\mathcal{X}})$
and let
 $\{\vartheta^{(\gamma)}_n\}_{n\geq 1}$
be a sequence of
$\{\vartheta^{(\gamma)}_n\}_{n\geq 1}$
be a sequence of
 ${\mathbb{V}}$
-valued random variables, both satisfying the assumptions of Definition 1.1. The common parametric probability distribution of
${\mathbb{V}}$
-valued random variables, both satisfying the assumptions of Definition 1.1. The common parametric probability distribution of
 $\{\vartheta^{(\gamma)}_n\}_{n\geq 1}$
is denoted by
$\{\vartheta^{(\gamma)}_n\}_{n\geq 1}$
is denoted by
 $\mathfrak{p}_{\gamma}$
. For any
$\mathfrak{p}_{\gamma}$
. For any
 $\theta\in \Theta$
, the process
$\theta\in \Theta$
, the process
 $\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
is the
$\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
is the
 ${\mathbb{X}}-$
valued IFS of Lipschitz maps given by
${\mathbb{X}}-$
valued IFS of Lipschitz maps given by
 \begin{equation} {X_0^{(\theta)}} \in {\mathbb{X}}, \textrm{ for all } n\geq 1, \quad {X_n^{(\theta)}} \;:\!=\; F_{\xi}\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big). \end{equation}
\begin{equation} {X_0^{(\theta)}} \in {\mathbb{X}}, \textrm{ for all } n\geq 1, \quad {X_n^{(\theta)}} \;:\!=\; F_{\xi}\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big). \end{equation}
The transition kernel of the Markov chain
 $\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
is denoted by
$\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
is denoted by
 ${P_{\theta}}$
, and
${P_{\theta}}$
, and
 $\mu_\theta$
is the probability distribution of
$\mu_\theta$
is the probability distribution of
 ${X_0^{(\theta)}}$
.
${X_0^{(\theta)}}$
.
The Markov chain
 $\{{X_n^{(\theta)}}\}_{n\in {\mathbb{N}}}$
must be thought of as a perturbed model of some ideal model
$\{{X_n^{(\theta)}}\}_{n\in {\mathbb{N}}}$
must be thought of as a perturbed model of some ideal model
 $\{X^{(\theta_0)}_n\}_{n\in {\mathbb{N}}}$
with
$\{X^{(\theta_0)}_n\}_{n\in {\mathbb{N}}}$
with
 $\theta_0 \in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
, where
$\theta_0 \in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
, where
 ${\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
denotes the interior of
${\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
denotes the interior of
 $\Theta$
. Next, pick
$\Theta$
. Next, pick
 $\theta_0 \in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
and let us introduce the following assumptions.
$\theta_0 \in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
and let us introduce the following assumptions.
Assumption 1.1.
There exists
 $a\ge 1$
such that
$a\ge 1$
such that
 $P_{\theta_0}$
is
$P_{\theta_0}$
is
 $V_a$
-geometrically ergodic with stationary distribution denoted by
$V_a$
-geometrically ergodic with stationary distribution denoted by
 $\pi_{\theta_0}$
; i.e.
$\pi_{\theta_0}$
; i.e.
 $P_{\theta_0}$
satisfies (1.3) for some
$P_{\theta_0}$
satisfies (1.3) for some
 $\rho_a\in(0,1)$
and
$\rho_a\in(0,1)$
and
 $C_a>0$
.
$C_a>0$
.
Assumption 1.2.
 $M_a \;:\!=\; \sup_{\theta \in \Theta} \mathbb{E}\big[ d\big(x_0, F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big)\big)^a\big]^{1/a} < \infty$
.
$M_a \;:\!=\; \sup_{\theta \in \Theta} \mathbb{E}\big[ d\big(x_0, F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big)\big)^a\big]^{1/a} < \infty$
.
Assumption 1.3.
 $\kappa_{a} \;:\!=\; \sup_{\theta \in \Theta} \mathbb{E}\big[ L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big)^a\big]^{1/a} < 1$
.
$\kappa_{a} \;:\!=\; \sup_{\theta \in \Theta} \mathbb{E}\big[ L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big)^a\big]^{1/a} < 1$
.
Assumption 1.4.
 $\Delta_\theta \;:\!=\; \| {P_{\theta}} - P_{\theta_0}\|_{0,a} \xrightarrow[\theta \rightarrow \theta_0]{} 0$
, where
$\Delta_\theta \;:\!=\; \| {P_{\theta}} - P_{\theta_0}\|_{0,a} \xrightarrow[\theta \rightarrow \theta_0]{} 0$
, where
 \begin{equation*} \| {P_{\theta}} - P_{\theta_0}\|_{0,a} \;:\!=\; \sup_{f\in{\mathcal{B}}_0,\, |f|_{0} \leq 1} | {P_{\theta}} f - P_{\theta_0} f|_a. \end{equation*}
\begin{equation*} \| {P_{\theta}} - P_{\theta_0}\|_{0,a} \;:\!=\; \sup_{f\in{\mathcal{B}}_0,\, |f|_{0} \leq 1} | {P_{\theta}} f - P_{\theta_0} f|_a. \end{equation*}
Assumption 1.1 is the natural starting point for our perturbation issues. Note that Assumptions 1.2 and 1.3 are nothing but the uniform version with respect to
 $\theta$
of Condition 1.1. As a by-product, it follows from Assumptions 1.2 and 1.3 that each
$\theta$
of Condition 1.1. As a by-product, it follows from Assumptions 1.2 and 1.3 that each
 ${P_{\theta}}$
satisfies a drift condition with respect to the function
${P_{\theta}}$
satisfies a drift condition with respect to the function
 $V_a$
. More precisely, let
$V_a$
. More precisely, let
 $\kappa \in(\kappa_a,1)$
. Then the following drift condition, uniform in
$\kappa \in(\kappa_a,1)$
. Then the following drift condition, uniform in
 $\theta\in\Theta$
, holds true (see Appendix A):
$\theta\in\Theta$
, holds true (see Appendix A):
 \begin{equation} \textrm{for\;all}\;\theta \in \Theta,\quad {P_{\theta}} V_a \le \delta_{a} V_a + K_a, \ \textrm{with} \ \delta_a\;:\!=\;{\kappa}^a \ \textrm{and} \ K_a\;:\!=\; \frac{(1+ \kappa_a + M_a)^a(1+M_a)^a}{(\kappa-\kappa_a)^a}.\end{equation}
\begin{equation} \textrm{for\;all}\;\theta \in \Theta,\quad {P_{\theta}} V_a \le \delta_{a} V_a + K_a, \ \textrm{with} \ \delta_a\;:\!=\;{\kappa}^a \ \textrm{and} \ K_a\;:\!=\; \frac{(1+ \kappa_a + M_a)^a(1+M_a)^a}{(\kappa-\kappa_a)^a}.\end{equation}
This implies that, for every
 $\theta\in \Theta$
,
$\theta\in \Theta$
,
 ${P_{\theta}}$
admits an invariant probability measure denoted by
${P_{\theta}}$
admits an invariant probability measure denoted by
 $\pi_\theta$
. The following natural questions are much more difficult to address: Is the map
$\pi_\theta$
. The following natural questions are much more difficult to address: Is the map
 $\theta\mapsto \pi_\theta$
continuous with respect to the total variation distance? Do the perturbed transition kernels
$\theta\mapsto \pi_\theta$
continuous with respect to the total variation distance? Do the perturbed transition kernels
 $P_\theta$
satisfy the
$P_\theta$
satisfy the
 $V_a$
-geometrical ergodicity when
$V_a$
-geometrical ergodicity when
 $\theta$
is close to
$\theta$
is close to
 $\theta_0$
? In our context of parametric perturbation of IFS, these questions are addressed in the following theorem using the results of [Reference Ferré, Hervé and Ledoux14, Reference Hervé and Ledoux23, Reference Rudolf and Schweizer43].
$\theta_0$
? In our context of parametric perturbation of IFS, these questions are addressed in the following theorem using the results of [Reference Ferré, Hervé and Ledoux14, Reference Hervé and Ledoux23, Reference Rudolf and Schweizer43].
Theorem 1.1. Under Assumptions 1.1–1.4, the following properties hold:
-
P 1 : For every
 $\rho \in (\rho_a,1)$
there exist an open neighbourhood
${\mathcal{V}}_{\theta_0}$
of
$\theta_0$
and a positive constant R such that,
\begin{equation*} \textrm{for\;all}\;\theta\in {\mathcal{V}}_{\theta_0},\; n\geq 1,\; \textrm{and}\ \; \; f\in{\mathcal{B}}_a,\; |{P^n_{\theta}}\, f - \pi_\theta(f)\textbf{1}_{{\mathbb{X}}}|_a \leq R \rho^{\, n} |f|_a. \end{equation*}
$\rho \in (\rho_a,1)$
there exist an open neighbourhood
${\mathcal{V}}_{\theta_0}$
of
$\theta_0$
and a positive constant R such that,
\begin{equation*} \textrm{for\;all}\;\theta\in {\mathcal{V}}_{\theta_0},\; n\geq 1,\; \textrm{and}\ \; \; f\in{\mathcal{B}}_a,\; |{P^n_{\theta}}\, f - \pi_\theta(f)\textbf{1}_{{\mathbb{X}}}|_a \leq R \rho^{\, n} |f|_a. \end{equation*}
-
P 2 :
$\lim_{\theta \rightarrow \theta_0} \| \pi_{\theta} - \pi_{\theta_0}\|_{\textrm{TV}}=0$
. More precisely,
(1.8)provided that
\begin{equation} \textit{for all } \theta \in \Theta, \quad \| \pi_{\theta} - \pi_{\theta_0}\|_{\textrm{TV}} \leq \frac{\exp\!(1) K_a D_a^{[\!\ln\!(\Delta_\theta^{-1})]^{-1}}}{(1-\delta_a)(1-\rho_a)} \Delta_\theta \ln\!(\Delta_\theta^{-1}), \end{equation}
$\Delta_\theta \in (0,\exp\!(\!-\!1))$
, where the constants
$\rho_a$
,
$C_a$
,
$\delta_a$
, and
$K_a$
are given in Assumption 1.1 and (1.7), and
$D_a = 2C_a(K_a+1)$
.
-
P 3 : We have, for every
$n\geq 1$
and for every
$\theta \in \Theta$
,provided that
\begin{align*} \| \mu_\theta {{P_{\theta}}}^n - \mu_{\theta_0} {P_{\theta_0}}^n\|_\textrm{TV} & \leq C_a {\rho_a}^{n} \sup_{|f|\le V}|\mu_\theta(f) - \mu_{\theta_0}(f)| \\[5pt] & \quad + \frac{\exp\!(1) G_a D_a^{[\ln\!(\Delta_\theta^{-1})]^{-1}}}{1-\rho_a}\Delta_\theta\ln\!(\Delta_\theta^{-1}), \end{align*}
$\Delta_\theta \in (0,\exp\!(\!-\!1))$
, with
$G_a \;:\!=\; \max\{K_a/(1-\delta_a) ,\, \mu_{\theta_0}(V_a)\}$
. In particular, if
${X_0^{(\theta)}}$
and
$X^{(\theta_0)}_0$
have the same probability distribution, say
$\mu$
, then we have
$\lim_{\theta \rightarrow \theta_0} \| \mu {{P_{\theta}}}^n - \mu {P_{\theta_0}}^n\|_\textrm{TV}=0$
.





















In the general framework of V-geometrically ergodic Markov chains, Property P1 and the first statement in P2 are proved in [Reference Ferré, Hervé and Ledoux14, Theorem 1] by using the Keller–Liverani perturbation theorem [Reference Keller and Liverani29]. The real-valued parameter
 $\varepsilon$
in [Reference Ferré, Hervé and Ledoux14] may be replaced with the
$\varepsilon$
in [Reference Ferré, Hervé and Ledoux14] may be replaced with the
 $\Theta$
-valued parameter
$\Theta$
-valued parameter
 $\theta$
. The inequality (1.8) in P2 follows from [Reference Hervé and Ledoux23, Proposition 2.1] or [Reference Rudolf and Schweizer43, (3.19)]. The formulation of [Reference Rudolf and Schweizer43, (3.19)] has been preferred to that in [Reference Hervé and Ledoux23, Proposition 2.1] in connection with Property P3. Property P3 is proved in [Reference Rudolf and Schweizer43, Theorem 3.2] by using the Wasserstein distance associated with a suitable metric on
$\theta$
. The inequality (1.8) in P2 follows from [Reference Hervé and Ledoux23, Proposition 2.1] or [Reference Rudolf and Schweizer43, (3.19)]. The formulation of [Reference Rudolf and Schweizer43, (3.19)] has been preferred to that in [Reference Hervé and Ledoux23, Proposition 2.1] in connection with Property P3. Property P3 is proved in [Reference Rudolf and Schweizer43, Theorem 3.2] by using the Wasserstein distance associated with a suitable metric on
 ${\mathbb{X}}$
defined from the Lyapunov function V, as introduced in [Reference Hairer and Mattingly19].
${\mathbb{X}}$
defined from the Lyapunov function V, as introduced in [Reference Hairer and Mattingly19].
The goal of this work is to present various applications when both the function F and the probability distribution
 $\mathfrak{p}$
of the noise in Definition 1.1 are perturbed, and to show that the weak continuity assumption, Assumption 1.4, is well suited to such a study. This last claim is highlighted by the following first simple application, where only the probability distribution of the noise is perturbed.
$\mathfrak{p}$
of the noise in Definition 1.1 are perturbed, and to show that the weak continuity assumption, Assumption 1.4, is well suited to such a study. This last claim is highlighted by the following first simple application, where only the probability distribution of the noise is perturbed.
Example 1.2. (IFS with perturbed noise.) Consider the generic IFS introduced in Definition 1.1 with noise probability distribution
 $\mathfrak{p}_0$
. Its transition kernel
$\mathfrak{p}_0$
. Its transition kernel
 $P_{\mathfrak{p}_0}$
is given, for all
$P_{\mathfrak{p}_0}$
is given, for all
 $f\in{\mathcal{B}}_0$
, by
$f\in{\mathcal{B}}_0$
, by
 $(P_{\mathfrak{p}_0}f)(x) = \int f(F(x,y))\, {\textrm{d}}\mathfrak{p}_0(y)$
. Let us consider the specific perturbation scheme
$(P_{\mathfrak{p}_0}f)(x) = \int f(F(x,y))\, {\textrm{d}}\mathfrak{p}_0(y)$
. Let us consider the specific perturbation scheme
 ${X_n^{(\theta)}} \;:\!=\; F\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big)$
for
${X_n^{(\theta)}} \;:\!=\; F\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big)$
for
 ${X_0^{(\theta)}} \in {\mathbb{X}}$
and all
${X_0^{(\theta)}} \in {\mathbb{X}}$
and all
 $n\geq 1$
, where
$n\geq 1$
, where
 $\{\vartheta^{(\gamma)}_n\}_{n\geq 1}$
is a sequence of
$\{\vartheta^{(\gamma)}_n\}_{n\geq 1}$
is a sequence of
 ${\mathbb{V}}$
-valued i.i.d. random variables with a common parametric probability distribution denoted by
${\mathbb{V}}$
-valued i.i.d. random variables with a common parametric probability distribution denoted by
 $\mathfrak{p}_{\gamma}$
. That is, we consider an IFS with perturbed noise but fixed function F (e.g. the matrix A is fixed in the VAR model introduced in Example 1.1). For any
$\mathfrak{p}_{\gamma}$
. That is, we consider an IFS with perturbed noise but fixed function F (e.g. the matrix A is fixed in the VAR model introduced in Example 1.1). For any
 $f\in {\mathcal{B}}_0$
such that
$f\in {\mathcal{B}}_0$
such that
 $|f|_0 \leq 1$
, we have, for all
$|f|_0 \leq 1$
, we have, for all
 $x\in {\mathbb{X}}$
,
$x\in {\mathbb{X}}$
,
 $| (P_{\mathfrak{p}_{\gamma}}f)(x) - (P_{\mathfrak{p}_0}f)(x)| \leq \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV}$
. It follows that
$| (P_{\mathfrak{p}_{\gamma}}f)(x) - (P_{\mathfrak{p}_0}f)(x)| \leq \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV}$
. It follows that
 \begin{align*} \|P_{\mathfrak{p}_{\gamma}} - P_{\mathfrak{p}_0}\|_{0,a} \leq \|P_{\mathfrak{p}_{\gamma}} - P_{\mathfrak{p}_0}\|_{0,0} \;:\!=\; \sup_{f\in{\mathcal{B}}_0,\, |f|_{0} \leq 1} | P_{\mathfrak{p}_{\gamma}} f - P_{\mathfrak{p}_0} f|_0 \leq \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV}. \end{align*}
\begin{align*} \|P_{\mathfrak{p}_{\gamma}} - P_{\mathfrak{p}_0}\|_{0,a} \leq \|P_{\mathfrak{p}_{\gamma}} - P_{\mathfrak{p}_0}\|_{0,0} \;:\!=\; \sup_{f\in{\mathcal{B}}_0,\, |f|_{0} \leq 1} | P_{\mathfrak{p}_{\gamma}} f - P_{\mathfrak{p}_0} f|_0 \leq \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV}. \end{align*}
Hence, Assumption 1.4 is satisfied provided that
 $\lim \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV} = 0$
.
$\lim \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV} = 0$
.
In Section 2, a second application of Theorem 1.1, which again illustrates the interest of Assumption 1.4, is provided for the real-valued Markov chain
 $X_n \;:\!=\; \alpha X_{n-1} + \sigma(X_{n-1})\vartheta_n$
, for which all the data
$X_n \;:\!=\; \alpha X_{n-1} + \sigma(X_{n-1})\vartheta_n$
, for which all the data
 $\alpha$
,
$\alpha$
,
 $\sigma(\!\cdot\!)$
and the probability distribution of the noise
$\sigma(\!\cdot\!)$
and the probability distribution of the noise
 $\vartheta_1$
are perturbed. This Markov chain is called an autoregressive process of order one with autoregressive conditional heteroscedastic errors of order one (AR(1)-ARCH(1)). Such autoregressive models with conditional heteroscedastic errors were introduced to allow the conditional variance of time-series models to depend on past information. It turns out that such processes fit many types of econometrics and financial data very well where stochastic volatility must be taken into account (see, e.g., [Reference Tsay46]). Note that the perturbation results of Section 2 can be extended to multivariate AR(p)-ARCH(q) processes with any order (p, q) [Reference Meitz and Saikkonen35] thanks to the material provided in Section 5.
$\vartheta_1$
are perturbed. This Markov chain is called an autoregressive process of order one with autoregressive conditional heteroscedastic errors of order one (AR(1)-ARCH(1)). Such autoregressive models with conditional heteroscedastic errors were introduced to allow the conditional variance of time-series models to depend on past information. It turns out that such processes fit many types of econometrics and financial data very well where stochastic volatility must be taken into account (see, e.g., [Reference Tsay46]). Note that the perturbation results of Section 2 can be extended to multivariate AR(p)-ARCH(q) processes with any order (p, q) [Reference Meitz and Saikkonen35] thanks to the material provided in Section 5.
In Section 3, a third application is presented in the framework of roundoff errors. In applied mathematics, any analytic material must be run on a computer to get practical answers. This concerns simulation, approximation, numerical schemes, and so on. Thus, when a Markov model is implemented on a computer, the original transition kernel P is replaced with a perturbed one, say
 $\tilde P$
, and their difference may have a great impact on the results. Such changes in computer simulations induced by floating point roundoff error were discussed in [Reference Breyer, Roberts and Rosenthal7, Reference Roberts, Rosenthal and Schwartz42]. In this case, the perturbed transition kernel takes the form
$\tilde P$
, and their difference may have a great impact on the results. Such changes in computer simulations induced by floating point roundoff error were discussed in [Reference Breyer, Roberts and Rosenthal7, Reference Roberts, Rosenthal and Schwartz42]. In this case, the perturbed transition kernel takes the form
 $\tilde P(x,A) \;:\!=\; P(x,h^{-1}(A))$
, where P is the transition kernel of a fixed IFS and where
$\tilde P(x,A) \;:\!=\; P(x,h^{-1}(A))$
, where P is the transition kernel of a fixed IFS and where
 $h \;:\; {\mathbb{X}}\rightarrow{\mathbb{X}}$
is close to the identity map. The weak continuity assumption, Assumption 1.4, is still proved to be well adapted, as illustrated in Proposition 3.1, for the VAR model defined in Example 1.1. Note that the function
$h \;:\; {\mathbb{X}}\rightarrow{\mathbb{X}}$
is close to the identity map. The weak continuity assumption, Assumption 1.4, is still proved to be well adapted, as illustrated in Proposition 3.1, for the VAR model defined in Example 1.1. Note that the function
 $F_{\xi}$
in (1.6) is fixed in Example 1.2 so that we do not have to divide by V(x) to prove Assumption 1.4. Indeed, the inequality
$F_{\xi}$
in (1.6) is fixed in Example 1.2 so that we do not have to divide by V(x) to prove Assumption 1.4. Indeed, the inequality
 $\|P_{\mathfrak{p}_{\gamma}} - P_{\mathfrak{p}_0}\|_{0,0} \leq \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV}$
in Example 1.2 is directly obtained and it automatically gives Assumption 1.4. When
$\|P_{\mathfrak{p}_{\gamma}} - P_{\mathfrak{p}_0}\|_{0,0} \leq \| \mathfrak{p}_{\gamma} - \mathfrak{p}_0 \|_\textrm{TV}$
in Example 1.2 is directly obtained and it automatically gives Assumption 1.4. When
 $F_{\xi}$
in (1.6) is not fixed as in Sections 2 and 3, the division by V(x) in the definition of
$F_{\xi}$
in (1.6) is not fixed as in Sections 2 and 3, the division by V(x) in the definition of
 $\|\!\cdot\!\|_{0,a}$
must be done to investigate Assumption 1.4.
$\|\!\cdot\!\|_{0,a}$
must be done to investigate Assumption 1.4.
In Section 4 we propose a new approach to prove the
 $V_a$
-geometrical ergodicity of IFSs of Lipschitz maps under Condition 1.1, together with a bound on the spectral gap of P (i.e. the infimum bound of the positive real numbers
$V_a$
-geometrical ergodicity of IFSs of Lipschitz maps under Condition 1.1, together with a bound on the spectral gap of P (i.e. the infimum bound of the positive real numbers
 $\rho_a$
satisfying (1.3)). In Section 5, further applications of Theorem 1.1 are presented. The goal of Section 5.1 is to show that the arguments developed in Sections 2 and 3 for specific IFSs of Lipschitz maps naturally extend to more general IFSs. In Section 5.2 we apply Theorem 1.1 to the case where the function F and the PDF
$\rho_a$
satisfying (1.3)). In Section 5, further applications of Theorem 1.1 are presented. The goal of Section 5.1 is to show that the arguments developed in Sections 2 and 3 for specific IFSs of Lipschitz maps naturally extend to more general IFSs. In Section 5.2 we apply Theorem 1.1 to the case where the function F and the PDF
 $\mathfrak{p}$
of
$\mathfrak{p}$
of
 $\{\vartheta_n\}_{n \ge 1}$
in (1.1) are perturbed, by thresholding and by truncation respectively.
$\{\vartheta_n\}_{n \ge 1}$
in (1.1) are perturbed, by thresholding and by truncation respectively.
Perturbation theory for Markov chains is a natural issue which has been widely developed in recent decades. As mentioned in [Reference Shardlow and Stuart45, p. 1126] (see also [Reference Ferré, Hervé and Ledoux14]), the strong continuity assumption introduced in [Reference Kartashov26, Reference Kartashov27], which involves the iterates of both perturbed and unperturbed transition kernels, does not hold in general for V-geometrically ergodic Markov chains, excepted for particular perturbed transition kernels (e.g. when
 $P_\theta = P_{0} + \theta D$
; see [Reference Altman, Avrachenkov and Núñez-Queija3]) and for uniformly ergodic Markov chains (i.e. when (1.3) holds with
$P_\theta = P_{0} + \theta D$
; see [Reference Altman, Avrachenkov and Núñez-Queija3]) and for uniformly ergodic Markov chains (i.e. when (1.3) holds with
 $a=0$
); see [Reference Alquier, Friel, Everitt and Boland1, Reference Johndrow, Mattingly, Mukherjee and Dunson25, Reference Mitrophanov39, Reference Mouhoubi and Assani40]. Similar questions arise for dynamical systems, and [Reference Keller28, p. 316] seems to be the first work which introduced a weaker continuity assumption using two norms as in Assumption 1.4 (instead of a single one in the standard theory). Then, the Keller–Liverani perturbation theorem [Reference Baladi4, Reference Keller and Liverani29, Reference Liverani31] has proved to be very powerful for studying the behaviour of the Sinai–Ruelle–Bowen measures of certain perturbed dynamical systems (see, e.g., [Reference Baladi4, Theorem 2.10] and [Reference Gouëzel and Liverani16, Theorem 2.8]). In the context of V-geometrically ergodic Markov chains, Keller’s approach is used in [Reference Shardlow and Stuart45] and the Keller–Liverani theorem is applied in [Reference Ferré, Hervé and Ledoux14, Reference Hervé and Ledoux23]. The recent works of [Reference Medina-Aguayo, Rudolf and Schweizer34, Reference Rudolf and Schweizer43] and references therein combine Keller’s approach and the elegant idea of [Reference Hairer and Mattingly19] using the Wasserstein distance associated with a suitable metric on
$a=0$
); see [Reference Alquier, Friel, Everitt and Boland1, Reference Johndrow, Mattingly, Mukherjee and Dunson25, Reference Mitrophanov39, Reference Mouhoubi and Assani40]. Similar questions arise for dynamical systems, and [Reference Keller28, p. 316] seems to be the first work which introduced a weaker continuity assumption using two norms as in Assumption 1.4 (instead of a single one in the standard theory). Then, the Keller–Liverani perturbation theorem [Reference Baladi4, Reference Keller and Liverani29, Reference Liverani31] has proved to be very powerful for studying the behaviour of the Sinai–Ruelle–Bowen measures of certain perturbed dynamical systems (see, e.g., [Reference Baladi4, Theorem 2.10] and [Reference Gouëzel and Liverani16, Theorem 2.8]). In the context of V-geometrically ergodic Markov chains, Keller’s approach is used in [Reference Shardlow and Stuart45] and the Keller–Liverani theorem is applied in [Reference Ferré, Hervé and Ledoux14, Reference Hervé and Ledoux23]. The recent works of [Reference Medina-Aguayo, Rudolf and Schweizer34, Reference Rudolf and Schweizer43] and references therein combine Keller’s approach and the elegant idea of [Reference Hairer and Mattingly19] using the Wasserstein distance associated with a suitable metric on
 ${\mathbb{X}}$
defined from the Lyapunov function V. Perturbation issues have also been investigated in the framework of roundoff errors [Reference Breyer, Roberts and Rosenthal7, Reference Roberts, Rosenthal and Schwartz42] (see Section 3) and in the special case of reversible transition kernels as in Markov chain Monte Carlo methods; see, e.g., [Reference Medina-Aguayo, Lee and Roberts33, Reference Negrea and Rosenthal41] and the references therein. The purpose of this paper is to show that the material developed in [Reference Ferré, Hervé and Ledoux14, Reference Hervé and Ledoux23, Reference Rudolf and Schweizer43] is very well suited to the perturbation of general IFSs. In the IFS context, Assumption 1.4 has so far only been investigated in [Reference Ferré, Hervé and Ledoux14, Reference Rudolf and Schweizer43] for the perturbation of univariate AR(1) processes
${\mathbb{X}}$
defined from the Lyapunov function V. Perturbation issues have also been investigated in the framework of roundoff errors [Reference Breyer, Roberts and Rosenthal7, Reference Roberts, Rosenthal and Schwartz42] (see Section 3) and in the special case of reversible transition kernels as in Markov chain Monte Carlo methods; see, e.g., [Reference Medina-Aguayo, Lee and Roberts33, Reference Negrea and Rosenthal41] and the references therein. The purpose of this paper is to show that the material developed in [Reference Ferré, Hervé and Ledoux14, Reference Hervé and Ledoux23, Reference Rudolf and Schweizer43] is very well suited to the perturbation of general IFSs. In the IFS context, Assumption 1.4 has so far only been investigated in [Reference Ferré, Hervé and Ledoux14, Reference Rudolf and Schweizer43] for the perturbation of univariate AR(1) processes
 $X_n \;:\!=\; \alpha X_{n-1} + \vartheta_n$
with respect to the contracting coefficient
$X_n \;:\!=\; \alpha X_{n-1} + \vartheta_n$
with respect to the contracting coefficient
 $\alpha$
. Our work shows that Assumption 1.4 allows us to deal with perturbation schemes of the general IFS (1.1) with respect to both function F and the probability distribution of
$\alpha$
. Our work shows that Assumption 1.4 allows us to deal with perturbation schemes of the general IFS (1.1) with respect to both function F and the probability distribution of
 $\vartheta_1$
.
$\vartheta_1$
.
Let us mention that this paper does not address the statistical issues when the model is misspecified. Indeed, we do not study the convergence properties of estimators of the parameters of the Markov model when the data are generated under the ‘wrong’ model and the size n of the data growths is large (see, e.g., [Reference Douc and Moulines11, Reference Greenwood and Wefelmeyer17] in the Markov context).
2. Robustness of AR(1) with ARCH(1) errors
According to Definition 1.2, we consider the perturbed AR(1)-ARCH(1) real-valued
 $\{{X_n^{(\theta)}}\}_{n \in {\mathbb{N}}}$
defined, for
$\{{X_n^{(\theta)}}\}_{n \in {\mathbb{N}}}$
defined, for
 ${X_0^{(\theta)}}$
a given real-valued random variable, by
${X_0^{(\theta)}}$
a given real-valued random variable, by
 \begin{equation} \textrm{for all } n\geq 1,\quad {X_n^{(\theta)}} \;:\!=\; F_{\xi}\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big),\end{equation}
\begin{equation} \textrm{for all } n\geq 1,\quad {X_n^{(\theta)}} \;:\!=\; F_{\xi}\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big),\end{equation}
where
 $F_{\xi}(x,v) = \alpha x + v (\beta + \lambda x^2)^{1/2}$
with constants
$F_{\xi}(x,v) = \alpha x + v (\beta + \lambda x^2)^{1/2}$
with constants
 $\alpha \in {\mathbb{R}}$
,
$\alpha \in {\mathbb{R}}$
,
 $\beta>0$
,
$\beta>0$
,
 $\lambda> 0$
, and
$\lambda> 0$
, and
 $\{\vartheta^{(\gamma)}_n\}_{n \in {\mathbb{N}}}$
has a common PDF
$\{\vartheta^{(\gamma)}_n\}_{n \in {\mathbb{N}}}$
has a common PDF
 $\mathfrak{p}_{\gamma}$
and is independent of
$\mathfrak{p}_{\gamma}$
and is independent of
 ${X_0^{(\theta)}}$
. Therefore, we have
${X_0^{(\theta)}}$
. Therefore, we have
 $\theta=(\xi,\gamma)$
with
$\theta=(\xi,\gamma)$
with
 $\xi\;:\!=\;(\alpha,\beta,\lambda) \in {\mathbb{R}}\times (0,+\infty)^2$
and
$\xi\;:\!=\;(\alpha,\beta,\lambda) \in {\mathbb{R}}\times (0,+\infty)^2$
and
 $\gamma \in \Gamma$
, where
$\gamma \in \Gamma$
, where
 $\Gamma$
is some metric space (typically
$\Gamma$
is some metric space (typically
 $\Gamma\subset{\mathbb{R}}$
). Thus,
$\Gamma\subset{\mathbb{R}}$
). Thus,
 $\Theta$
is a subset of
$\Theta$
is a subset of
 ${\mathbb{R}}\times (0,+\infty)^2 \times\Gamma$
. Here,
${\mathbb{R}}\times (0,+\infty)^2 \times\Gamma$
. Here,
 $d(x;\;x_0)=|x-x_0|$
and
$d(x;\;x_0)=|x-x_0|$
and
 $x_0\;:\!=\;0$
so that
$x_0\;:\!=\;0$
so that
 $V_a(x) = (1+|x|)^a$
. The Markov kernel
$V_a(x) = (1+|x|)^a$
. The Markov kernel
 ${P_{\theta}}$
of
${P_{\theta}}$
of
 $\big\{{X_n^{(\theta)}}\big\}_{n \in {\mathbb{N}}}$
is given by
$\big\{{X_n^{(\theta)}}\big\}_{n \in {\mathbb{N}}}$
is given by
 ${P_{\theta}}(x,A) \;:\!=\; \int_{\mathbb{R}} \textbf{1}_A(y) p_{\theta}(x,y)\, {\textrm{d}} y$
(
${P_{\theta}}(x,A) \;:\!=\; \int_{\mathbb{R}} \textbf{1}_A(y) p_{\theta}(x,y)\, {\textrm{d}} y$
(
 $A\in{\mathcal{X}}$
), with
$A\in{\mathcal{X}}$
), with
 \begin{equation} p_{\theta}(x,y) \;:\!=\; \big(\beta+\lambda x^2\big)^{-1/2} \mathfrak{p}_{\gamma}\bigg(\frac{y-\alpha x}{(\beta+\lambda x^2)^{1/2}}\bigg).\end{equation}
\begin{equation} p_{\theta}(x,y) \;:\!=\; \big(\beta+\lambda x^2\big)^{-1/2} \mathfrak{p}_{\gamma}\bigg(\frac{y-\alpha x}{(\beta+\lambda x^2)^{1/2}}\bigg).\end{equation}
Next, we report the following observations with respect to basic quantities required in Assumptions 1.2 and 1.3. First, it can be checked (see Lemma B.1) that
 \begin{equation} L_{F_\xi}(\vartheta_1) = \max\!\big(|\alpha-\sqrt{\lambda} \vartheta_1|,\,|\alpha+\sqrt{\lambda} \vartheta_1|\big). \end{equation}
\begin{equation} L_{F_\xi}(\vartheta_1) = \max\!\big(|\alpha-\sqrt{\lambda} \vartheta_1|,\,|\alpha+\sqrt{\lambda} \vartheta_1|\big). \end{equation}
Hence, the real number
 $\kappa_{a}$
in Assumption 1.3 is
$\kappa_{a}$
in Assumption 1.3 is
 \begin{equation} \kappa_{a} = \sup_{\theta\in \Theta} \bigg(\int_{{\mathbb{R}}} \max\!\big(|\alpha-\sqrt{\lambda} v|,\,|\alpha+\sqrt{\lambda} v|\big)^a \mathfrak{p}_{\gamma}(v)\, {\textrm{d}} v \bigg)^{1/a}.\end{equation}
\begin{equation} \kappa_{a} = \sup_{\theta\in \Theta} \bigg(\int_{{\mathbb{R}}} \max\!\big(|\alpha-\sqrt{\lambda} v|,\,|\alpha+\sqrt{\lambda} v|\big)^a \mathfrak{p}_{\gamma}(v)\, {\textrm{d}} v \bigg)^{1/a}.\end{equation}
Second, the real number
 $M_a$
in Assumption 1.2 is given by
$M_a$
in Assumption 1.2 is given by
 \begin{equation} M_a \;:\!=\; \sup_{\theta\in \Theta} \sqrt{\beta}\, \mathbb{E}\big[\big| \vartheta^{(\gamma)}_1 \big|^a \big]^{1/a} = \sup_{\theta\in \Theta} \sqrt{\beta} \bigg(\displaystyle\int_{{\mathbb{R}}} |v|^a \mathfrak{p}_{\gamma}(v) \, {\textrm{d}} v \bigg) ^{1/a}.\end{equation}
\begin{equation} M_a \;:\!=\; \sup_{\theta\in \Theta} \sqrt{\beta}\, \mathbb{E}\big[\big| \vartheta^{(\gamma)}_1 \big|^a \big]^{1/a} = \sup_{\theta\in \Theta} \sqrt{\beta} \bigg(\displaystyle\int_{{\mathbb{R}}} |v|^a \mathfrak{p}_{\gamma}(v) \, {\textrm{d}} v \bigg) ^{1/a}.\end{equation}
Note that if
 $\beta$
lies in a compact set, then
$\beta$
lies in a compact set, then
 $M_a < \infty$
under the following uniform moment condition for the PDF of
$M_a < \infty$
under the following uniform moment condition for the PDF of
 $\vartheta^{(\gamma)}_1$
:
$\vartheta^{(\gamma)}_1$
:
 $\sup_{\gamma \in \Gamma} \int_{{\mathbb{R}}} |v|^a \mathfrak{p}_{\gamma}(v) \, {\textrm{d}} v < \infty$
.
$\sup_{\gamma \in \Gamma} \int_{{\mathbb{R}}} |v|^a \mathfrak{p}_{\gamma}(v) \, {\textrm{d}} v < \infty$
.
Let us formulate the assumptions under which the conclusions of Theorem 1.1 hold true for
 $\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
. Let
$\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
. Let
 $\theta_0 = (\alpha_0,\beta_0,\lambda_0,\gamma_0)\in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
. We denote by
$\theta_0 = (\alpha_0,\beta_0,\lambda_0,\gamma_0)\in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
. We denote by
 ${\mathbb{L}}^1({\mathbb{R}})$
the usual Lebesgue space, and by
${\mathbb{L}}^1({\mathbb{R}})$
the usual Lebesgue space, and by
 $\|\!\cdot\!\|_{{\mathbb{L}}^1({\mathbb{R}})}$
its norm.
$\|\!\cdot\!\|_{{\mathbb{L}}^1({\mathbb{R}})}$
its norm.
Assumption 2.1.
There exists
 $a \ge 1$
such that:
$a \ge 1$
such that:
-
(a) For every
$r>0$
, the functionis positive on a subset of
\begin{equation*} y \mapsto g_{\theta_0,r} (y) \;:\!=\; \inf_{x\in [\!-\!r,r]} p_{\theta_0} (x,y) = \inf_{x\in [\!-\!r,r]} (\beta_0+\lambda_0 x^2)^{-1/2}\mathfrak{p}_{\gamma_0}\bigg(\frac{y-\alpha_0 x}{(\beta_0+\lambda_0 x^2)^{1/2}}\bigg) \end{equation*}
$[\!-\!r,r]$
that has a positive Lebesgue measure.
-
(b)
$M_a<\infty$
, where
$M_a$
is given in (2.5). -
(c)
$\kappa_{a} <1$
, where
$\kappa_a$
is given in (2.4).







Assumption 2.2.
 $\lim_{\gamma \rightarrow \gamma_0} \| \mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0}\|_{{\mathbb{L}}^1({\mathbb{R}})}=0$
.
$\lim_{\gamma \rightarrow \gamma_0} \| \mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0}\|_{{\mathbb{L}}^1({\mathbb{R}})}=0$
.
Proposition 2.1. Under Assumptions 2.1 and 2.2 for the AR(1)-ARCH(1) process given in (2.1), the assertions P 1 –P 3 of Theorem 1.1 hold.
Proof. Let
 $\theta_0 = (\alpha_0,\beta_0,\lambda_0,\gamma_0)\in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
, and let
$\theta_0 = (\alpha_0,\beta_0,\lambda_0,\gamma_0)\in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
, and let
 $a\ge 1$
in Assumption 2.1. As already discussed, the conditions in Assumptions 2.1(b) and (c) imply that Assumptions 1.2 and 1.3 of Theorem 1.1 hold. Moreover, we can use (A.1) to state that there exist
$a\ge 1$
in Assumption 2.1. As already discussed, the conditions in Assumptions 2.1(b) and (c) imply that Assumptions 1.2 and 1.3 of Theorem 1.1 hold. Moreover, we can use (A.1) to state that there exist
 $\delta_a < 1$
,
$\delta_a < 1$
,
 $K_a >0$
. and
$K_a >0$
. and
 $r_a>0$
such that
$r_a>0$
such that
 $P_{\theta_0} V_a \le \delta_{a} V_a + K_a \textbf{1}_{[\!-\!r_a,r_a]}$
.
$P_{\theta_0} V_a \le \delta_{a} V_a + K_a \textbf{1}_{[\!-\!r_a,r_a]}$
.
Next, Assumption 2.1(a) ensures that, for all
 $x\in [\!-\!r_a,r_a]$
and
$x\in [\!-\!r_a,r_a]$
and
 $A\in {\mathcal{X}}$
,
$A\in {\mathcal{X}}$
,
 $P_{\theta_0}(x,A) \geq \varphi_{r_a,\theta_0} (A)$
with the positive measure
$P_{\theta_0}(x,A) \geq \varphi_{r_a,\theta_0} (A)$
with the positive measure
 $\varphi_{r,\theta_0} ({\textrm{d}} y) = g_{\theta,r}(y)\, {\textrm{d}} y$
. In others words,
$\varphi_{r,\theta_0} ({\textrm{d}} y) = g_{\theta,r}(y)\, {\textrm{d}} y$
. In others words,
 $S = [\!-\!r_a,r_a]$
is a small set for
$S = [\!-\!r_a,r_a]$
is a small set for
 $P_{\theta_0}$
. Moreover,
$P_{\theta_0}$
. Moreover,
 $\varphi_{r,\theta_0} (S)>0$
from Assumption 2.1(a). Then, Assumption 1.1 holds true; see [Reference Baxendale5, Theorem 1.1] and [Reference Meyn and Tweedie36].
$\varphi_{r,\theta_0} (S)>0$
from Assumption 2.1(a). Then, Assumption 1.1 holds true; see [Reference Baxendale5, Theorem 1.1] and [Reference Meyn and Tweedie36].
The following lemma asserts that Assumption 1.4 holds true under Assumption 2.2, so the proof is complete.
Lemma 2.1.
If
 $\lim_{\gamma \rightarrow \gamma_0} \| \mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0} \|_{{\mathbb{L}}^1({\mathbb{R}})}=0$
then
$\lim_{\gamma \rightarrow \gamma_0} \| \mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0} \|_{{\mathbb{L}}^1({\mathbb{R}})}=0$
then
 $\lim_{ \theta \rightarrow \theta_0} \| {P_{\theta}} - P_{\theta_0}\|_{0,a}=0$
.
$\lim_{ \theta \rightarrow \theta_0} \| {P_{\theta}} - P_{\theta_0}\|_{0,a}=0$
.
Proof. Let
 $f \in {\mathcal{B}}_0$
be such that
$f \in {\mathcal{B}}_0$
be such that
 $|f |_0\le 1$
. We have, for all
$|f |_0\le 1$
. We have, for all
 $x \in {\mathbb{X}}$
,
$x \in {\mathbb{X}}$
,
 \begin{equation*} \frac{|({P_{\theta}} f)(x)- (P_{\theta_0}f)(x)|}{V_a(x)} = \frac{\big|\int_{{\mathbb{R}} } (p_{\theta} (x,y) - p_{\theta_0}(x,y))f(y) \, {\textrm{d}} y \big|}{V_a(x)} \le \frac{\int_{{\mathbb{R}} } \big|p_{\theta} (x,y) - p_{\theta_0}(x,y) \big|\, {\textrm{d}} y}{V_a(x)}. \end{equation*}
\begin{equation*} \frac{|({P_{\theta}} f)(x)- (P_{\theta_0}f)(x)|}{V_a(x)} = \frac{\big|\int_{{\mathbb{R}} } (p_{\theta} (x,y) - p_{\theta_0}(x,y))f(y) \, {\textrm{d}} y \big|}{V_a(x)} \le \frac{\int_{{\mathbb{R}} } \big|p_{\theta} (x,y) - p_{\theta_0}(x,y) \big|\, {\textrm{d}} y}{V_a(x)}. \end{equation*}
Let
 $\varepsilon >0$
. Since
$\varepsilon >0$
. Since
 $\lim_{x\rightarrow +\infty} V_a(x) = +\infty$
and the last term is bounded from above by
$\lim_{x\rightarrow +\infty} V_a(x) = +\infty$
and the last term is bounded from above by
 $2/V_a(x)$
, there exists
$2/V_a(x)$
, there exists
 $B>0$
such that
$B>0$
such that
 \begin{equation} |x| > B \Rightarrow \textrm{for all } \theta\in\Theta,\quad \frac{|({P_{\theta}} f)(x)- (P_{\theta_0})f(x)|}{V_a(x)} < \frac{\varepsilon}{2}. \end{equation}
\begin{equation} |x| > B \Rightarrow \textrm{for all } \theta\in\Theta,\quad \frac{|({P_{\theta}} f)(x)- (P_{\theta_0})f(x)|}{V_a(x)} < \frac{\varepsilon}{2}. \end{equation}
It follows that the conclusion of the lemma holds true provided that, under the condition
 $\lim_{\gamma \rightarrow \gamma_0} \| \mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0} \|_{{\mathbb{L}}^1({\mathbb{R}})}=0$
, we have
$\lim_{\gamma \rightarrow \gamma_0} \| \mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0} \|_{{\mathbb{L}}^1({\mathbb{R}})}=0$
, we have
 \begin{equation} \textrm{for all } A > 0, \quad \lim_{\theta \rightarrow \theta_0}\sup_{|x| \le A} \frac{\int_{{\mathbb{R}}}|p_{\theta}(x,y)- p_{\theta_0}(x,y)| \, {\textrm{d}} y}{V_a(x)} =0. \end{equation}
\begin{equation} \textrm{for all } A > 0, \quad \lim_{\theta \rightarrow \theta_0}\sup_{|x| \le A} \frac{\int_{{\mathbb{R}}}|p_{\theta}(x,y)- p_{\theta_0}(x,y)| \, {\textrm{d}} y}{V_a(x)} =0. \end{equation}
Indeed, (2.6) and (2.7) with
 $A=B$
ensure that
$A=B$
ensure that
 $\| {P_{\theta}} - P_{\theta_0}\|_{0,a} < \varepsilon$
when
$\| {P_{\theta}} - P_{\theta_0}\|_{0,a} < \varepsilon$
when
 $\theta$
is sufficiently close to
$\theta$
is sufficiently close to
 $\theta_0$
.
$\theta_0$
.
Let us prove (2.7). It follows from (2.2) that
 \begin{align} & \int_{{\mathbb{R}} } | p_{\theta} (x,y) - p_{\theta_0}(x,y))| \, {\textrm{d}} y \nonumber \\[5pt] & \quad \le \int_{{\mathbb{R}} } (\beta+\lambda x^2)^{-1/2}\bigg| \mathfrak{p}_{\gamma} \bigg(\frac{y-\alpha x}{(\beta+\lambda x^2)^{1/2}}\bigg) - \mathfrak{p}_{\gamma_0} \bigg(\frac{y-\alpha_0 x}{(\beta_0+\lambda_0 x^2)^{1/2}}\bigg) \bigg| \, {\textrm{d}} y \end{align}
\begin{align} & \int_{{\mathbb{R}} } | p_{\theta} (x,y) - p_{\theta_0}(x,y))| \, {\textrm{d}} y \nonumber \\[5pt] & \quad \le \int_{{\mathbb{R}} } (\beta+\lambda x^2)^{-1/2}\bigg| \mathfrak{p}_{\gamma} \bigg(\frac{y-\alpha x}{(\beta+\lambda x^2)^{1/2}}\bigg) - \mathfrak{p}_{\gamma_0} \bigg(\frac{y-\alpha_0 x}{(\beta_0+\lambda_0 x^2)^{1/2}}\bigg) \bigg| \, {\textrm{d}} y \end{align}
 \begin{align} + \int_{{\mathbb{R}} } \mathfrak{p}_{\gamma_0}\bigg(\frac{y-\alpha_0 x}{(\beta_0+\lambda_0 x^2)^{1/2}}\bigg) \big| (\beta+\lambda x^2)^{-1/2} - (\beta_0+\lambda_0 x^2)^{-1/2} \big| \, {\textrm{d}} y. \end{align}
\begin{align} + \int_{{\mathbb{R}} } \mathfrak{p}_{\gamma_0}\bigg(\frac{y-\alpha_0 x}{(\beta_0+\lambda_0 x^2)^{1/2}}\bigg) \big| (\beta+\lambda x^2)^{-1/2} - (\beta_0+\lambda_0 x^2)^{-1/2} \big| \, {\textrm{d}} y. \end{align}
First, using the change of variables
 $z = (y - \alpha x)/(\beta+\lambda x^2)^{1/2}$
in the integral (2.8) and the triangle inequality, we obtain
$z = (y - \alpha x)/(\beta+\lambda x^2)^{1/2}$
in the integral (2.8) and the triangle inequality, we obtain

where
 \begin{align*} b_{\beta,\lambda}(x) \;:\!=\; \bigg(\frac{\beta+\lambda x^2}{\beta_0+\lambda_0 x^2}\bigg)^{1/2}, \qquad a_{\alpha}(x) \;:\!=\; x \frac{\alpha-\alpha_0}{(\beta_0+\lambda_0 x^2)^{1/2}}. \end{align*}
\begin{align*} b_{\beta,\lambda}(x) \;:\!=\; \bigg(\frac{\beta+\lambda x^2}{\beta_0+\lambda_0 x^2}\bigg)^{1/2}, \qquad a_{\alpha}(x) \;:\!=\; x \frac{\alpha-\alpha_0}{(\beta_0+\lambda_0 x^2)^{1/2}}. \end{align*}
The first integral in (2.10) does not depend on x and is equal to
 $\|\mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0}\|_{{\mathbb{L}}^1({\mathbb{R}})}$
, which converges to 0 when
$\|\mathfrak{p}_{\gamma} - \mathfrak{p}_{\gamma_0}\|_{{\mathbb{L}}^1({\mathbb{R}})}$
, which converges to 0 when
 $\gamma \rightarrow \gamma_0$
from the assumption. Now let
$\gamma \rightarrow \gamma_0$
from the assumption. Now let
 $A>0$
be fixed. It follows from Lemma B.2 that
$A>0$
be fixed. It follows from Lemma B.2 that
 $\lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)}\sup_{|x|\le A} |b_{\beta,\lambda}(x) - 1| = 0$
and
$\lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)}\sup_{|x|\le A} |b_{\beta,\lambda}(x) - 1| = 0$
and
 $\lim_{\alpha \rightarrow \alpha_0}\sup_{|x|\le A} a_{\alpha}(x)= 0$
. Then, under Assumption 2.2, Lemma B.3 allows us to conclude that the second integral in (2.10) is such that
$\lim_{\alpha \rightarrow \alpha_0}\sup_{|x|\le A} a_{\alpha}(x)= 0$
. Then, under Assumption 2.2, Lemma B.3 allows us to conclude that the second integral in (2.10) is such that
 \begin{align*} \lim_{(\alpha,\beta,\lambda) \rightarrow (\alpha_0,\beta_0,\lambda_0)} \sup_{|x|\le A} \int_{{\mathbb{R}} }| \mathfrak{p}_{\gamma_0}(z) - \mathfrak{p}_{\gamma_0}(b_{\beta,\lambda}(x) z + a_{\alpha}(x))| \, {\textrm{d}} z = 0. \end{align*}
\begin{align*} \lim_{(\alpha,\beta,\lambda) \rightarrow (\alpha_0,\beta_0,\lambda_0)} \sup_{|x|\le A} \int_{{\mathbb{R}} }| \mathfrak{p}_{\gamma_0}(z) - \mathfrak{p}_{\gamma_0}(b_{\beta,\lambda}(x) z + a_{\alpha}(x))| \, {\textrm{d}} z = 0. \end{align*}
Second, let us consider the integral (2.9). We must show that the supremum of this integral on
 $x\in [\!-\!A,A]$
converges to 0 when
$x\in [\!-\!A,A]$
converges to 0 when
 $(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)$
. We obtain, for any
$(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)$
. We obtain, for any
 $x \in {\mathbb{R}}$
such that
$x \in {\mathbb{R}}$
such that
 $|x|\le A$
,
$|x|\le A$
,

with
 $b_\beta(A) \;:\!=\; (\beta/(\beta_0+\lambda_0 A^2))^{1/2} \leq \min_{|x|\leq A} b_{\beta,\lambda}(x)$
and
$b_\beta(A) \;:\!=\; (\beta/(\beta_0+\lambda_0 A^2))^{1/2} \leq \min_{|x|\leq A} b_{\beta,\lambda}(x)$
and
 $\int_{{\mathbb{R}}} \mathfrak{p}_{\gamma_0}(z)\,{\textrm{d}} z = 1$
. We know that
$\int_{{\mathbb{R}}} \mathfrak{p}_{\gamma_0}(z)\,{\textrm{d}} z = 1$
. We know that
 $\lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)}\sup_{|x|\le A} |b_{\beta,\lambda}(x) - 1|=0$
from Lemma B.2, so the expected convergence holds.
$\lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)}\sup_{|x|\le A} |b_{\beta,\lambda}(x) - 1|=0$
from Lemma B.2, so the expected convergence holds.
Remark 2.1. If the PDF
 $\mathfrak{p}_{\gamma_0}$
for the unperturbed AR(1)-ARCH(1) process is continuous on
$\mathfrak{p}_{\gamma_0}$
for the unperturbed AR(1)-ARCH(1) process is continuous on
 ${\mathbb{R}}$
, then Assumption 2.1(a) (stated to prove Assumption 1.1) can be omitted in Proposition 2.1. Actually, under the condition
${\mathbb{R}}$
, then Assumption 2.1(a) (stated to prove Assumption 1.1) can be omitted in Proposition 2.1. Actually, under the condition
 $\int_{\mathbb{R}} L_{F_{\xi_{0}}}(v)^a \mathfrak{p}_{\gamma_0}(v)\, {\textrm{d}} v < 1$
, which is contained in Assumption 2.1(c), Assumption 1.1 holds with any real number
$\int_{\mathbb{R}} L_{F_{\xi_{0}}}(v)^a \mathfrak{p}_{\gamma_0}(v)\, {\textrm{d}} v < 1$
, which is contained in Assumption 2.1(c), Assumption 1.1 holds with any real number
 $\rho_a$
(and the associated constant
$\rho_a$
(and the associated constant
 $C_a$
) such that
$C_a$
) such that
 \begin{align*} \bigg(\int_{\mathbb{R}} L_{F_{\xi_{0}}}(v)^a \mathfrak{p}_{\gamma_0}(v)\, {\textrm{d}} v\bigg)^{1/a} <\rho_a <1.\end{align*}
\begin{align*} \bigg(\int_{\mathbb{R}} L_{F_{\xi_{0}}}(v)^a \mathfrak{p}_{\gamma_0}(v)\, {\textrm{d}} v\bigg)^{1/a} <\rho_a <1.\end{align*}
Indeed, the kernel
 $p_{\theta_0}(x,y)$
given by (2.2) is continuous, so Remark 4.3 and Proposition 4.2 ensure that, under the conditions in Assumption 2.1(b) and (c),
$p_{\theta_0}(x,y)$
given by (2.2) is continuous, so Remark 4.3 and Proposition 4.2 ensure that, under the conditions in Assumption 2.1(b) and (c),
 $P_{\theta_0}$
satisfies (1.3) for any
$P_{\theta_0}$
satisfies (1.3) for any
 $\rho_a$
satisfying the above condition. In other words, if the PDF
$\rho_a$
satisfying the above condition. In other words, if the PDF
 $\mathfrak{p}_{\gamma_0}$
is continuous on
$\mathfrak{p}_{\gamma_0}$
is continuous on
 ${\mathbb{R}}$
, then only the conditions in Assumption 2.1(b) and (c) with
${\mathbb{R}}$
, then only the conditions in Assumption 2.1(b) and (c) with
 $\Theta=\{\theta_0\}$
are useful in obtaining Assumption 1.1.
$\Theta=\{\theta_0\}$
are useful in obtaining Assumption 1.1.
Remark 2.2. It is well known from Scheffé’s lemma [Reference Scheffé44] that the almost-everywhere pointwise convergence of the PDF
 $\mathfrak{p}_{\gamma}$
to the PDF
$\mathfrak{p}_{\gamma}$
to the PDF
 $\mathfrak{p}_{\gamma_0}$
when
$\mathfrak{p}_{\gamma_0}$
when
 $\gamma \rightarrow \gamma_0$
provides the
$\gamma \rightarrow \gamma_0$
provides the
 ${\mathbb{L}}^1({\mathbb{R}})$
-convergence required in Assumption 2.2.
${\mathbb{L}}^1({\mathbb{R}})$
-convergence required in Assumption 2.2.
3. Robustness of IFS under roundoff error
From [Reference Breyer, Roberts and Rosenthal7, Reference Roberts, Rosenthal and Schwartz42], the effect of roundoff errors using a Markov chain with transition kernel P means considering a Markov chain with a (perturbed) transition kernel of the form
 $\tilde P(x,A) \;:\!=\; P(x,h^{-1}(A))$
, where
$\tilde P(x,A) \;:\!=\; P(x,h^{-1}(A))$
, where
 $h \;:\; {\mathbb{X}}\rightarrow{\mathbb{X}}$
is such that h(x) is close to x. Let us consider an
$h \;:\; {\mathbb{X}}\rightarrow{\mathbb{X}}$
is such that h(x) is close to x. Let us consider an
 ${\mathbb{X}}$
-valued IFS as defined in Definition 1.1. Let
${\mathbb{X}}$
-valued IFS as defined in Definition 1.1. Let
 $(h_\theta)_{\theta\in \Theta}$
be a family of functions on
$(h_\theta)_{\theta\in \Theta}$
be a family of functions on
 ${\mathbb{X}}$
such that
${\mathbb{X}}$
such that
 $h_\theta\rightarrow \textrm{id}$
when
$h_\theta\rightarrow \textrm{id}$
when
 $\theta \rightarrow \theta_0$
in a sense to be specified later, where id denotes the identity map on
$\theta \rightarrow \theta_0$
in a sense to be specified later, where id denotes the identity map on
 ${\mathbb{X}}$
,
${\mathbb{X}}$
,
 $\Theta$
is a subset of a metric space, and
$\Theta$
is a subset of a metric space, and
 $\theta_0 \in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
. Then the associated roundoff IFS
$\theta_0 \in {\Theta}^{^{^{\!\!\!\!\kern-1pt\circ}}}$
. Then the associated roundoff IFS
 $\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
is defined as
$\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
is defined as
 \begin{equation*} \textrm{for}\;X^{(\theta)}_0\in {\mathbb{X}}\ \textrm{and}\;\textrm{all}\;n \ge 1,\ X^{(\theta)}_n = F_{\theta}\big( X^{(\theta)}_{n-1}, \vartheta_{n}\big), \end{equation*}
\begin{equation*} \textrm{for}\;X^{(\theta)}_0\in {\mathbb{X}}\ \textrm{and}\;\textrm{all}\;n \ge 1,\ X^{(\theta)}_n = F_{\theta}\big( X^{(\theta)}_{n-1}, \vartheta_{n}\big), \end{equation*}
where
 $F_{\theta}(x,v) \;:\!=\; {h_{\theta}}(F(x,v))$
and
$F_{\theta}(x,v) \;:\!=\; {h_{\theta}}(F(x,v))$
and
 $F_{\theta_0}(x,v) = \textrm{id}(F(x,v))= F(x,v)$
. The perturbed/roundoff transition kernels associated with
$F_{\theta_0}(x,v) = \textrm{id}(F(x,v))= F(x,v)$
. The perturbed/roundoff transition kernels associated with
 $\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
(or
$\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
(or
 $({h_{\theta}})_{\theta\in \Theta}$
) are given by
$({h_{\theta}})_{\theta\in \Theta}$
) are given by
 \begin{equation} \textrm{for all } f \in {\mathcal{B}}_0 \textrm{ and } x \in {\mathbb{X}}, \quad ({P_{\theta}} f)(x) = P(f \circ {h_{\theta}})(x) = \int_{{\mathbb{V}}} f(({h_{\theta}}\circ F)(x,v))\, {\textrm{d}}\mathfrak{p}(v). \end{equation}
\begin{equation} \textrm{for all } f \in {\mathcal{B}}_0 \textrm{ and } x \in {\mathbb{X}}, \quad ({P_{\theta}} f)(x) = P(f \circ {h_{\theta}})(x) = \int_{{\mathbb{V}}} f(({h_{\theta}}\circ F)(x,v))\, {\textrm{d}}\mathfrak{p}(v). \end{equation}
When the Markov kernel
 $P_{\theta_0}$
is assumed to be V-geometrically ergodic, the first natural question is to know whether
$P_{\theta_0}$
is assumed to be V-geometrically ergodic, the first natural question is to know whether
 ${P_{\theta}}$
remains V-geometrically ergodic for
${P_{\theta}}$
remains V-geometrically ergodic for
 $\theta$
close to
$\theta$
close to
 $\theta_0$
. The simplest way used in [Reference Roberts, Rosenthal and Schwartz42] to study this question is to assume that
$\theta_0$
. The simplest way used in [Reference Roberts, Rosenthal and Schwartz42] to study this question is to assume that
 $h_\theta \rightarrow \textrm{id}$
uniformly on
$h_\theta \rightarrow \textrm{id}$
uniformly on
 ${\mathbb{R}}^q$
when
${\mathbb{R}}^q$
when
 $\theta\rightarrow \theta_0$
(i.e., for all
$\theta\rightarrow \theta_0$
(i.e., for all
 $x\in {\mathbb{R}}^q$
,
$x\in {\mathbb{R}}^q$
,
 $\|h(x) - x\| \leq \varepsilon(\theta)$
with
$\|h(x) - x\| \leq \varepsilon(\theta)$
with
 $\lim_{\theta\rightarrow \theta_0} \varepsilon(\theta) = 0$
). However, as mentioned in [Reference Breyer, Roberts and Rosenthal7], this assumption is too restrictive in practice since the roundoff errors for some
$\lim_{\theta\rightarrow \theta_0} \varepsilon(\theta) = 0$
). However, as mentioned in [Reference Breyer, Roberts and Rosenthal7], this assumption is too restrictive in practice since the roundoff errors for some
 $x\in{\mathbb{R}}^q$
are obviously proportional to x. In [Reference Breyer, Roberts and Rosenthal7], the authors introduced the weaker assumption
$x\in{\mathbb{R}}^q$
are obviously proportional to x. In [Reference Breyer, Roberts and Rosenthal7], the authors introduced the weaker assumption
 $\|h(x) - x\| \leq \varepsilon(\theta)\|x\|$
with
$\|h(x) - x\| \leq \varepsilon(\theta)\|x\|$
with
 $\lim_{\theta\rightarrow \theta_0} \varepsilon(\theta) = 0$
, and proved that the V-geometric ergodicity property is stable for the roundoff Markov kernels under some mild assumptions on the function V. Below, as a by-product of Theorem 1.1, we again find this result in the specific instance of the roundoff process associated with a VAR model
$\lim_{\theta\rightarrow \theta_0} \varepsilon(\theta) = 0$
, and proved that the V-geometric ergodicity property is stable for the roundoff Markov kernels under some mild assumptions on the function V. Below, as a by-product of Theorem 1.1, we again find this result in the specific instance of the roundoff process associated with a VAR model
 $\{X_n\}_{n\in{\mathbb{N}}}$
, but more importantly the sensitivity of the probability distribution of
$\{X_n\}_{n\in{\mathbb{N}}}$
, but more importantly the sensitivity of the probability distribution of
 $X^{(\theta)}_n$
and of the stationary distribution of
$X^{(\theta)}_n$
and of the stationary distribution of
 $\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
when
$\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
when
 $\theta\rightarrow \theta_0$
is addressed too. These two issues are not investigated in [Reference Breyer, Roberts and Rosenthal7].
$\theta\rightarrow \theta_0$
is addressed too. These two issues are not investigated in [Reference Breyer, Roberts and Rosenthal7].
Let
 $\{X_n\}_{n\in{\mathbb{N}}}$
be an
$\{X_n\}_{n\in{\mathbb{N}}}$
be an
 ${\mathbb{R}}^q$
-valued VAR model as defined in Example 1.1. To simplify, we assume that, for some
${\mathbb{R}}^q$
-valued VAR model as defined in Example 1.1. To simplify, we assume that, for some
 $p\geq 1$
,
$p\geq 1$
,
 $\Theta$
is an open subset of
$\Theta$
is an open subset of
 ${\mathbb{R}}^p$
containing
${\mathbb{R}}^p$
containing
 $\theta_0\;:\!=\;0$
(the null vector of
$\theta_0\;:\!=\;0$
(the null vector of
 ${\mathbb{R}}^p$
), and we consider a family
${\mathbb{R}}^p$
), and we consider a family
 $(h_\theta)_{\theta\in \Theta}$
of functions on
$(h_\theta)_{\theta\in \Theta}$
of functions on
 ${\mathbb{X}}\;:\!=\;{\mathbb{R}}^q$
such that
${\mathbb{X}}\;:\!=\;{\mathbb{R}}^q$
such that
 $h_{0}=\textrm{id}$
. Thus, the roundoff process
$h_{0}=\textrm{id}$
. Thus, the roundoff process
 $\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
associated with
$\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}}}$
associated with
 $F_\theta(x,y) \;:\!=\; h_\theta(Ax+v)$
is the Markov chain with transition kernel
$F_\theta(x,y) \;:\!=\; h_\theta(Ax+v)$
is the Markov chain with transition kernel
 ${P_{\theta}}$
(see (3.1)),
${P_{\theta}}$
(see (3.1)),
 \begin{equation} \textrm{for all } f \in {\mathcal{B}}_0 \textrm{ and } x \in {\mathbb{X}}, \quad ({P_{\theta}} f)(x) = \int_{{\mathbb{R}}^q} f({h_{\theta}} (Ax + v)) \, {\textrm{d}} \mathfrak{p}(v). \end{equation}
\begin{equation} \textrm{for all } f \in {\mathcal{B}}_0 \textrm{ and } x \in {\mathbb{X}}, \quad ({P_{\theta}} f)(x) = \int_{{\mathbb{R}}^q} f({h_{\theta}} (Ax + v)) \, {\textrm{d}} \mathfrak{p}(v). \end{equation}
If
 $g \;:\; {\mathbb{R}}^q\rightarrow {\mathbb{R}}^q$
is differentiable and
$g \;:\; {\mathbb{R}}^q\rightarrow {\mathbb{R}}^q$
is differentiable and
 $z\in{\mathbb{R}}^q$
, we denote by
$z\in{\mathbb{R}}^q$
, we denote by
 $\nabla g(z)$
the Jacobian matrix of g at z, and we set
$\nabla g(z)$
the Jacobian matrix of g at z, and we set
 $\|\nabla g\|_\infty \;:\!=\; \sup_{z\in{\mathbb{R}}^q} \|\nabla g(z)\|$
, where
$\|\nabla g\|_\infty \;:\!=\; \sup_{z\in{\mathbb{R}}^q} \|\nabla g(z)\|$
, where
 $\|\!\cdot\!\|$
here denotes the induced matrix-norm of Example 1.1. For the sake of simplicity the norms chosen on
$\|\!\cdot\!\|$
here denotes the induced matrix-norm of Example 1.1. For the sake of simplicity the norms chosen on
 ${\mathbb{R}}^q$
and
${\mathbb{R}}^q$
and
 ${\mathbb{R}}^p $
are both denoted by
${\mathbb{R}}^p $
are both denoted by
 $\|\!\cdot\!\|$
. We introduce the following assumptions in order to apply Theorem 1.1 to
$\|\!\cdot\!\|$
. We introduce the following assumptions in order to apply Theorem 1.1 to
 $\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}} }$
.
$\big\{X^{(\theta)}_n\big\}_{n \in {\mathbb{N}} }$
.
Assumption 3.1.
 $\| A \| <1$
and there exists
$\| A \| <1$
and there exists
 $a \ge 1$
such that
$a \ge 1$
such that
 $\mathbb{E}[\|\vartheta_1\|^a]<\infty$
.
$\mathbb{E}[\|\vartheta_1\|^a]<\infty$
.
Assumption 3.2.
 $\sup_{\theta \in \Theta} \int_{{\mathbb{R}}^q} \|h_\theta(v)\|^a \mathfrak{p}(v)\, {\textrm{d}} v < \infty$
.
$\sup_{\theta \in \Theta} \int_{{\mathbb{R}}^q} \|h_\theta(v)\|^a \mathfrak{p}(v)\, {\textrm{d}} v < \infty$
.
Assumption 3.3.
For any
 $\theta\in \Theta$
,
$\theta\in \Theta$
,
 $h_{\theta}$
is differentiable on
$h_{\theta}$
is differentiable on
 ${\mathbb{R}}^q$
and
${\mathbb{R}}^q$
and
 $\sup_{\theta \in \Theta} \|\nabla h_\theta\|_\infty < \|A\|^{-1}$
.
$\sup_{\theta \in \Theta} \|\nabla h_\theta\|_\infty < \|A\|^{-1}$
.
Assumption 3.4.
-
(a) The probability distribution of
$\vartheta_1$
admits a bounded continuous PDF
$\mathfrak{p}$
satisfying the following monotonicity-type condition: there exists
$M>0$
such that, for every
$z_1,z_2\in{\mathbb{R}}^q$
,
$M \leq \|z_1\| \leq \|z_2\| \Rightarrow \mathfrak{p}(z_2) \leq \mathfrak{p}(z_1)$
. -
(b) For every
$\theta\in \Theta$
, the map
$h_\theta$
is a
${\mathcal{C}}^1$
-diffeomorphism on
${\mathbb{R}}^q$
with inverse function denoted by
$g_\theta$
, and the following conditions hold:-
(i) There exists
$c\in(0,1)$
such that, for all
$\theta\in \Theta$
and
$z\in{\mathbb{R}}^q$
,
$\|g_\theta(z) - z\| \leq c\|z\|$
. -
(ii) For all
$z\in{\mathbb{R}}^q$
,
$\lim_{\theta\rightarrow 0} g_\theta(z) = z$
. -
(iii)
$\sup_{\theta\in \Theta} \|\nabla g_\theta\|_\infty < \infty$
, and
$\lim_{\theta\rightarrow 0} \nabla g_\theta = \textrm{id}$
uniformly on each ball of
${\mathbb{R}}^q$
centred at 0, i.e. for all
$A >0$
and
$\eta>0$
there exists
$\alpha>0$
such that, for all
$\theta\in \Theta$
with
$\|\theta\| < \alpha$
,
$\sup_{\|z\|\leq A} \|\nabla g_\theta(z) - \textrm{id}\| < \eta$
.
-

























Proposition 3.1.
Under Assumptions 3.1–3.4 for a VAR process as defined in Example 1.1, the assertions P
1
–P
3
of Theorem 1.1 hold for every real number
 $\rho_a\in (\| A \|,1) $
(and associated constant
$\rho_a\in (\| A \|,1) $
(and associated constant
 $C_a$
).
$C_a$
).
Remark 3.1. The conditions in Assumption 3.4(b) focus on the inverse function
 $g_\theta$
of
$g_\theta$
of
 $h_\theta$
because
$h_\theta$
because
 $g_\theta$
naturally occurs in the proof after a change of variable. Note that, as in [Reference Breyer, Roberts and Rosenthal7], the uniform convergence
$g_\theta$
naturally occurs in the proof after a change of variable. Note that, as in [Reference Breyer, Roberts and Rosenthal7], the uniform convergence
 $\lim_{\theta\rightarrow 0} g_\theta = \textrm{id}$
(or
$\lim_{\theta\rightarrow 0} g_\theta = \textrm{id}$
(or
 $\lim_{\theta\rightarrow 0} h_\theta = \textrm{id}$
) is not required on the whole space
$\lim_{\theta\rightarrow 0} h_\theta = \textrm{id}$
) is not required on the whole space
 ${\mathbb{R}}^q$
in the above assumptions. For instance, the roundoff functions
${\mathbb{R}}^q$
in the above assumptions. For instance, the roundoff functions
 $h_\theta(x) = x + \theta x$
(simple perturbation of id on
$h_\theta(x) = x + \theta x$
(simple perturbation of id on
 ${\mathbb{R}}$
) satisfy the above assumptions, but neither the convergence
${\mathbb{R}}$
) satisfy the above assumptions, but neither the convergence
 $\lim_{\theta\rightarrow 0} g_\theta = \textrm{id}$
nor the convergence
$\lim_{\theta\rightarrow 0} g_\theta = \textrm{id}$
nor the convergence
 $\lim_{\theta\rightarrow 0} h_\theta = \textrm{id}$
are uniform on
$\lim_{\theta\rightarrow 0} h_\theta = \textrm{id}$
are uniform on
 ${\mathbb{R}}$
.
${\mathbb{R}}$
.
Proof. Recall that
 $\theta_0=0$
here. We know that Assumption 1.1 holds (see Remark 4.2). Next, for any
$\theta_0=0$
here. We know that Assumption 1.1 holds (see Remark 4.2). Next, for any
 $\theta\in \Theta$
and
$\theta\in \Theta$
and
 $z\in{\mathbb{R}}^q$
, set
$z\in{\mathbb{R}}^q$
, set
 $\Gamma_\theta(z) = |\det \nabla g_\theta(z)|$
. Then, using (3.2),
$\Gamma_\theta(z) = |\det \nabla g_\theta(z)|$
. Then, using (3.2),
 ${P_{\theta}}$
has the form
${P_{\theta}}$
has the form
 \begin{equation*} \textrm{for all}\;f \in {\mathcal{B}}_0\;\textrm{and}\;x\in{\mathbb{R}}^q,\; ({P_{\theta}} f)(x) = \int_{{\mathbb{R}}^q} f(z) \mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z)\, {\textrm{d}} z \end{equation*}
\begin{equation*} \textrm{for all}\;f \in {\mathcal{B}}_0\;\textrm{and}\;x\in{\mathbb{R}}^q,\; ({P_{\theta}} f)(x) = \int_{{\mathbb{R}}^q} f(z) \mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z)\, {\textrm{d}} z \end{equation*}
from the change of variable
 $z=h_\theta(Ax+v)$
. Recall that
$z=h_\theta(Ax+v)$
. Recall that
 ${P_{\theta}}$
is the transition kernel of the
${P_{\theta}}$
is the transition kernel of the
 ${\mathbb{R}}^q$
-valued IFS
${\mathbb{R}}^q$
-valued IFS
 $\big\{X^{(\theta)}_n\big\}_{n\in{\mathbb{N}}}$
associated with
$\big\{X^{(\theta)}_n\big\}_{n\in{\mathbb{N}}}$
associated with
 $F_\theta(x,v) \;:\!=\; h_\theta(Ax+v)$
. Then, Assumption 3.2 is just Assumption 1.2 (here
$F_\theta(x,v) \;:\!=\; h_\theta(Ax+v)$
. Then, Assumption 3.2 is just Assumption 1.2 (here
 $x_0=0$
), while Assumption 1.3 is implied by Assumption 3.3 from Taylor’s inequality applied to
$x_0=0$
), while Assumption 1.3 is implied by Assumption 3.3 from Taylor’s inequality applied to
 $h_\theta$
.
$h_\theta$
.
Next, we prove Assumption 1.4. For every
 $r>0$
, let
$r>0$
, let
 $B(0,r) = \{z\in {\mathbb{R}}^q \;:\; \|z\| \leq r\}$
. Let
$B(0,r) = \{z\in {\mathbb{R}}^q \;:\; \|z\| \leq r\}$
. Let
 $f\in {\mathcal{B}}_0$
be such that
$f\in {\mathcal{B}}_0$
be such that
 $|f|_0\leq 1$
, and let
$|f|_0\leq 1$
, and let
 $x\in{\mathbb{R}}^q$
. Fix
$x\in{\mathbb{R}}^q$
. Fix
 $\varepsilon >0$
. First, let
$\varepsilon >0$
. First, let
 $K\equiv K(\varepsilon)>0$
be such that
$K\equiv K(\varepsilon)>0$
be such that
 $(1+K)^{-a} < \varepsilon/2$
. Then
$(1+K)^{-a} < \varepsilon/2$
. Then
 \begin{equation} \textrm{for all } x\in {\mathbb{R}}^q\setminus B(0,K), \quad \frac{| ({P_{\theta}} f)(x) - (P_0 f)(x)|}{V(x)} \leq \frac{2}{V(x)} < \varepsilon. \end{equation}
\begin{equation} \textrm{for all } x\in {\mathbb{R}}^q\setminus B(0,K), \quad \frac{| ({P_{\theta}} f)(x) - (P_0 f)(x)|}{V(x)} \leq \frac{2}{V(x)} < \varepsilon. \end{equation}
Now we assume that
 $x\in B(0,K)$
. Note that
$x\in B(0,K)$
. Note that
 \begin{equation} | ({P_{\theta}} f)(x) - (P_0 f)(x) | \leq \int_{{\mathbb{R}}^q} |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)|\, {\textrm{d}} z \end{equation}
\begin{equation} | ({P_{\theta}} f)(x) - (P_0 f)(x) | \leq \int_{{\mathbb{R}}^q} |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)|\, {\textrm{d}} z \end{equation}
since
 $g_0=\textrm{id}$
. Set
$g_0=\textrm{id}$
. Set
 $d\;:\!=\;2/(1-c)$
, where c is given in Assumption 3.4(b)(i). Note that
$d\;:\!=\;2/(1-c)$
, where c is given in Assumption 3.4(b)(i). Note that
 $\|Ax\| \leq K$
and that Assumption 3.4(b)(i) provides, for all
$\|Ax\| \leq K$
and that Assumption 3.4(b)(i) provides, for all
 $z\in{\mathbb{R}}^q$
,
$z\in{\mathbb{R}}^q$
,
 $\|g_\theta(z)\| \geq (1-c)\|z\|$
. Then we have, for every
$\|g_\theta(z)\| \geq (1-c)\|z\|$
. Then we have, for every
 $z\in{\mathbb{R}}^q$
such that
$z\in{\mathbb{R}}^q$
such that
 $\|z\| \geq dK$
,
$\|z\| \geq dK$
,
 \begin{align*} \|g_\theta(z) - Ax\| \geq \|g_\theta(z)\| - \|Ax\| \geq (1-c)\|z\| - K \geq (1-c)\|z\| - \frac{1}{d}\|z\| \geq \frac{1-c}{2}\|z\|.\end{align*}
\begin{align*} \|g_\theta(z) - Ax\| \geq \|g_\theta(z)\| - \|Ax\| \geq (1-c)\|z\| - K \geq (1-c)\|z\| - \frac{1}{d}\|z\| \geq \frac{1-c}{2}\|z\|.\end{align*}
It follows from Assumption 3.4(a) that we have, for every
 $\theta\in \Theta$
,
$\theta\in \Theta$
,
 \begin{align*} \|z\| \geq B \equiv B(\varepsilon) \;:\!=\; \max\!(dM, dK) \Rightarrow \mathfrak{p}(g_\theta(z) - Ax) \leq \mathfrak{p}(d^{-1}z).\end{align*}
\begin{align*} \|z\| \geq B \equiv B(\varepsilon) \;:\!=\; \max\!(dM, dK) \Rightarrow \mathfrak{p}(g_\theta(z) - Ax) \leq \mathfrak{p}(d^{-1}z).\end{align*}
Since the function
 $z\mapsto \mathfrak{p}(d^{-1}z)$
is Lebesgue integrable on
$z\mapsto \mathfrak{p}(d^{-1}z)$
is Lebesgue integrable on
 ${\mathbb{R}}^q$
, we can choose
${\mathbb{R}}^q$
, we can choose
 $C\equiv C(\varepsilon)>0$
such that
$C\equiv C(\varepsilon)>0$
such that
 $\int_{\|z\| \geq C} \mathfrak{p}(d^{-1}z)\, {\textrm{d}} z \leq \varepsilon/2(\gamma+1)$
, where
$\int_{\|z\| \geq C} \mathfrak{p}(d^{-1}z)\, {\textrm{d}} z \leq \varepsilon/2(\gamma+1)$
, where
 $\gamma \;:\!=\; \sup_{\theta\in \Theta} \sup_{z\in{\mathbb{R}}^q} \Gamma_\theta(z)$
. Note that
$\gamma \;:\!=\; \sup_{\theta\in \Theta} \sup_{z\in{\mathbb{R}}^q} \Gamma_\theta(z)$
. Note that
 $\gamma < \infty$
from the first condition of Assumption 3.4(b)(iii) and from the continuity of the function
$\gamma < \infty$
from the first condition of Assumption 3.4(b)(iii) and from the continuity of the function
 $\det\!(\!\cdot\!)$
. Set
$\det\!(\!\cdot\!)$
. Set
 $D = \max\!(B,C)$
. We deduce from the triangle inequality that, for every
$D = \max\!(B,C)$
. We deduce from the triangle inequality that, for every
 $\theta\in \Theta$
,
$\theta\in \Theta$
,
 \begin{equation} \int_{\|z\| \geq D}|\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)|\, {\textrm{d}} z \leq (\gamma+1) \int_{{\|z\| \geq C}} \mathfrak{p}(d^{-1}z)\, {\textrm{d}} z \leq \frac{\varepsilon}{2}. \end{equation}
\begin{equation} \int_{\|z\| \geq D}|\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)|\, {\textrm{d}} z \leq (\gamma+1) \int_{{\|z\| \geq C}} \mathfrak{p}(d^{-1}z)\, {\textrm{d}} z \leq \frac{\varepsilon}{2}. \end{equation}
Now we investigate the integrand in (3.4) for
 $z\in B(0,D)$
(recall that
$z\in B(0,D)$
(recall that
 $x\in B(0,K)$
). First, setting
$x\in B(0,K)$
). First, setting
 $m\;:\!=\; \sup_{u\in{\mathbb{R}}^q} \mathfrak{p}(u)$
, we have, for every
$m\;:\!=\; \sup_{u\in{\mathbb{R}}^q} \mathfrak{p}(u)$
, we have, for every
 $z\in B(0,D)$
and
$z\in B(0,D)$
and
 $x\in B(0,K)$
,
$x\in B(0,K)$
,
 \begin{equation} |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)| \leq \gamma |\mathfrak{p}(g_\theta(z)-Ax) - \mathfrak{p}(z-Ax)| + m|\Gamma_\theta(z)-1|. \end{equation}
\begin{equation} |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)| \leq \gamma |\mathfrak{p}(g_\theta(z)-Ax) - \mathfrak{p}(z-Ax)| + m|\Gamma_\theta(z)-1|. \end{equation}
We have, for all
 $z\in B(0,D)$
,
$z\in B(0,D)$
,
 $\|g_\theta(z)\| \leq (1+c)D$
(using Assumption 3.4(b)(i)). From the standard statement for uniform convergence of differentiable functions, we deduce from the conditions in Assumption 3.4(b)(ii) and (b)(iii) that
$\|g_\theta(z)\| \leq (1+c)D$
(using Assumption 3.4(b)(i)). From the standard statement for uniform convergence of differentiable functions, we deduce from the conditions in Assumption 3.4(b)(ii) and (b)(iii) that
 $\lim_{\theta\rightarrow 0} g_\theta = \textrm{id}$
uniformly on B(0, D). Let
$\lim_{\theta\rightarrow 0} g_\theta = \textrm{id}$
uniformly on B(0, D). Let
 $\ell_D$
denote the volume of B(0, D) with respect to Lebesgue’s measure on
$\ell_D$
denote the volume of B(0, D) with respect to Lebesgue’s measure on
 ${\mathbb{R}}^q$
. From the previous uniform convergence and from the uniform continuity of
${\mathbb{R}}^q$
. From the previous uniform convergence and from the uniform continuity of
 $\mathfrak{p}$
on
$\mathfrak{p}$
on
 $B(0,(1+c)D+K)$
, there exists an open neighbourhood
$B(0,(1+c)D+K)$
, there exists an open neighbourhood
 ${\mathcal{V}}_0$
of
${\mathcal{V}}_0$
of
 $\theta=0$
in
$\theta=0$
in
 ${\mathbb{R}}^p$
such that
${\mathbb{R}}^p$
such that
 \begin{align*} \textrm{for all } \theta\in {\mathcal{V}}_0,\ z \in B(0,D),\ \textrm{and } x\in B(0,K),\quad |\mathfrak{p}(g_\theta(z)-Ax) - \mathfrak{p}(z-Ax)| < \frac{\varepsilon}{4\gamma \ell_D}.\end{align*}
\begin{align*} \textrm{for all } \theta\in {\mathcal{V}}_0,\ z \in B(0,D),\ \textrm{and } x\in B(0,K),\quad |\mathfrak{p}(g_\theta(z)-Ax) - \mathfrak{p}(z-Ax)| < \frac{\varepsilon}{4\gamma \ell_D}.\end{align*}
Moreover, there exists an open neighbourhood
 ${\mathcal{V}}'_{\!\!0} \subset {\mathcal{V}}_0$
of
${\mathcal{V}}'_{\!\!0} \subset {\mathcal{V}}_0$
of
 $\theta=0$
in
$\theta=0$
in
 ${\mathbb{R}}^p$
such that
${\mathbb{R}}^p$
such that
 \begin{align*} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0}, \textrm{ and } z \in B(0,D),\quad |\Gamma_\theta(z)-1| < \frac{\varepsilon}{4m \ell_D}\end{align*}
\begin{align*} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0}, \textrm{ and } z \in B(0,D),\quad |\Gamma_\theta(z)-1| < \frac{\varepsilon}{4m \ell_D}\end{align*}
from Assumption 3.4(b)(iii) and from the uniform continuity of the function
 $\det\!(\!\cdot\!)$
on every compact subset of the set
$\det\!(\!\cdot\!)$
on every compact subset of the set
 ${\mathcal{M}}_q({\mathbb{R}})$
of real
${\mathcal{M}}_q({\mathbb{R}})$
of real
 $q\times q$
matrices. It then follows from (3.6) that
$q\times q$
matrices. It then follows from (3.6) that
 \begin{align*} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0}, z \in B(0,D), \textrm{ and } x\in B(0,K), \quad |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)| \leq \frac{\varepsilon}{2 \ell_D}.\end{align*}
\begin{align*} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0}, z \in B(0,D), \textrm{ and } x\in B(0,K), \quad |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)| \leq \frac{\varepsilon}{2 \ell_D}.\end{align*}
Integrating this inequality on B(0, D) gives
 \begin{equation} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0} \textrm{ and } x\in B(0,K), \quad \int_{\|z\| \leq D} |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)|\, {\textrm{d}} z \leq \frac{\varepsilon}{2}. \end{equation}
\begin{equation} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0} \textrm{ and } x\in B(0,K), \quad \int_{\|z\| \leq D} |\mathfrak{p}(g_\theta(z)-Ax) \Gamma_\theta(z) - \mathfrak{p}(z-Ax)|\, {\textrm{d}} z \leq \frac{\varepsilon}{2}. \end{equation}
We deduce from (3.4), (3.5), and (3.7) that
 \begin{align*} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0} \textrm{ and } x\in B(0,K),\quad \frac{| ({P_{\theta}} f)(x) - (P_0 f)(x)|}{V(x)} \leq | ({P_{\theta}} f)(x) - (P_0 f)(x) | \leq \varepsilon.\end{align*}
\begin{align*} \textrm{for all } \theta\in {\mathcal{V}}'_{\!\!0} \textrm{ and } x\in B(0,K),\quad \frac{| ({P_{\theta}} f)(x) - (P_0 f)(x)|}{V(x)} \leq | ({P_{\theta}} f)(x) - (P_0 f)(x) | \leq \varepsilon.\end{align*}
4.
$\boldsymbol{V}_{\boldsymbol{a}}$
-geometric ergodicity of IFS

For
 ${a}\ge 1$
, define for any
${a}\ge 1$
, define for any
 $x\in{\mathbb{X}}$
,
$x\in{\mathbb{X}}$
,
 $p(x) \;:\!=\; 1 + d(x,x_0)$
, so that
$p(x) \;:\!=\; 1 + d(x,x_0)$
, so that
 $V_a(x) \;:\!=\; p(x)^a$
, and let us introduce the following space
$V_a(x) \;:\!=\; p(x)^a$
, and let us introduce the following space
 ${\mathcal{L}}_{a}$
:
${\mathcal{L}}_{a}$
:
 \begin{equation*} {\mathcal{L}}_{a} \;:\!=\; \bigg\{f \;:\; {\mathbb{X}}\rightarrow{\mathbb{C}} \;:\; m_{a}(f) \;:\!=\; \sup_{(x,y)\in {\mathbb{X}}^2,\,x\neq y}\bigg\{\frac{|f(x)-f(y)|}{d(x,y)\, (p(x) + p(y))^{a-1}} \bigg\} < \infty \bigg\}. \end{equation*}
\begin{equation*} {\mathcal{L}}_{a} \;:\!=\; \bigg\{f \;:\; {\mathbb{X}}\rightarrow{\mathbb{C}} \;:\; m_{a}(f) \;:\!=\; \sup_{(x,y)\in {\mathbb{X}}^2,\,x\neq y}\bigg\{\frac{|f(x)-f(y)|}{d(x,y)\, (p(x) + p(y))^{a-1}} \bigg\} < \infty \bigg\}. \end{equation*}
Such Lipschitz-weighted spaces were introduced in [Reference Le Page30] to obtain the quasi-compactness of Lipschitz kernels (see also [Reference Benda6, Reference Duflo13, Reference Hennion20, Reference Hennion and Hervé21, Reference Milhaud and Raugi38]). Note that, for
 $f\in{\mathcal{L}}_{a}$
, we have, for all
$f\in{\mathcal{L}}_{a}$
, we have, for all
 $x\in{\mathbb{X}}$
,
$x\in{\mathbb{X}}$
,
 $|f(x)|\leq |f(x_0)| + 2^{a-1}\,m_{a}(f)\,V_a(x)$
, so that
$|f(x)|\leq |f(x_0)| + 2^{a-1}\,m_{a}(f)\,V_a(x)$
, so that
 $|f|_{a} < \infty$
for any
$|f|_{a} < \infty$
for any
 $f\in{\mathcal{L}}_{a}$
. Hence,
$f\in{\mathcal{L}}_{a}$
. Hence,
 ${\mathcal{L}}_a \subset {\mathcal{B}}_a$
. Moreover,
${\mathcal{L}}_a \subset {\mathcal{B}}_a$
. Moreover,
 ${\mathcal{L}}_a$
is a Banach space when equipped with the norm, for all
${\mathcal{L}}_a$
is a Banach space when equipped with the norm, for all
 $f\in{\mathcal{L}}_{a}$
,
$f\in{\mathcal{L}}_{a}$
,
 $\|f\|_{a} \;:\!=\; m_{a}(f) + |f|_{a}$
.
$\|f\|_{a} \;:\!=\; m_{a}(f) + |f|_{a}$
.
Let
 $\{X_n\}_{n\in{\mathbb{N}}}$
be an IFS of Lipschitz maps as in Definition 1.1. For all
$\{X_n\}_{n\in{\mathbb{N}}}$
be an IFS of Lipschitz maps as in Definition 1.1. For all
 $x\in {\mathbb{X}}$
and
$x\in {\mathbb{X}}$
and
 $v\in {\mathbb{V}}$
, we set
$v\in {\mathbb{V}}$
, we set
 $F_v x \;:\!=\; F(x,v)$
. Recall that we set
$F_v x \;:\!=\; F(x,v)$
. Recall that we set
 $L_F(v) \;:\!=\;L(F_v)$
in Section 1. Since F is fixed in this section, we simply write L(v) for
$L_F(v) \;:\!=\;L(F_v)$
in Section 1. Since F is fixed in this section, we simply write L(v) for
 $L_F(v)$
. Similarly, for every
$L_F(v)$
. Similarly, for every
 $(v_1,\ldots,v_n)\in{\mathbb{V}}^n$
(
$(v_1,\ldots,v_n)\in{\mathbb{V}}^n$
(
 $n\in{\mathbb{N}}^*$
), define
$n\in{\mathbb{N}}^*$
), define
 \begin{equation} F_{v_n:v_1}\;:\!=\;F_{v_n}\circ \cdots\circ F_{v_1}, \qquad L(v_n\;:\;v_1) \;:\!=\; L(F_{v_n:v_1}). \end{equation}
\begin{equation} F_{v_n:v_1}\;:\!=\;F_{v_n}\circ \cdots\circ F_{v_1}, \qquad L(v_n\;:\;v_1) \;:\!=\; L(F_{v_n:v_1}). \end{equation}
By hypothesis we have
 $L(v)<\infty$
, and thus
$L(v)<\infty$
, and thus
 $L(v_n\;:\;v_1) <\infty$
. Note that, for each
$L(v_n\;:\;v_1) <\infty$
. Note that, for each
 $a\ge 1$
, the limit
$a\ge 1$
, the limit
 $\hat\kappa_a \;:\!=\; \lim_{n\rightarrow+\infty}\mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)^{{a}}]^{{1}/({na})}$
exists in
$\hat\kappa_a \;:\!=\; \lim_{n\rightarrow+\infty}\mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)^{{a}}]^{{1}/({na})}$
exists in
 $[0,+\infty]$
, since the sequence
$[0,+\infty]$
, since the sequence
 $(\mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)^{{a}}])_{n\in{\mathbb{N}}^*}$
is sub-multiplicative. In this section we first present a standard contraction/moment condition, Condition 4.1 (counterpart of Condition 1.1 in Section 1), for P given in (1.2) to have a geometric rate of convergence on
$(\mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)^{{a}}])_{n\in{\mathbb{N}}^*}$
is sub-multiplicative. In this section we first present a standard contraction/moment condition, Condition 4.1 (counterpart of Condition 1.1 in Section 1), for P given in (1.2) to have a geometric rate of convergence on
 ${\mathcal{L}}_a$
(see Proposition 4.1). Then the passage to
${\mathcal{L}}_a$
(see Proposition 4.1). Then the passage to
 $V_a$
-geometric ergodicity is addressed in Proposition 4.2.
$V_a$
-geometric ergodicity is addressed in Proposition 4.2.
Condition 4.1. For some
 ${a}\in[1,+\infty)$
,
${a}\in[1,+\infty)$
,
 \begin{align} \mathbb{E}[d(x_0, F(x_0,\vartheta_1)^{{a}})] & < \infty, \end{align}
\begin{align} \mathbb{E}[d(x_0, F(x_0,\vartheta_1)^{{a}})] & < \infty, \end{align}
 \begin{align} \widehat{\kappa}_a & < 1. \end{align}
\begin{align} \widehat{\kappa}_a & < 1. \end{align}
Note that (4.3) is equivalent to
 \begin{equation} \textrm{there exists } N\in{\mathbb{N}}^* \textrm{ such that } \mathbb{E}[L(\vartheta_N\;:\;\vartheta_1)^{{a}}] <1 ,\end{equation}
\begin{equation} \textrm{there exists } N\in{\mathbb{N}}^* \textrm{ such that } \mathbb{E}[L(\vartheta_N\;:\;\vartheta_1)^{{a}}] <1 ,\end{equation}
and Condition 1.1 in Section 1 corresponds to (4.2) and to (4.4) with
 $N=1$
.
$N=1$
.
The properties in the next proposition can be derived from the results of [Reference Duflo13, Chapter 6]; see also [Reference Benda6] for the existence and uniqueness of the invariant distribution. For convenience, in Appendix C the properties (4.5) and (4.6) are proved with explicit constants under the assumptions (4.2) and (4.4) with
 $N=1$
(i.e.
$N=1$
(i.e.
 $\mathbb{E}[L(\vartheta_1)^{a}] < 1$
).
$\mathbb{E}[L(\vartheta_1)^{a}] < 1$
).
Proposition 4.1. ([Reference Duflo13, Chapter 6].) Under Condition 4.1, P has a unique invariant distribution on
 $({\mathbb{X}},{\mathcal{X}})$
, denoted by
$({\mathbb{X}},{\mathcal{X}})$
, denoted by
 $\pi$
, and we have
$\pi$
, and we have
 $\pi(d(x_0,\cdot)^a)<\infty$
. Moreover, the Markov kernel P continuously acts on
$\pi(d(x_0,\cdot)^a)<\infty$
. Moreover, the Markov kernel P continuously acts on
 ${\mathcal{L}}_{a}$
, and for any
${\mathcal{L}}_{a}$
, and for any
 $\kappa\in(\widehat{\kappa}_a,1)$
, there exist positive constants
$\kappa\in(\widehat{\kappa}_a,1)$
, there exist positive constants
 $c\equiv c_\kappa$
and
$c\equiv c_\kappa$
and
 $c'\equiv c'_{\!\!\kappa}$
such that:
$c'\equiv c'_{\!\!\kappa}$
such that:
 \begin{align} \textit{for all } f\in {\mathcal{L}}_{a} \textit{ and } n\geq1,\quad |P^nf-\pi(f)\textbf{1}_{\mathbb{X}}|_{a} \leq c \kappa^n m_a(f);\; \end{align}
\begin{align} \textit{for all } f\in {\mathcal{L}}_{a} \textit{ and } n\geq1,\quad |P^nf-\pi(f)\textbf{1}_{\mathbb{X}}|_{a} \leq c \kappa^n m_a(f);\; \end{align}
 \begin{align} \textit{for all } f\in {\mathcal{L}}_{a} \textit{ and } n\geq1,\quad\|P^nf-\pi(f)\textbf{1}_{\mathbb{X}}\|_{a}\leq c'\kappa^n\|f\|_a. \end{align}
\begin{align} \textit{for all } f\in {\mathcal{L}}_{a} \textit{ and } n\geq1,\quad\|P^nf-\pi(f)\textbf{1}_{\mathbb{X}}\|_{a}\leq c'\kappa^n\|f\|_a. \end{align}
In particular, if
 $\kappa_{1,a} \;:\!=\; \mathbb{E}[L(\vartheta_1)^{a}]^{1/a} < 1$
, then
$\kappa_{1,a} \;:\!=\; \mathbb{E}[L(\vartheta_1)^{a}]^{1/a} < 1$
, then
 \begin{equation} \textit{for all } f\in {\mathcal{L}}_{a} \textit{ and } n\geq1,\quad |P^nf-\pi(f)\textbf{1}_{\mathbb{X}}|_{a} \leq c_1 {\kappa_{1,a}}^n m_a(f), \end{equation}
\begin{equation} \textit{for all } f\in {\mathcal{L}}_{a} \textit{ and } n\geq1,\quad |P^nf-\pi(f)\textbf{1}_{\mathbb{X}}|_{a} \leq c_1 {\kappa_{1,a}}^n m_a(f), \end{equation}
where the constant
 $c_1$
is defined by
$c_1$
is defined by
 $c_1 \;:\!=\; \xi^{(a-1)/a} \|\pi\|_1 (1 + \|\pi\|_a)^{a-1}$
, with
$c_1 \;:\!=\; \xi^{(a-1)/a} \|\pi\|_1 (1 + \|\pi\|_a)^{a-1}$
, with
 \begin{align*} \xi \;:\!=\; \sup_{n\geq 1}\,\sup_{x\in{\mathbb{X}}} \frac{(P^nV_a)(x)}{V_a(x)} < \infty, \qquad \|\pi\|_b \;:\!=\; \bigg(\int_{\mathbb{X}} V_b(y)\, {\textrm{d}}\pi(y)\bigg)^{{1}/{b}} \textit{ for } b = 1,a.\end{align*}
\begin{align*} \xi \;:\!=\; \sup_{n\geq 1}\,\sup_{x\in{\mathbb{X}}} \frac{(P^nV_a)(x)}{V_a(x)} < \infty, \qquad \|\pi\|_b \;:\!=\; \bigg(\int_{\mathbb{X}} V_b(y)\, {\textrm{d}}\pi(y)\bigg)^{{1}/{b}} \textit{ for } b = 1,a.\end{align*}
Under Condition 4.1, Property (4.5) with
 $f\;:\!=\;V_a$
and
$f\;:\!=\;V_a$
and
 $n\;:\!=\;1$
gives
$n\;:\!=\;1$
gives
 $PV_a\leq \xi_1 V_a$
for some
$PV_a\leq \xi_1 V_a$
for some
 $\xi_1\in(0,+\infty)$
, so that P continuously acts on
$\xi_1\in(0,+\infty)$
, so that P continuously acts on
 ${\mathcal{B}}_a$
. But it is worth noticing that Property (4.5) (or (4.7)) does not provide the
${\mathcal{B}}_a$
. But it is worth noticing that Property (4.5) (or (4.7)) does not provide the
 $V_a$
-geometric ergodicity (1.3) since (4.5) (or (4.7)) is only established for
$V_a$
-geometric ergodicity (1.3) since (4.5) (or (4.7)) is only established for
 $f\in{\mathcal{L}}_a$
. Under Condition 4.1, it was proved in [Reference Alsmeyer2, Proposition 5.2] that, if
$f\in{\mathcal{L}}_a$
. Under Condition 4.1, it was proved in [Reference Alsmeyer2, Proposition 5.2] that, if
 $\{X_n\}_{n\in{\mathbb{N}}}$
is Harris recurrent and the support of
$\{X_n\}_{n\in{\mathbb{N}}}$
is Harris recurrent and the support of
 $\pi$
has a non-empty interior, then
$\pi$
has a non-empty interior, then
 $\{X_n\}_{n\in{\mathbb{N}}}$
is
$\{X_n\}_{n\in{\mathbb{N}}}$
is
 $V_a$
-geometrically ergodic. Under Condition 4.1, the Markov chain
$V_a$
-geometrically ergodic. Under Condition 4.1, the Markov chain
 $\{X_n\}_{n\in{\mathbb{N}}}$
is shown to be
$\{X_n\}_{n\in{\mathbb{N}}}$
is shown to be
 $V_a$
-geometrically ergodic in [Reference Wu47, Proposition 7.2] provided that P and
$V_a$
-geometrically ergodic in [Reference Wu47, Proposition 7.2] provided that P and
 $P^N$
for some
$P^N$
for some
 $N\geq 1$
are Feller and strongly Feller, respectively. An alternative approach is proposed in Proposition 4.2 below. The bound (4.8) is the same as in [Reference Wu47, Proposition 7.2], but the Feller-type assumptions of [Reference Wu47] are replaced with the following:
$N\geq 1$
are Feller and strongly Feller, respectively. An alternative approach is proposed in Proposition 4.2 below. The bound (4.8) is the same as in [Reference Wu47, Proposition 7.2], but the Feller-type assumptions of [Reference Wu47] are replaced with the following:
 $P^\ell \;:\; {\mathcal{B}}_0\rightarrow{\mathcal{B}}_a$
for some
$P^\ell \;:\; {\mathcal{B}}_0\rightarrow{\mathcal{B}}_a$
for some
 $\ell\geq1$
is compact (see Remark 4.2 for comparisons).
$\ell\geq1$
is compact (see Remark 4.2 for comparisons).
Proposition 4.2.
Let us assume that Condition 4.1 holds, and that
 $P^\ell \;:\; {\mathcal{B}}_0\rightarrow {\mathcal{B}}_a$
for some
$P^\ell \;:\; {\mathcal{B}}_0\rightarrow {\mathcal{B}}_a$
for some
 $\ell\geq1$
is compact. Then P is
$\ell\geq1$
is compact. Then P is
 $V_a$
-geometrically ergodic, and the spectral gap
$V_a$
-geometrically ergodic, and the spectral gap
 $\rho_{V_a}(P)$
of P on
$\rho_{V_a}(P)$
of P on
 ${\mathcal{B}}_a$
(i.e. the infimum bound of the positive real numbers
${\mathcal{B}}_a$
(i.e. the infimum bound of the positive real numbers
 $\rho_a$
such that Property (1.3) holds) satisfies the following bound:
$\rho_a$
such that Property (1.3) holds) satisfies the following bound:
 \begin{equation} \rho_{V_a}(P) \leq \widehat{\kappa}_a. \end{equation}
\begin{equation} \rho_{V_a}(P) \leq \widehat{\kappa}_a. \end{equation}
Proof. To avoid confusion, we simply denote by P the action of
 $P(x,{\textrm{d}} y)$
on
$P(x,{\textrm{d}} y)$
on
 ${\mathcal{B}}_a$
, and we denote by
${\mathcal{B}}_a$
, and we denote by
 $P_{|\mathcal{L}_a}$
the restriction of P to
$P_{|\mathcal{L}_a}$
the restriction of P to
 ${\mathcal{L}}_a$
. Let
${\mathcal{L}}_a$
. Let
 $\delta$
and
$\delta$
and
 $\kappa$
be such that
$\kappa$
be such that
 $\widehat{\kappa}_a<\kappa<\delta<1$
. Then there exists
$\widehat{\kappa}_a<\kappa<\delta<1$
. Then there exists
 $N\in{\mathbb{N}}^*$
such that
$N\in{\mathbb{N}}^*$
such that
 $c \kappa^N m_a(V_a) \leq \delta^N$
, where
$c \kappa^N m_a(V_a) \leq \delta^N$
, where
 $c\equiv c_\kappa$
is defined in (4.5). Then, Property (4.5) applied to
$c\equiv c_\kappa$
is defined in (4.5). Then, Property (4.5) applied to
 $f\;:\!=\;V_a$
gives
$f\;:\!=\;V_a$
gives
 $P^N V_a \leq \delta^N V_a + \pi(V_a)$
. We deduce from [Reference Hervé and Ledoux23, Proposition 5.4 and Remark 5.5] that P is a power-bounded quasi-compact operator on
$P^N V_a \leq \delta^N V_a + \pi(V_a)$
. We deduce from [Reference Hervé and Ledoux23, Proposition 5.4 and Remark 5.5] that P is a power-bounded quasi-compact operator on
 ${\mathcal{B}}_a$
, and that its essential spectral radius
${\mathcal{B}}_a$
, and that its essential spectral radius
 $r_\textrm{ess}(P)$
satisfies
$r_\textrm{ess}(P)$
satisfies
 $r_\textrm{ess}(P) \leq \widehat{\kappa}_a$
since
$r_\textrm{ess}(P) \leq \widehat{\kappa}_a$
since
 $\delta$
is arbitrarily close to
$\delta$
is arbitrarily close to
 $\widehat{\kappa}_a$
(see, e.g., [Reference Hennion20] for the definition of the quasi-compactness and of the essential spectral radius of a bounded linear operator). From these properties it follows that the adjoint operator
$\widehat{\kappa}_a$
(see, e.g., [Reference Hennion20] for the definition of the quasi-compactness and of the essential spectral radius of a bounded linear operator). From these properties it follows that the adjoint operator
 $P^*$
of P is quasi-compact on the dual space
$P^*$
of P is quasi-compact on the dual space
 ${\mathcal{B}}'_{\!\!a}$
of
${\mathcal{B}}'_{\!\!a}$
of
 ${\mathcal{B}}_a$
, and that
${\mathcal{B}}_a$
, and that
 $r_\textrm{ess}(P^*) \leq \widehat{\kappa}_a$
.
$r_\textrm{ess}(P^*) \leq \widehat{\kappa}_a$
.
Next, let us establish that P is
 $V_a$
-geometrically ergodic from [Reference Hervé and Ledoux24, Proposition 2.1]. Let
$V_a$
-geometrically ergodic from [Reference Hervé and Ledoux24, Proposition 2.1]. Let
 $r_0\in(\widehat{\kappa}_a,1)$
. Prove that
$r_0\in(\widehat{\kappa}_a,1)$
. Prove that
 $\lambda\;:\!=\;1$
is the only eigenvalue of P on
$\lambda\;:\!=\;1$
is the only eigenvalue of P on
 ${\mathcal{B}}_a$
such that
${\mathcal{B}}_a$
such that
 $r_0 \le |\lambda| \leq 1$
. Let
$r_0 \le |\lambda| \leq 1$
. Let
 $\lambda\in{\mathbb{C}}$
be such an eigenvalue. Then
$\lambda\in{\mathbb{C}}$
be such an eigenvalue. Then
 $\lambda$
is also an eigenvalue of
$\lambda$
is also an eigenvalue of
 $P^*$
since P and
$P^*$
since P and
 $P^*$
have the same spectrum and
$P^*$
have the same spectrum and
 $r_\textrm{ess}(P^*) \leq \widehat{\kappa}_a < |\lambda|$
. Thus, there exists
$r_\textrm{ess}(P^*) \leq \widehat{\kappa}_a < |\lambda|$
. Thus, there exists
 $f'\in{\mathcal{B}}'_{\!\!a}$
such that
$f'\in{\mathcal{B}}'_{\!\!a}$
such that
 $f'\circ P = \lambda f'$
. But f
′ is also in
$f'\circ P = \lambda f'$
. But f
′ is also in
 ${\mathcal{L}}'_{\!\!a}$
since we have, for all
${\mathcal{L}}'_{\!\!a}$
since we have, for all
 $f\in{\mathcal{L}}_a$
,
$f\in{\mathcal{L}}_a$
,
 $|\langle f',f\rangle| \leq \|f'\|_{\mathcal{B}_a'}|f|_a \leq \|f'\|_{\mathcal{B}_a'}\|f\|_a$
. This proves that
$|\langle f',f\rangle| \leq \|f'\|_{\mathcal{B}_a'}|f|_a \leq \|f'\|_{\mathcal{B}_a'}\|f\|_a$
. This proves that
 $\lambda$
is an eigenvalue of the adjoint of
$\lambda$
is an eigenvalue of the adjoint of
 $P_{|\mathcal{L}_a}$
. Hence
$P_{|\mathcal{L}_a}$
. Hence
 $\lambda$
is a spectral value of
$\lambda$
is a spectral value of
 $P_{|\mathcal{L}_a}$
. More precisely,
$P_{|\mathcal{L}_a}$
. More precisely,
 $\lambda$
is an eigenvalue of
$\lambda$
is an eigenvalue of
 $P_{|\mathcal{L}_a}$
since, from (4.6),
$P_{|\mathcal{L}_a}$
since, from (4.6),
 $P_{|\mathcal{L}_a}$
is quasi-compact on
$P_{|\mathcal{L}_a}$
is quasi-compact on
 ${\mathcal{L}}_a$
and
${\mathcal{L}}_a$
and
 $r_\textrm{ess}(P_{|\mathcal{L}_a}) \le \widehat{\kappa}_a < r_0 \le |\lambda|$
. Finally, we have
$r_\textrm{ess}(P_{|\mathcal{L}_a}) \le \widehat{\kappa}_a < r_0 \le |\lambda|$
. Finally, we have
 $\lambda=1$
. Indeed, if
$\lambda=1$
. Indeed, if
 $\lambda\neq1$
, then any
$\lambda\neq1$
, then any
 $f\in{\mathcal{L}}_a$
satisfying
$f\in{\mathcal{L}}_a$
satisfying
 $Pf = \lambda f$
is such that
$Pf = \lambda f$
is such that
 $\pi(f)=0$
, and thus
$\pi(f)=0$
, and thus
 $f=0$
from (4.6) (pick
$f=0$
from (4.6) (pick
 $\kappa \in(\widehat{\kappa}_a, r_0))$
.
$\kappa \in(\widehat{\kappa}_a, r_0))$
.
Now prove that 1 is a simple eigenvalue of P on
 ${\mathcal{B}}_a$
. Using the previous property and the fact that P is power bounded and quasi-compact on
${\mathcal{B}}_a$
. Using the previous property and the fact that P is power bounded and quasi-compact on
 ${\mathcal{B}}_a$
, we know that
${\mathcal{B}}_a$
, we know that
 $P^n\rightarrow \Pi$
with respect to the operator norm on
$P^n\rightarrow \Pi$
with respect to the operator norm on
 ${\mathcal{B}}_a$
, where
${\mathcal{B}}_a$
, where
 $\Pi$
is the finite-rank eigenprojection on
$\Pi$
is the finite-rank eigenprojection on
 $\ker\!(P-I) = \ker\!(P-I)^2$
. The last equality holds since P is power bounded on
$\ker\!(P-I) = \ker\!(P-I)^2$
. The last equality holds since P is power bounded on
 ${\mathcal{B}}_a$
. Set
${\mathcal{B}}_a$
. Set
 $m\;:\!=\;\dim\ker\!(P-I)$
. From [47, Proposition 4.6] (see also [Reference Hervé22, Theorem 1]), there exist m linearly independent non-negative functions
$m\;:\!=\;\dim\ker\!(P-I)$
. From [47, Proposition 4.6] (see also [Reference Hervé22, Theorem 1]), there exist m linearly independent non-negative functions
 $f_1,\ldots,f_m\in\ker\!(P-I)$
and probability measures
$f_1,\ldots,f_m\in\ker\!(P-I)$
and probability measures
 $\mu_1,\ldots,\mu_m\in\ker\!(P^*-I)$
satisfying
$\mu_1,\ldots,\mu_m\in\ker\!(P^*-I)$
satisfying
 $\mu_k(V_a)<\infty$
such that, for all
$\mu_k(V_a)<\infty$
such that, for all
 $f\in{\mathcal{B}}_a$
,
$f\in{\mathcal{B}}_a$
,
 $\Pi f = \sum_{k=1}^m \mu_k(f) f_k$
. That 1 is a simple eigenvalue of P on
$\Pi f = \sum_{k=1}^m \mu_k(f) f_k$
. That 1 is a simple eigenvalue of P on
 ${\mathcal{B}}_a$
then follows from the first assertion of Proposition 4.1.
${\mathcal{B}}_a$
then follows from the first assertion of Proposition 4.1.
From [Reference Hervé and Ledoux24, Proposition 2.1] and the previous results, we have proved that, for any
 $r_0\in(\widehat{\kappa}_a,1)$
, we have
$r_0\in(\widehat{\kappa}_a,1)$
, we have
 $\rho_{V_a}(P) \leq r_0$
. Thus,
$\rho_{V_a}(P) \leq r_0$
. Thus,
 $\rho_{V_a}(P)\leq \widehat{\kappa}_a$
.
$\rho_{V_a}(P)\leq \widehat{\kappa}_a$
.
Remark 4.1. Inequality (4.8) means that, for any real number
 $\rho \in(\widehat{\kappa}_a,1)$
, there exists a constant
$\rho \in(\widehat{\kappa}_a,1)$
, there exists a constant
 $C\equiv C_{\rho}$
such that, for all
$C\equiv C_{\rho}$
such that, for all
 $n\geq1$
and
$n\geq1$
and
 $f\in{\mathcal{B}}_{a}$
,
$f\in{\mathcal{B}}_{a}$
,
 $|P^nf-\pi(f) \textbf{1}_{{\mathbb{X}}}|_a \leq C \rho^{n} |f|_a$
. Unfortunately, neither the proof of Proposition 4.1 nor that of [Reference Wu47, Proposition 7.2] give any information on the constant C. Computing such an explicit constant C is an intricate issue which is not addressed in this work (see, e.g., [Reference Baxendale5, Reference Hervé and Ledoux23, Reference Hervé and Ledoux24, Reference Lund and Tweedie32, Reference Meyn and Tweedie37] and the references therein). It is worth mentioning that explicit bounds on
$|P^nf-\pi(f) \textbf{1}_{{\mathbb{X}}}|_a \leq C \rho^{n} |f|_a$
. Unfortunately, neither the proof of Proposition 4.1 nor that of [Reference Wu47, Proposition 7.2] give any information on the constant C. Computing such an explicit constant C is an intricate issue which is not addressed in this work (see, e.g., [Reference Baxendale5, Reference Hervé and Ledoux23, Reference Hervé and Ledoux24, Reference Lund and Tweedie32, Reference Meyn and Tweedie37] and the references therein). It is worth mentioning that explicit bounds on
 $\rho$
and C are also provided in [Reference Galtchouk and Pergamenshchikov15] for a parametrized family of transition kernels.
$\rho$
and C are also provided in [Reference Galtchouk and Pergamenshchikov15] for a parametrized family of transition kernels.
Remark 4.2. Assume that every closed ball of
 ${\mathbb{X}}$
is compact. Let
${\mathbb{X}}$
is compact. Let
 $\{X_n\}_{n\in{\mathbb{N}}}$
be a Markov chain such that its transition kernel P satisfies the hypothesis that there exist a positive measure
$\{X_n\}_{n\in{\mathbb{N}}}$
be a Markov chain such that its transition kernel P satisfies the hypothesis that there exist a positive measure
 $\eta$
on
$\eta$
on
 $({\mathbb{X}},{\mathcal{X}})$
and a measurable function
$({\mathbb{X}},{\mathcal{X}})$
and a measurable function
 $K \;:\; {\mathbb{X}}^2\rightarrow [0,+\infty)$
such that
$K \;:\; {\mathbb{X}}^2\rightarrow [0,+\infty)$
such that
 \begin{equation} \textrm{for all } x\in{\mathbb{X}}, \quad P(x,{\textrm{d}} y) = K(x,y)\, {\textrm{d}}\eta(y). \end{equation}
\begin{equation} \textrm{for all } x\in{\mathbb{X}}, \quad P(x,{\textrm{d}} y) = K(x,y)\, {\textrm{d}}\eta(y). \end{equation}
If
 $P^{\ell}$
is strongly Feller for some
$P^{\ell}$
is strongly Feller for some
 $\ell\geq1$
, then
$\ell\geq1$
, then
 $P^{2\ell}$
is compact from
$P^{2\ell}$
is compact from
 ${\mathcal{B}}_0$
to
${\mathcal{B}}_0$
to
 ${\mathcal{B}}_a$
(see, e.g., [Reference Guibourg, Hervé and Ledoux18, Lemma 3]). Hence, if P admits a kernel as in (4.9), then assuming that
${\mathcal{B}}_a$
(see, e.g., [Reference Guibourg, Hervé and Ledoux18, Lemma 3]). Hence, if P admits a kernel as in (4.9), then assuming that
 $P^N$
is strongly Feller for some N in [Reference Wu47, Proposition 7.2] is more restrictive than the compactness hypothesis of Proposition 4.2. A detailed comparison with the approach in [Reference Wu47, Proposition 7.2] is provided in [Reference Guibourg, Hervé and Ledoux18] for general Markov kernels. Finally, note that the transition kernel P of a VAR process (see Example 1.1) is always strongly Feller. Indeed, let
$P^N$
is strongly Feller for some N in [Reference Wu47, Proposition 7.2] is more restrictive than the compactness hypothesis of Proposition 4.2. A detailed comparison with the approach in [Reference Wu47, Proposition 7.2] is provided in [Reference Guibourg, Hervé and Ledoux18] for general Markov kernels. Finally, note that the transition kernel P of a VAR process (see Example 1.1) is always strongly Feller. Indeed, let
 $f\in{\mathcal{B}}_0$
be such that
$f\in{\mathcal{B}}_0$
be such that
 $\|f\|_0\leq 1$
. Then we have
$\|f\|_0\leq 1$
. Then we have
 \begin{align*} \textrm{for all } (x,x')\in{\mathbb{R}}^q\times{\mathbb{R}}^q, \quad |(Pf)(x') - (Pf)(x)| \leq \int_{{\mathbb{R}}^q} |\mathfrak{p}(y-A(x'-x)) - \mathfrak{p}(y)|\, {\textrm{d}} y.\end{align*}
\begin{align*} \textrm{for all } (x,x')\in{\mathbb{R}}^q\times{\mathbb{R}}^q, \quad |(Pf)(x') - (Pf)(x)| \leq \int_{{\mathbb{R}}^q} |\mathfrak{p}(y-A(x'-x)) - \mathfrak{p}(y)|\, {\textrm{d}} y.\end{align*}
Since
 $t\mapsto \mathfrak{p}(\cdot-t)$
is continuous from
$t\mapsto \mathfrak{p}(\cdot-t)$
is continuous from
 ${\mathbb{R}}^q$
to the Lebesgue space
${\mathbb{R}}^q$
to the Lebesgue space
 ${\mathbb{L}}^1({\mathbb{R}}^q)$
, it follows that P is strongly Feller. Thus the
${\mathbb{L}}^1({\mathbb{R}}^q)$
, it follows that P is strongly Feller. Thus the
 $V_a$
-geometric ergodicity of P claimed in Example 1.1 follows from Proposition 4.2. See also [Reference Wu47, Section 8].
$V_a$
-geometric ergodicity of P claimed in Example 1.1 follows from Proposition 4.2. See also [Reference Wu47, Section 8].
Remark 4.3. If
 $\{X_n\}_{n\in{\mathbb{N}}}$
is an IFS of Lipschitz maps as in Definition 1.1 such that its transition kernel P satisfies the assumption in (4.9) with K continuous in the first variable, then P is strongly Feller, thus
$\{X_n\}_{n\in{\mathbb{N}}}$
is an IFS of Lipschitz maps as in Definition 1.1 such that its transition kernel P satisfies the assumption in (4.9) with K continuous in the first variable, then P is strongly Feller, thus
 $P^{2}$
is compact from
$P^{2}$
is compact from
 ${\mathcal{B}}_0$
to
${\mathcal{B}}_0$
to
 ${\mathcal{B}}_a$
, so that the conclusions of Proposition 4.2 hold true under Condition 4.1. Indeed, we have, for all
${\mathcal{B}}_a$
, so that the conclusions of Proposition 4.2 hold true under Condition 4.1. Indeed, we have, for all
 $(x,x')\in{\mathbb{X}}^2$
and for any
$(x,x')\in{\mathbb{X}}^2$
and for any
 $f \in {\mathcal{B}}_0$
,
$f \in {\mathcal{B}}_0$
,
 \begin{align*} |(Pf)(x') - (Pf)(x)| \leq \int_{\mathbb{X}} |K(x',y) - K(x,y)|\, {\textrm{d}}\eta(y).\end{align*}
\begin{align*} |(Pf)(x') - (Pf)(x)| \leq \int_{\mathbb{X}} |K(x',y) - K(x,y)|\, {\textrm{d}}\eta(y).\end{align*}
Since
 $K(\cdot,\cdot)\geq0$
,
$K(\cdot,\cdot)\geq0$
,
 $\int K(\cdot,y)\,{\textrm{d}}\eta(y) =1$
, and
$\int K(\cdot,y)\,{\textrm{d}}\eta(y) =1$
, and
 $\lim_{x^{\prime}\rightarrow x} K(x',y) = K(x,y)$
, we deduce from Scheffé’s theorem that
$\lim_{x^{\prime}\rightarrow x} K(x',y) = K(x,y)$
, we deduce from Scheffé’s theorem that
 $\lim_{x^{\prime}\rightarrow x} \int_{\mathbb{X}} |K(x',y) - K(x,y)|\, {\textrm{d}}\eta(y) = 0$
. This proves the desired statement. Note that the previous argument even shows that
$\lim_{x^{\prime}\rightarrow x} \int_{\mathbb{X}} |K(x',y) - K(x,y)|\, {\textrm{d}}\eta(y) = 0$
. This proves the desired statement. Note that the previous argument even shows that
 $\{Pf,\, |f|_0\leq 1\}$
is equicontinuous, so that the compactness of
$\{Pf,\, |f|_0\leq 1\}$
is equicontinuous, so that the compactness of
 $P \;:\; {\mathcal{B}}_0\rightarrow {\mathcal{B}}_1$
can be directly proved from Ascoli’s theorem.
$P \;:\; {\mathcal{B}}_0\rightarrow {\mathcal{B}}_1$
can be directly proved from Ascoli’s theorem.
Remark 4.4. In the proof of Proposition 4.2 the drift inequality
 $P^N V_a \leq \delta^N V_a + \pi(V_a)$
was written with any
$P^N V_a \leq \delta^N V_a + \pi(V_a)$
was written with any
 $\delta\in (\widehat{\kappa}_a,1)$
by using Property (4.5) of Proposition 4.1 in order to deduce the bound
$\delta\in (\widehat{\kappa}_a,1)$
by using Property (4.5) of Proposition 4.1 in order to deduce the bound
 $r_\textrm{ess}(P) \leq \widehat{\kappa}_a$
on the essential spectral radius of P (acting on
$r_\textrm{ess}(P) \leq \widehat{\kappa}_a$
on the essential spectral radius of P (acting on
 ${\mathcal{B}}_a$
). This bound was sufficient since the remainder of the proof of Proposition 4.2 is based on Property (4.6), from which we deduce the bound
${\mathcal{B}}_a$
). This bound was sufficient since the remainder of the proof of Proposition 4.2 is based on Property (4.6), from which we deduce the bound
 $r_\textrm{ess}(P_{|\mathcal{L}_a}) \le \widehat{\kappa}_a$
. Actually, for any
$r_\textrm{ess}(P_{|\mathcal{L}_a}) \le \widehat{\kappa}_a$
. Actually, for any
 $\delta\in (\widehat{\kappa}_a^{a},1)$
, the drift inequality
$\delta\in (\widehat{\kappa}_a^{a},1)$
, the drift inequality
 $P^N V_a \leq \delta^N V_a + K$
with some
$P^N V_a \leq \delta^N V_a + K$
with some
 $N\geq 1$
and
$N\geq 1$
and
 $K>0$
can be derived from Condition 4.1 by adapting the proof in Appendix A (here with
$K>0$
can be derived from Condition 4.1 by adapting the proof in Appendix A (here with
 $P_{\theta_0}=P$
and
$P_{\theta_0}=P$
and
 $\Theta=\{\theta_0\}$
). Then, the more accurate bound
$\Theta=\{\theta_0\}$
). Then, the more accurate bound
 $r_\textrm{ess}(P) \leq \widehat{\kappa}_a^{a}$
can be derived from [Reference Hervé and Ledoux23, Proposition 5.4 and Remark 5.5] under the compactness assumption of Proposition 4.2. See also [Reference Wu47, Proposition 7.2], which provides the same bound under Feller-type assumptions.
$r_\textrm{ess}(P) \leq \widehat{\kappa}_a^{a}$
can be derived from [Reference Hervé and Ledoux23, Proposition 5.4 and Remark 5.5] under the compactness assumption of Proposition 4.2. See also [Reference Wu47, Proposition 7.2], which provides the same bound under Feller-type assumptions.
5. Further applications
Theorem 1.1 was applied in Section 2 to real-valued AR(1) models with ARCH(1) errors (see Proposition 2.1), and in Section 3 to the roundoff errors of a VAR model (see Proposition 3.1). Although these applications have been presented for specific IFSs, it is worth noticing that they give a general road map for investigating the issues in P1–P3 of Section 1 for other instances of
 ${\mathbb{R}}^q$
-valued IFSs, provided that the probability distribution of the noise
${\mathbb{R}}^q$
-valued IFSs, provided that the probability distribution of the noise
 $\mathfrak{p}_\gamma$
in Definition 1.2 admits a PDF with respect to Lebesgue’s measure on
$\mathfrak{p}_\gamma$
in Definition 1.2 admits a PDF with respect to Lebesgue’s measure on
 ${\mathbb{V}}={\mathbb{R}}^q$
, and that the change of variable
${\mathbb{V}}={\mathbb{R}}^q$
, and that the change of variable
 $v \mapsto z = F_\xi(x,v)$
is valid for every
$v \mapsto z = F_\xi(x,v)$
is valid for every
 $x\in{\mathbb{R}}^q$
, where
$x\in{\mathbb{R}}^q$
, where
 $F_\xi(\cdot,\cdot)$
is the perturbed function involved in Definition 1.2. In Section 5.1 we propose two examples to support this claim. Finally, in Section 5.2 we discuss the robustness of IFSs of Lipschitz maps under perturbation caused by some thresholding and truncation.
$F_\xi(\cdot,\cdot)$
is the perturbed function involved in Definition 1.2. In Section 5.1 we propose two examples to support this claim. Finally, in Section 5.2 we discuss the robustness of IFSs of Lipschitz maps under perturbation caused by some thresholding and truncation.
5.1. A general non-linear time series model
Denoting by
 $\textrm{GL}_q({\mathbb{R}})$
the set of invertible real
$\textrm{GL}_q({\mathbb{R}})$
the set of invertible real
 $q\times q$
matrices, consider an IFS
$q\times q$
matrices, consider an IFS
 $\{X_n\}_{n\in{\mathbb{N}}}$
of the form
$\{X_n\}_{n\in{\mathbb{N}}}$
of the form
 \begin{equation} \textrm{for all } n\geq 1,\quad X_n = \psi(X_{n-1}) + B(X_{n-1}) \vartheta_n,\end{equation}
\begin{equation} \textrm{for all } n\geq 1,\quad X_n = \psi(X_{n-1}) + B(X_{n-1}) \vartheta_n,\end{equation}
where
 $\psi \;:\; {\mathbb{R}}^q\rightarrow {\mathbb{R}}^q$
,
$\psi \;:\; {\mathbb{R}}^q\rightarrow {\mathbb{R}}^q$
,
 $B\;:\; {\mathbb{R}}^q\rightarrow \textrm{GL}_q({\mathbb{R}})$
, and the random variables
$B\;:\; {\mathbb{R}}^q\rightarrow \textrm{GL}_q({\mathbb{R}})$
, and the random variables
 $\{\vartheta_n\}_{n\geq 1}$
have common PDF
$\{\vartheta_n\}_{n\geq 1}$
have common PDF
 $\mathfrak{p}$
. If
$\mathfrak{p}$
. If
 $B(x)=I_q$
for any
$B(x)=I_q$
for any
 $x \in {\mathbb{R}}^q$
, where
$x \in {\mathbb{R}}^q$
, where
 $I_q$
is the identity
$I_q$
is the identity
 $q\times q$
matrix, this Markov chain is called a functional-coefficient AR model. The Markov model (5.1) encompasses a very large class of non-linear time series models (see, e.g., [Reference Meyn and Tweedie36, Chapter 2], [Reference Tsay46, Chapter 4]), and [Reference Cline8, Reference Cline9, Reference Cline and Pu10, Reference Meitz and Saikkonen35, and references therein].
$q\times q$
matrix, this Markov chain is called a functional-coefficient AR model. The Markov model (5.1) encompasses a very large class of non-linear time series models (see, e.g., [Reference Meyn and Tweedie36, Chapter 2], [Reference Tsay46, Chapter 4]), and [Reference Cline8, Reference Cline9, Reference Cline and Pu10, Reference Meitz and Saikkonen35, and references therein].
As a generalization of Section 2, consider the following general parametric perturbation of the
 ${\mathbb{R}}^q$
-valued IFS
${\mathbb{R}}^q$
-valued IFS
 $\{X_n\}_{n\in{\mathbb{N}}}$
defined in (5.1):
$\{X_n\}_{n\in{\mathbb{N}}}$
defined in (5.1):
 \begin{equation*} \textrm{for all}\;n\geq 1,\; {X_n^{(\theta)}} = \psi_\xi\big({X_{n-1}^{(\theta)}}\big) + B_\xi\big({X_{n-1}^{(\theta)}}\big) \vartheta^{(\gamma)}_n, \end{equation*}
\begin{equation*} \textrm{for all}\;n\geq 1,\; {X_n^{(\theta)}} = \psi_\xi\big({X_{n-1}^{(\theta)}}\big) + B_\xi\big({X_{n-1}^{(\theta)}}\big) \vartheta^{(\gamma)}_n, \end{equation*}
with some parametrized maps
 $\psi_\xi \;:\; {\mathbb{R}}^q\rightarrow {\mathbb{R}}^q$
and
$\psi_\xi \;:\; {\mathbb{R}}^q\rightarrow {\mathbb{R}}^q$
and
 $B_\xi \;:\; {\mathbb{R}}^q\rightarrow \textrm{GL}_q({\mathbb{R}})$
, and with an i.i.d. sequence
$B_\xi \;:\; {\mathbb{R}}^q\rightarrow \textrm{GL}_q({\mathbb{R}})$
, and with an i.i.d. sequence
 $\big\{\vartheta^{(\gamma)}_n\big\}_{n\geq 1}$
of
$\big\{\vartheta^{(\gamma)}_n\big\}_{n\geq 1}$
of
 ${\mathbb{R}}^q$
-valued random variables with common parametric PDF denoted by
${\mathbb{R}}^q$
-valued random variables with common parametric PDF denoted by
 $\mathfrak{p}_{\gamma}$
(hence
$\mathfrak{p}_{\gamma}$
(hence
 $\theta=(\xi,\gamma)$
). Then, noticing that for every
$\theta=(\xi,\gamma)$
). Then, noticing that for every
 $x\in{\mathbb{R}}^q$
the change of variable
$x\in{\mathbb{R}}^q$
the change of variable
 $v\mapsto z\;:\!=\;\psi_\xi(x) + B_\xi(x) v$
is valid and leads to
$v\mapsto z\;:\!=\;\psi_\xi(x) + B_\xi(x) v$
is valid and leads to
 ${P_{\theta}}(x,A) \;:\!=\; \int_{\mathbb{R}} \textbf{1}_A(z) p_{\theta}(x,z)\, {\textrm{d}} z$
(
${P_{\theta}}(x,A) \;:\!=\; \int_{\mathbb{R}} \textbf{1}_A(z) p_{\theta}(x,z)\, {\textrm{d}} z$
(
 $A\in{\mathcal{X}}$
), with
$A\in{\mathcal{X}}$
), with
 \begin{equation} p_{\theta}(x,z) \;:\!=\; |\det B_\xi(x)|^{-1} \mathfrak{p}_\gamma( B_\xi(x)^{-1}(z- \psi_\xi(x))), \end{equation}
\begin{equation} p_{\theta}(x,z) \;:\!=\; |\det B_\xi(x)|^{-1} \mathfrak{p}_\gamma( B_\xi(x)^{-1}(z- \psi_\xi(x))), \end{equation}
the following remarks are relevant to investigating Assumptions 1.1–1.4 of Theorem 1.1.
Remark 5.1. If the PDF
 $\mathfrak{p}_{\gamma_0}$
of the unperturbed IFS (corresponding to some
$\mathfrak{p}_{\gamma_0}$
of the unperturbed IFS (corresponding to some
 $\theta_0=(\xi_0,\gamma_0)$
), as well as the functions
$\theta_0=(\xi_0,\gamma_0)$
), as well as the functions
 $\psi_{\xi_0}$
and
$\psi_{\xi_0}$
and
 $B_{\xi_0}$
, are continuous on
$B_{\xi_0}$
, are continuous on
 ${\mathbb{R}}^q$
, then it follows from Remark 4.3 and Proposition 4.2 that
${\mathbb{R}}^q$
, then it follows from Remark 4.3 and Proposition 4.2 that
 $P_{\theta_0}$
is
$P_{\theta_0}$
is
 $V_a$
-geometrically ergodic provided that the unperturbed IFS satisfies Condition 1.1. More precisely, in this case, Assumption 1.1 holds with any real number
$V_a$
-geometrically ergodic provided that the unperturbed IFS satisfies Condition 1.1. More precisely, in this case, Assumption 1.1 holds with any real number
 $\rho_a$
(and the associated constant
$\rho_a$
(and the associated constant
 $C_a$
) such that
$C_a$
) such that
 $\mathbb{E}\big[ L_{F_{\xi_{0}}}\big(\vartheta^{(\gamma_0)}_1\big)^a\big] ^{1/a} <\rho_a <1$
, where
$\mathbb{E}\big[ L_{F_{\xi_{0}}}\big(\vartheta^{(\gamma_0)}_1\big)^a\big] ^{1/a} <\rho_a <1$
, where
 $F_{\xi_{0}}(x,v) =\psi_{\xi_0}(x) + B_{\xi_0}(x) v$
.
$F_{\xi_{0}}(x,v) =\psi_{\xi_0}(x) + B_{\xi_0}(x) v$
.
Remark 5.2. The moment/contractive conditions (1.4) and (1.5) related to
 $\theta_0=(\xi_0,\gamma_0)$
in Remark 5.1 involve expectations which depend on the above function
$\theta_0=(\xi_0,\gamma_0)$
in Remark 5.1 involve expectations which depend on the above function
 $F_{\xi_0}$
and on the PDF
$F_{\xi_0}$
and on the PDF
 $\mathfrak{p}_{\gamma_0}$
. Hence, the conditions in Assumptions 1.2 and 1.3 consist in assuming that these expectations are respectively bounded and strictly less than 1 in a uniform way on the parameters
$\mathfrak{p}_{\gamma_0}$
. Hence, the conditions in Assumptions 1.2 and 1.3 consist in assuming that these expectations are respectively bounded and strictly less than 1 in a uniform way on the parameters
 $\theta\;:\!=\;(\xi,\gamma)$
near
$\theta\;:\!=\;(\xi,\gamma)$
near
 $\theta_0=(\xi_0,\gamma_0)$
(reducing the set
$\theta_0=(\xi_0,\gamma_0)$
(reducing the set
 $\Theta$
if necessary).
$\Theta$
if necessary).
Remark 5.3. Thanks to (5.2), Assumption 1.4 holds provided that, for every
 $A>0$
,
$A>0$
,
 \begin{align*} \lim_{\theta\rightarrow \theta_0} \sup_{\|x\| \leq A} \int_{{\mathbb{R}}^q} \frac{\big|p_{\theta}(x,z) - p_{\theta_0}(x,z)\big|}{(1+\|x\|)^a} \, {\textrm{d}} z = 0,\end{align*}
\begin{align*} \lim_{\theta\rightarrow \theta_0} \sup_{\|x\| \leq A} \int_{{\mathbb{R}}^q} \frac{\big|p_{\theta}(x,z) - p_{\theta_0}(x,z)\big|}{(1+\|x\|)^a} \, {\textrm{d}} z = 0,\end{align*}
since the previous integral is less than
 $2/(1+A)^a$
for
$2/(1+A)^a$
for
 $\|x\| > A$
. Moreover, the above integral on
$\|x\| > A$
. Moreover, the above integral on
 ${\mathbb{R}}^q$
can be decomposed on some ball of
${\mathbb{R}}^q$
can be decomposed on some ball of
 ${\mathbb{R}}^q$
and on its complement in order to use the uniform continuity and decay properties of the kernel
${\mathbb{R}}^q$
and on its complement in order to use the uniform continuity and decay properties of the kernel
 $p_{\theta}(\cdot,\cdot)$
(see the proof of Proposition 5.1 in Appendix D).
$p_{\theta}(\cdot,\cdot)$
(see the proof of Proposition 5.1 in Appendix D).
Next, as a generalization of Section 3, consider the IFS defined by (5.1) under roundoff error. If
 $(h_\theta)_{\theta\in \Theta}$
is the roundoff family with
$(h_\theta)_{\theta\in \Theta}$
is the roundoff family with
 $h_\theta$
close to
$h_\theta$
close to
 $h_0=\textrm{id}$
when
$h_0=\textrm{id}$
when
 $\theta\rightarrow 0$
, then the roundoff transition kernel
$\theta\rightarrow 0$
, then the roundoff transition kernel
 ${P_{\theta}}(x,A) = P\big(x,h_\theta^{-1}(A)\big)$
is written as
${P_{\theta}}(x,A) = P\big(x,h_\theta^{-1}(A)\big)$
is written as
 ${P_{\theta}}(x,A) \;:\!=\; \int_{\mathbb{R}} \textbf{1}_A(z) p_{\theta}(x,z)\, {\textrm{d}} z$
with
${P_{\theta}}(x,A) \;:\!=\; \int_{\mathbb{R}} \textbf{1}_A(z) p_{\theta}(x,z)\, {\textrm{d}} z$
with
 \begin{equation} p_{\theta}(x,z) \;:\!=\; \Gamma_\theta(z) \mathfrak{p}(B(x)^{-1}(g_\theta(z) - \psi(x)))\end{equation}
\begin{equation} p_{\theta}(x,z) \;:\!=\; \Gamma_\theta(z) \mathfrak{p}(B(x)^{-1}(g_\theta(z) - \psi(x)))\end{equation}
from the change of variable
 $v\mapsto z \;:\!=\; h_\theta(\psi(x) + B(x)v)$
, where
$v\mapsto z \;:\!=\; h_\theta(\psi(x) + B(x)v)$
, where
 $g_\theta$
denotes the inverse function of
$g_\theta$
denotes the inverse function of
 $h_\theta$
and
$h_\theta$
and
 $\Gamma_\theta(z) \;:\!=\; |\det B_\xi(x)|^{-1} |\det \nabla g_\theta(z)|$
. Using the kernels in (5.3), Remarks 5.1–5.3 then apply.
$\Gamma_\theta(z) \;:\!=\; |\det B_\xi(x)|^{-1} |\det \nabla g_\theta(z)|$
. Using the kernels in (5.3), Remarks 5.1–5.3 then apply.
5.2. Robustness of IFS under thresholding/truncation
Here we consider
 ${\mathbb{X}}\;:\!=\;{\mathbb{R}}^d$
(
${\mathbb{X}}\;:\!=\;{\mathbb{R}}^d$
(
 $d\geq 1$
) equipped with the Euclidean norm
$d\geq 1$
) equipped with the Euclidean norm
 $\|\!\cdot\!\|$
, and
$\|\!\cdot\!\|$
, and
 ${\mathbb{V}}\;:\!=\;{\mathbb{R}}^q$
(
${\mathbb{V}}\;:\!=\;{\mathbb{R}}^q$
(
 $q\geq 1$
) equipped with some norm still denoted by
$q\geq 1$
) equipped with some norm still denoted by
 $\|\!\cdot\!\|$
for the sake of simplicity. Let
$\|\!\cdot\!\|$
for the sake of simplicity. Let
 $\{X_n\}_{n\in{\mathbb{N}}}$
be an IFS of Lipschitz maps,
$\{X_n\}_{n\in{\mathbb{N}}}$
be an IFS of Lipschitz maps,
 \begin{equation} \textrm{for } X_0 \in {\mathbb{R}}^d \textrm{ and all } n\geq 1,\quad X_n \;:\!=\; F(X_{n-1},\vartheta_n),\end{equation}
\begin{equation} \textrm{for } X_0 \in {\mathbb{R}}^d \textrm{ and all } n\geq 1,\quad X_n \;:\!=\; F(X_{n-1},\vartheta_n),\end{equation}
with
 $F\;:\;{\mathbb{R}}^d\times {\mathbb{R}}^q \rightarrow {\mathbb{R}}^d$
and
$F\;:\;{\mathbb{R}}^d\times {\mathbb{R}}^q \rightarrow {\mathbb{R}}^d$
and
 $\{\vartheta_n\}_{n\geq 1}$
satisfying the assumptions of Definition 1.1. Suppose that the probability distribution of
$\{\vartheta_n\}_{n\geq 1}$
satisfying the assumptions of Definition 1.1. Suppose that the probability distribution of
 $\vartheta_1$
is absolutely continuous with respect to Lebesgue’s measure on
$\vartheta_1$
is absolutely continuous with respect to Lebesgue’s measure on
 ${\mathbb{R}}^q$
, with PDF denoted by
${\mathbb{R}}^q$
, with PDF denoted by
 $\mathfrak{p}$
. Assume that
$\mathfrak{p}$
. Assume that
 $\{X_n\}_{n\in {\mathbb{N}}}$
is V-geometrically ergodic. Then, a natural question is: what happens if we consider a perturbation of the IFS (5.4) caused by some thresholding and/or truncation? Such an issue may arise as soon as a numerical implementation of the model is considered. Thus, let us investigate the robustness of the IFS (5.4) when thresholding the function F on the infinite set
$\{X_n\}_{n\in {\mathbb{N}}}$
is V-geometrically ergodic. Then, a natural question is: what happens if we consider a perturbation of the IFS (5.4) caused by some thresholding and/or truncation? Such an issue may arise as soon as a numerical implementation of the model is considered. Thus, let us investigate the robustness of the IFS (5.4) when thresholding the function F on the infinite set
 ${\mathbb{X}}$
and truncating the PDF
${\mathbb{X}}$
and truncating the PDF
 $\mathfrak{p}$
on
$\mathfrak{p}$
on
 ${\mathbb{R}}^q$
.
${\mathbb{R}}^q$
.
More precisely, for any
 $\xi\in(0,+\infty)$
let
$\xi\in(0,+\infty)$
let
 $\Phi_\xi \;:\; {\mathbb{R}}^d\rightarrow {\mathbb{R}}^d$
be the following thresholding function at level
$\Phi_\xi \;:\; {\mathbb{R}}^d\rightarrow {\mathbb{R}}^d$
be the following thresholding function at level
 $\xi$
:
$\xi$
:
 \begin{equation*} \textrm{for all } x\in{\mathbb{R}}^d,\quad \Phi_\xi(x) = \min\bigg(\frac{\xi}{\|x\|} ,\, 1\bigg) x = \begin{cases} x & \textrm{if} \ \|x\| \leq \xi , \\[5pt] \xi\dfrac{x}{\|x\|} & \textrm{if} \ \|x\| > \xi. \end{cases}\end{equation*}
\begin{equation*} \textrm{for all } x\in{\mathbb{R}}^d,\quad \Phi_\xi(x) = \min\bigg(\frac{\xi}{\|x\|} ,\, 1\bigg) x = \begin{cases} x & \textrm{if} \ \|x\| \leq \xi , \\[5pt] \xi\dfrac{x}{\|x\|} & \textrm{if} \ \|x\| > \xi. \end{cases}\end{equation*}
Moreover, for any
 $\gamma\in(0,+\infty)$
, define the truncated PDF
$\gamma\in(0,+\infty)$
, define the truncated PDF
 $\mathfrak{p}_\gamma$
at level
$\mathfrak{p}_\gamma$
at level
 $\gamma$
, for all
$\gamma$
, for all
 $v\in{\mathbb{R}}^q$
, by
$v\in{\mathbb{R}}^q$
, by
 \begin{equation*} \mathfrak{p}_\gamma(v) = c_\gamma \mathfrak{p}(v) \textbf{1}_{B(0,\gamma)}(v)\;\textrm{with}\; c_\gamma \;:\!=\; \bigg(\!\int_{B(0,\gamma)} \mathfrak{p}(v)\, {\textrm{d}} v\bigg)^{-1}, \end{equation*}
\begin{equation*} \mathfrak{p}_\gamma(v) = c_\gamma \mathfrak{p}(v) \textbf{1}_{B(0,\gamma)}(v)\;\textrm{with}\; c_\gamma \;:\!=\; \bigg(\!\int_{B(0,\gamma)} \mathfrak{p}(v)\, {\textrm{d}} v\bigg)^{-1}, \end{equation*}
where
 $B(0,\gamma)$
denotes the ball centred at 0 with radius
$B(0,\gamma)$
denotes the ball centred at 0 with radius
 $\gamma$
in
$\gamma$
in
 ${\mathbb{R}}^q$
. Then, according to Definition 1.2, we consider the perturbed IFS
${\mathbb{R}}^q$
. Then, according to Definition 1.2, we consider the perturbed IFS
 $\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
defined by
$\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
defined by
 ${X_0^{(\theta)}} \in {\mathbb{X}}$
and
${X_0^{(\theta)}} \in {\mathbb{X}}$
and
 \begin{equation} \textrm{for all } n\geq 1,\quad {X_n^{(\theta)}} \;:\!=\; F_{\xi}\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big), \quad \textrm{ with } F_{\xi}(x,v) \;:\!=\; \Phi_\xi(F(x,v)),\end{equation}
\begin{equation} \textrm{for all } n\geq 1,\quad {X_n^{(\theta)}} \;:\!=\; F_{\xi}\big({X_{n-1}^{(\theta)}},\vartheta^{(\gamma)}_n\big), \quad \textrm{ with } F_{\xi}(x,v) \;:\!=\; \Phi_\xi(F(x,v)),\end{equation}
where the sequence
 $\big\{\vartheta^{(\gamma)}_n\big\}_{n\geq 1}$
of
$\big\{\vartheta^{(\gamma)}_n\big\}_{n\geq 1}$
of
 ${\mathbb{R}}^q$
-valued i.i.d. random variables is assumed to admit the common PDF
${\mathbb{R}}^q$
-valued i.i.d. random variables is assumed to admit the common PDF
 $\mathfrak{p}_\gamma$
. Note that the stability of quantitative bounds for Markov chains via truncation rather than thresholding is studied in [Reference Medina-Aguayo, Rudolf and Schweizer34]. However, it is worth mentioning that we cannot set
$\mathfrak{p}_\gamma$
. Note that the stability of quantitative bounds for Markov chains via truncation rather than thresholding is studied in [Reference Medina-Aguayo, Rudolf and Schweizer34]. However, it is worth mentioning that we cannot set
 $\Phi_\xi(x)=0$
for
$\Phi_\xi(x)=0$
for
 $x \in {\mathbb{R}}^d$
such that
$x \in {\mathbb{R}}^d$
such that
 $\|x\| > \xi$
, as in [Reference Medina-Aguayo, Rudolf and Schweizer34, Section 3.2, Theorem 9], since the resulting perturbed process is no longer an IFS of Lipschitz maps. Morevover, note that the study of
$\|x\| > \xi$
, as in [Reference Medina-Aguayo, Rudolf and Schweizer34, Section 3.2, Theorem 9], since the resulting perturbed process is no longer an IFS of Lipschitz maps. Morevover, note that the study of
 $\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
does not fit into the framework of Section 3. Indeed, the family
$\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
does not fit into the framework of Section 3. Indeed, the family
 $\{F_\xi, \xi>0 \}$
does not satisfy the assumptions of Section 3 since
$\{F_\xi, \xi>0 \}$
does not satisfy the assumptions of Section 3 since
 $\Phi_{\xi}$
is neither bijective nor differentiable. By contrast, each function
$\Phi_{\xi}$
is neither bijective nor differentiable. By contrast, each function
 $\Phi_{\xi}$
is 1-Lipschitz (i.e.
$\Phi_{\xi}$
is 1-Lipschitz (i.e.
 $L(\Phi_{\xi}) = 1$
), and this property is well suited to our perturbation approach. Therefore, Proposition 5.1 is stated in the general framework of Definition 1.1 up to the condition of absolute continuity of the probability distribution of
$L(\Phi_{\xi}) = 1$
), and this property is well suited to our perturbation approach. Therefore, Proposition 5.1 is stated in the general framework of Definition 1.1 up to the condition of absolute continuity of the probability distribution of
 $\vartheta_1$
. The proof of Proposition 5.1 is postponed to Appendix D.
$\vartheta_1$
. The proof of Proposition 5.1 is postponed to Appendix D.
Proposition 5.1.
Assume that the unperturbed IFS
 $\{X_n\}_{n\in{\mathbb{N}}}$
given in (5.4) satisfies Definition 1.1, with
$\{X_n\}_{n\in{\mathbb{N}}}$
given in (5.4) satisfies Definition 1.1, with
 $\vartheta_1$
having a PDF on
$\vartheta_1$
having a PDF on
 ${\mathbb{R}}^q$
. Moreover, suppose that Assumption 1.1 holds for some
${\mathbb{R}}^q$
. Moreover, suppose that Assumption 1.1 holds for some
 $a\geq 1$
, and that
$a\geq 1$
, and that
 $\widetilde{M}_a \;:\!=\; \mathbb{E}\big[ \|F(0,\vartheta_1)\|^a] ^{1/a} < \infty$
,
$\widetilde{M}_a \;:\!=\; \mathbb{E}\big[ \|F(0,\vartheta_1)\|^a] ^{1/a} < \infty$
,
 $\widetilde{\kappa}_a \;:\!=\; \mathbb{E}[ L_{F}(\vartheta_1)^a] ^{1/a} < 1$
, and
$\widetilde{\kappa}_a \;:\!=\; \mathbb{E}[ L_{F}(\vartheta_1)^a] ^{1/a} < 1$
, and
 $\mathbb{E}[\|\vartheta_1\|^a] < \infty$
. Let
$\mathbb{E}[\|\vartheta_1\|^a] < \infty$
. Let
 $\kappa_a\in(\widetilde{\kappa}_a,1)$
, and let
$\kappa_a\in(\widetilde{\kappa}_a,1)$
, and let
 $\Theta \;:\!=\; (0,+\infty)\times(\gamma_0,+\infty)$
, with
$\Theta \;:\!=\; (0,+\infty)\times(\gamma_0,+\infty)$
, with
 $\gamma_0>0$
defined by the condition, for all
$\gamma_0>0$
defined by the condition, for all
 $\gamma > \gamma_0$
,
$\gamma > \gamma_0$
,
 $c_\gamma \leq (\kappa_a/\widetilde{\kappa}_a)^a$
. Then, the perturbed IFS
$c_\gamma \leq (\kappa_a/\widetilde{\kappa}_a)^a$
. Then, the perturbed IFS
 $\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
defined by (5.5) with
$\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
defined by (5.5) with
 $\theta\in\Theta$
satisfies P
1
–P
3
of Theorem 1.1 with
$\theta\in\Theta$
satisfies P
1
–P
3
of Theorem 1.1 with
 $\Delta_\theta \rightarrow 0$
when
$\Delta_\theta \rightarrow 0$
when
 $\xi\rightarrow +\infty$
and
$\xi\rightarrow +\infty$
and
 $\gamma\rightarrow +\infty$
. More precisely, for every
$\gamma\rightarrow +\infty$
. More precisely, for every
 $\varepsilon\in (0,2)$
define
$\varepsilon\in (0,2)$
define
 $A_\varepsilon = 2^a\varepsilon^{-a} -1 $
. Then we have
$A_\varepsilon = 2^a\varepsilon^{-a} -1 $
. Then we have
 $\Delta_\theta \leq \varepsilon$
, provided that
$\Delta_\theta \leq \varepsilon$
, provided that
 $\theta\;:\!=\;(\xi,\gamma)\in \Theta$
is such that
$\theta\;:\!=\;(\xi,\gamma)\in \Theta$
is such that
 \begin{align*} |c_\gamma-1| + \bigg(1+\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a\bigg) \bigg(\frac{\mathbb{E}[\|\vartheta_1\|^a]}{\gamma^a} + \frac{(2A_\varepsilon\widetilde{\kappa}_a)^a + (2\widetilde{M}_a)^a}{\xi^a}\bigg)\leq \varepsilon.\end{align*}
\begin{align*} |c_\gamma-1| + \bigg(1+\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a\bigg) \bigg(\frac{\mathbb{E}[\|\vartheta_1\|^a]}{\gamma^a} + \frac{(2A_\varepsilon\widetilde{\kappa}_a)^a + (2\widetilde{M}_a)^a}{\xi^a}\bigg)\leq \varepsilon.\end{align*}
Appendix A. Proof of (1.7)
Suppose that Assumptions 1.2 and 1.3 are fulfilled. Then we prove the drift inequality (1.7) in Section 1. In fact, for any
 $\kappa \in (\kappa_{a},1)$
, we prove that the following strengthened inequality holds:
$\kappa \in (\kappa_{a},1)$
, we prove that the following strengthened inequality holds:
 \begin{equation} \textrm{for all } \theta \in \Theta, \quad {P_{\theta}} V_a \le \delta_{a} V_a + K_a \textbf{1}_{[\!-\!r_a,r_a]} ,\end{equation}
\begin{equation} \textrm{for all } \theta \in \Theta, \quad {P_{\theta}} V_a \le \delta_{a} V_a + K_a \textbf{1}_{[\!-\!r_a,r_a]} ,\end{equation}
where the constants
 $\delta_{a}<1$
and
$\delta_{a}<1$
and
 $K_a>0$
are given in (1.7), and where
$K_a>0$
are given in (1.7), and where
 $r_a \;:\!=\; (1+M_a+\kappa_a-\kappa)/(\kappa-\kappa_a)$
. We have, for any
$r_a \;:\!=\; (1+M_a+\kappa_a-\kappa)/(\kappa-\kappa_a)$
. We have, for any
 $\theta \in \Theta$
and any
$\theta \in \Theta$
and any
 $ x\in{\mathbb{X}}$
,
$ x\in{\mathbb{X}}$
,
 \begin{align*} \bigg(\frac{({P_{\theta}} V_a)(x)}{V_a(x)}\bigg)^{1/a} & = \bigg(\mathbb{E}\bigg[\bigg(\frac{1+d(F_{\xi}\big(x,\vartheta^{(\gamma)}_1\big);\;x_0)} {1+d(x;\;x_0)}\bigg)^a\bigg] \bigg)^{1/a} \\[5pt] & \leq \bigg(\mathbb{E}\bigg[\bigg( \frac{1 + d\big(F_{\xi}\big(x,\vartheta^{(\gamma)}_1\big);\;F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big)\big) + d\big(F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big);\;x_0\big)}{1+d(x;\;x_0)}\bigg)^a\bigg]\bigg)^{1/a} \\[5pt] & \leq \bigg(\mathbb{E}\bigg[\bigg(\frac{1}{1+d(x;\;x_0)} + L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big) + \frac{d\big(F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big);\;x_0\big)}{1+d(x;\;x_0)}\bigg)^a\bigg]\bigg)^{1/a} \\[5pt] & \leq \frac{1}{1+d(x;\;x_0)} + \mathbb{E}\big[ L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big)^a \big]^{1/a} + \frac{ \mathbb{E}\big[ d(F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big);\;x_0)^a\big]^{1/a}}{1+d(x;\;x_0)} \end{align*}
\begin{align*} \bigg(\frac{({P_{\theta}} V_a)(x)}{V_a(x)}\bigg)^{1/a} & = \bigg(\mathbb{E}\bigg[\bigg(\frac{1+d(F_{\xi}\big(x,\vartheta^{(\gamma)}_1\big);\;x_0)} {1+d(x;\;x_0)}\bigg)^a\bigg] \bigg)^{1/a} \\[5pt] & \leq \bigg(\mathbb{E}\bigg[\bigg( \frac{1 + d\big(F_{\xi}\big(x,\vartheta^{(\gamma)}_1\big);\;F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big)\big) + d\big(F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big);\;x_0\big)}{1+d(x;\;x_0)}\bigg)^a\bigg]\bigg)^{1/a} \\[5pt] & \leq \bigg(\mathbb{E}\bigg[\bigg(\frac{1}{1+d(x;\;x_0)} + L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big) + \frac{d\big(F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big);\;x_0\big)}{1+d(x;\;x_0)}\bigg)^a\bigg]\bigg)^{1/a} \\[5pt] & \leq \frac{1}{1+d(x;\;x_0)} + \mathbb{E}\big[ L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big)^a \big]^{1/a} + \frac{ \mathbb{E}\big[ d(F_{\xi}\big(x_0,\vartheta^{(\gamma)}_1\big);\;x_0)^a\big]^{1/a}}{1+d(x;\;x_0)} \end{align*}
using Holder’s inequality. It follows from Assumptions 1.2 and 1.3 that
 \begin{equation} \textrm{for all } \theta \in \Theta \textrm{ and } x \in {\mathbb{X}}, \quad \bigg(\frac{({P_{\theta}} V_a)(x)}{V_a(x)}\bigg)^{1/a} \le \frac{1}{1+d(x;\;x_0)} + \kappa_{a} + \frac{M_a}{1+d(x;\;x_0)}. \end{equation}
\begin{equation} \textrm{for all } \theta \in \Theta \textrm{ and } x \in {\mathbb{X}}, \quad \bigg(\frac{({P_{\theta}} V_a)(x)}{V_a(x)}\bigg)^{1/a} \le \frac{1}{1+d(x;\;x_0)} + \kappa_{a} + \frac{M_a}{1+d(x;\;x_0)}. \end{equation}
For any
 $\kappa \in (\kappa_{a},1)$
, set
$\kappa \in (\kappa_{a},1)$
, set
 $r_a \;:\!=\; (1+M_a+\kappa_a-\kappa)/(\kappa-\kappa_a)>0$
. Then we have, for every
$r_a \;:\!=\; (1+M_a+\kappa_a-\kappa)/(\kappa-\kappa_a)>0$
. Then we have, for every
 $x\in{\mathbb{X}}$
such that
$x\in{\mathbb{X}}$
such that
 $d(x;\;x_0) >r_a$
,
$d(x;\;x_0) >r_a$
,
 \begin{align*} \frac{1+M_a}{1+d(x;\;x_0)} \le \frac{1+M_a}{1+r_a} = \kappa - \kappa_{a}.\end{align*}
\begin{align*} \frac{1+M_a}{1+d(x;\;x_0)} \le \frac{1+M_a}{1+r_a} = \kappa - \kappa_{a}.\end{align*}
It follows that, for every
 $\theta \in \Theta$
and for every
$\theta \in \Theta$
and for every
 $x\in{\mathbb{X}}$
such that
$x\in{\mathbb{X}}$
such that
 $d(x;\;x_0) >r_a$
,
$d(x;\;x_0) >r_a$
,
 \begin{equation} ({P_{\theta}} V_a)(x)\le {\kappa}^a V_a(x). \end{equation}
\begin{equation} ({P_{\theta}} V_a)(x)\le {\kappa}^a V_a(x). \end{equation}
Moreover, for every
 $\theta \in \Theta$
and for every
$\theta \in \Theta$
and for every
 $x\in{\mathbb{X}}$
such that
$x\in{\mathbb{X}}$
such that
 $d(x;\;x_0) \le r_a$
, we deduce from (A.2) that
$d(x;\;x_0) \le r_a$
, we deduce from (A.2) that
 \begin{equation} ({P_{\theta}} V_a)(x)\le {F_a} V_a(x) \le {F_a} (1+r_a)^a,\end{equation}
\begin{equation} ({P_{\theta}} V_a)(x)\le {F_a} V_a(x) \le {F_a} (1+r_a)^a,\end{equation}
where
 $F_a \;:\!=\; (1+ \kappa_a + M_a)^a$
. Finally, combining (A.3) and (A.4) provides (A.1), and then (1.7) with
$F_a \;:\!=\; (1+ \kappa_a + M_a)^a$
. Finally, combining (A.3) and (A.4) provides (A.1), and then (1.7) with
 $\delta_a\;:\!=\;{\kappa_a}^a <1$
and
$\delta_a\;:\!=\;{\kappa_a}^a <1$
and
 $K_a\;:\!=\; {F_a} (1+r_a)^a >0$
.
$K_a\;:\!=\; {F_a} (1+r_a)^a >0$
.
Appendix B. Complements to Proposition 2.1
First, we prove (2.3).
Lemma B.1.
Let
 $(\alpha,\beta,\lambda) \in {\mathbb{R}}\times (0,+\infty)^2$
, and, for all
$(\alpha,\beta,\lambda) \in {\mathbb{R}}\times (0,+\infty)^2$
, and, for all
 $(x,v)\in{\mathbb{R}}^2$
,
$(x,v)\in{\mathbb{R}}^2$
,
 $F(x,v) \;:\!=\; \alpha x + v \sqrt{\beta + \lambda x^2}$
. Then we have, for every
$F(x,v) \;:\!=\; \alpha x + v \sqrt{\beta + \lambda x^2}$
. Then we have, for every
 $v\in{\mathbb{R}}$
,
$v\in{\mathbb{R}}$
,
 \begin{equation} L(v) \;:\!=\; \sup_{(x,y)\in {\mathbb{R}}^2,\,x\neq y} \frac{|F(x,v) - F(y,v)|}{|x-y|} = \max\!\big(|\alpha-\sqrt{\lambda} v|;\;|\alpha+\sqrt{\lambda} v|\big). \end{equation}
\begin{equation} L(v) \;:\!=\; \sup_{(x,y)\in {\mathbb{R}}^2,\,x\neq y} \frac{|F(x,v) - F(y,v)|}{|x-y|} = \max\!\big(|\alpha-\sqrt{\lambda} v|;\;|\alpha+\sqrt{\lambda} v|\big). \end{equation}
Proof. Let
 $v\in{\mathbb{R}}$
be fixed, and define, for all
$v\in{\mathbb{R}}$
be fixed, and define, for all
 $x\in{\mathbb{R}}$
,
$x\in{\mathbb{R}}$
,
 $F_v(x) \;:\!=\; F(x,v)$
. Then,
$F_v(x) \;:\!=\; F(x,v)$
. Then,
If
 $v=0$
, (B.1) is obvious. Assume that
$v=0$
, (B.1) is obvious. Assume that
 $v>0$
. Then
$v>0$
. Then
 $F'_{\!\!v}$
is strictly increasing, so that
$F'_{\!\!v}$
is strictly increasing, so that
 \begin{align*} \inf_{x\in{\mathbb{R}}} F'_{\!\!v}(x) = \lim_{x\rightarrow -\infty} F'_{\!\!v}(x) = \alpha - \sqrt{\lambda} v \leq \alpha + \sqrt{\lambda} v = \lim_{x\rightarrow +\infty} F'_{\!\!v}(x) = \sup_{x\in{\mathbb{R}}} F'_{\!\!v}(x).\end{align*}
\begin{align*} \inf_{x\in{\mathbb{R}}} F'_{\!\!v}(x) = \lim_{x\rightarrow -\infty} F'_{\!\!v}(x) = \alpha - \sqrt{\lambda} v \leq \alpha + \sqrt{\lambda} v = \lim_{x\rightarrow +\infty} F'_{\!\!v}(x) = \sup_{x\in{\mathbb{R}}} F'_{\!\!v}(x).\end{align*}
Then
 $L(v) \le \max\!(|\alpha - \sqrt{\lambda} v|;\; |\alpha + \sqrt{\lambda} v|)$
follows from Taylor’s inequality. If
$L(v) \le \max\!(|\alpha - \sqrt{\lambda} v|;\; |\alpha + \sqrt{\lambda} v|)$
follows from Taylor’s inequality. If
 $v<0$
, then
$v<0$
, then
 $F'_{\!\!v}$
is strictly decreasing, so that
$F'_{\!\!v}$
is strictly decreasing, so that
 \begin{align*} \inf_{x\in{\mathbb{R}}} F'_{\!\!v}(x) = \lim_{x\rightarrow +\infty} F'_{\!\!v}(x) = \alpha + \sqrt{\lambda} v \leq \alpha - \sqrt{\lambda} v = \lim_{x\rightarrow -\infty} F'_{\!\!v}(x) = \sup_{x\in{\mathbb{R}}} F'_{\!\!v}(x),\end{align*}
\begin{align*} \inf_{x\in{\mathbb{R}}} F'_{\!\!v}(x) = \lim_{x\rightarrow +\infty} F'_{\!\!v}(x) = \alpha + \sqrt{\lambda} v \leq \alpha - \sqrt{\lambda} v = \lim_{x\rightarrow -\infty} F'_{\!\!v}(x) = \sup_{x\in{\mathbb{R}}} F'_{\!\!v}(x),\end{align*}
and the same conclusion holds. That
 $L(v) \ge \max\!(|\alpha - \sqrt{\lambda} v|;\; |\alpha + \sqrt{\lambda} v|)$
follows from the inequality
$L(v) \ge \max\!(|\alpha - \sqrt{\lambda} v|;\; |\alpha + \sqrt{\lambda} v|)$
follows from the inequality
 $L(v)\ge |F'_{\!\!v}(x)|$
for any
$L(v)\ge |F'_{\!\!v}(x)|$
for any
 $x\in {\mathbb{R}}$
, which is easily deduced from the definition of L(v) in (B.1). Hence, we obtain
$x\in {\mathbb{R}}$
, which is easily deduced from the definition of L(v) in (B.1). Hence, we obtain
 $L(v) \ge \lim_{x \pm \infty} |F'_{\!\!v}(x)|$
. The proof of (B.1) is complete.
$L(v) \ge \lim_{x \pm \infty} |F'_{\!\!v}(x)|$
. The proof of (B.1) is complete.
Next, we prove the two following lemmas used in the proof of Proposition 2.1.
Lemma B.2.
Let
 $(\alpha_0,\beta_0,\lambda_0) \in {\mathbb{R}}\times (0,+\infty)^2$
. For any
$(\alpha_0,\beta_0,\lambda_0) \in {\mathbb{R}}\times (0,+\infty)^2$
. For any
 $(\alpha,\beta,\lambda) \in {\mathbb{R}} \times (0,+\infty)^2$
and for any
$(\alpha,\beta,\lambda) \in {\mathbb{R}} \times (0,+\infty)^2$
and for any
 $x \in {\mathbb{R}}$
, define
$x \in {\mathbb{R}}$
, define
 \begin{align*} b_{\beta,\lambda}(x)\;:\!=\; \bigg(\frac{\beta+\lambda x^2}{\beta_0+\lambda_0 x^2}\bigg)^{1/2}, \qquad a_{{\alpha}}(x) \;:\!=\; x \frac{\alpha-\alpha_0}{\sqrt{\beta_0+\lambda_0 x^2}\,}. \end{align*}
\begin{align*} b_{\beta,\lambda}(x)\;:\!=\; \bigg(\frac{\beta+\lambda x^2}{\beta_0+\lambda_0 x^2}\bigg)^{1/2}, \qquad a_{{\alpha}}(x) \;:\!=\; x \frac{\alpha-\alpha_0}{\sqrt{\beta_0+\lambda_0 x^2}\,}. \end{align*}
Then, for any
 $A>0$
,
$A>0$
,
 \begin{equation*} \lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)} \sup_{|x|\le A} |b_{\beta,\lambda}(x) - 1| = 0\; and\;\lim_{\alpha \rightarrow \alpha_0}\sup_{|x|\le A} a_{\alpha}(x)= 0. \end{equation*}
\begin{equation*} \lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)} \sup_{|x|\le A} |b_{\beta,\lambda}(x) - 1| = 0\; and\;\lim_{\alpha \rightarrow \alpha_0}\sup_{|x|\le A} a_{\alpha}(x)= 0. \end{equation*}
Proof. Let
 $A>0$
. We have, for any
$A>0$
. We have, for any
 $ x \in {\mathbb{R}}$
such that
$ x \in {\mathbb{R}}$
such that
 $|x| \le A$
,
$|x| \le A$
,
 \[ |b_{\beta,\lambda}(x)^2-1| = \bigg|\frac{\beta-\beta_0+(\lambda-\lambda_0) x^2}{\beta_0+\lambda_0 x^2} \bigg| \le \frac{1}{\beta_0} [ |\beta-\beta_0|+|\lambda-\lambda_0| A^2 ]. \]
\[ |b_{\beta,\lambda}(x)^2-1| = \bigg|\frac{\beta-\beta_0+(\lambda-\lambda_0) x^2}{\beta_0+\lambda_0 x^2} \bigg| \le \frac{1}{\beta_0} [ |\beta-\beta_0|+|\lambda-\lambda_0| A^2 ]. \]
Therefore, we have
 $\lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)} \sup_{|x| \le A}|b_{\beta,\lambda}(x)^2-1|=0$
. Since
$\lim_{(\beta,\lambda) \rightarrow (\beta_0,\lambda_0)} \sup_{|x| \le A}|b_{\beta,\lambda}(x)^2-1|=0$
. Since
 $1+b_{\beta,\lambda}(x) \geq 1$
, we have
$1+b_{\beta,\lambda}(x) \geq 1$
, we have
 $|b_{\beta,\lambda}(x)-1| \leq |b_{\beta,\lambda}(x)^2-1|$
, so that the first convergence is proved. The second one holds since
$|b_{\beta,\lambda}(x)-1| \leq |b_{\beta,\lambda}(x)^2-1|$
, so that the first convergence is proved. The second one holds since
 $\sup_{|x|\le A} \big| a_{{\alpha}}(x) \big| \le A |\alpha-\alpha_0|/\sqrt{\beta_0}$
.
$\sup_{|x|\le A} \big| a_{{\alpha}}(x) \big| \le A |\alpha-\alpha_0|/\sqrt{\beta_0}$
.
The following lemma is an easy extension of the classical continuity property of the map
 $f\mapsto f(\cdot +\, a)$
from
$f\mapsto f(\cdot +\, a)$
from
 ${\mathbb{R}}$
to
${\mathbb{R}}$
to
 ${\mathbb{L}}^1({\mathbb{R}})$
.
${\mathbb{L}}^1({\mathbb{R}})$
.
Lemma B.3.
For any
 $f \in {\mathbb{L}}^1({\mathbb{R}})$
,
$f \in {\mathbb{L}}^1({\mathbb{R}})$
,
 $\lim_{(a,b)\rightarrow (0,1)} \int_{{\mathbb{R}}}| f(a+bz) - f(z) | \, {\textrm{d}} z = 0$
.
$\lim_{(a,b)\rightarrow (0,1)} \int_{{\mathbb{R}}}| f(a+bz) - f(z) | \, {\textrm{d}} z = 0$
.
Proof. Let
 ${\mathcal{C}}_K({\mathbb{R}})$
be the set of continuous functions on
${\mathcal{C}}_K({\mathbb{R}})$
be the set of continuous functions on
 ${\mathbb{R}}$
with compact support. First, if
${\mathbb{R}}$
with compact support. First, if
 $g \in {\mathcal{C}}_K({\mathbb{R}})$
, then the desired convergence follows from Lebesgue’s theorem. Second, if
$g \in {\mathcal{C}}_K({\mathbb{R}})$
, then the desired convergence follows from Lebesgue’s theorem. Second, if
 $f \in {\mathbb{L}}^1({\mathbb{R}})$
, then we have, for every
$f \in {\mathbb{L}}^1({\mathbb{R}})$
, then we have, for every
 $g \in {\mathcal{C}}_K({\mathbb{R}})$
and for every
$g \in {\mathcal{C}}_K({\mathbb{R}})$
and for every
 $(a,b)\in{\mathbb{R}}^2$
such that
$(a,b)\in{\mathbb{R}}^2$
such that
 $b \geq \frac12$
,
$b \geq \frac12$
,
 \begin{align*} & \int_{{\mathbb{R}}}| f(a+b z) - f(z)| \, {\textrm{d}} z \\[5pt] & \le \int_{{\mathbb{R}}}| f(a+b z) - g(a+b z)| \, {\textrm{d}} z + \int_{{\mathbb{R}}}| g(a+b z) - g(z)| \, {\textrm{d}} z + \int_{{\mathbb{R}}}| g(z) - f(z)| \, {\textrm{d}} z \\[5pt] & \quad = \frac{1}{b} \int_{{\mathbb{R}}}| f(y) - g(y)| \, {\textrm{d}} y + \int_{{\mathbb{R}}}| g(a+b z) - g(z)| \, {\textrm{d}} z + \int_{{\mathbb{R}}}| g(z) - f(z)| \, {\textrm{d}} z \\[5pt] & \quad \le \int_{{\mathbb{R}}}| g(a+b z) - g(z)| \, {\textrm{d}} z + 3 \| f -g \|_{{\mathbb{L}}^1({\mathbb{R}})}. \end{align*}
\begin{align*} & \int_{{\mathbb{R}}}| f(a+b z) - f(z)| \, {\textrm{d}} z \\[5pt] & \le \int_{{\mathbb{R}}}| f(a+b z) - g(a+b z)| \, {\textrm{d}} z + \int_{{\mathbb{R}}}| g(a+b z) - g(z)| \, {\textrm{d}} z + \int_{{\mathbb{R}}}| g(z) - f(z)| \, {\textrm{d}} z \\[5pt] & \quad = \frac{1}{b} \int_{{\mathbb{R}}}| f(y) - g(y)| \, {\textrm{d}} y + \int_{{\mathbb{R}}}| g(a+b z) - g(z)| \, {\textrm{d}} z + \int_{{\mathbb{R}}}| g(z) - f(z)| \, {\textrm{d}} z \\[5pt] & \quad \le \int_{{\mathbb{R}}}| g(a+b z) - g(z)| \, {\textrm{d}} z + 3 \| f -g \|_{{\mathbb{L}}^1({\mathbb{R}})}. \end{align*}
We then conclude by using the density of
 ${\mathcal{C}}_K({\mathbb{R}})$
in
${\mathcal{C}}_K({\mathbb{R}})$
in
 ${\mathbb{L}}^1({\mathbb{R}})$
.
${\mathbb{L}}^1({\mathbb{R}})$
.
Appendix C. Proof of (4.5) and (4.6) under the assumptions (4.2) and (4.4) with
$\boldsymbol{N}=1$

Thoughout this section, the conditions (4.2) and (4.4) with
 $N=1$
are assumed to hold. Note that (4.4) with
$N=1$
are assumed to hold. Note that (4.4) with
 $N=1$
is
$N=1$
is
 $\kappa_{1,a} = \mathbb{E}[L(\vartheta_1)^{a}]^{1/a} < 1$
. We prove (4.5) and (4.6) of Proposition 4.1 with explicit constants. Under the general assumption
$\kappa_{1,a} = \mathbb{E}[L(\vartheta_1)^{a}]^{1/a} < 1$
. We prove (4.5) and (4.6) of Proposition 4.1 with explicit constants. Under the general assumption
 $\widehat{\kappa}_a<1$
of Assumption 4.1, the proofs of (4.5) and (4.6) are similar (replace P with
$\widehat{\kappa}_a<1$
of Assumption 4.1, the proofs of (4.5) and (4.6) are similar (replace P with
 $P^N$
where N is such that
$P^N$
where N is such that
 $\mathbb{E}[L(\vartheta_N\;:\;\vartheta_1)^{{a}}] < 1$
).
$\mathbb{E}[L(\vartheta_N\;:\;\vartheta_1)^{{a}}] < 1$
).
That the constant
 $\xi$
in Proposition 4.1 is finite can be easily deduced from the drift inequality (A.1) which holds here with
$\xi$
in Proposition 4.1 is finite can be easily deduced from the drift inequality (A.1) which holds here with
 $P_{\theta_0}=P$
,
$P_{\theta_0}=P$
,
 $\Theta=\{\theta_0\}$
, and with
$\Theta=\{\theta_0\}$
, and with
 $\kappa_{1,a}$
in place of
$\kappa_{1,a}$
in place of
 $\kappa_a$
. Now let us introduce some notation. If
$\kappa_a$
. Now let us introduce some notation. If
 $\mu$
is a probability measure on
$\mu$
is a probability measure on
 ${\mathbb{X}}$
and
${\mathbb{X}}$
and
 $X_0\sim\mu$
, we make a slight abuse of notation in writing
$X_0\sim\mu$
, we make a slight abuse of notation in writing
 $\{X_n^\mu\}_{n\in{\mathbb{N}}}$
for the associated IFS given in Definition 1.1. We simply write
$\{X_n^\mu\}_{n\in{\mathbb{N}}}$
for the associated IFS given in Definition 1.1. We simply write
 $\{X_n^x\}_{n\in{\mathbb{N}}}$
when
$\{X_n^x\}_{n\in{\mathbb{N}}}$
when
 $\mu\;:\!=\;\delta_x$
is the Dirac mass at some
$\mu\;:\!=\;\delta_x$
is the Dirac mass at some
 $x\in{\mathbb{X}}$
. We denote by
$x\in{\mathbb{X}}$
. We denote by
 ${\mathcal{M}}_a$
the set of all the probability measures
${\mathcal{M}}_a$
the set of all the probability measures
 $\mu$
on
$\mu$
on
 ${\mathbb{X}}$
such that
${\mathbb{X}}$
such that
 $\|\mu\|_a \;:\!=\; \big(\!\int_{\mathbb{X}} V_a(y)\, {\textrm{d}}\mu(y)\big)^{1/a} < \infty$
. Finally, for
$\|\mu\|_a \;:\!=\; \big(\!\int_{\mathbb{X}} V_a(y)\, {\textrm{d}}\mu(y)\big)^{1/a} < \infty$
. Finally, for
 $n\in{\mathbb{N}}$
and for any probability measures
$n\in{\mathbb{N}}$
and for any probability measures
 $\mu_1$
and
$\mu_1$
and
 $\mu_2$
on
$\mu_2$
on
 ${\mathbb{X}}$
, define
${\mathbb{X}}$
, define
 $\Delta_n(\mu_1,\mu_2) \;:\!=\; d\big(X_n^{\mu_1},X_n^{\mu_2}\big)\, \big(p(X_n^{\mu_1}) + p(X_n^{\mu_2})\big)^{a-1}$
.
$\Delta_n(\mu_1,\mu_2) \;:\!=\; d\big(X_n^{\mu_1},X_n^{\mu_2}\big)\, \big(p(X_n^{\mu_1}) + p(X_n^{\mu_2})\big)^{a-1}$
.
Lemma C.1.
We have, for all
 $n\geq1$
and
$n\geq1$
and
 $(\mu_1,\mu_2)\in {\mathcal{M}}_{a}\times{\mathcal{M}}_{a}$
,
$(\mu_1,\mu_2)\in {\mathcal{M}}_{a}\times{\mathcal{M}}_{a}$
,
 \begin{equation} \mathbb{E}[\Delta_n(\mu_1,\mu_2)] \leq \xi^{({a-1})/{a}} \kappa_{1,a}^{\, n} \mathbb{E}\big[d\big(X_0^{\mu_1},X_0^{\mu_2}\big)\big](\|\mu_1\|_a + \|\mu_2\|_a)^{a-1}. \end{equation}
\begin{equation} \mathbb{E}[\Delta_n(\mu_1,\mu_2)] \leq \xi^{({a-1})/{a}} \kappa_{1,a}^{\, n} \mathbb{E}\big[d\big(X_0^{\mu_1},X_0^{\mu_2}\big)\big](\|\mu_1\|_a + \|\mu_2\|_a)^{a-1}. \end{equation}
Furthermore, we have, for all
 $f\in{\mathcal{L}}_{a}$
,
$f\in{\mathcal{L}}_{a}$
,
 \begin{equation} \mathbb{E}\big[|f(X_{n}^{\mu_1}) - f(X_n^{\mu_2})|\big] \leq \xi^{({a-1})/{a}} m_{a}(f) \kappa_{1,a}^{n}\mathbb{E}\big[d\big(X_0^{\mu_1},X_0^{\mu_2}\big)\big] (\|\mu_1\|_a + \|\mu_2\|_a)^{a-1}. \end{equation}
\begin{equation} \mathbb{E}\big[|f(X_{n}^{\mu_1}) - f(X_n^{\mu_2})|\big] \leq \xi^{({a-1})/{a}} m_{a}(f) \kappa_{1,a}^{n}\mathbb{E}\big[d\big(X_0^{\mu_1},X_0^{\mu_2}\big)\big] (\|\mu_1\|_a + \|\mu_2\|_a)^{a-1}. \end{equation}
Proof. Note that
 $X_n^\mu = F_{\vartheta_n:\vartheta_1}X_0^{\mu}$
from Definition 1.1 and the notation introduced in (4.1). If
$X_n^\mu = F_{\vartheta_n:\vartheta_1}X_0^{\mu}$
from Definition 1.1 and the notation introduced in (4.1). If
 $a\;:\!=\;1$
, then (C.1) follows from the independence of the
$a\;:\!=\;1$
, then (C.1) follows from the independence of the
 $\vartheta_n$
and from the definitions of L(v) and
$\vartheta_n$
and from the definitions of L(v) and
 $\kappa_{1,a}$
. Now assume that
$\kappa_{1,a}$
. Now assume that
 $a\in(1,+\infty)$
. Without loss of generality, we can suppose that the sequence
$a\in(1,+\infty)$
. Without loss of generality, we can suppose that the sequence
 $\{\vartheta_n\}_{n\geq1}$
is independent of
$\{\vartheta_n\}_{n\geq1}$
is independent of
 $(X_0^{\mu_1},X_0^{\mu_2})$
. Also note that, if
$(X_0^{\mu_1},X_0^{\mu_2})$
. Also note that, if
 $\mu\in {\mathcal{M}}_{a}$
, then we have
$\mu\in {\mathcal{M}}_{a}$
, then we have
 $\mathbb{E}\big[p(X_n^{\mu})^a\big] = \int_{\mathbb{X}} (P^nV_a)(x) \, {\textrm{d}}\mu(x) \leq \xi \|\mu\|_a^a$
. From Holder’s inequality (use
$\mathbb{E}\big[p(X_n^{\mu})^a\big] = \int_{\mathbb{X}} (P^nV_a)(x) \, {\textrm{d}}\mu(x) \leq \xi \|\mu\|_a^a$
. From Holder’s inequality (use
 $1 = 1/a + (a-1)/a$
), we obtain
$1 = 1/a + (a-1)/a$
), we obtain
 \begin{align*} \mathbb{E}[\Delta_n(\mu_1,\mu_2)] & = \mathbb{E}[d(F_{\vartheta_n:\vartheta_1}X_0^{\mu_1},F_{\vartheta_n:\vartheta_1}X_0^{\mu_2}) (p(X_n^{\mu_1}) + p(X_n^{\mu_2}))^{a-1}] \\[5pt] & \leq \mathbb{E}[d(X_0^{\mu_1},X_0^{\mu_2})] \mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)(p(X_n^{\mu_1}) + p(X_n^{\mu_2}))^{a-1} ] \\[5pt] & \leq \mathbb{E}[d(X_0^{\mu_1},X_0^{\mu_2})] \mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)^{a}]^{{1}/{a}} \mathbb{E}[(p(X_n^{\mu_1}) + p(X_n^{\mu_2}))^{a}]^{({a-1})/{a}} \\[5pt] & \leq \mathbb{E}[d(X_0^{\mu_1},X_0^{\mu_2})] \mathbb{E}[L(\vartheta_1)^{a}]^{{n}/{a}} \xi^{({a-1})/{a}} (\|\mu_1\|_a + \|\mu_2\|_a)^{a-1}. \end{align*}
\begin{align*} \mathbb{E}[\Delta_n(\mu_1,\mu_2)] & = \mathbb{E}[d(F_{\vartheta_n:\vartheta_1}X_0^{\mu_1},F_{\vartheta_n:\vartheta_1}X_0^{\mu_2}) (p(X_n^{\mu_1}) + p(X_n^{\mu_2}))^{a-1}] \\[5pt] & \leq \mathbb{E}[d(X_0^{\mu_1},X_0^{\mu_2})] \mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)(p(X_n^{\mu_1}) + p(X_n^{\mu_2}))^{a-1} ] \\[5pt] & \leq \mathbb{E}[d(X_0^{\mu_1},X_0^{\mu_2})] \mathbb{E}[L(\vartheta_n\;:\;\vartheta_1)^{a}]^{{1}/{a}} \mathbb{E}[(p(X_n^{\mu_1}) + p(X_n^{\mu_2}))^{a}]^{({a-1})/{a}} \\[5pt] & \leq \mathbb{E}[d(X_0^{\mu_1},X_0^{\mu_2})] \mathbb{E}[L(\vartheta_1)^{a}]^{{n}/{a}} \xi^{({a-1})/{a}} (\|\mu_1\|_a + \|\mu_2\|_a)^{a-1}. \end{align*}
This proves (C.1); (C.2) follows from (C.1) and the definition of
 $m_{a}(f)$
.
$m_{a}(f)$
.
Now recall that we consider the case
 $N=1$
in (4.4). Let us prove the inequality (4.5) in this case (that is, (4.7)). Applying (C.2) to
$N=1$
in (4.4). Let us prove the inequality (4.5) in this case (that is, (4.7)). Applying (C.2) to
 $\mu_1\;:\!=\;\delta_x$
and
$\mu_1\;:\!=\;\delta_x$
and
 $\mu_2\;:\!=\;\pi$
gives
$\mu_2\;:\!=\;\pi$
gives
 \begin{align*} |P^nf(x) - \pi(f)| & \leq \mathbb{E}[\, |f(X_{n}^{x}) - f(X_{n}^{\pi})|\, ] \\[5pt] & \leq \xi^{({a-1})/{a}} m_{a}(f) \kappa_{1,a}^{n} \mathbb{E}[d(x,X_0^{\pi})](\|\delta_x\|_a + \|\pi\|_a)^{a-1}. \end{align*}
\begin{align*} |P^nf(x) - \pi(f)| & \leq \mathbb{E}[\, |f(X_{n}^{x}) - f(X_{n}^{\pi})|\, ] \\[5pt] & \leq \xi^{({a-1})/{a}} m_{a}(f) \kappa_{1,a}^{n} \mathbb{E}[d(x,X_0^{\pi})](\|\delta_x\|_a + \|\pi\|_a)^{a-1}. \end{align*}
Next, observe that
 $\|\delta_x\|_a=p(x)$
, and
$\|\delta_x\|_a=p(x)$
, and
 \begin{align*} \mathbb{E}[d(x,X_0^{\pi})] \leq \mathbb{E}[d(x,x_0) + d(x_0,X_0^{\pi})] \leq p(x) + \pi(d(x_0,\cdot)) \leq p(x) \|\pi\|_1.\end{align*}
\begin{align*} \mathbb{E}[d(x,X_0^{\pi})] \leq \mathbb{E}[d(x,x_0) + d(x_0,X_0^{\pi})] \leq p(x) + \pi(d(x_0,\cdot)) \leq p(x) \|\pi\|_1.\end{align*}
Hence,
 $\mathbb{E}[d(x,X_0^{\pi})] (\|\delta_x\|_a + \|\pi\|_a)^{a-1} \leq p(x)^a \|\pi\|_1 (1 + \|\pi\|_a)^{a-1}$
. This proves the expected inequality.
$\mathbb{E}[d(x,X_0^{\pi})] (\|\delta_x\|_a + \|\pi\|_a)^{a-1} \leq p(x)^a \|\pi\|_1 (1 + \|\pi\|_a)^{a-1}$
. This proves the expected inequality.
Finally, to prove (4.6), it remains to study
 $m_a(P^nf)$
for
$m_a(P^nf)$
for
 $f\in{\mathcal{L}}_a$
. Applying (C.2) to
$f\in{\mathcal{L}}_a$
. Applying (C.2) to
 $\mu_1\;:\!=\;\delta_x$
and
$\mu_1\;:\!=\;\delta_x$
and
 $\mu_2\;:\!=\;\delta_y$
for any
$\mu_2\;:\!=\;\delta_y$
for any
 $(x,y)\in{\mathbb{X}}^2$
gives
$(x,y)\in{\mathbb{X}}^2$
gives
 \begin{align*} \textrm{for all } f\in {\mathcal{L}}_a,\quad|P^nf(x) - P^nf(y)| \leq \xi^{({a-1})/{a}} m_a(f) \kappa_{1,a}^{n} d(x,y) (p(x) + p(y))^{a-1}.\end{align*}
\begin{align*} \textrm{for all } f\in {\mathcal{L}}_a,\quad|P^nf(x) - P^nf(y)| \leq \xi^{({a-1})/{a}} m_a(f) \kappa_{1,a}^{n} d(x,y) (p(x) + p(y))^{a-1}.\end{align*}
Thus,
 $m_a(P^nf) \leq \xi^{({a-1})/{a}} m_a(f) \kappa_{1,a}^{n}$
. Since
$m_a(P^nf) \leq \xi^{({a-1})/{a}} m_a(f) \kappa_{1,a}^{n}$
. Since
 $m_a(\textbf{1}_{X})=0$
, this gives
$m_a(\textbf{1}_{X})=0$
, this gives
 \begin{align*} m_a(P^nf-\pi(f)\textbf{1}_{X}) \leq \xi^{({a-1})/{a}} m_a(f) \kappa_{1,a}^{n}.\end{align*}
\begin{align*} m_a(P^nf-\pi(f)\textbf{1}_{X}) \leq \xi^{({a-1})/{a}} m_a(f) \kappa_{1,a}^{n}.\end{align*}
Appendix D. Proof of Proposition 5.1
For every
 $\theta\;:\!=\;(\xi,\gamma)\in \Theta \;:\!=\; (0,+\infty)\times(\gamma_0,+\infty)$
, the expectation
$\theta\;:\!=\;(\xi,\gamma)\in \Theta \;:\!=\; (0,+\infty)\times(\gamma_0,+\infty)$
, the expectation
 \begin{align*} \mathbb{E}\big[ \big\|F_{\xi}\big(0,\vartheta^{(\gamma)}_1\big)\big\|^a\big] =\int_{{\mathbb{R}}^d} \|\Phi_\xi(F(0,v))\|^a \mathfrak{p}_\gamma(v)\, {\textrm{d}} v \leq\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a \int_{{\mathbb{R}}^q} \|F(0,v)\|^a \mathfrak{p}(v)\, {\textrm{d}} v \end{align*}
\begin{align*} \mathbb{E}\big[ \big\|F_{\xi}\big(0,\vartheta^{(\gamma)}_1\big)\big\|^a\big] =\int_{{\mathbb{R}}^d} \|\Phi_\xi(F(0,v))\|^a \mathfrak{p}_\gamma(v)\, {\textrm{d}} v \leq\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a \int_{{\mathbb{R}}^q} \|F(0,v)\|^a \mathfrak{p}(v)\, {\textrm{d}} v \end{align*}
is finite, so Assumption 1.2 holds with
 $x_0=0$
and
$x_0=0$
and
 $M_a\;:\!=\; \widetilde{M}_a\kappa_a/\widetilde{\kappa}_a$
. Moreover, note that
$M_a\;:\!=\; \widetilde{M}_a\kappa_a/\widetilde{\kappa}_a$
. Moreover, note that
 $L_{\Phi_\xi} \leq 1$
, so that, for all
$L_{\Phi_\xi} \leq 1$
, so that, for all
 $v\in{\mathbb{V}}$
,
$v\in{\mathbb{V}}$
,
 $L_{F_\xi}(v) \leq L_{F}(v)$
. Hence, we have, for every
$L_{F_\xi}(v) \leq L_{F}(v)$
. Hence, we have, for every
 $\theta=(\xi,\gamma)\in \Theta$
,
$\theta=(\xi,\gamma)\in \Theta$
,
 \begin{align*} \mathbb{E}\big[ L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big)^a\big] =\int_{{\mathbb{R}}^d} L_{F_\xi}(v)^a \mathfrak{p}_\gamma(v)\, {\textrm{d}} v \leq c_\gamma\int_{{\mathbb{R}}^d} L_{F}(v)^a \mathfrak{p}(v)\, {\textrm{d}} v \leq c_\gamma {\widetilde{\kappa}_a}^a \leq \kappa_a^a.\end{align*}
\begin{align*} \mathbb{E}\big[ L_{F_\xi}\big(\vartheta^{(\gamma)}_1\big)^a\big] =\int_{{\mathbb{R}}^d} L_{F_\xi}(v)^a \mathfrak{p}_\gamma(v)\, {\textrm{d}} v \leq c_\gamma\int_{{\mathbb{R}}^d} L_{F}(v)^a \mathfrak{p}(v)\, {\textrm{d}} v \leq c_\gamma {\widetilde{\kappa}_a}^a \leq \kappa_a^a.\end{align*}
Thus, Assumption 1.3 holds. It remains to check Assumption 1.4 and to specify the error term
 $\Delta_\theta$
. Let P (respectively
$\Delta_\theta$
. Let P (respectively
 ${{P_{\theta}}}$
) denote the transition kernel of the unperturbed IFS
${{P_{\theta}}}$
) denote the transition kernel of the unperturbed IFS
 $\{X_n\}_{n\in{\mathbb{N}}}$
(respectively of the perturbed IFS
$\{X_n\}_{n\in{\mathbb{N}}}$
(respectively of the perturbed IFS
 $\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
). Let
$\{{X_n^{(\theta)}}\}_{n\in{\mathbb{N}}}$
). Let
 $\varepsilon > 0$
, and let
$\varepsilon > 0$
, and let
 $f\in{\mathcal{B}}_0$
be such that
$f\in{\mathcal{B}}_0$
be such that
 $|f|_0\leq 1$
. First, note that we have, for every
$|f|_0\leq 1$
. First, note that we have, for every
 $x\in{\mathbb{R}}^d$
satisfying
$x\in{\mathbb{R}}^d$
satisfying
 $\|x\| > A_\varepsilon$
,
$\|x\| > A_\varepsilon$
,
 \begin{equation} \frac{|({{P_{\theta}}}f)(x) - (Pf)(x)|}{V_a(x)} \leq \frac{2}{V_a(x)} \leq \varepsilon\end{equation}
\begin{equation} \frac{|({{P_{\theta}}}f)(x) - (Pf)(x)|}{V_a(x)} \leq \frac{2}{V_a(x)} \leq \varepsilon\end{equation}
by the definition of
 $A_\varepsilon$
in Proposition 5.1. Next, for every
$A_\varepsilon$
in Proposition 5.1. Next, for every
 $\theta\;:\!=\;(\xi,\gamma)\in \Theta$
and for every
$\theta\;:\!=\;(\xi,\gamma)\in \Theta$
and for every
 $x\in{\mathbb{R}}^d$
, define the following subsets
$x\in{\mathbb{R}}^d$
, define the following subsets
 $E_{\theta,x}$
and
$E_{\theta,x}$
and
 $G_{\theta,x}$
of
$G_{\theta,x}$
of
 ${\mathbb{R}}^q$
:
${\mathbb{R}}^q$
:
 \begin{align*} E_{\theta,x} & \;:\!=\; \{v\in {\mathbb{R}}^q \;:\; v\in B(0,\gamma),\, \|F(x,v)\| \leq \xi\}, \\[5pt] G_{\theta,x} & \;:\!=\; \{v\in {\mathbb{R}}^q \;:\; v\in B(0,\gamma),\, \|F(x,v)\| > \xi\}.\end{align*}
\begin{align*} E_{\theta,x} & \;:\!=\; \{v\in {\mathbb{R}}^q \;:\; v\in B(0,\gamma),\, \|F(x,v)\| \leq \xi\}, \\[5pt] G_{\theta,x} & \;:\!=\; \{v\in {\mathbb{R}}^q \;:\; v\in B(0,\gamma),\, \|F(x,v)\| > \xi\}.\end{align*}
From the definition of the thresholding function
 $\Phi_\xi$
, we have, for every
$\Phi_\xi$
, we have, for every
 $x\in {\mathbb{R}}^d$
,
$x\in {\mathbb{R}}^d$
,
 \begin{align*} ({{P_{\theta}}}f)(x) & = \int_{{\mathbb{R}}^q} f(F_{\xi}(x,v)) \mathfrak{p}_\gamma(v)\, {\textrm{d}} v \\[5pt] & = c_\gamma \int_{E_{\theta,x}} f(F(x,v)) \mathfrak{p}(v)\, {\textrm{d}} v + c_\gamma \int_{G_{\theta,x}} f(\eta_{x,v}) \mathfrak{p}(v)\, {\textrm{d}} v , \end{align*}
\begin{align*} ({{P_{\theta}}}f)(x) & = \int_{{\mathbb{R}}^q} f(F_{\xi}(x,v)) \mathfrak{p}_\gamma(v)\, {\textrm{d}} v \\[5pt] & = c_\gamma \int_{E_{\theta,x}} f(F(x,v)) \mathfrak{p}(v)\, {\textrm{d}} v + c_\gamma \int_{G_{\theta,x}} f(\eta_{x,v}) \mathfrak{p}(v)\, {\textrm{d}} v , \end{align*}
with
 $\eta_{x,v} \;:\!=\;\xi\|F(x,v)\|^{-1} F(x,v)$
. Hence,
$\eta_{x,v} \;:\!=\;\xi\|F(x,v)\|^{-1} F(x,v)$
. Hence,
 \begin{align*} |({{P_{\theta}}}f)(x) - (Pf)(x)| & \leq |c_\gamma-1| \int_{E_{\theta,x}} \mathfrak{p}(v)\, {\textrm{d}} v + (1+c_\gamma) \int_{{\mathbb{R}}^q \setminus E_{\theta,x}} \mathfrak{p}(v)\, {\textrm{d}} v \\[5pt] & \leq |c_\gamma-1| + \bigg(1+\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a\bigg) \bigg({\mathbb{P}}(\|\vartheta_1\| > \gamma) + {\mathbb{P}}(\|F(x,\vartheta_1)\| > \xi)\bigg)\end{align*}
\begin{align*} |({{P_{\theta}}}f)(x) - (Pf)(x)| & \leq |c_\gamma-1| \int_{E_{\theta,x}} \mathfrak{p}(v)\, {\textrm{d}} v + (1+c_\gamma) \int_{{\mathbb{R}}^q \setminus E_{\theta,x}} \mathfrak{p}(v)\, {\textrm{d}} v \\[5pt] & \leq |c_\gamma-1| + \bigg(1+\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a\bigg) \bigg({\mathbb{P}}(\|\vartheta_1\| > \gamma) + {\mathbb{P}}(\|F(x,\vartheta_1)\| > \xi)\bigg)\end{align*}
from the definition of
 ${\mathbb{R}}^q\setminus E_{\theta,x}$
and the condition
${\mathbb{R}}^q\setminus E_{\theta,x}$
and the condition
 $c_\gamma \leq (\kappa_a/\widetilde{\kappa}_a)^a$
. Now let
$c_\gamma \leq (\kappa_a/\widetilde{\kappa}_a)^a$
. Now let
 $x\in{\mathbb{R}}^d$
be such that
$x\in{\mathbb{R}}^d$
be such that
 $\|x\| \leq A_\varepsilon$
. Then, for all
$\|x\| \leq A_\varepsilon$
. Then, for all
 $v\in{\mathbb{R}}^q$
,
$v\in{\mathbb{R}}^q$
,
 $\|F(x,v)\| \leq L_{F}(v) A_\varepsilon + \|F(0,v)\|$
from
$\|F(x,v)\| \leq L_{F}(v) A_\varepsilon + \|F(0,v)\|$
from
 $F(x,v) = (F(x,v)-F(0,v)) + F(0,v)$
and the triangle inequality. Therefore,
$F(x,v) = (F(x,v)-F(0,v)) + F(0,v)$
and the triangle inequality. Therefore,
 $\big[ L_{F}(v) A_\varepsilon \leq {\xi}/{2}$
and
$\big[ L_{F}(v) A_\varepsilon \leq {\xi}/{2}$
and
 $\|F(0,v)\| \leq {\xi}/{2}\big] \Rightarrow \|F(x,v)\| \leq \xi$
, from which we deduce that
$\|F(0,v)\| \leq {\xi}/{2}\big] \Rightarrow \|F(x,v)\| \leq \xi$
, from which we deduce that
 \begin{align*} {\mathbb{P}}(\|F(x,\vartheta_1)\| > \xi ) & \leq {\mathbb{P}}\bigg(L_{F}(\vartheta_1) > \frac{\xi}{2A_\varepsilon}\bigg) + {\mathbb{P}}\bigg(\|F(0,\vartheta_1)\| > \frac{\xi}{2}\bigg) \\[5pt] & \leq \frac{(2A_\varepsilon)^a}{\xi^a}\mathbb{E}\big[L_{F}(\vartheta_1)^a\big] + \frac{2^a}{\xi^a}\mathbb{E}\big[\|F(0,\vartheta_1)\|^a\big] \\[5pt] & \leq \frac{(2A_\varepsilon \widetilde{\kappa}_a)^a + (2\widetilde{M}_a)^a}{\xi^a} \end{align*}
\begin{align*} {\mathbb{P}}(\|F(x,\vartheta_1)\| > \xi ) & \leq {\mathbb{P}}\bigg(L_{F}(\vartheta_1) > \frac{\xi}{2A_\varepsilon}\bigg) + {\mathbb{P}}\bigg(\|F(0,\vartheta_1)\| > \frac{\xi}{2}\bigg) \\[5pt] & \leq \frac{(2A_\varepsilon)^a}{\xi^a}\mathbb{E}\big[L_{F}(\vartheta_1)^a\big] + \frac{2^a}{\xi^a}\mathbb{E}\big[\|F(0,\vartheta_1)\|^a\big] \\[5pt] & \leq \frac{(2A_\varepsilon \widetilde{\kappa}_a)^a + (2\widetilde{M}_a)^a}{\xi^a} \end{align*}
from the Markov inequality. Consequently, we obtain that, for every
 $x\in{\mathbb{R}}^d$
such that
$x\in{\mathbb{R}}^d$
such that
 $\|x\| \leq A_\varepsilon$
,
$\|x\| \leq A_\varepsilon$
,
 \begin{align*} \frac{|({{P_{\theta}}}f)(x) - (Pf)(x)|}{V_a(x)} & \leq |({{P_{\theta}}}f)(x) - (Pf)(x)| \\[5pt] & \leq |c_\gamma-1| + \bigg(1+\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a\bigg) \bigg(\frac{\mathbb{E}\big[\|\vartheta_1\|^a\big]}{\gamma^a} + \frac{(2A_\varepsilon\widetilde{\kappa}_a)^a + (2\widetilde{M}_a)^a}{\xi^a}\bigg). \end{align*}
\begin{align*} \frac{|({{P_{\theta}}}f)(x) - (Pf)(x)|}{V_a(x)} & \leq |({{P_{\theta}}}f)(x) - (Pf)(x)| \\[5pt] & \leq |c_\gamma-1| + \bigg(1+\bigg(\frac{\kappa_a}{\widetilde{\kappa}_a}\bigg)^a\bigg) \bigg(\frac{\mathbb{E}\big[\|\vartheta_1\|^a\big]}{\gamma^a} + \frac{(2A_\varepsilon\widetilde{\kappa}_a)^a + (2\widetilde{M}_a)^a}{\xi^a}\bigg). \end{align*}
The conclusion of Proposition 5.1 follows from this and (D.1).
Acknowledgement
We thank the reviewers for their valuable comments, which have improved the manuscript. In particular the material of Section 5.2 addresses an issue raised by one of the reviewers.
Funding information
There are no funding bodies to thank relating to the creation of this article.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.
