



INTRODUCTION
An important aspect of communicative competence (see Canale & Swain, Reference Canale and Swain1980) is sociolinguistic competence, or the ability to employ variable (socio)linguistic forms in a nativelike manner based on linguistic factors, such as the phonetic or syntactic context in which the form is found, and extralinguistic factors, such as the formality of the context and the interlocutors’ gender, origin, and social class (see Bayley & Regan, Reference Bayley and Regan2004). This research shows that a large amount of exposure to the L2 leads to greater gains in sociolinguistic competence (Uritescu et al., Reference Uritescu, Mougeon, Rehner and Nadasdi2004). In fact, several studies have sought to determine whether time spent in locations where the target language is spoken plays a role in acquiring this type of competence, given that this provides learners with ample opportunities to be exposed to naturalistic L2 input (Baker Reference Baker, Bowles, Foote, Perpiñán and Bhatt2008; Regan et al., Reference Regan, Howard and Lemée2009). Some of this research has specifically examined whether L2 learners’ language develops differently when they are exposed to unique regional variation. In some cases, exposure appears to lead to L2 development of linguistic variation that more closely reflects the dialect to which they are exposed (e.g., Friesner & Dinkin, Reference Friesner and Dinkin2006; Geeslin et al., Reference Geeslin, García-Amaya, Hasler-Barker, Henriksen, Killam, Borgonovo, Español-Echevarría and Prévost2010; Raish, Reference Raish2015; Salgado-Robles Reference Salgado-Robles2011; Trentman, Reference Trentman2017). For example, Pozzi (Reference Pozzi2017) found that L2 learners of Spanish that studied abroad in Buenos Aires, Argentina significantly increased their production of the region-specific sheísmo/zheísmo (i.e., employing /ʃ/ or /ʒ/ for the orthographic “y/ll”). In another study, Raish (Reference Raish2015) observed that during a study abroad (SA) experience in Cairo, the majority of the students adopted the regional Egyptian Arabic [g] into their L2 Arabic speech. However, in other studies, employing region-specific uses of variable forms after exposure has been minimal or nonexistent (e.g., Escalante, Reference Escalante2018; Fox & McGory, Reference Fox, McGory, Bohn and Munro2007; George, Reference George2014; Ringer-Hilfinger, Reference Ringer-Hilfinger2012). For instance, Fox and McGory (Reference Fox, McGory, Bohn and Munro2007) examined the production of vowels by Japanese-speaking L2 learners of English who had resided in either Ohio or Alabama for at least 2 years. They found that L2 learners produced vowels that more closely reflected the Ohioan vowels regardless of their location of residence. In another example, Ringer-Hilfinger (Reference Ringer-Hilfinger2012) studied the L2 acquisition of the peninsular-Spanish voiceless interdental fricative [θ] by students during a semester-long sojourn in Spain. She found that even after SA, use of [θ] by the L2 learners was nearly nonexistent despite the fact that several learners were aware of and indicated frequent use of this feature.
Given that the results of the research on the acquisition of regional features are mixed, researchers have sought to determine why some features are acquired and others are not. This research has examined factors such as L2 proficiency (Geeslin et al., Reference Geeslin, García-Amaya, Hasler-Barker, Henriksen, Killam, Borgonovo, Español-Echevarría and Prévost2010), amount of contact with the target language (Li, Reference Li2010), language attitudes (e.g., Baker, Reference Baker, Bowles, Foote, Perpiñán and Bhatt2008; Ringer-Hilfinger, Reference Ringer-Hilfinger2012; Smith & Baker, Reference Smith and Baker2011), and the L2 learners’ social networks in the target language (e.g., Pope, Reference Pope, Sessarego and Tejedo-Herrero2016; Trentman, Reference Trentman2017; Uritescu et al., Reference Uritescu, Mougeon, Rehner and Nadasdi2004). In the current study, we seek to expand our knowledge of the L2 development of sociolinguistic competence and the effects of exposure to regional features of the target language by examining the L2 acquisition of variable /s/-weakening in Spanish.
Research shows that /s/-weakening is very common in the Spanish-speaking world and is constrained by a variety of linguistic and extralinguistic factors (Lipski, Reference Lipski and Díaz-Campos2011). With regard to the L2 acquisition of /s/-weakening, previous research suggests that although L2 learners are able to acquire the ability to perceive /s/-weakening (e.g., Schmidt, Reference Schmidt2018), they rarely produce it when classified according to the traditional tripartite division between (a) sibilance (e.g., ha[s]ta “until”), (b) aspiration (ha[h]ta), and (c) deletion (e.g., Geeslin & Gudmestad, Reference Geeslin and Gudmestad2011). In the present study, we not only examine the development of /s/-weakening during an SA experience according to the categorical tripartite division but also in a continuous manner based on three acoustic properties of /s/ as well.
/S/-WEAKENING IN SPANISH
Hualde (Reference Hualde2005) distinguishes between two allophones of the voiceless alveolar fricative in Spanish: the voiceless alveolar sibilant [s] and the phonetically reduced voiced alveolar sibilant [z]. When /s/ is fully realized, either the tip of the tongue and/or the predorsum rises to the alveolar ridge and creates constriction so that there is high-frequency sibilant frication. Before voiced consonants, however, the /s/ can be phonetically reduced (i.e., weakened) by undergoing anticipatory assimilation or gestural overlap of the voicing of a following consonant (e.g., mismo [‘miz.mo] “same”). The occurrence of /s/-voicing is considered phonetic reduction because it is physiologically easier for the vocal folds to continue vibrating across sound segments. It should be noted, however, that /s/-voicing assimilation is not categorical (e.g., García, Reference García2013; Schmidt & Willis, Reference Schmidt, Willis and Alvord2011). In fact, it is often incomplete because the /s/ may be only partially voiced (Campos-Astorkiza, Reference Campos-Astorkiza, Klassen, Liceras and Valenzuela2015), and it is constrained by additional factors (Chappell, Reference Chappell, Michnowicz and Dodsworth2011).
Beyond /s/-voicing, Lipski (Reference Lipski and Díaz-Campos2011) points out that more than half of the world’s Spanish speakers produce some form of /s/-weakening, such as /s/-aspiration, glottalization, shift of preconsonantal /s/ to [ɾ], and deletion (cf. Hualde, Reference Hualde2005). In many Spanish dialects, /s/-weakening is viewed as a progression from more to less robust realizations of /s/: a maintained voiceless sibilant [s], a partially weakened aspirated variant [h], and the fully reduced, deleted, or elided variant (Lipski, Reference Lipski and Díaz-Campos2011). The aspirated /s/ is seen as the result of a process of debuccalization during which the oral constriction in the alveolar region is lost, leaving only the airflow from the lungs (Widdison, Reference Widdison1997). The fully reduced deleted /s/, in comparison, is a complete phonetic elision of the /s/ segment.
Although /s/-weakening has historically been examined categorically, recent research has shown that it is gradient in nature, given that realizations may fall anywhere between complete maintenance and complete deletion (Erker, Reference Erker2010; File-Muriel & Brown, Reference File-Muriel and Brown2011; Minnick Fox, Reference Minnick Fox2006). As such, researchers have examined acoustic correlates that are considered to index /s/-weakening, namely percentage of /s/-voicing, duration, and center of gravity (COG), finding that weakened /s/ includes more voicing, has shorter durations, and has lower average COGs. This research demonstrates that examining acoustic measures of weakening in a gradient manner furnishes a clearer and more objective method for studying /s/-weakening.
FACTORS CONSTRAINING /S/-WEAKENING
As is true for many sociolinguistic variables, /s/-weakening is constrained by a variety of linguistic and extralinguistic factors, such as syllable position, word position, phonological context, morphemic status, linguistic priming, speech rate, lexical frequency, speech style, speaker origin, age, gender, and social class (see Lipski, Reference Lipski and Díaz-Campos2011). Regarding linguistic factors, /s/-weakening occurs most often in syllable-final (coda) position, word-finally before a consonant (ibid.), when the /s/ is preceded by another weakened /s/ (Poplack, Reference Poplack1980), in rapid speech, and among words that are relatively more frequent (File-Muriel & Brown, Reference File-Muriel and Brown2011). The role of the morphemic status of /s/, however, has received conflicting reports in the literature (Hundley, Reference Hundley1987; Lafford, Reference Lafford1989; Poplack, Reference Poplack1980), with some studies showing less reduction of /s/ when it carries morphemic value, such as when it functions as a second-person singular verbal inflection (e.g., hablas “2s speak”) or plural marker (e.g., las casas “the houses”), while others fail to find such an effect. As for extralinguistic factors, /s/-weakening tends to occur more often in colloquial speech (Terrell, Reference Terrell, Sankoff and Cedergren1981) as well as by speakers who are younger (e.g., Cedergren, Reference Cedergren1973), male (Fontanella de Weinberg, Reference Fontanella de Weinberg1973; Terrell, Reference Terrell, Sankoff and Cedergren1981), less educated and/or from lower social classes (e.g., Samper Padilla, Reference Samper Padilla1990), and/or from the geographical regions of southern Spain, the Canary Islands, Uruguay, Paraguay, Chile, most of Argentina, Eastern Bolivia, island and mainland coastal Caribbean areas, among other regions (Lipski, Reference Lipski1994). Finally, Lipski (Reference Lipski and Díaz-Campos2011) points out that elision of /s/ is often stigmatized, including in areas in which it is widespread.
L2 ACQUISITION OF /S/-WEAKENING
Very few studies have been conducted specifically on the L2 acquisition of /s/-weakening, and many focus on perception rather than production. For instance, Schmidt (Reference Schmidt2018) examined data gathered from L2 learners of Spanish who completed a computer-based task in which the learners heard invented words—some of which contained an aspirated-/s/ in word-medial, syllable-final position—and were instructed to select the word they heard from several options presented orthographically. She found that greater proficiency in Spanish, exposure to speakers of /s/-weakening dialects, and metalinguistic awareness of /s/-weakening led to more accurate identification of the aspirated /s/. Indeed, additional studies confirm Schmidt’s finding of the effect of proficiency and exposure to /s/-weakening on the perception of this feature (e.g., Bedinghaus, Reference Bedinghaus2015; George, Reference George2014). Escalante (Reference Escalante2018), for instance, studied the ability to perceive /s/-weakening by 11 L2 learnersFootnote 1 with novice to intermediate levels of proficiency at six different intervals during a year in Guayaquil, Ecuador, a region in which /s/-weakening occurs. Similar to previous studies, she found that learners improved their ability to accurately perceive /s/-weakening over time and those learners with higher proficiency did so to a greater degree.
Regarding the L2 production of /s/-weakening, the research so far has shown that L2 learners, even those who are highly proficient or have been exposed to /s/-weakening, do not tend to employ /s/-weakening. For example, Schmidt (Reference Schmidt2014) examined the production of preconsonantal /s/ by 14 advanced speakers of Spanish in controlled oral tasks. When coded categorically (voiced vs. unvoiced), she found that the L2 learners rarely produced /s/-voicing even when the following consonant was voiced. In another study, Sayahi (Reference Sayahi2005) impressionistically examined coda-final /s/ production in sociolinguistic interviews by 10 Spanish speakers from northern Morocco: five native speakers (NS) of Spanish and five L2 speakers of Spanish who had received no formal Spanish-language education. He found that although /s/ in syllable-final position was deleted by the NSs of Spanish 87% of the time, the L2 speakers maintained sibilant /s/ 94% of the time. Geeslin and Gudmestad (Reference Geeslin and Gudmestad2011) analyzed the production of /s/-weakening in role-plays completed by 130 L2 learners of Spanish at differing levels of proficiency. Based on impressionistic auditory coding of /s/, they found that only five learners from the highest two levels of proficiency produced any /s/-weakening. In addition, they found that learners who maintained contact with speakers from the country where they lived abroad tended to use the variants they were exposed to (e.g., /s/-weakening) more than those who did not. Finally, Escalante (Reference Escalante2018) also studied the production of /s/-weakening over time in sociolinguistic interviews by the L2 learners described previously. Over the course of the year abroad, the L2 learners almost never produced /s/-weakening when coded categorically. She also examined /s/ duration and COG and found that learners did not significantly change these two measures during their stay abroad.
In sum, research on the L2 acquisition of /s/-weakening has shown that higher proficiency and exposure to /s/-weakening dialects leads to a more accurate perception of a reduced /s/ but does not always lead to an increase in the production of weakened /s/ by L2 learners. However, no study has examined the L2 acquisition of /s/-weakening in Spanish through an analysis of all three continuous acoustic measures of voicing, duration, and COG as has been done in the first language (L1) research (e.g., File-Muriel & Brown, Reference File-Muriel and Brown2011). Examining these acoustic measures of weakening might reveal development of /s/-weakening that could have been missed in studies that included fewer acoustic measures and/or only examined /s/-weakening in categorical terms. In addition, no study has examined the development of /s/-weakening during SA by L2 learners who are exposed to an /s/-weakening dialect versus learners who study abroad in a region in which /s/-weakening is less prevalent. As such, the present study seeks to answer the following research questions:
RQ: After a semester-long SA experience, do L2 learners of Spanish progress toward NS norms with respect to:
-
a) Their production of sibilance versus reduced articulations (i.e., aspiration or deletion) of coda /s/?
-
b) Three phonetic properties of coda /s/: /s/-voicing, COG of /s/, and duration of /s/?
METHODOLOGY
PARTICIPANTS
The participants in this study were 22 L2 learners and 21 NSs of Spanish. The L2 learners participated in a semester-long (one semester ≈ 4 months) SA program in either Santiago, Dominican Republic (DR; N = 11) or Madrid, Spain (N = 11). The motivation behind selecting these two SA destination sites was to determine if extended exposure to /s/-weakening leads to development of this dialectal feature because /s/-weakening is a characteristic feature of Dominican Spanish—even among educated speakers—(Lipski, Reference Lipski1994) whereas /s/-weakening is not a distinctive feature of central-northern Spain, where Madrid is located (Hualde, Reference Hualde2005). Among the L2 learners, there were 15 females and 7 males, with ages that ranged from 19 to 21 years old (mean = 20.2, SD = 0.65). The L2 learners were all NSs of English, had completed at least four semesters of university-level Spanish language instruction prior to studying abroad, and did not have any previous extended experience in a Spanish-speaking country. During their sojourn abroad, they lived with host families. The DR students completed courses in Spanish with other L2 learners, whereas the Spain students enrolled in similar courses, but also some that included NSs and others that were taught in English. Finally, information gathered from the background questionnaire indicated that the amount of contact the students had with NSs during their stay varied greatly, with some having little contact outside of their courses and host family interactions, while others indicated extensive interactions outside of these contexts.
As for the 21 NSs, 10 were from the DR and 11 were from Spain. Among these speakers, there were 15 females and 6 males, and their ages ranged from 18 to 24 years old (mean = 20.8, SD = 1.89). The Spaniard participants were all born in Spain and had resided in the Madrid Community region for at least 10 years, while the Dominican participants all resided in and were originally from the Cibao region of the DR. All NS participants were undergraduate university students, with the exception of two that indicated plans to attend college in the near future. Hence, the NSs were comparable to each other and to the L2 learners with regard to age, male/female ratio, and education level.
DATA COLLECTION
The students completed the grammar test, the background questionnaire, and a semiguided interview in Spanish at each time of data collection. This was done shortly after arriving in their host country (Time 1) as well as shortly before returning home (Time 2; mean duration between interviews = 85.6 days, range = 82–92 days). The grammar test in Spanish was a 20-item cloze test in which students completed a narration by selecting the correct grammar form from three options. The mean score on the grammar test for the students was 55.7% (s = 14.3%), which is similar to that of the university students in their third year of Spanish (see Geeslin et al., Reference Geeslin, Linford, Fafulas, Long, Díaz-Campos, Amaro, Lord, de Prada Pérez and Aaron2013, p. 162).Footnote 2 The background questionnaire included questions regarding the students’ demographics; experience with Spanish and other languages; use of Spanish; attitudes toward the dialect, culture, and people of the SA region; and awareness of dialectal features. Finally, both learners and NS participants completed a semiguided interview from which the /s/-tokens were analyzed. The interviews were conducted in a quiet location (e.g., a university office) by a highly advanced NNS of Spanish who employs little to no /s/-weakening, and recorded using a Sony IC digital recorder model ICD-UX533 in LPCM with a sampling rate of 44.1 kHz and sampling encoding of 16 bits. The interview included questions related to the participants’ previous and current experiences and opinions and lasted on average 22 minutes each for the L2 learners and 14 minutes each for the NSs.
CODING PROCEDURE
The interviews (N = 65) were transcribed into standard orthography, and all orthographic instances of /s/ in coda position were highlighted, regardless of whether the participants produced the /s/ phonetically. We opted to only include tokens in coda position, given that this context has been shown to be one of the most common for /s/-weakening (Lipski, Reference Lipski1994, p. 209). In addition, we excluded tokens in which /s/ occurred in false starts, when there was audio overlap with the interviewer or other extraneous noises, or when /s/ was found in English words. After exclusions, the transcripts were used to locate and delimit approximately the first 100 occurrences of coda /s/ in the audio filesFootnote 3 using the acoustics software Praat (Boersma & Weenink, Reference Boersma and Weenink2019). The researchers manually delimited three items for each occurrence of coda /s/ based on auditory analysis and visual inspection of the waveform and spectrogram: (a) the /s/ segment, or a placeholder in the event of a deleted token (see details in the following text regarding /s/ token identification); (b) the word in which coda /s/ occurred; and (c) the three-word string in which /s/ occurred, which included the word in which /s/ occurred and the preceding and following words. In the event of a flanking pause, the boundary was limited to just the word with /s/ and the word on the other side or just the word with /s/ when it was flanked on both sides by pauses (N = 277). After this step, we further limited our data by excluding tokens of /s/ that represented the entirety of a morpheme, such as the plural allomorph “-s” (e.g., buenos “ᴍᴀꜱᴄ. ᴘʟᴜʀ. good”) and the second-person singular verbal marker “-s” (e.g., sabes “2ꜱ ᴘʀᴇꜱ. ɪɴᴅ. know”) because it was impossible to objectively determine if the absence of the /s/ morpheme was an instance of a deleted /s/ or a grammatical error. However, tokens of /s/ were included when the /s/ segment was only a part of a morpheme, such as with the second-person singular preterite marker (e.g., llamaste “2ꜱ ᴘʀᴇᴛ. call”), the first-person plural verbal marker (e.g., llevamos “1p take/took”), and the plural allomorph “-es” (e.g., españoles “ᴘʟᴜʀ. Spaniards”).Footnote 4 These exclusions left 4,319 tokens for analysis.
Categorical Dependent Variable
Each /s/ token was placed into one of three categories based on auditory review as well as visual inspection of the waveform and the spectrogram. The tokens categorized as sibilant were those in which there was sibilance present in the auditory signal, visual noise in the upper region of the spectrogram (6,000–11,025 Hz), and aperiodicity in the waveform, regardless of whether it was accompanied by voicing. Tokens of coda /s/ were delimited by placing the onset boundary of /s/ at the beginning of aperiodic noise represented by darkness in the upper regions of the spectrogram (when the window was set from 0 to 11,025 Hz), while the end of the /s/ segment was marked at the cessation of aperiodicity in the waveform and the discontinuance of upper-region darkness in the spectrogram (see Figure 1).

FIGURE 1. Praat screenshot of a sibilant token of /s/.
The tokens categorized as aspirated were those in which there was aperiodicity in the waveform, but sibilance was not perceived auditorily nor was there clear visual noise in the upper region of the spectrogram (see Figure 2).
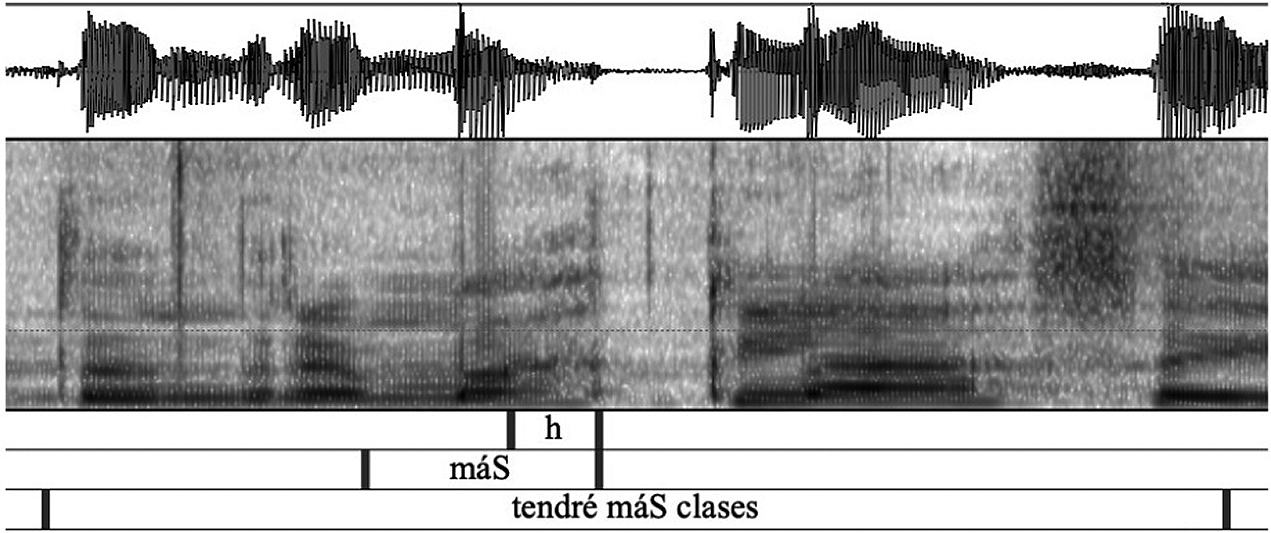
FIGURE 2. Praat screenshot of an aspirated token of /s/.
Finally, those instances in which there was no clear sound perceived auditorily or visually that might represent /s/ between the previous sound and the following sound (or pause) were categorized as deleted (see Figure 3). The delimited interval on tier 1 labeled “d” is a placeholder for the deleted /s/ token.

FIGURE 3. Praat screenshot of a deleted token of /s/.
Continuous Dependent Variables: /S/-Voicing, COG, and Duration
In addition to human-given categorical impressionistic codes, three continuous acoustic correlates were extracted using Praat. First, the percentage of voicelessness of each /s/ token was extracted from Praat’s Voice Report. This report determines the ratio of voiceless frames in a specified interval. These figures were converted into percentages by multiplying the ratio of voicelessness by 100. Deleted tokens of /s/ (n = 267) were excluded from the voicing analysis, as there is no sound to measure voicing. Also, Praat’s Voice Report cannot obtain a reliable estimate with shorter segments when very few glottal pulses occur, so tokens of /s/ shorter than 40 milliseconds were excluded from the analysis as well. This left 3,568 tokens of /s/ for the analysis of voicing.
Second, we obtained the COG of /s/ for each token. The COG of a sound is its average frequency in hertz and has been found to correlate with /s/-weakening (File-Muriel & Brown, Reference File-Muriel and Brown2011); weakened /s/ has lower COG values. To measure COG, the middle 50% of each /s/ was extracted and the lowest 750 Hz of the sound signal was eliminated with a Pass Hann filter in Praat. Examining the middle 50% of the tokens reduced the potential coarticulation effects from flanking sounds. Removing the lowest 750 Hz of the speech signal minimized the effect that voicing has on COG measurements because the majority of voicing is present in the lowest part of the frequency band. Similar to the voicing analysis, deleted tokens of /s/ were excluded from the analyses of COG, as there is no sound present in which to measure COG. This exclusion left 4,091 tokens of /s/ for the analysis of COG.
Finally, we measured the duration of /s/ in milliseconds from the beginning to the end of each /s/ token. Deleted tokens of /s/ were assigned a duration of 0 milliseconds. Hence, the number of tokens available for the analysis of the duration of /s/ was the full 4,319 tokens originally delimited.
Given that these continuous variables all indicate phonetic reduction, one would expect that as duration and COG of an /s/ decrease, the amount of voicing would increase. Indeed, Schmidt (Reference Schmidt2014) found this to be the case for /s/-voicing and /s/ segment duration in her study. In this study, Kendall’s rank correlation testsFootnote 5 confirmed this assumption as /s/-voicing had a significant negative correlation with duration (τ = −0.14, p < 0.001) and COG (τ = −0.15, p < 0.001) whereas duration and COG were positively correlated (τ = 0.11, p < 0.001). Additionally, we confirmed that these measures of /s/-weakening were appropriate, given that for the tokens categorized as sibilants, there was significantly less voicing, higher COG, and longer duration than the tokens categorized as aspirated in three Wilcoxon rank sum tests with continuity correction (voicing: W = 285,450, p < 0.001; COG: W = 30,366, p < 0.001; duration: W = 156,840, p < 0.001). See Table 1 for a summary of information on these correlations.
TABLE 1. Mean (and median) values for the three continuous variables organized by the categorical dependent variable for all participants

Independent Variables
We included four linguistic and one extralinguistic categorical factor in our analysis: word position (word-medial, word-final), preceding sound (high vowel, non-high vowel), following phonological context (voiced consonant, voiceless consonant, pause), prosodic stress, and grouping of participants (Time 1, Time 2, NS). Additionally, we examined three continuous independent variables: relative speech rate for each /s/ token by obtaining the duration in milliseconds of the three-word string in which /s/ occurred and dividing that number by the number of phonemes in the three words (excluding the /s/ token).Footnote 6 Second, we took the logarithm of the lexical frequency of each word as found in the Corpus del Español: Web/Dialects (Davies, Reference Davies2016). Based on this measure, the 10 most frequent words under analysis in our dataset were, in order: es “3s to be,” más “more,” este “this ᴍᴀsᴄ sɪɴɢ,” esta “this ꜰᴇᴍ sɪɴɢ,” nos “1ᴘ ᴏʙʟ ᴘʀᴏɴ,” está “3s to be,” desde “from,” hasta “until,” dos “two,” esto “this ɴᴇᴜᴛ.” We opted to use this large, pan-Hispanic external corpus rather than the corpus of interviews examined in this study to obtain a more realistic measure of lexical frequency to which the L2 learners were exposed as opposed to the lexical frequency of words employed within the limited number of topics discussed in the interviews. Finally, for the L2 learners, we included the raw scores on the grammar test at the beginning and end of the SA to determine if this measure of language proficiency affected the L2 acquisition of /s/-weakening.
Statistical Analyses
The categorical data were compared across groups/times by means of chi-square tests and the continuously coded data were subjected to mixed-effects linear regression, with speaker and lexical items entered as random effects (specifically random intercepts) and the previously mentioned independent variables as fixed effects. The lme4 R package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) was used for this purpose, while the lmerTest R package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017) was utilized to get p-values for the fixed effects, and the EMAtools R package (Kleiman, Reference Kleiman2017) was used to calculate Cohen’s d values.
RESULTS
A total of 4,319 tokens of coda /s/ were delimited and were distributed fairly evenly among the six groupings of participants: DRtime1 = 709 tokens, DRtime2 = 681, DRnative = 669, Spaintime1 = 727, Spaintime2 = 753, Spainnative = 780. We begin by presenting the results for the categorical coding of the dependent variable followed by the results for the continuous dependent variables.
Classification of /s/ into Categories
The results of the categorical coding of /s/ production show that students maintain sibilance almost categorically at both the beginning and the end of their SA experience (see Figure 4 and Table 2).

FIGURE 4. Distribution of impressionistic codes of /s/ as percentages by country and by speaker grouping.
TABLE 2. Distribution of impressionistic codes of /s/ (row-wise percentages)
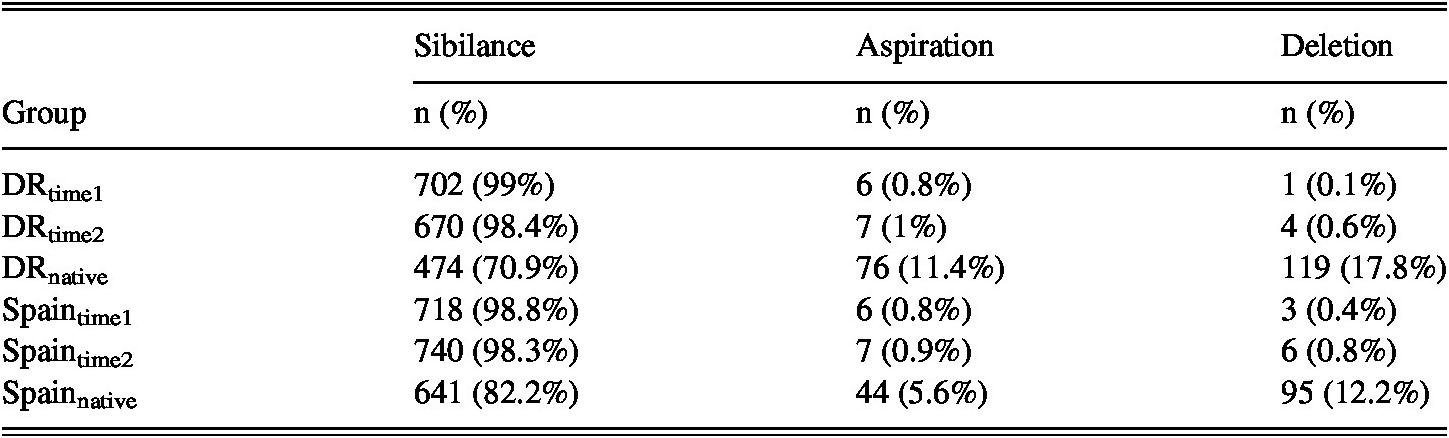
With the aspirated and deleted tokens of /s/ conflated into one category, the differences between the rates of sibilance versus aspiration/deletion production by the students at the beginning of their SA sojourn and its conclusion are not significant in chi-square tests in the DR (𝛘2 ≤ 0.6, df = 1, p = 0.4, ϕ = 0.03) or in Spain (𝛘2 = 0.3, df = 1, p = 0.6, ϕ = 0.02). As displayed in Figure 4 and Table 2, the NSs in both countries produced fewer sibilant tokens of /s/ than the students. Additionally, the Dominicans produce significantly fewer sibilants than the Spaniards (𝛘2 = 25.4, df = 1, p ≤ 0.001, ϕ = 0.13).
When coded impressionistically, the students in both countries produced near-categorical sibilants /s/ at both Time 1 and Time 2. Given these findings, we did not run a regression model for these data because regardless of the potential constraining factors, students maintained sibilant /s/.
VOICING OF /S/
Students in both countries voiced the /s/ interval to a significantly greater degree at Time 2 than Time 1 as indicated by the negative coefficient value and the negative Cohen’s d value at Time 2 displayed in the tables in Appendices A and B. However, the effect size for the DR students (−0.434) was nearly three times as large as the effect size for the Spain students (−0.153). Additionally, while the percentage of voicing of the /s/ interval among the students in both countries at Time 2 was not significantly different from their native-speaking counterparts, there were important differences between student groups. Specifically, in the DR, the absolute value of the effect size between Time 2 and Native is small (d = −0.151), whereas in Spain the absolute value of the effect size is much larger (d = 0.690), indicating that the DR students approximate more closely the Dominicans with respect to voicing than the Spain students approximate the Spaniards. Figure 5 presents these findings in visual form, as it displays two boxplots organized by country and grouping.

FIGURE 5. Boxplot of percentage voiced of /s/ by country and speaker grouping.
Turning to the factors that constrain /s/-voicing, Table 3 indicates the independent factors that significantly constrain /s/-voicing, as reported in six multifactorial mixed-effects linear regressions, one for each participant group with the asterisks indicating the relative p-value.
TABLE 3. Six mixed-effects linear regressions of /s/-voicing
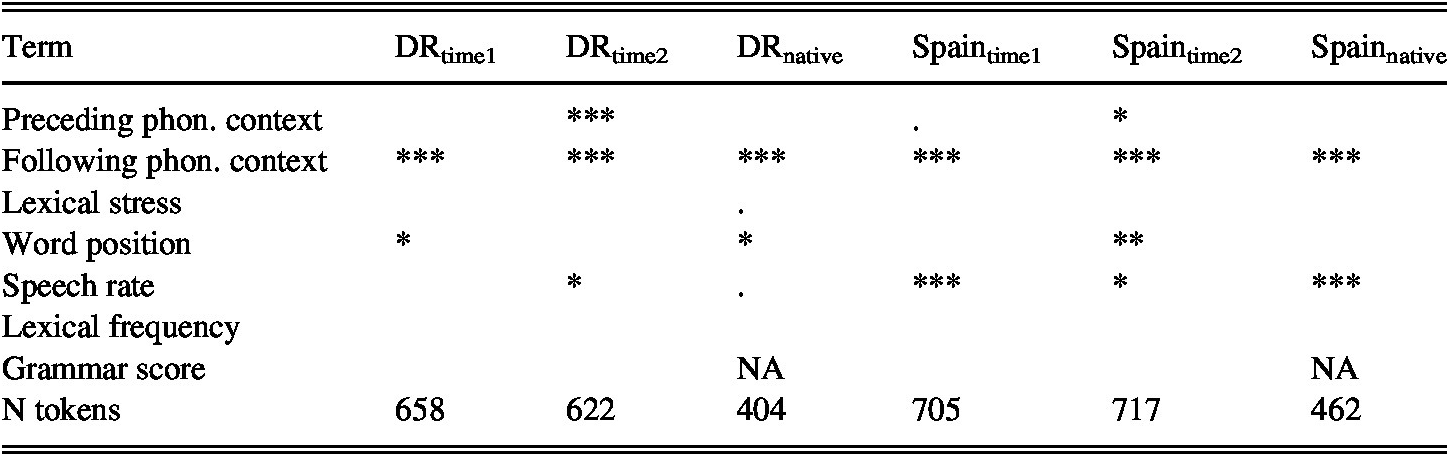
Note: *** p = 0.001; ** p = 0.01; * p = 0.05. p = 0.1 [empty] p > 0.1
Following phonological context was the only factor that significantly constrained /s/-voicing for each group at Time 1 and Time 2, as well as for the NSs in both countries. In every case, significantly more /s/-voicing occurred when /s/ was followed by a voiced consonant. Speech rate was significant for four of the six groupings of participants, and marginally significant for the Dominicans (p = 0.08). In each case in which this factor was significant, /s/-voicing increased as the rate of speech increased. In addition, for both groups of students, preceding phonological context also significantly constrained /s/-voicing at Time 2, such that there was more /s/-voicing in contexts preceded by high vowels than non-high vowels. Finally, word position was found to be significant for the DR students at Time 1, the Spain students at Time 2, and native Dominicans, as coda /s/ in word-final position was voiced to a greater degree than coda /s/ in word-medial position. Finally, grammar scores, lexical stress, and lexical frequency were never significant for any group.
COG OF /S/
The students in both countries increased the COG of coda /s/ away from that of the NSs in their respective host countries (see Appendix C and D for full results). In both cases, the negative coefficient of Time 1 suggests that the students at the beginning of their SA experiences articulated a lower COG of /s/ than at the end of their stays. The difference between Time 1 and Time 2 is appreciable in visual form in Figure 6.

FIGURE 6. Boxplot of COG of /s/ by country and speaker grouping.
As for factors constraining COG, Table 4 shows that speech rate significantly constrained COG for all groups and times; as speech rate increases, values of COG decrease for all groups. Following phonological context was also significant for all groups except the Spain students at Time 1. For this factor, the COG was significantly lower when /s/ was followed by a voiced consonant. Also, for the NSs and Spain students at Time 2, COG was significantly conditioned by the position of /s/ within the word, such that word-final /s/ has a significantly lower COG than word-medial /s/. In addition, for the native Dominicans, COG was significantly lower in atonic syllables. Finally, preceding phonological context, lexical frequency, and grammar test scores were not significant for any group.
TABLE 4. Six mixed-effects linear regressions of COG of /s/

DURATION OF /S/
The results of the analysis of the duration of /s/ show that the DR and Spain students significantly decrease the duration of their articulation of coda /s/ toward their native-speaking models, but still remain significantly different from their native-speaking counterparts at the end of their SA experiences. The coefficient for Time 1 in Appendix E shows that, on average, the duration of /s/ at Time 1 was 10.6 milliseconds longer than at Time 2 (the reference level not shown), but that the native Dominicans produced coda /s/ on average with a duration 30.7 milliseconds shorter than the students at Time 2. The p-values indicated that both of those differences were significant.
Similar results are viewable in the results of the mixed-effects linear regression of the data gathered in Spain (see Appendix F). On average, the students produced coda /s/ 13.8 milliseconds faster by Time 2, but the native Spaniards still produced coda /s/ significantly faster than the students at Time 2.
The results of the analysis of effect size show that the difference between Time 1 and Time 2 is larger for the Spain students than the DR students, as the Cohen’s d score for Time 1 in Appendix E is 0.112 while the corresponding value in Appendix F is 0.195. This difference can also be observed in Figure 7 as the box representing the middle 50% of the durations of coda /s/ produced by the students at Time 2 is comparatively lower than the Time 1 box, but more so in Spain than in the DR.

FIGURE 7. Boxplot of duration of /s/ by country and speaker grouping.
As viewable with the summary of the regressions in Table 5, speech rate and following phonological context significantly constrained duration of /s/ for all groups, such that duration was shorter as the rate of speech increased and when the following phonological context was not a pause. Also, word position significantly constrained the duration of /s/ for the DR students at Time 1 and Time 2 and for the Spain students at Time 1; among the students, word-medial /s/ was pronounced quicker than word-final /s/. Additionally, lexical stress significantly constrained /s/ duration for the native Dominicans such that coda /s/ was longer in tonic syllables than those in atonic ones. Similar to the results for COG, preceding phonological context, lexical frequency, and grammar test scores did not significantly constrain /s/ duration for any group.
TABLE 5. Six mixed-effects linear regressions of /s/ duration

DISCUSSION
The first part of the research question asks whether L2 learners become more nativelike by the end of a semester-long SA sojourn with respect to their production of coda /s/. Given previous research (e.g., Escalante, Reference Escalante2018; Geeslin & Gudmestad, Reference Geeslin and Gudmestad2011), it was expected that L2 learners would produce very few weakened /s/ forms (i.e., aspirated or deleted) when classified categorically even after extended exposure to an /s/-weakening dialect of Spanish, and the results of this study confirm that hypothesis. After a semester abroad, both groups of students showed no significant change in the percentage of sibilant /s/ realizations they produced, as they almost always articulated coda /s/ as a sibilant at the beginning and end of SA. As such, no factors appear to constrain the variable pronunciation of coda /s/. Based on these results alone, it appears that a semester abroad does not lead to the acquisition of nativelike /s/-weakening. This result is similar to previous studies on phonetic forms that show very minimal use of other dialectically indexed forms even after time abroad such as the peninsular-Spanish [θ] (e.g., George, Reference George2014; Ringer-Hilfinger, Reference Ringer-Hilfinger2012) or vowels in English (Fox & McGory Reference Fox, McGory, Bohn and Munro2007). However, our these findings contrast with research on the L2 acquisition of other sociolinguistic variables in which students demonstrated approximation of NS norms after increased exposure to these features (e.g., Geeslin et al., Reference Geeslin, García-Amaya, Hasler-Barker, Henriksen, Killam, Borgonovo, Español-Echevarría and Prévost2010; Kanwit et al., Reference Kanwit, Geeslin and Fafulas2015; Pozzi, Reference Pozzi2017; Raish, Reference Raish2015; Salgado-Robles, Reference Salgado-Robles2011).
Why do learners exhibit the use of some but not all regional features in their speech after being exposed to those features while abroad? For /s/-weakening, it is safe to assume that it is not due to infrequent use of this feature among NSs in the host community because the native Dominican speakers in our study employed /s/-weakening often even when talking with a non-NS interviewer (see Table 2). It also does not appear to be due to lacking the ability to perceive /s/-weakening because previous research has shown that L2 learners gain this ability after exposure to /s/-weakening dialects during stays abroad (Bedinghaus, Reference Bedinghaus2015; Schmidt, Reference Schmidt2018). Furthermore, 9 of the 11 DR students indicated that they were aware of Dominicans “dropping” the /s/ in speech, and all DR students completed a short course regarding Dominican Spanish in which /s/-weakening was discussed. The findings also suggest that students don’t maintain coda /s/ simply due to its communicative value when it marks person and number as proposed in Geeslin and Gudmestad (Reference Geeslin and Gudmestad2011) because tokens of /s/ were excluded when they represented the entirety of a morpheme. It is possible that L2 learners avoid producing /s/-weakening because of the stigma associated with the variable as suggested in Escalante (Reference Escalante2018). However, if this were the case, it would likely be an implicit bias (i.e., below the level of consciousness) because when the DR students were asked about their opinions regarding the Dominican dialect, only one student indicated that they thought /s/ deletion was incorrect, and most students had only positive things to say about the dialect, with several students indicating that they made a conscious effort to speak Spanish like a Dominican. Indeed, research finds that speakers’ implicit attitudes toward language may in some cases diverge from their explicit attitudes (Pantos & Perkins, Reference Pantos and Perkins2012) and conscious positive attitudes toward a given dialect do not always lead to the adoption of dialectal features (e.g., Ringer-Hilfinger, Reference Ringer-Hilfinger2012). It could also be that the inherent complexity of variable /s/-weakening, which also diverges substantially from the L2 learners’ L1 English sound system, is too difficult cognitively for L2 learners at this stage in their acquisition to integrate into their developing L2 system. In fact, the only speakers from the Geeslin and Gudmestad (Reference Geeslin and Gudmestad2011) study who showed /s/-weakening in their speech were those who had achieved an advanced level of proficiency. Finally, students’ maintenance of /s/ may have been affected by the fact that the interviewer does not produce /s/-weakening regularly in his speech. As such, learners may have maintained /s/ to converge their speech with that of the interviewer. In sum, these results suggest that learners at this level of proficiency do not develop this type of dialect-specific sociolinguistic competence even after a semester-long SA experience and that this does not appear to be due to a lack of exposure, perceptual abilities, the communicative value of morphemic /s/, or a conscious negative attitude toward /s/-weakening varieties of Spanish. Future research might seek to confirm if the lack of acquisition of this and other dialectal features is due to implicit bias, learner proficiency, convergence with the interviewer, and/or other factors.
The second part of the research question seeks to determine whether after a semester studying abroad, students become more nativelike with respect to three acoustic correlates of /s/-voicing, COG, and duration. First, the overall production of these variables by the L2 learners presents a mixed bag: after SA, /s/ voicing and duration by the L2 learners significantly moved toward the native-speaking norm, but for COG the opposite was true. Our L2 learners not only voiced /s/ tokens at Time 1 and Time 2, they significantly increased the amount of voicing of coda /s/ in the direction of the NSs between times. This finding contrasts with Schmidt (Reference Schmidt2014), who found that very few /s/ tokens (only 4.5%) produced by advanced L2 learners had a percentage of voicing at or above 60%. In our study, by the end of SA, 25.7% of the /s/ tokens produced by the DR students and 12.8% of the /s/ tokens produced by the Spain students were at or above 60% voicing. One possible explanation for these diverging results is that the L2 learners in her study completed very controlled tasks whereas the participants in the current study produced spontaneous speech. In fact, previous research has shown that for NSs, sibilant /s/ is voiced more in spontaneous speech than in controlled tasks (García, Reference García2013).
Another important finding regarding /s/-voicing is that the DR students changed the percentage of the /s/ interval that they voiced more than the Spain students. Furthermore, at the end of the SA experience, the mean percentage of voicing of the DR students (36.5%) was very close to that of the native Dominicans (33.3%). Looking at the results for /s/-voicing alone, it appears that L2 learners become more nativelike regarding /s/-voicing regardless of where they study abroad, but L2 learners who are exposed to a dialect of Spanish in which /s/-weakening is more common (i.e., the Dominican Republic) develop more nativelike weakening than those who are not. However, this idea is more nuanced than the results of /s/-voicing alone suggest. For example, regarding duration, despite the fact that both L2 groups continued to produce /s/ with a significantly higher duration than the NSs at Time 2, both learner groups significantly decreased the average duration of the /s/ tokens in the direction of the NSs, with the Spain students showing more nativelike development than the DR students. Regarding COG, both groups of students became significantly less nativelike by increasing this phonetic quality by the end of their semester abroad, but there does not appear to be a clear developmental difference between groups. Hence, whereas students progress toward the NS norm of /s/-weakening by increasing their /s/-voicing and decreasing their /s/ duration, the unique effect of dialect-specific input on the development of the production of /s/-weakening remains unclear given that students maintain sibilance despite exposure and they are not more nativelike with regard to COG and various constraining factors.
These results also raise another important question: Why do students become more nativelike with overall voicing and duration of /s/ but less nativelike with COG? One possibility is that this is a result of phonetic saliency (MacWhinney, Reference MacWhinney and Robinson2001). Voicing and duration of /s/ may be more salient cues in the auditory input than the phonetic quality of the frication of coda /s/, as measured by COG. As such, it may be easier for students to convert the amount of voicing and duration of /s/ in the input they receive into usable intake that subsequently reorganizes their developing L2 phonological system in Spanish (Schmidt, Reference Schmidt and Robinson2001). Indeed, the apparent lack of sensitivity to COG is reminiscent of what Brown and Copple (Reference Brown and Copple2018) found regarding the production of /p/, /t/, /k/ in English by heritage speakers of Spanish. These speakers produced nativelike VOT of /p/, /t/, /k/ in English, but the COG of their /p/, /t/, /k/ tokens in English more closely reflected the COG of Spanish /p/, /t/, /k/ rather than that of other English speakers. Another possibility is that shorter duration and increased voicing is not based on perception at all but rather is an artifact of increased oral fluency that often occurs during SA (García-Amaya, Reference García-Amaya, Collentine, García, Lafford and Marcos-Marín2009). It is logical to assume that a faster overall rate of speech would lead to shorter duration of /s/—as Escalante (Reference Escalante2018) found—as well as increased gestural overlap of voicing with the flanking sounds, which for coda /s/ always involves at least one voiced segment (i.e., a preceding vowel). COG, however, may be something that is either not directly affected by fluency or, for native English speakers, fluency affects COG in the opposite direction than it does in Spanish. This might explain why, despite being able to perceive /s/-aspiration after exposure to an /s/-weakening dialect, L2 learners do not produce more tokens of aspirated /s/ but demonstrate /s/-weakening by increased voicing and decreased duration. Whether these two acoustic correlates are precursors to the conversion of sibilance to aspiration or deletion among L2 learners is an interesting question that future studies may seek to address.
Concerning the factors constraining the three acoustic variables, both groups show similarities and differences between Time 1 and Time 2 and between each other and their native-speaker counterparts. First, speech rate and the following phonological context consistently played a role for almost all acoustic measures for both NS groups and the L2 learners at Time 2 (and often at Time 1). Faster speech and a following voiced consonant (or pause for duration) conditioned more /s/-weakening by increasing the amount of the /s/ interval that is voiced, lowering the COG values, and shortening the duration of /s/. These two factors were almost always significant for the L2 learners, even at Time 1, and they were the only two that were consistently significant for both groups of NSs for almost all acoustic measures. This suggests that speech rate and following phonological context are the strongest predictors of /s/-weakening, as found in previous research on L1 Spanish (Erker, Reference Erker2010; File-Muriel & Brown, Reference File-Muriel and Brown2011). Hence, the input to which the students are exposed is more consistent for these two factors, and as such, they appear to be more easily acquired by the L2 learners. Other factors such as word position, preceding phonological context, and lexical stress were not found to be as consistently significant as the other factors, although when they were significant, they affected the dependent variables in the expected direction. Conversely, lexical frequency, which has been found in previous research to be a significant predictor of /s/-weakening (e.g., File-Muriel & Brown, Reference File-Muriel and Brown2011), did not constrain /s/-weakening for any group. Although this finding was unexpected for the NSs, for the L2 learners it reflects previous research examining the L2 acquisition of this and other phonetic variables (Escalante, Reference Escalante2018; Solon et al., Reference Solon, Linford and Geeslin2018).
Regarding the independent factors that constrain the articulation of the three acoustic correlates of /s/-weakening, after their experience abroad, the Spain students appear to become more like the Spaniards than the DR students do to the Dominicans. In Spain, the students’ articulation of /s/ at Time 2 was conditioned by all, and only, the same factors that constrained the COG and duration of /s/ among the Spaniards. In contrast, in the DR, the students’ production of /s/ at Time 2 was never constrained by all of the same factors that conditioned the articulation of the Dominicans for any of the three phonetic properties studied here. Whether this result is directly attributable to the relative levels of overall /s/-weakening in the two countries is unclear and merits further attention in future research.
CONCLUSION
An overarching goal of this study is whether L2 learners demonstrated the acquisition of sociolinguistic competence by employing /s/-weakening in Spanish after extended exposure to this dialectal feature. This larger inquiry can be answered both affirmatively and negatively, depending on the manner in which one measures coda /s/ articulation. When analyzed categorically as one of three possible categories (i.e., sibilance, aspiration, or deletion), the answer appears to be no: Students do not change their near-categorical maintenance of sibilant realizations of coda /s/ after extended exposure to this feature. This finding reflects previous research on this and other dialectal features (e.g., Escalante, Reference Escalante2018; Fox & McGory Reference Fox, McGory, Bohn and Munro2007; Ringer-Hilfinger, Reference Ringer-Hilfinger2012) but diverges from studies that show development of other dialectal features (e.g., Friesner & Dinkin, Reference Friesner and Dinkin2006; Pozzi Reference Pozzi2017; Raish, Reference Raish2015). We suggest that these results may be due to factors such as implicit bias against /s/-weakening, the inherent complexity of /s/-weakening, and/or the effect of the interviewers’ speech on the L2 learners. In more general terms, our results suggest that the L2 acquisition of sociolinguistic competence is likely mitigated by factors beyond extended exposure.
When the phonetic qualities of coda /s/ are investigated, the answer to the larger question of whether the students become more nativelike was generally positive, but not for all acoustic measures. They became more nativelike by voicing more of the /s/ interval and by shortening the duration of /s/, but they did not become more nativelike with respect to the COG of the /s/ phone. In addition, whereas the DR students did not show clear development toward the NSs with regard to the constraining factors on /s/-weakening, the Spain students did for COG and duration. These findings suggest that observing the L2 development of sociolinguistic competence may require examining features in noncategorical manners to discover subtle changes in the learners’ speech.
Although this study sheds light on L2 acquisition of variable /s/-weakening and, more broadly, sociolinguistic competence, future research will need to confirm and expand on our findings. As suggested earlier, to better understand why learners acquire some dialectal features and not others, studies should examine language attitudes in further detail, including whether students have implicit bias against certain features and not others and if this affects the acquisition of these features. In addition, it would be beneficial to study L2 learners of higher proficiency and/or those that have been exposed to /s/-weakening during substantially more time than our students to determine if more advanced learners continue to become more nativelike with regard to /s/-weakening. Furthermore, it remains unclear what effects explicit teaching of, fostering positive attitudes toward, and/or encouragement to employ a regional feature by instructors has on its acquisition. Moreover, if a learner acquires a dialectal feature, how does this benefit them in their interactions with other Spanish speakers, especially in cases in which the dialectal feature they have acquired is stigmatized? Finally, future research would benefit from examining the effects of additional factors such as the specific attributes of the experience abroad, L2 identity (e.g., Drummond, Reference Drummond2012) and social networks, as previous research has shown this to affect the acquisition of regional features (e.g., Kennedy Terry, Reference Kennedy Terry2017; Pope, Reference Pope, Sessarego and Tejedo-Herrero2016; Pozzi, Reference Pozzi2017; Trentman, Reference Trentman2017; Uritescu et al., Reference Uritescu, Mougeon, Rehner and Nadasdi2004).
This research was partially supported by an undergraduate Research Assistant Award from the Office of Undergraduate Research and Scholarship at Grand Valley State University. We also thank the anonymous reviewers who provided insight and expertise that greatly assisted the research.
Appendix A Mixed-Effects Linear Regression of Voicing of /s/ in DR

N = 1,684; Log. likelihood = −8,117; AIC = 16,261, Note: The reference level of the grouping factor is Time 2 and, as such, it is not shown.
Appendix B Mixed-Effects Linear Regression of Voicing of /s/ in Spain
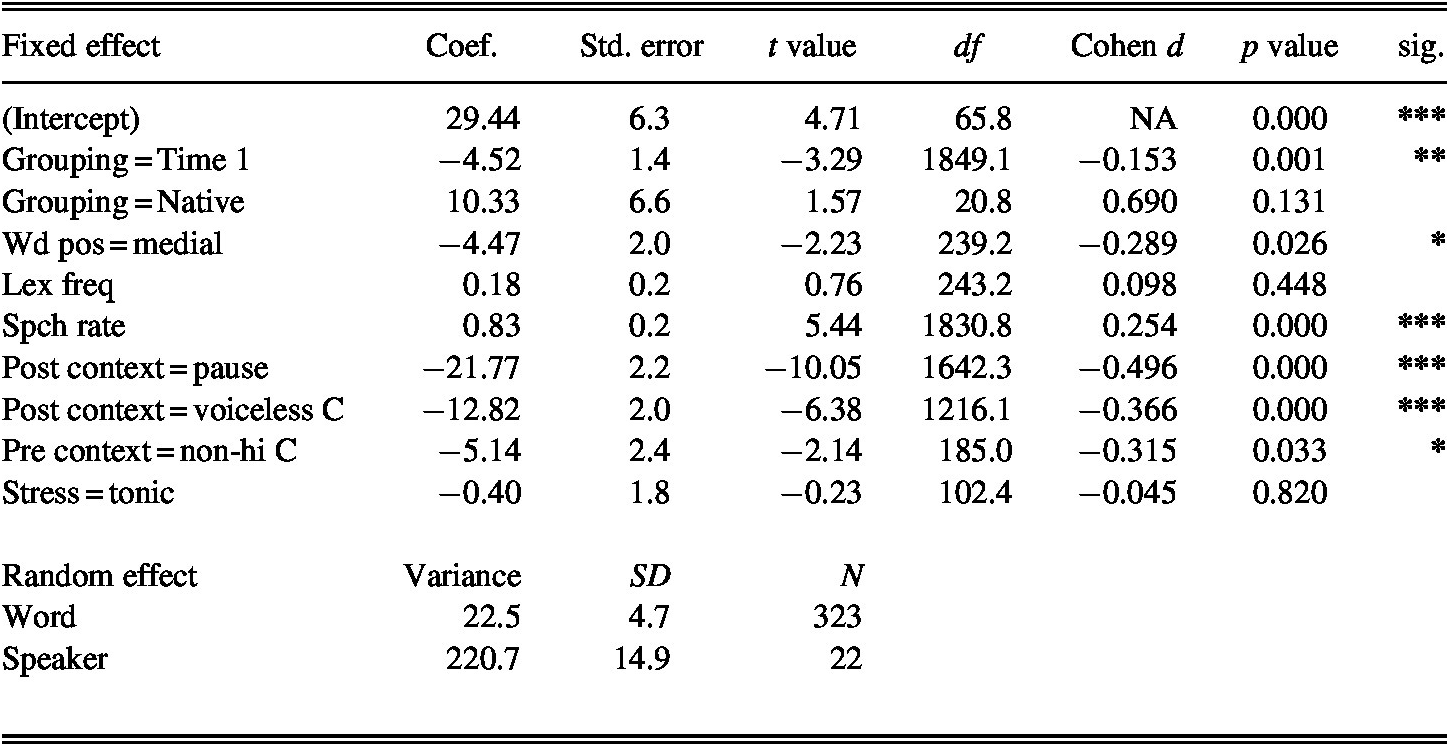
N = 1,884; Log. likelihood = −8,788; AIC = 17,602.
Appendix C Mixed-Effects Linear Regression of COG of /s/ in DR

N = 1,935; Log. likelihood = −16,627; AIC = 33,280.
Appendix D Mixed-Effects Linear Regression of COG of /s/ in Spain
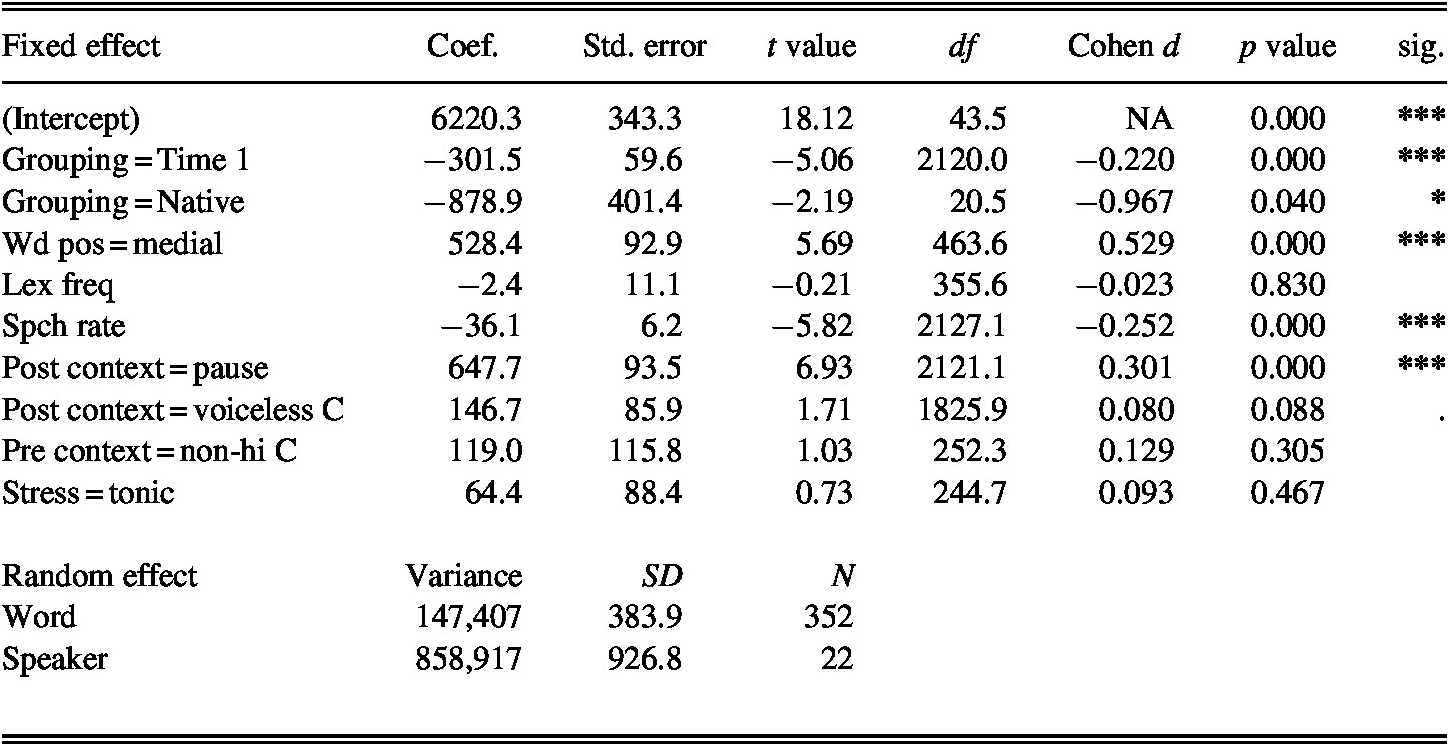
N = 2,156; Log. likelihood = −18,195; AIC = 36,415.
Appendix E Mixed-Effects Linear Regression of Duration of /s/ in DR

N = 2,059; Log. likelihood = −11,889; AIC = 23,802.
Appendix F Mixed-Effects Linear Regression of Duration of /s/ in Spain

N = 2,260: Log likelihood = −12,348; AIC = 24,720.













 Open access
Open access