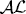1 Introduction
Automated planning represents one of the core components in the design of autonomous intelligent systems. The term refers to the task of finding a course of actions (i.e., a plan) that changes the state of the world from a given state to another state. An automated planner takes a planning problem as input, which consists of a domain description or an action theory, the initial state description, and the goal state description, and computes a solution of the problem if one exists. Automated planning has been an active research area of Artificial Intelligence for many years. It has established itself as a mature research area with its own annual conference, the International Conference on Automated Planning and Scheduling (ICAPS)Footnote 1 series starting from 1991, with several satellite workshops related to planning and scheduling as well as the planning competition for many tracks. Consequently, the literature on planning is enormous. The textbooks by (Ghallab et al. Reference Ghallab, Nau and Traverso2004) and 2016 includes more than 500 and 600 references, respectively. The monograph on planning with focus on abstraction and decomposition by (Yang Reference Yang1997) has more than 150 references. The survey on classical planning by (Hendler et al. Reference Hendler, Tate and Drummond1990) also referred to more than 100 papers. Similar observation can be made about the survey by (Weld Reference Weld1994), which mainly discusses partial order planning. There are also special collections or special issues on planning such as (Allen et al. Reference Allen, Kautz, Pelavin and Tenenberg1991; 1990). In addition, several planning systems addressing different aspects of planning have been developed,Footnote 2 which will be discussed in more details in Sections 3–5. Our goal in this paper is to provide a survey on answer set planning, a relatively late addition to the rich body of research in automated planning that has not been comprehensively surveyed so far.
Answer set planning, a term coined by (Lifschitz Reference Lifschitz1999), refers to the use of Answer Set Programming (ASP) in planning. In this approach, planning problems are translated to logic programs whose answer sets correspond to solutions of the original planning problems. This approach is related to the early approach to planning using automated theorem provers by (Green Reference Green1969). Although similar in the emphasis of using a general logical solver for planning, answer set planning and planning using automated theorem provers differ in that the former computes an answer set (or a full model) to find a solution whilst the latter identifies a solution with a proof of a query. Answer set planning is more closely related to the prominent approach of planning using satisfiability solvers (SAT-planning) proposed by (Kautz and Selman Reference Kautz and Selman1992) and (Kautz et al. Reference Kautz, McAllester, Selman, Aiello, Doyle and Shapiro1996), who showed, experimentally, that SAT-planning can reach the scalability and efficiency of contemporary heuristic-based planning systems. This success is, likely, one of the driving forces behind the research on using logic programs under the answer set semantics for planning. The idea of answer set planning was first discussed by (Subrahmanian and Zaniolo Reference Subrahmanian and Zaniolo1995) and further developed by (Dimopoulos et al. Reference Dimopoulos, Nebel and Köhler1997), who also demonstrated that answer set planning can be competitive with state-of-the-art domain-independent planner at the time.
Answer set planning offers a number of features which are advantageous for researchers. First, by virtue of the declarative nature of logic programming, answer set planning is itself declarative and elaboration tolerant. This enables a modular development of planning systems with special features. For example, to consider a particular set of solutions satisfying an user’s preferences, one only needs to develop rules expressing these preferences and adds them to the set of rules encoding the planning problem (Son and Pontelli Reference Son and Pontelli2006); to exploit the various types of domain knowledge in planning, one only needs to develop rules expressing them to the set of rules encoding the planning problem (Son et al. Reference Son, Baral, Nam and McIlraith2006). To the best of our knowledge, there exists no other planning system that can simultaneously exploit all three well-known types of domain knowledge – temporal, hierarchical, and procedural knowledge – as demonstrated by (Son et al. Reference Son, Baral, Nam and McIlraith2006). Other features of logic programming such as the use of variables, constraints, and choice atoms allow for a compact representation of answer set planners. For example, the basic code for generating a plan in classical setting requires only 10 basic rules and one constraint while a traditional implementation of a planning system in an imperative language may require thousands of lines. Second, the expressiveness of logic programming facilitates the integration of complex reasoning, such as reasoning with static causal laws, into ASP-based planners. To the best of our knowledge, only answer set planning systems deal directly with unrestricted static causal laws (Son et al. Reference Son, Tu, Gelfond and Morales2005a; Tu et al. Reference Tu, Son, Gelfond and Morales2011). Third, as demonstrated in several experimental evaluations (Gebser et al. Reference Gebser, Kaufmann, Otero, Romero, Schaub and Wanko2013; Son et al. Reference Son, Tu, Gelfond and Morales2005a; Tu et al. 2007; Reference Tu, Son, Gelfond and Morales2011), answer set planning systems perform well against other contemporary planning systems in various categories. Finally, the large body of theoretical building block results in logic programming supports the development of provably correct answer set planners. This is an important feature of answer set planning that is mostly neglected by the vast majority of work in planning, arguably difficult to obtain for planners realized using traditional imperative programming techniques and valuable for foundational research work.
Over the last 25 years, a variety of ASP-based planning systems have been developed, for example (Dimopoulos et al. Reference Dimopoulos, Gebser, LÜhne, Romero and Schaub2019), (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2000), (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b), (Gebser et al. Reference Gebser, Kaufmann, Otero, Romero, Schaub and Wanko2013), (Son et al. Reference Son, Tu, Gelfond and Morales2005a), (Tu et al. Reference Tu, Son and Baral2007), (Tu et al. Reference Tu, Son, Gelfond and Morales2011), (Morales et al. Reference Morales, Tu and Son2007), (Fandinno et al. Reference Fandinno, Laferriere, Romero, Schaub and Son2021), (Rizwan et al. Reference Rizwan, Patoglu and Erdem2020), (Spies et al. Reference Spies, You and Hayward2019), (Yalciner et al. Reference Yalciner, Nouman, Patoglu and Erdem2017), that address several challenges in planning, such as planning with incomplete information, non-deterministic actions, and sensing actions. These systems, in turn, provide the basis for investigation of ASP solutions to problems in areas like diagnosis (Balduccini and Gelfond Reference Balduccini and Gelfond2003), multi-agent path findings (Nguyen et al. Reference Nguyen, Obermeier, Son, Schaub and Yeoh2017; GÓmez et al. Reference GÓmez, HernÁndez and Baier2020), goal recognition design (Son et al. Reference Son, Sabuncu, Schulz-Hanke, Schaub and Yeoh2016), planning with preferences (Son and Pontelli Reference Son and Pontelli2006), planning with action cost (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003a), and robot task planning (Jiang et al. Reference Jiang, Zhang, Khandelwal and Stone2019). This progress has been amplified by the development of efficient and scalable answer set solvers, such as smodels (Niemelä and Simons Reference Niemelä and Simons1997), dlv (Eiter et al. Reference Eiter, Leone, Mateis, Pfeifer and Scarcello1997; Alviano et al. Reference Alviano, Calimeri, Dodaro, FuscÀ, Leone, Perri, Ricca, Veltri and Zangari2017; Alviano et al. Reference Alviano, Dodaro, Faber, Leone and Ricca2013), clasp (Gebser et al. 2007; Reference Gebser, Kaminski, Kaufmann and Schaub2019), and cmodels (Lierler and Maratea Reference Lierler and Maratea2004), together with the invention of action languages for reasoning about actions and change, such as the action languages
 $\mathcal{A}$
,
$\mathcal{A}$
,
 $\mathcal{B}$
, and
$\mathcal{B}$
, and
 $\mathcal{C}$
(Gelfond and Lifschitz Reference Gelfond and Lifschitz1998),
$\mathcal{C}$
(Gelfond and Lifschitz Reference Gelfond and Lifschitz1998),
 $\mathcal{A}_K$
with sensing actions (Lobo et al. Reference Lobo, Mendez and Taylor1997; Son and Baral Reference Son and Baral2001), and actions with nondeterminism (Giunchiglia et al. Reference Giunchiglia, Kartha and Lifschitz1997).
$\mathcal{A}_K$
with sensing actions (Lobo et al. Reference Lobo, Mendez and Taylor1997; Son and Baral Reference Son and Baral2001), and actions with nondeterminism (Giunchiglia et al. Reference Giunchiglia, Kartha and Lifschitz1997).
In this survey, we characterize planning problems using the three dimensions:
-
1. the type of action theories,
-
2. the degree of uncertainty about the initial state, and
-
3. the availability of knowledge-producing actions.
In particular, the literature has named the following classes of planning problems. Classical planning refers to planning problems with deterministic action theories and complete initial states. Conformant planning deals with the incompleteness of the initial state and nondeterministic action theories. Conditional planning considers knowledge producing actions and generates plans which might contain non-sequential constructs, such as if-then or while loop.
This paper presents a survey of research focused on ASP-based planning and its applications. It begins (Section 2) with a brief introduction of ASP and action language
 $\mathcal{B}$
, the main representation language for planning problems. It describes different encodings of answer set planning for problems with complete information and no sensing actions (Section 3). The paper then introduces two different approaches to planning with incomplete information (Section 4) and the description of a conditional planner, which solves planning problems in domains with sensing actions and incomplete information (Section 5). The survey explores next the problems of planning with preferences (Section 6), diagnosis (Section 7), planning in multiagent environments (MAEs) (Section 8), and planning and scheduling in real-world applications (Section 9). The paper concludes with a discussion about open challenges for answer set planning (Section 10).
$\mathcal{B}$
, the main representation language for planning problems. It describes different encodings of answer set planning for problems with complete information and no sensing actions (Section 3). The paper then introduces two different approaches to planning with incomplete information (Section 4) and the description of a conditional planner, which solves planning problems in domains with sensing actions and incomplete information (Section 5). The survey explores next the problems of planning with preferences (Section 6), diagnosis (Section 7), planning in multiagent environments (MAEs) (Section 8), and planning and scheduling in real-world applications (Section 9). The paper concludes with a discussion about open challenges for answer set planning (Section 10).
2 Background
2.1 Answer set programming
As usual, a logic program consists of rules of the form
 \begin{equation*} a_1 \vee \ldots \vee a_m \leftarrow a_{m+},\dots,a_n,{ not \:} a_{n+1},\dots,{ not \:} a_o,\end{equation*}
\begin{equation*} a_1 \vee \ldots \vee a_m \leftarrow a_{m+},\dots,a_n,{ not \:} a_{n+1},\dots,{ not \:} a_o,\end{equation*}
where each
 $a_i$
is an atom of form
$a_i$
is an atom of form
 $p(t_1,\dots,t_k)$
and all
$p(t_1,\dots,t_k)$
and all
 $t_i$
are terms, composed of function symbols and variables. Atoms
$t_i$
are terms, composed of function symbols and variables. Atoms
 $a_1$
to
$a_1$
to
 $a_m$
are often called head atom, while
$a_m$
are often called head atom, while
 $a_{m+1}$
to
$a_{m+1}$
to
 $a_n$
and
$a_n$
and
 ${ not \:} a_{n+1}$
to
${ not \:} a_{n+1}$
to
 ${ not \:} a_o$
are also referred to as positive and negative body literals, respectively. An expression is said to be ground, if it contains no variables. As usual,
${ not \:} a_o$
are also referred to as positive and negative body literals, respectively. An expression is said to be ground, if it contains no variables. As usual,
 ${ not \:}$
denotes (default) negation. A rule is called a fact if
${ not \:}$
denotes (default) negation. A rule is called a fact if
 $m=o=1$
, normal if
$m=o=1$
, normal if
 $m=1$
, and an integrity constraint if
$m=1$
, and an integrity constraint if
 $m=0$
. Semantically, a logic program produces a set of stable models, also called answers sets, which are distinguished models of the program determined by the stable model semantics; see the paper by (Gelfond and Lifschitz Reference Gelfond and Lifschitz1991) for details.
$m=0$
. Semantically, a logic program produces a set of stable models, also called answers sets, which are distinguished models of the program determined by the stable model semantics; see the paper by (Gelfond and Lifschitz Reference Gelfond and Lifschitz1991) for details.
To ease the use of ASP in practice, several simplifying notations and extensions have been developed. First of all, rules with variables are viewed as shorthands for the set of their ground instances. Additional language constructs include conditional literals and cardinality constraints (Simons et al. Reference Simons, Niemelä and Soininen2002). The former are of the form
 $a:{b_1,\dots,b_m}$
, the latter can be written as
$a:{b_1,\dots,b_m}$
, the latter can be written as
 $s\{d_1;\dots;d_n\}t$
,
Footnote 3
where a and
$s\{d_1;\dots;d_n\}t$
,
Footnote 3
where a and
 $b_i$
are possibly default-negated (regular) literals and each
$b_i$
are possibly default-negated (regular) literals and each
 $d_j$
is a conditional literal; s and t provide optional lower and upper bounds on the number of satisfied literals in the cardinality constraint. We refer to
$d_j$
is a conditional literal; s and t provide optional lower and upper bounds on the number of satisfied literals in the cardinality constraint. We refer to
 $b_1,\dots,b_m$
as a condition. The practical value of both constructs becomes apparent when used with variables. For instance, a conditional literal like
$b_1,\dots,b_m$
as a condition. The practical value of both constructs becomes apparent when used with variables. For instance, a conditional literal like
 $a(X):b(X)$
in a rule’s antecedent expands to the conjunction of all instances of a(X) for which the corresponding instance of b(X) holds. Similarly,
$a(X):b(X)$
in a rule’s antecedent expands to the conjunction of all instances of a(X) for which the corresponding instance of b(X) holds. Similarly,
 $2\;\{a(X):b(X)\}\;4$
is true whenever at least two and at most four instances of a(X) (subject to b(X)) are true. Finally, objective functions minimizing the sum of a set of weighted tuples
$2\;\{a(X):b(X)\}\;4$
is true whenever at least two and at most four instances of a(X) (subject to b(X)) are true. Finally, objective functions minimizing the sum of a set of weighted tuples
 $(w_i,\boldsymbol{t}_i)$
subject to condition
$(w_i,\boldsymbol{t}_i)$
subject to condition
 $c_i$
are expressed as
$c_i$
are expressed as
 $\#minimize\{w_1@l_1,\boldsymbol{t}_1:c_1;\dots;w_n@l_n,\boldsymbol{t}_n:c_n\}$
. Analogously, objective functions can be optimized using the
$\#minimize\{w_1@l_1,\boldsymbol{t}_1:c_1;\dots;w_n@l_n,\boldsymbol{t}_n:c_n\}$
. Analogously, objective functions can be optimized using the
 $\#{maximize}$
statement. Lexicographically ordered objective functions are (optionally) distinguished via levels indicated by
$\#{maximize}$
statement. Lexicographically ordered objective functions are (optionally) distinguished via levels indicated by
 $l_i$
. An omitted level defaults to 0. Furthermore,
$l_i$
. An omitted level defaults to 0. Furthermore,
 $w_i$
is a numeral constant and
$w_i$
is a numeral constant and
 $\boldsymbol{t}_i$
a sequence of arbitrary terms. Alternatively, the above minimize statement can be expressed by weak constraints of the form
$\boldsymbol{t}_i$
a sequence of arbitrary terms. Alternatively, the above minimize statement can be expressed by weak constraints of the form
 $\hookleftarrow c_i [w_i@l_i,\boldsymbol{t}_i]$
for
$\hookleftarrow c_i [w_i@l_i,\boldsymbol{t}_i]$
for
 $1\leq i\leq n$
.
$1\leq i\leq n$
.
As an example, consider the following rule:
 \begin{equation*}1 \{ \mathit{move}(D,P,T) : \mathit{disk}(D), \mathit{peg}(P) \} 1 \leftarrow \mathit{ngoal}(T-1), T\leq n.\end{equation*}
\begin{equation*}1 \{ \mathit{move}(D,P,T) : \mathit{disk}(D), \mathit{peg}(P) \} 1 \leftarrow \mathit{ngoal}(T-1), T\leq n.\end{equation*}
This rule has a single head atom consisting of a cardinality constraint; it comprises all instances of
 $\mathit{move}(D,P,T)$
where T is fixed by the two body literals and D and P vary over all instantiations of predicates
$\mathit{move}(D,P,T)$
where T is fixed by the two body literals and D and P vary over all instantiations of predicates
 $\mathit{disk}$
and
$\mathit{disk}$
and
 $\mathit{peg}$
, respectively. Given 3 pegs and 4 disks, this results in 12 instances of
$\mathit{peg}$
, respectively. Given 3 pegs and 4 disks, this results in 12 instances of
 $\mathit{move}(D,P,T)$
for each valid replacement of
$\mathit{move}(D,P,T)$
for each valid replacement of
 $\mathit{T}$
, among which exactly one must be chosen according to the above rule.
$\mathit{T}$
, among which exactly one must be chosen according to the above rule.
Full details of the input language of clingo, along with various examples and its semantics, can be found in the papers by (Gebser et al. Reference Gebser, Kaminski, Kaufmann, Lindauer, Ostrowski, Romero, Schaub and Thiele2015). The interested reader is also referred to the work by (Calimeri et al. Reference Calimeri, Faber, Gebser, Ianni, Kaminski, Krennwallner, Leone, Maratea, Ricca and Schaub2019) for the description of the ASP Core 2 Language.
A logic program can have zero, one, or multiple answer sets. This distinguishes answer set semantics from other semantics of logic programs such as the well-founded semantics of (Van Gelder et al. Reference Van Gelder, Ross and Schlipf1991) or perfect models semantics of (Przymusinski Reference Przymusinski1988). Answer set semantics, together with the introduction of choice rules and constraints, enables the development of ASP as proposed by (Lifschitz Reference Lifschitz1999). Following this approach, a problem can be solved by a logic program whose answer sets correspond one-to-one to the problem’s solutions. Choice rules are often used to generate potential solutions and constraints are used to eliminate potential but incorrect solutions.
2.2 Reasoning about actions: The action description language
 $\mathcal{B}$
$\mathcal{B}$

We review the basics of the action description language
 $\mathcal{B}$
(Gelfond and Lifschitz Reference Gelfond and Lifschitz1998). An action theory in
$\mathcal{B}$
(Gelfond and Lifschitz Reference Gelfond and Lifschitz1998). An action theory in
 $\mathcal{B}$
is defined over a set of actions A and a set of fluents F. A fluent literal is a fluent
$\mathcal{B}$
is defined over a set of actions A and a set of fluents F. A fluent literal is a fluent
 $f \in \mathbf{F}$
or its negation
$f \in \mathbf{F}$
or its negation
 $\neg f$
. A fluent formula is a Boolean formula constructed from fluent literals. An action theory is a set of laws of the form
$\neg f$
. A fluent formula is a Boolean formula constructed from fluent literals. An action theory is a set of laws of the form
 \begin{eqnarray} & \textbf{caused}(\varphi , f) \end{eqnarray}
\begin{eqnarray} & \textbf{caused}(\varphi , f) \end{eqnarray}
 \begin{eqnarray} & \textbf{causes}(a,f, \varphi) \end{eqnarray}
\begin{eqnarray} & \textbf{causes}(a,f, \varphi) \end{eqnarray}
 \begin{eqnarray} & \textbf{executable}(a, \varphi) \end{eqnarray}
\begin{eqnarray} & \textbf{executable}(a, \varphi) \end{eqnarray}
 \begin{eqnarray} & \textbf{initially}(f), \end{eqnarray}
\begin{eqnarray} & \textbf{initially}(f), \end{eqnarray}
where f and
 $\varphi$
are a fluent literal and a set of fluent literals, respectively, and a is an action. A law of the form (1) represents a static causal law, that is, a relationship between fluents. It conveys that whenever the fluent literals in
$\varphi$
are a fluent literal and a set of fluent literals, respectively, and a is an action. A law of the form (1) represents a static causal law, that is, a relationship between fluents. It conveys that whenever the fluent literals in
 $\varphi$
hold then so is f. A dynamic causal law is of the form (2) and represents the (conditional) effect of a while a law of the form (3) encodes an executability condition of a. Intuitively, an executability condition of the form (3) states that a can only be executed if
$\varphi$
hold then so is f. A dynamic causal law is of the form (2) and represents the (conditional) effect of a while a law of the form (3) encodes an executability condition of a. Intuitively, an executability condition of the form (3) states that a can only be executed if
 $\varphi$
holds. A dynamic law of the form (2) states that f is caused to be true after the execution of a in any state of the world where
$\varphi$
holds. A dynamic law of the form (2) states that f is caused to be true after the execution of a in any state of the world where
 $\varphi$
holds. When
$\varphi$
holds. When
 $\varphi = \emptyset$
in (3), we often omit laws of this type from the theory. Statements of the form (4) describe the initial state. They state that f holds in the initial state. We also often refer to
$\varphi = \emptyset$
in (3), we often omit laws of this type from the theory. Statements of the form (4) describe the initial state. They state that f holds in the initial state. We also often refer to
 $\varphi$
as the “precondition” for each particular law.
$\varphi$
as the “precondition” for each particular law.
An action theory is a pair
 $(D,\Gamma)$
where
$(D,\Gamma)$
where
 $\Gamma$
, called the initial state, consists of laws of the form (4) and D, called the domain, consists of laws of the form (1)–(3). For convenience, we sometimes denote the set of laws of the form (1) by
$\Gamma$
, called the initial state, consists of laws of the form (4) and D, called the domain, consists of laws of the form (1)–(3). For convenience, we sometimes denote the set of laws of the form (1) by
 $D_C$
.
$D_C$
.
Example 1 Let us consider a modified version of the suitcase s with two latches from the work by (Lin Reference Lin1995). We have a suitcase with two latches
 $l_1$
and
$l_1$
and
 $l_2$
.
$l_2$
.
 $l_1$
is up and
$l_1$
is up and
 $l_2$
is down. To open a latch (
$l_2$
is down. To open a latch (
 $l_1$
or
$l_1$
or
 $l_2$
), we need a corresponding key (
$l_2$
), we need a corresponding key (
 $k_1$
or
$k_1$
or
 $k_2$
, respectively). When the two latches are in the up position, the suitcase is unlocked. When one of the latches is down, the suitcase is locked. In this domain, we have that
$k_2$
, respectively). When the two latches are in the up position, the suitcase is unlocked. When one of the latches is down, the suitcase is locked. In this domain, we have that
 \begin{equation*}\mathbf{A} = \{open(l_i), close(l_i), get\_key(k_i) \mid i \in \{1,2\}\}\end{equation*}
\begin{equation*}\mathbf{A} = \{open(l_i), close(l_i), get\_key(k_i) \mid i \in \{1,2\}\}\end{equation*}
and
 \begin{equation*}\mathbf{F} = \{locked\} \cup \{up(l_i), holding(k_i) \mid i \in \{1,2\}\}.\end{equation*}
\begin{equation*}\mathbf{F} = \{locked\} \cup \{up(l_i), holding(k_i) \mid i \in \{1,2\}\}.\end{equation*}
The intuitive meaning of the actions and fluents is clear. The problem can be represented using the laws
 \begin{equation*}D^s = \left \{\begin{array}{ll}\textbf{causes}(open(l_i), up(l_i), \emptyset) & \\[4pt]\textbf{causes}(close(l_i), \neg up(l_i), \emptyset) & \\[4pt]\textbf{causes}(get\_key(k_i), holding(k_i), \emptyset) & \\[4pt]\textbf{executable}(open(l_i), \{holding(k_i)\}) & \\[4pt]\textbf{caused}(\{\neg up(l_i)\}, locked) & \\[4pt]\textbf{caused}(\{up(l_1), up(l_2)\}, \neg locked), & \\[4pt]\end{array}\right.\end{equation*}
\begin{equation*}D^s = \left \{\begin{array}{ll}\textbf{causes}(open(l_i), up(l_i), \emptyset) & \\[4pt]\textbf{causes}(close(l_i), \neg up(l_i), \emptyset) & \\[4pt]\textbf{causes}(get\_key(k_i), holding(k_i), \emptyset) & \\[4pt]\textbf{executable}(open(l_i), \{holding(k_i)\}) & \\[4pt]\textbf{caused}(\{\neg up(l_i)\}, locked) & \\[4pt]\textbf{caused}(\{up(l_1), up(l_2)\}, \neg locked), & \\[4pt]\end{array}\right.\end{equation*}
where, in all laws,
 $i = 1,2$
. The first three laws describe the effects of the action of opening a latch, closing a latch, or getting a key. The fourth law encodes that we can open the latch only when we have the right key. Observe that the omission of executability laws for
$i = 1,2$
. The first three laws describe the effects of the action of opening a latch, closing a latch, or getting a key. The fourth law encodes that we can open the latch only when we have the right key. Observe that the omission of executability laws for
 $close(l_i)$
or
$close(l_i)$
or
 $get\_key(k_i)$
indicates that these actions can always be executed. The last two laws are static causal laws encoding that the suitcase is locked when either of the two latches is in the down position and it is unlocked when the two latches are in the up position.
$get\_key(k_i)$
indicates that these actions can always be executed. The last two laws are static causal laws encoding that the suitcase is locked when either of the two latches is in the down position and it is unlocked when the two latches are in the up position.
A possible initial state of this domain is given by
 \begin{equation*}\Gamma^s = \left \{\begin{array}{lllll}\textbf{initially}(up(l_1)) \\[4pt]\textbf{initially}(\neg up(l_2)) \\[4pt]\textbf{initially}(locked) \\[4pt]\textbf{initially}(\neg holding(k_1)) \\[4pt]\textbf{initially}(holding(k_2)). \\[4pt]\end{array}\right .\end{equation*}
\begin{equation*}\Gamma^s = \left \{\begin{array}{lllll}\textbf{initially}(up(l_1)) \\[4pt]\textbf{initially}(\neg up(l_2)) \\[4pt]\textbf{initially}(locked) \\[4pt]\textbf{initially}(\neg holding(k_1)) \\[4pt]\textbf{initially}(holding(k_2)). \\[4pt]\end{array}\right .\end{equation*}
 $\diamond$
$\diamond$
A domain given in
 $\mathcal{B}$
defines a transition function from pairs of actions and states to sets of states whose precise definition is given below. Intuitively, given an action a and a state s, the transition function
$\mathcal{B}$
defines a transition function from pairs of actions and states to sets of states whose precise definition is given below. Intuitively, given an action a and a state s, the transition function
 $\Phi$
defines the set of states
$\Phi$
defines the set of states
 $\Phi(a,s)$
that may be reached after executing the action a in state s. The mapping to a set of states captures the fact that an action can potentially be non-deterministic and produce different results (e.g., an action open might be successful in opening a lock or not if we account for the possibility of a broken lock). If
$\Phi(a,s)$
that may be reached after executing the action a in state s. The mapping to a set of states captures the fact that an action can potentially be non-deterministic and produce different results (e.g., an action open might be successful in opening a lock or not if we account for the possibility of a broken lock). If
 $\Phi(a,s)$
is an empty set it means that the execution of a in s is undefined. We now formally define
$\Phi(a,s)$
is an empty set it means that the execution of a in s is undefined. We now formally define
 $\Phi$
.
$\Phi$
.
Let D be a domain in
 $\mathcal{B}$
. A set of fluent literals is said to be consistent if it does not contain f and
$\mathcal{B}$
. A set of fluent literals is said to be consistent if it does not contain f and
 $\neg f$
for some fluent f. An interpretation I of the fluents in D is a maximal consistent set of fluent literals of D. A fluent f is said to be true (resp. false) in I if
$\neg f$
for some fluent f. An interpretation I of the fluents in D is a maximal consistent set of fluent literals of D. A fluent f is said to be true (resp. false) in I if
 $f \in I$
(resp.
$f \in I$
(resp.
 $\neg f \in I$
). The truth value of a fluent formula in I is defined recursively over the propositional connectives in the usual way. For example,
$\neg f \in I$
). The truth value of a fluent formula in I is defined recursively over the propositional connectives in the usual way. For example,
 $f \wedge g$
is true in I if f is true in I and g is true in I. We say that a formula
$f \wedge g$
is true in I if f is true in I and g is true in I. We say that a formula
 $\varphi$
holds in I (or I satisfies
$\varphi$
holds in I (or I satisfies
 $\varphi$
), denoted by
$\varphi$
), denoted by
 $I \models \varphi$
, if
$I \models \varphi$
, if
 $\varphi$
is true in I.
$\varphi$
is true in I.
Let u be a consistent set of fluent literals and K a set of static causal laws. We say that u is closed under K if for every static causal law
 \begin{equation*}\textbf{caused}(\varphi,f)\end{equation*}
\begin{equation*}\textbf{caused}(\varphi,f)\end{equation*}
in K, if
 $u \models \bigwedge_{p \in \varphi} p$
then
$u \models \bigwedge_{p \in \varphi} p$
then
 $u \models f$
. By
$u \models f$
. By
 $Cl_K(u)$
we denote the least consistent set of literals from D that contains u and is also closed under K. It is worth noting that
$Cl_K(u)$
we denote the least consistent set of literals from D that contains u and is also closed under K. It is worth noting that
 $Cl_K(u)$
might be undefined when it is inconsistent. For instance, if u contains both f and
$Cl_K(u)$
might be undefined when it is inconsistent. For instance, if u contains both f and
 $\neg f$
for some fluent f, then
$\neg f$
for some fluent f, then
 $Cl_K(u)$
cannot contain u and be consistent; another example is that if
$Cl_K(u)$
cannot contain u and be consistent; another example is that if
 $u = \{f,g\}$
and K contains
$u = \{f,g\}$
and K contains
 \begin{equation*}\textbf{caused}(\{f\}, h) \quad \quad {and} \quad \quad \textbf{caused}(\{f, g\}, \neg h),\end{equation*}
\begin{equation*}\textbf{caused}(\{f\}, h) \quad \quad {and} \quad \quad \textbf{caused}(\{f, g\}, \neg h),\end{equation*}
then
 $Cl_K(u)$
does not exist because it has to contain both h and
$Cl_K(u)$
does not exist because it has to contain both h and
 $\neg h$
, which means that it is inconsistent.
$\neg h$
, which means that it is inconsistent.
Formally, a state of D is an interpretation of the fluents in F that is closed under the set of static causal laws
 $D_C$
of D.
$D_C$
of D.
An action a is executable in a state s if there exists an executability proposition
 \begin{equation*}\textbf{executable}(a, \varphi)\end{equation*}
\begin{equation*}\textbf{executable}(a, \varphi)\end{equation*}
in D such that
 $s \models \bigwedge_{p \in \varphi} p$
. Clearly, if
$s \models \bigwedge_{p \in \varphi} p$
. Clearly, if
 $\varphi = \emptyset$
, then a is executable in every state of D.
$\varphi = \emptyset$
, then a is executable in every state of D.
The direct effect of an action a in a state s is the set
 \begin{equation*}e(a,s) = \left \{f \mid\textbf{causes}(a, f, \varphi ) \in D, s \models \bigwedge_{\textstyle{p \in \varphi}}p \right \}.\end{equation*}
\begin{equation*}e(a,s) = \left \{f \mid\textbf{causes}(a, f, \varphi ) \in D, s \models \bigwedge_{\textstyle{p \in \varphi}}p \right \}.\end{equation*}
For a domain D, the set of states
 $\Phi(a,s)$
that may be reached by executing a in s, is defined as follows.
$\Phi(a,s)$
that may be reached by executing a in s, is defined as follows.
-
1. If a is executable in s, then
\begin{equation*}\Phi(a,s) = \{s' \mid s' \mbox{ is a state and }s' =Cl_{D_C}(e(a,s) \cup (s\cap s'))\}; \end{equation*}
-
2. If a is not executable in s, then
$\Phi(a,s) = \emptyset$
.


Intuitively, the states produced by
 $\Phi(a,s)$
are fixpoints of an equation, obtained by closing (with respect to all static causal laws) the set which includes the direct effects e(a,s) of action a and the fluents whose value does not change as we transition from s to s’ through action a (i.e.,
$\Phi(a,s)$
are fixpoints of an equation, obtained by closing (with respect to all static causal laws) the set which includes the direct effects e(a,s) of action a and the fluents whose value does not change as we transition from s to s’ through action a (i.e.,
 $s \cap s'$
).
$s \cap s'$
).
The presence of static causal laws introduces non-determinism to action theories, that is,
 $\Phi(a,s)$
can contain more than one element. For instance, consider the theory with the set of laws
$\Phi(a,s)$
can contain more than one element. For instance, consider the theory with the set of laws
 \begin{equation*}\{\textbf{causes}(a,f), \quad \textbf{caused}(\{f, \neg g\}, \neg h), \quad \textbf{caused}(\{f, \neg h\}, \neg g)\}. \end{equation*}
\begin{equation*}\{\textbf{causes}(a,f), \quad \textbf{caused}(\{f, \neg g\}, \neg h), \quad \textbf{caused}(\{f, \neg h\}, \neg g)\}. \end{equation*}
It is easy to check that
 \begin{equation*}\Phi(a, \{\neg f, \neg g, \neg h\}) = \{\{f, g, \neg h\}, \{f, \neg g, h\}\}.\end{equation*}
\begin{equation*}\Phi(a, \{\neg f, \neg g, \neg h\}) = \{\{f, g, \neg h\}, \{f, \neg g, h\}\}.\end{equation*}
Every domain D in
 $\mathcal{B}$
has a unique transition function
$\mathcal{B}$
has a unique transition function
 $\Phi$
, and we say
$\Phi$
, and we say
 $\Phi$
is the transition function of D. We illustrate the definition of the transition function in the next example.
$\Phi$
is the transition function of D. We illustrate the definition of the transition function in the next example.
Example 2 For the suitcase domain in Example 1, the initial state, given by the set of laws
 $\Gamma^s$
, is defined by
$\Gamma^s$
, is defined by
 \begin{equation*}s_0 = \{up(l_1), \neg up(l_2), locked, \neg holding(k_1), holding(k_2)\}.\end{equation*}
\begin{equation*}s_0 = \{up(l_1), \neg up(l_2), locked, \neg holding(k_1), holding(k_2)\}.\end{equation*}
In state
 $s_0$
, the three actions
$s_0$
, the three actions
 $open(l_2)$
,
$open(l_2)$
,
 $close(l_1)$
, and
$close(l_1)$
, and
 $close(l_2)$
are executable.
$close(l_2)$
are executable.
 $open(l_2)$
is executable since
$open(l_2)$
is executable since
 $holding(k_2)$
is true in
$holding(k_2)$
is true in
 $s_0$
while
$s_0$
while
 $close(l_1)$
and
$close(l_1)$
and
 $close(l_2)$
are executable since the theory (implicitly) contains the laws
$close(l_2)$
are executable since the theory (implicitly) contains the laws
 \begin{equation*}\textbf{executable}(close(l_1),\{\}) {and} \textbf{executable}(close(l_2),\{\})\end{equation*}
\begin{equation*}\textbf{executable}(close(l_1),\{\}) {and} \textbf{executable}(close(l_2),\{\})\end{equation*}
which indicate that these two actions are always executable. The following transitions are possible from state
 $s_0$
:
$s_0$
:
 \begin{eqnarray*} \{\: up(l_1), up(l_2), \neg locked,\neg holding(k_1), holding(k_2) \:\} & \in & \Phi(open(l_2), s_0).\nonumber\\ \{\: up(l_1), \neg up(l_2), locked,\neg holding(k_1), holding(k_2) \:\} & \in & \Phi(close(l_2), s_0).\nonumber\\ \{\: \neg up(l_1), \neg up(l_2), locked, holding(k_1),holding(k_2)\:\} & \in & \Phi(close(l_1), s_0).\nonumber\end{eqnarray*}
\begin{eqnarray*} \{\: up(l_1), up(l_2), \neg locked,\neg holding(k_1), holding(k_2) \:\} & \in & \Phi(open(l_2), s_0).\nonumber\\ \{\: up(l_1), \neg up(l_2), locked,\neg holding(k_1), holding(k_2) \:\} & \in & \Phi(close(l_2), s_0).\nonumber\\ \{\: \neg up(l_1), \neg up(l_2), locked, holding(k_1),holding(k_2)\:\} & \in & \Phi(close(l_1), s_0).\nonumber\end{eqnarray*}
 $\diamond$
$\diamond$
The transition function
 $\Phi$
is extended to define
$\Phi$
is extended to define
 $\widehat{\Phi}$
for reasoning about effects of action sequences in the usual way. For a sequence of actions
$\widehat{\Phi}$
for reasoning about effects of action sequences in the usual way. For a sequence of actions
 $\alpha = \langle a_0,\ldots,a_{n-1} \rangle$
and a state s,
$\alpha = \langle a_0,\ldots,a_{n-1} \rangle$
and a state s,
 $\widehat{\Phi}(\alpha, s)$
is a collection of states defined as follows:
$\widehat{\Phi}(\alpha, s)$
is a collection of states defined as follows:
-
•
$\widehat{\Phi}(\alpha, s) = \{s\}$
if
$\alpha = \langle \ \rangle$
; -
•
$\widehat{\Phi}(\alpha, s) = \Phi(a_0, s)$
if
$n=1$
; -
•
$\widehat{\Phi}(\alpha, s) = \bigcup_{s' \in \Phi(a_0, s)} \widehat{\Phi}(\alpha', s')$
if
$n > 1$
,
$ \Phi(a_0, s) \ne \emptyset$
, and
$ \widehat{\Phi}(\alpha', s') \ne \emptyset$
for every
$s' \in \Phi(a_0,s)$
where
$\alpha' = \langle a_1,\ldots,a_{n-1} \rangle$
.










A domain D is consistent if for every action a and state s, if a is executable in s, then
 $\Phi(a,s) \neq \emptyset$
. An action theory
$\Phi(a,s) \neq \emptyset$
. An action theory
 $(D,\Gamma)$
is consistent if D is consistent and
$(D,\Gamma)$
is consistent if D is consistent and
 $s_0 = \{f \mid\textbf{initially}(f)\in \Gamma\}$
is a state of D. In what follows, we consider only consistent action theories and refer to
$s_0 = \{f \mid\textbf{initially}(f)\in \Gamma\}$
is a state of D. In what follows, we consider only consistent action theories and refer to
 $s_0$
as the initial state of D. We call a sequence of alternate states and actions
$s_0$
as the initial state of D. We call a sequence of alternate states and actions
 $s_0a_0\ldots a_{k-1}s_k$
a trajectory if
$s_0a_0\ldots a_{k-1}s_k$
a trajectory if
 $s_{i+1} \in \Phi(a,s_i)$
for every
$s_{i+1} \in \Phi(a,s_i)$
for every
 $i=0,\ldots,k-1$
.
$i=0,\ldots,k-1$
.
A planning problem with respect to
 $\mathcal{B}$
is specified by a triple
$\mathcal{B}$
is specified by a triple
 $\langle D, \Gamma, \Delta \rangle$
where
$\langle D, \Gamma, \Delta \rangle$
where
 $(D,\Gamma)$
is an action theory in
$(D,\Gamma)$
is an action theory in
 $\mathcal{B}$
and
$\mathcal{B}$
and
 $\Delta$
is a set of fluent literals (or goal). A sequence of actions
$\Delta$
is a set of fluent literals (or goal). A sequence of actions
 $\alpha = \langle a_0,\ldots,a_{n-1} \rangle$
is then called an optimistic plan for
$\alpha = \langle a_0,\ldots,a_{n-1} \rangle$
is then called an optimistic plan for
 $\Delta$
if there exists some
$\Delta$
if there exists some
 $s \in \widehat{\Phi}(\alpha, s_0)$
such that
$s \in \widehat{\Phi}(\alpha, s_0)$
such that
 $s \models \Delta$
where
$s \models \Delta$
where
 $s_0$
is the initial state of D. Note that we use the term “optimistic plan” to refer to
$s_0$
is the initial state of D. Note that we use the term “optimistic plan” to refer to
 $\alpha$
, as used by (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b), instead of “plan” because the non-determinicity of D does not guarantee that the goal is achieved in every state reachable after the execution of
$\alpha$
, as used by (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b), instead of “plan” because the non-determinicity of D does not guarantee that the goal is achieved in every state reachable after the execution of
 $\alpha$
. However, if D is deterministic, that is,
$\alpha$
. However, if D is deterministic, that is,
 $|\Phi(a,s)| \le 1$
for every pair (a,s) of actions and states, then the two notions of “optimistic plan” and “plan” coincide.
$|\Phi(a,s)| \le 1$
for every pair (a,s) of actions and states, then the two notions of “optimistic plan” and “plan” coincide.
3 Planning with complete information
Given a planning problem
 $\mathcal{P} = \langle D,\Gamma, \Delta \rangle$
, answer set planning solves it by translating it into a logic program
$\mathcal{P} = \langle D,\Gamma, \Delta \rangle$
, answer set planning solves it by translating it into a logic program
 $\Pi(\mathcal{P}, n)$
whose answer sets correspond one-to-one to optimistic plans of length
$\Pi(\mathcal{P}, n)$
whose answer sets correspond one-to-one to optimistic plans of length
 $\le n$
of
$\le n$
of
 $\mathcal{P}$
. Intuitively, each answer set corresponds to a trajectory
$\mathcal{P}$
. Intuitively, each answer set corresponds to a trajectory
 $s_0a_0\ldots a_{n-1}s_n$
such that
$s_0a_0\ldots a_{n-1}s_n$
such that
 $s_n \models \Delta$
. As such, the choices that need to be made at each step k in program
$s_n \models \Delta$
. As such, the choices that need to be made at each step k in program
 $\Pi(\mathcal{P}, n)$
are either the action
$\Pi(\mathcal{P}, n)$
are either the action
 $a_k$
or the state
$a_k$
or the state
 $s_k$
. This leads to different encodings, referred to as action-based and state-based, which emphasize the object of the selection process.
$s_k$
. This leads to different encodings, referred to as action-based and state-based, which emphasize the object of the selection process.
Over the years, several types of encodings have been developed. We present below two of the most popular mappings of planning problems to logic programs. The first encoding, presented in Subsection 3.1, views the problem
 $\mathcal{P}$
as a set of laws in the language
$\mathcal{P}$
as a set of laws in the language
 $\mathcal{B}$
(Subsection 2.2) while the second encoding, illustrated in Subsection 3.2, views the problem as a set of facts. In both encodings, the program
$\mathcal{B}$
(Subsection 2.2) while the second encoding, illustrated in Subsection 3.2, views the problem as a set of facts. In both encodings, the program
 $\Pi(\mathcal{P}, n)$
contains the atom
Footnote 4
$\Pi(\mathcal{P}, n)$
contains the atom
Footnote 4
 $time(0..n)$
to represent the set of facts
$time(0..n)$
to represent the set of facts
 $\{time(0), \ldots, time(n)\}$
.
$\{time(0), \ldots, time(n)\}$
.
3.1 A direct encoding
The rules of
 $\Pi(\mathcal{P}, n)$
in this encoding are described by (Son et al. Reference Son, Baral, Nam and McIlraith2006). The main predicates in the program are:
$\Pi(\mathcal{P}, n)$
in this encoding are described by (Son et al. Reference Son, Baral, Nam and McIlraith2006). The main predicates in the program are:
-
1. holds(F,T) – the fluent literal F is true at time step T;
-
2. occ(A,T) – the action A occurs at time step T; and
-
3. possible(A,T) – the action A is executable at time step T.
The program contains two sets of rules. The first set of rules is domain dependent. The rules in the second set are generic and common to all problems. For a set of literals
 $\varphi$
, we use
$\varphi$
, we use
 $holds(\varphi, T)$
to denote the set
$holds(\varphi, T)$
to denote the set
 $\{holds(L, T) \mid L \in \varphi\}$
.
$\{holds(L, T) \mid L \in \varphi\}$
.
3.1.1 Domain-dependent rules
For each planning problem
 $\mathcal{P} = \langle D,\Gamma, \Delta \rangle$
, program
$\mathcal{P} = \langle D,\Gamma, \Delta \rangle$
, program
 $\Pi(\mathcal{P}, n)$
contains the following rules:
$\Pi(\mathcal{P}, n)$
contains the following rules:
-
1. For each element
$\textbf{initially}(f)$
of form (4) in
$\Gamma$
, the fact (5)stating that the fluent literal f holds at time step 0.
\begin{equation} holds(f, 0) \leftarrow\end{equation}
-
2. For each executability condition
$\textbf{executable}(a, \varphi)$
of form (3) in D, the rule (6)stating that it is possible to execute the action a at time step T if
\begin{equation} possible(a, T) \leftarrow time(T), holds(\varphi,T)\end{equation}
$\varphi$
holds at time step T.
-
3. For each dynamic causal law
$\textbf{causes}(a,f, \varphi)$
of form (2) in D, the rule (7)stating that if a occurs at time step T then the fluent literal f becomes true at
\begin{equation} \begin{array}{lll}holds(f, T+1) & \leftarrow & time(T), occ(a, T), holds(\varphi, T)\end{array}\end{equation}
$T+1$
if the conditions in
$\varphi$
hold.
-
4. For each static causal law
$\textbf{caused}(\varphi, f)$
of form (1) in D, the rule
Footnote 5
(8)which represents a straightforward translation of the static causal law into a logic programming rule.
\begin{equation} holds(f, T) \leftarrow time(T), holds(\varphi,T)\end{equation}
-
5. To guarantee that an action is executed only when it is executable, the constraint
(9)
\begin{equation} \leftarrow time(T), occ(A, T), { not \:} possible(A,T).\end{equation}













We demonstrate the above translation by listing the set of domain dependent rules for the domain from Example 1.
Example 3 Besides the set of facts encoding actions and fluents and the initial state (for each
 $a \in \mathbf{A}$
,
$a \in \mathbf{A}$
,
 $f \in \mathbf{F}$
and
$f \in \mathbf{F}$
and
 $\textbf{initially}(l)\in \Gamma^s$
),
$\textbf{initially}(l)\in \Gamma^s$
),
 \begin{equation*}action(a) \leftarrow fluent(f) \leftarrow holds(l,0) \leftarrow\end{equation*}
\begin{equation*}action(a) \leftarrow fluent(f) \leftarrow holds(l,0) \leftarrow\end{equation*}
the encoding of the suitcase domain in Example 1 contains the following rules for
 $i=1,2$
:
$i=1,2$
:
 \begin{equation*}\begin{array}{lll}holds(up(l_i), T+1) & \leftarrow & time(T), occ(open(l_i), T) \\[2pt]holds(\neg up(l_i), T+1) & \leftarrow & time(T), occ(close(l_i), T) \\[2pt]holds(holding(k_i), T+1) & \leftarrow & time(T), occ(get\_key(k_i), T) \\[2pt]possible(open(l_i), T) & \leftarrow & time(T), holds(holding(k_i), T) \\[2pt]holds(locked, T) & \leftarrow & time(T), holds(\neg up(l_i), T) \\[2pt]holds(\neg locked, T) & \leftarrow & time(T), holds(up(l_1), T), holds(up(l_2), T) \\[2pt]possible(close(l_i), T) & \leftarrow & time(T) \\[2pt]possible(get\_key(k_i), T) & \leftarrow & time(T). \\[2pt]\end{array}\end{equation*}
\begin{equation*}\begin{array}{lll}holds(up(l_i), T+1) & \leftarrow & time(T), occ(open(l_i), T) \\[2pt]holds(\neg up(l_i), T+1) & \leftarrow & time(T), occ(close(l_i), T) \\[2pt]holds(holding(k_i), T+1) & \leftarrow & time(T), occ(get\_key(k_i), T) \\[2pt]possible(open(l_i), T) & \leftarrow & time(T), holds(holding(k_i), T) \\[2pt]holds(locked, T) & \leftarrow & time(T), holds(\neg up(l_i), T) \\[2pt]holds(\neg locked, T) & \leftarrow & time(T), holds(up(l_1), T), holds(up(l_2), T) \\[2pt]possible(close(l_i), T) & \leftarrow & time(T) \\[2pt]possible(get\_key(k_i), T) & \leftarrow & time(T). \\[2pt]\end{array}\end{equation*}
Each of the first six rules corresponds to a law in
 $D^s$
. The last two rules are added because there is no restriction on the executability condition of
$D^s$
. The last two rules are added because there is no restriction on the executability condition of
 $close(l_i)$
or
$close(l_i)$
or
 $get\_key(k_i)$
.
$get\_key(k_i)$
.
 $\Diamond$
$\Diamond$
3.1.2 Domain independent rules
The set of domain independent rules of
 $\Pi(\mathcal{P}, n)$
consists of rules for generating action occurrences and encoding the frame axiom.
$\Pi(\mathcal{P}, n)$
consists of rules for generating action occurrences and encoding the frame axiom.
-
1. Action generation rule: To create plans,
$\Pi(\mathcal{P}, n)$
must contain rules that generate action occurrences of the form occ(a,t). This is encoded by the rule (10)stating that exactly one action must occur at each time step. It makes use of the cardinality atom
\begin{eqnarray}1 \{ occ(A,T) : action(A) \} 1 \leftarrow time(T), T < n \end{eqnarray}
$1 \{occ(A,T) : action(A) \} 1$
which is true for a time step T iff exactly one atom in the set
$\{occ(A,T) : action(A) \}$
is true. The former atom can be replaced by
$l \{occ(A,T) : action(A) \} u$
where
$0 \le l \le u$
to allow for different types of plans, e.g., for parallel plans,
$l>1$
.
-
2. Inertia rule: The frame axiom, which states that a property continues to hold unless it is changed, is encoded as follows:
(11)
\begin{eqnarray}holds(F, T{+}1) & \leftarrow & time(T), fluent(F), holds(F, T), { not \:} holds(\neg F, T{+}1) \quad \quad \end{eqnarray}
(12)
\begin{eqnarray}holds(\neg F, T{+}1) & \leftarrow & time(T), fluent(F), holds(\neg F, T), { not \:} holds(F, T{+}1) \end{eqnarray}
-
3. Consistency constraint: To ensure that states encoded by answer sets are consistent,
$\Pi(\mathcal{P}, n)$
contains the following constraint: (13)Observe that this constraint is needed because holds(f,t) and
\begin{eqnarray} & \leftarrow & fluent(F),holds(F, T), holds(\neg F, T). \end{eqnarray}
$holds(\neg f, t)$
are “consistent” for answer set solvers. It would not be needed if
$holds(\neg f, t)$
is encoded as
$\neg holds(f, t)$
.














3.1.3 Goal representation
The goal
 $\Delta$
is encoded by rules defining the predicate goal, which is true whenever
$\Delta$
is encoded by rules defining the predicate goal, which is true whenever
 $\Delta$
is true, and a rule that enforces that
$\Delta$
is true, and a rule that enforces that
 $\Delta$
must be true at time step n. For example, if
$\Delta$
must be true at time step n. For example, if
 $\Delta$
is a conjunction of literals
$\Delta$
is a conjunction of literals
 $p_1 \wedge \ldots \wedge p_k$
, then the rules
$p_1 \wedge \ldots \wedge p_k$
, then the rules
 \begin{eqnarray}goal & \leftarrow & holds(p_1, n), \ldots, holds(p_k, n) \end{eqnarray}
\begin{eqnarray}goal & \leftarrow & holds(p_1, n), \ldots, holds(p_k, n) \end{eqnarray}
 \begin{eqnarray} & \leftarrow & { not \:} goal \end{eqnarray}
\begin{eqnarray} & \leftarrow & { not \:} goal \end{eqnarray}
encode
 $\Delta$
and enforce that
$\Delta$
and enforce that
 $\Delta$
must be true at time step n.
$\Delta$
must be true at time step n.
3.1.4 Correctness of the encoding
Let
 $\mathcal{P} = (D,\Gamma,\Delta)$
and
$\mathcal{P} = (D,\Gamma,\Delta)$
and
 $\Pi(\mathcal{P},n)$
be the logic program consisting of
$\Pi(\mathcal{P},n)$
be the logic program consisting of
-
• the set of facts encoding fluents and literals in D;
-
• the set of domain-dependent rules encoding D and
$\Gamma$
(rules (5)–(9)) in which the domain of T is
$\{0,\ldots,n\}$
; -
• the set of domain-independent rules (rules (10)–(12)) in which the domain of T is
$\{0,\ldots,n\}$
; and



The following result shows the equivalence between optimistic plans achieving
 $\Delta$
and answer sets of
$\Delta$
and answer sets of
 $\Pi(\mathcal{P},n)$
. To formalize the theorem, we introduce some additional notation. For an answer set M of
$\Pi(\mathcal{P},n)$
. To formalize the theorem, we introduce some additional notation. For an answer set M of
 $\Pi(\mathcal{P},n)$
, we define
$\Pi(\mathcal{P},n)$
, we define
 \begin{equation*}s_i(M) = \{f \ \mid f {is a fluent literal and} holds(f,i) \in M\}.\end{equation*}
\begin{equation*}s_i(M) = \{f \ \mid f {is a fluent literal and} holds(f,i) \in M\}.\end{equation*}
Theorem 1 For a planning problem
 $\langle D,\Gamma,\Delta \rangle$
with a consistent action theory
$\langle D,\Gamma,\Delta \rangle$
with a consistent action theory
 $(D,\Gamma)$
,
$(D,\Gamma)$
,
 $s_0a_0\ldots a_{n-1}s_n$
is a trajectory achieving
$s_0a_0\ldots a_{n-1}s_n$
is a trajectory achieving
 $\Delta$
iff there exists an answer set M of
$\Delta$
iff there exists an answer set M of
 $\Pi(\mathcal{P},n)$
such that
$\Pi(\mathcal{P},n)$
such that
-
1.
$occ(a_i,i) \in M$
for
$i \in \{0,\ldots,n-1\}$
and -
2.
$s_i = s_i(M)$
for
$i \in \{0,\ldots,n\}$
.




-
1. The proof of Theorem 1 relies on the following observations: M is an answer set of
$\Pi(\mathcal{P},n)$
iff-
• for every i such that
$0 \le i < n$
, there exists some
$a_i \in \mathbf{A}$
such that
$occ(a_i, i) \in M$
and
$a_i$
is executable in
$s_i(M)$
; -
•
$s_0(M)$
is the initial state of the action theory
$(D,\Gamma)$
and is consistent. Furthermore, for every i such that
$0 \le i < n$
,
$s_{i+1}(M) \in \Phi(a_i, s_i(M))$
; and -
•
$\Delta$
is true in
$s_n(M)$
.
-












The theorem is similar to the correspondence between histories and answer sets explored by (Lifschitz and Turner Reference Lifschitz and Turner1999) and by (Son et al. Reference Son, Baral, Nam and McIlraith2006).
-
2. If
$(D,\Gamma)$
is deterministic then Theorem 1 can be simplified to “
$a_0,a_1,\ldots,a_{n-1}$
is a plan achieving
$\Delta$
iff there exists an answer set M of
$\Pi(\mathcal{P},n)$
such that
$occ(a_i,i) \in M$
for
$i \in \{0,\ldots,n-1\}$
.” -
3. A different variant of this encoding, which uses
$f(\vec{x}, t)$
and
$\neg f(\vec{x}, t)$
instead of
$holds(f(\vec{x}), t)$
and
$holds(\neg f(\vec{x}), t)$
, respectively, can be found in several papers related to answer set planning, for example, in the papers by (Lifschitz Reference Lifschitz1999) and (2002). -
4. The action language
$\mathcal{B}$
could be extended with various features such as default fluents, effects of action sequences, etc. as discussed by (Gelfond and Lifschitz Reference Gelfond and Lifschitz1998). These features can be easily included in the encoding of
$\Pi(\mathcal{P},n)$
. On the other hand, such features are rarely considered in action domains used by the planning community. For this reason, we do not consider such features in this survey. -
5. Readers familiar with current answer set solvers such as clingo or dlv could be wondering why
$holds(\neg f, t)$
is used instead of a perhaps more intuitive
$\neg holds(f,t)$
. Indeed, the former can be replaced by the latter. The use of
$holds(\neg f, t)$
is influenced by early Prolog programs written for reasoning about actions and changes by Michael Gelfond. A Prolog program that translates a planning problem to its ASP encoding can be found at https://www.cs.nmsu.edu/ tson/ASPlan/Knowledge/translate.pl. -
6. Different approaches to integrate various types of knowledge to answer set planning can be found in the work by (Dix et al. Reference Dix, Kuter and Nau2005) and (Son et al. Reference Son, Baral, Nam and McIlraith2006).















3.2 Meta encoding
The meta encoding presented in this section encodes a planning problem
 $\mathcal{P} = \langle D, \Gamma, \Delta \rangle$
as a set of facts, in addition to a set of domain-independent rules for reasoning about effects of actions. To distinguish this encoding from the previous one, we denote this encoding with
$\mathcal{P} = \langle D, \Gamma, \Delta \rangle$
as a set of facts, in addition to a set of domain-independent rules for reasoning about effects of actions. To distinguish this encoding from the previous one, we denote this encoding with
 $\Pi^m(\mathcal{P},n)$
. In this encoding, a set
$\Pi^m(\mathcal{P},n)$
. In this encoding, a set
 $\varphi$
is represented using the atom
$\varphi$
is represented using the atom
 $set(s_\varphi)$
, where
$set(s_\varphi)$
, where
 $s_\varphi$
is a new atom associated to
$s_\varphi$
is a new atom associated to
 $\varphi$
, and a set of atoms of the form
$\varphi$
, and a set of atoms of the form
 $\{member(s_\varphi, p) \mid p \in \varphi \}$
. The laws in D are represented by the set of facts
$\{member(s_\varphi, p) \mid p \in \varphi \}$
. The laws in D are represented by the set of facts
 \begin{eqnarray}caused(f, s_{\mathit{sf}}). & set(s_{\mathit{sf}}). & s_{\mathit{sf}} {is the identifier for } \varphi {in } \textbf{caused}(f, \varphi) {in} D \end{eqnarray}
\begin{eqnarray}caused(f, s_{\mathit{sf}}). & set(s_{\mathit{sf}}). & s_{\mathit{sf}} {is the identifier for } \varphi {in } \textbf{caused}(f, \varphi) {in} D \end{eqnarray}
 \begin{eqnarray}causes(a, f, s_{\mathit{df}}).& set(s_{\mathit{df}}). & s_{\mathit{df}} {is the identifier for } \varphi {in } \textbf{causes}(a, f, \varphi) {in} D \end{eqnarray}
\begin{eqnarray}causes(a, f, s_{\mathit{df}}).& set(s_{\mathit{df}}). & s_{\mathit{df}} {is the identifier for } \varphi {in } \textbf{causes}(a, f, \varphi) {in} D \end{eqnarray}
 \begin{eqnarray}executable(a, s_a). & set(s_a). & s_{a} {is the identifier for } \varphi {in} \textbf{executable}(a, \varphi) {in} D\;\;\;\;\end{eqnarray}
\begin{eqnarray}executable(a, s_a). & set(s_a). & s_{a} {is the identifier for } \varphi {in} \textbf{executable}(a, \varphi) {in} D\;\;\;\;\end{eqnarray}
and the set of facts encoding
 $s_{\mathit{sf}}$
,
$s_{\mathit{sf}}$
,
 $s_{\mathit{df}}$
, and
$s_{\mathit{df}}$
, and
 $s_a$
.
$s_a$
.
In addition to the action generation rule (10), the inertial rules (11)–(12), the goal representation rules (14)–(15), and the constraint stating that actions can occur only when they are executable (9), the program
 $\Pi^m(\mathcal{P},n)$
contains the following rules for reasoning about effects of actions:
$\Pi^m(\mathcal{P},n)$
contains the following rules for reasoning about effects of actions:
 \begin{eqnarray}holds(S, T) & \leftarrow & time(T), set(S), \end{eqnarray}
\begin{eqnarray}holds(S, T) & \leftarrow & time(T), set(S), \end{eqnarray}
 \begin{eqnarray} & & holds(F,T): fluent(F), member(S,F); \nonumber \\[4pt] & & holds(\neg F, T): fluent(F), member(S, \neg F). \nonumber \\[4pt]holds(L, T+1) & \leftarrow & time(T), causes(A, F, S), occ(A, T), holds(S, T) \end{eqnarray}
\begin{eqnarray} & & holds(F,T): fluent(F), member(S,F); \nonumber \\[4pt] & & holds(\neg F, T): fluent(F), member(S, \neg F). \nonumber \\[4pt]holds(L, T+1) & \leftarrow & time(T), causes(A, F, S), occ(A, T), holds(S, T) \end{eqnarray}
 \begin{eqnarray}holds(L, T) & \leftarrow & time(T), caused(L, S), holds(S, T) \end{eqnarray}
\begin{eqnarray}holds(L, T) & \leftarrow & time(T), caused(L, S), holds(S, T) \end{eqnarray}
 \begin{eqnarray}possible(A, T) & \leftarrow & time(T), executable(A, S), holds(S, T) \end{eqnarray}
\begin{eqnarray}possible(A, T) & \leftarrow & time(T), executable(A, S), holds(S, T) \end{eqnarray}
Rule (19) defines the truth of a set of fluents S at time step T, by declaring that S holds at T if all of its members are true at T. The intuition behind the rules (20)–(22) is clear. Similarly to Theorem 1, answer sets of
 $\Pi^m(\mathcal{P},n)$
correspond one-to-one to possible solutions (optimistic plans) of
$\Pi^m(\mathcal{P},n)$
correspond one-to-one to possible solutions (optimistic plans) of
 $\mathcal{P}$
.
$\mathcal{P}$
.
Remark 2 A similar encoding to
 $\Pi^m(\mathcal{P},n)$
is used in the system plasp version 3 by (Dimopoulos et al. 2019). A translation of planning problems from PDDL format to ASP facts can be found at https://github.com/potassco/plasp.
$\Pi^m(\mathcal{P},n)$
is used in the system plasp version 3 by (Dimopoulos et al. 2019). A translation of planning problems from PDDL format to ASP facts can be found at https://github.com/potassco/plasp.
3.3 Adding heuristics: Going for performance
By using ASP systems for solving planning problems, we employ general purpose systems rather than genuine planning systems. In particular, the distinction between action and fluent variables or fluent variables of successive states completely eludes the ASP system. Pioneering work in this direction was done by (Rintanen Reference Rintanen2012), where the implementation of SAT solvers was modified in order to boost performance of SAT planning. Inspired by this research direction, (Gebser et al. Reference Gebser, Kaufmann, Otero, Romero, Schaub and Wanko2013) developed a language extension for ASP systems that allows users to declare heuristic modifiers that take effect in the underlying ASP system clingo.
More precisely, a heuristic directive is of form
 \begin{equation*}\#\mathit{heuristic}\ a:b_1,\dots,b_m.\,[w,m],\end{equation*}
\begin{equation*}\#\mathit{heuristic}\ a:b_1,\dots,b_m.\,[w,m],\end{equation*}
where a is an atom and
 $b_1,\dots,b_m$
is a conjunction of literals; w is a numeral term and m a heuristic modifier, indicating how the solver’s heuristic treatment of a should be changed whenever
$b_1,\dots,b_m$
is a conjunction of literals; w is a numeral term and m a heuristic modifier, indicating how the solver’s heuristic treatment of a should be changed whenever
 $b_1,\dots,b_m$
holds. Clingo distinguishes four primitive heuristic modifiers:
$b_1,\dots,b_m$
holds. Clingo distinguishes four primitive heuristic modifiers:
-
init for initializing the heuristic value of a with w,
-
factor for amplifying the heuristic value of a by factor w,
-
level for ranking all atoms; the rank of a is w,
-
sign for attributing the sign of w as truth value to a.
For instance, whenever a is chosen by the solver, the heuristic modifier sign enforces that it becomes either true or false depending on whether w is positive or negative, respectively. The other three modifiers act on the atoms’ heuristic values assigned by the ASP solver’s heuristic function. Footnote 6 Moreover, for convenience, clingo offers the heuristic modifiers true and false that combine level and sign statement.
With them, we can directly describe the heuristic restriction used in the work by (Rintanen Reference Rintanen2011) to simulate planning by iterated deepening
 $A^*$
(Korf Reference Korf1985) through limiting choices to action variables, assigning those for time T before those for time T+1, and always assigning truth value true (where n is a constant indicating the planning horizon):
$A^*$
(Korf Reference Korf1985) through limiting choices to action variables, assigning those for time T before those for time T+1, and always assigning truth value true (where n is a constant indicating the planning horizon):
 \begin{equation*}\#\mathit{heuristic}\ \mathit{occ}(A,T) : \mathit{action}(A), \mathit{time}(T).\, [n-T,\mathit{true}].\end{equation*}
\begin{equation*}\#\mathit{heuristic}\ \mathit{occ}(A,T) : \mathit{action}(A), \mathit{time}(T).\, [n-T,\mathit{true}].\end{equation*}
Inspired by, and yet different from the work by (Rintanen Reference Rintanen2012), (Gebser et al. Reference Gebser, Kaufmann, Otero, Romero, Schaub and Wanko2013) devise a dynamic heuristic that aims at propagating fluents’ truth values backwards in time. Attributing levels via n-T+1 aims at proceeding depth-first from the goal fluents.
 \begin{align*}\#\mathit{heuristic}\ \mathit{holds}(F,T-1) &: \mathit{holds}(F,T).\, [n-T+1,\mathit{true}]\\[4pt]\#\mathit{heuristic}\ \mathit{holds}(F,T-1) &: fluent(F), time(T), not \mathit{holds}(F,T).\, [n-T+1,\mathit{false}].\end{align*}
\begin{align*}\#\mathit{heuristic}\ \mathit{holds}(F,T-1) &: \mathit{holds}(F,T).\, [n-T+1,\mathit{true}]\\[4pt]\#\mathit{heuristic}\ \mathit{holds}(F,T-1) &: fluent(F), time(T), not \mathit{holds}(F,T).\, [n-T+1,\mathit{false}].\end{align*}
In an experimental evaluation conducted by (Gebser et al. Reference Gebser, Kaufmann, Otero, Romero, Schaub and Wanko2013), this heuristic led to a speed-up of up to two orders of magnitude on satisfiable planning problems.
3.4 Context: Classical planning
Classical planning has been an intensive research area for many years. The famous Shakey robot
Footnote 7
used a planner for path planning. This project also led to the introduction of the Stanford Research Institute Problem Solver (STRIPS) language (Fikes and Nilsson Reference Fikes and Nilsson1971), the first representation language for planning domain description. This language has since evolved into the Planning Domain Definition Language (PDDL) (Ghallab et al. Reference Ghallab, Howe, Knoblock, McDermott, Ram, Veloso, Weld and Wilkins1998), a major planning domain description language. We noted that PDDL with state constraints is as expressive as
 $\mathcal{B}$
. It is worth noticing that state constraints are often not considered by the planning community even though the benefit of dealing directly with state constraints is known (Thiebaux et al. Reference Thiebaux, Hoffmann and Nebel2003). Furthermore, it is often assumed that state constraints in PDDL are stratified, for example, the dependency graph among fluent literals
Footnote 8
should be cycle free.
$\mathcal{B}$
. It is worth noticing that state constraints are often not considered by the planning community even though the benefit of dealing directly with state constraints is known (Thiebaux et al. Reference Thiebaux, Hoffmann and Nebel2003). Furthermore, it is often assumed that state constraints in PDDL are stratified, for example, the dependency graph among fluent literals
Footnote 8
should be cycle free.
Several planning algorithms have been developed and implemented such as forward or backward search over the state space (see, a survey by Hendler et al. Reference Hendler, Tate and Drummond1990) and search in the plans space (a.k.a. partial order planning, see, e.g. a survey by Weld Reference Weld1994). Such research also led to the development of domain-dependent planners which utilize domain knowledge to improve their scalability and efficiency (e.g., hierarchical planning systems Sacerdoti Reference Sacerdoti1974). Researchers realized early on that systematic state space search would not yield planning systems that are sufficiently scalable and efficient for practical applications. A significant milestone in the development of domain-independent planners is the invention of GraphPlan by (Blum and Furst Reference Blum and Furst1997). The basic data structure of GraphPlan, the planning graph, is an important resource for the development of planning heuristics (Kambhampati et al. Reference Kambhampati, Parker and Lambrecht1997). It plays a key role in the success of heuristic planners such as FF (Hoffmann and Nebel Reference Hoffmann and Nebel2001) and HSP (Bonet and Geffner Reference Bonet and Geffner2001) which dominate several International Planning Competitions (Long et al. Reference Long, Kautz, Selman, Bonet, Geffner, Köhler, Brenner, Hoffmann, Rittinger, Anderson, Weld, Smith and Fox2000; Bacchus Reference Bacchus2001; Gerevini et al. Reference Gerevini, Dimopoulos, Haslum and Saetti2004). This success is followed by several other systems (Helmert Reference Helmert2006; Richter and Helmert Reference Richter and Helmert2009; Helmert et al. Reference Helmert, Röger, Seipp, Karpas, Hoffmann, Keyder, Nissim, Richter and Westphal2011), whose impressive performance can be attributed to advances in the representation language for planning (e.g., the language SAS
 $^+$
that supports a compact representation of states Bäckström and Nebel Reference Bäckström and Nebel1995) and their underlying heuristics constructed via reachability analysis and techniques such as landmarks recognition, abstraction, operator ordering, and decomposition (Bonet and Helmert Reference Bonet and Helmert2010; Zhu and Givan Reference Zhu and Givan2004; Helmert and Domshlak Reference Helmert and Domshlak2009; Helmert and Geffner Reference Helmert and Geffner2008; Helmert and MattmÜller Reference Helmert and MattmÜller2008; Hoffmann et al. Reference Hoffmann, Porteous and Sebastia2004; Hoffmann Reference Hoffmann2005; Pommerening et al. Reference Pommerening, Röger, Helmert, Cambazard, Rousseau and Salvagnin2020; Richter and Helmert Reference Richter and Helmert2009; Röger and Helmert Reference Röger and Helmert2010; Vidal and Geffner Reference Vidal and Geffner2006). All of these planning systems implement a heuristic search algorithm. Therefore, their scalability and efficiency are heavily dependent on the implemented heuristic, that is, how discriminant is the heuristic and how efficient can it be computed. In most systems, completeness and efficiency have to be traded off. In some planner, an automatic mechanism for returning to systematic search is established whenever the heuristic deems not useful (e.g., the system FF).
$^+$
that supports a compact representation of states Bäckström and Nebel Reference Bäckström and Nebel1995) and their underlying heuristics constructed via reachability analysis and techniques such as landmarks recognition, abstraction, operator ordering, and decomposition (Bonet and Helmert Reference Bonet and Helmert2010; Zhu and Givan Reference Zhu and Givan2004; Helmert and Domshlak Reference Helmert and Domshlak2009; Helmert and Geffner Reference Helmert and Geffner2008; Helmert and MattmÜller Reference Helmert and MattmÜller2008; Hoffmann et al. Reference Hoffmann, Porteous and Sebastia2004; Hoffmann Reference Hoffmann2005; Pommerening et al. Reference Pommerening, Röger, Helmert, Cambazard, Rousseau and Salvagnin2020; Richter and Helmert Reference Richter and Helmert2009; Röger and Helmert Reference Röger and Helmert2010; Vidal and Geffner Reference Vidal and Geffner2006). All of these planning systems implement a heuristic search algorithm. Therefore, their scalability and efficiency are heavily dependent on the implemented heuristic, that is, how discriminant is the heuristic and how efficient can it be computed. In most systems, completeness and efficiency have to be traded off. In some planner, an automatic mechanism for returning to systematic search is established whenever the heuristic deems not useful (e.g., the system FF).
The idea of using automated theorem solvers in planning can be traced back to the work by (Green Reference Green1969) who demonstrated that automated reasoning systems can be used for planning. A significant step in this direction is proposed by (Kautz and Selman Reference Kautz and Selman1992) who introduced satisfiability planning and showed that with an improved satisfiability solver, SAT-based planning can be competitive with search based planners (Kautz et al. Reference Kautz, McAllester, Selman, Aiello, Doyle and Shapiro1996). This approach was later advanced by several other researchers and results in many SAT-based or logic programming-based planning systems (Chen et al. Reference Chen, Huang, Xing and Zhang2009; Dimopoulos et al. Reference Dimopoulos, Nebel and Köhler1997; Rintanen et al. Reference Rintanen, Heljanko and Niemelä2006; Robinson et al. Reference Robinson, Gretton, Pham and Sattar2009; Rintanen Reference Rintanen2012) that are often competitive or more efficient comparing to search-based planners. Constraint satisfaction techniques have also been employed in planning (Kautz and Walser Reference Kautz and Walser1999; Do and Kambhampati Reference Do and Kambhampati2003; Sideris and Dimopoulos Reference Sideris and Dimopoulos2010; Dovier et al. Reference Dovier, Formisano and Pontelli2009). As we have mentioned in the introduction, the success of SAT-base planning is likely the source of inspiration for the use of logic programming with answer sets semantics for planning. Indeed, there are several similarities between a SAT-based encoding of a planning program proposed by (Kautz and Selman Reference Kautz and Selman1992) and its ASP-encoding presented in this section. They share the following features:
-
• the use of time steps in representing the planning horizon: SAT-based encoding prefers to use
$f(\vec{x},t)$
and
$\neg f(\vec{x},t)$
instead of
$holds(f(\vec{x}),t)$
and
$holds(\neg f(\vec{x}),t)$
; -
• the encoding of actions’ executability and the effects of actions;
-
• the encoding of the frame axioms; and
-
• the encoding for action generation.




In this sense, one can say that SAT-planning and answer set planning are cousins to each other. Both relish the use of knowledge representation techniques and the development of logical solvers in planning. The key difference between them lies in the underlying representation language and solver.
Green’s idea has also been investigated in event calculus planning. The main reasoning system behind this approach is the event calculus, which is introduced by (Kowalski and Sergot Reference Kowalski and Sergot1986) for reasoning about narratives and database updates. An action theory (or a planning problem) can be described by an event calculus program that is similar to the program described in Section 3.1. In particular, this program consists of rules encoding the initial state, effects of actions, and solution to the frame axiom. Earlier development of event calculus does not consider static causal laws. This issue is addressed by (Shanahan Reference Shanahan1999). (Eshghi Reference Eshghi1988) introduced a variant of the event calculus, called EVP (an event calculus for planning), and combined it with abductive reasoning to create ABPLAN. We believe that this is the first planning system that integrates event calculus and abduction. (Denecker et al. Reference Denecker, Missiaen and Bruynooghe1992) developed SLDNFA, a procedure for temporal reasoning with abductive event calculus, and showed how this procedure can be used for planning. The authors of SLDNFA continued this line of research and developed CHICA (Missiaen et al. Reference Missiaen, Bruynooghe and Denecker1995). The underlying algorithm of this system is a specialized version of the abductive reasoning procedure for event calculus. An interesting feature of this system is that it allows for the user to specify the search strategy and heuristics at the domain level, allowing for domain dependent information to be exploited in the search for a solution. Other proof procedures for event calculus planning can be founded in the work by (Endriss et al. Reference Endriss, Mancarella, Sadri, Terreni and Toni2004), (Mueller Reference Mueller2006), and (Shanahan Reference Shanahan2000) and 1997. It is worth noting that a major discussion in these work is the condition for the soundness and completeness of the proof procedures, that is, the planning systems. To the best of our knowledge, most of the event calculus based planning systems are implemented on a Prolog system and no experimental evaluation against other planning systems has been conducted.
4 Conformant planning
The previous section assumes that the initial state
 $\Gamma$
in the planning problem
$\Gamma$
in the planning problem
 $\mathcal{P} = \langle D,\Gamma, \Delta \rangle$
is complete, that is, the truth value of each property of the world is known. In practice, this is not always a realistic assumption.
$\mathcal{P} = \langle D,\Gamma, \Delta \rangle$
is complete, that is, the truth value of each property of the world is known. In practice, this is not always a realistic assumption.
Example 4 (Bomb-In-The-Toilet Example) There may be a bomb in a package. The process of dunking the package into a toilet will disarm the bomb. This action can be executed only if the toilet is not clogged. Flushing the toilet will unclog it. This domain can be described by the following domain:
-
• Fluents: armed, clogged
-
• Actions: dunk, flush
-
• Domain description:
\begin{equation*}D_b = \left \{\begin{array}{lll}\textbf{causes}(dunk , \neg armed, \{ armed\}) \\[4pt]\textbf{causes}(flush, \neg clogged, \{\}) \\[4pt]\textbf{executable}(dunk, \{\neg clogged\}).\end{array}\right .\end{equation*}

Suppose that our goal is to disarm the bomb. However, we are not sure whether the toilet is clogged. In other words, the planning problem that we need to solve is
 $\mathcal{P}_{bomb} = \langle D_{bomb}, \emptyset, \neg armed\rangle$
.
$\mathcal{P}_{bomb} = \langle D_{bomb}, \emptyset, \neg armed\rangle$
.
 $\Diamond$
$\Diamond$
The problem
 $\mathcal{P}_{bomb}$
is an example of a planning problem with incomplete information. It is easy to see that
$\mathcal{P}_{bomb}$
is an example of a planning problem with incomplete information. It is easy to see that
 $\alpha= \langle dunk \rangle$
is not a good solution for
$\alpha= \langle dunk \rangle$
is not a good solution for
 $\mathcal{P}_{bomb}$
since
$\mathcal{P}_{bomb}$
since
 $\alpha$
is not executable when the toilet is clogged. On the other hand,
$\alpha$
is not executable when the toilet is clogged. On the other hand,
 $\beta= \langle flush, dunk \rangle$
is executable and achieves the goal in every possible initial state of the problem. (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b) refer to
$\beta= \langle flush, dunk \rangle$
is executable and achieves the goal in every possible initial state of the problem. (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b) refer to
 $\beta$
as a secure plan – a solution – for the conformant planning problem
$\beta$
as a secure plan – a solution – for the conformant planning problem
 $\mathcal{P}_{bomb}$
.
$\mathcal{P}_{bomb}$
.
Let D be an action theory and
 $\delta$
a set of fluent literals of D. We say that
$\delta$
a set of fluent literals of D. We say that
 $\delta$
is a partial state of D if there exists some state s such that
$\delta$
is a partial state of D if there exists some state s such that
 $\delta \subseteq s$
.
$\delta \subseteq s$
.
 $comp(\delta)$
, called the completion of
$comp(\delta)$
, called the completion of
 $\delta$
, denotes the set of all states s such that
$\delta$
, denotes the set of all states s such that
 $\delta \subseteq s$
. A literal
$\delta \subseteq s$
. A literal
 $\ell$
possibly holds in
$\ell$
possibly holds in
 $\delta$
if
$\delta$
if
 $\delta \not\models \overline{\ell}$
where
$\delta \not\models \overline{\ell}$
where
 $\overline{\ell}$
denotes the complement of
$\overline{\ell}$
denotes the complement of
 $\ell$
. A set of literals
$\ell$
. A set of literals
 $\lambda$
possibly holds in
$\lambda$
possibly holds in
 $\delta$
if every element of
$\delta$
if every element of
 $\lambda$
possibly holds in
$\lambda$
possibly holds in
 $\delta$
. In the following, we often use superscripts and subscripts to differentiate partial states from states.
$\delta$
. In the following, we often use superscripts and subscripts to differentiate partial states from states.
A conformant planning problem
 $\mathcal{P}$
is a tuple
$\mathcal{P}$
is a tuple
 $\langle {D},\delta^0,\Delta \rangle$
where D is an action theory and
$\langle {D},\delta^0,\Delta \rangle$
where D is an action theory and
 $\delta^0$
is a partial state of D.
$\delta^0$
is a partial state of D.
An action sequence
 $\alpha = \langle a_0,\dots,a_{n-1}\rangle$
is a solution (or conformant/secure plan) of
$\alpha = \langle a_0,\dots,a_{n-1}\rangle$
is a solution (or conformant/secure plan) of
 $\mathcal{P}$
if for every state
$\mathcal{P}$
if for every state
 $s_0 \in comp(\delta^0)$
,
$s_0 \in comp(\delta^0)$
,
 $\widehat{\Phi}(\alpha, s_0) \ne \emptyset$
and
$\widehat{\Phi}(\alpha, s_0) \ne \emptyset$
and
 $\Delta$
is true in every state belonging to
$\Delta$
is true in every state belonging to
 $\widehat{\Phi}(\alpha, s_0) \ne \emptyset$
.
$\widehat{\Phi}(\alpha, s_0) \ne \emptyset$
.
Observe that conformant planning belongs to a higher complexity class than classical planning (see, e.g., the work by Baral et al. Reference Baral, Kreinovich and Trejo2000; Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2000; Haslum and Jonsson 2000, or Turner Reference Turner2002). Even for action theories without static causal laws, checking whether a conformant problem has a polynomially bounded solution is
 $\Sigma^2_P$
-complete. Therefore, simply modifying the rules encoding the initial state (5) of
$\Sigma^2_P$
-complete. Therefore, simply modifying the rules encoding the initial state (5) of
 $\Pi(\mathcal{P},n)$
(e.g., by adding rules to complete the initial state) is insufficient. Different approaches have been proposed for conformant planning, each addressing the incomplete information in the initial state in a different way. In this section, we discuss two ASP-based approaches proposed by (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b), (Son et al. Reference Son, Tu, Gelfond and Morales2005b), and (Tu et al. Reference Tu, Son, Gelfond and Morales2011).
$\Pi(\mathcal{P},n)$
(e.g., by adding rules to complete the initial state) is insufficient. Different approaches have been proposed for conformant planning, each addressing the incomplete information in the initial state in a different way. In this section, we discuss two ASP-based approaches proposed by (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b), (Son et al. Reference Son, Tu, Gelfond and Morales2005b), and (Tu et al. Reference Tu, Son, Gelfond and Morales2011).
4.1 Conformant planning with a security check using logic program
(Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b) introduced the system dlv
 $^\mathcal{K}$
for planning with incomplete information. The system employs a representation language that is richer than the language
$^\mathcal{K}$
for planning with incomplete information. The system employs a representation language that is richer than the language
 $\mathcal{B}$
, since it considers additional features such as defaults and effects after a sequence of actions. For simplicity of the presentation, we present the approach used in dlv
$\mathcal{B}$
, since it considers additional features such as defaults and effects after a sequence of actions. For simplicity of the presentation, we present the approach used in dlv
 $^\mathcal{K}$
for conformant planning problems specified in
$^\mathcal{K}$
for conformant planning problems specified in
 $\mathcal{B}$
. We note that the original dlv
$\mathcal{B}$
. We note that the original dlv
 $^\mathcal{K}$
employs the direct encoding of planning problems as described in Remark 1, Item 3. We adapt it to the encoding used in the previous section.
$^\mathcal{K}$
employs the direct encoding of planning problems as described in Remark 1, Item 3. We adapt it to the encoding used in the previous section.
dlv
 $^\mathcal{K}$
generates a conformant plan for a problem
$^\mathcal{K}$
generates a conformant plan for a problem
 $\mathcal{P}$
in two steps. The first step consists of generating an optimistic plan; the second step is the verification that such plan is a secure plan, since an optimistic plan is not necessarily a secure plan. dlv
$\mathcal{P}$
in two steps. The first step consists of generating an optimistic plan; the second step is the verification that such plan is a secure plan, since an optimistic plan is not necessarily a secure plan. dlv
 $^\mathcal{K}$
implements Algorithm 1.
$^\mathcal{K}$
implements Algorithm 1.
The two tasks in Lines 1 and 2 in Algorithm 1 are implemented using different ASP programs. The generation step (Line 1) can be done using the program
 $\Pi_{c_{dlv}}(\mathcal{P},n)$
which consists of the program
$\Pi_{c_{dlv}}(\mathcal{P},n)$
which consists of the program
 $\Pi(\mathcal{P},n)$
together with the rules that specify the values of unknown fluents in the initial state:
$\Pi(\mathcal{P},n)$
together with the rules that specify the values of unknown fluents in the initial state:
 \begin{equation} holds(f, 0) \vee holds(\neg f, 0) \leftarrow \quad\quad (f {is a fluent and} \{f, \neg f\} \cap \delta^0 = \emptyset).\end{equation}
\begin{equation} holds(f, 0) \vee holds(\neg f, 0) \leftarrow \quad\quad (f {is a fluent and} \{f, \neg f\} \cap \delta^0 = \emptyset).\end{equation}
Algorithm 1: dlv
 $^\mathcal{K}$
Algorithm
$^\mathcal{K}$
Algorithm

It is easy to see that any answer set of
 $\Pi_{c_{dlv}}(\mathcal{P},n)$
contains an optimistic plan (Theorem 1). Assume that
$\Pi_{c_{dlv}}(\mathcal{P},n)$
contains an optimistic plan (Theorem 1). Assume that
 $\alpha = \langle a_0,\ldots,a_{n-1} \rangle$
is the sequence of actions generated by program
$\alpha = \langle a_0,\ldots,a_{n-1} \rangle$
is the sequence of actions generated by program
 $\Pi_{c_{dlv}}(\mathcal{P},n)$
, dlv
$\Pi_{c_{dlv}}(\mathcal{P},n)$
, dlv
 $^\mathcal{K}$
takes
$^\mathcal{K}$
takes
 $\alpha$
and the action theory
$\alpha$
and the action theory
 $(D, \delta^0)$
and creates a program that checks whether or not
$(D, \delta^0)$
and creates a program that checks whether or not
 $\alpha$
is a secure plan. If it is, then dlv
$\alpha$
is a secure plan. If it is, then dlv
 $^\mathcal{K}$
returns
$^\mathcal{K}$
returns
 $\alpha$
. Otherwise, it continues computing an optimistic plan and verifying that the plan is secure, until there are no additional optimistic plans available, which indicates that the problem has no solution. We next discuss the main idea in the second step of dlv
$\alpha$
. Otherwise, it continues computing an optimistic plan and verifying that the plan is secure, until there are no additional optimistic plans available, which indicates that the problem has no solution. We next discuss the main idea in the second step of dlv
 $^\mathcal{K}$
(Line 2).
$^\mathcal{K}$
(Line 2).
Intuitively, if
 $\alpha$
is a secure plan, then its execution in every possible initial state results in a final state in which the goal is satisfied. In other words,
$\alpha$
is a secure plan, then its execution in every possible initial state results in a final state in which the goal is satisfied. In other words,
 $\alpha$
is not a secure plan if there exists an initial state in which the execution of
$\alpha$
is not a secure plan if there exists an initial state in which the execution of
 $\alpha$
is not possible. This can happen in the following situations:
$\alpha$
is not possible. This can happen in the following situations:
-
• the goal is not satisfied after the execution of
$\alpha$
; -
• some action
$a_i$
in
$\alpha$
is not executable, that is,
$possible(a_i, i)$
is not true; or -
• some constraints are violated.




Let
 $Check(\mathcal{P}, \alpha, n)$
be the program obtained from
$Check(\mathcal{P}, \alpha, n)$
be the program obtained from
 $\Pi_{c_{dlv}}(\mathcal{P},n)$
by introducing a new atom, notex, which denotes that
$\Pi_{c_{dlv}}(\mathcal{P},n)$
by introducing a new atom, notex, which denotes that
 $\alpha$
is not secure and
$\alpha$
is not secure and
-
• replacing (9) with the rule
\begin{equation*}notex \leftarrow time(T), occ(A, T), { not \:} possible(A,T)\end{equation*}
-
• replacing (10) with the set of action occurrences
\begin{equation*}\{occ(a_i,i) \mid i=0,\ldots,n-1\}\end{equation*}
-
• replacing (13) with
\begin{equation*}\begin{array}{rcl} notex & \leftarrow & fluent(F), T > 0, holds(F, T), holds(\neg F, T) \\[4pt] & \leftarrow & fluent(F), holds(F, 0), holds(\neg F, 0)\end{array}\end{equation*}
-
• replacing (8), for each constraint
$\textbf{caused}(\varphi, \mathit{false})$
, with the rule
\begin{equation*}notex \leftarrow time(T), T > 0, holds(\varphi,T)\end{equation*}
-
• replacing (15) with
\begin{equation*}\leftarrow goal, { not \:} notex.\end{equation*}






If
 $Check(\mathcal{P}, \alpha, n)$
has an answer set M then either the goal is not satisfied or
$Check(\mathcal{P}, \alpha, n)$
has an answer set M then either the goal is not satisfied or
 $notex \in M$
. Observe that the rules replacing (13) and (8) guarantee that
$notex \in M$
. Observe that the rules replacing (13) and (8) guarantee that
 $\{f \mid holds(f, 0) \in M\} \cup \{\neg f \mid holds(\neg f, 0) \in M\}$
is a state of the action domain in
$\{f \mid holds(f, 0) \in M\} \cup \{\neg f \mid holds(\neg f, 0) \in M\}$
is a state of the action domain in
 $\mathcal{P}$
. If the goal is not satisfied and
$\mathcal{P}$
. If the goal is not satisfied and
 $notex\not\in M$
, then we have found an initial state from which the execution of
$notex\not\in M$
, then we have found an initial state from which the execution of
 $\alpha$
does not achieve the goal. Otherwise,
$\alpha$
does not achieve the goal. Otherwise,
 $notex\in M$
implies that
$notex\in M$
implies that
-
• an action
$a_i$
is not executable in the state at time step i or -
• there is some step
$j > 0$
such that the state at time step j is inconsistent or violates some static causal laws.


In either case, this means that there exists some initial state in which the execution of
 $\alpha$
fails, that is,
$\alpha$
fails, that is,
 $\alpha$
is not a secure plan. On the other hand, if
$\alpha$
is not a secure plan. On the other hand, if
 $Check(\mathcal{P}, \alpha, n)$
has no answer sets, then there are no possible initial states such that the execution of
$Check(\mathcal{P}, \alpha, n)$
has no answer sets, then there are no possible initial states such that the execution of
 $\alpha$
fails, that is,
$\alpha$
fails, that is,
 $\alpha$
is a secure plan.
$\alpha$
is a secure plan.
4.2 Approximation-based conformant planning
Approximation-based conformant planning deals with the complexity of conformant planning by proposing a deterministic approximation of the transition function
 $\Phi$
, denoted by
$\Phi$
, denoted by
 $\Phi^a$
, which maps pairs of actions and partial states such that for every
$\Phi^a$
, which maps pairs of actions and partial states such that for every
 $\delta$
,
$\delta$
,
 $\delta'$
, and s such that
$\delta'$
, and s such that
 $\Phi^a(a, \delta) = \delta'$
and
$\Phi^a(a, \delta) = \delta'$
and
 $ s \in comp(\delta)$
, it holds that
$ s \in comp(\delta)$
, it holds that
-
• a is executable in s; and
-
•
$\delta' \subseteq s'$
for every
$s' \in \Phi(a, s)$
.


Intuitively, the above conditions require
 $\Phi^a$
to be sound with respect to
$\Phi^a$
to be sound with respect to
 $\Phi$
. We say that
$\Phi$
. We say that
 $\Phi^a$
is sound approximation of
$\Phi^a$
is sound approximation of
 $\Phi$
if the above conditions are satisfied.
$\Phi$
if the above conditions are satisfied.
The function
 $\Phi^a$
is extended to define
$\Phi^a$
is extended to define
 $\widehat{\Phi^a}$
in the similar fashion as
$\widehat{\Phi^a}$
in the similar fashion as
 $\widehat{\Phi}$
: for an action sequence
$\widehat{\Phi}$
: for an action sequence
 $\alpha = \langle a_0, \ldots, a_{n-1} \rangle$
,
$\alpha = \langle a_0, \ldots, a_{n-1} \rangle$
,
-
•
$\widehat{\Phi^a}(\alpha, \delta) = \delta$
if
$\alpha = \langle \ \rangle$
; -
•
$\widehat{\Phi^a}(\alpha, \delta) = \Phi^a(a_0, \delta)$
for
$n=1$
; and -
•
$\widehat{\Phi^a}(\alpha, \delta) = \widehat{\Phi^a}(\alpha', \Phi^a(a_0, \delta))$
where
$\alpha' = \langle a_1, \ldots, a_{n-1} \rangle$
, if
$\widehat{\Phi^a}(\beta, \delta)$
is defined for every prefix
$\beta$
of
$\alpha$
.









Given a sound approximation
 $\Phi^a$
, we have that if
$\Phi^a$
, we have that if
 $\widehat{\Phi^a}(\alpha, \delta) = \delta'$
then for every
$\widehat{\Phi^a}(\alpha, \delta) = \delta'$
then for every
 $ s \in comp(\delta)$
,
$ s \in comp(\delta)$
,
 $\widehat{\Phi}(\alpha,s) \ne \emptyset$
and for every
$\widehat{\Phi}(\alpha,s) \ne \emptyset$
and for every
 $s' \in \widehat{\Phi}(\alpha,s) $
,
$s' \in \widehat{\Phi}(\alpha,s) $
,
 $\delta' \subseteq s'$
. This means that a sound approximation can be used for computing conformant plans. In the rest of this section, we define a sound approximation of
$\delta' \subseteq s'$
. This means that a sound approximation can be used for computing conformant plans. In the rest of this section, we define a sound approximation of
 $\Phi$
and use if for conformant planning. Because the program
$\Phi$
and use if for conformant planning. Because the program
 $\Pi(\mathcal{P},n)$
implements
$\Pi(\mathcal{P},n)$
implements
 $\Phi$
, we define the approximation by describing a program
$\Phi$
, we define the approximation by describing a program
 $\Pi^a(\mathcal{P},n)$
approximating
$\Pi^a(\mathcal{P},n)$
approximating
 $\Phi$
.
$\Phi$
.
Let a be an action and
 $\delta$
be a partial state. We say that a is executable in
$\delta$
be a partial state. We say that a is executable in
 $\delta$
if a occurs in an executability condition (3) and each literal in the precondition of the law holds in
$\delta$
if a occurs in an executability condition (3) and each literal in the precondition of the law holds in
 $\delta$
. A fluent literal l is a direct effect (resp. a possible direct effect) of a in
$\delta$
. A fluent literal l is a direct effect (resp. a possible direct effect) of a in
 $\delta$
if there exists a dynamic causal law (2) such that
$\delta$
if there exists a dynamic causal law (2) such that
 $\psi$
holds (resp. possibly holds) in
$\psi$
holds (resp. possibly holds) in
 $\delta$
. Observe that if a is executable in
$\delta$
. Observe that if a is executable in
 $\delta$
then it is executable in every state
$\delta$
then it is executable in every state
 $s \in comp(\delta)$
. Furthermore, the direct effects of a in
$s \in comp(\delta)$
. Furthermore, the direct effects of a in
 $\delta$
are also the direct effects of a in s, which in turn are the possible direct effects of a in
$\delta$
are also the direct effects of a in s, which in turn are the possible direct effects of a in
 $\delta$
.
$\delta$
.
We next present the program
 $\Pi^a(\mathcal{P},n)$
. Atoms of
$\Pi^a(\mathcal{P},n)$
. Atoms of
 $\Pi^a(\mathcal{P},n)$
are atoms of
$\Pi^a(\mathcal{P},n)$
are atoms of
 $\Pi(\mathcal{P},n)$
and those formed by the following (sorted) predicate symbols:
$\Pi(\mathcal{P},n)$
and those formed by the following (sorted) predicate symbols:
-
• de(l,T) is true if the fluent literal l is a direct effect of an action that occurs at the previous time step; and
-
• ph(l,T) is true if the fluent literal l possibly holds at time step T.
Similar to
 $holds(\varphi, T)$
, we write
$holds(\varphi, T)$
, we write
 $\rho(\varphi,T) = \{ \rho(l,T) \mid l \in \varphi \}$
and
$\rho(\varphi,T) = \{ \rho(l,T) \mid l \in \varphi \}$
and
 ${ not \:} \rho(\varphi,T) = \{{ not \:} \rho(l,T) \mid l \in \varphi \}$
for
${ not \:} \rho(\varphi,T) = \{{ not \:} \rho(l,T) \mid l \in \varphi \}$
for
 $\rho \in \{holds, de, ph\}$
. The rules in
$\rho \in \{holds, de, ph\}$
. The rules in
 $\Pi^a(\mathcal{P},n)$
include most of the rules from
$\Pi^a(\mathcal{P},n)$
include most of the rules from
 $\Pi(\mathcal{P},n)$
, except for the inertial rules, which need to be changed. In addition, it includes rules for reasoning about the direct and possible effects of actions.
$\Pi(\mathcal{P},n)$
, except for the inertial rules, which need to be changed. In addition, it includes rules for reasoning about the direct and possible effects of actions.
-
1. For each dynamic causal law (2) in D,
$\Pi^a(\mathcal{P},n)$
contains the rule (7) and the next rule (24)This rule indicates that f is a direct effect of the execution of a. The possible effects of a at T are encoded using the rule
\begin{eqnarray}de(f, T+1) & \leftarrow & time(T), occ(a,T), holds(\varphi,T). \end{eqnarray}
(25)which says that f might hold at
\begin{equation} ph(f,T+1) \leftarrow time(T), occ(a,T), { not \:} holds(\overline{\varphi}, T) , { not \:} de(\overline{f},T+1)\end{equation}
$T+1$
if a occurs at T and the precondition
$\varphi$
possibly holds at T.
-
2. For each static causal law (1) in D,
$\Pi^a(\mathcal{P},n)$
contains the rule (8) and the next rule (26)This rule propagates the possible holds relation between fluent literals.
\begin{eqnarray}ph(f,T)& {\leftarrow} & time(T), ph(\varphi,T). \end{eqnarray}
-
3. The rule (6) stating that a can occur if its executability condition is satisfied.
-
4. The inertial law is encoded as follows:
(27)
\begin{eqnarray}ph(L,T+1) & \leftarrow & time(T), fluent(L), { not \:} holds(\neg {L},T), { not \:} de(\neg {L},T+1) \quad \quad \end{eqnarray}
(28)
\begin{eqnarray}ph(\neg L,T+1) & \leftarrow & time(T), fluent(L), { not \:} holds( {L},T), { not \:} de( {L},T+1) \end{eqnarray}
(29)
\begin{eqnarray}holds(L,T) & \leftarrow & time(T), fluent(L), { not \:} ph(\neg {L},T), T \ne 0. \end{eqnarray}
(30)These rules capture the fact that L holds at time moment
\begin{eqnarray}holds(\neg L,T) & \leftarrow & time(T), fluent(L), { not \:} ph({L},T), T \ne 0. \end{eqnarray}
$T > 0$
if its negation cannot possibly hold at T. Furthermore, L possibly holds at time moment
$T+1$
if its negation does not hold at T and is not a direct effect of the action occurring at T. These rules, when used in conjunction with the rules (24)–(25), compute the effects of the occurrence of action at time moment T.
-
5.
$\Pi^a(\mathcal{P},n)$
also contains the rules of the form (9), (10), (13), and the rule encoding the initial state and the goal state as in
$\Pi(\mathcal{P},n)$
.















It can be shown that if
 $\delta$
is a partial state and x is an action executable in
$\delta$
is a partial state and x is an action executable in
 $\delta$
then the program
$\delta$
then the program
 $\Pi^a(\mathcal{P},1) \cup \{occ(x, 0)\}$
, where
$\Pi^a(\mathcal{P},1) \cup \{occ(x, 0)\}$
, where
 $\mathcal{P} = \langle D, \delta, \emptyset \rangle$
, has a unique answer set M and
$\mathcal{P} = \langle D, \delta, \emptyset \rangle$
, has a unique answer set M and
 $\{f \mid holds(f, 1) \in M\}$
is a partial state of D. For this reason,
$\{f \mid holds(f, 1) \in M\}$
is a partial state of D. For this reason,
 $\Pi^a(\mathcal{P},n)$
can be used to define a sound approximation
$\Pi^a(\mathcal{P},n)$
can be used to define a sound approximation
 $\Phi^a$
of
$\Phi^a$
of
 $\Phi$
. The soundness of
$\Phi$
. The soundness of
 $\Phi^a$
is discussed in details by (Tu et al. Reference Tu, Son, Gelfond and Morales2011). This property indicates that
$\Phi^a$
is discussed in details by (Tu et al. Reference Tu, Son, Gelfond and Morales2011). This property indicates that
 $\Pi^a(\mathcal{P},n)$
can be used as an ASP implementation of a conformant planner. The planner CPasp, as described by (Tu et al. Reference Tu, Son, Gelfond and Morales2011), employs this implementation.
$\Pi^a(\mathcal{P},n)$
can be used as an ASP implementation of a conformant planner. The planner CPasp, as described by (Tu et al. Reference Tu, Son, Gelfond and Morales2011), employs this implementation.
Remark 3
-
1. The key difference between CPasp and dlv
$^\mathcal{K}$
is the use of an approximation semantics, which leads to the elimination of the security check in CPasp and the use of a single call to the answer set solver to find a solution. -
2. (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b) defined the notion of sound and complete security check that can be used in the second step of dlv
$^\mathcal{K}$
algorithm. They also identified classes of planning problems in which different security checks are sound and complete. The security check described in Subsection 4.1 is an adaptation of the check
$\mathcal{SC}_1$
in the paper describing dlv
$^\mathcal{K}$
. It is sound and complete for domains called false-committed planning domains. For consistent action theories considered in this paper,
$\mathcal{SC}_1$
is sound and complete. Observe that this security check could be used together with the program
$\Pi(\mathcal{P},n)$
in the previous section to compute secure plans for non-deterministic domains. -
3. Alternative representation approaches may facilitate the search of solutions in certain domains. For example, as discussed by (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2004), the knowledge-state planning approach enables certain fluents to remain open (i.e., as three-valued fluents), simplifying the state representation. Actions enable to either gain or forget knowledge of such fluents. For example, in the bomb-in-the-toilet domain, encoded in dlv
$^\mathcal{K}$
, this approach makes optimistic and secure plans equivalent. -
4. CPasp, the conformant planner using
$\Pi^a(\mathcal{P},n)$
, performs well against logic-based conformant planning systems (e.g., dlv
$^\mathcal{K}$
). Tu et al. Reference Tu, Son, Gelfond and Morales2011 shows that CPasp and other logic-based systems are not as efficient and scalable in common benchmarks used by the planning community. CPasp also does not consider planning problem with disjunctive information. However, their performance is superior in domains with static causal laws (Son et al. Reference Son, Tu, Gelfond and Morales2005a). In addition, logic-based planning systems can generate parallel plans, while the existing heuristic search-based state-of-the-art conformant planning systems do not. -
5. Approximation has its own price. Approximation-based planning systems are incomplete. CPasp, for example, cannot solve the problem
$\mathcal{P}^1_{inc} = \langle D^1_{inc}, \emptyset, f \rangle$
where
$D^1_{inc}$
consists of two dynamic laws: More specifically,
\begin{equation*}\textbf{causes}(a, f, \{g\}) \quad \quad {and} \quad\quad \textbf{causes}(a, f, \{\neg g\}).\end{equation*}
$\Pi^a(\mathcal{P}^1_{inc},1)$
has no answer sets, while
$\mathcal{P}_{inc}$
has solution
$\langle a \rangle$
. Similarly, CPasp cannot solve the problem
$\mathcal{P}^2_{inc} = \langle D^2_{inc}, \emptyset, g \rangle$
where
$D^2_{inc}$
consists of the following laws: The main reason for the incompleteness of CPasp is that it fails to reason by cases. Syntactic conditions that guarantee that the proposed approximation is complete were proposed by (Tu et al. Reference Tu, Son, Gelfond and Morales2011) and (Son and Tu Reference Son and Tu2006). Those authors also showed that the majority of planning benchmarks in the literature satisfy the conditions. The reason why CPasp cannot solve some of the benchmarks is related to the presence of a disjunctive formulae in the initial state.
\begin{equation*}\textbf{causes}(a, f, \emptyset) \quad \quad \textbf{caused}(\{f,h\},g) \quad \quad \textbf{caused}(\{f,\neg h\}, g).\end{equation*}
-
6. Conformant planning using approximation is a successful approach in dealing with incomplete information. (Tran et al. Reference Tran, Nguyen, Son and Pontelli2013) have shown that, with additional techniques to reduce the search space, such as goal splitting and combination of one-of clauses, approximation-based planners perform exceptionally well compared to heuristic-based planning systems.
-
7. As with planning with complete information, ASP-based conformant planners such as CPasp do not include any heuristics (e.g., as those discussed in Subsection 3.3). This is a reason for the weak performance of CPasp compared to its search-based counterparts.The second reason that greatly affects the performance of ASP-based planners is the need for grounding before solving. In many benchmarks used by the planning community (see, e.g., the paper by Tran et al. Reference Tran, Nguyen, Son and Pontelli2013 for details), the initial belief state of a small instance already contains
$2^{10}$
states and the minimal plan length can easily reach 50. In most instances, grounding already fails. We believe that, besides the use of heuristic, adapting techniques to reduce the search space such as those proposed by (Tran et al. Reference Tran, Nguyen, Son and Pontelli2013) and developing incremental grounding technique for ASP solver (e.g., the work by PalÙ et al. Reference PalÙ, Dovier, Pontelli and Rossi2009) could help to scale up ASP-based conformant planners. -
8. Various approximation semantics for action domains with static causal laws have been defined (Son and Baral Reference Son and Baral2001; Son et al. Reference Son, Tu, Gelfond and Morales2005b; Tu et al. Reference Tu, Son and Baral2007). A discussion on their strengths and weaknesses can be found in the paper by (Tu et al. Reference Tu, Son, Gelfond and Morales2011). A discussion of the performance of CPasp against other planning systems is included in the next section.



















4.3 Context: Conformant planning
As with classical planning, several search-based conformant planners have been developed during the last three decades. Among them are GPT (Bonet and Geffner Reference Bonet and Geffner2000), CGP (Smith and Weld Reference Smith and Weld1998), CMBT (Cimatti and Roveri Reference Cimatti and Roveri2000), Conformant-FF (CFF) (Hoffmann and Brafman Reference Hoffmann and Brafman2006), KACMBP (Cimatti et al. Reference Cimatti, Roveri and Bertoli2004), POND (Bryce et al. Reference Bryce, Kambhampati and Smith2006), t0 (Palacios and Geffner Reference Palacios and Geffner2007; Palacios and Geffner Reference Palacios and Geffner2009), t1 (Albore et al. Reference Albore, Ramrez and Geffner2011), CpA Footnote 9 (Son et al. Reference Son, Tu, Gelfond and Morales2005a; Tran et al. Reference Tran, Nguyen, Pontelli and Son2009), CpLs (Nguyen et al. Reference Nguyen, Tran, Son and Pontelli2011), DNF (To et al. Reference To, Pontelli and Son2009), CNF (To et al. Reference To, Pontelli and Son2010a), PIP (To et al. Reference To, Pontelli and Son2010b), GC[LAMA] (Nguyen et al. Reference Nguyen, Tran, Son and Pontelli2012), and CPCES (Grastien and Scala Reference Grastien and Scala2020). With the exception of CMBT, KACMBP, t0, and GC[LAMA], the others planners are forward search-based planners.
Differently from classical planning, a significant hurdle in the development of an efficient and scalable conformant planner is the size of the initial belief state and the size of the search space, which is double exponential in the size of the planning problem (see, e.g., the work by Tran et al. Reference Tran, Nguyen, Son and Pontelli2013 for a detailed discussion on this issue). Each of the aforementioned planners deals with this challenge in a different way. Different representations of belief states are used in CFF, DNF, CNF, and PIP. Specifically, CFF and t1 make use of an implicit representation of a belief state as a sequence of actions from the initial state to the belief state. KACMBP, CMBP, and POND use a BDD-based representation (Bryant Reference Bryant1992). CpA approximates a belief state using a set of subsets of states (partial states). t0 and GC[LAMA] translate a conformant planning problem to a classical planning problem and use classical planners to compute solutions, avoiding the need to deal with an explicit belief state representation. Additional improvements have been proposed in terms of heuristics (Bryce et al. Reference Bryce, Kambhampati and Smith2006) and techniques to reduce the size of the initial belief state, such as the
 $\textbf{oneof}$
-combination technique (Tran et al. Reference Tran, Nguyen, Son and Pontelli2013). Such a technique is useful for planners employing an explicit disjunctive representation of belief states, as in CpA (Tran et al. Reference Tran, Nguyen, Son and Pontelli2013) and DNF (To et al. Reference To, Pontelli and Son2009); a significant amount of work is required to apply this technique to other planners, due to the different representations they use. Likewise, the
$\textbf{oneof}$
-combination technique (Tran et al. Reference Tran, Nguyen, Son and Pontelli2013). Such a technique is useful for planners employing an explicit disjunctive representation of belief states, as in CpA (Tran et al. Reference Tran, Nguyen, Son and Pontelli2013) and DNF (To et al. Reference To, Pontelli and Son2009); a significant amount of work is required to apply this technique to other planners, due to the different representations they use. Likewise, the
 $\textbf{oneof}$
-relaxation technique proposed by (To et al. Reference To, Pontelli and Son2010a) is useful in CNF but is difficult to use in other planners. Additional techniques proposed to improve performance include extensions of the GraphPlan to deal with incomplete information, used in CGP, backward search algorithms, as in CMBT, landmarks, used in CpLs, and sampling technique, used in CPCES.
$\textbf{oneof}$
-relaxation technique proposed by (To et al. Reference To, Pontelli and Son2010a) is useful in CNF but is difficult to use in other planners. Additional techniques proposed to improve performance include extensions of the GraphPlan to deal with incomplete information, used in CGP, backward search algorithms, as in CMBT, landmarks, used in CpLs, and sampling technique, used in CPCES.
SAT-based conformant planning is studied by several researchers (Castellini et al. Reference Castellini, Giunchiglia and Tacchella2003; Palacios and Geffner Reference Palacios and Geffner2005; Rintanen Reference Rintanen1999). The system C-Plan (Castellini et al. Reference Castellini, Giunchiglia and Tacchella2003) has similarities to dlv
 $^\mathcal{K}$
, in that it starts with a translation of the planning problem into a SAT-problem, identifies a potential plan, and then validates the plan. (Palacios and Geffner Reference Palacios and Geffner2005) propose the system compile-project-sat, which uses a single call to the SAT-solver to compute a conformant plan. They show that the validity check can be done in linear time if the planning problem is encoded in a logically equivalent theory in deterministic decomposable negation normal form (d-DNNF). As compile-project-sat calls the SAT-solver only once, it is similar to CPasp. However, compile-project-sat is complete, while CPasp is not. The system QBFPlan by (Rintanen Reference Rintanen1999) differs from C-Plan and compile-project-sat in that it translates the problem into a QBF-formula and uses a QBF-solver to compute the solutions. A detailed comparison between these planning systems with CPasp, directly or indirectly, can be found in the paper by (Tu et al. Reference Tu, Son, Gelfond and Morales2011).
$^\mathcal{K}$
, in that it starts with a translation of the planning problem into a SAT-problem, identifies a potential plan, and then validates the plan. (Palacios and Geffner Reference Palacios and Geffner2005) propose the system compile-project-sat, which uses a single call to the SAT-solver to compute a conformant plan. They show that the validity check can be done in linear time if the planning problem is encoded in a logically equivalent theory in deterministic decomposable negation normal form (d-DNNF). As compile-project-sat calls the SAT-solver only once, it is similar to CPasp. However, compile-project-sat is complete, while CPasp is not. The system QBFPlan by (Rintanen Reference Rintanen1999) differs from C-Plan and compile-project-sat in that it translates the problem into a QBF-formula and uses a QBF-solver to compute the solutions. A detailed comparison between these planning systems with CPasp, directly or indirectly, can be found in the paper by (Tu et al. Reference Tu, Son, Gelfond and Morales2011).
5 Planning with sensing actions
Conformant planning aims at addressing the completeness assumption of the initial state in classical planning but there are planning problems that do not admit any conformant plans as solution. The following example demonstrates this issue.
Example 5 (From the work by Reference Tu, Son and Baral Tu et al. 2007 ) Consider a security window with a lock that behaves as follows. The window can be in one of the three states open, closed, Footnote 10 or locked. Footnote 11 When the window is closed or open, pushing it up or down will open or close it, respectively. When the window is not open, flipping the lock will bring it to either the close or locked status.
Let us consider a security robot that needs to make sure that the window is locked after 9pm. The robot has been told that the window is not open (but whether it is locked or closed is unknown).
Intuitively, the robot can achieve its goal by performing the following steps:
-
(1) checks the window to determine the window’s status.
-
(2a) If the window is in the closed status, the robot will lock the window;
-
(2b) otherwise (i.e., the window is already in the locked status) the robot will not need to do anything.
Observe that no sequence of actions can achieve the goal from every possible initial situation. In other words, there exists no conformant plan achieving the goal.
 $\Diamond$
$\Diamond$
5.1 Action language
$\mathcal{B}$
with sensing actions and conditional plans

In order to solve the planning problem in Example 5, sensing actions are necessary. Intuitively, the execution of a sensing action does not change the world; instead, it changes the knowledge of the action’s performer. We extend the language
 $\mathcal{B}$
with knowledge laws of the following form:
$\mathcal{B}$
with knowledge laws of the following form:
 \begin{eqnarray}& \textbf{determines}(a,\theta), \end{eqnarray}
\begin{eqnarray}& \textbf{determines}(a,\theta), \end{eqnarray}
where
 $\theta$
is a set of fluent literals. An action occurring in a knowledge law is referred to as a sensing action. The knowledge law states that the values of the literals in
$\theta$
is a set of fluent literals. An action occurring in a knowledge law is referred to as a sensing action. The knowledge law states that the values of the literals in
 $\theta$
, sometimes referred to as sensed literals, will be known after a is executed. It is assumed that the literals in
$\theta$
, sometimes referred to as sensed literals, will be known after a is executed. It is assumed that the literals in
 $\theta$
are mutually exclusive, that is,
$\theta$
are mutually exclusive, that is,
-
1. for every pair of literals g and g’ in
$\theta$
,
$g \ne g'$
, the theory contains the static causal law and
\begin{equation*}\textbf{caused}(\{g\}, \neg g')\end{equation*}
-
2. for every literal g in
$\theta$
, the theory contains the static causal law
\begin{equation*}\textbf{caused}(\{\neg g' \mid g' \in \theta \setminus \{ g \}\}, g).\end{equation*}





We refer to this collection of static causal laws as
 $\textbf{oneof}(\theta)$
. We sometimes write
$\textbf{oneof}(\theta)$
. We sometimes write
 $\textbf{determines}(a,f)$
as a shorthand for
$\textbf{determines}(a,f)$
as a shorthand for
 $\textbf{determines}(a,\{f,\neg f\}).$
$\textbf{determines}(a,\{f,\neg f\}).$
Example 6 The planning problem instance
 $\mathcal{P}_{window} = (D_{window},\Gamma_{window},\Delta_{window})$
in Example 5 can be represented as follows.
$\mathcal{P}_{window} = (D_{window},\Gamma_{window},\Delta_{window})$
in Example 5 can be represented as follows.
 \begin{equation*}D_{window} = \left \{\begin{array}{lll}\textbf{executable}(push\_up, \{ closed\}) \\[2pt]\textbf{executable}(push\_down, \{ open\}) \\[2pt]\textbf{executable}(flip\_lock, \{ \neg open\}) \\\\\textbf{causes}(push\_down, closed, \{\}) \\[2pt]\textbf{causes}(push\_up, open, \{\}) \\[2pt]\textbf{causes}(flip\_lock, locked, \{closed\}) \\[2pt]\textbf{causes}(flip\_lock, closed, \{locked\}) \\\\\textbf{oneof}(\{open, locked, closed\})\\[2pt]\\\textbf{determines}(check, \{open,closed,locked\})\end{array}\right .\end{equation*}
\begin{equation*}D_{window} = \left \{\begin{array}{lll}\textbf{executable}(push\_up, \{ closed\}) \\[2pt]\textbf{executable}(push\_down, \{ open\}) \\[2pt]\textbf{executable}(flip\_lock, \{ \neg open\}) \\\\\textbf{causes}(push\_down, closed, \{\}) \\[2pt]\textbf{causes}(push\_up, open, \{\}) \\[2pt]\textbf{causes}(flip\_lock, locked, \{closed\}) \\[2pt]\textbf{causes}(flip\_lock, closed, \{locked\}) \\\\\textbf{oneof}(\{open, locked, closed\})\\[2pt]\\\textbf{determines}(check, \{open,closed,locked\})\end{array}\right .\end{equation*}
 \begin{equation*}\Gamma_{window} \;\; = \; \left \{\begin{array}{lll}\textbf{initially}(\neg open)\end{array}\right \}\end{equation*}
\begin{equation*}\Gamma_{window} \;\; = \; \left \{\begin{array}{lll}\textbf{initially}(\neg open)\end{array}\right \}\end{equation*}
 \begin{equation*}\Delta_{window} = \{ locked \}.\end{equation*}
\begin{equation*}\Delta_{window} = \{ locked \}.\end{equation*}
It has been pointed out by several researchers (Warren Reference Warren1976; Peot and Smith Reference Peot and Smith1992; Pryor and Collins Reference Pryor and Collins1996; Levesque Reference Levesque1996; Lobo et al. Reference Lobo, Mendez and Taylor1997; Son and Baral Reference Son and Baral2001; Turner Reference Turner2002) that the notion of a plan needs to be extended beyond a sequence of actions, in order to allow conditional statements such as if-then-else, while-do, or case-endcase to deal with incomplete information and sensing actions. If we are interested in bounded-length plans, then the following notion of conditional plans is sufficient.
Definition 1 (Conditional Plan)
-
1. The empty plan, that is, the plan
$\langle \rangle$
containing no actions, is a conditional plan. -
2. If a is a non-sensing action and p is a conditional plan then
$\langle a;p \rangle$
is a conditional plan. -
3. If a is a sensing action with knowledge law (31), where
$\theta = \{ g_1, \dots, g_n \}$
, and
$p_j$
’s are conditional plans then
$\langle a; \textbf{cases}(\{g_j \rightarrow p_j\}_{j=1}^{n}) \rangle$
is a conditional plan. -
4. Nothing else is a conditional plan.





Clearly, the notion of a conditional plan is more general than the notion of a plan as a sequence of actions. We refer to the conditional plan in Item 3 of Definition 1 as a case-plan and the
 $g_j \rightarrow p_j$
’s as its branches. Under the above definition, the following are two possible conditional plans in the domain
$g_j \rightarrow p_j$
’s as its branches. Under the above definition, the following are two possible conditional plans in the domain
 $D_{window}$
:
$D_{window}$
:
 \begin{equation*}p_1 = \langle push\_down;flip\_lock \rangle\end{equation*}
\begin{equation*}p_1 = \langle push\_down;flip\_lock \rangle\end{equation*}
 \begin{equation*}p_2 = \langle check; \; \textbf{cases} \left (\begin{array}{lll}open & \rightarrow & [] \\[2pt]closed & \rightarrow & [flip\_lock] \\[2pt]locked & \rightarrow & []\end{array}\right ) \rangle\end{equation*}
\begin{equation*}p_2 = \langle check; \; \textbf{cases} \left (\begin{array}{lll}open & \rightarrow & [] \\[2pt]closed & \rightarrow & [flip\_lock] \\[2pt]locked & \rightarrow & []\end{array}\right ) \rangle\end{equation*}
The semantics of the language
 $\mathcal{B}$
with knowledge laws also needs to be extended to account for sensing actions. Observe that, since it is possible that the initial state of the planning problem is incomplete, we will continue using the approximation
$\mathcal{B}$
with knowledge laws also needs to be extended to account for sensing actions. Observe that, since it is possible that the initial state of the planning problem is incomplete, we will continue using the approximation
 $\Phi^a$
proposed in the previous section as well as other notions, such as partial states, a fluent literal holds or possibly holds in a partial state, etc. To reason about the effects of sensing actions in a domain D, we define
$\Phi^a$
proposed in the previous section as well as other notions, such as partial states, a fluent literal holds or possibly holds in a partial state, etc. To reason about the effects of sensing actions in a domain D, we define
 \begin{equation} \Phi^a(a,\delta) = \{Cl_{D}(\delta \cup \{g \}) g \in \theta {and}Cl_{D}(\delta \cup \{g\}) {is consistent}\},\end{equation}
\begin{equation} \Phi^a(a,\delta) = \{Cl_{D}(\delta \cup \{g \}) g \in \theta {and}Cl_{D}(\delta \cup \{g\}) {is consistent}\},\end{equation}
where a is a sensing action executable in
 $\delta$
and
$\delta$
and
 $\theta$
is the set of sensed literals of a. If a is not executable in
$\theta$
is the set of sensed literals of a. If a is not executable in
 $\delta$
then
$\delta$
then
 $\Phi^a(a,\delta) = \bot$
(undefined). The definition of
$\Phi^a(a,\delta) = \bot$
(undefined). The definition of
 $\Phi^a(a,\delta)$
for a non-sensing action is defined as in the previous section. Intuitively, the execution of a can result in several partial states, in each of which exactly one sensed-literal in
$\Phi^a(a,\delta)$
for a non-sensing action is defined as in the previous section. Intuitively, the execution of a can result in several partial states, in each of which exactly one sensed-literal in
 $\theta$
holds.
$\theta$
holds.
As an example, consider
 ${D}_{window}$
in Example 5 and a partial state
${D}_{window}$
in Example 5 and a partial state
 $\delta_1 = \{\neg open\}$
. We have
$\delta_1 = \{\neg open\}$
. We have
 \begin{equation*}\begin{array}{rcl}Cl_{D_{window}}(\delta_1 \cup \{open\}) & = &\{ open, \neg open, closed, \neg closed, locked, \neg locked\} = \delta_{1,1} \\[2pt]Cl_{D_{window}}(\delta_1 \cup \{closed\}) & = &\{ \neg open, closed, \neg locked \} = \delta_{1,2} \\[2pt]Cl_{D_{window}}(\delta_1 \cup \{locked\}) & = &\{ \neg open, \neg closed, locked \} = \delta_{1,3}.\end{array}\end{equation*}
\begin{equation*}\begin{array}{rcl}Cl_{D_{window}}(\delta_1 \cup \{open\}) & = &\{ open, \neg open, closed, \neg closed, locked, \neg locked\} = \delta_{1,1} \\[2pt]Cl_{D_{window}}(\delta_1 \cup \{closed\}) & = &\{ \neg open, closed, \neg locked \} = \delta_{1,2} \\[2pt]Cl_{D_{window}}(\delta_1 \cup \{locked\}) & = &\{ \neg open, \neg closed, locked \} = \delta_{1,3}.\end{array}\end{equation*}
Among those,
 $\delta_{1,1}$
is inconsistent. Therefore, we have
$\delta_{1,1}$
is inconsistent. Therefore, we have
 $\Phi^a(check,\delta_1)=\{\delta_{1,2},\delta_{1,3}\}$
.
$\Phi^a(check,\delta_1)=\{\delta_{1,2},\delta_{1,3}\}$
.
The extended transition function
 $\widehat{\Phi^a}$
for computing the result of the execution of a conditional plan is defined as follows. Let
$\widehat{\Phi^a}$
for computing the result of the execution of a conditional plan is defined as follows. Let
 $\alpha$
be a conditional plan and
$\alpha$
be a conditional plan and
 $\delta$
a partial state.
$\delta$
a partial state.
-
1. If
$\alpha = \langle \rangle $
then
$\widehat{\Phi^a}(\alpha, \delta) = \delta$
. -
2. If
$\alpha = \langle a; \beta \rangle$
and a is a non-sensing action and
$\beta$
is a conditional plan then
$\widehat{\Phi^a}(\alpha, \delta) = \widehat{\Phi^a}(\beta, \Phi^a(a, \delta))$
. -
3. if
$\alpha = \langle a; \textbf{cases}(\{g_j \rightarrow \alpha_j\}_{j=1}^{n}) \rangle$
where a is a sensing action with the sensed-literals
$\theta = \{ g_1, \dots, g_n \}$
and
$\alpha_j$
’s are conditional plans then -
(a)
$\widehat{\Phi^a}(\alpha, \delta) = \widehat{\Phi^a}(\alpha_k, \delta_k)$
if there exists
$\delta_k \in \Phi^a(a, \delta)$
such that
$\delta_k \models g_k$
. -
(b)
$\widehat{\Phi^a}(\alpha, \delta) = \bot$
(undefined), otherwise. -
(4)
$\widehat{\Phi^a}(\alpha, \bot) = \bot$
for every
$\alpha$
.














Intuitively, the execution of a conditional plan progresses similarly to the execution of an action sequence until it encounters a case-plan. In this case, the sensing action is executed and the satisfaction of the formula in each branch is evaluated. If one of the formulae holds in the state resulting after the execution of the sensing action then the execution continues with the plan on that branch. Otherwise, the execution fails.
5.2 ASP-based conditional planning
Let us now describe an ASP-based conditional planner, called ASPcp, capable of generating conditional plans. The planner is a simple variation of the one described by (Tu et al. Reference Tu, Son and Baral2007). As in the previous sections, we translate a planning problem
 $\mathcal{P} = (D,\Gamma,\Delta)$
into a logic program
$\mathcal{P} = (D,\Gamma,\Delta)$
into a logic program
 $\Pi_{h,w}(\mathcal{P})$
whose answer sets represent solutions of
$\Pi_{h,w}(\mathcal{P})$
whose answer sets represent solutions of
 $\mathcal{P}$
. Before we present the rules of
$\mathcal{P}$
. Before we present the rules of
 $\Pi_{h,w}(\mathcal{P})$
, let us provide the intuition underlying the encoding.
$\Pi_{h,w}(\mathcal{P})$
, let us provide the intuition underlying the encoding.
First, let us observe that each plan
 $\alpha$
(Definition 1) corresponds to a labeled plan tree
$\alpha$
(Definition 1) corresponds to a labeled plan tree
 $T_\alpha$
defined as follows.
$T_\alpha$
defined as follows.
-
• If
$\alpha = \langle \: \rangle$
then
$T_\alpha$
is a tree with a single node. -
• If
$\alpha = \langle a \rangle$
, where a is a non-sensing action, then
$T_\alpha$
is a tree with a single node and this node is labeled with a. -
• If
$\alpha = \langle a; \beta \rangle$
, where a is a non-sensing action and
$\beta$
is a non-empty plan, then
$T_\alpha$
is a tree whose root is labeled with a and has only one subtree which is
$T_\beta$
. Furthermore, the link between a and
$T_\beta$
’s root is labeled with an empty string. -
• If
$\alpha = \langle a;\textbf{cases}(\{g_j \rightarrow \alpha_j\}_{j=1}^n) \rangle$
, where a is a sensing action, then
$T_\alpha$
is a tree whose root is labeled with a and has n subtrees
$\{T_{\alpha_j} \mid j \in \{1,\dots,n\}\}$
. For each j, the link from a to the root of
$T_{\alpha_j}$
is labeled with
$g_j$
.














For example, the plan tree for the plan
 \begin{equation*}\alpha =\left\langle check;\textbf{cases} \left (\begin{array}{lll} locked & \rightarrow & \langle \rangle; \\[2pt] open & \rightarrow & \langle push\_down;flip\_lock\rangle; \\[2pt] closed & \rightarrow & \langle flip\_lock; flip\_lock; flip\_lock \rangle \end{array} \right )\right\rangle\end{equation*}
\begin{equation*}\alpha =\left\langle check;\textbf{cases} \left (\begin{array}{lll} locked & \rightarrow & \langle \rangle; \\[2pt] open & \rightarrow & \langle push\_down;flip\_lock\rangle; \\[2pt] closed & \rightarrow & \langle flip\_lock; flip\_lock; flip\_lock \rangle \end{array} \right )\right\rangle\end{equation*}
is given in Figure 1 (shaded nodes indicate that there exists an action occurring at those nodes, while white nodes indicate that there is no action occurring at those nodes).

Fig. 1. A plan tree.
For a plan p, let w(p) be the number of leaves of
 $T_p$
and h(p) be the number of nodes along the longest path from the root to the leaves of
$T_p$
and h(p) be the number of nodes along the longest path from the root to the leaves of
 $T_p$
. w(p) and h(p) are called the width and height of
$T_p$
. w(p) and h(p) are called the width and height of
 $T_p$
respectively. Suppose w and h are two integers that such that
$T_p$
respectively. Suppose w and h are two integers that such that
 $w(p) \le w$
and
$w(p) \le w$
and
 $h(p) \le h$
.
$h(p) \le h$
.
Let us denote the leaves of
 $T_p$
by
$T_p$
by
 $x_1,\ldots,x_{w(p)}$
. We map each node y of
$x_1,\ldots,x_{w(p)}$
. We map each node y of
 $T_p$
to a pair of integers
$T_p$
to a pair of integers
 $n_y$
= (
$n_y$
= (
 $t_y$
,
$t_y$
,
 $p_y$
), where
$p_y$
), where
 $t_y$
, called the t-value of y, is the number of nodes along the path from the root to y minus 1, and
$t_y$
, called the t-value of y, is the number of nodes along the path from the root to y minus 1, and
 $p_y$
, called the p-value of y, is defined in the following way:
$p_y$
, called the p-value of y, is defined in the following way:
-
• For each leaf
$x_i$
of
$T_p$
,
$p_{x_i}$
is an arbitrary integer between 0 and w. Furthermore, there exists a leaf x such that
$p_x = 0$
, and there exist no
$i \ne j$
such that
$p_{x_i} = p_{x_j}$
. -
• For each interior node y of
$T_p$
with children
$y_1,\ldots,y_r$
,
$p_y = \min\{p_{y_1},\ldots,p_{y_r}\}$
.









For instance, Figure 2 shows some possible mappings with
 $h=3$
and
$h=3$
and
 $w=3$
for the tree in Figure 1. It is easy to see that if
$w=3$
for the tree in Figure 1. It is easy to see that if
 $w(p) \le w$
and
$w(p) \le w$
and
 $h(p) \le h$
then such a mapping always exists.
$h(p) \le h$
then such a mapping always exists.

Fig. 2. Possible mappings for the tree in Figure 1.
Furthermore, from the construction of
 $T_\alpha$
, independently of how the leaves of
$T_\alpha$
, independently of how the leaves of
 $T_\alpha$
are numbered, we have the following properties.
$T_\alpha$
are numbered, we have the following properties.
-
1. For every node y,
$t_y \le h$
and
$p_y \le w$
. -
2. For a node y, all of its children have the same t-value. That is, if y has r children
$y_1,\ldots,y_r$
then
$t_{y_i} = t_{y_j}$
for every
$1 \le i,j \le r$
. Furthermore, the p-value of y is the smallest one among the p-values of its children. -
3. The root of
$T_\alpha$
is always mapped to the pair (0,0).






The numbering schema of a plan tree provides a method for generating a conditional plan on a two-dimensional coordinated system (or grid) where the x- and y-axis correspond to the height and width of the plan tree, and where (0,0) is the initial state. Along a line of the same y-value is an action sequence and the execution of a sensing action creates branches on different lines, parallel to the x-axis. For example, the execution of the check action in the initial state of the plan tree in Figure 2 creates three branches, to lines 0, 1, and 2. In the following, we use path to indicate the branch number and refer to a coordinate (x,y) as a node.
Let us next describe the rules in program
 $\Pi_{h,w}(\mathcal{P})$
. Intuitively, the program is similar to the program
$\Pi_{h,w}(\mathcal{P})$
. Intuitively, the program is similar to the program
 $\Pi^a(\mathcal{P},n)$
in that it implements the approximation
$\Pi^a(\mathcal{P},n)$
in that it implements the approximation
 $\Phi^a$
and extends it to deal with sensing actions. Since a conditional plan is two-dimensional, all predicates holds, ph, possible, occ, de, etc. need to extend with a third parameter. That is, holds(L,T,P) – encoding that L holds at node (T,P) (the time step T and the line number P on the two-dimensional grid) – is used instead of holds(L,T). In addition,
$\Phi^a$
and extends it to deal with sensing actions. Since a conditional plan is two-dimensional, all predicates holds, ph, possible, occ, de, etc. need to extend with a third parameter. That is, holds(L,T,P) – encoding that L holds at node (T,P) (the time step T and the line number P on the two-dimensional grid) – is used instead of holds(L,T). In addition,
 $\Pi_{h,w}(\mathcal{P})$
uses the following additional atoms and predicates.
$\Pi_{h,w}(\mathcal{P})$
uses the following additional atoms and predicates.
-
•
$path(0..w)$
. -
• sense(a,g) if g is a sensed literal which belongs to
$\theta$
in a knowledge law of the form (31). -
•
$br(G,T,P,P_1)$
is true if there exists a branch from (T,P) to
$(T+1,P_1)$
labeled with G. For example, in Figure 2 (left), we have br(open,0,0,1), br(closed,0,0,0), and br(locked,0,1,2). -
• used(T,P) is true if (T,P) belongs to some extended branch of the plan tree. This allows us to know which paths are used in the construction of the plan and allows us to check if the plan satisfies the goal. In Figure 2 (left), we have used(t,0) for
$0 \le t \le h$
, and used(t,1) and used(t,2) for
$1 \le t \le h$
.






The rules of
 $\Pi_{h,w}(\mathcal{P})$
are divided into two groups. The first group consists of rules from
$\Pi_{h,w}(\mathcal{P})$
are divided into two groups. The first group consists of rules from
 $\Pi^a(\mathcal{P},n)$
adapted to the two dimensional array for conditional planning. The second group consists of rules for dealing with sensing actions. We next describe the first group of rules
Footnote 12
in
$\Pi^a(\mathcal{P},n)$
adapted to the two dimensional array for conditional planning. The second group consists of rules for dealing with sensing actions. We next describe the first group of rules
Footnote 12
in
 $\Pi_{h,w}(\mathcal{P})$
:
$\Pi_{h,w}(\mathcal{P})$
:
 \begin{eqnarray}holds(\Gamma,0,0)& \leftarrow & \end{eqnarray}
\begin{eqnarray}holds(\Gamma,0,0)& \leftarrow & \end{eqnarray}
 \begin{eqnarray}possible(a,T,P)& \leftarrow & holds(\varphi,T,P) \end{eqnarray}
\begin{eqnarray}possible(a,T,P)& \leftarrow & holds(\varphi,T,P) \end{eqnarray}
 \begin{eqnarray}holds(f, T+1, P) & \leftarrow & occ(a,T, P), holds(\varphi,T,P) \end{eqnarray}
\begin{eqnarray}holds(f, T+1, P) & \leftarrow & occ(a,T, P), holds(\varphi,T,P) \end{eqnarray}
 \begin{eqnarray}de(f, T+1, P) & \leftarrow & occ(a,T, P), holds(\varphi,T,P) \end{eqnarray}
\begin{eqnarray}de(f, T+1, P) & \leftarrow & occ(a,T, P), holds(\varphi,T,P) \end{eqnarray}
 \begin{eqnarray}ph(f,T+1, P) & \leftarrow & occ(a,T, P), { not \:} h(\overline{\varphi}, T, P) , { not \:} de(\overline{f},T+1,P) \quad \end{eqnarray}
\begin{eqnarray}ph(f,T+1, P) & \leftarrow & occ(a,T, P), { not \:} h(\overline{\varphi}, T, P) , { not \:} de(\overline{f},T+1,P) \quad \end{eqnarray}
 \begin{eqnarray}ph(f,T,P)& {\leftarrow} & ph(\varphi,T, P) \end{eqnarray}
\begin{eqnarray}ph(f,T,P)& {\leftarrow} & ph(\varphi,T, P) \end{eqnarray}
 \begin{eqnarray}holds(f,T,P)& \leftarrow & holds(\varphi,T,P) \end{eqnarray}
\begin{eqnarray}holds(f,T,P)& \leftarrow & holds(\varphi,T,P) \end{eqnarray}
 \begin{eqnarray}ph(L,T+1,P)& \leftarrow & fluent(L), { not \:} holds(\neg L,T), { not \:} de(\neg L,T,P) \end{eqnarray}
\begin{eqnarray}ph(L,T+1,P)& \leftarrow & fluent(L), { not \:} holds(\neg L,T), { not \:} de(\neg L,T,P) \end{eqnarray}
 \begin{eqnarray}ph(\neg L,T+1,P)& \leftarrow & fluent(L), { not \:} holds(L,T), { not \:} de(L,T,P) \end{eqnarray}
\begin{eqnarray}ph(\neg L,T+1,P)& \leftarrow & fluent(L), { not \:} holds(L,T), { not \:} de(L,T,P) \end{eqnarray}
 \begin{eqnarray}holds(L,T+1,P)& \leftarrow & fluent(L), { not \:} ph(\neg L,T,P) \end{eqnarray}
\begin{eqnarray}holds(L,T+1,P)& \leftarrow & fluent(L), { not \:} ph(\neg L,T,P) \end{eqnarray}
 \begin{eqnarray}holds(\neg L,T+1,P)& \leftarrow & fluent(L), { not \:} ph( L,T,P) \end{eqnarray}
\begin{eqnarray}holds(\neg L,T+1,P)& \leftarrow & fluent(L), { not \:} ph( L,T,P) \end{eqnarray}
 \begin{eqnarray}1\{occ(X,T,P) : action(X)\} 1 & \leftarrow & used(T,P), { not \:} goal(T,P) \end{eqnarray}
\begin{eqnarray}1\{occ(X,T,P) : action(X)\} 1 & \leftarrow & used(T,P), { not \:} goal(T,P) \end{eqnarray}
 \begin{eqnarray}& \leftarrow & occ(A,T,P), { not \:} possible(A,T,P). \end{eqnarray}
\begin{eqnarray}& \leftarrow & occ(A,T,P), { not \:} possible(A,T,P). \end{eqnarray}
In the above rules, L is a fluent literal, T is a time moment in the range
 $[0,h-1]$
, and P is in the range [0,w]. Rule (33) encodes the initial state. The rules (34)–(43) are used for computing the effects of the occurrence of a non-sensing action at the node (T,P). The rules (44) and (45) are used for generating action occurrences, similarly to the rules for generating action occurrences in the previous sections. The difference is that the selection restricts the generation of action occurrences to nodes marked as ‘used’ (see below).
$[0,h-1]$
, and P is in the range [0,w]. Rule (33) encodes the initial state. The rules (34)–(43) are used for computing the effects of the occurrence of a non-sensing action at the node (T,P). The rules (44) and (45) are used for generating action occurrences, similarly to the rules for generating action occurrences in the previous sections. The difference is that the selection restricts the generation of action occurrences to nodes marked as ‘used’ (see below).
The key distinction between
 $\Pi_{h,w}(\mathcal{P})$
and
$\Pi_{h,w}(\mathcal{P})$
and
 $\Pi^a(\mathcal{P},n)$
lies in the rules for dealing with sensing actions. We next describe this set of rules.
$\Pi^a(\mathcal{P},n)$
lies in the rules for dealing with sensing actions. We next describe this set of rules.
-
• Rules for reasoning about the effect of sensing actions: For each knowledge law (31) in D,
$\Pi_{h,w}(\mathcal{P})$
contains the following rules: (46)
\begin{eqnarray} 1\{br(g,T,P,X){:}new\_br(P,X)\}1 & \leftarrow & occ(a,T,P), sense(a,g). \end{eqnarray}
(47)
\begin{eqnarray}& \leftarrow & occ(a,T,P), sense(a, g), \nonumber \\[3pt] & & { not \:} br(g,T,P,P) \end{eqnarray}
(48)
\begin{eqnarray}& \leftarrow & occ(a,T,P), sense(a,g), \nonumber \\[3pt] & & holds(g, T,P) \end{eqnarray}
(49)When a sensing action occurs, it creates one branch for each of its sensed literals. This is encoded in the rule (46). The constraint (47) makes sure that the current branch P is continuing if a sensing action occurs at (T,P). The rule (48) is a constraint that prevents a sensing action to occur if one of its sensed literals is already known. To simplify the selection of branches, rule (49) forces a new branch at least at the same level as the current branch. The intuition behinds these rules can be seen in Figure 3.
\begin{eqnarray}new\_br(P,P_1) & \leftarrow & P \le P_1. \end{eqnarray}
Fig. 3. Sensing action a that senses
$\{g_1,g_2,g_3\}$
occurs at (t,p) - disallowed (Left) vs. allowed (Right). -
• Inertia rules for sensing actions: This group of rules encodes the fact that the execution of a sensing action does not change the world. However, there is a one-to-one correspondence between the set of sensed literals and the set of possible partial states.
(50)
\begin{eqnarray}& \leftarrow & P_1 < P_2, P_2 < P, br(G_1,T,P_1,P), \nonumber \\[3pt] & & br(G_2,T,P_2,P) \end{eqnarray}
(51)
\begin{eqnarray}& \leftarrow & P_1 \le P, G_1 \ne G_2, br(G_1,T,P_1,P), \nonumber \\[3pt] & & br(G_2,T,P_1,P) \end{eqnarray}
(52)
\begin{eqnarray}& \leftarrow & P_1 < P, br(G,T,P_1,P), used(T,P) \end{eqnarray}
(53)
\begin{eqnarray}used(T+1,P) & \leftarrow & P_1 < P, br(G,T,P_1,P) \end{eqnarray}
(54)
\begin{eqnarray}holds(G,T+1,P) & \leftarrow & P_1 \le P, br(G,T,P_1,P) \end{eqnarray}
(55)
\begin{eqnarray}holds(L,T+1,P)& \leftarrow & P_1 < P, br(G,T,P_1,P),holds(L,T,P_1) \end{eqnarray}
(56)
\begin{eqnarray}used(0,0) & \leftarrow & \end{eqnarray}
(57)The first three rules, together with rule (49), make sure that branches are separate from each other. The next rule is used to mark a node as used if there is a branch in the plan that reaches that node. This allows us to know which paths on the grid are used in the construction of the plan and allows us to check if the plan satisfies the goal (see rule (58)). The two rules (54)–(55), along with rule (53), encode the possible partial state corresponding to the branch denoted by literal G after a sensing action is performed at
\begin{eqnarray}used(T+1,P)& \leftarrow & used(T,P). \end{eqnarray}
$(T,P_1)$
. They indicate that the partial state at
$(T+1,P)$
should contain G (Rule (54)) and literals that hold in
$(T,P_1)$
(Rule (55)). The last two rules mark nodes that have been used in the construction of the conditional plan.
-
• Goal representation: Checking for goal satisfaction needs to be done on all branches. This is encoded as follows.
(58)
\begin{eqnarray}goal(T_1,P) & \leftarrow & holds(\Delta,T_1,P) \end{eqnarray}
(59)
\begin{eqnarray}goal(T_1,P) & \leftarrow & holds(L,T_1,P), holds(\neg L,T_1,P) \end{eqnarray}
(60)The first rule in this group says that the goal is satisfied at a node if all of its subgoals are satisfied at that node. The last rule guarantees that if a path P is used in the construction of a plan then the goal must be satisfied at the end of this path, that is, at node (h,P). The second rule provides an avenue to stop the generation of actions when an inconsistent state is encountered – by declaring the goal reached. As discussed by (Tu et al. Reference Tu, Son and Baral2007), the properties of the encoding of consistent action theories prevent this method from generating plans leading to inconsistent states.
\begin{eqnarray}& \leftarrow & used(h+1,P), { not \:} goal(h+1,P). \end{eqnarray}





















Remark 4
-
1.
$\Pi_{h,w}(\mathcal{P})$
is slightly different from the program presented in the paper by (Tu et al. Reference Tu, Son and Baral2007) in that
$\Phi^a$
is slightly different from the semantics used in that paper. By setting
$w = 0$
, this program is a conformant planner. The experiments conducted by (Tu et al. Reference Tu, Son and Baral2007) show that
$\Pi_{h,w}(\mathcal{P})$
performs reasonably well. -
2. Extracting a conditional plan from an answer set S of
$\Pi_{h,w}(\mathcal{P})$
is not as simple as it is done in the previous sections because of the case-plan. For any pair of integers i and k such that
$0 \le i \le h, 0 \le k \le w$
, we define
$p^k_i(S)$
as follows: Intuitively,
\begin{equation*}p^k_i(S) = \left \{\begin{array}{ll}\langle \rangle & {if} i = h {or} occ(a,i,k) \not \in S {for all} a \\[3pt]\langle a;p^k_{i+1}(S) \rangle & {if} occ(a,i,k) \in S {and} \\[3pt] & a {is a non-sensing action}\\[3pt]\langle a;\textbf{cases}(\{g_j \rightarrow p_{i+1}^{k_j}(S)\}^n_{j=1}) \rangle &{if} occ(a,i,k) \in S, \\[3pt]& a {is a sensing action}, {and}\\[3pt]& br(g_j,i,k,k_j) \in S{for} 1 \le j \le n\end{array}\right.\end{equation*}
$p^k_i(S)$
is the conditional plan whose corresponding tree is rooted at node (i,k) on the grid
$h \times w$
. Therefore,
$p^0_0(S)$
is a solution to
$\mathcal{P}$
.
-
3. The semantics of
$\mathcal{B}$
with knowledge laws does not prevent a sensing action to occur when some of its sensed literals is known. It is easy to see that in this case, the branching, enforced by rule (46), is unnecessary. Rule (48) disallows such redundant action occurrences. It is shown by (Tu et al. Reference Tu, Son and Baral2007) that any solution of
$\mathcal{P} = \langle D, \Gamma, \Delta \rangle$
can be reduced to an equivalent plan without redundant occurrences of sensing actions which can be found by
$\Pi_{h,w}(\mathcal{P})$
. -
4. Because the execution of a sensing action creates multiple branches and some of them might be inconsistent (equation (32)), rule (59) prevents any action to occur at node (T,P) when the partial state at (T,P) is inconsistent. To mark that the path ends at this node, we say that the goal is achieved. (Tu et al. Reference Tu, Son and Baral2007) showed that for a consistent planning problem, any solution generated by
$\Pi_{h,w}(\mathcal{P})$
corresponds to a correct solution. -
5. The comparison between ASP-based systems, like CPasp and
$\Pi_{h,w}(\mathcal{P})$
, and conformant planning or conditional planning systems, such as CMBP (Cimatti and Roveri Reference Cimatti and Roveri2000), dlv
$^\mathcal{K}$
(Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b), C-Plan (Castellini et al. Reference Castellini, Giunchiglia and Tacchella2003), CFF (Brafman and Hoffmann Reference Brafman and Hoffmann2004), KACMBP (Cimatti et al. Reference Cimatti, Roveri and Bertoli2004),
$t_0$
(Palacios and Geffner Reference Palacios and Geffner2007), and POND (Bryce et al. Reference Bryce, Kambhampati and Smith2006), has been presented in the papers by (Tu et al. Reference Tu, Son and Baral2007) and 2011. The comparison shows that ASP-based planning systems perform much better than other systems in domains with static causal laws. -
6.
$\Pi_{h,w}(\mathcal{P})$
, similar to CPasp, makes a single call to the ASP solver to compute a conditional plan. This is possible because of it uses an approximation semantics that reduces the complexity of conditional planning, for polynomially-bounded plan, to NP-complete. Otherwise, this would not be possible because conditional planning for polynomially-bounded length plan is PSPACE-complete (Turner Reference Turner2002). Naturally, as with CPasp, this also implies that
$\Pi_{h,w}(\mathcal{P})$
is incomplete.





















5.3 Context: Conditional planning
As we mentioned earlier, the need for plans with conditionals and/or loops has been identified very earlier on by (Warren Reference Warren1976), who developed Warplan-C, a Prolog program that can generate conditional plans and programs given the problem specification. Warplan-C has only 66 clauses and is conjectured to be complete. The system was developed at the same time as other non-linear planning systems, such as Noah by (Sacerdoti Reference Sacerdoti1974). These earlier systems do not deal with sensing actions. Other systems that generate plans with if-then statements and can prepare for contingencies are Cassandra (Pryor and Collins Reference Pryor and Collins1996) and CNLP (Peot and Smith Reference Peot and Smith1992). These two systems extend partial order planning algorithms for computing conditional plans.
XII (Golden et al. Reference Golden, Etzioni and Weld1996) and PUCCINI (Golden Reference Golden1998) are two systems that employ partial order planning to generate conditional plans for problems with incomplete information and can deal with sensing actions. SGP (Weld et al. Reference Weld, Anderson and Smith1998) and POND (Bryce et al. Reference Bryce, Kambhampati and Smith2006) are conditional planners that work with sensing actions. These systems extend the planning graph algorithm (Blum and Furst Reference Blum and Furst1997) to deal with sensing actions. The main difference between SGP and POND is that the former searches solutions within the planning graph, whereas the latter uses it as a means of computing the heuristic function.
CoPlaS, developed by (Lobo Reference Lobo1998), is a regression Prolog-based planner that uses a high-level action description language, similar to the language
 $\mathcal{B}_K$
described in this section, to represent and reason about effects of actions, including sensing actions. (Van Nieuwenborgh et al. Reference Van Nieuwenborgh, Eiter and Vermeir2007) introduced
$\mathcal{B}_K$
described in this section, to represent and reason about effects of actions, including sensing actions. (Van Nieuwenborgh et al. Reference Van Nieuwenborgh, Eiter and Vermeir2007) introduced
 $\mathcal{K}_c$
, an extension of language
$\mathcal{K}_c$
, an extension of language
 $\mathcal{K}$
, to deal with sensing actions and compute conditional plans as defined in this section using dlv
$\mathcal{K}$
, to deal with sensing actions and compute conditional plans as defined in this section using dlv
 $^\mathcal{K}$
. (Thielscher Reference Thielscher2000) presented FLUX, a constraint logic programming based planner, which is capable of generating and verifying conditional plans. QBFPlan is another conditional planner, based on a QBF theorem prover, is described in the paper by (Rintanen Reference Rintanen1999). This system, however, does not consider sensing actions.
$^\mathcal{K}$
. (Thielscher Reference Thielscher2000) presented FLUX, a constraint logic programming based planner, which is capable of generating and verifying conditional plans. QBFPlan is another conditional planner, based on a QBF theorem prover, is described in the paper by (Rintanen Reference Rintanen1999). This system, however, does not consider sensing actions.
Research in developing conditional planners, however, has not attracted as much attention compared to other types of planning domains in recent years. Rather, the focus has been on synthesizing controllers or reactive modules which exhibit specific behaviors in different environments (Aminof et al. Reference Aminof, De Giacomo, Lomuscio, Murano and Rubin2020; Camacho et al. Reference Camacho, Bienvenu and McIlraith2019; Camacho et al. Reference Camacho, Baier, Muise and McIlraith2018; Treszkai and Belle Reference Treszkai and Belle2020). This is similar to the effort of generating programs satisfying a specification as discussed earlier (e.g., the work by Warren Reference Warren1976) or attempts to compute policies (see, e.g., the book by Bellman Reference Bellman1957) for Markov Decision Processes (MDP) or Partially Observable Markov Decision Processes (POMDP). To the best of our knowledge, little attention has been paid to this research direction within the ASP community. We present this as a challenge to ASP in the last section of the paper.
6 Planning with preferences
The previous sections analyze answer set planning with the focus on solving different classes of planning problems, such as planning with complete information, incomplete information, and sensing actions. In this section, we present another extension of the planning problem, by illustrating the use of answer set planning in planning with preferences.
The problem of planning with preferences arises in situations where the user not only wants a plan to achieve a goal, but has specific preferences or biases about the plan. This situation is common when the space of possible plans for a goal is dense, that is, finding “a” plan is not difficult, but many of the plans may have features which are undesirable to the user. This type of situations is very common in practical planning problems.
Example 7 Traveling from one place to another is a frequently considered problem (e.g., a traveler, a transportation vehicle, an autonomous vehicle). A planning problem in the travel domain can be represented by the following elements:
-
• a set of fluents of the form
$at(\ell)$
, where
$\ell$
denotes a location, such as home, school, neighbor, airport, etc.; -
• an initial location
$\ell_i$
; -
• a destination location
$\ell_f$
; and -
• a set of actions of the form
$method(\ell_1,\ell_2)$
where
$\ell_1$
and
$\ell_2$
are two distinct locations and method is one of the available transportation methods, such as drive, walk, ride_train, bus, taxi, fly, bike, etc. The problem may include conditions that restrict the applicability of actions in certain situations. For example, one can ride a taxi only if the taxi has been called, which can be done only if one has some money; one can fly from one place to another if one has a ticket; etc.







Problems in this domain are often rich in solutions because of the large number of actions which can be used in the construction of a plan. For this reason, a user looking for a solution to a problem often considers some additional features, or personal preferences, in selecting a plan. For example, the user might be biased in terms of the distance to travel using a transportation method, the overall cost, the time to destination, the comfort of a vehicle, etc. However, a user would accept a plan that does not satisfy her preferences if she has no other choice.
 $\Diamond$
$\Diamond$
Preferences can come in different shapes and forms. The most common types of preferences are:
-
• Preferences about a state: the user prefers to be in a state s that satisfies a property
$\phi$
rather than a state s’ that does not satisfy it, in case both lead to the satisfaction of the goal; for example, being in a 5-star hotel is preferable to being in a 1-star hotel, if the distance to the conference site is the same; -
• Preferences about an action: the user prefers to perform (or avoid) an action a, whenever it is feasible and it allows the goal to be achieved; for example, one might prefer to walk to destination whenever possible;
-
• Preferences about a trajectory: the user prefers a trajectory that satisfies a certain property
$\psi$
over those that do not satisfy this property; for example, one might prefer plans that do not involve traveling through Los Angeles during peak traffic hours; -
• Multidimensional preferences: the user has a set of preferences, with an ordering among them. A plan satisfying a more favorable preference is given priority over those that satisfy less favorable preferences; for example, plans that minimize time to destination might be preferable to plans minimizing cost.


(Son and Pontelli Reference Son and Pontelli2006) proposed a general method for integrating diverse classes of preferences into answer set planning. Their approach is articulated in two components:
-
• Development of a preference specification language: this language supports the specification of different types of preferences; its semantics should enable the definition of a partial order among possible solutions of the planning problem.
-
• Implementation: the implementation proposed by (Son and Pontelli Reference Son and Pontelli2006) maps preference formulae to mathematical formulae, representing the weight of each formula, and makes use of the
$\mathtt{maximize}$
statement in ASP to optimize the solution to the planning problem. The original paper defines rules for computing the weights of preference formulae in ASP.

We next introduce the preference specification language proposed by (Son and Pontelli Reference Son and Pontelli2006).
6.1 A preference specification language
The proposed preference specification language addresses the description of three classes of preferences: basic desires, atomic preferences, and general preferences.
For a planning problem
 $\mathcal{P} = \langle D, \Gamma, \Delta \rangle$
, a basic desire can be in of the following possible forms:
$\mathcal{P} = \langle D, \Gamma, \Delta \rangle$
, a basic desire can be in of the following possible forms:
-
(a) a state formula, which is a fluent formula
$\varphi$
or a formula of the form occ(a) for some action a, or -
(b) a goal preference, of the form
$\textbf{goal}(\varphi)$
, where
$\varphi$
is a fluent formula.



Basic desire formula.
A basic desire formula is a formula built over basic desires, the traditional propositional operators (
 $\wedge$
,
$\wedge$
,
 $\vee$
, and
$\vee$
, and
 $\neg$
), and the modalities
$\neg$
), and the modalities
 $\textbf{next}$
,
$\textbf{next}$
,
 $\textbf{always}$
,
$\textbf{always}$
,
 $\textbf{eventually}$
, and
$\textbf{eventually}$
, and
 $\textbf{until}$
. The BNF for the basic desire formulae is
$\textbf{until}$
. The BNF for the basic desire formulae is
 \begin{equation*}\psi \stackrel{def}{=} \varphi \mid \psi_1 \wedge \psi_2 \mid \psi_1 \vee \psi_2 \mid \neg \psi_1 \mid \textbf{next}(\psi_1) \mid \textbf{until}(\psi_1,\psi_2) \mid \textbf{always}(\psi_1) \mid \textbf{eventually}(\psi),\end{equation*}
\begin{equation*}\psi \stackrel{def}{=} \varphi \mid \psi_1 \wedge \psi_2 \mid \psi_1 \vee \psi_2 \mid \neg \psi_1 \mid \textbf{next}(\psi_1) \mid \textbf{until}(\psi_1,\psi_2) \mid \textbf{always}(\psi_1) \mid \textbf{eventually}(\psi),\end{equation*}
where
 $\varphi$
represents a state formula or a goal preference and
$\varphi$
represents a state formula or a goal preference and
 $\psi$
,
$\psi$
,
 $\psi_1$
, or
$\psi_1$
, or
 $\psi_2$
are basic desire formulae.
$\psi_2$
are basic desire formulae.
Intuitively, a basic desire formula specifies a property that a user would like to see satisfied by the provided plan. For example, to express the fact that a user would like to take the taxi or the bus to go to school, we can write:
 \begin{equation*}\textbf{eventually}(occ(bus(home,school)) \vee occ(taxi(home,school))).\end{equation*}
\begin{equation*}\textbf{eventually}(occ(bus(home,school)) \vee occ(taxi(home,school))).\end{equation*}
If the user’s desire is not to call a taxi, we can write
 \begin{equation*}\textbf{always}(\neg occ(call\_taxi(home))).\end{equation*}
\begin{equation*}\textbf{always}(\neg occ(call\_taxi(home))).\end{equation*}
If the user’s desire is not to see any taxi around his home, we can use the basic desire formula
 \begin{equation*}\textbf{always}(\neg available\_taxi(home)).\end{equation*}
\begin{equation*}\textbf{always}(\neg available\_taxi(home)).\end{equation*}
Note that these encodings have different consequences – the last formula prevents taxis to be present, independently from whether the taxi has been called.
The following are several basic desire formulae that are often of interest to users.
-
• Strong Desire: For two formulae
$\varphi_1$
and
$\varphi_2$
,
$\varphi_1 < \varphi_2$
denotes
$\varphi_1 \wedge \neg \varphi_2$
. -
• Weak Desire: For two formulae
$\varphi_1$
and
$\varphi_2$
,
$\varphi_1 <^w \varphi_2$
denotes
$\varphi_1 \vee \neg \varphi_2$
. -
• Enabled Desire: For two actions
$a_1$
and
$a_2$
,
$a_1 <^e a_2$
stands for
$(executable(a_1) \wedge executable(a_2)) \Rightarrow (occ(a_1) < occ(a_2))$
where
$executable(a) = \bigwedge_{l \in \varphi} l $
if
$\textbf{executable}(a, \varphi) \in D$
. -
• Action Class Desire: For actions with the same set of parameters and effects such as drive or walk, we write
$drive <^e walk$
to denote the desire
$\bigvee_{l_1, l_2 \in S, \: l_1 \ne l_2} (drive(l_1, l_2) <^e walk(l_1, l_2))$
where S is a set of pre-defined locations. Intuitively, this preference states that we prefer to drive rather than to walk between locations belonging to the set S. For example, if
$S = \{home, school\}$
then this preference says that we prefer to drive from home to school and vice versa.

















Atomic preference.
Basic desire formulae are expressive enough to describe a significant portion of preferences that frequently occur in real-world domains. It is also often the case that the user may provide a variety of desires, and some desires are stronger than others; knowledge of such biases about desires becomes important when it is not possible to concurrently satisfy all the provided desires. In this situation, an ordering among the desires is introduced. An atomic preference formula is a formula of the form
 \begin{equation*} \varphi_1 \lhd \varphi_2 \lhd \cdots \lhd \varphi_n, \end{equation*}
\begin{equation*} \varphi_1 \lhd \varphi_2 \lhd \cdots \lhd \varphi_n, \end{equation*}
where
 $\varphi_1, \dots, \varphi_n$
are basic desire formulae. The atomic preference formula states that trajectories that satisfy
$\varphi_1, \dots, \varphi_n$
are basic desire formulae. The atomic preference formula states that trajectories that satisfy
 $\varphi_1$
are preferable to those that satisfy
$\varphi_1$
are preferable to those that satisfy
 $\varphi_2$
, etc.
$\varphi_2$
, etc.
Let us consider again the travel domain. Besides time and cost, users often have their preferences based on the level of comfort and/or safety of the available transportation methods. These preferences can be represented by the formulae Footnote 13
 \begin{equation*}\mathit{cost} = \textbf{always}(\mathit{walk} <^e \mathit{bus} <^e \mathit{drive} <^e \mathit{flight})\end{equation*}
\begin{equation*}\mathit{cost} = \textbf{always}(\mathit{walk} <^e \mathit{bus} <^e \mathit{drive} <^e \mathit{flight})\end{equation*}
and
 \begin{equation*}\mathit{time} = \textbf{always}(\mathit{flight} <^e \mathit{drive} <^e \mathit{bus} <^e \mathit{walk})\end{equation*}
\begin{equation*}\mathit{time} = \textbf{always}(\mathit{flight} <^e \mathit{drive} <^e \mathit{bus} <^e \mathit{walk})\end{equation*}
and
 \begin{equation*}\mathit{comfort} = \textbf{always}(\mathit{flight} <^e (drive \vee bus) <^e walk)\end{equation*}
\begin{equation*}\mathit{comfort} = \textbf{always}(\mathit{flight} <^e (drive \vee bus) <^e walk)\end{equation*}
and
 \begin{equation*}\mathit{safety} = \textbf{always}(walk <^e \mathit{flight} <^e (drive \vee bus)).\end{equation*}
\begin{equation*}\mathit{safety} = \textbf{always}(walk <^e \mathit{flight} <^e (drive \vee bus)).\end{equation*}
These four desires can be combined to produce the following two atomic preferences
 \begin{equation*}\Psi^t_1 = \mathit{comfort} \lhd \mathit{safety} \:\:\: {and} \:\:\:\Psi^t_2 = cost \lhd time.\end{equation*}
\begin{equation*}\Psi^t_1 = \mathit{comfort} \lhd \mathit{safety} \:\:\: {and} \:\:\:\Psi^t_2 = cost \lhd time.\end{equation*}
Intuitively,
 $\Psi^t_1$
is a comparison between level of comfort and safety, while
$\Psi^t_1$
is a comparison between level of comfort and safety, while
 $\Psi^t_2$
is a comparison between affordability and duration.
$\Psi^t_2$
is a comparison between affordability and duration.
General preference formulae.
Suppose that a user would like to travel as comfortably and as cheaply as possible. Such a preference can be viewed as a multi-dimensional preference, which cannot be easily captured using atomic preferences or basic desires. General preference formulae support the representation of such multi-dimensional preferences.
Formally, a general preference formula is a formula satisfying one of the following conditions:
-
• An atomic preference
$\Psi$
is a general preference; -
• If
$\Psi_1, \Psi_2$
are general preferences, then
$\Psi_1 \& \Psi_2$
,
$\Psi_1 \mid \Psi_2$
, and
$!\: \Psi_1$
are general preferences; -
• If
$\Psi_1, \Psi_2, \dots, \Psi_k$
is a collection of general preferences, then
$\Psi_1 \lhd \Psi_2 \lhd \cdots \lhd \Psi_k$
is a general preference.







In the above definition, the operators
 $\&, \mid, !$
are used to express different ways to combine preferences. For example, the preference
$\&, \mid, !$
are used to express different ways to combine preferences. For example, the preference
 $\Psi^t_1 \& \Psi^t_2$
indicates that the user prefers trajectories that are most preferred according to both
$\Psi^t_1 \& \Psi^t_2$
indicates that the user prefers trajectories that are most preferred according to both
 $\Psi^t_1$
and
$\Psi^t_1$
and
 $\Psi^t_2$
;
$\Psi^t_2$
;
 $\Psi^t_1 \mid \Psi^t_2$
states that, among trajectories with the same cost, the user prefers trajectories that are most comfortable or vice versa. A detailed discussion of general preferences can be found in the paper by (Son and Pontelli Reference Son and Pontelli2006).
$\Psi^t_1 \mid \Psi^t_2$
states that, among trajectories with the same cost, the user prefers trajectories that are most comfortable or vice versa. A detailed discussion of general preferences can be found in the paper by (Son and Pontelli Reference Son and Pontelli2006).
Semantics.
In order to define the semantics of the preference language, we need to start from describing whether a trajectory
 $\alpha = s_0a_0\ldots a_{n-1} s_n$
satisfies a basic desire formula. We write
$\alpha = s_0a_0\ldots a_{n-1} s_n$
satisfies a basic desire formula. We write
 $\alpha \models \varphi$
to denote that
$\alpha \models \varphi$
to denote that
 $\alpha$
satisfies a basic desire
$\alpha$
satisfies a basic desire
 $\varphi$
. The definition of
$\varphi$
. The definition of
 $\models$
is straightforward, and we report here only some of the cases (the complete definition can be found in the paper by Son and Pontelli Reference Son and Pontelli2006), where
$\models$
is straightforward, and we report here only some of the cases (the complete definition can be found in the paper by Son and Pontelli Reference Son and Pontelli2006), where
 $\alpha[i] = s_i a_i \ldots a_{n-1}s_n$
.
$\alpha[i] = s_i a_i \ldots a_{n-1}s_n$
.
-
•
$\alpha \models occ(a)$
if
$a_0=a$
; -
•
$\alpha \models \ell$
if
$s_0\models \ell$
and
$\ell$
is a fluent; -
•
$\alpha \models \textbf{always}(\varphi)$
if for all
$0\leq i < n$
we have
$\alpha[i]\models\varphi$
; -
•
$\alpha \models \textbf{next}(\varphi)$
if
$\alpha[1] \models \varphi$
.










The satisfaction of desires is used to define two relations between trajectories, one expressing preference between trajectories and one capturing the fact that two trajectories are indistinguishable, denoted by
 $\prec_\Psi$
and
$\prec_\Psi$
and
 $\approx_{\Psi}$
, respectively, where
$\approx_{\Psi}$
, respectively, where
 $\Psi$
is a preference formula. For two trajectories
$\Psi$
is a preference formula. For two trajectories
 $\alpha$
and
$\alpha$
and
 $\beta$
,
$\beta$
,
-
1. if
$\Psi$
is a basic desire then
$\alpha \prec_\Psi \beta$
(
$\alpha$
is more preferred than
$\beta$
with respect to
$\Psi$
) if
$\alpha \models \Psi$
and
$\beta \not\models \Psi$
;
$\alpha \approx_{\Psi} \beta$
denotes that
$\alpha \models \Psi$
iff
$\beta \models \Psi$
. -
2. if
$\Psi$
is an atomic preference
$\varphi_1 \lhd \varphi_2 \lhd \cdots \lhd \varphi_n$
then
$\alpha \prec_{\Psi} \beta$
if
$\exists (1 \leq i \leq n)$
such that-
(a)
$\forall (1 \leq j < i)$
we have that
$\alpha \approx_{\varphi_j} \beta$
, and -
(b)
$\alpha \prec_{\varphi_i} \beta$
.
$\alpha \approx_{\Psi} \beta$
denotes that
$\alpha \approx_{\varphi_j} \Psi$
for every
$j=1,\ldots,n$
.
-
-
3. if
$\Psi$
is a general preference and has the form
$\Psi = \Psi_1 \lhd \cdots \lhd \Psi_k$
then
$\alpha \prec_\Psi \beta$
is defined similar to the second case. Otherwise,
$\alpha \prec_\Psi \beta$
-
(a) if
$\Psi = \Psi_1 \& \Psi_2$
and
$\alpha \prec_{\Psi_1} \beta$
and
$\alpha \prec_{\Psi_2} \beta$
-
(b) if
$\Psi = \Psi_1 \mid \Psi_2$
and (i)
$\alpha \prec_{\Psi_1} \beta$
and
$\alpha \approx_{\Psi_2} \beta$
; or (ii)
$\alpha \prec_{\Psi_2} \beta$
and
$\alpha \approx_{\Psi_1} \beta$
; or (iii)
$\alpha \prec_{\Psi_1} \beta$
and
$\alpha \prec_{\Psi_2} \beta$
. -
(c) if
$\Psi = \:! \Psi_1$
and
$\beta \prec_{\Psi_1} \alpha$
.




































In all cases,
 $\alpha \approx_{\Psi} \beta$
iff
$\alpha \approx_{\Psi} \beta$
iff
 $\alpha \approx_{\Psi'} \beta$
where
$\alpha \approx_{\Psi'} \beta$
where
 $\Psi'$
is a component of
$\Psi'$
is a component of
 $\Psi$
.
$\Psi$
.
The following proposition holds (Son and Pontelli Reference Son and Pontelli2006).
Proposition 1
 $\prec_\Psi$
is a partial order and
$\prec_\Psi$
is a partial order and
 $\approx_{\Psi}$
is an equivalent relation.
$\approx_{\Psi}$
is an equivalent relation.
The above proposition shows that maximal elements with respect to
 $\prec_\Psi$
exist, that is, most preferred trajectories exist.
$\prec_\Psi$
exist, that is, most preferred trajectories exist.
6.2 Implementation: Computing preferred plans
Given a planning problem
 $\mathcal{P}$
and a preference formula
$\mathcal{P}$
and a preference formula
 $\Psi$
, a preferred trajectory can be computed using the following steps:
$\Psi$
, a preferred trajectory can be computed using the following steps:
-
1. Use one of the programs, denoted by
$\mathit{Plan}(\mathcal{P},n)$
, introduced in Sections 3–4 to compute a potential solution
$\alpha$
for
$\mathcal{P}$
; -
2. Associate to
$\alpha$
a number, which represents the degree of satisfaction of
$\alpha$
with respect to
$\Psi$
; and -
3. Use the
$\#maximize$
statement of clingo to compute a most preferred trajectory.







This process requires an appropriate encoding of
 $\Psi$
. This is usually achieved by converting
$\Psi$
. This is usually achieved by converting
 $\Psi$
to a canonical form, which provides a convenient way to translate
$\Psi$
to a canonical form, which provides a convenient way to translate
 $\Psi$
into a set of facts with predefined predicates. For example, a basic desire formula can be encoded using the predicates and, or,
$\Psi$
into a set of facts with predefined predicates. For example, a basic desire formula can be encoded using the predicates and, or,
 $\neg$
, occ,
$\neg$
, occ,
 $\textbf{next}$
,
$\textbf{next}$
,
 $\textbf{until}$
,
$\textbf{until}$
,
 $\textbf{eventually}$
,
$\textbf{eventually}$
,
 $\textbf{always}$
, and final (stands for goal, to avoid confusion with the goal predicate defined in the previous sections). This translation can be done using a script (e.g., Son and Pontelli Reference Son and Pontelli2006 presented a Prolog program for such translation).
$\textbf{always}$
, and final (stands for goal, to avoid confusion with the goal predicate defined in the previous sections). This translation can be done using a script (e.g., Son and Pontelli Reference Son and Pontelli2006 presented a Prolog program for such translation).
An atomic preference can be represented using an ordered set, consisting of a declaration atomic(id), indicating that id is an atomic preference, and a set of atoms of the form
 $member(id, \mathit{formula}, order)$
, where id, formula, and order represent the atomic preference identifier, the formula, and the order of the formula in id, respectively. Finally, a general preference can be encoded using the predicates
$member(id, \mathit{formula}, order)$
, where id, formula, and order represent the atomic preference identifier, the formula, and the order of the formula in id, respectively. Finally, a general preference can be encoded using the predicates
 $\&$
,
$\&$
,
 $\mid$
, and
$\mid$
, and
 $!$
, and the basic representations of basic desires and atomic preferences. In the following, we use
$!$
, and the basic representations of basic desires and atomic preferences. In the following, we use
 $\Pi(\Psi)$
to denote the set of facts encoding
$\Pi(\Psi)$
to denote the set of facts encoding
 $\Psi$
.
$\Psi$
.
Since the first task in computing a most preferred trajectory is checking whether or not a trajectory satisfies a basic desire, we need to add to
 $\mathit{Plan}(\mathcal{P},n)$
rules for this purpose. This task can be achieved by a set of domain-independent rules
$\mathit{Plan}(\mathcal{P},n)$
rules for this purpose. This task can be achieved by a set of domain-independent rules
 $\Pi_{\mathit{pref}}$
defining the predicate
$\Pi_{\mathit{pref}}$
defining the predicate
 $holds(sat(\varphi), t)$
, which states that the basic desire formula
$holds(sat(\varphi), t)$
, which states that the basic desire formula
 $\varphi$
is satisfied by the trajectory
$\varphi$
is satisfied by the trajectory
 $s_t a_t \ldots a_{n-1} s_n$
.
$s_t a_t \ldots a_{n-1} s_n$
.
 $\Pi_{\mathit{pref}}$
contains the following groups of rules:
$\Pi_{\mathit{pref}}$
contains the following groups of rules:
-
• Rules for checking the satisfaction of a propositional formula at a time step: such as
\begin{equation*}\begin{array}{lcl}holds(sat(F), T) &\leftarrow & fluent(F), holds(F,T)\\[3pt]holds(sat(and(F,G)), T) &\leftarrow& holds(sat(F), T), holds(sat(G),T)\end{array}\end{equation*}
-
• Rules for checking the satisfaction of a temporal formula at a time step: such as
\begin{equation*}holds(sat(\textbf{next}(F)), T) \leftarrow holds(sat(F), T+1)\end{equation*}
-
• Rules for checking the occurrence of an action:
\begin{equation*}holds(sat(occ(A)), T) \leftarrow occ(A,T)\end{equation*}
-
• Rules for checking the satisfaction of a goal formula:
\begin{equation*}holds(sat(final(F)), 0) \leftarrow holds(sat(F), n).\end{equation*}




The following proposition holds.
Proposition 2 An answer set S of
 $\mathit{Plan}(\mathcal{P},n) \cup \Pi(\varphi) \cup \Pi_{\mathit{pref}}$
contains
$\mathit{Plan}(\mathcal{P},n) \cup \Pi(\varphi) \cup \Pi_{\mathit{pref}}$
contains
 $holds(sat(\varphi), 0)$
if and only if the trajectory corresponds to S satisfies
$holds(sat(\varphi), 0)$
if and only if the trajectory corresponds to S satisfies
 $\varphi$
.
$\varphi$
.
The above proposition shows that
 $\mathit{Plan}(\mathcal{P},n) \cup \Pi(\varphi) \cup \Pi_{\mathit{pref}}$
can be used to compute a most preferred trajectory with respect to a basic desire formula. To do so, we only need to tell clingo that an answer set containing
$\mathit{Plan}(\mathcal{P},n) \cup \Pi(\varphi) \cup \Pi_{\mathit{pref}}$
can be used to compute a most preferred trajectory with respect to a basic desire formula. To do so, we only need to tell clingo that an answer set containing
 $holds(sat(\varphi), 0)$
is preferred.
$holds(sat(\varphi), 0)$
is preferred.
To compute a most preferred plan with respect to a general preference or an atomic formula, (Son and Pontelli Reference Son and Pontelli2006) proposed a set of rules that assigns a number to a formula and then use the
 $\#maximize$
statement of clingo to select a most preferred trajectory. The proposed rules were developed at the time the answer set solvers did provide only limited capability to work with numbers. For this reason, we omit the detail about these rules here. Features provided in more recent versions of answer set solvers, such as multiple optimization statements and weighted tuples, are likely to enable a simpler and more efficient implementation. For example, we could translate an atomic preference
$\#maximize$
statement of clingo to select a most preferred trajectory. The proposed rules were developed at the time the answer set solvers did provide only limited capability to work with numbers. For this reason, we omit the detail about these rules here. Features provided in more recent versions of answer set solvers, such as multiple optimization statements and weighted tuples, are likely to enable a simpler and more efficient implementation. For example, we could translate an atomic preference
 \begin{equation*}\varphi_1 \lhd \varphi_2 \ldots \lhd \varphi_n\end{equation*}
\begin{equation*}\varphi_1 \lhd \varphi_2 \ldots \lhd \varphi_n\end{equation*}
to a statement
 \begin{equation*}\#maximize \{1@n : holds(sat(\varphi_1), 0); \ldots ; n@1 : holds(sat(\varphi_n), 0)\}\end{equation*}
\begin{equation*}\#maximize \{1@n : holds(sat(\varphi_1), 0); \ldots ; n@1 : holds(sat(\varphi_n), 0)\}\end{equation*}
as a part of
 $\Pi(\Psi)$
.
$\Pi(\Psi)$
.
Remark 5
-
1. The encoding of
$\Pi(\Psi)$
presented in this paper does not employ any advanced features of ASP, which were introduced to simplify the encoding of preferences such as the framework for preferences specification asprin, introduced by (Brewka et al. Reference Brewka, Delgrande, Romero and Schaub2015a) and 2015b. Analogously, a more elegant encoding of preference formulae can be achieved using other extensions of ASP focused on rankings of answer sets, such as logic programming with ordered disjunctions (Brewka Reference Brewka2002). This encoding, however, cannot be used with clingo or dlv because none of these solvers supports ordered disjunctions. -
2. The discussion in this section focuses on expressing preferences over trajectories, that is, sequences of actions and states. It can be extended to conditional plans and used with the planner in Section 5. This extension can, for example, define preferences over branches in a conditional plan.

6.3 Context: Planning with preferences
Planning with preferences has attracted a lot of attention by the planning community. An excellent survey of several systems developed before 2008 and their strengths and weaknesses can be found in the paper by (Baier and McIlraith Reference Baier and McIlraith2008). Preferences have also been included in extensions of PDDL, such as PDDL3 (Gerevini and Long Reference Gerevini and Long2005). The majority of systems described in the survey employ PDDL3 where preferences are, ultimately, described by a numeric value. As such, most of the planning with preferences systems in the literature can be characterized as cost optimal, where the cost of actions plays a key role in deciding the preference of a solution. Hierarchical task planning is also frequently used in these systems. Representative systems in this direction are HPlan-P (Sohrabi et al. Reference Sohrabi, Baier and McIlraith2009), LPRPG-P (Coles and Coles Reference Coles and Coles2011), and PGPlanner (Das et al. Reference Das, Odom, Islam, Doppa, Roth and Natarajan2019). ChoPlan, developed by (Bidoux et al. Reference Bidoux, Pignon and BÉnaben2019), is a system which encodes a PDDL3 planning problem as a multi-attribute utility theory and a heuristic based on Choquet integrals to derive solutions.
satplan(P), developed by (Giunchiglia and Maratea Reference Giunchiglia and Maratea2007), shows that SAT-based planning is also competitive with other planning paradigms. (Giunchiglia and Maratea Reference Giunchiglia and Maratea2011) present a survey of SAT-based planning with preferences. In recent years, SMT-based planning has become more popular than SAT-based planning, thanks to the expressiveness of SMT compared to SAT and the availability of efficient SMT solvers. SMT-based planning, which can work with numeric variables, provides an excellent way to deal with preferences (Scala et al. Reference Scala, Ramrez, Haslum and ThiÉbaux2016). It is worth observing that ASP-based planning with action costs has been considered earlier by (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003a) and more recently by (Khandelwal et al. Reference Khandelwal, Yang, Leonetti, Lifschitz and Stone2014).
7 Planning and diagnosis
While planning and diagnosis are often considered two separate and independent tasks, some researchers have suggested that ties exist between them, to the point that it is possible to reduce diagnostic reasoning to planning. In this section, we present this view, and specifically focus on the approach from (Baral and Gelfond Reference Baral and Gelfond2000) and (Balduccini and Gelfond Reference Balduccini and Gelfond2003), under which planning tasks and diagnostic tasks share (a) the same domain representation and (b) the same core reasoning algorithms.
In this section, the term diagnosis describes a type of reasoning task in which an agent identifies and interprets discrepancies between the domain’s expected behavior and the domain’s actual/observed behavior. Consider the following example.
Example 8
(From the paper by Reference Balduccini and Gelfond
Balduccini and Gelfond 2003
) Consider the analog circuit
 $\cal {AC}$
from Figure 4.
$\cal {AC}$
from Figure 4.
We assume that switches
 $sw_1$
and
$sw_1$
and
 $sw_2$
are mechanical components that cannot be damaged. Relay r is a magnetic coil. If not damaged, it is activated when
$sw_2$
are mechanical components that cannot be damaged. Relay r is a magnetic coil. If not damaged, it is activated when
 $sw_1$
is closed, causing
$sw_1$
is closed, causing
 $sw_2$
to close. Undamaged bulb b emits light if
$sw_2$
to close. Undamaged bulb b emits light if
 $sw_2$
is closed. For simplicity of presentation we consider an agent capable of performing only one action,
$sw_2$
is closed. For simplicity of presentation we consider an agent capable of performing only one action,
 $close(sw_1)$
. The environment can be represented by two damaging exogenous
Footnote 14
actions: brk, which causes b to become faulty, and srg, which damages r and also b assuming that b is not protected. Suppose that the agent operating this device is given a goal of lighting the bulb. He realizes that this can be achieved by closing the first switch, performs the operation, and discovers that the bulb is not lit. The domain’s behavior does not match the agent’s expectations. The agent needs to determine the reason for this state of affairs and ways to correct the problem.
$close(sw_1)$
. The environment can be represented by two damaging exogenous
Footnote 14
actions: brk, which causes b to become faulty, and srg, which damages r and also b assuming that b is not protected. Suppose that the agent operating this device is given a goal of lighting the bulb. He realizes that this can be achieved by closing the first switch, performs the operation, and discovers that the bulb is not lit. The domain’s behavior does not match the agent’s expectations. The agent needs to determine the reason for this state of affairs and ways to correct the problem.
 $\Diamond$
$\Diamond$
In the following, we focus on non-intrusive and observable domains, in which the agent’s environment does not normally interfere with his work and the agent normally observes all of the domain occurrences of exogenous actions. The agent is, however, aware that these assumptions can be contradicted by observations. The agent is ready to observe and to take into account occasional occurrences of exogenous actions that alter the behavior of the environment. Moreover, discrepancies between expectations and observations may force the agent to conclude that additional exogenous actions have occurred, but remained unobserved.
To model the domain, let us introduce a finite set of components C, disjoint from A and F previously introduced. Let us also assume the existence of a set F
 $_0$
$_0$
 $\subseteq$
F of observable fluents (i.e., fluents that can be directly observed by the agent), such that
$\subseteq$
F of observable fluents (i.e., fluents that can be directly observed by the agent), such that
 $ab(c) \in \textbf{F_0}$
for every component of C. Fluent ab(c) intuitively indicates that the c is “faulty.” Let us point out that the use of the relation ab in diagnosis dated back to the work by (Reiter Reference Reiter1987). The set A is further partitioned into two disjoint sets:
$ab(c) \in \textbf{F_0}$
for every component of C. Fluent ab(c) intuitively indicates that the c is “faulty.” Let us point out that the use of the relation ab in diagnosis dated back to the work by (Reiter Reference Reiter1987). The set A is further partitioned into two disjoint sets:
 $\textbf {A_s}$
, corresponding to agent actions, and
$\textbf {A_s}$
, corresponding to agent actions, and
 $\textbf{A_e}$
consisting of exogenous actions. Additionally, exogenous and agent actions are allowed to occur concurrently. With respect to the formalization methodology introduced in Section 2.2, this is achieved by (1) introducing the notion of compound action, that is, a set of agent and exogenous actions, (2) redefining
$\textbf{A_e}$
consisting of exogenous actions. Additionally, exogenous and agent actions are allowed to occur concurrently. With respect to the formalization methodology introduced in Section 2.2, this is achieved by (1) introducing the notion of compound action, that is, a set of agent and exogenous actions, (2) redefining
 $\Phi(a,s)$
so that a is a compound action, and (3) extending the notion of trajectory to be a sequence
$\Phi(a,s)$
so that a is a compound action, and (3) extending the notion of trajectory to be a sequence
 $s_0 a_0 \ldots a_{k-1} s_k$
of states and compound actions.
$s_0 a_0 \ldots a_{k-1} s_k$
of states and compound actions.
A core principle of this approach is that the discrepancies between agent’s expectations and observations are explained in terms of occurrences of unobserved exogenous actions. The observed behavior of the domain is represented by a particular trajectory, referred to as the actual trajectory.
A diagnostic domain is a pair
 $\langle D, W \rangle$
where D is a domain and W is the domain’s actual trajectory.
$\langle D, W \rangle$
where D is a domain and W is the domain’s actual trajectory.
Information about the behavior of the domain up to a certain step n is captured by the recorded history
 $H_n$
, that is a set of observations of the form:
$H_n$
, that is a set of observations of the form:
-
1. obs(l,t) – meaning that fluent literal l was observed to be true at step t;
-
2. hpd(a,t) – stating that action
$a \in$
A was observed to happen at time t.

The link between diagnostic domain and recorded history is established by the following:
Consider a diagnostic domain
 $\langle D, W \rangle$
with
$\langle D, W \rangle$
with
 $W = s^{w}_0a^{w}_0\ldots a^{w}_{n-1}s^{w}_n$
, and let
$W = s^{w}_0a^{w}_0\ldots a^{w}_{n-1}s^{w}_n$
, and let
 $H_n$
be a recorded history up to step n.
$H_n$
be a recorded history up to step n.
-
1. A trajectory
$s_0a_0 \ldots a_{n-1}s_n$
is a model of
$H_n$
if for any
$0 \leq t \leq n$
-
(a)
$a_t = \{a : hpd(a,t) \in H_n\}$
; -
(b) if
$obs(l,t) \in H_n$
then
$l \in s_t$
. -
2.
$H_n$
is consistent if it has a model. -
3.
$H_n$
is sound if, for any l, a, and t, if
$obs(l,t), hpd(a,t) \in H_n$
then
$l \in s^{w}_t$
and
$a \in a^{w}_t$
. -
4. A fluent literal l holds in a model M of
$H_n$
at time
$t \leq n $
(
$M \models holds(l,t)$
) if
$l \in s_t$
;
$H_n$
entails h(l,t)(
$H_n \models holds(l,t)$
) if, for every model M of
$H_n$
,
$M \models holds(l,t)$
.



















Note also that a recorded history may be consistent, but not sound – which is the case if the recorded history is incompatible with the actual trajectory.
Example 8 can thus be formalized as:
 \begin{equation*}\begin{array}{l}\mbox{\% Fluents:}\\[3pt]fluent(active(r)) \leftarrow fluent(on(b)) \leftarrow fluent(prot(b)) \leftarrow \\[3pt]fluent(closed(sw_1)) \leftarrow fluent(closed(sw_2)) \leftarrow \\[3pt]fluent(ab(r)) \leftarrow fluent(ab(b)) \leftarrow\\[3pt]\mbox{\% Agent Actions:}\\[3pt]a\_act(close(sw_1)) \leftarrow\\[3pt]\mbox{\%Exogenous Actions}\\[3pt]x\_act(brk) \leftarrow x\_act(srg) \leftarrow\end{array}\end{equation*}
\begin{equation*}\begin{array}{l}\mbox{\% Fluents:}\\[3pt]fluent(active(r)) \leftarrow fluent(on(b)) \leftarrow fluent(prot(b)) \leftarrow \\[3pt]fluent(closed(sw_1)) \leftarrow fluent(closed(sw_2)) \leftarrow \\[3pt]fluent(ab(r)) \leftarrow fluent(ab(b)) \leftarrow\\[3pt]\mbox{\% Agent Actions:}\\[3pt]a\_act(close(sw_1)) \leftarrow\\[3pt]\mbox{\%Exogenous Actions}\\[3pt]x\_act(brk) \leftarrow x\_act(srg) \leftarrow\end{array}\end{equation*}
Note the use of relations
 $a\_act$
and
$a\_act$
and
 $x\_act$
to distinguish agent actions and exogenous actions. The laws describing the normal and abnormal/malfunctioning behavior of the domain are:
$x\_act$
to distinguish agent actions and exogenous actions. The laws describing the normal and abnormal/malfunctioning behavior of the domain are:
 \begin{equation*}D_{\mathcal{AC}} = \left\{\begin{array}{lll}\mbox{\% normal } && \mbox{\% abnormal} \\[3pt]\textbf{causes}(close(sw_1),closed(sw_1),\emptyset) && \textbf{causes}(brk,ab(b),\emptyset)\\[3pt]\textbf{caused}(\{closed(sw_1), \neg ab(r)\}, active(r)) && \textbf{causes}(srg, ab(r),\emptyset)\\[3pt]\textbf{caused}(\{active(r)\}, closed(sw_2)) && \textbf{causes}(srg, ab(b),\{\neg prot(b)\})\\[3pt]\textbf{caused}(\{closed(sw_2), \neg ab(b)\}, on(b)) && \textbf{caused}(\{ab(b)\}, \neg on(b))\\[3pt]\textbf{caused}(\{\neg closed(sw_2)\}, \neg on(b)) && \textbf{caused}(\{ab(r)\}, \neg active(r))\\[3pt]\textbf{executable}(close(sw_1), \{\neg closed(sw_1)\})\end{array}\right..\end{equation*}
\begin{equation*}D_{\mathcal{AC}} = \left\{\begin{array}{lll}\mbox{\% normal } && \mbox{\% abnormal} \\[3pt]\textbf{causes}(close(sw_1),closed(sw_1),\emptyset) && \textbf{causes}(brk,ab(b),\emptyset)\\[3pt]\textbf{caused}(\{closed(sw_1), \neg ab(r)\}, active(r)) && \textbf{causes}(srg, ab(r),\emptyset)\\[3pt]\textbf{caused}(\{active(r)\}, closed(sw_2)) && \textbf{causes}(srg, ab(b),\{\neg prot(b)\})\\[3pt]\textbf{caused}(\{closed(sw_2), \neg ab(b)\}, on(b)) && \textbf{caused}(\{ab(b)\}, \neg on(b))\\[3pt]\textbf{caused}(\{\neg closed(sw_2)\}, \neg on(b)) && \textbf{caused}(\{ab(r)\}, \neg active(r))\\[3pt]\textbf{executable}(close(sw_1), \{\neg closed(sw_1)\})\end{array}\right..\end{equation*}
Now consider a recorded history:
 \begin{equation*}H_1 =\left\{\begin{array}{l}hpd(close(sw_1),0)\\[3pt]obs(\neg closed(sw_1),0)\\[3pt]obs(\neg closed(sw_2),0)\\[3pt]obs(\neg ab(b),0)\\[3pt]obs(\neg ab(r),0)\\[3pt]obs(prot(b),0).\end{array}\right.\end{equation*}
\begin{equation*}H_1 =\left\{\begin{array}{l}hpd(close(sw_1),0)\\[3pt]obs(\neg closed(sw_1),0)\\[3pt]obs(\neg closed(sw_2),0)\\[3pt]obs(\neg ab(b),0)\\[3pt]obs(\neg ab(r),0)\\[3pt]obs(prot(b),0).\end{array}\right.\end{equation*}
One can check that
 $s_0 \ close(sw_1) \ s_1$
is the only model of
$s_0 \ close(sw_1) \ s_1$
is the only model of
 $H_1$
, where
$H_1$
, where
 $s_0$
is the state depicted in Figure 4. Additionally,
$s_0$
is the state depicted in Figure 4. Additionally,
 $H_1 \models holds(on(b),1)$
.
$H_1 \models holds(on(b),1)$
.

Fig. 4. Analog circuit
 $\cal{AC}$
.
$\cal{AC}$
.
Next, we formalize the key notions of diagnosis. Let
 $\delta=\langle D, W \rangle$
be a diagnostic domain. A configuration is a pair
$\delta=\langle D, W \rangle$
be a diagnostic domain. A configuration is a pair
 \begin{equation}{\cal S} = \langle H_n,O^{m}_n\rangle,\end{equation}
\begin{equation}{\cal S} = \langle H_n,O^{m}_n\rangle,\end{equation}
where
 $H_n$
is the recorded history up to step n and
$H_n$
is the recorded history up to step n and
 $O^{m}_n$
is a set of observations between steps n and
$O^{m}_n$
is a set of observations between steps n and
 $m \geq n$
. Leveraging this notion, we can now define a symptom as a configuration
$m \geq n$
. Leveraging this notion, we can now define a symptom as a configuration
 $\langle H_n,O^{m}_n\rangle$
such that
$\langle H_n,O^{m}_n\rangle$
such that
 $H_{n}$
is consistent and
$H_{n}$
is consistent and
 $H_{n} \cup O^{m}_n$
is not.
$H_{n} \cup O^{m}_n$
is not.
Once a symptom has been identified, the next step of the diagnostic process aims at finding its possible reasons. Specifically, a diagnostic explanation E of symptom
 ${\cal S} = \langle H_n,O^{m}_n\rangle$
is defined as a set
${\cal S} = \langle H_n,O^{m}_n\rangle$
is defined as a set
 \begin{equation}E \subseteq \{hpd(a_i,t) : 0 \leq t < n \mbox{ and } a_i \in \mbox\textbf{A}_e\},\end{equation}
\begin{equation}E \subseteq \{hpd(a_i,t) : 0 \leq t < n \mbox{ and } a_i \in \mbox\textbf{A}_e\},\end{equation}
such that
 $H_{n} \cup O^{m}_n \cup E$
is consistent.
$H_{n} \cup O^{m}_n \cup E$
is consistent.
7.1 Diagnostic reasoning as answer set planning
As we said earlier, answer set planning can be used to determine whether a diagnosis is needed and for computing diagnostic explanations. Next, we introduce an ASP-based program for these purposes. Consider a domain D whose behavior up to step n is described by recorded history
 $H_n$
. Reasoning about D and
$H_n$
. Reasoning about D and
 $H_n$
can be accomplished by a translation to a logic program
$H_n$
can be accomplished by a translation to a logic program
 $\Pi(D, H_n)$
that follows the approach outlined in Section 3. Focusing for simplicity on the direct encoding,
$\Pi(D, H_n)$
that follows the approach outlined in Section 3. Focusing for simplicity on the direct encoding,
 $\Pi(D, H_n)$
consists of:
$\Pi(D, H_n)$
consists of:
-
• the domain dependent rules from Section 3.1.1;
-
• the rules related to inertia and consistency of states (11)–(13);
-
• domain independent rule establishing the relationship between observations and the basic relations of
$\Pi$
: (63)
\begin{eqnarray}occ(A,T) \leftarrow hpd(A,T) \end{eqnarray}
(64)
\begin{eqnarray}holds(L,0) \leftarrow obs(L,0)\end{eqnarray}
-
• the reality check axiom, that is a rule ensuring that in any answer set the agent’s expectations match the available observations (variable L ranges over fluent literals):
(65)
\begin{eqnarray}\leftarrow obs(L,T), { not \:} holds(L,T).\end{eqnarray}




The following theorem establishes an important relationship between models of a recorded history and answer sets of the corresponding logic program.
Theorem 2 If the initial situation of
 $H_n$
is complete, that is for any fluent f,
$H_n$
is complete, that is for any fluent f,
 $H_n$
contains obs(f,0) or
$H_n$
contains obs(f,0) or
 $obs(\neg f,0)$
, then M is a model of
$obs(\neg f,0)$
, then M is a model of
 $H_n$
iff M is defined by some answer set of
$H_n$
iff M is defined by some answer set of
 $\Pi(D, H_n)$
.
$\Pi(D, H_n)$
.
The proof of the theorem is in two steps. First, one shows that the theorem holds for
 $n=1$
, that is, that for a history
$n=1$
, that is, that for a history
 $H_1$
there is a one-to-one correspondence between the transitions of the form
$H_1$
there is a one-to-one correspondence between the transitions of the form
 $s_0a_0s_1$
and the answer sets of
$s_0a_0s_1$
and the answer sets of
 $\Pi(D,H_1)$
. Then, induction is leveraged to extend the correspondence to histories of arbitrary length. The complete proof can be found in the paper by (Balduccini and Gelfond Reference Balduccini and Gelfond2003).
$\Pi(D,H_1)$
. Then, induction is leveraged to extend the correspondence to histories of arbitrary length. The complete proof can be found in the paper by (Balduccini and Gelfond Reference Balduccini and Gelfond2003).
Next, we focus on identifying the need for diagnosis. Given a domain D and
 ${\cal S} = \langle H_n,O^{m}_n\rangle$
, we introduce:
${\cal S} = \langle H_n,O^{m}_n\rangle$
, we introduce:
 \begin{equation}\mathit{TEST}({\cal S})= \Pi(D, H_n) \cup O^m_{n}.\end{equation}
\begin{equation}\mathit{TEST}({\cal S})= \Pi(D, H_n) \cup O^m_{n}.\end{equation}
The following corollary forms the basis of this approach to diagnosis.
Corollary 1 Let
 ${\cal S} = \langle H_n,O^{m}_n\rangle$
where
${\cal S} = \langle H_n,O^{m}_n\rangle$
where
 $H_n$
is consistent. A configuration
$H_n$
is consistent. A configuration
 ${\cal S}$
is a symptom iff
${\cal S}$
is a symptom iff
 $\mathit{TEST}({\cal S})$
has no answer set.
$\mathit{TEST}({\cal S})$
has no answer set.
Once a symptom has been identified, diagnostic explanations can be found by means of the answer sets of the diagnostic program
 \begin{equation}\Pi_d({\cal S})= \mathit{TEST}({\cal S}) \cup\{\ \ \ 1 \{ occ(A,T) : x\_act(A) \} 1 \leftarrow time(T), T < n.\ \ \ \}\end{equation}
\begin{equation}\Pi_d({\cal S})= \mathit{TEST}({\cal S}) \cup\{\ \ \ 1 \{ occ(A,T) : x\_act(A) \} 1 \leftarrow time(T), T < n.\ \ \ \}\end{equation}
Specifically, every answer set X of
 $\Pi_d({\cal S})$
encodes a diagnostic explanation
$\Pi_d({\cal S})$
encodes a diagnostic explanation
 \begin{equation*}E=\{hpd(a,t) \,\,|\,\, occ(a,t) \in X \land a \in \mbox{\textbf{A}$_e$} \}.\end{equation*}
\begin{equation*}E=\{hpd(a,t) \,\,|\,\, occ(a,t) \in X \land a \in \mbox{\textbf{A}$_e$} \}.\end{equation*}
Note that the choice rule shown in (67) is simply a restriction of (10) to exogenous actions. As a result,
 $\Pi_d({\cal S})$
can be viewed as a variant of the translation
$\Pi_d({\cal S})$
can be viewed as a variant of the translation
 $\Pi(\mathcal{P},n)$
of a planning problem, where planning occurs over the past
$\Pi(\mathcal{P},n)$
of a planning problem, where planning occurs over the past
 $0..n\!-\!1$
time steps and over exogenous actions only, and the goal states are described by the observations from
$0..n\!-\!1$
time steps and over exogenous actions only, and the goal states are described by the observations from
 ${\cal S}$
.
${\cal S}$
.
Example 9 Consider the domain from Example 8. According to
 $H_1$
initially switches
$H_1$
initially switches
 $sw_1$
and
$sw_1$
and
 $sw_2$
are open, all circuit components are ok,
$sw_2$
are open, all circuit components are ok,
 $sw_1$
is closed by the agent, and b is protected. The expectation is that b will be on at 1. Suppose that, instead, the agent observes that at time 1 bulb b is off, that is
$sw_1$
is closed by the agent, and b is protected. The expectation is that b will be on at 1. Suppose that, instead, the agent observes that at time 1 bulb b is off, that is
 $O_1 = \{obs(\neg on(b),1) \}$
.
$O_1 = \{obs(\neg on(b),1) \}$
.
 $\mathit{TEST}({\cal S}_0)$
, where
$\mathit{TEST}({\cal S}_0)$
, where
 ${\cal S}_0 = \langle H_1,O_1\rangle$
, has no answer sets and thus, by Corollary 1,
${\cal S}_0 = \langle H_1,O_1\rangle$
, has no answer sets and thus, by Corollary 1,
 ${\cal S}_0$
is indeed a symptom. The diagnostic explanations of
${\cal S}_0$
is indeed a symptom. The diagnostic explanations of
 ${\cal S}_0$
can be found by computing the answer sets of
${\cal S}_0$
can be found by computing the answer sets of
 $\Pi_d(\mathcal{S})$
. Specifically, there are three diagnostic explanations:
$\Pi_d(\mathcal{S})$
. Specifically, there are three diagnostic explanations:
 \begin{equation*}\begin{array}{l}E_1 = \{occ(brk,0)\} \\[3pt] E_2 = \{occ(srg,0)\} \\[3pt] E_3 = \{occ(brk,0), occ(srg,0)\}.\end{array}\end{equation*}
\begin{equation*}\begin{array}{l}E_1 = \{occ(brk,0)\} \\[3pt] E_2 = \{occ(srg,0)\} \\[3pt] E_3 = \{occ(brk,0), occ(srg,0)\}.\end{array}\end{equation*}
Remark 6
-
1. Other interpretations of the relationship between agent and environment are possible, yielding substantial differences in the overall approach to diagnosis. The interested reader is referred to the paper by (Baral et al. Reference Baral, Kreinovich and Trejo2000).
-
2. In contrast to the approach by (Baral et al. Reference Baral, Kreinovich and Trejo2000), the approach presented in this survey assumes that a recorded history is consistent only if observations about fluents can be explained without assuming the occurrence of actions not recorded in
$H_n$
. -
3. In the paper by (Balduccini and Gelfond Reference Balduccini and Gelfond2003), the formalization of diagnostic reasoning presented here is extended to incorporate an account of the agent’s interaction with the domain in order to collect physical evidence that confirms or refutes the diagnostic explanations computed. This is accomplished by introducing the notions of candidate diagnosis and of diagnosis.
-
4. Theorem 2 is similar to the result from the paper by (Turner Reference Turner1997), which deals with a different language and uses the definitions by (McCain and Turner Reference McCain and Turner1995). If the initial situation of
$H_n$
is incomplete, one can adopt techniques discussed elsewhere in this paper or the awareness axioms by (Balduccini and Gelfond Reference Balduccini and Gelfond2003). -
5. As discussed in the paper by (Balduccini and Gelfond Reference Balduccini and Gelfond2003), the diagnostic process may not always lead to a unique solution. In those cases, the agent may need to perform further actions, such as repairing or replacing components, and observe their outcomes. (Balduccini and Gelfond Reference Balduccini and Gelfond2003) provided a specialized algorithm to achieve this. An alternative, and potentially more general, option consists in leveraging conditional planning techniques (see Section 5.2), that is, by creating a conditional plan that determines the true diagnosis as proposed by (Baral et al. Reference Baral, Kreinovich and Trejo2000).


7.2 Context: Planning and diagnosis
Classical diagnosis such as the foundational work by (Reiter Reference Reiter1987) aimed at providing a formal answer to the question of “what is wrong with a system given its (current failed) state.” Central to classical diagnosis is the use of the model of the system to reason about failures. Earlier formalizations considered a single state of the system and are often referred to as model based diagnosis, which is summarized by (De Kleer and Kurien Reference De Kleer and Kurien2003). Later formalization such as the proposal by (Feldman et al. Reference Feldman, Pill, Wotawa, Matei and de Kleer2020) considers a finite trace of states, taking into consideration the transitions at different time points in need of a diagnosis. This is closedly related to dynamic diagnosis, as described in this paper, which has been considered in the literature (Baral et al. Reference Baral, Kreinovich and Trejo2000; Baroni et al. Reference Baroni, Lamperti, Pogliano and Zanella1999; Cordier and ThiÉbaux Reference Cordier and ThiÉbaux1994; McIlraith Reference McIlraith1997; Thielscher Reference Thielscher1997; ThiÉbaux et al. Reference ThiÉbaux, Cordier, Jehl and Krivine1996; Williams and Nayak Reference Williams and Nayak1996).
The close relationship between model based diagnosis and satisfiability led to several methods for computing diagnosis using satisfiability such as the method proposed by (Grastien and Anbulagan 2013), (Metodi et al. Reference Metodi, Stern, Kalech and Codish2014), or described in several publications on diagnosing sequential circuits (e.g., by Feldman et al. Reference Feldman, Pill, Wotawa, Matei and de Kleer2020). In a recent work by (Wotawa Reference Wotawa2020), ASP has been used in the context of model-based diagnosis.
8 Planning in MAE
The formalizations presented in the previous sections can be also extended to deal with various problems in MAEs. In these problems, the planning (or reasoning) activity can be carried out either by one system (a.k.a. centralized planning) or multiple systems (a.k.a. distributed planning). In the following subsections, we discuss the use of ASP in these settings.
8.1 Centralized multiagent planning
We will start with the Multi-Agent Path Finding (MAPF) problem which appears in a variety of application domains, such as autonomous aircraft towing vehicles (Morris et al. Reference Morris, Pasareanu, Luckow, Malik, Ma, Kumar and Koenig2016), autonomous warehouse systems (Wurman et al. Reference Wurman, D’Andrea and Mountz2008), office robots (Veloso et al. Reference Veloso, Biswas, Coltin and Rosenthal2015), and video games (Silver Reference Silver2005).
A MAPF problem is defined by a tuple
 $\mathcal{M} = (R, (V,E), s, d)$
where
$\mathcal{M} = (R, (V,E), s, d)$
where
-
• R is a set of robots,
-
• (V,E) is an undirected graph, with the set of vertices V and the set of edges E,
-
• s is an injective function from R to V, s(r) denotes the starting location of robot r, and
-
• d is an injective function from R to V, d(r) denotes the destination of robot r.
Robots can move from one vertex to one of its neighbors in one step. A collision occurs when two robots move to the same location (vertex collision) or traveling on the same edge (edge collision). The goal is to find a collision-free plan for all robots to reach their destinations. Optimal plans, with the minimal number of steps, are often preferred.
A simple MAPF problem is depicted in Figure 5. In this problem, we have two robots
 $r_1$
and
$r_1$
and
 $r_2$
on a graph with five vertices
$r_2$
on a graph with five vertices
 $p_1, \ldots, p_5$
. Initially,
$p_1, \ldots, p_5$
. Initially,
 $r_1$
is at
$r_1$
is at
 $p_2$
and
$p_2$
and
 $r_2$
is at
$r_2$
is at
 $p_4$
. The goal consists of moving robot
$p_4$
. The goal consists of moving robot
 $r_1$
to location
$r_1$
to location
 $p_5$
and robot
$p_5$
and robot
 $r_2$
to location
$r_2$
to location
 $p_3$
.
$p_3$
.

Fig. 5. A multi-agent path finding problem.
It is easy to see that a MAPF
 $\mathcal{M} = (R, (V,E), s, d)$
can be represented by
$\mathcal{M} = (R, (V,E), s, d)$
can be represented by
-
• a set
$\{\mathcal{P}_r \mid r \in R\}$
of path-planning problems for the robots in R, where for each
$r \in R$
,
$\mathcal{P}_r = \langle D_r, at(r, s(r)), at(r, d(r)) \rangle$
is a planning problem with
\begin{equation*}D_r = \left \{\begin{array}{lll}\textbf{causes}(move(r,l,l'), at(r,l'), \{at(r,l)\}) && \mbox{ for } (l,l') \in E \\[3pt]\textbf{caused}(\{at(r,l)\}, \neg at(r,l')) \} && \mbox{ for } l \ne l', l,l' \in V \\[3pt]\end{array}\right.\end{equation*}
-
• the set of constraints representing the collisions.




ASP-based solutions of MAPF problems have been proposed for both action-based as well as state-based encodings. In the context of this survey, we will focus on an action-based encoding. Consider a MAPF problem
 $\mathcal{M}= (R, (V,E), s, d)$
. The program developed in Section 3 for a single-agent planning problem can be used to develop a program solving
$\mathcal{M}= (R, (V,E), s, d)$
. The program developed in Section 3 for a single-agent planning problem can be used to develop a program solving
 $\mathcal{M}$
, denoted by
$\mathcal{M}$
, denoted by
 $\Pi(\mathcal{M},n)$
, as follows.
$\Pi(\mathcal{M},n)$
, as follows.
 $\Pi(\mathcal{M},n)$
contains the following groups of rules:
$\Pi(\mathcal{M},n)$
contains the following groups of rules:
-
1. the set of atoms
$\{agent(r) \mid r \in R\}$
encoding the robots; -
2. the collection of the rules from
$\Pi(\mathcal{P}_r, n)$
; and -
3. the constraints to avoid collisions:
(68)
\begin{eqnarray}& \leftarrow & agent(R), agent(R'), R \ne R' , \end{eqnarray}
(69)
\begin{eqnarray}&& holds(at(R, V), T), holds(at(R', V), T) \nonumber \\[3pt]& \leftarrow & agent(R), agent(R'), R \ne R' , \end{eqnarray}
\begin{eqnarray}& & holds(at(R, V), T), holds(at(R', V'), T), \nonumber \\[3pt]& & holds(at(R, V'), T+1), holds(at(R', V), T+1). \nonumber\end{eqnarray}





Rule (68) prevents two robots to be at the same location at the same time, while rule (69) guarantees that edge-collisions will not occur. These two constraints and the correctness of
 $\Pi(\mathcal{P}_r,n)$
imply that
$\Pi(\mathcal{P}_r,n)$
imply that
 $\Pi(\mathcal{M},n)$
computes solutions of length n for the MAPF problem
$\Pi(\mathcal{M},n)$
computes solutions of length n for the MAPF problem
 $\mathcal{M}$
.
$\mathcal{M}$
.
The proposed method for solving MAPF problems can be generalized to multi-agent planning as considered by the multi-agent community in the setting discussed by (Durfee Reference Durfee1999). We assume that a multi-agent planning problem
 $\mathcal{M}$
for a set of agents R is specified by a pair
$\mathcal{M}$
for a set of agents R is specified by a pair
 $(\mathcal{P}_{r \in R}, \mathcal{C})$
where
$(\mathcal{P}_{r \in R}, \mathcal{C})$
where
 $\mathcal{P}_r = \langle D_r, \Delta_r, \Gamma_r \rangle $
is the planning problem for agent r and
$\mathcal{P}_r = \langle D_r, \Delta_r, \Gamma_r \rangle $
is the planning problem for agent r and
 $\mathcal{C}$
is a set of global constraints. For simplicity of the presentation, we will assume that
$\mathcal{C}$
is a set of global constraints. For simplicity of the presentation, we will assume that
-
• the agents in R share the same set of fluents and, wherever needed, parameterized with the names of the agents; for example, if an agent is carrying something then carrying(r, o) will be used instead of carrying(o) as in a single-agent domain;
-
• the actions in the domain in
$D_r$
are parameterized with the agent’s name r, for example, we will use the action move(r,l,l’) instead of the traditional encoding move(l,l’); -
• the constraints in
$\mathcal{C}$
are of the form (70)where sa is a set of actions in
\begin{equation}\textbf{executable}(sa, \varphi),\end{equation}
$\bigcup_{r \in R} D_r$
and
$\varphi$
is a set of literals. This can be used to represent parallel actions, non-concurrent actions, etc.





For a multi-agent planning problem
 $\mathcal{M} = (\mathcal{P}_{r \in R}, \mathcal{C})$
where
$\mathcal{M} = (\mathcal{P}_{r \in R}, \mathcal{C})$
where
 $\mathcal{P}_r = \langle D_r, \Delta_r, \Gamma_r \rangle$
, the program
$\mathcal{P}_r = \langle D_r, \Delta_r, \Gamma_r \rangle$
, the program
 $\Pi(\mathcal{M},n)$
that computes solution for
$\Pi(\mathcal{M},n)$
that computes solution for
 $\mathcal{M}$
consists of
$\mathcal{M}$
consists of
-
1. the set of agent declarations, agent(r) for
$r \in R$
; -
2. the collection Footnote 15 of the rules from
$\Pi(\mathcal{P}_r, n)$
with the following modifications: -
• the action specification of the form action(a) is replaced by action(r,a);
-
• the action generation rule is replaced by
where, without the loss of generality, we assume that every
\begin{equation*}1 \{occ(A, T) : action(R, A)\} 1 \leftarrow time(T), agent(R),\end{equation*}
$D_r$
contains the action noop that is always executable and has no effect;




3. for each constraint of form (70), we create a new “collective” action named
 $sa_{id}$
, add
$sa_{id}$
, add
 $action(sa_{id})$
to the set of actions in
$action(sa_{id})$
to the set of actions in
 $\mathcal{M}$
(and make the (70) its executability condition, translated into ASP as for any other action) and, for each
$\mathcal{M}$
(and make the (70) its executability condition, translated into ASP as for any other action) and, for each
 $a \in sa$
, the following rule is added to
$a \in sa$
, the following rule is added to
 $\Pi(\mathcal{P}_r, n)$
:
$\Pi(\mathcal{P}_r, n)$
:
 \begin{eqnarray}occ(a, T) & \leftarrow & occ(sa_{id}, T). \end{eqnarray}
\begin{eqnarray}occ(a, T) & \leftarrow & occ(sa_{id}, T). \end{eqnarray}
8.2 Distributed planning
A main drawback of centralized planning is that it cannot exploit the structural organization of agents (e.g. hierarchical organization of agents) in the planning process. Distributed planning has been proposed as an alternative to centralized planning that aims at exploiting the independence between agents and/or groups of agents. We discuss distributed planning in two settings: fully collaborative agents and partially-cooperative or non-cooperative agents.
8.2.1 Fully collaborative agents
When agents are fully collaborative, a possible way to exploit structural relationships between agents is to allow each group of agents to plan for itself (e.g., using the planning system described in Section 3 and then employ a centralized post-planning process (a.k.a. the controller/scheduler) to create the joint plan for all agents. The controller takes the output of these planners – individual plans – and merges them into an overall plan. One of the main tasks of the controller is to resolve conflicts between individual plans. This issue arises because individual groups plan without knowledge of other groups (e.g., robot
 $r_1$
does not know the location of robot
$r_1$
does not know the location of robot
 $r_2$
). When the controller is unable to resolve all possible conflicts, the controller will identify plans that need to be changed and request different individual plans from specific individual groups.
$r_2$
). When the controller is unable to resolve all possible conflicts, the controller will identify plans that need to be changed and request different individual plans from specific individual groups.
Any implementation of distributed planning requires some communication capabilities between the controller and the individual planning systems. For this reason, a client-server architecture is often employed in the implementation of distributed planning. A client plans for an individual group of agents and the server is responsible for merging the individual plans from all groups. Although specialized parallel ASP solvers exist (e.g., the systems discussed in the papers by Le and Pontelli Reference Le and Pontelli2005 and Schneidenbach et al. Reference Schneidenbach, Schnor, Gebser, Kaminski, Kaufmann and Schaub2009), there has been no attempt to use parallel ASP solvers in distributed planning. Rather, distributed planning using ASP has been implemented using a combination of Prolog and ASP, where communication between server and clients is achieved through Prolog-based message passing, and planning is done using ASP (e.g., the system described in the paper by Son et al. Reference Son, Pontelli and Nguyen2009a).
Observe that the task of resolving conflicts is not straightforward and can require multiple iterations with individual planner(s) before the controller can create a joint plan. Consider again the two robots in Figure 5. If they are to generate their own plans, then the first set of individual solutions can be
 \begin{equation}{\begin{array}{l}occ(move(r_1, p_2, p_4), 0), occ(move(r_1, p_4, p_5), 1)\end{array}}\end{equation}
\begin{equation}{\begin{array}{l}occ(move(r_1, p_2, p_4), 0), occ(move(r_1, p_4, p_5), 1)\end{array}}\end{equation}
and
 \begin{equation}{\begin{array}{l}occ(move(r_2, p_4, p_2), 0), occ(move(r_2, p_2, l_3), 1).\end{array}}\end{equation}
\begin{equation}{\begin{array}{l}occ(move(r_2, p_4, p_2), 0), occ(move(r_2, p_2, l_3), 1).\end{array}}\end{equation}
A parallel execution of these two plans will result in a violation of the constraint stating that two robots cannot be at the same location at the same time. One can see that the controller needs to insert a few actions into both plans (e.g.
 $r_1$
must move to either
$r_1$
must move to either
 $l_1$
or
$l_1$
or
 $l_3$
before moving to
$l_3$
before moving to
 $l_4$
).
$l_4$
).
Let
 $\mathcal{M}$
be a multiagent planning problem and
$\mathcal{M}$
be a multiagent planning problem and
 $P_{\{r \in R\}}$
be the plans received by the controller. The feasibility of merging these plans into a single plan for all agents can be checked using ASP. Let
$P_{\{r \in R\}}$
be the plans received by the controller. The feasibility of merging these plans into a single plan for all agents can be checked using ASP. Let
 $\pi_n$
be the program obtained from
$\pi_n$
be the program obtained from
 $\Pi(\mathcal{M},n)$
(described in Subsection 8.1) by adding to
$\Pi(\mathcal{M},n)$
(described in Subsection 8.1) by adding to
 $\Pi(\mathcal{M},n)$
$\Pi(\mathcal{M},n)$
-
• the set of action occurrences in
$P_{\{r \in R\}}$
, that is,
\begin{equation*}\bigcup_{\{r \in R\}} \{occurs(a, t) \mid occ(a,t) \in P_r\}\end{equation*}
-
• for
$r \in R$
, rules mapping time steps from 0 to n to time steps used in
$P_r$
(
$r \in R$
), where
\begin{equation*}\begin{array}{l}1 \{map(r, T, J) : time(J) \} 1 \leftarrow time(T), T< n, T \le \max_r \\[3pt]\leftarrow map(r, T, J), map(p, T', J'), T < T', J > J',\end{array}\end{equation*}
$\max_r$
is the maximal index in
$P_r$
. Intuitively, map(r, i, j) indicates that the
$i{\rm th}$
action in
$P_r$
should occur in the
$j{\rm th}$
position in the joint plan. This mapping must conform to the order of action occurrences in
$P_r$
.
-
• a rule ensuring that an atom
$occurs(a, j) \in P_r$
must occur at the specified position:
\begin{equation*}\leftarrow occ(a, t), map(r, t, j), { not \:} occurs(a, j).\end{equation*}














It can be checked that
 $\pi_4$
would generate an answer set consisting of
$\pi_4$
would generate an answer set consisting of
 \begin{equation*}\begin{array}{l}occ(move(r_1, p_2, p_1), 0), occ(move(r_2, p_4, p_2), 0),\\[3pt]occ(move(r_2, p_2, l_3), 1), occ(move(r_1, p_1, p_2), 1),\\[3pt]occ(move(r_1, p_2, p_1), 2), \\[3pt]occ(move(r_2, p_4, p_2), 3)\end{array}\end{equation*}
\begin{equation*}\begin{array}{l}occ(move(r_1, p_2, p_1), 0), occ(move(r_2, p_4, p_2), 0),\\[3pt]occ(move(r_2, p_2, l_3), 1), occ(move(r_1, p_1, p_2), 1),\\[3pt]occ(move(r_1, p_2, p_1), 2), \\[3pt]occ(move(r_2, p_4, p_2), 3)\end{array}\end{equation*}
which corresponds to the mapping map(1, 0, 2), map(1, 1, 3), map(2, 0, 0), map(2, 1, 1) and is a successful merge of the two plans in (72)–(73).
Observe that the program
 $\pi_n$
might have no answer sets, which indicates that the merging of the plans
$\pi_n$
might have no answer sets, which indicates that the merging of the plans
 $P_{\{r \in R\}}$
is unsuccessful. For instance,
$P_{\{r \in R\}}$
is unsuccessful. For instance,
 $\pi_3$
has no answer set, that is, the two plans in (72)–(73) cannot be merged with less than four steps.
$\pi_3$
has no answer set, that is, the two plans in (72)–(73) cannot be merged with less than four steps.
8.2.2 Non/Partially-collaborative agents
Centralized planning or distributed planning with an overall controller is most suitable in applications with collaborative (or non-competitive) agents such as the robots in the MAPF problems. In many applications, this assumption does not hold, for example, agents may need to withhold certain private information and thus do not want to share their information freely; or agents may be competitive and have conflicting goals. In these situations, distributed planning as described in the previous subsection is not applicable and planning will have to rely on a message passing architecture, for example, via peer-to-peer communications. Furthermore, an online planning approach might be more appropriate. Next, we describe an ASP approach that is implemented centrally by (Son et al. Reference Son, Pontelli and Sakama2009b) but could also be implemented distributedly.
In this approach, the planning process is interleaved with a negotiation process among agents. As an example, consider the robots in Figure 5 and assume that the robots can communicate with each other, but they cannot reveal their location. The following negotiation between
 $r_2$
and
$r_2$
and
 $r_1$
could take place:
$r_1$
could take place:
-
•
$r_2$
(to
$r_1$
): “can you (
$r_1$
) move out of
$l_2$
,
$l_3$
, and
$l_4$
?” (because
$r_2$
needs to make sure that it can move to location
$l_2$
and
$l_3$
). This can be translated to the formula
$\varphi_1 = \neg at(r_1, l_2) \wedge \neg at(r_1, l_3) \wedge \neg at(r_1, l_4)$
sent from
$r_2$
to
$r_1$
. -
•
$r_1$
(to
$r_2$
): “I can do so after two steps but I would also like for you (
$r_2$
) to move out of
$l_2$
,
$l_4$
, and
$l_5$
after I move out of those places.” This means that
$r_1$
agrees to satisfy the formula sent by
$r_2$
but also has some conditions of its own. This can be represented by the formula
$\varphi_1 \supset \varphi_2 = \neg at(r_2, l_2) \wedge \neg at(r_2, l_4) \wedge \neg at(r_2, l_5)$
. -
•
$r_2$
(to
$r_1$
): “that is good; however, do not move through
$l_4$
to get out of the area.” -
• etc.
























The negotiation will continue until either the agent accepts (or refutes) the latest proposal from the other agent. A formal ASP based negotiation framework (e.g., the system described by Son et al. Reference Son, Pontelli, Nguyen and Sakama2014) could be used for this purpose.
Observe that during a negotiation, none of the robots changes its location or executes any action. After a successful negotiation, each robot has some additional information to take into consideration in its planning. In this example, if the two robots agree after the second proposal by
 $r_2$
, robot
$r_2$
, robot
 $r_1$
agrees to move out of
$r_1$
agrees to move out of
 $l_2$
,
$l_2$
,
 $l_3$
, and
$l_3$
, and
 $l_4$
but should do so without passing by
$l_4$
but should do so without passing by
 $l_4$
; robot
$l_4$
; robot
 $r_2$
knows that he can have
$r_2$
knows that he can have
 $l_2$
,
$l_2$
,
 $l_3$
, and
$l_3$
, and
 $l_4$
for itself after sometime and also knows that it can stand at
$l_4$
for itself after sometime and also knows that it can stand at
 $l_4$
until
$l_4$
until
 $r_1$
is out of the requested area; etc. Note, however, that this is not yet sufficient for the two robots to achieve their goals. To do so, they also need to agree on the timing of their moves. For example,
$r_1$
is out of the requested area; etc. Note, however, that this is not yet sufficient for the two robots to achieve their goals. To do so, they also need to agree on the timing of their moves. For example,
 $r_1$
can tell
$r_1$
can tell
 $r_2$
that
$r_2$
that
 $l_2$
,
$l_2$
,
 $l_3$
, and
$l_3$
, and
 $l_4$
will be free after two steps;
$l_4$
will be free after two steps;
 $r_2$
responds that, if it is the case, then
$r_2$
responds that, if it is the case, then
 $l_2$
,
$l_2$
,
 $l_4$
, and
$l_4$
, and
 $l_5$
will be free after 2 steps; etc. This information will help the robots come up with plans for their own goals.
$l_5$
will be free after 2 steps; etc. This information will help the robots come up with plans for their own goals.
To the best of our knowledge, only a prototype implementation of the approach to interleaving negotiation and planning has been presented (Son et al. Reference Son, Pontelli and Sakama2009b). It is also not implemented distributedly.
Remark 7
-
1. There are two different ways to enforce the collision-free constraint in the MAPF encoding. One can, for example, replace (69) with the rule
\begin{equation*}\begin{array}{rcl}& \leftarrow & agent(R), agent(R'), R \ne R' , \nonumber \\[3pt]& & holds(at(R, V), T), holds(at(R', V'), T), \nonumber \\[3pt]& & occ(move(R, V, V'), T), occ(move(R', V', V), T+1) \nonumber\end{array}\end{equation*}
-
2. ASP-based solutions for various extensions of the MAPF problems have been discussed by (Nguyen et al. Reference Nguyen, Obermeier, Son, Schaub and Yeoh2017) and (GÓmez et al. Reference GÓmez, HernÁndez and Baier2020). The encoding proposed by (GÓmez et al. Reference GÓmez, HernÁndez and Baier2020) is special in that its grounded program has a linear size to the number of agents. An ASP-based solution for this problem has been applied in a real-world application (Gebser et al. Reference Gebser, Obermeier, Schaub, Ratsch-Heitmann and Runge2018). An environment for experimenting with MAPF has been developed by (Gebser et al. Reference Gebser, Obermeier, Schaub, Ratsch-Heitmann and Runge2018). A preliminary implementation of a MAPF solver on distributed platform can be found in the paper by (Pianpak et al. Reference Pianpak, Son, Toups and Yeoh2019).
-
3. We observe that little attention has been paid to ASP based distributed planning. This also holds for the ASP based distributed computing platforms. Perhaps the need to attack problems in multi-agent systems will eventually lead to a truly distributed platform that could push the investigation of using ASP in this research direction to the next level. We note that the need for such platform exists and ad-hoc combinations with other programming language have been developed by (Le et al. Reference Le, Son, Pontelli and Yeoh2015).

8.3 Context: Planning in MAEs
Planning in MAEs has been extensively investigated by the multi-agent research community. There exists a broad literature in this direction which addresses several issues, such as coordination, sharing of resources, use of shared resources, execution of joint actions, centralized or distributed computation of plans, sharing of tasks, etc. Earlier works in multiagent planning (e.g. see the papers Allen and Zilberstein Reference Allen and Zilberstein2009; Brafman and Domshlak Reference Brafman and Domshlak2008; Bernstein et al. Reference Bernstein, Givan, Immerman and Zilberstein2002; Brenner Reference Brenner2003; Crosby et al. Reference Crosby, Jonsson and Rovatsos2014; Durfee Reference Durfee1999; de Weerdt et al. Reference de Weerdt, Bos, Tonino and Witteveen2003; de Weerdt and Clement Reference de Weerdt and Clement2009; Goldman and Zilberstein Reference Goldman and Zilberstein2004; Guestrin et al. Reference Guestrin, Koller and Parr2001; Nair et al. Reference Nair, Tambe, Yokoo, Pynadath and Marsella2003; Nissim and Brafman Reference Nissim and Brafman2012; Peshkin and Savova Reference Peshkin and Savova2002; Shoham and Leyton-Brown Reference Shoham and Leyton-Brown2009; TorreÑo et al. Reference TorreÑo, Onaindia and Sapena2012; Vlassis Reference Vlassis2007) focus on generating plans for multiple agents, coordinating the execution of plans, and does not take into consideration knowledge, beliefs, or privacy of agents. Work in planning for multiple self-interested agents can be found in the papers (Gmytrasiewicz and Doshi Reference Gmytrasiewicz and Doshi2005; Rathnasabapathy et al. Reference Rathnasabapathy, Doshi and Gmytrasiewicz2006; Poupart and Boutilier Reference Poupart and Boutilier2003; Sonu and Doshi Reference Sonu and Doshi2015).
The planning problem in MAEs discussed in this section focuses on the setting in which each agent has its own goal, similar to the setting discussed in earlier work on multiagent planning. It should be noted that MAPF has attracted a lot of attention in recent years due to its widespread applicability such as in warehouse or airtraffic control, leading to the organization of the yearly MAPF workshop at IJCAI and/or ICAPS conferences and several tutorials on the topic. A good description of this problem can be found in the papers (BartÁk et al. Reference BartÁk, Svancara, SkopkovÁ, Nohejl and Krasicenko2019; Stern et al. Reference Stern, Sturtevant, Felner, Koenig, Ma, Walker, Li, Atzmon, Cohen, Kumar, BartÁk and Boyarski2019). Challenges and opportunities in MAPF and its extensions have been described by (Salzman and Stern Reference Salzman and Stern2020). As with planning, search-based approaches to solving MAPF are frequently used. Early MAPF solvers, such as the ones described in the papers (Goldenberg et al. Reference Goldenberg, Felner, Stern, Sharon, Sturtevant, Holte and Schaeffer2014; Wagner and Choset Reference Wagner and Choset2015; Sharon et al. Reference Sharon, Stern, Felner and Sturtevant2015; Boyarski et al. Reference Boyarski, Felner, Stern, Sharon, Tolpin, Betzalel and Shimony2015; Cohen et al. Reference Cohen, Uras, Kumar, Xu, Ayanian and Koenig2016; Wang and Botea Reference Wang and Botea2011; Luna and Bekris Reference Luna and Bekris2011; de Wilde et al. 2014), can compute optimal, boundedly-suboptimal, or suboptimal solutions of MAPF. (Erdem et al. 2013), (Yu and LaValle Reference Yu and LaValle2016), and (Surynek et al. Reference Surynek, Felner, Stern and Boyarski2016) applied ASP, mixed-integer programming, and satisfiability testing, respectively, to solve the original MAPF problem. Suboptimal solutions of MAPF using SAT is discussed by (Surynek et al. Reference Surynek, Felner, Stern and Boyarski2018). (Surynek Reference Surynek2019b) presents an SMT-based MAPF solver.
Several extensions of the MAPF problem have been introduced. (Ma and Koenig Reference Ma and Koenig2016) generalize MAPF to combined Target Assignment and Path Finding (TAPF), where agents are partitioned into teams and each team is given a set of targets that they need to reach. MAPF with deadlines is introduced by (Ma et al. Reference Ma, Wagner, Felner, Li, Kumar and Koenig2018). Extensions of the MAPF problem with delay probabilities have been described by (Ma et al. Reference Ma, Kumar and Koenig2017). The answer set planning implementation by (Nguyen et al. Reference Nguyen, Obermeier, Son, Schaub and Yeoh2017) shows that TAPF can be efficiently solved by answer set planning in multi-agent environments.
(Andreychuk et al. Reference Andreychuk, Yakovlev, Atzmon and Stern2019) investigate MAPF with continuous time, which removes the assumption that transitions between nodes are uniform. (BartÁk and Svancara Reference BartÁk and Svancara2019) present a SAT-based approach to deal with this extension, while (Surynek Reference Surynek2019a) describe an SMT-based MAPF solver for MAPF with continuous time and geometric agents.
(Atzmon et al. Reference Atzmon, Stern, Felner, Wagner, BartÁk and Zhou2020) focus on the issue of unexpected delays of agents and introduce the notion of k-robust MAPF plan, which can still be successfully executed when at most k delays happen. This paper also studies a probabilistic extension of k-robust MAPF plan, called pk-robots MAPF plan.
A more realistic version of MAPF, which allows agents to exchange packages and transfer payload, is considered by (Ma et al. Reference Ma, Tovey, Sharon, Kumar and Koenig2016). Discussion of the problems where robots have kinematic constraints can be found in the paper (Hönig et al. Reference Hönig, Kumar, Cohen, Ma, Xu, Ayanian and Koenig2016).
It is worth noting that all of the aforementioned approaches to solving MAPF are centralized. (Pianpak et al. Reference Pianpak, Son, Toups and Yeoh2019) propose a distributed ASP-based MAPF solver. In a recent paper, (GÓmez et al. Reference GÓmez, HernÁndez and Baier2021) present a compact ASP encoding for solving optimal sum-of-cost MAPF that is competitive with other approaches.
9 Planning with scheduling and extensions of ASP
Research on applications of ASP planning has also given impulse to, and is intertwined with, work on extensions of ASP. Let us consider the scenario from the following example.
Example 10
(From the paper by Reference Balduccini, Delgrande and Faber
Balduccini 2011
) In a typical scenario from the domain of industrial printing, orders for the printing of books or magazines are more or less continuously received by the print shop. Each order involves the execution of multiple jobs. First, the pages are printed on (possibly different) press sheets. The press sheets are often large enough to accommodate several (10 to 100) pages, and thus a suitable layout of the pages on the sheets must be found. Next, the press sheets are cut in smaller parts called signatures. The signatures are then folded into booklets whose page size equals the intended page size of the order. Finally the booklets are bound together to form the book or magazine to be produced. The decision process is made more complex by the fact that multiple models of devices may be capable of performing a job. Furthermore, many decisions have ramifications and inter-dependencies. For example, selecting a large press sheet would prevent the use of a small press. The underlying decision-making process is often called production planning. Another set of decisions deals with scheduling. Here one needs to determine when the various jobs will be executed using the devices available in the print shop. Multiple devices of the same model may be available, thus even competing jobs may be run in parallel. Conversely, some of the devices can be offline – or go suddenly offline while production is in progress – and the scheduler must work around that. Typically, one wants to find a schedule that minimizes the tardiness of the orders while giving priority to the more important orders. Since orders are received on a continuous basis, one needs to be able to update the schedule in an incremental fashion, in a way that causes minimal disruption to the production, and can satisfy rush orders, which need to be executed quickly and take precedence over the others. Similarly, the scheduler needs to react to sudden changes in the print shop, such as a device going offline during production.
 $\Diamond$
$\Diamond$
This problem involves a combination of planning, configuration (of the devices involved) and scheduling. While ASP can certainly be used to represent the problem, computation presents challenges. In particular, the presence of variables with large domains has a tendency to cause a substantial increase in the size of the grounding of ASP programs. Under these conditions, both the grounding process itself and the following solving algorithms may take an unacceptable amount of time and/or memory. Similar challenges have been encountered in the ASP encoding of planning problems with large number of actions and steps (see, e.g., the discussion by Son and Pontelli Reference Son and Pontelli2007).
Various extensions of ASP have been proposed over time to overcome this challenge. Some approaches, for example, in response to large planning problems, rely on the avoidance of grounding, as illustrated in systems with lazy grounding (see, e.g., the papers by PalÙ et al. Reference PalÙ, Dovier, Pontelli and Rossi2009; Cat et al. Reference Cat, Denecker, Bruynooghe and Stuckey2015, and Taupe et al. Reference Taupe, Weinzierl and Friedrich2019) or on the use of top-down execution models (see, e.g., the papers by Bonatti et al. 2008 and Marple and Gupta Reference Marple and Gupta2013). At the core of the attempts focused on combination of planning and scheduling is the integration of ASP with techniques from constraint solving; this approach enables the effective ability to handle variables with large domains (especially numerical) efficiently.
(Elkabani et al. Reference Elkabani, Pontelli and Son2004) provided an initial exploration of the combination of ASP with constraint logic programming, mostly focused on supporting the introduction of aggregates in ASP. (Baselice et al. Reference Baselice, Bonatti and Gelfond2005) were among the first to propose a methodology for achieving such an integration as a way to extend the capabilities of the ASP framework. In their approach, the syntax and semantics of ASP is extended to enable the encoding of numerical constraints within the ASP syntax. (Mellarkod et al. Reference Mellarkod, Gelfond and Zhang2008) and (Gebser et al. Reference Gebser, Ostrowski and Schaub2009) proposed solvers that support variants of ASP defined along the lines of the approach by (Baselice et al. Reference Baselice, Bonatti and Gelfond2005), and specific ASP and constraint solvers are modified and integrated. In particular, the approach discussed in the clingcon systems (Ostrowski and Schaub Reference Ostrowski and Schaub2012; Banbara et al. Reference Banbara, Kaufmann, Ostrowski and Schaub2017) explores the integration of constraint solving techniques with techniques like clause learning and back-jumping.
Experimental results show that these approaches lead to increased scalability, enabling the efficient resolution of planning domains of larger size. Later research extends and generalizes the language (Bartholomew and Lee Reference Bartholomew and Lee2013), increasing the efficiency of the resolution algorithms; these extensions have been eventually integrated in the mainstream clingo solver (Gebser et al. Reference Gebser, Kaminski, Kaufmann, Ostrowski, Schaub and Wanko2016). Notably, its extension with difference constraints, viz. clingo[DL], is operationally used by Swiss Railway for routing and scheduling train networks (Abels et al. Reference Abels, Jordi, Ostrowski, Schaub, Toletti, Wanko, Balduccini, Lierler and Woltran2019).
All of these approaches rely on a clear-box architecture (Balduccini and Lierler Reference Balduccini, Lierler, Lamma and Swift2013), that is, an architecture where the ASP components of the algorithm and its constraint solving components are tightly integrated and modified specifically to interact with each other. A different approach is proposed by (Balduccini Reference Balduccini, Faber and Lee2009) and later extensions. In that line of research, the goal is to enable the reuse, without modifications, of existing ASP and constraint solving algorithms. The intuition is that such an arrangement allows one to employ the best solvers available and makes it easy to analyze the performance of different combinations of solvers on a given task. This enabled researchers to propose a black-box architecture (and, later, a more advanced gray-box architecture), where the ASP and the constraint solving components are unaware of each other and are connected only by a thin “upper layer” of the architecture, which is responsible for exchanging data between the components and triggering their execution. The architecture proposed by (Balduccini and Lierler Reference Balduccini and Lierler2017) is illustrated in Figure 6. Intuitively, answer sets are computed first by an off-the-shelf ASP solver. Special atoms are gathered by the “upper layer” and translated into a constraint satisfaction problem, which is solved by an off-the-shelf constraint solver. Solutions to the overall problem correspond to pairs formed by an answer set and a solution to the constraint satisfaction problem extracted from that answer set.

Fig. 6. Architecture of the EZCSP solver (Balduccini Reference Balduccini, Delgrande and Faber2011).
This approach features an embedding of constraint solving constructs directly within the ASP language – that is, without the need to extend the syntax and semantics of ASP – by means of pre-interpreted relations known to the “upper layer” of the architecture (and some syntactic sugars for increased ease of formalization). For instance, constraint variables for the start time of jobs from Example 10 can be declared in the language described in the paper (Balduccini Reference Balduccini, Delgrande and Faber2011) by means of the rule
 \begin{equation}cspvar(st(D,J),0,MT) \leftarrow job(J),\ job\_device(J,D),max\_time(MT),\end{equation}
\begin{equation}cspvar(st(D,J),0,MT) \leftarrow job(J),\ job\_device(J,D),max\_time(MT),\end{equation}
where cspvar is a special relation that the “upper layer” knows how to translate into a variable declaration for a numerical constraint solver. Similarly, the effect on start times of precedences between jobs can be encoded by the ASP rule
 \begin{equation}\begin{array}{l}required(st(D2,J2) \geq st(D1,J1) + Len1) \leftarrow \\[3pt] job(J1),\ job(J2),\ job\_device(J1,D1),\ job\_device(J2,D2), \\[3pt] precedes(J1,J2),\ job\_len(J1,Len1),\end{array}\end{equation}
\begin{equation}\begin{array}{l}required(st(D2,J2) \geq st(D1,J1) + Len1) \leftarrow \\[3pt] job(J1),\ job(J2),\ job\_device(J1,D1),\ job\_device(J2,D2), \\[3pt] precedes(J1,J2),\ job\_len(J1,Len1),\end{array}\end{equation}
where “
 $\geq$
” is a syntactic sugar for the predicate
$\geq$
” is a syntactic sugar for the predicate
 $at\_least$
, written in the infix notation, and it is replaced by a pre-interpreted function symbol during pre-processing. As before, the “upper layer” is aware of the relation required and translates the corresponding atoms to numerical constraints. A problem involving a combination of planning and scheduling such as that described in Example 10 can be elegantly and efficiently solved by extending a planning problem
$at\_least$
, written in the infix notation, and it is replaced by a pre-interpreted function symbol during pre-processing. As before, the “upper layer” is aware of the relation required and translates the corresponding atoms to numerical constraints. A problem involving a combination of planning and scheduling such as that described in Example 10 can be elegantly and efficiently solved by extending a planning problem
 $\langle D, \Gamma, \Delta \rangle$
with statements such as (74) and (75).
$\langle D, \Gamma, \Delta \rangle$
with statements such as (74) and (75).
Later research on this topic (Balduccini and Lierler Reference Balduccini, Lierler, Lamma and Swift2013; Balduccini and Lierler Reference Balduccini and Lierler2017) uncovered an interesting result: contrary to what one might expect, there is no clear winner in the performance comparison between black-box and white-box architectures (and gray-box as well); different classes of problems are more efficiently solved by a different architecture. Furthermore, (Balduccini et al. Reference Balduccini, Magazzeni, Maratea and Leblanc2017) showed that the EZCSP architecture can be used in planning with PDDL+ domains.
10 Conclusions and future directions
This paper surveys the progress made over the last 20+ years in the area of answer set planning. It focuses on the encoding in ASP of different classes of planning problems: when the initial state is complete, incomplete, and with or without sensing actions. In addition, the paper shows that answer set planning can reach the level of scalability and efficiency of state-of-the-art specialized planners, if useful information which can be exploited to guide the search process in planning, such as heuristics, is provided to the answer set solver. The paper also reviews some of the main research topics related to planning, such as planning with preferences, diagnosis, planning in MAEs, and planning integrated with scheduling. We note that research related to answer set planning has been successfully applied in different application domains, often in combination with other types of reasoning, such as planning for the shuttle spacecraft by (Nogueira et al. Reference Nogueira, Balduccini, Gelfond, Watson and Barry2001), planning and scheduling (Balduccini Reference Balduccini, Delgrande and Faber2011), robotics (Aker et al. Reference Aker, Erdogan, Erdem and Patoglu2011), scheduling (Abels et al. Reference Abels, Jordi, Ostrowski, Schaub, Toletti, Wanko, Balduccini, Lierler and Woltran2019; Dodaro et al. Reference Dodaro, GalatÀ, Khan, Maratea and Porro2019; Gebser et al. Reference Gebser, Obermeier, Schaub, Ratsch-Heitmann and Runge2018), and multi-agent path findings (GÓmez et al. Reference GÓmez, HernÁndez and Baier2021; Nguyen et al. Reference Nguyen, Obermeier, Son, Schaub and Yeoh2017). Section 9 also discusses the potential impacts that the use of answer set planning in real-world applications can have on the development of ASP.
In spite of this extensive body of research, there are still several challenges for answer set planning.
Performance of ASP Planning:
We note that extensive experimental comparisons with state-of-the-art compatible planning systems have been conducted. For example, (Gebser et al. Reference Gebser, Kaufmann, Otero, Romero, Schaub and Wanko2013) experimented with classical planning, (Eiter et al. Reference Eiter, Faber, Leone, Pfeifer and Polleres2003b) and (Tu et al. Reference Tu, Son, Gelfond and Morales2011) worked with incomplete information and non-deterministic actions, and (Tu et al. Reference Tu, Son and Baral2007) with planning with sensing actions. The detailed comparisons can be found in the aforementioned papers and several other references that have been discussed throughout the paper. These comparisons demonstrate that ASP planning is competitive with other approaches to planning, such as heuristic based planning or SAT-based planning.
The flexibility and expressiveness of ASP provide a simple way for answer set planning to exploit various forms of domain knowledge. To the best of our knowledge, no heuristic planning system can take advantages of all well-known types of domain knowledge, such as hierarchical structure, temporal knowledge, and procedural knowledge, whist they can be easily integrated into a single answer set planning system, as demonstrated by (Son et al. Reference Son, Baral, Nam and McIlraith2006).
It is important to note that the performance of answer set planning systems depends heavily on the performance of the answer set solvers used in computing the solutions. As such, it is expected that these answer set planing systems can benefit from the advancements made by the ASP community. On the other hand, this hand-off approach also gives rise to limitations of ASP-based planning systems, such as scalability, heuristics, and ability to work with numeric values. It is worth noting that heuristics can be specified for guiding the answer set solver (e.g., as done by Gebser et al. Reference Gebser, Kaufmann, Otero, Romero, Schaub and Wanko2013 in planning) and there are considerable efforts in integrating answer set solvers and constraint solvers (see Section 9). However, there exists no answer set planning system that works with PDDL+, similarly to the system SMTPlan by (Cashmore et al. Reference Cashmore, Magazzeni and Zehtabi2020) which employs SMT planning for hybrid systems described in PDDL+. An ASP-based planning system for PDDL+ is proposed by (Balduccini et al. Reference Balduccini, Magazzeni, Maratea and Leblanc2017). Yet, this system cannot deal with all features of PDDL+ as SMTPlan. The issue of numeric constraints is also related to the next challenge.
Probabilistic planning:
This research topic is the objective of intensive research within the automated planning community. Similarly to other planning paradigms, competitions among different probabilistic planning systems are organized within ICAPS (International Conference on Automated Planning and Scheduling, for example, https://ipc2018-probabilistic.bitbucket.io/) and attract several research groups from academia and industry.
Probabilistic planning is concerned with identifying an optimal policy for an agent in a system specified by a Markov decision problem (MDP) or a Partial observable MDP (POMDP). While algorithms for computing an optimal policy are readily available (e.g., value iteration algorithm by Bellman Reference Bellman1957, topological value iteration by Dai et al. 2011, ILAO* by Hansen and Zilberstein Reference Hansen and Zilberstein2001, LRTPD by Bonet and Geffner Reference Bonet and Geffner2003, UCB by Kocsis and SzepesvÁri Reference Kocsis and SzepesvÁri2006, as well as the work of Kaelbling et al. Reference Kaelbling, Littman and Cassandra1998; the interested readers is also referred to the survey by Shani et al. Reference Shani, Pineau and Kaplow2013), scalability and efficiency remain significant issues in this research area.
Computing MDP and POMPD in logic programming will be a significant challenge for ASP, due to the fact that answer set solvers are not developed to easily operate with real numbers. In addition, the exponential number of states of a MDP or POMPD require a representation language suitable for use with ASP. This challenge can be addressed using probabilistic action languages, such as the ones proposed by (Baral et al. Reference Baral, Nam and Tuan2002) or by (Wang and Lee Reference Wang and Lee2019). On the other hand, working with real numbers means that the grounding-then-solving method to compute answer sets is no longer adequate. First of all, the presence of real numbers implies that the grounding process might not terminate. While discretization can be used to alleviate the grounding problem, it could increase the size of the grounded program significantly, creating problems (e.g., lack of memory) for the solving process. A potential approach to address these challenges is to integrate constraint solvers into answer set solvers, creating hybrid systems that can effectively deal with numeric constraints. Research in this direction has been summarized in Section 9. The recent implementation by (Abels et al. Reference Abels, Jordi, Ostrowski, Schaub, Toletti, Wanko, Balduccini, Lierler and Woltran2019) demonstrates that ASP based system can work effectively with a huge number of numeric constraints.
Epistemic planning:
In recent years, epistemic multiagent planning (EMP) has gained significant interest within the planning community. (Löwe et al. Reference Löwe, Pacuit and Witzel2011) propose a general epistemic planning framework. Complexity of EMP has been studied in the papers (Aucher and Bolander Reference Aucher and Bolander2013; Bolander et al. Reference Bolander, Jensen, Schwarzentruber, Yang and Wooldridge2015; Charrier et al. Reference Charrier, Maubert and Schwarzentruber2016). Studies of EMP can be found in several papers (Bolander and Andersen Reference Bolander and Andersen2011; Engesser et al. Reference Engesser, Bolander, MattmÜller and Nebel2017; van der Hoek and Wooldridge Reference van der Hoek and Wooldridge2002; Huang et al. Reference Huang, Fang, Wan and Liu2017; Löwe et al. Reference Löwe, Pacuit and Witzel2011; Eijck Reference Eijck2004) and many planners have been developed (Burigana et al. Reference Burigana, Fabiano, Dovier and Pontelli2020; Fabiano et al. Reference Fabiano, Burigana, Dovier and Pontelli2020; Le et al. Reference Le, Fabiano, Son and Pontelli2018; Muise et al. Reference Muise, Belle, Felli, McIlraith, Miller, Pearce and Sonenberg2015; Kominis and Geffner Reference Kominis and Geffner2015; Kominis and Geffner Reference Kominis and Geffner2017; Wan et al. Reference Wan, Yang, Fang, Liu and Xu2015). With the exception of the planner developed by (Burigana et al. Reference Burigana, Fabiano, Dovier and Pontelli2020), which employs ASP, the majority of the proposed systems are heuristic search based planners. Some EMP planners, such as those proposed by (Muise et al. Reference Muise, Belle, Felli, McIlraith, Miller, Pearce and Sonenberg2015), (Kominis and Geffner Reference Kominis and Geffner2015) and 2017, translate an EMP problem into a classical planning problem and use classical planners to find solutions.
A multi-agent planning problem of this type is different from the planning problems discussed in Section 8, in that it considers the knowledge and beliefs of agents, and explores the use of actions that manipulate such knowledge and beliefs. This is necessary for planning in non-collaborative and competitive environments. The difficulty in this task lies in that the result of the execution of an action (by an agent or a group of agents) will change the state of the world and the state of knowledge and belief of other agents. Inevitably, some agents may have false beliefs about the world. Semantically, the transitions from the state of affair, that includes the state of the world and the state of knowledge and beliefs of the agents, to another state of affair could be modeled by transitions between Kripke structures (see, e.g., the books Fagin et al. Reference Fagin, Halpern, Moses and Vardi1995; Van Ditmarsch et al. Reference Van Ditmarsch, van der Hoek and Kooi2007). A Kripke structure consists of a set of worlds and a set of binary accessibility relations over the worlds. A practical challenge is related to the size of the Kripke structures, in terms of the number of worlds – as this can double after the execution of each action. Intuitively, this requires the ability to generate new terms in the answer set solvers during resolution. Multi-shot solvers (see, e.g., the paper Gebser et al. Reference Gebser, Kaminski, Kaufmann and Schaub2019) could provide a good platform for epistemic planning. Preliminary encouraging results on the use of ASP in this context have been recently presented by (Burigana et al. Reference Burigana, Fabiano, Dovier and Pontelli2020).
Explainable Planning (XAIP):
This is yet another problem that has only recently been investigated but attracted considerable attention from the planning community, leading to the organization of a a yearly workshop on XAIP associated with ICAPS (e.g., https://icaps20subpages.icaps-conference.org/workshops/xaip/). Several questions for XAIP are discussed by (Fox et al. Reference Fox, Long and Magazzeni2017). In XAIP, a human questions the planner (a robot’s planning system) about its proposed solution. The focus is on explaining why a planner makes a certain decision. For example, why an action is included (or not included) in the plan? Why is the proposed plan optimal? Why can a goal not be achieved? Why should (or should not) the human consider replanning?
(Chakraborti et al. Reference Chakraborti, Sreedharan, Zhang and Kambhampati2017), for example, describe model reconciliation problem (MRP) and propose methods for solving it. In a MRP, the human and the robot have their own planning problems. The goal in both problems are the same, but the action specifications and the initial states might be different. The robot generates an optimal plan and informs the human of its plan. The human declares that it is not an optimal plan according to their planning problem specification. The robot, which is aware of the human’s problem specification, needs to present to the human the reasons why its plan is optimal and what is wrong in the human’s problem specification. Often, the answer is in the form of a collection of actions, actions’ preconditions and effects, and literals from the initial states that should be added to, or removed from, the human’s problem specification so that the robot’s plan will be an optimal plan of the updated specification. While explanations have been extensively investigated by the logic programming community, explainable planning using ASP has been investigated only recently by (Nguyen et al. Reference Nguyen, Stylianos, Son and Yeoh2020).