Refine search
Actions for selected content:
26 results
New method based on genetic algorithm and Minkowski fractal for multiband antenna designs
-
- Journal:
- International Journal of Microwave and Wireless Technologies / Volume 16 / Issue 3 / April 2024
- Published online by Cambridge University Press:
- 03 October 2023, pp. 466-477
-
- Article
- Export citation
-
In this paper, a new method based on a genetic algorithm and Minkowski Island fractal is proposed for multiband antennas. Three-antenna configurations are chosen to validate the proposed optimization procedure. The first configuration is a wide-band antenna, operating in the WLAN (wireless local area network) UNII-2C band. The second configuration is a dual-band antenna, operating in the WLAN UNII-2 and UNII-2C bands. In contrast, the third is a tri-band antenna operating in the UNII-2, UNII-2C, and UNII-3 bands. The optimization process is accelerated by using the Computer Simulation Technology (CST) Application Programming Interface which allows all genetic operators to be performed in MATLAB while the numerical calculations are running in the internal CST Finite-Difference Time-Domain -solver using parallel computing with GPU acceleration. All three designed configurations are manufactured using a
 $\textstyle0.8\;\text{mm}$ thick FR4 epoxy substrate with a relative dielectric constant of
$\textstyle0.8\;\text{mm}$ thick FR4 epoxy substrate with a relative dielectric constant of  $4.8$. The return loss and the radiation pattern’s measurements agree well with the simulation results. Further, the methodology presented can be very effective in terms of size reduction; the designed antennas are
$4.8$. The return loss and the radiation pattern’s measurements agree well with the simulation results. Further, the methodology presented can be very effective in terms of size reduction; the designed antennas are  $24 \times 24 \times 0.8\;{\textrm{m}}{{\textrm{m}}^3}$ (
$24 \times 24 \times 0.8\;{\textrm{m}}{{\textrm{m}}^3}$ ( $460\;{\textrm{m}}{{\textrm{m}}^3}$).
$460\;{\textrm{m}}{{\textrm{m}}^3}$).




1 - Mathematics, Models and Architectures
- from Part I - Computing
-
- Book:
- Mathematics for Future Computing and Communications
- Published online:
- 03 December 2021
- Print publication:
- 16 December 2021, pp 6-53
-
- Chapter
- Export citation
Anytime Monte Carlo
-
- Journal:
- Data-Centric Engineering / Volume 2 / 2021
- Published online by Cambridge University Press:
- 29 June 2021, e7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Monte Carlo algorithms simulates some prescribed number of samples, taking some random real time to complete the computations necessary. This work considers the converse: to impose a real-time budget on the computation, which results in the number of samples simulated being random. To complicate matters, the real time taken for each simulation may depend on the sample produced, so that the samples themselves are not independent of their number, and a length bias with respect to compute time is apparent. This is especially problematic when a Markov chain Monte Carlo (MCMC) algorithm is used and the final state of the Markov chain—rather than an average over all states—is required, which is the case in parallel tempering implementations of MCMC. The length bias does not diminish with the compute budget in this case. It also occurs in sequential Monte Carlo (SMC) algorithms, which is the focus of this paper. We propose an anytime framework to address the concern, using a continuous-time Markov jump process to study the progress of the computation in real time. We first show that for any MCMC algorithm, the length bias of the final state’s distribution due to the imposed real-time computing budget can be eliminated by using a multiple chain construction. The utility of this construction is then demonstrated on a large-scale SMC
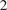 $ {}^2 $ implementation, using four billion particles distributed across a cluster of 128 graphics processing units on the Amazon EC2 service. The anytime framework imposes a real-time budget on the MCMC move steps within the SMC
$ {}^2 $ implementation, using four billion particles distributed across a cluster of 128 graphics processing units on the Amazon EC2 service. The anytime framework imposes a real-time budget on the MCMC move steps within the SMC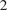 $ {}^2 $ algorithm, ensuring that all processors are simultaneously ready for the resampling step, demonstrably reducing idleness to due waiting times and providing substantial control over the total compute budget.
$ {}^2 $ algorithm, ensuring that all processors are simultaneously ready for the resampling step, demonstrably reducing idleness to due waiting times and providing substantial control over the total compute budget.
9 - Finite-Difference Methods for Initial-Value Problems
- from Part II - Numerical Methods
-
- Book:
- Matrix, Numerical, and Optimization Methods in Science and Engineering
- Published online:
- 18 February 2021
- Print publication:
- 04 March 2021, pp 466-526
-
- Chapter
- Export citation
Bayesian dynamic modeling and monitoring of network flows
-
- Journal:
- Network Science / Volume 7 / Issue 3 / September 2019
- Published online by Cambridge University Press:
- 23 September 2019, pp. 292-318
-
- Article
- Export citation
Development of a computationally efficient voice conversion system on mobile phones
- Part of
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 8 / 2019
- Published online by Cambridge University Press:
- 04 January 2019, e4
- Print publication:
- 2019
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A review of literature on parallel constraint solving
-
- Journal:
- Theory and Practice of Logic Programming / Volume 18 / Issue 5-6 / September 2018
- Published online by Cambridge University Press:
- 02 August 2018, pp. 725-758
-
- Article
-
- You have access
- Export citation
JASMIN-based Two-dimensional Adaptive Combined Preconditioner for Radiation Diffusion Equations in Inertial Fusion Research
- Part of
-
- Journal:
- East Asian Journal on Applied Mathematics / Volume 7 / Issue 3 / August 2017
- Published online by Cambridge University Press:
- 07 September 2017, pp. 495-507
- Print publication:
- August 2017
-
- Article
- Export citation
-
We present a JASMIN-based two-dimensional parallel implementation of an adaptive combined preconditioner
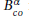 for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel -GMRES solver with the help of the default BoomerAMG in the HYPRE library. Numerical results demonstrate that our proposed parallel incomplete LU preconditioner (ILU) is of higher efficiency than the counterpart in the Euclid library, and that the proposed parallel -GMRES solver is more robust and more efficient than the default BoomerAMG-GMRES solver.
for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel -GMRES solver with the help of the default BoomerAMG in the HYPRE library. Numerical results demonstrate that our proposed parallel incomplete LU preconditioner (ILU) is of higher efficiency than the counterpart in the Euclid library, and that the proposed parallel -GMRES solver is more robust and more efficient than the default BoomerAMG-GMRES solver.
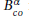 for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel
for the solution of linear problems arising in the finite volume discretisation of one-group and multi-group radiation diffusion equations. We first propose the attribute of patch-correlation for cells of a two-dimensional monolayer piecewise rectangular structured grid without any suspensions based on the patch hierarchy of JASMIN, classify and reorder these cells via their attributes, and derive the conversion of cell-permutations. Using two cell-permutations, we then construct some parallel incomplete LU factorisation and substitution algorithms, to provide our parallel GPU-Accelerated LOBPCG Method with Inexact Null-Space Filtering for Solving Generalized Eigenvalue Problems in Computational Electromagnetics Analysis with Higher-Order FEM
- Part of
-
- Journal:
- Communications in Computational Physics / Volume 22 / Issue 4 / October 2017
- Published online by Cambridge University Press:
- 28 July 2017, pp. 997-1014
- Print publication:
- October 2017
-
- Article
- Export citation
Towards Textbook Efficiency for Parallel Multigrid
-
- Journal:
- Numerical Mathematics: Theory, Methods and Applications / Volume 8 / Issue 1 / February 2015
- Published online by Cambridge University Press:
- 03 March 2015, pp. 22-46
- Print publication:
- February 2015
-
- Article
- Export citation
A Nominally Second-Order Cell-Centered Finite Volume Scheme for Simulating Three-Dimensional Anisotropic Diffusion Equations on Unstructured Grids
-
- Journal:
- Communications in Computational Physics / Volume 16 / Issue 4 / October 2014
- Published online by Cambridge University Press:
- 03 June 2015, pp. 841-891
- Print publication:
- October 2014
-
- Article
- Export citation
Effect of CPU Cache Size on OpenMP Computing Performance in Fluid-Film Lubrication Analysis
-
- Journal:
- Journal of Mechanics / Volume 31 / Issue 2 / April 2015
- Published online by Cambridge University Press:
- 12 August 2014, pp. 123-129
- Print publication:
- April 2015
-
- Article
- Export citation
Simulation of disc-bulge-halo galaxies using parallel GPU based codes
-
- Journal:
- Proceedings of the International Astronomical Union / Volume 10 / Issue S312 / August 2014
- Published online by Cambridge University Press:
- 07 March 2016, pp. 79-81
- Print publication:
- August 2014
-
- Article
-
- You have access
- Export citation
A Scalable Numerical Method for Simulating Flows Around High-Speed Train Under Crosswind Conditions
-
- Journal:
- Communications in Computational Physics / Volume 15 / Issue 4 / April 2014
- Published online by Cambridge University Press:
- 03 June 2015, pp. 944-958
- Print publication:
- April 2014
-
- Article
- Export citation
A Survey on Parallel Computing and its Applications in Data-Parallel Problems Using GPU Architectures
-
- Journal:
- Communications in Computational Physics / Volume 15 / Issue 2 / February 2014
- Published online by Cambridge University Press:
- 03 June 2015, pp. 285-329
- Print publication:
- February 2014
-
- Article
-
- You have access
- Export citation
A comparison of coupled and uncoupled solversfor the cardiac Bidomain model∗∗∗
-
- Journal:
- ESAIM: Mathematical Modelling and Numerical Analysis / Volume 47 / Issue 4 / July 2013
- Published online by Cambridge University Press:
- 07 June 2013, pp. 1017-1035
- Print publication:
- July 2013
-
- Article
- Export citation
Numerical assessment of 3D macrodispersion in heterogeneous porous media
-
- Journal:
- Mechanics & Industry / Volume 14 / Issue 6 / 2013
- Published online by Cambridge University Press:
- 21 January 2014, pp. 461-464
- Print publication:
- 2013
-
- Article
- Export citation
Parallel Iterative Solution Schemes for the Analysis of Air Foil Bearings
-
- Journal:
- Journal of Mechanics / Volume 28 / Issue 3 / September 2012
- Published online by Cambridge University Press:
- 09 August 2012, pp. 413-422
- Print publication:
- September 2012
-
- Article
- Export citation
A Parallel Domain Decomposition Algorithm for Simulating Blood Flow with Incompressible Navier-Stokes Equations with Resistive Boundary Condition
-
- Journal:
- Communications in Computational Physics / Volume 11 / Issue 4 / April 2012
- Published online by Cambridge University Press:
- 20 August 2015, pp. 1279-1299
- Print publication:
- April 2012
-
- Article
- Export citation
Greedy algorithms for optimal computing of matrix chain products involving square denseand triangular matrices
-
- Journal:
- RAIRO - Operations Research / Volume 45 / Issue 1 / January 2011
- Published online by Cambridge University Press:
- 14 March 2011, pp. 1-16
- Print publication:
- January 2011
-
- Article
- Export citation
