Studies agree on a significant global mean sea level rise in the 20th century and its recent 21st century acceleration in the satellite record. At regional scale, the evolution of sea level probability distributions is often assumed to be dominated by changes in the mean. However, a quantification of changes in distributional shapes in a changing climate is currently missing. To this end, we propose a novel framework quantifying significant changes in probability distributions from time series data. The framework first quantifies linear trends in quantiles through quantile regression. Quantile slopes are then projected onto a set of four orthogonal polynomials quantifying how such changes can be explained by independent shifts in the first four statistical moments. The framework proposed is theoretically founded, general, and can be applied to any climate observable with close-to-linear changes in distributions. We focus on observations and a coupled climate model (GFDL-CM4). In the historical period, trends in coastal daily sea level have been driven mainly by changes in the mean and can therefore be explained by a shift of the distribution with no change in shape. In the modeled world, robust changes in higher order moments emerge with increasing 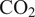 $ {\mathrm{CO}}_2 $ concentration. Such changes are driven in part by ocean circulation alone and get amplified by sea level pressure fluctuations, with possible consequences for sea level extremes attribution studies.
$ {\mathrm{CO}}_2 $ concentration. Such changes are driven in part by ocean circulation alone and get amplified by sea level pressure fluctuations, with possible consequences for sea level extremes attribution studies.
Consider the coupon collector problem where each box of a brand of cereal contains a coupon and there are n different types of coupons. Suppose that the probability of a box containing a coupon of a specific type is 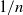 $1/n$, and that we keep buying boxes until we collect at least m coupons of each type. For
$1/n$, and that we keep buying boxes until we collect at least m coupons of each type. For 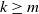 $k\geq m$ call a certain coupon a k-ton if we see it k times by the time we have seen m copies of all of the coupons. Here we determine the asymptotic distribution of the number of k-tons after we have collected m copies of each coupon for any k in a restricted range, given any fixed m. We also determine the asymptotic joint probability distribution over such values of k, and the total number of coupons collected.
$k\geq m$ call a certain coupon a k-ton if we see it k times by the time we have seen m copies of all of the coupons. Here we determine the asymptotic distribution of the number of k-tons after we have collected m copies of each coupon for any k in a restricted range, given any fixed m. We also determine the asymptotic joint probability distribution over such values of k, and the total number of coupons collected.


