The integration of Artificial Neural Networks (ANNs) and Feature Extraction (FE) in the context of the Sample- Partitioning Adaptive Reduced Chemistry approach was investigated in this work, to increase the on-the-fly classification accuracy for very large thermochemical states. The proposed methodology was firstly compared with an on-the-fly classifier based on the Principal Component Analysis reconstruction error, as well as with a standard ANN (s-ANN) classifier, operating on the full thermochemical space, for the adaptive simulation of a steady laminar flame fed with a nitrogen-diluted stream of n-heptane in air. The numerical simulations were carried out with a kinetic mechanism accounting for 172 species and 6,067 reactions, which includes the chemistry of Polycyclic Aromatic Hydrocarbons (PAHs) up to C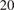 $ {}_{20} $
. Among all the aforementioned classifiers, the one exploiting the combination of an FE step with ANN proved to be more efficient for the classification of high-dimensional spaces, leading to a higher speed-up factor and a higher accuracy of the adaptive simulation in the description of the PAH and soot-precursor chemistry. Finally, the investigation of the classifier’s performances was also extended to flames with different boundary conditions with respect to the training one, obtained imposing a higher Reynolds number or time-dependent sinusoidal perturbations. Satisfying results were observed on all the test flames.
$ {}_{20} $
. Among all the aforementioned classifiers, the one exploiting the combination of an FE step with ANN proved to be more efficient for the classification of high-dimensional spaces, leading to a higher speed-up factor and a higher accuracy of the adaptive simulation in the description of the PAH and soot-precursor chemistry. Finally, the investigation of the classifier’s performances was also extended to flames with different boundary conditions with respect to the training one, obtained imposing a higher Reynolds number or time-dependent sinusoidal perturbations. Satisfying results were observed on all the test flames.

