The \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}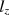 statistic (Drasgow et al. in Br J Math Stat Psychol 38:67–86, 1985) is one of the most popular person-fit statistics (Armstrong et al. in Pract Assess Res Eval 12(16):1–10, 2007). Snijders (Psychometrika 66:331–342, 2001) derived the asymptotic null distribution of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
statistic (Drasgow et al. in Br J Math Stat Psychol 38:67–86, 1985) is one of the most popular person-fit statistics (Armstrong et al. in Pract Assess Res Eval 12(16):1–10, 2007). Snijders (Psychometrika 66:331–342, 2001) derived the asymptotic null distribution of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}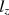 when the examinee ability parameter is estimated. He also suggested the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l^*_z$$\end{document}
when the examinee ability parameter is estimated. He also suggested the \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l^*_z$$\end{document}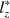 statistic, which is the asymptotically correct standardized version of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
statistic, which is the asymptotically correct standardized version of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}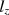 . However, Snijders (Psychometrika 66:331–342, 2001) only considered tests with dichotomous items. In this paper, the asymptotic null distribution of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
. However, Snijders (Psychometrika 66:331–342, 2001) only considered tests with dichotomous items. In this paper, the asymptotic null distribution of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}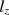 is derived for mixed-format tests (those that include both dichotomous and polytomous items). The asymptotically correct standardized version of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}
is derived for mixed-format tests (those that include both dichotomous and polytomous items). The asymptotically correct standardized version of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l_z$$\end{document}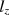 , which can be considered as the extension of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l^*_z$$\end{document}
, which can be considered as the extension of \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$l^*_z$$\end{document}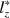 to such tests, is suggested. The Type I error rate and power of the suggested statistic are examined from several simulated datasets. The suggested statistic is computed using a real dataset. The suggested statistic appears to be a satisfactory tool for assessing person fit for mixed-format tests.
to such tests, is suggested. The Type I error rate and power of the suggested statistic are examined from several simulated datasets. The suggested statistic is computed using a real dataset. The suggested statistic appears to be a satisfactory tool for assessing person fit for mixed-format tests.

