We provide asymptotics for the range 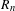 $R_{n}$ of a random walk on the
$R_{n}$ of a random walk on the 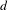 $d$-dimensional lattice indexed by a random tree with
$d$-dimensional lattice indexed by a random tree with  $n$ vertices. Using Kingman’s subadditive ergodic theorem, we prove under general assumptions that
$n$ vertices. Using Kingman’s subadditive ergodic theorem, we prove under general assumptions that 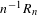 $n^{-1}R_{n}$ converges to a constant, and we give conditions ensuring that the limiting constant is strictly positive. On the other hand, in dimension
$n^{-1}R_{n}$ converges to a constant, and we give conditions ensuring that the limiting constant is strictly positive. On the other hand, in dimension  $4$, and in the case of a symmetric random walk with exponential moments, we prove that
$4$, and in the case of a symmetric random walk with exponential moments, we prove that 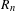 $R_{n}$ grows like
$R_{n}$ grows like 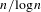 $n/\!\log n$. We apply our results to asymptotics for the range of a branching random walk when the initial size of the population tends to infinity.
$n/\!\log n$. We apply our results to asymptotics for the range of a branching random walk when the initial size of the population tends to infinity.

