
A sequence 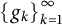 $\left \{g_k\right \}_{k=1}^{\infty }$
in a Hilbert space
$\left \{g_k\right \}_{k=1}^{\infty }$
in a Hilbert space 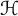 ${\cal H}$
has the expansion property if each
${\cal H}$
has the expansion property if each 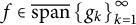 $f\in \overline {\text {span}} \left \{g_k\right \}_{k=1}^{\infty }$
has a representation
$f\in \overline {\text {span}} \left \{g_k\right \}_{k=1}^{\infty }$
has a representation  $f=\sum _{k=1}^{\infty } c_k g_k$
for some scalar coefficients
$f=\sum _{k=1}^{\infty } c_k g_k$
for some scalar coefficients 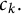 $c_k.$
In this paper, we analyze the question whether there exist small norm-perturbations of
$c_k.$
In this paper, we analyze the question whether there exist small norm-perturbations of 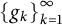 $\left \{g_k\right \}_{k=1}^{\infty }$
which allow to represent all
$\left \{g_k\right \}_{k=1}^{\infty }$
which allow to represent all 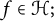 $f\in {\cal H};$
the answer turns out to be yes for frame sequences and Riesz sequences, but no for general basic sequences. The insight gained from the analysis is used to address a somewhat dual question, namely, whether it is possible to remove redundancy from a sequence with the expansion property via small norm-perturbations; we prove that the answer is yes for frames
$f\in {\cal H};$
the answer turns out to be yes for frame sequences and Riesz sequences, but no for general basic sequences. The insight gained from the analysis is used to address a somewhat dual question, namely, whether it is possible to remove redundancy from a sequence with the expansion property via small norm-perturbations; we prove that the answer is yes for frames 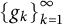 $\left \{g_k\right \}_{k=1}^{\infty }$
such that
$\left \{g_k\right \}_{k=1}^{\infty }$
such that 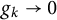 $g_k\to 0$
as
$g_k\to 0$
as  $k\to \infty ,$
as well as for frames with finite excess. This particular question is motivated by recent progress in dynamical sampling.
$k\to \infty ,$
as well as for frames with finite excess. This particular question is motivated by recent progress in dynamical sampling.

