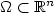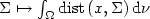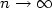Refine search
Actions for selected content:
2 results
EXPLORATION–EXPLOITATION POLICIES WITH ALMOST SURE, ARBITRARILY SLOW GROWING ASYMPTOTIC REGRET
- Part of
-
- Journal:
- Probability in the Engineering and Informational Sciences / Volume 34 / Issue 3 / July 2020
- Published online by Cambridge University Press:
- 26 January 2019, pp. 406-428
-
- Article
- Export citation
Long-term planning versus short-term planning in the asymptotical location problem
-
- Journal:
- ESAIM: Control, Optimisation and Calculus of Variations / Volume 15 / Issue 3 / July 2009
- Published online by Cambridge University Press:
- 30 May 2008, pp. 509-524
- Print publication:
- July 2009
-
- Article
- Export citation
-
Given the probability measure ν over the given region $\Omega\subset \mathbb{R}^n$
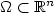 , we consider the optimal location of a setΣ composed by n points in Ω in order to minimize theaverage distance $\Sigma\mapsto \int_\Omega \mathrm{dist}\,(x,\Sigma)\,{\rm d}\nu$
, we consider the optimal location of a setΣ composed by n points in Ω in order to minimize theaverage distance $\Sigma\mapsto \int_\Omega \mathrm{dist}\,(x,\Sigma)\,{\rm d}\nu$ 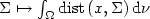 (theclassical optimal facility location problem). The paper compares twostrategies to find optimal configurations: the long-term one whichconsists in placing all n points at once in an optimal position, and the short-term one which consists in placing the points one by one addingat each step at most one point and preserving the configurationbuilt at previous steps. We show that the respective optimizationproblems exhibit qualitatively different asymptotic behavior as $n\to\infty$
(theclassical optimal facility location problem). The paper compares twostrategies to find optimal configurations: the long-term one whichconsists in placing all n points at once in an optimal position, and the short-term one which consists in placing the points one by one addingat each step at most one point and preserving the configurationbuilt at previous steps. We show that the respective optimizationproblems exhibit qualitatively different asymptotic behavior as $n\to\infty$ 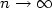 , although the optimization costs in both cases have the same asymptotic orders of vanishing.
, although the optimization costs in both cases have the same asymptotic orders of vanishing.