Refine search
Actions for selected content:
46 results
The complexity of intersecting subproducts with subgroups in Cartesian powers
- Part of
-
- Journal:
- Glasgow Mathematical Journal , First View
- Published online by Cambridge University Press:
- 07 October 2025, pp. 1-7
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Given a finite abelian group
 $G$ and
$G$ and  $t\in \mathbb{N}$, there are two natural types of subsets of the Cartesian power
$t\in \mathbb{N}$, there are two natural types of subsets of the Cartesian power  $G^t$; namely, Cartesian powers
$G^t$; namely, Cartesian powers  $S^t$ where
$S^t$ where  $S$ is a subset of
$S$ is a subset of  $G$ and (cosets of) subgroups
$G$ and (cosets of) subgroups  $H$ of
$H$ of  $G^t$. A basic question is whether two such sets intersect. In this paper, we show that this decision problem is NP-complete. Furthermore, for fixed
$G^t$. A basic question is whether two such sets intersect. In this paper, we show that this decision problem is NP-complete. Furthermore, for fixed  $G$ and
$G$ and  $S$, we give a complete classification: we determine conditions for when the problem is NP-complete and show that in all other cases the problem is solvable in polynomial time. These theorems play a key role in the classification of algebraic decision problems in finitely generated rings developed in later work of the author.
$S$, we give a complete classification: we determine conditions for when the problem is NP-complete and show that in all other cases the problem is solvable in polynomial time. These theorems play a key role in the classification of algebraic decision problems in finitely generated rings developed in later work of the author.










Complexity of Faceted Explanations in Propositional Abduction
-
- Journal:
- Theory and Practice of Logic Programming , First View
- Published online by Cambridge University Press:
- 05 September 2025, pp. 1-19
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Keeping your distance is hard
-
-
- Book:
- Games of No Chance 6
- Published online:
- 18 May 2025
- Print publication:
- 05 June 2025, pp 433-446
-
- Chapter
- Export citation

Proof Complexity Generators
-
- Published online:
- 29 May 2025
- Print publication:
- 26 June 2025
Chapter 4 - Primer
- from Part I - Background
-
- Book:
- Working with Network Data
- Published online:
- 06 June 2024
- Print publication:
- 13 June 2024, pp 39-62
-
- Chapter
- Export citation
The atomic properties of stress
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Dyadic Existential Rules
-
- Journal:
- Theory and Practice of Logic Programming / Volume 24 / Issue 2 / March 2024
- Published online by Cambridge University Press:
- 24 August 2023, pp. 227-249
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Existential rules form an expressive
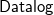 ${{\textsf{Datalog}}}$-based language to specify ontological knowledge. The presence of existential quantification in rule-heads, however, makes the main reasoning tasks undecidable. To overcome this limitation, in the last two decades, a number of classes of existential rules guaranteeing the decidability of query answering have been proposed. Unfortunately, only some of these classes fully encompass
${{\textsf{Datalog}}}$-based language to specify ontological knowledge. The presence of existential quantification in rule-heads, however, makes the main reasoning tasks undecidable. To overcome this limitation, in the last two decades, a number of classes of existential rules guaranteeing the decidability of query answering have been proposed. Unfortunately, only some of these classes fully encompass 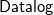 ${{\textsf{Datalog}}}$ and, often, this comes at the price of higher computational complexity. Moreover, expressive classes are typically unable to exploit tools developed for classes exhibiting lower expressiveness. To mitigate these shortcomings, this paper introduces a novel general syntactic condition that allows us to define, systematically and in a uniform way, from any decidable class
${{\textsf{Datalog}}}$ and, often, this comes at the price of higher computational complexity. Moreover, expressive classes are typically unable to exploit tools developed for classes exhibiting lower expressiveness. To mitigate these shortcomings, this paper introduces a novel general syntactic condition that allows us to define, systematically and in a uniform way, from any decidable class 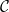 $\mathcal{C}$ of existential rules, a new class called
$\mathcal{C}$ of existential rules, a new class called 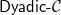 ${{\textsf{Dyadic-}\mathcal{C}}}$ enjoying the following properties: (i) it is decidable; (ii) it generalizes
${{\textsf{Dyadic-}\mathcal{C}}}$ enjoying the following properties: (i) it is decidable; (ii) it generalizes 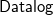 ${{\textsf{Datalog}}}$; (iii) it generalizes
${{\textsf{Datalog}}}$; (iii) it generalizes 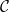 $\mathcal{C}$; (iv) it can effectively exploit any reasoner for query answering over
$\mathcal{C}$; (iv) it can effectively exploit any reasoner for query answering over 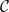 $\mathcal{C}$; and (v) its computational complexity does not exceed the highest between the one of
$\mathcal{C}$; and (v) its computational complexity does not exceed the highest between the one of 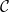 $\mathcal{C}$ and the one of
$\mathcal{C}$ and the one of 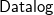 ${{\textsf{Datalog}}}$.
${{\textsf{Datalog}}}$.
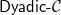
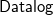
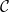
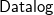
Exact convergence analysis for metropolis–hastings independence samplers in Wasserstein distances
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 05 June 2023, pp. 33-54
- Print publication:
- March 2024
-
- Article
- Export citation
Implicit computation complexity in higher-order programming languages: A Survey in Memory of Martin Hofmann
-
- Journal:
- Mathematical Structures in Computer Science / Volume 32 / Issue 6 / June 2022
- Published online by Cambridge University Press:
- 15 March 2022, pp. 760-776
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
EXPLORING THE LANDSCAPE OF RELATIONAL SYLLOGISTIC LOGICS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 3 / September 2021
- Published online by Cambridge University Press:
- 21 October 2020, pp. 728-765
- Print publication:
- September 2021
-
- Article
- Export citation
DECIDING SOME MALTSEV CONDITIONS IN FINITE IDEMPOTENT ALGEBRAS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 85 / Issue 2 / June 2020
- Published online by Cambridge University Press:
- 16 June 2020, pp. 539-562
- Print publication:
- June 2020
-
- Article
- Export citation
Deciding the Existence of Minority Terms
- Part of
-
- Journal:
- Canadian Mathematical Bulletin / Volume 63 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 24 October 2019, pp. 577-591
- Print publication:
- September 2020
-
- Article
-
- You have access
- Export citation
-
This paper investigates the computational complexity of deciding if a given finite idempotent algebra has a ternary term operation
 $m$ that satisfies the minority equations
$m$ that satisfies the minority equations 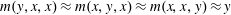 $m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class
$m(y,x,x)\approx m(x,y,x)\approx m(x,x,y)\approx y$. We show that a common polynomial-time approach to testing for this type of condition will not work in this case and that this decision problem lies in the class NP .

16 - Fast Gamblet Transform
- from Part III - The Banach Space Setting
-
- Book:
- Operator-Adapted Wavelets, Fast Solvers, and Numerical Homogenization
- Published online:
- 10 October 2019
- Print publication:
- 24 October 2019, pp 297-344
-
- Chapter
- Export citation
9 - Reasoning about Generic ω-Sequences
-
- Book:
- The Metaphysics and Mathematics of Arbitrary Objects
- Published online:
- 24 May 2019
- Print publication:
- 13 June 2019, pp 162-188
-
- Chapter
- Export citation
CONSISTENCY PROOF OF A FRAGMENT OF PV WITH SUBSTITUTION IN BOUNDED ARITHMETIC
-
- Journal:
- The Journal of Symbolic Logic / Volume 83 / Issue 3 / September 2018
- Published online by Cambridge University Press:
- 23 October 2018, pp. 1063-1090
- Print publication:
- September 2018
-
- Article
- Export citation
-
This article presents a proof that Buss’s
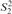 $S_2^2$ can prove the consistency of a fragment of Cook and Urquhart’s PV from which induction has been removed but substitution has been retained. This result improves Beckmann’s result, which proves the consistency of such a system without substitution in bounded arithmetic
$S_2^2$ can prove the consistency of a fragment of Cook and Urquhart’s PV from which induction has been removed but substitution has been retained. This result improves Beckmann’s result, which proves the consistency of such a system without substitution in bounded arithmetic 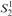 $S_2^1$.
$S_2^1$.Our proof relies on the notion of “computation” of the terms of PV. In our work, we first prove that, in the system under consideration, if an equation is proved and either its left- or right-hand side is computed, then there is a corresponding computation for its right- or left-hand side, respectively. By carefully computing the bound of the size of the computation, the proof of this theorem inside a bounded arithmetic is obtained, from which the consistency of the system is readily proven.
This result apparently implies the separation of bounded arithmetic because Buss and Ignjatović stated that it is not possible to prove the consistency of a fragment of PV without induction but with substitution in Buss’s
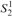 $S_2^1$. However, their proof actually shows that it is not possible to prove the consistency of the system, which is obtained by the addition of propositional logic and other axioms to a system such as ours. On the other hand, the system that we have considered is strictly equational, which is a property on which our proof relies.
$S_2^1$. However, their proof actually shows that it is not possible to prove the consistency of the system, which is obtained by the addition of propositional logic and other axioms to a system such as ours. On the other hand, the system that we have considered is strictly equational, which is a property on which our proof relies.
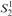
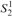
A GENERAL POSITION PROBLEM IN GRAPH THEORY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 98 / Issue 2 / October 2018
- Published online by Cambridge University Press:
- 18 July 2018, pp. 177-187
- Print publication:
- October 2018
-
- Article
-
- You have access
- Export citation
-
The paper introduces a graph theory variation of the general position problem: given a graph
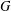 $G$, determine a largest set
$G$, determine a largest set 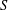 $S$ of vertices of
$S$ of vertices of 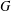 $G$ such that no three vertices of
$G$ such that no three vertices of 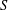 $S$ lie on a common geodesic. Such a set is a max-gp-set of
$S$ lie on a common geodesic. Such a set is a max-gp-set of 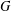 $G$ and its size is the gp-number
$G$ and its size is the gp-number 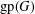 $\text{gp}(G)$ of
$\text{gp}(G)$ of 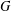 $G$. Upper bounds on
$G$. Upper bounds on 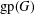 $\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
$\text{gp}(G)$ in terms of different isometric covers are given and used to determine the gp-number of several classes of graphs. Connections between general position sets and packings are investigated and used to give lower bounds on the gp-number. It is also proved that the general position problem is NP-complete.
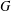
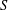
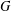
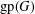
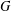
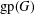
Connectivity in Hypergraphs
-
- Journal:
- Canadian Mathematical Bulletin / Volume 61 / Issue 2 / 01 June 2018
- Published online by Cambridge University Press:
- 20 November 2018, pp. 252-271
- Print publication:
- 01 June 2018
-
- Article
-
- You have access
- Export citation
ON SEMIGROUPS WITH PSPACE-COMPLETE SUBPOWER MEMBERSHIP PROBLEM
- Part of
-
- Journal:
- Journal of the Australian Mathematical Society / Volume 106 / Issue 1 / February 2019
- Published online by Cambridge University Press:
- 30 May 2018, pp. 127-142
- Print publication:
- February 2019
-
- Article
-
- You have access
- Export citation
-
Fix a finite semigroup
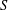 $S$ and let
$S$ and let 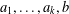 $a_{1},\ldots ,a_{k},b$ be tuples in a direct power
$a_{1},\ldots ,a_{k},b$ be tuples in a direct power 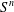 $S^{n}$. The subpower membership problem (SMP) for
$S^{n}$. The subpower membership problem (SMP) for 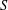 $S$ asks whether
$S$ asks whether 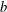 $b$ can be generated by
$b$ can be generated by 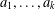 $a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all
$a_{1},\ldots ,a_{k}$. For combinatorial Rees matrix semigroups we establish a dichotomy result: if the corresponding matrix is of a certain form, then the SMP is in P; otherwise it is NP-complete. For combinatorial Rees matrix semigroups with adjoined identity, we obtain a trichotomy: the SMP is either in P, NP-complete, or PSPACE-complete. This result yields various semigroups with PSPACE-complete SMP including the six-element Brandt monoid, the full transformation semigroup on three or more letters, and semigroups of all  $n$ by
$n$ by  $n$ matrices over a field for
$n$ matrices over a field for 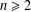 $n\geq 2$.
$n\geq 2$.
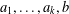
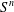
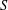
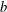
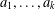


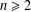
When you must forget: Beyond strong persistence when forgetting in answer set programming*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 17 / Issue 5-6 / September 2017
- Published online by Cambridge University Press:
- 30 August 2017, pp. 837-854
-
- Article
- Export citation
Precise complexity guarantees for pointer analysis via Datalog with extensions*
-
- Journal:
- Theory and Practice of Logic Programming / Volume 16 / Issue 5-6 / September 2016
- Published online by Cambridge University Press:
- 14 October 2016, pp. 916-932
-
- Article
- Export citation
