In this paper we consider positional games where the winning sets are edge sets of tree-universal graphs. Specifically, we show that in the unbiased Maker-Breaker game on the edges of the complete graph  $K_n$, Maker has a strategy to claim a graph which contains copies of all spanning trees with maximum degree at most
$K_n$, Maker has a strategy to claim a graph which contains copies of all spanning trees with maximum degree at most  $cn/\log (n)$, for a suitable constant
$cn/\log (n)$, for a suitable constant  $c$ and
$c$ and  $n$ being large enough. We also prove an analogous result for Waiter-Client games. Both of our results show that the building player can play at least as good as suggested by the random graph intuition. Moreover, they improve on a special case of earlier results by Johannsen, Krivelevich, and Samotij as well as Han and Yang for Maker-Breaker games.
$n$ being large enough. We also prove an analogous result for Waiter-Client games. Both of our results show that the building player can play at least as good as suggested by the random graph intuition. Moreover, they improve on a special case of earlier results by Johannsen, Krivelevich, and Samotij as well as Han and Yang for Maker-Breaker games.
Given an  $n\times n$ symmetric matrix
$n\times n$ symmetric matrix  $W\in [0,1]^{[n]\times [n]}$, let
$W\in [0,1]^{[n]\times [n]}$, let  ${\mathcal G}(n,W)$ be the random graph obtained by independently including each edge
${\mathcal G}(n,W)$ be the random graph obtained by independently including each edge  $jk\in \binom{[n]}{2}$ with probability
$jk\in \binom{[n]}{2}$ with probability  $W_{jk}=W_{kj}$. Given a degree sequence
$W_{jk}=W_{kj}$. Given a degree sequence  $\textbf{d}=(d_1,\ldots, d_n)$, let
$\textbf{d}=(d_1,\ldots, d_n)$, let  ${\mathcal G}(n,\textbf{d})$ denote a uniformly random graph with degree sequence
${\mathcal G}(n,\textbf{d})$ denote a uniformly random graph with degree sequence  $\textbf{d}$. We couple
$\textbf{d}$. We couple  ${\mathcal G}(n,W)$ and
${\mathcal G}(n,W)$ and  ${\mathcal G}(n,\textbf{d})$ together so that asymptotically almost surely
${\mathcal G}(n,\textbf{d})$ together so that asymptotically almost surely  ${\mathcal G}(n,W)$ is a subgraph of
${\mathcal G}(n,W)$ is a subgraph of  ${\mathcal G}(n,\textbf{d})$, where
${\mathcal G}(n,\textbf{d})$, where  $W$ is some function of
$W$ is some function of  $\textbf{d}$. Let
$\textbf{d}$. Let  $\Delta (\textbf{d})$ denote the maximum degree in
$\Delta (\textbf{d})$ denote the maximum degree in  $\textbf{d}$. Our coupling result is optimal when
$\textbf{d}$. Our coupling result is optimal when  $\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$, that is,
$\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$, that is,  $W_{ij}$ is asymptotic to
$W_{ij}$ is asymptotic to  ${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for every
${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for every  $i,j\in [n]$. We also have coupling results for
$i,j\in [n]$. We also have coupling results for  $\textbf{d}$ that are not constrained by the condition
$\textbf{d}$ that are not constrained by the condition  $\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$. For such
$\Delta (\textbf{d})^2\ll \|\textbf{d}\|_1$. For such  $\textbf{d}$ our coupling result is still close to optimal, in the sense that
$\textbf{d}$ our coupling result is still close to optimal, in the sense that  $W_{ij}$ is asymptotic to
$W_{ij}$ is asymptotic to  ${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for most pairs
${\mathbb P}(ij\in{\mathcal G}(n,\textbf{d}))$ for most pairs  $ij\in \binom{[n]}{2}$.
$ij\in \binom{[n]}{2}$.
Every countable group G can be embedded in a finitely generated group  $G^*$ that is hopfian and complete, that is,
$G^*$ that is hopfian and complete, that is,  $G^*$ has trivial centre and every epimorphism
$G^*$ has trivial centre and every epimorphism  $G^*\to G^*$ is an inner automorphism. Every finite subgroup of
$G^*\to G^*$ is an inner automorphism. Every finite subgroup of  $G^*$ is conjugate to a finite subgroup of G. If G has a finite presentation (respectively, a finite classifying space), then so does
$G^*$ is conjugate to a finite subgroup of G. If G has a finite presentation (respectively, a finite classifying space), then so does  $G^*$. Our construction of
$G^*$. Our construction of  $G^*$ relies on the existence of closed hyperbolic 3-manifolds that are asymmetric and non-Haken.
$G^*$ relies on the existence of closed hyperbolic 3-manifolds that are asymmetric and non-Haken.
We show that the image of a subshift X under various injective morphisms of symbolic algebraic varieties over monoid universes with algebraic variety alphabets is a subshift of finite type, respectively a sofic subshift, if and only if so is X. Similarly, let G be a countable monoid and let A, B be Artinian modules over a ring. We prove that for every closed subshift submodule 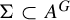 $\Sigma \subset A^G$ and every injective G-equivariant uniformly continuous module homomorphism
$\Sigma \subset A^G$ and every injective G-equivariant uniformly continuous module homomorphism 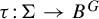 $\tau \colon \! \Sigma \to B^G$, a subshift
$\tau \colon \! \Sigma \to B^G$, a subshift 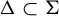 $\Delta \subset \Sigma $ is of finite type, respectively sofic, if and only if so is the image
$\Delta \subset \Sigma $ is of finite type, respectively sofic, if and only if so is the image 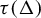 $\tau (\Delta )$. Generalizations for admissible group cellular automata over admissible Artinian group structure alphabets are also obtained.
$\tau (\Delta )$. Generalizations for admissible group cellular automata over admissible Artinian group structure alphabets are also obtained.
Let
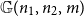 ${\mathbb{G}(n_1,n_2,m)}$
be a uniformly random m-edge subgraph of the complete bipartite graph
${\mathbb{G}(n_1,n_2,m)}$
be a uniformly random m-edge subgraph of the complete bipartite graph
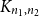 ${K_{n_1,n_2}}$
with bipartition
${K_{n_1,n_2}}$
with bipartition
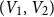 $(V_1, V_2)$
, where
$(V_1, V_2)$
, where
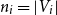 $n_i = |V_i|$
,
$n_i = |V_i|$
,
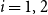 $i=1,2$
. Given a real number
$i=1,2$
. Given a real number
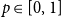 $p \in [0,1]$
such that
$p \in [0,1]$
such that
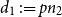 $d_1 \,{:\!=}\, pn_2$
and
$d_1 \,{:\!=}\, pn_2$
and
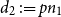 $d_2 \,{:\!=}\, pn_1$
are integers, let
$d_2 \,{:\!=}\, pn_1$
are integers, let
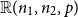 $\mathbb{R}(n_1,n_2,p)$
be a random subgraph of
$\mathbb{R}(n_1,n_2,p)$
be a random subgraph of
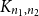 ${K_{n_1,n_2}}$
with every vertex
${K_{n_1,n_2}}$
with every vertex
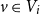 $v \in V_i$
of degree
$v \in V_i$
of degree
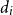 $d_i$
,
$d_i$
,
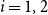 $i = 1, 2$
. In this paper we determine sufficient conditions on
$i = 1, 2$
. In this paper we determine sufficient conditions on
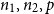 $n_1,n_2,p$
and m under which one can embed
$n_1,n_2,p$
and m under which one can embed
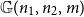 ${\mathbb{G}(n_1,n_2,m)}$
into
${\mathbb{G}(n_1,n_2,m)}$
into
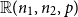 $\mathbb{R}(n_1,n_2,p)$
and vice versa with probability tending to 1. In particular, in the balanced case
$\mathbb{R}(n_1,n_2,p)$
and vice versa with probability tending to 1. In particular, in the balanced case
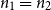 $n_1=n_2$
, we show that if
$n_1=n_2$
, we show that if
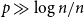 $p\gg\log n/n$
and
$p\gg\log n/n$
and
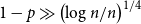 $1 - p \gg \left(\log n/n \right)^{1/4}$
, then for some
$1 - p \gg \left(\log n/n \right)^{1/4}$
, then for some
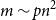 $m\sim pn^2$
, asymptotically almost surely one can embed
$m\sim pn^2$
, asymptotically almost surely one can embed
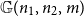 ${\mathbb{G}(n_1,n_2,m)}$
into
${\mathbb{G}(n_1,n_2,m)}$
into
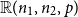 $\mathbb{R}(n_1,n_2,p)$
, while for
$\mathbb{R}(n_1,n_2,p)$
, while for
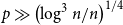 $p\gg\left(\log^{3} n/n\right)^{1/4}$
and
$p\gg\left(\log^{3} n/n\right)^{1/4}$
and
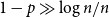 $1-p\gg\log n/n$
the opposite embedding holds. As an extension, we confirm the Kim–Vu Sandwich Conjecture for degrees growing faster than
$1-p\gg\log n/n$
the opposite embedding holds. As an extension, we confirm the Kim–Vu Sandwich Conjecture for degrees growing faster than
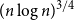 $(n \log n)^{3/4}$
.
$(n \log n)^{3/4}$
.
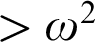 ${>}\ \omega ^2$
-Fickle Recursively Enumerable Turing Degrees
${>}\ \omega ^2$
-Fickle Recursively Enumerable Turing Degrees
Given a finite lattice L that can be embedded in the recursively enumerable (r.e.) Turing degrees 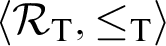 $\langle \mathcal {R}_{\mathrm {T}},\leq _{\mathrm {T}}\rangle $
, we do not in general know how to characterize the degrees
$\langle \mathcal {R}_{\mathrm {T}},\leq _{\mathrm {T}}\rangle $
, we do not in general know how to characterize the degrees  $\mathbf {d}\in \mathcal {R}_{\mathrm {T}}$
below which L can be bounded. The important characterizations known are of the
$\mathbf {d}\in \mathcal {R}_{\mathrm {T}}$
below which L can be bounded. The important characterizations known are of the 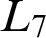 $L_7$
and
$L_7$
and 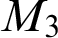 $M_3$
lattices, where the lattices are bounded below
$M_3$
lattices, where the lattices are bounded below 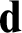 $\mathbf {d}$
if and only if
$\mathbf {d}$
if and only if 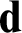 $\mathbf {d}$
contains sets of “fickleness”
$\mathbf {d}$
contains sets of “fickleness” 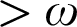 $>\omega $
and
$>\omega $
and  $\geq \omega ^\omega $
respectively. We work towards finding a lattice that characterizes the levels above
$\geq \omega ^\omega $
respectively. We work towards finding a lattice that characterizes the levels above 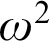 $\omega ^2$
, the first non-trivial level after
$\omega ^2$
, the first non-trivial level after  $\omega $
. We introduced a lattice-theoretic property called “
$\omega $
. We introduced a lattice-theoretic property called “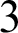 $3$
-directness” to describe lattices that are no “wider” or “taller” than
$3$
-directness” to describe lattices that are no “wider” or “taller” than 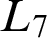 $L_7$
and
$L_7$
and 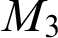 $M_3$
. We exhaust the 3-direct lattices L, but they turn out to also characterize the
$M_3$
. We exhaust the 3-direct lattices L, but they turn out to also characterize the 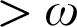 $>\omega $
or
$>\omega $
or 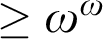 $\geq \omega ^\omega $
levels, if L is not already embeddable below all non-zero r.e. degrees. We also considered upper semilattices (USLs) by removing the bottom meet(s) of some 3-direct lattices, but the removals did not change the levels characterized. This leads us to conjecture that a USL characterizes the same r.e. degrees as the lattice on which the USL is based. We discovered three 3-direct lattices besides
$\geq \omega ^\omega $
levels, if L is not already embeddable below all non-zero r.e. degrees. We also considered upper semilattices (USLs) by removing the bottom meet(s) of some 3-direct lattices, but the removals did not change the levels characterized. This leads us to conjecture that a USL characterizes the same r.e. degrees as the lattice on which the USL is based. We discovered three 3-direct lattices besides 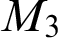 $M_3$
that also characterize the
$M_3$
that also characterize the  $\geq \omega ^\omega $
-levels. Our search for a
$\geq \omega ^\omega $
-levels. Our search for a 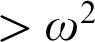 $>\omega ^2$
-candidate therefore involves the lattice-theoretic problem of finding lattices that do not contain any of the four
$>\omega ^2$
-candidate therefore involves the lattice-theoretic problem of finding lattices that do not contain any of the four  $\geq \omega ^\omega $
-lattices as sublattices.
$\geq \omega ^\omega $
-lattices as sublattices.
Abstract prepared by Liling Ko.
E-mail: ko.390@osu.edu
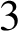 $3$
-MANIFOLDS IN
$3$
-MANIFOLDS IN
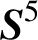 $\boldsymbol {S}^5$
$\boldsymbol {S}^5$
In this note, we show that given a closed connected oriented
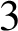 $3$
-manifold M, there exists a knot K in M such that the manifold
$3$
-manifold M, there exists a knot K in M such that the manifold
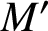 $M'$
obtained from M by performing an integer surgery admits an open book decomposition which embeds into the trivial open book of the
$M'$
obtained from M by performing an integer surgery admits an open book decomposition which embeds into the trivial open book of the
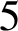 $5$
-sphere
$5$
-sphere
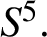 $S^5.$
$S^5.$
The bandwidth theorem of Böttcher, Schacht, and Taraz [Proof of the bandwidth conjecture of Bollobás andKomlós, Mathematische Annalen, 2009] gives a condition on the minimum degree of an n-vertex graph G that ensures G contains every r-chromatic graph H on n vertices of bounded degree and of bandwidth
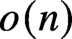 $o(n)$
, thereby proving a conjecture of Bollobás and Komlós [The Blow-up Lemma, Combinatorics, Probability, and Computing, 1999]. In this paper, we prove a version of the bandwidth theorem for locally dense graphs. Indeed, we prove that every locally dense n-vertex graph G with
$o(n)$
, thereby proving a conjecture of Bollobás and Komlós [The Blow-up Lemma, Combinatorics, Probability, and Computing, 1999]. In this paper, we prove a version of the bandwidth theorem for locally dense graphs. Indeed, we prove that every locally dense n-vertex graph G with
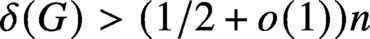 $\delta (G)> (1/2+o(1))n$
contains as a subgraph any given (spanning) H with bounded maximum degree and sublinear bandwidth.
$\delta (G)> (1/2+o(1))n$
contains as a subgraph any given (spanning) H with bounded maximum degree and sublinear bandwidth.
We provide a finite basis for the class of Borel functions that are not in the first Baire class, as well as the class of Borel functions that are not 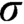 $\sigma $
-continuous with closed witnesses.
$\sigma $
-continuous with closed witnesses.
We prove some open book embedding results in the contact category with a constructive approach. As a consequence, we give an alternative proof of a theorem of Etnyre and Lekili that produces a large class of contact 3-manifolds admitting contact open book embeddings in the standard contact 5-sphere. We also show that all the Ustilovsky 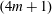 $(4m+1)$-spheres contact open book embed in the standard contact
$(4m+1)$-spheres contact open book embed in the standard contact 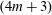 $(4m+3)$-sphere.
$(4m+3)$-sphere.
It is proved that the free topological vector space 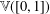 $\mathbb{V}([0,1])$ contains an isomorphic copy of the free topological vector space
$\mathbb{V}([0,1])$ contains an isomorphic copy of the free topological vector space 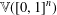 $\mathbb{V}([0,1]^{n})$ for every finite-dimensional cube
$\mathbb{V}([0,1]^{n})$ for every finite-dimensional cube 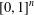 $[0,1]^{n}$, thereby answering an open question in the literature. We show that this result cannot be extended from the closed unit interval
$[0,1]^{n}$, thereby answering an open question in the literature. We show that this result cannot be extended from the closed unit interval 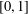 $[0,1]$ to general metrisable spaces. Indeed, we prove that the free topological vector space
$[0,1]$ to general metrisable spaces. Indeed, we prove that the free topological vector space  $\mathbb{V}(X)$ does not even have a vector subspace isomorphic as a topological vector space to
$\mathbb{V}(X)$ does not even have a vector subspace isomorphic as a topological vector space to 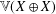 $\mathbb{V}(X\oplus X)$, where
$\mathbb{V}(X\oplus X)$, where 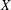 $X$ is a Cook continuum, which is a one-dimensional compact metric space. This is also shown to be the case for a rigid Bernstein set, which is a zero-dimensional subspace of the real line.
$X$ is a Cook continuum, which is a one-dimensional compact metric space. This is also shown to be the case for a rigid Bernstein set, which is a zero-dimensional subspace of the real line.

