Ecological inference (EI) is the process of learning about individual behavior from aggregate data. We relax assumptions by allowing for “linear contextual effects,” which previous works have regarded as plausible but avoided due to nonidentification, a problem we sidestep by deriving bounds instead of point estimates. In this way, we offer a conceptual framework to improve on the Duncan–Davis bound, derived more than 65 years ago. To study the effectiveness of our approach, we collect and analyze 8,430 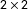 $2\times 2$ EI datasets with known ground truth from several sources—thus bringing considerably more data to bear on the problem than the existing dozen or so datasets available in the literature for evaluating EI estimators. For the 88% of real data sets in our collection that fit a proposed rule, our approach reduces the width of the Duncan–Davis bound, on average, by about 44%, while still capturing the true district-level parameter about 99% of the time. The remaining 12% revert to the Duncan–Davis bound.
$2\times 2$ EI datasets with known ground truth from several sources—thus bringing considerably more data to bear on the problem than the existing dozen or so datasets available in the literature for evaluating EI estimators. For the 88% of real data sets in our collection that fit a proposed rule, our approach reduces the width of the Duncan–Davis bound, on average, by about 44%, while still capturing the true district-level parameter about 99% of the time. The remaining 12% revert to the Duncan–Davis bound.
We study the problem of choosing the best subset of 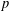 $p$ features in linear regression, given
$p$ features in linear regression, given  $n$ observations. This problem naturally contains two objective functions including minimizing the amount of bias and minimizing the number of predictors. The existing approaches transform the problem into a single-objective optimization problem. We explain the main weaknesses of existing approaches and, to overcome their drawbacks, we propose a bi-objective mixed integer linear programming approach. A computational study shows the efficacy of the proposed approach.
$n$ observations. This problem naturally contains two objective functions including minimizing the amount of bias and minimizing the number of predictors. The existing approaches transform the problem into a single-objective optimization problem. We explain the main weaknesses of existing approaches and, to overcome their drawbacks, we propose a bi-objective mixed integer linear programming approach. A computational study shows the efficacy of the proposed approach.

