

We study the distribution of 2-Selmer ranks in the family of quadratic twists of an elliptic curve 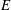 $\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}E$ over an arbitrary number field
$\def \xmlpi #1{}\def \mathsfbi #1{\boldsymbol {\mathsf {#1}}}\let \le =\leqslant \let \leq =\leqslant \let \ge =\geqslant \let \geq =\geqslant \def \Pr {\mathit {Pr}}\def \Fr {\mathit {Fr}}\def \Rey {\mathit {Re}}E$ over an arbitrary number field 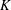 $K$. Under the assumption that
$K$. Under the assumption that 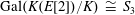 ${\rm Gal}(K(E[2])/K) \ {\cong }\ S_3$, we show that the density (counted in a nonstandard way) of twists with Selmer rank
${\rm Gal}(K(E[2])/K) \ {\cong }\ S_3$, we show that the density (counted in a nonstandard way) of twists with Selmer rank  $r$ exists for all positive integers
$r$ exists for all positive integers  $r$, and is given via an equilibrium distribution, depending only on a single parameter (the ‘disparity’), of a certain Markov process that is itself independent of
$r$, and is given via an equilibrium distribution, depending only on a single parameter (the ‘disparity’), of a certain Markov process that is itself independent of 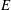 $E$ and
$E$ and 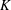 $K$. More generally, our results also apply to
$K$. More generally, our results also apply to 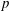 $p$-Selmer ranks of twists of two-dimensional self-dual
$p$-Selmer ranks of twists of two-dimensional self-dual 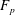 ${\bf F}_p$-representations of the absolute Galois group of
${\bf F}_p$-representations of the absolute Galois group of 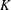 $K$ by characters of order
$K$ by characters of order 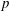 $p$.
$p$.
Arbitrage-free prices u of European contracts on risky assets whoselog-returns are modelled by Lévy processes satisfya parabolic partial integro-differential equation (PIDE) $\partial_t u + {\mathcal{A}}[u] = 0$ 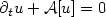 .This PIDE is localized tobounded domains and the error due to this localization isestimated. The localized PIDE is discretized by theθ-scheme in time and a wavelet Galerkin method with N degrees of freedom in log-price space. The dense matrix for ${\mathcal{A}}$
.This PIDE is localized tobounded domains and the error due to this localization isestimated. The localized PIDE is discretized by theθ-scheme in time and a wavelet Galerkin method with N degrees of freedom in log-price space. The dense matrix for ${\mathcal{A}}$ 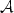 can be replaced by a sparse matrix in the wavelet basis, and the linear systemsin each implicit time step are solved approximativelywith GMRES in linear complexity. The total work of the algorithm for M time steps is bounded byO(MN(log(N))2) operations and O(Nlog(N)) memory.The deterministic algorithm gives optimal convergence rates (up to logarithmic terms) for the computed solutionin the same complexity as finite difference approximationsof the standard Black–Scholes equation.Computational examples for various Lévy price processes are presented.
can be replaced by a sparse matrix in the wavelet basis, and the linear systemsin each implicit time step are solved approximativelywith GMRES in linear complexity. The total work of the algorithm for M time steps is bounded byO(MN(log(N))2) operations and O(Nlog(N)) memory.The deterministic algorithm gives optimal convergence rates (up to logarithmic terms) for the computed solutionin the same complexity as finite difference approximationsof the standard Black–Scholes equation.Computational examples for various Lévy price processes are presented.

