


1. Introduction
Since the seminal work of Markowitz (Reference Markowitz1952), the mean-variance criterion has emerged as a cornerstone in mathematical finance, highlighted by significant contributions such as Li and Ng (Reference Li and Ng2000) and Zhou and Li (Reference Zhou and Li2000). It is well known that mean-variance problem has an inherent issue of time inconsistency, thereby Bellman optimality principle cannot be applied. Many studies addressing this issue resort to a pre-commitment strategy at the initial time and employ the Lagrangian method to solve the mean-variance problem as seen in the aforementioned works. However, the pre-committed solution lacks time consistency and is applicable only for a decision-maker at the initial time.
In pursuit of a time-consistent strategy, Björk and Murgoci (Reference Björk and Murgoci2010) formulated the problem within a game theoretic framework and derived the extended Hamilton–Jacobi–Bellman (HJB) equation through a verification theorem. Based on this groundwork, Björk et al. (Reference Björk, Murgoci and Zhou2014) assumed that the insurer’s risk aversion is inversely proportional to the current wealth and obtained the time-consistent strategy. Björk et al. (Reference Björk, Khapko and Murgoci2017) provided a general framework for handling time-inconsistency, leading to the so-called equilibrium policy that can be regarded as a subgame perfect Nash equilibrium in dynamic games. Expanding on these efforts, Dai et al. (Reference Dai, Jin, Kou and Xu2021) proposed a dynamic portfolio choice model with the mean-variance criterion for log-returns, and derived time-consistent portfolio policies which are analytically tractable even under some incomplete market settings. Furthermore, the game theoretic approach to tackling time-inconsistent problems has also been extended in the actuarial literature, as demonstrated by works from Zeng et al. (Reference Zeng, Li and Gu2016), Chen and Shen (Reference Chen and Shen2019), and Li and Young (Reference Li and Young2021).
In this paper, we consider the scenario where model parameters are partially or completely unknown, aiming to learn a practical exploratory equilibrium policy under the mean-variance criterion within an incomplete market, as discussed in Dai et al. (Reference Dai, Dong and Jia2023). In fact, the stochastic control problems under the continuous-time RL framework with continuous state and action have attracted extensive attention from scholars recently. Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a) first established a continuous-time RL framework with continuous state and action from the perspective of stochastic control and proved that the optimal exploration strategy for the linear-quadratic (LQ) control problem in the infinite time horizon is Gaussian. Furthermore, Wang and Zhou (Reference Wang and Zhou2020) applied this RL framework for the first time to solve the continuous-time mean-variance problem. Motivated by Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a), Dai et al. (Reference Dai, Dong and Jia2023) extended the exploratory stochastic control framework to an incomplete market, where the asset return correlates with a stochastic market state, and learned an equilibrium policy under a mean-variance criterion. Jiang et al. (Reference Jiang, Saunders and Weng2022) studied the exploratory Kelly problem by considering both the amount of investment in stock and the portion of wealth in stock as the control for a general time-varying temperature parameter. Han et al. (Reference Han, Wang and Zhou2023) first introduced another kind of index that can measure the randomness of actions called Choquet regularization. They showed that the optimal exploration distribution of LQ control problem with infinite time horizon is no longer necessarily Gaussian as in Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a), but are dictated by the choice of Choquet regularizers. Guo et al. (Reference Guo, Han and Wang2025) further studied an exploratory mean-variance problem with the Choquet regularizers being used to measure the level of exploration.
Interactions among agents in real-world settings frequently involve a complex interplay of both competitive and cooperative behaviors. In contrast to the frameworks considered in the aforementioned literature, this paper focuses on a scenario with two competitive agents who evaluate not only their individual wealth but also the wealth gap relative to their opponent. This formulation aligns with the broader class of nonzero-sum stochastic differential games, tracing its foundational roots to seminal contributions by Isaacs (Reference Isaacs1965) and Pontryagin (Reference Pontryagin1967).
In financial markets, investors often exhibit concern for their wealth relative to that of other market participants – a phenomenon commonly referred to as relative performance concern. This behavioral trait significantly influences investment decisions and market dynamics. Empirical and theoretical studies have documented that relative performance concerns can exacerbate speculative behavior and contribute to the emergence and persistence of asset bubbles. For example, DemMarzo et al. (2008) demonstrated that investors’ concern with their relative performance induces herd behavior, thereby sustaining bubbles even when asset prices deviate significantly from their fundamental values. Foundational analyses by Abel (Reference Abel1990) and Gali (Reference Gali1994) emphasized the pervasive role of relative concerns in human decision-making processes. Within the portfolio optimization literature, Espinosa and Touzi (Reference Espinosa and Touzi2015) incorporated concerns about relative wealth by modeling the wealth gap and showed that greater emphasis on relative wealth often leads investors to take on more risk, thus increasing systemic market risk. Building on this framework, numerous subsequent studies explicitly model objective functions that integrate weighted terms of individual wealth and wealth gaps, including Bensoussan et al. (Reference Bensoussan, Siu, Yam and Yang2014), Siu et al. (Reference Siu, Yam, Yang and Zhao2016), Hu and Wang (Reference Hu and Wang2018), Deng et al. (Reference Deng, Zeng and Zhu2018), Zhu et al. (Reference Zhu, Guan and Li2020), and Wang et al. (Reference Wang, Zhang, Jin and Qian2021). To the best of our knowledge, (non)zero-sum games in the continuous-time RL settings have not been considered before except in Sun and Jia (Reference Sun and Jia2023) where an entropy-regularized continuous-time LQ two-agent zero-sum stochastic differential game problem was considered, and they designed a policy iteration method to derive the optimal strategy for a case with only one unknown model parameter.
Compared with the existing literature, this paper presents three main differences and contributions.
First, in traditional time-consistent optimization problems, policy iteration typically relies on the policy improvement theorem, as detailed in Jia and Zhou (Reference Jia and Zhou2022b) and Guo et al. (Reference Guo, Han and Wang2025). This theorem ensures that each iteration enhances the overall strategy. However, for time-inconsistent problems, although iterating policies is still feasible, there is no guarantee that each iteration leads to an improved policy. This presents a significant challenge when attempting to extend policy iteration methods to time-inconsistent settings. Nevertheless, we show that, our approach guarantees uniform convergence of the equilibrium strategy, in contrast to the local convergence typically observed in the single-agent framework, as shown in Dai et al. (Reference Dai, Dong and Jia2023).
Second, unlike single-agent scenarios, our nonzero-sum game problem naturally fits within the domain of applying RL techniques in multi-agent systems. The pioneering work of Littman (Reference Littman1994) introduces Q-learning in zero-sum games, marking the early development of multi-agent reinforcement learning. Building on this, Littman (Reference Littman2001) proposed the Friend-or-foe Q-learning algorithm for general-sum games, while Foerster et al. (Reference Foerster, Nardelli, Farquhar, Afouras, Torr, Kohli and Whiteson2017) proposed a centralized multi-agent learning method using deep learning, which enhances the collaborative to improve agent collaboration in complex tasks. Although centralized algorithms theoretically guarantee convergence and stability, they often encounter practical challenges, including dimensionality explosion and increased system complexity. For further discussion on multi-agent algorithms, we refer to Yang and Wang (Reference Yang and Wang2020) and Zhang et al. (Reference Zhang and Yang2021). In contrast, the unique structure of our model allows the differential stochastic game to be decomposed into two independent single-agent problems within a centralized multi-agent framework, thus mitigating the dimensionality explosion inherent in centralized methods. To the best of our knowledge, this paper is the first to address equilibrium policies in time-inconsistent problems within the context of reinforcement learning for nonzero-sum differential games.
Third, in contrast to Jiang et al. (Reference Jiang, Saunders and Weng2022), Dai et al. (Reference Dai, Dong and Jia2023), and Sun and Jia (Reference Sun and Jia2023), we replace the differential entropy used for regularization with Choquet regularizers. As noted in Han et al. (Reference Han, Wang and Zhou2023) and Guo et al. (Reference Guo, Han and Wang2025), Choquet regularizers offer several theoretical and practical advantages to RL. The broad class of Choquet regularizers enable the comparison and selection of specific regularizers to meet the unique objectives of each learning problem. In particular, it is more natural for agents to choose different regularizers based on their individual preferences, further enhancing the flexibility and applicability of our approach.
The rest of the paper is organized as follows. In Section 2, we introduce the exploratory mean-variance problem within the framework of RL under the nonzero-sum differential game setting. Section 3 presents the Nash equilibrium mean-variance policy. In Section 4, we show a policy iteration procedure and analyze its convergence based on the Gaussian mean return model. In Section 5, we propose an RL algorithm based on the convergence analysis, and provide numerical results to illustrate the implementation of the algorithm in Section 6. Finally, we conclude in Section 7. A summary of the notation used throughout the paper is provided in the Appendix.
2. Formulation of problem
Throughout the paper, we assume that
 $(\Omega,\mathcal F, \mathbb P)$
be an atomless probability space. With a slight abuse of notation, we denote by
$(\Omega,\mathcal F, \mathbb P)$
be an atomless probability space. With a slight abuse of notation, we denote by
 $\mathcal M$
both the set of Borel probability measures on
$\mathcal M$
both the set of Borel probability measures on
 $\mathbb R$
and the set of distribution functions of real random variables. For
$\mathbb R$
and the set of distribution functions of real random variables. For
 $\Pi \in \mathcal M$
and
$\Pi \in \mathcal M$
and
 $x \in \mathbb R$
, we have
$x \in \mathbb R$
, we have
 $\Pi(x)=\Pi((\!-\!\infty , x])$
. Let
$\Pi(x)=\Pi((\!-\!\infty , x])$
. Let
 $\mathcal M ^p,\ p \in [1,\infty)$
, be the subset of
$\mathcal M ^p,\ p \in [1,\infty)$
, be the subset of
 $\mathcal M$
whose elements have finite p-th order moment. We write
$\mathcal M$
whose elements have finite p-th order moment. We write
 $X \sim \Pi$
if random variable X has distribution
$X \sim \Pi$
if random variable X has distribution
 $\Pi$
, and
$\Pi$
, and
 $X \overset{d}= Y$
if X and Y have the same distribution. For
$X \overset{d}= Y$
if X and Y have the same distribution. For
 $\Pi \in \mathcal M^2$
, we denote by
$\Pi \in \mathcal M^2$
, we denote by
 $\mu(\Pi)$
and
$\mu(\Pi)$
and
 $\sigma ^2 (\Pi)$
the mean and variance of
$\sigma ^2 (\Pi)$
the mean and variance of
 $\Pi$
, respectively.
$\Pi$
, respectively.
2.1 Exploratory wealth process
In the financial market under study, we posit the inherent incompleteness of the market as in Basak and Chabakauri (Reference Basak and Chabakauri2010) and Dai et al. (Reference Dai, Jin, Kou and Xu2021), allowing for continuous trading in both a risk-free asset and a risky asset within the finite time horizon [0, T]. The price process
 $S_0(t)$
governing the risk-free asset is given by
$S_0(t)$
governing the risk-free asset is given by
 \begin{align*} \mathrm{d} S_0(t) = rS_0(t)\mathrm{d} t,\end{align*}
\begin{align*} \mathrm{d} S_0(t) = rS_0(t)\mathrm{d} t,\end{align*}
where
 $r\gt0$
represents the constant risk-free interest rate. The price process S(t) of the risky asset is given by
$r\gt0$
represents the constant risk-free interest rate. The price process S(t) of the risky asset is given by
 \begin{align} \dfrac{\mathrm{d} S(t)}{S(t)}=a(t,Y(t))\mathrm{d} t+b(t,Y(t))\mathrm{d} W(t).\end{align}
\begin{align} \dfrac{\mathrm{d} S(t)}{S(t)}=a(t,Y(t))\mathrm{d} t+b(t,Y(t))\mathrm{d} W(t).\end{align}
Here, W(t) is a Brownian motion defined on the filtered probability space
 $(\Omega, \mathcal F, \{\mathcal F_t\}_{0\leqslant t\leqslant T}, \mathbb P)$
adhering to standard conditions. Additionally, Y(t) is a diffusion process satisfying
$(\Omega, \mathcal F, \{\mathcal F_t\}_{0\leqslant t\leqslant T}, \mathbb P)$
adhering to standard conditions. Additionally, Y(t) is a diffusion process satisfying
 \begin{align*} \mathrm{d} Y(t)=m(t,Y(t))\mathrm{d} t+v(t,Y(t))[\rho dW(t)+\sqrt{1-\rho ^2}d\widetilde W(t)],\end{align*}
\begin{align*} \mathrm{d} Y(t)=m(t,Y(t))\mathrm{d} t+v(t,Y(t))[\rho dW(t)+\sqrt{1-\rho ^2}d\widetilde W(t)],\end{align*}
where
 $\rho \in [\!-\!1,1]$
, and the Brownian motion
$\rho \in [\!-\!1,1]$
, and the Brownian motion
 $\widetilde W(t)$
is defined on
$\widetilde W(t)$
is defined on
 $(\Omega, \mathcal F, \{\mathcal F_t\}_{0\leqslant t\leqslant T}, \mathbb P)$
independent of W(t). In the market context,
$(\Omega, \mathcal F, \{\mathcal F_t\}_{0\leqslant t\leqslant T}, \mathbb P)$
independent of W(t). In the market context,
 $a(\cdot,\cdot)$
,
$a(\cdot,\cdot)$
,
 $b(\cdot,\cdot)$
,
$b(\cdot,\cdot)$
,
 $m(\cdot,\cdot)$
, and
$m(\cdot,\cdot)$
, and
 $v(\cdot,\cdot)$
are deterministic functions of t and y, with all randomness entering through Y(t). However, these functions themselves are unknown. Particularly, we are in the case of the complete market with constant parameters, where
$v(\cdot,\cdot)$
are deterministic functions of t and y, with all randomness entering through Y(t). However, these functions themselves are unknown. Particularly, we are in the case of the complete market with constant parameters, where
 $a(t, y) \equiv a$
and
$a(t, y) \equiv a$
and
 $b(t, y) \equiv b$
. The process Y(t) is modeled as a diffusion representing macroeconomic or systemic risk factors. The parameter
$b(t, y) \equiv b$
. The process Y(t) is modeled as a diffusion representing macroeconomic or systemic risk factors. The parameter
 $\rho$
quantifies the correlation between the state process Y(t) and the stock price process S(t), thus characterizing the degree to which market-wide risk factors influence asset price dynamics.
$\rho$
quantifies the correlation between the state process Y(t) and the stock price process S(t), thus characterizing the degree to which market-wide risk factors influence asset price dynamics.
Remark 1. Market incompleteness arises because the stochastic evolution of Y(t) affects the dynamics of the risky asset, yet cannot be fully hedged through trading in S(t) and
 $S_0(t)$
. This feature aligns with empirical observations, where financial markets exhibit unspanned stochastic volatility, unhedgeable economic risks, and other uncertainties. The market model described above exhibits substantial generality, encompassing numerous well-known models, such as the time-varying Gaussian mean return model and the stochastic volatility model; see Example 1 below. For a more detailed discussion on market incompleteness and the nonreplicability of contingent claims in such settings, we refer to Sections 1.4 and 5.4 of Föllmer and Schied (Reference Föllmer and Schied2011).
$S_0(t)$
. This feature aligns with empirical observations, where financial markets exhibit unspanned stochastic volatility, unhedgeable economic risks, and other uncertainties. The market model described above exhibits substantial generality, encompassing numerous well-known models, such as the time-varying Gaussian mean return model and the stochastic volatility model; see Example 1 below. For a more detailed discussion on market incompleteness and the nonreplicability of contingent claims in such settings, we refer to Sections 1.4 and 5.4 of Föllmer and Schied (Reference Föllmer and Schied2011).
Example 1.
-
(i) If the stock price S(t) and the market price of risk Y(t) are governed by
 $\frac{\mathrm{d} S(t)}{S(t)} =(r+\sigma Y(t)) \mathrm{d} t+\sigma \mathrm{d} W(t)$
and
$\mathrm{d} Y(t) =\iota \left(Y-Y(t)\right) \mathrm{d} t+v \mathrm{d}[\rho dW(t)+\sqrt{1-\rho ^2}d\widetilde W(t)],$
where
$r, \sigma, \iota, v$
, Y are all positive constants and
$\rho \in [\!-\!1,1]$
. This model, termed the time-varying Gaussian mean return model, effectively captures the intricate interplay between the dynamics of stock prices and market risk over time.
$\frac{\mathrm{d} S(t)}{S(t)} =(r+\sigma Y(t)) \mathrm{d} t+\sigma \mathrm{d} W(t)$
and
$\mathrm{d} Y(t) =\iota \left(Y-Y(t)\right) \mathrm{d} t+v \mathrm{d}[\rho dW(t)+\sqrt{1-\rho ^2}d\widetilde W(t)],$
where
$r, \sigma, \iota, v$
, Y are all positive constants and
$\rho \in [\!-\!1,1]$
. This model, termed the time-varying Gaussian mean return model, effectively captures the intricate interplay between the dynamics of stock prices and market risk over time. -
(ii) If the stock price S(t) and a state variable Y(t) follow
$\frac{\mathrm{d} S(t)}{S(t)}=(r+\sigma Y(t)^{\frac{1+\alpha}{2 \alpha}}) \mathrm{d} t+Y(t)^{\frac{1}{2 \alpha}} \mathrm{d} W(t)$
and
$\mathrm{d} Y(t)=\iota (Y-Y(t)) d t+v \sqrt{Y(t)} \mathrm{d} [\rho dW(t)+\sqrt{1-\rho ^2}d\widetilde W(t)],$
where
$\alpha \neq 0$
is the constant elasticity of the market price of risk
$\sigma Y(t)^{\frac{1}{2}}, \sigma \in \mathbb{R}, \iota\gt0, v\gt0$
,
$Y \in \mathbb{R}$
and
$\rho \in [\!-\!1,1]$
are all constants, then it is a stochastic volatility model. This formulation characterizes a stochastic volatility model, acknowledging the nonlinear relationship between the state variable and market risk elasticity.










Researchers, including Merton (Reference Merton1980), Kim and Omberg (Reference Kim and Omberg1996), Liu (Reference Liu2001), Wachter (Reference Wachter2002), Basak and Chabakauri (Reference Basak and Chabakauri2010), Dai et al. (Reference Dai, Jin, Kou and Xu2021), and Dai et al. (Reference Dai, Dong and Jia2023), have extensively explored dynamic portfolio choice problems within the framework of these two market settings and their specific variations.
In what follows, we consider a nonzero-sum game involving two competing agents or companies, referred as Agent 1 and Agent 2 for simplicity. Both agents have access to the financial market. For
 $i \in \{1,2\}$
, let
$i \in \{1,2\}$
, let
 $u_i(t)$
represent the discounted amount of Agent i invested in the risky asset at time t, and the rest of the wealth is invested in the risk-free asset. Define
$u_i(t)$
represent the discounted amount of Agent i invested in the risky asset at time t, and the rest of the wealth is invested in the risk-free asset. Define
 $\boldsymbol{u}_i=\{u_i(t),0\leqslant t\leqslant T\}$
and
$\boldsymbol{u}_i=\{u_i(t),0\leqslant t\leqslant T\}$
and
 \begin{equation}\theta(t,Y(t))=\frac{a(t,Y(t))-r}{b(t,Y(t))}.\end{equation}
\begin{equation}\theta(t,Y(t))=\frac{a(t,Y(t))-r}{b(t,Y(t))}.\end{equation}
Then the dynamic of discounted wealth process of Agent i under strategy
 $u_i$
is given as
$u_i$
is given as
 \begin{align} \mathrm{d} X_i^{u_i}(t)&=u_i(t)b(t,Y(t))[\theta(t,Y(t))\mathrm{d} t+\mathrm{d} W(t)].\end{align}
\begin{align} \mathrm{d} X_i^{u_i}(t)&=u_i(t)b(t,Y(t))[\theta(t,Y(t))\mathrm{d} t+\mathrm{d} W(t)].\end{align}
Based on Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a), we extend the control process (2.3) to a distributional control process and define the exploratory discounted wealth process for agents. Denote by
 $\Pi_i(t) \in \mathcal M^2$
the probability distribution function of the control
$\Pi_i(t) \in \mathcal M^2$
the probability distribution function of the control
 $u_i$
at time t, where
$u_i$
at time t, where
 $\mathcal M^2$
represents the set of distribution functions with finite second-order moment on
$\mathcal M^2$
represents the set of distribution functions with finite second-order moment on
 $\mathbb R$
. Let
$\mathbb R$
. Let
 $\boldsymbol{\Pi}_i=\{\Pi_i(t),0\leqslant t\leqslant T\}$
and we write
$\boldsymbol{\Pi}_i=\{\Pi_i(t),0\leqslant t\leqslant T\}$
and we write
 $\boldsymbol{\Pi}_i \in \mathcal M^2$
for simplicity. In contrast to the approach presented in Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a), we additionally consider the correlation between the discounted wealth process and the market state, as well as the correlation between the two agents.
$\boldsymbol{\Pi}_i \in \mathcal M^2$
for simplicity. In contrast to the approach presented in Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a), we additionally consider the correlation between the discounted wealth process and the market state, as well as the correlation between the two agents.
Now, we attempt to derive the exploratory version of the wealth process
 $X_i^{u_i}$
associated with randomized policy
$X_i^{u_i}$
associated with randomized policy
 $\Pi_i$
. Such a structure can also be found in Dai et al. (Reference Dai, Dong and Jia2023), Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a), Wang and Zhou (Reference Wang and Zhou2020). Let
$\Pi_i$
. Such a structure can also be found in Dai et al. (Reference Dai, Dong and Jia2023), Wang et al. (Reference Wang, Zariphopoulou and Zhou2020a), Wang and Zhou (Reference Wang and Zhou2020). Let
 $W^n(t)$
and
$W^n(t)$
and
 $\widetilde W^n(t),n=1,2,...,N,$
represent N paths independently sampled from W(t) and
$\widetilde W^n(t),n=1,2,...,N,$
represent N paths independently sampled from W(t) and
 $\widetilde W(t)$
, respectively. Moreover, let
$\widetilde W(t)$
, respectively. Moreover, let
 $X_i^n(t)$
be the copies of the discounted wealth process of Agent i under strategy
$X_i^n(t)$
be the copies of the discounted wealth process of Agent i under strategy
 $u_i^n$
sampled from
$u_i^n$
sampled from
 $\Pi_i$
. Then, for
$\Pi_i$
. Then, for
 $n=1,2,...,N$
and
$n=1,2,...,N$
and
 $i \in \{1,2\}$
, the increments of
$i \in \{1,2\}$
, the increments of
 $Y^n(t)$
and the corresponding
$Y^n(t)$
and the corresponding
 $X_i^n(t)$
can be written as
$X_i^n(t)$
can be written as
 \begin{align}\begin{aligned} \Delta Y^n(t)&\equiv Y^n(t+\Delta t)-Y^n(t)\\&\approx m(t,Y^n(t))\Delta t+v(t,Y^n(t))[\rho \Delta W^n(t)+\sqrt{1-\rho ^2}\Delta \widetilde W^n(t)],\end{aligned}\end{align}
\begin{align}\begin{aligned} \Delta Y^n(t)&\equiv Y^n(t+\Delta t)-Y^n(t)\\&\approx m(t,Y^n(t))\Delta t+v(t,Y^n(t))[\rho \Delta W^n(t)+\sqrt{1-\rho ^2}\Delta \widetilde W^n(t)],\end{aligned}\end{align}
and
 \begin{align}\begin{aligned} \Delta X_i^n(t)&\equiv X_i^n(t+\Delta t)-X_i^n(t)\\&\approx u_i^n(t)b(t,Y^n(t))[\theta(t,Y^n(t))\Delta t+\Delta W^n(t)].\end{aligned}\end{align}
\begin{align}\begin{aligned} \Delta X_i^n(t)&\equiv X_i^n(t+\Delta t)-X_i^n(t)\\&\approx u_i^n(t)b(t,Y^n(t))[\theta(t,Y^n(t))\Delta t+\Delta W^n(t)].\end{aligned}\end{align}
We denote the exploratory discounted wealth process of Agent i by
 $X_i^{\Pi_i}(t)$
. Consequently,
$X_i^{\Pi_i}(t)$
. Consequently,
 $X_i^n(t)$
can be viewed as an independent sample from
$X_i^n(t)$
can be viewed as an independent sample from
 $X_i^{\Pi_i}(t)$
. By the law of large numbers and using (2.4) and (2.5), we observe that, as
$X_i^{\Pi_i}(t)$
. By the law of large numbers and using (2.4) and (2.5), we observe that, as
 $N \to \infty$
,
$N \to \infty$
,
 \begin{align}\begin{split} &\dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\approx \dfrac{1}{N}\sum\limits_{n=1}^N u_i^n(t)b(t,Y^n(t))[\theta(t,Y^n(t))\Delta t+\Delta W^n(t)]\\ &\overset{a.s.}\longrightarrow \mathbb E\left[b(t,Y(t))\theta(t,Y(t))\int_U u\mathrm{d}\Pi_i(t,u)\right]\Delta t,\end{split}\end{align}
\begin{align}\begin{split} &\dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\approx \dfrac{1}{N}\sum\limits_{n=1}^N u_i^n(t)b(t,Y^n(t))[\theta(t,Y^n(t))\Delta t+\Delta W^n(t)]\\ &\overset{a.s.}\longrightarrow \mathbb E\left[b(t,Y(t))\theta(t,Y(t))\int_U u\mathrm{d}\Pi_i(t,u)\right]\Delta t,\end{split}\end{align}
 \begin{align}\begin{split} &\dfrac{1}{N}\sum\limits_{n=1}^N (\Delta X_i^n(t))^2\approx \dfrac{1}{N}\sum\limits_{n=1}^N (u_i^n(t)b(t,Y^n(t)))^2\Delta t \\ &\overset{a.s.}\longrightarrow \mathbb E\left[b^2(t,Y(t))\int_U u^2\mathrm{d}\Pi_i(t,u)\right]\Delta t,\end{split}\end{align}
\begin{align}\begin{split} &\dfrac{1}{N}\sum\limits_{n=1}^N (\Delta X_i^n(t))^2\approx \dfrac{1}{N}\sum\limits_{n=1}^N (u_i^n(t)b(t,Y^n(t)))^2\Delta t \\ &\overset{a.s.}\longrightarrow \mathbb E\left[b^2(t,Y(t))\int_U u^2\mathrm{d}\Pi_i(t,u)\right]\Delta t,\end{split}\end{align}
and
 \begin{align}\begin{split} &\dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\Delta Y^n(t)\approx \dfrac{1}{N}\sum\limits_{n=1}^N u_i^n(t)b(t,Y^n(t))\rho v(t,Y^n(t))\Delta t\\ &\overset{a.s.}\longrightarrow \mathbb E\left[\rho b(t,Y(t))v(t,Y(t))\int_U u\mathrm{d}\Pi_i(t,u)\right]\Delta t.\end{split}\end{align}
\begin{align}\begin{split} &\dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\Delta Y^n(t)\approx \dfrac{1}{N}\sum\limits_{n=1}^N u_i^n(t)b(t,Y^n(t))\rho v(t,Y^n(t))\Delta t\\ &\overset{a.s.}\longrightarrow \mathbb E\left[\rho b(t,Y(t))v(t,Y(t))\int_U u\mathrm{d}\Pi_i(t,u)\right]\Delta t.\end{split}\end{align}
It is well known from the law of large numbers that
 $$ \dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\overset{a.s.}\longrightarrow \mathbb E[\Delta X_i^{\Pi_i}(t)], \dfrac{1}{N}\sum\limits_{n=1}^N (\Delta X_i^n(t))^2\overset{a.s.}\longrightarrow \mathbb E[(\Delta X_i^{\Pi_i}(t))^2],$$
$$ \dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\overset{a.s.}\longrightarrow \mathbb E[\Delta X_i^{\Pi_i}(t)], \dfrac{1}{N}\sum\limits_{n=1}^N (\Delta X_i^n(t))^2\overset{a.s.}\longrightarrow \mathbb E[(\Delta X_i^{\Pi_i}(t))^2],$$
and
 \begin{align*} \dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\Delta Y^n(t)\overset{a.s.}\longrightarrow \mathbb E[\Delta X_i^{\Pi_i}(t)\Delta Y(t)].\end{align*}
\begin{align*} \dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_i^n(t)\Delta Y^n(t)\overset{a.s.}\longrightarrow \mathbb E[\Delta X_i^{\Pi_i}(t)\Delta Y(t)].\end{align*}
These together with (2.6)–(2.8), motivate our confidence in the dynamic of
 $\Delta X_i^{\Pi_i}(t)$
, which can be expressed as
$\Delta X_i^{\Pi_i}(t)$
, which can be expressed as
 \begin{align}\begin{split} \mathrm{d} X_i^{\Pi_i}(t)&=b(t,Y(t))\theta(t,Y(t))\mu_i(t)\mathrm{d} t+b(t,Y(t))[\mu_i(t)\mathrm{d} W(t)+\sigma_i(t)\mathrm{d} \overline W_i(t)],\end{split}\end{align}
\begin{align}\begin{split} \mathrm{d} X_i^{\Pi_i}(t)&=b(t,Y(t))\theta(t,Y(t))\mu_i(t)\mathrm{d} t+b(t,Y(t))[\mu_i(t)\mathrm{d} W(t)+\sigma_i(t)\mathrm{d} \overline W_i(t)],\end{split}\end{align}
where
 $$\mu_i(t)=\int_U u\mathrm{d}\Pi_i(t,u), \;\;\sigma^2_i(t)=\int_U u^2\mathrm{d}\Pi_i(t,u)-\mu^2_i(t)$$
$$\mu_i(t)=\int_U u\mathrm{d}\Pi_i(t,u), \;\;\sigma^2_i(t)=\int_U u^2\mathrm{d}\Pi_i(t,u)-\mu^2_i(t)$$
with
 $\overline W_i$
being the Brownian motion independent of W(t) and
$\overline W_i$
being the Brownian motion independent of W(t) and
 $\widetilde W(t)$
. The remaining consideration involves the correlation between
$\widetilde W(t)$
. The remaining consideration involves the correlation between
 $\overline W_1(t)$
and
$\overline W_1(t)$
and
 $\overline W_2(t)$
. It is observed that, as
$\overline W_2(t)$
. It is observed that, as
 $N\to \infty$
,
$N\to \infty$
,
 \begin{align*} &\dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_1^n(t)\Delta X_2^n(t)\approx \dfrac{1}{N}\sum\limits_{n=1}^N u_1^n(t)u_2^n(t)b^2(t,Y^n(t))\\ &\overset{a.s.}\longrightarrow \mathbb E\left[\mu_1(t)\mu_2(t)b^2(t,Y(t))\right]\Delta t,\end{align*}
\begin{align*} &\dfrac{1}{N}\sum\limits_{n=1}^N \Delta X_1^n(t)\Delta X_2^n(t)\approx \dfrac{1}{N}\sum\limits_{n=1}^N u_1^n(t)u_2^n(t)b^2(t,Y^n(t))\\ &\overset{a.s.}\longrightarrow \mathbb E\left[\mu_1(t)\mu_2(t)b^2(t,Y(t))\right]\Delta t,\end{align*}
leading to
 $\langle \overline W_1,\overline W_2 \rangle =0$
. By Lévy’s theorem, we conclude that
$\langle \overline W_1,\overline W_2 \rangle =0$
. By Lévy’s theorem, we conclude that
 $\overline W_1$
is independent of
$\overline W_1$
is independent of
 $\overline W_2$
.
$\overline W_2$
.
Remark 2. Indeed, the above construction follows from the framework of relaxed stochastic control. In classical control theory, the strategy
 $u(\omega,t)$
is a stochastic process that takes a deterministic value for fixed
$u(\omega,t)$
is a stochastic process that takes a deterministic value for fixed
 $\omega$
and t. When we randomize the strategy
$\omega$
and t. When we randomize the strategy
 $u(\omega,t)$
to
$u(\omega,t)$
to
 $\Pi(\omega,t)$
, then for each fixed
$\Pi(\omega,t)$
, then for each fixed
 $\omega$
and t,
$\omega$
and t,
 $\Pi(\omega,t)$
is a distribution on U, which we write as
$\Pi(\omega,t)$
is a distribution on U, which we write as
 $\Pi_t(\omega,\mathrm d u)$
. For any t, we can view
$\Pi_t(\omega,\mathrm d u)$
. For any t, we can view
 $\Pi_t(\omega,B)$
with
$\Pi_t(\omega,B)$
with
 $B \in \mathcal B(U)$
, as a probability kernel with source
$B \in \mathcal B(U)$
, as a probability kernel with source
 $(\Omega,\mathcal F_t)$
and target
$(\Omega,\mathcal F_t)$
and target
 $(U,\mathcal B(U))$
. By standard measure-theoretic results,
$(U,\mathcal B(U))$
. By standard measure-theoretic results,
 $\Pi_t(\omega,\cdot)$
together with the probability
$\Pi_t(\omega,\cdot)$
together with the probability
 $\mathbb P$
on
$\mathbb P$
on
 $(\Omega,\mathcal F_t)$
uniquely induces a measure
$(\Omega,\mathcal F_t)$
uniquely induces a measure
 $\mathbb Q$
on
$\mathbb Q$
on
 $(\Omega\times U,\mathcal F_t\times \mathcal B(U))$
satisfying
$(\Omega\times U,\mathcal F_t\times \mathcal B(U))$
satisfying
 $ \mathbb Q(\mathrm d\omega,\mathrm d u)=\Pi_t(\omega,\mathrm d u)\mathbb P(\mathrm d\omega).$
The sampling described above is thus carried out on the probability space
$ \mathbb Q(\mathrm d\omega,\mathrm d u)=\Pi_t(\omega,\mathrm d u)\mathbb P(\mathrm d\omega).$
The sampling described above is thus carried out on the probability space
 $(\Omega\times U,\mathcal F_t\times \mathcal B(U),\mathbb Q)$
. Therefore, by the generalized Fubini theorem, for any measurable function f on
$(\Omega\times U,\mathcal F_t\times \mathcal B(U),\mathbb Q)$
. Therefore, by the generalized Fubini theorem, for any measurable function f on
 $(\Omega\times U,\mathcal F_t\times \mathcal B(U),\mathbb Q)$
, we have
$(\Omega\times U,\mathcal F_t\times \mathcal B(U),\mathbb Q)$
, we have
 \begin{align*} \mathbb E^{\mathbb Q}[f]=\int_{\Omega\times U}f\mathrm d \mathbb Q=\int_{\Omega}\int_U f(\omega,u)\Pi_t(\omega,\mathrm d u)\mathrm d \mathbb P=\mathbb E\left[\int_U f(\omega,u)\Pi_t(\omega,\mathrm d u)\right].\end{align*}
\begin{align*} \mathbb E^{\mathbb Q}[f]=\int_{\Omega\times U}f\mathrm d \mathbb Q=\int_{\Omega}\int_U f(\omega,u)\Pi_t(\omega,\mathrm d u)\mathrm d \mathbb P=\mathbb E\left[\int_U f(\omega,u)\Pi_t(\omega,\mathrm d u)\right].\end{align*}
For
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $j\neq i$
, assume that Agent i takes into account not only his own wealth but also the wealth gap between himself and Agent j at the terminal time T. Given a strategy
$j\neq i$
, assume that Agent i takes into account not only his own wealth but also the wealth gap between himself and Agent j at the terminal time T. Given a strategy
 $\Pi_j\in \mathcal M^2$
employed by Agent j, Agent i will choose a strategy
$\Pi_j\in \mathcal M^2$
employed by Agent j, Agent i will choose a strategy
 $\Pi_i$
to maximize the following objective
$\Pi_i$
to maximize the following objective
 \begin{align}\begin{split} &\;\mathbb E_t[(1-k_i)X_i^{\Pi_i}(T)+k_i(X_i^{\Pi_i}(T)-X_j^{\Pi_j}(T))]-\dfrac{\gamma_i}{2}\mathrm{Var}_t[(1-k_i)X_i^{\Pi_i}(T)+k_i(X_i^{\Pi_i}(T)-X_j^{\Pi_j}(T))]\\ &=\mathbb E_t[X_i^{\Pi_i}(T)-k_iX_j^{\Pi_j}(T)]-\dfrac{\gamma_i}{2}\mathrm{Var}_t[X_i^{\Pi_i}(T)-k_iX_j^{\Pi_j}(T)],\end{split}\end{align}
\begin{align}\begin{split} &\;\mathbb E_t[(1-k_i)X_i^{\Pi_i}(T)+k_i(X_i^{\Pi_i}(T)-X_j^{\Pi_j}(T))]-\dfrac{\gamma_i}{2}\mathrm{Var}_t[(1-k_i)X_i^{\Pi_i}(T)+k_i(X_i^{\Pi_i}(T)-X_j^{\Pi_j}(T))]\\ &=\mathbb E_t[X_i^{\Pi_i}(T)-k_iX_j^{\Pi_j}(T)]-\dfrac{\gamma_i}{2}\mathrm{Var}_t[X_i^{\Pi_i}(T)-k_iX_j^{\Pi_j}(T)],\end{split}\end{align}
where
 $\mathbb E_t(\!\cdot\!)$
and
$\mathbb E_t(\!\cdot\!)$
and
 $\mathrm{Var}_t(\!\cdot\!)$
denote the conditional expectation and variance with given
$\mathrm{Var}_t(\!\cdot\!)$
denote the conditional expectation and variance with given
 $X_1^{\Pi_1}(t)$
,
$X_1^{\Pi_1}(t)$
,
 $X_2^{\Pi_2}(t)$
and Y(t), respectively,
$X_2^{\Pi_2}(t)$
and Y(t), respectively,
 $\gamma_i\gt0$
represents the risk-aversion coefficient for Agent i, and
$\gamma_i\gt0$
represents the risk-aversion coefficient for Agent i, and
 $k_i\in (0,1)$
measures the sensitivity of Agent i to the performance of Agent j. Notably, a larger
$k_i\in (0,1)$
measures the sensitivity of Agent i to the performance of Agent j. Notably, a larger
 $k_i$
implies that Agent i emphasis on the relative performance against his opponent (Agent j), thereby intensifying the competitiveness of the game. Similar models addressing relative performance concerns, which do not incorporate RL, have been studied in the literature. For related discussions, see, for example, Bensoussan et al. (Reference Bensoussan, Siu, Yam and Yang2014), as well as the relevant references cited in our introduction.
$k_i$
implies that Agent i emphasis on the relative performance against his opponent (Agent j), thereby intensifying the competitiveness of the game. Similar models addressing relative performance concerns, which do not incorporate RL, have been studied in the literature. For related discussions, see, for example, Bensoussan et al. (Reference Bensoussan, Siu, Yam and Yang2014), as well as the relevant references cited in our introduction.
Remark 3. Unlike the objective of maximizing the insurer’s utility in a nonzero-sum game (see, e.g., Browne, Reference Browne2000 and Bensoussan et al. Reference Bensoussan, Siu, Yam and Yang2014), we consider a mean-variance objective as in Wang et al. (Reference Wang, Zhang, Jin and Qian2019) and (Reference Wang, Zhang, Jin and Qian2021). On one hand, the agents seek to maximize the expected wealth gap; on the other hand, they prioritize stability and predictability over excessive volatility. By minimizing the variance of the wealth gap, the agent reduces uncertainty in their relative wealth position, aligning with standard assumptions of risk aversion.
Let
 $\hat X_i^{\Pi_i,\Pi_j}(t)=X_i^{\Pi_i}(t)-k_iX_j^{\Pi_j}(t)$
be the wealth difference of the two agents. It is obvious from (2.9) that
$\hat X_i^{\Pi_i,\Pi_j}(t)=X_i^{\Pi_i}(t)-k_iX_j^{\Pi_j}(t)$
be the wealth difference of the two agents. It is obvious from (2.9) that
 $\hat X_i^{\Pi_i,\Pi_j}(t)$
follows the dynamic
$\hat X_i^{\Pi_i,\Pi_j}(t)$
follows the dynamic
 \begin{align}\begin{split} \mathrm{d} \hat X_i^{\Pi_i,\Pi_j}(t)&=b(t,Y(t))[\theta(t,Y(t))(\mu_i(t)-k_i\mu_j(t))\mathrm{d} t\\ &\quad +(\mu_i(t)-k_i\mu_j(t))\mathrm{d} W(t)+\sigma_i(t)\mathrm{d}\overline W_i(t)-k_i\sigma_j(t)\mathrm{d}\overline W_j(t)].\end{split}\end{align}
\begin{align}\begin{split} \mathrm{d} \hat X_i^{\Pi_i,\Pi_j}(t)&=b(t,Y(t))[\theta(t,Y(t))(\mu_i(t)-k_i\mu_j(t))\mathrm{d} t\\ &\quad +(\mu_i(t)-k_i\mu_j(t))\mathrm{d} W(t)+\sigma_i(t)\mathrm{d}\overline W_i(t)-k_i\sigma_j(t)\mathrm{d}\overline W_j(t)].\end{split}\end{align}
2.2 Objective function
We employ the Choquet regularizer
 $\Phi_h$
to quantify randomness. Given a concave function
$\Phi_h$
to quantify randomness. Given a concave function
 $h\;:\;[0,1]\to \mathbb{R}$
of bounded variation with
$h\;:\;[0,1]\to \mathbb{R}$
of bounded variation with
 $h(0)=h(1)=0$
and
$h(0)=h(1)=0$
and
 $\Pi\in \mathcal M$
, the Choquet regularizer
$\Pi\in \mathcal M$
, the Choquet regularizer
 $\Phi_h$
on
$\Phi_h$
on
 $\mathcal M$
is defined as
$\mathcal M$
is defined as
 \begin{equation}\Phi_h(\Pi)= \int_\mathbb{R} h\circ \Pi([x,\infty))\mathrm{d} x.\end{equation}
\begin{equation}\Phi_h(\Pi)= \int_\mathbb{R} h\circ \Pi([x,\infty))\mathrm{d} x.\end{equation}
We denote the set of
 $h\;:\;[0,1]\to \mathbb{R}$
by
$h\;:\;[0,1]\to \mathbb{R}$
by
 $\mathcal H$
. In fact, (2.12) is a signed Choquet integral characterized by Wang et al. (Reference Wang, Wei and Willmot2020c) via comonotonic additivity, which essentially builds on the seminal works of Schmeidler (Reference Schmeidler1989) and Yaari (Reference Yaari1987).
$\mathcal H$
. In fact, (2.12) is a signed Choquet integral characterized by Wang et al. (Reference Wang, Wei and Willmot2020c) via comonotonic additivity, which essentially builds on the seminal works of Schmeidler (Reference Schmeidler1989) and Yaari (Reference Yaari1987).
As stated in Lemma 2.2 of Han et al. (Reference Han, Wang and Zhou2023), the regularizer
 $\Phi_h$
is rigorously defined and serves as an important metric for quantifying the degree of randomness or exploration within the context of RL. Specifically, the concavity of h ensures that
$\Phi_h$
is rigorously defined and serves as an important metric for quantifying the degree of randomness or exploration within the context of RL. Specifically, the concavity of h ensures that
 $\Phi_h$
is also concave. This means that
$\Phi_h$
is also concave. This means that
 $\Phi_h(\lambda \Pi_1 + (1-\lambda) \Pi_2 ) \geqslant \lambda \Phi_h( \Pi_1) + (1-\lambda) \Phi_h(\Pi_2 )$
for all
$\Phi_h(\lambda \Pi_1 + (1-\lambda) \Pi_2 ) \geqslant \lambda \Phi_h( \Pi_1) + (1-\lambda) \Phi_h(\Pi_2 )$
for all
 $\Pi_1,\Pi_2\in \mathcal M$
and
$\Pi_1,\Pi_2\in \mathcal M$
and
 $\lambda\in [0,1],$
which intuitively implies that the linear combination of two distributions is more random. Moreover, the condition
$\lambda\in [0,1],$
which intuitively implies that the linear combination of two distributions is more random. Moreover, the condition
 $h(0)=h(1)=0$
means for any
$h(0)=h(1)=0$
means for any
 $c\in\mathbb{R}$
,
$c\in\mathbb{R}$
,
 $\Phi_h(\delta_c)=0$
, where
$\Phi_h(\delta_c)=0$
, where
 $\delta_c$
is the Dirac mass at c. This indicates that degenerate distributions do not have any randomness measured by
$\delta_c$
is the Dirac mass at c. This indicates that degenerate distributions do not have any randomness measured by
 $\Phi_h$
. Additionally, the agents have the flexibility to opt for different regularizers, contingent upon their preferences, as reflected by the distortion function h. For more detailed discussions about the properties associated with
$\Phi_h$
. Additionally, the agents have the flexibility to opt for different regularizers, contingent upon their preferences, as reflected by the distortion function h. For more detailed discussions about the properties associated with
 $\Phi_h$
, we refer to Han et al. (Reference Han, Wang and Zhou2023) and Guo et al. (Reference Guo, Han and Wang2025).
$\Phi_h$
, we refer to Han et al. (Reference Han, Wang and Zhou2023) and Guo et al. (Reference Guo, Han and Wang2025).
It is useful to note that
 $\Phi_h$
admits a quantile representation, see Lemma 1 of Wang et al. (Reference Wang, Wang and Wei2020b). For a distribution
$\Phi_h$
admits a quantile representation, see Lemma 1 of Wang et al. (Reference Wang, Wang and Wei2020b). For a distribution
 $\Pi\in\mathcal{M}$
, let its left-quantile for
$\Pi\in\mathcal{M}$
, let its left-quantile for
 $p\in(0,1]$
be defined as
$p\in(0,1]$
be defined as
 $$Q_\Pi(p)=\inf \left\{x\in \mathbb{R}\;:\; \Pi(x) \geqslant p\right\}, $$
$$Q_\Pi(p)=\inf \left\{x\in \mathbb{R}\;:\; \Pi(x) \geqslant p\right\}, $$
then we have
 \begin{equation}\Phi_h(\Pi) =\int_0^1 Q_\Pi(1-p) \mathrm{d} h(p) \end{equation}
\begin{equation}\Phi_h(\Pi) =\int_0^1 Q_\Pi(1-p) \mathrm{d} h(p) \end{equation}
if h is left-continuous.
For any fixed
 $\Pi_j \in \mathcal M^2$
, we incorporate the Choquet regularizer
$\Pi_j \in \mathcal M^2$
, we incorporate the Choquet regularizer
 $\Phi_{h_i}$
for Agent i, along with the exploration weight function
$\Phi_{h_i}$
for Agent i, along with the exploration weight function
 $\lambda_i(t)$
, into the mean-variance criterion (2.10). This regularizer plays a role analogous to differential entropy in entropy-regularized reinforcement learning (e.g., Wang et al., Reference Wang, Zariphopoulou and Zhou2020a; Wang and Zhou, Reference Wang and Zhou2020), serving to prevent the learned policy from collapsing to a deterministic solution. Thus, each agent aims to achieve an exploratory mean-variance problem within the framework of RL. This yields the corresponding objective function
$\lambda_i(t)$
, into the mean-variance criterion (2.10). This regularizer plays a role analogous to differential entropy in entropy-regularized reinforcement learning (e.g., Wang et al., Reference Wang, Zariphopoulou and Zhou2020a; Wang and Zhou, Reference Wang and Zhou2020), serving to prevent the learned policy from collapsing to a deterministic solution. Thus, each agent aims to achieve an exploratory mean-variance problem within the framework of RL. This yields the corresponding objective function
 \begin{align} J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j)\;:\!=\;\mathbb E_t\left[\int_t^T\lambda_i(s)\Phi_{h_i}(\Pi_i(s))ds+\hat X_i^{\Pi_i,\Pi_j}(T)\right]-\dfrac{\gamma_i}{2}\mathrm{Var}_t[\hat X_i^{\Pi_i,\Pi_j}(T)],\end{align}
\begin{align} J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j)\;:\!=\;\mathbb E_t\left[\int_t^T\lambda_i(s)\Phi_{h_i}(\Pi_i(s))ds+\hat X_i^{\Pi_i,\Pi_j}(T)\right]-\dfrac{\gamma_i}{2}\mathrm{Var}_t[\hat X_i^{\Pi_i,\Pi_j}(T)],\end{align}
where
 $\hat X_i^{\Pi_i,\Pi_j}(t)=\hat x_i$
and
$\hat X_i^{\Pi_i,\Pi_j}(t)=\hat x_i$
and
 $\ Y(t)=y$
with t representing the initial time.
$\ Y(t)=y$
with t representing the initial time.
Remark 4. We note that a larger
 $\lambda_i(t)$
promotes increased exploration, as it results in a higher weight on
$\lambda_i(t)$
promotes increased exploration, as it results in a higher weight on
 $\Phi_{h_i}(\Pi_i(t))$
. When
$\Phi_{h_i}(\Pi_i(t))$
. When
 $\lambda_i(t) \equiv \lambda_i$
, the exploration weight remains constant over time. It is often more realistic to set
$\lambda_i(t) \equiv \lambda_i$
, the exploration weight remains constant over time. It is often more realistic to set
 $\lambda_i(t)$
to decrease over time; for instance,
$\lambda_i(t)$
to decrease over time; for instance,
 $\lambda(t)$
may follow a power-decaying pattern, expressed as
$\lambda(t)$
may follow a power-decaying pattern, expressed as
 $\lambda_i(t) = \lambda_0 (T+\lambda)^{\lambda_0}/(t+\lambda)^{\lambda_0+1} $
with
$\lambda_i(t) = \lambda_0 (T+\lambda)^{\lambda_0}/(t+\lambda)^{\lambda_0+1} $
with
 $\lambda_0, \lambda \gt 0$
. Alternatively,
$\lambda_0, \lambda \gt 0$
. Alternatively,
 $\lambda_i(t)$
may decay exponentially with
$\lambda_i(t)$
may decay exponentially with
 $\lambda_i(t) = \lambda_0 e^{\lambda_0(T-t)}$
with
$\lambda_i(t) = \lambda_0 e^{\lambda_0(T-t)}$
with
 $\lambda_0 \gt 0$
. For further discussions on selecting
$\lambda_0 \gt 0$
. For further discussions on selecting
 $\lambda_i(t)$
, we refer to Section 3.4 of Jiang et al. (Reference Jiang, Saunders and Weng2022).
$\lambda_i(t)$
, we refer to Section 3.4 of Jiang et al. (Reference Jiang, Saunders and Weng2022).
For
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
, denote by
$i\neq j$
, denote by
 $\mathcal A(\boldsymbol{\Pi}_j)$
the set of all admissible feedback control of
$\mathcal A(\boldsymbol{\Pi}_j)$
the set of all admissible feedback control of
 $\boldsymbol{\Pi}_i$
. Given
$\boldsymbol{\Pi}_i$
. Given
 $\boldsymbol{\Pi}_j \in \mathcal M^2$
,
$\boldsymbol{\Pi}_j \in \mathcal M^2$
,
 $\boldsymbol{\Pi}_i$
is said to be in
$\boldsymbol{\Pi}_i$
is said to be in
 $\mathcal A(\boldsymbol{\Pi}_j)$
if the following conditions hold:
$\mathcal A(\boldsymbol{\Pi}_j)$
if the following conditions hold:
-
(i) For each
$s\in[t,T]$
,
$\Pi_i(s)\in \mathcal M^2(\mathbb R)$
; -
(ii) There exists a deterministic mapping
$\xi_i\;:\;[t,T]\times\mathbb R \times\mathbb R\to \mathcal M^2(\mathbb R)$
, such that
$\Pi_i(s)=\xi_i(s,\hat X_i^{\Pi_i,\Pi_j}(s),Y(s))$
; -
(iii) For any
$A \in \mathcal B(\mathbb R)$
,
$\{\int_A\Pi_i(s,u)\mathrm{d} u, t\leqslant s \leqslant T\} $
is
$\mathcal F_s$
–progressively measurable; -
(iv)
$\mathbb E_t\int_t^T [|b(s,Y(s))\theta(s,Y(s))(\mu_i(s)-k_i\mu_j(s))|+b^2(s,Y(s))(\mu_i^2(s)+\sigma^2_i(s))]ds\lt \infty$
; -
(v)
$\mathbb E_t\int_t^T|\lambda_i(s)\Phi_{h_i}(\Pi_i(s))|ds \lt\infty $
.









Next, we define the profile of the game, which encapsulates the comprehensive strategic behavior of both agents in the game.
Definition 1. A strategy pair
 $(\boldsymbol{\Pi}_1,\boldsymbol{\Pi}_2)$
is called the profile of the game if it satisfies the following conditions: given the strategy
$(\boldsymbol{\Pi}_1,\boldsymbol{\Pi}_2)$
is called the profile of the game if it satisfies the following conditions: given the strategy
 $\boldsymbol{\Pi}_2$
,
$\boldsymbol{\Pi}_2$
,
 $\boldsymbol{\Pi}_1$
is an admissible feedback control, and conversely, given the strategy
$\boldsymbol{\Pi}_1$
is an admissible feedback control, and conversely, given the strategy
 $\boldsymbol{\Pi}_1$
,
$\boldsymbol{\Pi}_1$
,
 $\boldsymbol{\Pi}_2$
is also an admissible feedback control.
$\boldsymbol{\Pi}_2$
is also an admissible feedback control.
As mentioned in the introduction, to seek the time-consistent equilibrium strategy, we formulate the time-inconsistent dynamic optimization problem into a noncooperative game theoretic framework proposed by Björk and Murgoci (Reference Björk and Murgoci2014) and Björk et al. (Reference Björk, Khapko and Murgoci2017).
Definition 2. Let
 $(\boldsymbol{\Pi}_1,\boldsymbol{\Pi}_2)$
be a profile of the game. For
$(\boldsymbol{\Pi}_1,\boldsymbol{\Pi}_2)$
be a profile of the game. For
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
,
$i\neq j$
,
 $\boldsymbol{\Pi}_i$
is said to be equilibrium response of Agent i if for a fixed
$\boldsymbol{\Pi}_i$
is said to be equilibrium response of Agent i if for a fixed
 $\Delta$
and for any initial state
$\Delta$
and for any initial state
 $(t,\hat x_i,y)$
and an arbitrary
$(t,\hat x_i,y)$
and an arbitrary
 $\eta_i\in\mathcal M^2$
,
$\eta_i\in\mathcal M^2$
,
 $\boldsymbol{\Pi}_i^{\eta_i,\Delta}$
defined by
$\boldsymbol{\Pi}_i^{\eta_i,\Delta}$
defined by
 \begin{align*} \Pi_i^{\eta_i,\Delta}(s)=\left\{ \begin{aligned} &\eta_i,&t\leqslant s\leqslant t+\Delta,\\ &\Pi_i(s),&t+\Delta\leqslant s\leqslant T, \end{aligned} \right. \end{align*}
\begin{align*} \Pi_i^{\eta_i,\Delta}(s)=\left\{ \begin{aligned} &\eta_i,&t\leqslant s\leqslant t+\Delta,\\ &\Pi_i(s),&t+\Delta\leqslant s\leqslant T, \end{aligned} \right. \end{align*}
satisfying
 \begin{align*} \liminf\limits_{\Delta\rightarrow 0^+}\dfrac{J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j)-J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i^{\eta_i,\Delta},\boldsymbol{\Pi}_j)}{\Delta}\geqslant 0. \end{align*}
\begin{align*} \liminf\limits_{\Delta\rightarrow 0^+}\dfrac{J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j)-J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i^{\eta_i,\Delta},\boldsymbol{\Pi}_j)}{\Delta}\geqslant 0. \end{align*}
The equilibrium response
 $\boldsymbol{\Pi}_i$
of Agent i can be viewed as a mapping of
$\boldsymbol{\Pi}_i$
of Agent i can be viewed as a mapping of
 $\boldsymbol{\Pi}_j$
, and thus can be written as
$\boldsymbol{\Pi}_j$
, and thus can be written as
 $\boldsymbol{\Pi}_i=\kappa_i(\boldsymbol{\Pi}_j)$
at this point. Furthermore, the equilibrium response value function of Agent i is defined as
$\boldsymbol{\Pi}_i=\kappa_i(\boldsymbol{\Pi}_j)$
at this point. Furthermore, the equilibrium response value function of Agent i is defined as
 \begin{align*} \widetilde V_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_j)\;:\!=\;J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j). \end{align*}
\begin{align*} \widetilde V_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_j)\;:\!=\;J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j). \end{align*}
3. Time-consistent Nash equilibrium
In this section, we present the Nash equilibrium for a general incomplete market. It is important to emphasize that the uniqueness of the equilibrium policy remains an open question in the context of time-inconsistent optimization problems, as discussed by Ekeland and Pirvu (Reference Ekeland and Pirvu2008). Therefore, within the framework of game theory, we focus on a specific Nash equilibrium defined below.
Definition 3. A profile
 $(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
is called the time-consistent Nash equilibrium of the game if for
$(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
is called the time-consistent Nash equilibrium of the game if for
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
,
$i\neq j$
,
 $\boldsymbol{\Pi}_i^*$
is the equilibrium response of Agent i, that is
$\boldsymbol{\Pi}_i^*$
is the equilibrium response of Agent i, that is
 $\boldsymbol{\Pi}_1^*=\kappa_1(\boldsymbol{\Pi}_2^*)$
and
$\boldsymbol{\Pi}_1^*=\kappa_1(\boldsymbol{\Pi}_2^*)$
and
 $\boldsymbol{\Pi}_2^*=\kappa_2(\boldsymbol{\Pi}_1^*)$
. Furthermore, the equilibrium value function of Agent i is given by
$\boldsymbol{\Pi}_2^*=\kappa_2(\boldsymbol{\Pi}_1^*)$
. Furthermore, the equilibrium value function of Agent i is given by
 \begin{align*} V_i(t,\hat x_i,y)\;:\!=\;\widetilde V_i(t,\hat x_i,y;\;\boldsymbol{\Pi}^*_j)=J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i^*,\boldsymbol{\Pi}_j^*). \end{align*}
\begin{align*} V_i(t,\hat x_i,y)\;:\!=\;\widetilde V_i(t,\hat x_i,y;\;\boldsymbol{\Pi}^*_j)=J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}_i^*,\boldsymbol{\Pi}_j^*). \end{align*}
3.1 Verification theorem
Analogous to the work of Björk et al. (Reference Björk, Khapko and Murgoci2017) on optimization problems involving a broad class of objective functionals, we present the following verification theorem.
Let
 $\mathcal{D}=[0,T]\times\mathbb{R}^2$
and then for any
$\mathcal{D}=[0,T]\times\mathbb{R}^2$
and then for any
 $\varphi\in C^{1,2,2}(\mathcal{D})$
, we can denote the infinitesimal generator of
$\varphi\in C^{1,2,2}(\mathcal{D})$
, we can denote the infinitesimal generator of
 $(\hat X^{\Pi_i,\Pi_j}(t),Y(t))$
by
$(\hat X^{\Pi_i,\Pi_j}(t),Y(t))$
by
 \begin{equation}\begin{aligned} \mathcal L^{\Pi_i,\Pi_j}\varphi(t, x, y)=&\displaystyle\frac{\partial\varphi}{\partial t}+b(t,y)\theta(t,y)(\mu_i(t)-k_i\mu_j(t)) \frac{\partial\varphi}{\partial x} +\frac{1}{2}b^2(t,y)\left((\mu_i(t)-k_i\mu_j(t))^2\right.\\&\left.+\sigma^2_i(t)+k^2_i\sigma^2_j(t)\right)\frac{\partial^2\varphi}{\partial x^2} + m(t,y)\frac{\partial\varphi}{\partial y}+\frac{1}{2}v^2(t,y) \frac{\partial^2\varphi}{\partial y^2}\\&+ \rho v(t,y) b(t,y)(\mu_i(t)-k_i \mu_j(t))\frac{\partial^2\varphi}{\partial x \partial y }.\end{aligned}\end{equation}
\begin{equation}\begin{aligned} \mathcal L^{\Pi_i,\Pi_j}\varphi(t, x, y)=&\displaystyle\frac{\partial\varphi}{\partial t}+b(t,y)\theta(t,y)(\mu_i(t)-k_i\mu_j(t)) \frac{\partial\varphi}{\partial x} +\frac{1}{2}b^2(t,y)\left((\mu_i(t)-k_i\mu_j(t))^2\right.\\&\left.+\sigma^2_i(t)+k^2_i\sigma^2_j(t)\right)\frac{\partial^2\varphi}{\partial x^2} + m(t,y)\frac{\partial\varphi}{\partial y}+\frac{1}{2}v^2(t,y) \frac{\partial^2\varphi}{\partial y^2}\\&+ \rho v(t,y) b(t,y)(\mu_i(t)-k_i \mu_j(t))\frac{\partial^2\varphi}{\partial x \partial y }.\end{aligned}\end{equation}
Let
 $\hat X_i^{u_i,u_j}(t)=X_i^{u_i}(t)-k_iX_j^{u_j}(t)$
and denote the infinitesimal generator of
$\hat X_i^{u_i,u_j}(t)=X_i^{u_i}(t)-k_iX_j^{u_j}(t)$
and denote the infinitesimal generator of
 $(\hat X_i^{u_i,u_j}(t),Y(t))$
by
$(\hat X_i^{u_i,u_j}(t),Y(t))$
by
 $\mathcal L^{u_i,u_j}$
. It can be directly verified that
$\mathcal L^{u_i,u_j}$
. It can be directly verified that
 $\mathcal L^{\Pi_i,\Pi_j}\varphi(t, x, y)=\int_{\mathbb R}\int_{\mathbb R}\mathcal L^{u_i,u_j}\varphi(t, x, y)\mathrm{d}\Pi_i(u_i)\mathrm{d}\Pi_j(u_j)$
.
$\mathcal L^{\Pi_i,\Pi_j}\varphi(t, x, y)=\int_{\mathbb R}\int_{\mathbb R}\mathcal L^{u_i,u_j}\varphi(t, x, y)\mathrm{d}\Pi_i(u_i)\mathrm{d}\Pi_j(u_j)$
.
Theorem 1 (Verification theorem). For
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
, fix
$i\neq j$
, fix
 $\boldsymbol{\Pi}_j$
and suppose that functions
$\boldsymbol{\Pi}_j$
and suppose that functions
 $V_i(t,x,y)\in C^{1,2,2}(\mathcal{D})$
,
$V_i(t,x,y)\in C^{1,2,2}(\mathcal{D})$
,
 $g_i(t,x,y)\in C^{1,2,2}(\mathcal{D})$
and strategy
$g_i(t,x,y)\in C^{1,2,2}(\mathcal{D})$
and strategy
 $\boldsymbol{\Pi}_i$
satisfy the following properties:
$\boldsymbol{\Pi}_i$
satisfy the following properties:
-
(i)
$V_i$
and
$g_i$
solve the extended HJB system (3.2)and
\begin{align} &\sup\limits_{\Pi_i\in \mathcal M^2}\left\{\mathcal L^{\Pi_i,\Pi_j}V_i(t,\hat x_i,y)-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}g_i^2(t,\hat x_i,y)+\gamma_ig_i\mathcal L^{\Pi_i,\Pi_j}g_i(t,\hat x_i,y)+\lambda_i(t)\Phi_{h_i}(\Pi_i) \right\}=0, \end{align}
(3.3)with
\begin{align} \mathcal L^{\Pi_i^*,\Pi_j}g_i(t,\hat x_i,y)=0 \end{align}
(3.4)where
\begin{align} V_i(T,\hat x_i,y)=\hat x_i,\ g_i(T,\hat x_i,y)=\hat x_i, \end{align}
$\mathcal L^{\Pi_i,\Pi_j}$
is the infinitesimal generator given by (3.1).
-
(ii)
$\Pi_i^*$
realizes the supremum in (3.2) and
$\boldsymbol{\Pi}^*_i=\{\Pi^*_i(t),0\leqslant t\leqslant T\}$
is admissible.








Then
 $\boldsymbol{\Pi}^*_i$
is the equilibrium response of Agent i. Furthermore,
$\boldsymbol{\Pi}^*_i$
is the equilibrium response of Agent i. Furthermore,
 $V_i(t,\hat x_i,y)=J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}^*_i,\boldsymbol{\Pi}_j)$
is the equilibrium response value function of Agent i and
$V_i(t,\hat x_i,y)=J_i(t,\hat x_i,y;\;\boldsymbol{\Pi}^*_i,\boldsymbol{\Pi}_j)$
is the equilibrium response value function of Agent i and
 $g_i(t,\hat x_i,y)=\mathbb E_t[\hat X_i^{\Pi^*_i,\Pi_j}(T)]$
.
$g_i(t,\hat x_i,y)=\mathbb E_t[\hat X_i^{\Pi^*_i,\Pi_j}(T)]$
.
3.2 Solution to the general case
While the preservation of the uniqueness of equilibrium response remains uncertain, the aforementioned theorem provides a constructive framework for identifying a specific Nash equilibrium. We first concentrate on the equilibrium response of Agent 1, and analogous results for Agent 2 can be obtained using the same method. It is assumed that the equilibrium value function
 $V_1$
and the function
$V_1$
and the function
 $g_1$
can be precisely expressed as
$g_1$
can be precisely expressed as
 \begin{align} V_1(t,x,y)=x+D_1(t,y),\;\;\;g_1(t,x,y)=x+d_1(t,y).\end{align}
\begin{align} V_1(t,x,y)=x+D_1(t,y),\;\;\;g_1(t,x,y)=x+d_1(t,y).\end{align}
It is obvious that
 $D_1(T,y)=d_1(T,y)=0$
. Using (3.1) and substituting (3.5) into (3.2), we streamline (3.2) to
$D_1(T,y)=d_1(T,y)=0$
. Using (3.1) and substituting (3.5) into (3.2), we streamline (3.2) to
 \begin{align}\begin{split} \sup\limits_{\Pi_1\in \mathcal M^2}&\left\{ \dfrac{\partial D_1(t,y)}{\partial t}+b(t,y)\theta(t,y)(\mu_1(t)-k_1\mu_2(t))+m(t,y)\dfrac{\partial D_1(t,y)}{\partial y}\right.\\ &-\dfrac{\gamma_1}{2}b^2(t,y)[(\mu_1^2(t)+\sigma_1^2(t))+k_1^2(\mu_2^2(t)+\sigma_2^2(t))-2k_1\mu_1(t)\mu_2(t)]\\ &-\dfrac{\gamma_1}{2}v^2(t,y)\left(\dfrac{\partial d_1(t,y)}{\partial y} \right)^2+\dfrac{1}{2}v^2(t,y)\dfrac{\partial ^2 D_1(t,y)}{\partial y^2}\\ &\left.-\gamma_1\rho v(t,y)b(t,y)(\mu_1(t)-k_1\mu_2(t))\dfrac{\partial d_1(t,y)}{\partial y}+\lambda_1(t)\Phi_{h_1}(\Pi_1)\right\}=0.\end{split}\end{align}
\begin{align}\begin{split} \sup\limits_{\Pi_1\in \mathcal M^2}&\left\{ \dfrac{\partial D_1(t,y)}{\partial t}+b(t,y)\theta(t,y)(\mu_1(t)-k_1\mu_2(t))+m(t,y)\dfrac{\partial D_1(t,y)}{\partial y}\right.\\ &-\dfrac{\gamma_1}{2}b^2(t,y)[(\mu_1^2(t)+\sigma_1^2(t))+k_1^2(\mu_2^2(t)+\sigma_2^2(t))-2k_1\mu_1(t)\mu_2(t)]\\ &-\dfrac{\gamma_1}{2}v^2(t,y)\left(\dfrac{\partial d_1(t,y)}{\partial y} \right)^2+\dfrac{1}{2}v^2(t,y)\dfrac{\partial ^2 D_1(t,y)}{\partial y^2}\\ &\left.-\gamma_1\rho v(t,y)b(t,y)(\mu_1(t)-k_1\mu_2(t))\dfrac{\partial d_1(t,y)}{\partial y}+\lambda_1(t)\Phi_{h_1}(\Pi_1)\right\}=0.\end{split}\end{align}
We can see from (3.6) that the supremum only depends on the mean and variance of
 $\Pi_1$
except
$\Pi_1$
except
 $\Phi_{h_1}(\Pi_1)$
. We proceed with our analysis relying on the crucial Lemma 1.
$\Phi_{h_1}(\Pi_1)$
. We proceed with our analysis relying on the crucial Lemma 1.
Lemma 1 (Theorem 3.1 of Liu et al. Reference Liu, Cai, Lemieux and Wang2020). If h is continuous and not constantly zero, then a maximizer
 $\Pi^*$
to the optimization problem
$\Pi^*$
to the optimization problem
 \begin{align}\max_{\Pi \in \mathcal M^2}\Phi_h (\Pi) \mbox{ subject to } \mu (\Pi) =m \;\mbox{and}\; \sigma^2 (\Pi) = s^2\end{align}
\begin{align}\max_{\Pi \in \mathcal M^2}\Phi_h (\Pi) \mbox{ subject to } \mu (\Pi) =m \;\mbox{and}\; \sigma^2 (\Pi) = s^2\end{align}
has the following quantile function
 \begin{equation}Q_{\Pi^*}(p) = m + s\frac{ h'(1-p) }{ ||h'||_2}, \;\; \mbox{ a.e. }p\in (0,1),\end{equation}
\begin{equation}Q_{\Pi^*}(p) = m + s\frac{ h'(1-p) }{ ||h'||_2}, \;\; \mbox{ a.e. }p\in (0,1),\end{equation}
and the maximum value of (3.7) is
 $\Phi_h(\Pi^*)= s||h'||_2$
.
$\Phi_h(\Pi^*)= s||h'||_2$
.
Let
 $\Lambda_1(\Pi_1)$
denote the expression enclosed in braces in (3.6). We then have the following proposition.
$\Lambda_1(\Pi_1)$
denote the expression enclosed in braces in (3.6). We then have the following proposition.
Proposition 1. Let
 $h_1\in \mathcal H$
be a continuous function. For any strategy
$h_1\in \mathcal H$
be a continuous function. For any strategy
 $\boldsymbol{\Pi}_1=\{\Pi_1(t),0\leqslant t\leqslant T\}\in \mathcal A(\boldsymbol{\Pi}_2)$
with mean process
$\boldsymbol{\Pi}_1=\{\Pi_1(t),0\leqslant t\leqslant T\}\in \mathcal A(\boldsymbol{\Pi}_2)$
with mean process
 $\{\mu_1(t)\}_{0\leqslant t\leqslant T}$
and variance process
$\{\mu_1(t)\}_{0\leqslant t\leqslant T}$
and variance process
 $\{\sigma_1(t)^2\}_{0\leqslant t\leqslant T}$
, there exists a strategy
$\{\sigma_1(t)^2\}_{0\leqslant t\leqslant T}$
, there exists a strategy
 $\boldsymbol{\Pi}^*_1=\{\Pi^*_1(t),0\leqslant t\leqslant T\}\in \mathcal A(\boldsymbol{\Pi}_2)$
defined by
$\boldsymbol{\Pi}^*_1=\{\Pi^*_1(t),0\leqslant t\leqslant T\}\in \mathcal A(\boldsymbol{\Pi}_2)$
defined by
 \begin{equation*}Q_{\Pi^*_1(t)}(p) = \mu_1(t) + \sigma_1(t)\frac{ h_1'(1-p) }{ ||h_1'||_2}, \;\; \;\;\mbox{ a.e.}\;p\in (0,1),\;\;0\leqslant t\leqslant T,\end{equation*}
\begin{equation*}Q_{\Pi^*_1(t)}(p) = \mu_1(t) + \sigma_1(t)\frac{ h_1'(1-p) }{ ||h_1'||_2}, \;\; \;\;\mbox{ a.e.}\;p\in (0,1),\;\;0\leqslant t\leqslant T,\end{equation*}
which shares the same mean and variance processes as
 $\boldsymbol{\Pi}_1$
and satisfies
$\boldsymbol{\Pi}_1$
and satisfies
 $\Lambda_1(\Pi_1(t)) \leqslant \Lambda_1(\Pi^*_1(t))$
.
$\Lambda_1(\Pi_1(t)) \leqslant \Lambda_1(\Pi^*_1(t))$
.
Proof. From (3.6),
 $\Lambda_1(\Pi_1)$
depends on
$\Lambda_1(\Pi_1)$
depends on
 $\Pi_1$
only through
$\Pi_1$
only through
 $\mu_1(\Pi_1)$
,
$\mu_1(\Pi_1)$
,
 $\sigma^2_1(\Pi_1)$
and
$\sigma^2_1(\Pi_1)$
and
 $\Phi_{h_1}(\Pi_1)$
. Since
$\Phi_{h_1}(\Pi_1)$
. Since
 $\boldsymbol{\Pi}_1^*$
has the same mean and variance processes as
$\boldsymbol{\Pi}_1^*$
has the same mean and variance processes as
 $\boldsymbol{\Pi}_1$
, the problem reduces to finding
$\boldsymbol{\Pi}_1$
, the problem reduces to finding
 $\boldsymbol{\Pi}_1^*$
that maximizes
$\boldsymbol{\Pi}_1^*$
that maximizes
 \begin{align} \max\limits_{\Pi_1(t)\in \mathcal{M^2}}\Phi_{h_1}(\Pi_1(t))\ \ \text{subject to }\mu_1(\Pi_1(t))=\mu_1(t),\ \sigma_1(\Pi_1(t))^2=\sigma_1(t)^2 \;\;\text{for all }t\in[0,T].\end{align}
\begin{align} \max\limits_{\Pi_1(t)\in \mathcal{M^2}}\Phi_{h_1}(\Pi_1(t))\ \ \text{subject to }\mu_1(\Pi_1(t))=\mu_1(t),\ \sigma_1(\Pi_1(t))^2=\sigma_1(t)^2 \;\;\text{for all }t\in[0,T].\end{align}
By Lemma 1, the maximizer
 $\Pi_1^*(t)$
of this problem has quantile function
$\Pi_1^*(t)$
of this problem has quantile function
 $$Q_{\Pi_1^*(t)}(p)=\mu_1(t)+\sigma_1(t)\dfrac{h_1'(1-p)}{\Vert h_1'\Vert_2},$$
$$Q_{\Pi_1^*(t)}(p)=\mu_1(t)+\sigma_1(t)\dfrac{h_1'(1-p)}{\Vert h_1'\Vert_2},$$
and satisfies
 $\Phi_{h_1}(\Pi_1^*(t))=\sigma_1(t)\Vert h_1'\Vert_2.$
This completes the proof.
$\Phi_{h_1}(\Pi_1^*(t))=\sigma_1(t)\Vert h_1'\Vert_2.$
This completes the proof.
To find the equilibrium response of Agent 1, we need to solve problem (3.6). Let
 $\mu_1^*(t)$
and
$\mu_1^*(t)$
and
 $\sigma_1^*(t)$
represent the mean and standard deviation of equilibrium response of Agent 1. As in the proof of Proposition 1, with given
$\sigma_1^*(t)$
represent the mean and standard deviation of equilibrium response of Agent 1. As in the proof of Proposition 1, with given
 $\mu_1(t)$
and
$\mu_1(t)$
and
 $\sigma_1(t)$
,
$\sigma_1(t)$
,
 $\Lambda_1(\Pi_1(t))$
only depends on
$\Lambda_1(\Pi_1(t))$
only depends on
 $\Phi_{h_1}(\Pi_1(t))$
. Thus, we can rewrite (3.6) as
$\Phi_{h_1}(\Pi_1(t))$
. Thus, we can rewrite (3.6) as
 \begin{align*} \max\limits_{\Pi_1\in \mathcal{M^2}}\Lambda_1(\Pi_1)=\max\limits_{m\in \mathbb R,s\gt0}\max\limits_{\substack{\Pi_1\in \mathcal{M^2}\\ \mu_1(\Pi_1)=m,\sigma_1(\Pi_1)^2=s^2}}\Lambda_1(\Pi_1).\end{align*}
\begin{align*} \max\limits_{\Pi_1\in \mathcal{M^2}}\Lambda_1(\Pi_1)=\max\limits_{m\in \mathbb R,s\gt0}\max\limits_{\substack{\Pi_1\in \mathcal{M^2}\\ \mu_1(\Pi_1)=m,\sigma_1(\Pi_1)^2=s^2}}\Lambda_1(\Pi_1).\end{align*}
The inner maximization problem is equivalent to (3.7) or (3.9), and its maximizer
 $\Pi_1$
satisfies
$\Pi_1$
satisfies
 $\Phi_{h_1}(\Pi_1)= s\Vert h_1'\Vert_2$
. Substituting it back into
$\Phi_{h_1}(\Pi_1)= s\Vert h_1'\Vert_2$
. Substituting it back into
 $\Lambda(\Pi_1)$
, we obtain
$\Lambda(\Pi_1)$
, we obtain
 \begin{align*} (\mu_1^*(t),\sigma_1^*(t))=&\mathop{\textrm{arg max}}\limits_{m\in \mathbb R,s\gt0}\left\{b(t,y)\theta(t,y)(m-k_1\mu_2(t))\right.\\ &-\dfrac{\gamma_1}{2}b^2(t,y)[(m^2+s^2)+k_1^2(\mu_2^2(t)+\sigma_2^2(t))-2k_1m\mu_2(t)]\\ &\left.-\gamma_1\rho v(t,y)b(t,y)(m-k_1\mu_2(t))\dfrac{\partial d_1(t,y)}{\partial y}+\lambda_1(t)s\Vert h_1'\Vert_2\right\}.\end{align*}
\begin{align*} (\mu_1^*(t),\sigma_1^*(t))=&\mathop{\textrm{arg max}}\limits_{m\in \mathbb R,s\gt0}\left\{b(t,y)\theta(t,y)(m-k_1\mu_2(t))\right.\\ &-\dfrac{\gamma_1}{2}b^2(t,y)[(m^2+s^2)+k_1^2(\mu_2^2(t)+\sigma_2^2(t))-2k_1m\mu_2(t)]\\ &\left.-\gamma_1\rho v(t,y)b(t,y)(m-k_1\mu_2(t))\dfrac{\partial d_1(t,y)}{\partial y}+\lambda_1(t)s\Vert h_1'\Vert_2\right\}.\end{align*}
By the first-order condition, we deduce that
 \begin{align*} b(t,y)\theta(t,y)-\gamma_1b^2(t,y)\mu_1^*(t)+k_1\gamma_1\mu_2(t)b^2(t,y)-\gamma_1\rho v(t,y)b(t,y)\dfrac{\partial d_1(t,y)}{\partial y}=0,\end{align*}
\begin{align*} b(t,y)\theta(t,y)-\gamma_1b^2(t,y)\mu_1^*(t)+k_1\gamma_1\mu_2(t)b^2(t,y)-\gamma_1\rho v(t,y)b(t,y)\dfrac{\partial d_1(t,y)}{\partial y}=0,\end{align*}
and
 \begin{align*} -\gamma_1b^2(t,y)\sigma_1^*(t)+\lambda_1(t)\Vert h_1'\Vert_2=0.\end{align*}
\begin{align*} -\gamma_1b^2(t,y)\sigma_1^*(t)+\lambda_1(t)\Vert h_1'\Vert_2=0.\end{align*}
So the mean and standard deviation of equilibrium response of Agent 1 are
 \begin{align} \mu_1^*(t)&=\dfrac{\theta(t,y)}{\gamma_1b(t,y)}+k_1\mu_2(t)-\dfrac{\rho v(t,y)}{b(t,y)}\dfrac{\partial d_1(t,y)}{\partial y},\end{align}
\begin{align} \mu_1^*(t)&=\dfrac{\theta(t,y)}{\gamma_1b(t,y)}+k_1\mu_2(t)-\dfrac{\rho v(t,y)}{b(t,y)}\dfrac{\partial d_1(t,y)}{\partial y},\end{align}
and
 \begin{align} \sigma_1^*(t)&=\dfrac{\lambda_1(t)\Vert h_1'\Vert_2}{\gamma_1b^2(t,y)}.\end{align}
\begin{align} \sigma_1^*(t)&=\dfrac{\lambda_1(t)\Vert h_1'\Vert_2}{\gamma_1b^2(t,y)}.\end{align}
By substituting (3.10) and (3.11) back into (3.3) and (3.6), we then get that
 $d_1(t,y)$
and
$d_1(t,y)$
and
 $D_1(t,y)$
, respectively, satisfy
$D_1(t,y)$
, respectively, satisfy
 \begin{align*} \dfrac{\partial d_1(t,y)}{\partial t}+(m(t,y)-\rho v(t,y)\theta(t,y))\dfrac{\partial d_1(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 d_1(t,y)}{\partial y^2}+\dfrac{\theta^2(t,y)}{\gamma_1}=0,\end{align*}
\begin{align*} \dfrac{\partial d_1(t,y)}{\partial t}+(m(t,y)-\rho v(t,y)\theta(t,y))\dfrac{\partial d_1(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 d_1(t,y)}{\partial y^2}+\dfrac{\theta^2(t,y)}{\gamma_1}=0,\end{align*}
and
 \begin{align*} &\dfrac{\partial D_1(t,y)}{\partial t}+m(t,y)\dfrac{\partial D_1(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 D_1}{\partial y^2}(t,y)\\ &-\dfrac{\gamma_1}{2}(1-\rho^2)v^2(t,y)\left(\dfrac{\partial d_1}{\partial y}(t,y)\right)^2 -\rho v(t,y)\theta(t,y)\dfrac{\partial d_1}{\partial y}\\ &+\dfrac{\theta^2(t,y)}{2\gamma_1}-\dfrac{\gamma_1k_1^2}{2}b^2(t,y)\sigma_2^2(t)+\dfrac{\lambda_1^2(t)\Vert h_1'\Vert_2^2}{2\gamma_1b^2(t,y)}=0.\end{align*}
\begin{align*} &\dfrac{\partial D_1(t,y)}{\partial t}+m(t,y)\dfrac{\partial D_1(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 D_1}{\partial y^2}(t,y)\\ &-\dfrac{\gamma_1}{2}(1-\rho^2)v^2(t,y)\left(\dfrac{\partial d_1}{\partial y}(t,y)\right)^2 -\rho v(t,y)\theta(t,y)\dfrac{\partial d_1}{\partial y}\\ &+\dfrac{\theta^2(t,y)}{2\gamma_1}-\dfrac{\gamma_1k_1^2}{2}b^2(t,y)\sigma_2^2(t)+\dfrac{\lambda_1^2(t)\Vert h_1'\Vert_2^2}{2\gamma_1b^2(t,y)}=0.\end{align*}
Repeating the procedure outlined above can yield results for Agent 2. So if
 $(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
constitutes a Nash equilibrium, we have
$(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
constitutes a Nash equilibrium, we have
 \begin{align} \left\{ \begin{aligned} \mu_1^*(t)-k_1\mu_2^*(t)&=\dfrac{\theta(t,y)}{\gamma_1b(t,y)}-\dfrac{\rho v(t,y)}{b(t,y)}\dfrac{\partial d_1(t,y)}{\partial y},\\ \mu_2^*(t)-k_2\mu_1^*(t)&=\dfrac{\theta(t,y)}{\gamma_2b(t,y)}-\dfrac{\rho v(t,y)}{b(t,y)}\dfrac{\partial d_2(t,y)}{\partial y}. \end{aligned} \right.\end{align}
\begin{align} \left\{ \begin{aligned} \mu_1^*(t)-k_1\mu_2^*(t)&=\dfrac{\theta(t,y)}{\gamma_1b(t,y)}-\dfrac{\rho v(t,y)}{b(t,y)}\dfrac{\partial d_1(t,y)}{\partial y},\\ \mu_2^*(t)-k_2\mu_1^*(t)&=\dfrac{\theta(t,y)}{\gamma_2b(t,y)}-\dfrac{\rho v(t,y)}{b(t,y)}\dfrac{\partial d_2(t,y)}{\partial y}. \end{aligned} \right.\end{align}
The solution to the system of equations can be directly calculated as
 \begin{align} \left\{ \begin{aligned} \mu_1^*(t)&=\dfrac{1}{1-k_1k_2}\left[\dfrac{\theta(t,y)}{b(t,y)}\left(\dfrac{1}{\gamma_1}+\dfrac{k_1}{\gamma_2}\right)-\dfrac{\rho v(t,y)}{b(t,y)}\left(\dfrac{\partial d_1(t,y)}{\partial y}+\dfrac{k_1\partial d_2(t,y)}{\partial y}\right)\right],\\ \mu_2^*(t)&=\dfrac{1}{1-k_1k_2}\left[\dfrac{\theta(t,y)}{b(t,y)}\left(\dfrac{1}{\gamma_2}+\dfrac{k_2}{\gamma_1}\right)-\dfrac{\rho v(t,y)}{b(t,y)}\left(\dfrac{\partial d_2(t,y)}{\partial y}+\dfrac{k_2\partial d_1(t,y)}{\partial y}\right)\right]. \end{aligned} \right.\end{align}
\begin{align} \left\{ \begin{aligned} \mu_1^*(t)&=\dfrac{1}{1-k_1k_2}\left[\dfrac{\theta(t,y)}{b(t,y)}\left(\dfrac{1}{\gamma_1}+\dfrac{k_1}{\gamma_2}\right)-\dfrac{\rho v(t,y)}{b(t,y)}\left(\dfrac{\partial d_1(t,y)}{\partial y}+\dfrac{k_1\partial d_2(t,y)}{\partial y}\right)\right],\\ \mu_2^*(t)&=\dfrac{1}{1-k_1k_2}\left[\dfrac{\theta(t,y)}{b(t,y)}\left(\dfrac{1}{\gamma_2}+\dfrac{k_2}{\gamma_1}\right)-\dfrac{\rho v(t,y)}{b(t,y)}\left(\dfrac{\partial d_2(t,y)}{\partial y}+\dfrac{k_2\partial d_1(t,y)}{\partial y}\right)\right]. \end{aligned} \right.\end{align}
Summarizing the above, we get following theorem.
Theorem 2. For
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
, let
$i\neq j$
, let
 $d_i(t,y)$
and
$d_i(t,y)$
and
 $D_i(t,y)$
be the solutions of
$D_i(t,y)$
be the solutions of
 \begin{align} \dfrac{\partial d_i(t,y)}{\partial t}+(m(t,y)-\rho v(t,y)\theta(t,y))\dfrac{\partial d_i(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 d_i}{\partial y^2}+\dfrac{\theta^2(t,y)}{\gamma_i}=0, \end{align}
\begin{align} \dfrac{\partial d_i(t,y)}{\partial t}+(m(t,y)-\rho v(t,y)\theta(t,y))\dfrac{\partial d_i(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 d_i}{\partial y^2}+\dfrac{\theta^2(t,y)}{\gamma_i}=0, \end{align}
and
 \begin{align} \begin{split} &\dfrac{\partial D_i(t,y)}{\partial t}+m(t,y)\dfrac{\partial D_i(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 D_i}{\partial y^2}(t,y)\\ &-\dfrac{\gamma_i}{2}(1-\rho^2)v^2(t,y)\left(\dfrac{\partial d_i}{\partial y}(t,y)\right)^2 -\rho v(t,y)\theta(t,y)\dfrac{\partial d_i}{\partial y}(t,y)\\ &+\dfrac{\theta^2(t,y)}{2\gamma_i}-\dfrac{\gamma_ik_i^2}{2}b^2(t,y)\sigma_j^2(t)+\dfrac{\lambda_i^2(t)\Vert h_i'\Vert_2^2}{2\gamma_ib^2(t,y)}=0, \end{split} \end{align}
\begin{align} \begin{split} &\dfrac{\partial D_i(t,y)}{\partial t}+m(t,y)\dfrac{\partial D_i(t,y)}{\partial y}+\dfrac{1}{2}v^2(t,y)\dfrac{\partial^2 D_i}{\partial y^2}(t,y)\\ &-\dfrac{\gamma_i}{2}(1-\rho^2)v^2(t,y)\left(\dfrac{\partial d_i}{\partial y}(t,y)\right)^2 -\rho v(t,y)\theta(t,y)\dfrac{\partial d_i}{\partial y}(t,y)\\ &+\dfrac{\theta^2(t,y)}{2\gamma_i}-\dfrac{\gamma_ik_i^2}{2}b^2(t,y)\sigma_j^2(t)+\dfrac{\lambda_i^2(t)\Vert h_i'\Vert_2^2}{2\gamma_ib^2(t,y)}=0, \end{split} \end{align}
with terminal condition
 $D_i(T,y)=d_i(T,y)=0$
. Then
$D_i(T,y)=d_i(T,y)=0$
. Then
 $(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
with quantile functions
$(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
with quantile functions
 \begin{align} \begin{split} Q_{\Pi_i^*(t)}(p)=&\dfrac{1}{1-k_1k_2}\left[\dfrac{\theta(t,y)}{b(t,y)}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)-\dfrac{\rho v(t,y)}{b(t,y)}\left(\dfrac{\partial d_i(t,y)}{\partial y}+\dfrac{k_i\partial d_j(t,y)}{\partial y}\right)\right]\\ &+\dfrac{\lambda_i(t)}{\gamma_ib^2(t,y)}h_i'(1-p) \end{split} \end{align}
\begin{align} \begin{split} Q_{\Pi_i^*(t)}(p)=&\dfrac{1}{1-k_1k_2}\left[\dfrac{\theta(t,y)}{b(t,y)}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)-\dfrac{\rho v(t,y)}{b(t,y)}\left(\dfrac{\partial d_i(t,y)}{\partial y}+\dfrac{k_i\partial d_j(t,y)}{\partial y}\right)\right]\\ &+\dfrac{\lambda_i(t)}{\gamma_ib^2(t,y)}h_i'(1-p) \end{split} \end{align}
is a Nash equilibrium with
 $p\in (0,1)$
, and
$p\in (0,1)$
, and
 $V_i(t,x,y)=x+D_i(t,y)$
is the equilibrium value function of Agent i.
$V_i(t,x,y)=x+D_i(t,y)$
is the equilibrium value function of Agent i.
From (3.16), it is evident that the equilibrium distribution of Agent i is uniquely determined by his own Choquet regularizer,
 $h'_i$
, and remains independent of his opponent’s regularizer,
$h'_i$
, and remains independent of his opponent’s regularizer,
 $h_j$
. Furthermore, (3.11) and (3.13) show that while the mean of Agent i’s distribution depends on both his own parameters and those of his opponent, the variance is solely determined by his own parameters, specifically
$h_j$
. Furthermore, (3.11) and (3.13) show that while the mean of Agent i’s distribution depends on both his own parameters and those of his opponent, the variance is solely determined by his own parameters, specifically
 $\lambda_i$
,
$\lambda_i$
,
 $h_i$
, and
$h_i$
, and
 $\gamma_i$
. These insights align with intuitive expectations in the context of RL. Although an opponent’s risk tolerance, sensitivity, or strategic decisions can influence the expected outcomes of the decision-making process, the degree of exploration, as reflected by variance, is solely a function of the agent’s intrinsic characteristics. Additionally, (3.11) shows that larger value of
$\gamma_i$
. These insights align with intuitive expectations in the context of RL. Although an opponent’s risk tolerance, sensitivity, or strategic decisions can influence the expected outcomes of the decision-making process, the degree of exploration, as reflected by variance, is solely a function of the agent’s intrinsic characteristics. Additionally, (3.11) shows that larger value of
 $\lambda_i$
indicates a stronger emphasis on exploration, leading to more dispersed exploration around the current position of Agent i. In contrast, an increase in the risk aversion parameter
$\lambda_i$
indicates a stronger emphasis on exploration, leading to more dispersed exploration around the current position of Agent i. In contrast, an increase in the risk aversion parameter
 $\gamma_i$
reflects a more cautious approach, leading to reduced variance in the exploratory strategy.
$\gamma_i$
reflects a more cautious approach, leading to reduced variance in the exploratory strategy.
3.3 Solution to Gauss mean return model
In this subsection, we examine the Gaussian mean return model as a special case of the state process Y(t) shown in Example 1, that is,
 \begin{align} a(t,y)=r+\sigma y,\ b(t,y)=\sigma,\ m(t,y)=\iota(Y-y),\ v(t,y)=v,\end{align}
\begin{align} a(t,y)=r+\sigma y,\ b(t,y)=\sigma,\ m(t,y)=\iota(Y-y),\ v(t,y)=v,\end{align}
where r,
 $\sigma$
,
$\sigma$
,
 $\iota$
, v, and Y are positive constants. Thus, by (2.2), we have
$\iota$
, v, and Y are positive constants. Thus, by (2.2), we have
 $\theta(t,y)=y$
. We formulate the following proposition as a direct consequence of Theorem 2.
$\theta(t,y)=y$
. We formulate the following proposition as a direct consequence of Theorem 2.
Proposition 2. For the Gauss mean return model,
 $p\in (0,1)$
,
$p\in (0,1)$
,
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
, profile
$i\neq j$
, profile
 $(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
with quantile functions
$(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
with quantile functions
 \begin{align} \begin{split} Q_{\Pi_i^*(t)}(p)=&\dfrac{1}{1-k_1k_2}\left[\dfrac{y}{\sigma}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)-\dfrac{\rho v}{\sigma}\left((a_2^i(t)+k_ia_2^j(t))y+(a_1^i(t)+k_ia_1^j(t))\right)\right]\\ &+\dfrac{\lambda_i(t)}{\gamma_i\sigma^2}h_i'(1-p), \end{split} \end{align}
\begin{align} \begin{split} Q_{\Pi_i^*(t)}(p)=&\dfrac{1}{1-k_1k_2}\left[\dfrac{y}{\sigma}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)-\dfrac{\rho v}{\sigma}\left((a_2^i(t)+k_ia_2^j(t))y+(a_1^i(t)+k_ia_1^j(t))\right)\right]\\ &+\dfrac{\lambda_i(t)}{\gamma_i\sigma^2}h_i'(1-p), \end{split} \end{align}
is a Nash equilibrium. Moreover, the corresponding equilibrium value function
 $V_i$
and
$V_i$
and
 $g_i$
have the following form
$g_i$
have the following form
 \begin{equation} V_i(t,\hat x_i,y)=\hat x_i+\dfrac{1}{2}b_2^i(t)y^2+b_1^i(t)y+b_0^i(t), \end{equation}
\begin{equation} V_i(t,\hat x_i,y)=\hat x_i+\dfrac{1}{2}b_2^i(t)y^2+b_1^i(t)y+b_0^i(t), \end{equation}
and
 \begin{equation} g_i(t,\hat x_i,y)=\hat x_i+\dfrac{1}{2}a_2^i(t)y^2+a_1^i(t)y+a_0^i(t), \end{equation}
\begin{equation} g_i(t,\hat x_i,y)=\hat x_i+\dfrac{1}{2}a_2^i(t)y^2+a_1^i(t)y+a_0^i(t), \end{equation}
where
 $a^i_n(t)$
,
$a^i_n(t)$
,
 $b^i_n(t)$
,
$b^i_n(t)$
,
 $n=0,1,2$
, are continuously differentiable functions defined as
$n=0,1,2$
, are continuously differentiable functions defined as
 \begin{align} \left\{ \begin{aligned} a_0^i(t)&=\dfrac{\iota^2 Y^2}{\gamma_i(\iota +\rho v)^2}\left(T-t+\frac{1-e^{-2(\iota+\rho v)(T-t)}}{2(\iota+\rho v)}-\frac{2(1-e^{-(\iota+\rho v)(T-t)})}{(\iota+\rho v)}\right)\\&\;\;\;\;+\dfrac{v^2}{2\gamma_i(\iota +\rho v)}\left(T-t-\frac{1-e^{-2(\iota+\rho v)(T-t)}}{2(\iota+\rho v)}\right), \\ a_1^i(t)&=\dfrac{\iota Y}{\gamma_i(\iota +\rho v)^2}[1-e^{-(\iota+\rho v)(T-t)}]^2,\\ a_2^i(t)&=\dfrac{1}{\gamma_i(\iota +\rho v)}[1-e^{-2(\iota+\rho v)(T-t)}], \end{aligned} \right. \end{align}
\begin{align} \left\{ \begin{aligned} a_0^i(t)&=\dfrac{\iota^2 Y^2}{\gamma_i(\iota +\rho v)^2}\left(T-t+\frac{1-e^{-2(\iota+\rho v)(T-t)}}{2(\iota+\rho v)}-\frac{2(1-e^{-(\iota+\rho v)(T-t)})}{(\iota+\rho v)}\right)\\&\;\;\;\;+\dfrac{v^2}{2\gamma_i(\iota +\rho v)}\left(T-t-\frac{1-e^{-2(\iota+\rho v)(T-t)}}{2(\iota+\rho v)}\right), \\ a_1^i(t)&=\dfrac{\iota Y}{\gamma_i(\iota +\rho v)^2}[1-e^{-(\iota+\rho v)(T-t)}]^2,\\ a_2^i(t)&=\dfrac{1}{\gamma_i(\iota +\rho v)}[1-e^{-2(\iota+\rho v)(T-t)}], \end{aligned} \right. \end{align}
and
 \begin{align} \left\{ \begin{aligned} {b_2^i}'(t)=&\;2\iota b_2^i(t)+\gamma_i(1-\rho^2)v^2a_2^i(t)^2+2\rho va_2^i(t) -\dfrac{1}{\gamma_i},\\ {b_1^i}'(t)=&\;\iota b_1^i(t)-\iota Yb_2^i(t)+\gamma_i(1-\rho^2)v^2a_2^i(t)a_1^i(t)+\rho va_1^i(t),\\ {b_0^i}'(t)=&-\iota Yb_1^i(t)-\dfrac{v^2}{2}b_2^i(t)+\dfrac{\gamma_i(1-\rho^2)v^2}{2}a_1^i(t)^2\\ &+\dfrac{\gamma_ik_i^2\sigma^2}{2}\sigma_j(t)^2-\dfrac{\lambda_i^2(t)\Vert h_i'\Vert_2^2}{2\gamma_i\sigma^2}, \end{aligned} \right. \end{align}
\begin{align} \left\{ \begin{aligned} {b_2^i}'(t)=&\;2\iota b_2^i(t)+\gamma_i(1-\rho^2)v^2a_2^i(t)^2+2\rho va_2^i(t) -\dfrac{1}{\gamma_i},\\ {b_1^i}'(t)=&\;\iota b_1^i(t)-\iota Yb_2^i(t)+\gamma_i(1-\rho^2)v^2a_2^i(t)a_1^i(t)+\rho va_1^i(t),\\ {b_0^i}'(t)=&-\iota Yb_1^i(t)-\dfrac{v^2}{2}b_2^i(t)+\dfrac{\gamma_i(1-\rho^2)v^2}{2}a_1^i(t)^2\\ &+\dfrac{\gamma_ik_i^2\sigma^2}{2}\sigma_j(t)^2-\dfrac{\lambda_i^2(t)\Vert h_i'\Vert_2^2}{2\gamma_i\sigma^2}, \end{aligned} \right. \end{align}
with
 $b_0^i(T)=b_1^i(T)= b_2^i(T)=0$
.
$b_0^i(T)=b_1^i(T)= b_2^i(T)=0$
.
Proof. For the Gauss mean return model, (3.14) can be simplified as
 \begin{align} \dfrac{\partial d_i(t,y)}{\partial t}+[\iota(Y-y)-\rho v y]\dfrac{\partial d_i(t,y)}{\partial y}+\dfrac{v^2}{2}\dfrac{\partial^2d_i(t,y)}{\partial y^2}+\dfrac{y^2}{\gamma_i}=0. \end{align}
\begin{align} \dfrac{\partial d_i(t,y)}{\partial t}+[\iota(Y-y)-\rho v y]\dfrac{\partial d_i(t,y)}{\partial y}+\dfrac{v^2}{2}\dfrac{\partial^2d_i(t,y)}{\partial y^2}+\dfrac{y^2}{\gamma_i}=0. \end{align}
By letting
 $d_i(t,y)=\dfrac{1}{2}a_2^i(t)y^2+a_1^i(t)y+a_0^i(t)$
and substituting it into (3.23), we obtain
$d_i(t,y)=\dfrac{1}{2}a_2^i(t)y^2+a_1^i(t)y+a_0^i(t)$
and substituting it into (3.23), we obtain
 \begin{align} \left\{ \begin{aligned} {a_2^i}'(t)&=2a_2^i(t)(\iota +\rho v)-\dfrac{2}{\gamma_i},& a_2^i(T)=0,\\ {a_1^i}'(t)&=a_1^i(t)(\iota +\rho v)-a_2^i(t)\iota Y,& a_1^i(T)=0,\\ {a_0^i}'(t)&=-a_1^i(t)\iota Y-\dfrac{v^2}{2}a_2^i(t),& a_0^i(T)=0. \end{aligned} \right. \end{align}
\begin{align} \left\{ \begin{aligned} {a_2^i}'(t)&=2a_2^i(t)(\iota +\rho v)-\dfrac{2}{\gamma_i},& a_2^i(T)=0,\\ {a_1^i}'(t)&=a_1^i(t)(\iota +\rho v)-a_2^i(t)\iota Y,& a_1^i(T)=0,\\ {a_0^i}'(t)&=-a_1^i(t)\iota Y-\dfrac{v^2}{2}a_2^i(t),& a_0^i(T)=0. \end{aligned} \right. \end{align}
It can be shown that (3.21) is the solution to (3.24). By substituting
 $d_i$
into (3.16), we derive (3.18). Consequently,
$d_i$
into (3.16), we derive (3.18). Consequently,
 $(\boldsymbol{\Pi}^*_1,\boldsymbol{\Pi}^*_2)$
is indeed a Nash equilibrium. Similarly, by simplifying (3.15), we can get
$(\boldsymbol{\Pi}^*_1,\boldsymbol{\Pi}^*_2)$
is indeed a Nash equilibrium. Similarly, by simplifying (3.15), we can get
 $D_i(t,y)=\dfrac{1}{2}b_2^i(t)y^2+b_1^i(t)y+b_0^i(t)$
with
$D_i(t,y)=\dfrac{1}{2}b_2^i(t)y^2+b_1^i(t)y+b_0^i(t)$
with
 $b^i_n(t)$
,
$b^i_n(t)$
,
 $n=0,1,2$
, given by (3.22).
$n=0,1,2$
, given by (3.22).
By setting
 $y=(a-r)/\sigma,$
$y=(a-r)/\sigma,$
 $\iota=0$
and
$\iota=0$
and
 $v=0$
in (3.17), the price dynamics (2.1) reduces to the classical Black-Scholes model. In this case, the market becomes complete and the corresponding results are straightforward, as stated below.
$v=0$
in (3.17), the price dynamics (2.1) reduces to the classical Black-Scholes model. In this case, the market becomes complete and the corresponding results are straightforward, as stated below.
Corollary 1. In the Black-Scholes model, for
 $p\in (0,1)$
,
$p\in (0,1)$
,
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
, profile
$i\neq j$
, profile
 $(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
with quantile functions
$(\boldsymbol{\Pi}_1^*,\boldsymbol{\Pi}_2^*)$
with quantile functions
 \begin{align} Q_{\Pi_i^*(t)}(p)=&\dfrac{1}{1-k_1k_2}\left[\dfrac{a-r}{\sigma^2}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)\right] +\dfrac{\lambda_i(t)}{\gamma_i\sigma^2}h_i'(1-p) \end{align}
\begin{align} Q_{\Pi_i^*(t)}(p)=&\dfrac{1}{1-k_1k_2}\left[\dfrac{a-r}{\sigma^2}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)\right] +\dfrac{\lambda_i(t)}{\gamma_i\sigma^2}h_i'(1-p) \end{align}
is a Nash equilibrium.
In the Black-Scholes model, the influence of
 $k_1$
,
$k_1$
,
 $k_2$
,
$k_2$
,
 $\gamma_1$
, and
$\gamma_1$
, and
 $\gamma_2$
on the equilibrium strategies is clearly reflected in (3.25), aligning with the properties of Gauss mean return model discussed in Section 6.
$\gamma_2$
on the equilibrium strategies is clearly reflected in (3.25), aligning with the properties of Gauss mean return model discussed in Section 6.
4. Policy iteration
In this section, we employ the policy iteration method to find equilibrium strategies in two steps. For
 $i, j \in \{1, 2\}$
and
$i, j \in \{1, 2\}$
and
 $i \neq j$
, we first fix
$i \neq j$
, we first fix
 $\boldsymbol{\Pi}_j$
and estimate the associated value function
$\boldsymbol{\Pi}_j$
and estimate the associated value function
 $V_i^{\boldsymbol{\Pi}_i}$
given a policy
$V_i^{\boldsymbol{\Pi}_i}$
given a policy
 $\boldsymbol{\Pi}_i$
. Then we update the previous policy
$\boldsymbol{\Pi}_i$
. Then we update the previous policy
 $\boldsymbol{\Pi}_i$
to a new one
$\boldsymbol{\Pi}_i$
to a new one
 $\tilde{\boldsymbol{\Pi}}_i$
based on the obtained value function
$\tilde{\boldsymbol{\Pi}}_i$
based on the obtained value function
 $V_i^{\boldsymbol{\Pi}_i}$
. Despite the learning process not leading to a monotone iteration algorithm due to the “optimality” is in the sense of equilibrium, we demonstrate that the iterative process converges uniformly to the desired equilibrium policy.
$V_i^{\boldsymbol{\Pi}_i}$
. Despite the learning process not leading to a monotone iteration algorithm due to the “optimality” is in the sense of equilibrium, we demonstrate that the iterative process converges uniformly to the desired equilibrium policy.
Assuming
 $\boldsymbol{\Pi}_j$
is fixed, and letting
$\boldsymbol{\Pi}_j$
is fixed, and letting
 $\boldsymbol{\Pi}_i$
be an admissible strategy for
$\boldsymbol{\Pi}_i$
be an admissible strategy for
 $i, j \in \{1,2\}$
with
$i, j \in \{1,2\}$
with
 $i \neq j$
, we denote the value function under
$i \neq j$
, we denote the value function under
 $\boldsymbol{\Pi}_i$
as
$\boldsymbol{\Pi}_i$
as
 $V_i^{\boldsymbol{\Pi}_i}(t,\hat x_i,y)=J_i(t,\hat x_i,y;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j)$
. Similarly, we define
$V_i^{\boldsymbol{\Pi}_i}(t,\hat x_i,y)=J_i(t,\hat x_i,y;\boldsymbol{\Pi}_i,\boldsymbol{\Pi}_j)$
. Similarly, we define
 $g_i^{\boldsymbol{\Pi}_i}(t,\hat x_i,y)=\mathbb E_t[\hat X_i^{\Pi_i,\Pi_j}(T)]$
. According to Björk et al. (Reference Björk, Khapko and Murgoci2017), the functions
$g_i^{\boldsymbol{\Pi}_i}(t,\hat x_i,y)=\mathbb E_t[\hat X_i^{\Pi_i,\Pi_j}(T)]$
. According to Björk et al. (Reference Björk, Khapko and Murgoci2017), the functions
 $V_i^{\boldsymbol{\Pi}_i}$
and
$V_i^{\boldsymbol{\Pi}_i}$
and
 $g_i^{\boldsymbol{\Pi}_i}$
satisfy the following equations
$g_i^{\boldsymbol{\Pi}_i}$
satisfy the following equations
 \begin{align} &\mathcal L^{\Pi_i,\Pi_j}V^{\boldsymbol{\Pi}_i}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}{g^{\boldsymbol{\Pi}_i}_i}^2+\gamma_ig^{\boldsymbol{\Pi}_i}_i\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i}_i+\lambda_i(t)\Phi_{h_i}(\Pi_i)=0,\end{align}
\begin{align} &\mathcal L^{\Pi_i,\Pi_j}V^{\boldsymbol{\Pi}_i}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}{g^{\boldsymbol{\Pi}_i}_i}^2+\gamma_ig^{\boldsymbol{\Pi}_i}_i\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i}_i+\lambda_i(t)\Phi_{h_i}(\Pi_i)=0,\end{align}
and
 \begin{align} \mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i}_i(t,\hat x_i,y)=0,\end{align}
\begin{align} \mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i}_i(t,\hat x_i,y)=0,\end{align}
with
 \begin{align} V^{\boldsymbol{\Pi}_i}_i(T,\hat x_i,y)=\hat x_i,\;\;\ g^{\boldsymbol{\Pi}_i}_i(T,\hat x_i,y)=\hat x_i.\end{align}
\begin{align} V^{\boldsymbol{\Pi}_i}_i(T,\hat x_i,y)=\hat x_i,\;\;\ g^{\boldsymbol{\Pi}_i}_i(T,\hat x_i,y)=\hat x_i.\end{align}
Theorem 3. For
 $p\in (0,1)$
,
$p\in (0,1)$
,
 $i,j\in\{1,2\}$
, and
$i,j\in\{1,2\}$
, and
 $i\neq j$
, with
$i\neq j$
, with
 $\boldsymbol{\Pi}_j$
fixed, let
$\boldsymbol{\Pi}_j$
fixed, let
 $\boldsymbol{\Pi}_i^0$
be the initial policy of Agent i with quantile function given by
$\boldsymbol{\Pi}_i^0$
be the initial policy of Agent i with quantile function given by
 \begin{align} Q_{\Pi_i^0(t)}(p)=\dfrac{y}{\gamma_i\sigma}+k_i\mu_j(t)-\dfrac{\rho v}{\sigma}(a_2^{i0}(t)y+a_1^{i0}(t))+\psi^0 h_i'(1-p).\end{align}
\begin{align} Q_{\Pi_i^0(t)}(p)=\dfrac{y}{\gamma_i\sigma}+k_i\mu_j(t)-\dfrac{\rho v}{\sigma}(a_2^{i0}(t)y+a_1^{i0}(t))+\psi^0 h_i'(1-p).\end{align}
Choose one policy
 $$\Pi_i(t)\in \mathop{\textrm{arg max}}\limits_{\Pi_i\in\mathcal M^2}\{\mathcal L^{\Pi_i,\Pi_j}V^{\boldsymbol{\Pi}_i^n}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}{g^{\boldsymbol{\Pi}_i^n}_i}^2+\gamma_ig^{\boldsymbol{\Pi}_i^n}_i\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i^n}_i+\lambda_i(t)\Phi_{h_i}(\Pi_i)\},$$
$$\Pi_i(t)\in \mathop{\textrm{arg max}}\limits_{\Pi_i\in\mathcal M^2}\{\mathcal L^{\Pi_i,\Pi_j}V^{\boldsymbol{\Pi}_i^n}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}{g^{\boldsymbol{\Pi}_i^n}_i}^2+\gamma_ig^{\boldsymbol{\Pi}_i^n}_i\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i^n}_i+\lambda_i(t)\Phi_{h_i}(\Pi_i)\},$$
and denote this policy as
 $\boldsymbol{\Pi}_i^{n+1}$
,
$\boldsymbol{\Pi}_i^{n+1}$
,
 $n=0,1,2,...$
Then the following statements holds.
$n=0,1,2,...$
Then the following statements holds.
-
(i) The sequence of updated policies
$\boldsymbol{\Pi}_i^{n}$
for
$n\geqslant 1$
has the quantile function (4.5)where
\begin{align} Q_{\Pi_i^n(t)}(p)=\dfrac{y}{\gamma_i\sigma}+k_i\mu_j(t)-\dfrac{\rho v}{\sigma}(a_2^{in}(t)y+a_1^{in}(t))+\dfrac{\lambda_i(t)}{\gamma_i\sigma^2} h_i'(1-p), \end{align}
$a_1^{in}$
and
$a_2^{in}$
satisfy (4.6)
\begin{align} \left\{ \begin{aligned} {a_2^{in}}'(t)&=2\iota a_2^{in}(t)+2\rho va_2^{in-1}(t) -\dfrac{2}{\gamma_i},&a_2^{in}(T)=0,\\ {a_1^{in}}'(t)&=\iota a_1^{in}(t) +\rho va_1^{in-1}(t)-a_2^{in}(t)\iota Y,& a_1^{in}(T)=0. \end{aligned} \right. \end{align}
-
(ii) As
$n\to \infty$
,
$a_1^{in}(t)$
and
$a_2^{in}$
uniformly converge to
$a_1^i$
and
$a_2^i$
in (3.21), respectively.











Proof.
-
(i) Note that
$\boldsymbol{\Pi}_i^0$
satisfies and
$$\begin{aligned} &\mathcal L^{\Pi_i,\Pi_j}V^{\boldsymbol{\Pi}^0_i}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}({g^{\boldsymbol{\Pi}^0_i}_i})^2+\gamma_ig^{\boldsymbol{\Pi}^0_i}_i\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}^0_i}_i+\lambda_i(t)\Phi_{h_i}(\Pi_i)=0, \end{aligned}$$
(4.7)Consider
\begin{align} \mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}^0_i}_i(t,\hat x_i,y)=0. \end{align}
$V^{\boldsymbol{\Pi}^0_i}_i(t,\hat x_i,y)=\hat x_i+D^{\boldsymbol{\Pi}^0_i}_i(t,y)$
and
$g^{\boldsymbol{\Pi}^0_i}_i(t,\hat x_i,y)=\hat x_i+d^{\boldsymbol{\Pi}^0_i}_i(t,y)$
. Substituting
$g^{\boldsymbol{\Pi}^0_i}_i$
into (4.7), we get (4.8)Assuming
\begin{align} \dfrac{\partial d_i^{\boldsymbol{\Pi}^0_i}(t,y)}{\partial t}+\iota(Y-y)\dfrac{\partial d_i^{\boldsymbol{\Pi}^0_i}(t,y)}{\partial y}+\dfrac{v^2}{2}\dfrac{\partial^2d_i^{\boldsymbol{\Pi}^0_i}(t,y)}{\partial y^2}+\dfrac{y^2}{\gamma_i}-\rho v(a_2^{i0}(t)y^2+a_1^{i0}(t)y)=0. \end{align}
$d_i^{\boldsymbol{\Pi}^0_i}(t,y)=\dfrac{1}{2}a_2^{i1}(t)y^2+a_1^{i1}(t)y+a_0^{i1}(t)$
and substituting it into (4.8), we get (4.9)By policy iteration, we know that
\begin{align} \left\{ \begin{aligned} {a_2^{i1}}'(t)&=2\iota a_2^{i1}(t)+2\rho va_2^{i0}(t) -\dfrac{2}{\gamma_i},&a_2^{i1}(T)=0,\\ {a_1^{i1}}'(t)&=\iota a_1^{i1}(t) +\rho va_1^{i0}(t)-a_2^{i1}(t)\iota Y,& a_1^{i1}(T)=0,\\ {a_0^{i1}}'(t)&=-a_1^{i1}(t)\iota Y-\dfrac{v^2}{2}a_2^{i1}(t),&a_0^{i1}(T)=0. \end{aligned} \right. \end{align}
By the first-order conditions, we have
\begin{align*} \Pi_i^1(t)\in \mathop{\textrm{arg max}}\limits_{\Pi_i\in\mathcal M^2}\left\{\mathcal L^{\Pi_i,\Pi_j}V^{\boldsymbol{\Pi}_i^0}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}{g^{\boldsymbol{\Pi}_i^0}_i}^2+\gamma_ig^{\boldsymbol{\Pi}_i^0}_i\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i^0}_i+\lambda_i(t)\Phi_{h_i}(\Pi_i)\right\}. \end{align*}
(4.10)Repeating the above procedure, we then get (4.5) and (4.6).
\begin{align} \mu_i^1(t) =\dfrac{y}{\gamma_i\sigma}+k_i\mu_j(t)-\dfrac{\rho v}{\sigma}(a_2^{i1}(t)y+a_1^{i1}(t)),\;\;\text{and}\;\; \sigma_i^1(t)&=\dfrac{\lambda_i(t)\Vert h_i'\Vert_2}{\gamma_i\sigma^2}. \end{align}
-
(ii) Denote
$M=\sup\limits_{t\in[0,T]}|a_2^i(t)-a_2^{i0}(t)|$
,
$m=\sup\limits_{t\in[0,T]}|a_1^i(t)-a_1^{i0}(t)|$
,
$\Delta_{k+1}(t)=a_2^i(t)-a_2^{i(k+1)}(t)$
and
$\delta_{k+1}(t)=a_1^i(t)-a_1^{i(k+1)}(t)$
. We claim that (4.11)The case for
\begin{align} |\Delta_n(t)|\leqslant \dfrac{[2\rho v(T-t)]^n}{n!}M. \end{align}
$n=0$
is trivial. By induction, we assume that the inequality holds for
$n=K$
. Then it follows from (3.24) and (4.6) that
$\Delta_{k+1}(t)$
satisfies Solving this differential equation, we obtain
\begin{align*} \Delta_{k+1}'(t)=2\iota \Delta_{k+1}(t)+2\rho v\Delta_k(t),\quad \Delta_{k+1}(T)=0. \end{align*}
$\Delta_{k+1}(t)=-\int_t^T2\rho ve^{2\iota(t-s)}\Delta_k(s)\mathrm{d} s$
. Consequently, Thus, (4.8) holds. Similarly, we can prove by induction that
\begin{align*} |\Delta_{k+1}(t)|\leqslant\int_t^T2\rho v|\Delta_{k}(s)|\mathrm{d} s\leqslant\int_t^T2\rho v\dfrac{[2\rho v(T-s)]^k}{k!}M\mathrm{d} s=\dfrac{[2\rho v(T-t)]^{k+1}}{(k+1)!}M. \end{align*}
Thus,
\begin{align*} |\delta_n(t)|\leqslant\dfrac{[\rho v(T-t)]^n}{n!}m+\dfrac{\iota Y}{\rho v} \dfrac{[2\rho v(T-t)]^{n+1}}{(n+1)!}M. \end{align*}
$a_1^{in}(t)$
and
$a_2^{in}$
uniformly converge to
$a_1^i$
and
$a_2^i$
as
$n\to \infty$
, respectively.




























Theorem 3 shows that the iteration does not change the form of the policy (see (4.5)), and thus, it suffices to parameterize the iterative policy through two deterministic functions
 $(a_1^{(in)}(t), a_2^{(in)}(t))$
. In particular, when the initial policy chosen as the form of the equilibrium policy in Proposition 2, our algorithm is guaranteed to uniformly converge to the equilibrium policy.
$(a_1^{(in)}(t), a_2^{(in)}(t))$
. In particular, when the initial policy chosen as the form of the equilibrium policy in Proposition 2, our algorithm is guaranteed to uniformly converge to the equilibrium policy.
The next result guarantees the convergence of policies as the two agents iterate simultaneously.
Theorem 4. For an initial profile
 $(\boldsymbol{\Pi}^0_1,\boldsymbol{\Pi}^0_2)$
, assume that two agents iterate simultaneously by (4.5) and the updated sequence is defined by
$(\boldsymbol{\Pi}^0_1,\boldsymbol{\Pi}^0_2)$
, assume that two agents iterate simultaneously by (4.5) and the updated sequence is defined by
 $(\boldsymbol{\Pi}_1^n,\boldsymbol{\Pi}_2^n)$
,
$(\boldsymbol{\Pi}_1^n,\boldsymbol{\Pi}_2^n)$
,
 $n=0,1,2,...$
Then for
$n=0,1,2,...$
Then for
 $p\in (0,1)$
,
$p\in (0,1)$
,
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
,
$i\neq j$
,
 $Q_{\Pi_i^n(t)}(p)$
converges uniformly to
$Q_{\Pi_i^n(t)}(p)$
converges uniformly to
 $Q_{\Pi_i^*(t)}(p)$
of (3.18) as
$Q_{\Pi_i^*(t)}(p)$
of (3.18) as
 $n\to\infty$
.
$n\to\infty$
.
Proof. We just need to prove that the mean and variance of
 $\Pi_i$
converge to the mean and variance of
$\Pi_i$
converge to the mean and variance of
 $\Pi_i^*$
. The convergence of variance is obvious according to the proof of Theorem 3(i) and (4.10). Let
$\Pi_i^*$
. The convergence of variance is obvious according to the proof of Theorem 3(i) and (4.10). Let
 $\mu_i^n(t)$
be the mean of
$\mu_i^n(t)$
be the mean of
 $\Pi_i^n(t)$
. Based on (3.10), we have
$\Pi_i^n(t)$
. Based on (3.10), we have
 \begin{align*} \begin{bmatrix} \mu_1^{n+1}(t)\\ \mu_2^{n+1}(t) \end{bmatrix}= \begin{bmatrix} 0\;\;\; & k_1 \\ k_2\;\;\; & 0 \end{bmatrix} \begin{bmatrix} \mu_1^{n}(t)\\ \mu_2^{n}(t) \end{bmatrix}+ \begin{bmatrix} \dfrac{y}{\gamma_1\sigma}-\dfrac{\rho v}{\sigma}(a_2^1(t)y+a_1^1(t))\\[4mm] \dfrac{y}{\gamma_2\sigma}-\dfrac{\rho v}{\sigma}(a_2^2(t)y+a_1^2(t)) \end{bmatrix}. \end{align*}
\begin{align*} \begin{bmatrix} \mu_1^{n+1}(t)\\ \mu_2^{n+1}(t) \end{bmatrix}= \begin{bmatrix} 0\;\;\; & k_1 \\ k_2\;\;\; & 0 \end{bmatrix} \begin{bmatrix} \mu_1^{n}(t)\\ \mu_2^{n}(t) \end{bmatrix}+ \begin{bmatrix} \dfrac{y}{\gamma_1\sigma}-\dfrac{\rho v}{\sigma}(a_2^1(t)y+a_1^1(t))\\[4mm] \dfrac{y}{\gamma_2\sigma}-\dfrac{\rho v}{\sigma}(a_2^2(t)y+a_1^2(t)) \end{bmatrix}. \end{align*}
Consider the normed space
 $\mathbb R^2$
with
$\mathbb R^2$
with
 $\Vert\cdot\Vert$
defined as
$\Vert\cdot\Vert$
defined as
 $\Vert \vec{x}\Vert=\max\{x_1,x_2\}$
for
$\Vert \vec{x}\Vert=\max\{x_1,x_2\}$
for
 $\vec{x}=[x_1,x_2]'\in \mathbb R^2$
. It is well known that
$\vec{x}=[x_1,x_2]'\in \mathbb R^2$
. It is well known that
 $(\mathbb R^2,\Vert\cdot\Vert)$
is a Banach space. Define
$(\mathbb R^2,\Vert\cdot\Vert)$
is a Banach space. Define
 \begin{align*} f(\vec{x})=\begin{bmatrix} 0\;\;\; & k_1 \\ k_2\;\;\; & 0 \end{bmatrix} \vec{x}+ \begin{bmatrix} \dfrac{y}{\gamma_1\sigma}-\dfrac{\rho v}{\sigma}(a_2^1(t)y+a_1^1(t))\\[4mm] \dfrac{y}{\gamma_2\sigma}-\dfrac{\rho v}{\sigma}(a_2^2(t)y+a_1^2(t)) \end{bmatrix}. \end{align*}
\begin{align*} f(\vec{x})=\begin{bmatrix} 0\;\;\; & k_1 \\ k_2\;\;\; & 0 \end{bmatrix} \vec{x}+ \begin{bmatrix} \dfrac{y}{\gamma_1\sigma}-\dfrac{\rho v}{\sigma}(a_2^1(t)y+a_1^1(t))\\[4mm] \dfrac{y}{\gamma_2\sigma}-\dfrac{\rho v}{\sigma}(a_2^2(t)y+a_1^2(t)) \end{bmatrix}. \end{align*}
We have
 $\Vert f(\vec{x})-f(\vec{y})\Vert\leqslant \max\{k_1,k_2\}\Vert \vec{x}-\vec{y} \Vert$
, establishing f as a contraction mapping with a unique fixed point. By (3.12), the fixed point is precisely
$\Vert f(\vec{x})-f(\vec{y})\Vert\leqslant \max\{k_1,k_2\}\Vert \vec{x}-\vec{y} \Vert$
, establishing f as a contraction mapping with a unique fixed point. By (3.12), the fixed point is precisely
 $[\mu_1^*(t),\mu_2^*(t)]'$
. Thus, the mean of
$[\mu_1^*(t),\mu_2^*(t)]'$
. Thus, the mean of
 $\Pi_i^n(t)$
also converges. Moreover, let M
′ be an uniformly upper bound of
$\Pi_i^n(t)$
also converges. Moreover, let M
′ be an uniformly upper bound of
 $|\mu_i^0(t)-\mu_i^*(t)|$
. Then, we have
$|\mu_i^0(t)-\mu_i^*(t)|$
. Then, we have
 \begin{align*} \left\Vert\begin{bmatrix} \mu_1^{n}(t)\\ \mu_2^{n}(t) \end{bmatrix}- \begin{bmatrix} \mu_1^{*}(t)\\ \mu_2^{*}(t) \end{bmatrix}\right\Vert=& \left\Vert\begin{bmatrix} 0 & k_1 \\ k_2 & 0 \end{bmatrix} \begin{bmatrix} \mu_1^{n-1}(t)-\mu_1^*(t)\\ \mu_2^{n-1}(t)-\mu_2^*(t) \end{bmatrix}\right\Vert\\ =&\left\Vert\begin{bmatrix} 0 & k_1 \\ k_2 & 0 \end{bmatrix}^n \begin{bmatrix} \mu_1^{0}(t)-\mu_1^*(t)\\ \mu_2^{0}(t)-\mu_2^*(t) \end{bmatrix}\right\Vert\\ \leqslant & M'(\max\{k_1,k_2\})^n. \end{align*}
\begin{align*} \left\Vert\begin{bmatrix} \mu_1^{n}(t)\\ \mu_2^{n}(t) \end{bmatrix}- \begin{bmatrix} \mu_1^{*}(t)\\ \mu_2^{*}(t) \end{bmatrix}\right\Vert=& \left\Vert\begin{bmatrix} 0 & k_1 \\ k_2 & 0 \end{bmatrix} \begin{bmatrix} \mu_1^{n-1}(t)-\mu_1^*(t)\\ \mu_2^{n-1}(t)-\mu_2^*(t) \end{bmatrix}\right\Vert\\ =&\left\Vert\begin{bmatrix} 0 & k_1 \\ k_2 & 0 \end{bmatrix}^n \begin{bmatrix} \mu_1^{0}(t)-\mu_1^*(t)\\ \mu_2^{0}(t)-\mu_2^*(t) \end{bmatrix}\right\Vert\\ \leqslant & M'(\max\{k_1,k_2\})^n. \end{align*}
Thus, for
 $p\in (0,1)$
,
$p\in (0,1)$
,
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
,
$i\neq j$
,
 $Q_{\Pi_i^n(t)}(p)$
converges uniformly to
$Q_{\Pi_i^n(t)}(p)$
converges uniformly to
 $Q_{\Pi_i^*(t)}(p)$
of (3.18) as
$Q_{\Pi_i^*(t)}(p)$
of (3.18) as
 $n\to\infty$
.
$n\to\infty$
.
5. RL algorithm design
In this section, we devise an algorithm to learn the Nash equilibrium. As mentioned in the introduction, game scenarios involve multiple agents in the environment, requiring the utilization of multi-agent reinforcement learning algorithms, which inherently introduce greater complexity. Specifically, in single-agent reinforcement learning, a basic assumption is the stability of the environment, wherein the transition probability and reward function remain constant. However, when other intelligent agents are introduced into the environment, this assumption no longer holds true. In a multi-agent context, any change in one agent’s strategy can significantly impact other agents, leading to dynamic evolution of the environment with their strategies. Moreover, as the number of agents increases, the complexity of training also escalates. Fortunately, in our model, each agent will only affect the mean of the other agent’s strategy. According to (3.12), the difference
 $\mu_i(t)-k_i\mu_j(t)$
for
$\mu_i(t)-k_i\mu_j(t)$
for
 $i,j\in\{1,2\}$
and
$i,j\in\{1,2\}$
and
 $i\neq j$
remains fixed, regardless of how the agents adjust their strategies. Thus, once the difference is known, we can directly apply the learning procedure outlined in Theorem 4. This allows us to reduce the game problem into two independent optimization problems. We then apply the method proposed in Section 4 to learn the difference. Below, we briefly introduce this method.
$i\neq j$
remains fixed, regardless of how the agents adjust their strategies. Thus, once the difference is known, we can directly apply the learning procedure outlined in Theorem 4. This allows us to reduce the game problem into two independent optimization problems. We then apply the method proposed in Section 4 to learn the difference. Below, we briefly introduce this method.
Assume that the risk-free interest rate r, the risk-aversion coefficient
 $\gamma_1, \gamma_2$
, the sensitivity coefficient
$\gamma_1, \gamma_2$
, the sensitivity coefficient
 $k_1, k_2$
, and the exploration weight
$k_1, k_2$
, and the exploration weight
 $\lambda_1, \lambda_2$
are known. The agents have no prior knowledge of S(t) and Y(t), but can observe the pair (S(t),Y(t)) at each time t. In the continuous time setting, we discretize the interval [0, T] into N subintervals with equal length
$\lambda_1, \lambda_2$
are known. The agents have no prior knowledge of S(t) and Y(t), but can observe the pair (S(t),Y(t)) at each time t. In the continuous time setting, we discretize the interval [0, T] into N subintervals with equal length
 $\Delta t=t_{k+1}-t_k, k=0,1,...,N-1$
. Based on (2.1) and (2.3), we get
$\Delta t=t_{k+1}-t_k, k=0,1,...,N-1$
. Based on (2.1) and (2.3), we get
 \begin{align*} \mathrm{d} X_i^{u_i}(t)=u_i(t)\dfrac{\mathrm{d} e^{-rt}S(t)}{e^{-rt}S(t)}.\end{align*}
\begin{align*} \mathrm{d} X_i^{u_i}(t)=u_i(t)\dfrac{\mathrm{d} e^{-rt}S(t)}{e^{-rt}S(t)}.\end{align*}
Therefore, when the Agent i follows strategy
 $\Pi_i(t_k)$
at time
$\Pi_i(t_k)$
at time
 $t_k$
and samples action
$t_k$
and samples action
 $u_i(t_k)$
from
$u_i(t_k)$
from
 $\Pi_i(t_k)$
, the discounted wealth at
$\Pi_i(t_k)$
, the discounted wealth at
 $t_{k+1}$
is
$t_{k+1}$
is
 \begin{align*} X_i^{\Pi_i}(t_{k+1})\approx X_i^{\Pi_i}(t_k)+u_i(t_k)\dfrac{e^{-rt_{k+1}}S(t_{k+1})-e^{-rt_k}S(t_k)}{e^{-rt_k}S(t_k)}.\end{align*}
\begin{align*} X_i^{\Pi_i}(t_{k+1})\approx X_i^{\Pi_i}(t_k)+u_i(t_k)\dfrac{e^{-rt_{k+1}}S(t_{k+1})-e^{-rt_k}S(t_k)}{e^{-rt_k}S(t_k)}.\end{align*}
Assume that the policy
 $\boldsymbol{\Pi}_j$
of Agent j is fixed, and that both
$\boldsymbol{\Pi}_j$
of Agent j is fixed, and that both
 $\Pi_i(t)$
and
$\Pi_i(t)$
and
 $\Pi_j(t)$
have density
$\Pi_j(t)$
have density
 $\pi_i(t)$
and
$\pi_i(t)$
and
 $\pi_j(t)$
. The algorithm for learning the difference
$\pi_j(t)$
. The algorithm for learning the difference
 $\mu_i(t)-k_i\mu_j(t)$
is based on the standard idea of policy evaluation followed by policy update. We do not adopt the approach of generalized policy iteration, in which policy evaluation and policy update interact with each other. There are three main reasons for this. First, Theorem 3 guarantees a convergence rate that is sufficiently fast, making the generalized policy iteration unnecessary. Second, unlike classical reinforcement learning, our equilibrium strategy involves two value functions,
$\mu_i(t)-k_i\mu_j(t)$
is based on the standard idea of policy evaluation followed by policy update. We do not adopt the approach of generalized policy iteration, in which policy evaluation and policy update interact with each other. There are three main reasons for this. First, Theorem 3 guarantees a convergence rate that is sufficiently fast, making the generalized policy iteration unnecessary. Second, unlike classical reinforcement learning, our equilibrium strategy involves two value functions,
 $V_i$
and
$V_i$
and
 $g_i$
, which complicates the policy evaluation step, particularly in the context of generalized policy iteration. Third, as previously discussed, our policy update does not always yield an improved policy, which further limits the applicability of generalized policy iteration.
$g_i$
, which complicates the policy evaluation step, particularly in the context of generalized policy iteration. Third, as previously discussed, our policy update does not always yield an improved policy, which further limits the applicability of generalized policy iteration.
We represent the policy
 $\boldsymbol{\Pi}_i$
of Agent i using its quantile function. By Theorem 3, the quantile function can be defined as
$\boldsymbol{\Pi}_i$
of Agent i using its quantile function. By Theorem 3, the quantile function can be defined as
 \begin{align}Q_{\Pi_i^{\Psi}(t)}(p)=k_i\mu_j(t)+\psi_0 \dfrac{y}{\gamma_i}-\psi_0\psi_1(a_2^{i0}(t)y+a_1^{i0}(t))+\dfrac{\lambda_i}{\gamma_i \psi_2^2} h_i'(1-p),\end{align}
\begin{align}Q_{\Pi_i^{\Psi}(t)}(p)=k_i\mu_j(t)+\psi_0 \dfrac{y}{\gamma_i}-\psi_0\psi_1(a_2^{i0}(t)y+a_1^{i0}(t))+\dfrac{\lambda_i}{\gamma_i \psi_2^2} h_i'(1-p),\end{align}
where
 $\Psi = (\psi_0,\psi_1,\psi_2)\in\mathbb R^3$
denotes the set of parameters to be learned, and
$\Psi = (\psi_0,\psi_1,\psi_2)\in\mathbb R^3$
denotes the set of parameters to be learned, and
 $a_1^{i0}$
and
$a_1^{i0}$
and
 $a_2^{i0}$
are functions that will be updated according to Theorem 3(i). The parameters
$a_2^{i0}$
are functions that will be updated according to Theorem 3(i). The parameters
 $\Psi$
can be initialized either randomly or using predetermined constants, and
$\Psi$
can be initialized either randomly or using predetermined constants, and
 $a_1^{i0}$
and
$a_1^{i0}$
and
 $a_2^{i0}$
can be initialized as zero functions.
$a_2^{i0}$
can be initialized as zero functions.
For policy evaluation procedure, based on Proposition 2, we parameterize
 $V_i$
and
$V_i$
and
 $g_i$
in the form of (3.19) and (3.20), respectively, as follows
$g_i$
in the form of (3.19) and (3.20), respectively, as follows
 \begin{align} \begin{split} V_i^{\Theta}(t,\hat x_i,y)&=\hat x_i+\dfrac{1}{2}p(\theta_i^{V,2},T-t)y^2+p(\theta_i^{V,1},T-t)y+p(\theta_i^{V,0},T-t),\\ g_i^{\Theta}(t,\hat x_i,y)&=\hat x_i+\dfrac{1}{2}p(\theta_i^{g,2},T-t)y^2+p(\theta_i^{g,1},T-t)y+p(\theta_i^{g,0},T-t), \end{split}\end{align}
\begin{align} \begin{split} V_i^{\Theta}(t,\hat x_i,y)&=\hat x_i+\dfrac{1}{2}p(\theta_i^{V,2},T-t)y^2+p(\theta_i^{V,1},T-t)y+p(\theta_i^{V,0},T-t),\\ g_i^{\Theta}(t,\hat x_i,y)&=\hat x_i+\dfrac{1}{2}p(\theta_i^{g,2},T-t)y^2+p(\theta_i^{g,1},T-t)y+p(\theta_i^{g,0},T-t), \end{split}\end{align}
where
 $p(\theta,t)$
is a suitable parametric function with coefficient vector
$p(\theta,t)$
is a suitable parametric function with coefficient vector
 $\theta\in \mathbb R^d$
. The full parameter set is denoted by
$\theta\in \mathbb R^d$
. The full parameter set is denoted by
 $\Theta=(\theta_i^{V,0},\theta_i^{V,1},\theta_i^{V,2},\theta_i^{g,0},\theta_i^{g,1},\theta_i^{g,2})\in\mathbb R^{6d}$
. A typical choice for
$\Theta=(\theta_i^{V,0},\theta_i^{V,1},\theta_i^{V,2},\theta_i^{g,0},\theta_i^{g,1},\theta_i^{g,2})\in\mathbb R^{6d}$
. A typical choice for
 $p(\theta,t)$
is a linear combination of the first d terms of a basis expansion, such as a truncated Taylor or Fourier series, where
$p(\theta,t)$
is a linear combination of the first d terms of a basis expansion, such as a truncated Taylor or Fourier series, where
 $\theta$
denotes the corresponding coefficients. Since
$\theta$
denotes the corresponding coefficients. Since
 $g^{\boldsymbol{\Pi}_i}$
satisfies
$g^{\boldsymbol{\Pi}_i}$
satisfies
 $\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i}_i(t,\hat x_i,y)=0$
with terminal condition
$\mathcal L^{\Pi_i,\Pi_j}g^{\boldsymbol{\Pi}_i}_i(t,\hat x_i,y)=0$
with terminal condition
 $g^{\boldsymbol{\Pi}_i}_i(T,\hat x_i,y)=\hat x_i$
for any
$g^{\boldsymbol{\Pi}_i}_i(T,\hat x_i,y)=\hat x_i$
for any
 $\boldsymbol{\Pi}_i$
, it can be interpreted via the Feynman-Kac formula as the value function of a time-consistent optimal problem. This allows it to be evaluated using continuous-time reinforcement learning. Theorem 3 in Jia and Zhou (Reference Jia and Zhou2022a) and Theorem 4 in Jia and Zhou (Reference Jia and Zhou2022b) show that
$\boldsymbol{\Pi}_i$
, it can be interpreted via the Feynman-Kac formula as the value function of a time-consistent optimal problem. This allows it to be evaluated using continuous-time reinforcement learning. Theorem 3 in Jia and Zhou (Reference Jia and Zhou2022a) and Theorem 4 in Jia and Zhou (Reference Jia and Zhou2022b) show that
 $g^{\boldsymbol{\Pi}_i}$
can be estimated by minimizing the martingale loss function
$g^{\boldsymbol{\Pi}_i}$
can be estimated by minimizing the martingale loss function
 \begin{align*} \mathrm{ML}_{g}(\Theta)\;:\!=\;\dfrac{1}{2}\mathbb{E}\left[\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - g_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))\right)^2\Delta t\right],\end{align*}
\begin{align*} \mathrm{ML}_{g}(\Theta)\;:\!=\;\dfrac{1}{2}\mathbb{E}\left[\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - g_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))\right)^2\Delta t\right],\end{align*}
which corresponds to the continuous-time analogue of the Monte Carlo policy evaluation with function approximation (e.g., Sutton and Barto, Reference Sutton and Barto2018). Then we can use the stochastic gradient descent method to minimize
 $\mathrm{ML}_{g}(\Theta)$
, which is a standard method in reinforcement learning. The gradient of
$\mathrm{ML}_{g}(\Theta)$
, which is a standard method in reinforcement learning. The gradient of
 $\mathrm{ML}_{g}(\Theta)$
with respect to
$\mathrm{ML}_{g}(\Theta)$
with respect to
 $\Theta$
can be computed as
$\Theta$
can be computed as
 \begin{align} \nabla_g \Theta=-\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - g_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))\right)\dfrac{\partial g_i^{\Theta}}{\partial \Theta}\Delta t,\end{align}
\begin{align} \nabla_g \Theta=-\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - g_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))\right)\dfrac{\partial g_i^{\Theta}}{\partial \Theta}\Delta t,\end{align}
and the parameters
 $\Theta$
are updated according to
$\Theta$
are updated according to
 \begin{align*} \Theta_{n+1}=\Theta_n-\alpha_g\nabla_g \Theta.\end{align*}
\begin{align*} \Theta_{n+1}=\Theta_n-\alpha_g\nabla_g \Theta.\end{align*}
Once
 $g_i$
is evaluated, we can proceed to evaluate
$g_i$
is evaluated, we can proceed to evaluate
 $V_i$
, which satisfies
$V_i$
, which satisfies
 \begin{align} \mathcal L^{\Pi_i,\Pi_j}V_i(t,\hat x_i,y) + R(t,\hat x_i,y)= 0,\;\;\;V_i(T,\hat x_i,y)=\hat x_i,\end{align}
\begin{align} \mathcal L^{\Pi_i,\Pi_j}V_i(t,\hat x_i,y) + R(t,\hat x_i,y)= 0,\;\;\;V_i(T,\hat x_i,y)=\hat x_i,\end{align}
where the residual term is given by
 $$R(t,\hat x_i,y)=-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}g_i^2+\gamma_i g_i\mathcal L^{\Pi_i,\Pi_j}g_i+\lambda_i(t)\Phi_{h_i}(\Pi_i). $$
$$R(t,\hat x_i,y)=-\dfrac{\gamma_i}{2}\mathcal L^{\Pi_i,\Pi_j}g_i^2+\gamma_i g_i\mathcal L^{\Pi_i,\Pi_j}g_i+\lambda_i(t)\Phi_{h_i}(\Pi_i). $$
The structure of (5.4), together with the Feynman-Kac formula, implies that
 $V_i$
can also be interpreted as the value function of a time-consistent optimal control problem. Consequently,
$V_i$
can also be interpreted as the value function of a time-consistent optimal control problem. Consequently,
 $V_i$
can be evaluated analogously to
$V_i$
can be evaluated analogously to
 $g_i$
, by minimizing a martingale loss function
$g_i$
, by minimizing a martingale loss function
 \begin{align*} \mathrm{ML}_{V}(\Theta)\;:\!=\;\dfrac{1}{2}\mathbb{E}\left[\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - V_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))+\sum\limits_{l=k}^{N-1}R(t_l,\hat X_i(t_l),Y(t_l))\Delta t\right)^2\Delta t\right],\end{align*}
\begin{align*} \mathrm{ML}_{V}(\Theta)\;:\!=\;\dfrac{1}{2}\mathbb{E}\left[\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - V_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))+\sum\limits_{l=k}^{N-1}R(t_l,\hat X_i(t_l),Y(t_l))\Delta t\right)^2\Delta t\right],\end{align*}
and the gradient of
 $\mathrm{ML}_{V}(\Theta)$
with respect to
$\mathrm{ML}_{V}(\Theta)$
with respect to
 $\Theta$
can be computed as
$\Theta$
can be computed as
 \begin{align} \nabla_V \Theta=-\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - V_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))+\sum\limits_{l=k}^{N-1}R(t_l,\hat X_i(t_l),Y(t_l))\Delta t\right)\dfrac{\partial V_i^{\Theta}}{\partial \Theta}\Delta t.\end{align}
\begin{align} \nabla_V \Theta=-\sum\limits_{k=0}^{N-1} \left(\hat X_i(T) - V_i^{\Theta}(t_k,\hat X_i(t_k),Y(t_k))+\sum\limits_{l=k}^{N-1}R(t_l,\hat X_i(t_l),Y(t_l))\Delta t\right)\dfrac{\partial V_i^{\Theta}}{\partial \Theta}\Delta t.\end{align}
Then
 $\Theta$
can be updated as
$\Theta$
can be updated as
 \begin{align*} \Theta_{n+1}=\Theta_n-\alpha_V\nabla_V \Theta.\end{align*}
\begin{align*} \Theta_{n+1}=\Theta_n-\alpha_V\nabla_V \Theta.\end{align*}
By applying Itô’s formula, for any
 $\varphi\in C^{1,2,2}$
and strategy
$\varphi\in C^{1,2,2}$
and strategy
 $\Pi_i$
of Agent i, we have
$\Pi_i$
of Agent i, we have
 \begin{align*}\begin{split} &\mathbb E_t[\varphi(t+\Delta t,\hat X_i^{\Pi_i,\Pi_j}(t+\Delta t),Y(t+\Delta t))]-\varphi(t,\hat X_i^{\Pi_i,\Pi_j}(t),Y(t))\\ & =\mathbb E_t\int_t^{t+\Delta t}\mathcal L^{\Pi_i,\Pi_j}\varphi(s,\hat X_i^{\Pi_i,\Pi_j}(s),Y(s))\mathrm{d} s,\end{split}\end{align*}
\begin{align*}\begin{split} &\mathbb E_t[\varphi(t+\Delta t,\hat X_i^{\Pi_i,\Pi_j}(t+\Delta t),Y(t+\Delta t))]-\varphi(t,\hat X_i^{\Pi_i,\Pi_j}(t),Y(t))\\ & =\mathbb E_t\int_t^{t+\Delta t}\mathcal L^{\Pi_i,\Pi_j}\varphi(s,\hat X_i^{\Pi_i,\Pi_j}(s),Y(s))\mathrm{d} s,\end{split}\end{align*}
and thus
 \begin{align} \mathcal L^{\Pi_i,\Pi_j}\varphi(t,\hat X_i^{\Pi_i,\Pi_j}(t),Y(t))\approx \dfrac{\varphi(t+\Delta t,\hat X_i^{\Pi_i,\Pi_j}(t+\Delta t),Y(t+\Delta t))-\varphi(t,\hat X_i^{\Pi_i,\Pi_j}(t),Y(t))}{\Delta t}.\end{align}
\begin{align} \mathcal L^{\Pi_i,\Pi_j}\varphi(t,\hat X_i^{\Pi_i,\Pi_j}(t),Y(t))\approx \dfrac{\varphi(t+\Delta t,\hat X_i^{\Pi_i,\Pi_j}(t+\Delta t),Y(t+\Delta t))-\varphi(t,\hat X_i^{\Pi_i,\Pi_j}(t),Y(t))}{\Delta t}.\end{align}
We can use (5.6) to approximate
 $R(t,\hat x_i,y)$
by replacing
$R(t,\hat x_i,y)$
by replacing
 $\varphi$
with
$\varphi$
with
 $V_i$
,
$V_i$
,
 $g_i$
and
$g_i$
and
 $g_i^2$
.
$g_i^2$
.
For policy update procedure, we want to maximize the following function
 \begin{align} L_i(\Psi;t,\hat x,y)\;:\!=\;\mathcal L^{\Pi^{\Psi}_i(t),\Pi_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi^{\Psi}_i(t),\Pi_j}{g^{\Theta}_i}^2+\gamma_ig^{\Theta}_i\mathcal L^{\Pi^{\Psi}_i(t),\Pi_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i(t))\end{align}
\begin{align} L_i(\Psi;t,\hat x,y)\;:\!=\;\mathcal L^{\Pi^{\Psi}_i(t),\Pi_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal L^{\Pi^{\Psi}_i(t),\Pi_j}{g^{\Theta}_i}^2+\gamma_ig^{\Theta}_i\mathcal L^{\Pi^{\Psi}_i(t),\Pi_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i(t))\end{align}
for all possible
 $t,\hat x,y$
. By the proof of Theorem 3, we only need to maximize
$t,\hat x,y$
. By the proof of Theorem 3, we only need to maximize
 $L_i(\Psi;\;t,\hat x,y)$
at initial state
$L_i(\Psi;\;t,\hat x,y)$
at initial state
 $(t_0,\hat x_0,y_0)$
. First, we can update policy (5.1) to
$(t_0,\hat x_0,y_0)$
. First, we can update policy (5.1) to
 \begin{align} Q_{\Pi_i^{\Psi}(t)}(p)=k_i\mu_j(t)+\psi_0 \dfrac{y}{\gamma_i}-\psi_0\psi_1(a_2^{i1}(t)y+a_1^{i1}(t))+\dfrac{\lambda_i(t)}{\gamma_i \psi_2^2} h_i'(1-p),\end{align}
\begin{align} Q_{\Pi_i^{\Psi}(t)}(p)=k_i\mu_j(t)+\psi_0 \dfrac{y}{\gamma_i}-\psi_0\psi_1(a_2^{i1}(t)y+a_1^{i1}(t))+\dfrac{\lambda_i(t)}{\gamma_i \psi_2^2} h_i'(1-p),\end{align}
where
 $a_2^{i1}(t)y+a_1^{i1}(t)$
comes from the derivative of evaluated
$a_2^{i1}(t)y+a_1^{i1}(t)$
comes from the derivative of evaluated
 $g^{\Theta}$
with respect to y. Then we only need to maximize
$g^{\Theta}$
with respect to y. Then we only need to maximize
 $L_i(\Psi;\;t_0,\hat x_0,y_0)$
with respect to
$L_i(\Psi;\;t_0,\hat x_0,y_0)$
with respect to
 $\Psi$
. The maximization of
$\Psi$
. The maximization of
 $L_i(\Psi;\;t_0,\hat x_0,y_0)$
can also be achieved by stochastic gradient ascent method. Since
$L_i(\Psi;\;t_0,\hat x_0,y_0)$
can also be achieved by stochastic gradient ascent method. Since
 \begin{align*} \mathcal{L}^{\Pi_i,\Pi_j}\varphi(t,\hat x,y)=\int_R\int_R\mathcal{L}^{u_i,u_j}\varphi(t,\hat x,y)\pi_j(u_j)\pi_i(u_i) \mathrm{d} u_j\mathrm{d} u_i,\end{align*}
\begin{align*} \mathcal{L}^{\Pi_i,\Pi_j}\varphi(t,\hat x,y)=\int_R\int_R\mathcal{L}^{u_i,u_j}\varphi(t,\hat x,y)\pi_j(u_j)\pi_i(u_i) \mathrm{d} u_j\mathrm{d} u_i,\end{align*}
then we have
 \begin{align*} \dfrac{dL_i}{d\Psi}=&\int_R\int_R\left[\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right)\pi_j(u_j)\dfrac{\partial \pi_i^{\Psi}(u_i)}{\partial \Psi}\right.\\ &+\left.\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi}\pi_j(u_j)\pi_i(u_i)\right]\mathrm{d} u_j\mathrm{d} u_i.\\ =&\int_R\int_R\left[\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right)\pi_j(u_j)\pi_i(u_i)\dfrac{\frac{\partial \pi_i^{\Psi}(u_i)}{\partial \Psi}}{\pi_i(u_i)}\right.\\ &+\left.\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi}\pi_j(u_j)\pi_i(u_i)\right]\mathrm{d} u_j\mathrm{d} u_i.\\ =&\int_R\int_R\left[\dfrac{\partial \log \pi_i^{\Psi}(u_i)}{\partial \Psi}\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right)\right.\\ &+\left.\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi}\right]\pi_j(u_j)\pi_i(u_i)\mathrm{d} u_j\mathrm{d} u_i.\end{align*}
\begin{align*} \dfrac{dL_i}{d\Psi}=&\int_R\int_R\left[\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right)\pi_j(u_j)\dfrac{\partial \pi_i^{\Psi}(u_i)}{\partial \Psi}\right.\\ &+\left.\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi}\pi_j(u_j)\pi_i(u_i)\right]\mathrm{d} u_j\mathrm{d} u_i.\\ =&\int_R\int_R\left[\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right)\pi_j(u_j)\pi_i(u_i)\dfrac{\frac{\partial \pi_i^{\Psi}(u_i)}{\partial \Psi}}{\pi_i(u_i)}\right.\\ &+\left.\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi}\pi_j(u_j)\pi_i(u_i)\right]\mathrm{d} u_j\mathrm{d} u_i.\\ =&\int_R\int_R\left[\dfrac{\partial \log \pi_i^{\Psi}(u_i)}{\partial \Psi}\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right)\right.\\ &+\left.\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi}\right]\pi_j(u_j)\pi_i(u_i)\mathrm{d} u_j\mathrm{d} u_i.\end{align*}
Thus, the gradient of
 $L_i(\Psi)$
with respect to
$L_i(\Psi)$
with respect to
 $\Psi$
can be computed as
$\Psi$
can be computed as
 \begin{align} \nabla\Psi=\dfrac{\partial \log \pi_i^{\Psi}(u_i)}{\partial \Psi}\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right) +\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi},\end{align}
\begin{align} \nabla\Psi=\dfrac{\partial \log \pi_i^{\Psi}(u_i)}{\partial \Psi}\left(\mathcal{L}^{u_i,u_j}V^{\Theta}_i-\dfrac{\gamma_i}{2}\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\gamma_ig^{\Theta}_i\mathcal{L}^{u_i,u_j}g^{\Theta}_i+\lambda_i\Phi_{h_i}(\Pi^{\Psi}_i)\right) +\lambda_i\dfrac{\partial \Phi_{h_i}(\Pi_i^{\Psi})}{\partial \Psi},\end{align}
and the infinitesimal generator
 $\mathcal{L}^{u_i,u_j}$
can be approximated by samples. Note that if the distribution
$\mathcal{L}^{u_i,u_j}$
can be approximated by samples. Note that if the distribution
 $\Pi^{\Psi}$
is supported on
$\Pi^{\Psi}$
is supported on
 $[S^{\Psi}_{\min},S^{\Psi}_{\max}]$
that depends on the parameter
$[S^{\Psi}_{\min},S^{\Psi}_{\max}]$
that depends on the parameter
 $\Psi$
, then the gradient computation must also account for the derivatives of the interval endpoints,
$\Psi$
, then the gradient computation must also account for the derivatives of the interval endpoints,
 $S^{\Psi}_{\min}$
and
$S^{\Psi}_{\min}$
and
 $S^{\Psi}_{\max}$
, with respect to
$S^{\Psi}_{\max}$
, with respect to
 $\Psi$
. Then we can update
$\Psi$
. Then we can update
 $\Psi$
as
$\Psi$
as
 \begin{align*} \Psi_{n+1}=\Psi_n+\alpha_{\Psi}\nabla\Psi.\end{align*}
\begin{align*} \Psi_{n+1}=\Psi_n+\alpha_{\Psi}\nabla\Psi.\end{align*}
By repeating policy evaluation and policy update, we can obtain the final policy. The complete procedure is summarized in Algorithm 1.
Algorithm 1

6. Numerical results
Given the variety of Choquet regularizers available, it is possible to select different regularizers for each agent. In Equation (2.13), h′(x) represents the “probability weight” assigned to x when calculating the (nonlinear) Choquet expectation (see, e.g., Gilboa and Schmeidler, Reference Gilboa and Schmeidler1989 and Quiggin, Reference Quiggin1982). Consequently, the choice of the distortion function h can directly influence the agent’s attitude toward risk. As shown by Han et al. (Reference Han, Wang and Zhou2023), Choquet regularizers can generate several widely used exploratory samplers, such as the
 $\varepsilon$
-greedy strategy, exponential, uniform, and Gaussian. Below, we assume that the agents adopt different Choquet regularizers, resulting in their optimal exploration distributions being normal and exponential, respectively.
$\varepsilon$
-greedy strategy, exponential, uniform, and Gaussian. Below, we assume that the agents adopt different Choquet regularizers, resulting in their optimal exploration distributions being normal and exponential, respectively.
Assume that Agent 1 applies the the Choquet regularizer
 \begin{equation} \Phi_{h_1} (\Pi_1)=\int_0^1 Q_{\Pi_1}(p) z (p) \mathrm{d} p,\end{equation}
\begin{equation} \Phi_{h_1} (\Pi_1)=\int_0^1 Q_{\Pi_1}(p) z (p) \mathrm{d} p,\end{equation}
where z is the quantile function of a standard normal distribution, yielding
 $h_1(p)=\int_0^p z(1-s)\mathrm{d} s$
with
$h_1(p)=\int_0^p z(1-s)\mathrm{d} s$
with
 $p\in [0,1]$
. Further, Agent 2 uses the Choquet regularizer
$p\in [0,1]$
. Further, Agent 2 uses the Choquet regularizer
 \begin{equation} \Phi_{h_2} (\Pi_2) = -\int_0^1 Q_{\Pi_2}(1-p)(\log(p)+1) \mathrm{d} p.\end{equation}
\begin{equation} \Phi_{h_2} (\Pi_2) = -\int_0^1 Q_{\Pi_2}(1-p)(\log(p)+1) \mathrm{d} p.\end{equation}
It is known as the cumulative residual entropy (e.g., Rao et al., Reference Rao, Chen, Vemuri and Wang2004 and Hu and Chen, Reference Hu and Chen2020) and
 $h_2(p)= -p\log p$
with
$h_2(p)= -p\log p$
with
 $p\in [0,1]$
. For Gauss mean return model, let
$p\in [0,1]$
. For Gauss mean return model, let
 $$\mu_i^*(t)= \dfrac{1}{1-k_1k_2}\left[\dfrac{y}{\sigma}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)-\dfrac{\rho v}{\sigma}\left((a_2^i(t)+k_ia_2^j(t))y+(a_1^i(t)+k_ia_1^j(t))\right)\right],$$
$$\mu_i^*(t)= \dfrac{1}{1-k_1k_2}\left[\dfrac{y}{\sigma}\left(\dfrac{1}{\gamma_i}+\dfrac{k_i}{\gamma_j}\right)-\dfrac{\rho v}{\sigma}\left((a_2^i(t)+k_ia_2^j(t))y+(a_1^i(t)+k_ia_1^j(t))\right)\right],$$
where
 $a^i_n(t)$
,
$a^i_n(t)$
,
 $n=1,2$
, are given by (3.21). Based on (3.16), the equilibrium distribution
$n=1,2$
, are given by (3.21). Based on (3.16), the equilibrium distribution
 $\Pi_1^*$
is a normal distribution given as
$\Pi_1^*$
is a normal distribution given as
 $${\Pi}_1^{*} (\!\cdot\!;\;t)= {\mathcal N}\left(\mu_1^*(t), \dfrac{\lambda_1^2(t)}{\gamma_1^2\sigma^4}\right),$$
$${\Pi}_1^{*} (\!\cdot\!;\;t)= {\mathcal N}\left(\mu_1^*(t), \dfrac{\lambda_1^2(t)}{\gamma_1^2\sigma^4}\right),$$
and the equilibrium distribution
 $\Pi_2^*$
is an exponential distribution given as
$\Pi_2^*$
is an exponential distribution given as
 $$ \Pi_2^*(u;\;t) = 1-\exp\left[\dfrac{\gamma_2 \sigma^2}{\lambda_2(t)}(\mu_2(t)-u)-1 \right].$$
$$ \Pi_2^*(u;\;t) = 1-\exp\left[\dfrac{\gamma_2 \sigma^2}{\lambda_2(t)}(\mu_2(t)-u)-1 \right].$$
We first investigate the influence of parameters
 $k_i$
,
$k_i$
,
 $\gamma_i$
and t on the equilibrium strategies of both agents. We assume that
$\gamma_i$
and t on the equilibrium strategies of both agents. We assume that
 $\lambda_1(t)=\lambda_2(t) = \lambda_0 e^{\lambda_0(T-t)}$
. Unless otherwise specified, the parameters in (3.16) are set as in Table 1.Footnote
1
$\lambda_1(t)=\lambda_2(t) = \lambda_0 e^{\lambda_0(T-t)}$
. Unless otherwise specified, the parameters in (3.16) are set as in Table 1.Footnote
1
Table 1. Parameter values used in the model.


Figure 1. The effects of t,
 $k_1$
,
$k_1$
,
 $k_2$
,
$k_2$
,
 $\gamma_1$
, and
$\gamma_1$
, and
 $\gamma_2$
on the Nash equilibrium.
$\gamma_2$
on the Nash equilibrium.
In Figure 1, we set
 $T=20$
to make the differences between the plotted curves visually distinguishable. The first and second rows display the density functions for Agent 1 at
$T=20$
to make the differences between the plotted curves visually distinguishable. The first and second rows display the density functions for Agent 1 at
 $t = 0.1$
and
$t = 0.1$
and
 $t = 18$
, respectively, while the third and fourth rows correspond to Agent 2’s density functions. For clarity, we focus on the characteristics of the parameters for Agent 1, as Agent 2’s performance with respect to these parameters is similar. The key observations are as follows.
$t = 18$
, respectively, while the third and fourth rows correspond to Agent 2’s density functions. For clarity, we focus on the characteristics of the parameters for Agent 1, as Agent 2’s performance with respect to these parameters is similar. The key observations are as follows.
-
(i) As
$k_1$
increases, Agent 1 tends to adopt riskier strategies, leading to a higher mean investment in risky assets. This suggests that greater sensitivity to the opponent’s performance enhances Agent 1’s motivation to outperform. -
(ii) As Agent 1’s risk aversion parameter
$\gamma_1$
rises, the mean of the equilibrium distribution decreases. This indicates that higher levels of risk aversion prompt Agent 1 to adopt more cautious strategies, reducing their expected investment in risky assets. -
(iii) As Agent 2 becomes more sensitive to Agent 1’s behavior (i.e., as
$k_2$
increases), Agent 1 tends to adopt riskier strategies to increase the likelihood of achieving higher returns. This suggests that Agent 2’s increased sensitivity further motivates Agent 1 to excel. Economically, when relative wealth is taken into account, a larger
$k_2$
leads Agent 2 to hold more risky assets, which in turn compels Agent 1 to increase its holdings of risky assets as well in order to maintain the current position and avoid falling behind. -
(iv) As Agent 2 becomes more risk-seeking (i.e., as
$\gamma_2$
decreases), Agent 1 adopts more aggressive strategies, investing a higher mean in risky assets. This adjustment is necessary to prevent Agent 1 from losing market share or competitive advantages if they fail to align their strategy with the increased risks. -
(v) Comparing the equilibrium strategies between the first and second rows, the main difference lies in time t. Since a time-decaying temperature parameter
$ \lambda_1(t)$
is employed, it means that as time progresses, the weight assigned to exploration decreases as time progresses. Consequently, the variance of the equilibrium strategies also decreases, as reflected in (3.11).






It is noteworthy that an agent’s own parameters consistently have a greater impact on their strategy than those of their opponent. This outcome is expected. For instance, when the opponent places greater emphasis on the wealth gap, it is the opponent who adjusts their behavior by increasing their own investment. The optimal response of the original decision-maker remains relatively stable, as the opponent’s concern for relative performance predominantly affects their own risk-taking behavior, rather than prompting significant changes in the other agent’s strategy.
Furthermore, Figure 1 shows that the mean of the equilibrium strategies decreases over time t. This trend can be attributed to the negative value chosen for the parameter
 $\rho$
. In the following, we investigate how the mean strategy evolves with respect to both
$\rho$
. In the following, we investigate how the mean strategy evolves with respect to both
 $\rho$
and t.
$\rho$
and t.
Figure 2 shows that as the correlation
 $\rho$
increases, the mean of the strategies for both Agent 1 and Agent 2 decrease. This is because positive correlation between the Brownian shocks driving the asset price and the factor process Y(t) increases uncertainty in the asset dynamics, increasing effective risk exposure and making the investor more cautious. However, when risks are negatively correlated (
$\rho$
increases, the mean of the strategies for both Agent 1 and Agent 2 decrease. This is because positive correlation between the Brownian shocks driving the asset price and the factor process Y(t) increases uncertainty in the asset dynamics, increasing effective risk exposure and making the investor more cautious. However, when risks are negatively correlated (
 $\rho \in [\!-\!1,0)$
), adverse movements in Y(t) tend to offset those in the asset price through the diffusion term, effectively providing a natural hedging effect that reduces risk. As a result, the investor is willing to allocate more on average under negative correlation.
$\rho \in [\!-\!1,0)$
), adverse movements in Y(t) tend to offset those in the asset price through the diffusion term, effectively providing a natural hedging effect that reduces risk. As a result, the investor is willing to allocate more on average under negative correlation.

Figure 2. The effects of t and
 $\rho$
on the mean of the Nash equilibrium.
$\rho$
on the mean of the Nash equilibrium.
Additionally, for negatively correlated risks, we find that the mean investment decreases as time t increases. This is because as time advances toward the terminal time T, the opportunity to exploit this hedging effect through dynamic rebalancing diminishes. The shorter the remaining horizon, the less effective the negative correlation becomes at mitigating risk over time, leading the investor to reduce the position. Conversely, when risks are positively correlated, the mean investment increases with time t. At early stages, the cumulative risk from positively correlated shocks is higher, prompting caution. However, as t approaches T, the remaining exposure horizon shortens, reducing the impact of correlated shocks on total risk and allowing the investor to increase the allocation. Specifically, when
 $\rho = 0$
, the shocks driving the factor process Y(t) and the asset price are independent. In this case, the mean investment is time-invariant, resulting in identical values at different t, as can be seen directly from (3.18).
$\rho = 0$
, the shocks driving the factor process Y(t) and the asset price are independent. In this case, the mean investment is time-invariant, resulting in identical values at different t, as can be seen directly from (3.18).
Next, we conduct numerical experiments with simulated data to demonstrate our Algorithm 1 for Gauss mean return model and Black-Scholes model. We first emphasize that there are some factors that affect the accuracy of the algorithm. First of all, Theorems 3 and 4 give theoretical convergence, which provides support for algorithm design, but the theoretical results depend on the parameters of the market model and these parameters are actually unknown. Secondly, as mentioned earlier, a very important property in classical reinforcement learning is that the strategy obtained after each update is better than before, but this property no longer holds in time-inconsistent problem. These increases the impact of errors on the convergence in each algorithm iteration, which may affect the convergence to the true equilibrium strategy. Finally, due to the use of maximizing
 $L_i(\Psi;\;t_0,\hat X_i(t_0),Y(t_0))$
instead of maximizing
$L_i(\Psi;\;t_0,\hat X_i(t_0),Y(t_0))$
instead of maximizing
 $L_i(\Psi;\;t,\hat x,y)$
for all possible
$L_i(\Psi;\;t,\hat x,y)$
for all possible
 $t,\hat x,y$
, each iteration highly relies on the current sample, and different samples may cause the algorithm to converge to different strategies. Meanwhile, similar to classical reinforcement learning, due to the time horizon is finite, each sample only has
$t,\hat x,y$
, each iteration highly relies on the current sample, and different samples may cause the algorithm to converge to different strategies. Meanwhile, similar to classical reinforcement learning, due to the time horizon is finite, each sample only has
 $N+1$
time points, which is far less than the number required to make the strategy maximizing
$N+1$
time points, which is far less than the number required to make the strategy maximizing
 $L_i(\Psi;\;t_0,\hat X_i(t_0),Y(t_0))$
and maximizing
$L_i(\Psi;\;t_0,\hat X_i(t_0),Y(t_0))$
and maximizing
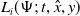 $L_i(\Psi;\;t,\hat x,y)$
for all possible
$L_i(\Psi;\;t,\hat x,y)$
for all possible
 $t,\hat x,y$
close enough. In summary, due to various reasons, algorithms for time-inconsistency problems rely more on model settings, especially parameter selection, than the classical reinforcement learning.
$t,\hat x,y$
close enough. In summary, due to various reasons, algorithms for time-inconsistency problems rely more on model settings, especially parameter selection, than the classical reinforcement learning.
We use the stock process parameters detailed in Table 1. Additionally, the other parameter settings for the algorithm are presented in Table 2. For Gauss mean return model, the value function is parameterized as in (5.2) with
 $p(\theta,t)$
chosen as
$p(\theta,t)$
chosen as
 \begin{align*} p(\theta,t)=\theta_1t^2+\theta_0t.\end{align*}
\begin{align*} p(\theta,t)=\theta_1t^2+\theta_0t.\end{align*}
The policy is parameterized as (5.1) with suitable initial values selected based on the problem context. From Theorem 3, we know that the optimal values of
 $\psi_0$
and
$\psi_0$
and
 $\psi_2$
are reciprocals of each other, and only once policy update is needed to get the optimal value of
$\psi_2$
are reciprocals of each other, and only once policy update is needed to get the optimal value of
 $\psi_2$
. Therefore, before starting training, we can perform a pretraining to get optimal
$\psi_2$
. Therefore, before starting training, we can perform a pretraining to get optimal
 $\psi_2$
to reduce the amount of subsequent training. We examine the behavior of the mean value under Nash equilibrium when Agent 1 adopts a normal distribution and Agent 2 follows an exponential distribution. The corresponding Choquet regularizers are specified in Equations (6.1) and (6.2). Figure 3 presents the mean of the discounted value invested in the risky asset under Nash equilibrium, evaluated at the market state
$\psi_2$
to reduce the amount of subsequent training. We examine the behavior of the mean value under Nash equilibrium when Agent 1 adopts a normal distribution and Agent 2 follows an exponential distribution. The corresponding Choquet regularizers are specified in Equations (6.1) and (6.2). Figure 3 presents the mean of the discounted value invested in the risky asset under Nash equilibrium, evaluated at the market state
 $Y(t) = 0.273$
, while Figure 4 illustrates the learning trajectory of
$Y(t) = 0.273$
, while Figure 4 illustrates the learning trajectory of
 $\psi_2$
, which captures the evolution of the variance. By comparing the mean and variance of learned policy with the true policy in Figures 3 and 4, we observed that our experimental results closely approximate the theoretical values. This underscores the effectiveness of our approach in approximating Nash equilibrium solutions. Owing to the asymmetry and heavier tail of the exponential distribution compared to the normal distribution, Figure 4 shows that the trajectory under exponential-distribution-based exploration exhibits greater volatility, though it still converges to the true value. From this standpoint, the normal distribution may appear to yield more stable learning dynamics. However, this interpretation should be viewed with caution, as the regularizers used here capture agents’ subjective preferences rather than purely statistical features of the distributions.
$\psi_2$
, which captures the evolution of the variance. By comparing the mean and variance of learned policy with the true policy in Figures 3 and 4, we observed that our experimental results closely approximate the theoretical values. This underscores the effectiveness of our approach in approximating Nash equilibrium solutions. Owing to the asymmetry and heavier tail of the exponential distribution compared to the normal distribution, Figure 4 shows that the trajectory under exponential-distribution-based exploration exhibits greater volatility, though it still converges to the true value. From this standpoint, the normal distribution may appear to yield more stable learning dynamics. However, this interpretation should be viewed with caution, as the regularizers used here capture agents’ subjective preferences rather than purely statistical features of the distributions.
Table 2. Parameter settings for the algorithm.


Figure 3. The mean value of Nash equilibrium.

Figure 4. Convergence of the learned
 $\psi_2$
.
$\psi_2$
.
For Black-Scholes model, policy evaluation and policy updates can still be implemented using the methods mentioned above. The difference is that the quantile function of the policy
 $\boldsymbol{\Pi}_i$
is given by
$\boldsymbol{\Pi}_i$
is given by
 \begin{align*} Q_{\Pi_i^{\Psi}(t)}(p)=k_i\mu_j(t)+\psi_0 \dfrac{y}{\gamma_i}+\dfrac{\lambda_i}{\gamma_i \psi_1^2} h_i'(1-p),\end{align*}
\begin{align*} Q_{\Pi_i^{\Psi}(t)}(p)=k_i\mu_j(t)+\psi_0 \dfrac{y}{\gamma_i}+\dfrac{\lambda_i}{\gamma_i \psi_1^2} h_i'(1-p),\end{align*}
and the value function is parameterized as
 \begin{align*} V_i^{\Theta}(t,\hat x_i)=\hat x_i+\theta_i^{V}(T-t)\ \text{ and }\ g_i^{\Theta}(t,\hat x_i)=\hat x_i+\theta_i^{g}(T-t).\end{align*}
\begin{align*} V_i^{\Theta}(t,\hat x_i)=\hat x_i+\theta_i^{V}(T-t)\ \text{ and }\ g_i^{\Theta}(t,\hat x_i)=\hat x_i+\theta_i^{g}(T-t).\end{align*}
From Corollary 1, we know that the optimal strategy does not change over time and the optimal value of
 $1/\psi_0$
and
$1/\psi_0$
and
 $\psi_1$
is
$\psi_1$
is
 $\sigma$
. Thus we are actually learning the optimal
$\sigma$
. Thus we are actually learning the optimal
 $\sigma$
. We plot the density function of the equilibrium policy in Figure 5 when
$\sigma$
. We plot the density function of the equilibrium policy in Figure 5 when
 $Y(t)=0.273$
and
$Y(t)=0.273$
and
 $\sigma=0.15$
. We can see that the output of our algorithm closely approximates the theoretical value. Note that the “true” value or policy in Figures 3–5 is computed under the assumption of full knowledge of all model parameters shown in Tables 1 and 2.
$\sigma=0.15$
. We can see that the output of our algorithm closely approximates the theoretical value. Note that the “true” value or policy in Figures 3–5 is computed under the assumption of full knowledge of all model parameters shown in Tables 1 and 2.

Figure 5. Learned policy for Black-Scholes model.
7. Conclusion
This paper introduces a framework for continuous-time RL in a competitive market, where two agents consider both their own wealth and their opponent’s wealth under the mean-variance criterion. The Nash equilibrium distributions are derived through dynamic programming, revealing that an agent’s mean of equilibrium distribution for exploration is influenced not only by his own parameters but also by those of his opponent, while the variance of the distribution is solely determined by the agent’s own model parameters.
In addition, we investigate the impact of model parameters on the equilibrium strategies, providing valuable insights into decision-making dynamics in competitive financial markets. Furthermore, we design an algorithm to study Nash equilibrium policies, and our experimental results indicate that the output of our algorithm closely approximates the theoretical value.
Notation
-
$\mathcal M$
-
Set of Borel probability measures or distribution functions on
$\mathbb R$
. -
$\mathcal M^p$
-
Subset of
$\mathcal M$
with finite p-th order moment,
$p \in [1,\infty)$
. -
$S_0(t)$
-
Price process of the risk-free asset.
- S(t)
-
Price process of the risky asset.
- Y(t)
-
Process of the state variable representing macroeconomic or systemic risk factors.
-
$W,\widetilde W,\overline W_i$
-
Brownian motions.
-
$\rho$
-
Correlation coefficient between Y(t) and W(t),
$\rho \in [\!-\!1,1]$
. -
$\gamma_i$
-
Risk aversion coefficient of Agent i.
-
$k_i$
-
Sensitivity coefficient of Agent i to the wealth gap with Agent j.
-
$\lambda_i$
-
Exploration weight of Agent i.
-
$u_i$
-
Control variable of Agent i at some time t.
-
$\boldsymbol{u}_i$
-
Control process of Agent i,
$\boldsymbol{u}_i=\{u_i(t),0\leqslant t\leqslant T\}$
. -
$X_i^{u_i}(t)$
-
Discounted wealth process of Agent i under control
$u_i$
. -
$\hat X_i^{u_i,u_j}(t)$
-
$X_i^{u_i}(t)-k_i X_j^{u_j}$
.
-
$\Pi_i$
-
A distribution randomized from control
$u_i$
. -
$\pi_i$
-
Density function of
$\Pi_i$
. -
$\boldsymbol{\Pi}_i$
-
Randomized control process of Agent i,
$\boldsymbol{\Pi}_i=\{\Pi_i(t),0\leqslant t\leqslant T\}$
. -
$X_i^{\Pi_i}(t)$
-
Exploratory discounted wealth process of Agent i under randomized control
$\Pi_i$
. -
$\hat X_i^{\Pi_i,\Pi_j}(t)$
-
$X_i^{\Pi_i}(t)-k_i X_j^{\Pi_j}(t)$
.
-
$\mathcal L^{u_i,u_j}$
-
Infinitesimal generator of
$(\hat X_i^{u_i,u_j}(t),Y(t))$
. -
$\mathcal L^{\Pi_i,\Pi_j}$
-
Infinitesimal generator of
$(\hat X_i^{\Pi_i,\Pi_j}(t),Y(t))$
. -
$\mu_i$
-
Mean of the distribution
$\Pi_i$
. -
$\sigma_i^2$
-
Variance of the distribution
$\Pi_i$
. -
$Q_{\Pi_i}(p)$
-
Left-quantile function of the distribution
$\Pi_i$
. -
$h_i$
-
Distortion function of Choquet regularizer for Agent i.
-
$\Phi_{h_i}$
-
Choquet regularizer for Agent i.
-
$V_i,g_i$
-
Value functions of Agent i.
-
$\Theta$
-
Parameters of an approximate value function.
-
$V_i^{\Theta},g_i^{\Theta}$
-
Parametrized approximations of value functions
$V_i$
and
$g_i$
. -
$\Psi$
-
Parameters of an approximate policy.
-
$\Pi_i^{\Psi}$
-
Parametrized approximation of
$\Pi_i$
.

















































Acknowledgements
The research of Junyi Guo was supported by the National Natural Science Foundation of China (No. 12271274). The research of Xia Han was supported by the National Natural Science Foundation of China (Grant Nos. 12301604, 12371471, and 12471449) and the Fundamental Research Funds for the Central Universities, Nankai University (Grant No. 63231138).
Competing interests
The authors declare none.














