




Highlights
-
• The study explored the knowledge and processing of double and triple cognates.
-
• L1–L2–L3 cognates were known better than L2–L3 cognates.
-
• L2–L3 cognates showed no advantage over non-cognates.
-
• Low-frequency L1–L2–L3 cognates showed a processing advantage over L2–L3 cognates.
-
• Cognitive skills impacted L3 processing speed and L3 proficiency in word knowledge.
1. Introduction
Some tourists visiting Italy realize that they can understand and quickly learn many Italian words, such as attenzione or silenzio, because they sound and look familiar. Probably, those tourists speak languages containing cognates with Italian, that is, words whose form and meaning are very similar across languages (Otwinowska et al., Reference Otwinowska, Foryś-Nogala, Kobosko and Szewczyk2020). Capitalizing on cross-linguistic similarity (cognateness) is known to facilitate the acquisition of second language (L2) and third language (L3) vocabulary (Ecke, Reference Ecke2015). Still, the precise similarity-based mechanisms underlying L3 lexical learning remain unexplored. It is unclear how the acquisition of L3 words is influenced by their similarity to just one versus all previously learned languages.
Therefore, we carried out a large-scale study testing the role of cumulative L1–L2–L3 similarity versus L2–L3 similarity in L3 word knowledge and visual recognition. We investigated speakers of L1-Polish, L2-English, and L3-Italian, focusing on three word types: non-cognates (e.g., gorzki/bitter/amaro), L2–L3 cognates (e.g., skromny/modest/modesto), and L1–L2–L3 cognates (e.g., stabilny/stable/stabile). Moreover, we checked whether participants’ L3 word knowledge and real-time processing were modulated by their L2-English and L3-Italian proficiency, cognitive aptitudes (i.e., working memory and associative learning), and word guessing tendencies. To the best of our knowledge, this is the first study comprehensively examining the knowledge and online processing of L3 cognates in natural languages when controlling for an array of individual differences.
2. Cross-linguistic similarity in learning and processing L2 and L3 vocabulary
2.1. Cross-linguistic influences and language co-activation
The term “L3” refers to a third or additional language that the user/learner has been acquiring during their lifetime (De Angelis, Reference De Angelis2007). L3 acquisition relies on the previous languages that co-exist in the learner’s mind (e.g., Festman, Reference Festman2021) and are always co-activated to some degree (e.g., Kroll et al., Reference Kroll, Dussias, Bice and Perrotti2015; Rice & Tokowicz, Reference Rice and Tokowicz2020). Co-activating alternate connections across the language network leads to their interactions (Sharwood Smith, Reference Sharwood Smith2021) called cross-linguistic influences (CLIs). In L3 acquisition, CLI is possible across all known languages and is often triggered by cross-linguistic similarity (for overviews concerning morpho-syntactic CLI, see Angelovska & Hahn, Reference Angelovska and Hahn2017; Puig-Mayenco et al., Reference Puig-Mayenco, González Alonso and Rothman2020).
Lexical cross-linguistic similarity is, among others, manifested by the presence of cognates, that is, words similar formally and semantically across languages (Otwinowska et al., Reference Otwinowska, Foryś-Nogala, Kobosko and Szewczyk2020). The bulk of knowledge on lexical CLI comes from research on cognates across two languages. For instance, L1–L2 cognates are learned and retrieved faster and are more resistant to forgetting than other L2 words (e.g., Ellis & Beaton, Reference Ellis and Beaton1993; Lotto & De Groot, Reference Lotto and De Groot1998). Cognates are also more “learnable” than other words, meaning that L2 learners at a particular proficiency level know more L2 cognates than non-cognates of comparable frequency (Otwinowska & Szewczyk, Reference Otwinowska and Szewczyk2019). This can be explained by language co-activation: When learners encounter a cognate, stronger form-meaning links are created in the mind than in the case of non-cognates, leading to faster learning (see Kroll et al., Reference Kroll, Dussias, Bice and Perrotti2015; Marecka et al., Reference Marecka, Szewczyk, Otwinowska, Durlik, Foryś-Nogala, Kutyłowska and Wodniecka2021; Rice & Tokowicz, Reference Rice and Tokowicz2020). In visual processing, L2–L1 cognates are recognized and reacted to more quickly than non-cognates, a phenomenon called the cognate facilitation effect (e.g., Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002; Lemhöfer et al., Reference Lemhöfer, Dijkstra and Michel2004), explained by mental lexicon organization. Thanks to formal similarity, when a cognate is read, the orthographic representations from both languages are co-activated, leading to the activation of a common semantic representation, enhancing translation or recognition of the word (Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002). Overall, in L2 acquisition, language co-activation due to cross-linguistic similarity leads to robust facilitation in learning and processing.
2.2. Learning L3 words
There is a dearth of research exploring CLI in L3 lexical acquisition (see Festman, Reference Festman2021; Hirosh & Degani, Reference Hirosh and Degani2018). Some studies have focused on how monolinguals and bilinguals cope with varied grapheme–phoneme or grapheme–grapheme mappings in specially constructed L3 nonwords (e.g., Bartolotti & Marian, Reference Bartolotti and Marian2019; Escudero et al., Reference Escudero, Broersma and Simon2013; Kaushanskaya & Marian, Reference Kaushanskaya and Marian2009). They showed that, in the case of conflicting L1–L3 orthographic or phonetic mappings, bilinguals outperformed monolinguals in novel word learning, probably because the activation of their L2 blocked the negative CLI from the L1.
Other research, which used natural L3 words (e.g., Bogulski et al., Reference Bogulski, Bice and Kroll2019; Hall et al., Reference Hall, Newbrand, Ecke, Sperr, Marchand and Hayes2009; Hirosh & Degani, Reference Hirosh and Degani2021; Mulík et al., Reference Mulík, Carrasco-Ortiz and Amengual2019; Vanhove, Reference Vanhove2016), has not directly focused on CLI mechanisms. Two studies tested learners’ conscious reliance on CLI. They showed that, when presented with novel cognates, L3 learners rely on L1–L3 similarity (Vanhove, Reference Vanhove2016) or L1 and L2 similarity (Hall et al., Reference Hall, Newbrand, Ecke, Sperr, Marchand and Hayes2009), although they are not fully aware of this reliance. Two studies concentrated on the language of instruction in L3 acquisition (Bogulski et al., Reference Bogulski, Bice and Kroll2019; Hirosh & Degani, Reference Hirosh and Degani2021). They showed that L3 learning via the L2 yielded lower results than learning via the L1, even when the wordlists included cognates bearing both L1–L3 and L2–L3 similarity. This may be explained either by more experience in inhibiting the L1 than the L2 during learning (Bogulski et al., Reference Bogulski, Bice and Kroll2019) or by more cognitive resources available when processing new information in the L1 than in the L2 (Hirosh & Degani, Reference Hirosh and Degani2021). On the contrary, recent research with trilinguals (de Bruin et al., Reference de Bruin, Hoversten and Martin2023) has shown that CLI was stronger between their L3 and L2 than between L1 and L2. Also, the CLI that participants experienced between their non-native languages (L2 and L3) was associated with weaker inhibition of those languages compared with their native language (L1). The authors suggest that because trilinguals apply more inhibition over their L1, their non-native languages might experience more interaction. This aligns with Bardel and Falk’s (Reference Bardel and Falk2007, 2012) L2-status model of CLI in L3 acquisition, which assumes that L2 may be more available than L1 for building up L3 knowledge, due to the cognitive similarity of both non-native languages.
Crucially, none of the abovementioned research directly addressed questions pertaining to the source languages of CLI in L3 acquisition (for an overview, see Hirosh & Degani, Reference Hirosh and Degani2018), related to two broad hypotheses called the one-to-one versus many-to-one transfer (De Angelis, Reference De Angelis2007). Essentially, one-to-one transfer means that CLI to L3 has a single source, and many-to-one transfer means that CLI can come from L1, L2, or both. Testing the one-to-one versus many-to-one scenarios involves determining which languages constitute the strongest source(s) of transfer, an issue already tackled for the L3 morphosyntax (for discussion, see Puig-Mayenco et al., Reference Puig-Mayenco, González Alonso and Rothman2020), but not the lexicon. To the best of our knowledge, only two studies (Bartolotti & Marian, Reference Bartolotti and Marian2017; Suhonen, Reference Suhonen2020) investigated directions of CLI in L3 vocabulary acquisition. Suhonen (Reference Suhonen2020) focused on meaning-based CLI (translation ambiguity) using L2-like and L3-like nonwords and natural L3 stimuli. His word-learning experiments, which manipulated word meanings across languages, showed multidirectional CLI, both from the L1 and the L2 to the L3 and from the L3 to the L2 at all stages of word acquisition. Bartolotti and Marian (Reference Bartolotti and Marian2017) focused on the role of formal similarity and tested two CLI mechanisms of L3 word learning. The scaffolding account assumed that a newly encountered L3 form gets linked to a similar word in just one of the known languages, and this single link suffices to enhance learning. The accumulation account posited that learning of L3 words is contingent on the frequency of sublexical features shared across L1–L2–L3, which enhance learning in an additive manner. This is compatible with the Parasitic Model (Ecke, Reference Ecke2015) of the multilingual lexicon, whereby novel L3 words are initially “parasitically” connected to the known L1 or L2 words. Any similarity between the “host” (L1 or L2) and the “parasite” (L3) word enhances learning, with more similarities leading to stronger learning effects.
To test the scaffolding account against the accumulation account, Bartolotti and Marian (Reference Bartolotti and Marian2017) asked English–German bilinguals to learn L3 nonwords of four types: two types of double cognates (orthographically similar to either L1-English or L2-German), triple cognates (similar to both L1-English and L2-German), and non-cognates. Participants were first presented with written L3 word forms matched with pictures, and then performed blocks of word recognition and production trials with feedback, which facilitated further learning. The results showed that double cognates with either English or German were learned better than non-cognates, but triple cognates did not show any additive advantages. Bartolotti and Marian (Reference Bartolotti and Marian2017) claimed that this supports the scaffolding account, suggesting that a similarity to any previously known language suffices to facilitate L3 word learning.
2.3. Processing L3 words
Conversely, psycholinguistic research shows that cumulative CLI may enhance processing L3 words (e.g., Lemhöfer et al., Reference Lemhöfer, Dijkstra and Michel2004; Poarch & Van Hell, Reference Poarch and Van Hell2014; Szubko-Sitarek, Reference Szubko-Sitarek2011; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002), especially for identical cognates. For instance, Lemhöfer et al. (Reference Lemhöfer, Dijkstra and Michel2004) used the lexical decision task (LDT) to compare the speed of recognizing non-cognates, double cognates (L1–L3), and triple cognates (L1–L2–L3). Dutch–English–German trilinguals performed a visual Lexical Decision task in their L3-German. The results showed that both cognate types were processed faster than non-cognates, but the facilitation effects were more robust for triple cognates. Similarly, Szubko-Sitarek (Reference Szubko-Sitarek2011) tested how Polish–English–German trilinguals recognize words in their L3-German and found a processing advantage of L1–L2–L3 cognates over L1–L3 cognates. Lijewska (Reference Lijewska2022) investigated Polish–German–English trilinguals who read English sentences of varying context constrainability, which contained non-identical L1–L2–L3 cognates. The study found that cognates were recognized equally fast irrespective of context, but no cognate facilitation was found, as demonstrated by early and late eye-tracking measures. Lijewska (Reference Lijewska2022) ascribed these results to the lesser cross-linguistic overlap in her cognates than those used in previous studies. In her further analysis, she found a significant facilitation for the Polish–English (L1–L3) cross-language overlap, but not for the German–English (L2–L3) overlap, suggesting stronger transfer from the L1 than the L2.
Regarding L3 production, Poarch and Van Hell (Reference Poarch and Van Hell2014) examined picture naming in L2-English and L3-Dutch by German–English–Dutch trilinguals, who were immersed in their L3-Dutch. For L2-English, the L1–L2–L3 cognates were named faster and more accurately than both L1–L2 and L2–L3 cognates and non-cognates. For L3-Dutch, triple cognates were named faster than non-cognates, and all cognates surpassed non-cognates in accuracy. These findings resonate with the recognition data from the LD studies discussed above, corroborating that cumulative similarity enhances the activation and retrieval of L2 and L3 words, but stand in contrast to Bartolotti and Marian’s (Reference Bartolotti and Marian2017) results.
Summing up, comprehensive research on CLI in L3 word learning and processing is still scarce. To the best of our knowledge, only Bartolotti and Marian (Reference Bartolotti and Marian2017) tested hypotheses concerning the role of cumulative versus single-sourced CLI in L3 word learning. Utilizing specially constructed L3 nonwords, they demonstrated that single-sourced similarity sufficed to learn the word, giving support to the scaffolding account. This, however, contrasts with the results on natural L3 word recognition and production (e.g., Lemhöfer et al., Reference Lemhöfer, Dijkstra and Michel2004; Poarch & Van Hell, Reference Poarch and Van Hell2014; Szubko-Sitarek, Reference Szubko-Sitarek2011), which demonstrated enhanced cognate facilitation for cumulative L1–L2–L3 similarity. Given the scarcity of research on the amount and direction of CLI in L3 vocabulary acquisition and the conflicting results, with the present study, we aim to provide more evidence on the role of cumulative versus single-sourced similarity in L3 word knowledge and online processing.
2.4. The current study
We present a large-scale cross-sectional study on the role of CLI in L3 word acquisition, aimed at bridging the gap between the existing lines of research. Therefore, we have included measures of L3 word knowledge as well as measures of online word recognition accuracy and processing speed. The study involved speakers of three European typologically distant languages: L1-Polish, L2-English, and L3-Italian. We examined the impact of cumulative cognateness (L1–L2–L3 triple cognates across Polish, English, and Italian) versus single-sourced cognateness (L2–L3 double cognates across English and Italian) on L3 word knowledge and processing speed. Following Bardel and Falk (Reference Bardel, Falk, Amaro, Flynn and Rothman2012) and de Bruin et al. (Reference de Bruin, Hoversten and Martin2023), we assumed that the L2 might exert stronger CLI on the L3 than the L1, if sufficiently activated. Thus, in the study, we focused on L2–L3, but not L1–L3, double cognates.
We also assumed that CLI may be modulated by the following learner-related variables: language proficiency, guessing tendency, and cognitive aptitudes (for overviews, see, e.g., Angelovska & Hahn, Reference Angelovska and Hahn2017; Dijkstra & Van Heuven, Reference Dijkstra, Van Heuven, Rueschemeyer and Gaskell2018). For instance, the magnitude of cognate facilitation may depend on L2 and L3 proficiency (e.g., Bartolotti & Marian, Reference Bartolotti and Marian2017; Poarch & Van Hell, Reference Poarch and Van Hell2014; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002). Also, proficiency interacts with learners’ capacity to detect cross-linguistic similarity, whereby participants with higher L2 proficiency are better at inferring the meanings of unknown L3 cognates (Berthele, Reference Berthele2011; Vanhove & Berthele, Reference Vanhove and Berthele2017). Thus, for our study, we recruited participants of various L2 and L3 proficiency levels. Also, we acknowledged that participants’ sensitivity to cognates may be related to their cognitive aptitudes (Berthele, Reference Berthele2011), which are an important source of variance and stable determinants of an L2 learner’s success (Wen et al., Reference Wen, Biedroń and Skehan2017). Thus, we explored whether working memory and associative learning interact with cross-linguistic similarity in L3 word learning and real-time processing. Finally, a tendency to guess the meaning of the keywords was included in the analyses to account for learners’ strategic guessing based on cross-linguistic similarity (e.g., Otwinowska & Szewczyk, Reference Otwinowska and Szewczyk2019). The study pursued the following research questions:
RQ1. Is the effect of cumulative L1–L2–L3 similarity different from the effect of L2–L3 similarity with respect to the knowledge of L3 words?
RQ2. What is the role of the learner’s individual differences (cognitive aptitudes, guessing tendency, and L2 and L3 proficiency) in the knowledge of different types of L3 words?
RQ3. Is the effect of cumulative L1–L2–L3 similarity different from the effect of L2–L3 similarity with respect to the online processing of L3 words?
RQ4. What is the role of the learner’s individual differences (cognitive aptitudes, guessing tendency, and L2 and L3 proficiency) in the online processing of different types of L3 words?
We hypothesized that L1–L2–L3 cognates would be known better and processed faster than L2–L3 cognates and that both cognate types would be known better and processed faster than non-cognates. We further hypothesized that word- and learner-related variables (e.g., word frequency or cognitive aptitudes) would modulate the effects of CLI. For instance, frequency in L3 Italian might be less important for words bearing more similarity to the previous languages. Moreover, guessing might be more detrimental to cognates compared with non-cognates. Finally, we hypothesized that higher proficiency in L2 would positively influence the knowledge and processing speed of L3 words that are cognate to L2.
Importantly, in our operationalization of L3 word knowledge, we assumed the concept of “word learnability” (ease of learning), proposed by Otwinowska and Szewczyk (Reference Otwinowska and Szewczyk2019). They tested participants’ L2 word knowledge at a given point in time, assuming that any differences among cognates, false cognates, and non-cognates matched in L2 frequency must reflect their learnability. Thus, our stimuli (L1–L2–L3 cognates, L2–L3 cognates, and non-cognates) were matched on L3 frequency, reflecting the likelihood of participants’ having encountered them in the input. We reasoned that if the words had an equal chance of being encountered, any differences in how well participants know them must reflect differences in the word learnability.
Regarding the operationalization of the variables, as indices of vocabulary knowledge, we considered (1) participants’ ability to translate the keywords from L2 to L3 and (2) their ability to use them correctly in a sentence. To investigate online processing, we looked at the accuracy and speed of recognizing L3-Italian keywords in the LDT. The choice of the measures and instruments is presented in the “Methods” section below.
3. Methods
3.1. Participants
The participants of the study were 96 PolishFootnote 1 undergraduate and graduate university students of Italian Studies at two public universities in Warsaw, Poland. All were native speakers of Polish and were Polish-dominant (we excluded one student with native to Russian and Ukrainian). All participants completed at least 12 years of formal education in English as a foreign language, as it is a mandatory subject in the Polish educational system.
All participants attended courses in L3-Italian, whose level (from A1 to B2) and intensity (from 6 to 10 hours a week) depended on the year of study. To cover a wide range of levels of L3-Italian knowledge, participants’ proficiency ranged between A1 and C1 CEFR (Council of Europe, 2001). We excluded one participant who spent over 5 years in Italy, which we qualified as a prolonged immersion in Italian. Measures of participants’ proficiency in their L2-English and L3-Italian were obtained from the DIALANG Vocabulary Placement Tests (Alderson & Huhta, Reference Alderson and Huhta2005). Measures of their cognitive aptitudes were taken from the Polish Reading Span (PRSPAN; Biedroń & Szczepaniak, Reference Biedroń and Szczepaniak2012) and the LLAMA-B (Meara, Reference Meara2005).
Participants also provided a list of known languages, the order of their acquisition, and self-assessed proficiency (see Table 1). Apart from English and Italian, 22 claimed to know French, 17 Spanish, 11 Russian, 2 Dutch and Korean, and 1 Hebrew, Old Greek, Latin, Turkish, and Japanese. We did not gather data concerning participants’ Age of Acquisition or the frequency of language use.
Table 1. Summary of the information on foreign languages known by the participants gathered via a self-report questionnaire
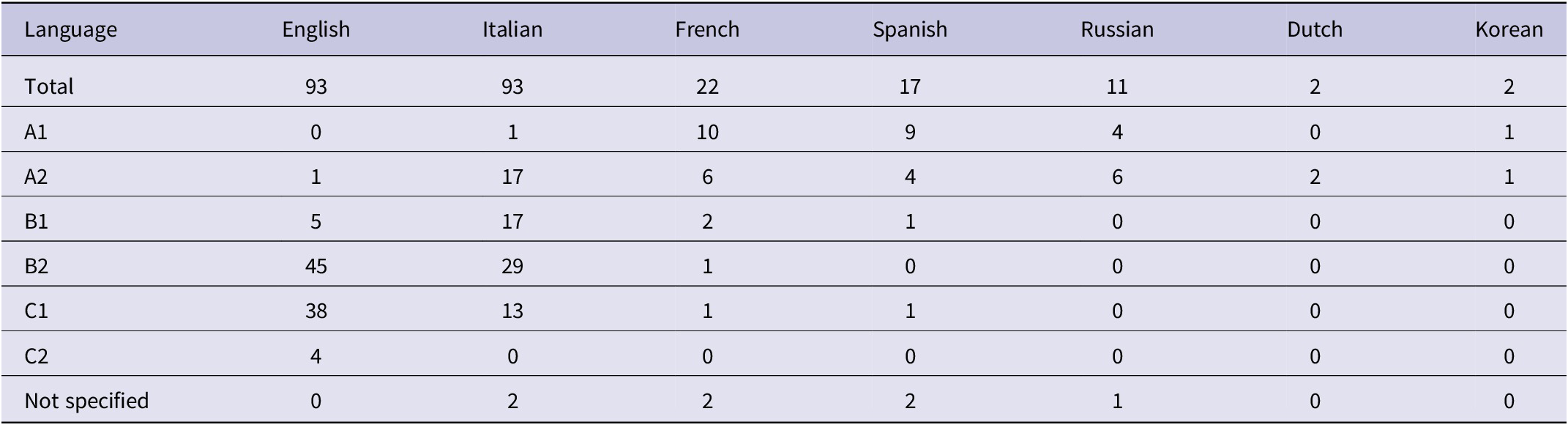
Note: Additionally, one participant reported knowledge of Hebrew (A2), another of Old Greek and Latin (both B2), one of Turkish (level not specified), and one of Japanese (A1).
Based on data analysis, we excluded one more participant whose answers in the main vocabulary knowledge task were unreliable because of extensive guessing. The final sample included 93 participants (79 females, M age = 21.82, SD = 3.31, range = 18–40; see Appendix S1 and Table S1 in the Supplementary Material for participant-related variables).
3.2. Materials
Additional information on the study materials and procedure can be found in Appendices S1–S4 in the Supplementary Material.
3.3. Stimuli
3.3.1. Words
The target stimuli (henceforth: keywords) were 120 Italian words: 40 triple (L1–L2–L3) cognates (e.g., kryzys-crisis-crisis; aktywny-active-attivo), 40 double (L2–L3) cognates (e.g., napięcie-tension-tensione; pionowy-vertical-verticale), and 40 non-cognates (e.g., choroba-illness-malattia; uparty-stubborn-testardo). The cognates were non-identical and varied in their orthographic similarity, as measured by the L2–L3 Levenshtein distance normalized for the word length (L2–L3 cognates: M = 0.28, SD = 0.17, range = 0.08–0.71; L1–L2–L3 cognates: M = 0.29, SD = 0.18, range = 0–0.63). For each group of words, half of the items were nouns, and the other half were adjectivesFootnote 2 (see Supplementary Appendix S2 for the complete stimuli list, Supplementary Appendix S3 for item-related variables, and Table S2 in the Supplementary Material for the descriptive statistics of the keywords).
Initially, a list of over 220 stimuli was pre-selected by a team of linguists specializing in English and Italian. We eliminated morphologically complex and polysemous items and false cognates (similar form, different meaning). Prior to the study, 185 stimuli were piloted on L3-Italian learners (first pilot: 58 participants, B1 level; second pilot: 46 participants of varied proficiency). The first pilot included 48 words (16 non-cognates, 16 double cognates, and 16 triple cognates), and the second pilot included 168 words (55 non-cognates, 55 double cognates, and 58 triple cognates). This led to deleting items that yielded floor effects (e.g., lutto) or ceiling effects (e.g., entusiasmo), that were problematic to translate (e.g., igenico) or to use in a sentence (e.g., esausto), or that yielded correct translations different from expected (e.g., caro instead of costoso). Altogether, the initial screening and the two pilots allowed us to arrive at the final list of 120 keywords.
Across groups, the keywords did not differ in terms of their mean log frequency in L1 (SUBTLEX-PL; Mandera et al., Reference Mandera, Keuleers, Wodniecka and Brysbaert2015), log frequency in L2 (SUBTLEX-US; Brysbaert et al., Reference Brysbaert, New and Keuleers2012), log frequency in L3 (SUBTLEX-IT; Crepaldi et al., Reference Crepaldi, Amenta, Mandera, Keuleers and Brysbaert2015), concreteness in L2-English (Brysbaert et al., Reference Brysbaert, Warriner and Kuperman2014), length in L1, L2, L3, and Levenshtein distance between L2-English and L3-Italian (see Table S2 in the Supplementary Material).
3.3.2. L2-English nonwords
To control for guessing in the word-knowledge task, we incorporated 40 English nonwords created using the Wuggy pseudoword generator (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010). To avoid high resemblance to the existing words (and false positives in the task), we generated nonwords based on non-cognates (see Supplementary Appendix S2). The non-cognates and nonwords were matched for the sub-syllabic structure, letter length, and transition frequencies. The ratio of overlapping segments was 2/3. From the Wuggy output, we eliminated nonwords that could be confused with existing English words (e.g., sstuddorn ~ stubborn) and made sure that half of the nonwords had adjectival and half nominal endings.
3.3.3. L3-Italian nonwords
For the LDT, we generated 120 Italian nonwords with the use of the Italian version of Wuggy (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010). The nonwords were matched for the sub-syllabic structure, letter length, and transition frequencies with the keywords in L3-Italian (see Supplementary Appendix S2).
3.4. Instruments
3.4.1. Measuring word knowledge: L3 vocabulary knowledge test (L3 test)
To test vocabulary knowledge in L3-Italian, we used a task adapted from the Vocabulary Knowledge Scale (VKS; Paribakht & Wesche, Reference Paribakht and Wesche1993). The original VKS is a self-reported scale measuring both receptive and productive vocabulary knowledge on a five-level continuum (1. I don’t remember having seen this word before; 2. I have seen the word before, but I don’t know what it means; 3. I have seen this word and I think it means…; 4. I know this word. It means…; 5. I can use this word in a sentence…). In the original VKS, the keyword and the instructions are presented in participants’ L2, who also provide answers in the L2.
In our adapted task (henceforth: L3 test), we aimed to elicit only the productive knowledge of L3-Italian words, which also limited the amount of cognate guessing, commonly observed in L2–L1 translation (Otwinowska & Szewczyk, Reference Otwinowska and Szewczyk2019). Moreover, to account for the CLI across the three languages, we wanted to co-activate the L1, L2, and L3 within a single task. Therefore, in the L3 test, the keywords were presented in L2-English, the instructions in L1-Polish, while the answers (words and sentences) were provided in L3-Italian. Such a language scheme was determined in an extensive pilot study, where 58 trilinguals were randomly divided into four groups. Across groups, participants had equal upper-intermediate knowledge of L2-English and equal intermediate knowledge of L3-Italian. We tested four versions of the task using the Latin square design, counterbalanced for the language of instructions and the language of keyword presentation: (1) keywords in L1 and instructions in L2, (2) keywords in L2 and instructions in L1, (3) keywords in L1 and instructions in L1, and (4) keywords in L2 and instructions in L2. Following the pilot, we decided on using version 2 of the L3 test (keywords in L2-English and instructions in L1-Polish). Importantly, presenting the keywords in L2-English did not advantage L1–L2–L3 cognates over L2–L3 cognates and allowed for controlling for the receptive knowledge of the L2-English forms of the keywords (only the known L2 words could be translated to L3-Italian).
The L3 test was administered via Qualtrics (https://www.qualtrics.com/uk/). Each level of the task (from 0 to 3; see below) was presented on the consecutive screen with no possibility to go back. Each keyword was presented in L2-English, with the information on its part of speech and a cue related to its meaning. The L2 word together with the cues was displayed on each consecutive screen.
-
• At Level 0, participants indicated if they knew the L2-English form of the keyword (yes/no). If the English version of the keyword was unknown, the procedure displayed the next keyword.
-
• At Level 1, participants indicated if they knew the L3-Italian version of the L2-English keyword (yes/no). The initial letter of the target Italian form was provided to limit the elicitation of synonyms (e.g., frontier corresponds to frontiera or confine). If the word was unknown, the procedure moved on to the next keyword.
-
• At Level 2, participants had to write the L3-Italian translation of the L2-English keyword and indicate their confidence about the correctness of their answer. If a participant indicated guessing at Level 2, they could not proceed to Level 3.
-
• At Level 3, participants created a sentence in L3-Italian employing the keyword. The sentence was at least seven words long and had to demonstrate the knowledge of the meaning of the keyword, whose part of speech could not be changed.
3.4.2. Measuring word real-time processing: L3 lexical decision task
To tap into the online processing of the keywords in L3-Italian, we used an LDT in PsychoPy (Peirce et al., Reference Peirce, Gray, Simpson, MacAskill, Höchenberger, Sogo, Kastman and Lindeløv2019). The task included the same set of 120 L3-Italian keywords and 120 Italian nonwords. Participants decided as quickly and as accurately as possible if the string of letters on the screen was an Italian word or not. They responded by pressing with their index fingers one of the designated buttons (Yes or No) on a computer keyboard. The task contained a practice block of 16 items (8 words and 8 nonwords) and two experimental blocks of 120 items each, presented in a randomized order. Each trial started with an asterisk presented in the center of the screen for 500 milliseconds. No time limit was set for displaying each stimulus. There was a short break halfway through the task.
3.4.3. Background questionnaire
An online questionnaire gathered participants’ demographic information, foreign language-learning history, and self-rated proficiency in their languages.
3.4.4. Proficiency tests in L2 and L3
To test participants’ proficiency in L2 and L3, we used the English and Italian versions of the DIALANG Vocabulary Placement test (https://dialangweb.lancaster.ac.uk/; Alderson & Huhta, Reference Alderson and Huhta2005). The test is an untimed LDT, whereby the participants decide which of the 75 forms (50 words and 25 nonwords) are real words in the target language. Participants’ scores (0–1,000, continuous variable) correspond to the CEFR (Council of Europe, 2001): 0–100 to A1 level, 101–200 to A2 level, 201–400 to B1 level, 401–600 to B2 level, 601–900 to C1 level, and 901–1,000 to C2 level.
3.4.5. Computerized Polish reading span test
As a measure of working memory, we used a computerized version of the Polish Reading Span validated with speakers of L1-Polish (PRSPAN; Biedroń & Szczepaniak, Reference Biedroń and Szczepaniak2012), administered via PsychoPy (Peirce et al., Reference Peirce, Gray, Simpson, MacAskill, Höchenberger, Sogo, Kastman and Lindeløv2019). PRSPAN is a dual task that involves reading sentences to judge their plausibility while attempting to memorize two-syllable nouns that appear together with the sentences (see also Engle et al., Reference Engle, Tuholski, Laughlin and Conway1999). The task consists of eight blocks (from 3–10 sentences and words per block; 52 trials in total). The stimulus sentences are displayed for 5 seconds and preceded by a 500-millisecond interval. At the end of each block, the participant recalls the nouns in the order of presentation. To calculate the final results, we averaged the scores of word recall and sentence judgment components of the PRSPAN (see Walter, Reference Walter2004; Waters & Caplan, Reference Waters and Caplan1996) to include both parts of the dual procedure and avoid setting random participant exclusion thresholds (see Juffs & Harrington, Reference Juffs and Harrington2011). In contrast to Waters and Caplan (Reference Waters and Caplan1996), our formula did not include the reaction times (RTs) of sentence judgment, as the task already imposed a strict time limit. Both subtasks reached satisfactory reliability (Cronbach’s α for word recall equaled 0.86; sentence judgment 0.81). Moreover, the averaged PRSPAN scores and raw scores for word recall were highly intercorrelated (r = 0.86, p < .001).
3.4.6. LLAMA-B
The LLAMA-B of the LLAMA Battery (Meara, Reference Meara2005) was used to tap into associative learning, a cognitive capacity involved in memorizing the form-meaning mappings. In the LLAMA-B, participants learn the names of 20 unfamiliar figures resembling alien creatures (e.g., ahau, cib, and manik). Following the learning phase, participants need to identify the figure whose name is displayed on the screen. There are 20 test trials, and the scores range between 0 and 100.
3.5. Procedure
The research was approved by the Rector’s Ethics Committee of the University of Warsaw. The participants were recruited by academic teachers of Italian Studies at two public universities in Warsaw, Poland. Participation was voluntary, each participant signed an informed consent, and those who completed all tasks received financial remuneration.
The study spanned over three sessions, with a maximum break of 5 days between the sessions. Due to the COVID-19 pandemic, Sessions 1 and 2 (approximately 2 hours each) were conducted online, whereas Session 3 was done on-site (50 minutes). To avoid fatigue effects, the L3 test was divided into two parts, counterbalanced across participants. Thus, Online Session 1 included the first part of the L3 test (60 words and 20 nonwords), the background questionnaire, and the DIALANG tests (L2-English and L3-Italian). Online Session 2 included the second part of the L3 test (60 words and 20 nonwords). On-Site Session 3, conducted in a quiet room on the university premises, included the LDT, the PRSPAN, and the LLAMA B.
3.5.1. L3-test scoring, analysis and missing data
The L3-test results were rated by two proficient academic teachers of Italian at the level of word translation and sentence production (inter-rater agreement κ = .976, 95% CI [0.96, 0.99]; κ = .965, 95% CI [0.95, 0.98]). In rare doubtful cases, a native-speaker of Italian was consulted (see Supplementary Appendix S4 for the detailed scoring criteria).
The L3-test scores at the word level and the sentence level were transformed to binomial scores (0 or 1). At the word level, scores 2 and 1 were recoded as 1, whereas 0 remained the same. At the sentence level, scores 3 and 2 were recoded as 1, and scores 1 and 0 as 0. Confidence ratings were used to assess whether the L3-Italian translation of the L2-English keywords was guessed. The answer was considered “guessed” when the participant indicated “I am guessing” or chose “I am sure” but obtained 0 points for the word score.
The word and sentence scores in the L3 test were treated as missing data if the participants indicated not knowing the keyword in L2-English. We treated L3-test sentence scores as missing data if participants chose “I am guessing” at the word level. In both cases, the procedure prevented them from proceeding to the subsequent step.
3.5.2. Lexical decision task analysis
Following a commonly applied protocol for analyzing RTs of word recognition in the LDT (e.g., Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010), participants with low accuracy in distinguishing words from nonwords were excluded from the analysis (the error threshold was 20%Footnote 3). Consequently, data from 37 participants were discarded. Second, we removed four keywords with accuracy rates below 60%, that is, concavo (concave), galassia (galaxy), squalo (shark), and viziato (spoilt) (see Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010, for a similar data trimming procedure). Finally, we excluded one more participant whose accuracy on the final set of keywords was less than 80%. As expected, the excluded participants displayed lower L3 proficiency than those qualified for the analyses, t(91) = 3.87, p < .001, d = 0.83. The main analysis was performed on 55 participants and 116 items. Next, we identified erroneous responses, outliers below 300 milliseconds, and those whose RTs fell 3 SD above the mean calculated per word type (i.e., separately for non-cognates, double cognates, and triple cognates). Altogether, the removed data accounted for 7.4% of the dataset and were substituted with values derived via a multiple-imputation procedure. Finally, to attenuate non-normality, the data were inverse transformed according to the formula: RT = −1,000/RT (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010).
Additionally, the LD data were analyzed for recognition accuracy, that is, how likely the participants were to recognize the Italian keywords as real words. We excluded six participants, whose data were unreliable due to the overrepresentation of affirmative responses (80% of the stimuli). As participant-level covariates, we included the number of false alarms (i.e., nonwords recognized as words) and the rate of nonword guessing obtained in the L3 test. Both covariates were used to control for participants’ response patterns (e.g., guessing) in yes/no vocabulary tests (see Huibregtse et al., Reference Huibregtse, Admiraal and Meara2002).
3.6. Statistical analysis
All results were analyzed in R (R Core Team, 2023) using generalized linear mixed models (GLMMs; lme4 package) (Bates, Mächler et al., Reference Bates, Mächler, Bolker and Walker2015) for the L3-test data and linear mixed models (lme4 package) for the LD data. The alpha value was set at 0.05. To deal with convergence issues, we used the Bound Optimization by Quadratic Approximation (BOBYQA) optimizer (Powell, Reference Powell2009). The GLMMs were diagnosed for influential data with Cook’s distance computed with the influence.ME package (Nieuwenhuis et al., Reference Nieuwenhuis, Te Grotenhuis and Pelzer2012). The diagnostics rendered the exclusion of one participant and one word from the LD model for recognition accuracy.
3.6.1. Variables used
Due to bimodal data distribution (i.e., most participants showed either none or full word knowledge with relatively few middle scores; see Appendix S6 in the Supplementary Material), two dependent binomial variables were derived from the L3 test (i.e., Word score and Sentence score) and were used as measures of offline L3 vocabulary knowledge. The third model used the RT scores from the LD task as the dependent variable, and the fourth model incorporated the Recognition accuracy of the L3 keywords in the LDT (coded binomially). In all models, the random effects were the intercepts for participants and keywords and all possible slopes. The fixed effects were word type (non-cognates, L2–L3 cognates, and L1–L2–L3 cognates), log-transformed frequency in Italian, word length in Polish and Italian, proficiency (DIALANG) in English and Italian, associative learning (LLAMA-B), working memory (PRSPAN), and three variables used to control for guessing in the case of the L3 test (see Supplementary Appendix S5). Frequency in Polish and English and length in English were excluded from the models due to collinearity issues (r > 0.60). All continuous predictors were standardized (z-scores). The factor representing word type was treatment coded (reference: L2–L3 cognates).
3.6.2. Model building
Following Meteyard and Davies (Reference Meteyard and Davies2020), we started our exploratory analysis with the random effects. First, both random intercepts were entered, and then all possible random slopes were entered at once. Subsequently, for the sake of parsimony (Bates, Kliegl et al., Reference Bates, Kliegl, Vasishth and Baayen2015), all slopes that reached singularity or had variance close to zero were removed if it improved fit, as assessed by the Akaike Information Criterion. Next, all main fixed effects (without interactions) were entered at once to build the base model, which included the factor Word type and item-related and subject-related covariates. In subsequent steps, nonsignificant and nonessential fixed effects (defined a priori for all the analyses; see Appendix S5 in the Supplementary Material) were removed if such removal did not worsen model fit, as assessed by the likelihood ratio tests (LRTs). Importantly, all fixed effects that were a priori considered essential were kept in the model irrespective of fit. In the final step, we added all interactions of interest to explore if subject-related and item-related variables interacted with Word Type. Then, the models were reduced by removing nonessential and nonsignificant interactions (defined a priori) that did not improve model fit (based on LRTs). The final most parsimonious model contained all essential fixed effects and all statistically significant nonessential predictors. The data and the analysis scripts are available at https://osf.io/n4y6u/.
3.6.3. Missing data
Among the L3-test covariates, only two variables had missing data: Italian Proficiency (3.2%) and LLAMA-B (2.2%), which were completed with their sample means. As the RTs of the LDT had approximately 7.4% of missing data, a multiple imputation (MI; Heymans & Eekhout, Reference Heymans and Eekhout2019) procedure was used. The MI method utilized was the Fully Conditional Specification (MCMC), with the maximum iterations set to 50 for five imputations and utilizing predictive mean matching. All fixed effects (including interactions) to be used in the main analyses were entered as predictors in the MI procedure. The model-building process was conducted on the first imputed dataset (out of five). The results reported below correspond to the pooled results of the five imputations, following Rubin’s rules.
4. Results
4.1. L3 word scores
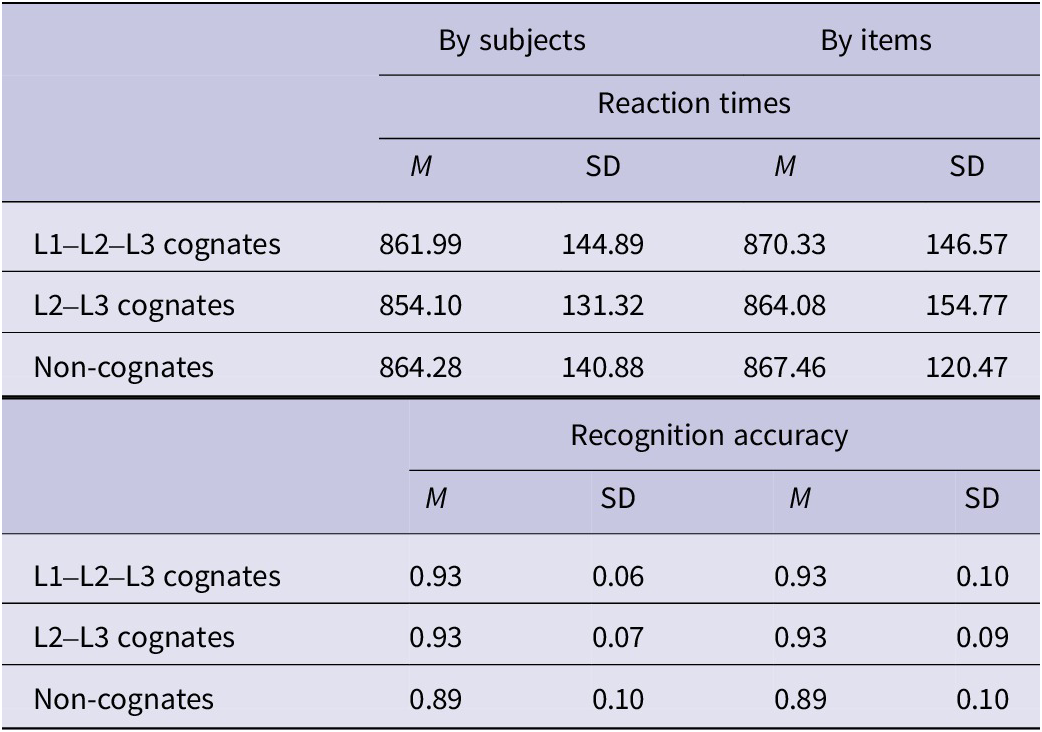
RQ1 asked whether the effect of cumulative L1–L2–L3 similarity was different from the effect of L2–L3 similarity regarding the knowledge of L3-Italian keywords. Table 2 shows raw Word and Sentence scores in the L3 test (see also Figures S1 and S2 in the Supplementary Material).
Table 2. Descriptive statistics of the raw scores in the word translation and sentence production parts of the L3 test, aggregated by subjects and by items

The results of the mixed-effects logistic regression model for Word scores (Table 3 and Figure 1; see also Table S3 in the Supplementary Material for the random effects) showed that, when all other variables assumed mean values, L1–L2–L3 cognates stood a higher chance of being translated correctly than L2–L3 cognates (the probability of a correct response equaled 69% for L2–L3 cognates, and 82% for L1–L2–L3 cognates, p = .019). In contrast, no difference was found between L2–L3 cognates and non-cognates (p = .136). Moreover, L3 Frequency significantly predicted the L3-test scores. This effect did not differ across word types, as shown by the Frequency in Italian × Word type interaction (L2–L3 vs. L1–L2–L3: p = .109; L2–L3 vs. non-cognates: p = .219).
Table 3. Fixed-effects estimates in the model for the accuracy of translating the L3-test keywords

Note: Number of data points: 10,266; Subjects: 93; Items: 120; contrasts are treatment coded with the reference-level L2–L3 cognates. Marginal R 2 of the model is 0.32. For the random effects, see Appendix S6 and Table A1 in the Supplementary Material. * p < .05. ** p < .01. *** p < .001.
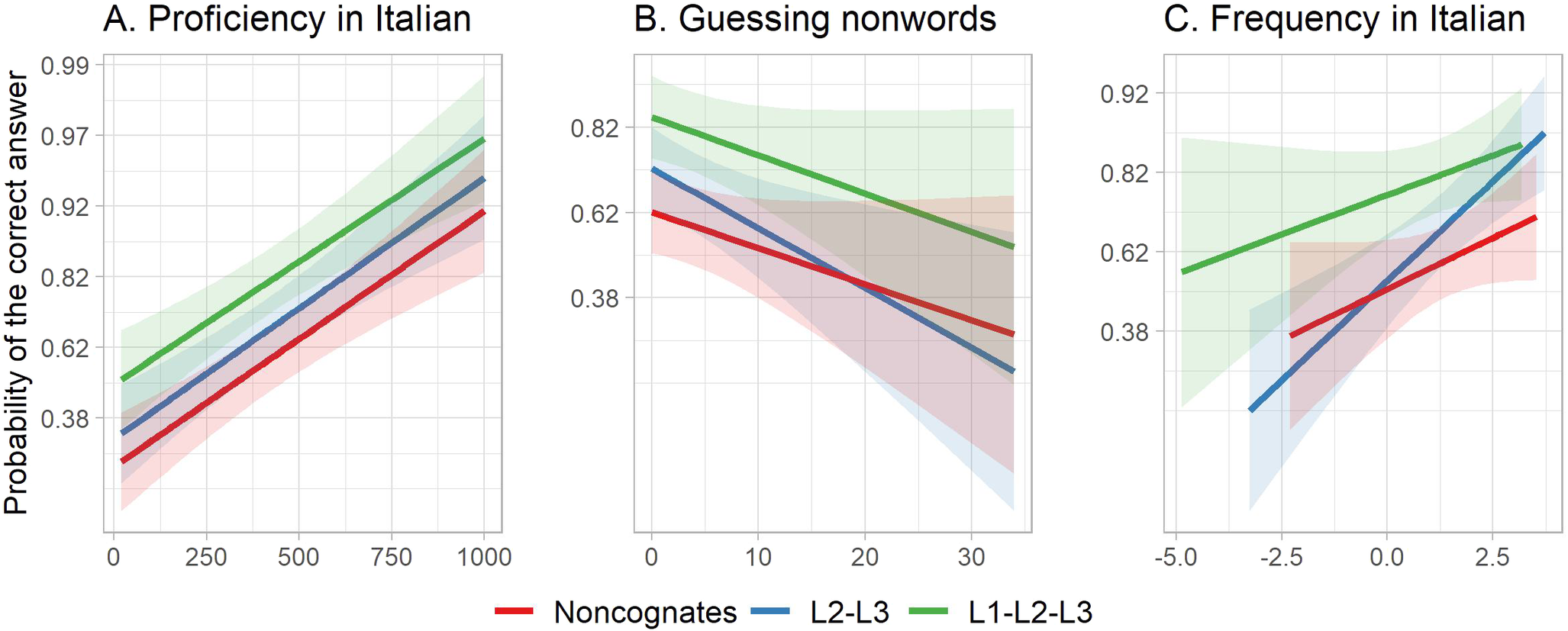
Figure 1. Model predictions for the role of individual differences in the ability to translate the L1–L2–L3 cognates, L2–L3 cognates, and non-cognates in the L3 test (Panel A: Proficiency in Italian; Panel B: Guessing tendency measured by nonwords; Panel C: Frequency in Italian).
In RQ2, we asked whether the effects of individual differences (e.g., proficiency and working memory) on performing the L3 test differed across L1–L2–L3 cognates, L2–L3 cognates, and non-cognates.
The results obtained for the Word scores show that L3-Italian proficiency significantly predicted the correct translation of L2–L3 cognates (p < .001), but the effect of L2-English proficiency was nonsignificant (p = .445). Moreover, as shown by the Word type × Italian proficiency interaction, higher proficiency in L3-Italian was similarly beneficial for all the word types (L2–L3 vs. L1–L2–L3: p = .567; L2–L3 vs. non-cognates: p = .837). Finally, participants’ Guessing tendencies (measured via guessing the L3-test keywords and nonwords) hampered performance on the L3 test (p = .004 and p = .006, respectively). Interestingly, as shown by the interaction with Word type, we did not observe any significant differences in the effect of Guessing nonwords between L2–L3 and L1–L2–L3 cognates (p = .109) or L2–L3 cognates and non-cognates (p = .084). Moreover, this detrimental effect of guessing tendencies diminished with the growing proficiency in L3-Italian, as shown by the Italian proficiency × Nonword guessing interaction (p = .041). Finally, Working memory and the LLAMA-B were both nonsignificant (p = .445 and p = .961, respectively).
4.2. L3 sentence scores
Regarding the Sentence score, the results (Table 4 and Figure 2; see Table S4 in the Supplementary Material for the random effects) show that, keeping all other variables constant, L1–L2–L3 cognates were more likely to be used correctly in a sentence than L2–L3 cognates (the probability of a correct response equaled 56% for L2–L3 cognates, and 70% for L1–L2–L3 cognates, p = .022). Moreover, no significant difference was observed between non-cognates and L2–L3 cognates (p = .418). Also, higher Frequency in Italian boosted the chance of correctly using a given keyword in a sentence (p < .001).
Table 4. Fixed-effects estimates in the model for the accuracy of using the L3-test keywords in sentences
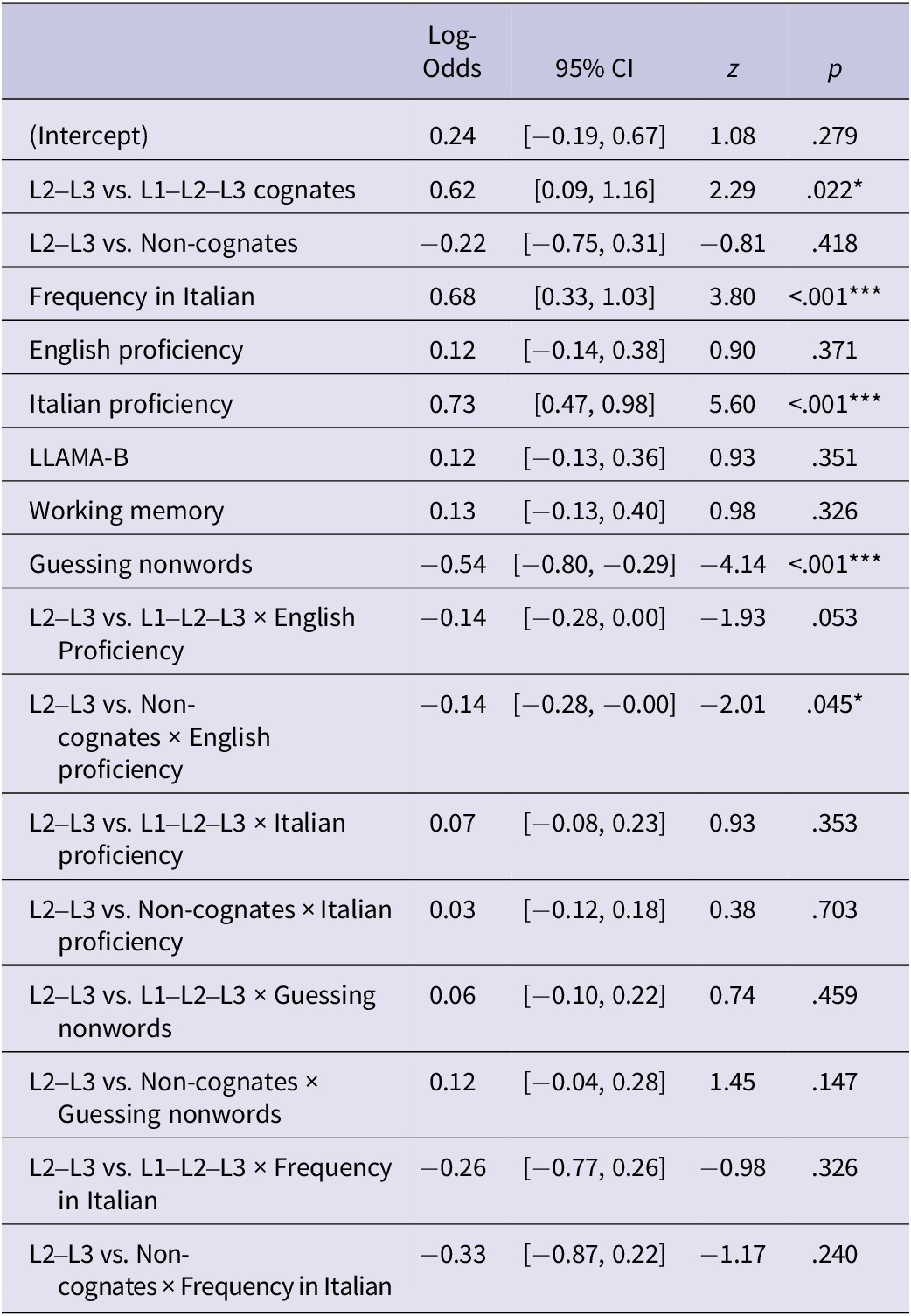
Note: Number of data points: 9,445; Subjects: 93; Items: 120; contrasts are treatment coded with the reference-level L2–L3 cognates. Marginal R 2 of the model is 0.31. For the random effects of the model, see Appendix S6 and Table A2 in the Supplementary Material. * p < .05. *** p < .001.
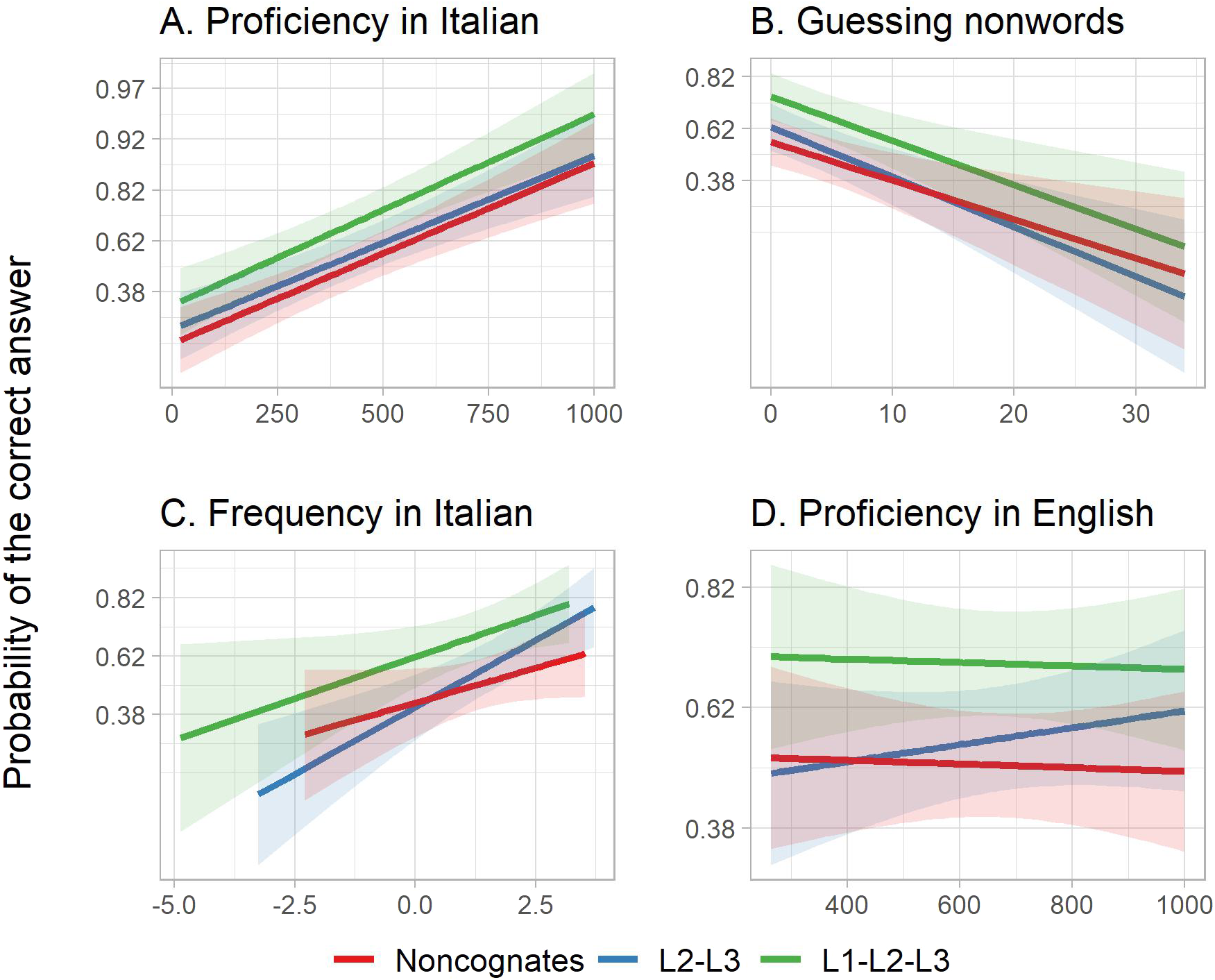
Figure 2. Model predictions for the role of individual differences in the ability to use the L1–L2–L3 cognates, L2–L3 cognates, and non-cognates in sentences in the L3 test (Panel A: Proficiency in Italian; Panel B: Guessing tendency measured by nonwords; Panel C: Frequency in Italian; Panel D: Proficiency in English).
The analysis for Sentences found significant positive effects of Proficiency in L3-Italian and an adverse effect of Guessing, measured by the nonword component of the L3 test. In contrast, English proficiency had no effect on L2–L3 cognates. Interestingly, the significant interaction between English proficiency and Word type suggests that L2 proficiency had even less impact on non-cognates (p = .045). Finally, all the remaining tested interactions were nonsignificant, suggesting that learner-related features and Frequency in L3-Italian impacted all word types equally.
4.3. Lexical decision in L3
RQ3 asked whether the effect of cumulative L1–L2–L3 similarity was different from the effect of L2–L3 similarity during the online processing of L3-Italian keywords. To seek answers to RQ3, we carried out an LDT. The data were analyzed in terms of both speed and accuracy of recognizing the L3 words.
The raw results for the speed and accuracy of recognizing the keywords are summarized in Table 5 (see also Figure S3 in the Supplementary Material). Data from 38 participants were excluded from the analyses of RTs because of low accuracy rates in recognizing keywords. Therefore, below, we report results from a subsample of 55 subjects, whose accuracy scores in the LD task reached the threshold of 80%.
Table 5. Descriptive statistics of the reaction times and response accuracy, expressed in milliseconds, obtained in the lexical decision task, aggregated by subjects and by items
The model (Table 6; Table S5 in the Supplementary Material) showed no differences in the speed of recognizing L2–L3 cognates and non-cognates, as well as L2–L3 and L1–L2–L3 cognates (p > 0.50 in both cases). Regarding item-related features, and consistent with previous LD research, word length in Italian hampered the speed of word recognition (p < .001). Frequency in Italian enhanced the speed of recognizing L2–L3 cognates (p < .001), but as shown by the Word type × Frequency in L3 interaction, the effect was reduced for triple cognates, whose speed of recognition was independent of Frequency. As shown in Figure 3, triple cognates were recognized at comparable rates regardless of their L3 frequency.
Table 6. Fixed-effects estimates in the model for the speed of keyword recognition in the lexical decision task
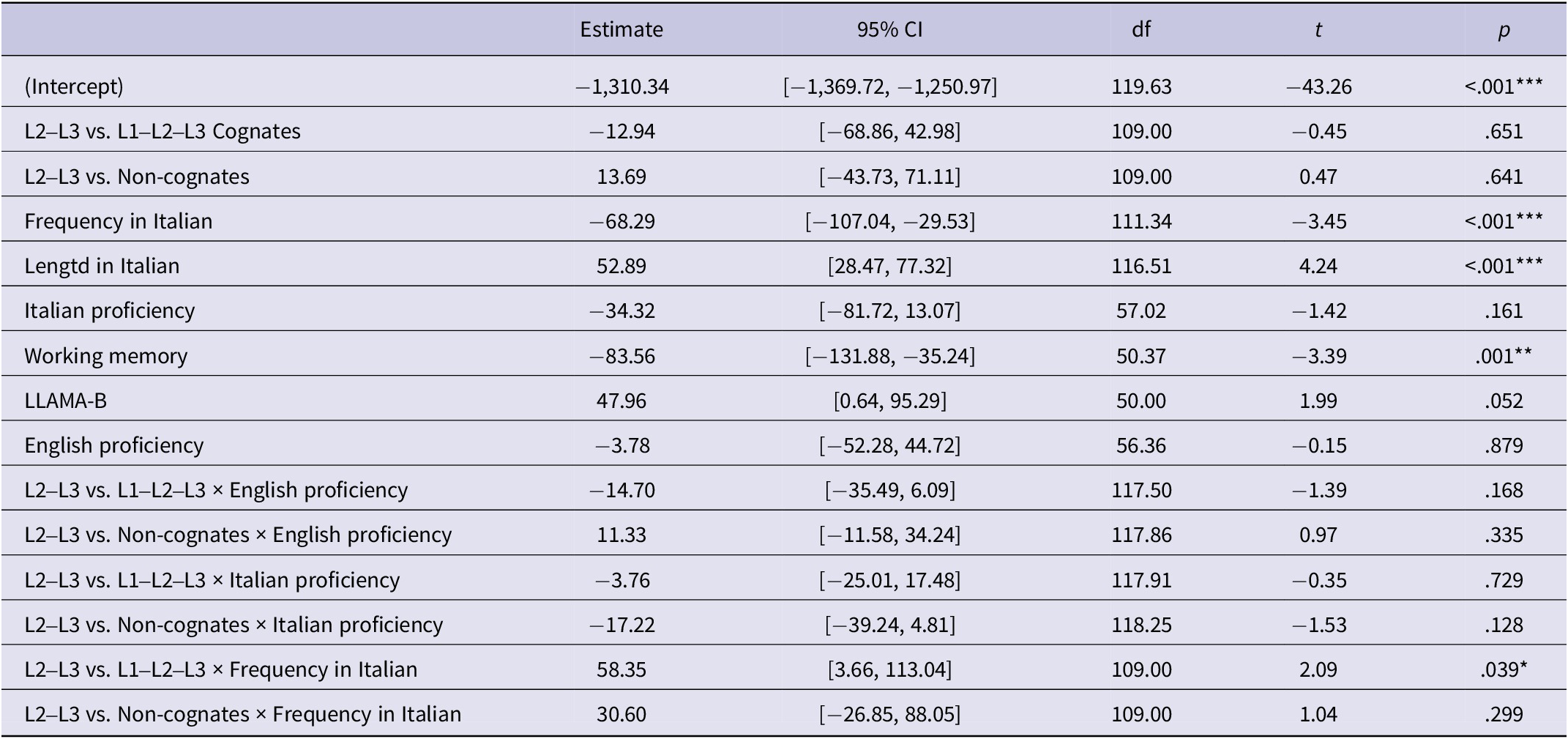
Note: Number of data points: 6,380; Subjects: 55; Items: 116; contrasts are treatment coded with the reference-level L2–L3 cognates. Pooled marginal R2 of the model is approximately 0.13. For the random effects of the model, see Appendix S6 and Table A3 in the Supplementary Material. * p < .05. ** p < .01. *** p < .001.
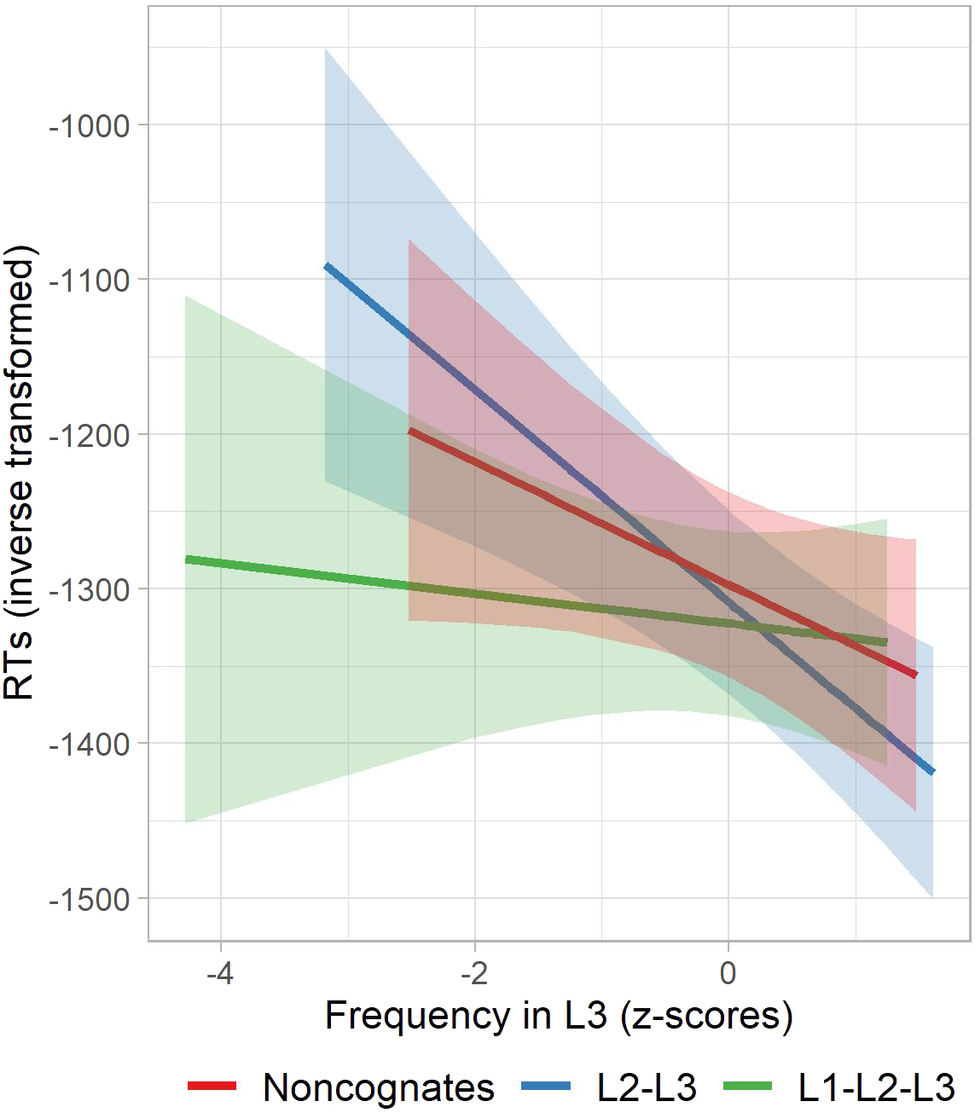
Figure 3. Model predictions for the role of L3 frequency in recognizing the L1–L2–L3 cognates, L2–L3 cognates, and non-cognates in the lexical decision task. The graph has been plotted based on the data from imputation no. 3, whose model coefficients were closest to the final pooled model.
Regarding participant-related variables, Working memory capacity was a significant predictor of the speed of recognizing the keywords (p = .001). Moreover, higher scores in the LLAMA-B had an overall negative effect on the speed of recognizing the keywords; however, this effect was only on the verge of significance (p = .052). Interestingly, the higher the LLAMA-B score, the longer it took the participant to recognize the L3 keywords. Finally, similar to the results reported for the L3 test, no significant effects were observed for the interactions between Word type and subject-related covariates.
Regarding recognition accuracy, we investigated the probability of recognizing Italian words as real words while keeping participants’ guessing of nonwords constant. We found that non-cognates were recognized with lower accuracy than L2–L3 cognates (Log-Odds = −0.93, z = −2.62, p = .009). However, there was no difference between L2–L3 and L1–L2–L3 cognates (Log-Odds = −0.11, z = −0.31, p = .759). Italian proficiency and Working memory had an overall positive effect on keyword recognition (Log-Odds = 0.62, z = 4.37, p < .001; Log-Odds = 0.23, z = 2.24, p = .025, respectively). As expected, the number of False positives raised the probability of a correct judgment (Log-Odds = 0.43, z = 4.01, p < .001), but the impact of Guessing was negative (Log-Odds = −0.44, z = −4.74, p < .001). Crucially, English proficiency increased the chances of recognizing L2–L3 cognates (Log-Odds = 0.34, z = 2.81, p = .005), but this effect was significantly reduced for non-cognates (Log-Odds = −0.27, z = −2.55, p = .011), and triple cognates (Log-Odds = −0.26, z = −2.27, p = .023) as shown by Word type × English proficiency interaction. Finally, whereas Frequency in Italian facilitated the recognition of L2–L3 cognates (Log-Odds = 0.79, z = 3.28, p = .001), it appeared to be neutral to L1–L2–L3 cognates (Log-Odds = −0.75, z = −2.18, p = .029; see Tables S6 and S7 in the Supplementary Material for the full model).
5. General discussion
Our cross-sectional study examined how the knowledge and real-time processing of L3 words are influenced by CLI resulting from similarity to one language (one-to-one CLI) versus all previous languages (many-to-one CLI; De Angelis, Reference De Angelis2007). In particular, we re-approached Bartolotti and Marian’s (Reference Bartolotti and Marian2017) accumulation account, whereby an overlap across L1–L2–L3 might cumulate to enhance learning, versus their scaffolding account, whereby the L2–L3 overlap suffices to boost learning to a similar extent. Unlike Bartolotti and Marian (Reference Bartolotti and Marian2017), who used L3 nonwords, we used real L3-Italian words and examined participants with L1-Polish, L2-English, and L3-Italian. We manipulated cross-linguistic similarity across the stimuli to include triple cognates (L1–L2–L3), double cognates (L2–L3), and non-cognates, and co-activated all three languages in the word-knowledge task (L3 test). To obtain an L3 word-processing measure, we also checked the visual recognition of our L3-Italian keywords using the LDT.
Our study involved participants from a range of L3-Italian proficiency levels to explore whether L3 vocabulary knowledge and processing could be modulated by participants’ L3-Italian and L2-English proficiency, associative memory, and working memory. Finally, we controlled for participants’ guessing tendencies by means of confidence ratings (e.g., Otwinowska et al., Reference Otwinowska, Foryś-Nogala, Kobosko and Szewczyk2020; Otwinowska & Szewczyk, Reference Otwinowska and Szewczyk2019) and the implementation of nonwords within the L3 test (e.g., Silva & Otwinowska, Reference Silva and Otwinowska2019).
To answer RQ1 concerning the role of similarity in L3 word knowledge, our data showed that the effect of L1–L2–L3 similarity was significantly larger than the effect of L2–L3 with respect to the knowledge of L3 words. Importantly, our L3 test did not give any advantage to L1-Polish (a stronger linguistic system) over L2-English. In fact, the keywords were presented in L2-English, enhancing access to that language. Still, the L1–L2–L3 cognates were known better than L2–L3 cognates, but no difference was found between L2–L3 cognates and non-cognates. The same effects were replicated for the production of L3 sentences containing the keywords.
To explain the results, let us first consider our operationalization of “word learnability” based on Otwinowska and Szewczyk (Reference Otwinowska and Szewczyk2019). We assumed that if the L3 word types (L1–L2–L3 cognates, L2–L3 cognates, and non-cognates) were matched on their L3 frequencies, participants at a certain L3 proficiency level should have an equal chance of encountering them in the input. What follows, any differences in keyword knowledge must reflect differences in their learnability. Since our L1–L2–L3 cognates were known more accurately and confidently, and were better used in L3 sentences, they might be easier to learn than double cognates.
Considering the design of the study, there are two interpretations of the obtained result. First, the advantage of L1–L2–L3 cognates stemmed solely from the L1 (a language best entrenched in the speaker’s cognitive system), given that the similarity to L2 alone did not facilitate the knowledge of L2–L3 cognates in the L3 test. Alternatively, the advantage of triple cognates was induced by the accumulation of cross-linguistic similarities from both L1 and L2 (many-to-one CLI; De Angelis, Reference De Angelis2007), a possibility we discuss below. First, for our L1–L2–L3 cognates, the similarity between the L2–L3 word forms was more pronounced than between the L1–L3 forms (compare L1: spontaniczny, L2: spontaneous, and L3: spontaneo). The mean orthographic overlap (nLD) was significantly larger for the L2-English and L3-Italian forms (M = 0.29, SD = 0.17) than for the L1-Polish and L3-Italian forms (M = 0.46, SD = 0.18), t(39) = −4.96, p < .001. This indicates that orthographically, the influence of the learners’ L1-Polish was less likely than that of L2-English. Also, in the L3 test, we presented the keywords only in L2-English, which essentially gave a boost to the L2–L3 formal similarity. Finally, for each keyword, we controlled whether its L2-English form was known to the participant. Thus, it appears unlikely that the boost for L1–L2–L3 cognates came solely from L1-Polish, and L2-English was not involved in the retrieval of the target L3 forms.
Recent research with trilinguals (de Bruin et al., Reference de Bruin, Hoversten and Martin2023) has shown that CLI experienced by trilinguals between their L2 and L3 was related to weaker inhibition of a non-native than the native language (L1). The authors suggest that trilinguals apply more inhibition over their L1, so their non-native languages might experience more interaction. In our case, the results by de Bruin et al. (Reference de Bruin, Hoversten and Martin2023) can be interpreted as follows. Our participants translated from their L2 to their L3, that is, the two languages that are more prone to CLI than the L1. Since the L1 is quite strongly inhibited in trilingual production, for our L1–L2–L3 cognates, the sole influence of the L1 could rather be excluded. Instead, the role of the L2-English might have surfaced when it was “backed up” by the L1. This tentative interpretation is also in line with natural tendencies in cognate learning (Ecke, Reference Ecke2015). Assuming that CLI is based on co-activating alternate connections across the language network (Sharwood Smith, Reference Sharwood Smith2021), a more dense network of connections should lead to more co-activation, and thus to better learning and word retrieval of triple cognates.
In contrast to our findings, Bartolotti and Marian (Reference Bartolotti and Marian2017) showed that a single-sourced similarity (from either L1 or L2) advantaged word learnability comparably to cumulative similarity. Why were our results different from theirs? Bartolotti and Marian (Reference Bartolotti and Marian2017) used only nonwords, which were four letters long and always followed the consonant–vowel consonant–consonant pattern. Within this restricted pattern, cross-linguistic similarity to the L1 and L2 was manipulated (e.g., words similar to both English and German were nist or baft; words similar to English: sumb or gonk; words similar to German: gach or kenf; and words dissimilar: gofp or kowm). Our study used natural L3-Italian words controlled for their overlap with L1-Polish and L2-English, but more diverse in length (e.g., pear-pera vs. generosity-generosità) and part of speech (e.g., sequence-sequenza, noun vs. aggressive-aggressivo, adjective). Admittedly, our study was less strictly controlled than Bartolotti and Marian’s (Reference Bartolotti and Marian2017), but more ecologically valid due to using varied and natural stimuli. Moreover, we considered L2 and L3 vocabulary knowledge acquired over the years of exposure. Thus, in contrast to short-time experiments, L3 knowledge in our study was influenced by multiple factors such as participants’ individual differences and their unique exposure to the L2 and L3. Such complexity of language learning “in the wild” might explain why the single-sourced L2–L3 similarity did not promote L3 word learning over and above other factors (either controlled or not in the study). In fact, in our multivariate analyses, we only managed to explain approximately 30% of the variance in the L3-test scores, which means that many factors that had influenced learning were not accounted for. Possibly, research with a larger participant sample is necessary to single out the role of L2–L3 similarity for words learned in a naturalistic setting.
Let us move on to RQ3 concerning the role of similarity in L3 word processing. For the speed of recognizing the keywords, counter to some previous research (e.g., Lemhöfer et al., Reference Lemhöfer, Dijkstra and Michel2004; Szubko-Sitarek, Reference Szubko-Sitarek2011), but similar to Lijewska (Reference Lijewska2022), we observed no differences among L1–L2–L3 cognates, L2–L3 cognates, and non-cognates. This might be explained by including non-identical cognates, which generally yield less facilitation than identical cognates (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010). Importantly, in contrast to other tasks, this analysis had to be carried out on a subsample of participants with higher L3 proficiency, which restricts the comparability of the samples involved in the LDT and L3-test analyses.
Unlike other measures, the results of the accuracy of responses in the LDT showed an advantage of L2–L3 cognates over non-cognates, but no difference between L2–L3 and L1–L2–L3 cognates. Possibly, L2 similarity might be sufficient to boost task performance in tasks tapping into speeded form recognition. Undoubtedly, recognizing words in the LDT was much easier than producing words and sentences in the L3 test. Finally, an important advantage of L1–L2–L3 cognates observed in both LD analyses consisted in their independence of L3 frequency effects, which suggests that L1–L2–L3 cognates can be learned with fewer encounters than other word types.
Our RQ2 and RQ4 asked about the role of the learner’s individual differences in the acquisition and processing of L3 vocabulary. In line with earlier research (e.g., Angelovska & Hahn, Reference Angelovska and Hahn2017; Dijkstra & Van Heuven, Reference Dijkstra, Van Heuven, Rueschemeyer and Gaskell2018), we assumed that CLI in L3 will be modulated by learner-related variables. We also hypothesized that higher proficiency in L2 would positively influence the knowledge and processing speed of L2-cognates.
Surprisingly, for both the L3 test and the LDT, we observed hardly any interactions between word type and measures of individual differences. An important exception was the relationship between L2-English proficiency and the accuracy of recognizing L2–L3 cognates in the LDT, reduced for L1–L2–L3 cognates and non-cognates. On the other hand, English proficiency did not predict performance on the L3 test. This, however, might have stemmed from the design of the task. All instances when participants did not know the keyword in L2-English in the L3 test were considered missing data, so they were never punished in the analysis for the lack of L2 form knowledge. By contrast, proficiency in L3 was a strong predictor of target-word knowledge but did not interact with word type: All words benefited equally from higher proficiency in Italian.
Also, our L3-test results showed no effects of vocabulary learning aptitude (associative memory) and working memory capacity. It is tenable that individuals with better associative learning and memory skills are better at utilizing crosslinguistic similarity (Berthele, Reference Berthele2011; Vanhove & Berthele, Reference Vanhove and Berthele2017); however, no such relationship was observed in the present study. Possibly, vocabulary learning aptitude enhanced general proficiency in L3, which also involved better knowledge of the L3 words. Indeed, we observed that the scores in the LLAMA-B and Italian proficiency were significantly but weakly correlated (r = .26, p = .016). Finally, guessing hampered L3-test performance: Participants with a higher propensity for guessing scored lower across all word types.
For both RTs and accuracy in the LDT, we found a positive effect of working memory capacity on the speed of L3 word recognition. By contrast, associative declarative memory (LLAMA-B) might have hampered the speed of recognizing L3 vocabulary, meaning that those with more declarative (metacognitive) knowledge spent more time responding. This might be accounted for by the fact that the LD task was administered after the L3 test, which might have triggered a more declarative (i.e., less automatized) processing, increasing the RTs.
Summing up, contrary to our hypotheses, we did not find significant differences between the knowledge of L2–L3 cognates and non-cognates, and the L2 proficiency effects were observed only for simple recognition, which may call into question the postulated overall CLI coming from the L2 (L2-Status factor; Bardel & Falk, Reference Bardel and Falk2007). However, we found discrepant results regarding CLI from L2 in tasks tapping into different levels of word knowledge. L2–L3 similarity sufficed to boost accuracy in a simple LD recognition task. On the other hand, in tasks tapping into word production, the advantage was shown only for L1–L2–L3 cognates. Does this result come from the many-to-one CLI (De Angelis, Reference De Angelis2007) or is it the effect of the L1 alone? Although we argue for the former interpretation, our results are not conclusive in this respect due to a limitation of our study, namely, the lack of the L1–L3 condition. Thus, further research with three types of similarity (L1–L3, L2–L3, and L1–L2–L3) is needed to disentangle the extent to which the advantage of triple similarity stems from the accumulation of cross-linguistic similarities, and the extent to which it comes from the L1.
6. Conclusions
Studies in L3 lexical CLI are still scarce. Unlike many previous studies comparing the knowledge and real-time processing of double cognates (L1–L2, L1–L3, or L2–L3) to non-cognates, we also investigated the learnability of triple (L1–L2–L3) cognates. Following Bartolotti and Marian (Reference Bartolotti and Marian2017), we focused on the cumulative versus single-sourced CLI in L3 word knowledge and processing. Bartolotti and Marian (Reference Bartolotti and Marian2017) found no difference in learning L2–L3 and L1–L2–L3 cognates, which they attributed to the primacy of single-sourced CLI over cumulative CLI. In our study, the L1–L2–L3 similarity advantaged the knowledge of L3 keywords, compared to single-sourced L2–L3 similarity. The influence of L2–L3 similarity surfaced only in the recognition component of the LDT. Also, the LDT data showed that, in contrast to other word types, L1–L2–L3 cognate processing was independent of L3 frequency. Finally, the RT data in the LDT showed no general advantage of cognates over non-cognates. This boils down to the fact that nonidentical cognates may not be faster to recognize visually than non-cognates, even if their similarity stretches across three languages (e.g., Lijewska, Reference Lijewska2022). Thus, our study implies that cognate facilitation effects in multilingual learners should be studied relative to the degrees of lexical cross-linguistic similarity.
Another crucial implication pertains to research designs in multilingualism studies. Our study showed that, in long-term learning, the influence of CLIs is less straightforward than that in a controlled short-term experiment like Bartolotti and Marian (Reference Bartolotti and Marian2017). These diverse results underscore that future L3 vocabulary projects should not be restricted to one context, that is, psycholinguistic experiments with strictly controlled conditions. Such experiments can be combined with less controlled, but more ecologically valid paradigms. This will allow us to answer questions about CLI and the architecture of the multilingual mental lexicon in a more comprehensive way.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S1366728925000410.
Data availability statement
The data that support the findings of this study are openly available on the OSF platform at https://osf.io/n4y6u/.
Acknowledgements
We are grateful to Adriana Biedroń for granting us access to the PRSPAN task and to Davide Crepaldi for sharing the Italian version of the Wuggy software. We would also like to thank the editors and reviewers of Bilingualism: Language and Cognition for their valuable feedback on the previous versions of the paper.
Funding statement
This research was supported by Grant No. 2019/35/B/HS2/02236 from the National Science Centre, Poland awarded to Agnieszka Otwinowska-Kasztelanic.
Competing interests
The authors declare none.
Ethics statement
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration (https://www.wma.net/what-we-do/medical-ethics/declaration-of-helsinki/doh-oct2008/) of 1975, as revised in 2008.












 Open access
Open access