




Highlights
-
• Study of understanding and processing of code-blended utterances.
-
• Novel application of Acceptability Judgment Task methodology.
-
• Supports the proposal that sign and speech contribute content to a single proposition.
-
• ASL/English code-blending uses a single derivation realized with two languages.
-
• Contributes to understanding of human-general bilingual language use.
1. Introduction
It is well-known that bilingual people do not always completely separate their languages; in fact, code-switching and other types of language ‘mixing’ form a particularly interesting area of study, including attention to constraints on these forms (Deuchar, Reference Deuchar2020; MacSwan, Reference MacSwan2000). Recently, researchers have discussed the same phenomenon in the context of bimodal bilingualism, when the languages a bilingual person uses occupy the visual/manual and the auditory/vocal modalities (i.e., they are a sign language and a spoken language). In particular, bimodal bilinguals make use of a unique type of language mixing known as code-blending (Emmorey et al., Reference Emmorey, Borinstein, Thompson and Gollan2008), by which aspects of the two languages can be produced simultaneously. This is only possible because the languages primarily occupy different articulators, but we consider it to be the natural result of combining languages in different modalities (Lillo-Martin et al., Reference Lillo-Martin, Quadros and Chen Pichler2016).
While code-blending has long been informally observed by members of bimodal bilingual communities (Bishop & Hicks, Reference Bishop and Hicks2005), it has only been subject to research in recent years (the works cited by Bishop & Hicks and by Emmorey and colleagues being among the earliest). One important observation coming out of this research is the notion that in any particular code-blended utterance, the languages together contribute to a single proposition. While it might be logically possible that two different ideas are expressed simultaneously, this is not what is observed. Instead, the two languages might express essentially the same content (sometimes called ‘full code-blending’), or one language might express a subset of the content of the other; in limited cases, it is also observed that each language might contribute different parts of the content. However, it seems that code-blended utterances can usually be translated as a single sentence, rather than a conjunction of two different sentences, one for each language. This ‘one proposition’ concept is the first hypothesis regarding code-blending that our investigation addresses.
Given the existence of code-blending, an immediate linguistic question concerns what constraints there are on the generation of code-blended utterances. How can a human mind form and produce an utterance using two languages at the same time? What is the role of the mental grammar for each language? Do the constraints proposed to apply in the context of code-switching carry over to the code-blending phenomenon? These are among the questions that our research aims to address. The study reported here was designed to add important data to the discussion of these broader questions.
To provide more relevant background motivating our study, in the next sections we discuss in more detail the phenomenon of code-blending and previous studies of it. Then we introduce theoretical proposals that have been made regarding code-blending and what different predictions these proposals make. Following that, we introduce our study in more detail.
1.1. Code-blending
Code-blending involves the use of a spoken language and a sign language. Here we restrict attention to the natural sign languages that emerge when deaf people form a community; more specifically, in this paper our focus is on code-blending of American Sign Language (ASL) and English, although we will also discuss code-blending with other language pairs.
Approximately 80% of the children born to deaf adults are themselves hearing (Mitchell et al., Reference Mitchell, Young, Bachleda and Karchmer2006). Typically, if the parents use a sign language with their children, the children will grow up bilingual as signers of that sign language and speakers of the spoken language used in the surrounding community. In many ways, their linguistic context is akin to that of heritage language users, and this is a useful framework for understanding bimodal bilinguals (Chen Pichler et al., Reference Chen Pichler, Lillo-Martin and Palmer2018). However, the experiences of hearing children with deaf parents lead many of them to have a unique identity as ‘Codas’ (child of deaf adults). Like other members of a linguistic minority community, Codas engage in language mixing practices, producing utterances that are only fully understood by others who are also bilingual in the same two languages. Here we focus on the linguistic characteristics of these bilingual utterances.
Code-blended utterances can take different types of characteristics. In ‘full’ blending, the content of an utterance is fully expressed in both languages, although grammatical aspects may differ in ways to be discussed more below. An example is given in (1) below, taken from the video instructions for our study.Footnote 1 In our notation, the co-occurrence of sign and speech is indicated through the use of vertical alignment of text. Note that the alignment indicates the temporal properties of the surface form of sign and speech; it is not intended to represent constituent structure or the like. Further information about glossing conventions can be found in footnote 2.Footnote 2

In other code-blended utterances, one or the other language provides more of the content and/or structural characteristics.Footnote 3 We refer to this language as the ‘base’ language. The concept of a base language is similar to the idea of ‘matrix’ language in the Matrix Language Framework (Myers-Scotton, Reference Myers-Scotton1997), but our analysis uses different details and implementation. For example, in (2) English is the base language, providing the bulk of the content and structural characteristics. On the other hand, in (3) ASL is the base language, with only limited content in English. As these examples illustrate, there is no expectation that both languages provide full propositional content, nor must what is ‘missing’ in one language correspond to a null constituent.


1.2. Previous research
Previous research with adult and child bimodal bilinguals has identified the existence of code-blending in several pairs of signed and spoken language (although the phenomenon has not always been given the name ‘code-blending’). The following observations are relevant to our current discussion.
First, code-blending seems to be a natural outcome of bimodal bilingualism. In addition to ASL/English code-blending, researchers have reported on the existence of code-blending in Brazilian Sign Language (Libras) and Brazilian Portuguese (Quadros, Reference Quadros2018; Quadros & Lillo-Martin, Reference Quadros and Lillo-Martin2018; Quadros, Lillo-Martin, et al., Reference Quadros, Lillo-Martin, Chen Pichler, Zeshan, Webster and Bradford2020), Sign Language of the Netherlands and Dutch (van den Bogaerde & Baker, Reference van den Bogaerde and Baker2005, Reference van den Bogaerde, Baker, Bishop and Hicks2009), Langue des signes du Québec (LSQ) and French (Petitto et al., Reference Petitto, Katerelos, Levy, Gauna, Tétreault and Ferraro2001), Italian Sign Language (LIS) and Italian (Branchini & Donati, Reference Branchini and Donati2016; Donati & Branchini, Reference Donati, Branchini, Biberauer and Roberts2013), and other language pairs.
Importantly, code-blending is not random, but – like unimodal code-switching – it is linguistically constrained. For example, Emmorey et al. (Reference Emmorey, Borinstein, Thompson and Gollan2008) found that single-sign code-blends were much more likely to contain a verb than any other category. They also observed that either ASL or English could be characterized as the matrix language in multi-word code-blends, but that there was an asymmetry in single-word code-blends: these always involved English as the matrix language. Although there has not been a theoretical proposal to account for these particular patterns, researchers have been interested in developing theories to account for code-blending, which we turn to next.
1.3. Theoretical proposals
Emmorey et al. (Reference Emmorey, Borinstein, Thompson and Gollan2008) presented a proposed model of ASL-English code-blend production based on Levelt’s (Reference Levelt1989) speech production model together with the co-speech gestural production aspects of Kita and Özyürek’s (Reference Kita and Özyürek2003) proposal. A highly relevant aspect of their model for our purposes is the generation of a single message that gets realized in both speech and sign.
Taking into consideration the basic facts about code-blending as well as theoretical models of code-switching such as that by MacSwan (Reference MacSwan2000) and proposals about other bimodal bilingual language mixing phenomena by Koulidobrova (Reference Koulidobrova2012, Reference Koulidobrova2017), Lillo-Martin et al. (Reference Lillo-Martin, Koulidobrova, Quadros, Chen Pichler, Biller, Chung and Kimball2012, Reference Lillo-Martin, Quadros and Chen Pichler2016, et seq.) proposed that code-blended utterances are the output of a single derivation which combines aspects of the grammatical characteristics of both languages. A simplified model of this ‘language synthesis’ proposal is given in Figure 1.
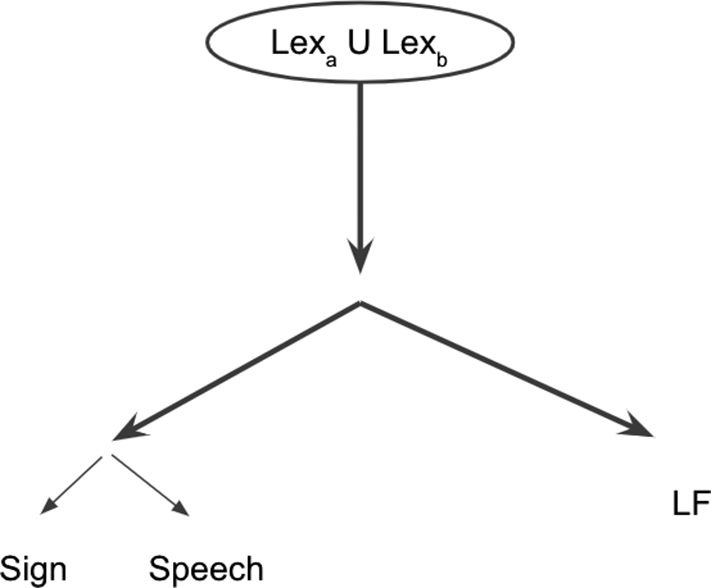
Figure 1. Language synthesis model.
The Synthesis model assumes, à la Distributed Morphology (DM; Halle & Marantz, Reference Halle, Marantz, Hale and Keyser1993), that the syntactic representation of an utterance is abstract in at least the following two ways.
First, the model assumes ‘late insertion’ (Halle & Marantz, Reference Halle, Marantz, Hale and Keyser1993): at the beginning of a derivation, the terminal nodes in the phrase-structure tree have grammatical and semantic information, but lack phonological information, which is inserted ‘late’ by rules of exponent or vocabulary insertion. At the point of Spell-Out, phonologically-specified lexical entries from either or both languages can be inserted. For example, a single abstract structure with a determiner and noun: [DP D-def [NP N-HOUSE]] could receive at least four realizations in Spanish-English code-switching by inserting English or Spanish vocabulary items at each terminal node: la house, the casa, la casa, the house. For a review of work exploiting this (and related) tenets of the DM framework to develop a constrained model of code-switching/mixing, see López (Reference López, Alexiadou, Kramer, Marantz and Oltra-Massuetto appear) as well as work cited there, such as Alexiadou and Lohndal (Reference Alexiadou and Lohndal2018) and López (Reference López2018).
Second, the model assumes ‘late lexicalization’ (Embick & Noyer, Reference Embick and Noyer2001: 562): syntactic structure is abstract and represents only constituency/hierarchical relations, leaving linear order as part of Spell-Out and the mapping of syntactic structure to phonological representations. On this view, now accepted across a number of frameworks (see also Marantz, Reference Marantz1984, pp. 69–90; Chomsky, Reference Chomsky1995, pp. 334ff), linear order is only established in a post-syntactic module. In this model, two languages may share an identical syntactic structure (e.g., a VP containing the verb and object) but may differ in the linear order of two sisters (OV, VO). Frameworks allowing for such late linearization, such as DM, thus allow for some differences in word (constituent) order between languages consistent with the claim that the underlying syntactic structure is shared, as in the overall Synthesis model.
In other words, the model may posit a single derivation to capture the observation that code-blended utterances express a unified proposition, not separate messages in each language. A consequence of this assumption is that the grammatical structures of what is expressed in sign and in speech are constrained. Both languages can follow the same surface word order, which might be generated by features from one or the other, while allowing for the possibility that in some contexts, the languages might follow different surface word orders derived from the same underlying structure.
A contrasting perspective on the derivation of code-blended utterances was offered by Donati and Branchini (Branchini & Donati, Reference Branchini and Donati2016; Donati & Branchini, Reference Donati, Branchini, Biberauer and Roberts2013), whose empirical content comes from bimodal bilingual users of LIS and spoken Italian. While ASL and English both have SVO as ‘basic’ word order and many other grammatical similarities, LIS and Italian differ more grammatically. Italian is underlyingly SVO, but LIS is SOV. The realization of sentences with negation, WH-questions, and other syntactic structures necessarily involves greater differences between the two languages than the required differences between ASL and English. The authors observed that blended utterances reflect these differences: in some examples of code-blending, the word order of LIS and that of Italian are quite different (4–5).

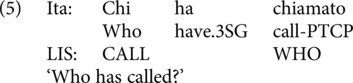
In view of such cases, Donati and Branchini proposed that some code-blended utterances can be generated by two distinct simultaneous derivations. They furthermore observed (Reference Branchini and Donati2016) that in such cases, the phonology, prosody and morphology of each language are preserved. This follows from the idea that each language output is generated separately from the other. Donati and Branchini also observe instances of code-blending in which one language is dominant, with the other following along. In these cases, they assume a single derivation.
The two models of code-blending make different predictions about some types of potential code-blends. One distinction concerns the constraints on elements that can be blended. The dual-derivation approach leads to the expectation that morphology and phonology of each language will be preserved when the syntax is different. However, there is nothing in the model that specifically restricts distinct derivational histories for the two languages. Considering that much research on bilingual language production finds evidence for tight integration (see, e.g., Putnam et al., Reference Putnam, Carlson and Reitter2018), we expect that further development of this model will consider the nature of such constraints. In fact, the authors do not specify any restrictions to a single proposition for code-blended utterances, but we will assume that this is part of their model. On the other hand, the synthesis model allows for only limited differences in the surface output of speech versus sign. In order to assess what constraints apply to code-blended utterances for ASL/English bimodal bilinguals, we chose to run an acceptability judgment test, previously used in code-switching research (e.g., Stadthagen-González et al., Reference Stadthagen-González, Parafita Couto, Párraga and Damian2019).
The task is described in detail in the following sections. Prior to the study described here, we ran a pilot study (Lillo-Martin et al., Reference Lillo-Martin, Quadros, Bobaljik, Gagne, Kwok, Laszakovits, Klamt and Wurmbrand2020). The pilot study used the same methodology and many of the same item types as the version described here. We also ran a parallel study using code-blending in Brazilian Sign Language and Brazilian Portuguese (Quadros et al., Reference Quadros, Lillo-Martin, Klamt, Rodrigues and Saab2023). These studies confirmed the viability of the use of this methodology and provided the foundation for the predictions described below.
2. Method
2.1. Participants
Participants were Coda adults (n = 44, ages 18–65, mean age 33.2), all of whom self-reported at least one deaf parent (35 reported both parents deaf; 4 mother only; 5 father only). They self-rated their English fluency on a scale of 1–7, 7 high, with a mean of 6.73, and ASL fluency mean of 6.18 (range 2–7). All participants were recruited online using social media and snowball email recruitment methods.
2.2. Procedure
All procedures were conducted in accordance with protocols approved by the University of Connecticut and Gallaudet University Institutional Review Boards. The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.
Potentially interested participants emailed the research coordinator, who sent internet links to complete the study on their own. The preliminary link contained the consent information in printed English and a video of the information presented in code-blending. Those who agreed to participate clicked ‘yes’ on the form and were directed to a background/demographic survey in printed English. Following the demographic survey, instructions were presented using both printed English and videos with code-blending; then 6 practice items using code-blended videos were given. Each practice item was followed by a discussion of the item presented in a code-blended video. The instructions and practice items were designed to encourage participants to consider typical instances of code-blending use by Codas. After completing the practice items, participants could move on to the four test surveys described in detail below. Each survey list began with a recap of the instructions presented in printed English and a code-blended video. Participants were told they could complete the surveys with breaks as they desired.Footnote 4 Participants were compensated with a $10 gift card for each completed survey, with a bonus of an additional $10 gift card if they completed all surveys.
2.3. Materials
A set of 104 code-blended items was developed for this acceptability judgment task. The types of items presented are summarized in Table 1. The full set was divided into 4 lists, resulting in 26 items in each list. Each item type had the same number of questions in each list. Each list was then randomized separately so that the same item types appeared in different orders across the lists and did not appear together in the lists. Participants were assigned one of 24 specific orders in which to complete the 4 lists.
Table 1. Acceptability task item types
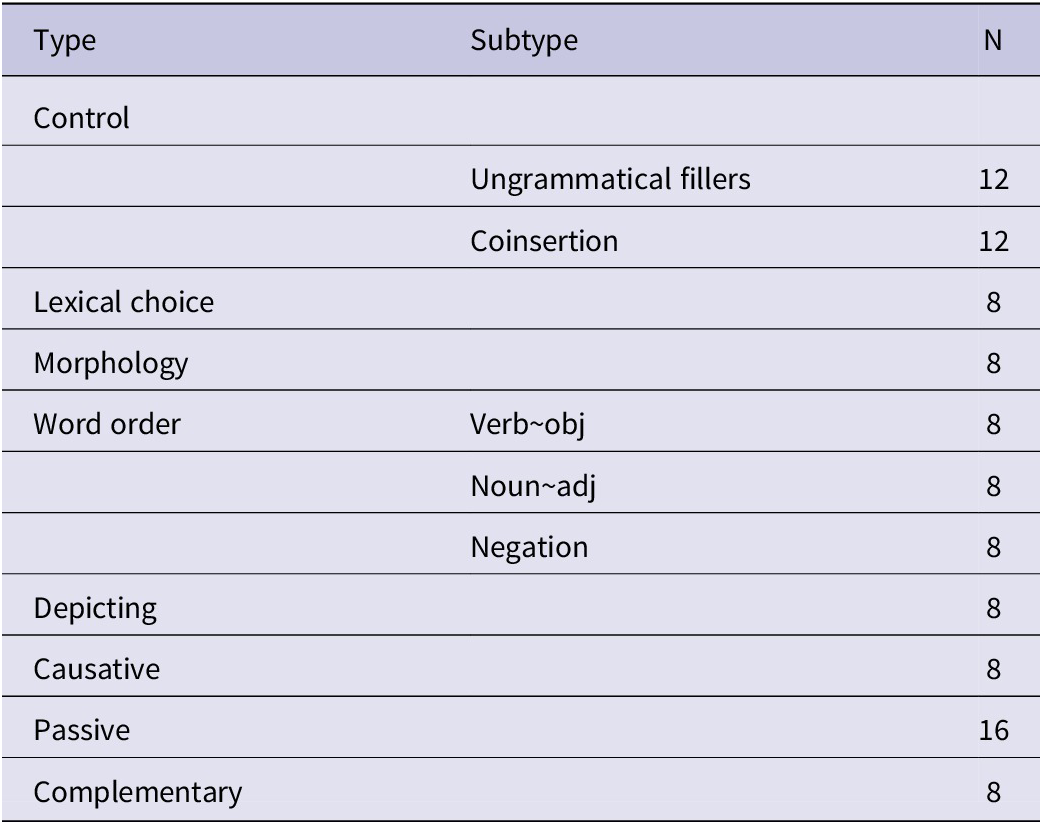
We also consulted with two deaf ASL language experts regarding our expectations about the ASL portion of the blended utterances (for sentences with more than two ASL signs). Their responses are discussed below in connection with specific item types.
The task was completed using Google Forms independently by participants on their own time. Participants were provided five links: one consent and instructions/practice link and then four links randomized in order as described above.
Each item began with a presentation of the stimulus video. Beneath the video, participants selected one of three ordinal options: thumbs down (which we refer to in this text as a 1, and interpret to mean unacceptable), thumbs up (3, or acceptable), or so-so (2, in-between). We were primarily interested in the participants’ judgments of the acceptability of the stimuli rather than possible degrees of acceptability, so we encouraged them to use the thumbs-up and thumbs-down options as much as possible. If participants found some reason not to respond to any items, they had the option to select ‘cannot judge’. The response screen is illustrated in Figure 2.

Figure 2. Response options for Acceptability Judgment Task.
2.4. Item types
In this subsection, we describe the characteristics of each item type. For each subcategory, we used multiple examples designed to elicit more ‘unacceptable’ responses, labeled ‘Mismatching’, and multiple examples designed to elicit more ‘acceptable’ responses, labeled ‘Matching’. A full list of stimuli by glosses with accompanying videos can be found on OSF.
2.4.1. Control items
We developed two types of control items. First, we made a group of ungrammatical fillers designed to elicit fairly consistent responses of unacceptable (score of 1). They involve code-blending of word salad sentences created by rearranging the word order of acceptable full sentences, then blending the result. An example is given in (6).

For grammatical fillers, based on our previous research and research reports from others, we expected that sentences with matching translation equivalents would be fairly consistently rated ‘acceptable’ (score of 3). Half of these examples are English-based, with one or more ASL signs blended, and half of them are ASL-based, with one or more English words blended. Examples were given in (2–3) above. We note that ASL-based items like (3) were consistently judged as acceptable by our Deaf consultants.
2.4.2. Lexical choice
Based on previous reports (e.g., Lillo-Martin et al., Reference Lillo-Martin, Quadros, Bobaljik, Gagne, Kwok, Laszakovits, Klamt and Wurmbrand2020; Quadros, Reference Quadros2018; Quadros & Lillo-Martin, Reference Quadros and Lillo-Martin2018), we expected that in some cases, blending of signed and spoken lexical items which are not precise translation equivalents would be acceptable. For example, the English name ‘Tweety’ was blended with the ASL signs YELLOW BIRD in responses reported by Emmorey et al. (Reference Emmorey, Borinstein, Thompson and Gollan2008). Half of the items in this category were designed to be acceptable (as in 7), and half were designed to be unacceptable (as in 8).


2.4.3. Morphology
Morphological differences between English and ASL code-blended elements have previously been observed. For example, English requires plural marking on nouns, but this is generally not found in ASL. In ASL, similar to the observation by Pfau and Steinbach (Reference Pfau and Steinbach2006) for German Sign Language (DGS), a limited number of nouns can indicate plural referents by reduplication across a horizontal plane. For most nouns, however, a single form is used whether in singular or plural contexts. Another morphological difference is that ASL has the option of morphologically marking aspectual characteristics such as continuative (Klima & Bellugi, Reference Klima and Bellugi1979), while English would be required to use a phrase to express such information. We included four items with contrasting morphological marking of quantity and four items with contrasting morphological marking of aspect; for each set of 4, half were expected to be acceptable (as in 9) and half unacceptable (as in 10).


2.4.4. Word order
Both English and ASL have been analyzed as using Subject-Verb-Object order in pragmatically neutral contexts, but ASL has more productive options for word order variations (see, e.g., Fischer, Reference Fischer and Li1975; Leeson & Saeed, Reference Leeson, Saeed, Pfau, Steinbach and Woll2012). We constructed two items in which both ASL and English employ V-O order (such as (11)), and two items in which both employ O-V order in contexts where this order is acceptable in ASL but not in English (as in (12)). We also included two items in which the two languages use opposite orders, with English following V-O and ASL using O-V, in contexts where this order is acceptable in ASL (see 13). Finally, we included two items in which the two languages use opposite orders, with English using O-V and ASL using V-O (14).
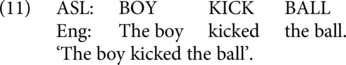

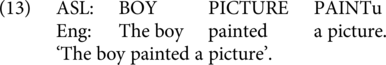

We also tested word order in Noun Phrases. While English uses Adj-N order, ASL uses both Adj-N and N-Adj (see, e.g., Neidle & Nash, Reference Neidle, Nash, Pfau, Steinbach and Woll2012). We included one item with matching Adj-N order; one item with matching N-Adj order (as in 15); two crossing items in which ASL uses N-Adj and English uses Adj-N (as in 16); and two crossing items in which ASL uses Adj-N and English uses N-Adj (as in 17). We also took advantage of the use of noun modifications indicating size in ASL to compare modification in ASL with matching or mismatching expressions in English.

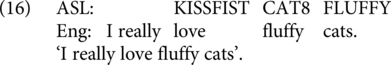

2.4.5. Negation
We included eight items to test judgments of examples in which the word order of negation in ASL either matches English in pre-verbal position, is separated from the English negative element by a relatively short distance, or is separated from the English negative element by a relatively long distance. Because the analysis of the negative items had to be conducted separately from the others and the results were inconclusive, we present all information about negation items in the Supplementary Materials available on OSF.
2.4.6. Depicting
In ASL, signs known as ‘depicting’ or ‘classifier predicates’ express multiple meaning components in a single sign, using the handshape to represent an entity or the handling of an object, while the movement generally represents the path movement of an entity or relative locations between entities (this description grossly oversimplifies; see, e.g., Zwitserlood, Reference Zwitserlood, Pfau, Steinbach and Woll2012). We included four items in which the use of a depicting sign in ASL was combined with an English expression of compatible meaning (as in 18), and four items in which the ASL and English expressed different meanings (as in 19).


2.4.7. Causative
In English and ASL, transitive verbs are often used to express causative events. Similar events can be expressed using an inchoative structure. It has been claimed that ASL lacks a transitive/inchoative alternation (Benedicto & Brentari, Reference Benedicto and Brentari2004); however, we have observed some variability across signers regarding such structures. We included some items in which ASL and English surface forms contrasted in transitivity because of such observations. We included two items in which both ASL and English use a transitive causative structure (as in 20) and two in which both use an intransitive inchoative (as in 21). We included two items in which English used a transitive causative while blending with an ASL intransitive inchoative (as in 22) to check whether this difference in argument structure would still form an acceptable blend. Finally, the last two items were used to examine the relationship between handling classifiers and causatives; typically, a handling classifier can be used to show an agentive interpretation, while an entity classifier represents an interpretation without an explicit agent (Benedicto & Brentari, Reference Benedicto and Brentari2004). These two items used the entity classifier together with an English causative transitive (as in 23).


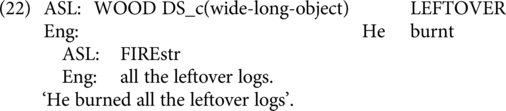

2.4.8. Passive
While English has a well-known passive construction, there is no equivalent in ASL (Villanueva, Reference Villanueva2010). There are various operations that can be used to bring a grammatical object into the foreground (e.g., topicalization) and/or background the grammatical subject (e.g., using a null subject). The status of passive as a type of construction in Catalan Sign Language (LSC) is discussed by Barberà and Hofherr (Reference Barberà and Hofherr2017), in which it is concluded that agent-backgrounding constructions should not be analyzed as passives. We believe the same is true for ASL. Hence, the question can be raised how code-blending would apply when English passive sentences are used.
There are several possibilities which we included in the present study. One possibility is to use a full passive in English and have ASL follow the English structure, including use of the by-phrase through fingerspelling B-Y. The ASL language experts we consulted considered such usage to be heavily influenced by English. Another option is to use a so-called ‘short’ passive in English with no by-phrase. ASL can then follow the English word order without the use of a highly English-coded marker such as the fingerspelled B-Y (as in 24), which is judged fully acceptable by the ASL language experts. Yet another option is to produce the ASL using a structure sometimes known as role shift, where a change in body position and/or facial expression can indicate the reaction of a referent affected by an action. Then, the order of the noun phrases in ASL can match English, but the role shift makes it clear that the first noun phrase is an object (as in 25). These versions are all expected to be acceptable, with English as the base language to differing degrees. We included 4 each of the first two types and 2 of the last type.

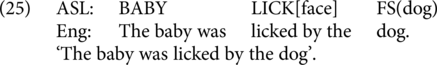
On the other hand, we do not expect it to be acceptable to blend an English passive sentence with an ASL active sentence. Although both languages would express the same truth-conditional content, the use of opposing grammatical structures is incompatible with the one-derivation assumption of the synthesis model. We included 6 items of this type (as in 26).
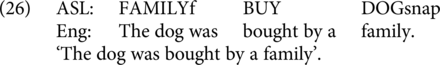
2.4.9. Complementary
The last category contains two unique types of items, one set of which we expected to be acceptable and the other of which we expected to be unacceptable. Both sets were designed to explore in more detail the issue of how the information expressed in ASL and in English contributes to a single proposition.
First, we tried a set of items in which English employed an idiom and the ASL signs were a literal translation of the idiom (as in 27). We expected participants to reject these items as not conveying the same information in ASL and English.

On the other hand, we also had a set of items in which the sign was intended to add some additional information beyond what was expressed in English (as in 28). The English utterance was a full, complete sentence, but the interpretation would be changed by adding in what was expressed in ASL.

2.5. Analysis
To evaluate the hypothesis that participants would assign an overall high rating (thumbs-up, to which we assign a value of 3) to the items we created to be ‘matching’, and a low rating (thumbs-down, to which we assign a value of 1) to the items we created to be ‘mismatching’, we fit a mixed-effects binary logistic regression model to determine the log-odds of a 3 response given the item’s group and subcategory. We allowed the relationship between an item’s rating and group to vary by subcategory through an interaction term. Note that this binary approach contrasts a response of 3 (acceptable) to non-3 responses (2 or 1; the ‘cannot judge’ responses were discarded). It was not possible to analyze the data using all three categories separately because not enough 2 responses were made (see Figure 3); therefore, we combined 1 and 2 responses for this statistical analysis since they had the smallest number of responses. This means that responses of 2 are treated as ‘not fully acceptable’ as opposed to a possible analysis considering responses of 2 as ‘not fully unacceptable’.
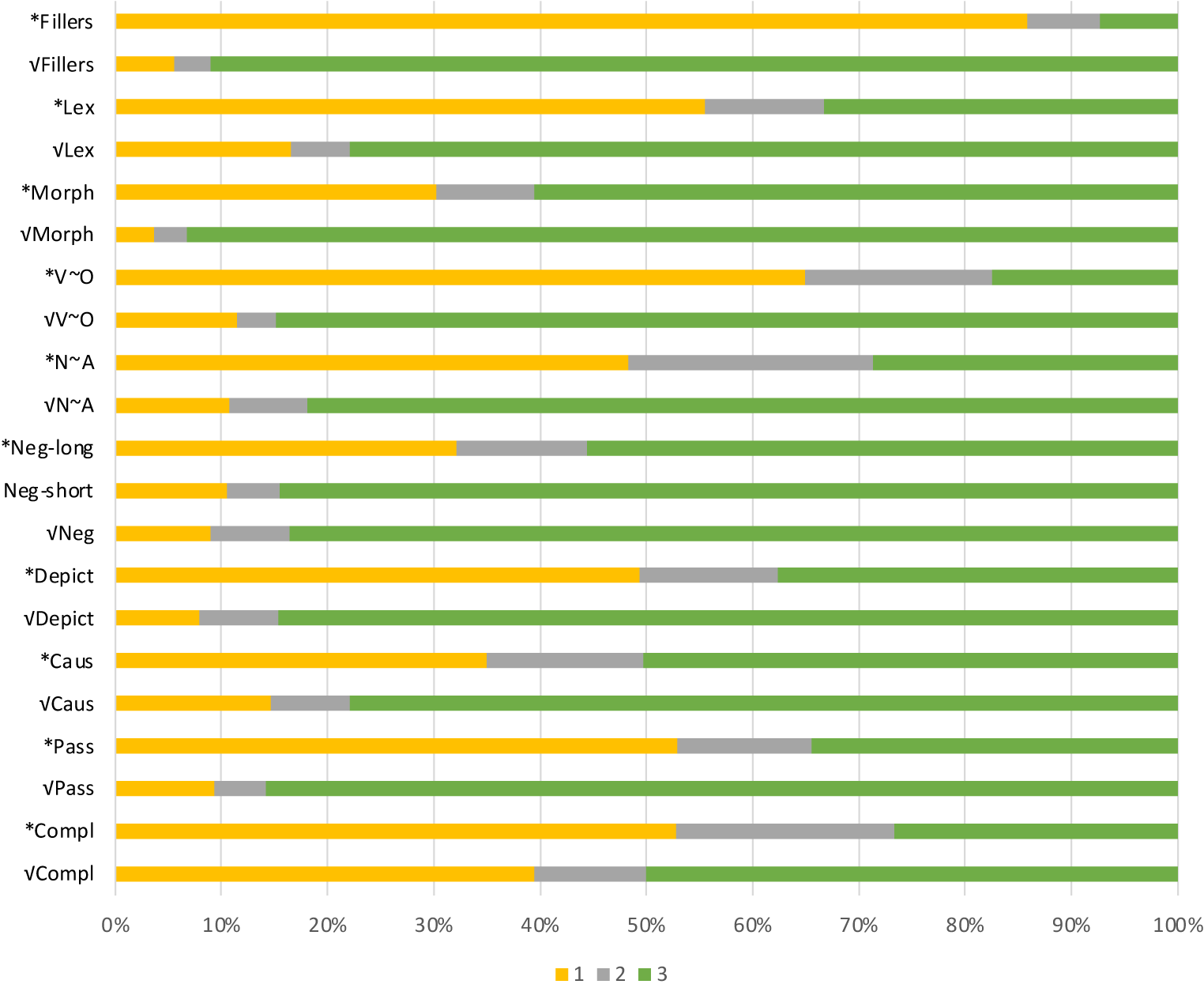
Figure 3. Proportion of 1, 2, or 3 responses for each subcategory.
While the effect of a respondent’s age and ASL fluency self-rating on acceptability ratings was not a focus of this study, we controlled for potential systematic relationships by including them in the model as fixed effects. We also note that additional variation is introduced to the model through repeated measures within individuals and through the specific items presented within each subcategory. We adjusted our standard deviations to account for this additional uncertainty by including the participant and item number associated with each rating as random effects (random intercepts) in the model. The models were fit via maximum likelihood estimation using the glmmTMB (version 1.1.8) (Brooks et al., Reference Brooks, Kristensen, Benthem, Magnusson, Berg, Nielsen, Skaug, Mächler and Bolker2017) function in the glmmTMB package in R (version 4.3.2) (R Core Team, 2021). Estimated marginal means were calculated using the ggeffects package (version 1.4.0) (Lüdecke, Reference Lüdecke2018).
3. Results
For a preliminary overview of the responses, Figure 3 gives a representation of the overall proportion of 1, 2, or 3 responses to each subcategory, separated into match (√) and mismatch (*) types. Regression coefficients for the mixed-effects binary logistic regression model are presented in Table 2. Further quantitative analyses are presented in the following subsections; qualitative discussion of the results by item type is presented in Section 4.
Table 2. Exponentiated regression coefficients (odds ratios)

1 CI = Confidence Interval
We see that, at a significance level of .05, there is strong evidence that the odds of a rating of 3 are significantly higher for an item in the match group than in the mismatch group (p-value < .05). We also see that there are significant relationships between subcategory and an item’s rating. The strength and magnitude of these relationships depend on whether the item is in the match or mismatch category. On the other hand, age and ASL fluency do not have a statistically significant relationship with the response.
The meaning of the regression coefficients in Table 2 can be difficult to interpret. To visualize these relationships, we used the model to estimate the probability of a 3 response for items (estimated marginal means) in each group and subcategory, as illustrated in Figure 4.
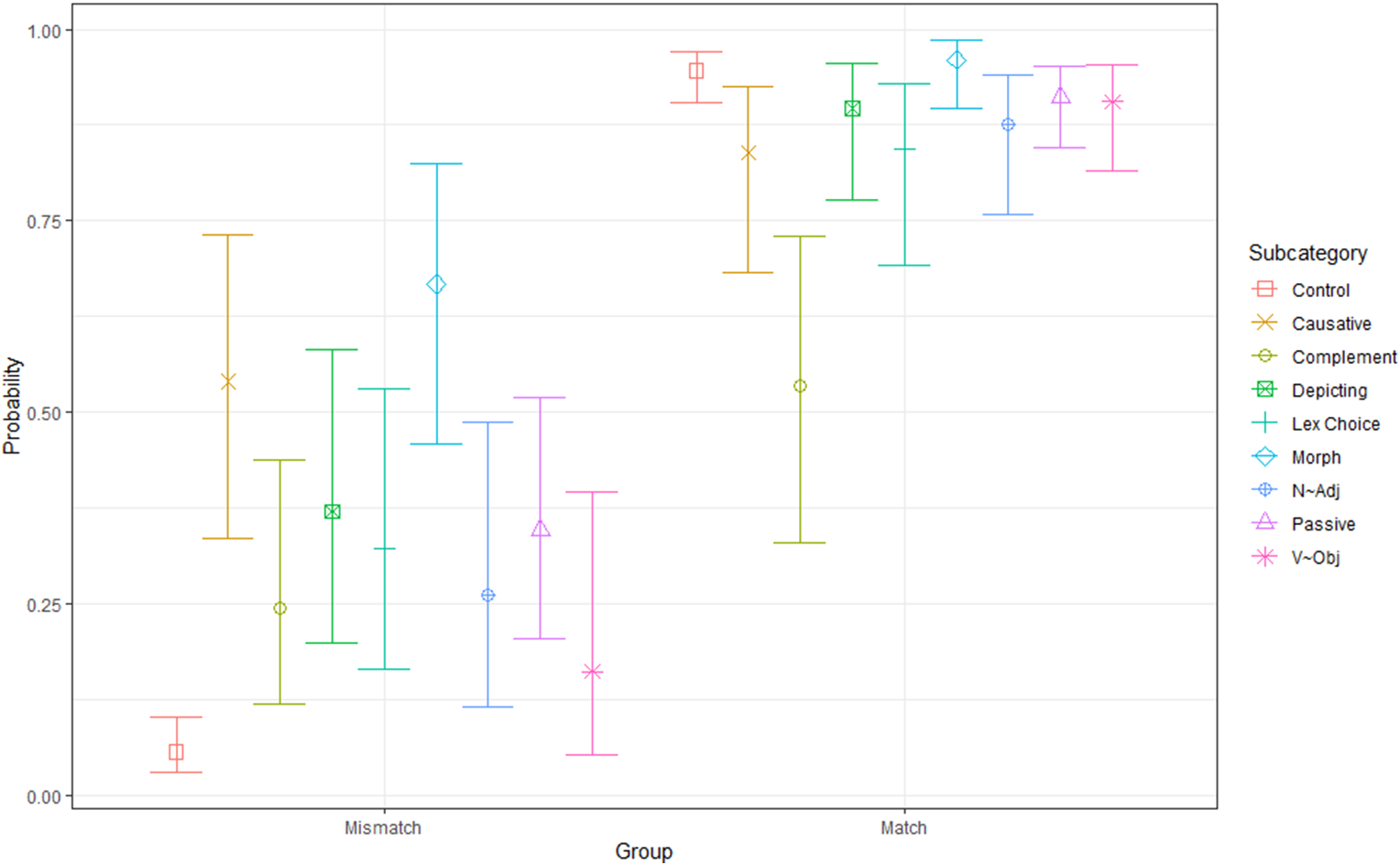
Figure 4. Predicted probability of selecting a 3 response by Group and Subcategory.
Points indicate estimated probability with lines representing 95% confidence intervals. For each of the probabilities, age and American Sign Language (ASL) fluency rating are set to the average for participants in the study.
We see that within the control subcategory, the estimated probability of a response of 3 is very low for an item in the mismatch group and very high for an item in the match group. The confidence bounds associated with these estimates are also very narrow, suggesting the efficacy of our model.
To explore the overall effect of group and subcategory on the odds of selecting a 3, we also consider the marginal odds ratios comparing match and mismatch items for each subcategory. Age and ASL self-fluency ratings are set to their average values for these comparisons. Results are reported in Table 3.
Table 3. Marginal odds ratios by subcategory
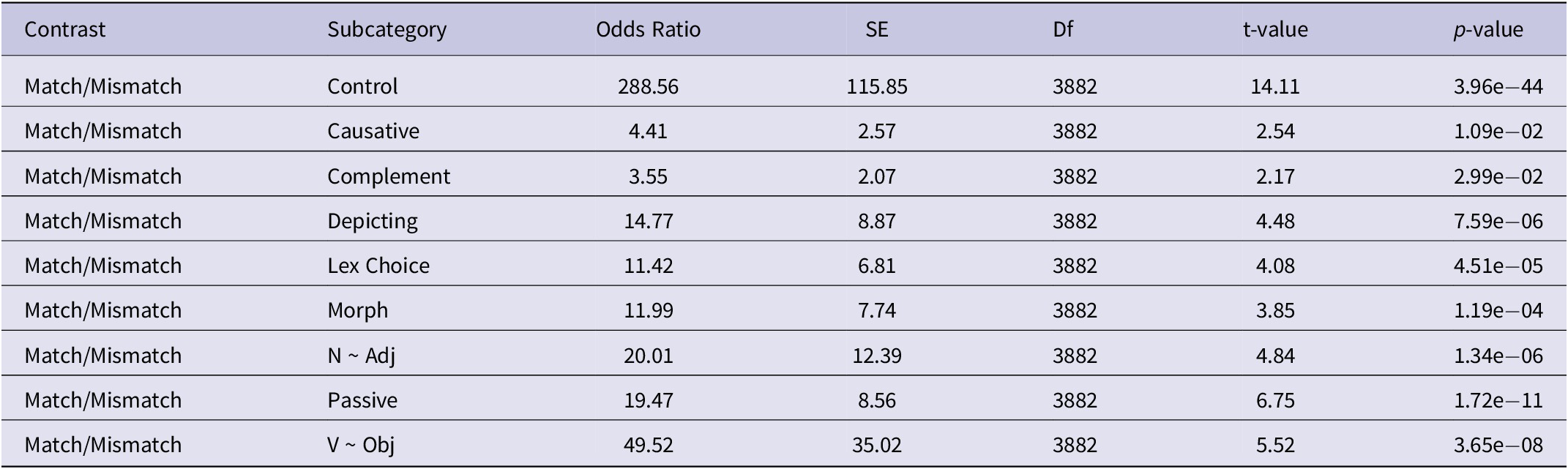
Age and American Sign Language (ASL) fluency are set to the average value
We see that for an item in the control subcategory, the odds of a participant responding with a 3 are approximately 289 times higher than the odds of a participant responding with a 3 for an item in the mismatch category. We find this odds ratio to be significantly different from 1 at a level of .05 because the p-value associated with the odds ratio is approximately zero. The odds ratios associated with other subcategories can be interpreted similarly.
The low p-values suggest that across all subcategories, the odds ratio comparing the match and mismatch groups is significantly different from 1. In other words, there is a statistically significant effect such that, on average, the odds of a 3 are higher for an item in the match group than for an item in the mismatch group.
Despite the significant contrast for each subcategory, we also see that the performance on the subcategories is not uniform. We will explore the patterns of responses for each subcategory in the Discussion section.
4. Discussion
In this section we discuss the results for each subcategory of items, then turn to a general discussion. We focus on the proportion of responses rating each item type as a ‘3’, as illustrated in Figure 3, contrasting those items we expected to be acceptable (‘matching’) with those we anticipated to be unacceptable (‘mismatching’). Note that by focusing on the proportion of ‘3’ responses, we do not consider the possible role of ‘2’ responses, which will be discussed further in the general discussion.
4.1. Results by item type
4.1.1. Control items
As expected, the proportion of ‘3’ responses to the ungrammatical fillers was very low, .07. In contrast, the proportion of ‘3’ responses to the grammatical fillers was very high, .91. Overall, across the complete set, items we expected to be matching received a high proportion of ‘3’ responses (.83), and those we expected to be mismatching received a relatively low proportion of ‘3’ responses (.34), with variation across the assorted subcategories. We therefore conclude that participants were able to make distinctions between acceptable and unacceptable types of code-blending, which gives us confidence that their judgments on other item types will be interpretable.
4.1.2. Lexical choice
As expected, participants differentiated between what we anticipated to be acceptable (.78 proportion of ‘3’ responses) versus unacceptable (.33 proportion of ‘3’ responses) lexical choice items. Acceptable examples included blending the English word ‘called’ with the ASL sign for a VIDEO-CALL. One unexpected result was a high overall rating (.80 proportion of ‘3’ responses) for blending the English word ‘bank,’ used to refer to a riverbank with the ASL fingerspelled item #BANK, which is generally thought to be restricted to referring to financial institutions. The ASL experts we consulted agreed that this sign was not appropriate in this context. Apparently, this sign is not so restricted for the majority of the participants in this study.
4.1.3. Morphology
Although we did observe an overall significant difference in the proportion of ‘3’ responses between our matching (.93) and mismatching (.60) morphology items, the proportion of ‘3’ responses on the mismatching items was higher than expected. Two of the mismatching items received unexpectedly high proportions of ‘3’ responses (.83 and .77). One item blended the English plural ‘dishes’ with a singular ASL sign PLATE. Although it is common to blend English plurals with singular ASL signs, we anticipated that this item would be less acceptable because the sign PLATE is one of a limited number of signs that can be (and often is) produced with repeated horizontal movement to indicate plurality (cf. Pfau & Steinbach, Reference Pfau and Steinbach2006). One of the ASL experts we consulted also agreed that the sign should have been produced with multiple markings. The other unexpected rating came for an item which combined the English phrase ‘wrote a letter’ with the ASL sign WRITE modified for what is commonly referred to as ‘unrealized inceptive’, to mean ‘started to write but did not complete the action’. The ASL experts agreed that this sign does not indicate completed action, but the blended item received a relatively high acceptability rating.
For the two mismatching morphology items receiving lower proportions of ‘3’ responses, the ASL signs included modifications that were not represented in the English versions. We will return to discuss this contrast later in the General Discussion section.
4.1.4. Word order – Verb ~ Obj
In the Verb~Obj category, the items expected to be rated acceptable included cases in which both ASL and English used surface VO order, cases in which both used surface OV order, and cases in which ASL used surface OV order while English used surface VO order (‘crossing’ cases). All of these cases received high proportions of ‘3’ responses (.85 overall). However, crossings in which ASL uses VO and English uses OV order had a much lower proportion of ‘3’ responses (.18), resulting in a significant effect of matching for this group.
As discussed in the introduction, blending that uses either language as the ‘base’ is generally highly acceptable, as long as both languages contribute to the same proposition. In addition, we see evidence for the idea that linearization can affect the word order of speech and sign differently, resulting in VO order for English combined with OV order for ASL. However, such crossing examples are not as highly accepted as other types of blending, which may reflect a greater processing load associated with them. All of the Verb~Obj crossing examples involve two-sign VPs, which may impose lower processing requirements in comparison to longer stretches. This possibility is left for future research.
4.1.5. Word order – Noun ~ Adj
The Noun~Adj category, like the Verb~Obj category, includes examples in which the two languages use the same order, AN or NA, and examples in which the languages use crossing orders, with ASL following NA and English following AN; these received an overall high proportion of ‘3’ responses (.82). In contrast, the items in which ASL follows AN while English follows NA received low proportions of ‘3’ responses (.29). As before, the crossing items used two-sign phrases, imposing relatively low processing demands.
Within this category we also included two examples in which the descriptive element modifies the form of the noun rather than being expressed as a separate word in ASL. The anticipated acceptable item received a very high proportion of ‘3’ responses (.90), and the anticipated unacceptable item received a low proportion (.12). The latter was unacceptable not for syntactic reasons, but because the content expressed by ASL and English was different (ASL used a modification to indicate a very small object, while English used the word ‘huge’).
4.1.6. Depicting
Accounting for the derivation of blending with depiction is challenging, but a proposal within the Synthesis model is made in Quadros, Davidson, et al. (Reference Quadros, Davidson, Lillo-Martin and Emmorey2020). In general, it is possible to blend a depicting sign with a phrase in English that conveys compatible information. This phrase may consist of a VP with modifiers that can include PPs, Adverbs and even sound effects. The examples in our matching stimuli included PPs and NPs; the proportion of ‘3’ responses they received was .85. The mismatching stimuli received only .38 proportion of ‘3’ responses. These items were unacceptable because the ASL classifier handshape did not match the English or because the movement/location represented by the ASL sign was not accurately expressed in English.
4.1.7. Causative
Stimulus items in which both ASL and English used transitive or intransitive verbs received an overall acceptable rating, with a .78 proportion of ‘3’ responses. Those mismatching items in which English used a transitive structure while ASL used an intransitive structure were significantly less likely to receive a ‘3’ rating, at .50. While the difference between the matching and mismatching items is significant, the proportion of ‘3’ responses is higher than would be expected. In this category, it is not that case that any particular item(s) received a high proportion of ‘3’ responses, but all of the items received higher ‘3’ responses than expected. This category will be discussed further in Section 4.2, General Discussion.
4.1.8. Passive
Our primary prediction was that the items displaying passive in English blended with active in ASL would not be acceptable. We contrasted such items with items in which English used a passive and ASL followed English word order. The matching items had a .86 proportion of ‘3’ responses, so they were generally acceptable, with little variability across different subtypes. On the other hand, the mismatching items had a significantly lower .34 proportion of ‘3’ responses.
4.1.9. Complementary
There were two subcategories in this category; one was expected to yield relatively high acceptance and the other relatively low acceptance. We start with the latter.
As anticipated, blending of an English idiom with literal translation equivalents in ASL is strongly rejected, with only .27 proportion of ‘3’ responses. In fact, we take it that such examples violate the primary requirement that the expressions of the two languages contribute to a single proposition, since the literal translation equivalents in ASL cannot be interpreted idiomatically. When we discuss examples like this with Codas, they are generally received with laughter and would only be used as a joke.
On the other hand, our anticipated acceptable subcategory did not receive a high rating, with only .50 proportion of ‘3’ responses overall. One item in the category that was rated as acceptable (.72 proportion of ‘3’ responses) uses the ASL sign JUST-PERFECT together with the English sentence, ‘I went to the store and saw this cake, and I just knew I had to get it’. However, other similar items received much lower ratings. For example, the English sentence, ‘My classes were online the whole year,’ was blended with the ASL sign CORONAVIRUS, with the intended interpretation being, ‘Due to the coronavirus, my classes were online the whole year’; this item received a .38 proportion of ‘3’ responses. More research is needed to distinguish between acceptable and unacceptable items of this type.
4.2. General discussion
The results of our acceptability judgment task confirm the overall idea that code-blending is not random but is linguistically constrained. They also provide supporting evidence for the conclusion that code-blends express a single proposition, and they allow us to explore what this characterization means.
The ‘complementary’ category of items provides a particularly good illustration of the need for code-blending to express a single proposition. The items we expected to be mismatched involved English idioms with corresponding literal ASL translation equivalents. Such items were soundly rejected and are generally met with laughter in any discussion. Clearly, the ASL literal translation equivalents are not interpreted as expressing the same proposition as the English idioms. We note, however, that in some cases such literal translations are used in language play; for example, some people at Gallaudet University use the ASL sign ‘RULE’ placed on the weak hand thumb (rather than the palm, as in the citation form) to humorously express the notion ‘rule of thumb’. Some of the social factors involved in this kind of code-blending are discussed by Bishop and Hicks (Reference Bishop and Hicks2005).
Considering this conclusion, we can look at the mismatching causative examples in which one language (English) uses a transitive causative verb and the other (ASL) an intransitive inchoative. It should be noted that because ASL uses an intransitive structure, it expresses less information than the English versions, which could be a factor contributing to lower ratings. On the other hand, half of the co-insertion items also expressed less information in ASL than in English, but these items had a .89 proportion of ‘3’ responses. We find it likely that the lowered ratings of the mismatching items are primarily due to the use of conflicting argument structures in the two languages (transitive versus intransitive). Nevertheless, the relatively higher proportion of ‘3’ responses to the intended mismatching items requires further discussion.
On further inspection of the items in this group, some possible alternative interpretations emerged. Because of the need for prosodic accommodation between the production of speech and sign, the actual timing of blending in the two items where English used a transitive surface structure and ASL used an intransitive surface structure involved production of the verb and the theme simultaneously, after the noun phrase referring to the agent had already been spoken. Then, it is possible that some participants analyzed these as involving transitive structures for both ASL and English, with the ASL subject null (a structure generally permitted in ASL) and the VPs crossing, as in the Verb~Obj items. This prosodic accommodation did not occur in the classifier items. However, one of the ASL language experts we consulted interpreted the signed component of one of these items as involving an agent who was not identified, potentially the signer (we did not ask about the other item). Possibly, the distinction between handling and entity classifiers for some of our participants does not require the entity classifiers to lack a syntactic agent, unlike previous analyses (Benedicto & Brentari, Reference Benedicto and Brentari2004). Structures like the ones in this category would be an interesting topic for further study.
The passive examples provide a stronger case for the proposal that structural misalignment leads to unacceptability due to the unavailability of a single grammatical derivation. In the mismatching passive examples, the same amount of information is conveyed in the two languages, but the structure used involves the passive construction in English and active in ASL. We consider these to represent conflicting syntactic derivations rather than potentially different propositions, since the events each describes are the same. Following current theoretical views on passive in languages like English, active and passive clauses involve a Voice head with an Agent specification. The two configurations differ, however, in the features of Voice, which either require a DP in its specifier (active) or do not allow a DP (passive). Under a one-derivation approach, the same head cannot involve conflicting features, and thus blending active and passive would be expected to be excluded. Further investigation might target other cases where truth conditions are constant but discourse features or other grammatical differences exist to assess whether this approach to understanding the concept of one proposition is successful.
We do want to keep in mind that our approach to constraints on code-blending should not require that each language express the same propositional content, since it is very often observed that one language will express more content than the other. As previously noted, one argument may not be expressed at all in one language; additionally, our morphology and depicting examples indicate that some content, such as temporal aspect or plural number, may be expressed differently or not at all in either language. On the other hand, conflicting information is rejected by our participants. For example, if an ASL-depicting predicate indicates a particular kind of referent or spatial relationship which is different from the English expression, such cases are considered mismatching and are not accepted.
The distinction between subsets of information and conflicting information will require further study. Recall that a noun sign in ASL not marked for number is compatible with either a singular or plural noun in English, even for nouns that our ASL language experts preferred with reduplication. A noun sign marked for plural is incompatible with a singular noun in English. Compare this to the case of code-switching between an article and noun in a pair of languages for which only one marks grammatical gender, such as Spanish-English. Substantial research indicates that code-switching displays two options: use of analogical gender (e.g., la table, the [+fem] table, as mesa ‘table’ is [+fem]); or use of the default masculine gender (el table). Liceras et al. (Reference Liceras, Fernández Fuertes, Perales, Pérez-Tattam and Spradlin2008) find that the default gender assignment predominates in multiple contexts. Similarly, in our data, the default unmarked form in ASL is compatible with singular or plural in English.
The verb cases we examined revealed a slightly different pattern. Use of a multiply-inflected verb in ASL (FS(email)[+]) with a singular event description in English was rejected. However, the response was different for the unrealized inceptive verbal modification. While our ASL experts agreed that the sign we used indicated that a writing event did not take place, the Coda participants did not reject blending this sign with English, ‘wrote a letter’. This contrast may be related to the fact that the form of the unrealized inceptive involves stopping the movement of the sign before it is completed, as opposed to other inflections which involve reduplication. Whether this is the key difference between these examples remains for further study.
While our model places grammatical constraints on the derivation of code-blended utterances, it also allows for limited differences in the surface forms of signed and spoken outputs. The word order examples in our study illustrate this, together with the effect of late linearization. In the Verb~Object and Adjective~Noun item types, participants accepted cases in which word order was crossed, but only when the signs employed an order allowed in ASL while the spoken words employed an order allowed in English. In all of the cases in these categories, the overt items being linearized were a single verb and a single noun or a single noun and a single adjective. Thus, we assume that at linearization, it is possible to select different orders for the two languages when neither asymmetrically c-commands the other, but both are dominated by a single node.
While on the topic of producing speech and sign simultaneously, we note that when the lexical content is aligned, production appears (and intuitively feels to the producer) smoother and more fluent, as compared to when the lexical content is not aligned. In the latter case, prosodic accommodations need to be made so that the output is appropriately chunked. The sign model producing the items in our study had to practice such cases more than the aligned ones, and studies of code-blended production have reported this need for prosodic accommodation (Quadros et al., Reference Quadros, Lillo-Martin, Klamt, Rodrigues and Saab2023; Quadros & Lillo-Martin, Reference Quadros and Lillo-Martin2018). We take it that this relates to the production aspect of code-blending rather than syntactic derivations.
Performance factors might also play a role in some cases where participants gave a rating of ‘2’. Recall that our analysis pits judgments of ‘3’ against judgments of ‘1’ or ‘2’, treating a response of ‘2’ as not fully acceptable. It can be seen in Figure 3 that our instructions to participants to use a response of ‘2’ as little as possible were successful: only 8% of overall responses were ‘2’s. In addition, the proportion of ‘2’ responses to our anticipated matching items was rather low (5%). This gives us more confidence that 2 responses can be grouped with responses of 1 for our analysis.
Nevertheless, the anticipated mismatching items did not always receive as low a proportion of ‘3’ responses as might have been expected. There may be an overall tendency for participants to be over-accepting. Furthermore, it should be noted that the ‘mismatching’ control items we employed involved word salad; therefore, the bar for a rating of 1 might have been so low that participants gave more ratings of ‘2’ or ‘3’ than they would have in other circumstances (the overall proportion of ‘3’ responses was indeed .60). Further research should consider these questions in more depth.
Finally, we turn to comparison between our results for ASL/English and the results reported by Donati and Branchini for LIS/Italian. There are several possible reasons for the different patterns of results.
First, it should be emphasized that the default/basic/underlying word order for ASL and English is the same: Subject-Verb-Object; and although there are many cases where different word orders are used in ASL (e.g., OSV and SOV can be used in particular instances, negation and modals can be sentence-final and various WH-question structures different from English can be used), nevertheless the overlapping word orders are generally also acceptable. This is different from LIS and Italian, where overlapping word orders are much less common, as LIS is underlyingly SOV and the use of sentence-final position for negation and wh-words is preferred (Geraci et al., Reference Geraci, Bayley, Cardinaletti, Cecchetto and Donati2015). As previously noted, the processing of multiple simultaneous word orders may be more demanding than that of overlapping word orders, which may account for why these cases are less acceptable and produced less often in code-blending of languages which allow for more common surface orders (Quadros et al., Reference Quadros, Lillo-Martin, Klamt, Rodrigues and Saab2023). However, if this is the only grammatical option for a language pair, then it may be used, and the repeated use of such structures may ease the processing load (cf. the ‘satiation’ effect, Snyder, Reference Snyder2000).
We withhold judgment on how two simultaneous distinct derivations are used in LIS/Italian and what constraints apply to such derivations. We rely on the work of Donati and Branchini to understand these cases in more detail. However, it seems clear to us that such dual derivations are dispreferred, or not found acceptable at all, for ASL/English bimodal bilinguals.
5. Conclusions
We have presented evidence here that the simultaneous production of a sign language and a spoken language – code-blending – is linguistically constrained. First, together with others, we find support for the notion that code-blending involves the joint expression of a single proposition. While we have made some suggestions about the nature of this constraint, it is important for future research to refine and expand understanding of what counts. For example, we observed cases where morphological contrasts between the languages are completely compatible, especially when these contrasts involve morphological marking in one language and a neutral or default form in the other language. However, we observed at least one case involving conflicting morphological marking which was rated as acceptable, while others with conflicting marking were not (see discussion of ‘Morphology’ and ‘Depicting’ items). In another type of example, we have frequently found that when some content is presented in only one of the languages, this does not impair acceptability (for example, if ASL is the ‘matrix’ language and only a portion of the utterance is presented in English; see discussion of ‘Control’ items); however, some cases where we attempted to add information that was only conveyed in one language were not highly rated (see discussion of ‘Complementary’ items).
We also found evidence consistent with the notion that code-blended utterances are generated via a single derivation. The strongest such evidence comes from our examination of stimuli in which the spoken English uses a passive construction while the ASL structure is active. Given what we know about the ‘single proposition’ requirement, we do not think that these examples are unacceptable due to violations of this requirement. Rather, we interpret the low ratings assigned to them as an indication that parallel simultaneous derivation of an active sentence in one language and a passive sentence in the other is not possible.
While our participants strongly rejected the active/passive blends, their responses also indicated that the surface word order of sign and speech need not be exactly matching. Crossing surface order of verbs and their direct objects, as well as nouns and modifying adjectives, was generally accepted. These cases all involved relatively simple structures, with a single word (verb, noun, adjective) or article+noun switching places. These can be analyzed as involving contrasting linearization of sister nodes.
Recent research has identified psycholinguistic processing characteristics of code-blended utterances, showing that theories of bilingual language processing must take bimodal bilingualism into account. In the current work, we add proposals and supporting evidence for linguistic constraints that apply to bimodal bilingual language ‘mixing’. We hope that further work will increase understanding of this important bilingual phenomenon.
Data availability statement
The data that support the findings of this study are openly available on the OSF site at this link: https://osf.io/rmzbj/.
Acknowledgements
We are grateful to the participants in the study reported here and to other Codas who have shared their language with us. We gratefully acknowledge the support of the University of Connecticut Statistical Consulting Services, particularly Timothy Moore and Zoe Gibbs.
This material is based upon work supported by the National Science Foundation under Grant No. 1734120. Any opinions, findings and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Competing interests
The authors declare none.








 Open access
Open access