


1. Introduction
During spoken language comprehension, one of the challenging tasks that listeners need to tackle is to extract information from rapidly unfolding acoustic signals. To do so, listeners utilize linguistic and non-linguistic contextual cues to predict forthcoming information. Speech processing would be facilitated if the incoming information aligns with these predictions. Word predictability is commonly operationalized as ‘cloze probability’, meaning the probability of words being used in a non-speeded, offline sentence completion test (DeLong et al., Reference DeLong, Urbach and Kutas2005; Kutas & Hillyard, Reference Kutas and Hillyard1984; Wlotko & Federmeier, Reference Wlotko and Federmeier2012). In addition to contextual cues, prosody has also been shown to influence spoken sentence comprehension (Allbritton et al., Reference Allbritton, McKoon and Ratcliff1996; Kjelgaard & Speer, Reference Kjelgaard and Speer1999; Lehiste, Reference Lehiste1973; Price et al., Reference Price, Ostendorf, Shattuck-Hufnagel and Fong1991). It is therefore crucial to investigate how the brain copes with the situation in which various levels of predictive violations are encountered, and it is also important to understand how and to what extent prosody interacts with cloze probability during language comprehension.
1.1. Semantic prediction in language comprehension
In natural conversation, interlocutors can successfully ‘take over’ and complete each other’s sentences immediately (Pickering & Garrod, Reference Pickering and Garrod2004). This implies that language comprehension is not a passive process but an active anticipation that progresses with the context heard/read. Prediction is a core and ubiquitous mechanism of the brain function (Friston, Reference Friston2010). During the process of language comprehension, probabilistic predictions across multiple levels of representations enable rapid understanding of the content we read or hear, leading to more efficient comprehension (Kuperberg & Jaeger, Reference Kuperberg and Jaeger2016). The strength and precision of prediction may be influenced by various factors such as memory capacity (Ding et al., Reference Ding, Zhang, Liang and Li2023), world knowledge (Hagoort et al., Reference Hagoort, Hald, Bastiaansen and Petersson2004), age (Federmeier et al., Reference Federmeier, McLennan, De Ochoa and Kutas2002; Wlotko et al., Reference Wlotko, Federmeier and Kutas2012), etc.
There is clear evidence indicating that at least within highly constrained sentence contexts, comprehenders are able to predict the semantic features of upcoming words. Eye tracking studies consistently show that when a word has higher predictability within a given context, readers tend to spend less time fixating on that word, and these words are also more likely to be skipped (Clifton et al., Reference Clifton, Ferreira, Henderson, Inhoff, Liversedge, Reichle and Schotter2016; Kliegl et al., Reference Kliegl, Dambacher, Dimigen, Jacobs and Sommer2012). Furthermore, previous studies have shown that the N400, an event-related potential (ERP) component reflecting semantic processing, is reduced in response to words that match the semantic predictions generated by highly predictable (relative to less predictable) contexts (DeLong & Kutas, Reference DeLong and Kutas2016; Kutas & Federmeier, Reference Kutas and Federmeier2011). For instance, when reading/hearing ‘The terrorists planted a bomb in the airport and four people were killed in the…’, comprehenders can easily predict that the last word is ‘explosion’ (Thornhill & Van Petten, Reference Thornhill and Van Petten2012). In other words, comprehenders are able to access a unique lexical-semantic representation (e.g., <explosion>) distinct from any other word (e.g., <terminal>) ahead of its availability from the bottom-up input. Therefore, compared to ‘explosion’, ‘terminal’ would elicit a larger N400 amplitude. Some researchers argue that the N400 reflects the magnitude of prediction error (DeLong et al., Reference DeLong, Urbach and Kutas2005; Kutas & Federmeier, Reference Kutas and Federmeier2011; Nieuwland & Van Berkum, Reference Nieuwland and Van Berkum2006). Indeed, the correlation between cloze probability and N400 amplitude has been consistently observed (Kutas & Federmeier, Reference Kutas and Federmeier2011), with some studies reporting correlations of 0.8 or higher, indicating a strong association.
In addition, several studies have reported differential modulation of brain activities preceding the predicted occurrence of words in highly predictable versus less predictable sentence contexts. These include larger negative ERP effects (Freunberger & Roehm, Reference Freunberger and Roehm2017; Grisoni et al., Reference Grisoni, Miller and Pulvermüller2017), increased θ power (Dikker & Pylkkänen, Reference Dikker and Pylkkänen2013; Piai et al., Reference Piai, Anderson, Lin, Dewar, Parvizi, Dronkers and Knight2016), and suppression of α/β power (Piai et al., Reference Piai, Roelofs and Maris2014; Piai et al., Reference Piai, Roelofs, Rommers and Maris2015; Rommers et al., Reference Rommers, Dickson, Norton, Wlotko and Federmeier2017; Wang et al., Reference Wang, Hagoort and Jensen2018). These predictive effects are neuroanatomically localized to the neocortex and subcortical regions (Dikker & Pylkkänen, Reference Dikker and Pylkkänen2013; Piai et al., Reference Piai, Roelofs, Rommers and Maris2015; Wang et al., Reference Wang, Hagoort and Jensen2018). They are attributed to the processes of generating predictions and/or accessing lexical semantic representations corresponding to the predicted words themselves.
Furthermore, in the past three decades, a substantial body of research on prediction-related phenomena has not only revealed N400 but also shown isolated late positivities or biphasic effects, where larger N400s are followed by larger late positive waves, also known as the post-N400 positivity (PNP) (e.g., DeLong et al., Reference DeLong, Quante and Kutas2014; DeLong & Kutas, Reference DeLong and Kutas2016; Van Petten & Luka, Reference Van Petten and Luka2006; Van Petten & Luka, Reference Van Petten and Luka2012). Van Petten and Luka (Reference Van Petten and Luka2012) noted in their review that there are two distinct topographical distributions of the PNP. One exhibits a parietal distribution, more prominent in studies comparing semantic congruent versus incongruent sentence completions (e.g., Daltrozzo et al., Reference Daltrozzo, Wioland and Kotchoubey2007; Diaz & Swaab, Reference Diaz and Swaab2007; Pijnacker et al., Reference Pijnacker, Geurts, Van Lambalgen, Buitelaar and Hagoort2010), while the other demonstrates a frontal distribution, more prevalent in comparisons of high- versus low-cloze probability (e.g., Federmeier & Kutas, Reference Federmeier and Kutas2005; Kutas, Reference Kutas1993; Moreno et al., Reference Moreno, Federmeier and Kutas2002). Kuperberg (Reference Kuperberg, Miller, Cutting and McCardle2013) presented a slightly different contrast, suggesting that they are errors in event or structural predictions that trigger posterior PNPs (P600s), while errors in lexical predictions trigger more anterior PNPs. However, a common thread is that anterior/frontal PNPs reflect some form of cost associated with prediction violations. Researchers interpret these two PNP distributions based on different functions corresponding to different brain regions. The parietal distribution of PNP bears high similarity to the topographical distribution of syntactic/semantic P600, hence attributed to reprocessing, repair, and retrieval of problematic sentences (Friederici et al., Reference Friederici, Hahne and Mecklinger1996; Hahne & Friederici, Reference Hahne and Friederici1999; O’Rourke & Van Petten, Reference O’Rourke and Van Petten2011). In contrast, although several functional interpretations of the frontal PNP have been proposed, there is currently no consensus. Thornhill and Van Petten (Reference Thornhill and Van Petten2012) as well as Kuperberg (Reference Kuperberg, Miller, Cutting and McCardle2013) posited that it indexes sensitivity to specific lexical forms rather than conceptual expectancies. Other proposals included inhibiting expected but unencountered words (Kutas, Reference Kutas1993) and arguments linking it to learning/adaptation mechanisms (Davenport & Coulson, Reference Davenport and Coulson2013; Kuperberg & Jaeger, Reference Kuperberg and Jaeger2016), where mental models are updated to reflect probabilities in the current environment. Kuperberg and Jaeger (Reference Kuperberg and Jaeger2016) further suggested that the PNP may index a form of ‘model-switching’, reflecting resource reallocation to models corresponding more directly to statistical patterns.
In recent years, the hierarchical predictive coding framework has been employed to explain predictive processing in language comprehension (Heilbron et al., Reference Heilbron, Armeni, Schoffelen, Hagoort and De Lange2022; Ryskin & Nieuwland, Reference Ryskin and Nieuwland2023). In this framework, individuals continuously generate top-down expectations based on world knowledge and long-term memory (Eddine et al., Reference Eddine, Brothers, Wang, Spratling and Kuperberg2024; Huettig, Reference Huettig2015; Ryskin & Nieuwland, Reference Ryskin and Nieuwland2023; Spratling, Reference Spratling2017). When the bottom-up input fails to meet these expectations, prediction errors arise, reflected in the amplitude of the N400. The detection of prediction errors triggers further cognitive processes to resolve this mismatch. These cognitive processes may include attention adjustment, working memory updating, semantic re-evaluation, and inhibitory control. In the predictive framework, the resolution of prediction errors is reflected in late-stage brain activity. For instance, Wang et al. (Reference Wang, Schoot, Brothers, Alexander, Warnke, Kim and Kuperberg2023) utilized MEG and ERPs to track the temporal dynamics and localization of brain activity elicited by expected, unexpected plausible, and implausible words during incremental language comprehension. The results demonstrated that, within the 300- to 500-ms time window, the three conditions produced progressively larger responses within left temporal cortex (prediction error). In the 600- to 1000-ms time window, unexpected plausible words elicited significant neural activity in the left inferior frontal and middle temporal cortices, which may indicate the resolution process of prediction errors, including the retrieval of new patterns and the generation of new predictions.
1.2. Prosodic facilitation in spoken language comprehension
Speech comprehension requires the integration of multiple cues, such as syntax, semantics, prosody, and others. Accentuation is a kind of prosodic feature in the speech signal that reflects the relative prominence of specific syllables, words, or phrases within a rhythmic structure through modulation of pitch or syllable duration (Shattuck-Hufnagel & Turk, Reference Shattuck-Hufnagel and Turk1996).
A lot of psycholinguistic research on accentuation primarily focuses on its correspondence with information structure. Previous behavioral studies have found that speech processing is facilitated when new information (or focused information) is accented, and old information is unaccented (Bock & Mazzella, Reference Bock and Mazzella1983; Dahan et al., Reference Dahan, Tanenhaus and Chambers2002; Terken & Nooteboom, Reference Terken and Nooteboom1987; Yang & Li, Reference Yang and Li2004). ERP studies have found that unaccented new information or accented old information can lead to processing difficulties and increased neural activities, such as the N400 or P600 components (Bögels et al., Reference Bögels, Schriefers, Vonk and Chwilla2011; Hruska et al., Reference Hruska, Alter, Steinhauer, Steube, Cave, Guaitella and Santi2001; Ito & Garnsey, Reference Ito and Garnsey2004; Wang et al., Reference Wang, Bastiaansen, Yang and Hagoort2011). These studies prove that accentuation plays a crucial role in spoken language comprehension.
Furthermore, accentuation can modulate selective attention, which in turn influences speech processing. Some researchers have found that accentuation can regulate listeners’ selective attention during speech processing (Astheimer & Sanders, Reference Astheimer and Sanders2009; Cutler et al., Reference Cutler, Dahan and Van Donselaar1997; Ito & Speer, Reference Ito and Speer2008). For instance, Cutler (Reference Cutler1976), using a phoneme monitoring task, observed an accelerated phoneme monitoring speed at accented positions, and speculated that the result likely stemmed from the listener’s focused attention. Sanford et al. (Reference Sanford, Sanford, Molle and Emmott2006) employed a change detection task in which participants were auditorily presented with discourse twice and were asked to determine whether there was anything changed between the two presentations. Critical words were produced with either a noncontrastive or a contrastive accent. Their results showed that participants exhibited superior detection to word changes in the contrastive accent condition compared to the noncontrastive accent condition, suggesting that accentuation can modulate listeners’ selective attention during language processing.
In addition, accentuation can modulate general cognitive processes, which in turn influence speech processing. For example, relative to unaccented counterparts, accented counterparts elicited a positive deflection between 200 and 500 ms (Dimitrova et al., Reference Dimitrova, Stowe, Redeker and Hoeks2012), and accented words within discourse increased the N400 amplitude (Li et al., Reference Li, Hagoort and Yang2008; Li & Ren, Reference Li and Ren2012; Wang et al., Reference Wang, Bastiaansen, Yang and Hagoort2011, Reference Wang, Bastiaansen, Yang and Hagoort2012). Studies employing single-sentence paradigms have reported broadly distributed N400 effects, with central maxima observed for words with unpredictable accentuation, but fronto-lateral expectancy negativity observed for words with predictable accentuation (Heim & Alter, Reference Heim and Alter2006). These findings suggest that in online spoken language comprehension (Li & Yang, Reference Li and Yang2013), accentuation interacts with long-term memory and directs listeners’ attention to salient constituents of discourse, leading to more detailed and comprehensive processing. In contrast, unaccented information undergoes relatively shallow analysis (Baumann & Schumacher, Reference Baumann and Schumacher2012; Wang et al., Reference Wang, Bastiaansen, Yang and Hagoort2011). This is consistent with the neuroimaging findings in Kristensen et al. (Reference Kristensen, Wang, Petersson and Hagoort2013), indicating that accentuated language activates a general attention network.
Taken together, some previous studies have shown that accented information attracts more attentional resources, facilitating faster and deeper processing (e.g. Li et al., Reference Li, Deng, Yang and Wang2018; Sun et al., Reference Sun, Sommer and Li2022; Wang et al., Reference Wang, Hagoort and Yang2009; Wang et al., Reference Wang, Bastiaansen, Yang and Hagoort2011), and that as the cloze probability of critical words decreases during sentence comprehension, the level of prediction error increases, which requires additional cognitive resources to process these novel details that deviate from the context of the sentence (Federmeier & Kutas, Reference Federmeier and Kutas1999; Van Berkum et al., Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005). However, it is still unclear how accentuation and predictability of words interact during language comprehension.
1.3. The current study
We aimed to investigate how accentuation influences the processing of lexical items with varying levels of cloze probability. Specifically, we auditorily presented a high-constrain sentence context with disyllabic words varying in three cloze probability levels embedded at the sentence-final position. Additionally, we manipulated the accentuation of the critical words to examine the neural activities involved in processing these words at different cloze probability levels.
Thereby, we address the following two research questions: (1) whether the modulation of attention resources introduced by accentuation interacts with the predictive error and (2) to what extent the processing of highly predicted and less predicted words influenced by accentuation.
We expect that accentuation modulates selective attention, thereby influencing the speed and depth of sentence processing. That is, we predict that accented critical words capture more attentional resources, enabling the rapid detection of predictive errors and providing additional cognitive resources for deep semantic processing (Li et al., Reference Li, Ren, Zheng and Chen2020; Wang et al., Reference Wang, Bastiaansen, Yang and Hagoort2011). In other words, accentuation should interact with cloze probability, with accented critical words of low cloze probabilities yielding the greatest N400 and PNP amplitudes. The data and methods used in the study are presented in the following sections.
2. Methods
2.1. Participants
The current study used a 2 (accentuation: accented, unaccented) × 3 (cloze probability: high, medium, low) within-participants design. An a priori power analysis conducted via G*Power 3.1.9.7 (Faul et al., Reference Faul, Erdfelder, Lang and Buchner2007) showed that 19 participants were required to observe a significant (α = 0.05) interaction at .80 power. To be on the safe side, twenty-six college students were recruited as participants for the study, with ages ranging from 19 to 25 years (male = 7; M±SD = 22.5±1.5). All participants were native Chinese speakers. They all had normal or corrected-to-normal vision and had no hearing impairments, reading difficulties, or neurological disorders. The research was approved by the Ethics Committee of Liaoning Normal University. Prior to the experiment, participants provided informed consent. After the experiment, they received monetary compensation for their participation.
2.2. Materials
A total of 240 sets of sentence contexts were created, with 6 kinds of sentence continuation in each set, varying in predictability and accentuation of the disyllabic critical words embedded in the sentence-final position. The predictability of the critical words was determined by their cloze probabilities obtained in a rating experiment. In this experiment, twenty volunteers (8 males, aged between 19 and 25) who did not participate in the main experiment provided cloze probability ratings for the critical words on a seven-point scale. Ratings between 6 and 7 were regarded as high-cloze words, between 3 and 5 as medium-cloze words, and between 1 and 2 as low-cloze words. Critical words with high-cloze probabilities were highly predictable and semantically congruent with the preceding context. Critical words with medium-cloze probabilities were less predictable but semantically congruent with the preceding context. Critical words with low-cloze probabilities were impossible to predict by the preceding context and semantically incongruent with the preceding context. A one-way ANOVA (analysis of variance) was conducted on the ratings of the critical words. Results showed that the ratings of the three level of cloze probability differed significantly, F (1,719) =1356, p<.001, ηp2 = 0.89 (see Table 2 Column 1 for details).
Additionally, we recruited 20 participants (4 males, aged between 19 and 28) to provide 7-point Likert ratings for lexical frequency, concreteness, and imaginability for each word in the three-level cloze probability. The results of the one-way repeated measures ANOVA conducted on the ratings across the three dimensions indicated that there were no significant differences between the three cloze probabilities: Lexical frequency: F (2,38) = 1.25, p = 0.29, ηp 2= 0.06; Concreteness: F (2,38) = 0.23, p = 0.69, ηp 2= 0.01; and Imaginability: F (2,38) = 2.35, p = 0.13, ηp 2= 0.11 (see Table 2 Columns 2–4 for details).
In addition to the manipulation of cloze probabilities, all sentences were produced with two types of accentuation. For the accented condition, the disyllabic critical nouns in the sentence-final position were accented; for the unaccented condition, a disyllabic noncritical noun in the sentence fragments preceding the final critical words was accented (see Table 1 for material examples). In total, 1440 test sentences (240 constraint contexts × 3 cloze conditions × 2 types of accentuation) were recorded by a phonetically trained male native Chinese speaker in a soundproof booth, at a sampling rate of 44.1 kHz and 16-bit resolution.
Table 1. Examples of stimuli
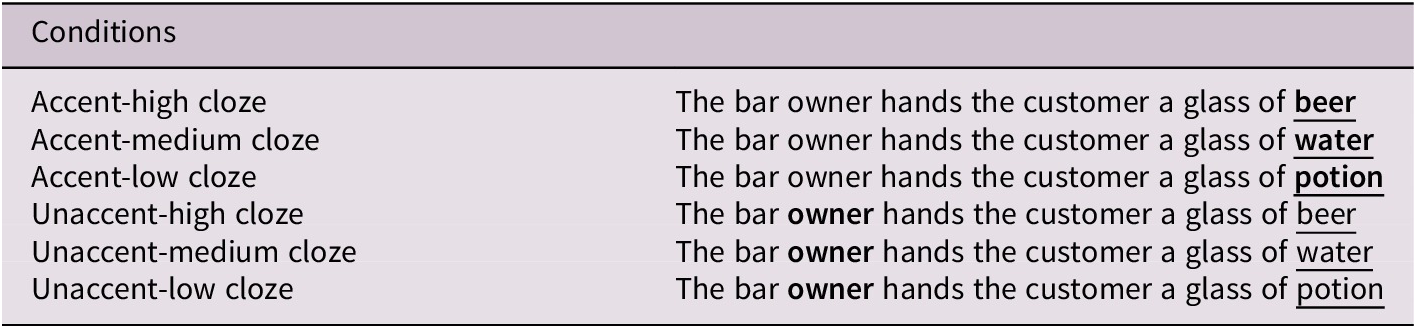
Table 2. Ratings for critical words’ cloze probability, lexical frequency, concreteness, and imageability (M±SD)

Using Praat software (Boersma & Weenink, Reference Boersma and Weenink2022) with publicly available scripts (Feinberg, Reference Feinberg2018; Puts & Cardenas, Reference Puts and Cardenas2018), the average sound pressure level (SPL) of each sentence was normalized to a uniform level of 70 dB based on previous studies (Li et al., Reference Li, Deng, Yang and Wang2018; Sun et al., Reference Sun, Sommer and Li2022), to avoid specific responses to general loudness differences. Each sentence was divided into two parts: the sentence fragment preceding the critical word and the critical word itself. To ensure that the speaker successfully and correctly accented the critical words, paired-sample t-tests were performed on the mean syllable duration, maximal pitch, and SPL between the critical words and the sentence fragment preceding the critical words in the accented and unaccented conditions (see Table 3 for details). On average, relative to unaccented critical words, accented critical words showed significantly higher F0 maxima, SPL, and longer duration. Overall, the acoustic features of the current accentuation pattern align with previous studies (Chen & Gussenhoven, Reference Chen and Gussenhoven2008; Li et al., Reference Li, Deng, Yang and Wang2018). For the sentence fragments preceding the critical words, the mean duration was longer and the F0 maxima were higher under the unaccented condition compared to the accented condition. The SPL values were not significantly different between the two conditions.
Table 3. Acoustic parameters of critical words (CWs) and the preceding sentence fragments under the two accent conditions

Note: *p<.05; **p<.01; ***p<.001; Acc. = accented, Un-acc. = unaccented.
Additionally, we statistically analyzed the acoustic parameters (duration, pitch, and intensity) of critical words with different cloze probabilities under accented and unaccented conditions using a two-way repeated measures ANOVA (see Table 4 for details). Duration results indicated a significant main effect of accent, F (1, 239) = 1873.80, p < .001, ηp2 = 0.89; accented words had a longer duration than unaccented words. Pitch results revealed a significant main effect of accent, F (1, 239) = 327.65, p < .001, ηp2 = 0.58; accented words had a higher pitch compared to unaccented words. A significant main effect of cloze probability was also found, F (2, 478) = 11.85, p < .001, ηp2 = 0.05; high-cloze words had the highest pitch, followed by low-cloze words, with medium-cloze words having the lowest pitch. Intensity results showed a significant main effect of accent, F (1, 239) = 5844.78, p < .001, ηp2 = 0.58; accented words were louder than unaccented words. A significant main effect of cloze probability was again found here, F (2, 478) = 22.71, p < .001, ηp2 = 0.09; high-cloze words had the highest intensity, followed by medium-cloze words, and low-cloze words had the lowest intensity. There was a significant interaction between accent and cloze probability, F (2, 478) = 15.66, p = .001, ηp2 = 0.06. Further simple effects analysis indicated that under the accented condition, only high- and low-cloze words showed a significant difference, F (2, 238) = 7.42, p < .001, while under the unaccented condition, all three cloze levels differed significantly from one another, F (2, 238) = 25.99, p < .001.
Table 4. Acoustic parameters of critical words (CWs) in the two accent conditions

2.3. Procedure
The overall experimental materials comprised 1440 test sentences (240 constraint contexts × 3 cloze conditions × 2 types of accentuation) and 90 filler sentences. The filler sentences differed from the critical sentences in length and structure to prevent participants from predicting the sentence-final words (e.g., 小明最近读了一篇论文。Xiao Ming read a paper recently.).
To ensure that participants would not hear the same sentence context under different conditions more than once, a Latin Square design was employed to generate six lists of stimuli, such that each participant heard only one of the lists. Each list contained an equal number of items (40 sentences) for each condition, resulting in a total of 240 sentences per list. Sentences of each list were separated into three blocks, with each block consisting of 135 sentences (120 experimental sentences and 15 filler sentences) and lasting approximately 20 minutes. There were brief intervals between blocks. Prior to the formal experiment, participants conducted an initial practice session of 20 trials to acquaint themselves with the experimental procedures. The list order was counterbalanced across participants. The sentences within each list were presented in a random order.
The experiment took place in a softly lit, quiet, and comfortable room. Participants sat in front of a 23-inch LCD monitor and wore headphones with volume adjusted to their preference. In a given trial, participants first saw a fixation cross and simultaneously heard a beep sound for 500 ms. Then, participants heard a sentence while the fixation cross stayed on the screen. They were asked to keep looking at the fixation cross when hearing the sentence. As soon as the auditory signal ended, the fixation cross disappeared, and a 400-ms blank interval followed. After the interval, a probe word appeared on the screen, and participants had to determine whether the probe word appeared in the sentence they had just heard by pressing either ‘J’ or ‘F’ within 3000 ms. Half of the participants pressed the ‘J’ key for ‘yes’ and the ‘F’ key for ‘no’. The other half pressed the ‘J’ key for ‘no’ and the ‘F’ key for ‘yes’. Probe words were two-character nouns (content words) that can either be literal repetitions of the two-character nouns from the preceding sentence, regardless of their position, or any two-character nouns that are semantically unrelated to the preceding sentence. The whole experiment consisted of 50% yes responses and 50% no responses. Finally, participants saw a 400-ms blank screen before the commencement of the next trial. The experimental procedure is shown in Figure 1.
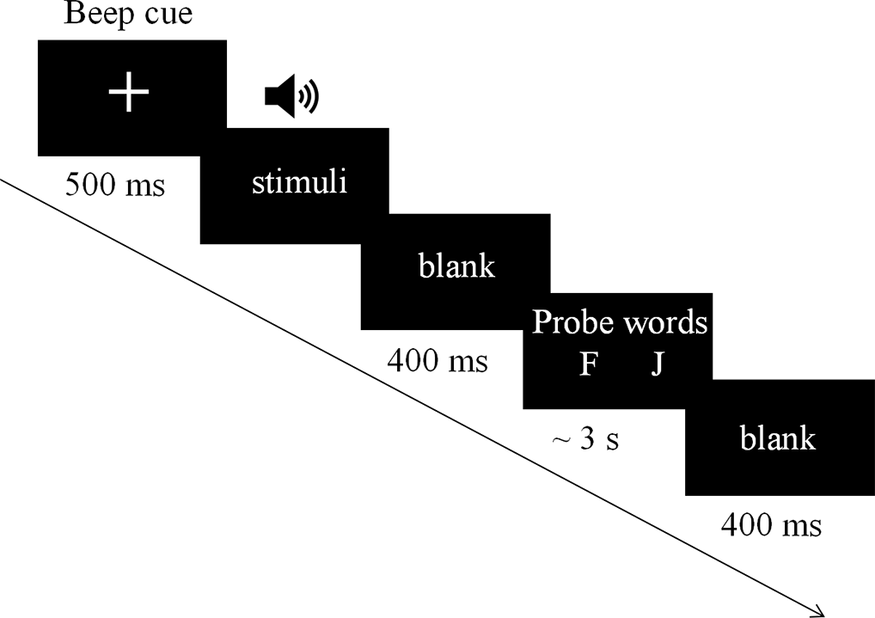
Figure 1. A single trial of the experimental procedure.
2.4. EEG acquisition and analysis
The EEG data were recorded from 64 cap-mounted Ag/AgCl electrodes (ANT Neuro EEGO Inc., Germany), placed according to the extended international 10–20 system. During recordings, a 100 Hz low-pass filter was applied; the sampling rate was 500 Hz. CPz was used as the online reference, and offline analysis involved re-referencing by subtracting the average from bilateral mastoids (M1, M2) from the EEG data in each channel. Impedances were kept below 5 KΩ for all electrodes. The collected EEG data were preprocessed using the EEGLAB toolbox (version 2023.0) in MATLAB software (R2018b). The preprocessing steps included bandpass filtering (0.1 to 30 Hz), segmenting the EEG data into epochs from 200 ms before to 800 ms after the onset of the critical words, corrected with a 200-ms prestimulus baseline. Eye movements were corrected using the ‘Independent Ocular Component Correction’ model in EEGLAB. Epochs with signals exceeding ±80 μV in any given channel were excluded. After artifact rejection, there was an average of 36 valid trials per condition (40 trials under each condition originally).
Combined with visual inspection of the data, and previous relevant research (DeLong et al., Reference DeLong, Quante and Kutas2014; Li & Ren, Reference Li and Ren2012; Nieuwland et al., Reference Nieuwland, Barr, Bartolozzi, Busch-Moreno, Darley, Donaldson, Ferguson, Fu, Heyselaar, Huettig, Husband, Ito, Kazanina, Kogan, Kohút, Kulakova, Mézière, Politzer-Ahles, Rousselet and Zu Wolfsthurn2020; Thornhill & Van Petten, Reference Thornhill and Van Petten2012; Van Berkum et al., Reference Van Berkum, Brown, Zwitserlood, Kooijman and Hagoort2005), the average ERP amplitudes obtained from various regions of interest (ROIs) were used as dependent variables. Two two-way repeated measures ANOVAs were conducted on the average amplitudes of the evoked brain potentials for the 300- to 450- and 500- to 700-ms time windows, respectively. The factors examined were the type of accentuation (accented, unaccented) and cloze probability level (high, medium, low). For the N400, we selected the electrodes CP1, CPz, CP2, P1, Pz, and P2 as ROIs. For the PNP, although previous research has reported two distinct topographical distributions, considering the current experimental design involving different cloze probabilities in conjunction with Van Petten and Luka (Reference Van Petten and Luka2012)’s review and the observed topographical differences (Figure 3B), we selected F1, Fz, F2, FC1, FCz, and FC2 electrodes as the ROIs. The p-values in all ANOVAs were adjusted using the Greenhouse–Geisser correction for nonsphericity. The results are given in the following sections.
2.5. Results
2.5.1. Behavioral results
To ensure that accentuation and cloze probability processing were not influenced by keypresses, participants were required to make behavioral judgments 400 ms after stimulus presentation. Therefore, reaction times were not analyzed; only accuracy rates were considered.
A two-way repeated measures ANOVA was conducted on the accuracy rates (ARs) of the behavioral data, with accentuation type (accented, unaccented) and cloze probability level (high, medium, low) treated as independent variables. The results did not show any significant effects, all ps > .05 (see Table 5).
Table 5. Accuracy rates under different conditions (M±SD)

2.5.2. ERP results
For the results of the N400 analysis, there was a significant main effect of cloze probability level, F (2,21) = 3.39, p = 0.043, ηp2 = 0.13. Pairwise comparisons showed a trend of the medium-cloze condition inducing larger N400 amplitudes compared to the high-cloze condition, p = 0.054. There was also a significant interaction between accentuation type and cloze probability level, F (1,22) = 3.55, p = 0.037, ηp2 = 0.14. Further simple effects analysis revealed that under the accented condition, the medium-cloze condition induced larger N400 amplitudes compared to the high-cloze condition, F (1,22) = 4.75, p = 0.02, and the low-cloze condition produced larger N400 amplitudes relative to the high-cloze condition, F (1,22) = 4.75, p = 0.023. However, under unaccented conditions, there were no significant differences observed among medium-cloze, low-cloze, and high-cloze conditions, all ps > .62. (see Figures 2A and 3A).
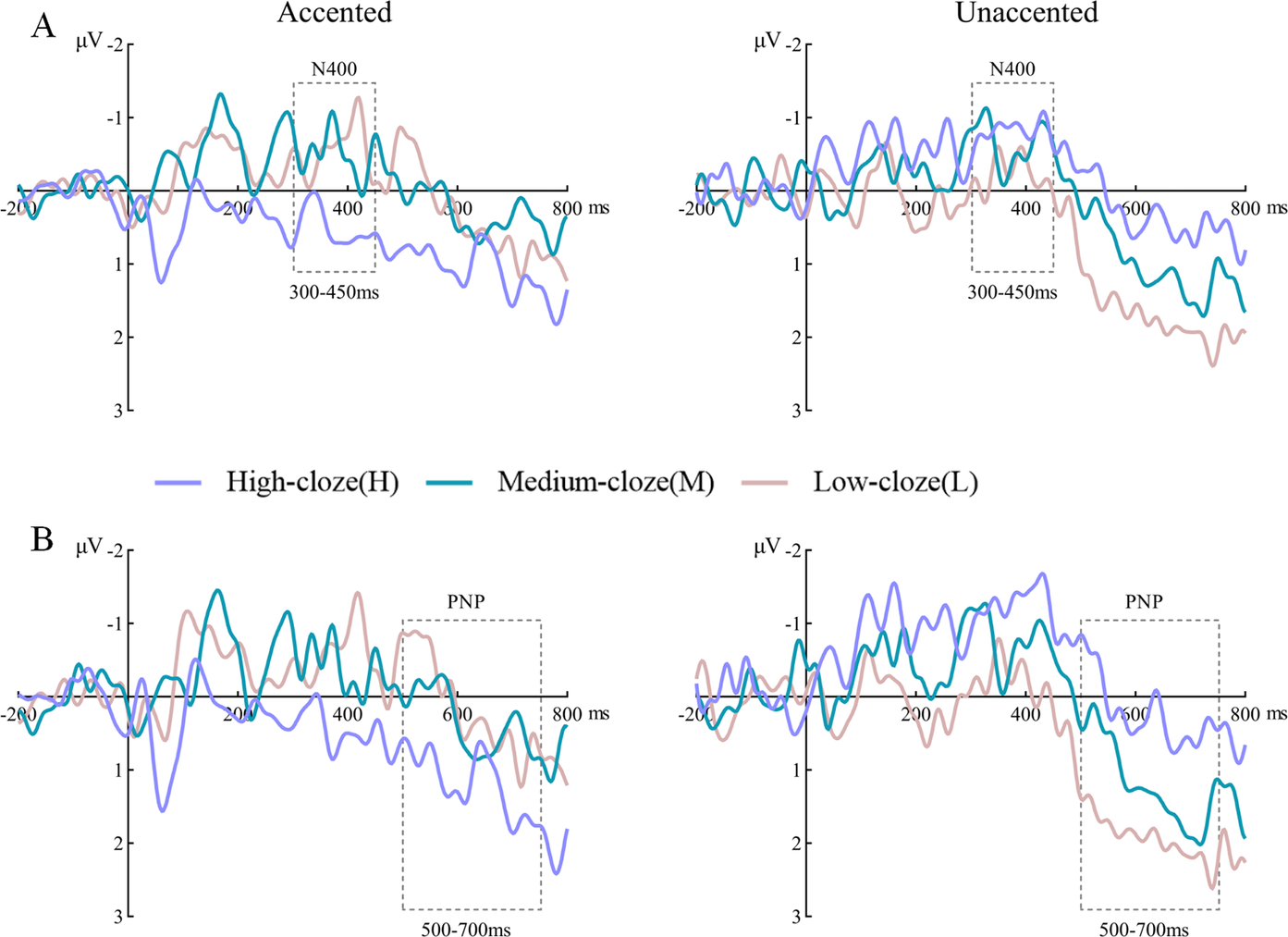
Figure 2 A. Average waveform of the N400 component at Pz with different cloze probability levels under the accented condition (left) and unaccented condition (right). B. Average waveform of the PNP component at Fz with different cloze probability levels under the accented condition (left) and unaccented condition (right).
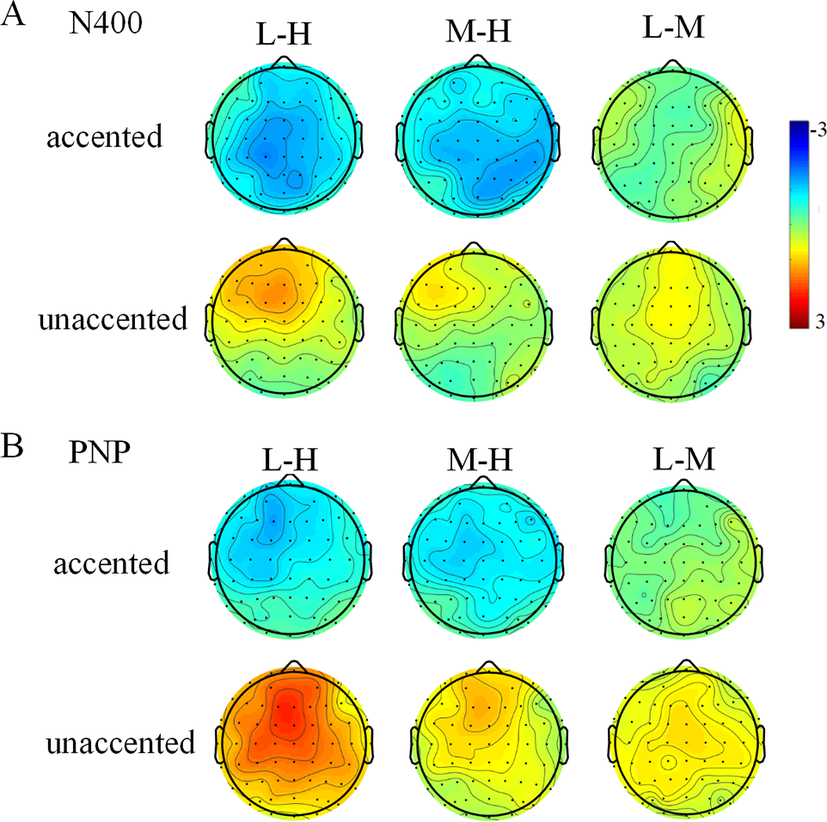
Figure 3 A. Topographical maps of low-cloze minus high-cloze, medium-cloze minus high-cloze, low-cloze minus medium-cloze under both accented and unaccented conditions within the 300-450 ms time window. B. The topographical maps of low-cloze minus high-cloze, medium-cloze minus high-cloze, low-cloze minus medium-cloze under both accented and unaccented conditions within the 500-700 ms time window.H: high-cloze; M: medium-cloze; L: low-cloze.
For the PNP analysis, results showed a significant main effect of accentuation type, F (1,22) = 6.47, p = 0.018, ηp2 = 0.23, suggesting that the unaccented condition induced larger PNP amplitudes compared to the accented condition. Moreover, although no main effect of cloze probability level was found, F (2,21) = 0.70, p = 0.490, ηp2 = 0.03, a significant interaction between accentuation type and cloze probability level was observed, F (2,21) = 27.92, p = 0.003, ηp2 = 0.24. Simple effects analysis revealed that under the unaccented condition, the medium-cloze condition induced larger PNP amplitudes than the high-cloze condition, F (2,21) = 4.83, p = 0.039, and the low-cloze condition yielded larger PNP amplitudes than the high-cloze condition, F (2,21) = 10.21, p = 0.004. Under the accented condition, there were no significant differences observed among medium-, low-, and high-cloze conditions, all ps > .22 (see Figures 2B and 3B).
3. Discussion
This study employed the ERP technique to investigate the neural processing of disyllabic words varying in levels of cloze probability and types of accentuation during spoken sentence comprehension. Our ERP results showed that the neural processing of disyllabic words is not only influenced by their cloze probabilities but also by their degrees of accentuation during spoken sentence comprehension. These findings will be discussed in more below.
Regarding the ERP results in the 300- to 450-ms time window, the main effect of cloze probability was observed, with larger N400 amplitudes yielded by lower cloze words, consistent with the findings from numerous previous ERP studies (DeLong et al., Reference DeLong, Quante and Kutas2014; Federmeier, Reference Federmeier2007; Kutas, Reference Kutas1993; Thornhill & Van Petten, Reference Thornhill and Van Petten2012). The current N400 effect can be explained within the predictive framework. Compared to highly predictable words, unexpected words involved greater processing demands, leading to larger prediction errors, which caused increased N400 amplitudes.
More importantly, a significant interaction between cloze probability and accentuation was also found, with the accented low- and medium-cloze words eliciting larger N400 amplitudes compared to the accented high-cloze words. This result revealed that an influence of cloze probability on the N400 amplitudes only emerged in the accented condition. During online speech processing, accentuation can modulate listeners’ time-selective attention, influencing the speed and depth of semantic processing (Li & Ren, Reference Li and Ren2012). According to the “good enough” language comprehension strategy (Ferreira et al., Reference Ferreira, Bailey and Ferraro2002), readers and listeners do not process all information carried by a sentence to the same extent for reasons of processing efficiency. Specifically, the depth of information processing (i.e., the level of fine-grained processing) typically depends on the importance and salience of the information (Cooper et al., Reference Cooper, Eady and Mueller1985; Eady et al., Reference Eady, Cooper, Klouda, Mueller and Lotts1986; Pierrehumbert, Reference Pierrehumbert1980), and the allocation of attention resources plays a crucial role. Accentuation, a form of focal information, has been shown to induce attentional bias (Cutler & Fodor, Reference Cutler and Fodor1979; Dahan & Tanenhaus, Reference Dahan and Tanenhaus2005). In the current study, listeners may have selectively allocated more attention to the accented critical words and engaged themselves in more in-depth processing, thus rapidly detecting different levels of semantic incongruence. Conversely, when the critical words were unaccented, listeners may have paid relatively less attention to them, and adopted the shallow processing approach, leading to an inability to immediately detect the semantic incongruences caused by the critical words of medium- and low-cloze probabilities. Therefore, no N400 effect was obtained for the unaccented words in the medium- and low-cloze conditions.
An alternative explanation for the N400 interaction is also possible. In high-constrain contexts, participants can generate specific semantic and phonological predictions for the final critical words, with semantic access to the high-cloze words being rapid and efficient without excessive semantic processing (Wang et al., Reference Wang, Bastiaansen, Yang and Hagoort2011). When medium-cloze and low-cloze words were accented, since they were not highly predicted, participants not only needed to adopt additional attentional resources but they also had to put more cognitive efforts into fine-grained semantic processing to integrate the medium- and low-cloze words into the given contexts, leading to larger N400 amplitudes. Furthermore, the additional recruitment of attentional resources may have been so great that they overwhelmed the differences of cognitive efforts spent on the medium- and low-cloze words. Thus, the N400 difference between the medium- and low-cloze words under the accented condition disappeared.
For the ERP results in the 500- to 700-ms time window, the main effect of accentuation was observed, with larger PNP amplitudes elicited over the frontal regions under the unaccented condition compared to the accented condition, which is consistent with previous studies (Baumann & Schumacher, Reference Baumann and Schumacher2012; Li et al., Reference Li, Zhang and Yang2017; Li et al., Reference Li, Deng, Yang and Wang2018). This result may be due to the fact that when the sentence-final words are highly predictable, listeners tend to expect them to be accented. Therefore, when the words are unaccented, greater PNP amplitudes are yielded, reflecting the difficulty of integrating unaccented information into the given context.
Moreover, a significant interaction between cloze probability and accentuation was also observed, with the unaccented low- and medium-cloze words eliciting larger PNP amplitudes compared to the unaccented high-cloze words, mirroring the N400 interaction effect. In addition, the PNP effects were more anteriorly distributed, which is dissimilar to the centro-parietally distributed N400 effects in topographical distribution. The absence of an N400 effect for the unaccented critical words suggests that participants did not immediately detect their semantic incongruence. Therefore, the PNP effects elicited by the unaccented words can be considered, to some extent, a result of shallow processing due to the absence of accentuation on the focal information (critical words), leading to delayed detection of semantic incongruences, which manifests in the PNP time window. In fact, Wang et al. (Reference Wang, Hagoort and Yang2009) investigated the impact of information structure on the depth of semantic processing, revealing that focus position affects semantic processing. In their study, participants quickly detected whether semantic violations occurred at the focus position, as reflected by the N400 component, while no N400 difference was observed for semantic violations in the nonfocus position. This result also supports the view that shallow processing may occur at times during language comprehension.
As expected, the PNP effect showed a frontal distribution, different from the typical late positive component observed in the central-parietal region. Previous studies investigating words with varying levels of cloze probability interpreted the frontally distributed PNP effect as reflecting uncertainty in semantic predictions within the sentence or discourse context (Delong et al., Reference Delong, Urbach, Groppe and Kutas2011; Federmeier, Reference Federmeier, Wlotko, De Ochoa-Dewald and Kutas2007; Otten & Van Berkum, Reference Otten and Van Berkum2008). Additionally, Kutas (Reference Kutas1993) proposed that the fronto-central PNP reflects inhibition of predicted but unfulfilled words. Based on Kutas (Reference Kutas1993), Federmeier et al. (Reference Federmeier, McLennan, De Ochoa and Kutas2002) speculated about the inhibitory interactions between frontal and temporal regions during language comprehension. They proposed that the successful generation of the predicted words is modulated by inhibitory regulation from the left frontal cortex over the activated, stored word-form networks in the temporal regions. In the current study, participants formed predictions about the upcoming sentence-final critical words based on the sentence context. Although the appearing medium- and low-cloze critical words evidently contradicted these predictions, the participants still needed to integrate the current words into the existing sentence context. Therefore, the frontal cortex had to inhibit the activated representations initiated by the sentence context to support the semantic processing of the medium- and low-cloze critical words. This inhibitory process was reflected by the late positive responses with a fronto-central distribution. Furthermore, from Figures 2B and 3B (even if statistical significance was not reached), it can be seen that although both low- and medium-cloze conditions elicited larger PNPs than the high-cloze condition, the former elicited a greater effect. This may indicate that listeners expended more cognitive resources in inhibiting the appropriate words predicted by the semantic context under the low-cloze condition. Given that there is no unified explanation for the frontally distributed late positive component, future studies should investigate the neurocognitive functions of the late positive component.
As a caution, we cannot completely rule out the possibility that the acoustic properties of the sentence fragments preceding the critical words may signal the position of accented (versus unaccented) words. Accordingly, consistent with previous research (Cutler & Fodor, Reference Cutler and Fodor1979), the prosody of the preceding context, such as the duration of the sentence fragments (Table 3), may predict the position and nature of the upcoming critical words, facilitating their rapid processing. Furthermore, the critical words in this study appear after continuous spoken sentences. Consequently, there is significant overlap between the ERP and the preceding words, eliciting auditory evoked responses to each new phoneme, as well as ERPs to the critical words, which may contribute to the noisy EEG signals (Figure 2).
4. Conclusion
The present study extends previous research by testing the neural processing of accented and unaccented words varying with cloze probabilities. The current design enables us to systematically investigate the processing of accentuation on lexical predictability during spoken sentence comprehension. Our data revealed that under highly constrained sentence contexts, accented and unaccented words of different cloze probabilities produced different patterns of N400 and PNP amplitudes, reflecting a gradation of prediction violation modulated by accentuation of the critical words. The pattern of the ERP results is likely due to differences of attention allocation in the processing of the accented and unaccented words with different degrees of predictability.
Data availability statement
Data will be made available on request.
Acknowledgements
This research was supported by the Shenzhen Science and Technology Innovation Bureau Project (20220811005233001). Additional funding was provided by the Scientific Research and Innovation Team of Liaoning Normal University. We thank Weijing Xing for her assistance with data collection. Special thanks to Prof. Werner Sommer for offering his suggestions and providing support.
Competing interests
No potential conflict of interest was reported by the authors.









 Open access
Open access