


Introduction
A central goal of theories of language variation and change is accounting for how language change comes about and spreads across linguistic contexts (cf. De Smet, Reference De Smet2012b; Timberlake, Reference Timberlake and Li1977; Weinreich, Labov, & Herzog, Reference Weinreich, Labov, Herzog, Lehmann and Malkiel1968). There is overwhelming consensus that language change unfolds gradually across linguistic environments (De Smet, Reference De Smet2012a; Timberlake, Reference Timberlake and Li1977). The gradual process whereby the consequences of a prior reanalysis are overtly manifested in the grammar of a language is referred to as actualization (Andersen, Reference Andersen and Andersen2001; Harris & Campbell, Reference Harris and Campbell1995; Hopper & Traugott, Reference Hopper and Traugott2003 [1993]; Timberlake, Reference Timberlake and Li1977). Actualization thus involves the gradual mapping out of a new underlying structure across linguistic contexts (Timberlake, Reference Timberlake and Li1977:141), and can be perceived as a “special manifestation” (De Smet, Reference De Smet2016:84) of Weinreich et al.’s (Reference Weinreich, Labov, Herzog, Lehmann and Malkiel1968:183) constraints problem: what are the possible conditions for change that determine the progression of change across diverse linguistic environments?
An enduring concern of variationist studies has long been uncovering this route by which grammatical innovations incrementally spread in the linguistic system (e.g., Aaron, Reference Aaron2010; Dion, Reference Dion2023; Naro, Reference Naro1981; Poplack, Lealess, & Dion, Reference Poplack, Lealess and Dion2013; Poplack & Malvar, Reference Poplack and Malvar2007; Torres Cacoullos & Walker, Reference Torres Cacoullos and Walker2009), which I will henceforth refer to as the course of actualization (De Smet, Reference De Smet2012b; see also De Smet, Reference De Smet2009). A pressing issue for a theory of actualization—beyond ascertaining the route by which grammar change unfolds—lies in establishing why changes take place in one particular order instead of another (De Smet, Reference De Smet2012b; Dietrich, Reference Dietrich2024). Over the past decade, there has been growing recognition that the process of actualization is largely driven by similarity-based generalizations (De Smet, Reference De Smet2012b): change is actualized firstly in contexts that in some (syntactic, formal, probabilistic, etc.) aspect resemble already established uses and where it can infiltrate the grammar inconspicuously. From there, innovations spread across linguistic environments through successive stepwise similarity-based generalizations (De Smet, Reference De Smet2012b; Naro, Reference Naro1981; see also Andersen, Reference Andersen and Andersen2001; Timberlake, Reference Timberlake and Li1977). This means that the more similarity in form or distribution there is between two contexts or structures, or the stronger the constructional network ties between two structures, the more probable it is that an innovation will be extended.
Importantly though, such generalizations and extensions are also sensitive to frequency. Abstract patterns that are frequent are more likely to extend their domains of application and to serve as analogical models for generalization (Bybee, Reference Bybee2010:7; De Smet, Reference De Smet2012a:57); in addition, high type frequency sparks productivity and the extension of a construction to involve new items (Bybee, Reference Bybee2010:67). Taken together, these observations mean that extensions largely hinge on frequency, since “as an expression becomes more frequent in one grammatical context, its mental retrievability improves, which in turn makes it more easily available in different yet closely related (analogous) grammatical contexts” (De Smet, Reference De Smet2016:83). For this reason, frequent constructions have a “gravitational pull” (De Smet, Reference De Smet2012a:72) and can easily recruit new members to their environment. Granted that the supporting constructions guiding extensions are specific for each item and each language, De Smet (Reference De Smet2012b:608-609) predicted that the course of actualization is item-specific as well as language-specific. In other words, variable phenomena’s courses of actualization are highly contingent because the possible generalizations differ between structures and languages and their networks of supporting constructions (De Smet & Fischer, Reference De Smet, Fischer, Hundt, Mollin and Pfenninger2017:243).
However, a point that remains less clear pertains to cross-varietal stability during actualization of change: if the same instance of change is attested across different varieties of the same language, to what extent can we expect the course of actualization to be non-contingent on regional varieties? This question is intriguing, because the cognitive organization of one’s language along with the linguistic and cognitive routines of a language user can differ from one individual to another and, on an aggregate level, between communities and social groups (Barking, Backus, & Mos, Reference Barking, Backus and Mos2022; Bresnan & Ford, Reference Bresnan and Ford2010:204; Röthlisberger, Grafmiller, & Szmrecsanyi, Reference Röthlisberger, Grafmiller and Szmrecsanyi2017; Szmrecsanyi, Grafmiller, Heller, & Röthlisberger, Reference Szmrecsanyi, Grafmiller, Heller and Röthlisberger2016; Verhagen, Mos, Backus, & Schilperoord, Reference Verhagen, Mos, Backus and Schilperoord2018; see also Schneider, Reference Schneider2023). That is, patterns of language use and processing are largely socio-cognitively determined (cf. Schmid, Reference Schmid2020). This means that actualization pathways, being a reflex of cognitive mechanisms and processes, could potentially vary from one community to another (cf. Bresnan & Ford, Reference Bresnan and Ford2010:205).
From this, various questions with considerable theoretical bearing surface: when grammatical innovations spread across different environments in the linguistic system, do the cognitive underpinnings of this process—namely, actualization—bring about parallel pathways of change in different populations of speakers? What are “universal” cognitive constraints and to what extent is the course of actualization shaped by community-specific patterns in language use?
The present study aims to contribute to our understanding of these key issues. Tackling these questions requires a comparative cross-dialectal approach that examines how change unfolds across linguistic contexts in different varieties. Work along this line of research has already been conducted, most prominently within the area of variationism and, specifically, making use of the comparative variationist method (Poplack & Tagliamonte, Reference Poplack and Tagliamonte2001). The comparative sociolinguistic approach compares the synchronic degree of generalization of a particular (innovative) linguistic variant across linguistic contexts and communities to infer the progression of language change in different dialects. Even if varieties might differ in rates of change, comparative variationist studies generally presume that when several varieties exhibit the same instance of variation between structures, these dialects are heading towards the same target on a common cline of grammaticalization, with some varieties being more advanced than others (Tagliamonte, Reference Tagliamonte2013:186; Tagliamonte, Durham, & Smith, Reference Tagliamonte, Durham and Smith2014:80). However, from a diachronic and fundamentally cognitive perspective on the actualization of change, the comparative variationist enterprise presents some theoretical complexities that merit attention. The first challenge involves the socio-cognitive side of language change. If we assume that actualization is largely based on similarity-based generalizations and extensions between networks of supporting constructions (De Smet, Reference De Smet2012b), we would also need to consider that the point of departure underlying such extensions are analogical models; these models, in turn, are sensitive to frequency (cf. Bybee, Reference Bybee2006), in the sense that frequent and conventionalized structures and usage patterns tend to serve as models for generalization (Bybee, Reference Bybee2010:63) because they have a “gravitational pull” that attracts other structures (De Smet, Reference De Smet2012a:72). However, what is important to keep in mind is that the input structures that are most frequent in one speech community may differ from the most frequent structures in another community, which means that the substructure steering the course of actualization may, in fact, be variable across varieties of a language (cf. Grafmiller, Szmrecsanyi, Röthlisberger, & Heller, Reference Grafmiller, Szmrecsanyi, Röthlisberger and Heller2018:2; Verhagen et al., Reference Verhagen, Mos, Backus and Schilperoord2018). Thus, in adopting a synchronic comparative perspective, the dynamics of change and its dependency on language use in a specific community are largely left unaddressed (as are the idiosyncrasies of the individual and the respective speech communities in terms of the composition of their probabilistic grammars [Barking et al., Reference Barking, Backus and Mos2022; Szmrecsanyi et al., Reference Szmrecsanyi, Grafmiller, Heller and Röthlisberger2016; Verhagen et al., Reference Verhagen, Mos, Backus and Schilperoord2018]).
Secondly, comparative sociolinguistic studies are generally limited to a particular synchronic snapshot of different varieties of language. Needless to say, given the synchrony of the data, the incremental stages of change that have taken place in the respective varieties can only be inferred rather than ascertained. While this is only natural considering the nature of the data, the general (implicit) idea underlying the comparative (variationist) approach seems to be that grammaticalization is unidirectional, because when this approach perceives that grammaticalization appears to be parallel between varieties of a language, synchronic states of variation in different varieties are thought to reflect different stages of diachronic change on the same cline of grammaticalization.
Taken together, what all of this shows is that to understand the extent to which the course of actualization is, or is not, contingent on a particular speech community or variety, or what the underlying motivations for convergence or divergence could potentially be, what is needed is an approach that simultaneously tests the effect of independent (socio-cognitive and structural) factors, linguistic varieties, and their evolution in real time—all in one single model.
However, in addition to data sparsity issues (after all, diachronic corpus data does not generally come in abundance), such an approach can also turn out to be complicated for statistical reasons: constructing a statistical model (e.g., a mixed-effects logistic regression model) that includes three-way interactions between independent effects, regional varieties, and real time tends to generate overcomplicated models with (quasi-)separation, convergence errors, “large p small n” issues, and unreliable estimates, among other undesirable consequences.
The present study proposes to tackle these issues using Bayesian mixed-effects regression modelling, a technique that can more easily handle (quasi-)separation, low or zero variance, and model identifiability issues where frequentist methods (e.g., generalized linear mixed-effects models using, for instance, the lme4 package in R) would otherwise run into convergence problems (Kimball, Shantz, Eager, & Roy, Reference Kimball, Shantz, Eager and Roy2019; see also Grafmiller, Reference Grafmiller, Schützler and Sönning2023:8; Levshina, Reference Levshina, Schützler and Schlüter2022b). By outlining a multivariate, diachronic, real-time approach to the comparative analysis of the actualization of language change, the present study addresses the issue of cross-varietal actualization, modelling three-way interactions between factors relating to cognition and usage, regional varieties, and real time (for a similar approach, see Grafmiller, Reference Grafmiller, Schützler and Sönning2023; Wolk, Bresnan, Rosenbach, & Szmrecsanyi, Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013). Adopting a usage-based perspective on language change (Aaron, Reference Aaron2010; Bybee, Reference Bybee2006, Reference Bybee2007), it is hypothesized that, to the extent that domain-general cognitive mechanisms and processes along with usage factors steer the course of actualization, they should operate similarly across varieties of a language (cf. Grafmiller et al., Reference Grafmiller, Szmrecsanyi, Röthlisberger and Heller2018:3). This, in turn, would mean that actualization should largely align cross-varietally in terms of the contexts that are affected by change and the order in which extensions take place.
To test this prediction, this study analyzes an instance of ongoing syntactic change in Spanish, namely the conventionalization of definite articles in oblique relative clauses (ORCs) (la casa en que nací versus la casa en la que nací, ‘the house in which I was born’). The use of a definite article in the relative has become increasingly conventionalized across varieties of Spanish over the last centuries. In this study, more than 8,000 occurrences of Spanish ORCs from Argentinean, Peruvian, and Colombian Spanish are analyzed using Bayesian mixed-effects logistic regression. A set of factors all relating to cognitive and usage-constrained effects are coded and their effects are measured as a function of regional variety and real time. The analysis confirms the hypothesis by showing that, across the analyzed varieties, there are virtually no significant differences in the effects of the analyzed factors, suggesting that the considered cognitive and usage factors constrain and guide actualization in a highly similar manner. These findings provide robust empirical support for a usage-based view on actualization with a strong cognitive commitment, and furthermore advance our understanding and statistical modelling of the cross-varietal actuation of change.
The remainder of the paper is structured as follows. The next section outlines the linguistic variable under scrutiny. Subsequently, the hypothesized cognitive and usage-conditioned constraints and their operationalization are discussed. This section is followed by a methodological section, describing the methodological approach of the paper and explaining the Bayesian cross-varietal diachronic variationist approach. Following this, the results are presented, while the last section advances a general discussion along with some concluding remarks.
The variable use of the definite article in Spanish ORCs: background
The linguistic variable that this paper deals with is the variable use of the definite article in Spanish oblique relative clauses (henceforth ORCs). These alternatives are illustrated in the examples below, with the definite article absent in (1) but present in (2). The noun phrase (NP) antecedent is in bold and the ORC is underlined.
(1)
La Gaceta de Buenos Aires publicaba después una carta de Cullen a Rosas en que habían indicios claros […].
‘The Gaceta de Buenos Aires subsequently published a letter from Cullen to Rosas in which there were clear indications…’
(Domingo Faustino Sarmiento, Facundo. Civilización y barbarie, 1845–1874, Argentina, CORDE)
(2)
Mockus lanzó la idea de que se instaurara una cátedra práctica en los colegios del Distrito en la que los profesores se sentaran a tomar trago con los alumnos y luego analizaran los efectos que les produjo el alcohol en su comportamiento.
‘Mockus proposed that a practical course should be imparted in the schools of the districts in which the professors would sit down to consume alcohol with the pupils, and after that they would analyze the effects that the alcohol had on their demeanor.’
(El tiempo, 1997-04-07, “Propuestas que no le cuajaron,” Colombia, CREA)
Since the 18th century, the definite article in ORCs (2) has been conventionalizing in different varieties of Spanish (Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; Girón Alconchel, Reference Girón Alconchel2004, Reference Girón Alconchel and Company2006; Guzmán Riverón, Reference Guzmán Riverón2012). In the 18th century, the change was still highly incipient (cf. Nevalainen & Raumolin-Brunberg, Reference Nevalainen and Raumolin-Brunberg2017:54-55) in Latin American varieties of Spanish. Tellingly, Guzmán Riverón’s (Reference Guzmán Riverón2012:201) data indicates that the innovative variant only constituted about 7% of the author’s data from the first half of the 18th century. In contrast, in European Spanish, it was more advanced (Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021:499; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017:495, Reference Blas Arroyo and Vellón Lahoz2018:16). In the 21st century, the [preposition + definite article + que] variant is highly conventionalized (cf. Schmid, Reference Schmid2020:87-88) in European Spanish (Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017:471) while its conventionalization is progressing at a much slower rate in Latin American varieties (Santana Marrero, Reference Santana Marrero2004).
In what follows, the constraints that are expected to condition the variation between the two variants are detailed.
Cognitive and usage-conditioned constraints on variant selection and change: on the role and operationalization of accessibility
This study focuses on the influence of effects that are, in the scope of a cognitive theory of language, directly linked to cognitive and usage-determined effects on variable coding options. Concretely, I will evaluate a recent proposal advanced by Levshina (Reference Levshina2022a) who formulated the Principle of Negative Correlation between Accessibility and Costs, according to which there is a tendency “to use shorter forms to express more predictable, expected, typical etc. meanings, and longer forms to express less predictable, expected, typical, etc. meanings” (Levshina, Reference Levshina2022a:24; see also Jaeger, Reference Jaeger2010). Starting from this principle, Levshina predicted that “language users should spend less effort and time on highly accessible information, and more effort and time on less accessible information” (Levshina, Reference Levshina2022a:22). The implication of this principle would be that the more accessible the antecedent of an ORC is, the more likely it is to favor the shorter variant of the ORC (without the definite article). Conversely, less accessible antecedents trigger the longer variant of the ORC (with the definite article). This is because the usefulness of the definite article increases when the tie between the antecedent NP and the ORC is weaker. Through the use of anaphora (e.g., en la que), the speaker aids the addressee in retrieving the antecedent.
In light of this, it seems that the definite article in the ORCs could potentially have emerged as an accessibility marker. Its role is (initially) to signal to the interlocutor how easily the antecedent can be retrieved, and it is a measure of the processing cost involved in retrieving the antecedent (Ariel, Reference Ariel1990:16). In what follows, constraints that condition the accessibility of a referent will be reviewed and linked to the linguistic variable under study.
One key accessibility constraint is the distance between an antecedent and a referring expression (Arnold, Reference Arnold2010). Larger distances and lower degrees of unity between an antecedent and a referring expression lead to lower degrees of accessibility of the antecedent (Ariel, Reference Ariel1990:28-29; Arnold, Reference Arnold2010; Clark & Sengul, Reference Clark and Sengul1979; Hawkins, Reference Hawkins1999). As for the variable article use in Spanish ORCs, an effect of the distance between the antecedent and the ORC has been observed both diachronically and synchronically (Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; Guzmán Riverón, Reference Guzmán Riverón2012:182, 198; López García, Reference López García1994:440-442; Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017:477, 479; among others). Here, distance was operationalized as the number of words (cf. Tagliamonte & Baayen, Reference Tagliamonte and Baayen2012). Since anaphoric reference reactivates its referent in the working memory (McKoon & Ratcliff, Reference McKoon and Ratcliff1980), it seems plausible to assume that overtly manifested syntactic properties such as gender or number agreement in other structures than the antecedent lexeme itself (e.g., through resumptive pronouns or antecedent-agreeing dislocated adjectives) should plausibly lead to an activation of the head noun. Therefore, the distance was calculated as the number of words between the antecedent or the latest anaphoric expression to the antecedent.
Another factor considered in this study is the restrictiveness of the relative clause. According to López García (Reference López García1994:440-442), the definite article in the ORC anchors the relative pronoun to the antecedent NP, which is particularly useful in nonrestrictive relatives, being more detached than restrictive ones (see also Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021:495). It is therefore hypothesized that nonrestrictive relatives are more inaccessible vis-à-vis restrictive ones and should, therefore, favor the definite article variant.
Definiteness also influences accessibility: definite antecedents are generally more accessible than indefinite antecedents (Ariel, Reference Ariel, Fretheim and Gundel1996:22). Therefore, accessibility marking is more expected when the antecedent NP is indefinite, since retrieval is cognitively more costly when the antecedent is underspecified. This aligns with earlier findings on the linguistic variable of interest here, since the innovative article variant is mostly used with indefinite antecedents (Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021:500; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018:41; Girón Alconchel, Reference Girón Alconchel and Company2006:1530; Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017:476). The definiteness of the antecedent (definite, indefinite, or zero-marked) was established based on its last mention, which most frequently was the antecedent lexeme itself (e.g., una casa ‘a house’) but which could also include, for instance, a definite demonstrative pronoun (e.g., aquella ‘the one/that [one]’) referencing the previous mention of an antecedent (definite or indefinite).
Similarly, the grammatical number is known to influence cross-linguistic patterns of grammatical coding: more frequent functions (i.e., singular) tend to have zero or shorter markers than less frequent ones (e.g., plural [Du Bois, Reference Du Bois and Haiman1985:363; Greenberg, Reference Greenberg1966:32]). Singular NPs are inherently more accessible than plural because singular tends to refer to more concretely delimited entities, whereas plural is often underspecified and indefinite (see also Jaeger & Wasow, Reference Jaeger, Wasow, Cover and Kin2005). So far, however, this effect has not been found to influence the variable article use in Spanish ORCs significantly (Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017).
The concreteness of the noun also affects accessibility of an antecedent. The so-called concreteness effect refers to the faster and easier cognitive processing of concrete nouns, whereas abstract nouns are cognitively costlier to process in different types of tasks (see Jessen, Heun, Erb, Granath, Klose, Papassotiropoulos, & Grodd, Reference Jessen, Heun, Erb, Granath, Klose, Papassotiropoulos and Grodd2000). Antecedent concreteness has nonetheless appeared to be non-significant in quantitative studies on the linguistic variable under study here (Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; however, see Girón Alconchel, Reference Girón Alconchel and Company2006). Ideally, the degree of concreteness of a particular word is determined on the basis of some external measurement, such as concreteness scores (e.g., Guasch, Ferré, & Fraga, Reference Guasch, Ferré and Fraga2016). However, since Guasch et al.’s (Reference Guasch, Ferré and Fraga2016) concreteness scores do not match the lexical items analyzed here, an alternative approach to approximate the concreteness effect is opted for. Psycholinguistic research suggests that word length is correlated with the abstractness/concreteness of the lexical item (Lewis & Frank, Reference Lewis and Frank2016; Reilly, Hung, & Westbury, Reference Reilly, Hung and Westbury2017; Reilly, Westbury, Kean, & Peelle, Reference Reilly, Westbury, Kean and Peelle2012; see also Lievers, Bolognesi, & Winter, Reference Lievers, Bolognesi and Winter2021). It is therefore hypothesized that longer words could potentially be perceived as more abstract and, therefore, render higher probabilities of the definite article variant, and vice versa.
Yet another effect known to influence accessibility is the syntactic function of a discourse entity and its thematic prominence. Topical and subject referents are generally more accessible and, hence, more likely to be expressed using underspecified referential expressions (see Arnold, Reference Arnold2010:190-192). As concerns the ORCs under study here, the potential influence of topicality or subjecthood has not been systematically analyzed (though see Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; Girón Alconchel, Reference Girón Alconchel and Company2006:1527). Considering the large quantity of data coded in the present study, an automatic coding process was used to code this variable. Given that subject and topic referents can bring about similar effects in terms of accessibility (Arnold, Reference Arnold2010), and considering that an automatic process was opted for, the analysis does not distinguish between syntactic prominence and topicality, and instead focuses solely on syntactic function. Using the Spanish transformer pipeline of spaCy (Explosion, 2023), the data was automatically parsed for dependency relations. In this study, subjecthood and non-subjecthood were contrasted. The dependency relations of the taxonomy that were considered to most directly reflect subjecthood were nsubj and root, which were contrasted with the other dependency relations. It should be noted, however, that the corpora only provide a limited Keyword in Context (KWIC), which potentially reduces the accuracy of the classification. To evaluate the classification performance, a random sample of 400 occurrences were hand-coded, indicating that the spaCy pipeline achieved an accuracy of 89%, with an F1 score of 0.73 and a Matthews Correlation Coefficient of 0.68. These evaluation metrics suggest that while the classification is generally satisfactory, there remains some room for improvement. The results should be interpreted with these limitations in mind.
Lastly, accessibility is also associated with frequency. Higher-frequency structures are more predictable (and accessible) than lower-frequency counterparts because of their frequent use (Ariel, Reference Ariel1990:22; Bybee, Reference Bybee2007:243; Haspelmath, Reference Haspelmath2021:624). The use of accessibility markers should therefore also be correlated with frequency and, hence, used most often when the antecedent NP consists of hapax legomena or other lower-frequency nouns, whereas higher-frequency antecedents are inherently more accessible due to their overall cognitive salience (see also Marttinen Larsson, Reference Marttinen Larsson2024). Neurolinguistic research aligns well with this prediction, demonstrating that during antecedent retrieval, higher-frequency words are more easily accessed and assigned an antecedent role, whereas lower-frequency words are harder to retrieve (Heine, Tamm, Hofmann, Hutzler, & Jacobs, Reference Heine, Tamm, Hofmann, Hutzler and Jacobs2006). This study approaches the effect of the antecedent’s frequency by measuring attraction, that is, the constructional predictability of a specific lexeme in a construction, which can also be described as the information content of an antecedent lexeme given a construction (here, an ORC), calculated as the number of occurrences of a given lexeme divided by the total frequency of ORCs in the relevant macroregional dataset (Levshina, Reference Levshina2018:7). Lower values of attraction reflect antecedents that are frequency-wise unpredictable (e.g., hapax legomena and other lower-frequency antecedent lexemes, such as una tempestad ‘a storm’), whereas higher values indicate that the antecedent is recurrently documented (e.g., el año ‘the year,’ la carta ‘the letter,’ etc.) as ORC antecedents in the corpus. The antecedent lexeme was annotated in its basic form. Proper and place names were coded as [Name] and time references (dates, exact times, etc.) as [Time_reference].
Having outlined the hypothesized effects, we can predict (in line with Levshina, Reference Levshina2022a:24) that the longer variant [preposition + definite article + que] should firstly be used in contexts involving inaccessible antecedents (i.e., distant, indefinite, plural, abstract, non-subject/non-topic, and low-frequency antecedents). Over time, actualization should progress as a function of how (in)accessible antecedents are, with actualization moving from contexts involving inaccessibility towards those of increasing accessibility. More importantly for the purposes of the present study, if the actualization of the change is indeed a reflex of fundamentally cognitive processes, we expect diachronic macro-level tendencies to align cross-varietally. The next section describes the methodology and statistical approach.
Methodology and statistical modelling
The consulted corpora are the Corpus diacrónico del español (CORDE, data up to 1974) and the Corpus de Referencia del Español Actual (CREA, data between 1975 and 2000). While ORCs may be introduced by a variety of prepositions, this study limits itself to en (‘in' [cf. Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017]).
Data is only compiled from Latin American varieties (in contrast to Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; Girón Alconchel, Reference Girón Alconchel2004, Reference Girón Alconchel and Company2006; Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017, among others, who all focus on European Spanish). The analyzed time period was limited to mid-19th century up to 2000. This temporal scope is warranted for two reasons: firstly, because it constitutes the era following Latin America’s independence from Spain (approximately mid-19th century and onwards), a critical period for processes of variation and change in Spanish (Caravedo, Reference Caravedo, Codita and de la Torre2019:26); secondly, because the progression of the innovative article variant is still highly incipient during the 18th century (Guzmán Riverón, Reference Guzmán Riverón2012).
The corpus searches included en que and its variants with definite articles (el/la/los/las). The data was subsequently binned into three rough time periods (∼1850–1899, 1900–1949, 1950–2000) to gain an overview of the diachronic distribution of the data, revealing more well-populated distributions in the most modern parts of the dataset, and much scarcer ones during earlier time periods. Therefore, drawing a random sample of the entire dataset would yield a diachronically skewed sample. A diachronically stratified random sample of the data was drawn to circumvent this skewedness (see further below). Note that the data was only for sampling purposes; in the analysis itself, time is included as a numerical predictor.
The three regional varieties that were most well-represented across each time period were selected for analysis: Argentinian, Peruvian, and Colombian Spanish. All data from the first two time periods were extracted for subsequent annotation. For the most recent time period, a random sample of n = 1700 occurrences was extracted for each regional variety. Data cleaning involved excluding the lexicalized expression la medida en que ‘the extent to which,’ which does not exhibit variation (following Santana Marrero, Reference Santana Marrero2004:68). The antecedent did, at times, fall outside of the left context of the KWIC. In these cases, larger excerpts were manually extracted and added to the dataset. Despite these precautions, there were, nonetheless, a few occurrences that were N/A coded and excluded due to insufficient contextual information.
Bayesian mixed-effects logistic regression was conducted using the brm function in the brms package (version 2.21.0, Bürkner, Reference Bürkner2021) in R (version 4.4.1, R Core Team, 2022). Additional descriptive statistics of the dataset are in the Appendix. The script and data used for the analysis can be accessed through OSF: https://doi.org/10.17605/OSF.IO/FVZKU. The descriptive statistics can be found in Tables A1–A15 in the Appendix. For general information on Bayesian statistics, I refer the reader to Kruschke (Reference Kruschke2015). Some basic remarks are in order, though. Bayesian models do not yield p values, but instead provide posterior distributions from which parameter estimates and credible intervals (CrI) are computed. A CrI indicates that there is a 95% probability that the true parameter value lies within this interval. To test the significance of an effect, an equivalence test is carried out (Region of Practical Equivalence, ROPE). ROPE represents the range of values considered practically equivalent to the null hypothesis. If the highest density interval lies outside the ROPE, it can be taken as evidence for a significant effect (Makowski, Ben-Shachar, & Lüdecke, Reference Makowski, Ben-Shachar and Lüdecke2019). Moreover, Bayesian models include priors which reflect prior beliefs about the parameters. Here, weakly informative priors with a Cauchy distribution were included, centered at 0 with a scale parameter of 10 for the intercept and 2.5 for all other model parameters. These priors provide regularization while avoiding strong prior beliefs from being imposed on the posterior distribution (following Gelman, Jakulin, Grazia Pittau, & Su, Reference Gelman, Jakulin, Grazia Pittau and Su2008).
The dependent variable contained two levels: zero (en que) or definite article variant (en el que, en la que, en los que, en las que).
The independent variables included: attraction (log), distance (log), word length (log), definiteness, grammatical number, and year (centered). The reference level of each categorical factor is set to the most frequent level. Random effects included antecedent lexeme and author (based on the corpus metadata).Footnote 1 The final datasets retained for subsequent analysis consisted of n = 3553 for Argentina; n = 2611 for Peru; and n = 2382 for Colombia.
As mentioned in the introductory section, the cross-dialectal diachronic analysis consists of constructing a regression model consisting of three-way interactions between the respective predictors, regional variety, and real time. If no statistically meaningful differences surface between historical regional varieties and the predictors, this would suggest the existence of cross-varietally comparable trajectories of actualization. It is important to note that, while empirically robust, this approach does not conclusively prove the absence of differences. Rather, if no meaningful differences emerge between the regional varieties in their trajectories of change, this would suggest that there is sufficient evidence to support stability in actualization trajectories across dialects.
In accordance with the hierarchy principle, all three-way interaction terms also included lower-level interactions and main effects. Following Tizón-Couto and Lorenz (Reference Tizón-Couto and Lorenz2021), this paper adopts a deductive modeling approach, meaning that, with the analysis being grounded in a previously specified theory, all the tested variables are included in the final model rather than stripping the model of insignificant interactions or main effects. In doing so, the analysis is well-suited to directly test the formulated hypotheses independently of whether the analyzed interactions exhibit meaningful differences between regional varieties and/or over time.
The Bayesian mixed-effects logistic regression model was specified to run 6000 iterations (3000 warmup, 2400 total post-warmup draws) on four chains. The target acceptance rate was set to 0.99 to reduce the risk of divergent transitions and increase the validity of the posterior samples (see Bürkner, Reference Bürkner2021:10). Several model diagnostics were utilized: Rhat values for all parameters in the final model are 1.0, meaning that all the chains converge and mix well. Bulk-ESS and tail-ESS are all well above 1000, indicating that the estimates of posterior quantiles are reliable. Posterior predictive checks show that the observed data aligns very well with the predicted data, thus reaffirming the validity of the model’s predictions. Lastly, Leave-One-Out cross-validation with moment matching (Paananen, Bürkner, Vehtari, & Gabry, Reference Paananen, Bürkner, Vehtari and Gabry2024) indicated that the model’s effective number of parameters (p_loo = 580.9, SE = 14.8) was considerably lower than the model’s total number of parameters (2265), revealing no indications of overfitting. Moreover, all Pareto K estimates were lower than 0.7, signaling that these estimates are reliable. In the next section, the results are presented.
Results
Figure 1 shows density plots on the conventionalization of the innovative variant over time, indicating that the innovative [en + definite article + que] variant gains substantially in frequency throughout the analyzed time span. In the Colombian data, this variant is almost absent until approximately the 1960s, when a rapid phase of change is initiated. In contrast, the Argentinean and Peruvian data shows a much earlier use of the construction, and a seemingly steadier change over the analyzed timespan. These frequency differences notwithstanding, the question that will be the focus in the remainder of the analysis is whether these communities differ or coincide in their pathways of actualization, that is, how change is mapped out across linguistic environments.
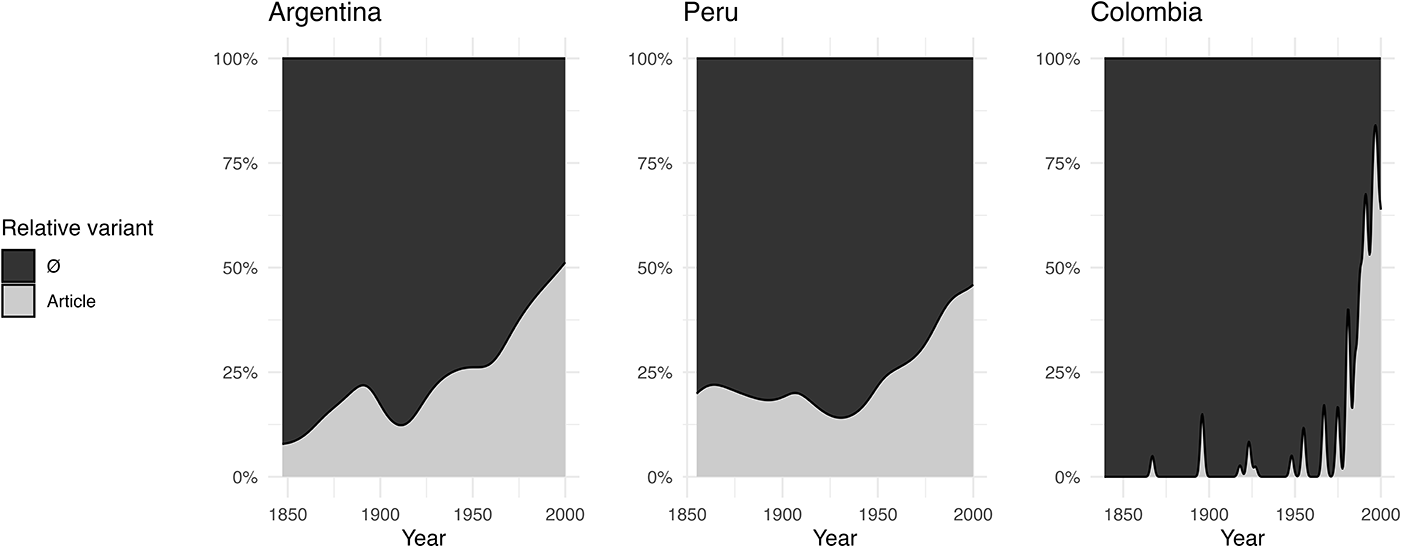
Figure 1. Density plots of the conventionalization of the [en + definite article + que] variant across the three macroregional varieties. Bandwidth is adjusted to 1.
The final regression model is shown in Table 1. The meaningful (significant) effects are marked in bold.
Table 1. Results from Bayesian mixed-effects logistic regression model
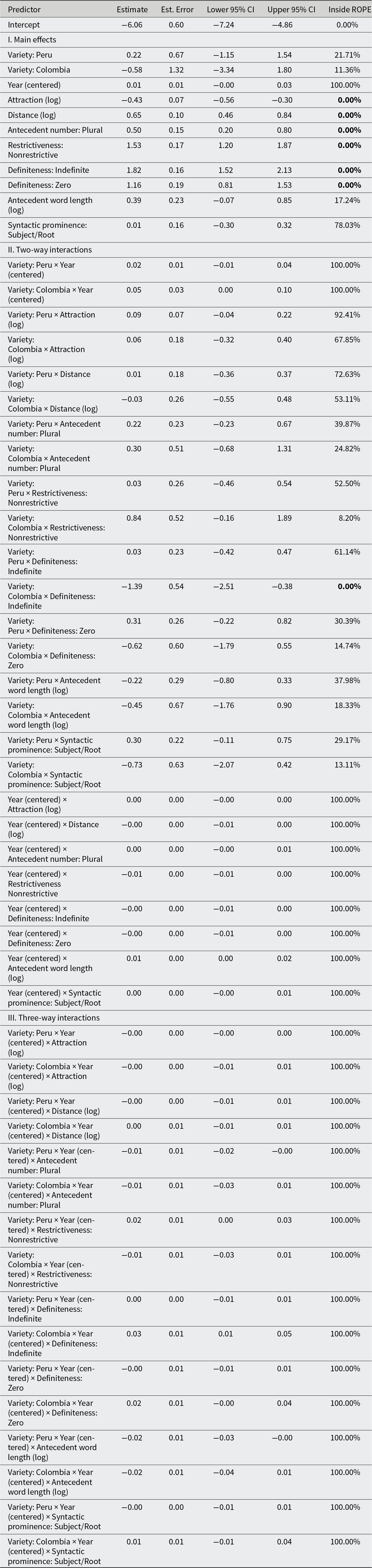
As Table 1 shows, in the vast majority of cases the included interactions did not show statistically credible effects, meaning that, as concerns the process of change and the included varieties at hand, actualization does principally unfold in a comparable manner across the analyzed varieties The only exception is the interaction between variety (Colombia) × definiteness (Indefinite). I will return to the interpretation of this finding below.
Focusing exclusively on the main effects, numerous factors constrain the analyzed variation, namely: attraction, distance, antecedent number, restrictiveness, and definiteness (see the first part of Table 1). As indicated by the ROPE (Table 1), antecedent word length and syntactic prominence were not significant. While the reason underlying the statistical non-significance of antecedent word length and syntactic prominence warrants further scrutiny (but see the background section on the inherent limitations of the operationalization of these variables), due to space limitations the rest of the analysis will focus on the factors that do have a meaningful effect on the analyzed variation. What is worth noting, however, is that the same factors were significant and nonsignificant across historical macroregional varieties. This confirms that actualization largely hinges on cognitive and usage-conditioned constraints, and—importantly—that their conditioning is shared across different regional varieties.
To facilitate the interpretation of the interactions, the effects from the regression model are depicted using the R package interactions (version 1.2.0, Long, Reference Long2019).
Attraction
In Figure 2, the influence of attraction is depicted. Lower values of attraction (i.e., the lower tercile median) indicate that the antecedent is (relatively) infrequent; conversely, higher values (i.e., the upper tercile median) reflect antecedents that are (relatively) frequent. In accessibility parlance, this means that lower values are symptomatic of antecedents that are less accessible than antecedents that are frequency-wise highly accessible.
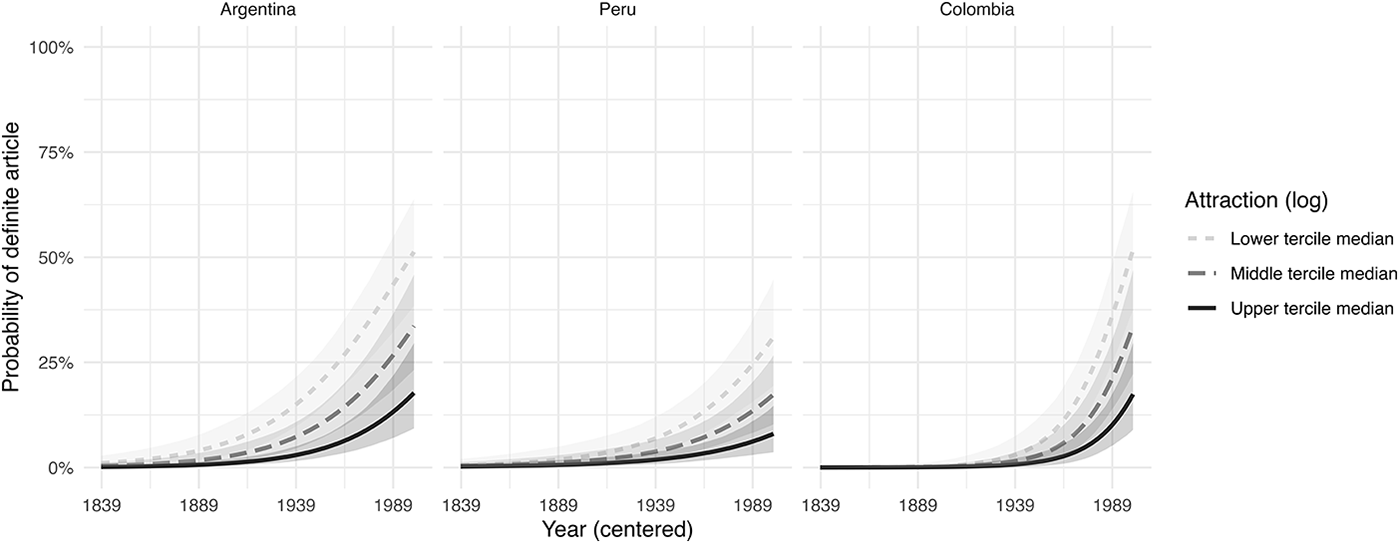
Figure 2. Predicted probabilities of [en + definite article+ que] under the constraint of attraction. Values of attraction are depicted per tercile medians (lower, middle, upper).
As Figure 2 shows, the analyzed varieties are strikingly similar in their trajectories of actualization. The probability of the [en + definite article + que] variant is significantly influenced by attraction in all the varieties: hapax legomena antecedents and other lower-frequency antecedents trigger use of the definite article ORC, whereas higher-frequency antecedents tend not to trigger use of the definite article. This observation corroborates the hypothesis that higher-frequency antecedents benefit from an overall expectedness which endows them with a privileged ease of maintenance and access in working memory. Conversely, less predictable antecedents are more frequently activated through a definite article. There is also likely an entrenchment effect at play here: more frequent collostructional patterns (that is, [high frequency antecedent + relative clause] as in el año en (el) que ‘the year in which’) hold out against the incorporation of the definite article to a larger extent, because frequently co-occurring structures are entrenched in the memory of the language user (Langacker, Reference Langacker1987). Their entrenchment renders modifying them more unlikely than less entrenched patterns (e.g., [low frequency antecedent + relative clause] as in la tempestad en (la) que ‘the storm in which’; see Levshina, Reference Levshina2018).
Antecedent number
In consonance with the formulated hypothesis, the longer [en + definite article + que] variant is favored by plural antecedents (Figure 3). This is arguably because the definite article serves to disambiguate and reactivate inaccessible antecedents, and plural entities are cognitively more complex to construct than a single reference (Jaeger & Wasow, Reference Jaeger, Wasow, Cover and Kin2005). Moreover, Figure 3 shows that the trajectories of actualization converge between the three varieties.
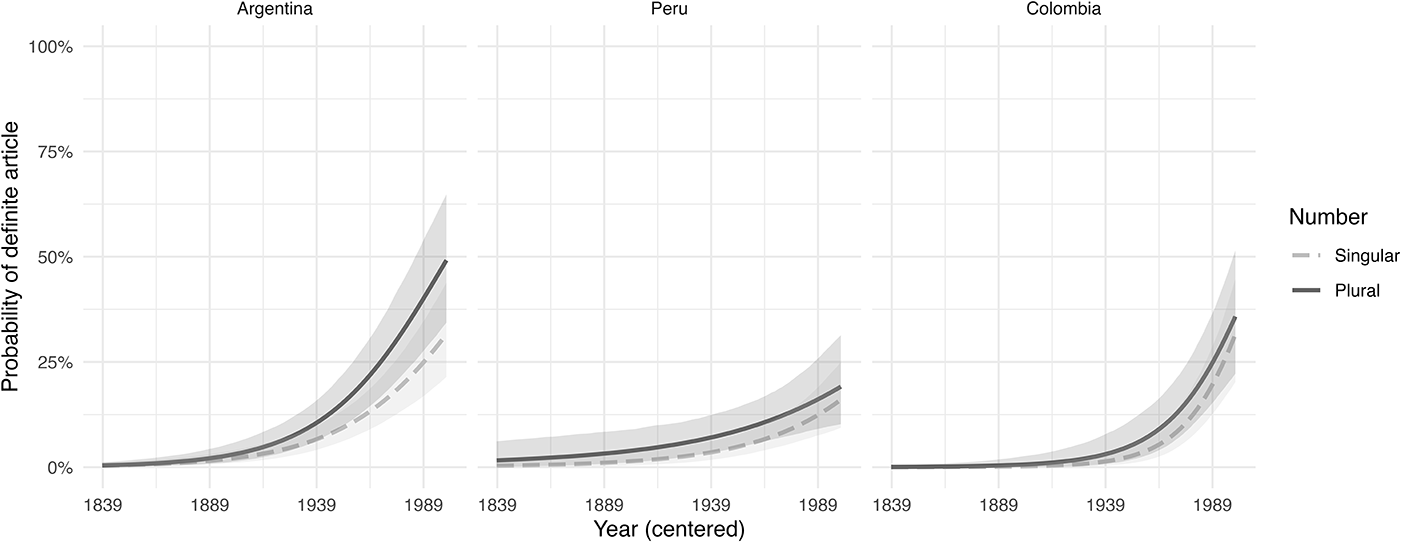
Figure 3. Predicted probabilities of [en + definite article + que] under the constraint of antecedent number.
Distance
Figure 4 shows the effect of the distance between the antecedent and the ORC. The lower tercile median shows smaller distances, whereas higher values indicate larger distances. This predictor is highly influential in constraining the use of the [en + definite article + que] variant: the more distanced the antecedent, the more probable the use of the definite article. This finding echoes the results of earlier studies on the linguistic variable and on relative clauses in general (Ariel, Reference Ariel1990:28-29; Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021:500; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018; Clark & Sengul, Reference Clark and Sengul1979; Guzmán Riverón, Reference Guzmán Riverón2012:182; Hawkins, Reference Hawkins1999; Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017:477). Considering that distance pressures are derived online in the discourse, this finding suggests that part of the variation is entirely motivated by processing effects. Again, the effect is cross-varietally stable.
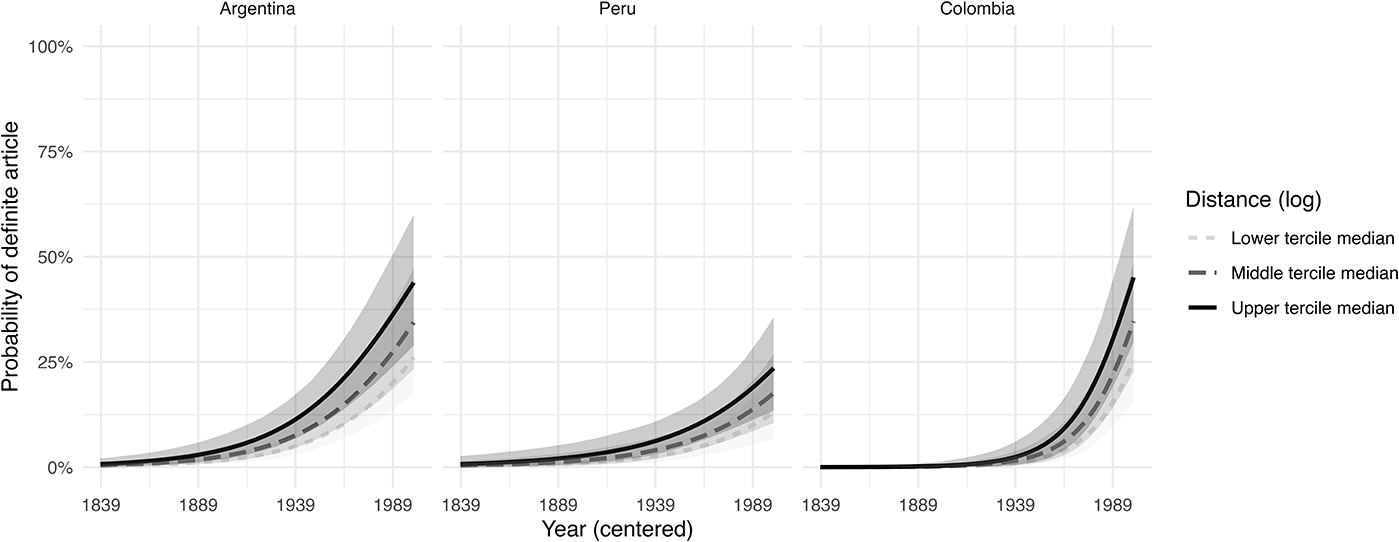
Figure 4. Predicted probabilities of [en + definite article + que] under the constraint of distance.
Restrictiveness
Figure 5 depicts the result obtained for the predictor restrictiveness. In line with earlier studies (see background section), nonrestrictive relative clauses particularly favor the [en + definite article + que] variant, whereas the variant spreads to involve restrictive ORCs only at a much later stage. Again, actualization progresses along entirely parallel pathways across the three analyzed varieties.
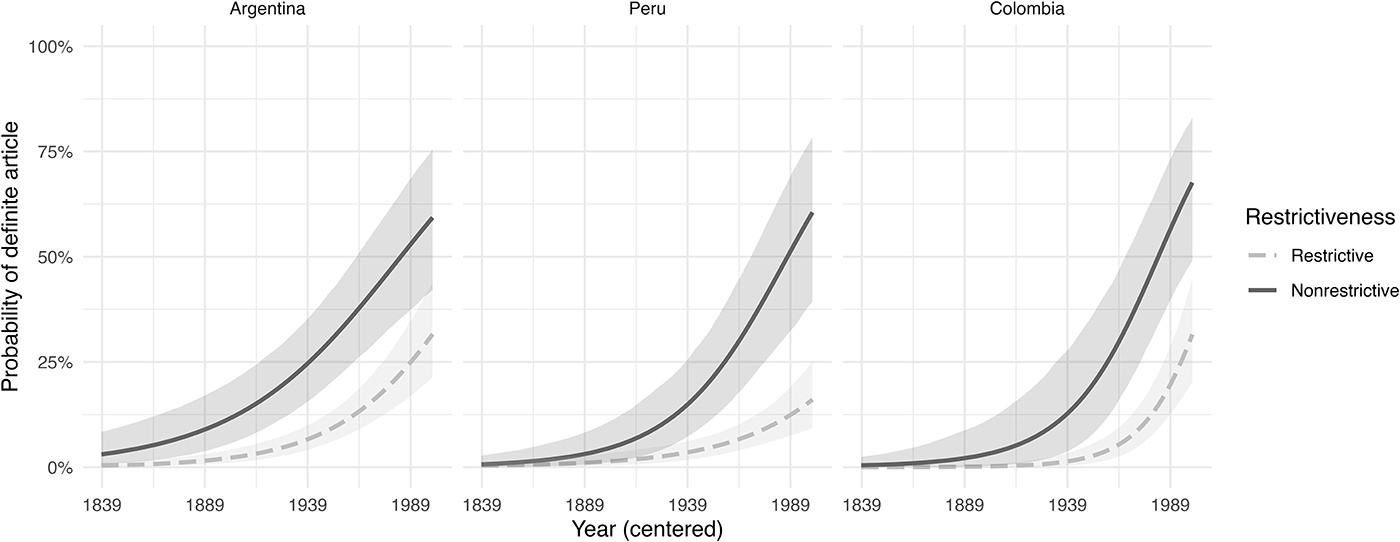
Figure 5. Predicted probabilities of [en + definite article + que] under the constraint of restrictiveness.
Definiteness
Figure 6 shows that the influence of definiteness. This is the only predictor which was significant in an interaction with variety (see Table 1), revealing that Colombian Spanish is less likely to use the [en + definite article + que] with indefinite antecedents compared to Argentinian Spanish (cf. log-odds: −1.39, Table 1). The mechanisms underlying this effect are not immediately apparent from the current dataset and merit dedicated investigation in future studies. Apart from this difference, which also appears to be levelled out over time (cf. Figure 6), the trajectories of change are parallel, suggesting a largely uniform course of actualization.

Figure 6. Predicted probabilities of [en + definite article + que] under the constraint of definiteness.
In general, the use of the [en + definite article + que] variant is particularly favored when the antecedent NP is indefinite. In the Colombian data, the difference between indefinite and zero-marked antecedents is minimal. What is shared across the analyzed datasets is that the use of the variant is probabilistically most improbable with definite antecedent NPs. This result agrees with what earlier studies on this linguistic variable have found (Blas Arroyo, Reference Blas Arroyo and Díaz-Campos2021:500; Blas Arroyo & Vellón Lahoz, Reference Blas Arroyo and Vellón Lahoz2017, Reference Blas Arroyo and Vellón Lahoz2018:41; Girón Alconchel, Reference Girón Alconchel and Company2006:1530; Vellón Lahoz & Moya Isach, Reference Vellón Lahoz and Moya Isach2017:476; see also Ariel, Reference Ariel, Fretheim and Gundel1996:22).
As can be seen across the three varieties, the use of the [en + definite article + que] variant is usually higher with indefinites. Only more recently has the innovative variant spread to involve definite antecedents.
Discussion and concluding remarks
This study analyzed the real-time mapping out of syntactic change across linguistic environments from a cross-dialectal perspective, seeking to determine to what extent pathways of actualization converge or diverge across varieties of a language. Actualization—defined as the gradual mapping out of new grammatical behavior across linguistic environments—was approximated through the diachronic analysis of real-time effects of fundamentally cognitive processes (cf. Wolk et al., Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013). The fundamental question that the study sought to shed light on was this: When multiple varieties of a language undergo the same syntactic change, do they follow parallel trajectories of actualization? In pursuing this issue, the study has showcased the potential of a cross-varietal diachronic variationist approach to studies on language change.
Overall, the diachronic data show that the definite article in oblique relative clauses is conventionalizing in all the analyzed varieties. The results indicate that the same cognitive and usage-determined factors guide the course of actualization in the different varieties. Moreover, cross-dialectal comparisons of the courses of actualization reveal that trajectories are largely parallel varieties: The definite article is initially inserted in ORCs when it is most informative, that is, with plural, non-definite, and frequency-wise unpredictable and inaccessible antecedents. I argue that, under these conditions and in an initial phase, the definite article serves as an accessibility marker (cf. Ariel, Reference Ariel1990). However, during the actualization of the change, the innovative variant spreads to environments in which it is less informative in terms of accessibility. The order in which it spreads across environments reflects gradience in accessibility: from hapax legomena antecedents to mid-frequency antecedents and, only later, to high-frequency antecedents; from plural to singular antecedents; and from indefinite antecedents to zero-marked antecedents and, later on, definite antecedents. In other words, the order of diffusion is determined by the degree to which it is purposeful in terms of accessibility. This finding aligns well with the predicted course of change: innovative forms that are longer and costlier should first be used to convey less accessible meanings, and subsequently spread towards high-accessibility contexts (Jaeger, Reference Jaeger2010; Levshina, Reference Levshina2022a:135; see also Marttinen Larsson, Reference Marttinen Larsson2024).
Over time, the accessibility effect seems to partially grammaticalize (cf. Jaeger, Reference Jaeger2010:49-50). Other indicators that the [en + definite article + que] variant is, indeed, grammaticalizing are its increased frequency of use (in terms of token frequency; Hopper & Traugott, Reference Hopper and Traugott2003 [1993]), the scope increase of the structure in terms of contexts of use (Tabor & Traugott, Reference Tabor, Traugott, Ramat and Hopper1998:262), and the semantic change undergone by the definite article (i.e., accessibility is lost and only number and gender are maintained; cf. Girón Alconchel, Reference Girón Alconchel2004). Blas Arroyo and Vellón Lahoz (Reference Blas Arroyo and Vellón Lahoz2018) examined the potential grammaticalization of en (el) que in European Spanish across three centuries, identifying only modest frequency increases along with enduring linguistic conditioning. However, the study’s capability to ascertain whether grammaticalization has taken place is restricted by their methodology of using separate Rbrul models for each century rather than a single regression model incorporating time interactions.
Utilizing a real-time diachronic approach, the present study has offered empirical support substantiating the hypothesis that the [en + definite article + que] variant is currently grammaticalizing (cf. Girón Alconchel, Reference Girón Alconchel2004, Reference Girón Alconchel and Company2006; among others), as suggested by the innovation’s scope increase, its higher frequency of use, and the semantic loss undergone by the accessibility marker. Moreover, this cross-varietal diachronic inquiry has also verified that numerous domain-general cognitive and usage factors steer actualization (e.g., De Smet, Reference De Smet2012b; Schmid, Reference Schmid2020; Wolk et al., Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013). Crucially, these factors operate similarly across varieties of a language, even when the grammatical change is taking place at different rates and at different times. This implies that the cognitive mechanisms that trigger and fuel variation and change are largely ubiquitous (cf. Langacker, Reference Langacker and Li1977:99-100) and sheds light onto a fundamental principle underlying the analyzed process of change: while language varieties may actuate change at different times, cognitive processes guide the course of actualization uniformly across varieties, resulting in parallel pathways of change.
The cognitive corpus linguistic approach used in this study naturally presupposes that historical corpus data is capable of illuminating effects that are operative online in cognitive processing (Wolk et al., Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013). This is not entirely uncontroversial, given that language data from offline corpora can, strictly speaking, only provide indirect evidence of processes that occurred online in the mind of language users of past time periods, which raises the question of how well these offline sources mirror psychological reality and cognitive processes (Arppe, Gilquin, Glynn, Hilpert, & Zeschel, Reference Arppe, Gilquin, Glynn, Hilpert and Zeschel2010; Kortmann, Reference Kortmann2021; Wolk et al., Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013:414). If we regard the cognitive realism of historical corpus data as an empirical issue, this study has demonstrated that numerous predictions formulated on the basis of experimental psycholinguistic and cognitive research are borne out on historical corpus data (see also Wolk et al., Reference Wolk, Bresnan, Rosenbach and Szmrecsanyi2013). This synergy between synchronic experimental research and diachronic linguistics provides a framework for effectively modeling how linguistic innovations become established in the grammar during the course of actualization and the cognitive underpinnings of this process.
With the above in mind, the findings presented in this study allow for the formulation a series of predictions for future diachronic, cognitivist, corpus-based research. For one, it is not only conceivable, but expected that, to the extent that different speech communities exhibit shifting input probabilities between structures (i.e., lexical items), micro level divergencies should be observed between regional varieties during the course of actualization (cf. Bresnan & Hay, Reference Bresnan and Hay2008:255-256). The availability of different linguistic material in the mental lexicon is largely socially determined, and the mental representation of certain structures (or lexemes) hinges on how frequently the language user is exposed to it (Verhagen et al., Reference Verhagen, Mos, Backus and Schilperoord2018). Therefore, when an instance of change is underway across different varieties, it is predicted that the different lexical items that partake in, or are affected by, change (e.g., the lexical items that occupy a constructional slot) will vary according to their cognitive salience (accessibility) in the mental lexicon of a speaker and, by extension, their degree of activation in a specific speech community or social group.
Secondly, this study has identified that the actualization of change largely aligns cross-varietally in terms of the contexts that are affected by change and the order in which extensions take place (cf. De Smet, Reference De Smet2012b). In accordance with these findings, it is also predicted that micro level divergencies as the ones discussed above should, nevertheless, hinge on the same cognitive principles and thus align on the macro level. What this means is that, even if, for instance, the concrete lexical items that occupy certain constructional slots or that are otherwise affected by change may likely differ cross-varietally, the cognitive motivations that account for how change unfolds will align. Consequently, during changes that involve reduction (e.g., Marttinen Larsson, Reference Marttinen Larsson2024), the specific structures or items that are omittable or reducible may differ between regional varieties, but these structures or items will all be highly accessible (predictable) in the respective speech communities or in certain social groups; conversely, cross-varietal changes that involve enhancement (such as the one analyzed in the present study) will most likely show gradience that is fundamentally conditioned by inaccessibility (see Levshina’s, Reference Levshina2022a:230) Hypothesis of Construction–Lexeme Accessibility and Formal Length; see also Bresnan & Hay, Reference Bresnan and Hay2008; Jaeger, Reference Jaeger2010). Empirical verification of these predictions will be profitable lines of inquiry in future intervarietal diachronic studies on the cognitive underpinnings of actualization.
Acknowledgements
I acknowledge the financial support of the Swedish Research Council (grant no. 2022-00303, “Pathways of development around the Spanish-speaking world: diachronic variation and change in 19th–21st century Spanish morpho-syntax”). I am grateful to four anonymous reviewers for valuable comments and suggestions. I would also like to thank Miriam Bouzouita, Marta Garbelli, Laura Merino Hernández, and Antoine Primerano for their feedback, as well as the audiences at the 6th Variation and Language Processing Conference (Vigo, June 26–28, 2024), the 57th Annual Meeting of the Societas Linguistica Europaea (Helsinki, August 21–24, 2024), and Congreso Internacional de Lenguas Iberorrománicas (Helsinki, January 10–12, 2024). I am grateful to Johnatan Bonilla for his support with the spaCy annotation. The usual disclaimers apply.
Competing interests
The author declares none.
Appendix
The tables found in this Appendix (Tables A1–A15) show the distribution of the data across three time periods in each regional variety, cross-tabulated by each predictor variable included in the multivariate analysis.
Table A1. Distribution of variants across time periods in Argentinean data

Table A2. Distribution of variants across time periods in Peruvian data

Table A3. Distribution of variants across time periods in Colombian data

Table A4. Distribution of variants across grammatical number in Argentinean data

Table A5. Distribution of variants across grammatical number in Peruvian data

Table A6. Distribution of variants across grammatical number in Colombian data

Table A7. Distribution of variants across restrictiveness in Argentinean data

Table A8. Distribution of variants across restrictiveness in Peruvian data

Table A9. Distribution of variants across restrictiveness in Colombian data

Table A10. Distribution of variants across definiteness in Argentinean data

Table A11. Distribution of variants across definiteness in Peruvian data

Table A12. Distribution of variants across definiteness in Colombian data

Table A13. Distribution of variants across syntactic function in Argentinean data

Table A14. Distribution of variants across syntactic function in Peruvian data

Table A15. Distribution of variants across syntactic function in Colombian data
























 Open access
Open access