


1. Introduction and recommendations
There is too much translationese in too many of our multilingual resources. The problem appears to be worse for low-resource languages. There is a considerable literature establishing that LLMs (large language models) are more effective for high-resource languages (English, Chinese, and Arabic) than for low-resource languages (Ahuja et al. Reference Ahuja, Diddee, Hada, Ochieng, Ramesh, Jain, Nambi, Ganu, Segal, Ahmed, Bali, Sitaram, Bouamor, Pino and Bali2023; Koehn and Knowles, Reference Koehn, Knowles, Luong, Birch, Neubig and Finch2017; Limisiewicz et al. Reference Limisiewicz, Blevins, Gonen, Ahia, Zettlemoyer, Ku, Martins and Srikumar2024; Nie et al. Reference Nie, Feng, Li, Zhang, Zhang, Long and Zhang2024; Wu and Dredze Reference Wu, Dredze, Gella, Rei, Petroni, Lewis, Strubell, Seo, Hajishirzi, Gella, Welbl, Rei, Petroni, Lewis, Strubell, Seo and Hajishirzi2020).
Much has been written about risks and LLMs. These risks may be worse in low-resource languages. Guardrails appear to be more effective in high-resource languages than low-resource languages; Yong, Menghini, and Bach (Reference Yong, Menghini and Bach2023) reported that guardrails can be circumvented by asking inappropriate questions in low-resource languages where guardrails are less effective. There are similar challenges with toxicity (Church et al. Reference Church, Schoene, Ortega, Chandrasekar and Kordoni2023).Footnote a In Nigeria, for example, tweets are more toxic in Hausa than in English because moderation processes are more effective in English.
Given the widespread use of translation from English, Anglo-centric biases are likely. Much has been written about biases in LLMs. For example, Mihalcea et al. (Reference Mihalcea, Ignat, Bai, Borah, Chiruzzo, Jin, Kwizera, Nwatu, Poria and Solorio2024) is titled, “Why AI Is WEIRD…,” where WEIRD is an acronym for Western, Educated, Industrialized, Rich and Democratic. Ojo et al. (Reference Ojo, Ogueji, Stenetorp and Adelani2023) asked “How good are Large Language Models for African Languages?” and found that LLMs for African languages are not as good as LLMs for English. We believe the root causes involve relatively poor resources, both in terms of quantity as well as quality.
One of the quality issues involves the use of translation in popular resources for training LLMs. Much of the widespread use of translation in our multilingual resources can (and should) be avoided. But when it is necessary to translate, as much as possible, we should translate in the “right” direction. As will be discussed in Section 8 and Table 8, many of our resources translate in the “wrong” direction.
What do we mean by the “right” and “wrong” direction? Figure 3 of Xu et al. (Reference Xu, Kim, Sharaf and Awadalla2023) reports higher BLEU scores for → than →. Assuming that machines are stronger in high-resource languages than low-resource languages, when possible, machines should translate into their stronger language and avoid translating from their stronger language. This advice follows standard practice among professional translators. Professional translators prefer to translate into their stronger language and avoid translating from their stronger language.Footnote b There are good reasons for this standard practice. We should do likewise when we develop LLMs.
In short, when collecting resources for training and testing LLMs, we recommend the following:
1. Invest more in quality control (by native speakers),
2. Avoid translation when possible, and
3. When translation is necessary, it is better to translate in the “right” direction:
(a) “right” direction: weaker (low-resource) → stronger (high-resource)
(b) “wrong” direction: vice versa.
This advice is perhaps more important for testing LLMs than training LLMs, given suggestions about the effectiveness of powerful training methods in machine learning. Such methods may be effective even in the presence of noise: Arpit et al. Reference Arpit, Jastrzebski, Ballas, Krueger, Bengio, Kanwal and Maharaj2017; Chaudhury and Yamasaki Reference Chaudhury and Yamasaki2021. Even so, training with less noise is likely to be more effective than training with more noise, and therefore, we should do what we can to reduce dependencies on translationese.Footnote c
2. Quality
There are shocking issues with quality in many of our resources:
a significant fraction contains less than 50% sentences of acceptable quality… these issues are easy to detect even for non-proficient speakers (Caswell et al. Reference Caswell, Kreutzer, Wang, Wahab, Esch, Ulzii-Orshikh, Tapo, Subramani, Sokolov, Sikasote, Setyawan, Sarin, Samb, Sagot, Rivera, Rios Gonzales, Papadimitriou, Osei, Suarez and Adeyemi2021)
Their conclusion is based on an audit of five popular multilingual corpora:
1. CCAligned (El-Kishky et al. Reference El-Kishky, Chaudhary, Guzmán, Koehn, Webber, Cohn, He and Liu2020),
2. ParaCrawl (Bañón et al. Reference Bañón, Chen, Haddow, Heafield, Hoang, Esplà-Gomis, Forcada, Kamran, Kirefu, Koehn, Ortiz Rojas, Pla Sempere, Ramírez-Sánchez, Sarrías, Strelec, Thompson, Waites, Wiggins, Zaragoza, Jurafsky, Chai, Schluter and Tetreault2020; Esplà-Gomis et al. Reference Esplà-Gomis, Forcada, Ramırez-Sánchez, Hoang, Forcada, Way, Tinsley, Shterionov, Rico and Gaspari2019),
3. WikiMatrix (Schwenk et al. Reference Schwenk, Chaudhary, Sun, Gong, Guzmán, Merlo, Tiedemann and Tsarfaty2021),
4. OSCAR (Suárez, Sagot, and Romary Reference Suárez, Sagot and Romary2019; Ortiz Suárez, Romary, and Sagot Reference Ortiz Suárez, Romary, Sagot, Jurafsky, Chai, Schluter and Tetreault2020) and
5. mC4 (Xue et al. Reference Xue, Constant, Roberts, Kale, Al-Rfou, Siddhant, Barua, Raffel, Toutanova, Rumshisky, Zettlemoyer, Hakkani-Tur, Beltagy, Bethard, Cotterell, Chakraborty and Zhou2021)
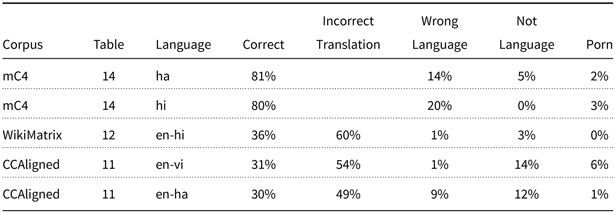
Many details for many languages are reported in the appendices of Caswell et al. (Reference Caswell, Kreutzer, Wang, Wahab, Esch, Ulzii-Orshikh, Tapo, Subramani, Sokolov, Sikasote, Setyawan, Sarin, Samb, Sagot, Rivera, Rios Gonzales, Papadimitriou, Osei, Suarez and Adeyemi2021), a few of which are shown in Table 1. Caswell et al. (Reference Caswell, Kreutzer, Wang, Wahab, Esch, Ulzii-Orshikh, Tapo, Subramani, Sokolov, Sikasote, Setyawan, Sarin, Samb, Sagot, Rivera, Rios Gonzales, Papadimitriou, Osei, Suarez and Adeyemi2021) also concluded that quality is worse for low-resource languages, though that conclusion is based on more languages than those in Table 1.
Table 1. Poor quality (based on Tables 11–14 of Caswell et al. (Reference Caswell, Kreutzer, Wang, Wahab, Esch, Ulzii-Orshikh, Tapo, Subramani, Sokolov, Sikasote, Setyawan, Sarin, Samb, Sagot, Rivera, Rios Gonzales, Papadimitriou, Osei, Suarez and Adeyemi2021))
Quality needs to be taken seriously, especially in low-resource languages. In ArtELingo-28 (Mohamed et al. Reference Mohamed, Li, Ahmad, Haydarov, Torr, Church, Elhoseiny, Al-Onaizan, Bansal and Chen2024), we created a dataset with annotations of WikiArt in 28 languages including Hausa. This project invested 6.3K hours for annotators plus an additional 2.5K hours for coordinators (quality assurance). Most projects do not invest as much in quality control, but we hope this paper will help persuade the community to invest more in quality.
3. Translationese is more or less predictable
There have been several studies of translationese in Corpus-based Lexicography. Baker (Reference Baker2004) and Xiao (Reference Xiao2009) report predictable differences in word frequencies between translationese and natural language, as one would expect. This section describes an experiment with LLMs that shows similar differences in fluency.
As will be discussed in Section 4, there is quite a bit of translation in Wikipedia. Wikipedia is porting much of their content to more languages using a combination of machine translation, post-editing, human translation, and various quality control steps.Footnote d Although these processes are so effective that native speakers may not be aware of the use of translation, we are able to show in Table 2 that source text is more predictable (fluent) than target text.
Table 2. Source text is more predictable (fluent) than target text (for these models)
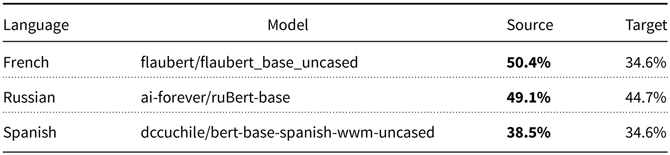
Table 2 is based on intermediate files published by Wikipedia. For each language pair, there is a file containing sentences in the source and target language.Footnote e The six scores in Table 2 are based on six samples of 10k sentences from these intermediate files, covering three languages in both source and target conditions. Table 2 shows a difference in fluency between:
1. Source: text originally written in language x, and
2. Target (Translationese): translations from some other language into x
To estimate fluency, we remove a token randomly from each test sentence and estimate how often the model correctly predicts the missing token. The scores in Table 2 report accuracies averaged over 10k sentences.
3.1 Trace: a proposed intrinsic metric
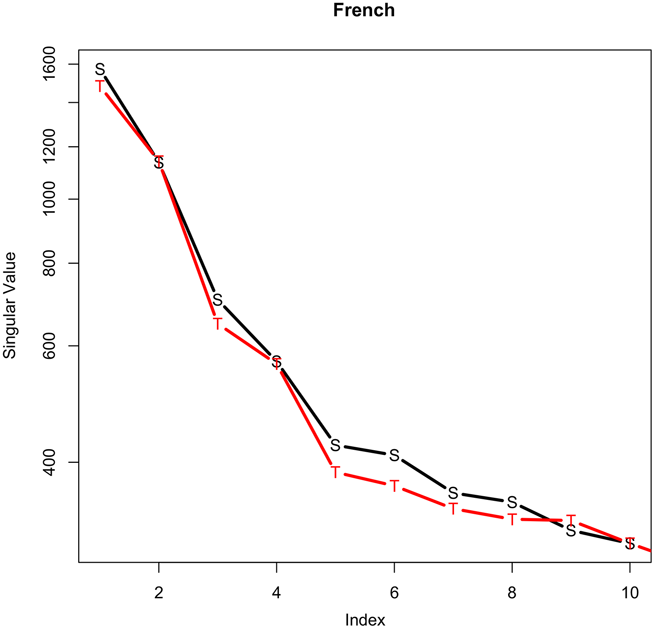
Figure 1. For the first 10 values in D, source (black S) is usually above target (red T).
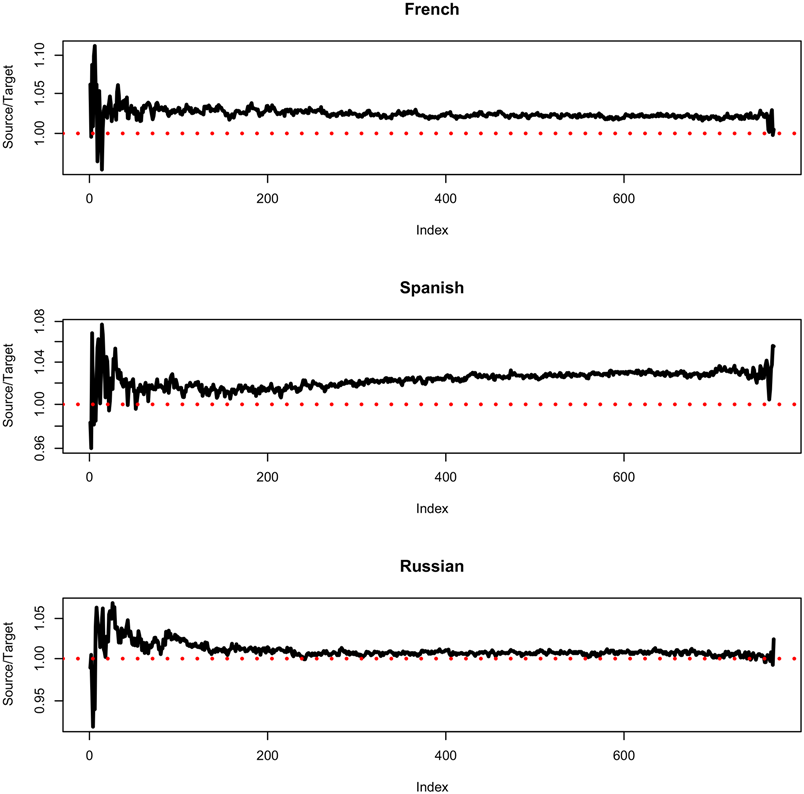
Figure 2. The pattern in Figure 1 holds over D. Ratio (S/D) is usually above 1 (red).
We propose trace as an intrinsic metric to make a similar point to Table 2. This metric can be used to compare embeddings over models, languages, and different sources of text. Reliability of the proposed metric will be established by showing that scores are relatively stable over multiple batches. The machine learning literature tends to focus on extrinsic downstream evaluations such as Table 2, though intrinsic metrics may be easier to compute than extrinsic metrics.
Traces are computed from embeddings. For each model and each test set of n = 10k sentences in Table 2, we compute an embedding,  $Z \in \mathbb{R}^{n \times d}$. After normalizing Z,Footnote f we use SVD to approximate
$Z \in \mathbb{R}^{n \times d}$. After normalizing Z,Footnote f we use SVD to approximate  $Z \approx U\,D V^T$. Trace is simply: sum(D).
$Z \approx U\,D V^T$. Trace is simply: sum(D).
Figure 1 shows the first 10 values of D for two cases: the source case (S) and the target case (T). Note that S is usually above T. Both S and T use the French model in Table 2; the difference is whether the test set contains French with translation (T) or without (S).
Figure 2 shows the pattern in Figure 1 holds over most of the 768 values in D for the French row in Table 2. The other two panels of Figure 2 are like the top panel, but for different languages, using different models and different test sets. In all three panels, the ratios are usually above the red baseline of 1.
We have found trace to be a useful figure of merit for comparing D from different models, languages, and corpora, though there are a number of alternatives:
1. Spectral radius: max(D)
2. Condition number: max(D)/min(D)
3. Trace: sum(D)
4. Determinant: prod(D)
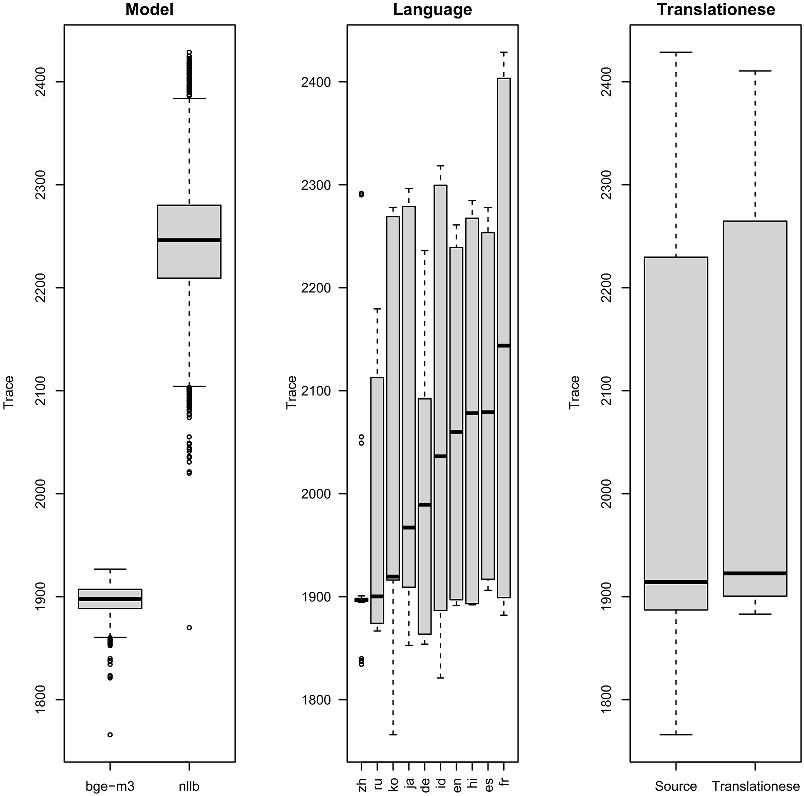
Figure 3. The trace depends on at least three factors: (a) model, (b) language, and (c) translationese. An analysis of variance (ANOVA) shows that (a) accounts for more of the variance than (b), and (b) accounts for more than (c).
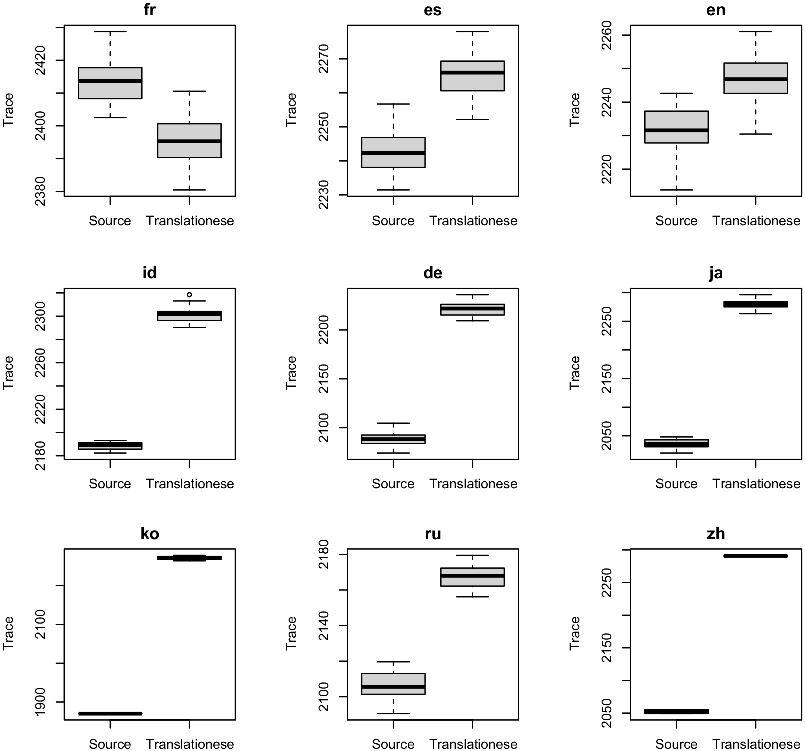
Figure 4. There are small but significant differences in traces between texts in the source language and translationese. These differences are shown for many batches over nine languages using the NLLB model.
We have applied many models to many batches of text in many languages. Figure 3 summarizes the trace over many experiments using data from Wikipedia with (a) two models, BGE-ME and NLLB, (b) ten languages, and (c) source versus translationese. All three factors are significant, but an analysis of variance (ANOVA) shows that (a) accounts for more variance than (b), and (b) accounts for more variance than (c). To see the translationese effect (c), we need to condition on the other two factors, as in Figure 4. Figure 4 shows the translationese factor for a single model (NLLB) and nine languages. The translationese effect is robust, as indicated by the relatively thin bars. The bars summarize batches. We have 60 batches for common cases (English and Spanish, with and without translation). The bars are somewhat thinner for more unusual cases where we have fewer batches, but in all cases, the translationese bar is different from the alternative.
That said, the directionality of the translationese effect is different from Table 2. It appears that NLLB favors translationese (except for French), unlike models in Table 2. We suspect these preferences may reflect differences in training data. In any case, since the translationese bars are different from the other bars, we conclude that translationese is not representative of natural language.
In addition to that conclusion, this section introduced a novel intrinsic metric based on traces to compare embeddings over models, languages, etc. Reliability of the proposed metric was established by showing that traces are relatively stable over batches.
4. Wikipedia is full of translationese
Although translation has played a major role in helping the community to make considerable progress, the community is also well-aware of its limitations. Unfortunately, the community may not be aware of how much translationese there is in popular corpora. Clark et al. (Reference Clark, Choi, Collins, Garrette, Kwiatkowski, Nikolaev and Palomaki2020), for example, start with a criticism of translationese and then recommend Wikipedia as a translation-free alternative, though in fact, much of Wikipedia is also based on translation, especially for low-resource languages such as Hausa, as will be discussed in Table 8.
We were surprised to discover that 90% of Hausa pages such as thisFootnote g have links to similar pages in other languages such as this.Footnote h That is, a crawl of Hausa pages found links to the same content in other languages on 51,019 of 56,492 pages.
5. Translationese in test sets
As mentioned in the recommendations above, we are particularly concerned about the use of translation in test sets. Unfortunately, translation is common in many test sets, as illustrated in Table 3. It can be difficult to generalize performance on translationese to tasks of interest. Poncelas et al. (Reference Poncelas, Lohar, Hadley, Way, Denkowski and Federmann2020) discuss the impact of translationese on sentiment analysis, and conclude: “sentiment classifiers do not classify translated data as well as original sentences.”
Table 3. Three test sets that were translated from English to other languages

Translation often makes the task harder than tasks of interest, but sometimes translationese is easier. In Table 9, we will discuss a case where translationese makes the task too easy. XNLI is an example where translationese makes the task too hard. XNLI hinges on connecting the dots between two text strings (premise and hypothesis). Translation is likely to make it harder to connect the dots, even with excellent translations.
Unfortunately, the translations in XNLI are far from excellent. For example, cream skimming (“to prioritize easy cases”) is translated to French as la crème de la crème (“the best of the best”). There are many more examples of dubious translations in XNLI in other languages such as Chinese, as illustrated in Table 4. It appears that the Wikipedia quality control processes described in footnote d are more effective than the quality control processes for translating test sets for machine learning experiments.
Table 4. Examples of poorly translated Chinese in XNLI, followed by back-translations to English to demonstrate the poor quality of the Chinese
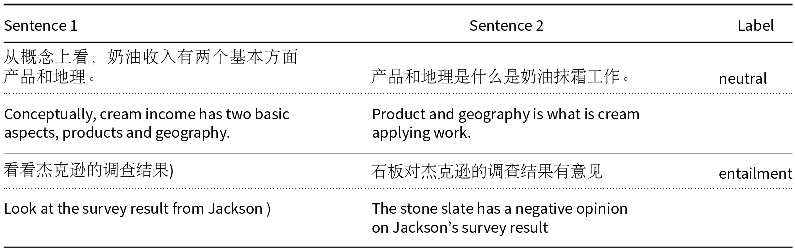
In summary, we view translationese as a form of noise that makes it hard to generalize from a task based on translation to a task of interest that does not involve translation. Machine learning assumes the training set is representative of (and identically distributed to) the population of interest. In general, one would expect poor translations and inadequate processes for quality control to increase noise, decreasing confidence in generalizations from the test set to tasks of interest.
Another example of translationese in test sets is FLORES Goyal et al. (Reference Goyal, Gao, Chaudhary, Chen, Wenzek, Ju, Krishnan, Ranzato, Guzmán and Fan2022), the test set for NLLB (No Language Left Behind) (Costa-jussà et al. Reference Costa-jussà, Cross, Çelebi, Elbayad, Heafield, Heffernan, Kalbassi, Lam, Licht and Maillard2022; NLLB Team 2024). Given the concerns about quality in section 2, one might not be surprised by quality concerns in FLORES. According to Abdulmumin et al. (Reference Abdulmumin, Mkhwanazi, Mbooi, Muhammad, Ahmad, Putini, Mathebula, Shingange, Gwadabe, Marivate, Haddow, Kocmi, Koehn and Monz2024), much of the Hausa in FLORES appears to be machine translation output (with little if any post-editing), and some of the “Hausa” is not even grammatical. We suspect quality is worse for translationese than for natural language. In addition, we conjecture the gap to be larger for low-resource languages than for high-resource languages.
The FLORES dev set translates a tiny set of 997 sentences from English into 200 languages. The 997 English sentences were selected from three sources: en.wikinews.org, en.wikivoyage.org, and en.wikibooks.org. This sample is too small (and too specialized) to be representative of many genres of English, let alone hundreds of other languages (and many genres of interest).
6. Balanced Corpora and representative sampling
Translationese is not representative of the target language. Representative sampling and stratified sampling are important concepts in Statistics and Machine Learning. The term, balanced corpora, comes from lexicography. The Brown Corpus (Francis and Kučera, Reference Francis and Kucera1982), for example, was designed to be representative of contemporary American English when it was collected in the 1960s at Brown University. Similarly, the British National Corpus (BNC) (Aston and Burnard Reference Aston and Burnard1998) was designed to be representative of British English in the 1990s. Both of these corpora can be viewed as a stratified sample over genres. Fiction is different from non-fiction, and local news is different from international news. For example, the word “said” is as frequent as a function word in the news, but rare in technical abstracts. Users of these corpora are expected to scale statistics based on these strata appropriately, depending on the populations of interest (in tasks of interest).
7. Translationese in lexical resources
Translationese is also common in lexical resources such as WordNet (Miller Reference Miller1995) and NRC-VADFootnote i (Mohammad Reference Mohammad2018). Both WordNet and NRC-VAD started out as lexicons for English, but later, global versions became available. For WordNet, there is a convenient NLTK interfaceFootnote j that provides translations of synsets to a few dozen languages. This approach assumes the English ontology (is-a links) is universal, which seems unlikely.
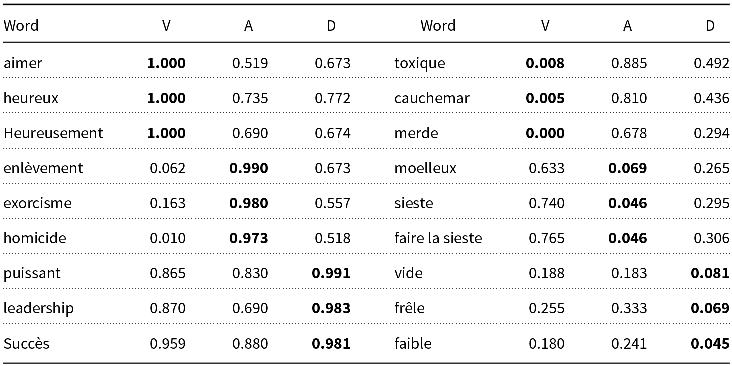
NRC-VAD is similar. NRC-VAD started out as a list of 20k English words with VAD (Valence, Arousal, and Dominance) values. Some examples are shown in Table 5. VAD can be viewed as an embedding of words into a vector space using a framework from the 1950s (Osgood, Suci, and Tannenbaum Reference Osgood, Suci and Tannenbaum1957). The multilingual version used machine translation (Google) to translate 20k English words to more than 100 languages, as illustrated in Table 6. This use of translation assumes the VAD values for English are universal, which seems unlikely.
Table 5. Words with extreme VAD (Valance, Arousal, Dominance) values. Very large and very small values are highlighted in bold
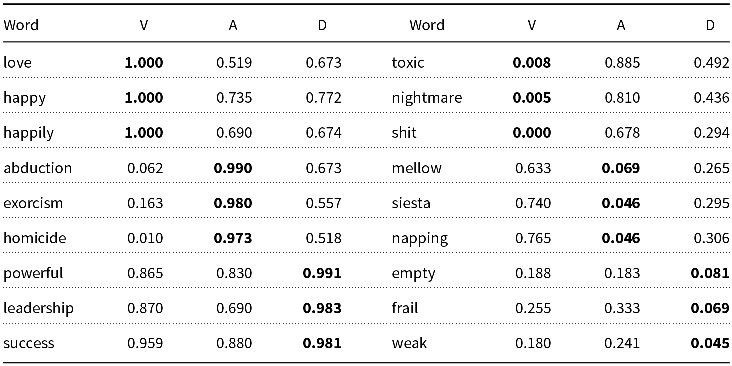
Table 6. French version of Table 5 (assumes VAD values are universal)
8. Too much translation in the “Wrong” direction
There is often an asymmetry in directionality. Of course, many pages in Wikipedia are not translated, but when a page is translated from one language to another, it is more likely for the translation to start with a page in a high-resource language such as English than a page in a low-resource language such as Hausa. It may be a sensible policy for Wikipedia to focus on this direction since they have more content in high-resource languages, but it is not ideal for training LLMs.
Table 7. Some resources for languages are in Table 8. Semantic Scholar is a promising opportunity with less translationese than Wikipedia
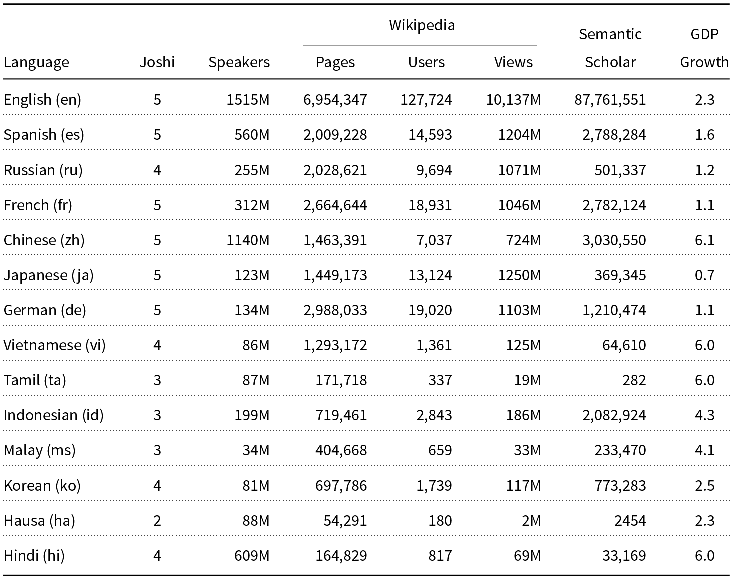

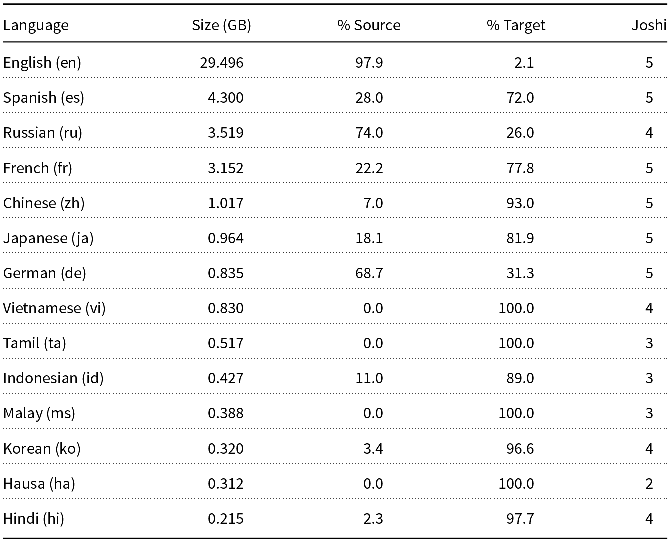
Table 8. Much of Wikipedia translates in the “wrong” direction from high-resource languages near the top of the table into low-resource languages near the bottom
As mentioned above, professional translators typically translate from their weaker language into their stronger language, and not vice versa. By this reasoning, we expect that machine translation should have better fluency when translating from a low-resource language to a high-resource language, but many resources translate in the more challenging direction: out of English as opposed to into English.
Figure 5 shows that Wikipedia has more content in high-resource languages and that most of the source for translation in Wikipedia comes from high-resource languages. The data in Figure 5 are borrowed from Tables 7–8. Table 7 estimates Wikipedia’s content for some widely spoken languages. The columns in Table 7 are based on the following sources:
1. Joshi classification of availability of resourcesFootnote k (Joshi et al. Reference Joshi, Santy, Budhiraja, Bali, Choudhury, Jurafsky, Chai, Schluter and Tetreault2020)
2. SpeakersFootnote l
3. Wikipedia pages and active usersFootnote m
-
4. Wikipedia views per month (averaged over 5 years)Footnote n
5. GDP growth over 10 yearsFootnote o
Table 8 estimates directionality in Wikipedia. Directionality is based on footnote e, a list of files for many language pairs. If we sum file sizes for files that translate out of English and files that translate into English, we find 29.5 GB. The % Source and % Target columns estimate how much of this translation goes in one direction as opposed to the other. In general, the % Source column is larger for high-resource languages than low-resource languages. English, for example, is usually the source (97.9% by file sizes), and rarely the target. In contrast, Hausa has less (0%) source.
If we were to use translation to produce parallel corpora, it would be better to translate in the “right” direction (from Hausa to English), but when we use Wikipedia to create parallel corpora, we are translating in the “wrong” direction. It makes sense for Wikipedia to translate in the direction they did, because they are trying to port their content to more languages. It happens that they have more content in high-resource language than low-resource languages. But when we use this data for our purposes, we should be aware that this directionality is not ideal for training LLMs for low-resource languages.
Table 7 shows that Semantic Scholar (S2) is a promising untapped alternative to Wikipedia with less translationese. The challenge is how to take advantage of this opportunity. The two suggestions below involve a number of steps such as translation (in the “right” direction), LID (language identification), cross-language information retrieval, and fine-tuning LLMs.
1. create parallel corpora by translating in the “right” direction, or
2. create comparable corpora by finding comparable text in high-resource languages
9. Scaling from standard benchmarks to practical use cases
Many of the steps above go beyond the scope of this paper, but while starting to investigate opportunities for taking advantage of S2, we discovered some challenges with standard benchmarks, even on a relatively simple task: LID. In general, both for LID and many other tasks, performance tends to be better on benchmarks such as FLORES than on use cases of interest such as S2 because:
1. Over-fitting: Off-the-shelf tools may have been trained on popular test sets.
2. Priors: Output labels (languages) are equally likely in many test sets (e.g., FLORES), but not in use cases of interest. In S2, for example, 83% is English, 2% is Indonesian, and 0.02% is Hausa.
3. Dirty data, closed-world assumptions and reject modeling: Most off-the-shelf LID tools assume the input is reasonable, and output one of n languages, but S2 is not like that. A common failure mode in Table 1 is “not language.”
4. Translation: Translation is more common in popular resources than use cases of interest. There is considerable translation in FLORES, but not on S2. Most of the translation in FLORES is in the “wrong” direction. Evaluations based on translationese may not generalize to S2.
Consider LID, a relatively simple case. Table 9 shows an evaluation of an off-the-shelf LID tool, cld3 Botha et al. (Reference Botha, Pitler, Ma, Bakalov, Salcianu, Weiss, McDonald, Petrov, Palmer, Hwa and Riedel2017), on five languages, using the dev split from FLORES (Goyal et al. Reference Goyal, Gao, Chaudhary, Chen, Wenzek, Ju, Krishnan, Ranzato, Guzmán and Fan2022). As mentioned above, the dev split contains 997 English sentences, translated to 100 languages.
Table 9. LID (cld3 Botha et al. (Reference Botha, Pitler, Ma, Bakalov, Salcianu, Weiss, McDonald, Petrov, Palmer, Hwa and Riedel2017)) performs (too) well on FLORES (Goyal et al. Reference Goyal, Gao, Chaudhary, Chen, Wenzek, Ju, Krishnan, Ranzato, Guzmán and Fan2022) dev set (997 rows per language)
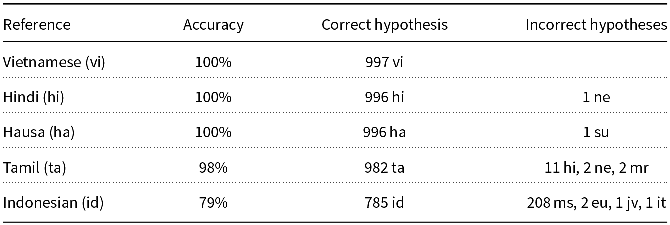
We are concerned that “your mileage may vary.” That is, performance on an evaluation such as Table 9 may be misleading, if we are interested in performance on S2. Note that performance in Table 9 is (too) good, except for a confusion between Indonesian and Malay, a difficult minimal pair. Table 9 shows that cld3 correctly labeled all 977 rows in Vietnamese and all but one row in Hindi and Hausa.
Given the impressive results in Table 9, we were disappointed by the precision of cld3 on abstracts in Semantic Scholar (S2). To estimate precision on S2, we made a sample of 50 abstracts labeled Hausa and found that only 12% were Hausa.
Most of the “abstracts” labeled Hausa were not only not Hausa, but they were not even abstracts. Dirty data are a reality. A small percentage of the “abstracts” in S2 are not abstracts. Unfortunately, it appears that cld3 tends to assign many of these non-abstracts to low-resource languages such as Hausa. While performing this pilot experiment, we discovered effective prompts for rejecting non-abstracts. These prompts may also be effective for addressing “not language” defects in Table 1.
The larger take-away lesson is that there is too much translationese in too many of our resources. The consequences are bad for training LLMs, but even worse for testing. Evaluations such as Table 9 can be seriously misleading. It turns out that it is harder to take advantage of S2 than it might appear because too much of the literature is based on misleading evaluations that suggest the field is doing better than it is.
Based on evaluations such as Table 9, one might have thought that LID was a solved problem and that it would be relatively straightforward to find Hausa articles in S2. LID is a relatively simple task. Much of the literature on other steps such as cross-language information retrieval is also based on Wikipedia (and translationese), for example (Sun and Duh, Reference Sun, Duh, Webber, Cohn, He and Liu2020), though the community may not be aware of how much translationese there is in Wikipedia. Fortunately, the quality control processes on translation are more effective for Wikipedia than for many of the test sets in our field such as those in Table 3. Evaluations on those test sets may be even more problematic than evaluations based on Wikipedia, given how much Wikipedia is investing in quality control processes.
10. Conclusions and recommendations
There is good news and bad news. The bad news: there is too much translationese in too many of our resources. Audits are producing shocking conclusions: less than 50% … acceptable quality (Caswell et al. Reference Caswell, Kreutzer, Wang, Wahab, Esch, Ulzii-Orshikh, Tapo, Subramani, Sokolov, Sikasote, Setyawan, Sarin, Samb, Sagot, Rivera, Rios Gonzales, Papadimitriou, Osei, Suarez and Adeyemi2021). Worse, the community may not be aware of the poor quality. There is too much (poor) translation in popular datasets. Poor test sets produce misleading results.
As mentioned above, we should invest more in quality control. When possible, we should avoid translation. When translation is necessary, it is better to translate in the “right” direction (into high-resource languages) than the “wrong” direction (out of high-resource languages). The literature from Corpus-based Lexicography as well as experiments with LLMs in Section 3 suggest that translationese is different from texts that were originally written in the source language.
That said, ANOVA analyses mentioned above showed that other factors (models and language) account for more of the variance than translationese. Thus, translationese is, perhaps, a third-order effect. While the field is struggling with first and second-order effects, it may be appropriate to move third-order effects to the parking lot, but even so, we should be thinking about how to address these third-order effects in the future.
Too many of our resources are catch-as-catch-can. For example, since most of the content in Wikipedia happens to be in high-resource languages, when they want to port their content to more markets, it makes sense for them to translate in the direction they do. But unfortunately, this is the “wrong” direction for our purposes (developing LLMs).
The good news is that there is plenty of text in source languages of interest. For example, there are millions of articles in Semantic Scholar in Indonesian. There are opportunities to create parallel corpora by translating these articles in the “right” direction, as well as opportunities to create comparable corpora by finding comparable articles in other languages.
Competing interests
None
Ethical standards
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Author contributions
All authors approved the final submitted draft.















 Open access
Open access