


To address the rise in non-communicable diseases (NCDs), including obesity, cancer and cardiovascular disease, linked to unhealthy food environments(1–Reference Jaime, Duran and Sarti3), World Health Organization (WHO) and Pan American Health Organization (PAHO) have advised governments to develop and implement a set of public policies and regulatory measures to promote healthier food environments(4,5) . These measures include restricting the sale of ultra-processed foods (UPF) – industrial formulations containing parts of whole foods and food additives with cosmetic functions, designed to be hyper-palatable and ready-to-consume – in schools, regulating marketing directed at children, taxing sugary drinks, and implementing mandatory front-of-package nutritional labelling (FOPNL)(Reference Swinburn, Sacks and Hall2,4–7) .
Mandatory FOPNL empowers citizens to identify products high in calories, sugars, sodium and fats, while encouraging healthier and informed choices(8,Reference Palacios, Magnus and Arrieta9) . Beyond influencing individual purchasing behaviour, the implementation of FOPNL has been shown to drive broader changes in the food environment by encouraging product reformulation(8–Reference Crosbie, Gomes and Olvera10). For instance, a preliminary evaluation of FOPNL’s impact in Chile revealed a significant reduction in the proportion of products labeled as ‘high in’ energy and critical nutrients across multiple food and beverage categories(11). Similarly, in Mexico, within just one year of implementing FOPNL, food manufacturers began reformulating products to lower critical nutrient levels, ensuring compliance with the new labelling standards(Reference Reyes, Taillie and Popkin12).
In Brazil, nutrition labelling has been mandatory since 2006(13). However, it was not until 2020 that a new food labelling regulation was approved introducing FOPNL alongside other measures, such as restrictions on nutritional claims and enhancements to the nutritional facts label to improve comparability between food products(14,15) . Despite these advancements, the limited availability of nutritional composition data for foods in Brazil poses challenges for monitoring and evaluating food labelling policies. This issue is exacerbated by the rapid introduction and updating of new food products, particularly UPF, in the retail market(Reference Wen16–Reference Vandevijvere, Jaacks and Monteiro18). To address these challenges, combining commercial and government data is recommended for assessing the retail food market(Reference Wen16–Reference Vandevijvere, Jaacks and Monteiro18).
Companies such as Mintel’s Global New Products Database (Mintel-GNPD)(Reference Solis19), Kantar(20) and Euromonitor(21) provide extensive data on food retailing. Each company employs distinct methods to collect this information; for instance, Mintel-GNPD gathers data directly from product labels in various, which may vary across countries for newly launched products on the market(Reference Solis19). Countries including the USA, Chile and Australia have used these commercial datasets to evaluate public policies(Reference Ng and Dunford17,Reference Taillie, Bercholz and Popkin22,Reference Dickie, Woods and Lawrence23) . However, these datasets may have inherent limitations, and their availability can vary across countries(Reference Bandy, Adhikari and Jebb24).
PAHO recommends evaluating several attributes to select appropriate secondary data for monitoring population health(25). These attributes include population representativeness, ensuring the absence of significant selection bias; periodicity, to enable continuous assessment through regular data collection; validity, ensuring accurate measurement of parameters without distortion, bias or systematic errors; timeliness, emphasising the availability and reliability of data for effective decision-making in the policy process and the potential for data stratification based on specific interests, among other factors(25).
Brazil’s recent nutrition labelling regulations necessitate ongoing monitoring to evaluate their impact on industry compliance, product reformulation and shifts in consumer purchasing behavior. These processes are essential for determining whether the policy’s objectives are being achieved and for resolving unexpected setbacks(Reference Mais, Borges and Khandpur26). To date, we have not identified any studies in the literature that evaluate the attributes of commercial databases on Brazilian food and beverage labels, specifically focusing on nutritional composition for monitoring and evaluating policies. However, one study has assessed health and nutrition claims from commercial databases for similar purposes(Reference Kikuta, Borges and Duran27). Therefore, this study aimed to assess whether the information on nutrition composition available in this commercial dataset is suitable for policy evaluation in Brazil.
Methods
Study design
This cross-sectional study utilised two data sources: secondary data from a private company (referred to as commercial data) and label data collected by Brazilian researchers in supermarkets, which served as the gold standard.
The selected commercial data source fulfills key attributes, such as periodic updates on the Brazilian food supply since 1996; and the timeliness, as it provides current packaged food and beverage label data during the implementation of the new nutrition labelling policy(25). In this study, we focused on two attributes emphasised by PAHO: representativeness and validity. To achieve this, the study used a robust method established in the literature to validate a secondary data source by comparing it with a gold standard or reference dataset(Reference Souza, Alexandre and Guirardello28,Reference Szklo and Nieto29) . Using a dataset containing nutrition label information as the gold standard reference, we developed a validation process for the nutritional composition variables in the commercial dataset.
Brazilian Food Labels Database sampling procedures
Data from the 2017 Brazilian Food Labels Database (BFLD) served as the ‘gold standard’ due to its standardised sampling, collection, processing and data entry procedures for food and beverage packages. Data collection was conducted by experts in the field, using international nutritional labelling analysis protocols(30). Reliability analyses conducted during data collection ensured data quality, supporting its use in multiple studies across Brazil(Reference Duran, Ricardo and Mais31–Reference Fagundes Grilo, Taillie and Zancheta Ricardo33). The procedures for data collection and treatment of the primary database will be described below.
Data on food and beverage labels were collected from the five largest food retailers in Brazil – four located in São Paulo and one in Salvador – which together account for 69·7 % of the national grocery retail market share(Reference Duran, Ricardo and Mais31). These retailers were selected based on Euromonitor data on annual retail sales volume in Brazil(Reference Duran, Ricardo and Mais31). The researchers geo-coded the addresses of all stores belonging to the selected retailers by their companies’ websites and customer service sites. The stores were categorised into low-, middle- or high-income neighbourhoods based on a 1-kilometer Euclidean buffer(Reference Duran, Ricardo and Mais31). Neighbourhood income levels were determined using the average per capita family income from the 2010 Brazilian Population Census(Reference Duran, Ricardo and Mais31). The stores within each income category were further divided into tertiles based on mean neighbourhood income. From each tertile, one store from the highest and lowest income categories was selected, prioritising stores with larger physical areas. However, for one retail chain, data collection was restricted to its distribution centre. More information can be found elsewhere(Reference Duran, Ricardo and Mais31).
Data collection took place between April and June 2017. Fieldworkers photographed all sides of food and beverage packages, excluding alcoholic beverages, nutritional supplements, infant formulas and breast milk substitutes, following the methodology proposed by Kanter et al. (2017)(Reference Kanter, Reyes and Corvalań34). Nutritionists entered information from food labels, including nutritional composition, product characteristics, brand and other details, directly into an online platform (Redcap) using previously validated methods(Reference Kanter, Reyes and Corvalań34). Intra- and inter-rater reliability tests were conducted on a 10 % sample of the data using the intraclass correlation coefficient, yielding excellent values (≥ 0·90) for all assessed nutrients(Reference Duran, Ricardo and Mais31).
Products entered during the training phase and with duplicate records were excluded, resulting in a total of 12 956 foods and beverage items. Additional exclusions included items with multiple package sizes (n 358), multipack products (n 86), products lacking nutritional information (n 815) or ingredient lists (n 178) and those with missing portion sizes and/or calorie values (n 85). After these exclusions, the final BFLD comprised 11 434 food and beverage items.
Commercial database sampling procedures
For our commercial database sampling, we used data from Mintel, a global private research company that produces the Global New Products Database (GNPD) and other services related to the food consumer experience. This database provides detailed information on packaged food products, including product descriptions, brand, price, package size, claims, nutrition facts and other attributes. Mintel-GNPD continuously monitors the launch of new food products across retailers in more than fifty countries, including Brazil, Chile, Colombia, the United States, Australia, India, China and New Zealand(Reference Solis19). Additional details about Mintel’s data can be found elsewhere(Reference Solis19).
In this study, we analysed data provided by Mintel-GNPD on the nutritional composition of 68 057 unique food and beverage products launched in Brazil between 2001 and 2017. This timeframe was selected because Mintel-GNPD includes newly launched or reformulated products; therefore, by using data from this entire period, we aimed to approximate the prevalence of products available on the market up to 2017. The database includes only the most up-to-date version of each product as of the study’s reference year (2017). We excluded products that do not qualify as foods or beverages under Brazilian food labelling regulations, including dietary supplements (n 372), alcoholic beverages (n 5) and infant formulas (n 79). Additionally, packaged culinary preparations, such as lasagnas or other ready-to-eat frozen meals produced in markets or non-industrial kitchens and commonly available in Brazilian markets, were excluded (n 557) as they require a different analytical method and were not the focus of this study. Products without universal product codes (n 2) were also excluded, resulting in a final sample of 67 042 food and beverage items.
Validation process
The validation process was conducted in two stages. First, we analysed the distribution of foods and beverages by categories and subcategories in both databases. Second, we assessed the agreement between products matched across the datasets in relation to the mandatory nutrition facts variables required in Brazil in 2017, including calories, carbohydrates, proteins, total fats, saturated fats, trans-fats, sodium and fibre. Additionally, given the updated nutrition labelling norms published in 2020, which mandated total sugar labelling, we also included total sugar in the analysis.
For the first stage, products in both databases were categorised according to the classification system from the 2017–2018 Brazilian Household Budget Survey, which is based on the Nova food classification. This system includes unprocessed or minimally processed foods (e.g. rice, milk, poultry, beans, beef, fruits, pasta, corn flour, cassava flour, wheat flour, roots and tubers, eggs, vegetables, pork, fish, cereals, offal and other similar foods); processed culinary ingredients (e.g. vegetable oil, sugar, animal fat, starch and other ingredients); processed foods (e.g. bread, cheese, processed meat and other similar items) and UPF, such as cured meats, sweet and savory biscuits, cheese, cakes and pies, bread, candies, carbonated beverages, chocolate, pizza or pastry dough, ready-to-eat meals, non-carbonated beverages, dairy beverages, ice cream, sauces and condiments and other UPF(35).
In addition to these food categories, we introduced a new category called non-sugar sweetener within the ultra-processed subcategories to encompass non-nutritive sweeteners. A detailed description of the foods and beverages included in each category and subcategory is provided in online supplementary material, Supplemental Material 1.
As part of our analysis, we conducted a sensitivity assessment by identifying products in both databases with brands that accounted for up to 80 % of sales in the Brazilian market, as reported by Euromonitor(21). Given that the majority of these brands (approximately 60 %) are classified as UPF, our analysis focused on UPF subcategories(Reference Vandevijvere, Jaacks and Monteiro18).
In the second step, we linked the BFLD (11 434 items) and Mintel-GNPD (67 042 items) databases using universal product codes to identify products common to both, enabling the comparison of congruent products to evaluate the agreement between the gold standard database and the commercial database. We excluded products with duplicate universal product codes (n 41), resulting in a total of 6065 common food and beverage items across both databases. To ensure the accuracy of paired products, we also verified variables such as product names and descriptions. Details of the foods and beverages from the BFLD that did not match those in the Mintel-GNPD are provided in online supplementary material, Supplemental Material 2.
This new database integrates information from both sources, including product details such as name, description, brand, food categories and nutritional composition. The nutritional data include portion size, energy value, carbohydrates, total sugars, proteins, total fats, saturated fats, trans-fats, sodium and fibre. In the Mintel-GNPD, these data were extracted from a concatenated variable labeled ‘nutrition,’ which combined all the nutritional information. Variables for each nutrient per 100 g or ml were created and subsequently used in the agreement analysis.
Statistical Analysis
We assessed the distribution of food products through descriptive analysis, applying a 95 % confidence interval (CI), percentage difference (p.p.), and P value from proportion test to compare the prevalence of products across both databases. Additionally, we conducted a sensitivity analysis to determine whether, beyond the similarity in the overall distribution of food products, there was alignment in the products from top-selling brands across the databases. To verify this, we repeated the descriptive analyses on products from brands representing up to 80 % of sales in the Brazil(21).
To evaluate the suitability of the Mintel-GNPD’s nutritional composition variables in comparison with a traditionally collected database (BFLD), we conducted paired t tests to compare mean values (P ≥ 0·05) between matched products in food categories with more than thirty products, and the Wilcoxon–Mann-Whitney test for food categories with fewer than thirty products. The intraclass correlation coefficient (ICC) was also calculated to assess the agreement between matched products, focusing on the total variability of the nutrients of interest(Reference Hsu, Lachenbruch, Balakrishnan, Colton and Everitt36). For the interpretation of this coefficient with variation from 0 to 1, we used the following parameters: < 0·4 indicates weak correlation; 0·4 to 0·6 reasonable correlation; 0·6 to 0·8 good correlation and > 0·8 excellent correlation(Reference Cicchetti37).
We calculated the agreement between matched products for the following nutritional composition variables: energy (kcal); carbohydrates (g), total sugars (g), proteins (g), total fats (g), saturated fats (g), trans-fats (g), fibre (g) and sodium (mg) per 100 g or ml of foods and beverages. The analysis was performed by food category according to the Nova food classification and for the UPF subcategories, given its higher prevalence among UPF in this study and its significance for public policies(Reference Monteiro, Cannon and Levy38).
We also evaluated the impact of outliers on energy content on the agreement between matched products as energy information reflects the contribution of other macronutrients (carbohydrates, proteins, and fats). Products with energy values below the second percentile or above the 98th percentile (kcal per 100 g) within each food subcategory were excluded, resulting in a final sample of 5540 products. The agreement analyses, including the paired t test or the Wilcoxon–Mann-Whitney test and ICC, were then repeated on this subsample. Furthermore, probability density plots were generated to examine the overlap in the distributions of energy and critical nutrients (total sugar, trans-fat and sodium) across all products in the Mintel-GNPD and BFLD databases.
All statistical analyses were performed using Stata/MP 16.1 (StataCorp LLC) software.
Results
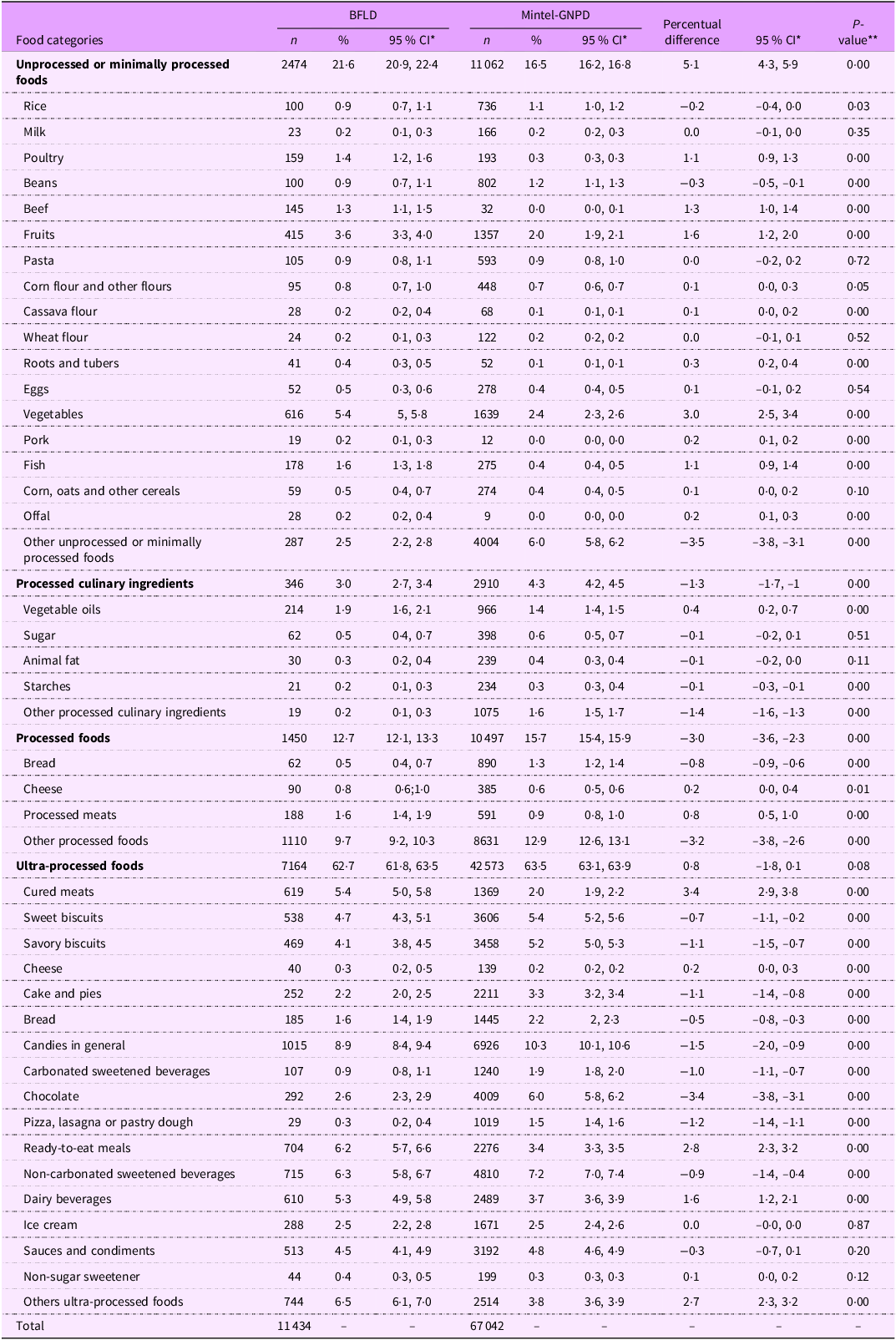
The BFLD included a total of 11 434 products, with 21·6 % categorized as unprocessed or minimally processed foods, 3·0 % as processed culinary ingredients, 12·7 % as processed foods and 62·7 % as UPF. In comparison, the Mintel-GNPD database contained 67 042 products, with 16·5 % classified as unprocessed or minimally processed foods, 4·3 % as processed culinary ingredients, 15·7 % as processed foods and 63·5 % as UPF (Table 1).
Table 1. Percentage of the products in the Brazilian Food Labels Database (BFLD) and Mintel Global New Products Database (Mintel – GNPD), by food categories and subcategories

* 95 % CI, **P value from proportion test.
The percentage of UPF showed no statistically significant differences between the BFLD (62·7 %; 95 % CI: 61·8, 63·5) and the Mintel-GNPD (63·5 %; 95 % CI: 63·1, 63·9). Certain UPF subcategories exhibited higher percentages (approximately 1 % variation) in the Mintel-GNPD compared with the BFLD. For example, savory biscuits (BFLD: 4·1 %; Mintel-GNPD: 5·2 %), sweet biscuits (BFLD: 4·7 %; Mintel-GNPD: 5·4 %), cakes and pies (BFLD: 2·2 %; Mintel-GNPD: 3·3 %), bread (BFLD: 1·6 %; Mintel-GNPD: 2·2 %), candies in the general (BFLD: 8·9 %; Mintel-GNPD: 10·3 %), carbonated sweetened beverages (BFLD: 0·9 %; Mintel-GNPD: 1·9 %), non-carbonated sweetened beverages (BFLD: 6·3 %; Mintel-GNPD: 7·2 %) and pizza, lasagna or pastry dough (BFLD: 0·3 %; Mintel-GNPD: 1·5 %). In contrast, the percentage of unprocessed or minimally processed foods was lower in the Mintel-GNPD (16·5 %; 95 % CI: 16·2, 16·8) compared with the BFLD (21·6 %; 95 % CI: 20·9, 22·4) (Table 1).
The sensitivity analyses revealed a higher prevalence of UPF from top-selling brands in the BFLD at 32·1 % (95 % CI: 31·1, 33·2) compared with 25·1 % (95 % CI: 24·7, 25·5) in the Mintel-GNPD (see online supplementary material, Supplemental Material 3). Across most UPF subcategories, the difference in the percentage of products between the two databases did not exceed five percentage points, except for the chocolate subcategory, which exhibited a disparity of 12·8 percentage points.
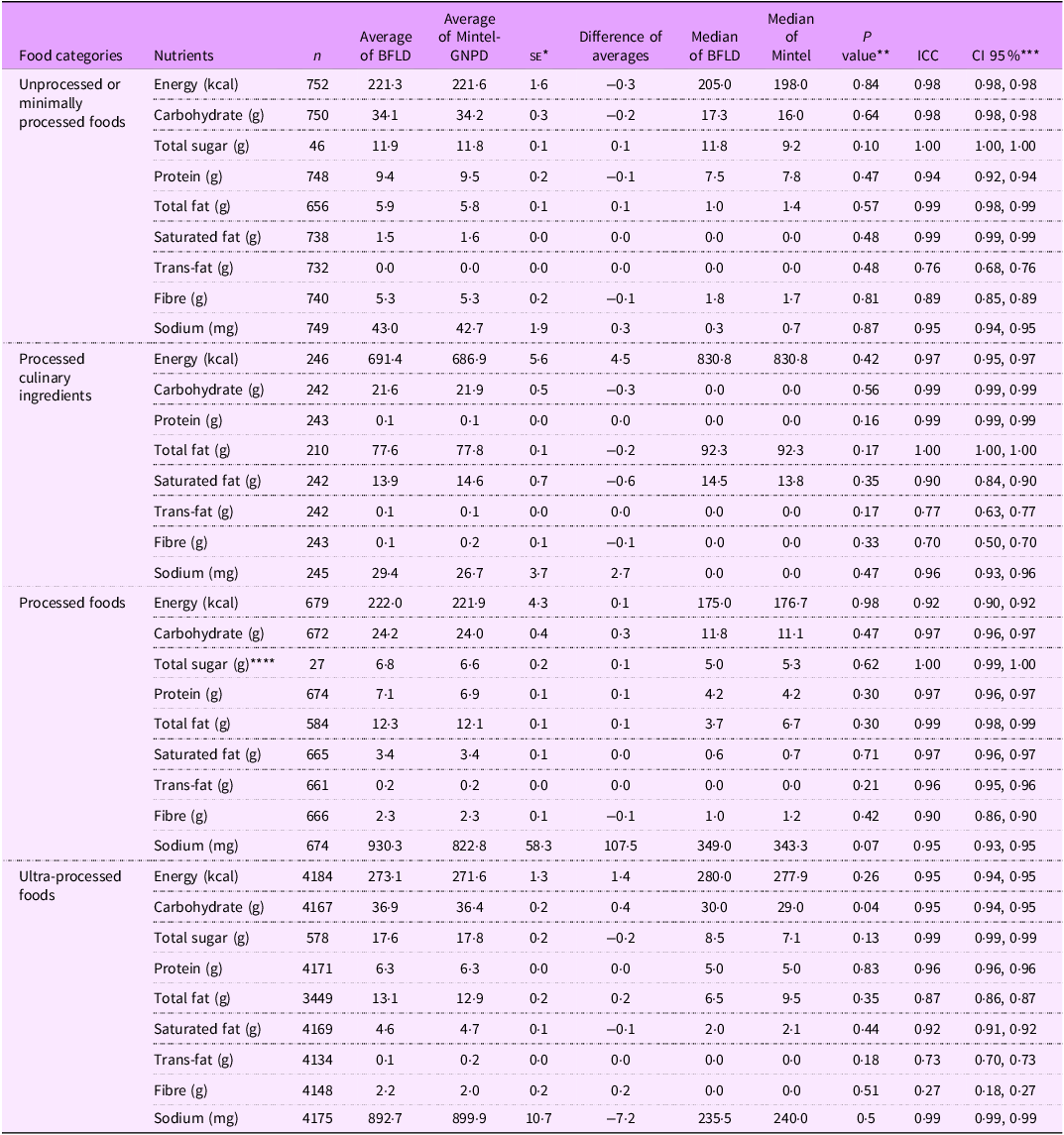
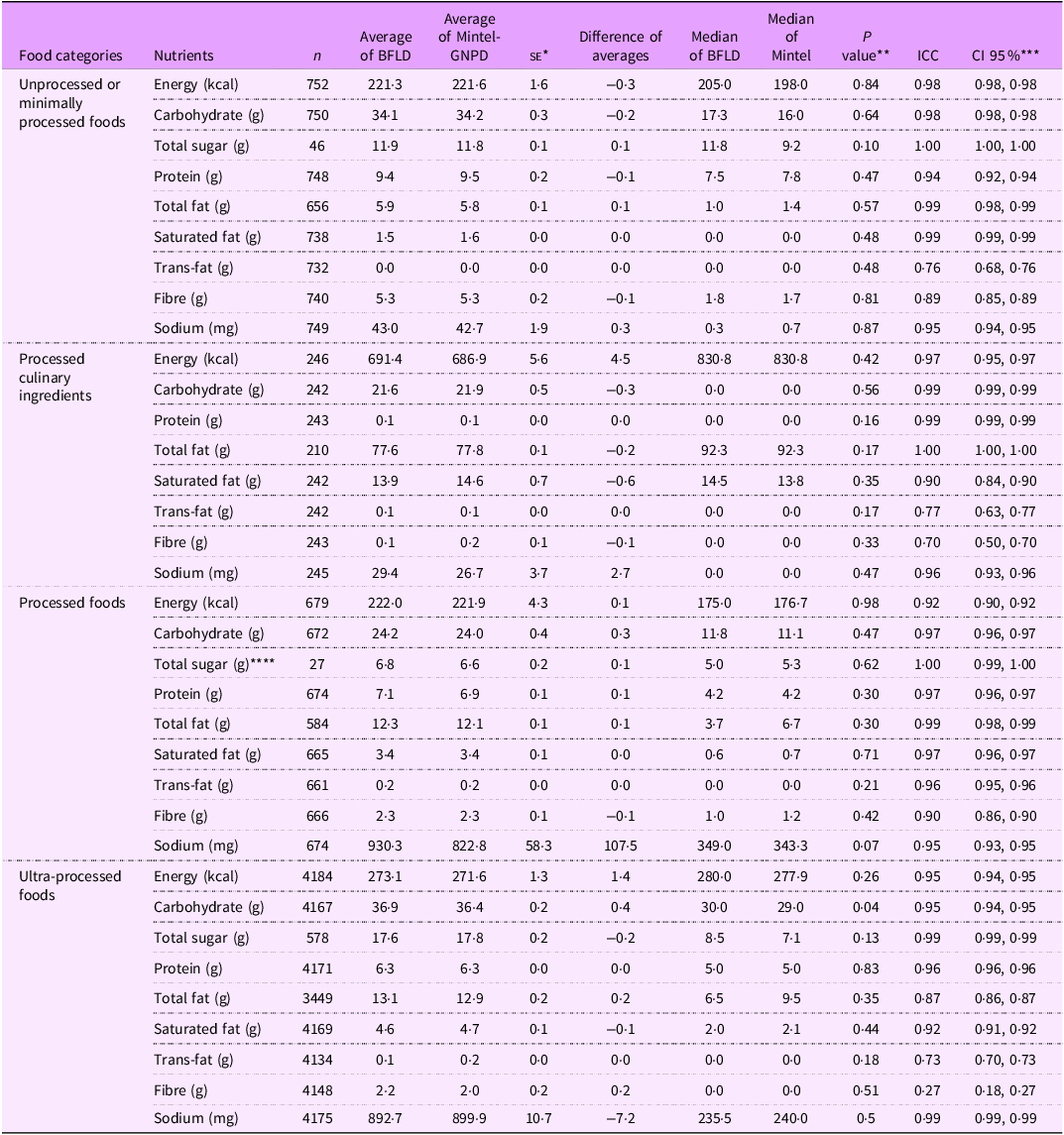
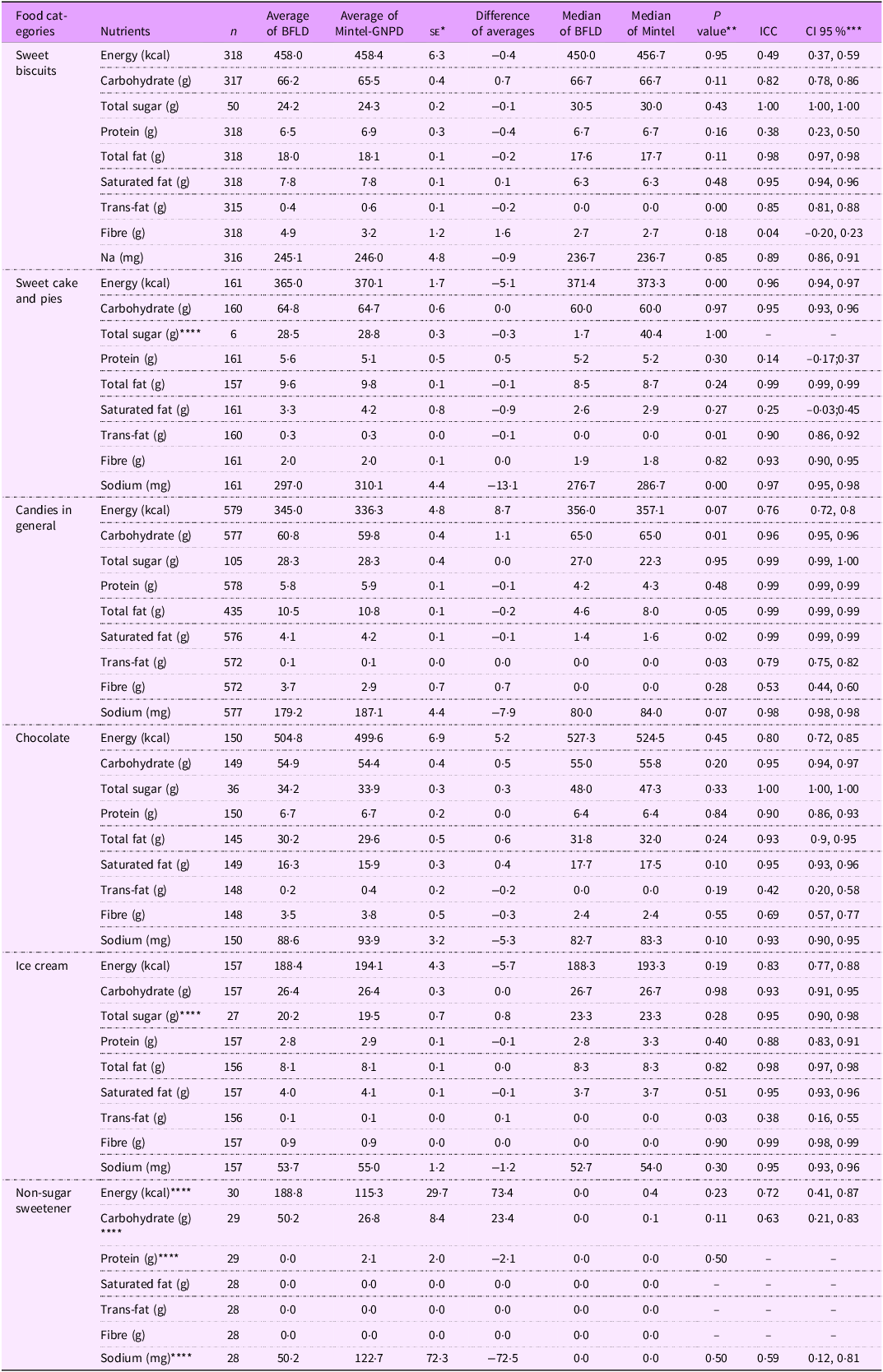
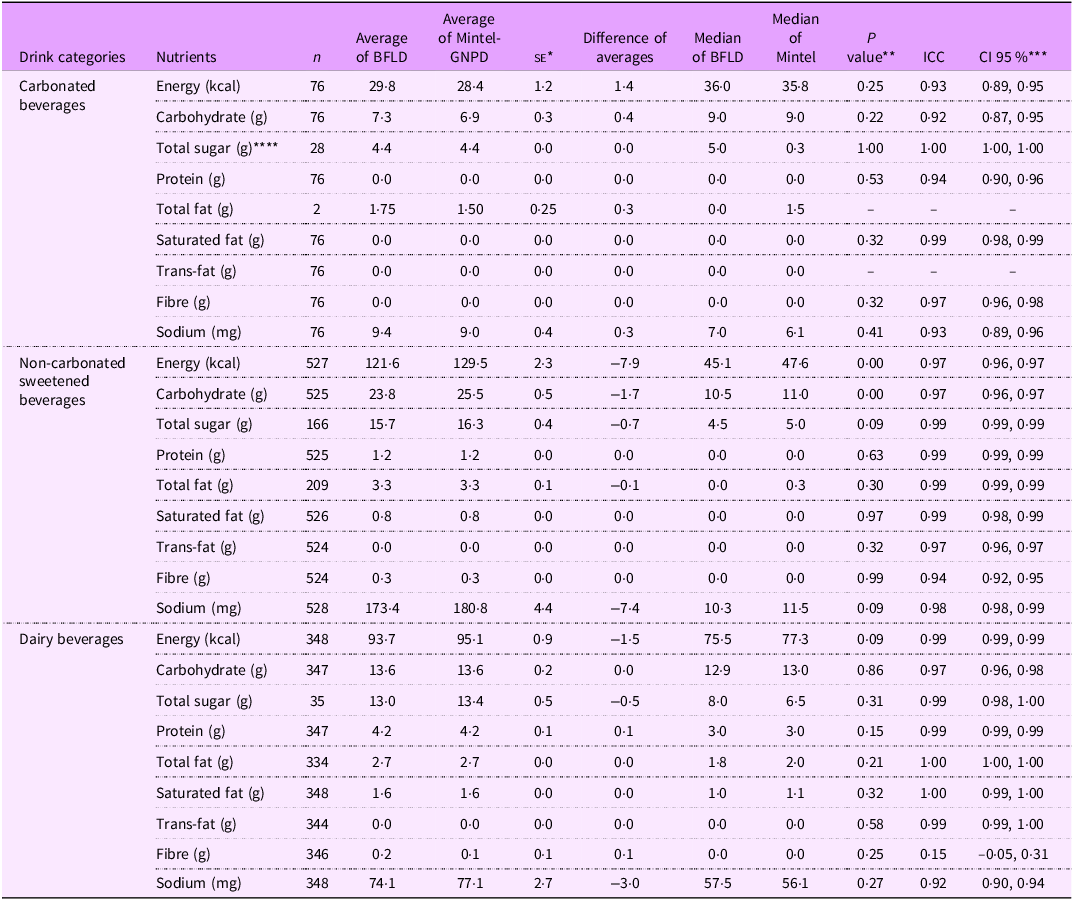
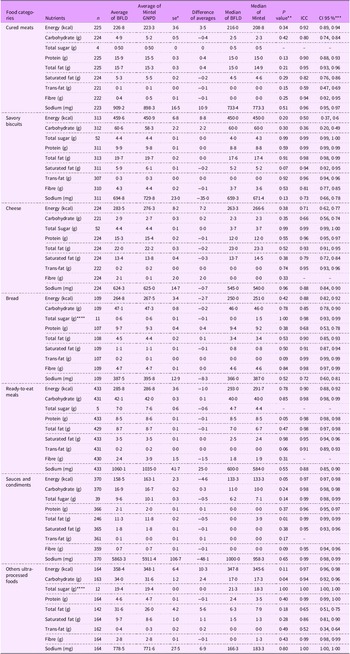
In the second stage, average nutrient content showed no significant differences between matched products in the two databases across the NOVA food categories (P > 0·05), except for carbohydrates per 100 g or ml (P = 0·04) (as shown in Table 2). The analysis of UPF subcategories (as presented in Tables 3, 4, and 5) revealed no significant differences (P > 0·05) in the average nutrient quantities for cured meats, salted biscuits, cheese, bread, sweetened carbonated beverages, chocolates, ready-to-eat meals, dairy beverages and ice cream between the two databases (BFLD and Mintel-GNPD). However, significant differences were identified in the trans-fat content of sweet biscuits, candies in general, ice cream and the calorie and carbohydrate content of cakes, pies and non-carbonated sweetened beverages.
Table 2. Concordance analysis of nutrient amounts per 100 g or ml between matched products from the Brazilian Food Labels Database (BFLD) and Mintel Global New Products Database (Mintel – GNPD) by NOVA food categories
* SE - Standard Error; **P value of paired t test; ***Intraclass Correlation Coefficient (ICC) and CI95% of the ICC; ****Wilcoxon test.
Table 3. Concordance analysis of nutrient amounts per 100 g or ml between matched products from the Brazilian Food Labels Database (BFLD) and Mintel Global New Products Database (Mintel – GNPD) by ultra-processed sweet products subcategories

* SE - Standard Error; **P value of paired t test; ***Intraclass Correlation Coefficient (ICC) and CI95% of the ICC; ****Wilcoxon test.
Table 4. Concordance analysis of nutrient amounts per 100 g or ml between matched products from the Brazilian Food Labels Database (BFLD) and Mintel Global New Products Database (Mintel – GNPD) by ultra-processed beverages subcategories

* SE - Standard Error; **P value of paired t test; ***Intraclass Correlation Coefficient (ICC) and CI95% of the ICC; ****Wilcoxon test.
Table 5. Concordance analysis of nutrient amounts per 100 g or ml between matched products from the Brazilian Food Labels Database (BFLD) and Mintel Global New Products Database (Mintel – GNPD) by ultra-processed other products subcategories
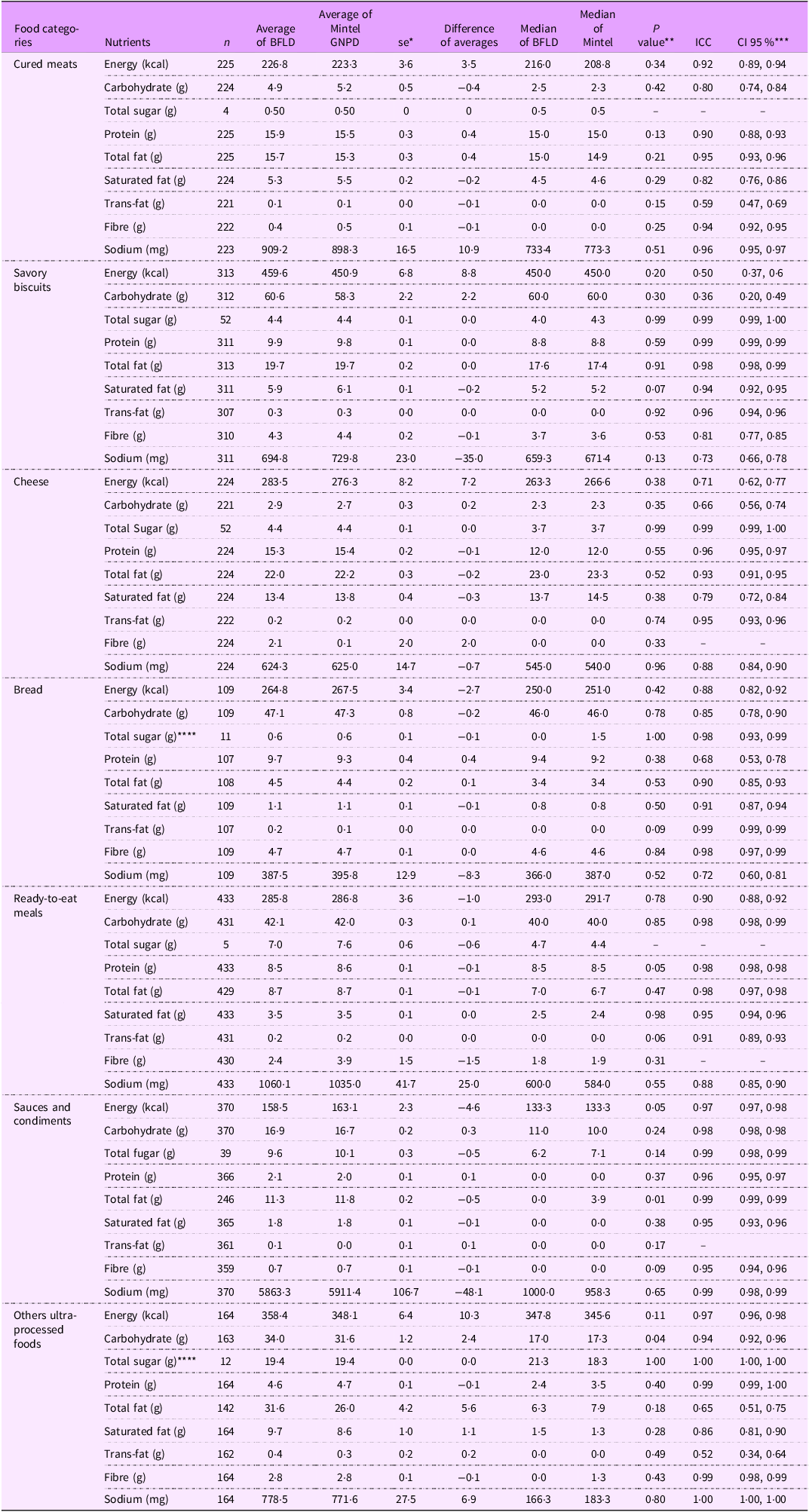
* SE - Standard Error; **P value of paired t test; ***Intraclass Correlation Coefficient (ICC) and CI95% of the ICC; ****Wilcoxon test.
The ICC indicated good (ICC: 0·6–0·8) to excellent (ICC > 0·8) agreement for most nutrients across Nova food categories between matched products in the two databases (Table 2). The UPF category demonstrated good to excellent agreement for energy (ICC: 0·95), carbohydrates (ICC: 0·95), total sugars (ICC: 0·99), proteins (ICC: 0·96), total fats (ICC: 0·87), saturated fats (ICC: 0·92), trans-fats (ICC: 0·73) and sodium (ICC: 0·99), but weak agreement for fibre (ICC: 0·27).
Among the UPF subcategories, the ICC results were generally consistent (Tables 3, 4 and 5), showing good to excellent agreement for most nutrients. However, we noted variability in the agreement between databases for specific nutrients, especially in trans-fat and fibre, where the agreement ranged from reasonable (ICC: 0·4–0·6) to weak (ICC < 0·4) in some subcategories, such as cured meats, sweet biscuits, cheese, read-to-eat meals, among others. Both the paired t test and ICC did not show improvements in the results when excluding outliers across NOVA classification categories. Despite these discrepancies, probability density plots (see online supplementary material, Supplemental Material 6) indicated that the distributions of energy and critical nutrients were largely overlapping across both databases. This similarity in nutrient distribution supported the predominantly good to excellent agreement observed in the statistical tests conducted on the sample of matched products.
Discussion
The results indicate similarity in the percentage of UPF between data collected from food and beverage packages in the five major food retailers in Brazil in 2017 and a commercial data provided by Mintel. Furthermore, for most variables (energy, carbohydrates, total sugar, protein, total fat, saturated fat, trans-fat, fibre and sodium), no significant differences were found between matched products, and the agreement across databases for these nutrients ranged from good to excellent. Nevertheless, discrepancies were noted for some nutrients, such as trans-fat and fibre, especially when analyses were further stratified by UPF subcategories.
Researchers in Australia, Spain, India and the UK have used Mintel-GNPD to examine their food and beverages in the food retail and nutritional composition and also found a higher proportion of UPF in their database(Reference Dickie, Woods and Lawrence23,Reference Boukid, Baune and Gagaoua39–Reference Costa-Font and Revoredo-Giha41) . As seen in the literature and observed in the present study, this commercial data have the greatest potential for assessing the availability of UPF, rather than unprocessed foods(Reference Azzopardi, Lacy and Woods42). These data demonstrate potential for evaluating UPF composition and supporting regulatory efforts in public health research, especially given the strong association between UPF consumption and health outcomes(Reference Pagliai, Dinu and Madarena43).
In our sample, the Mintel-GNPD includes a smaller proportion of UPF from top-selling brands compared with the BFLD, which can be attributed to the Mintel-GNPD focus on products launched or relaunched in the retail market. However, while this dataset may not encompass all products from top-selling brands available in the Brazilian market, it allows for the monitoring of new market trends and product reformulations, including those from top-selling brands. Additionally, the Mintel-GNPD facilitates the monitoring of the nutritional composition of foods and beverages introduced in the Brazilian retail market, as well as the presence of FOPNL(Reference Borges, Kikuta and Nunes44), the health and nutritional claims of products(Reference Kikuta, Borges and Duran27) and other elements such as advertising and environmental claims.
The nutritional composition information obtained from the Mintel-GNPD aligns with those from the gold standard (BFLD) between matched products for most nutrients across the NOVA food classification categories. However, some discrepancies were observed in the statistical tests for carbohydrates and fibre within the UPF category. For carbohydrates, a P value of 0·04 was observed for the difference in means, despite the medians showing minimal variation (BFLD median: 30; Mintel-GNPD median: 29). This discrepancy is likely due to asymmetry in carbohydrate values within this category, characterised by a high concentration of values at zero, common in both zero-calorie and regular products, as illustrated in the Bland–Altman plot in online supplementary material, Supplemental Material 4. For fibre, weak agreement between the datasets was observed, which may be attributed to the ICC’s sensitivity to overall variability rather than just paired variability. In this sample, fibre amounts show variability, with most products reporting values of zero, while some products contain substantial amounts of fibre. This distribution is further illustrated in the Bland–Altman graph provided in online supplementary material, Supplemental Material 5. It is worth noting that the BFLD also has limitations. Unlike the Mintel-GNPD, the BFLD was developed using traditional methods of collecting label information, where researchers followed international protocols for monitoring food labels and had greater control over the data collection process. However, some errors may still be present and may highlight opportunities to improve the data digitisation process by adopting more efficient methods for gathering information from packaged product labels, such as using artificial intelligence.
Within the UPF subcategories, we observed agreement between matched products, although discrepancies were more prevalent for some nutrients, such as trans-fat, fibre and sodium, among others. These discrepancies may be attributed to the size of the sample (due to greater stratification of the data), or specific nuances in nutrition labelling regulations. For example, it is not mandatory to declare trans-fat amounts on labels if the value is equal to or less than 0·1 grams per serving(14). To further investigate this, we randomly reviewed product photographs on the Mintel website and confirmed that the information matched the data recorded in the dataset. Additionally, we verified that the distributions of calories and critical nutrients in both datasets overlapped, confirming the data quality not only for the matched products but also for the entire Mintel-GNPD, as shown in online supplementary material, Supplemental Material 6.
It is important to note that the Mintel-GNPD commercial dataset is not publicly accessible, as its data are produced by the private sector. The specific methods used for data collection and processing are not fully detailed, which may introduce certain limitations. For example, the selection process for data collection of packaged products is unclear. As a result, the dataset may not fully capture the availability of packaged products across different regions, particularly for categories such as unprocessed or minimally processed foods(Reference Ng and Popkin45). Furthermore, Mintel-GNPD focuses on launched products, which may include items that are not widely consumed in the Brazilian market.
However, commercial packaged food and beverages datasets, such as the one analysed in this study, as well as others such as Simplus(46) and Nielsen(47), are valuable tools for monitoring and evaluating public policies, particularly given the challenges associated with data collection in loco (Reference Pravst, Hribar and Žmitek48). In general, these databases may be expensive; however, they require fewer resources since the data is already collected and structured. Additionally, commercial databases are continuously updated and typically include data from multiple countries, enabling comparisons of food retailing across different regions(Reference Bandy, Adhikari and Jebb24). Nevertheless, it is crucial to assess the quality of this data, as their reliability may vary depending on the location.
This study is not without limitations. The primary limitation stems from the use of universal product codes to match database entries, which can sometimes associate the same UPC with different products. To mitigate this issue, we incorporated additional variables, such as product names and descriptions, into the linking process. Another limitation is that agreement was assessed only for matched products rather than the full Mintel dataset, which may limit generalisability. To address this, we followed validation approaches recommended by the specialised literature, employed a robust gold standard already supporting public policies and analysed a broader sample, in this case, all matched products, representing approximately 53 % of the gold standard dataset. Furthermore, verification of the full dataset was not feasible due to the high cost of data collection and the large volume of products. Nevertheless, probability density plots indicated overlapping distributions of calories and critical nutrients (total sugar, saturated fat, and sodium). A further limitation involves comparing data collected in a single year from the BFLD with accumulated data spanning 2001–2017 from Mintel-GNPD, which may include products no longer available on the market. To address this, we evaluated the suitability of the data for products paired between the two databases. Finally, our study evaluated the sustainability of these commercial data in comparison with Brazilian food retail data, acknowledging potential limitations in extrapolating the findings to products in Mintel’s database from other countries.
However, our results align with a systematic review suggesting that commercial data, particularly purchase and consumption data, can serve as a valuable resource for public health nutrition researchers(Reference Pravst, Hribar and Žmitek48). In addition, to the best of our knowledge, this is the first study to assess the suitability of the Mintel-GNPD dataset in Brazil by comparing it with a food labelling dataset collected and developed by researchers following international protocols for monitoring and evaluating nutrition labelling policies.
Conclusion
Our findings suggest that Mintel-GNPD provides reliable data on the availability of UPF in the Brazilian retail market and similar nutritional composition to a sample of matched foods available for purchase in stores. The commercial database can support research aimed at monitoring and evaluating labelling and food and beverage composition in Brazil, including policy compliance. Given the opportunities that commercial datasets provide to policy monitoring and impact evaluation, future work should evaluate whether the profile of products in commercial datasets is consistent with foods collected from store shelves in other settings.
Supplementary material
For supplementary material accompanying this paper visit https://doi.org/10.1017/S1368980025101456
Acknowledgements
We thank Professor Larissa Ávila Mator and the students Ana Clara Estevam Pereira, Jonathan Ricardo Smaile Fusco, and Thomás Sperandio Denadai for their support in the analyses and Dr. Lilian S. Pedraza for her valuable contributions to the discussions of this research. We also acknowledge Colansa for financial support for the publication of this paper.
Authorship
B.S.N. were responsible for conceptualisation, data curation, formal analysis, investigation, methodology and writing – original draft preparation. C.B. and A.C.D. were responsible for conceptualisation, formal analysis, project administration, supervision, visualisation and writing – review & editing. M.F.G. contributed with conceptualisation and writing – review & editing.
Financial support
This study was funded by a grant awarded by Bloomberg Philanthropies through a sub award agreement between the Center for Epidemiological Studies for Nutrition and Health, University of São Paulo and the University of North Carolina at Chapel Hill (grant number: 5104695). Beatriz Silva Nunes was granted a master’s scholarship from the Brazilian Coordination of Superior Level Staff Improvement (grant number: 88887.639661/2021-00). The funders had no role in the study design, data collection and analysis, decision to publish or preparation of the manuscript.
Competing interests
None declared.
Ethics of human subject participation
This manuscript did involve human participants in the study.



 Open access
Open access