




1. Introduction
One of the biggest challenges in bilingualism research is accurately determining relative language dominance from language background data. While standardized questionnaires exist for collecting such data, there is no widely accepted formula for calculating dominance. These questionnaires differ in focus and detail, with commonly used examples including the Language History Questionnaire (LHQ) (Li et al., Reference Li, Zhang, Tsai and Puls2014), Bilingual Language Profile (BLP) (Birdsong et al., Reference Birdsong, Gertken and Amengual2012), Language Experience and Proficiency Questionnaire (LEAP-Q) (Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007), and Language Use Questionnaire (LUQ) (Kastenbaum et al., Reference Kastenbaum, Bedore, Peña, Sheng, Mavis, Sebastian-Vaytadden and Kiran2019; Marte et al., Reference Marte, Carpenter, Scimeca, Russell-Meill, Peñaloza, Grasemann and Kiran2025). They typically assess factors such as language exposure, proficiency, age of acquisition, and frequency of use to estimate bilinguals’ relative proficiency (e.g., Blumenfeld & Marian, Reference Blumenfeld and Marian2013; Grant & Dennis, Reference Grant and Dennis2017; Mercier et al., Reference Mercier, Pivneva and Titone2014; Titone et al., Reference Titone, Libben, Mercier, Whitford and Pivneva2011). However, despite efforts to gather increasingly comprehensive linguistic background data, the challenge of quantifying language dominance and the degree of multilingualism from these data remain unresolved.
Some of the primary methods used to compute language dominance in the literature include (A) self-reported dominance scores (e.g., Birdsong et al., Reference Birdsong, Gertken and Amengual2012; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007), which ask bilinguals to rate their dominance on a Likert scale, relying on subjective judgments (Amengual, Reference Amengual2016; Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007; Lemhöfer et al., Reference Lemhöfer, Dijkstra and Michel2004; Paap & Greenberg, Reference Paap and Greenberg2013). (B) Specific performance metrics, where researchers assess dominance using vocabulary size, lexical retrieval, morphological and syntax competence, or verbal fluency measures (e.g., Bonvin et al., Reference Bonvin, Brugger and Berthele2023; Gollan et al., Reference Gollan, Weissberger, Runnqvist, Montoya and Cera2012; Paradis & Nicoladis, Reference Paradis and Nicoladis2007; Pienemann et al., Reference Pienemann, Keßler and Itani-Adams2011). (C) Principal component analyses (PCA) to reduce all language background variables to a single dimension (e.g., Chen et al., Reference Chen, Marte, Kiran and Blanco-Elorrieta2025; Kastenbaum et al., Reference Kastenbaum, Bedore, Peña, Sheng, Mavis, Sebastian-Vaytadden and Kiran2019) or (D) average scores, which vary on whether they exclusively include language background variables or whether they combine language experience measures (e.g., proficiency) with some objective measure. For example, Robinson Anthony and Blumenfeld (Reference Robinson Anthony and Blumenfeld2019) created a composite dominance score by combining two subjective measures – self-reported language abilities (speaking, understanding, listening, and reading) and exposure to Spanish and English – with an objective proficiency score from the MINT (Gollan et al., Reference Gollan, Weissberger, Runnqvist, Montoya and Cera2012; see also Gálvez-McDonough et al., Reference Gálvez-McDonough, Blumenfeld, Barragán-Diaz, Anthony and Riès2024).
While these approaches have been important stepping stones, they (i) assign equal weight to every background measure despite the likelihood that their contributions to language dominance vary, and (ii) do not incorporate established insights about bilingual language acquisition into these calculations. Importantly, the heterogeneity in these approaches highlights a critical issue in the field: despite many bilingualism studies collecting extensive language background data, there is no clear, standardized method to synthesize this information into a single measure of language dominance or degree of multilingualism, which makes it difficult to apply the collected data in systematic ways during analysis and interpretation. Furthermore, without a unified formula, the field risks obtaining inconsistent or noncomparable results, undermining the generalizability of results across bilingualism studies.
Thus, a more theoretically and empirically grounded approach to measuring language dominance is needed. In this article, we introduce formulas for calculating both a language dominance index and a degree-of-multilingualism score derived from two key variables: self-rated proficiency and age of acquisition (AoA). It is well established that later AoA is generally associated with lower ultimate proficiency, and numerous studies have attempted to characterize this relationship in detail (Hakuta et al., Reference Hakuta, Bialystok and Wiley2003; Hartshorne et al., Reference Hartshorne, Tenenbaum and Pinker2018; Johnson & Newport, Reference Johnson and Newport1989; Sebastián-Gallés et al., Reference Sebastián-Gallés, Echeverría and Bosch2005; Vanhove, Reference Vanhove2013). Although the existence of a biologically constrained critical period for language acquisition remains debated (Critical Period Hypothesis; Johnson & Newport, Reference Johnson and Newport1989), AoA nonetheless covaries with sociolinguistic factors such as amount of exposure, language of education, and patterns of daily use, all of which influence ultimate attainment. For this reason, AoA must be considered when deriving a robust measure of language dominance. Self-rated proficiency is included as a practical proxy for overall language ability, allowing assessment without lengthy standardized testing. These formulas integrate these key predictors while minimizing redundancy, providing a replicable, time-efficient method of characterizing bilingual experience. The specific implementation of these parameters, and empirical validation demonstrating that the combination of AoA and self-rated proficiency is sufficient for language dominance calculation, is detailed in Section 2.3.1. An interactive calculator for these measures as well as the code associated with the calculations are available at https://neulabnyu.com/language-dominance-score.
2. Methods
2.1. Language dominance measure
The goal of computing a language dominance measure is to obtain a continuous score ranging from −1 (fully dominant in one language) to 1 (fully dominant in the other), with 0 indicating a perfect balance between both languages. Here, we applied the following approach to obtain this value in a streamlined, theoretically informed manner.
2.1.1. Step 1: Deriving normalized proficiency scores
For each participant and language, we averaged self-rated scores for listening, speaking, writing, and reading into a composite proficiency score, then normalized it between 0 and 1 relative to each participant’s highest rating to account for individual biases in self-reporting and ensure that a participant’s strongest language received a perfect proficiency score.
Here, we rely on self-rated proficiency over standardized test measures. This choice does not affect the nature of the formula or dominance calculation; it is driven by an accuracy-cost trade-off given that self-rated proficiency is highly correlated with objective measures such as the MINT (Gollan et al., Reference Gollan, Weissberger, Runnqvist, Montoya and Cera2012; Luk & Bialystok, Reference Luk and Bialystok2013; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007) and does not appear to provide additional explanatory power.
We tested this directly analyzing data from a sample of n = 38 (age: 18–32 [M = 20.30, SD = 2.67]; 27 female, 11 male; Blanco-Elorrieta et al., Reference Blanco-Elorrieta, Ding, Pylkkänen and Poeppel2020), which contained both self-rated proficiency and standardized scores in speaking, hearing, reading, writing using the Woodcock–Muñoz English Language Survey (Woodcock et al., Reference Woodcock, Muñoz-Sandoval, Ruef and Alvarado2005). Variance analyses showed that the averaged self-rated ability accounted for over 97% of variance in standardized scores across all language abilities (speaking = 97.8%; listening = 98.3%; reading = 98%; writing = 97.9%), confirming that self-assessments effectively capture language proficiency.
Thus, given that standardized testing imposes practical costs including increased time, resources, and participant burden/stress, while offering little additional explanatory value beyond self-rated proficiency, we advocate for the most parsimonious and least labor-intensive approach.
2.1.2. Step 2: Modeling AoA effects on ultimate proficiency potential
To model how ultimate language proficiency varies as a function of age of first exposure (AoA), we drew on the largest empirical dataset to date examining this relationship. As Vanhove (Reference Vanhove2013) noted, most prior studies relied on relatively small samples (typically 50–250 participants), which limits the precision of estimates. In contrast, Hartshorne et al. (Reference Hartshorne, Tenenbaum and Pinker2018) analyzed data from hundreds of thousands of bilinguals, providing a more reliable basis for parameterizing our model. Their analysis treated ultimate attainment of grammar as the integral of learning rate over time. They observed that the learning rate remains stable until approximately 17.4 years of age, after which it declines steadily. Because achieving native-like proficiency requires accruing sufficient years of experience during this period of maximal learning rate, this decline translates into a reduction in ultimate proficiency for learners who begin after roughly 10–12 years of age.
Guided by these findings, we set the tipping point in our model at 10 years of age. However, we departed from Hartshorne et al.’s approach in one respect: rather than modeling a continuous decline after the tipping point, we imposed an upper limit of approximately 80% of maximum potential for learners who begin after age 18. This ceiling was motivated by our own replication of Hartshorne et al.’s results, which showed that an AoA of 18 corresponds to an ultimate attainment of roughly 80%. While Hartshorne et al. modeled actual outcomes, our focus here was on the theoretical maximum potential constrained by AoA. Individual differences among very late learners are expected to be captured in Step 1 through self-rated proficiency, and additional language domains (e.g., semantics and vocabulary) may be less sensitive to AoA effects. To model the earlier characteristics, we transformed the averaged AoA across the four language components (with the averaged AoA of the first acquired languages was corrected to 0) using the following logistic function:
 $$ 1-\frac{0.2}{1+{e}^{-0.75 AoA+10}} $$
$$ 1-\frac{0.2}{1+{e}^{-0.75 AoA+10}} $$
Having modeled the effect of age of acquisition on attained proficiency, we then multiply this AoA factor with the scaled self-rated ability from Step 1 to obtain a composite proficiency score for each language.
 $$ Ability\times \left(1-\frac{0.2}{1+{e}^{-0.75 AoA+10}}\right) $$
$$ Ability\times \left(1-\frac{0.2}{1+{e}^{-0.75 AoA+10}}\right) $$
2.1.3. Step 3: Calculating language dominance
Finally, language dominance is defined as the difference in scaled proficiency between the pair of languages of interest (denoted as L1 and L2 in the formula):
 $$ {\displaystyle \begin{array}{l}\hskip1.5em {Ability}_{L1}\times \left(1-\frac{0.2}{1+{e}^{-0.75{AoA}_{L1}+10}}\right)\\ {}-{Ability}_{L2}\times \left(1-\frac{0.2}{1+{e}^{-0.75{AoA}_{L2}+10}}\right)\end{array}} $$
$$ {\displaystyle \begin{array}{l}\hskip1.5em {Ability}_{L1}\times \left(1-\frac{0.2}{1+{e}^{-0.75{AoA}_{L1}+10}}\right)\\ {}-{Ability}_{L2}\times \left(1-\frac{0.2}{1+{e}^{-0.75{AoA}_{L2}+10}}\right)\end{array}} $$
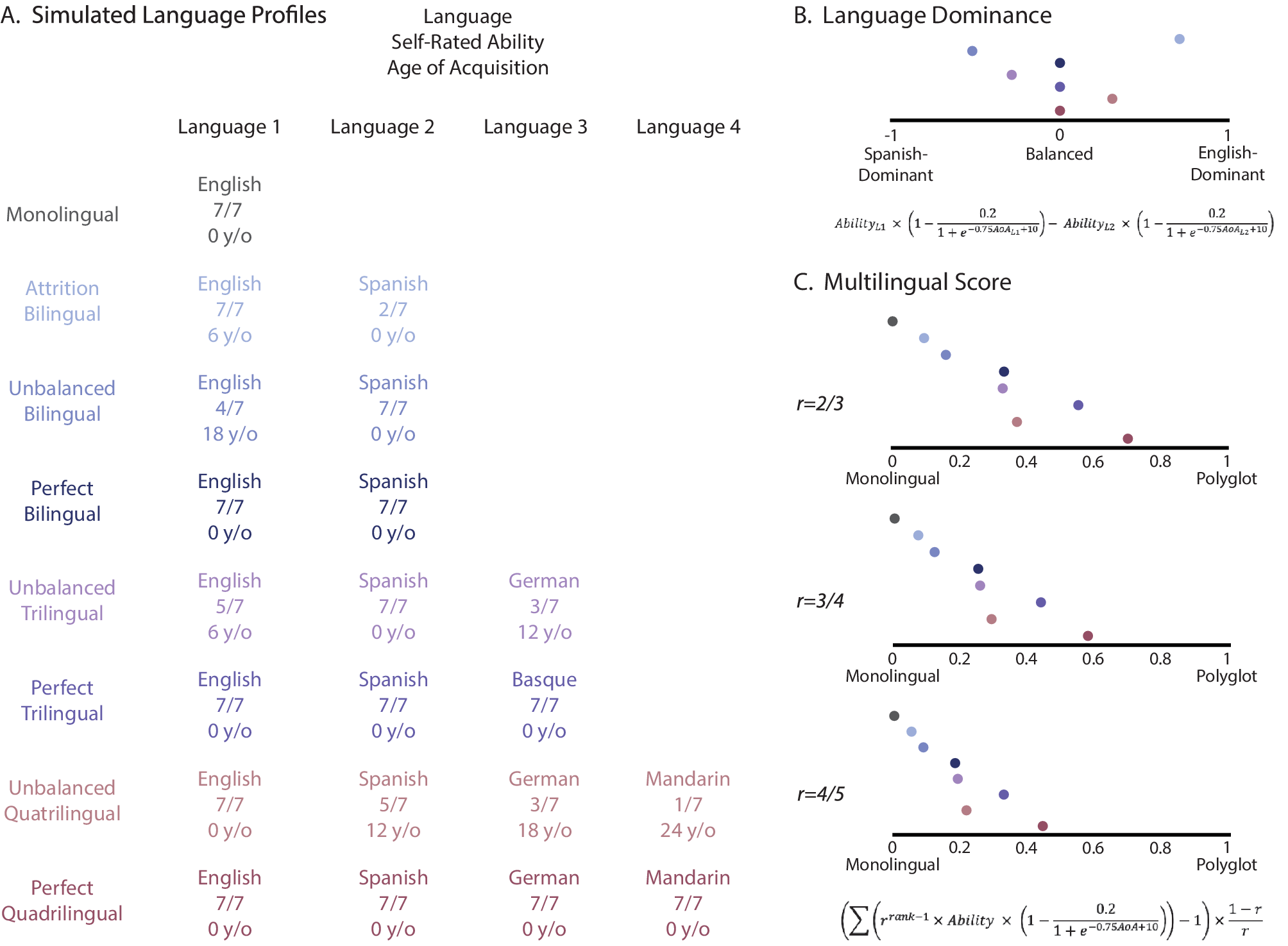
This value ranges from −1 to 1, where a value closer to 1 or −1 indicates a strong dominance in one language over the other, whereas values closer to zero indicate balanced bilingualism. For multiple examples of Language Profile simulations and corresponding Language Dominance calculations see Figure 1.

Figure 1. Language dominance and multilingual score in simulated language background profiles. (A) Simulated language profiles with the languages they speak, self-rated ability, and age of acquisition. (B) Language dominance measure for each of the simulated profiles. (C) Multilingual score with different common ratios that scales the weight of each additional language.
2.2. Multilingualism score
Alongside a dominance formula, the field’s shift toward viewing bilingualism as a spectrum calls for a continuous measure that precisely quantifies degree of bilingualism. We propose an efficient multilingual scale that takes each participant’s ability rating and AoA in each language and outputs a value from zero to one, where zero corresponds to a perfect monolingual, and one to a hypothetical perfect polyglot. Steps 1 and 2 are as in the Language Dominance Calculation.
 $$ Ability\times \left(1-\frac{0.2}{1+{e}^{-0.75 AoA+10}}\right) $$
$$ Ability\times \left(1-\frac{0.2}{1+{e}^{-0.75 AoA+10}}\right) $$
2.2.1. Step 4: Calculate each language’s weight
Each language’s weighting reflects the differential contribution of adding an additional language to one’s language experience, where, intuitively, the distance between a perfect monolingual and a perfect bilingual should be more pronounced than the distance between a perfect quadrilingual and a perfect quintilingual.
To compute this weighing, we first ordered each participant’s languages from their most proficient language (L1) to their least proficient language (Ln). If two languages had identical proficiency scores, their ranking was considered indistinguishable, and their order was randomized. Once the languages had been ranked, we had to determine the function by which the weight of each additional language would decrease. However, unlike the effect of AoA, the precise magnitude of this effect is empirically undefined. Here, we decided to use a geometric sequence in the form of
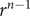 $ {r}^{n-1} $
, where the initial value is 1 and the consecutive values are always scaled by the same ratio (
$ {r}^{n-1} $
, where the initial value is 1 and the consecutive values are always scaled by the same ratio (
 $ r $
, the common ratio). The ratio should be between 0 and 1 so that the weights are always positive while decreasing in magnitude. A ratio closer to 1 would suggest that each additional language contributes similarly to how multilingual one is (e.g., the distance between a perfect monolingual and a perfect bilingual is the same as a perfect bilingual and a perfect trilingual). In contrast, a ratio closer to 0 would mean that one’s multilingual-ness is purely reduced to their first two languages, while acquiring a third language have no additional effect on how multilingual one is. This is theoretically motivated to ensure that each additional language carries progressively less weight than the previous one by the same proportion.
$ r $
, the common ratio). The ratio should be between 0 and 1 so that the weights are always positive while decreasing in magnitude. A ratio closer to 1 would suggest that each additional language contributes similarly to how multilingual one is (e.g., the distance between a perfect monolingual and a perfect bilingual is the same as a perfect bilingual and a perfect trilingual). In contrast, a ratio closer to 0 would mean that one’s multilingual-ness is purely reduced to their first two languages, while acquiring a third language have no additional effect on how multilingual one is. This is theoretically motivated to ensure that each additional language carries progressively less weight than the previous one by the same proportion.
 $$ w={r}^{\mathit{\operatorname{rank}}-1} $$
$$ w={r}^{\mathit{\operatorname{rank}}-1} $$
2.2.2. Step 5: Compute the final multilingualism score
To compute the final multilingual measure, we compute a weighted sum of language proficiencies. Then, we scale the resulting scores from 0 to 1. The unscaled weighted sum has a minimum value of 1 for monolingual speakers and approaches
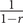 $ \frac{1}{1-r} $
for a hypothetical polyglot that speaks infinite languages perfectly. This means that the total range of unscaled values is
$ \frac{1}{1-r} $
for a hypothetical polyglot that speaks infinite languages perfectly. This means that the total range of unscaled values is
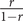 $ \frac{r}{1-r} $
. To scale the measure appropriately, we first subtract 1 to set the monolingual score to 0. Then, we multiply it by the inverse of the total possible range,
$ \frac{r}{1-r} $
. To scale the measure appropriately, we first subtract 1 to set the monolingual score to 0. Then, we multiply it by the inverse of the total possible range,
 $ \frac{1-r}{r} $
, ensuring the values are normalized within a 0 to 1 scale. The resulting weight function can be expressed as below.
$ \frac{1-r}{r} $
, ensuring the values are normalized within a 0 to 1 scale. The resulting weight function can be expressed as below.
 $$ \left(\sum \left({r}^{\mathit{\operatorname{rank}}-1}\times Ability\times \left(1-\frac{0.2}{1+{e}^{-0.75 AoA+10}}\right)\right)-1\right)\times \frac{1-r}{r} $$
$$ \left(\sum \left({r}^{\mathit{\operatorname{rank}}-1}\times Ability\times \left(1-\frac{0.2}{1+{e}^{-0.75 AoA+10}}\right)\right)-1\right)\times \frac{1-r}{r} $$
Here, we tested three values for the common ratio:
 $ \frac{2}{3} $
,
$ \frac{2}{3} $
,
 $ \frac{3}{4} $
, and
$ \frac{3}{4} $
, and
 $ \frac{4}{5} $
, corresponding to decreased weights of 0.67, 0.75, and 0.8 for each additional language, respectively.
$ \frac{4}{5} $
, corresponding to decreased weights of 0.67, 0.75, and 0.8 for each additional language, respectively.
 $ \frac{3}{4} $
provided the most accurate approximation based on our simulated language profiles (see Figure 1) and thus was the weighing function we settled on.
$ \frac{3}{4} $
provided the most accurate approximation based on our simulated language profiles (see Figure 1) and thus was the weighing function we settled on.
2.3. Validating our proposed measure
While these formulas were designed based on theoretical and empirical foundations from prior research, their practical applicability required experimental validation. Thus, we next validated their robustness by testing them on two large, real-world datasets from different populations. Dataset 1 included language background information from 131 healthy (mostly young, age: 18–60 [M = 25.73, SD = 7.80], 76 female, 53 male, 2 nonbinary) monolinguals and bilinguals who completed a language questionnaire derived from LEAP-Q (Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007) and Language Use Questionnaire (LUQ; Kastenbaum et al., Reference Kastenbaum, Bedore, Peña, Sheng, Mavis, Sebastian-Vaytadden and Kiran2019; Marte et al., Reference Marte, Carpenter, Scimeca, Russell-Meill, Peñaloza, Grasemann and Kiran2025). Dataset 2 consisted of 139 older bilingual individuals with aphasia (age: 18–82 [M = 46.69, SD = 17.00], gender information unavailable), who completed the LUQ. We chose these datasets to ensure that our measures can capture variance across both young/typical and older/clinical populations, enhancing their generalizability.
2.3.1. Is including only age of acquisition and proficiency enough?
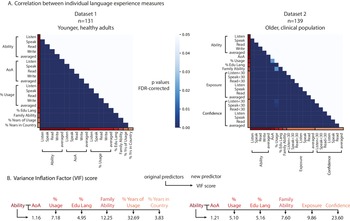
In recent years, language background questionnaires have become increasingly detailed, collecting extensive information about participants’ linguistic history, including exposure and proficiency across different age ranges, education levels, and familial language backgrounds. While these additions provide a more granular view, we propose a simpler approach – a formula that relies on only two key variables, under the assumption that they sufficiently capture the essential variance in language background. To test this assumption, we conducted multiple Pearson’s correlation analyses across all language background factors in both datasets (excluding poststroke factors). Even after correcting for false discovery rate across multiple comparisons, we found that all language background variables were significantly correlated with each other in both datasets, indicating that they largely captured the same underlying variance (see Figure 2).

Figure 2. Relationship between different language background predictors. (A) Pearson’s correlation between each pair of language background measures. All measures are highly correlated (p < 0.05, FDR-corrected). (B) Variance inflection factor (VIF) scores. AoA: age of acquisition. % Usage: percentage of time using the language, averaged across different age brackets. % Edu Lang: percentage that the language is used as the instruction language in school. Family Ability: averaged ability of the language in both parents and siblings, whenever applicable. % Years of Usage: percentage of years in life where the language was in use. % Years in Country: percentage of years in life spent in a country with the language as their official language. Exposure: averaged language exposure across different age brackets. Confidence: averaged level of confidence across different age brackets. <30 indicates that the measure is only considering the profile before age 30.
To confirm that only AoA and ability contribute unexplained variance – making them the essential factors for our dominance and multilingualism formulas – we calculated the variance inflation factor (VIF) among the language background measures. VIF quantifies multicollinearity: if adding a new predictor to the model results in a VIF score above 5, it indicates severe redundancy, meaning the new variable contributes little unique variance beyond what an existing predictor already captures.
Here, we examined whether any additional language background variable accounted for meaningful variance beyond the normalized self-rated ability as in Step 1. First, we tested AoA and found that in both Dataset 1 and Dataset 2, it could account for variance over and above that accounted for by self-rated ability (Dataset 1: VIF = 1.16; Dataset 2: VIF = 1.21). Subsequently, we tested the rest of the predictors on both self-rated ability and AoA. Across both datasets, the only predictor that consistently had a score below 5 is the percentage of years spent in a country where the language of interest is the official language (% Years in Country, VIF = 3.83, Dataset 1), which could be an indicator of language immersion. All other predictors showed substantial multicollinearity, with VIF values well above the threshold (e.g., percentage usage across life (VIF = 7.18 and 5.10, respectively), percentage of language used in Education (VIF = 4.95 and 5.16), averaged ability of the Family (VIF = 12.25 and 7.60).
These results confirm that beyond AoA, no additional predictor provided independent explanatory power (except for % of Years in Country, but see Validation and Discussion next). Therefore, our decision to use only self-rated ability and AoA is empirically justified, as adding more variables would create redundancy without contributing meaningful new information.
2.3.2. Validation against multidimensional (PCA) approaches
Finally, we compared the performance of our language dominance measure against multidimensional approaches that have emerged in recent years (Chen et al., Reference Chen, Marte, Kiran and Blanco-Elorrieta2025; Kastenbaum et al., Reference Kastenbaum, Bedore, Peña, Sheng, Mavis, Sebastian-Vaytadden and Kiran2019; Marte et al., Reference Marte, Carpenter, Scimeca, Russell-Meill, Peñaloza, Grasemann and Kiran2025). Our measure offers a simplified and streamlined approach by deriving the dominance score from the two key dimensions that account for the most variance across language background questionnaires. However, an alternative approach could be to leverage the high-dimensional language background data and apply dimensionality reduction to derive dominance measures through principal component analysis (PCA).
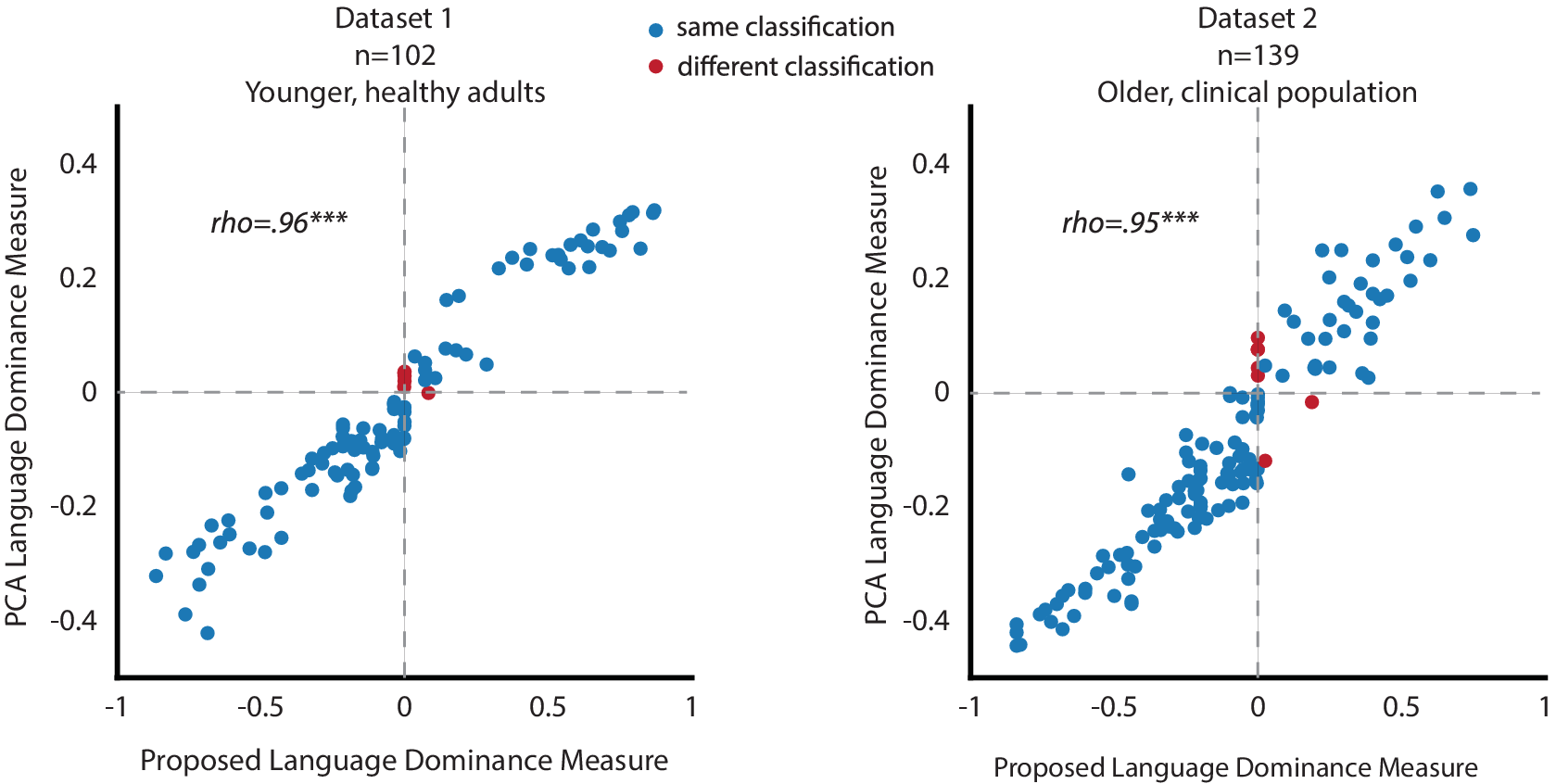
Here, we compared our language dominance measure to a PCA-based dominance calculation in Dataset 1 (n = 102 excluding monolinguals) and Dataset 2. Following prior work (Chen et al., Reference Chen, Marte, Kiran and Blanco-Elorrieta2025), we calculated the difference between English and participants’ L2Footnote 1 across all variables in each language background questionnaire (LEAP-Q and LUQ). We standardized the data to have a mean of 0 and a standard deviation of 1, ensuring comparability across all dimensions. Then, we derived a PCA-based dominance score by projecting individual data points onto the first principal component. To interpret the signage and magnitude of the projected values, we scaled them linearly between −1 and 1 based on the projection value of two simulated monolingual profiles on both sides. Like in our language dominance measure, −1 and 1 in the scaled PCA represents monolinguals on both sides, and 0 indicates a perfectly balanced bilingual. We fit PCA separately to each of the two datasets because they contain different language background questions.
We used two approaches to assess the similarity between the two language dominance measures. First, we calculated Spearman’s rank correlations between the PCA-based dominance score and our proposed dominance measure. Second, we categorized participants as either English-dominant or L2-dominant based on both measures: scores between −1 and 0 indicated L2 dominance, while scores between 0 and 1 indicated English dominance. A strong correlation and a low percentage of classification differences would suggest that our simpler, theoretically grounded measure closely aligns with the more complex, PCA-based approach.
In both datasets, the first principal component explained the majority of the variance (Dataset 1: 86.0%; Dataset 2: 79.4%), confirming the validity of using one component to derive a language dominance score. The two dominance measures were strongly correlated (Dataset 1: rho = .96, p < 0.001; Dataset 2: rho = .95, p < 0.001; Figure 3), demonstrating that collecting large amounts of language background data and applying multidimensional analyses does not yield a more accurate dominance calculation. For the categorical classification, 94.1% of the participants in Dataset 1 and 95.0% of the participants in Dataset 2 were consistently classified by the two dominance measures. Further inspection of the people who were classified differently showed that they were very close to a perfectly balanced bilingual (value of <0.03 in at least one of the two measures), making the classification into categorical dominance groups essentially moot.

Figure 3. Comparison between our proposed theoretically grounded and PCA-based language dominance measures. Blue dots represent data points classified in the same dominance group across both measures, while red dots indicate data points assigned to different dominance groups in the two measures. The two language dominance measures produce nearly identical results, showing a near-perfect correlation with only a few data points classified differently.
3. Discussion
In this study, we addressed a long-standing challenge in bilingualism research: the accurate and standardized assessment of language dominance and degree of multilingualism. While existing assessment tools provide valuable insights into linguistic background, they often rely on heterogeneous methodologies that limit cross-study comparability. Our proposed formulas offer a computationally streamlined approach to measuring language dominance on a continuous scale, providing a replicable and efficient alternative to existing methods.
One key innovation of our approach is the reliance on self-rated proficiency and AoA as the primary variables for dominance calculation. Through multiple empirical validations, we demonstrated that these two variables capture the vast majority of variance in bilingual language profiles, rendering additional background measures largely redundant. This supports the decision to prioritize a parsimonious model that reduces participant burden and enhances methodological consistency without sacrificing predictive accuracy. One could further refine the measure to incorporate the percentage of years in life spent in a country with the language as their official language, which is the only other measure that showed a VIF score lower than 5 and suggested low multicollinearity. This variable can be a measure of language immersion that is modeled for language attainment in Hartshorne et al. (Reference Hartshorne, Tenenbaum and Pinker2018). However, given the high similarity between the language dominance derived from our measure and the PCA approach where the information was available, we do not think it is necessary for the current purpose.
Furthermore, our logistic transformation of AoA introduces a biologically informed adjustment that accounts for the diminishing impact of later language exposure on ultimate proficiency. This function, derived from a large-scale study of bilingual language attainment (e.g., Hartshorne et al., Reference Hartshorne, Tenenbaum and Pinker2018), allows us to model a realistic trajectory of proficiency development, ensuring that the dominance measure reflects both self-reported ability and age-related constraints on language learning.
The strong correlation between our dominance measure and PCA-based dominance scores (rho = .96 and rho = .95, p < .001) demonstrates that our simple formula achieves results comparable to high-dimensional statistical methods. These findings suggest that complex, multidimensional statistical techniques do not necessarily offer superior assessments of language dominance; instead, a well-calibrated, theoretically motivated formula can yield equally reliable results while maintaining ease of application.
Beyond dominance calculations, we also introduced a multilingualism score that situates bilingualism/multilingualism within a broader, continuous spectrum of language experience. By weighting each language’s contribution to an individual’s linguistic repertoire, our approach acknowledges the differential impact of adding additional languages to one’s language profile. This measure aligns with recent shifts in the field toward viewing bilingualism as a gradient rather than a categorical variable, providing a quantitative framework for researchers investigating multilingual populations.
Overall, we propose a standardized and replicable method for measuring language dominance and multilingualism, grounded in both empirical evidence and biological constraints. By offering a computationally efficient and easily implementable framework, that does not rely on labor intensive language background collecting practices, our approach has the potential to enhance cross-study comparability and methodological consistency in bilingualism research, providing a valuable tool for future investigations into multilingual language experience.
Data availability statement
All data and code for this project are available on the Open Science Framework at https://osf.io/h28k3/.
Acknowledgements
This research was supported by NIH grant R00DC019973 and NSF grant 2446452 to EBE.
Competing interests
The authors declare no competing interests.

 Open access
Open access