


1 Introduction
Item response theory (IRT) offers useful psychometric insights from a given item response dataset by modeling the probabilistic relationships between item responses and parameters (van der Linden, Reference van der Linden2016). Parametric IRT models postulate ability parameter(s) per examinee and a set of item parameter(s) per item, where the probability of an item response is a function of these parameters. Since biases and errors that occur from the estimation of these parameters can have negative impacts on subsequent decision-making processes, the accuracy of the parameter estimation is crucial.
For the estimation of these parameters, marginal maximum likelihood (MML) estimation has been widely used to separate the ability parameters from the item parameters and construct asymptotically consistent estimators (Baker & Kim, Reference Baker and Kim2004; Glas, Reference Glas and Linden2016). In addition, the MML with the expectation–maximization algorithm (MML-EM; Bock & Aitkin, Reference Bock and Aitkin1981), which expedites the MML estimation, is widely used for the parameter estimation of IRT models.
Meanwhile, the MML-EM procedure is typically implemented with the normality assumption on the latent distribution (distribution of the latent variable). However, the normality assumption can be violated in practice. For instance, bimodal latent distributions can be observed from the achievement gap within a group of students or from an innate human tendency to be inclined to one side of the latent scale (Harvey & Murry, Reference Harvey and Murry1994; Yadin, Reference Yadin2013). Also, skewed latent distributions can be observed by a subgroup that exhibits extreme scale scores or by ceiling/floor effects from the test difficulty relative to the population level in the latent scale (Ho & Yu, Reference Ho and Yu2015; Woods, Reference Woods, Reise and Revicki2015). The violation of the normality assumption can increase estimation biases, and the estimation of the latent distribution can correct the biases to some extent by reflecting the non-normality (Li, Reference Li2024; Woods, Reference Woods, Reise and Revicki2015).
Some methods have been proposed to estimate the latent distribution to relax the normality assumption, thereby decreasing estimation biases: the empirical histogram method (EHM; Bock & Aitkin, Reference Bock and Aitkin1981; Mislevy, Reference Mislevy1984), the two-component normal mixture model (2NM; Li, Reference Li2021; Mislevy, Reference Mislevy1984), the Ramsay-curve method (RCM; Woods, Reference Woods2006), the log-linear smoothing method (LLS; Casabianca & Lewis, Reference Casabianca and Lewis2015), and the Davidian-curve method (DCM; Woods & Lin, Reference Woods and Lin2009).
Meanwhile, the accuracy of density estimation can be further enhanced by adopting asymptotic mean integrated squared error (AMISE) as the loss function. All of the aforementioned methods rely on the likelihood function, which could be attributed to its alignment with the EM algorithm and theoretically ensured convergence (Dempster et al., Reference Dempster, Laird and Rubin1977). This alignment may explain why previous studies have focused almost exclusively on the maximum likelihood estimation (MLE) approach. However, research in density estimation suggests that AMISE is often a more appropriate criterion for achieving accurate density estimates than MLE (Gramacki, Reference Gramacki2018; Silverman, Reference Silverman1986; Wand & Jones, Reference Wand and Jones1995). Therefore, rather than adhering strictly to the likelihood function for the sake of EM alignment, adopting AMISE can be considered the preferable choice for improving the accuracy of latent distribution estimation in IRT, unless it undermines the EM convergence.
In the density estimation literature, many studies have focused on the utilization of the kernel density estimation (KDE) method, along with the AMISE criterion, to find the best density estimation method that can be generally applied to various distribution shapes (e.g., Gramacki, Reference Gramacki2018; Sheather, Reference Sheather2004; Silverman, Reference Silverman1986; Wand & Jones, Reference Wand and Jones1995). This can be attributed to the broad applicability of KDE and its statistical tractability, especially when the Gaussian kernel is adopted. Up to this point, Sheather and Jones’s (Reference Sheather and Jones1991) approach has been proven to be the most recommendable method for KDE in unidimensional density estimation (Jones et al., Reference Jones, Marron and Sheather1996).
This article, thus, aims to propose the application of KDE in the latent distribution estimation of IRT, especially to adopt Sheather and Jones’s (Reference Sheather and Jones1991) approach. KDE is expected to outperform existing methods on average as it minimizes the AMISE instead of the likelihood, which can be a more suitable loss function for density estimation.
Furthermore, KDE has an advantage over some of the existing methods regarding computation time. Although RCM, LLS, and DCM show an acceptable density estimation accuracy with their hyperparameters controlling the degree of density smoothing, their implementations entail a model selection process, which can be considered as an additional cost for estimating the latent distribution. That is, they need to invest a certain amount of extra time to fit several models according to the hyperparameters that determine the complexity of the distribution, then the best model is determined through a model selection process. In contrast, KDE does not require this model selection process as it has only one density parameter that can be inferred within a single model-fitting procedure. Therefore, KDE can carry out the estimation of latent distribution without necessitating multiple model-fitting procedures, while yielding good performance in estimating the latent distribution.
The objectives of this article are two-fold. First, we propose the approach of applying KDE to latent distribution estimation in IRT. Second, we validate the approach through computer simulations. Simulation studies are particularly valuable because they can uncover characteristics of methods that may be overlooked in theoretical derivations and equations. For example, prior works have shown that the seemingly superior performance of EHM, as reflected in its highest log-likelihood, is in fact the result of overfitting, and that the EM algorithm can fail to converge for semi-nonparametric methods, such as RCM and DCM despite their theoretical guarantees in the EM convergence (Woods, Reference Woods2006; Woods & Lin, Reference Woods and Lin2009). Thus, simulations aim to evaluate the practical effectiveness of methods, including their stability, accuracy, and computational efficiency, which cannot be directly inferred from theory alone.
The following sections provide mathematical details of the model (Sections 2 and 3), examine its stability, accuracy, and computation time in parameter estimation (Section 4), illustrate its implementation using empirical data (Section 5), and conclude the article with a discussion (Section 6).
2 Estimation of latent density
This section aims to explain how the latent density estimation of IRT can be reduced to an ordinary density estimation problem by the EM algorithm of the MML-EM procedure. In particular, it is illustrated through the equations that item parameters and the latent density can be estimated separately, simplifying the problem.
2.1 Marginal log-likelihood
Let
 $f(x|\theta , \boldsymbol {\tau })$
be the probability of observed response x given ability parameter
$f(x|\theta , \boldsymbol {\tau })$
be the probability of observed response x given ability parameter
 $\theta $
and item parameter vector
$\theta $
and item parameter vector
 $\boldsymbol {\tau }$
. For example, when the two-parameter logistic model (2PL; Birnbaum, Reference Birnbaum, Lord and Novick1968) is used, the function becomes
$\boldsymbol {\tau }$
. For example, when the two-parameter logistic model (2PL; Birnbaum, Reference Birnbaum, Lord and Novick1968) is used, the function becomes
 $$ \begin{align} \begin{aligned} P(\theta, \boldsymbol{\tau}) = \Pr(x=1|\theta, \boldsymbol{\tau}) = \frac{\exp(a(\theta-b)}{1+\exp(a(\theta-b))}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} P(\theta, \boldsymbol{\tau}) = \Pr(x=1|\theta, \boldsymbol{\tau}) = \frac{\exp(a(\theta-b)}{1+\exp(a(\theta-b))}, \end{aligned} \end{align} $$
 $$ \begin{align} \begin{aligned} f(x|\theta, \boldsymbol{\tau}) = P(\theta, \boldsymbol{\tau})^{x}(1-P(\theta, \boldsymbol{\tau}))^{1-x}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} f(x|\theta, \boldsymbol{\tau}) = P(\theta, \boldsymbol{\tau})^{x}(1-P(\theta, \boldsymbol{\tau}))^{1-x}, \end{aligned} \end{align} $$
where
 $x\in \{0,1\}$
,
$x\in \{0,1\}$
,
 $\boldsymbol {\tau }=\left [a,b\right ]^{'}$
, and a and b are item discrimination and difficulty parameters, respectively. Then, the likelihood of the jth test taker (
$\boldsymbol {\tau }=\left [a,b\right ]^{'}$
, and a and b are item discrimination and difficulty parameters, respectively. Then, the likelihood of the jth test taker (
 $j=1,2,\ldots ,N$
) can be expressed as follows:
$j=1,2,\ldots ,N$
) can be expressed as follows:
 $$ \begin{align} \begin{aligned} L_{j}(\theta_{j}, \mathbf{T}|\mathbf{x}_j)=\prod_{i=1}^{I}{f(x_{ji}|\theta_{j}, \boldsymbol{\tau} _{i})}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} L_{j}(\theta_{j}, \mathbf{T}|\mathbf{x}_j)=\prod_{i=1}^{I}{f(x_{ji}|\theta_{j}, \boldsymbol{\tau} _{i})}, \end{aligned} \end{align} $$
where i denotes items (
 $i=1,2,\ldots ,I$
),
$i=1,2,\ldots ,I$
),
 $\mathbf {T}$
is item parameter matrix, and
$\mathbf {T}$
is item parameter matrix, and
 $\mathbf {x}_j=[x_{j1}, \ldots , x_{ji}, \ldots , x_{jI}]^{\text {T}}$
is the vector of the jth test taker’s item responses.
$\mathbf {x}_j=[x_{j1}, \ldots , x_{ji}, \ldots , x_{jI}]^{\text {T}}$
is the vector of the jth test taker’s item responses.
The MML-EM procedure uses a quadrature scheme to facilitate the EM algorithm. Although other quadrature schemes can be adopted, such as adaptive quadrature (e.g., Haberman, Reference Haberman2006), equidistant points are typically used to approximate the integral. For example, we can focus on the
 $\theta $
range from
$\theta $
range from
 $-6.05$
to
$-6.05$
to
 $6.05$
to include the density mass as much as possible when assuming that the mean and standard deviation of the latent density are 0 and 1, respectively. Dividing the range into 121 equal width intervals of 0.1, the quadrature points are then set at the midpoints of these intervals, resulting in points at
$6.05$
to include the density mass as much as possible when assuming that the mean and standard deviation of the latent density are 0 and 1, respectively. Dividing the range into 121 equal width intervals of 0.1, the quadrature points are then set at the midpoints of these intervals, resulting in points at
 $-6.0, -5.9, -5.8, \ldots , 6.0$
. Using the latent density
$-6.0, -5.9, -5.8, \ldots , 6.0$
. Using the latent density
 $g(\theta , \boldsymbol {\xi })$
with the density parameter vector
$g(\theta , \boldsymbol {\xi })$
with the density parameter vector
 $\boldsymbol {\xi }$
, the marginal log-likelihood of the N test takers becomes
$\boldsymbol {\xi }$
, the marginal log-likelihood of the N test takers becomes
 $$ \begin{align} \begin{aligned} \log{L} &= \log{L(\mathbf{T}, \boldsymbol{\xi}|\mathbf{X})}\\ &= \log{\left\{\prod_{j=1}^{N}\left[ \int_{-\infty}^{\infty}{L_{j}(\theta, \mathbf{T}|\mathbf{x}_j)}g(\theta, \boldsymbol{\xi}) \, d\theta \right]\right\}}\\ &=\sum_{j=1}^{N}\log{\left[ \int_{-\infty}^{\infty}{L_{j}(\theta, \mathbf{T}|\mathbf{x}_j)}g(\theta, \boldsymbol{\xi}) \, d\theta \right]} \\ &\approx \sum_{j=1}^{N}\log{\left[ \sum_{q=1}^{Q}L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{x}_j)A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \log{L} &= \log{L(\mathbf{T}, \boldsymbol{\xi}|\mathbf{X})}\\ &= \log{\left\{\prod_{j=1}^{N}\left[ \int_{-\infty}^{\infty}{L_{j}(\theta, \mathbf{T}|\mathbf{x}_j)}g(\theta, \boldsymbol{\xi}) \, d\theta \right]\right\}}\\ &=\sum_{j=1}^{N}\log{\left[ \int_{-\infty}^{\infty}{L_{j}(\theta, \mathbf{T}|\mathbf{x}_j)}g(\theta, \boldsymbol{\xi}) \, d\theta \right]} \\ &\approx \sum_{j=1}^{N}\log{\left[ \sum_{q=1}^{Q}L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{x}_j)A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]}, \end{aligned} \end{align} $$
where
 $\mathbf {X}$
is the item response matrix with
$\mathbf {X}$
is the item response matrix with
 $\mathbf {X}_{j,i}=x_{ji}$
. The subscript j on
$\mathbf {X}_{j,i}=x_{ji}$
. The subscript j on
 $\theta $
is discarded by the independent and identically distributed (
$\theta $
is discarded by the independent and identically distributed (
 $iid$
) assumption. Approximating the integral by summation using a quadrature scheme,
$iid$
) assumption. Approximating the integral by summation using a quadrature scheme,
 $\theta _{q}^{*}$
denotes the qth quadrature point (
$\theta _{q}^{*}$
denotes the qth quadrature point (
 $q=1,2,\ldots ,Q$
) and
$q=1,2,\ldots ,Q$
) and
 $A(\theta _{q}^{*})=\frac {g(\theta _{q}^{*})}{\sum ^{Q}_{q=1}{g(\theta _{q}^{*})}}$
is a normalized latent distribution at
$A(\theta _{q}^{*})=\frac {g(\theta _{q}^{*})}{\sum ^{Q}_{q=1}{g(\theta _{q}^{*})}}$
is a normalized latent distribution at
 $\theta _{q}^{*}$
. The superscript
$\theta _{q}^{*}$
. The superscript
 $*$
is introduced to emphasize the discretization of the continuous variable
$*$
is introduced to emphasize the discretization of the continuous variable
 $\theta $
.
$\theta $
.
2.2 Likelihood of latent density
In the expectation step (E-step) of the MML-EM procedure, the quantity
 $\gamma _{jq}$
is calculated using Bayes’ theorem (Baker & Kim, Reference Baker and Kim2004):
$\gamma _{jq}$
is calculated using Bayes’ theorem (Baker & Kim, Reference Baker and Kim2004):
 $$ \begin{align} \gamma_{jq} = \Pr_{j}(\theta^{*} = \theta_{q}^{*}) = \frac{L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi})}{\sum_{q=1}^{Q}L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi})}, \end{align} $$
$$ \begin{align} \gamma_{jq} = \Pr_{j}(\theta^{*} = \theta_{q}^{*}) = \frac{L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi})}{\sum_{q=1}^{Q}L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi})}, \end{align} $$
which is the posterior probability of the jth test taker at
 $\theta ^{*} = \theta _{q}^{*}$
.
$\theta ^{*} = \theta _{q}^{*}$
.
Using the results from the E-step, the marginal likelihood of the M-step can be expressed as follows:
 $$ \begin{align} \log{L(\mathbf{T}, \boldsymbol{\xi}|\mathbf{X})} &\approx \sum_{j=1}^{N}\log{\left[ \sum_{q=1}^{Q}L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]}\notag\\ &= \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\left[ L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]} - \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\gamma_{jq}} \notag\\ &= \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\left[ L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X}) \right]} + \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\left[A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]} - \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\gamma_{jq}} \notag\\ &= \qquad \ell_{item} \qquad + \qquad \ell_{density} \qquad - \qquad \text{constant}\,. \end{align} $$
$$ \begin{align} \log{L(\mathbf{T}, \boldsymbol{\xi}|\mathbf{X})} &\approx \sum_{j=1}^{N}\log{\left[ \sum_{q=1}^{Q}L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]}\notag\\ &= \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\left[ L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X})A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]} - \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\gamma_{jq}} \notag\\ &= \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\left[ L_{j}(\theta_{q}^{*}, \mathbf{T}|\mathbf{X}) \right]} + \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\left[A(\theta_{q}^{*}, \boldsymbol{\xi}) \right]} - \sum_{j=1}^{N}\sum_{q=1}^{Q}\gamma_{jq}\log{\gamma_{jq}} \notag\\ &= \qquad \ell_{item} \qquad + \qquad \ell_{density} \qquad - \qquad \text{constant}\,. \end{align} $$
The separation of the likelihood demonstrates the statistical independence of the item parameters
 $\mathbf {T}$
and density parameters
$\mathbf {T}$
and density parameters
 $\boldsymbol {\xi }$
. Consequently, the density parameters depend only on
$\boldsymbol {\xi }$
. Consequently, the density parameters depend only on
 $\ell _{density}$
.
$\ell _{density}$
.
2.3 Existing methods
Several latent density estimation methods have been proposed to flexibly model the distribution of latent traits in IRT. These methods vary in how they represent the latent distribution, ranging from simple empirical estimates to flexible nonparametric approaches. While these approaches aim to relax the normality assumption underlying the MML estimation, they differ in estimation accuracy, interpretability, computational burden, and availability of model evaluation criteria.
EHM (Bock & Aitkin, Reference Bock and Aitkin1981; Mislevy, Reference Mislevy1984) is a nonparametric approach that directly utilizes the expected frequencies calculated in the E-step of the EM algorithm. Specifically, it estimates the latent density at each quadrature point as the normalized sum of posterior probabilities across respondents. This method is computationally efficient and easy to implement, since results from the E-step can be directly transformed into a density estimate without additional computation. However, because it does not apply any smoothing, EHM is sensitive to sampling noise, which can result in erratic density shapes and suboptimal item parameter estimates (Li, Reference Li2021; Woods, Reference Woods, Reise and Revicki2015; Woods & Lin, Reference Woods and Lin2009).
DCM (Woods & Lin, Reference Woods and Lin2009) and RCM (Woods, Reference Woods2006) both aim to improve upon EHM by smoothing the noisy expected frequencies. These methods differ in the functional forms they employ for density estimation, but share a common estimation strategy and model selection procedure. DCM models the latent distribution as a squared polynomial multiplied by a standard normal density. The order of the polynomial, denoted by h, determines the complexity of the distribution: when
 $h = 1$
, the model reduces to the normal distribution, while larger values of h allow for increasingly flexible density shapes. To ensure that the resulting function is a proper probability distribution, the polynomial coefficients are constrained via a polar coordinate transformation. On the other hand, RCM uses basis splines, where the order of the splines and the number of breaks are the hyperparameters that control the smoothness of the density. In the estimation of density parameters of RCM, it employs a normal prior to improve estimation stability. However, the standard deviation of the prior is often chosen through trial and error. Both methods require the selection of smoothing parameter(s), which is typically achieved by fitting multiple models and selecting the best one based on the Hannan–Quinn (HQ) criterion (Hannan & Quinn, Reference Hannan and Quinn1979). This criterion, which is similar to information criteria, such as the Akaike information criterion (AIC) and the Bayesian information criterion (BIC), balances model flexibility and overfitting. For RCM, however, visual inspection of the candidate models is also necessary in addition to the HQ criterion.
$h = 1$
, the model reduces to the normal distribution, while larger values of h allow for increasingly flexible density shapes. To ensure that the resulting function is a proper probability distribution, the polynomial coefficients are constrained via a polar coordinate transformation. On the other hand, RCM uses basis splines, where the order of the splines and the number of breaks are the hyperparameters that control the smoothness of the density. In the estimation of density parameters of RCM, it employs a normal prior to improve estimation stability. However, the standard deviation of the prior is often chosen through trial and error. Both methods require the selection of smoothing parameter(s), which is typically achieved by fitting multiple models and selecting the best one based on the Hannan–Quinn (HQ) criterion (Hannan & Quinn, Reference Hannan and Quinn1979). This criterion, which is similar to information criteria, such as the Akaike information criterion (AIC) and the Bayesian information criterion (BIC), balances model flexibility and overfitting. For RCM, however, visual inspection of the candidate models is also necessary in addition to the HQ criterion.
LLS (Casabianca & Lewis, Reference Casabianca and Lewis2015) is another approach that aims to regularize the noisy frequency estimates from EHM by fitting a log-linear model to the expected posterior counts. It expands the log-density as a linear combination of polynomials, and its hyperparameter controls the smoothness of the density by determining the highest degree of the polynomials. However, unlike DCM, the model selection strategy of LLS has not been clearly established to determine the optimal hyperparameter.
The 2NM (Li, Reference Li2021; Mislevy, Reference Mislevy1984) is a parametric alternative that extends the standard normality assumption by modeling the latent distribution as a weighted sum of two normal distributions. This added flexibility allows 2NM to capture deviations from normality, such as skewness or bimodality. The density parameters are estimated using a secondary EM algorithm nested within the MML-EM framework. While the parametric form of 2NM offers advantages, such as interpretability and analytic simplicity, it also imposes constraints on flexibility, making it less capable of capturing complex or highly irregular latent distributions compared to nonparametric or semi-nonparametric approaches.
3 Kernel density estimation in IRT
3.1 Kernel density estimation
KDE is a nonparametric density estimation method that assigns a kernel function to each observed data point (Silverman, Reference Silverman1986). Let the vector
 $\mathbf {z}=\left [Z_{1}, \, Z_{2}, \, \dots , \, Z_{N}\right ]^{\text {T}}$
denote N observed data points. The kernel functions formulate the density as follows:
$\mathbf {z}=\left [Z_{1}, \, Z_{2}, \, \dots , \, Z_{N}\right ]^{\text {T}}$
denote N observed data points. The kernel functions formulate the density as follows:
 $$ \begin{align} g(z|h)= \frac{1}{Nh}\sum_{j=1}^{N}{K\left(\frac{z-Z_{j}}{h}\right)}, \end{align} $$
$$ \begin{align} g(z|h)= \frac{1}{Nh}\sum_{j=1}^{N}{K\left(\frac{z-Z_{j}}{h}\right)}, \end{align} $$
where
 $K(\cdot )$
is the kernel function and h is the hyperparameter called bandwidth. The bandwidth controls the degree of density smoothing by determining the width of the kernel function. For example, when the Gaussian kernel is applied, the bandwidth h represents the standard deviations of the kernels. Among the available kernel functions, such as Epanechnikov, biweight, triangular, Gaussian, and uniform, the Gaussian kernel is most commonly adopted due to the minimal influence of kernel choice on the resulting density estimates and the differentiability of the Gaussian form (Gramacki, Reference Gramacki2018; Silverman, Reference Silverman1986). Following this convention, the present study focuses on the Gaussian kernel and its applications.
$K(\cdot )$
is the kernel function and h is the hyperparameter called bandwidth. The bandwidth controls the degree of density smoothing by determining the width of the kernel function. For example, when the Gaussian kernel is applied, the bandwidth h represents the standard deviations of the kernels. Among the available kernel functions, such as Epanechnikov, biweight, triangular, Gaussian, and uniform, the Gaussian kernel is most commonly adopted due to the minimal influence of kernel choice on the resulting density estimates and the differentiability of the Gaussian form (Gramacki, Reference Gramacki2018; Silverman, Reference Silverman1986). Following this convention, the present study focuses on the Gaussian kernel and its applications.
In Figure 1, for illustrative purposes, the standard normal distribution (dotted lines) is estimated using four different bandwidth values (i.e., 0.4, 0.7, 1.0, and 1.3). Using the seven data points generated from the standard normal distribution, seven kernel functions (dashed lines) are formulated. Mathematically, kernel functions are Gaussian distributions with their means as the seven data points and a common standard deviation of h, and are scaled by the total sample size:
 $\frac {1}{N}=\frac {1}{7}$
. The estimated densities (solid lines) are summations of the kernel functions. Among the four density estimates, the standard normal distribution is best recovered when
$\frac {1}{N}=\frac {1}{7}$
. The estimated densities (solid lines) are summations of the kernel functions. Among the four density estimates, the standard normal distribution is best recovered when
 $h=0.7$
. In comparison, the function is under-smoothed when
$h=0.7$
. In comparison, the function is under-smoothed when
 $h=0.4$
, resulting in a bimodal distribution. When
$h=0.4$
, resulting in a bimodal distribution. When
 $h=1.0$
and
$h=1.0$
and
 $h=1.3$
, the flatter shapes compared to the standard normal distribution indicate that they were over-smoothed. Considering that the optimal bandwidth is
$h=1.3$
, the flatter shapes compared to the standard normal distribution indicate that they were over-smoothed. Considering that the optimal bandwidth is
 $h=0.7177$
for this example, it is shown that the density estimate is most accurate when the bandwidth h was closest to the optimal value (see Gramacki, Reference Gramacki2018 for the formula for calculating the optimal bandwidth when the true density is known).
$h=0.7177$
for this example, it is shown that the density estimate is most accurate when the bandwidth h was closest to the optimal value (see Gramacki, Reference Gramacki2018 for the formula for calculating the optimal bandwidth when the true density is known).

Figure 1 Estimated densities according to different h values.
Importantly, the bandwidth h of KDE determines the degree of smoothing, without necessitating an estimation of additional distribution parameters. This characteristic of KDE obviates the need to include multiple model-fitting procedures and a model selection process to accurately estimate the latent density.
3.2 Bandwidth estimation and approximate mean integrated square error (AMISE)
As bandwidth estimation (or optimal bandwidth selection) itself becomes the density estimation of KDE, the search for an optimal bandwidth is crucial to obtain accurate density estimates. To this end, existing literature on density estimation has focused on the AMISE criterion for bandwidth estimation (see Gramacki, Reference Gramacki2018; Silverman, Reference Silverman1986; Wand & Jones, Reference Wand and Jones1995). Consequently, within this context, the optimal bandwidth can be defined as the one that minimizes the AMISE criterion.
AMISE is the approximation of the mean integrated squared error (MISE) obtained from a Taylor expansion (Jones, Reference Jones1991; Sheather, Reference Sheather2004; Silverman, Reference Silverman1986; Wand & Jones, Reference Wand and Jones1995), where
 $\text {MISE}(\hat {g})=E\left [\int {\left \{\hat {g}(\theta )-g(\theta )\right \}^{2}\, dx}\right ]$
is an appropriate index for evaluating the density estimation results (Jones, Reference Jones1991). AMISE can be expressed as
$\text {MISE}(\hat {g})=E\left [\int {\left \{\hat {g}(\theta )-g(\theta )\right \}^{2}\, dx}\right ]$
is an appropriate index for evaluating the density estimation results (Jones, Reference Jones1991). AMISE can be expressed as
 $$ \begin{align} \text{AMISE}(\hat{g}_{h})= \frac{1}{Nh}R(K)+\frac{h^4}{4}\mu_2(K)^2R(g"), \end{align} $$
$$ \begin{align} \text{AMISE}(\hat{g}_{h})= \frac{1}{Nh}R(K)+\frac{h^4}{4}\mu_2(K)^2R(g"), \end{align} $$
where
 $\hat {g}_{h}$
is the density estimate using the bandwidth h,
$\hat {g}_{h}$
is the density estimate using the bandwidth h,
 $R(K)=\int {K(t)^2\, dt}$
,
$R(K)=\int {K(t)^2\, dt}$
,
 $\mu _2(K)=\int {t^2K(t)\, dt}$
, and
$\mu _2(K)=\int {t^2K(t)\, dt}$
, and
 $R(g")=\int {g"(t)^2\, dt}$
. When the Gaussian kernel is used for the kernel K, it can be obtained from a simple algebra that
$R(g")=\int {g"(t)^2\, dt}$
. When the Gaussian kernel is used for the kernel K, it can be obtained from a simple algebra that
 $R(K)=\left (2\sqrt {\pi }\right )^{-1}$
and
$R(K)=\left (2\sqrt {\pi }\right )^{-1}$
and
 $\mu _2(K)=1$
.
$\mu _2(K)=1$
.
Another equation can be obtained by differentiating Equation (8) with respect to h and equating it to
 $0$
:
$0$
:
 $$ \begin{align} \hat{h}_{\text{AMISE}}=\left[\frac{R(K)}{N\mu_2(K)^2\psi_4}\right]^{\frac{1}{5}}, \end{align} $$
$$ \begin{align} \hat{h}_{\text{AMISE}}=\left[\frac{R(K)}{N\mu_2(K)^2\psi_4}\right]^{\frac{1}{5}}, \end{align} $$
where
 $\hat {h}_{\text {AMISE}}$
denotes the bandwidth estimate from the AMISE criterion,
$\hat {h}_{\text {AMISE}}$
denotes the bandwidth estimate from the AMISE criterion,
 $\psi _d=E_{t}\left [g^{(d)}(t)\right ]$
, and
$\psi _d=E_{t}\left [g^{(d)}(t)\right ]$
, and
 $\psi _4=\int {g^{(4)}(t)g(t)\, dt}=\int {g"(t)^2\, dt}=R(g")$
. Unfortunately, Equation (9) is not a closed-form solution to estimate h as it depends on the information from an unknown density g, which is
$\psi _4=\int {g^{(4)}(t)g(t)\, dt}=\int {g"(t)^2\, dt}=R(g")$
. Unfortunately, Equation (9) is not a closed-form solution to estimate h as it depends on the information from an unknown density g, which is
 $\psi _4=R(g")$
. Therefore, one of the widely used strategies is to calculate the estimate
$\psi _4=R(g")$
. Therefore, one of the widely used strategies is to calculate the estimate
 $\hat {\psi }_4$
and plug it into Equation (9), and consequently, the accurate estimation of
$\hat {\psi }_4$
and plug it into Equation (9), and consequently, the accurate estimation of
 $\psi _4$
determines the overall performance of KDE (Gramacki, Reference Gramacki2018; Sheather, Reference Sheather2004; Sheather & Jones, Reference Sheather and Jones1991; Wand & Jones, Reference Wand and Jones1995).
$\psi _4$
determines the overall performance of KDE (Gramacki, Reference Gramacki2018; Sheather, Reference Sheather2004; Sheather & Jones, Reference Sheather and Jones1991; Wand & Jones, Reference Wand and Jones1995).
3.3 Plug-in method
Among the three types of bandwidth selection methods—rule-of-thumb, cross-validation, and plug-in—the plug-in method is known to produce a bandwidth estimator that has an efficient convergence rate to the parameter and small bias and variance (Gramacki, Reference Gramacki2018; Harpole et al., Reference Harpole, Woods, Rodebaugh, Levinson and Lenze2014; Sheather, Reference Sheather2004; Sheather & Jones, Reference Sheather and Jones1991; Wand & Jones, Reference Wand and Jones1995). Due to its precision and efficiency in bandwidth estimation, the plug-in method has been a recommended option for density estimation in statistical software programs, such as R and SAS (R Core Team, 2025; SAS Institute Inc., 2020).
Direct plug-in (DPI) and solve-the-equation (STE) are two types of plug-in methods. Within the overall scheme of the
 $\psi _{4}$
estimation, both plug-in methods utilize
$\psi _{4}$
estimation, both plug-in methods utilize
 $\psi _{d+2}$
in estimating
$\psi _{d+2}$
in estimating
 $\psi _{d}$
, where an even number d is the order of differentiation and
$\psi _{d}$
, where an even number d is the order of differentiation and
 $p_d$
is a pilot bandwidth introduced to estimate
$p_d$
is a pilot bandwidth introduced to estimate
 $\psi _{d}=E\left (g^{(d)}(x)\right )$
(Gramacki, Reference Gramacki2018; Sheather, Reference Sheather2004; Wand & Jones, Reference Wand and Jones1995). That is, we start the algorithm by setting d to a specific value (e.g.,
$\psi _{d}=E\left (g^{(d)}(x)\right )$
(Gramacki, Reference Gramacki2018; Sheather, Reference Sheather2004; Wand & Jones, Reference Wand and Jones1995). That is, we start the algorithm by setting d to a specific value (e.g.,
 $d=8$
), then iteratively estimate
$d=8$
), then iteratively estimate
 $\psi _{d-2}$
using
$\psi _{d-2}$
using
 $\psi _{d}$
until we get the estimate of
$\psi _{d}$
until we get the estimate of
 $\psi _4$
. In this study, we focus on STE (Sheather & Jones, Reference Sheather and Jones1991) between the two, which is the most widely used method in unidimensional density estimation due to its small bias and variance in bandwidth estimation (Gramacki, Reference Gramacki2018; Harpole et al., Reference Harpole, Woods, Rodebaugh, Levinson and Lenze2014; Jones et al., Reference Jones, Marron and Sheather1996; Sheather, Reference Sheather2004; Sheather & Jones, Reference Sheather and Jones1991). STE is a suggested option in R (R Core Team, 2025) and is set as the default in SAS (SAS Institute Inc., 2020). Note that, at the time of writing this article, STE is not fully extended to multidimensional cases. In comparison, DPI showed more accurate and stable performance in estimating the multidimensional bandwidth compared to rule-of-thumb and cross-validation (Chacón & Duong, Reference Chacón and Duong2010; Duong & Hazelton, Reference Duong and Hazelton2003).
$\psi _4$
. In this study, we focus on STE (Sheather & Jones, Reference Sheather and Jones1991) between the two, which is the most widely used method in unidimensional density estimation due to its small bias and variance in bandwidth estimation (Gramacki, Reference Gramacki2018; Harpole et al., Reference Harpole, Woods, Rodebaugh, Levinson and Lenze2014; Jones et al., Reference Jones, Marron and Sheather1996; Sheather, Reference Sheather2004; Sheather & Jones, Reference Sheather and Jones1991). STE is a suggested option in R (R Core Team, 2025) and is set as the default in SAS (SAS Institute Inc., 2020). Note that, at the time of writing this article, STE is not fully extended to multidimensional cases. In comparison, DPI showed more accurate and stable performance in estimating the multidimensional bandwidth compared to rule-of-thumb and cross-validation (Chacón & Duong, Reference Chacón and Duong2010; Duong & Hazelton, Reference Duong and Hazelton2003).
To implement STE, some additional equations are used:
 $$ \begin{align} p_{d} = \left[ \frac{2K^{(d)}(0)}{-\mu_{2}(K)\psi_{d+2}(p_{d+2})N} \right]^{\frac{1}{d+3}}, \end{align} $$
$$ \begin{align} p_{d} = \left[ \frac{2K^{(d)}(0)}{-\mu_{2}(K)\psi_{d+2}(p_{d+2})N} \right]^{\frac{1}{d+3}}, \end{align} $$
 $$ \begin{align} \psi_{d}^{N} = \left[ \frac{(-1)^{d/2}d!}{(2\hat{\sigma})^{d+1}\left(\frac{d}{2}\right)!\pi^{1/2}} \right]^{1/9}, \end{align} $$
$$ \begin{align} \psi_{d}^{N} = \left[ \frac{(-1)^{d/2}d!}{(2\hat{\sigma})^{d+1}\left(\frac{d}{2}\right)!\pi^{1/2}} \right]^{1/9}, \end{align} $$
and
 $$ \begin{align} p(h) = \left[ \frac{2K^{(4)}(0)\mu_2(K)\hat{\psi}_4(p_4)}{-\hat{\psi}_6(p_6)R(K)} \right]^{1/7}h^{5/7}. \end{align} $$
$$ \begin{align} p(h) = \left[ \frac{2K^{(4)}(0)\mu_2(K)\hat{\psi}_4(p_4)}{-\hat{\psi}_6(p_6)R(K)} \right]^{1/7}h^{5/7}. \end{align} $$
Above, Equation (10) provides the unbiased estimator of
 $p_d$
using the information of
$p_d$
using the information of
 $\psi _{d+2}$
, Equation (11) is the formula to compute
$\psi _{d+2}$
, Equation (11) is the formula to compute
 $\psi _d$
assuming that the distribution is normal, and Equation (12) expresses a pilot bandwidth
$\psi _d$
assuming that the distribution is normal, and Equation (12) expresses a pilot bandwidth
 $p_4$
as a function of h (Gramacki, Reference Gramacki2018; Sheather & Jones, Reference Sheather and Jones1991).
$p_4$
as a function of h (Gramacki, Reference Gramacki2018; Sheather & Jones, Reference Sheather and Jones1991).
The algorithm can be summarized as follows (Gramacki, Reference Gramacki2018):
-
Step 1: Calculate
 $\psi _{6}^{N}$
and
$\psi _{8}^{N}$
from Equation (11).
$\psi _{6}^{N}$
and
$\psi _{8}^{N}$
from Equation (11). -
Step 2: Calculate
$p_4$
and
$p_6$
from Equation (10) using
$\psi _{6}^{N}$
and
$\psi _{8}^{N}$
. -
Step 3: Estimate
$\psi _{4}(p_4)$
and
$\psi _{6}(p_6)$
using
$p_4$
and
$p_6$
, respectively. -
Step 4: Estimate
$\psi _{4}$
using the estimator
$\hat {\psi }\left (p(h)\right )$
, where
$p(h)$
is calculated from Equation (12) using
$\hat {\psi }_4(p_4)$
and
$\hat {\psi }_6(p_6)$
obtained from Step 3. -
Step 5: The estimated bandwidth
$\hat {h}$
is the numerical solution of Equation (9) when
$\hat {\psi }\left (p(h)\right )$
is plugged into the equation.

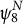















Note that the illustrated algorithm above is the two-step algorithm where “two-step” refers to the process of starting from
 $d=8$
and terminating at
$d=8$
and terminating at
 $d=4$
. In the same way, the three-step algorithm starts from
$d=4$
. In the same way, the three-step algorithm starts from
 $d=10$
, then sequentially moves to
$d=10$
, then sequentially moves to
 $8$
,
$8$
,
 $6$
, and
$6$
, and
 $4$
. Although increasing the number of steps reduces bias, the two-step algorithm is generally preferred due to the trade-off between bias and variance.
$4$
. Although increasing the number of steps reduces bias, the two-step algorithm is generally preferred due to the trade-off between bias and variance.
3.4 Application of KDE to IRT
As with other IRT latent density estimation methods, KDE can be applied to the latent density estimation of IRT by treating
 $\hat {f}_{q}=\sum _{j=1}^{N}\gamma _{jq}$
as observed data points, where
$\hat {f}_{q}=\sum _{j=1}^{N}\gamma _{jq}$
as observed data points, where
 $\hat {f}_{q}$
is the expected frequency of test takers at
$\hat {f}_{q}$
is the expected frequency of test takers at
 $\theta ^{*}=\theta ^{*}_{q}$
. For the ease of programming,
$\theta ^{*}=\theta ^{*}_{q}$
. For the ease of programming,
 $\hat {f}$
is rounded in this study. Suppose, for illustration, that we are in the ith iteration of the MML-EM procedure, where “i” temporarily denotes the sequence of the EM iteration, not related to the subscript i used for items. Using
$\hat {f}$
is rounded in this study. Suppose, for illustration, that we are in the ith iteration of the MML-EM procedure, where “i” temporarily denotes the sequence of the EM iteration, not related to the subscript i used for items. Using
 $\hat {f}_{q}$
obtained from the E-step of the ith EM iteration, the STE algorithm in Section 3.3 is implemented to get
$\hat {f}_{q}$
obtained from the E-step of the ith EM iteration, the STE algorithm in Section 3.3 is implemented to get
 $\hat {h}$
during the M-step of the ith EM iteration. The density estimate
$\hat {h}$
during the M-step of the ith EM iteration. The density estimate
 $g(\theta |\hat {h})$
(see Equation (7)) is first scaled to have a mean of 0 and a standard deviation of 1 using linear interpolation and extrapolation, which is also applied to DCM to identify the latent scale (Woods & Lin, Reference Woods and Lin2009). Then, it becomes the estimated latent distribution of the ith EM iteration, which, in turn, is used in the E-step of the
$g(\theta |\hat {h})$
(see Equation (7)) is first scaled to have a mean of 0 and a standard deviation of 1 using linear interpolation and extrapolation, which is also applied to DCM to identify the latent scale (Woods & Lin, Reference Woods and Lin2009). Then, it becomes the estimated latent distribution of the ith EM iteration, which, in turn, is used in the E-step of the
 $(i+1)$
th EM iteration. When the MML-EM procedure converges,
$(i+1)$
th EM iteration. When the MML-EM procedure converges,
 $g(\theta |\hat {h})$
from the last EM iteration is taken as the estimated latent distribution.
$g(\theta |\hat {h})$
from the last EM iteration is taken as the estimated latent distribution.
Unlike other methods that employ additional density parameters according to the hyperparameter h, only the bandwidth h is involved during the application of KDE. As a result, KDE can yield a smoothed latent density estimate within a single MML-EM procedure.
4 Simulation study
4.1 Compared methods
To evaluate the accuracy of the KDE method in parameter estimation using computer simulation techniques, the performance of KDE is assessed under various simulation conditions by comparing it with three existing approaches: the normality-assumption method (NM), EHM, and DCM.
NM refers to the conventional approach that does not estimate the latent distribution but instead assumes normality. It serves as a baseline model—similar to a null model—against which the advantages of more flexible approaches can be evaluated. In a strict sense, NM differs from the other approaches because it does not attempt to estimate the latent density.
EHM provides a baseline among density estimation methods, as it relies on normalized histograms without smoothing. DCM further smooths the non-smoothed density estimate produced by EHM at every EM iteration. DCM has shown competitive accuracy among existing methods and can offer a meaningful benchmark for assessing new techniques (Woods & Lin, Reference Woods and Lin2009). In addition, its principled model selection procedure based on the HQ criterion makes it particularly suitable for fair comparisons.
Other methods, such as RCM, LLS, and 2NM, are omitted from the comparison due to challenges in evaluating their performance on equal grounds. RCM and LLS both involve subjective decisions in the model selection process: RCM requires trial and error in setting the standard deviation of the prior distribution and often relies on visual inspection, while LLS lacks a clear model selection guideline. The 2NM method depends heavily on the choice of the true density in the simulation design due to its parametric nature. This dependency is misaligned with the focus of the present study on density estimation methods applicable when little or no information about the true density is available, which is the motivation for adopting nonparametric approaches.
Accordingly, NM, EHM, and DCM are chosen to represent the null, lower, and upper bounds of existing approaches in terms of flexibility and performance.
4.2 Simulation design
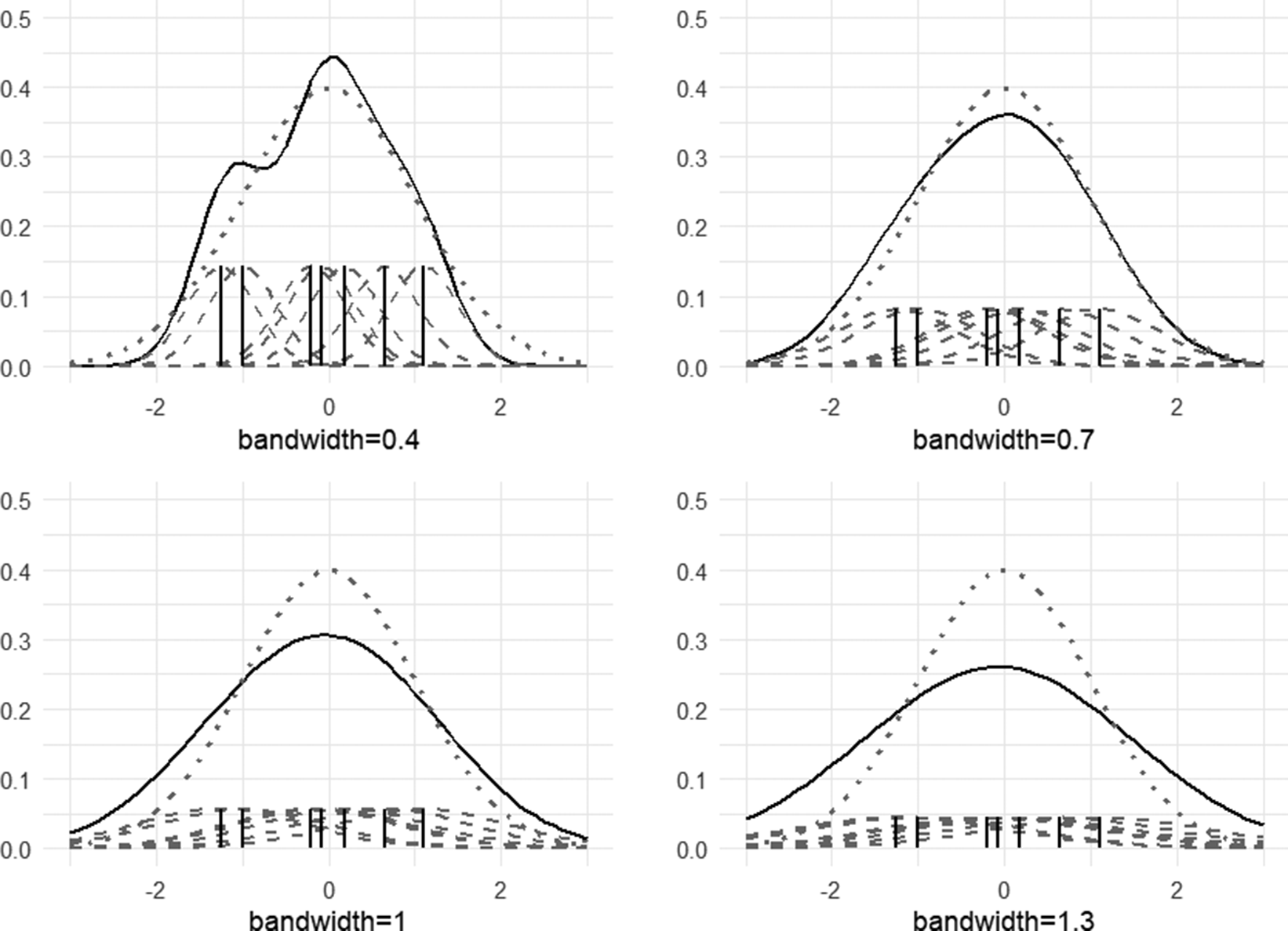
The simulation conditions are formulated by three factors that can potentially affect the results: the shape of the latent distribution, the length of the tests, and the number of test takers. Figure 2 shows the four shapes of the latent distribution used for the simulation study: normal, skewed, bimodal, and skewed bimodal. The three non-normal distributions are formulated by a mixture of two normal components, and their mean and variance are
 $0$
and
$0$
and
 $1$
, respectively (see Li, Reference Li2021 for reparameterization of the two-component normal mixture distribution to fix the overall mean and variance). Setting the standard normal distribution as a reference, the skewed and bimodal distributions represent the two types of normality violation, and the skewed bimodal distribution represents the combination of the two sources of violation. The skewness values of the normal and bimodal distributions are both 0. In contrast, the skewed and skewed bimodal distributions have skewness values of approximately 0.6 and 0.5, respectively. These values were chosen to approximate the skewness observed in the IRT scale score distributions of the U.S. state-level testing programs (Ho & Yu, Reference Ho and Yu2015). For example, the median skewness of the 24 IRT scale score distributions in Colorado was approximately
$1$
, respectively (see Li, Reference Li2021 for reparameterization of the two-component normal mixture distribution to fix the overall mean and variance). Setting the standard normal distribution as a reference, the skewed and bimodal distributions represent the two types of normality violation, and the skewed bimodal distribution represents the combination of the two sources of violation. The skewness values of the normal and bimodal distributions are both 0. In contrast, the skewed and skewed bimodal distributions have skewness values of approximately 0.6 and 0.5, respectively. These values were chosen to approximate the skewness observed in the IRT scale score distributions of the U.S. state-level testing programs (Ho & Yu, Reference Ho and Yu2015). For example, the median skewness of the 24 IRT scale score distributions in Colorado was approximately
 $-0.6$
, whereas in New York, it was approximately
$-0.6$
, whereas in New York, it was approximately
 $0.7$
, ignoring the sign of skewness. The shape of the skewed bimodal distribution is designed to resemble the example of bimodal test score distributions presented in Sibbald (Reference Sibbald2014). Although a symmetric bimodal distribution may not frequently occur in practice as a latent distribution, it is included in the simulation conditions to examine the effect of bimodality independently of skewness. Test lengths of 8, 15, 30, and 60 items can be viewed as representing very short, short, medium, and long tests, respectively. Very short or short tests include brief scales, such as the 8-item version of the Center for Epidemiologic Studies Depression (CES-D8) scale (Missinne et al., Reference Missinne, Vandeviver, Van de Velde and Bracke2014) and end-of-chapter quizzes in online learning platforms, where the latent distribution has a relatively strong influence on parameter estimation. Examples of long tests are large-scale educational assessments, such as the Scholastic Aptitude Test and the American College Testing. Lastly, the number of test takers is varied—set at 500, 1,000, and 2,000—to examine the performance of the methods with respect to sample size.
$0.7$
, ignoring the sign of skewness. The shape of the skewed bimodal distribution is designed to resemble the example of bimodal test score distributions presented in Sibbald (Reference Sibbald2014). Although a symmetric bimodal distribution may not frequently occur in practice as a latent distribution, it is included in the simulation conditions to examine the effect of bimodality independently of skewness. Test lengths of 8, 15, 30, and 60 items can be viewed as representing very short, short, medium, and long tests, respectively. Very short or short tests include brief scales, such as the 8-item version of the Center for Epidemiologic Studies Depression (CES-D8) scale (Missinne et al., Reference Missinne, Vandeviver, Van de Velde and Bracke2014) and end-of-chapter quizzes in online learning platforms, where the latent distribution has a relatively strong influence on parameter estimation. Examples of long tests are large-scale educational assessments, such as the Scholastic Aptitude Test and the American College Testing. Lastly, the number of test takers is varied—set at 500, 1,000, and 2,000—to examine the performance of the methods with respect to sample size.

Figure 2 Normal, skewed, bimodal, and skewed bimodal distributions used for the simulation study.
For each of the 48 simulation conditions (4 distributions
 $\times $
4 test lengths
$\times $
4 test lengths
 $\times $
3 sample sizes), 200 item response datasets are generated using the 2PL (Birnbaum, Reference Birnbaum, Lord and Novick1968) and fitted by NM, EHM, DCM, and KDE. For the random sampling of item parameters, the a parameter is generated from a uniform distribution from
$\times $
3 sample sizes), 200 item response datasets are generated using the 2PL (Birnbaum, Reference Birnbaum, Lord and Novick1968) and fitted by NM, EHM, DCM, and KDE. For the random sampling of item parameters, the a parameter is generated from a uniform distribution from
 $0.8$
to
$0.8$
to
 $2.5$
, and the b parameter is generated from the standard normal distribution truncated at
$2.5$
, and the b parameter is generated from the standard normal distribution truncated at
 $\pm 2$
. These parameters serve as true values in calculating the evaluation criteria in Equations (14) and (15). The IRTest package (Li, Reference Li2024; R Core Team, 2025)—an R package specialized in latent density estimation of IRT—is used for both data generation and model fitting. The source code for the simulation study is available at https://github.com/SeewooLi/KDE_IRT_code. The KDE option in IRTest has been developed particularly for this study. An MML-EM procedure is considered to be successfully converged when the maximum parameter change drops below 0.0001 within the specified maximum number of EM iterations. The maximum number of iterations is set to 200 for NM, DCM, and KDE, and to 2,000 for EHM to accommodate its slower convergence. These settings are consistent with previous studies that used similar criteria to determine convergence of the MML-EM procedure (Woods, Reference Woods2006; Woods & Lin, Reference Woods and Lin2009). An AMD Ryzen 7 5700G processor is used for the study.
$\pm 2$
. These parameters serve as true values in calculating the evaluation criteria in Equations (14) and (15). The IRTest package (Li, Reference Li2024; R Core Team, 2025)—an R package specialized in latent density estimation of IRT—is used for both data generation and model fitting. The source code for the simulation study is available at https://github.com/SeewooLi/KDE_IRT_code. The KDE option in IRTest has been developed particularly for this study. An MML-EM procedure is considered to be successfully converged when the maximum parameter change drops below 0.0001 within the specified maximum number of EM iterations. The maximum number of iterations is set to 200 for NM, DCM, and KDE, and to 2,000 for EHM to accommodate its slower convergence. These settings are consistent with previous studies that used similar criteria to determine convergence of the MML-EM procedure (Woods, Reference Woods2006; Woods & Lin, Reference Woods and Lin2009). An AMD Ryzen 7 5700G processor is used for the study.
The accuracy of the density estimation is evaluated by the integrated squared error (ISE). In particular, ISE from NM can indicate the degree to which the true density deviates from the normal distribution, because NM assumes the latent distribution to be normal and, thus, does not estimate it. The ISE criterion can be written as follows:
 $$ \begin{align} \begin{aligned} \text{ISE}(\hat{g})&=\int^{\infty}_{-\infty}{\left[ \hat{g}(\theta) - g(\theta) \right]^2\,d\theta}\\ &\approx \sum^{121}_{q=1}{\frac{1}{10}\left[ \hat{g}(\theta^{*}_{q}) - g(\theta^{*}_{q}) \right]^2}. \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \text{ISE}(\hat{g})&=\int^{\infty}_{-\infty}{\left[ \hat{g}(\theta) - g(\theta) \right]^2\,d\theta}\\ &\approx \sum^{121}_{q=1}{\frac{1}{10}\left[ \hat{g}(\theta^{*}_{q}) - g(\theta^{*}_{q}) \right]^2}. \end{aligned} \end{align} $$
The integration is approximated by the quadrature scheme of using 121 equally spaced grids from
 $-6$
to 6.
$-6$
to 6.
Lastly, the root mean square error (RMSE) evaluates the accuracy of the estimation of the ability parameter
 $\theta $
, item characteristic curve (ICC), and the item parameters (a and b):
$\theta $
, item characteristic curve (ICC), and the item parameters (a and b):
 $$ \begin{align} \begin{aligned} \text{RMSE}(\hat{\text{ICC}})=\sqrt{\frac{1}{I}\sum^{I}_{i=1}{\sum^{121}_{q=1}{ \left(\hat{P}_{i}(\theta^{*}_{q}) - P_{i}(\theta^{*}_{q})\right)^2 \hat{A}(\theta^{*}_{q}) }}}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \text{RMSE}(\hat{\text{ICC}})=\sqrt{\frac{1}{I}\sum^{I}_{i=1}{\sum^{121}_{q=1}{ \left(\hat{P}_{i}(\theta^{*}_{q}) - P_{i}(\theta^{*}_{q})\right)^2 \hat{A}(\theta^{*}_{q}) }}}, \end{aligned} \end{align} $$
 $$ \begin{align} \begin{aligned} \text{RMSE}(\hat{\tau})=\sqrt{\frac{1}{I}\sum^{I}_{i=1}{\left(\hat{\tau} - \tau\right)^2}}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \text{RMSE}(\hat{\tau})=\sqrt{\frac{1}{I}\sum^{I}_{i=1}{\left(\hat{\tau} - \tau\right)^2}}, \end{aligned} \end{align} $$
and
 $$ \begin{align} \begin{aligned} \text{RMSE}(\hat{\theta})=\sqrt{\frac{1}{N}\sum^{N}_{i=1}{\left(\hat{\theta} - \theta\right)^2}}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \text{RMSE}(\hat{\theta})=\sqrt{\frac{1}{N}\sum^{N}_{i=1}{\left(\hat{\theta} - \theta\right)^2}}, \end{aligned} \end{align} $$
where
 $\hat {P}_{i}(\theta ^{*}_{q})$
in Equation (1) is the estimated ICC of Item i evaluated at
$\hat {P}_{i}(\theta ^{*}_{q})$
in Equation (1) is the estimated ICC of Item i evaluated at
 $\theta ^{*}_{q}$
,
$\theta ^{*}_{q}$
,
 $\hat {A}(\theta ^{*}_{q})$
is the estimated normalized density (see Section 2.1) at the qth grid, and
$\hat {A}(\theta ^{*}_{q})$
is the estimated normalized density (see Section 2.1) at the qth grid, and
 $\tau $
represents either the a or b parameter. Expected a priori (EAP) scores are used for
$\tau $
represents either the a or b parameter. Expected a priori (EAP) scores are used for
 $\hat {\theta }$
. Based on 200 data replications, the average RMSE and ISE values for each method are reported in Section 4.3.
$\hat {\theta }$
. Based on 200 data replications, the average RMSE and ISE values for each method are reported in Section 4.3.
4.3 Results
The MML-EM procedure successfully converged for both the NM and KDE models across all datasets (i.e., 200 replications for each of the 48 simulation conditions) within 200 EM iterations, using a convergence threshold of 0.0001. In contrast, 2.51% (241 out of 9,600) of the “best” DCMs and 8.53% (8,184 out of 96,000) of all DCMs failed to converge successfully. For EHM, the MML-EM procedure did not converge within 2,000 EM iterations in 8.92% of cases (856 out of 9,600), where many of the non-converged cases occurred when the number of items was 8 (499 cases). The average computation times for model fitting were 4.86 seconds for NM, 17.74 seconds for EHM, 78.76 seconds for DCM, and 4.26 seconds for KDE. The relatively longer time of EHM is mainly due to its slow convergence that required a large number of iterations for model fitting, and the substantially longer duration observed for DCM is largely due to the need to fit 10 models. Interestingly, the average elapsed time for NM exceeded that of KDE, despite KDE involving an additional step for bandwidth estimation. Two factors may explain this finding. First, computation in the E-step dominates the overall MML-EM procedure, as it involves evaluating probabilities for every combination of item, person, and latent grid point. Thus, the additional cost of the bandwidth estimation in KDE is comparatively negligible. Second, density estimation in KDE may have facilitated faster identification of a local maximum on the likelihood surface compared to NM, requiring 44.5 iterations for convergence in KDE versus 49.5 for NM.
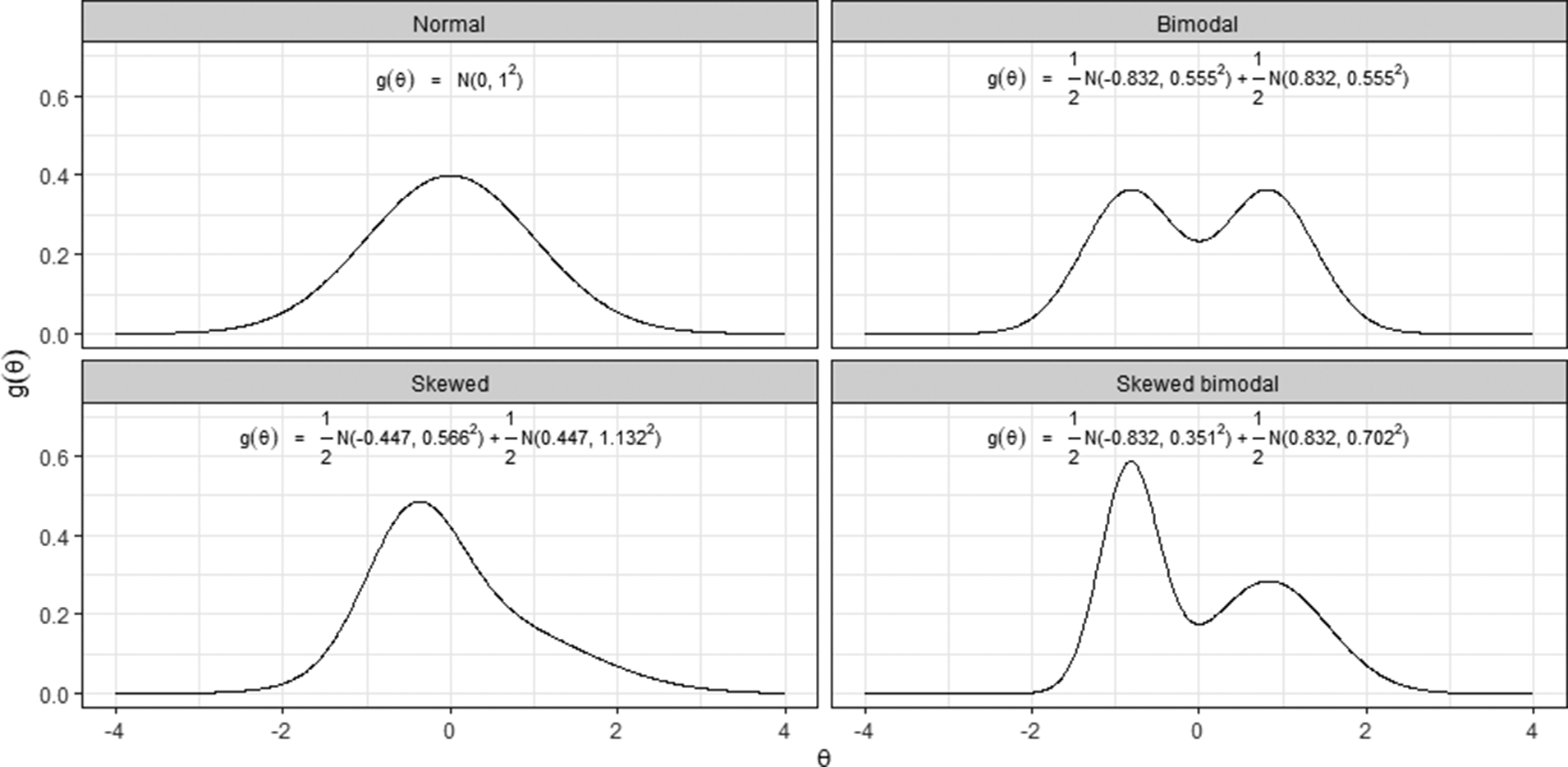
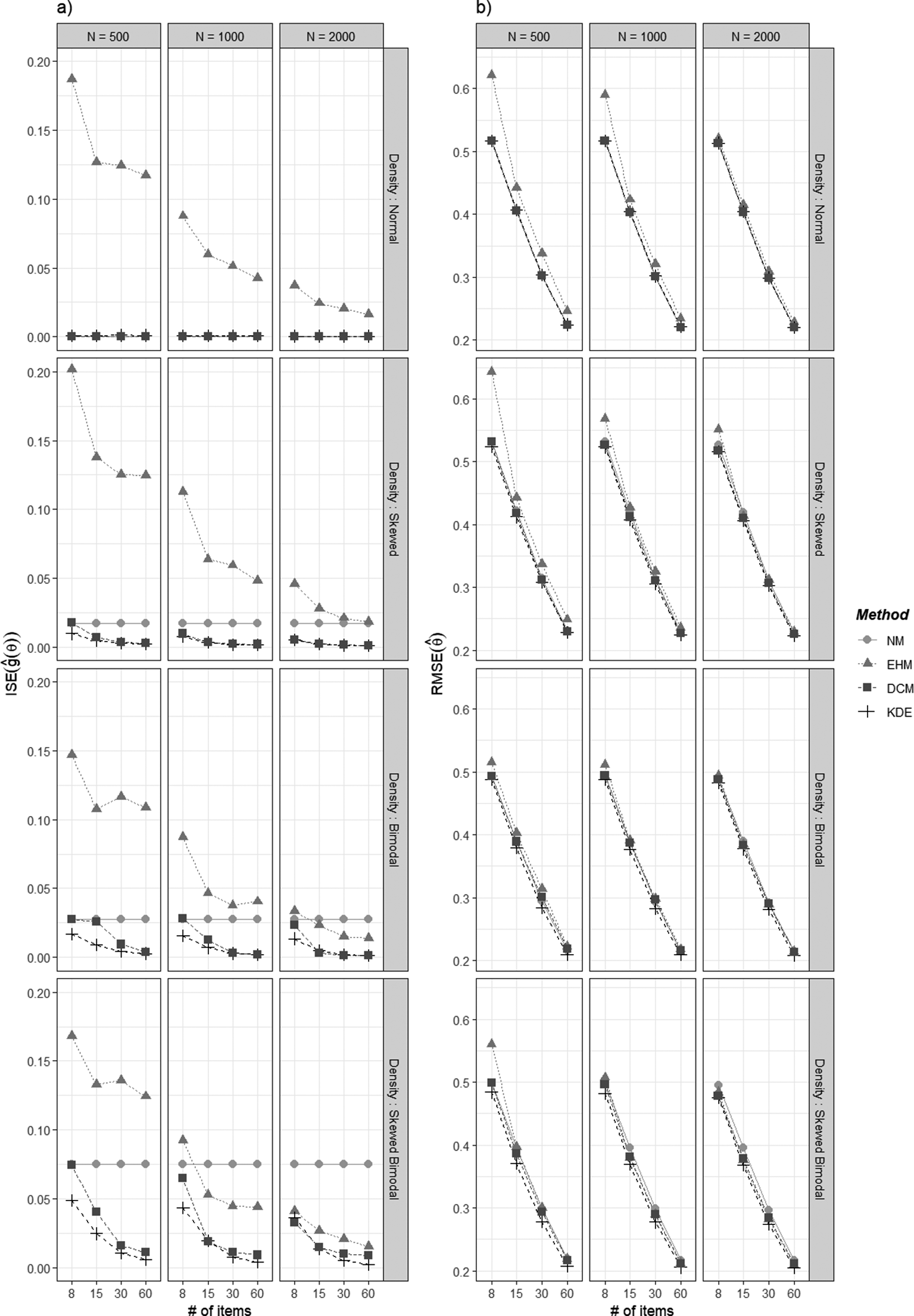
Figures 3 and 4 summarize the simulation results using the RMSE and ISE criteria, where lower values indicate greater estimation accuracy. Tables A1 and A2 in the Appendix report the calculated RMSE and ISE values. As illustrated in Figure 3, RMSE values generally decreased as both the sample size and the number of items increased. Under the normal latent distribution, NM, DCM, and KDE exhibited nearly identical RMSE values, whereas EHM produced larger RMSE values unless the number of items was sufficiently large. Under non-normal latent distributions, DCM and KDE achieved lower RMSE values than NM. The performance of EHM in these non-normal conditions varied depending on the simulation design: it effectively reduced RMSE relative to NM when both the sample size and the number of items were adequate, but yielded higher RMSE otherwise. Notably, although there are some cases in which EHM or DCM slightly outperformed KDE, KDE consistently produced the smallest or comparable RMSE values across all conditions, indicating its robust accuracy. The advantage of KDE, relative to the other methods, was particularly pronounced when the sample size and the number of items were limited.

Figure 3 Simulation results of
 $RMSE(\hat {ICC})$
,
$RMSE(\hat {ICC})$
,
 $RMSE(\hat {a})$
, and
$RMSE(\hat {a})$
, and
 $RMSE(\hat {b})$
.
$RMSE(\hat {b})$
.
Note: Panels (a)–(c) present RMSE values for ICC, a, and b, respectively.

Figure 4 Simulation results of
 $ISE(\hat {g}(\theta ))$
and
$ISE(\hat {g}(\theta ))$
and
 $RMSE(\hat {\theta })$
.
$RMSE(\hat {\theta })$
.
Note: Panels (a) and (b) present
 $ISE(\hat {g}(\theta ))$
and
$ISE(\hat {g}(\theta ))$
and
 $RMSE(\hat {\theta })$
, respectively.
$RMSE(\hat {\theta })$
, respectively.
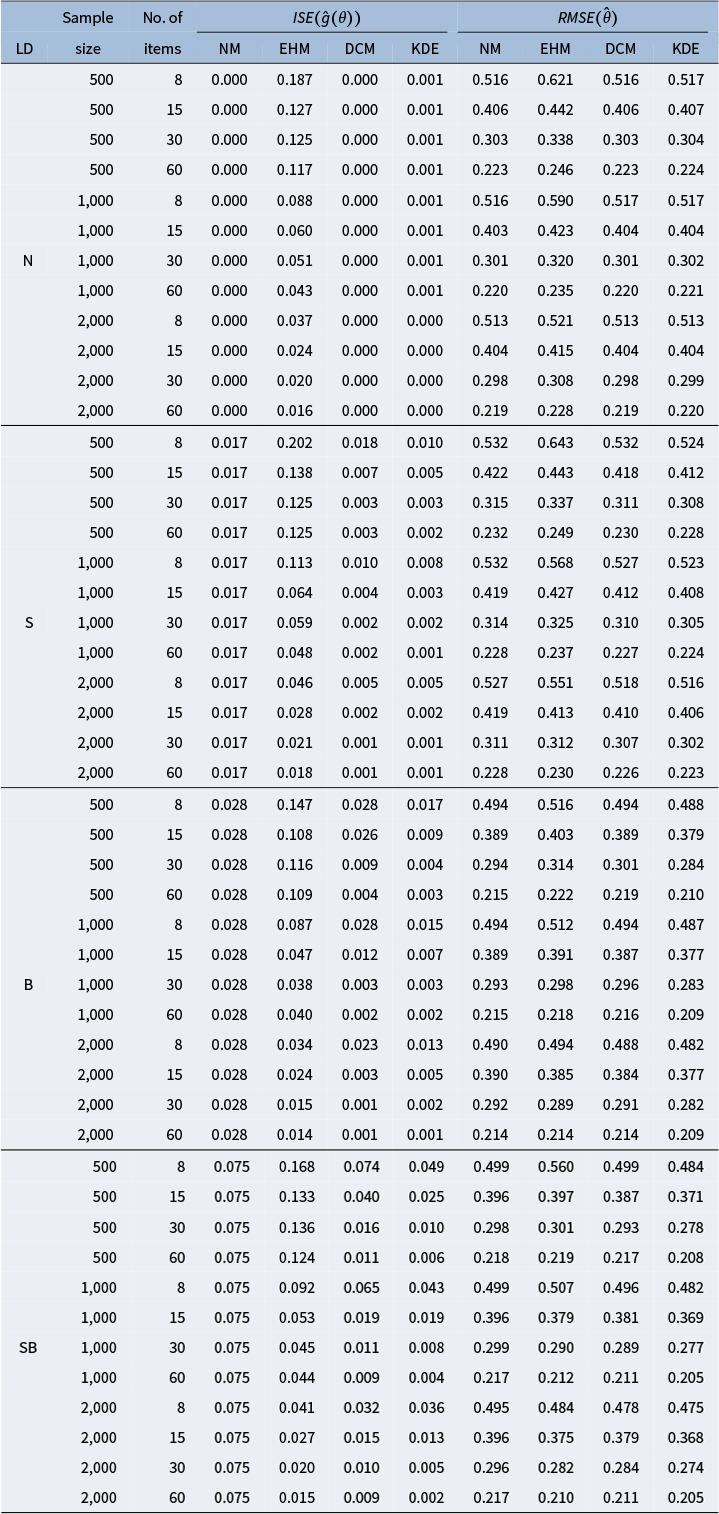
The ISE values are presented in Figure 4a. Consistent with the item-level results (i.e., ICC and the a and b parameters), the accuracy of latent density estimation generally improved with larger sample sizes and greater numbers of items for EHM, DCM, and KDE. The ISE values of EHM often exceeded those of NM due to overfitting. In comparison, both DCM and KDE accurately recovered the normal latent distribution and substantially reduced ISE under non-normal conditions in most cases. However, the recovery of the latent distribution by DCM was limited when both the sample size and the number of items were small. KDE achieved the lowest or nearly lowest ISE values across all conditions, with the one exception (skewed bimodal distribution, 8 items, and 500 examinees) where DCM slightly outperformed KDE. These findings could explain the accuracy of KDE in item parameter estimation, as accurate identification of the latent distribution influences the precision of the item parameter estimates.
In parallel, Figure 4b shows that KDE also provided an accurate recovery of the ability parameters, with
 $RMSE(\hat {\theta })$
values that were the lowest or comparable to those of EHM and DCM across the simulation conditions. Although the enhanced accuracy of KDE in ability estimation may be practically meaningful in contexts such as high-stakes testing, the results in Panel (b) indicate that the number of items exerted the greatest influence on the accuracy of ability parameter estimates.
$RMSE(\hat {\theta })$
values that were the lowest or comparable to those of EHM and DCM across the simulation conditions. Although the enhanced accuracy of KDE in ability estimation may be practically meaningful in contexts such as high-stakes testing, the results in Panel (b) indicate that the number of items exerted the greatest influence on the accuracy of ability parameter estimates.
5 Empirical illustration
The effectiveness of KDE can be illustrated using real data. For this purpose, the CES-D8 scale (e.g., Missinne et al., Reference Missinne, Vandeviver, Van de Velde and Bracke2014; Radloff, Reference Radloff1977) is employed. The scale measures depressive symptomatology in the general population through binary items asking the presence of symptoms associated with depression. The CES-D8 was administered in the COVID-19 Coping Study (Kobayashi & Finlay, Reference Kobayashi and Finlay2022), which is publicly available at https://www.openicpsr.org/openicpsr/project/131022/version/V3/view. The source code for the following analyses is available at https://github.com/SeewooLi/KDE_IRT_code. For illustration, we use item responses from 2,372 respondents collected during the 6th month of the study.
Following the estimation procedures outlined in Section 4, the MML-EM algorithm successfully converged for all models considered (NM, EHM, DCM, and KDE). Based on the HQ criterion (Hannan & Quinn, Reference Hannan and Quinn1979), the DCM with a hyperparameter of
 $h=3$
was selected as optimal.
$h=3$
was selected as optimal.
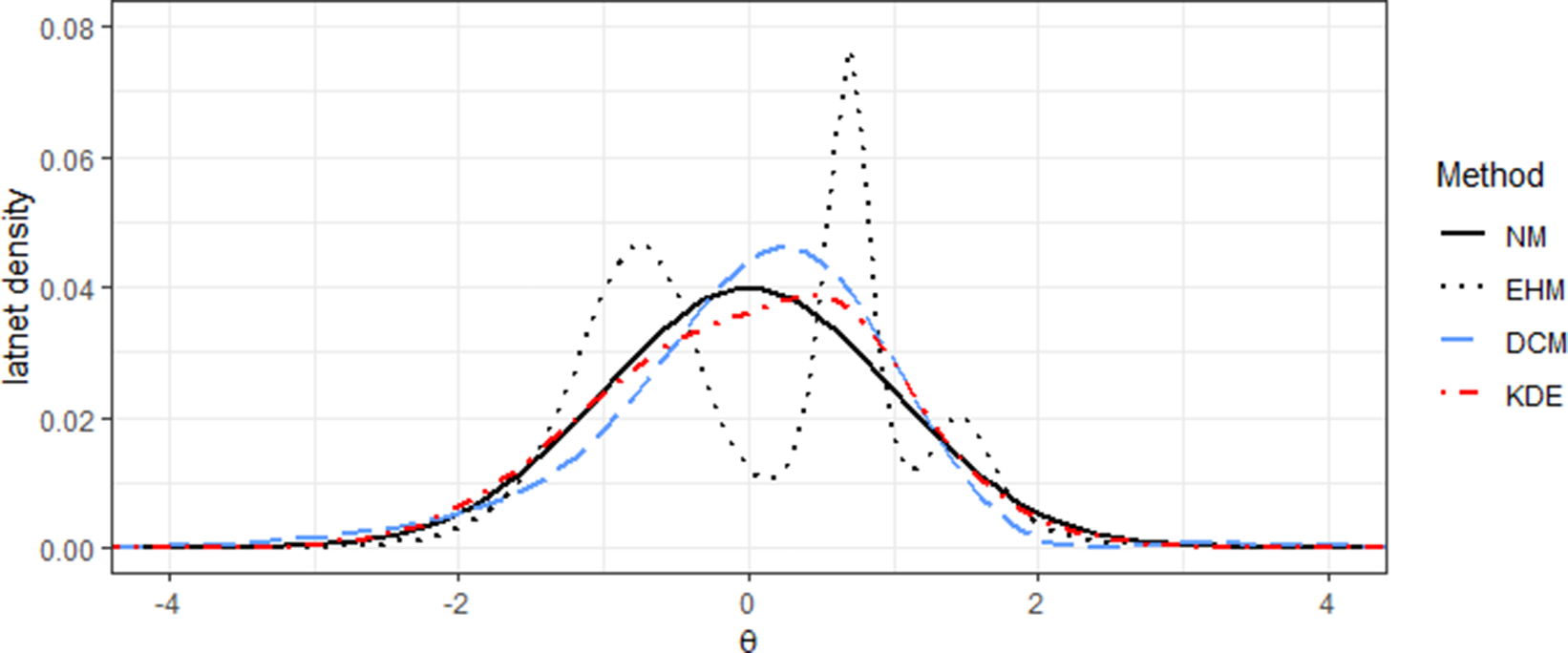
Figure 5 shows the estimated densities from EHM, DCM, and KDE. All methods indicate moderate left skewness, suggesting the existence of a small subgroup with distinct response patterns. However, the density shapes vary: both DCM and KDE produce smooth estimates, while EHM yields a jagged distribution that may not accurately reflect the true latent distribution.

Figure 5 The estimated latent densities from EHM, DCM, and KDE for the CES-D8 data.
Note: The standard normal distribution represents the latent distribution of NM, which is typically not estimated.
To quantify the effectiveness of the density estimation methods, summed score likelihood-based statistics (Li & Cai, Reference Li and Cai2012, Reference Li and Cai2018) can be used:
 $$ \begin{align} \begin{aligned} \bar{X}^2=N\sum_{s=0}^{S-1}\frac{\left(p_s-\hat{\pi}_s\right)^2}{\hat{\pi}_s}, \end{aligned} \end{align} $$
$$ \begin{align} \begin{aligned} \bar{X}^2=N\sum_{s=0}^{S-1}\frac{\left(p_s-\hat{\pi}_s\right)^2}{\hat{\pi}_s}, \end{aligned} \end{align} $$
where
 $S = 9 = 1 + 8$
represents the total number of summed scores, including the summed score of 0. Here,
$S = 9 = 1 + 8$
represents the total number of summed scores, including the summed score of 0. Here,
 $p_s$
denotes the observed proportion of summed score s, and
$p_s$
denotes the observed proportion of summed score s, and
 $\hat {\pi }_s$
denotes the model-implied proportion. Notation is simplified for illustrative purposes without sacrificing mathematical rigor. Asymptotically, the tail area of
$\hat {\pi }_s$
denotes the model-implied proportion. Notation is simplified for illustrative purposes without sacrificing mathematical rigor. Asymptotically, the tail area of
 $\bar {X}^2$
can be approximated by a central chi-squared distribution with degrees of freedom
$\bar {X}^2$
can be approximated by a central chi-squared distribution with degrees of freedom
 $S-1-2$
, where
$S-1-2$
, where
 $-1$
accounts for the constraint that the proportions must sum to 1, and
$-1$
accounts for the constraint that the proportions must sum to 1, and
 $-2$
accounts for the location and scale of the summed score distribution (Li & Cai, Reference Li and Cai2018). The statistic can be used to detect the distributional assumption violations of the latent variable, with a lower statistic supporting the null hypothesis that the specified latent distribution is true. While this statistic suffices for the demonstration of the effectiveness of KDE, a correction factor can be applied if the statistic is used for formal hypothesis testing (see Li & Cai, Reference Li and Cai2018).
$-2$
accounts for the location and scale of the summed score distribution (Li & Cai, Reference Li and Cai2018). The statistic can be used to detect the distributional assumption violations of the latent variable, with a lower statistic supporting the null hypothesis that the specified latent distribution is true. While this statistic suffices for the demonstration of the effectiveness of KDE, a correction factor can be applied if the statistic is used for formal hypothesis testing (see Li & Cai, Reference Li and Cai2018).
The resulting
 $\bar {X}^2$
statistics are 13.05 (p-value
$\bar {X}^2$
statistics are 13.05 (p-value
 $ = 0.042$
) for NM, 1.93 (p-value
$ = 0.042$
) for NM, 1.93 (p-value
 $ = 0.926$
) for EHM, 7.55 (p-value
$ = 0.926$
) for EHM, 7.55 (p-value
 $ = 0.273$
) for DCM, and 6.26 (p-value
$ = 0.273$
) for DCM, and 6.26 (p-value
 $ = 0.395$
) for KDE. The NM statistic rejects the null hypothesis under the type-I error level of 0.05, indicating that the normal distribution is an inadequate representation of the latent distribution. In contrast, EHM, DCM, and KDE substantially reduce
$ = 0.395$
) for KDE. The NM statistic rejects the null hypothesis under the type-I error level of 0.05, indicating that the normal distribution is an inadequate representation of the latent distribution. In contrast, EHM, DCM, and KDE substantially reduce
 $\bar {X}^2$
and yield higher p-values, showing that the estimated densities align well with the observed distribution.
$\bar {X}^2$
and yield higher p-values, showing that the estimated densities align well with the observed distribution.
Nevertheless, the unsmoothed EHM density may not be a realistic population distribution, potentially reflecting random noise, as suggested by Section 4. While both DCM and KDE produce practically acceptable population distributions, the slightly higher p-value for KDE may indicate a better fit between its estimated density and the true latent distribution.
6 Discussion
This article proposed a new approach to estimating the latent distribution of IRT, motivated by the recognition that violations of latent density assumptions can introduce bias into parameter estimates. The approach adopts the STE algorithm developed by Sheather and Jones (Reference Sheather and Jones1991) to implement KDE, a widely recommended technique for general-purpose density estimation. By leveraging this method, the proposed approach enables accurate and efficient parameter estimation in IRT contexts. The article illustrated the statistical aspects of the method and evaluated it through a simulation study and an analysis of empirical data.
Although the use of the AMISE criterion to estimate latent density does not theoretically guarantee an increase in the likelihood—a common requirement in the EM algorithm literature (e.g., Minka, Reference Minka1998; Neal & Hinton, Reference Neal, Hinton and Jordan1998)—the convergence results from the simulation study demonstrated that the AMISE-based method yields robust EM convergence. Interestingly, although EHM and DCM are better aligned with the EM algorithm framework, KDE showed better convergence results than EHM and DCM; the EM convergence of EHM and DCM was often unsuccessful. This could imply that the AMISE criterion of KDE generally works in a way that increases the likelihood, even though it does not directly handle the likelihood.
The simulation study further demonstrated that the proposed method yields parameter estimates that are either superior to or on par with those obtained from existing methods, for both item and ability parameters. The model’s accuracy in parameter estimation can be attributed to its effectiveness in recovering the true latent distribution. The empirical analysis illustrated these findings: the estimated density of EHM could be unrealistic as a population distribution because of overfitting the data, and KDE provided a better match between the observed and model-implied summed score distributions than DCM for the CES-D8 dataset.
Meanwhile, alternative approaches can be utilized to address non-normality in the latent distribution, such as mixture IRT modeling (e.g., Sen & Cohen, Reference Sen and Cohen2019; von Davier & Rost, Reference von Davier, Rost and Linden2016). Whereas the latent density estimation in the context of this study assumes a single homogeneous population, mixture modeling posits that the data arise from a composite of latent subpopulations, thereby modeling non-normality using a mixture of the subpopulation distributions. When the research objective involves identifying latent classes, latent density estimates can serve as a diagnostic indicator of potential population heterogeneity.
From a practical standpoint, the proposed method also offers a significant computational advantage, as it does not require a model selection process. Existing methods to estimate the latent distribution of IRT typically require users to fit several models to determine the optimal degree of density smoothing through a model selection process. For example, 10 models are fitted to implement DCM as its hyperparameter h generally takes values of
 $h=1,2,\ldots ,10$
. In contrast, a single model fitting procedure suffices to employ KDE, thereby reducing a significant amount of computation time. This efficiency becomes even more valuable in the context of multidimensional IRT, where the number of quadrature points increases exponentially with the number of latent dimensions.
$h=1,2,\ldots ,10$
. In contrast, a single model fitting procedure suffices to employ KDE, thereby reducing a significant amount of computation time. This efficiency becomes even more valuable in the context of multidimensional IRT, where the number of quadrature points increases exponentially with the number of latent dimensions.
Future research could investigate the effectiveness of KDE under broader conditions, including applications to different IRT models, polytomous data, and multidimensional latent traits. When extended to multidimensional settings, the DPI algorithm can be used in place of the STE algorithm, which is currently limited to unidimensional estimation. Under these new scenarios, the comparative advantages of KDE demonstrated in this study should be re-evaluated within these new contexts.
Admittedly, considering that the performance of KDE was established on an average level through the simulation study, the estimated latent density from KDE might not always be the best solution for every given dataset. However, due to its stability in MML-EM convergence, accurate parameter estimation, and efficient computation time, KDE can be a good starting point to estimate the latent distribution of IRT when the normality assumption is in question.
Acknowledgements
An AI-based tool (gpt-5-mini) was used during the proofreading stage for grammar and language checking. The authors take full responsibility for the content of the manuscript, including all analyses, interpretations, and conclusions.
Funding statement
There are no funding from commercial entities, that could be perceived as impacting the integrity or objectivity of this research.
Competing interests
The authors declare none.
Appendix
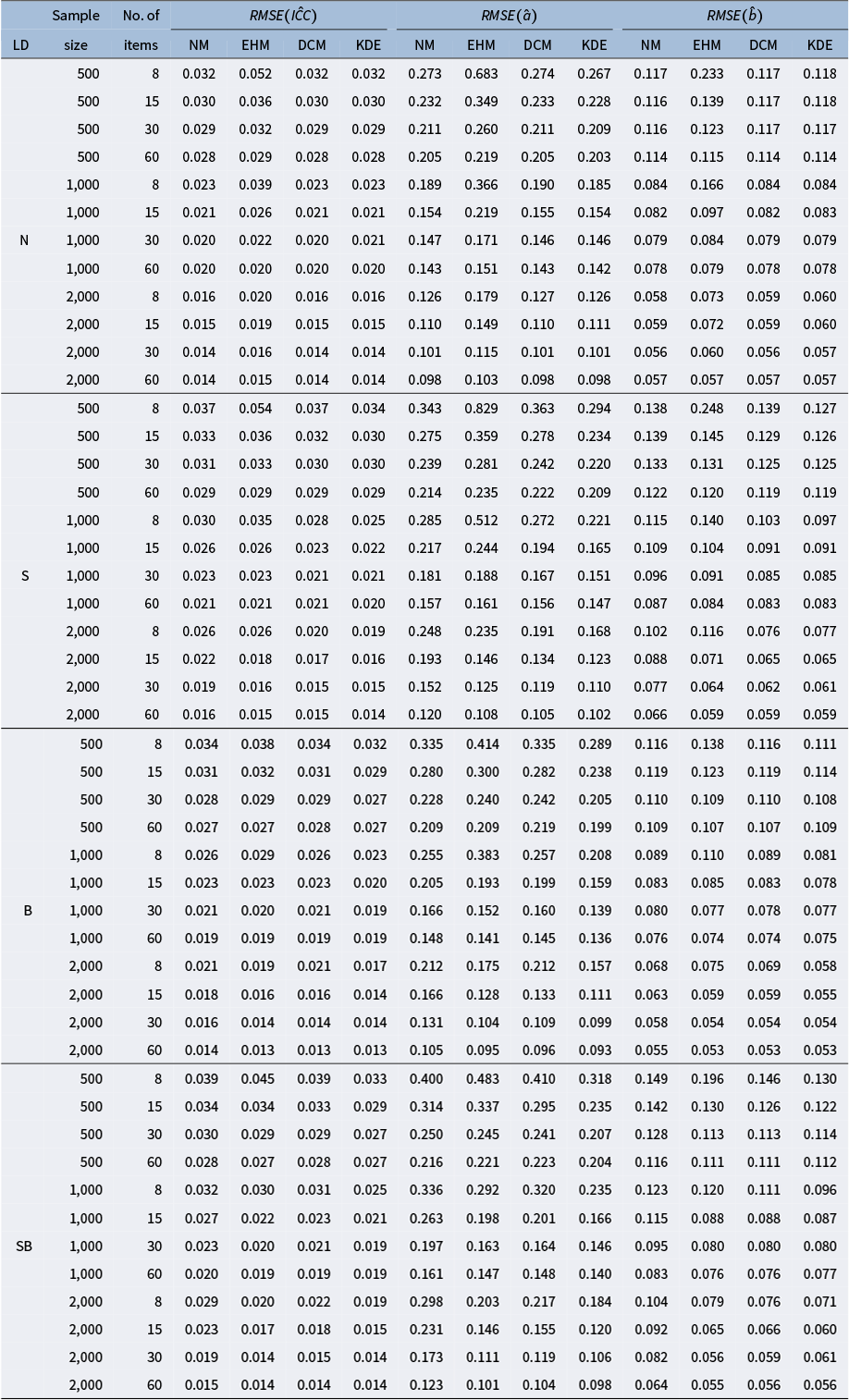
Table A1 Simulation results of
 $RMSE(\hat {ICC})$
,
$RMSE(\hat {ICC})$
,
 $RMSE(\hat {a})$
, and
$RMSE(\hat {a})$
, and
 $RMSE(\hat {b})$
$RMSE(\hat {b})$

Note: “LD,” “N,” “S,” “B,” and “SB” stand for latent distribution, normal, skewed, bimodal, and skewed bimodal, respectively.
Table A2 Simulation results of
 $ISE(\hat {g}(\theta ))$
and
$ISE(\hat {g}(\theta ))$
and
 $RMSE(\hat {\theta })$
$RMSE(\hat {\theta })$

Note: “LD,” “N,” “S,” “B,” and “SB” stand for latent distribution, normal, skewed, bimodal, and skewed bimodal, respectively.














 Open access
Open access