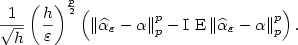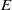 $E$-INVERSIVE SEMIGROUP
$E$-INVERSIVE SEMIGROUP
In this paper we investigate some subclasses of strongly regular congruences on an 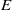 $E$-inversive semigroup
$E$-inversive semigroup 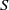 $S$. We describe the minimum and the maximum strongly orthodox congruences on
$S$. We describe the minimum and the maximum strongly orthodox congruences on 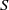 $S$ whose characteristic trace coincides with the characteristic trace of given congruences and, in each case, we present an alternative characterization for them. A description of all strongly orthodox congruences on
$S$ whose characteristic trace coincides with the characteristic trace of given congruences and, in each case, we present an alternative characterization for them. A description of all strongly orthodox congruences on 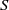 $S$ with characteristic trace
$S$ with characteristic trace  $\tau $ is given. Further, we investigate the kernel relation of strongly orthodox congruences on an
$\tau $ is given. Further, we investigate the kernel relation of strongly orthodox congruences on an 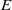 $E$-inversive semigroup and give the least and the greatest element in the class of the same kernel with a given congruence.
$E$-inversive semigroup and give the least and the greatest element in the class of the same kernel with a given congruence.
A semigroup  $S$ is called idempotent-surjective (respectively, regular-surjective) if whenever
$S$ is called idempotent-surjective (respectively, regular-surjective) if whenever 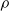 $\rho $ is a congruence on
$\rho $ is a congruence on 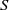 $S$ and
$S$ and 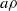 $a\rho $ is idempotent (respectively, regular) in
$a\rho $ is idempotent (respectively, regular) in 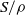 $S/ \rho $, then there is
$S/ \rho $, then there is 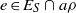 $e\in {E}_{S} \cap a\rho $ (respectively,
$e\in {E}_{S} \cap a\rho $ (respectively, 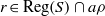 $r\in \mathrm{Reg} (S)\cap a\rho $), where
$r\in \mathrm{Reg} (S)\cap a\rho $), where 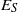 ${E}_{S} $ (respectively,
${E}_{S} $ (respectively, 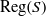 $\mathrm{Reg} (S)$) denotes the set of all idempotents (respectively, regular elements) of
$\mathrm{Reg} (S)$) denotes the set of all idempotents (respectively, regular elements) of 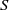 $S$. Moreover, a semigroup
$S$. Moreover, a semigroup 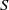 $S$ is said to be idempotent-regular-surjective if it is both idempotent-surjective and regular-surjective. We show that any regular congruence on an idempotent-regular-surjective (respectively, regular-surjective) semigroup is uniquely determined by its kernel and trace (respectively, the set of equivalence classes containing idempotents). Finally, we prove that all structurally regular semigroups are idempotent-regular-surjective.
$S$ is said to be idempotent-regular-surjective if it is both idempotent-surjective and regular-surjective. We show that any regular congruence on an idempotent-regular-surjective (respectively, regular-surjective) semigroup is uniquely determined by its kernel and trace (respectively, the set of equivalence classes containing idempotents). Finally, we prove that all structurally regular semigroups are idempotent-regular-surjective.
We consider a diffusion process X t smoothed with (small)sampling parameter ε. As in Berzin, León and Ortega(2001), we consider a kernel estimate $\widehat{\alpha}_{\varepsilon}$ 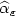 with window h(ε) of afunction α of its variance. In order to exhibit globaltests of hypothesis, we derive here central limit theorems forthe Lp deviations such as \[ \frac1{\sqrt{h}}\left(\frac{h}\varepsilon\right)^{\frac{p}2}\left(\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p-\mbox{I E}\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p\right).\]
with window h(ε) of afunction α of its variance. In order to exhibit globaltests of hypothesis, we derive here central limit theorems forthe Lp deviations such as \[ \frac1{\sqrt{h}}\left(\frac{h}\varepsilon\right)^{\frac{p}2}\left(\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p-\mbox{I E}\left\|\widehat{\alpha}_{\varepsilon}-{\alpha}\right\|_p^p\right).\]