Refine search
Actions for selected content:
31 results
Social Enterprise Performance: The Role of Market and Social Entrepreneurship Orientations
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 32 / Issue 1 / February 2021
- Published online by Cambridge University Press:
- 01 January 2026, pp. 45-60
-
- Article
- Export citation
Middle-Class Formal Volunteering over Time: Case of Switzerland (2006–2020)
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 36 / Issue 4 / August 2025
- Published online by Cambridge University Press:
- 01 January 2026, pp. 421-434
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Factors Influencing Voluntary Disclosure in the Annual Reports of Portuguese Foundations
-
- Journal:
- Voluntas: International Journal of Voluntary and Nonprofit Organizations / Volume 28 / Issue 5 / October 2017
- Published online by Cambridge University Press:
- 01 January 2026, pp. 2278-2311
-
- Article
- Export citation
Bayesian Structural Equation Envelope Model
-
- Journal:
- Psychometrika / Volume 90 / Issue 4 / September 2025
- Published online by Cambridge University Press:
- 08 August 2025, pp. 1236-1257
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
A Class of Distribution-Free Models for Longitudinal Mediation Analysis
-
- Journal:
- Psychometrika / Volume 79 / Issue 4 / October 2014
- Published online by Cambridge University Press:
- 01 January 2025, pp. 543-568
-
- Article
- Export citation
Advantages of Using Unweighted Approximation Error Measures for Model Fit Assessment
-
- Journal:
- Psychometrika / Volume 88 / Issue 2 / June 2023
- Published online by Cambridge University Press:
- 01 January 2025, pp. 413-433
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Influence Analysis of Structural Equation Models with Polytomous Variables
-
- Journal:
- Psychometrika / Volume 64 / Issue 4 / December 1999
- Published online by Cambridge University Press:
- 01 January 2025, pp. 461-473
-
- Article
- Export citation
Analysis of Structural Equation Model with Ignorable Missing Continuous and Polytomous Data
-
- Journal:
- Psychometrika / Volume 67 / Issue 2 / June 2002
- Published online by Cambridge University Press:
- 01 January 2025, pp. 261-288
-
- Article
- Export citation
Forecasting Intra-individual Changes of Affective States Taking into Account Inter-individual Differences Using Intensive Longitudinal Data from a University Student Dropout Study in Math
-
- Journal:
- Psychometrika / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 01 January 2025, pp. 533-558
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
The longitudinal process that leads to university student dropout in STEM subjects can be described by referring to (a) inter-individual differences (e.g., cognitive abilities) as well as (b) intra-individual changes (e.g., affective states), (c) (unobserved) heterogeneity of trajectories, and d) time-dependent variables. Large dynamic latent variable model frameworks for intensive longitudinal data (ILD) have been proposed which are (partially) capable of simultaneously separating the complex data structures (e.g., DLCA; Asparouhov et al. in Struct Equ Model 24:257–269, 2017; DSEM; Asparouhov et al. in Struct Equ Model 25:359–388, 2018; NDLC-SEM, Kelava and Brandt in Struct Equ Model 26:509–528, 2019). From a methodological perspective, forecasting in dynamic frameworks allowing for real-time inferences on latent or observed variables based on ongoing data collection has not been an extensive research topic. From a practical perspective, there has been no empirical study on student dropout in math that integrates ILD, dynamic frameworks, and forecasting of critical states of the individuals allowing for real-time interventions. In this paper, we show how Bayesian forecasting of multivariate intra-individual variables and time-dependent class membership of individuals (affective states) can be performed in these dynamic frameworks using a Forward Filtering Backward Sampling method. To illustrate our approach, we use an empirical example where we apply the proposed forecasting method to ILD from a large university student dropout study in math with multivariate observations collected over 50 measurement occasions from multiple students (\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$N = 122$$\end{document}
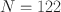 ). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
). More specifically, we forecast emotions and behavior related to dropout. This allows us to predict emerging critical dynamic states (e.g., critical stress levels or pre-decisional states) 8 weeks before the actual dropout occurs.
Learning Bayesian Networks: A Copula Approach for Mixed-Type Data
-
- Journal:
- Psychometrika / Volume 89 / Issue 2 / June 2024
- Published online by Cambridge University Press:
- 27 December 2024, pp. 658-686
-
- Article
- Export citation
Effects of Genetic Relatedness of Kin Pairs on Univariate ACE Model Performance
-
- Journal:
- Twin Research and Human Genetics / Volume 26 / Issue 4-5 / August 2023
- Published online by Cambridge University Press:
- 06 October 2023, pp. 257-268
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Genome-wide association study identifies significant SNP and related genes associated with body size in Yorkshire pigs using latent variable modelling
-
- Journal:
- The Journal of Agricultural Science / Volume 161 / Issue 4 / August 2023
- Published online by Cambridge University Press:
- 07 September 2023, pp. 599-605
-
- Article
- Export citation
Time-lagged associations between two adverse childhood experiences and later-life cognitive function through educational attainment and stroke
-
- Journal:
- Journal of the International Neuropsychological Society / Volume 30 / Issue 2 / February 2024
- Published online by Cambridge University Press:
- 04 July 2023, pp. 107-116
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Exploring the Genetic Association between Obesity and Serum Lipid Levels Using Bivariate Methods
-
- Journal:
- Twin Research and Human Genetics / Volume 25 / Issue 6 / December 2022
- Published online by Cambridge University Press:
- 06 January 2023, pp. 234-244
-
- Article
-
- You have access
- HTML
- Export citation
Meta-analysis of structural evidence for the Hierarchical Taxonomy of Psychopathology (HiTOP) model
-
- Journal:
- Psychological Medicine / Volume 53 / Issue 2 / January 2023
- Published online by Cambridge University Press:
- 14 May 2021, pp. 533-546
-
- Article
- Export citation
3 - Explaining Variation in Island Species–Area Relationship (ISAR) Model Parameters between Different Archipelago Types: Expanding a Global Model of ISARs
- from Part II - Diversity–Area Relationships: The Different Types and Underlying Factors
-
-
- Book:
- The Species–Area Relationship
- Published online:
- 11 March 2021
- Print publication:
- 18 March 2021, pp 51-77
-
- Chapter
- Export citation
Depression and worry symptoms predict future executive functioning impairment via inflammation
-
- Journal:
- Psychological Medicine / Volume 52 / Issue 15 / November 2022
- Published online by Cambridge University Press:
- 03 March 2021, pp. 3625-3635
-
- Article
- Export citation
Parental rearing and personality traits as predictors for adolescents with obsessive–compulsive disorder (OCD)
-
- Journal:
- Development and Psychopathology / Volume 34 / Issue 1 / February 2022
- Published online by Cambridge University Press:
- 12 January 2021, pp. 387-394
-
- Article
- Export citation
The comparison of standard and fully recursive multivariate models for genetic evaluation of growth traits in Markhoz goat: predictive ability of models and ranking of animals
-
- Journal:
- The Journal of Agricultural Science / Volume 158 / Issue 6 / August 2020
- Published online by Cambridge University Press:
- 23 October 2020, pp. 511-517
-
- Article
- Export citation
-
Data of 2780 Markhoz kids originated from 1216 dams and 211 sires during 1993–2016 in Markhoz Goat Breeding Station, located in Sanandaj, Iran, were used. Traits investigated were body weights at birth, weaning, six-month age [six months weight (6MW)], nine-month age and yearling age [yearling weight (YW)]. Two considered multivariate models including standard multivariate model (SMM) and fully recursive multivariate model (FRM) were compared using deviance information criterion (DIC) and predictive ability measures including mean square of error (MSE) and Pearson's correlation coefficient between the observed and predicted values $(r(y,\hat{y}))$
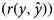 of records. Spearman's rank correlation coefficients between posterior means of direct genetic effects of the studied traits of kids under SMM and FRM were also calculated across all, 50, 10 and 1% top-ranked animals. In general, FRM performed better than SMM in terms of lower DIC and MSE and also higher $r\lpar y\comma \;\hat{y}\rpar$
of records. Spearman's rank correlation coefficients between posterior means of direct genetic effects of the studied traits of kids under SMM and FRM were also calculated across all, 50, 10 and 1% top-ranked animals. In general, FRM performed better than SMM in terms of lower DIC and MSE and also higher $r\lpar y\comma \;\hat{y}\rpar$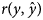 . For all traits, the lowest MSE and the highest $r\lpar y\comma \;\hat{y}\rpar$
. For all traits, the lowest MSE and the highest $r\lpar y\comma \;\hat{y}\rpar$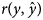 were obtained under FRM. All structural coefficients estimated under FRM were statistically significant except for that of 6MW on YW. Comparisons of Spearman's rank correlations between posterior means of direct genetic effects of kids for growth traits under SMM and FRM revealed that taking the causal relationships among the studied growth traits of Markhoz goat into account may cause considerable re-ranking for the animals in terms of estimated breeding values, especially for the top-ranked animals. It may be concluded that FRM had more plausibility over SMM for genetic evaluation of the studied growth traits in Markhoz goat.
were obtained under FRM. All structural coefficients estimated under FRM were statistically significant except for that of 6MW on YW. Comparisons of Spearman's rank correlations between posterior means of direct genetic effects of kids for growth traits under SMM and FRM revealed that taking the causal relationships among the studied growth traits of Markhoz goat into account may cause considerable re-ranking for the animals in terms of estimated breeding values, especially for the top-ranked animals. It may be concluded that FRM had more plausibility over SMM for genetic evaluation of the studied growth traits in Markhoz goat.
Testing efficacy of a multi-site environmental education programme in a demographically and biologically diverse setting
-
- Journal:
- Environmental Conservation / Volume 47 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 12 December 2019, pp. 60-66
-
- Article
- Export citation
