

No CrossRef data available.
Article contents
Bootstrap percolation in random geometric graphs
Published online by Cambridge University Press: 31 May 2023
Abstract
Following Bradonjić and Saniee, we study a model of bootstrap percolation on the Gilbert random geometric graph on the 2-dimensional torus. In this model, the expected number of vertices of the graph is n, and the expected degree of a vertex is 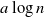 $a\log n$ for some fixed
$a\log n$ for some fixed 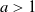 $a>1$. Each vertex is added with probability p to a set
$a>1$. Each vertex is added with probability p to a set 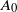 $A_0$ of initially infected vertices. Vertices subsequently become infected if they have at least
$A_0$ of initially infected vertices. Vertices subsequently become infected if they have at least 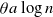 $ \theta a \log n $ infected neighbours. Here
$ \theta a \log n $ infected neighbours. Here 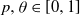 $p, \theta \in [0,1]$ are taken to be fixed constants.
$p, \theta \in [0,1]$ are taken to be fixed constants.
We show that if 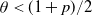 $\theta < (1+p)/2$, then a sufficiently large local outbreak leads with high probability to the infection spreading globally, with all but o(n) vertices eventually becoming infected. On the other hand, for
$\theta < (1+p)/2$, then a sufficiently large local outbreak leads with high probability to the infection spreading globally, with all but o(n) vertices eventually becoming infected. On the other hand, for 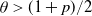 $ \theta > (1+p)/2$, even if one adversarially infects every vertex inside a ball of radius
$ \theta > (1+p)/2$, even if one adversarially infects every vertex inside a ball of radius 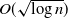 $O(\sqrt{\log n} )$, with high probability the infection will spread to only o(n) vertices beyond those that were initially infected.
$O(\sqrt{\log n} )$, with high probability the infection will spread to only o(n) vertices beyond those that were initially infected.
In addition we give some bounds on the 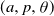 $(a, p, \theta)$ regions ensuring the emergence of large local outbreaks or the existence of islands of vertices that never become infected. We also give a complete picture of the (surprisingly complex) behaviour of the analogous 1-dimensional bootstrap percolation model on the circle. Finally we raise a number of problems, and in particular make a conjecture on an ‘almost no percolation or almost full percolation’ dichotomy which may be of independent interest.
$(a, p, \theta)$ regions ensuring the emergence of large local outbreaks or the existence of islands of vertices that never become infected. We also give a complete picture of the (surprisingly complex) behaviour of the analogous 1-dimensional bootstrap percolation model on the circle. Finally we raise a number of problems, and in particular make a conjecture on an ‘almost no percolation or almost full percolation’ dichotomy which may be of independent interest.
MSC classification
Primary:
60G55: Point processes
Information
- Type
- Original Article
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press on behalf of Applied Probability Trust
References
Aizenman, M. and Lebowitz, J. (1988). Metastability effects in bootstrap percolation. J. Phys. A 21, 3801–3813.CrossRefGoogle Scholar
Amini, H. (2010). Bootstrap percolation in living neural networks. J. Statist. Phys. 141, 459–475.Google Scholar
Amini, H., Cont, R. and Minca, A. (2016). Resilience to contagion in financial networks. Math. Finance 26, 329–365.Google Scholar
Amini, H. and Fountoulakis, N. (2014). Bootstrap percolation in power-law random graphs. J. Statist. Phys. 155, 72–92.Google Scholar
Arratia, R., Goldstein, L. and Gordon, L. (1989). Two moments suffice for Poisson approximations: the Chen–Stein method. Ann. Prob. 17, 9–25.Google Scholar
Balister, P., Bollobás, B., Sarkar, A. and Walters, M. (2005). Connectivity of random k-nearest-neighbour graphs. Adv. Appl. Prob. 37, 1–24.Google Scholar
Balister, P., Bollobás, B., Sarkar, A. and Walters, M. (2009). A critical constant for the k nearest-neighbour model. Adv. Appl. Prob., 41, 1–12.CrossRefGoogle Scholar
Balister, P., Bollobás, B., Sarkar, A. and Kumar, S. (2007). Reliable density estimates for coverage and connectivity in thin strips of finite length. In Proc. 13th Annual ACM International Conference on Mobile Computing and Networking, Association for Computing Machinery, New York, pp. 75–86.Google Scholar
Balogh, J., Bollobás, B., Duminil-Copin, H. and Morris, R. (2012). The sharp threshold for bootstrap percolation in all dimensions. Trans. Amer. Math. Soc. 364, 2667–2701.CrossRefGoogle Scholar
Balogh, J. and Pittel, B. (2007). Bootstrap percolation on the random regular graph. Random Structures Algorithms 30, 257–286.Google Scholar
Bollobás, B. (2006). The Art of Mathematics: Coffee Time in Memphis. Cambridge University Press.Google Scholar
Bollobás, B. et al. (2014). Bootstrap percolation on Galton–Watson trees. Electron J. Prob. 19, article no. 13.CrossRefGoogle Scholar
Bollobás, B. and Leader, I. (1991). Edge-isoperimetric inequalities in the grid. Combinatorica 11, 299–314.CrossRefGoogle Scholar
Bradonjić, M. and Saniee, I. (2014). Bootstrap percolation on random geometric graphs. Prob. Eng. Inf. Sci. 28, 169–181.Google Scholar
Candellero, E. and Fountoulakis, N. (2016). Bootstrap percolation and the geometry of complex networks. Stoch. Process. Appl. 126, 234–264.Google Scholar
Chalupa, J., Leath, P. and Reich, G. (1979). Bootstrap percolation on a Bethe lattice. J. Phys. C 12, L31–L35.Google Scholar
Dreyer, P. and Roberts, F. (2009). Irreversible k-threshold processes: graph-theoretical threshold models of the spread of disease and of opinion. Discrete Appl. Math. 157, 1615–1627.Google Scholar
Einarsson, H. et al. (2019). Bootstrap percolation with inhibition. Random Structures Algorithms 55, 881–925.Google Scholar
Falgas-Ravry, V. and Walters, M. (2012). Sharpness in the k-nearest-neighbours random geometric graph model. Adv. Appl. Prob. 44, 617–634.Google Scholar
Fountoulakis, N., Kang, M., Koch, C. and Makai, T. (2018). A phase transition regarding the evolution of bootstrap processes in inhomogeneous random graphs. Ann. Appl. Prob. 28, 990–1051.CrossRefGoogle Scholar
Gao, J., Zhou, T. and Hu, Y. (2015). Bootstrap percolation on spatial networks. Sci. Reports 5, 1–10.Google ScholarPubMed
González-Barrios, J. and Quiroz, A. (2003). A clustering procedure based on the comparison between the k nearest neighbors graph and the minimal spanning tree. Statist. Prob. Lett. 62, 23–34.Google Scholar
Granovetter, M. (1978). Threshold models of collective behavior. Amer. J. Sociol. 83, 1420–1443.Google Scholar
Gravner, J. and Sivakoff, D. (2017). Bootstrap percolation on products of cycles and complete graphs. Electron. J. Prob. 22, article no. 29.Google Scholar
Holroyd, A. (2003). Sharp metastability threshold for two-dimensional bootstrap percolation. Prob. Theory Relat. Fields 125, 195–224.Google Scholar
Janson, S. (2009). On percolation in random graphs with given vertex degrees. Electron. J. Prob. 14, 87–118.Google Scholar
Janson, S., Kozma, R., Ruszinkó, M. and Sokolov, Y. (2019). A modified bootstrap percolation on a random graph coupled with a lattice. Discrete Appl. Math. 258, 152–165.CrossRefGoogle Scholar
Janson, S., Łuczak, T., Turova, T. and Vallier, T. (2012). Bootstrap percolation on the random graph
 $G_{n, p}$
. Ann. Appl. Prob. 22, 1989–2047.CrossRefGoogle Scholar
$G_{n, p}$
. Ann. Appl. Prob. 22, 1989–2047.CrossRefGoogle Scholar
 $G_{n, p}$
. Ann. Appl. Prob. 22, 1989–2047.CrossRefGoogle Scholar
$G_{n, p}$
. Ann. Appl. Prob. 22, 1989–2047.CrossRefGoogle ScholarKoch, C. and Lengler, J. (2016). Bootstrap percolation on geometric inhomogeneous random graphs. In 43rd International Colloquium on Automata, Languages, and Programming (ICALP 2016), Schloss Dagstuhl—Leibniz-Zentrum für Informatik, Dagstuhl, pp. 147:1–147:15.Google Scholar
Koch, C. and Lengler, J. (2021). Bootstrap percolation on geometric inhomogeneous random graphs. Internet Mathematics. Available at https://arxiv.org/abs/1603.02057.Google Scholar
Penrose, M. (1997). The longest edge of the random minimal spanning tree. Ann. Appl. Prob. 7, 340–361.Google Scholar
Ramos, M. et al. (2015). How does public opinion become extreme?. Sci. Reports 5, article no. 10032.Google Scholar
Whittemore, A. (2021). Bootstrap percolation on random geometric graphs. Doctoral Thesis. University of Nebraska.Google Scholar
Xue, F. and Kumar, P. (2004). The number of neighbors needed for connectivity of wireless networks. Wireless Networks 10, 169–181.Google Scholar