


Introduction
Industry 4.0 aims to innovate industries through the Internet of Things (IoT), cyber-physical systems, artificial intelligence (AI), Big Data, cloud computing, and robotics (Iqbal et al., Reference Iqbal, Lee and Ren2022; Maddikunta et al., Reference Maddikunta, Pham, Prabadevi, Deepa, Dev, Gadekallu, Ruby and Liyanage2022; Nahavandi, Reference Nahavandi2019), with a focus on enhancing fabrication efficiency via automation (Maddikunta et al., Reference Maddikunta, Pham, Prabadevi, Deepa, Dev, Gadekallu, Ruby and Liyanage2022; Nahavandi, Reference Nahavandi2019). This includes the implementation of robots to replace human workers in the Industry 4.0 paradigm.
Bringing human workers back to factories
However, Industry 4.0 has not yet been successfully implemented worldwide (Iqbal et al., Reference Iqbal, Lee and Ren2022; Nahavandi, Reference Nahavandi2019). The first reason is that Industry 4.0 involves the integration of various advanced technologies, requiring support from infrastructures that are not yet available in most countries outside the United States and European Union (Chien et al., Reference Chien, Hong and Guo2017). Second, the highly customized demands of modern businesses (Alves et al., Reference Alves, Lima and Gaspar2023; Gan et al., Reference Gan, Musa and Yap2023; Maddikunta et al., Reference Maddikunta, Pham, Prabadevi, Deepa, Dev, Gadekallu, Ruby and Liyanage2022) make fully automated systems prone to failure. Automation systems with high buildup costs cannot gain an advantage in the small production quantities of customized orders (Iqbal et al., Reference Iqbal, Lee and Ren2022). The third reason is that Industry 4.0 does not strongly consider environmental sustainability (Nahavandi, Reference Nahavandi2019). The reduction of the carbon footprint in manufacturing is receiving greater attention from public interest groups, international organizations, and governments (Nahavandi, Reference Nahavandi2019). Consumers are also increasingly supporting environmentally friendly companies (Nahavandi, Reference Nahavandi2019). Balancing environmental protection with high-efficiency production will be a critical issue in modern industry.
Furthermore, the biggest issue may be the ethical problem of removing human workers from the production line. In the conceptual framework of Industry 4.0, humans are considered obstacles to improving productivity. As a result, automation is prioritized over human labor, leading to a decline in employment rates (Iqbal et al., Reference Iqbal, Lee and Ren2022). This approach faces opposition from labor unions, congress, and governments (Iqbal et al., Reference Iqbal, Lee and Ren2022; Nahavandi, Reference Nahavandi2019).
Nevertheless, practitioners have become aware of the drawbacks associated with the original concepts of Industry 4.0. Consequently, they have revised the interactions between humans and machines (Romero et al., Reference Romero, Bernus, Noran, Stahre and Fast-Berglund2016). The main modification emphasizes a human-centric approach, as proposed by a nonprofit, industry-driven association in Europe (Romero et al., Reference Romero, Bernus, Noran, Stahre and Fast-Berglund2016). Recently, Industry 5.0, which builds upon the technologies developed in Industry 4.0 (Iqbal et al., Reference Iqbal, Lee and Ren2022), has emphasized the vision of creating sustainable, human-centric, and resilient industries. The most prominent aspect of Industry 5.0 is the reintegration of human workers into shop floors, which has garnered significant interest from researchers (Alves et al., Reference Alves, Lima and Gaspar2023; Cimino et al., Reference Cimino, Elbasheer, Longo, Nicoletti and Padovano2023; Longo et al., Reference Longo, Padovano and Umbrello2020; Moller et al., Reference Moller, Vakilzadian and Haas2022; Papetti et al., Reference Papetti, Gregori, Pandolfi, Peruzzini and Germani2020; Romero and Stahre, Reference Romero, Stahre and Taisch2020). The primary goal is to leverage human creativity and intelligence in smart manufacturing systems (Iqbal et al., Reference Iqbal, Lee and Ren2022), thereby ensuring the well-being of workers (Moller et al., Reference Moller, Vakilzadian and Haas2022).
A human-centric solution for the smart factory
A human-centric solution in Industry 5.0 is an autonomous production system with humans in and on the loop (Nahavandi, Reference Nahavandi2019). Humans and machines coexist and cooperate (Demir et al., Reference Demir, Döven and Sezen2019; Johri et al., Reference Johri, Singh, Sharma and Rastogi2021) based on Industry 4.0, forming a human–cyber-physical system (HCPS; Romero et al., Reference Romero, Bernus, Noran, Stahre and Fast-Berglund2016). The robots in the HCPS collaborate with human workers, acting as another worker who stands beside them to assist in finishing a job. These collaborative robots, called cobots, are equipped with human intelligence by machine learning algorithms. Cobots not only observe and learn how an operator performs a task but also have machine recognition (Maddikunta et al., Reference Maddikunta, Pham, Prabadevi, Deepa, Dev, Gadekallu, Ruby and Liyanage2022; Nahavandi, Reference Nahavandi2019). Cobots receive data from wearable sensors on human workers (Fortino et al., Reference Fortino, Galzarano, Gravina and Li2015; Kong et al., Reference Kong, Yang, Huang and Luo2018; Maddikunta et al., Reference Maddikunta, Pham, Prabadevi, Deepa, Dev, Gadekallu, Ruby and Liyanage2022; Montini et al., Reference Montini, Cutrona, Gladysz, Dell’Oca, Landolfi and Bettoni2022). The AI algorithm processes the data so that cobots can locate the operator’s position, analyze the worker’s posture, know the goal of the ongoing task, and perceive the human coworker’s expectations. With this information, cobots autonomously decide what to do and how to assist human workers (Maddikunta et al., Reference Maddikunta, Pham, Prabadevi, Deepa, Dev, Gadekallu, Ruby and Liyanage2022; Nahavandi, Reference Nahavandi2019). Accordingly, wearable sensors and wireless communication protocols in IoT, and machine recognition algorithms in AI play essential roles in the human-centric solution in Industry 5.0.
The challenges of human activity recognition (HAR) of human–robot collaboration
HAR has been recognized as an essential component of human–robot collaboration (Lucci et al., Reference Lucci, Monguzzi, Zanchettin and Rocco2022; Martinez-Villasenor and Ponce, Reference Martímez-Villaseñor and Ponce2019). However, HAR in the industrial sector differs from the recognition of activities of daily living (ADL), which has been well-documented in the literature (Al-Amin et al., Reference Al-Amin, Qin, Tao, Doell, Lingard, Yin and Leu2020). ADL literature focuses on the recognition of a complete and unsegmented action. In industry, a human operator’s activity within a task needs to be divided into fine elements so that the collaborative robot can respond to each recognized element. One approach is to apply gesture recognition in human–robot collaboration (Liu and Wang, Reference Liu and Wang2018). However, gestures are subtasks that may impact the operator’s performance in the main task. Additionally, requiring operators to memorize gestures may increase their mental workload (Lucci et al., Reference Lucci, Monguzzi, Zanchettin and Rocco2022).
A review of HAR (Wang et al., Reference Wang, Chen, Hao, Peng and Hu2019) has reported that most research has focused on people’s ADL. With technological advancements, HAR applications have rapidly developed in various fields, including security and surveillance, smart homes, entertainment, medical healthcare, and gait analysis (Wang et al., Reference Wang, Chen, Hao, Peng and Hu2019). Unfortunately, these types of HAR have limited impact on human–robot collaboration, as operators on a shop floor perform tasks with many continuous elements.
Moreover, most existing public databases are based on ADL (Anguita et al., Reference Anguita, Ghio, Oneto, Parra and Reyes-Ortiz2013; Banos et al., Reference Banos, Garcia, Holgado-Terriza, Damas, Pomares, Rojas, Saez, Villalonga, Pecchia, Chen, Nugent and Bravo2014; Chavarriaga et al., Reference Chavarriaga, Sagha, Calatroni, Digumarti, Tröster, Millán and Roggen2013; Micucci et al., Reference Micucci, Mobilio and Napoletano2017; Reiss and Stricker, Reference Reiss and Stricker2012; Stisen et al., Reference Stisen, Blunck, Bhattacharya, Prentow, Kjærgaard, Dey, Sonne and Jensen2015; Sztyler and Stuckenschmidt, Reference Sztyler and Stuckenschmidt2016). In comparison to ADL, databases or research focused on manufacturing or standard operating instructions on a shop floor are relatively limited (Zappi et al., Reference Zappi, Lombriser, Stiefmeier, Farella, Roggen, Benini and Tröster2008).
Worker and machine process chart for HAR in human–robot collaboration
To realize the vision of human–robot collaboration, the cobot must identify and understand every element being processed by the human worker. This requires decomposing activities into various operational elements, similar to how an industrial engineer creates a worker and machine process chart (Freivalds, Reference Freivalds2009) using motion and time study methods. With this information, the cobot can perceive which element the operator is working on and autonomously decide how to collaborate with the worker, rather than relying on preprogrammed responses.
An important task for industrial engineers is to establish standard operating procedures (SOPs) for various production plants, ensuring high-efficiency performance while considering the welfare of workers. By utilizing professional methods from motion and time study, engineers first observe the sequence of workers’ actions, breaking them down and categorizing them into a series of sequential motions. The time required for each sequential motion is then measured. These sequential motions are further evaluated to determine if they can be optimized through the principles of elimination, rearrangement, combination, or simplification. Subsequently, using a selected benchmark worker, the industrial engineer uses a stopwatch to measure the time required for each sequential motion and allows for a certain margin, establishing the standard time for each task. Production site managers can use this SOP and timing as training material for new employees. For employees whose performance does not meet the standard, a comparison of their sequential motions can help identify whether their actions are correct, and comparing the time taken for each sequential motion with the standard time can guide them toward improvement.
However, classical motion and time study has some drawbacks. Industrial engineers traditionally use stopwatches and manual paper records to observe workers’ actions and timing, which incurs significant labor and time costs, introduces subjective variations, and can reduce accuracy due to visual errors. The presence of engineers in the workplace may make workers uncomfortable, affecting their performance, and even creating tension or conflict, leading to a stressful work atmosphere.
This research proposes integrating the concept of motion and time study with sequential motion recognition in human activity, which not only promises to realize the human–robot collaboration envisioned in Industry 5.0 but also helps workers improve their performance, enables site managers to create more effective training programs, and assists industrial engineers in completing system improvements more efficiently.
In short, cobots must be equipped with HAR intelligence that can recognize processing elements in specific tasks to achieve effective human–robot collaboration in a smart factory.
Motivation and objective
The vision of smart factories within the Industry 5.0 framework involves applying human-centric solutions to enable autonomous human–robot collaboration. Recognizing the operational elements of a task performed by an operator using HAR methods is essential to realizing this vision. However, there is relatively little research on this topic in the literature. Therefore, before achieving human–robot collaboration, this study is motivated by the need to fill this critical research gap.
This study addresses the limitations of traditional methods by employing machine learning models for HAR with intelligent technology. As a pilot study combining the concepts of motion and time study and HAR, this research focuses on sequential motion recognition. Once the motion recognition technology is successfully developed, the operational time for each sequential motion can be estimated based on the number of data samples and sampling frequency, thereby achieving the goal of improving production performance. If the method proposed in this study successfully achieves the goal of “sequential motion recognition in human activity,” it would demonstrate that this innovative concept could be extended to any manufacturing industry that utilizes SOPs.
The aim of this research is to apply machine learning methods to recognize sequential motions in operations, aligning with the vision of human–robot collaboration in Industry 5.0. Additionally, the research seeks to assist industrial engineers in developing SOPs, training personnel, and improving performance in the workplace. HAR automates information gathering, saving time and avoiding disputes by replacing time-consuming and potentially controversial traditional motion and time study methods. Additionally, HAR results provide valuable feedback for new employee training, enabling supervisors to design programs that improve performance and productivity on the shop floor.
Related works
To develop machine learning models for HAR, data on human movement are collected using various types of devices and then fed into training models. These devices can be divided into two categories: vision-based and sensor-based. Preprocessing and feature extraction are vital for the collected data before it is used for model training. In this section, we discuss the literature related to these topics.
Data collecting devices
Vision-based sensors in HAR
In vision-based action recognition, traditional RGB cameras are popular and affordable for HAR researchers. The relevant literature has explored various features of RGB images and classification methods (Aggarwal and Ryoo, Reference Aggarwal and Ryoo2011; Poppe, Reference Poppe2010; Ramanathan et al., Reference Ramanathan, Yau and Teoh2014; Weinland et al., Reference Weinland, Ronfard and Boyer2011). However, intensive image processing and computer vision algorithms require considerable hardware resources, and RGB images, which lack 3D motion data, need to be processed (Aggarwal and Xia, Reference Aggarwal and Xia2014).
Compared to RGB cameras, three categories of devices providing 3D kinematics information of the human body have been widely used in HAR research. The first category includes the expensive optical motion capture (OMC) system. This method involves attaching reflective markers to specific joints on the human body and using multiple infrared cameras to estimate the 3D coordinates of each joint. The OMC method is considered the gold standard in biomechanics studies, and many HAR studies using OMC are available in the literature (Aurand et al., Reference Aurand, Dufour and Marras2017; Zhu and Wang, Reference Zhu and Sheng2011).
The second category of equipment utilizes stereo cameras to obtain 3D data, including depth, through stereo matching and depth calculation (Argyriou et al., Reference Argyriou, Petrou and Barsky2010). However, stereoscopic 3D reconstruction algorithms are computationally intensive and extremely sensitive to the illumination and complexity of the background environment (Aggarwal and Xia, Reference Aggarwal and Xia2014), which makes them less prevalent today.
A third approach is based on distance or depth sensors. In the last decade, low-cost RGB depth cameras have become highly cost-effective and have been used for real-time 3D motion capture in HAR studies (Jalal et al., Reference Jalal, Kim, Kim, Kamal and Kim2017; Khan et al., Reference Khan, Afzal and Lee2022; Qi et al., Reference Qi, Wang, Su and Aliverti2022; Yadav et al., Reference Yadav, Tiwari, Pandey and Akbar2021). Compared to traditional RGB images obtained by conventional cameras, the depth images generated by depth cameras are less sensitive to changes in illumination, and the performance of HAR is higher since the 3D kinematics of joints are utilized (Shotton et al., Reference Shotton, Sharp, Kipman, Fitzgibbon, Finocchio, Blake, Cook and Moore2013).
Although vision-based methods are still popular in HAR studies, they face several challenges that limit their performance. For example, obstructions between the human body and the camera, variations in movement between different individuals, and cluttered backgrounds can all hinder effectiveness (Vrigkas et al., Reference Vrigkas, Nikou and Kakadiaris2015). Furthermore, vision-based methods are limited by the camera’s field of view and the effective space of the camera setup. These limitations make it difficult for vision-based HAR to be applied outside the laboratory.
Sensor-based sensors in HAR
To overcome vision-based device limitations, recent years have seen the development of wearable inertial sensors equipped with accelerometers and gyroscopes. These sensors not only provide 3D acceleration and angular velocity data but also derive 3D joint coordinates, similar to depth cameras. This shift has gained traction in the HAR community, offering a notable advantage for field studies (Xu et al., Reference Xu, Yang, Cao and Li2017). Numerous studies leverage portable devices such as smartphones, smartwatches, and inertial measurement units (IMUs) with embedded inertial sensors for data collection and analysis (Baldominos et al., Reference Baldominos, Cervantes, Saez and Isasi2019; Burns and Whyne, Reference Burns and Whyne2018; Reyes-Ortiz et al., Reference Reyes-Ortiz, Oneto, Samà, Parra and Anguita2016; San-Segundo et al., Reference San-Segundo, Echeverry-Correa, Salamea and Pardo2016; Shoaib et al., Reference Shoaib, Bosch, Incel, Scholten and Havinga2016; Xu et al., Reference Xu, Yang, Cao and Li2017).
The sensor technology efficiently addresses broader areas and dynamic lighting conditions. Advancements in low power consumption and computational capabilities empower inertial sensing for long-term recording, computation, and continuous interaction with individuals. In addition to three-axis acceleration and angular velocity, wearable inertial sensors can also derive human joint 3D coordinates, similar to those obtained from depth cameras.
Data preprocessing and feature extraction
HAR involves a sequential chain of activities, beginning with capturing raw data from various sensors, followed by preprocessing to eliminate discomfort and noise, segmenting time-series data for target recognition, extracting features based on data attributes, reducing data dimensionality for feature refinement, building and training the classification model, and finally, verifying model performance (Bulling et al., Reference Bulling, Blanke and Schiele2014).
Sliding windows play a crucial role in time series data classification and are commonly used in segmentation methods. These windows can be nonoverlapping or have fixed-size overlapping structures. Determining the optimal window size is vital, considering variations in sensor placement and activity periods. Empirical determination of window length is a practical approach (Burns and Whyne, Reference Burns and Whyne2018; Jalal et al., Reference Jalal, Kim, Kim, Kamal and Kim2017; Janidarmian et al., Reference Janidarmian, Roshan Fekr, Radecka and Zilic2017).
Human activities form a time series data set, necessitating analysis through time windows rather than individual data frames. Feature extraction is essential for comparing activity differences, with widely applied time-domain features, such as median, mean, standard deviation, entropy, kurtosis, and skewness. Frequency domain features, including spectral entropy, peak power, and peak frequency, have gained popularity. Additionally, wavelet domain features derived through wavelet transform are explored in the literature (Burns and Whyne, Reference Burns and Whyne2018; Hassan et al., Reference Hassan, Uddin, Mohamed and Almogren2018; He et al., Reference He, Tan and Zhang2018; Ignatov, Reference Ignatov2018; Wang et al., Reference Wang, Zhang, Gao, Ma, Feng and Wang2017).
In summary, the literature highlights the significance of sliding windows in HAR research, discussing their use, distinctions between nonoverlapping and fixed-size overlapping windows, the critical importance of determining the optimal window size for effective data classification, and the impact of window overlap on model performance.
Machine learning models for HAR
HAR involves understanding and classifying actions based on data from human movement, typically framed as a pattern classification problem solvable by machine or deep learning models (Konar and Saha, Reference Konar and Saha2018).
AI algorithms used in HAR are divided into traditional machine learning-based and deep learning-based methods. Recent review papers have surveyed the models used in the literature (Bozkurt, Reference Bozkurt2021; Dua et al., Reference Dua, Singh, Challa, Semwal, Sai Kumar, Khare, Tomar, Ahirwal, Semwal and Soni2022; Kulsoom et al., Reference Kulsoom, Narejo, Mehmood, Chaudhry, Butt and Bashir2022). Frequently utilized in research studies are support vector machine (SVM), k-nearest neighbor (kNN), Gaussian mixed model (GMM), decision tree (DT), naïve Bayes (NB), random forest (RF), and hidden Markov model (HMM). Moreover, developing new deep learning-based models is a hot research topic in related communities. For deep learning-based methods, researchers often implement convolutional neural networks (CNN), deep neural networks (DNN), recurrent neural networks (RNN), deep belief networks (DBN), and long short-term memory (LSTM) in their investigations. Combining two algorithms to improve the model’s performance is also common. For example, LSTM is frequently embedded in CNN or RNN, and hybrid methods with SVM, HMM-SVM, or kNN-SVM are regularly adopted in machine learning models.
The field of HAR has witnessed significant advancements in recent years, driven by the proliferation of wearable sensors and the remarkable capabilities of deep learning algorithms. Deep learning has emerged as a powerful tool for extracting meaningful features from sensor data and accurately classifying human activities.
Studies on sequential motion recognition in human activity
The majority of HAR research has traditionally focused on ADL (Wang et al., Reference Wang, Chen, Hao, Peng and Hu2019). However, recent studies have shifted toward decomposing and recognizing elements within individual activities. One study proposed an HMM-based classification system for online classification of IMU and force sensor data from a lower limb exoskeleton, achieving an average accuracy of 84.5% in walking motion element recognition (Beil et al., Reference Beil, Ehrenberger, Scherer, Mandery and Asfour2018).
In a study on industrial lifting operation involving three elements, acceleration measurements were captured and used to develop a classifier within the HMM framework, achieving an impressive average accuracy of 99.8% (Ishibashi and Fujii, Reference Ishibashi and Fujii2021).
Another study assessed the recognition of eight elements in martial arts using motion data from IMUs. Among various sequence-based methods, the features of kinematics data extracted by a dynamic time warping (DTW) algorithm with kNN classifier achieved the highest accuracies 99.6% (Li et al., Reference Li, Khoo and Yap2022).
A separate study proposed a method for recognizing a nine-element industrial assembly activity by combining CNN and LSTM techniques with IMU and video data. The model achieved accuracies of 88% for IMU-based skeleton data, 77% for RGB spatial video, and 63% for RGB video-based skeleton (Tuli et al., Reference Tuli, Patel and Manns2022).
In a follow-up study of Tuli et al. (Reference Tuli, Patel and Manns2022), a method was introduced for automatically generating process time analyses of manual assembly processes with five elements. This method detected approximately 76% of manual operations in a proposed use case scenario (Jonek et al., Reference Jonek, Tuli, Manns, Galizia and Bortolini2023).
In contrast to recognizing entire elements, human–robot collaboration often relies on time stamp-based activity recognition, as validated by a single participant. One study introduced a general library of atomic predicates, which can be combined with first-order logic for modeling general industrial assembly processes in human–robot collaboration using RGBD data. The methodology achieved average accuracies of 99.3% in a complex collaborative assembly use case involving seven elements (Lucci et al., Reference Lucci, Monguzzi, Zanchettin and Rocco2022).
Another study presented an innovative operator advice model utilizing deep learning. This model incorporated three independent cameras and a decision tree classifier as a motion recognition mechanism. Applied to a human–robot collaborative task with five manual and four robot elements, the model demonstrated promising performance with an accuracy of 95.1% across the five manual elements (Wang and Santoso, Reference Wang and Santoso2022).
In summary, breaking down a human operator’s task into finer elements is essential for efficient analysis by industrial engineers. Within the framework of Industry 5.0, research related to the decomposition and recognition of operators’ actions is particularly important.
Materials and methods
This study simulates actual semiconductor IC product shipment manual operations to validate the effectiveness of the HAR machine learning model. Participants, wearing IMUs in the laboratory, completed three tasks according to the SOP. The kinematics data collected during this process follow the activity recognition development process proposed by Bulling et al. (Reference Bulling, Blanke and Schiele2014), which includes preprocessing raw data from motion capture devices, segmenting time-series data, extracting features based on data attributes, establishing and training an activity classification model, and verifying its performance.
Participants
Sixteen participants (8 males, mean height = 174.6 cm, SD = 5.3 cm; 8 females, mean height = 161.6 cm, SD = 4.7 cm), aged 18–50, underwent simulated tasks. Wearable sensors (XSENS) with 13 upper-body sensors collected acceleration, angular velocity, and quaternion data at 60 Hz (Figure 1). Supplementary spatial coordinates were obtained from OMC and Microsoft Kinect V2, placed 3 m in front of participants at a height of 1.5 m, with sampled at 30 Hz.

Figure 1. The positions of 13 XSENSs on the front and back of the human body.
The movements of three laboratory members, who were trained as benchmark workers according to the SOP, serve as the training dataset for the machine learning model.
Logistic tasks
Inspired by the author’s previous work experience, this study uses the shipping operations of a semiconductor design company as a case study to preliminarily verify the feasibility of the proposed research idea. Among the various operations involved in shipping to end customers, preparing and folding large and small cardboard boxes, placing goods inside, and sealing the boxes represent the basic building blocks of logistics operations, which are often performed manually. This study mimicked logistics operations in semiconductor design houses, specifically focusing on adherence to the JEDEC packaging standard for shipping. The standard involves using a JEDEC-6A outer carton containing six JEDEC-6B inner boxes, each housing ICs. The research simulated tasks such as the assembly of inner boxes (T1), outer carton assembly (T2), and final carton packing for shipment (T3). Although these operations are relatively simple, they reflect real-world tasks encountered by the author during industrial work, and the boxes used are identical to those in real-world applications.
The SOP for assembly of inner boxes comprises four elements (Figure 2): Element 1 (S1) is “fixed inner box material,” Element 2 (S2) is “assemble the left side of the inner box,” Element 3 (S3) is “assemble the right side of the inner box,” and Element 4 (S4) is “close the top cover.” Outer carton assembly consists of three elements in the SOP (Figure 3): Element 1 (S1) is “fixed outer carton material,” Element 2 (S2) is “sealing the carton bottom,” and Element 3 (S3) is “turn the bottom of the carton facing upward.” Final carton packing consists of two elements in the SOP (Figure 4): Element 1 (S1) is “placing the inner boxes into the carton,” and Element 2 (S2) is “sealing the carton.” Participants executed T1, T2, and T3 sequentially, following instructions from the experimental controller. They maintained a natural stance with hands hanging down for 1–2 s at the beginning and end of each task.

Figure 2. Operational elements decomposition of the assembly of the inner box (T1).

Figure 3. Operational elements decomposition of the assembly of outer carton (T2).

Figure 4. Operational elements decomposition of the final packing of the carton for shipment (T3).
Data preprocessing
Research by Wang and Santoso (Reference Wang and Santoso2022) and Hashemi (Reference Hashemi2019) suggests that maximum absolute (MA) scaler normalization yields higher recognition accuracy than min–max (MM) normalization. Therefore, this study employs both normalization methods and compares their outcomes.
In the segmentation phase, the commonly used sliding window method is employed, which involves distinguishing between non-overlapping and fixed-size overlapping sliding windows. Determining the optimal window size is crucial, with studies by Janidarmian et al. (Reference Janidarmian, Roshan Fekr, Radecka and Zilic2017) indicating that this varies based on body sensor locations. Increasing the overlap in the sliding window improves model performance, as noted by Burns and Whyne (Reference Burns and Whyne2018). Additionally, some literature suggests empirically determining the window length (Jalal et al., Reference Jalal, Kim, Kim, Kamal and Kim2017).
After segmentation, a dimensional reduction procedure using principal components analysis is applied, retaining sensor data from both hands. Three window lengths, one-third, one-half, and two-thirds of the average length of training samples, are employed with a 75% overlap for window segmentation and optimal size determination. Zero padding, a standard method during insufficient sample length, is used, following recommendations (Hashemi, Reference Hashemi2019; Um et al., Reference Um, Babakeshizadeh and Kulić2017).
Feature selection and machine learning model training
In the feature extraction phase, the study selects quaternions, three-axis accelerations, and three-axis angular velocities from the IMUs during the operation process to derive 11 commonly used time-domain features (see Table 1 for details).
Table 1. Time-domain features applied in this study

Four machine learning algorithms – SVM, RF, NB, and LSTM – are applied in this research. NB is frequently used as a baseline for comparison with other algorithms in practice. The training and prediction time of NB is rapid because it is a parametric classifier. Many related studies, such as those by Sefen et al. (Reference Sefen, Baumbach, Dengel and Abdennadher2016) and Liu et al. (Reference Liu, Nie, Liu and Rosenblum2016), have used this classifier for HAR.
SVM is another popular parametric classifier. Its advantages include insusceptibility to outliers, as classification is determined by the support vector, and support for both linear and nonlinear separation through different kernel tricks. SVM is also commonly applied in HAR research, such as in studies by Burns et al. (Reference Burns, Leung, Hardisty, Whyne, Henry and McLachlin2018) and Subasi et al. (Reference Subasi, Radhwan, Kurdi and Khateeb2018), and has achieved good accuracy.
RF is a classification model composed of many decision trees, based on ensemble learning. The final output class of the random forest is determined by the majority vote of the output classes of the many decision trees, which helps avoid the overfitting problem. The random forest algorithm often achieves the highest accuracy in HAR literature, as seen in studies by Baldominos et al. (Reference Baldominos, Cervantes, Saez and Isasi2019), Xu et al. (Reference Xu, Yang, Cao and Li2017), and Chetty and White (Reference Chetty and White2016).
In recent years, deep neural networks with more than four layers have sparked a new wave of AI research and applications in deep learning. Among the various deep learning models, CNNs imitate the neural circuits of the visual processing area of the human brain, enabling them to recognize and classify objects in static images with excellent performance. RNNs, a type of neural network that processes sequential data such as sound, language, and video, can use previous outputs as inputs for the next time step, making them a neural network with short-term memory. LSTM improves upon RNN by using a conveyor belt-like memory line and multiple gates to filter and process data requiring long-term memory, making it similar to the hippocampus of the human brain, responsible for processing both short-term and long-term memory. The research topic of this study involves the decomposition and recognition of the movements of industrial operation personnel, which falls under the analysis of sequential data. In the literature, Pienaar and Malekian (Reference Pienaar and Malekian2019) used LSTM for HAR and achieved excellent results. Therefore, this study chose LSTM as the representative method in deep learning.
Results
Due to cardboard boxes obstructing participants’ bodies, the Microsoft Kinect V2 produced distorted postures (Fig. 5), leading to the exclusion of its kinematic data from this study. Therefore, only RGB images were retained for the analysis of misclassification by the machine learning models.

Figure 5. The Microsoft Kinect Skeleton diagram reveals significant distortions in body posture compared to the actual body position.
Data preprocessing
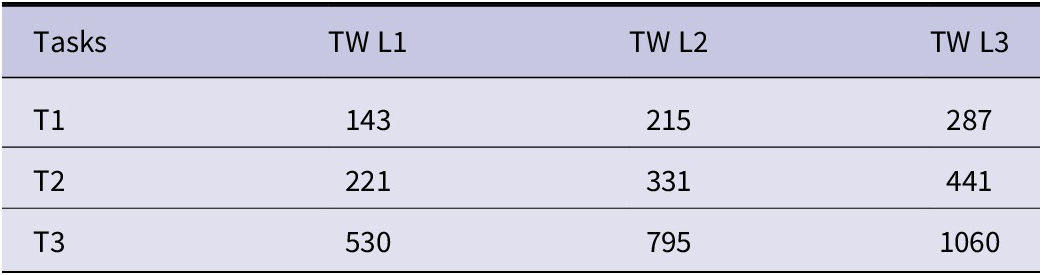
After normalizing the XSENS-collected variables, samples were segmented using time windows (TW) with lengths 1/3 (L1), 1/2 (L2), and 2/3 (L3) of the average training sample length, incorporating a 75% overlap. Table 2 displays the determined optimal time window size.
Table 2. The determined optimal time window size for tasks in this study
Models training and implementation
The study divided the data into two parts: testing data reserved for participants P1–P3 to verify model performance and training data using the remaining participants for learning. During the experiment, the researchers observed that three participants (P1–P3) exhibited movements inconsistent with the standard actions we set, so their data were excluded from the training set to ensure the accuracy of the trained models. However, we utilized the imperfect data when testing our models to determine whether the models could recognize incorrect and inefficient operational elements performed by workers. The validation results showed that nonmatching elements were accurately identified. This provided strong evidence that our research objective of developing machine learning models to aid industrial engineers in improving workforce productivity on the shop floor was met.
Classification of operational elements in inner box assembly (T1)
In the assembly of inner boxes, four operational elements were identified. Posttraining, the optimal classification model for each algorithm was determined (Table 3), with all four algorithms achieving peak accuracy at a time window length (WL) of 287 frames (L3). SVM and RF exhibited improved accuracy (Accu.) with MA normalization, while NB and LSTM demonstrated enhanced accuracy with MM normalization. Notably, SVM attained the highest accuracy at 96.1% and an F1 score at 0.910, with a model training time (TT) only slightly exceeding 0.05 seconds compared to NB.
Table 3. The best model for the inner box assembly (T1)
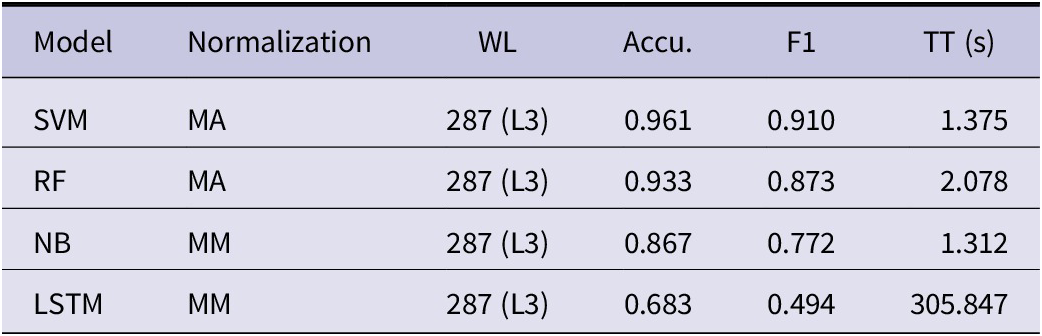
Figure 6 shows the confusion matrix of the SVM model classification results. Participants 1 and 3 accurately classified the operational elements. However, for Participant 2, the confusion matrix indicates that the actual left side of the assembled box (S2) was predicted as the operational element of closing the cover (S4).
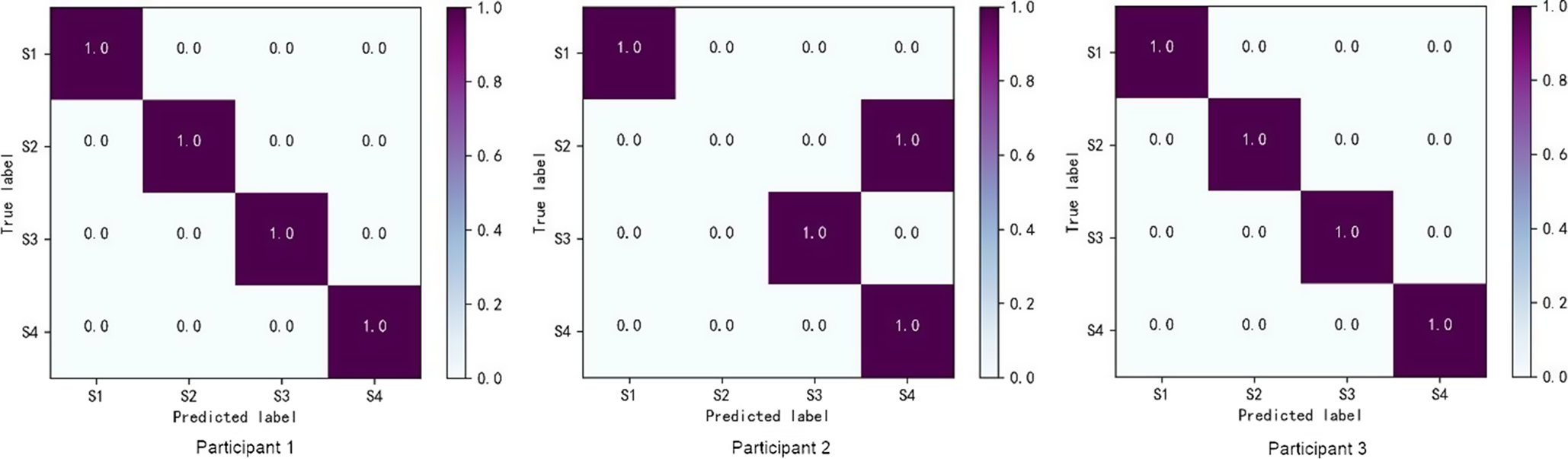
Figure 6. The confusion matrix of the best SVM model with MA normalization and a window width of 287 frames for T1 in the participant-independent validation phase.
Figures 7 and 8 display images of operational elements S2 and S4 performed by Participant 2. Participant 2 exhibited confusion and a lack of proficiency in these two actions. These figures illustrate that assembling the inner box relies heavily on the use both hands, requiring more delicacy than the other tasks. Therefore, when training the classification model, the weight of hand motion data in the assembly of the inner box task can be increased prior to training the model.

Figure 7. The video clip of Participant 2 performing the S2 element of the assembly of the inner box (T1) from (a) to (c) in order.

Figure 8. The video clip of Participant 2 performing the S4 element of the assembly of the inner box (T1) from (a) to (c) in order.
Classification of operational elements in outer carton assembly (T2)
Table 4 illustrates the best classification model for assembling outer cartons for each algorithm. Except for LSTM, all other algorithms achieved identical accuracy and F1 scores with both normalization methods. When different algorithms achieved the same accuracy and F1 scores with varying normalization methods, the model with the shorter training time was selected as the best model. In this study, the NB algorithm had the fastest training time and achieved the highest accuracy of 97.9% with a window size of 441 frames (L3).
Table 4. The best model for the outer carton assembly (T2)

Figure 9 presents the confusion matrix of the classification results. Participant 2 experienced confusion between fixing the outer carton (S1) and turning the bottom of the carton up (S3). However, Participants 2 and 3 were accurately classified into their respective operational elements.

Figure 9. The confusion matrix of the best NB model with MM normalization and a window width of 441 frames for T2 in the participant-independent validation phase.
Figures 10 and 11 showcase the video frames of the two subsets of operational elements performed by Participant 1 while executing fixing the inner box (S1) and turning the bottom of the carton up (S3). For S3, participants were only required to rotate the carton from the bottom to the top so that the opening of the carton faced upward, finally of Participant 1 during the carton facing upward (S3), it can be observed that Participant 1 performs a movement of tidying up the opening of the carton. It is speculated that this additional movement contributed to the misclassification of the operational element.

Figure 10. The video clip of Participant 1 performing the S1 element of the assembly of the outer carton (T2).

Figure 11. The video clip of Participant 1 performing the S3 element of the assembly of the outer carton (T2).
Classification of operational elements in packing task (T3)
Table 5 illustrates the top-performing model among various classification algorithms for the packing operation. Apart from LSTM, the other algorithms exhibited identical accuracy and F1 values with both normalization methods (see Table 5). Likewise, the model with the shorter training time was chosen as the optimal one. Throughout this study, all four algorithms achieved 100% accuracy and an F1 value of 1. Notably, both SVM and RF attained 100% accuracy and an F1 value of 1 across three different window lengths of training, with the results from the shortest window length being considered representative. While NB reached the highest accuracy solely at the window length of 795 frames (L2), it incurred additional time. Although LSTM did not achieve the highest accuracy and F1 value at window lengths 795 frames (L2) and 1060 frames (L3), it matched the 100% accuracy and F1 value of 1 achieved by other algorithms at window length 530 frames (L1).
Table 5. The best model for the packing task (T3)

Figure 12 demonstrates the SVM model’s accurate classification of the two operational elements in the packing operation – placing the inner box into the outer carton (S1) and sealing the carton (S2) – as performed by all three participants.

Figure 12. The confusion matrix of the best SVM model with MM normalization and a window width of 530 frames for T3 in the participant-independent validation phase. All predictions are correct.
Discussion
Although this study also attempted to use vision-based devices to collect kinematic data, the highly distorted skeleton diagram in Figure 5 raised concerns about the reliability of the data. We found that when an object is positioned between the vision-based device and the operator, accurate data cannot be obtained. This result is consistent with findings in the literature (Vrigkas et al., Reference Vrigkas, Nikou and Kakadiaris2015). However, RGB images are helpful in analyzing misclassifications (see Figures 7, 8, 10, and 11). Therefore, sensor-based and vision-based devices should be used together whenever possible.
Table 6 compares the best performance between the literature and the current study. Several factors can affect the performance of prediction models. The first factor is the type of study. In theory, the prediction accuracy of participant-dependent studies tends to be higher than that of participant-independent studies because in participant-dependent studies, the training and testing data come from the same participants. In other words, the trained model has already “seen” the data. Therefore, in Table 6, the accuracy of participant- dependent studies is nearly perfect, except for the study by Beli et al. (Reference Beil, Ehrenberger, Scherer, Mandery and Asfour2018). If the data come from a small number of participants or even just one (Lucci et al., Reference Lucci, Monguzzi, Zanchettin and Rocco2022; Wang and Santoso, Reference Wang and Santoso2022), the results are also outstanding. After all, the more participants there are, the greater the variability, and thus, accuracy decreases.
Table 6. The comparison of the best models in the literature and the current study

a The number of participants for the model development was not reported.
Note: EE = entire element; ETS = elements in timestamp; ADL = activity of daily living; Ind. = industrial operation; SP = sport; HMM = hidden Markov model; DTW = dynamic time warping; Logic = applying pure logic but not any machine learning model; YOLO = you only look once; PD = participant-dependent; PI = participant-independent.
The second factor is the degree of distinction between the classification targets. For example, Ishibashi and Fujii (Reference Ishibashi and Fujii2021) studied the lifting of a box from the floor to a workbench, while Li et al. (Reference Li, Khoo and Yap2022) focused on martial arts movements. These actions are larger and more distinct, unlike the fine hand movements targeted in this study, which are more difficult to distinguish.
The third factor is the algorithm. Lucci et al. (Reference Lucci, Monguzzi, Zanchettin and Rocco2022) utilized the logic of the positions of the workpiece and the operator’s hands, along with the sequence of the machine’s operations, rather than a machine learning algorithm. Although the programming is more complex, if the algorithm is well-designed, the accuracy can also be nearly perfect.
In the three tasks of this study, the hand movements were smallest in the inner box assembly, larger in the outer carton assembly, and largest in the packing task. Consequently, the degree of distinction between the movements increased from low to high. This result also explains the differences in accuracy shown in Tables 3, 4, and 5.
Another interesting finding of this study is that the performance of simple, traditional machine learning models was better than that of the deep learning LSTM model (Tables 3, 4, and 5). The training time for LSTM exceeded 1,000 seconds, whereas the training times for SVM, RF, and NB were all under 3 seconds. Moreover, SVM achieved the highest accuracy, with a minimum value of 0.961 occurring in the task with the lowest distinction, the inner box assembly (Table 3). Although the accuracy of RF and NB was slightly lower in the inner box assembly, they performed as well as SVM in tasks with higher distinction, such as the outer carton assembly (0.979 in Table 4) and the packing task (1.000 in Table 5). Our findings for SVM, RF, and NB align with the results in the literature (Baldominos et al., Reference Baldominos, Cervantes, Saez and Isasi2019; Burns et al., Reference Burns, Leung, Hardisty, Whyne, Henry and McLachlin2018; Chetty and White, Reference Chetty and White2016; Liu et al., Reference Liu, Nie, Liu and Rosenblum2016; Sefen et al., Reference Sefen, Baumbach, Dengel and Abdennadher2016; Subasi et al., Reference Subasi, Radhwan, Kurdi and Khateeb2018; Xu et al., Reference Xu, Yang, Cao and Li2017).
Although the accuracy of LSTM in this study was not as high as that of SVM, RF, and NB, its accuracy across the three tasks was 0.683, 0.800, and 1.000, respectively. Compared with the two studies in Table 6 that used CNN for feature extraction and LSTM as the classifier – 760 in Jonek et al. (Reference Jonek, Tuli, Manns, Galizia and Bortolini2023) and 0.880 in Tuli et al. (Reference Tuli, Patel and Manns2022) – these results are quite comparable. However, the reason for LSTM’s relatively lower accuracy remains unknown and requires further investigation in future studies.
The results of this study (Tables 3, 4, and 5) demonstrate that operational motion analysis can be performed without expert knowledge and significant manual effort. This approach provides insights into the process, which can be used to identify novices’ awkward operations (Figures 7, 8, 10, and 11). Therefore, HAR has the potential for optimization to increase productivity, supporting the argument of Jonek et al. (Reference Jonek, Tuli, Manns, Galizia and Bortolini2023), and can help junior workers follow SOPs, consistent with the claim of Wang and Santoso (Reference Wang and Santoso2022).
Recently, Industry 5.0, inheriting all the advanced technologies from Industry 4.0 (Iqbal et al., Reference Iqbal, Lee and Ren2022), emphasizes the vision of building sustainable, human-centric, and resilient industries. The critical focus of Industry 5.0 is reintroducing human workers to the shop floors, which has attracted significant interest from researchers (Alves et al., Reference Alves, Lima and Gaspar2023; Cimino et al., Reference Cimino, Elbasheer, Longo, Nicoletti and Padovano2023). The primary objective is to enhance human creativity and intelligence in smart manufacturing systems (Iqbal et al., Reference Iqbal, Lee and Ren2022), while ensuring the well-being of workers (Moller et al., Reference Moller, Vakilzadian and Haas2022). Therefore, the application of time series-based HAR in human–robot collaboration is crucial for Industry 5.0, and the emergence of related research (Lucci et al., Reference Lucci, Monguzzi, Zanchettin and Rocco2022; Wang and Santoso, Reference Wang and Santoso2022) aligns with this trend. However, future studies in this domain should consider using a more diverse set of participants to develop and validate models.
Conclusions
The primary objective of this study was to develop machine learning models for HAR tailored to manufacturing tasks, diverging from traditional HAR in ADL. Focusing exclusively on recognizing detailed operational elements provides a crucial foundation for enhancing work efficiency. To achieve this goal, the machine learning model must identify the specific operating elements of tasks performed by workers rather than the entire operation.
The training dataset from three benchmark workers consists of thousands of data points with specific motion trajectory patterns, ensuring the trained model’s robustness to recognize movements performed by different participants. With machine learning models capable of recognizing sequential motions, industrial engineers in Industry 5.0 can adopt intelligent methods to replace traditional, manual motion and time study approaches, enabling more rapid and objective improvements in production efficiency.
This study replicated shipping logistics operations in a semiconductor design house to build, train, and validate machine learning models. Results indicate that
-
1. SVM, RF, and NB machine learning models developed in this study accurately classify various operational elements in three tasks using time window segmentation, overlapping, and normalization techniques.
-
2. In cases of misclassifications, RGB clips can be used to scrutinize the effectiveness and correctness of employee movements. This enables supervisors to devise targeted training plans and assists industrial engineers in conducting motion and time studies with modern tools. The method proposed in this study can improve the efficiency of industrial engineers and on-site supervisors, reduce workloads, and mitigate conflicts stemming from workers feeling surveilled and dissatisfaction from feeling disrespected.
Despite favorable outcomes, there are limitations:
-
1. Although the research meets the theoretical functional requirements of traditional industrial engineering in motion and time studies, a more detailed decomposition of operational elements may be necessary for realistic applications in today’s highly complex manufacturing tasks. For example, the current research decomposed a single operation into only four simple assembly steps, but in actual industrial settings, these hand operations are often broken down into more than 10 subactions, with a need to differentiate between left- and right-hand movements.
-
2. Operation completion time is an objective indicator of work efficiency improvement. Comparing the completion time of each step to the standard operation time would be useful and should be investigated in future research.
-
3. The decomposition of motion elements still relies on human intervention. Future integration of unsupervised learning may cluster motions of standard workers into operational elements for each task, reducing the workload on industrial engineers.
Data availability statement
The data in this study are available for researchers who are interested in this topic. Please contact Professor Chiuhsiang Joe Lin via cjoelin@mail.ntust.edu.tw to acquire the data.
Funding statement
This work was supported by the Ministry of Science and Technology (MOST) of Taiwan [MOST 108–2221-E-011-018-MY3].
Competing interest
The authors declare none.



















 Open access
Open access