


No CrossRef data available.
Article contents
Lapse risk modeling in insurance: a Bayesian mixture approach
Published online by Cambridge University Press: 01 September 2023
Abstract
This paper focuses on modeling surrender time for policyholders in the context of life insurance. In this setup, a large lapse rate at the first months of a contract is often observed, with a decrease in this rate after some months. The modeling of the time to cancelation must account for this specific behavior. Another stylized fact is that policies which are not canceled in the study period are considered censored. To account for both censoring and heterogeneous lapse rates, this work assumes a Bayesian survival model with a mixture of regressions. The inference is based on data augmentation allowing for fast computations even for datasets of over millions of clients. Moreover, frequentist point estimation based on Expectation–Maximization algorithm is also presented. An illustrative example emulates a typical behavior for life insurance contracts, and a simulated study investigates the properties of the proposed model. A case study is considered and illustrates the flexibility of our proposed model allowing different specifications of mixture components. In particular, the observed censoring in the insurance context might be up to 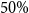 $50\%$ of the data, which is very unusual for survival models in other fields such as epidemiology. This aspect is exploited in our simulated study.
$50\%$ of the data, which is very unusual for survival models in other fields such as epidemiology. This aspect is exploited in our simulated study.
Information
- Type
- Original Research Paper
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press on behalf of Institute and Faculty of Actuaries
References
Bolancé, C., Guillen, M. & Padilla Barreto, A. (2016). Predicting Probability of Customer Churn in Insurance, vol. 254
Google Scholar
Brockett, P.L., Golden, L.L., Guillen, M., Nielsen, J. P., Parner, J. & Perez-Marin, A.M. (2008). Survival analysis of a household portfolio of insurance policies: how much time do you have to stop total customer defection? Journal of Risk & Insurance, 75(3), 713–737.CrossRefGoogle Scholar
Carpenter, B., Gelman, A., Hoffman, M.D., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M.A., Guo, J., Li, P. & Riddell, A. (2017). Stan: a probabilistic programming language. Grantee Submission, 76(1), 1–32.Google Scholar
Demarqui, F.N., Dey, D.K., Loschi, R.H. & Colosimo, E.A. (2014). Fully semiparametric Bayesian approach for modeling survival data with cure fraction. Biometrical Journal, 56(22), 198–218.CrossRefGoogle ScholarPubMed
Dempster, A.P., Laird, N.M. & Rubin, D.B. (1977). Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society. Series B (Methodological), 39(1), 1–38.CrossRefGoogle Scholar
Dong, Y., Frees, E.W., Huang, F. & Hui, F.K.C. (2022). Multi-state modelling of customer churn. ASTIN Bulletin, 52(3), 735–764.CrossRefGoogle Scholar
Eddelbuettel, D. & Sanderson, C. (2014). Rcpparmadillo: accelerating r with high-performance c++ linear algebra. Computational Statistics and Data Analysis, 71, 1054–1063.CrossRefGoogle Scholar
Eling, M. & Kiesenbauer, D. (2014). What policy features determine life insurance lapse? an analysis of the german market. Journal of Risk & Insurance, 81(2), 241–269.CrossRefGoogle Scholar
Eling, M. & Kochanski, M. (2013). Research on lapse in life insurance: what has been done and what needs to be done? Journal of Risk Finance, 14(4), 392–413.CrossRefGoogle Scholar
Friedman, M. (1982). Piecewise exponential models for survival data with covariates. The Annals of Statistics, 10(1), 101–113.CrossRefGoogle Scholar
Frühwirth-Schnatter, S. (2006). Finite Mixture and Markov Switching Models. Berlin, Germany: Springer Science & Business Media.Google Scholar
Gamerman, D. (1994). Bayes estimation of the piece-wise exponential distribution. IEEE Transactions on Reliability, 43(1), 128–131.CrossRefGoogle Scholar
Gamerman, D. & Lopes, H. (2006). Markov Chain Monte Carlo: Stochastic Simulation for Bayesian Inference. Texts in Statistical Science. United Kingdom: Chapman & Hall/CRC.CrossRefGoogle Scholar
Gatzert, N., Hoermann, G. & Schmeiser, H. (2009). The impact of the secondary market on life insurers’ surrender profits. Journal of Risk & Insurance, 76(4), 887–908.CrossRefGoogle Scholar
Guillen, M., Nielsen, J.P., Scheike, T.H. & Pérez-Marín, A.M. (2012). Time-varying effects in the analysis of customer loyalty: a case study in insurance. Expert Systems with Applications, 39(3), 3551–3558.CrossRefGoogle Scholar
Guillen, M., Parner, J., Densgsoe, C. & Perez-Marin, A.M. (2003). Using Logistic Regression Models to Predict and Understand Why Customers Leave an Insurance Company. Intelligent and Other Computational Techniques in Insurance: Theory and Applications. Singapore: World Scientific Publishing.Google Scholar
Günther, C.-C., Tvete, I.F., Aas, K., Sandnes, G.I. & Borgan, Ø. (2014). Modelling and predicting customer churn from an insurance company. Scandinavian Actuarial Journal, 2014(1), 58–71.CrossRefGoogle Scholar
Hemming, K. & Shaw, J.E.H. (2002). A parametric dynamic survival model applied to breast cancer survival times. Journal of the Royal Statistical Society: Series C (Applied Statistics), 51(4), 421–435.Google Scholar
Hoffman, M.D. & Gelman, A. (2014). The no-u-turn sampler: adaptively setting path lengths in hamiltonian monte carlo. Journal of Machine Learning Research, 15(1), 1593–1623.Google Scholar
Hu, S., O’Hagan, A., Sweeney, J. & Ghahramani, M. (2021). A spatial machine learning model for analysing customers’ lapse behaviour in life insurance. Annals of Actuarial Science, 15(2), 367–393.CrossRefGoogle Scholar
Hu, X., Yang, Y., Chen, L. & Zhu, S. (2020). Research on a customer churn combination prediction model based on decision tree and neural network (pp. 129–132). In 2020 IEEE 5th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA).CrossRefGoogle Scholar
Ibrahim, J.G., Chen, M.-H. & Sinha, D. (2001). Bayesian Survival Analysis. Springer Series in Statistics (SSS) Berlin, Germany: Springer.CrossRefGoogle Scholar
Ishwaran, H., Kogalur, U.B., Blackstone, E.H. & Lauer, M.S. (2008). Random survival forests. The Annals of Applied Statistics, 2(3), 841–860.CrossRefGoogle Scholar
Jedidi, K., Ramaswamy, V. & DeSarbo, W.S. (1993). A maximum likelihood method for latent class regression involving a censored dependent variable. Psychometrika, 58(3), 375–394.CrossRefGoogle Scholar
Kalbfleisch, J.D. & Prentice, R.L. (2002). The Statistical Analysis of Failure Time Data, 2nd edition. John Wiley & Sons.CrossRefGoogle Scholar
Kim, S., Chen, M.-H., Dey, D. & Gamerman, D. (2007). Bayesian dynamic models for survival data with a cure fraction. Lifetime Data Analysis, 13(1), 17–35.CrossRefGoogle ScholarPubMed
Knoller, C., Kraut, G. & Schoenmaekers, P. (2015). On the propensity to surrender a variable annuity contract: an empirical analysis of dynamic policyholder behavior. The Journal of Risk and Insurance, 83(4), 979–1006.CrossRefGoogle Scholar
Kuo, W., Tsai, C. & Chen, W.-K. (2003). An empirical study on the lapse rate: the cointegration approach. The Journal of Risk and Insurance, 70(3), 489–508.CrossRefGoogle Scholar
Mayrink, V.D., Duarte, J.D.N. & Demarqui, F.N. (2021). pexm: a jags module for applications involving the piecewise exponential distribution. Journal of Statistical Software, 100(8), 1–28.CrossRefGoogle Scholar
Milhaud, X. & Dutang, C. (2018). Lapse tables for lapse risk management in insurance: a competing risk approach. European Actuarial Journal, 8(1), 97–126.CrossRefGoogle Scholar
Park, T. & Casella, G. (2008). The Bayesian Lasso. Journal of the American Statistical Association, 103(482), 681–686.CrossRefGoogle Scholar
Stan Development Team. (2018). RStan: the R interface to Stan. R package version 2.17.3.Google Scholar
Tanner, M.A. & Wong, W.H. (1987). The calculation of posterior distributions by data augmentation. Journal of the American statistical Association, 82(398), 528–540.CrossRefGoogle Scholar
Tibshirani, R. (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society (Series B), 58(1), 267–288.Google Scholar