


1. Introduction
Reliable mortality modeling is essential for various domains such as actuarial science, public health, and demography. Understanding and predicting mortality rates enable policymakers to make informed decisions, support financial planning in insurance and pension systems, and aid in the assessment of population health trends. Consequently, there is a growing need for more flexible and robust methodologies to understand uncertainties around mortality modeling.
Over the past few decades, various models have been developed to enhance the accuracy of mortality forecasting, each offering unique approaches and advantages. The Age-Period-Cohort (APC) model incorporates the main effects affecting mortality, which are age, period, and cohort effect (Clayton & Schifflers, Reference Clayton and Schifflers1987). The Lee-Carter model (Lee & Carter, Reference Lee and Carter1992) also stands as a seminal method, utilizing a singular time-varying factor to capture mortality trends. Further advancements include the Cairns-Blake-Dowd (CBD) model, which simplifies the model using a linear age trend (Cairns et al., Reference Cairns, Blake and Dowd2006), the Renshaw-Haberman model, which adds the cohort effect to the Lee-Carter (Haberman & Renshaw, Reference Haberman and Renshaw2011), and the Age-Period-Cohort-Interaction (APCI) model (Richards et al., Reference Richards, Currie, Kleinow and Ritchie2019), which extends the APC model by incorporating interactions between age and period effect for a more comprehensive analysis. These models, among others, have significantly contributed to the field by capturing various aspects of mortality, enabling actuaries to make more informed predictions and decisions.
Given the diversity of mortality forecasting models, selecting the most appropriate model can be challenging. Mortality model selection has usually been performed using a model selection criterion such as AIC or BIC, as, for example, is performed in Cairns et al. (Reference Cairns, Blake, Dowd, Coughlan, Epstein, Ong and Balevich2009). This strategy involves fitting many models and then ranking them according to one of these criteria. This process can be manual and laborious, particularly if there are many models being considered. In addition, the models are fitted independently, and there is no opportunity of borrowing strengths between the many models. Moreover, even if several models are equally supported, this process will ultimately involve choosing only one of them and hence disregarding the information provided by others. Furthermore, this procedure typically does not allow for joint estimation of model and parameter uncertainties, both of which are important to incorporate all sources of uncertainty and avoid producing over-optimistic prediction intervals.
A more comprehensive alternative to traditional model selection is Bayesian model selection, which offers a solution that could address some of the limitations of conventional approaches. The advantages of adopting a Bayesian framework in mortality modeling and forecasting have been extensively discussed by Czado et al. (Reference Czado, Delwarde and Denuit2005) and Wong et al. (Reference Wong, Forster and Smith2018). This approach has been demonstrated in numerous studies, including (but not limited to) Cairns et al. (Reference Cairns, Blake, Dowd, Coughlan and Khalaf-Allah2011), Hilton et al. (Reference Hilton, Dodd, Forster and Smith2019), Li et al. (Reference Li, Zhou, Zhu, Chan and Chan2019), Pedroza (Reference Pedroza2006). Bayesian model selection has recently started gaining popularity in mortality modeling. Wong et al. (Reference Wong, Forster and Smith2023) demonstrated the use of marginal likelihoods, and hence Bayes factors, in comparing several stochastic mortality models for mortality forecasting. Barigou et al. (Reference Barigou, Goffard, Loisel and Salhi2022) illustrated the use of marginal likelihoods, stacking, and pseudo-Bayesian model averaging approaches to compare and combine several mortality models to determine the best approach for achieving the result. However, both of these methods do not allow the competing models to interact or to borrow strengths among them. In this work, we propose a Bayesian probabilistic framework that views both the model choice and the parameters as part of the same parameter space.
The first step is to define a modeling framework that can accommodate a wide range of models. To achieve high flexibility, it is key to ensure that the framework has a high modeling power by encompassing a large variety of models, such as the ones already considered in the literature. Next, we perform inference using the Reversible Jump Markov chain Monte Carlo (RJMCMC), developed by Green (Reference Green1995), which is an extension of the Metropolis-Hastings algorithm to propose moves between models of different dimensions. Its use in the mortality modeling literature has so far been limited, which can likely be due to the challenges of slow mixing and inadequate exploration of the model space, making it difficult to efficiently perform transitions between models. This is because to achieve efficient transition between models, it is necessary to propose appropriate parameters, as proposing poorly fitting parameters will result in a high rejection rate. In our inference strategy, to obtain appropriate parameters, we propose to sample them from an approximation of the posterior distribution of the proposed parameters, which will require an optimization over the new set of parameters. This optimization can be computationally costly if the number of parameters to optimize is large. Therefore, to minimize the number of parameters required in the optimization, it is also crucial to ensure that the framework will allow for gradual transitions between models through small, incremental changes in the model structure, which will involve a change in only a small number of parameters. To the best of our knowledge, this is the first time that such a joint approach has been applied in the context of mortality modeling.
We apply our model selection framework to two types of data. The first involves mortality data stratified by age and period (AP data), while the second involves data stratified by age, period, and another stratifying variable, which in our case is insurance product (APP data). In the case of AP data, we define a framework aiming to encompass a large variety of models present in the literature, such as the LC, CBD, and APC, as well as new models combining different features of the models mentioned in the introduction. The framework also allows us to obtain a wide range of intermediate models bridging the transition between the models already mentioned. In the APP case, we define a model framework starting from the APCI model and extending each term of the model by allowing it to vary with product. We have chosen the APCI as our base model for two main reasons. First, the APCI is commonly used as a benchmark for fitting mortality models (e.g., Continuous Mortality Investigation Bureau, 2016 and Kaufhold et al., Reference Kaufhold, Brück and Neidhardt2024). Second, as we will discuss in the relevant section, the APCI allows us to define extensions that lead to fewer changes in model constraints, which will facilitate the inference.
Introducing stratification variables into mortality models, such as insurance product, has been addressed through various approaches in the literature. For example, Carter & Lee (Reference Carter and Lee1992) propose the joint-k model, which assumes that mortality rates of all groups are jointly driven by a single time-varying index. Li & Lee (Reference Li and Lee2005) propose to model different groups by further stratifying the Lee-Carter. Villegas & Haberman (Reference Villegas and Haberman2014) build a mortality model by modeling group-specific mortality rates with respect to a reference population modeled through a Lee-Carter model with a cohort effect.
For both types of data, we apply the model to a case study. In the AP case, we consider mortality data from different countries as part of the Human Mortality Database (HMD, 2024). In the APP case, we consider mortality data from different insurance products provided by the Continuous Mortality Investigation (CMI).
The paper is structured as follows. The general inferential strategy used for model selection, as well as notations and a short background of the statistical theory, is presented in Section 2. Section 3 will discuss the framework for AP data, as well as the inference and the application to the case study, while Section 4 will discuss the framework for APP data and the related case study. Section 5 summarizes the paper and presents some possible future directions.
2. Background and theory
In this section, we set up the notation and describe the theoretical background of our modeling and inference procedure. We assume to have data covering ages
 $x_{1},\ldots ,x_{n_X}$
and periods
$x_{1},\ldots ,x_{n_X}$
and periods
 $t_1,\ldots ,t_{n_T}$
, where
$t_1,\ldots ,t_{n_T}$
, where
 $n_X$
and
$n_X$
and
 $n_T$
are the total number of ages and periods, respectively. The number of cohorts is denoted by
$n_T$
are the total number of ages and periods, respectively. The number of cohorts is denoted by
 $n_C = n_X + n_T - 1$
. We will denote by
$n_C = n_X + n_T - 1$
. We will denote by
 $d_{x,t}$
and
$d_{x,t}$
and
 $E_{x,t}$
the number of deaths and exposure for age
$E_{x,t}$
the number of deaths and exposure for age
 $x$
and period
$x$
and period
 $t$
, respectively. We model deaths using the Poisson framework (Brouhns et al., Reference Brouhns, Denuit and Vermunt2002),
$t$
, respectively. We model deaths using the Poisson framework (Brouhns et al., Reference Brouhns, Denuit and Vermunt2002),
 $d_{x,t} \sim \text{Poisson}(E_{x,t} m_{x,t})$
, where
$d_{x,t} \sim \text{Poisson}(E_{x,t} m_{x,t})$
, where
 $m_{x,t}$
is the mortality rate for the
$m_{x,t}$
is the mortality rate for the
 $x$
-th age and the
$x$
-th age and the
 $t$
-th period. In the case of APP data, we add the subscript
$t$
-th period. In the case of APP data, we add the subscript
 $p$
to all the previous quantities to denote product, for example,
$p$
to all the previous quantities to denote product, for example,
 $d_{x,t,p}$
denotes the number of deaths for the
$d_{x,t,p}$
denotes the number of deaths for the
 $x$
-th age,
$x$
-th age,
 $t$
-th period and
$t$
-th period and
 $p$
-th and product for APP data. The total number of products is denoted by
$p$
-th and product for APP data. The total number of products is denoted by
 $n_P$
.
$n_P$
.
We perform model selection in a Bayesian framework. To set up some notations, we denote the data as
 $d$
, the parameters as
$d$
, the parameters as
 $\theta$
, and the model as
$\theta$
, and the model as
 $M$
, and we denote the posterior distribution of the model
$M$
, and we denote the posterior distribution of the model
 $M$
and the parameters
$M$
and the parameters
 $\theta$
conditional on the data
$\theta$
conditional on the data
 $d$
by
$d$
by
 $p(\theta , M | d)$
, which is proportional to the likelihood,
$p(\theta , M | d)$
, which is proportional to the likelihood,
 $p(d | \theta , M)$
, and the prior,
$p(d | \theta , M)$
, and the prior,
 $p(\theta , M)$
. Since we are performing model selection, we assume to have a set of models
$p(\theta , M)$
. Since we are performing model selection, we assume to have a set of models
 $(M_1,\ldots ,M_K)$
, each with a set of parameter
$(M_1,\ldots ,M_K)$
, each with a set of parameter
 $\theta _k$
, and we denote by
$\theta _k$
, and we denote by
 $n_k$
the dimension of model
$n_k$
the dimension of model
 $M_k$
. We denote by
$M_k$
. We denote by
 $p(\theta _k, M_k) = p(\theta _k | M_k) p(M_k)$
the joint prior on the model and the corresponding model parameters. We note that choosing a prior on the model of the form
$p(\theta _k, M_k) = p(\theta _k | M_k) p(M_k)$
the joint prior on the model and the corresponding model parameters. We note that choosing a prior on the model of the form
 $p(M_k) \propto \frac {1}{n_k}$
corresponds to a posterior distribution with the same form as BIC, while choosing
$p(M_k) \propto \frac {1}{n_k}$
corresponds to a posterior distribution with the same form as BIC, while choosing
 $p(M_k) \propto \text{exp}(-n_k)$
corresponds to AIC, since the log-posterior distribution
$p(M_k) \propto \text{exp}(-n_k)$
corresponds to AIC, since the log-posterior distribution
 $\ell + \log(p(M_k))$
is equal to
$\ell + \log(p(M_k))$
is equal to
 $\ell - \log(n_k)$
in the first case and
$\ell - \log(n_k)$
in the first case and
 $\ell - n_k$
in the second case (with
$\ell - n_k$
in the second case (with
 $\ell$
being the log-likelihood), which corresponds to the expression of the BIC and AIC, respectively. In all the following, we have assumed a prior
$\ell$
being the log-likelihood), which corresponds to the expression of the BIC and AIC, respectively. In all the following, we have assumed a prior
 $p(M_k)$
corresponding to the AIC penalty.
$p(M_k)$
corresponding to the AIC penalty.
When proposing a move between models of different dimensions, the standard Metropolis-Hastings algorithm cannot be used anymore because of the difference in dimensions between models, and instead, we resort to the RJMCMC algorithm (Green, Reference Green1995), which we briefly review. The RJMCMC relies on defining two proposal distributions:
-
• The move from model
 $M_k$
to
$M_{k'}$
happens with probability
$q(k \rightarrow k')$
.
$M_k$
to
$M_{k'}$
happens with probability
$q(k \rightarrow k')$
. -
• Once a move is proposed, to define the parameter of the new proposed model, for each proposed model transition from
$k$
to
$k'$
, a latent variable
$u$
of dimension
$\zeta _{k \rightarrow k'}$
is sampled from a distribution
$q_{k \rightarrow k'}(u)$
, such that the new set of parameters
$\theta _{k'}$
of the proposed model
$k'$
can be obtained as
$\theta _{k'} = g_{k \rightarrow k'}(\theta _{k},u)$
.











Finally, the new model is accepted with probability
 \begin{equation} \alpha [(k, \theta _k),(k', \theta _{k'})] = \text{min}\left \{ 1, \frac { p(d | \theta _{k'}, M_{k'}) p(\theta _{k'} | M_{k'}) p(M_{k'}) q(k' \rightarrow k) q_{k' \rightarrow k}(u')}{ p(d | \theta _{k}, M_{k}) p(\theta _k | M_k) p(M_k) q(k \rightarrow k') q_{k \rightarrow k'}(u)} \left | \frac {\partial g_{k \rightarrow k'}(\theta _k, u)}{\partial (\theta _k, u)} \right | \right \} \end{equation}
\begin{equation} \alpha [(k, \theta _k),(k', \theta _{k'})] = \text{min}\left \{ 1, \frac { p(d | \theta _{k'}, M_{k'}) p(\theta _{k'} | M_{k'}) p(M_{k'}) q(k' \rightarrow k) q_{k' \rightarrow k}(u')}{ p(d | \theta _{k}, M_{k}) p(\theta _k | M_k) p(M_k) q(k \rightarrow k') q_{k \rightarrow k'}(u)} \left | \frac {\partial g_{k \rightarrow k'}(\theta _k, u)}{\partial (\theta _k, u)} \right | \right \} \end{equation}
where
 $q(k' \rightarrow k)$
and
$q(k' \rightarrow k)$
and
 $q_{k' \rightarrow k}(u')$
are the transition probabilities of the reverse move and
$q_{k' \rightarrow k}(u')$
are the transition probabilities of the reverse move and
 $u'$
is defined such that
$u'$
is defined such that
 $\theta _k^{\prime } = g_{k \rightarrow k'}(g_{k' \rightarrow k}(\theta _k^{\prime },u'),u)$
. A requirement of RJMCMC is the dimension matching condition:
$\theta _k^{\prime } = g_{k \rightarrow k'}(g_{k' \rightarrow k}(\theta _k^{\prime },u'),u)$
. A requirement of RJMCMC is the dimension matching condition:
 $n_k + \zeta _{k \rightarrow k'} = n_{k'} + \zeta _{k' \rightarrow k}$
. It follows that in the case where
$n_k + \zeta _{k \rightarrow k'} = n_{k'} + \zeta _{k' \rightarrow k}$
. It follows that in the case where
 $n_k + \zeta _{k \rightarrow k'} = n_{k'}$
, we have
$n_k + \zeta _{k \rightarrow k'} = n_{k'}$
, we have
 $\zeta _{k' \rightarrow k} = 0$
, with the last expression meaning that the reverse move to the smaller model is deterministic. For example, when models are nested, if we can find a proposal (from the smaller to the larger model) with a dimension equal to the difference in the model dimensions, the proposal to the smaller model will be deterministic.
$\zeta _{k' \rightarrow k} = 0$
, with the last expression meaning that the reverse move to the smaller model is deterministic. For example, when models are nested, if we can find a proposal (from the smaller to the larger model) with a dimension equal to the difference in the model dimensions, the proposal to the smaller model will be deterministic.
Generally, the closer the proposal distribution
 $q_{k \rightarrow k'}(u)$
to the posterior distribution of the variables
$q_{k \rightarrow k'}(u)$
to the posterior distribution of the variables
 $u$
, the more efficient the sampling scheme will be. To achieve this, we choose as proposal distributions
$u$
, the more efficient the sampling scheme will be. To achieve this, we choose as proposal distributions
 $q(u)$
a Laplace approximation of the posterior distribution. The Laplace approximation is given by a normal distribution
$q(u)$
a Laplace approximation of the posterior distribution. The Laplace approximation is given by a normal distribution
 $\text{N}(\mu ^{\star }, \Sigma ^{\star })$
, where
$\text{N}(\mu ^{\star }, \Sigma ^{\star })$
, where
 $\mu ^{\star }$
is the set of a parameters corresponding to the maximum of the posterior distribution, and
$\mu ^{\star }$
is the set of a parameters corresponding to the maximum of the posterior distribution, and
 $\Sigma ^{\star }$
is the inverse of the negative Hessian of the posterior distribution computed in
$\Sigma ^{\star }$
is the inverse of the negative Hessian of the posterior distribution computed in
 $\mu _{\star }$
. We note that since this corresponds to solving an optimization tasks for each proposal, it is preferred to choose moves with the smallest possible dimension changes
$\mu _{\star }$
. We note that since this corresponds to solving an optimization tasks for each proposal, it is preferred to choose moves with the smallest possible dimension changes
 $\zeta _{k \rightarrow k'}$
and
$\zeta _{k \rightarrow k'}$
and
 $\zeta _{k' \rightarrow k}$
, since this will require performing optimization tasks over smaller number of variables.
$\zeta _{k' \rightarrow k}$
, since this will require performing optimization tasks over smaller number of variables.
We give a simple example of how RJMCMC works in practice. Let us consider two models for age-only data: model
 $1$
, having mortality as a constant
$1$
, having mortality as a constant
 $\text{log}(m_{x}) = a$
, and model
$\text{log}(m_{x}) = a$
, and model
 $2$
, having a age-varying mortality
$2$
, having a age-varying mortality
 $\text{log}(m_{x}) = a_x$
. We could propose the move in two different ways. In the first case, when going from model
$\text{log}(m_{x}) = a_x$
. We could propose the move in two different ways. In the first case, when going from model
 $1$
to model
$1$
to model
 $2$
, we can propose
$2$
, we can propose
 $a_x$
from a proposal distribution
$a_x$
from a proposal distribution
 $q_{1\rightarrow 2}(a_x)$
(of dimension
$q_{1\rightarrow 2}(a_x)$
(of dimension
 $n_X$
), and for the reverse move (from model
$n_X$
), and for the reverse move (from model
 $2$
to model
$2$
to model
 $1$
), we propose
$1$
), we propose
 $a$
from a proposal distribution
$a$
from a proposal distribution
 $q_{2\rightarrow 1}(a)$
(of dimension
$q_{2\rightarrow 1}(a)$
(of dimension
 $1$
). The dimension matching condition is satisfied as
$1$
). The dimension matching condition is satisfied as
 $n_1 (= 1) + \zeta _{1 \rightarrow 2} (= n_X) = n_2 (= n_X) + \zeta _{2 \rightarrow 1} (= 1)$
. Alternatively, we could design the move from model
$n_1 (= 1) + \zeta _{1 \rightarrow 2} (= n_X) = n_2 (= n_X) + \zeta _{2 \rightarrow 1} (= 1)$
. Alternatively, we could design the move from model
 $1$
to model
$1$
to model
 $2$
by only proposing the increments
$2$
by only proposing the increments
 $\epsilon _x$
from
$\epsilon _x$
from
 $a$
to
$a$
to
 $a_x$
, such that
$a_x$
, such that
 $a_x = a + \epsilon _x$
, where
$a_x = a + \epsilon _x$
, where
 $\sum _x \epsilon _x = 0$
(and therefore,
$\sum _x \epsilon _x = 0$
(and therefore,
 $\epsilon _x$
is of dimension
$\epsilon _x$
is of dimension
 $n_X - 1$
). The dimension matching condition is again satisfied since
$n_X - 1$
). The dimension matching condition is again satisfied since
 $n_1 (= 1) + \zeta _{1 \rightarrow 2} (= n_X - 1) = n_2 (= n_X)$
, and the reverse move is deterministic, where the proposed
$n_1 (= 1) + \zeta _{1 \rightarrow 2} (= n_X - 1) = n_2 (= n_X)$
, and the reverse move is deterministic, where the proposed
 $a$
is the mean of the current
$a$
is the mean of the current
 $a_x$
. As mentioned, the second strategy is likely to be more efficient, since it only requires finding the maximum of one posterior distribution on a smaller dimensional space (
$a_x$
. As mentioned, the second strategy is likely to be more efficient, since it only requires finding the maximum of one posterior distribution on a smaller dimensional space (
 $X -1$
) against finding the maximum of two posterior distributions (of dimension
$X -1$
) against finding the maximum of two posterior distributions (of dimension
 $1$
and
$1$
and
 $n_X$
).
$n_X$
).
3. Mortality model selection for age-period data
In this section, we will define a modeling framework for building mortality models for age and period data and will next use this framework to perform model selection. We define our framework by separating the log-mortality rate into three terms: age-effect, period and age-period effect, and cohort effect, which have already been considered in a wide variety of models (Cairns et al., Reference Cairns, Blake, Dowd, Coughlan, Epstein, Ong and Balevich2009).
We assume that the log-mortality rate can be expressed as
 \begin{equation} \text{log}(m_{x,t}) = f_1(x) + f_2(t, f_3(x)) + f_4(t-x) \end{equation}
\begin{equation} \text{log}(m_{x,t}) = f_1(x) + f_2(t, f_3(x)) + f_4(t-x) \end{equation}
where
 $f_1(x)$
is the age effect,
$f_1(x)$
is the age effect,
 $f_2(t, f_3(x))$
encompasses the period and the age-period effects, and
$f_2(t, f_3(x))$
encompasses the period and the age-period effects, and
 $f_4(t-x)$
is the cohort effect. We model each term in the following way:
$f_4(t-x)$
is the cohort effect. We model each term in the following way:
-
• Age effect: we assume that age effect can be modeled linearly (
$f_1(x) = a + b (x - \bar {x})$
), where
$\bar {x} = \frac {1}{n_X} \sum _{i=1}^{n_X} x_i$
, or nonlinearly (
$f_1(x) = a_x$
). We introduce the variable
$\delta _1$
, which has value
$1$
if the age effect is not linear and
$2$
if the effect is linear. -
• Period effect: we assume that the period effect can be modeled in three ways and introduce the variable
$\delta _2$
to represent each outcome: independent from age
$(f_2(t,f_3(x)) = k^1_t)$
(
$\delta _2 = 1$
), modeled through an interaction with age
$(f_2(t,f_3(x)) = k^2_t (1 + f_3(x))$
(
$\delta _2 = 2$
), and a sum of the previous two
$(f_2(t,f_3(x)) = k^1_t + k^2_t f_3(x))$
, (
$\delta _2 = 3$
). -
• Age-period effect: if we have chosen an interaction between age and period (
$\delta _2 = 2$
or
$3$
), we introduce the variable
$\delta _3$
that is
$1$
if the age term in the interaction is modeled linearly with respect to age (
$f_3(x) = \bar {b}(x - \bar {x})$
, where
$\bar {b}$
is the slope) and
$2$
if modeled nonlinearly (
$f_3(x) = b_x$
). -
• Cohort effect: we introduce the variable
$\delta _4$
that is
$2$
if there is a cohort effect
$\gamma _{c}$
in the model (
$f_4(c) = \gamma _c$
), where
$c = t - x$
, and
$1$
otherwise (
$f_4(c) = 0$
).




























After reparametrization, the terms in the log-mortality rate in (2) can be expressed as
 \begin{equation*} f_1(x) = \begin{cases} a_x \hspace {1.81cm} \text{if } \delta _1 = 1 \\[5pt] a + b (x - \bar {x}) \quad \text{if } \delta _1 = 2 \end{cases} \hspace {1cm} f_2(t, f_3(x)) = \begin{cases} k^1_t \hspace {1.9cm} \text{if } \delta _2 = 1 \\[5pt] k^2_t (1 + f_3(x)) \hspace {.4cm} \text{if } \delta _2 = 2 \\[5pt] k^1_t + k^2_t f_3(x) \hspace {.5cm} \text{if } \delta _2 = 3 \end{cases} \end{equation*}
\begin{equation*} f_1(x) = \begin{cases} a_x \hspace {1.81cm} \text{if } \delta _1 = 1 \\[5pt] a + b (x - \bar {x}) \quad \text{if } \delta _1 = 2 \end{cases} \hspace {1cm} f_2(t, f_3(x)) = \begin{cases} k^1_t \hspace {1.9cm} \text{if } \delta _2 = 1 \\[5pt] k^2_t (1 + f_3(x)) \hspace {.4cm} \text{if } \delta _2 = 2 \\[5pt] k^1_t + k^2_t f_3(x) \hspace {.5cm} \text{if } \delta _2 = 3 \end{cases} \end{equation*}
 \begin{equation*} f_3(x) = \begin{cases} \bar {b} (x - \bar {x}) \hspace {.42cm} \text{if } \delta _3 = 1 \\[5pt] b_x \hspace {1.3cm} \text{if } \delta _3 = 2 \end{cases} \hspace {1cm} f_4(t - x) = \begin{cases} 0 \hspace {.9cm} \text{if } \delta _4 = 1 \\[5pt] \gamma _{t-x} \hspace {.42cm} \text{if } \delta _4 = 2 \end{cases} \end{equation*}
\begin{equation*} f_3(x) = \begin{cases} \bar {b} (x - \bar {x}) \hspace {.42cm} \text{if } \delta _3 = 1 \\[5pt] b_x \hspace {1.3cm} \text{if } \delta _3 = 2 \end{cases} \hspace {1cm} f_4(t - x) = \begin{cases} 0 \hspace {.9cm} \text{if } \delta _4 = 1 \\[5pt] \gamma _{t-x} \hspace {.42cm} \text{if } \delta _4 = 2 \end{cases} \end{equation*}
The complete list of models that can be obtained as a result of the different choices is summarized in Table 1. It can be seen that models such as the APC, LC, and CBD, are also included. However, as mentioned, we are also able to achieve intermediate models between the ones already considered.
Table 1. Complete set of models that can be obtained in the framework for each choice of
 $\delta _1$
,
$\delta _1$
,
 $\delta _2$
,
$\delta _2$
,
 $\delta _3$
, and
$\delta _3$
, and
 $\delta _4$
. We have also denoted in brackets the models defined in Table 1 of Cairns et al. (Reference Cairns, Blake, Dowd, Coughlan, Epstein, Ong and Balevich2009)
$\delta _4$
. We have also denoted in brackets the models defined in Table 1 of Cairns et al. (Reference Cairns, Blake, Dowd, Coughlan, Epstein, Ong and Balevich2009)

The set of identifiability constraints (ICs) are:
-
•
$\sum _t k^1_t = 0$
, since any constant added to
$k^1_t$
can be absorbed into
$f_1(x)$
. -
•
$\sum _t k^2_t = 0$
, since we can remove a constant
$C$
from
$k^2_t$
and absorb
$C f_3(x)$
into
$f_1(x)$
. However, if
$\delta _2 = \delta _3 = 2$
, this constraint is not strictly necessary since the nonlinear term
$C b_x$
cannot be absorbed into the linear term
$a + b (x - \bar {x})$
. For reasons described later, we assume the constraint throughout anyway. -
•
$\sum _{x} b_x = 0$
. If
$\delta _2 = 3$
, we also need on
$b_x$
the additional constraint
$b_{x_1} = -1$
, since we can otherwise replace
$b_x$
with
$C b_x$
and absorb the rest of the constants into the other parameters. -
•
$\sum _{c} \gamma _{c} = 0$
, since any additive constant can be absorbed into
$f_1(x)$
. -
• If
$\delta _2 = 1$
or
$\delta _2 = 3$
, following Cairns et al. (Reference Cairns, Blake, Dowd, Coughlan, Epstein, Ong and Balevich2009), another constraint is needed since we can remove a term
$C ( (t - \bar {t}) - (x - \bar {x}))$
from
$\gamma _{t-x}$
, for any real constant
$C$
, where
$\bar {t} = \frac {1}{n_T} \sum _{i=1}^{n_T} t_i$
, and add
$- C (x - \bar {x})$
to
$a_x$
and
$ C (t - \bar {t})$
to
$k_t$
. We, therefore, choose to assume no linear trend by enforcing
$\sum c \gamma _c = 0$
. We note that although not immediately apparent, it is necessary to assume another constraint on
$\gamma _c$
also if only a term of the form
$k_t b_x$
is present (
$\delta _2 = 2$
) and therefore we choose to impose the previous constraint also for
$\delta _2 = 2$
. -
• When
$\delta _1=1,\delta _2=3,\delta _3=1$
, we also need another constraint on the cohort effect, since we can add a quadratic term
$a_1 + a_2 ( (t - \bar {t}) - (x - \bar {x})) + a_2 ((t - \bar {t}) - (x - \bar {x}))^2$
(but still with mean zero and no linear trend) to
$\gamma _{t-x}$
, and remove it from
$f_1(x)$
,
$k^1_t$
and
$k^2_t$
, obtaining an equivalent model. We therefore impose
$\sum c^2 \gamma _{c} = 0$
.

















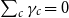























We note that our constraints are slightly different than those usually used in the literature because of the different parametrizations we have used.
3.1 Inference
We sample from the posterior distribution of
 $(\theta _1,\delta _1,\theta _2,\delta _2,\theta _3,\delta _3,\theta _4,\delta _4)$
, where
$(\theta _1,\delta _1,\theta _2,\delta _2,\theta _3,\delta _3,\theta _4,\delta _4)$
, where
 $\theta _i$
is the set of parameters of
$\theta _i$
is the set of parameters of
 $f_i$
, using an MCMC algorithm. The algorithm will alternate between sampling each set of parameters
$f_i$
, using an MCMC algorithm. The algorithm will alternate between sampling each set of parameters
 $\theta _i$
and the model configuration
$\theta _i$
and the model configuration
 $\delta _i$
of each term in (2), conditional on the rest of the parameters and the current model configuration. We start the MCMC from the simplest model
$\delta _i$
of each term in (2), conditional on the rest of the parameters and the current model configuration. We start the MCMC from the simplest model
 $(2,1,1,1)$
and choose as starting value of
$(2,1,1,1)$
and choose as starting value of
 $(a,b)$
the MLE using a model of the form
$(a,b)$
the MLE using a model of the form
 $\text{log}(m_{x,t}) = a + b (x - \bar {x})$
, and
$\text{log}(m_{x,t}) = a + b (x - \bar {x})$
, and
 $k^1_t = 0$
.
$k^1_t = 0$
.
3.1.1 Parameters update
For the parameter
 $\theta _i$
, we sample from the posterior distribution of the parameters with a Metropolis-Hastings algorithm using as proposal the Laplace approximation of the posterior distribution. To find the Laplace approximation, we maximize the log-posterior distribution
$\theta _i$
, we sample from the posterior distribution of the parameters with a Metropolis-Hastings algorithm using as proposal the Laplace approximation of the posterior distribution. To find the Laplace approximation, we maximize the log-posterior distribution
 $\text{log}(p(\theta _i | \theta _{-i}, d))$
to find the optimal
$\text{log}(p(\theta _i | \theta _{-i}, d))$
to find the optimal
 $\hat {\theta _i}$
and the Hessian
$\hat {\theta _i}$
and the Hessian
 $\hat {H}$
at the maximum. We use an explicit expression of the solution
$\hat {H}$
at the maximum. We use an explicit expression of the solution
 $\hat {\theta _i}$
and of the Hessian
$\hat {\theta _i}$
and of the Hessian
 $\hat {H}$
when analytically available, and resort to using an optimization procedure such as the optim function in R when analytical expressions are not available. To achieve better performances, we also provide optim with the explicit expression of the gradient
$\hat {H}$
when analytically available, and resort to using an optimization procedure such as the optim function in R when analytical expressions are not available. To achieve better performances, we also provide optim with the explicit expression of the gradient
 $\nabla _{\theta _i} \text{log}(p(\theta _i | \theta _{-i}, d))$
. We have used a Laplace approximation using a Student’s t distribution in place of a normal distribution, since acceptance rate using a normal distribution can in some cases be too small when the current points is very distant from the mean of the Laplace approximation, because of the light tails of the normal. The Student’s t approximation has been chosen by matching the mean and the scale matrix and using
$\nabla _{\theta _i} \text{log}(p(\theta _i | \theta _{-i}, d))$
. We have used a Laplace approximation using a Student’s t distribution in place of a normal distribution, since acceptance rate using a normal distribution can in some cases be too small when the current points is very distant from the mean of the Laplace approximation, because of the light tails of the normal. The Student’s t approximation has been chosen by matching the mean and the scale matrix and using
 $\nu = 10$
degrees of freedom. The proposed value
$\nu = 10$
degrees of freedom. The proposed value
 $\theta _i^*$
from
$\theta _i^*$
from
 $t_{\nu }(\hat {\theta _i}, \hat {H})$
is accepted with probability
$t_{\nu }(\hat {\theta _i}, \hat {H})$
is accepted with probability
 \begin{equation*} \min \left \{1, \frac {p(d | \theta _i^*, \theta _{-i}) t_{\nu }(\theta _i | \hat {\theta _i}, \hat {H})}{p(d | \theta _i, \theta _{-i}) t_{\nu }(\theta _i^{\star } | \hat {\theta _i}, \hat {H})}\right \}. \end{equation*}
\begin{equation*} \min \left \{1, \frac {p(d | \theta _i^*, \theta _{-i}) t_{\nu }(\theta _i | \hat {\theta _i}, \hat {H})}{p(d | \theta _i, \theta _{-i}) t_{\nu }(\theta _i^{\star } | \hat {\theta _i}, \hat {H})}\right \}. \end{equation*}
If constraints are not present on the parameters, we update each parameter individually; otherwise, we update parameters in blocks. To handle constraints in the updates, we reparametrize each set of parameters in terms of a set of free variables, ensuring that all constraints are automatically satisfied. We detail how constraints are enforced in each model in Section
 $1$
of the Supplementary Material.
$1$
of the Supplementary Material.
3.1.2 Model space update
To explore the model space, we propose to change each variable
 $\delta _i$
at a time. For
$\delta _i$
at a time. For
 $\delta _1$
,
$\delta _1$
,
 $\delta _3$
, and
$\delta _3$
, and
 $\delta _4$
, we simply propose the value
$\delta _4$
, we simply propose the value
 $2$
if we are currently in the value
$2$
if we are currently in the value
 $1$
and vice versa. For
$1$
and vice versa. For
 $\delta _2$
, we propose the following transitions:
$\delta _2$
, we propose the following transitions:
 $(\delta _2 = 1) \Rightarrow (\delta _2^{\star } = 2, \delta _3^{\star } = 1)$
,
$(\delta _2 = 1) \Rightarrow (\delta _2^{\star } = 2, \delta _3^{\star } = 1)$
,
 $(\delta _2 = 2) \Rightarrow (\delta _2^{\star } = 1)$
,
$(\delta _2 = 2) \Rightarrow (\delta _2^{\star } = 1)$
,
 $(\delta _2 = 2) \Rightarrow (\delta _2^{\star } = 3)$
, and
$(\delta _2 = 2) \Rightarrow (\delta _2^{\star } = 3)$
, and
 $(\delta _2 = 3) \Rightarrow (\delta _2^{\star } = 2)$
. If more than one move is available from the current configuration, we choose each of them with equal probability.
$(\delta _2 = 3) \Rightarrow (\delta _2^{\star } = 2)$
. If more than one move is available from the current configuration, we choose each of them with equal probability.
To formally describe the updates, we set up some notation. We assume that the current model
 $\delta$
has parameter
$\delta$
has parameter
 $(\eta _1,\eta _2)$
and the new proposed model
$(\eta _1,\eta _2)$
and the new proposed model
 $\delta ^{\star }$
has parameter
$\delta ^{\star }$
has parameter
 $(\eta _1,\eta _2^{\star })$
(noting that
$(\eta _1,\eta _2^{\star })$
(noting that
 $\eta _2$
or
$\eta _2$
or
 $\eta _2^{\star }$
can also be empty). For example, if the current model is nested within the proposed model, we have
$\eta _2^{\star }$
can also be empty). For example, if the current model is nested within the proposed model, we have
 $\eta _2 = \emptyset$
.
$\eta _2 = \emptyset$
.
The moves we will consider fall into one of the following cases:
-
1.
$\eta _2 = \emptyset$
,
$\eta _2^* \neq \emptyset$
. This is the case where we are proposing to add new parameters to the model. In this case, we can simply choose as auxiliary variables
$u$
the new set of parameters
$\eta _2^{\star }$
. Specifically, we generate
$u = \eta _2^{\star }$
from the normal Laplace approximation to the posterior
$p(\eta _2 | \eta _1, \delta ^*, d)$
, and accept the proposed model with the new set of parameters,
$((\eta _1,\eta _2^*),\delta ^*)$
with probability
\begin{equation*} \text{min}\left \{ 1, \frac {p(d | (\eta _1, \eta _2^*),\delta ^*) p(\eta _1, \eta _2 | \delta ^*) p(\delta ^*) q(\delta ^* \rightarrow \delta ) }{p(d | \eta _1, \delta ) p(\eta _1 | \delta ) p(\delta ) q(\delta \rightarrow \delta ^*) \text{N}(\eta _2^* | \hat {\eta _2}, \hat {H})} \right \}. \end{equation*}
-
2.
$\eta _2^* = \emptyset$
,
$\eta _2 \neq \emptyset$
. This is the case where we are proposing to remove parameters of the model. In this case, the acceptance ratio is the inverse of the ratio in the previous move. -
3.
$\eta _2 \neq \eta _2^*$
both not empty. This is the case where we are proposing to change the parameters of the current model. In this case, we choose as auxiliary variables
$u = \eta _2^*$
and
$u' = \eta _2$
. The new model is accepted with probability as in (1).













We will need to pay particular attention to the cases where the move will cause changes in the ICs on the set of parameters that do not change (
 $\eta _1$
). When this happens, we cannot straightforwardly use the updates defined above because the dimension matching condition is not satisfied anymore. There are three possible ways to work around this. One option is to propose jointly the new set of parameters
$\eta _1$
). When this happens, we cannot straightforwardly use the updates defined above because the dimension matching condition is not satisfied anymore. There are three possible ways to work around this. One option is to propose jointly the new set of parameters
 $\eta _2^*$
and the subset of parameters of
$\eta _2^*$
and the subset of parameters of
 $\eta _1$
for which the ICs change. The drawback is that this would require an optimization over a large number of parameters, which is costly. Another option is to simply impose the ICs also for the model where these are not theoretically needed. The preferred option is to reparametrize the model such that the reduction in ICs is replaced with the addition of new variables, which are then proposed together with the variables
$\eta _1$
for which the ICs change. The drawback is that this would require an optimization over a large number of parameters, which is costly. Another option is to simply impose the ICs also for the model where these are not theoretically needed. The preferred option is to reparametrize the model such that the reduction in ICs is replaced with the addition of new variables, which are then proposed together with the variables
 $\eta ^*$
. We can now describe each different update of
$\eta ^*$
. We can now describe each different update of
 $\delta _i$
:
$\delta _i$
:
-
• Update
$\delta _1$
To propose the move from
$\delta _1$
to
$\delta ^*_1$
, we use the third type of update by choosing as auxiliary variables
$u = a_x$
(if
$\delta ^{*}_1 = 1$
) and
$u = (a,b)$
(if
$\delta ^{*}_1 = 2$
). In the case
$\delta _2 = 2$
or
$\delta _2 = 3$
, changing
$\delta _1$
causes a change in the ICs on
$k^2_t$
, since
$\sum _t k^2_t = 0$
is required when
$\delta _1 = 1$
but it is not in the case
$\delta _1 = 2$
. We therefore choose to keep the IC
$\sum _t k^2_t = 0$
throughout to avoid complicating the RJMCMC. In the case where
$(\delta _2, \delta _3, \delta _4) = (3,1,2)$
, the move from
$\delta _1 = 1$
to
$\delta _2 = 2$
causes the constraints
$\sum c^2 \gamma _c = 0$
on
$\gamma _c$
to drop. As mentioned above, we aim to reparametrize the model with fewer constraint (
$\delta _1 = 1$
) such that the new constraint
$\sum c^2 \gamma _c = 0$
is added (and therefore, a degree of freedom is lost) by adding an additional variable into the model. To find the parametrization, we note that the additional constraint
$\sum c^2 \gamma _c = 0$
removes quadratic trend from
$\gamma _{t-x}$
, hence, if this constraint is added, we need to introduce a quadratic term with zero mean and no linear trend into the model. Therefore, we propose to reparametrize the modelwith constraint
\begin{equation*} a + b(x - \bar {x}) + k^1_t + k^2_t \bar {b} (x - \bar {x}) + \gamma _{t-x} \qquad \end{equation*}
$\sum \gamma _c = \sum c \gamma _c = 0$
, to the formwith constraint
\begin{equation*} a + b(x - \bar {x}) + k^1_t + k^2_t \bar {b} (x - \bar {x}) + h_{\zeta }(t-x) + \gamma _{t-x} \qquad \end{equation*}
$\sum \gamma _c = \sum c \gamma _c = \sum c^2 \gamma _c = 0$
, where
$h_{\zeta }(c) = \zeta \frac {(n_C + 1)(n_C + 2)}{6}- \zeta n_C (c + n_X) + \zeta (c + n_X)^2$
, and
$\zeta$
is a free parameter.
$h_{\zeta }(c)$
is a quadratic polynomial in
$c$
that follows that specific parametrization to satisfy the existing constraints
$\sum _c h_{\zeta }(c) = \sum _c c h_{\zeta }(c) = 0$
. The degree of freedom lost because of the constraint has been absorbed in the parameter
$\zeta$
. Having the two models the same constraints, we can propose
$\delta ^*_1 = 2$
from
$\delta _1 = 1$
by proposing
$u = (a,b, \eta )$
and in the opposite move, we propose
$u = a_x$
.
-
• Update
$\delta _2$
We separately consider each move:-
–
$(\delta _2 = 1) \leftrightarrow (\delta _2 = 2, \delta _3 = 1)$
:To perform the move
$(\delta _2 = 1) \rightarrow (\delta ^*_2 = 2, \delta ^*_3 = 1)$
, we use the first type of update by proposing
$\bar {b}$
. The opposite move is performed deterministically, by setting
$\bar {b} = 0$
. -
–
$(\delta _2 = 2) \leftrightarrow (\delta _2 = 3)$
In this update, we need to pay particular attention to the cases where the ICs of other parameters change as a consequence of the change in
$\delta _2$
. As it can be seen in Table 1, this happens where
$(\delta _1, \delta _3, \delta _4) = (1,1,2)$
(since
$\sum c^2 \gamma _c = 0$
applies only for
$\delta _2 = 3$
), and when
$\delta _3 = 2$
(since
$b_{x_1} = -1$
applies only for
$\delta _2 = 3$
). We discuss each case separately.-
*
$\delta _3 = 1$
and,
$\delta _1 = 2$
or
$\delta _4 = 1$
. This is the case in which no ICs change on the rest of the parameters. In this case, we use the third update by using
$u = k^2_t$
when moving to
$\delta ^*_2 = 2$
and
$u = (k^1_t, k^2_t)$
when moving to
$\delta ^*_2 = 3$
. -
*
$\delta _3 = 2$
. In this case, the ICs on
$b_x$
change. We propose to reparameterize the model for
$\delta _2 = 2$
:in the form
\begin{equation*} f_1(x) + k^1_t + k^1_t b_x + f_4(t-x) \qquad \end{equation*}
with the additional constraint
\begin{equation*} f_1(x) + k^1_t + k^1_t \bar {b} b_x + f_4(t-x) \qquad \end{equation*}
$b_{x_1} = -1$
. The degree of freedom lost because of the constraint has been absorbed in the parameter
$\bar {b}$
. Now that the model has the same constraints as the model of the case
$\delta _2 = 3$
we can move to
\begin{equation*} f_1(x) + k^1_t + k^2_t b_x + f_4(t-x) \qquad \end{equation*}
$\delta ^*_2 = 3$
by proposing
$u = (k^1_t, k^2_t)$
and we move to
$\delta ^*_2 = 2$
by proposing
$u = (k^2_t, \bar {b})$
.
-
*
$(\delta _1, \delta _3, \delta _4) = (1,1,2)$
. In this case, the constraint
$\sum c^2 \gamma _c = 0$
does not hold for
$\delta _2 = 2$
. Similarly to what we did in the
$\delta _1$
case, we propose to reparametrize the model for
$\delta _2 = 2$
:with constraint
\begin{equation*} a_x + k^2_t + k^2_t \bar {b} (x - \bar {x}) + \gamma _{t-x} \qquad \end{equation*}
$\sum \gamma _c = \sum c \gamma _c = 0$
, towith constraints
\begin{equation*} a_x + k^2_t + k^2_t \bar {b} (x - \bar {x}) + h_{\zeta }(t-x) + \gamma _{t-x} \qquad \end{equation*}
$\sum \gamma _c = \sum c \gamma _c = \sum c^2 \gamma _c = 0$
, Having the two models the same constraints, we can propose
$\delta ^*_2 = 3$
from
$\delta _2 = 2$
by proposing
$u = (k^1_t,k^2_t)$
and in the opposite move we can propose
$u = (k^2_t, \bar {b}, \zeta )$
.
-
-
-
• Update
$\delta _3$
We distinguish two cases.-
–
$\delta _2 = 2$
: in this case we are moving between the models
$k^2_t (1 + \bar {b}(x- \bar {x}))$
and
$f_2(t,f_3(x)) = k^2_t (1 + b_x)$
. We use the third type of update, using the auxiliary variables
$u = b_x$
in the move from
$\delta _3 = 1$
to
$\delta _3^* = 2$
and
$u = \bar {b}$
in the reverse move. -
–
$\delta _2 = 3$
: in this case we are moving between the models
$f_2(t,f_3(x)) = k_t^1 + k^2_t (x - \bar {x})$
and
$k^1_t + k^2_t b_x$
. Since one model is nested within the other, we can use the first type of update with
$u = \bar {b}_x$
when moving from
$\delta _3 = 1$
to
$\delta _3^* = 2$
and the second type of update in the reverse move.We separately consider the case
$(\delta _1, \delta _2, \delta _4) = (1,3,2)$
, since the change from
$\delta _3 = 1$
to
$\delta ^*_3 = 2$
causes the constraint
$\sum c^2 \gamma _c = 0$
to drop.Similarly to before, we reparametrize the model
$a_x + k^1_t + k^2_t (x - \bar {x}) + \gamma _{t-x}$
, with constraints
$\sum \gamma _c = \sum c \gamma _c = 0$
to the model
$a_x + k^1_t + k^2_t (x - \bar {x}) + h_{\zeta }(t - x) + \gamma _{t-x}$
, with constraints
$\sum \gamma _c = \sum c \gamma _c = \sum c^2 \gamma _c = 0$
. Next, to change between the two models, we use the first type of update with
$u = (\zeta , b_x)$
. The reverse move is deterministic.
-
-
• Update
$\delta _4$
The move from
$\delta _4 = 1$
to
$\delta _4^* = 2$
falls into the first scheme and is performed by choosing
$u = \gamma _{c}$
, while the move from
$\delta _4 = 2$
to
$\delta _4^* = 1$
falls into the second scheme and is a deterministic move.

















































































































We note that even in cases where models are nested, we have not used the first/second type of update as in our experiments, the acceptance ratio was too low. The scheme is summarized in Figure 1.

Figure 1 Summary of the model moves
 $\delta \rightarrow \delta ^{\star }$
. We use
$\delta \rightarrow \delta ^{\star }$
. We use
 $\tilde {m}_{x,t}$
to denote all the residual terms.
$\tilde {m}_{x,t}$
to denote all the residual terms.
3.2 Simulation study
We have performed a simulation study to assess the ability of the model selection procedure to identify the true model. For each of the
 $20$
models, we have simulated
$20$
models, we have simulated
 $4$
different datasets and for each dataset, and we run the model with
$4$
different datasets and for each dataset, and we run the model with
 $2$
chains of
$2$
chains of
 $5000$
burn-in iterations and
$5000$
burn-in iterations and
 $5000$
iterations. We have used flat priors on all the model parameters. We have used the following settings to perform the simulations:
$5000$
iterations. We have used flat priors on all the model parameters. We have used the following settings to perform the simulations:
-
•
$f_1(x)$
: if
$\delta _1 = 2$
, we set
$f_1(x) = a + b (x - \bar {x})$
, with
$a = -3.5, b = 0.105$
, if
$\delta _1 = 1$
, we set
$f_1(x) = a + b (x - \bar {x}) + \epsilon _x$
, with
$a,b$
as before and
$\epsilon _x \sim \text{N}(0, 0.3^2)$
. -
•
$f_2(t)$
, If
$\delta _2 = 1$
or
$\delta _2 = 2$
, we let
$k^1_t$
(or
$k^2_t$
) vary linearly from
$0.675$
to
$-0.675$
. If
$\delta _2 = 3$
, we let
$k^1_t$
vary on a grid from
$-0.675$
to
$0.675$
and assume
$k^2_t = k^1_t + \epsilon _t$
, with
$\epsilon _t \sim \text{N}(0, 0.3^2)$
(and then centering
$\epsilon _t$
). -
•
$f_3(x)$
. if
$\delta _3 = 1$
, we assume
$\bar {b} = 0.0818$
, if
$\delta _3 = 2$
, we set
$b_x = \bar {b} (x - \bar {x}) + \epsilon _x$
, with
$\epsilon _x \sim \text{N}(0, 0.3^2)$
. If
$b_{x_1} = -1$
, we have renormalized to account for it. -
•
$f_4(t-x)$
: if
$\delta _4 = 2$
, we have simulated
$\gamma _{t-x} = A \eta$
, where
$\eta \sim N(0, 0.3^2)$
is a
$(n_C-2)$
or
$(n_C-3)$
dimensional vector, and
$A$
is a
$n_C \times (n_C-2)$
(or
$n_C \times (n_C-3)$
) projection matrix such that
$\gamma _{t-x}$
will satisfy the relevant constraints.







































The previous values have been chosen to reflect values typically obtained from real data. The results are presented in Table 2. The inference algorithm can generally recover the true model, except for a few instances. When the true model was not selected, very similar models were selected instead. An issue we have noticed is that the model
 $(1,3,1,2)$
is often selected even when it is not the correct model. In our experiments, we noticed that this was due to issues with slow mixing related to this model, since when
$(1,3,1,2)$
is often selected even when it is not the correct model. In our experiments, we noticed that this was due to issues with slow mixing related to this model, since when
 $b_x \approx k (x - \bar {x})$
the model approaches unidentifiability (as another constraint on the cohort effect would be needed).
$b_x \approx k (x - \bar {x})$
the model approaches unidentifiability (as another constraint on the cohort effect would be needed).
Table 2. Results of the simulation study. In each cell, we report the posterior probability of each model averaged across the
 $4$
simulations. The true model used to simulate the data is indicated by the row, while the model for which the posterior probability is reported is indicated by the column. The index of the model is the same as the order used in Table 1
$4$
simulations. The true model used to simulate the data is indicated by the row, while the model for which the posterior probability is reported is indicated by the column. The index of the model is the same as the order used in Table 1


Figure 2 HMD data results: 95% PCI of the log-mortality rates
 $m_{x,t}$
. The dots represent the crude rates.
$m_{x,t}$
. The dots represent the crude rates.
3.3 Case study: Human mortality database
We apply the models defined in the previous section to mortality data of
 $40$
countries as part of the Human Mortality Database (HMD, 2024). For each country, we selected a subset of data comprising individuals aged between
$40$
countries as part of the Human Mortality Database (HMD, 2024). For each country, we selected a subset of data comprising individuals aged between
 $60$
and
$60$
and
 $90$
, and covering the period from
$90$
, and covering the period from
 $1990$
to
$1990$
to
 $2022$
. We note that some data are available on a smaller timescale, and in that case, we use the subset of data available within that period. For each country, we ran the MCMC for
$2022$
. We note that some data are available on a smaller timescale, and in that case, we use the subset of data available within that period. For each country, we ran the MCMC for
 $2$
chains of
$2$
chains of
 $10,000$
iterations, with
$10,000$
iterations, with
 $20,000$
burn-in iterations. We have used flat priors on all the model parameters. The posterior credible intervals (PCI) of the estimated log-mortality rates are presented in Figure 2. For simplicity, we only show here the results for a few countries (the full results are presented in the Supplementary Material). We also present the posterior probabilities of the model selection procedure in Table 3. In many countries, it can be seen that the evidence for the selection of one term is strong enough that the posterior probability is
$20,000$
burn-in iterations. We have used flat priors on all the model parameters. The posterior credible intervals (PCI) of the estimated log-mortality rates are presented in Figure 2. For simplicity, we only show here the results for a few countries (the full results are presented in the Supplementary Material). We also present the posterior probabilities of the model selection procedure in Table 3. In many countries, it can be seen that the evidence for the selection of one term is strong enough that the posterior probability is
 $1$
, while for other countries, multiple models are selected. The countries with the largest exposure, such as USA, Russia, Japan, Germany, and the UK, select the most complex model,
$1$
, while for other countries, multiple models are selected. The countries with the largest exposure, such as USA, Russia, Japan, Germany, and the UK, select the most complex model,
 $(1,3,2,2)$
,
$(1,3,2,2)$
,
 $a_x + k^1_t + k^2_t b_x + \gamma _{t-x}$
. Countries with lower exposures, such as Croatia, Norway, and Slovakia are the ones that result in higher uncertainty in the model selection. The rest of the mortality rates are presented in Section
$a_x + k^1_t + k^2_t b_x + \gamma _{t-x}$
. Countries with lower exposures, such as Croatia, Norway, and Slovakia are the ones that result in higher uncertainty in the model selection. The rest of the mortality rates are presented in Section
 $2.1$
of the Supplementary Material, while the MCMC mixing summaries are reported in Section
$2.1$
of the Supplementary Material, while the MCMC mixing summaries are reported in Section
 $2.2$
of the Supplementary Material. To evaluate parameter mixing, we have reported summaries of the effective sample size and the Gelman–Rubin diagnostics. To evaluate the model choice mixing, we have reported two quantities. First, we have reported the posterior model probabilities across different chains. Excessive variation between these two probabilities shows poor mixing. In addition, we have looked at adjusted acceptance rates toward different model configurations. The rationale behind the proposed efficiency rate is the following. If the MCMC is perfectly efficient, we expect the probability of transition from model
$2.2$
of the Supplementary Material. To evaluate parameter mixing, we have reported summaries of the effective sample size and the Gelman–Rubin diagnostics. To evaluate the model choice mixing, we have reported two quantities. First, we have reported the posterior model probabilities across different chains. Excessive variation between these two probabilities shows poor mixing. In addition, we have looked at adjusted acceptance rates toward different model configurations. The rationale behind the proposed efficiency rate is the following. If the MCMC is perfectly efficient, we expect the probability of transition from model
 $i$
to model
$i$
to model
 $j$
,
$j$
,
 $p(\delta ^{(t)} = j | \delta ^{(t-1)} = i)$
, to be close to the posterior probability of model
$p(\delta ^{(t)} = j | \delta ^{(t-1)} = i)$
, to be close to the posterior probability of model
 $j$
,
$j$
,
 $p(\delta = j| d)$
. Therefore, can look at the ratio
$p(\delta = j| d)$
. Therefore, can look at the ratio
 $\frac {p(\delta ^{(t)} = j | \delta ^{(t-1)} = i)}{p(\delta = j| d)}$
as a measure of efficiency, and we term this as “efficiency rate” in the Supplementary Material. Excessive variation from
$\frac {p(\delta ^{(t)} = j | \delta ^{(t-1)} = i)}{p(\delta = j| d)}$
as a measure of efficiency, and we term this as “efficiency rate” in the Supplementary Material. Excessive variation from
 $1$
can be seen as a measure of poor mixing in the RJMCMC. As shown in the summaries, aside from a few countries such as Russia, Japan, and Germany, parameter mixing is generally acceptable, and even when individual model terms do not exhibit adequate effective sample sizes, the mortality rate tends to mix well. This suggests that the slow mixing is likely due to autocorrelation in the MCMC between the different model terms. Model mixing can only be evaluated for countries that select more than one model. For some of these countries, such as Canada and Slovakia, the diagnostics indicate that model mixing is less satisfactory. Although it is unrealistic to expect efficiency rates close to
$1$
can be seen as a measure of poor mixing in the RJMCMC. As shown in the summaries, aside from a few countries such as Russia, Japan, and Germany, parameter mixing is generally acceptable, and even when individual model terms do not exhibit adequate effective sample sizes, the mortality rate tends to mix well. This suggests that the slow mixing is likely due to autocorrelation in the MCMC between the different model terms. Model mixing can only be evaluated for countries that select more than one model. For some of these countries, such as Canada and Slovakia, the diagnostics indicate that model mixing is less satisfactory. Although it is unrealistic to expect efficiency rates close to
 $1$
, our results show that, in some cases, the rates are close to
$1$
, our results show that, in some cases, the rates are close to
 $0$
, highlighting how the RJMCMC can struggle to transition between models. We note that, to the best of our knowledge, the efficiency rate has not been used in the literature, so there are no standard benchmarks to contextualize the efficiency of our procedure. However, we can conclude that efficiency rates below 1% are strong evidence of poor RJMCMC performance. The within-chain model probabilities support a similar conclusion, as the model proportions can for some countries differ noticeably between chains.
$0$
, highlighting how the RJMCMC can struggle to transition between models. We note that, to the best of our knowledge, the efficiency rate has not been used in the literature, so there are no standard benchmarks to contextualize the efficiency of our procedure. However, we can conclude that efficiency rates below 1% are strong evidence of poor RJMCMC performance. The within-chain model probabilities support a similar conclusion, as the model proportions can for some countries differ noticeably between chains.
Table 3. HMD data results: posterior probabilities of each model
 $(\delta _1,\delta _2,\delta _3,\delta _4)$
$(\delta _1,\delta _2,\delta _3,\delta _4)$

4. APCI model stratified by product
In this section, we demonstrate how to define mortality models for data stratified by an additional variable, that is, the APP data. For example, the additional stratifying variable could represent different insurance products, sexes, or countries. For simplicity, we will refer to this additional stratifying variable as “product” throughout this section. Note that the notation used here is different from the one used in the previous section.
We build the model by extending the APCI model (Richards et al., Reference Richards, Currie, Kleinow and Ritchie2019). As mentioned in the introduction, we have chosen this base model for two main reasons. First, the APCI model is one of the most popular models used to fit mortality data and is currently used by the CMI (Continuous Mortality Investigation Bureau, 2024). Second, we aim to define an extension of the base model that involves fewer changes in the ICs when each model changes according to product, which, similar to the previous section, will help the design of the RJMCMC framework, and the APCI serves this purpose well.
According to the APCI model, log-mortality is modeled as
 \begin{equation*} \text{log}(m_{x,t}) = a_x + b_x (t - \bar {t}) + k_t + \gamma _{t-x} \ , \end{equation*}
\begin{equation*} \text{log}(m_{x,t}) = a_x + b_x (t - \bar {t}) + k_t + \gamma _{t-x} \ , \end{equation*}
where
 $a_x$
represents the age effect,
$a_x$
represents the age effect,
 $b_x$
represents the change in period effect by age,
$b_x$
represents the change in period effect by age,
 $k_t$
represents the period effect and
$k_t$
represents the period effect and
 $\gamma _{t-x}$
represents the cohort effect. The ICs that we use are
$\gamma _{t-x}$
represents the cohort effect. The ICs that we use are
 $\sum _x b_x = \sum _t k_t = \sum _{c} \gamma _{c} = \sum _c c \gamma _c = \sum _c c^2 \gamma _c = 0$
. We then extend the base APCI model to allow for product effect by proposing different functional forms for the terms
$\sum _x b_x = \sum _t k_t = \sum _{c} \gamma _{c} = \sum _c c \gamma _c = \sum _c c^2 \gamma _c = 0$
. We then extend the base APCI model to allow for product effect by proposing different functional forms for the terms
 $a_x$
,
$a_x$
,
 $b_x$
and
$b_x$
and
 $k_t$
.
$k_t$
.
-
• For
$a_x$
, we propose the product forms: (a)
$a_x$
(no change), (b)
$a_x + c^1_p$
, and (c)
$a_{x,p}$
, and we denote each choice with the latent variable
$\delta _1 = 1$
,
$2$
and
$3$
, respectively. The ICs are
$\sum c^1_p = 0$
. -
• For
$b_x$
, we propose the product forms: (a)
$b_x$
(no change) and (b)
$b_x c^2_p$
, modeled with the latent variable
$\delta _2 = 1$
and
$2$
, respectively. The ICs are
$\sum c^2_p = n_P$
, since
$c^2_p$
appears in a product with
$b_x$
. -
• For
$k_t$
, we propose the forms: (a)
$k_t$
(no change) and (b)
$k_t + k^2_t c^3_p$
, modeled with the latent variable
$\delta _3 = 1$
and
$2$
, respectively. The ICs are the following.
$\sum k^2_t = 0$
, since any constant
$K c^3_p$
can be incorporated into
$ c^1_p$
(or into
$a_{x,p}$
),
$\sum c^3_p = 0$
since any additive constant can be incorporated into
$k_t$
.
$c^3_1 = 1$
, Since
$c_p$
can still be multiplied by a constant which can be incorporated into
$k^2_t$
.






























Similarly to the previous section, we note that some constraints depend on the modeling choices. The third constraint
 $\sum c^2 \gamma _c = 0$
is not necessary when
$\sum c^2 \gamma _c = 0$
is not necessary when
 $\delta _2 = 2$
.
$\delta _2 = 2$
.
 $\sum k^2_t = 0$
only holds if
$\sum k^2_t = 0$
only holds if
 $\delta _1 \neq 1$
, and
$\delta _1 \neq 1$
, and
 $\sum _{x} b_x = 0$
only holds in the case
$\sum _{x} b_x = 0$
only holds in the case
 $\delta _2 = 1$
. We note that we still assume
$\delta _2 = 1$
. We note that we still assume
 $\sum _x b_x = 0$
also in the case
$\sum _x b_x = 0$
also in the case
 $\delta _2 = 2$
since, in our experiments, the model was very close to being unidentifiable without the constraint
$\delta _2 = 2$
since, in our experiments, the model was very close to being unidentifiable without the constraint
 $\sum _x b_x = 0$
. Moreover, similarly to the previous section, to help the design of the RJMCMC, we choose to still impose the constraint
$\sum _x b_x = 0$
. Moreover, similarly to the previous section, to help the design of the RJMCMC, we choose to still impose the constraint
 $\sum k^2_t = 0$
even when
$\sum k^2_t = 0$
even when
 $\delta _1 = 1$
.
$\delta _1 = 1$
.
The model for age-period-product data can be summarized as
 \begin{equation*} \text{log}(m_{x,t,p}) = a_{\delta _1}(x,p) + b_{\delta _2}(x,p) (t - \bar {t}) + k_{\delta _3}(t,p) + \gamma _{t- x} \end{equation*}
\begin{equation*} \text{log}(m_{x,t,p}) = a_{\delta _1}(x,p) + b_{\delta _2}(x,p) (t - \bar {t}) + k_{\delta _3}(t,p) + \gamma _{t- x} \end{equation*}
where
 \begin{equation*}a_{\delta _1}(x,p) = \begin{cases} a_x \hspace {.9cm} \text{ if } \delta _1 = 1 \\[5pt] a_x + c^1_p \hspace {.2cm}\text{ if } \delta _1 = 2 \\[5pt] a_{x,p} \hspace {.7cm} \text{ if } \delta _1 = 3 \end{cases}\!\!\!\!\!, b_{\delta _2}(x,p) = \begin{cases} b_{x} \hspace {.5cm} \text{ if } \delta _2 = 1 \\[5pt] b_x c^2_p \hspace {.2cm }\text{ if } \delta _2 = 2 \\[5pt] \end{cases}\!\!\!\!\!, k_{\delta _3}(t,p) = \begin{cases} k_{t} \hspace {1.3cm} \text{ if } \delta _3 = 1 \\[5pt] k_t + k^2_t c^3_p \hspace {.3cm} \text{ if } \delta _3 = 2 \\[5pt] \end{cases}\!\!\!\!\!. \end{equation*}
\begin{equation*}a_{\delta _1}(x,p) = \begin{cases} a_x \hspace {.9cm} \text{ if } \delta _1 = 1 \\[5pt] a_x + c^1_p \hspace {.2cm}\text{ if } \delta _1 = 2 \\[5pt] a_{x,p} \hspace {.7cm} \text{ if } \delta _1 = 3 \end{cases}\!\!\!\!\!, b_{\delta _2}(x,p) = \begin{cases} b_{x} \hspace {.5cm} \text{ if } \delta _2 = 1 \\[5pt] b_x c^2_p \hspace {.2cm }\text{ if } \delta _2 = 2 \\[5pt] \end{cases}\!\!\!\!\!, k_{\delta _3}(t,p) = \begin{cases} k_{t} \hspace {1.3cm} \text{ if } \delta _3 = 1 \\[5pt] k_t + k^2_t c^3_p \hspace {.3cm} \text{ if } \delta _3 = 2 \\[5pt] \end{cases}\!\!\!\!\!. \end{equation*}
The full set of models is presented in Table 4.
Table 4. Complete set of models for the APP data

4.1 Inference
We sample from the posterior distribution of
 $(\theta _1,\delta _1,\theta _2,\delta _2,\theta _3,\delta _3,\gamma _{c})$
, where
$(\theta _1,\delta _1,\theta _2,\delta _2,\theta _3,\delta _3,\gamma _{c})$
, where
 $\theta _1$
are the parameter of
$\theta _1$
are the parameter of
 $a_{\delta _1}(x,p)$
,
$a_{\delta _1}(x,p)$
,
 $\theta _2$
are the parameter of
$\theta _2$
are the parameter of
 $b_{\delta _2}(x,p)$
, and
$b_{\delta _2}(x,p)$
, and
 $\theta _3$
are the parameter of
$\theta _3$
are the parameter of
 $k_{\delta _3}(t,p)$
, with an MCMC algorithm. We iteratively sample the parameters
$k_{\delta _3}(t,p)$
, with an MCMC algorithm. We iteratively sample the parameters
 $\theta _1$
,
$\theta _1$
,
 $\theta _2$
,
$\theta _2$
,
 $\theta _3$
, and
$\theta _3$
, and
 $\gamma _{c}$
and the model choices
$\gamma _{c}$
and the model choices
 $\delta _1$
,
$\delta _1$
,
 $\delta _2$
and
$\delta _2$
and
 $\delta _3$
.
$\delta _3$
.
The scheme follows the same ideas used for the AP model for both the parameter updates and the model space, where we use a Metropolis-Hastings update with Laplace approximation to the proposal for the parameter updates, and explore the model space by proposing to change each variable
 $\delta _i$
at a time. We separately discuss each proposal using the notation introduced in Section 3.1.2.
$\delta _i$
at a time. We separately discuss each proposal using the notation introduced in Section 3.1.2.
-
• Updating
$\delta _1$
-
–
$\delta _1 = 1 \leftrightarrow \delta _1 = 2$
: To move from model
$1$
(
$a_x$
) to model
$2$
(
$a_x + c^1_p$
), we use the first type of update by proposing to add the variables
$c^1_p$
. As proposal distribution for
$c^1_p$
, we choose the Laplace approximation to the posterior of
$(c^1_1,\ldots ,c^1_{P-1})$
, since
$c^1_P = - \sum _{p=1}^{P-1} c^1_p$
. The reverse move is deterministic. -
–
$\delta _1 = 2 \leftrightarrow \delta _1 = 3$
: to move from model
$2$
(
$a_x + c^1_p$
) to model
$3$
(
$a_{x,p}$
), we propose to use the third type of update by proposing
$u = \left \{ a_{x,p} \right \}$
, when moving to
$\delta _1 = 3$
and proposing
$(a_x, c^1_p)$
when moving to
$\delta _1 = 2$
.
-
-
• Updating
$\delta _2$
We use the first type of update when moving from
$\delta _2 = 1$
to
$\delta _2^* = 2$
by proposing the variables
$u = c^2_p$
. The reverse move is deterministic. -
• Updating
$\delta _3$
To move from model
$1$
(
$k_t$
) to model
$2$
(
$k_t + k^2_t c^3_p$
), we use the first type of update by proposing the variables
$u = (k^2_t, c^3_p)$
. The reverse move is deterministic.





























4.2 Case study: Insurance products
We apply the previously described framework on mortality data stratified by different products. The data were sourced by the CMI and were provided by different life insurance providers. The available products are pension annuities in payment (Annuities), term assurances (TA), accelerated critical illness (ACI), and standalone critical illness (SCI). The data range from
 $2016$
to
$2016$
to
 $2020$
and cover both males and females and across varying commencement years, durations, and sum assured bands. In our example, we have used ages from
$2020$
and cover both males and females and across varying commencement years, durations, and sum assured bands. In our example, we have used ages from
 $50$
to
$50$
to
 $80$
. We note that the data come with several limitations, such as very low exposure for some combination of age, year, and product as shown in Figure 3. However, working in a Bayesian framework naturally allows the model to take the low sample size into account in the estimation. For more details on the data, we refer the reader to the CMI Working Papers 117 and 162 (Continuous Mortality Investigation Bureau, 2019, 2022). We have run
$80$
. We note that the data come with several limitations, such as very low exposure for some combination of age, year, and product as shown in Figure 3. However, working in a Bayesian framework naturally allows the model to take the low sample size into account in the estimation. For more details on the data, we refer the reader to the CMI Working Papers 117 and 162 (Continuous Mortality Investigation Bureau, 2019, 2022). We have run
 $2$
chains of
$2$
chains of
 $50,000$
iterations with
$50,000$
iterations with
 $5000$
burn-in iterations. Because of the lack of data, we have used priors
$5000$
burn-in iterations. Because of the lack of data, we have used priors
 $a_{x,p} \sim \text{N}(-3,3^2)$
for
$a_{x,p} \sim \text{N}(-3,3^2)$
for
 $\delta _1 = 3$
. We have used flat priors elsewhere.
$\delta _1 = 3$
. We have used flat priors elsewhere.

Figure 3 Insurance product case study: log(Exposures).
The credible intervals of the log-mortality curves are shown in Figure 4. It is clear that individuals associated with term assurance products exhibit lower mortality than those associated with other products. Surprisingly, mortality rates for the TA product are lower than the ones for the Annuities product, which is counter-intuitive since individuals signing up to the Annuities product are generally expected to live longer. For older ages, the conclusion for the products ACI and SCI is less clear since the variability of their estimates considerably increases in older ages, which results from the very low exposure as visible in Figure 3.

Figure 4 Insurance product case study:
 $95$
% PCI of the log-mortality rates. The crude mortality rates are represented by the dots. Data points where the crude mortality rates are
$95$
% PCI of the log-mortality rates. The crude mortality rates are represented by the dots. Data points where the crude mortality rates are
 $0$
are represented by a triangle.
$0$
are represented by a triangle.
The posterior probabilities of the model choice variables are shown in Table 5. The most supported model has the form
 \begin{equation*}a_{x,p} + b_x (t - \bar {t}) + (k_t + k^2_t c^3_p) + \gamma _{t-x}\end{equation*}
\begin{equation*}a_{x,p} + b_x (t - \bar {t}) + (k_t + k^2_t c^3_p) + \gamma _{t-x}\end{equation*}
with a posterior probability of
 $0.99871$
, followed by the model
$0.99871$
, followed by the model
 \begin{equation*}a_{x,p} + b_x c^2_p (t - \bar {t}) + (k_t + k^2_t c^3_p) + \gamma _{t-x}\end{equation*}
\begin{equation*}a_{x,p} + b_x c^2_p (t - \bar {t}) + (k_t + k^2_t c^3_p) + \gamma _{t-x}\end{equation*}
with a lower posterior probability of
 $0.00129$
. We note that this result highlights the advantage of using our model selection framework, where the preferred model shares (with high probability) the term
$0.00129$
. We note that this result highlights the advantage of using our model selection framework, where the preferred model shares (with high probability) the term
 $b_x (t- \bar {t})$
across all the different products. By contrast, fitting the model separately for each product would involve specifying a separate term
$b_x (t- \bar {t})$
across all the different products. By contrast, fitting the model separately for each product would involve specifying a separate term
 $b_{x,p} (t - \bar {t})$
for each
$b_{x,p} (t - \bar {t})$
for each
 $p$
, which may not be the most ideal choice (as in the case here).
$p$
, which may not be the most ideal choice (as in the case here).
We also present in Figure 5 the posterior distributions for the parameters of the model. In Figure 5c, we report the PCI of
 $k(t,p)$
. It can be seen that the period effect is generally negative, since mortality tends to decrease with time, but for some products, the trend is not always present, potentially as a result of the small sample size (only
$k(t,p)$
. It can be seen that the period effect is generally negative, since mortality tends to decrease with time, but for some products, the trend is not always present, potentially as a result of the small sample size (only
 $5$
years of data). In Figure 5b, we present the PCIs of
$5$
years of data). In Figure 5b, we present the PCIs of
 $b_x$
, which represents the interaction between age and period effect, after accounting for age and period effect individually. Lower values of
$b_x$
, which represents the interaction between age and period effect, after accounting for age and period effect individually. Lower values of
 $b_x$
represent larger improvement in mortality as the period increases, and vice versa. In our results, it can be seen that for older ages, the improvement in mortality is lower. The result seems to suggest that ages between
$b_x$
represent larger improvement in mortality as the period increases, and vice versa. In our results, it can be seen that for older ages, the improvement in mortality is lower. The result seems to suggest that ages between
 $60$
and
$60$
and
 $75$
are the ones who are likely to experience the largest improvement in mortality in the long run. We note that, due to the different parametrization used, the interpretation of
$75$
are the ones who are likely to experience the largest improvement in mortality in the long run. We note that, due to the different parametrization used, the interpretation of
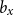 $b_x$
here differs from the interpretation under the standard constraints. However, we suggest analyzing the results with care because of the very small number of years used (only
$b_x$
here differs from the interpretation under the standard constraints. However, we suggest analyzing the results with care because of the very small number of years used (only
 $5$
years). Some MCMC diagnostics are reported in Section
$5$
years). Some MCMC diagnostics are reported in Section
 $3$
of the Supplementary Material. Similarly to the previous case study, parameter mixing is satisfactory for the mortality rate
$3$
of the Supplementary Material. Similarly to the previous case study, parameter mixing is satisfactory for the mortality rate
 $m_{x,t,p}$
, while mixing worsens for each model term. Results for the model mixing are encouraging, although we noticed one model is selected very rarely, making it difficult to properly assess the efficiency of the RJMCMC.
$m_{x,t,p}$
, while mixing worsens for each model term. Results for the model mixing are encouraging, although we noticed one model is selected very rarely, making it difficult to properly assess the efficiency of the RJMCMC.
Table 5. Product data: posterior probabilities on the model choice variables
 $\delta _i$
$\delta _i$

5. Conclusion
In this paper, we introduced a novel Bayesian probabilistic framework for mortality model selection using Reversible Jump Markov chain Monte Carlo (RJMCMC). Our approach addresses key limitations of traditional model selection methods by incorporating model uncertainty directly into the inference process. To apply Bayesian model selection, we have defined two modeling frameworks: for AP data, our model-building process is inspired by the different models available in the literature, while for APP data, we have defined a framework extending the APCI model.

Figure 5 Product insurance data: results.
For AP data, we applied the framework to mortality data of 40 countries in the HMD, focusing on individuals aged 60–90 from years 1990 to 2022. The results show that, for a number of countries, more than one model is supported, reinforcing the importance of taking multiple models into account. For APP data, we applied the framework to mortality data stratified by different insurance products. The results show large posterior variances for specific combinations of age and years because of data sparsity. This highlights the benefits of a Bayesian approach where uncertainty is properly accounted for when the sample size is low. However, this also suggests that it would be ideal to take full advantage of the Bayesian approach and define a joint prior over different ages and years in order to borrow strengths when data are sparse.
We emphasize that the ideas laid out in this paper need not be restricted to model selection of AP- or APP-based data, but can be extended to other types of data, provided a model-building framework is defined. Future extension could include extending the framework for AP data to more complex models. For APP data, since we have worked under the assumption that the stratifying variable is a categorical variable, it would be interesting to consider continuous variables, such as duration.
We remark that the methods proposed here do not come without significant practical challenges. Although parameter mixing is acceptable, the diagnostics show that model mixing could still be improved, as the RJMCMC sometimes struggles escaping the current model configuration. In the future, a more efficient RJMCMC proposal could be considered. We also note that changes in ICs between different models render proposing moves between models challenging to implement and therefore limit the ease in extending the current framework. As detailed in Section 3.1.2, the change in the constraints requires us to handle each move with a tailored scheme, which makes the extension to new models challenging. We also note that the challenges commonly associated with Bayesian frameworks, such as slow mixing, are particularly exacerbated in a model selection setting. Specifically, slow parameter mixing translates into fewer accepted moves, as regions where model changes are likely to occur are explored less frequently.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S1748499525100146.
Acknowledgement
We thank the CMI for providing the data on the insurance products. We also thank Charlotte Midford who has supported us in promoting this work.
Data availability statement
The authors confirm that the data and code supporting the findings of this study are available as supplementary materials accompanying the article.
Funding statement
This research received no funding.
Competing interests
The authors declare that they have no conflicts of interest regarding the publication of this article. No financial or personal relationships that could have influenced the work have been disclosed.

























 Open access
Open access