


Introduction
Much research on spoken word identification has been conducted using a priming method where two phonologically overlapping words are presented as the prime and target. In this research, second language (L2) speakers have often shown phonological facilitation that is normally not observed in speakers of the native language (L1) (see Bordag et al., Reference Bordag, Gor and Opitz2022; Gor, Reference Gor2018, Reference Gor, Godfroid and Hopp2023; Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021 for reviews). This facilitation has been interpreted as an indication of form confusion that is associated with unfaithful phonological encoding of L2 words. The current study explores the possibility that in visual word recognition, similar effects would be observed in L2 speakers when their orthographic representations are not precise.
Fuzzy lexical representations hypothesis
The fuzzy lexical representations (FLRs) hypothesis (Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021) proposes that when learning new words, learners’ initial representations in the mental lexicon are fuzzy because their forms, as well as their meanings and form-meaning mappings, have not yet been properly encoded. Therefore, according to the FLRs hypothesis, the form representations of low-familiarity words are not easily differentiated from other similarly sounding or looking words due to their poorly defined boundaries. Although fuzziness can exist in both L1 and L2 representations, the FLRs hypothesis suggests that fuzziness in L2 representations persists substantially longer than that in L1 representations because the encoding of L2 words is much less efficient than that of L1 words.
Evidence of fuzzy L2 phonological representations is found in medium-term auditory priming research, in which the prime and target are separated by several intervening stimuli (Barrios et al., Reference Barrios, Jiang and Idsardi2016; Darcy et al., Reference Darcy, Dekydspotter, Sprouse, Glover, Kaden, McGuire and Scott2012; Pallier et al., Reference Pallier, Colomé and Sebastián-Gallés2001). This research exploits the repetition priming effect which refers to faster or more accurate identification of a target after encountering the same word earlier as the prime. An important finding was obtained when minimal pairs of words differentiated by a difficult L2 phonemic contrast (e.g., /netǝ/-/nɛtǝ/ differentiated by /e/-/ɛ/ in Catalan but not differentiated in Spanish) were used as the prime and target. L2 speakers whose native language does not discriminate the two phonemes of an L2 contrast showed form facilitation when these minimal pairs were presented, whereas L1 speakers did not. In the previous studies (Barrios et al., Reference Barrios, Jiang and Idsardi2016; Darcy et al., Reference Darcy, Dekydspotter, Sprouse, Glover, Kaden, McGuire and Scott2012; Pallier et al., Reference Pallier, Colomé and Sebastián-Gallés2001), the phonological facilitation in L2 was interpreted to have originated from repetition priming that occurred for prime-target pairs with a confusing phonemic contrast because these pairs, that were not clearly differentiated from each other, had overlapping phonological representations in the L2 speakers’ mental lexicon.
Although the FLRs hypothesis was originally conceptualized concerning the difficulty of perception of L2 sounds, second language acquisition (SLA) research suggests that the fuzziness in L2 words may not be limited to their phonological representations. For example, L2 vocabulary acquisition studies show that L2 learners often display form confusion (e.g., perceiving infirmary as infirmity) and dependence on deceptively transparent spellings (e.g., guessing germination as a word related to germ) when visually processing L2 words (e.g., Jiang & Zhang, Reference Jiang and Zhang2021; Laufer, Reference Laufer, Coady and Huckin1997; Park, Reference Park2024).
In addition, in both unmasked short-term priming and masked priming visual word recognition experiments, where orthographic neighbors (i.e., words differing by a single letter) served as primes and targets, L2 speakers typically demonstrated a priming pattern that differed from that of L1 speakers. Whereas nonword primes produced facilitation for word targets, word primes produced either form inhibition or an absence of form facilitation in L1 (e.g., Davis & Lupker, Reference Davis and Lupker2006; Forster & Veres, Reference Forster and Veres1998).Footnote 1 Based on the Interactive Activation (IA) model (McClelland & Rumelhart, Reference McClelland and Rumelhart1981), which has been most frequently adopted to explain the different patterns of priming produced by word and nonword primes, no form facilitation for L1 word prime-word target pairs was interpreted as the result of lexical competition between the prime and target or their neighbors. Form facilitation for nonword prime-word target pairs, meanwhile, was interpreted to have occurred since the prime preactivated the sublexical components of orthographically similar words thereby aiding target identification while not taking part in lexical competition (Davis & Lupker, Reference Davis and Lupker2006; Nakayama et al., Reference Nakayama, Sears and Lupker2008).
Unlike in L1, visually presented word primes usually yielded orthographic facilitation for visually presented word targets in L2. Some studies report form inhibition from masked L2 (English) word primes in native French speakers with high English proficiency (Bijeljac-Babic et al., Reference Bijeljac-Babic, Biardeau and Grainger1997) and no form priming from newly acquired unmasked (Elgort, Reference Elgort2011) or masked L2 word primes (Elgort & Warren, Reference Elgort and Warren2014) in L2 learners of English from various L1 backgrounds. However, other studies found form facilitation from L2 (English) word primes in masked priming experiments with proficient Chinese (Jiang, Reference Jiang2021; Qiao & Forster, Reference Qiao and Forster2017) and Japanese (Nakayama & Lupker, Reference Nakayama and Lupker2018) learners of English. In addition, research that investigated morphological processing during recognition of morphologically complex words presents similar findings (Diependaele et al., Reference Diependaele, Duñabeitia, Morris and Keuleers2011; Heyer & Clahsen, Reference Heyer and Clahsen2015; Jiang & Wu, Reference Jiang and Wu2022; Li, Jiang, & Gor, Reference Li, Jiang and Gor2017; Li & Taft, Reference Li and Taft2020; Li, Taft, & Xu, Reference Li, Taft and Xu2017). L1 speakers did not show form facilitation for prime-target pairs that overlapped in their orthographic forms (e.g., freeze-free) unless the pairs were morphologically or semantically related. In contrast, proficient L2 learners of English usually showed form facilitation even for such pairs regardless of their first languages (Dutch, Spanish, German, or Chinese).
Given this research showing relatively strong form facilitation in L2, potential reasons for this phenomenon have been discussed. Based on the episodic L2 hypothesis (Jiang & Forster, Reference Jiang and Forster2001; Witzel & Forster, Reference Witzel and Forster2012), Qiao and Forster (Reference Qiao and Forster2017) proposed that L2 words are stored in episodic memory, a different memory system than lexical memory in which L1 words are represented. They suggested that lexical competition might be limited only to words stored in lexical memory. Other studies (Jiang & Wu, Reference Jiang and Wu2022; Nakayama & Lupker, Reference Nakayama and Lupker2018; Li & Taft, Reference Li and Taft2020) hypothesized that form facilitation in L2 may be caused by weak lexical competition between word-level units. Furthermore, Jiang (Reference Jiang2021) suggested the possibility that L2 speakers are sometimes not able to clearly discriminate the masked prime from the target due to their low resolution of L2 orthographic representations. If so, orthographic L2 neighbor primes might be perceived as repetition primes.
Since the locus of weak lexical competition in L2 is argued to be weak L2 representations (Bordag et al., Reference Bordag, Gor and Opitz2022; Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021), all the above-mentioned accounts, except for Qiao and Forster’s explanation (Reference Qiao and Forster2017), suggest that L2 representations may be weaker than L1 representations. However, the above-mentioned findings are unable to convincingly demonstrate that L2 orthographic representations remain fuzzy for an extended period due to the following reasons.
First, in the previous lexical decision tasks (LDTs), unknown or unfamiliar L2 words could have been included in word stimuli. Previous research discovered that unmasked short-term or masked nonword primes produce form facilitation in L1 by preactivating the overlapped sublexical components of the target without lexical competition. Thus, if many of the stimuli were unfamiliar to L2 participants just like nonwords, it would not be surprising to see form facilitation from these stimuli (Elgort, Reference Elgort2011; Elgort & Warren, Reference Elgort and Warren2014; Jiang, Reference Jiang2021). Second, it is probable that L2 speakers were not able to successfully process masked L2 word primes. Although some studies suggest that L2 speakers can successfully process the masked prime within a short stimulus onset asynchrony (SOA) (e.g., 50 ms in Gollan et al., Reference Gollan, Forster and Frost1997), the inaccessibility of the masked L2 word prime due to slower lexical access has sometimes been claimed in the SLA research (e.g., Grainger & Beauvillain, Reference Grainger and Beauvillain1988).
To overcome the second limitation, the present study utilizes an unmasked priming experiment to test the key assumption of the FLRs hypothesis that even L2 words that are correctly identified as words offline can still produce form facilitation (Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021). However, if we use a standard short-term priming paradigm, in which the visible prime is quickly followed by the target, the involvement of strategic effects caused by participants’ awareness of the relationship between the prime and target could be more active. Therefore, to hide this relationship, we use a LDT with medium-term priming where both the prime and target are presented as part of continuous trials, and they are separated by several other intervening trials. In the medium-term priming LDT, it would be less likely for participants to perceive the relationship between the prime and target, so the involvement of strategic effects is expected to be minimized (Forster & Davis, Reference Forster and Davis1984).
Mechanism of medium-term orthographic priming
Before describing the specific design of the present study, the mechanism of medium-term orthographic priming needs to be addressed because it is not considered identical to the above-mentioned mechanism of short-term orthographic priming proposed based on McClelland and Rumelhart’s IA model (Reference McClelland and Rumelhart1981). Unmasked short-term or masked priming is usually understood to be produced by temporary activation of representations that lasts only a few seconds (Ferrand & Grainger, Reference Ferrand and Grainger1993; Forster & Davis, Reference Forster and Davis1984; Grainger et al., Reference Grainger, Kiyonaga and Holcomb2006). However, in medium-term priming experiments, there are always gaps of more than several seconds between the prime and target. Therefore, medium-term orthographic priming should be understood based on the way long-term repetition priming operates, as will be explained below.
While different theories of long-term repetition priming have been proposed (e.g., Gordon, Reference Gordon1988; Oliphant, Reference Oliphant1983; Ratcliff & McKoon, Reference Ratcliff and McKoon1997; Tenpenny, Reference Tenpenny1995), Bowers (Reference Bowers1994, Reference Bowers1996, Reference Bowers2000a, Reference Bowers2000b) thoroughly explored this phenomenon and suggested a plausible mechanism of long-term repetition priming in visual word recognition based on the findings of a series of experiments. According to Bower’s account, long-term repetition priming is not the function of explicit memory because amnestic patients whose episodic memory was damaged also show this phenomenon. In addition, Bowers (Reference Bowers1994) found that whereas participants’ recognition and recall of targets that they had studied were greatly affected by levels-of-processing manipulation (i.e., the greater the encoding of targets a task required during the study phase, the better their recognition and recall were in the test phase), long-term repetition priming was not sensitive to this manipulation. Therefore, Bowers argued that long-term priming is the function of implicit memory rather than explicit memory.
Bowers (Reference Bowers1994, Reference Bowers1996, Reference Bowers2000a) introduced two views of the specific operation of implicit memory in long-term repetition priming. The first view regards priming as the product of new memory representations acquired during a single study episode, which are called perceptual representations. This view was proposed based on the finding that nonwords that do not have already-established representations often showed long-term repetition priming. On the other hand, the second view considers that separate representations exist for each word in our vocabulary and that long-term repetition priming is the outcome of the modification of these preexisting abstract representations. The latter view is supported by the finding that priming was observed for morphologically related pairs (e.g., cars-car) but not for pairs that share a similar form (e.g., card-car).
Given these two contrasting views, Bowers (Reference Bowers1996) conducted several priming experiments and found that long-term repetition priming for high-shift words (i.e., words that are composed with lower-case letters that look different from their upper-case letters such as RAGE-rage) was as strong as that for low-shift words (e.g., SOCK-sock). This finding supports the view that priming is produced by abstract representations because the former prime-target pairs do not have a perceptual similarity. At the same time, he found that repetition priming for high-shift nonwords (e.g., DAGE-dage) was greatly reduced compared to that for low-shift nonwords (e.g., BISS-biss) unlike repetition priming for words. This finding supports the view that priming is produced by newly acquired perceptual representations. Combining these two findings, Bowers concluded that when word recognition gains normal access to the already-established orthographic representations, priming is mediated by preexisting orthographic codes. However, when materials cannot gain normal access to the orthographic representations, priming reflects newly acquired perceptual representations.
While arguing for the role of already-established representations in long-term repetition priming, Bowers (Reference Bowers1994, Reference Bowers1996, Reference Bowers2000a) intentionally used the term modification rather than activation. The latter term implies that priming is due to an “active” state of word codes that persists for a few seconds following the encoding of words. This concept is frequently used in unmasked short-term and masked priming research. On the other hand, the former term suggests that priming is the product of a structural change to preexisting word codes that acts to strengthen the representations, and this term is often used in long-term repetition priming research. In other words, according to Bowers, long-term priming for words is a by-product of learning within the orthographic system.
According to the long-term repetition priming mechanism proposed by Bowers (Reference Bowers1994, Reference Bowers1996, Reference Bowers2000a), it is predicted that L1 speakers will not show form priming for words in visual word recognition. This is because modification of the orthographic representation of the prime would not affect target recognition since the prime and target have discrete representations. We also predict that the long-term repetition priming mechanism operates similarly in L2. However, based on the FLRs hypothesis (Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021), L2 speakers are expected to show facilitative priming for visually similar word pairs (e.g., clever–clover). This will occur because the boundaries of orthographic representations of similar-looking L2 words are blurry, such that the representations of the prime and target will be modified (strengthened) together when the prime is encountered sometimes before the target, just as they were in medium-term phonological priming experiments (Barrios et al., Reference Barrios, Jiang and Idsardi2016; Darcy et al., Reference Darcy, Dekydspotter, Sprouse, Glover, Kaden, McGuire and Scott2012; Pallier et al., Reference Pallier, Colomé and Sebastián-Gallés2001).
Present study
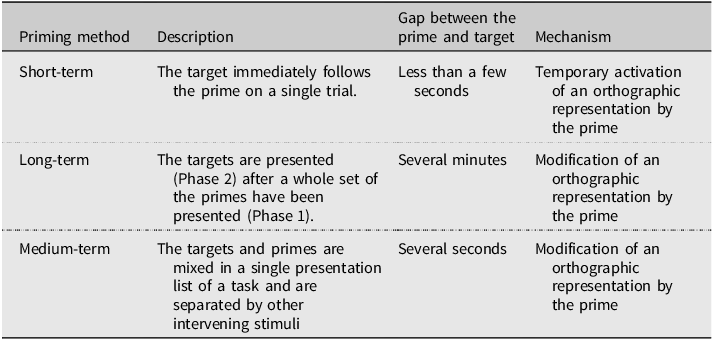
The present study tests the hypothesis that L1 and L2 speakers will show different patterns of medium-term orthographic priming because many L2 representations remain fuzzy, unlike L1 representations (Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021). Table 1 shows the typical characteristics of short-, long-, and medium-term priming methods that have been used in previous research. We consider that long- and medium-term priming are operated by the same mechanism (i.e., through the modification of an orthographic representation of the target by the prime), and no overt distinction between these two priming methods has been made in the literature. However, for the consistency of the terminology in the literature, we use the term medium-term priming for any facilitative or inhibitory effect that is produced by the prime which is presented several stimuli earlier than the target, following the use of this terminology in the previous phonological priming studies (Barrios et al., Reference Barrios, Jiang and Idsardi2016; Darcy et al., Reference Darcy, Dekydspotter, Sprouse, Glover, Kaden, McGuire and Scott2012; Pallier et al., Reference Pallier, Colomé and Sebastián-Gallés2001).
Table 1. Typical characteristics of short-, long-, and medium-term priming methods
In the main experiment (i.e., in the LDT), a repetition priming condition is included as a control condition to show that medium-term repetition priming occurs if the same word stimuli are presented repeatedly. Under the repetition priming condition, both L1 and L2 speakers are predicted to show facilitative priming since the strengthened representation of the prime through the first encounter will contribute to easier recognition of the target.
To investigate whether the patterns or magnitudes of orthographic priming are modulated by the quality of orthographic representations, this study also uses two independent variables related to this construct. The first variable, word frequency, has been shown to modulate the patterns of form priming for L2 words in auditory phonological priming experiments and is treated as a proxy for word familiarity (Gor & Cook, Reference Gor and Cook2020). The second variable is the levels of participants’ orthographic precision, measured with spelling dictation and recognition tasks developed by Andrews and her colleagues for English as L1 (Andrews & Hersch, Reference Andrews and Hersch2010; Andrews & Lo, Reference Andrews and Lo2012; Andrews et al., Reference Andrews, Veldre and Clarke2020). These two spelling tasks, devised based on Perfetti’s claim that spelling performance provides a good index for the quality of orthographic representations (Reference Perfetti, Gough, Ehri and Treiman1992), have recently been validated through a series of evaluations (Andrews et al., Reference Andrews, Veldre and Clarke2020).
At the same time, considering Bowers’s claim that a stimulus that does not gain normal access to the existing representations can produce long-term repetition priming through newly established perceptual representations (1996), unfamiliar L2 word stimuli are excluded from the present study. Although medium-term repetition priming for unfamiliar stimuli is thought to originate from specific perceptual representations (Tenpenny, Reference Tenpenny1995), L2 speakers may perceive two unfamiliar but similar-looking items as identical. This is because they may struggle to decode and encode L2 letter strings, particularly if their L1 uses a different script or if their exposure to L2 is limited. Thus, excluding unfamiliar L2 word stimuli will ensure that the orthographic priming observed in this study is produced from orthographic representations, and not from perceptual representations. The exclusion of unfamiliar words will also be helpful for clearly illustrating that even familiar L2 words remain fuzzy for quite a while.
In the present medium-term orthographic priming experiment, we predict that L2 speakers will show form facilitation whereas L1 speakers will show a lack of form priming. In addition, we predict that form facilitation in the L2 will be modulated by the frequency of word primes and participants’ levels of orthographic precision.
Method
Participants
Thirty native English-speaking participants (20 females) and 30 Korean learners of English (20 females) were recruited. L1 speakers were ages 18–34 (M: 21.4) years old and were recruited from nine universities in the U.S. through a flyer that was circulated through email and Social Network Services. L2 speakers were ages 20–30 (M: 24.4) years old and were recruited from four universities in South Korea through a flyer posted on university bulletin boards where part-time jobs are advertised. These two groups of participants had received similar formal education (M: 14.9 years vs. 15.3 years), and L2 speakers reported that they had begun learning English at around age 8 (range: 3∼13).
The L2 speakers were required to have a TOEIC (Test of English for International Communication) score higher than 850 (possible test score range: 10–990) within two years of this study. TOEIC is a paper-and-pencil, multiple-choice standardized English proficiency test that measures non-native speakers’ reading and listening comprehension skills. According to the Educational Testing Service (ETS, n.d.), the developer of the TOEIC, TOEIC scores higher than 785 are comparable to the B2 level (independent user) on the Common European Framework of Reference for Languages (CEFR), and TOEIC scores higher than 945 are comparable to the C1 level (proficient user) on the CEFR. This threshold for screening of participants (i.e., higher than 850 on TOEIC) was set to ensure that L2 speakers would know most of the L2 word stimuli used in the present study. These participants’ average TOEIC score was 921 (range: 855–990).
Materials
The critical lexical decision items consisted of 80 six- to ten-letter English orthographic neighbor pairs (e.g., clever-clover) that were neither homophones nor had an overt semantic relation between the prime and target. These pairs were also not morphologically related to each other. Out of the 80 critical pairs, 40 pairs comprised the high-frequency prime condition, and the other 40 comprised the low-frequency prime condition.
The targets across the low- and high-frequency prime conditions were matched to be comparable in length, SUBTELX-US frequency (Brysbaert & New, Reference Brysbaert and New2009), number of orthographic neighbors, and mean bigram frequency. The primes were also matched across the two prime conditions regarding length, number of orthographic neighbors, and mean bigram frequency, but they differed in frequency as noted above. The unrelated control primes were paired with the related primes on all the lexical properties listed above under each of the two prime conditions.
In addition to the 80 critical stimulus pairs, 20 word pairs (e.g., combat-combat) were used for the repetition priming condition to make sure that medium-term priming indeed occurred in the present experiment. If repetition priming was found and form priming was not found, it would suggest that the lack of form priming is not just due to a deficiency in the experimental design. The words used under the repetition priming condition were comparable to the low-frequency word form primes in length, SUBTELX-US frequency, number of orthographic neighbors, and mean bigram frequency. The means and standard deviations of the lexical characteristics of the word stimuli are presented in Table 2.
Table 2. Means (and standard deviations in the parentheses) of the lexical characteristics of word stimuli
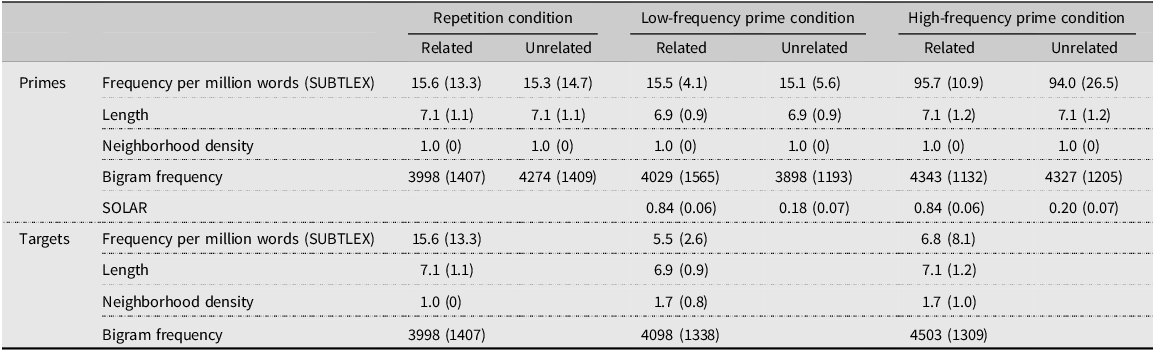
*SOLAR values represent the degrees of matching between the prime and target (Davis & Bowers, Reference Davis and Bowers2006).
One hundred nonword targets that were primed either by the same nonwords, form-related nonwords, or unrelated nonwords were also included in the stimuli. All the nonwords were one-letter different from a real word, and the phonotactic feasibility and orthographic depth of these nonwords were not considered.
The stimuli were divided into two lists of prime-target pairs having similar lexical properties. These two lists were counterbalanced, so if a target was paired with a related prime in the first list (List 1), it was paired with an unrelated prime in the second list (List 2), and vice versa. A Latin Square design was used such that all participants responded to all targets that were all presented only once except for the stimuli presented twice under the word and nonword repetition prime conditions. Half of the participants were provided with List 1, and the other half of the participants were provided with List 2. Each list consisted of 20 blocks of 10 primes, 10 targets, and two fillers. Within each block, a sub-block of primes was separated from a sub-block of targets by two fillers, and within each sub-block, the presentation order of stimuli was randomized (see Figure 1 for an example of a block). This arrangement of the block created a gap of 2 ∼ 20 trials between the prime and target.
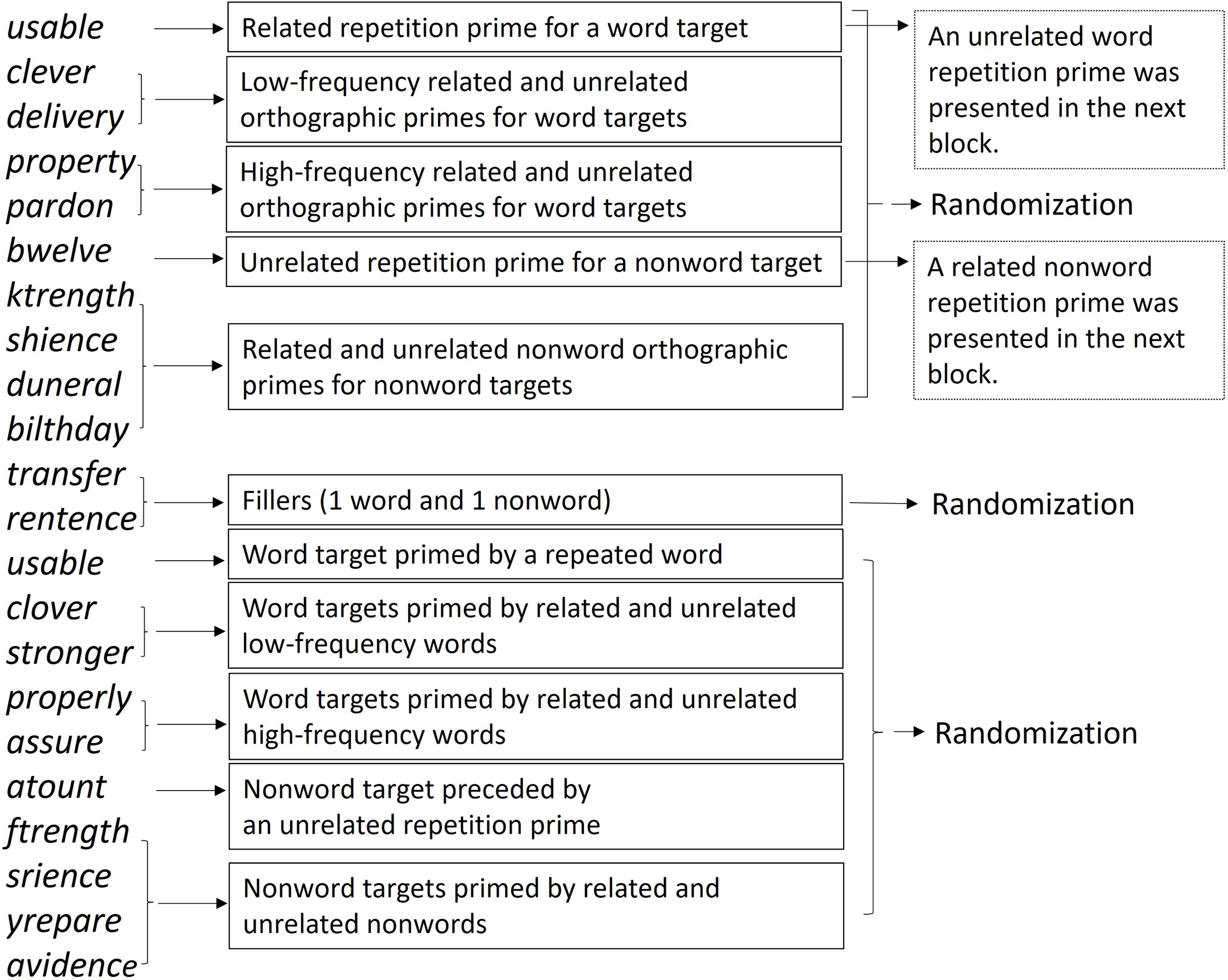
Figure 1. An example of a block of stimuli in List 1.
To prevent unwanted effects of previously encountered stimuli that looked similar to the targets, when selecting stimuli, every effort was made to ensure that (a) no other neighbor of the target except for its related prime was included in the whole list, and that (b) no other stimulus except for its related prime shared more than three letters with the target at a similar position. All stimuli used in the LDT can be found in Appendix S1.Footnote 2
Measures of individual differences in word knowledge
Spelling dictation and spelling recognition tasks
In the spelling dictation task, participants first heard each of 20 words (along with a sentence that provided context) only once by clicking the “play audio” button in Qualtrics. They then typed the spelling of each word in a blank. According to Cronbach’s alpha, the internal consistency of the task (k = 20) was .77 for L1 speakers (N = 30) and .73 for L2 speakers (N = 30).
The spelling recognition task consisted of 88 items, half spelled correctly, and half misspelled. Using Qualtrics, the list of items was displayed on a computer screen, with binary choice buttons “Correct” and “Wrong” presented next to each item. Participants were then asked to choose one of the two options. According to Cronbach’s alpha, the internal consistency of the task (k = 88) was .97 for L1 speakers (N = 30) and .97 for L2 speakers (N = 30) (see the Appendix of Andrews et al., Reference Andrews, Veldre and Clarke2020 for the spelling dictation and recognition items).
The spelling dictation and recognition tasks included low-frequency words with challenging spellings to ensure sufficient difficulty for distinguishing good spellers from poor spellers among L1 speakers. Therefore, to measure L2 speakers’ spelling knowledge of known words rather than their vocabulary knowledge, at the end of the experiment, the full list of the spelling task items was presented on the screen to these participants, and they were asked to provide the L1 translations of these words. The items, for which correct L1 translations were not supplied, were excluded from all the analyses reported in this paper.
Translation and familiarity rating tasks
L2 speakers were provided with a list of 160 words that were used under the form priming condition in the LDT (40 form-related primes, 40 unrelated primes, and 80 targets). Participants were asked to type the L1 translation of each word in the blank presented next to it, and to indicate the level of familiarity with the given word on a presented scale of five: (1) I have never seen this word before; (2) I don’t remember what it means; (3) I think I know this word; (4) I know this word; and (5) I know this word very well. After these tasks were completed, L2 speakers were further requested to translate all spelling task items (n = 160) into corresponding L1 words.
These participants’ L1 translations of the LDT stimuli were separately scored by the first author (a native speaker of Korean) and another native Korean L2 learner of English, but translations of the items used in the spelling dictation and the spelling recognition tasks were scored only by the first author. Percentage agreement between the two raters was 97.7% (Cohen’s Kappa was .93). All disagreements were resolved through discussions between the two raters.
Procedure
All experiments were conducted online. If participants indicated their willingness to take part in the study after reading the consent form, the first author arranged a schedule for a virtual meeting with each participant. The virtual meeting was set to rule out the possibility of cheating and to check whether participants were in a quiet room without any distractors around them as required by the flyer and the consent form.
After performing a masked priming LDT that lasted about 8–10 minutes,Footnote 3 participants carried out the spelling dictation and recognition tasks that took about 15 minutes. No item in either spelling task was used as a stimulus in the following medium-term priming LDT.
After the spelling tasks, the medium-term priming LDT that was programed and displayed using PsychoPy (Morys-Carter, Reference Morys-Carter2021) followed. During the LDT, participants were asked to decide whether a stimulus they saw on the screen was an English word, and to press the “j” (for a “yes” response) or the “f” key (for a “no” response) as accurately and quickly as possible, but not so quickly that they made too many errors (Forster & Veres, Reference Forster and Veres1998). Because the LDT was untypically very long (462 trials, see below), a programed self-paced break was provided in the middle of the task. The main lexical decision trials were preceded by 10 practice trials and 6 “buffer” trials, among which there were equal numbers of word and nonword stimuli. In addition, 6 buffer trials were also given after the self-paced break when participants resumed performing the task. These trials were not used for data analyses. The LDT with 462 stimuli (200 primes + 200 targets + 10 practice items + 12 buffer items + 40 fillers) took about 15 minutes.
After the LDT, L2 participants were further requested to carry out the translation and familiarity rating tasks. They then translated all spelling task items as well. It took about 30 minutes to complete all these translation and familiarity rating tasks.
During the entire experiment, participants were asked to turn on their webcam. During the spelling tasks and the translation tasks, they were also asked to share their screen with the experimenter on the virtual conference application Zoom to prevent cheating.
Results
Spelling scores
As noted earlier, L2 speakers’ responses were excluded from the analysis if they did not provide a correct L1 translation for spelling task items (51.5% of the spelling dictation and 27.9% of the spelling recognition responses). Then, to compare L1 and L2 speakers’ spelling scores, each participant’s summed raw scores from the spelling dictation and the spelling recognition tasks were converted to percentage scores. An independent t-test revealed that L1 speakers’ spelling scores (M = 85.0, SD = 8.26) were significantly higher than L2 speakers’ scores (M = 76.2, SD = 8.42), (t(58) = 4.07, p < .001, CI-2.5% = 4.46, CI-97.5% = 13.08, Cohen’s d = 1.05) (see Figure 2). This indicates that L1 speakers had more precise orthographic representations of English words than L2 speakers in general, and likely, of the experimental stimuli also.
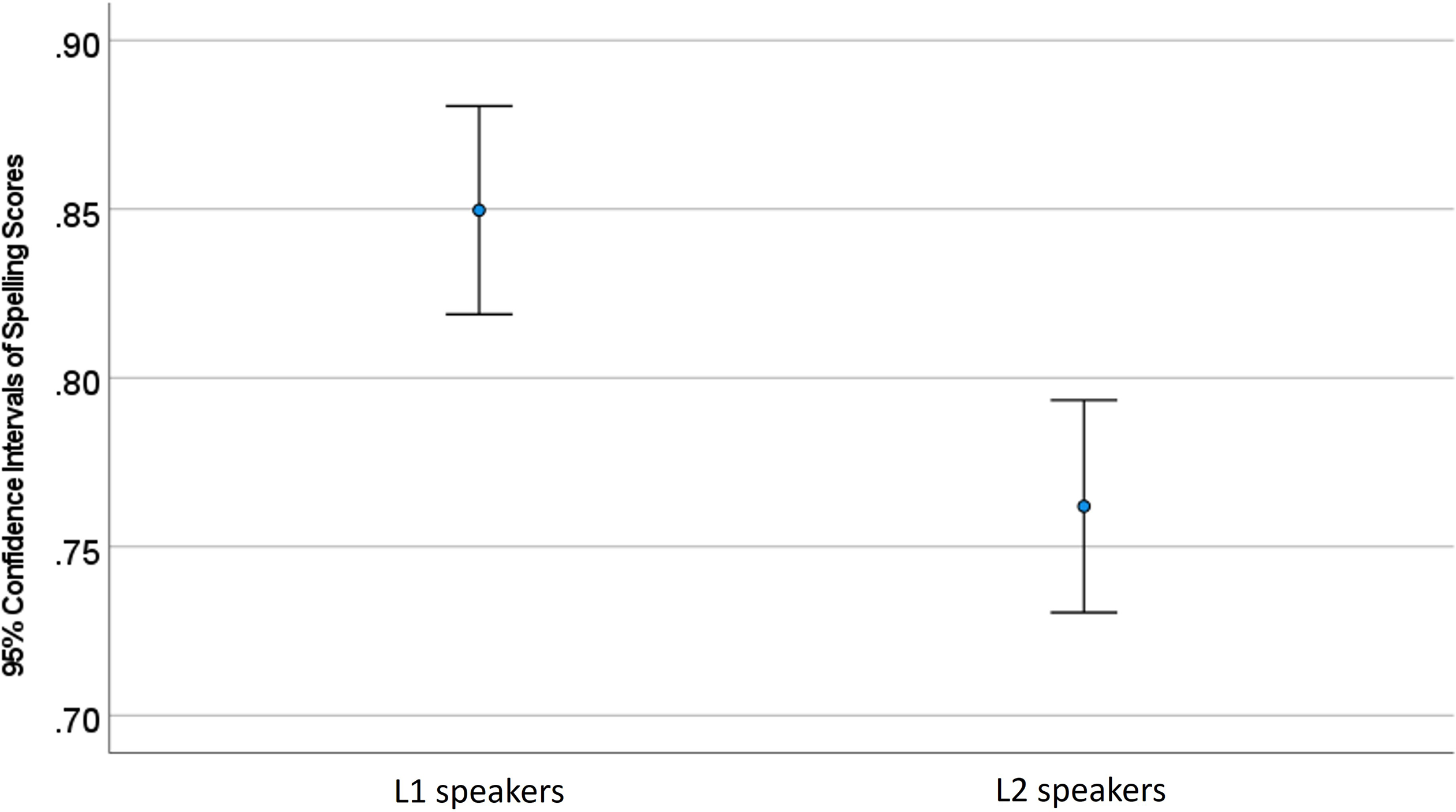
Figure 2. L1 and L2 speakers’ spelling scores.
Lexical decision task
Although we had planned to replace participants with error rates higher than 15%, no participant exceeded this threshold level, so no replacement was made. To avoid the influence of outliers, reaction times (RTs) more than two standard deviations (SDs) above or below the mean for a given participant were trimmed to the cutoff value of 2 SDs for that participant (Elgort, Reference Elgort2011; Forster & Veres, Reference Forster and Veres1998). This resulted in the exclusion of 4.3% of L1 speakers’ and 4.2% of L2 speakers’ responses. Because it was not straightforward to interpret the data from targets that followed incorrectly responded to primes, those targets were also excluded from the remaining data set (4.1% for L1 and 5.7% for L2 speakers). After that, when analyzing RT data, incorrect responses (5.4% for L1 and 8.3% for L2 speakers) were additionally removed. Although participants responded to both the prime and target, only their responses to the targets were used as the dependent variable (see Table S1 for the gaps in RTs between prime and target trials).
During statistical analyses, the data from the repetition prime condition were analyzed separately from those from the form prime (low- and high-frequency prime) conditions. Contrast coding (–0.5, +0.5) was used for the variable Relatedness (related vs. unrelated primes). Contrast coding (–0.5, +0.5) was also used for the two form prime conditions (which was labeled as Frequency). For the participant Group variable, treatment coding (“0” for L1 and “1” for L2 speakers) was used.
Linear mixed-effects models (for latency analyses) and logistic mixed-effects models (for accuracy analyses) were fitted using lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) in R to address differences caused by random sampling from populations and varying difficulty levels of measurement items. When using linear mixed-effects models, t and p values were obtained with the package lmerTest (Kuznetsova, Brockhoff & Christensen, Reference Kuznetsova, Brockhoff and Christensen2017). In each statistical model, inverse-transformed (–1000/RT) correct response latency to or accuracy (i.e., “0” for incorrect and “1” for correct responses) on the target was the dependent variable, and Participant and Item were fitted as random effects. Other predictors (Relatedness, Frequency (low- vs. high-frequency primes), and Group (L1 vs. L2 participants)) were fitted as fixed effects. We also examined whether adding a random slope of each fixed effect or of any interaction between fixed effects would improve model fit. Following Cunnings’s suggestion (Reference Cunnings2012), if adding a random slope significantly improved the model fit, this variable was retained unless indicators for overparameterization (a high correlation between random slope and random intercept, r = 1 or NaN) were observed (Baayen, Davidson & Bates, Reference Baayen, Davidson and Bates2008); otherwise, they were dropped. If models failed to converge when a random slope was added, this random slope was dropped.
Repetition priming for words
Table 3 presents the mean RTs and error rates (ERs) for word targets under the repetition prime and the two (the low- and high-frequency) form prime conditions. Specific outputs of the models for repetition priming in RTs and accuracy for word targets are presented in Table S2. Analysis of RTs (with L1 speakers as the reference category for Group) revealed a significant main effect of Group (t = 5.31, p < .001). This effect indicates that L1 speakers responded significantly faster than L2 speakers. On the other hand, the main effect of Relatedness (t = –1.66, p = .097) was not significant in L1 speakers. However, the interaction between Relatedness and Group was significant (t = –5.74, p < .001), suggesting that the magnitudes of facilitative repetition priming differed between L1 and L2 speakers.
Table 3. Mean reaction times (in milliseconds) and error rates (in percent) for word targets
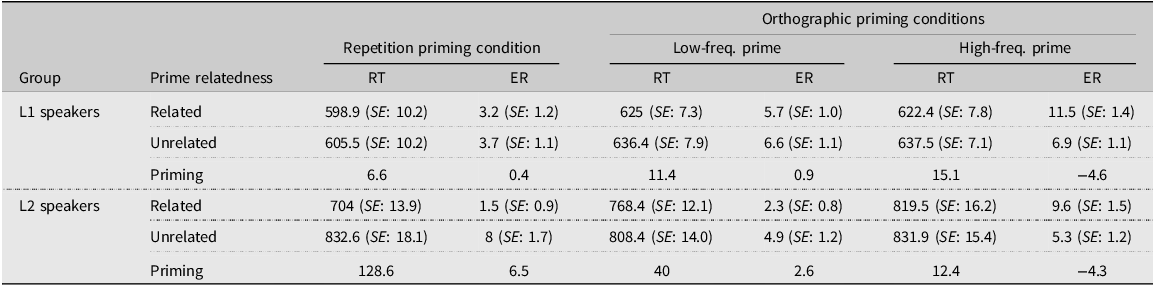
To determine the nature of the Relatedness × Group interaction, the effects of the predictors in L2 speakers were inspected after changing the reference category for Group. The analysis found a significant main effect of Relatedness (t = –9.56, p < .001). This suggests that the repetition prime produced significant facilitation in L2 speakers’ RTs.
Accuracy analysis (with L1 speakers as the reference category for Group) showed that the interaction between Relatedness and Group was significant (z = 2.21, p = .027). The main effect of Relatedness (z =.30, p = .768) or Group (z = –.20, p = .844) was non-significant. To understand the Relatedness × Group interaction, the effect of Relatedness was examined after switching the reference category for Group to L2 speakers. In L2 speakers, the form facilitation (6.5%) was significant (z = 3.15, p = .002).
In brief, no repetition priming in L1 speakers was observed. In contrast, L2 speakers showed significant repetition priming for word targets both in RTs and accuracy. These results from L2 speakers show that the lexical decision stimuli indeed produced facilitative priming if they were repeated, at least, in this participant group. The potential mechanisms of the repetition priming for L1 and L2 words will be discussed in the subsequent discussion section.
Form priming for word targets
We operationalized “unfamiliar stimuli” as those whose meanings were indicated to be unknown in the familiarity rating task (i.e., the stimuli with “I have never seen this word before” or “I don’t remember what it means” responses) or whose correct L1 translations were not provided in the translation task. The exclusion of these data resulted in a loss of 31.4% of L2 speakers’ RT data (299 responses) under the low-frequency prime condition (222 unfamiliar targets + 40 targets preceded by unfamiliar unrelated primes + 37 targets preceded by unfamiliar related primes) and 26.2% of those (247 responses) under the high-frequency prime condition (235 unfamiliar targets + 7 targets preceded by unfamiliar unrelated primes + 5 targets preceded by unfamiliar related primes).Footnote 4 After the exclusion, 2,233 responses from L1 speakers and 1,427 responses from L2 speakers were used for analysis. Note that because unfamiliar stimuli were excluded from the data set, facilitative priming for L2 words could not have occurred because unknown L2 words were processed as nonwords.
The output of a model for RT analysis (with L1 speakers as the reference category) (see Table S4 for specific model output) shows a significant main effect of Relatedness (t = –2.81, p = .005) and that of Group (t = 5.63, p < .001). A significant interaction between Frequency and Group (t = 1.98, p = .048) was also observed. A post-hoc test in which the effect of Frequency in each Group was examined while switching the reference category for Group revealed that this interaction was significant because the main effect of Frequency was relatively stronger in L2 participants (t = 1.30, p = .191) than in L1 participants (t = 0.19, p = .851).
The model output also showed a significant three-way interaction between Relatedness, Frequency, and Group (t = 2.39, p = .017). However, unlike our prediction, the interaction between Relatedness and Group was not significant (t = –.56, p = .575). This non-significant interaction and the significant main effect of Relatedness indicate that form facilitation occurred in L1 participants, and that the magnitude of form facilitation did not significantly differ between L1 and L2 participants. To understand the nature of the significant Relatedness × Frequency × Group interaction, a post-hoc test was necessary. The results of the post-hoc test will be presented in a subsequent section.
In the accuracy analysis (see Table S5 for specific model output), only the interaction between Relatedness and Frequency was significant (z = –2.64, p = .008). This was because participants in both groups showed significant inhibition under the high-frequency prime condition (z = –3.07, p = .002) whereas they showed a trend toward facilitation under the low-frequency prime condition (z = 0.79, p = .428).
Repetition priming for nonwords
Table 4 presents the mean RTs and ERs for nonword targets under the repetition prime and form prime conditions. In analysis for RTs (see Table S6 for specific model output), only the main effect of Group was significant (t = 5.29, p < .001). In analysis for accuracy (see Table S7 for specific model output), none of the main effects nor the interaction was significant.
Table 4. Mean reaction times (in milliseconds) and error rates (in percent) for nonword targets
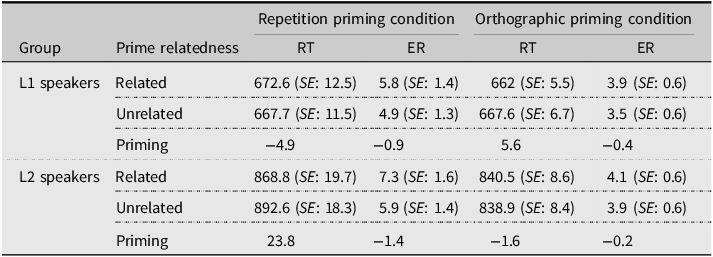
Form priming for nonword targets
In analysis for RTs (see Table S8 for specific model output), only the main effect of Group was significant (t = 5.04, p < .001). In analysis for accuracy (see Table S9 for specific model output), none of the main effects nor the interaction was significant.
The effect of orthographic precision
To determine the nature of the Relatedness × Frequency × Group interaction that was observed in RT data for orthographic priming for word targets, post-hoc analyses were performed after separating L1 and L2 participants’ data. In these analyses, to understand how the levels of participants’ orthographic precision affected the form priming, participants’ z-transformed spelling scores (SpellZ) were added to models as a predictor.
In both statistical models for L1 and L2 participants, participants’ inverse-transformed RTs were the dependent variable. SpellZ was fitted in the models for each participant group as a fixed effect in addition to the other predictors (Relatedness and Frequency). In the model for L2 participants’ data, standardized English proficiency test scores (TOEICZ) were also added as a covariate to control for the effect of proficiency separately from orthographic precision.Footnote 5 The same model-building procedure that was described earlier was adopted. The outputs of the models for L1 and L2 speakers are presented in Table S10. Considering the potential of an inflated type I error rate caused by the multiple statistical tests for two groups, the alpha level was adjusted to .025.
In L1 participants, the only significant effect was the main effect of Relatedness (t = –2.78, p = .005). In L2 participants, the main effect of Relatedness was also significant (t = –3.47, p < .001). The post-hoc tests also uncovered that the three-way interaction between Relatedness, Frequency, and Group, which was observed in the initial model with the combined data set of L1 and L2 participants, was significant because Frequency affected form priming differently across the two participant groups. Form facilitation was numerically greater under the high-frequency prime condition (15.1 ms) than under the low-frequency prime condition (11.4 ms) in L1 speakers (t = –1.02, p = .307). On the other hand, form facilitation was marginally significantly stronger under the low-frequency prime condition (40.0 ms) than under the high-frequency prime condition (12.4 ms) in L2 speakers after Bonferroni correction (i.e., at the alpha level of .025) (t = 2.01, p = .036). The other significant effect in L2 speakers was the interaction between Relatedness and SpellZ (t = 2.52, p = .012). Figure 3 which depicts the effect of SpellZ on the orthographic priming in the two participant groups reveals that this significant Relatedness × SpellZ interaction indicates that L2 speakers’ individual differences in orthographic precision determined the magnitude of the facilitative form priming in L2. Specifically, the poorer the L2 speakers’ levels of orthographic representations were, the stronger the form facilitation was. It needs to be noted that the same interaction was not significant in L1 speakers (t = 0.33, p = .738). As illustrated in Figure 3, the magnitude of the form facilitation was almost the same regardless of L1 speakers’ spelling scores. None of the other main effects or interactions were significant.
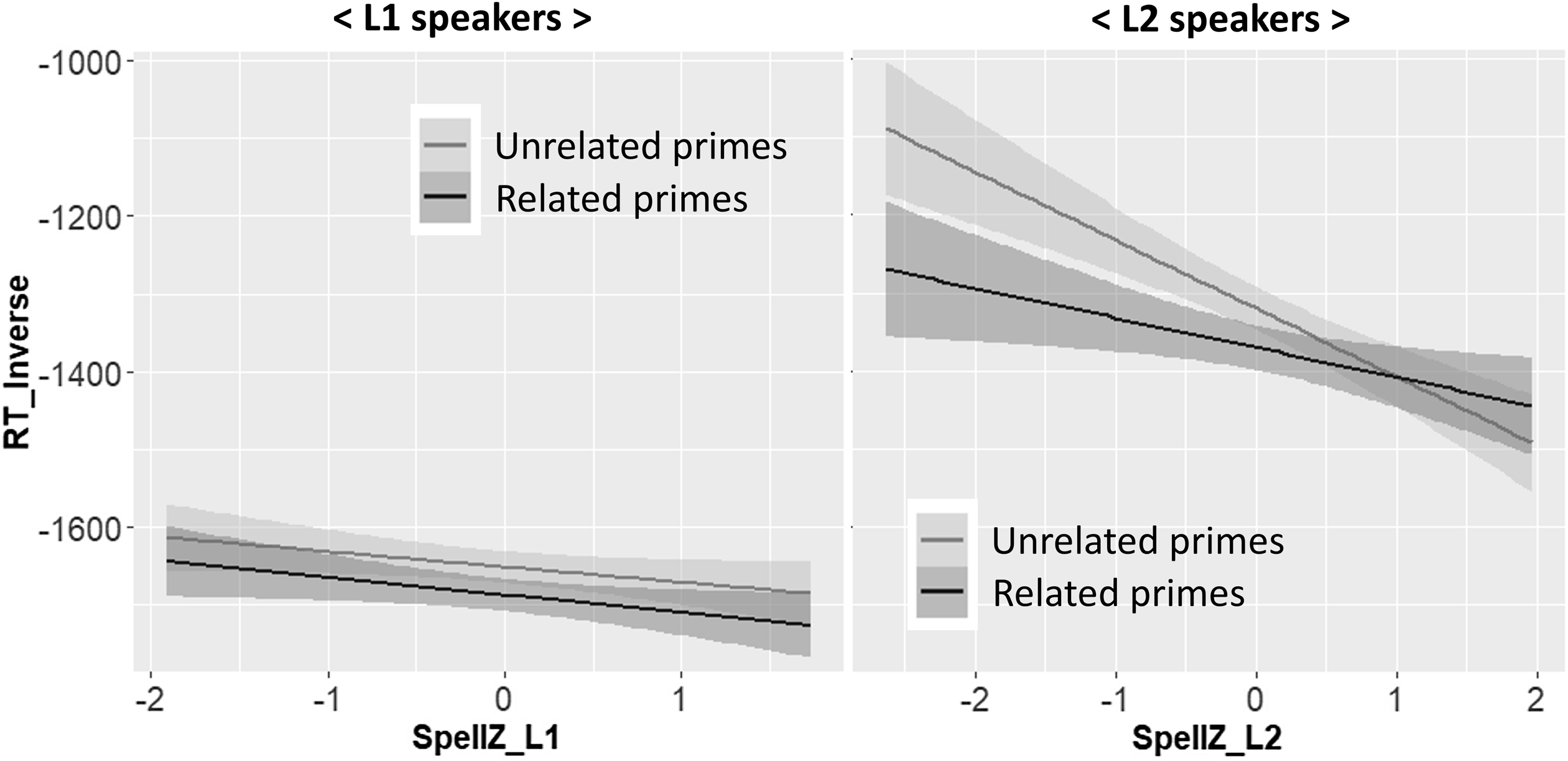
Figure 3. The interaction between Relatedness and orthographic precision (SpellZ) in L1 and L2 speakers.
In short, both L1 and L2 speakers showed significant form facilitation for word prime-target pairs and the lack of form priming for nonword prime-target pairs. However, a significant Relatedness × Frequency × Group interaction observed in the RT analysis for word prime-target pairs suggests that prime frequency modulated the orthographic priming differently across the two participant groups. Whereas low-frequency primes produced somewhat stronger form facilitation than high-frequency primes in L2 speakers, the effect of prime frequency on form facilitation was minimal in L1 speakers. In addition, while participants’ spelling scores did not modulate the form priming in L1, they did in L2.
Discussion
The FLRs hypothesis (Gor et al., Reference Gor, Cook, Bordag, Chrabaszcz and Opitz2021) suggests that many L2 word form representations are not as precise as those of L1 words due to unfaithful encoding of L2 word forms associated with insufficient exposure to L2. The current study was conducted to examine whether L2 orthographic representations are indeed imprecise as posited by the FLRs hypothesis. It was predicted that unlike in L1 speakers, form facilitation would be observed in L2 speakers because the orthographic representations of similarly looking L2 words are not clearly discriminable. Evidence for the assumption that the locus of form facilitation for L2 words is their orthographic representations was also expected to be found in the modulating role of prime frequency and L2 speakers’ spelling proficiency in orthographic priming. The results we obtained from L2 speakers are consistent with our predictions. However, contrary to our expectations, L1 speakers showed a lack of repetition priming and significant form facilitation. In order to correctly interpret L2 speakers’ data, L1 speakers’ results should first be validly interpreted. This section will propose potential mechanisms of repetition and form priming that might have operated for L1 and L2 speakers in the present study.
Repetition priming
In the present study, the repetition priming condition was included as a control condition to show that facilitative priming indeed occurred in both L1 and L2 during lexical decisions if the same word was presented repeatedly. However, a lack of priming was observed in L1 speakers under this priming condition. Although this result is different from our prediction, according to previous research, there is the so-called frequency attenuation effect in long-term repetition priming (e.g., Forster & Davis, Reference Forster and Davis1984; Scarborough et al., Reference Scarborough, Gerard and Cortese1979). This effect refers to a phenomenon that while repetition priming for low-frequency words is strong, for high-frequency words it is weak. In addition, some studies even report an absence of repetition priming in lexical decisions (Bowers, Reference Bowers2000b; Rajaram & Roediger, Reference Rajaram and Roediger1993). In particular, based on the null long-term repetition priming for high-frequency words observed in his study, Bowers (Reference Bowers2000b) suggested that because the orthographic representations of high-frequency words are already strong, one more encounter with these words does not further strengthen their representations.
To determine whether the lack of repetition priming observed in L1 in the present study was because many of the stimuli presented under the repetition priming condition were high-frequency words for L1 speakers, post-hoc analyses were performed. For these analyses, the stimuli were split into two groups based on frequency, and this categorical variable was labeled as WordFreq. The strength of repetition priming in each subset of the stimuli was then examined. The results from L1 speakers’ RT data (see Table S11 for model formulas and specific model outputs) show that although the interaction between Relatedness and WordFreq was not significant (t = 1.47, p = .142), the facilitative repetition priming for the half of the word stimuli with relatively lower frequency (16.3 ms) approached significance after Bonferroni correction (i.e., at the alpha level of .025) (t = –2.22, p = .027). On the other hand, the repetition priming for the other half of word stimuli with relatively higher frequency (–2.3 ms) was not significant (t = –0.19, p = .847). These results suggest that repetition priming was absent in L1 speakers not because something went wrong during the experiment but because many of the word stimuli used under the repetition prime condition were high-frequency words with little room for further improvement in their orthographic representations.
Unlike L1 speakers, L2 speakers showed very strong facilitative repetition priming (128.6-ms reduction in response latency and 6.5% improvement in accuracy). According to the theoretical framework of repetition priming developed by Bowers (Reference Bowers1996, Reference Bowers2000a, Reference Bowers2000b), this means that word repetition primes were low-frequency words to L2 participants. To confirm that this was indeed the reason for the strong repetition priming observed for L2 words, post-hoc analyses were carried out after having split the word stimuli into two groups by frequency. The results revealed that 221.1 ms of facilitative repetition priming for words with lower frequency (t = –9.10, p < .001) and 69.3 ms of facilitative repetition priming for words with higher frequency (t = –5.09, p < .001) were both significant. However, a significant interaction between Relatedness and WordFreq (t = 3.46, p < .001) was also observed indicating that the repetition priming for the former stimuli was significantly greater than the priming for the latter stimuli (see Table S11 for model formulas and specific model output).Footnote 6 These findings are consistent with the hypothesized mechanism of long-term repetition priming which posits that “priming is a manifestation of learning that improves the perceptual encoding of repeated items, with low-frequency words benefiting more than high-frequency words (Bowes, Reference Bowers2000a, p. 94).” The results also suggest that this mechanism operated similarly across L1 and L2 speakers.
Orthographic priming
In the present study, L1 speakers showed significant facilitative orthographic priming. Although significant form priming in L1 was unexpected, previous research on long-term repetition priming provides an explanation for this phenomenon. Specifically, in the literature on long-term repetition priming, it has often been suggested that strengthening the sublexical orthographic representations of the prime and their association with corresponding phonological information, as well as strengthening its lexical representation, might contribute to repetition priming (Bowers, Reference Bowers1994, Reference Bowers1996, Reference Bowers2000a). In addition, Bowers (Reference Bowers2002) indeed showed that prime-target pairs that have similar orthographic forms can produce significant orthographic priming if they share a sufficient portion of sublexical, phonological components (e.g. mint-hint but not pint-hint). Unlike in typical form priming studies that usually used short words (i.e., four- to six-letter words) (e.g., Forster & Davis, Reference Forster and Davis1984; Scarborough et al., Reference Scarborough, Gerard and Cortese1979), the present study used longer words (i.e., six- to ten-letter words). Since there were great overlaps in orthographic and phonological features between the prime and target (e.g., five-letter and -phoneme overlaps in clever-clover), it can be reasoned that the strengthening of sublexical orthographic representations and their association with corresponding sublexical phonological representations might have occurred during prime identification thus leading to the facilitative orthographic priming for L1 word targets.
One may point out that this interpretation is unparsimonious given the lack of repetition priming observed in L1 because if the overlap in sublexical components was the reason for form facilitation for L1 words, repetition priming should also be observed. However, a close examination of the lexical properties of the stimuli (see Table 2) helps to understand these unanticipated findings. As mentioned above, word stimuli used under the repetition prime condition might not have been further strengthened because L1 participants already had reached a saturation level. Because word primes used under the form priming conditions had a frequency comparable to (15.5 opm) or higher (95.7 opm) than the frequency of word repetition primes (15.6 opm), it is reasonable to suppose that those word form primes would also not produce repetition priming if they had been repeated. However, the targets presented under the two orthographic priming conditions had much lower frequency (5.5 opm under the low-frequency condition and 6.8 opm under the high-frequency prime condition) compared to repetition and orthographic primes. Therefore, it can be hypothesized that although form primes, which were familiar words to L1 participants, could not be further strengthened due to their already strong orthographic representations, they still provided a positive boost to sublexical components of the targets that had much lower frequency than the primes. Since there was still some room for further strengthening in the representations of the L1 targets, form facilitation could have been produced in the present study.
As for orthographic priming in L2, the 12.4 ms of the facilitative form priming observed under the high-frequency prime condition seems similar to the 11.4 ms and 15.1 ms of facilitative form priming observed under each of the two orthographic priming conditions in L1 speakers. Thus, one may consider that at least high-frequency L2 word primes were processed just like L1 word primes.
However, this interpretation requires caution. First, in the present study, lexical decisions in L2 were made much more slowly than those in L1 (see Table 3 and Figure 3). Since it is known that the shorter the RTs to first-encountered words, the weaker the facilitative repetition priming is (e.g., Forster & Davis, Reference Forster and Davis1984; Gordon, Reference Gordon1985; Scarborough et al., Reference Scarborough, Gerard and Cortese1979), it may not be reasonable to consider that the form facilitation found in L2 speakers’ long RT range (M RT to targets presented under the high-frequency orthographic prime condition without encountering related primes: 831.9 ms) is comparable to the form facilitation observed in L1 speakers’ shorter RT range (M RT to targets presented under the high-frequency orthographic prime condition without encountering their related primes: 637.5 ms) in terms of the strength of priming. Second, the form facilitation in L2 appeared to be more susceptible to Frequency (i.e., low- vs. high-frequency primes) compared to that in L1. Third, the L1 and L2 form facilitation differed in their sensitivity to spelling proficiency. The facilitative form priming in L2 was modulated by participants’ levels of orthographic precision such that whereas some participants with poor orthographic representations (i.e., L2 speakers whose spelling scores were lower than the average L2 speakers’ mean spelling score) showed considerable facilitative priming, others with precise orthographic representations (i.e., L2 speakers whose spelling scores were 1 standard deviation (SD) higher than the average) showed the absence of form facilitation as illustrated in Figure 3. In contrast, the form facilitation in L1 was not modulated by participants’ spelling scores such that L1 participants showed similar sizes of form facilitation regardless of their levels of orthographic precision. These contrasting findings between L1 and L2 participants suggest that the orthographic priming in L1 and L2 might be qualitatively different.
Since the facilitation in the L2 was modulated by participants’ spelling proficiency, and since this form facilitation seemed to be stronger under the low-frequency prime condition than under the high-frequency prime condition (although the interaction between Relatedness and Frequency in L2 did not reach significance after Bonferroni correction), we propose that the form facilitation in L2 was observed because repetition priming occurred for orthographic prime-target word pairs due to the fuzzy boundaries of L2 orthographic representations. For example, when L2 participants encountered a word prime (e.g., clever), the orthographic representation of its orthographic neighbor (i.e., a target such as clover) may sometimes have also been modified since the prime was not clearly distinguishable from the target. In addition, this phenomenon would have occurred more frequently for low-frequency primes because the orthographic representations of these primes were fuzzier than those of high-frequency primes. However, this form confusion might have occurred less frequently if L2 participants had relatively more precise orthographic representations.
If repetition priming is the source of the form facilitation in L2, an explanation is necessary for why the strengthening of sublexical representations, which occurred in L1, did not occur in L2, resulting in the lack of form facilitation among better L2 spellers. Certain models of L1 word recognition (e.g., McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Seidenberg & McClelland, Reference Seidenberg and McClelland1989) hypothesize that there are some associations between words that share letter strings. In addition, another model that incorporates learning mechanisms (Harm & Seidenberg, Reference Harm and Seidenberg1999) argues for the role of phonology in acquisition of L1 reading skills. To be more specific, L1 speakers usually have phonological knowledge of words before learning how to read. Then, while learning the orthographic forms of words, they acquire how a particular letter string matches up with phonemes through numerous encounters with the same letter string in different words, mostly through reading. For that reason, strong associations between words that share the same letter strings would naturally be established.
On the other hand, L2 speakers often learn the spellings of individual L2 words through memorization without prior knowledge of their pronunciation. Therefore, L2 speakers would have less opportunities to develop connections between graphemes and phonemes resulting in orthographic representations that are often poorly matched to phonological representations. Accordingly, modification of sublexical orthographic representations and strengthening of their associations with corresponding phonological components by an orthographic prime that requires a strong association between graphemes and phonemes would be less likely to occur.
Evidence supporting this hypothesis was obtained from supplementary analysis. Bowers (Reference Bowers2002) found that long-term orthographic priming was significant in L1 if prime-target pairs rhymed whereas it was not if prime-target pairs did not rhyme in the lexical decision task. Form facilitation from rhyming L1 prime-target pairs was also observed in unmasked short-term priming experiments when targets were low-frequency words (Colombo, Reference Colombo1986; Colombo & Lupker, Reference Lupker and Colombo1994).
We examined whether a similar phenomenon occurred in the present study. For this analysis, a variable Rhyme was created. In this variable, rhyming prime-target pairs were coded as “0” and non-rhyming pairs were coded as “1.” A fixed effects model was fitted with inverse-transformed response latency as the dependent variable, and Relatedness, Frequency, and Rhyme as the predictors. The results from L1 speakers’ data showed a significant interaction between Relatedness and Rhyme (t = 2.27, p = .023) indicating that the patterns of orthographic priming for L1 words differed depending on whether prime-target pairs rhymed or not. Post-hoc tests found that 54 rhyming prime-target pairs produced 23 ms of significant facilitative priming (t = –3.57, p < .001) whereas the other 26 non-rhyming prime-target pairs yielded –7 ms of null priming (t = –1.62, p = .106) (see Table S12 for specific model output), replicating the patterns of orthographic priming observed in the previous studies (Bowers, Reference Bowers2002; Colombo, Reference Colombo1986; Colombo & Lupker, Reference Lupker and Colombo1994). In these previous studies, it was assumed that the repetition of rhyming segments would make the completion of the target’s phonological codes in word-final positions relatively fast, allowing the evaluation of its lexical status to begin rapidly at both phonological and orthographic levels.
It also needs to be noted that in the same analysis with L2 speakers’ data set, the Relatedness × Rhyme interaction was not significant (t = 0.18, p = .855) suggesting that rhyming codes did not make an impact on the orthographic priming in L2. The different roles of word-final phonological segments across L1 and L2 speakers support our hypothesis that the locus of the form priming for L1 words was different from that for L2 words.Footnote 7
Finally, before concluding, a significant interaction between Relatedness and Frequency found in the accuracy analysis needs to be explained. This interaction suggests that in both L1 and L2 speakers, form inhibition occurred under the high-frequency prime condition whereas a trend toward form facilitation was produced under the low-frequency prime condition.
The form inhibition observed under the high-frequency prime condition in L1 does not seem to support our claim that the sublexical representations of targets were strengthened by the prime. However, it should be noted that no theory of representations, to our best knowledge, predicts form inhibition in mid-term or long-term priming experiments. For example, suppression of a target by its orthographic neighbor prime caused by lexical competition is believed to last for only a few seconds (Ferrand & Grainger, Reference Ferrand and Grainger1993; Forster & Davis, Reference Forster and Davis1984; Grainger et al., Reference Grainger, Kiyonaga and Holcomb2006). Thus, it is not appropriate to consider that this form inhibition in accuracy was produced by suppressed levels of activation of the target by the prime.
Although we do not know the exact reason for this phenomenon, a plausible explanation is found in the literature. As shown in Table 2, the gaps in frequency between primes and targets were much bigger under the high-frequency prime condition than under the low-frequency prime conditions. Bowers (Reference Bowers2000b) reported that high-frequency words produced facilitative repetition priming in the perceptual identification task but not in the lexical decision task. Based on these findings, Bowers (Reference Bowers2000a) suggested that whereas priming for low-frequency words reflects a change in sensitivity caused by a modification of orthographic representations, priming for high-frequency words reflects a bias. To be more specific, he claimed that facilitative repetition priming for high-frequency words in which further improvement of representations is not possible occurred in perceptual identifications because participants tended to perceive test words as previously studied words (see also Ratcliff & McKoon, Reference Ratcliff and McKoon1997).
Of course, if a bias was involved in the present experiment, an expected result is form facilitation in accuracy. This is because a wrong perception of a target (e.g., expedience) as a prime (e.g., experience) would lead to a correct “yes” decision. However, some models of word recognition suggest that word identification involves two steps: (1) initial visual input analysis and (2) post-access verification, not only in L1 (e.g., Forster & Veres, Reference Forster and Veres1998) but also in L2 (Jiang et al., Reference Jiang, Li and Guo2020). It was also found that post-access verification is stronger when accuracy is stressed over speed in lexical decisions (Forster & Veres, Reference Forster and Veres1998) as in the present study.
Based on these models (Forster & Veres, Reference Forster and Veres1998; Jiang et al., Reference Jiang, Li and Guo2020), it can be hypothesized that a bias hindered the post-access verification process when the gap in frequency between the prime and target was remarkably great. For example, when participants encountered expedience after seeing experience, they might have perceived expedience as experience at a very early stage of word identification, which led to a transient lexical confusion. Then, when participants realized that the target was actually not experience during the verification stage, they might have wrongly judged that the target was not a word before expedience with a very weak representation was retrieved. On the other hand, if experience had not been encountered before expedience, it would have been easier for participants to correctly respond to expedience since there was no interference of the bias. In other words, it means that although primes indeed strengthened the representations of the target, the original levels of robustness of some lexical representations were still too low to overcome the bias that was caused by a recent encounter with the much more familiar prime. However, when the gaps in familiarity levels between the prime and the target were not too large to overcome for participants, they may have been less influenced by this bias and were able to make use of the strengthened representations of the target by the prime for a correct lexical decision.
To sum up, significant form facilitation was observed for L2 orthographic neighbor prime-target pairs (e.g., clever-clover). The effects of word frequency and orthographic precision on form priming in L2 suggest that repetition priming caused by form confusion sometimes occurred for similarly looking L2 word pairs particularly when stimuli were low-familiarity words and when L2 participants had imprecise orthographic representations. Based on these findings, the study suggests that fuzziness resides not only in L2 phonological representations (Barrios et al., Reference Barrios, Jiang and Idsardi2016; Darcy et al., Reference Darcy, Dekydspotter, Sprouse, Glover, Kaden, McGuire and Scott2012; Pallier et al., Reference Pallier, Colomé and Sebastián-Gallés2001) but also in L2 orthographic representations.
Limitations and future research
This study had several limitations. First, although we recruited only proficient L2 speakers and carefully selected L2 word stimuli that were predicted to be known to these participants, a considerable amount of L2 stimuli was removed from analysis. Therefore, although we set the experimental environments to be comparable across the participant groups and the prime conditions before the data exclusion, the imbalanced data set could have influenced the results. Second, when designing the LDT, we matched the lexical properties of repetition primes with those of low-frequency primes to show that the primes with comparable lexical properties produced different patterns of priming across the repetition and orthographic conditions (i.e., facilitative priming under the repetition prime condition and null priming under the low-frequency prime condition) in L1. However, it would have been preferable if the lexical properties of targets were matched across the different prime conditions for a more straightforward interpretation of the results. Third, the present study is limited in its generalization of the findings because previous research suggests that visual L2 word recognition is influenced by various factors such as the script, orthographic depth, and type of L1 (e.g., alphabetic vs. logographic languages) as well as its relation to L2 (see Jiang, Reference Jiang2018, p. 160–170, for a review). Therefore, future research incorporating methodological improvements and participants from diverse L1 backgrounds is necessary to deepen our understanding of the nature of L2 orthographic representations.
Fourth, following the procedure used in previous short-term orthographic priming studies that employed longer (eight-letter) words (Forster & Veres, Reference Forster and Veres1998; Elgort, Reference Elgort2011), the present study did not take into account (a) the phonotactic feasibility and (b) the orthographic depth of nonword LDT stimuli. Based on Forster and Veres’ (Reference Forster and Veres1998) findings, which suggest that stronger post-access verification resulting from difficult lexical decisions leads to weaker form facilitation, weaker facilitative orthographic priming is expected in both L1 and L2 when phonotactically feasible or orthographically shallow nonwords are used. Nonetheless, considering the effects of these factors in future research would be beneficial.
Finally, while form facilitation in L2 observed in previous auditory medium-term priming experiments is attributed to unsuccessful phonological encoding of difficult L2 phonemic contrasts (e.g., /i/-/ɪ/ as in sheep-ship), a specific factor that produces form facilitation in visual word recognition has not yet been identified.Footnote 8 We hypothesize that there may be more than one factor, and as an anonymous reviewer suggested, one possibility is that certain word pairs (e.g., clever-clover) are more visually confusable than others (e.g., professor-processor) due to greater visual similarity between specific letters (e.g., “e” and “o” may appear more similar than “f” and “c”). Future research could investigate whether this factor influences visual L2 word recognition.
Replication package
Replication data and materials for this article can be found at https://osf.io/j6nk8/.
Acknowledgments
The present study was developed from the first author’s qualifying paper for the Ph.D. Program in Second Language Acquisition at the University of Maryland. We are grateful to Dr. Ross and the anonymous reviewers for their constructive feedback, and to Stefanie Simmons for her assistance in creating the study materials.








 Open access
Open access