


1. Introduction
There are two approaches to probability theory: the first is the frequentist interpretation, also known as standard, orthodox, or classical statistics, and the second is the Bayesian interpretation (Daykin et al., Reference Daykin, Pentikäinen and Pesonen1994; Lee, Reference Lee2012; Gelman, Reference Gelman2013; Klugman et al., Reference Klugman, Panjer and Willmot2019; Murphy, Reference Murphy2022, Reference Murphy2023). This distinction also applies to the various statistical and modeling approaches.
The Bayesian interpretation has multiple advantages, but frequentist approaches are still popular and widely used for two main reasons. First, they are computationally ‘cheap’ compared to Bayesian methods, and second, they do not presuppose knowledge regarding priors. Bayesian inference is, nevertheless, widely applied in various domains of science (Parr et al., Reference Parr, Pezzulo and Friston2022; Palmer, Reference Palmer2022; Harrison et al., Reference Harrison, Bays and Rideaux2023), and it has become the foundation of machine learning (Murphy, Reference Murphy2022, Reference Murphy2023). Bayesian approaches are also gaining popularity in disciplines like insurance and reinsurance, which have traditionally been dominated by frequentist approaches (Bühlmann and Straub, Reference Bühlmann and Straub1970; Bühlmann and Gisler, Reference Bühlmann and Gisler2005; Zhang et al., Reference Zhang, Dukic and Guszcza2012; Klugman et al., Reference Klugman, Panjer and Willmot2019; Goffard et al., Reference Goffard, Piette and Peters2023).
Reinsurance companies face multiple challenges when using models for assessing the assumed risks and for taking business decisions like risk selection, transactional pricing, reserving, investing, and corporate risk management, and they rely on a variety of methods and tools for managing these risks (Antal, Reference Antal2009; Albrecher, Reference Albrecher2017; Mildenhall, Reference Mildenhall2022). The actuarial models implemented by a reinsurer are based on simplified assumptions, and reinsurers know that the underlying assumptions are rarely fulfilled in the real world. One way to deal with the issue is to complement experience-based rating models with exposure-based models. The latter can incorporate all relevant features of the generative process that affect the rating. All such features must be calibrated, which is accomplished with market data. However, cedent-specific features (hidden variables) must also be reflected in the rating of reinsurance contracts. This is done via an ‘expert-based’ credibility weighting of experience-based rates and exposure-based rates. One such approach is to evaluate the experience-based rate for a ‘working layer’ and to use this rate for calibrating the exposure-based rates for high layers (Desmedt et al., Reference Desmedt, Snoussi, Chenut and Walhin2012).
The framework presented in this article attempts to resolve the calibration issue in an ‘optimal’ way. This is accomplished by using the claims experience of a cedent and Bayesian inference to adjust the calibration parameters within the exposure-based generative model. The approach is generic, and it coherently integrates all available information.
1.1. Motivation
This article claims that the integrated rating framework introduced in the following sections is superior to standard rating approaches applied by reinsurers (see Figures 1, 2, and Table 1) and that it can support reinsurers in optimizing their underwriting policy. These two claims are based on the following considerations:
Agency, Markov blankets, and minimizing surprise:
Agents use the available information about their external world to continuously update their internal representation of the external world (perceptual inference). This internal representation is used to derive an optimal ‘strategy’ for acting on the external world (active inference). Biological agents apply active inference to minimize surprise (Parr et al., Reference Parr, Pezzulo and Friston2022), and this principle also applies to corporate agents.
The various activities of a reinsurer, particularly the rating and underwriting processes, can be represented by a hierarchy of Markov blankets (a description of Markov blankets can be found in Murphy, Reference Murphy2023). At the top of this hierarchy, the reinsurer acts as a corporate agent. It receives various kinds of information from the external world and acts on the external world to pursue its corporate goals. At the bottom of the hierarchy, the pricing actuaries and the underwriters assess the individual contract’s risk and the expected loss costs by combining the submission data provided by cedents with market information and expertise. This assessment is combined with other criteria in the decision process on higher levels within the Markov blanket hierarchy.
The role of rating in reinsurance:
The net premiums and the loss costs drive the bottom-line result of a reinsurer. A bias of a few percentage points in the loss-ratio estimates on an aggregate portfolio level can lead to a substantial systematic adverse development of reserves and erase the bottom-line profit anticipated when assuming the contracts. Reinsurers are, therefore, using various sources of information to model the potential future claims activity of the assumed contracts. This assessment is used for risk selection, setting terms and conditions, initial reserving, investment decisions, and corporate risk management.
The integrated rating framework introduced in this article attempts to minimize the bias and uncertainty in the loss-cost estimates on a contract level. This minimization is critical to a reinsurer’s attempt to implement an optimal underwriting policy.
An integrated rating approach is superior to a standard experience-based rating:
An exposure-based generative model attempts to replicate the relevant features of the generative processes in the external world by considering the available information coherently. This includes past and anticipated future developments in the market and in the cedent’s portfolio. The prior (default) generative model is obtained by combining the idiosyncratic exposure of a cedent with loss models derived from market data. Bayesian inference is applied to the cedent’s claims experience and prior assumptions to reflect the cedent’s idiosyncratic features in the calibrated posterior generative model.
Hence, the calibrated generative model coherently reflects all available information about the respective market, the underlying client portfolio, and the client’s claims experience. Projecting the claims experience to the future cover period and developing the open claims (as done in experience-based rating) can thus not provide extra information about the claims process to be expected in the future cover period. An experience-based model lacks the extra information reflected in the generative model. Trending and developing past claims is not equivalent to the explicit approach implemented within generative models; therefore, standard experience-based rating approaches are inferior to an integrated rating framework.
An integrated rating approach is superior to a standard exposure-based rating:
Standard exposure-based rating approaches combine the most recent cedent exposure (projected to the cover period) with market loss models, but they do not reflect the cedent’s claims experience. Standard exposure-based rating relies on the prior generative model, which is inferior to a calibrated posterior generative model.
An integrated rating approach is superior to standard blending approaches:
One blending approach (Desmedt et al., Reference Desmedt, Snoussi, Chenut and Walhin2012) uses the burning-cost rate of a reference layer (as derived with the help of an experience-based rating model) to calibrate the frequencies within the exposure-based model. An alternative approach applies a credibility-based blending of the experience-based and exposure-based rates. No blending approach can, however, overcome the inherent shortcomings of the underlying experience-based and exposure-based rating approaches; therefore, the blending of rates is inferior to an integrated rating framework.
Caveat:
The generic integration framework can be applied to any exposure-based rating model, provided that the probability distributions for the model features to be calibrated can be extracted (either analytically, via numerical approximations, or simulation) and that the derived calibration parameters can be fed back into the generative model.
The integrated approach is only as strong as its weakest link, that is, as the weakest module within the exposure-based generative model. Applying the calibration framework to an exposure-based generative model composed of frequency and severity modules might, for example, be appropriate for short-tail business. However, such a simplified model cannot adequately reflect the impact of the development of long-tail claims. An integrated rating approach relying on an oversimplistic generative model is superior to the respective exposure-based rating model, but it might be inferior to an experience-based rating approach that reflects the claims development.

Figure 1. The standard rating framework in reinsurance comprises experience rating, exposure rating, and expert-based blending. Bottom panel: Experience rating is based on the observed claims reported by the cedent. The development of these claims with occurrence years
 $o \in \{-T, \dots, -1\}$
(with
$o \in \{-T, \dots, -1\}$
(with
 $T=10$
) results from applying policy conditions
$T=10$
) results from applying policy conditions
 $\S_o$
to the economic loss
$\S_o$
to the economic loss
 $\chi_o$
emanating from the generative process. The claims experience is projected to the future cover period
$\chi_o$
emanating from the generative process. The claims experience is projected to the future cover period
 $o=+1$
and developed. The statistics derived from the claims triangle for
$o=+1$
and developed. The statistics derived from the claims triangle for
 $o=+1$
is used to rate the reinsurance contracts. Upper right panel: Exposure rating combines the cedent’s most recent exposure profiles
$o=+1$
is used to rate the reinsurance contracts. Upper right panel: Exposure rating combines the cedent’s most recent exposure profiles
 $\Sigma_{-1}$
with market models
$\Sigma_{-1}$
with market models
 $\Omega_{-1}$
and underwriting expertise. The profiles and the market models are projected to the cover period and processed in the exposure model
$\Omega_{-1}$
and underwriting expertise. The profiles and the market models are projected to the cover period and processed in the exposure model
 $\Psi_{1}$
. The rating-relevant statistics for
$\Psi_{1}$
. The rating-relevant statistics for
 $o=+1$
are obtained by applying the anticipated insurance conditions
$o=+1$
are obtained by applying the anticipated insurance conditions
 $\S_1$
.
$\S_1$
.

Figure 2. Integrated rating framework. The exposure-based generative model attempts to emulate the generative process. The framework uses the market experience
 $\Omega_o$
, the exposure profiles
$\Omega_o$
, the exposure profiles
 $\Sigma_o$
, the exposure models
$\Sigma_o$
, the exposure models
 $\Psi_o$
, and the policy conditions
$\Psi_o$
, and the policy conditions
 $\S_o$
to generate samples with simulated claims for
$\S_o$
to generate samples with simulated claims for
 $o \in \{-T, \dots, -1\}$
(with
$o \in \{-T, \dots, -1\}$
(with
 $T=10$
). The respective observed claims reported by the cedent for
$T=10$
). The respective observed claims reported by the cedent for
 $o \in \{-T, \dots, -1 \}$
and Bayesian inference are used to calibrate the generative model. The calibrated exposure model is projected to the future cover period
$o \in \{-T, \dots, -1 \}$
and Bayesian inference are used to calibrate the generative model. The calibrated exposure model is projected to the future cover period
 $o=+1$
to derive the statistics for rating the reinsurance contracts.
$o=+1$
to derive the statistics for rating the reinsurance contracts.
Table 1. Comparison of the integrated rating framework with the standard framework.

1.2. Plan of the article
This article discusses the coherent integration of the available information in reinsurance rating using generative models. Section 2 describes the standard rating approaches applied in reinsurance. Section 3 introduces the concept of generative models and discusses how they can be used in an integrated framework. Section 4 covers appropriate statistics, while Section 5 discusses the calibration of the generative models with Bayesian inference. Finally, Section 6 analyzes the framework in more detail using ‘toy models’. Technical details are provided in the Online Supplementary Material.
2. Experience and exposure rating in reinsurance
One major challenge for reinsurance companies is the lack of direct access to detailed information related to the covered portfolios, that is, they have no direct access to large datasets that relate the claim characteristics (frequency, severity, and development patterns) to the respective exposure information (objects at risk, policyholders, and policy terms), and the risk factors (covered perils and threads). Reinsurers thus rely on market information
 $\mathcal{D}^{market}$
provided by specialized organizations, for example, Verisk (Verisk, 2024), and on idiosyncratic submission data provided by their cedents. For nonproportional contracts, the submission data comprise the cedent’s claims experience
$\mathcal{D}^{market}$
provided by specialized organizations, for example, Verisk (Verisk, 2024), and on idiosyncratic submission data provided by their cedents. For nonproportional contracts, the submission data comprise the cedent’s claims experience
 $\mathcal{D}^{claims}$
in excess of a threshold and the cedent’s exposure profiles
$\mathcal{D}^{claims}$
in excess of a threshold and the cedent’s exposure profiles
 $\mathcal{D}^{exposure}$
.
$\mathcal{D}^{exposure}$
.
Reinsurers combine the various data sources when creating models for the claims activity expected to occur in the cedent portfolio during the future cover period; these models are used to derive the statistics required to rate the reinsurance contracts
 $\mathcal{D}^{cover}$
. Reinsurers use an extensive suite of proprietary and vendor rating tools that are specifically designed for different markets, different lines of business, different perils, and distinct kinds of contracts. The rating is, however, either based on the claims experience of a cedent (experience rating), on the exposure of a cedent combined with market models (exposure rating), or on a combination of the two approaches. The ‘standard rating framework’ applied by a reinsurer is depicted in Figure 1, and a comparison of the various approaches is provided in Table 1. The integrated approach attempts to overcome the drawbacks of standard rating approaches by coherently combining all available information. The benefits come, however, at the cost of higher procedural and computational efforts.
$\mathcal{D}^{cover}$
. Reinsurers use an extensive suite of proprietary and vendor rating tools that are specifically designed for different markets, different lines of business, different perils, and distinct kinds of contracts. The rating is, however, either based on the claims experience of a cedent (experience rating), on the exposure of a cedent combined with market models (exposure rating), or on a combination of the two approaches. The ‘standard rating framework’ applied by a reinsurer is depicted in Figure 1, and a comparison of the various approaches is provided in Table 1. The integrated approach attempts to overcome the drawbacks of standard rating approaches by coherently combining all available information. The benefits come, however, at the cost of higher procedural and computational efforts.
A comprehensive description of rating models is beyond the scope of this article. A variety of approaches can, however, be found in books (Daykin et al., Reference Daykin, Pentikäinen and Pesonen1994; Albrecher, Reference Albrecher2017; Klugman et al., Reference Klugman, Panjer and Willmot2019; Mildenhall, Reference Mildenhall2022), articles (Panjer, Reference Panjer1981; Sundt and Jewell, Reference Sundt and Jewell1981; Schnieper, Reference Schnieper1991; Bernegger, Reference Bernegger1997; Riegel, Reference Riegel2010; Desmedt et al., Reference Desmedt, Snoussi, Chenut and Walhin2012; Zhang et al., Reference Zhang, Dukic and Guszcza2012), conference papers (White and Mrazek, Reference White and Mrazek2004; Mata and Verheyen, Reference Mata and Verheyen2005; Bernegger, Reference Bernegger2012; Clark, Reference Clark2014; Huang, Reference Huang2014; Devlin, Reference Devlin2018), lecture notes (Antal, Reference Antal2009), and technical publications by corporations and professional organizations (Guggisberg, Reference Guggisberg2004; Billeter and Salghetti-Drioli, Reference Billeter and Salghetti-Drioli2016; Verisk, 2024; CAS, 2024; CARe, 2024).
2.1. Experience rating
Experience rating in reinsurance uses the claims experience
 $\mathcal{D}_{\iota}^{claims}$
(as reported by the cedent company
$\mathcal{D}_{\iota}^{claims}$
(as reported by the cedent company
 ${\iota}$
) to infer a stochastic model
${\iota}$
) to infer a stochastic model
 $\Pr(\boldsymbol{{x}} \mid \mathcal{D}_{\iota}^{claims})$
for the expected future claims activity
$\Pr(\boldsymbol{{x}} \mid \mathcal{D}_{\iota}^{claims})$
for the expected future claims activity
 $\boldsymbol{{x}}$
within the underlying portfolio. This model is used to evaluate the relevant statistics
$\boldsymbol{{x}}$
within the underlying portfolio. This model is used to evaluate the relevant statistics
 $\mathbb{E}[\boldsymbol{{h}}(\boldsymbol{{x}} \mid \mathcal{D}_{\iota}^{cover}) \mid \mathcal{D}_{\iota}^{claims} ]$
for the cover
$\mathbb{E}[\boldsymbol{{h}}(\boldsymbol{{x}} \mid \mathcal{D}_{\iota}^{cover}) \mid \mathcal{D}_{\iota}^{claims} ]$
for the cover
 $\mathcal{D}_{\iota}^{cover}$
provided to the cedent company
$\mathcal{D}_{\iota}^{cover}$
provided to the cedent company
 ${\iota}$
during the future contractual period. The operator
${\iota}$
during the future contractual period. The operator
 $\boldsymbol{{h}}: \boldsymbol{{x}}^{insured} \mapsto \boldsymbol{{x}}^{cover}$
projects the insured claim objects
$\boldsymbol{{h}}: \boldsymbol{{x}}^{insured} \mapsto \boldsymbol{{x}}^{cover}$
projects the insured claim objects
 $\boldsymbol{{x}}^{insured}$
to the covered claim objects
$\boldsymbol{{x}}^{insured}$
to the covered claim objects
 $\boldsymbol{{x}}^{cover}$
by applying the terms defined in
$\boldsymbol{{x}}^{cover}$
by applying the terms defined in
 $\mathcal{D}_{\iota}^{cover}$
.
$\mathcal{D}_{\iota}^{cover}$
.
The experience rating process (depicted in the lower part of Figure 1) involves several steps, among which the projection and the development of past claims are most critical. The claims experience must be projected (‘trended’) to the future cover period, where the ‘as-if’ claims are used for rating the reinsurance contracts. This projection must reflect changes in the cedents portfolio and inflationary effects that impact the claims’ frequency, severity, and development patterns. The development of the claims reported for past occurrence years is known up to the submission date
 $t^{sub}$
. This development comprises the temporal evolution of the cumulative paid amount
$t^{sub}$
. This development comprises the temporal evolution of the cumulative paid amount
 $P(t)\;:\!=\;\sum_i p_i \cdot \mathbb{1}_{t_i \le t}$
and the incurred loss amount
$P(t)\;:\!=\;\sum_i p_i \cdot \mathbb{1}_{t_i \le t}$
and the incurred loss amount
 $I(t)\;:\!=\;\mathbb{E}[U\mid \mathcal{D}_t]=P(t)+O(t)$
, where
$I(t)\;:\!=\;\mathbb{E}[U\mid \mathcal{D}_t]=P(t)+O(t)$
, where
 $\mathcal{D}_t$
is all past information prior to time t,
$\mathcal{D}_t$
is all past information prior to time t,
 $p_i$
is the amount paid at time
$p_i$
is the amount paid at time
 $t_i$
, and
$t_i$
, and
 $O(t)\;:\!=\;\mathbb{E}[\sum_i p_i \cdot \mathbb{1}_{t_i > t}]$
is the best estimate at time t for the outstanding payments. The ultimate loss amount
$O(t)\;:\!=\;\mathbb{E}[\sum_i p_i \cdot \mathbb{1}_{t_i > t}]$
is the best estimate at time t for the outstanding payments. The ultimate loss amount
 $U\;:\!=\;P(t)=I(t)$
for any
$U\;:\!=\;P(t)=I(t)$
for any
 $t \ge t^{clos}$
is thus known for closed claims and estimated for open claims. The claims triangle is completed by developing P(t) and I(t) either per individual claim or on a portfolio level (Schnieper, Reference Schnieper1991).
$t \ge t^{clos}$
is thus known for closed claims and estimated for open claims. The claims triangle is completed by developing P(t) and I(t) either per individual claim or on a portfolio level (Schnieper, Reference Schnieper1991).
The primary strength of experience rating is that it is based on the cedent’s specific claims experience and that standardized actuarial approaches are applied across markets, lines of business, and products. There are, however, several weaknesses; some claims have not yet been reported; claims reported for old years are well developed, but they might no longer be representative; claims reported for the most recent years are representative, but they are not yet developed; the count of trended claims with an incurred loss amount exceeding the reporting threshold is often small; and experience rating cannot reflect significant portfolio changes or new risks covered by the underlying insurance policies.
2.2. Exposure rating
Reinsurers use an extensive suite of exposure-based rating models. These models combine the risk profiles provided by the cedent with market statistics, expert knowledge, and, depending on the specific nature of the model, other modeling features, for example, scientific models emulating natural perils. There are two kinds of exposure models: the first combines the exposure with probability distributions (exposure curves), and the second relies on generative models that simulate significant numbers of events applied to the exposure.
Models of the first kind are computationally cheap as they do not require Monte Carlo simulations. The models can, however, also be implemented as generative models, and there is no need to distinguish between the two kinds in the context of this article.
Models of the second kind attempt to replicate the corresponding generative processes in the world, for example, natural catastrophes, accidents, and defaulting corporations. These models can be used to rate individual reinsurance contracts (primary scope) and for corporate risk management (secondary scope). The primary scope is accomplished by exposing a contract to all relevant events and evaluating the respective loss amounts for the contract. The secondary scope is accomplished by aggregating the loss amounts of individual events across all contracts.
The strength of exposure-based rating models is that they reflect a cedent’s (projected) future portfolio; they are aligned with the broader market experience; the same model is used for rating individual contracts and for corporate risk management. The weaknesses of exposure rating are that: a specific model is required for each business niche; calibrating the models is challenging; the models do not reflect the claims experience of a cedent; the models might not adequately reflect recent developments; and exposure models of the second kind are computationally expensive.
3. Integrated rating approach
3.1. Ensemble modeling
Ensemble forecast is fundamental in predictive science, that is, in attempts to make predictions about the chaotic world and in understanding and quantifying the uncertainty of such predictions. It is applied in astronomy, meteorology, engineering, chemistry, biology, medicine, ecology, economics, conflict management, etc. (Palmer, Reference Palmer2022). The methodology is also applied in insurance and reinsurance, particularly to assess risks attributed to natural disasters (see Section 2.2).
3.2. Generic process
The basic idea underlying a fully integrated rating approach is presented in Figure 2. Standard experience-based rating models require that all claims incurred and reported in prior years (including their temporal development till the submission date) are projected to the future cover period. These ‘as-if’ claims are used to derive the required statistics. This projection (see Figure 1) is accomplished by scaling frequency, severity, and payments by respective exposure metrics and trend factors. This nontrivial step is completely avoided in the integrated rating approach, where the experience is related to the respective past exposure-based model. This alternative approach thus permits us to adequately consider all known (and presupposed) developments in the underlying portfolio and the broader market environment. Such developments can encompass portfolio size and composition, terms of insurance policies, reporting thresholds, court practices, claims inflation, technological developments, reserving practices, etc.
Hence, the approach requires that such an exposure-based model be available for each past year for which the claims experience is considered in the rating process. The aim is to use the exposure-based generative model to produce all the statistics needed to rate the reinsurance contracts that will be enforced in the future cover period. This process is briefly described in Section 2.2 and shown in the upper right of Figure 2. However, the generative model must be adequately calibrated before being used for this rating purpose. This calibration task is performed by running the generative model with the exposure in each prior year, applying the respective policy and contract terms, and comparing the simulated claims with the respective observed claims.

3.3. Claim generator
The purpose of generative models is to replicate real-world generative processes as closely as required for the respective scope. In the context of reinsurance rating, a loss model needs to generate all relevant features of the observed claims provided to the reinsurer via the cedent’s submission data. The format and content of the submission data vary by market, line of business, product, and cedent. There is, however, a generic claim format that captures the key features of nonlife insurance claims and the variations can be mapped to this format. The following features characterize the reported insurance claims:
A tuple containing static claim features (administrative attributes), for example, policyholder, inception and expiration dates of the policy, policy ID, claim administrator, claim ID, event ID, status of the claim, etc.
A tuple containing categorical attributes describing the nature of the claim, for example, line of business, geo-encoding, type of cover, risk category, kind of event causing the claim, etc.
Critical dates like the occurrence (accident) date, the reporting date, and – depending on the status – the closure (settlement) date.
Incurred pattern, that is, the development of the best estimate for the ultimate amount to be paid by the cedent company.
Payment pattern, that is, the development of the aggregate payments (including the breakdown into components).
The critical dates and the development patterns (reported, incurred, and paid) matter from the perspective of quantitative analysis and model calibration. The reporting pattern is associated with true IBNR (incurred but not reported) and the incurred pattern with IBNER (incurred but not enough reserved). In contrast to IBNR, which is adverse, IBNER can either be adverse, adequate, or favorable, depending on whether the estimate of the incurred amount turns out to be too low, correct, or too high. The underlying payment pattern affects the amount and the timing of the payments of the loss portion covered by the reinsurer. The three development patterns depend on multiple factors (related to the policyholder, the cedent, and other agents), and they must be modeled and calibrated separately.
4. Reduced statistics
4.1. Challenge
The primary scope of a product-specific generative model used in exposure-based rating is to adequately emulate the relevant features of the generative process and provide all claim features that might affect the rating. This implies the generation of significant samples that populate the relevant regions in the sample space
 $\Omega$
, and the simulated claims must entail all rating-relevant features. The model must be calibrated, which is accomplished by running the generative model retrospectively. The simulated claims sets generated for the past observation period of length T (denoted by the occurrence years
$\Omega$
, and the simulated claims must entail all rating-relevant features. The model must be calibrated, which is accomplished by running the generative model retrospectively. The simulated claims sets generated for the past observation period of length T (denoted by the occurrence years
 $o \in \{-T, \dots, -1 \}$
defined relative to the submission year
$o \in \{-T, \dots, -1 \}$
defined relative to the submission year
 $o=0$
) are compared to the observed claims for this period.
$o=0$
) are compared to the observed claims for this period.
The calibration tuple
 $\boldsymbol{{C}}\;:\!=\;(\boldsymbol{{c}}_1, \dots, \boldsymbol{{c}}_M)$
containing the calibration parameters
$\boldsymbol{{C}}\;:\!=\;(\boldsymbol{{c}}_1, \dots, \boldsymbol{{c}}_M)$
containing the calibration parameters
 $\boldsymbol{{c}}_{\ell}$
is evaluated outside of the generative model and fed back into the model. The generative model can, therefore, be treated as an independent module interacting with the generic calibration framework. The iterative calibration procedure starts with default calibration parameters
$\boldsymbol{{c}}_{\ell}$
is evaluated outside of the generative model and fed back into the model. The generative model can, therefore, be treated as an independent module interacting with the generic calibration framework. The iterative calibration procedure starts with default calibration parameters
 $\boldsymbol{{c}}_{\ell}^{(0)}=\textbf{0}$
for all features
$\boldsymbol{{c}}_{\ell}^{(0)}=\textbf{0}$
for all features
 $\ell$
to be calibrated. The generative model accepts the calibration tuple
$\ell$
to be calibrated. The generative model accepts the calibration tuple
 $\boldsymbol{{C}}^{(s)}$
and the simulation count
$\boldsymbol{{C}}^{(s)}$
and the simulation count
 $K^{(s+1)}$
as input, and it applies the calibration parameters
$K^{(s+1)}$
as input, and it applies the calibration parameters
 $\boldsymbol{{c}}_{\ell}^{(s)}$
to the respective modules
$\boldsymbol{{c}}_{\ell}^{(s)}$
to the respective modules
 $\ell$
. The generative model provides
$\ell$
. The generative model provides
 $K^{(s+1)}$
sets containing simulated claims for the observation period T as an output. The calibration framework compares the simulated sets with the observed set and derives an updated calibration tuple
$K^{(s+1)}$
sets containing simulated claims for the observation period T as an output. The calibration framework compares the simulated sets with the observed set and derives an updated calibration tuple
 $\boldsymbol{{C}}^{(s+1)}$
(see Section 5.2).
$\boldsymbol{{C}}^{(s+1)}$
(see Section 5.2).
The challenge is to derive adequate statistics that permit the evaluation of the calibration parameters
 $\boldsymbol{{c}}_{\ell}$
. This challenge is addressed by introducing a generic claim object
$\boldsymbol{{c}}_{\ell}$
. This challenge is addressed by introducing a generic claim object
 $\boldsymbol{{L}}$
that covers the rating needs (see Figure 4):
$\boldsymbol{{L}}$
that covers the rating needs (see Figure 4):
 \begin{equation} \begin{array}{l@{\quad}c@{\quad}l}\boldsymbol{{L}} & \;:\!=\; & \left(\boldsymbol{{D}}, s, t^{occ}, t^{rep}, [t^{clo}], \left\{(I_i,t_i)\right\}_{1\le i \le N^I}, \left\{(P_j,t_j)\right\}_{1\le j \le N^P} \right) \\[5pt] \end{array}\end{equation}
\begin{equation} \begin{array}{l@{\quad}c@{\quad}l}\boldsymbol{{L}} & \;:\!=\; & \left(\boldsymbol{{D}}, s, t^{occ}, t^{rep}, [t^{clo}], \left\{(I_i,t_i)\right\}_{1\le i \le N^I}, \left\{(P_j,t_j)\right\}_{1\le j \le N^P} \right) \\[5pt] \end{array}\end{equation}
where the tuple
 $\boldsymbol{{D}}$
is a descriptor comprising the static claim features (see Section 3.3), s the status of the claim (
$\boldsymbol{{D}}$
is a descriptor comprising the static claim features (see Section 3.3), s the status of the claim (
 $\textrm{`open'}$
,
$\textrm{`open'}$
,
 $\textrm{`closed'}$
, or
$\textrm{`closed'}$
, or
 $\textrm{`re-opened'}$
),
$\textrm{`re-opened'}$
),
 $t^{occ}$
the occurrence (accident) date,
$t^{occ}$
the occurrence (accident) date,
 $t^{rep}$
the reporting date,
$t^{rep}$
the reporting date,
 $t^{clo}$
the closure date (in the case
$t^{clo}$
the closure date (in the case
 $s=\textrm{`closed'}$
),
$s=\textrm{`closed'}$
),
 $N^I$
the count of incurred adjustments,
$N^I$
the count of incurred adjustments,
 $I_i$
the incurred amount as estimated at time
$I_i$
the incurred amount as estimated at time
 $t_i$
,
$t_i$
,
 $N^P$
the count of payments, and
$N^P$
the count of payments, and
 $P_j$
the cumulative paid amount at time
$P_j$
the cumulative paid amount at time
 $t_j^+$
. The claim object
$t_j^+$
. The claim object
 $\boldsymbol{{L}}$
is thus composed of multiple partially interdependent random variables.
$\boldsymbol{{L}}$
is thus composed of multiple partially interdependent random variables.
Some cedents evaluate the development patterns at discrete points in time (e.g., on an annual basis). The observation period T is then decomposed into
 $N^T$
discrete subperiods of length
$N^T$
discrete subperiods of length
 $\Delta t = T / N^T$
and the representation of the claims along the timeline is aligned with the time grid
$\Delta t = T / N^T$
and the representation of the claims along the timeline is aligned with the time grid
 $\{t_0, \dots, t_{N^T}\}$
. The patterns I(t) and P(t) are approximated with
$\{t_0, \dots, t_{N^T}\}$
. The patterns I(t) and P(t) are approximated with
 $\left\{(t_k, P_k,I_k)\right\}_{0 \le k \le N^T}$
where
$\left\{(t_k, P_k,I_k)\right\}_{0 \le k \le N^T}$
where
 $t_k = t_0 + \Delta t \cdot k$
,
$t_k = t_0 + \Delta t \cdot k$
,
 $I_k=I(t_k^+)$
, and
$I_k=I(t_k^+)$
, and
 $P_k=P(t_k^+)$
.
$P_k=P(t_k^+)$
.
The simulated claims and the observed claims are represented by elements
 $\omega$
within the high-dimensional sample space
$\omega$
within the high-dimensional sample space
 $\Omega$
, and the generative model is calibrated if the observed claims are ‘close’ to the simulated claims, that is, if they are located within the highest density region(s)
$\Omega$
, and the generative model is calibrated if the observed claims are ‘close’ to the simulated claims, that is, if they are located within the highest density region(s)
 $HDR\;:\!=\;\{H_i\} \subset \Omega$
defined as follows (see also Lee, Reference Lee2012):
$HDR\;:\!=\;\{H_i\} \subset \Omega$
defined as follows (see also Lee, Reference Lee2012):
-
1. The sub-spaces
 $H_i$
and
$H_j$
are disjunct:
$i \neq j \rightarrow H_i \cap H_j = \{\}$
.
$H_i$
and
$H_j$
are disjunct:
$i \neq j \rightarrow H_i \cap H_j = \{\}$
. -
2. The density within the HDR equals or exceeds the threshold density
$p_0$
, that is, we have
$p(\omega) \ge p_0$
for all
$\omega \in HDR$
and
$p(\omega)<p_0$
for all
$\omega \in \Omega \setminus HDR$
. -
3. The threshold density
$p_0$
is determined by the condition
$\Pr(\omega \in HDR \mid\omega \in \Omega) \overset{!}{=} P_{HDR}$
, for example,
$P_{HDR}= 95\%$
.











Identifying the HDR is easy in the case of low-dimensional, uni-modal parametric probability distributions and extremely difficult in the case of high-dimensional, multi-modal, nonparametric probability distributions. The calibration criterion is formalized with the following sets containing the observed claims
 $\boldsymbol{{L}}^{obs}_{o,i}$
and the simulated claims
$\boldsymbol{{L}}^{obs}_{o,i}$
and the simulated claims
 $\boldsymbol{{L}}^{sim}_{o,i,k}$
:
$\boldsymbol{{L}}^{sim}_{o,i,k}$
:
 \begin{equation} \begin{array}{l@{\quad}c@{\quad}l@{\quad}c@{\quad}l}\mathcal{S}_{k=0} & \;:\!=\; & \mathcal{S}^{obs} & \;:\!=\; &\left\{ \left\{ \boldsymbol{{L}}^{obs}_{o,i} \right\}_{1 \le i \le N^{rep}_o}\right\}_{-T \le o \le -1} \\[5pt] \mathcal{S}_{k>0} & \;:\!=\; & \mathcal{S}^{sim}_k & \;:\!=\; & \left\{ \left\{ \boldsymbol{{L}}^{sim}_{o,i,k} \right\}_{1 \le i \le N^{rep}_{o,k}}\right\}_{-T \le o \le -1} \; \textrm{for} \; k \in \{1, \dots, K\} \\[5pt] \end{array}\end{equation}
\begin{equation} \begin{array}{l@{\quad}c@{\quad}l@{\quad}c@{\quad}l}\mathcal{S}_{k=0} & \;:\!=\; & \mathcal{S}^{obs} & \;:\!=\; &\left\{ \left\{ \boldsymbol{{L}}^{obs}_{o,i} \right\}_{1 \le i \le N^{rep}_o}\right\}_{-T \le o \le -1} \\[5pt] \mathcal{S}_{k>0} & \;:\!=\; & \mathcal{S}^{sim}_k & \;:\!=\; & \left\{ \left\{ \boldsymbol{{L}}^{sim}_{o,i,k} \right\}_{1 \le i \le N^{rep}_{o,k}}\right\}_{-T \le o \le -1} \; \textrm{for} \; k \in \{1, \dots, K\} \\[5pt] \end{array}\end{equation}
where
 $N^{rep}_o$
is the count of reported claims for the occurrence year o, K is the number of simulations runs,
$N^{rep}_o$
is the count of reported claims for the occurrence year o, K is the number of simulations runs,
 $N^{rep}_{o,k}$
is the count of simulated claims with
$N^{rep}_{o,k}$
is the count of simulated claims with
 $t^{rep}_{o,i,k} \le t^{sub}$
generated in the
$t^{rep}_{o,i,k} \le t^{sub}$
generated in the
 $k^{th}$
run for the occurrence year o, and
$k^{th}$
run for the occurrence year o, and
 $t^{sub}$
is the submission date. The generative model is adequately calibrated if the observed set
$t^{sub}$
is the submission date. The generative model is adequately calibrated if the observed set
 $\mathcal{S}_0$
cannot be identified as an outlier within the set of sets
$\mathcal{S}_0$
cannot be identified as an outlier within the set of sets
 $\left\{ \mathcal{S}_k \right\}_{0 \le k \le K}$
. The challenge is defining appropriate metrics that permit quantifying this criterion and deriving the calibration tuple
$\left\{ \mathcal{S}_k \right\}_{0 \le k \le K}$
. The challenge is defining appropriate metrics that permit quantifying this criterion and deriving the calibration tuple
 $\boldsymbol{{C}}$
in the case of a mismatch.
$\boldsymbol{{C}}$
in the case of a mismatch.
4.2. Roadmap for a solution
The n-dimensional sample space
 $\Omega$
(with
$\Omega$
(with
 $n\approx 2\cdot N^T$
in the grid representation) must be decomposed, that is, the high-dimensional tuples describing the patterns I(t) and P(t) must be projected to low-dimensional objects. This is accomplished by identifying the relevant features of the claims, that is, the high-dimensional claim objects
$n\approx 2\cdot N^T$
in the grid representation) must be decomposed, that is, the high-dimensional tuples describing the patterns I(t) and P(t) must be projected to low-dimensional objects. This is accomplished by identifying the relevant features of the claims, that is, the high-dimensional claim objects
 $\boldsymbol{{L}}$
(4.1) are projected to low-dimensional tuples
$\boldsymbol{{L}}$
(4.1) are projected to low-dimensional tuples
 $\boldsymbol{{Z}}$
:
$\boldsymbol{{Z}}$
:
 \begin{equation*}\begin{array}{l@{\quad}c@{\quad}l@{\quad}c@{\quad}l}\boldsymbol{\zeta} & : & \boldsymbol{{L}} & \mapsto & \boldsymbol{{Z}}=(Z_1, \dots, Z_M) \\[5pt] \boldsymbol{\zeta}_{\ell} & : & \boldsymbol{{L}} & \mapsto & {Z_{\ell}} \end{array}\end{equation*}
\begin{equation*}\begin{array}{l@{\quad}c@{\quad}l@{\quad}c@{\quad}l}\boldsymbol{\zeta} & : & \boldsymbol{{L}} & \mapsto & \boldsymbol{{Z}}=(Z_1, \dots, Z_M) \\[5pt] \boldsymbol{\zeta}_{\ell} & : & \boldsymbol{{L}} & \mapsto & {Z_{\ell}} \end{array}\end{equation*}
This is done with the calibration scope in mind, and this objective leads to the constraint
 $\dim(\boldsymbol{{Z}}) \overset{!}{=} \dim(\boldsymbol{{C}}) = M \ll \dim(\boldsymbol{{L}})=n$
, where the calibration tuple
$\dim(\boldsymbol{{Z}}) \overset{!}{=} \dim(\boldsymbol{{C}}) = M \ll \dim(\boldsymbol{{L}})=n$
, where the calibration tuple
 $\boldsymbol{{C}}=(\boldsymbol{{c}}_1, \dots, \boldsymbol{{c}}_M)$
contains the calibration parameters
$\boldsymbol{{C}}=(\boldsymbol{{c}}_1, \dots, \boldsymbol{{c}}_M)$
contains the calibration parameters
 $\boldsymbol{{c}}_{\ell}$
to be applied to the features
$\boldsymbol{{c}}_{\ell}$
to be applied to the features
 $\ell$
within the generative model.
$\ell$
within the generative model.
Remark 4.1. A calibration parameter
 $\boldsymbol{{c}}_{\ell}$
(a scalar or a low-dimensional vector) is assigned to each feature
$\boldsymbol{{c}}_{\ell}$
(a scalar or a low-dimensional vector) is assigned to each feature
 $\ell$
of the generative model, but the actual calibration might be confined to a subset of these features.
$\ell$
of the generative model, but the actual calibration might be confined to a subset of these features.
Ideally,
 $\boldsymbol{{Z}}$
is defined on an orthogonal basis while preserving the key features of the claim
$\boldsymbol{{Z}}$
is defined on an orthogonal basis while preserving the key features of the claim
 $\boldsymbol{{L}}$
. The component
$\boldsymbol{{L}}$
. The component
 ${Z_{\ell}}$
then strongly responds to the corresponding calibration parameter
${Z_{\ell}}$
then strongly responds to the corresponding calibration parameter
 $\boldsymbol{{c}}_{\ell}$
, and it is insensitive to all other calibration parameters (i.e., the non-diagonal elements in the Jacobi matrix
$\boldsymbol{{c}}_{\ell}$
, and it is insensitive to all other calibration parameters (i.e., the non-diagonal elements in the Jacobi matrix
 ${\partial Z_i}(\boldsymbol{{C}}) / \partial \boldsymbol{{c}}_j$
are insignificant compared to the diagonal elements).
${\partial Z_i}(\boldsymbol{{C}}) / \partial \boldsymbol{{c}}_j$
are insignificant compared to the diagonal elements).
The simulation process implemented in the generative model aims to replicate the generative process leading to the observed claims. The projection
 $\boldsymbol{\zeta}$
is, therefore, applied to the observed claims
$\boldsymbol{\zeta}$
is, therefore, applied to the observed claims
 $\boldsymbol{{L}}^{obs}_{o,j}$
and the simulated claims
$\boldsymbol{{L}}^{obs}_{o,j}$
and the simulated claims
 $\boldsymbol{{L}}^{sim}_{o,i,k}$
. The sets containing the observed and the simulated reduced claim components
$\boldsymbol{{L}}^{sim}_{o,i,k}$
. The sets containing the observed and the simulated reduced claim components
 ${Z_{\ell}}_{,\kappa}\;:\!=\;\boldsymbol{\zeta}_{\ell}(\boldsymbol{{L}}_{\kappa})$
are used to calibrate the feature
${Z_{\ell}}_{,\kappa}\;:\!=\;\boldsymbol{\zeta}_{\ell}(\boldsymbol{{L}}_{\kappa})$
are used to calibrate the feature
 $\ell$
within the generative model (see Section 5.2). Any distortion in the observed variables is replicated in the simulated variables, and there is no need for the marginal random variables
$\ell$
within the generative model (see Section 5.2). Any distortion in the observed variables is replicated in the simulated variables, and there is no need for the marginal random variables
 ${Z_{\ell}}_{,\kappa}$
to be iid.
${Z_{\ell}}_{,\kappa}$
to be iid.
4.3. Tuple with reduced random variables
The calibration procedure is used for an overall adjustment of the frequencies, the severities, the lags, and the pattern counts. The patterns are thus characterized by respective representative statistics as captured in the following reduced claim representation
 $\boldsymbol{{Z}}_{\kappa} = \boldsymbol{\zeta}(\boldsymbol{{L}}_{\kappa})$
:
$\boldsymbol{{Z}}_{\kappa} = \boldsymbol{\zeta}(\boldsymbol{{L}}_{\kappa})$
:
 \begin{equation} \boldsymbol{{Z}}_{\kappa} \;:\!=\; \left(t^{occ}_{\kappa}, (N^{inc}_{\kappa}, N^{rep}_{\kappa}, \tau^{rep}_{\kappa}), (N^{clo}_{\kappa}, \tau^{clo}_{\kappa}), (N^I_{\kappa}, I^*_{\kappa}, \tau^I_{\kappa}), (N^P_{\kappa}, P^*_{\kappa}, \tau^P_{\kappa}) \right) \end{equation}
\begin{equation} \boldsymbol{{Z}}_{\kappa} \;:\!=\; \left(t^{occ}_{\kappa}, (N^{inc}_{\kappa}, N^{rep}_{\kappa}, \tau^{rep}_{\kappa}), (N^{clo}_{\kappa}, \tau^{clo}_{\kappa}), (N^I_{\kappa}, I^*_{\kappa}, \tau^I_{\kappa}), (N^P_{\kappa}, P^*_{\kappa}, \tau^P_{\kappa}) \right) \end{equation}
where the index ‘
 $\kappa \equiv o,i$
’ indicates the
$\kappa \equiv o,i$
’ indicates the
 $i^{\textrm{th}}$
claim in occurrence year o in the case of observed claims and ‘
$i^{\textrm{th}}$
claim in occurrence year o in the case of observed claims and ‘
 $\kappa \equiv o,i,k$
’ the
$\kappa \equiv o,i,k$
’ the
 $i^\textrm{th}$
claim in occurrence year o in the
$i^\textrm{th}$
claim in occurrence year o in the
 $k^{\textrm{th}}$
simulation run in the case of simulated claims.
$k^{\textrm{th}}$
simulation run in the case of simulated claims.
All variables
 ${Z_{\ell}}_{,o,i[,k]}$
are defined in Table 2 on a claim level, aggregated into
${Z_{\ell}}_{,o,i[,k]}$
are defined in Table 2 on a claim level, aggregated into
 ${Z_{\ell}}_{,o[,k]}$
on an annual level, and into
${Z_{\ell}}_{,o[,k]}$
on an annual level, and into
 ${Z_{\ell}}_{[,k]}$
on a period level (Table 2 comprises the extra variable
${Z_{\ell}}_{[,k]}$
on a period level (Table 2 comprises the extra variable
 $N^0_{o[,k]}$
indicating claim-free years).
$N^0_{o[,k]}$
indicating claim-free years).
Table 2. Comprehensive list with reduced random variables
 $\boldsymbol{{Z}}$
on a claim level, an annual level, and a period level.
$\boldsymbol{{Z}}$
on a claim level, an annual level, and a period level.

Remark 4.2. The structure of the claim objects
 $\boldsymbol{{L}}_{\kappa}$
and the constraints determine the structure of the reduced random variables
$\boldsymbol{{L}}_{\kappa}$
and the constraints determine the structure of the reduced random variables
 $\boldsymbol{{Z}}_{\kappa}$
. The reduced variables introduced in (4.3) and defined in Table 2 capture the key features of a claim. Some variables are, however, interdependent (see Section 5.3.1). A subset is thus chosen for calibration, and the remaining variables are used as test variables.
$\boldsymbol{{Z}}_{\kappa}$
. The reduced variables introduced in (4.3) and defined in Table 2 capture the key features of a claim. Some variables are, however, interdependent (see Section 5.3.1). A subset is thus chosen for calibration, and the remaining variables are used as test variables.
The relationship between
 $\boldsymbol{{Z}}_{\kappa}$
and
$\boldsymbol{{Z}}_{\kappa}$
and
 $\boldsymbol{{L}}_{\kappa}$
, the temporal evolution of the incurred amount
$\boldsymbol{{L}}_{\kappa}$
, the temporal evolution of the incurred amount
 $I_{\kappa}(t)$
, the cumulative paid amount
$I_{\kappa}(t)$
, the cumulative paid amount
 $P_{\kappa}(t)$
, and the two reduced random variables
$P_{\kappa}(t)$
, and the two reduced random variables
 $\tau^I_{\kappa}(t)$
and
$\tau^I_{\kappa}(t)$
and
 $\tau^P_{\kappa}(t)$
are shown in Figures 3 and 4. The incurred lag
$\tau^P_{\kappa}(t)$
are shown in Figures 3 and 4. The incurred lag
 $\tau^I_{\kappa}(t)$
evaluated at time
$\tau^I_{\kappa}(t)$
evaluated at time
 $t > t^{rep}_{\kappa}$
can either be larger, equal, or smaller than the reporting lag
$t > t^{rep}_{\kappa}$
can either be larger, equal, or smaller than the reporting lag
 $\tau^{rep}_{\kappa}$
. The three cases correspond to an adverse, adequate, and favorable IBNER development, respectively. The paid lag
$\tau^{rep}_{\kappa}$
. The three cases correspond to an adverse, adequate, and favorable IBNER development, respectively. The paid lag
 $\tau^P_{\kappa}(t)$
evaluated at time
$\tau^P_{\kappa}(t)$
evaluated at time
 $t > t^{rep}_{\kappa}$
is always larger than the reporting lag
$t > t^{rep}_{\kappa}$
is always larger than the reporting lag
 $\tau^{rep}_{\kappa}$
(losses are paid post claims being made).
$\tau^{rep}_{\kappa}$
(losses are paid post claims being made).

Figure 3. Claim representation and reduced variables (‘
 $\kappa \equiv o,i$
’ or ‘
$\kappa \equiv o,i$
’ or ‘
 $\kappa\equiv o,i,k$
’). The available information, that is, the occurrence date
$\kappa\equiv o,i,k$
’). The available information, that is, the occurrence date
 $t_{\kappa}^{occ}$
, the reporting date
$t_{\kappa}^{occ}$
, the reporting date
 $t^{rep}_{\kappa}$
, the submission date
$t^{rep}_{\kappa}$
, the submission date
 $t^{sub}$
, the incurred pattern
$t^{sub}$
, the incurred pattern
 $I_{\kappa}(t)$
(a), and the paid pattern
$I_{\kappa}(t)$
(a), and the paid pattern
 $P_{\kappa}(t)$
(b) are shown in black. The derived reduced variables, that is, the reporting lag
$P_{\kappa}(t)$
(b) are shown in black. The derived reduced variables, that is, the reporting lag
 $\tau^{rep}_{\kappa}$
, the incurred amount
$\tau^{rep}_{\kappa}$
, the incurred amount
 $I^*_{\kappa}$
, the incurred lag
$I^*_{\kappa}$
, the incurred lag
 $\tau_{\kappa}^{I}$
, the count of incurred adjustments
$\tau_{\kappa}^{I}$
, the count of incurred adjustments
 $N_{\kappa}^{I}$
, the cumulative paid amount
$N_{\kappa}^{I}$
, the cumulative paid amount
 $P_{\kappa}^*$
, the paid lag
$P_{\kappa}^*$
, the paid lag
 $\tau_{\kappa}^{P}$
, and the count of payments
$\tau_{\kappa}^{P}$
, and the count of payments
 $N_{\kappa}^{P}$
are shown in gray (see definitions in Table 2). The temporal development is taken from the ‘increase’ case shown in Figure 4 by evaluating the patterns at time
$N_{\kappa}^{P}$
are shown in gray (see definitions in Table 2). The temporal development is taken from the ‘increase’ case shown in Figure 4 by evaluating the patterns at time
 $t=75 \textrm{ [months]}$
.
$t=75 \textrm{ [months]}$
.

Figure 4. Patterns and lags as defined in Table 2 and Figure 3 (t in months [mos.] since
 $t^{occ}$
and ‘
$t^{occ}$
and ‘
 $\kappa \equiv o,i$
’ or ‘
$\kappa \equiv o,i$
’ or ‘
 $\kappa\equiv o,i,k$
’). (a) The solid gray curve shows the temporal evolution of the cumulative paid amount
$\kappa\equiv o,i,k$
’). (a) The solid gray curve shows the temporal evolution of the cumulative paid amount
 $P_{\kappa}(t)$
. The other curves depict five examples for the development of the incurred amount
$P_{\kappa}(t)$
. The other curves depict five examples for the development of the incurred amount
 $I_{\kappa}(t)$
. Two adverse cases are represented by ‘dash-dotted’ lines, the adequate case by a ‘solid’ line, and two favorable cases by ’dashed’ lines. (b) Temporal evolution of the respective incurred lags
$I_{\kappa}(t)$
. Two adverse cases are represented by ‘dash-dotted’ lines, the adequate case by a ‘solid’ line, and two favorable cases by ’dashed’ lines. (b) Temporal evolution of the respective incurred lags
 $\tau^I_{\kappa}(t)$
. The incurred lags are initially equal to the reporting lag
$\tau^I_{\kappa}(t)$
. The incurred lags are initially equal to the reporting lag
 $\tau^{rep}_{\kappa}=15 \textrm{ [months]}$
, and they subsequently increase in the ‘adverse’ cases, remain stable in the ‘adequate’ case, and decrease in the ‘favorable’ cases. (c) Temporal evolution of the respective paid-over-incurred ratios
$\tau^{rep}_{\kappa}=15 \textrm{ [months]}$
, and they subsequently increase in the ‘adverse’ cases, remain stable in the ‘adequate’ case, and decrease in the ‘favorable’ cases. (c) Temporal evolution of the respective paid-over-incurred ratios
 $P_{\kappa}(t)/I_{\kappa}(t)$
. (d) Temporal evolution of the paid lags
$P_{\kappa}(t)/I_{\kappa}(t)$
. (d) Temporal evolution of the paid lags
 $\tau^P_{\kappa}(t)$
for the five cases of incurred patterns.
$\tau^P_{\kappa}(t)$
for the five cases of incurred patterns.

Figure 5. Calibration of the annual ‘observations’
 $N_o$
(depicted by diamonds). The pmfs of the models for the occurrence years
$N_o$
(depicted by diamonds). The pmfs of the models for the occurrence years
 $o \in \{ -T, \dots,-1 \}$
(with
$o \in \{ -T, \dots,-1 \}$
(with
 $T=12$
), the resulting pmf of the average over the period (plotted at
$T=12$
), the resulting pmf of the average over the period (plotted at
 $o=0$
), and the projection (plotted at
$o=0$
), and the projection (plotted at
 $o=+1$
) are shown in the upper part of the four charts. The fitted
$o=+1$
) are shown in the upper part of the four charts. The fitted
 ${\log}\mathcal{N}$
distributions are shown in the lower part, and ticks indicate the means and standard deviations. The distributions shown in (c) and (d) are obtained by rerunning the, respectively, calibrated models.
${\log}\mathcal{N}$
distributions are shown in the lower part, and ticks indicate the means and standard deviations. The distributions shown in (c) and (d) are obtained by rerunning the, respectively, calibrated models.

5. Bayesian inference and model calibration
5.1. Bayesian inference
The Bayesian interpretation combines prior knowledge with observed data when estimating the parameters of parametric probability distributions. It distinguishes between the intrinsic uncertainty stemming from the stochastic process and the epistemic uncertainty stemming from the uncertainty in the parameter estimates (see Figures 6 and 7). This so-called Bayesian inference is particularly convenient when applied to conjugate priors (Fink, Reference Fink1997; Gelman, Reference Gelman2013; Klugman et al., Reference Klugman, Panjer and Willmot2019; Parr et al., Reference Parr, Pezzulo and Friston2022; Palmer, Reference Palmer2022; Murphy, Reference Murphy2023). Depending on the kind of distributions, a closed form might be available for the posterior predictive distribution (Fink, Reference Fink1997). However, Bayesian inference is also applicable in situations that deviate from the ideal case, that is, when the observed random variables are not iid or when dealing with nonparametric probability distributions (Parr et al., Reference Parr, Pezzulo and Friston2022; Palmer, Reference Palmer2022; Murphy, Reference Murphy2023).

Figure 6. Conditional calibration statistics. The calibration of the sample model presented in Figure 5 is run 100 times, conditional on the given set of observations
 $\{N_o\}_{-T \leq o \leq -1}$
. The simulated differential cdfs
$\{N_o\}_{-T \leq o \leq -1}$
. The simulated differential cdfs
 $F(\Delta X)$
(with
$F(\Delta X)$
(with
 ${\Delta X}^{(m)}\;:\!=\; X^{(m)} -\mathbb{E}[X]$
) are depicted in the four panels. Top: Deviation statistics for the scale-only calibration. Bottom: Deviation statistics for the linear-trend calibration. Left: Deviation statistics for the scale parameters a and c, and the trend parameter
${\Delta X}^{(m)}\;:\!=\; X^{(m)} -\mathbb{E}[X]$
) are depicted in the four panels. Top: Deviation statistics for the scale-only calibration. Bottom: Deviation statistics for the linear-trend calibration. Left: Deviation statistics for the scale parameters a and c, and the trend parameter
 $b^*=b \cdot (T-1)$
, respectively. Right: Resulting deviation statistics for the overall mean
$b^*=b \cdot (T-1)$
, respectively. Right: Resulting deviation statistics for the overall mean
 $\hat{\mu}$
, the calibrated means at
$\hat{\mu}$
, the calibrated means at
 $o=-T$
and
$o=-T$
and
 $o=-1$
, and the projected mean at
$o=-1$
, and the projected mean at
 $o=+1$
.
$o=+1$
.

Figure 7. Unconditional calibration statistics. Deviation statistics as shown in Figure 6 (note the different scales), but without conditioning on
 $\{N_o\}_{-T \leq o \leq -1}$
, that is, a new set of observations
$\{N_o\}_{-T \leq o \leq -1}$
, that is, a new set of observations
 $\{{N_o}^{(m)} \}_{-T \leq o \leq -1}$
is drawn for each simulation run
$\{{N_o}^{(m)} \}_{-T \leq o \leq -1}$
is drawn for each simulation run
 $m \in \{1, \dots, 100 \}$
.
$m \in \{1, \dots, 100 \}$
.
The observed random variables
 $\boldsymbol{{L}}_{\kappa}^{obs}$
are complex objects emanating from real-world generative processes that evolve over time. They cannot be used directly for evaluating the calibration tuple
$\boldsymbol{{L}}_{\kappa}^{obs}$
are complex objects emanating from real-world generative processes that evolve over time. They cannot be used directly for evaluating the calibration tuple
 $\boldsymbol{{C}}$
to be applied to the exposure-based generative model; the model is, therefore, calibrated with reduced random variables
$\boldsymbol{{C}}$
to be applied to the exposure-based generative model; the model is, therefore, calibrated with reduced random variables
 $\boldsymbol{{Z}}_{\kappa}^{obs}$
(see Section 4.3 and Table 2).
$\boldsymbol{{Z}}_{\kappa}^{obs}$
(see Section 4.3 and Table 2).
Applying Bayesian inference requires that the ‘conditional distributions’ and the respective ‘prior distributions’ are represented (or approximated) by parametric distributions. The parameters to be calibrated are identified, the respective prior distributions are specified, and the posterior estimates are fed back into the generative model. This is accomplished with scaling factors applied to corresponding parameters that determine the frequency, the severity, and the development patterns. The incurred lag is, however, either positive or negative; thus, a ‘translate’ parameter is used to calibrate the incurred pattern.
A Monte Carlo simulation generates claim objects
 $\boldsymbol{{L}}_{\kappa}^{sim}$
that replicate all relevant features of the observed claims
$\boldsymbol{{L}}_{\kappa}^{sim}$
that replicate all relevant features of the observed claims
 $\boldsymbol{{L}}_{\kappa}^{obs}$
. The simulated claims and the observed claims are reduced and denoted
$\boldsymbol{{L}}_{\kappa}^{obs}$
. The simulated claims and the observed claims are reduced and denoted
 $\boldsymbol{{X}}_{\kappa}\;:\!=\;\boldsymbol{\zeta}(\boldsymbol{{L}}_{\kappa}^{sim})$
and
$\boldsymbol{{X}}_{\kappa}\;:\!=\;\boldsymbol{\zeta}(\boldsymbol{{L}}_{\kappa}^{sim})$
and
 $\boldsymbol{{Y}}_{\kappa}\;:\!=\;\boldsymbol{\zeta}(\boldsymbol{{L}}_{\kappa}^{obs})$
, respectively. Data slices
$\boldsymbol{{Y}}_{\kappa}\;:\!=\;\boldsymbol{\zeta}(\boldsymbol{{L}}_{\kappa}^{obs})$
, respectively. Data slices
 $\mathcal{X}_{\ell,o}$
and
$\mathcal{X}_{\ell,o}$
and
 $\mathcal{Y}_{\ell,o}$
containing the simulated random variables
$\mathcal{Y}_{\ell,o}$
containing the simulated random variables
 ${X_{\ell}}_{,o,i,k}$
and the observed random variables
${X_{\ell}}_{,o,i,k}$
and the observed random variables
 ${Y_{\ell}}_{,o,j}$
on a claim level, respectively, are extracted for the feature
${Y_{\ell}}_{,o,j}$
on a claim level, respectively, are extracted for the feature
 $\ell$
and the occurrence year o.
$\ell$
and the occurrence year o.
Marginal probability distributions
 $f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell})\;:\!=\;f_{\ell}(x;\; \boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}))$
are derived by fitting the parametric distributions
$f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell})\;:\!=\;f_{\ell}(x;\; \boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}))$
are derived by fitting the parametric distributions
 $f_{\ell}(x;\; \boldsymbol{\theta}^0_{\ell,o})$
to the simulated distributions
$f_{\ell}(x;\; \boldsymbol{\theta}^0_{\ell,o})$
to the simulated distributions
 $g(x \mid \mathcal{X}_{\ell,o})$
and by linking the parameter tuple
$g(x \mid \mathcal{X}_{\ell,o})$
and by linking the parameter tuple
 $\boldsymbol{\theta}_{\ell,o}$
to the calibration parameter
$\boldsymbol{\theta}_{\ell,o}$
to the calibration parameter
 $\boldsymbol{{c}}_{\ell}$
(see Section 5.2). Applying Bayesian inference permits us to derive posterior distributions
$\boldsymbol{{c}}_{\ell}$
(see Section 5.2). Applying Bayesian inference permits us to derive posterior distributions
 $p(\boldsymbol{{c}}_{\ell})$
and maximum a posteriori (MAP) estimates for the parameters
$p(\boldsymbol{{c}}_{\ell})$
and maximum a posteriori (MAP) estimates for the parameters
 $\boldsymbol{{c}}_{\ell}$
given the observations
$\boldsymbol{{c}}_{\ell}$
given the observations
 $\mathcal{Y}_{\ell,o}$
. The calibration is either performed with calibration scalars
$\mathcal{Y}_{\ell,o}$
. The calibration is either performed with calibration scalars
 ${c_{\ell}}$
or with calibration vectors, for example,
${c_{\ell}}$
or with calibration vectors, for example,
 $\boldsymbol{{c}}_{\ell}\;:\!=\;({a_{\ell}}, {b_{\ell}})$
in the case of a linear-trend calibration. Analogous procedures are applied if the calibration is performed on an annual level or a period level.
$\boldsymbol{{c}}_{\ell}\;:\!=\;({a_{\ell}}, {b_{\ell}})$
in the case of a linear-trend calibration. Analogous procedures are applied if the calibration is performed on an annual level or a period level.

5.2. Generic calibration process
5.2.1. Overview
Bayesian inference presupposes parametric probability distributions for the observed random variables and prior distributions for the calibration parameters. The probability distributions implemented within a generative model (considered an independent module) are not directly accessible by the generic calibration framework. The calibration framework furthermore involves probability distributions for multiple occurrence years o. Hence, the calibration is performed with the help of proxy distributions
 $f_{\ell}(x;\; \boldsymbol{\theta}_{\ell,o})$
fitted to the simulated probability distributions
$f_{\ell}(x;\; \boldsymbol{\theta}_{\ell,o})$
fitted to the simulated probability distributions
 $g(x \mid \mathcal{X}_{\ell,o}^c)$
derived from the sets
$g(x \mid \mathcal{X}_{\ell,o}^c)$
derived from the sets
 $\mathcal{X}_{\ell,o}^c$
containing the simulated claim-level random variables (respective probability distributions can be derived in an analogous way from annual-level sets
$\mathcal{X}_{\ell,o}^c$
containing the simulated claim-level random variables (respective probability distributions can be derived in an analogous way from annual-level sets
 $\mathcal{X}_{\ell,o}^a$
or from the period-level sets
$\mathcal{X}_{\ell,o}^a$
or from the period-level sets
 $\mathcal{X}_{\ell}^p$
):
$\mathcal{X}_{\ell}^p$
):
 \begin{equation} g(x \mid \mathcal{X}_{\ell,o}^c) \;:\!=\; \Pr(X=x\mid \mathcal{X}_{\ell,o}^c) = \frac{1}{\sum_{k=1}^K N_{o,k}^{rep}} \cdot \sum_{k=1}^K \sum_{i=1}^{N_{o,k}^{rep}} \mathbb{1}_{x={X_{\ell}}_{,o,i,k}}\end{equation}
\begin{equation} g(x \mid \mathcal{X}_{\ell,o}^c) \;:\!=\; \Pr(X=x\mid \mathcal{X}_{\ell,o}^c) = \frac{1}{\sum_{k=1}^K N_{o,k}^{rep}} \cdot \sum_{k=1}^K \sum_{i=1}^{N_{o,k}^{rep}} \mathbb{1}_{x={X_{\ell}}_{,o,i,k}}\end{equation}
Conditional annual probability distributions
 $f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell}) \;:\!=\; f_{\ell}(x;\;\boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}))$
are obtained by linking the parameter tuples
$f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell}) \;:\!=\; f_{\ell}(x;\;\boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}))$
are obtained by linking the parameter tuples
 $\boldsymbol{\theta}_{\ell,o}$
to the calibration parameter
$\boldsymbol{\theta}_{\ell,o}$
to the calibration parameter
 $\boldsymbol{{c}}_{\ell}$
.
$\boldsymbol{{c}}_{\ell}$
.
Remark 5.1. The selection of appropriate distribution families
 $f_{\ell}()$
for the model features
$f_{\ell}()$
for the model features
 $\ell$
depends on the variables
$\ell$
depends on the variables
 ${Z_{\ell}}_{,\kappa}=\boldsymbol{\zeta}_{\ell}(\boldsymbol{{L}}_{\kappa})$
being discrete or continuous, the support, the shape, the number of modes, and the tail behavior. The calibration is, however, determined by the HDR (see definition in Section 4.1) of the probability distribution. In the case of uni-modal distributions, it is thus not overly sensitive to the selection if the support and the first few moments are preserved (see Sections 6.3 and 6.6).
${Z_{\ell}}_{,\kappa}=\boldsymbol{\zeta}_{\ell}(\boldsymbol{{L}}_{\kappa})$
being discrete or continuous, the support, the shape, the number of modes, and the tail behavior. The calibration is, however, determined by the HDR (see definition in Section 4.1) of the probability distribution. In the case of uni-modal distributions, it is thus not overly sensitive to the selection if the support and the first few moments are preserved (see Sections 6.3 and 6.6).
The calibration is performed for each feature
 $\ell$
with the respective observed random variables
$\ell$
with the respective observed random variables
 ${Y_{\ell}}_{,o,j}$
, the simulated random variables
${Y_{\ell}}_{,o,j}$
, the simulated random variables
 ${X_{\ell}}_{,o,i,k}$
, and the priors
${X_{\ell}}_{,o,i,k}$
, and the priors
 $\pi(\boldsymbol{{c}}_{\ell})$
:
$\pi(\boldsymbol{{c}}_{\ell})$
:
-
1. Annual data slices
$\mathcal{Y}_{\ell,o}\;:\!=\;\{{Y_{\ell}}_{,o,j}\}_{1 \leq j \leq N_o^{obs}}$
and
$\mathcal{X}_{\ell,o}\;:\!=\;\{{X_{\ell}}_{,o,i,k}\}_{1 \leq i \leq N_{o,k}^{sim}, 1 \leq k \leq K}$
containing the observed reduced components
${Y_{\ell}}_{,o,j } = \boldsymbol{\zeta}_{\ell}(\boldsymbol{{L}}^{obs}_{o,j })$
and the simulated reduced components
${X_{\ell}}_{,o,i,k} = \boldsymbol{\zeta}_{\ell}(\boldsymbol{{L}}^{sim}_{o,i,k})$
, respectively, are extracted for the feature
$\ell$
. -
2. A parametric probability distribution family
$f_{\ell}()$
is used to specify conditional annual probability distributions
$f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell}) \;:\!=\; f_{\ell}(x;\; \boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}))$
. -
3. Annual prior parameters
$\boldsymbol{\theta}^0_{\ell,o}$
are obtained by fitting the distributions
$f_{\ell}(x;\;\boldsymbol{\theta}^0_{\ell,o})$
to the simulated marginal distributions
$g(x \mid \mathcal{X}_{\ell,o})$
(5.1).










Bayesian inference applied to the set of observations
 $\mathcal{Y}_{\ell} \;:\!=\; \{\mathcal{Y}_{\ell,o}\}_{-T \leq o \leq -1}$
is used to update the prior distribution
$\mathcal{Y}_{\ell} \;:\!=\; \{\mathcal{Y}_{\ell,o}\}_{-T \leq o \leq -1}$
is used to update the prior distribution
 $\boldsymbol{\pi}(\boldsymbol{{c}}_{\ell})$
for the calibration parameter
$\boldsymbol{\pi}(\boldsymbol{{c}}_{\ell})$
for the calibration parameter
 $\boldsymbol{{c}}_{\ell}$
, that is, to derive the conditional posterior distribution
$\boldsymbol{{c}}_{\ell}$
, that is, to derive the conditional posterior distribution
 $p(\boldsymbol{{c}}_{\ell} \mid \mathcal{Y}_{\ell})$
. This is accomplished by postulating
$p(\boldsymbol{{c}}_{\ell} \mid \mathcal{Y}_{\ell})$
. This is accomplished by postulating
 $\mathbb{E}_{\pi}[\boldsymbol{{c}}_{\ell}] \overset{!}{=} \textbf{0}$
and linking the calibration parameter
$\mathbb{E}_{\pi}[\boldsymbol{{c}}_{\ell}] \overset{!}{=} \textbf{0}$
and linking the calibration parameter
 $\boldsymbol{{c}}_{\ell}$
to the parameters
$\boldsymbol{{c}}_{\ell}$
to the parameters
 $\boldsymbol{\theta}_{\ell,o}$
with the condition
$\boldsymbol{\theta}_{\ell,o}$
with the condition
 $\boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}=\textbf{0}) \overset{!}{=} \boldsymbol{\theta}_{\ell,o}^0$
for all o (see Section 5.2.4). The tuple
$\boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}=\textbf{0}) \overset{!}{=} \boldsymbol{\theta}_{\ell,o}^0$
for all o (see Section 5.2.4). The tuple
 $\boldsymbol{\theta}_{\ell,o} = (\vartheta_{\ell,o}, [\varphi_{\ell,o}, \varsigma_{\ell,o}, \varrho_{\ell,o}, \dots])$
is assumed to comprise only one parameter
$\boldsymbol{\theta}_{\ell,o} = (\vartheta_{\ell,o}, [\varphi_{\ell,o}, \varsigma_{\ell,o}, \varrho_{\ell,o}, \dots])$
is assumed to comprise only one parameter
 $\vartheta_{\ell,o}$
that is linked to the calibration parameter
$\vartheta_{\ell,o}$
that is linked to the calibration parameter
 $\boldsymbol{{c}}_{\ell}$
, that is,
$\boldsymbol{{c}}_{\ell}$
, that is,
 $\boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}) = (\vartheta_{\ell,o}(\boldsymbol{{c}}_{\ell}), [\varphi_{\ell,o}^0, \varsigma_{\ell,o}^0, \varrho_{\ell,o}^0, \dots])$
with
$\boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}) = (\vartheta_{\ell,o}(\boldsymbol{{c}}_{\ell}), [\varphi_{\ell,o}^0, \varsigma_{\ell,o}^0, \varrho_{\ell,o}^0, \dots])$
with
 $\vartheta_{\ell,o}(\boldsymbol{{c}}_{\ell}=\textbf{0}) \overset{!}{=} \vartheta_{\ell,o}^0$
.
$\vartheta_{\ell,o}(\boldsymbol{{c}}_{\ell}=\textbf{0}) \overset{!}{=} \vartheta_{\ell,o}^0$
.
A scalar calibration parameter
 ${c_{\ell}}$
is used to jointly adjust the scale (or location) across all occurrence years o via conditional parameters
${c_{\ell}}$
is used to jointly adjust the scale (or location) across all occurrence years o via conditional parameters
 $\vartheta_{\ell,o}({c_{\ell}})$
(see Section 5.2.4). A two-dimensional calibration vector
$\vartheta_{\ell,o}({c_{\ell}})$
(see Section 5.2.4). A two-dimensional calibration vector
 $\boldsymbol{{c}}_{\ell} =({a_{\ell}},{b_{\ell}})$
is alternatively used to adjust the parameters
$\boldsymbol{{c}}_{\ell} =({a_{\ell}},{b_{\ell}})$
is alternatively used to adjust the parameters
 $\vartheta_{\ell,o}({c_{\ell}}_{,o})$
by postulating a linear trend
$\vartheta_{\ell,o}({c_{\ell}}_{,o})$
by postulating a linear trend
 ${c_{\ell}}_{,o}= {a_{\ell}}+{b_{\ell}} \cdot (o-o_0)$
(see Section 5.2.8).
${c_{\ell}}_{,o}= {a_{\ell}}+{b_{\ell}} \cdot (o-o_0)$
(see Section 5.2.8).
Remark 5.2. The procedure can – in principle – calibrate temporal developments that involve more than two parameters, for example, nonlinear trends or periodic processes. This is, however, rarely feasible in practice due to the scarcity of data and low signal-to-noise ratios.
The generic calibration procedure can be applied independently to each feature
 $\ell$
of the generative model (i.e., to the frequency generator, the severity generator, and the pattern generators) if the following conditions are (nearly) fulfilled:
$\ell$
of the generative model (i.e., to the frequency generator, the severity generator, and the pattern generators) if the following conditions are (nearly) fulfilled:
-
C1: The features
$\ell_1$
and
$\ell_2$
of a claim are independent:
$\ell_1 \ne \ell_2\ \rightarrow Y_{\ell_1, o, j_1} \perp \!\!\! \perp Y_{\ell_2, o, j_2}$
. -
C2: The occurrence years
$o_1$
and
$o_2$
are independent:
$o_1 \ne o_2 \rightarrow {Y_{\ell}}_{,o_1, j_1} \perp \!\!\! \perp {Y_{\ell}}_{,o_2, j_2}$
. -
C3: The
$N^{rep}_o$
claims reported for the occurrence year o are iid:
$ {Y_{\ell}}_{,o,j} \overset{iid}{\sim} f_{\ell}(\boldsymbol{\theta}_{\ell,o})$
.








The conditional marginal probability distributions
 $f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell})$
can be used to calibrate the distinctive features
$f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell})$
can be used to calibrate the distinctive features
 $\ell$
of the generative model (C1), probability distributions
$\ell$
of the generative model (C1), probability distributions
 $f_{\ell}(x;\;\boldsymbol{\theta}^0_{\ell,o})$
can be fitted to the simulated distributions
$f_{\ell}(x;\;\boldsymbol{\theta}^0_{\ell,o})$
can be fitted to the simulated distributions
 $g(x \mid \mathcal{X}_{\ell,o})$
derived for the occurrence years o (C2), and the conditional likelihood for observing the random variables in the sets
$g(x \mid \mathcal{X}_{\ell,o})$
derived for the occurrence years o (C2), and the conditional likelihood for observing the random variables in the sets
 $\mathcal{Y}_{\ell,o}$
can be evaluated (C3).
$\mathcal{Y}_{\ell,o}$
can be evaluated (C3).
Remark 5.3. Modified calibration procedures are applied in cases where these conditions are not fulfilled (see Section 5.3).
5.2.2. Calibration in three steps
The generic calibration procedure is first described for random variables defined on a claim level and then adapted to the annual and period levels (see definitions in Table 2).
-
1st step: A Monte Carlo simulation is run K times, and in run k the generative model draws the random counts
$N^{inc}_{o,k}$
, and it generates the random claims
$\boldsymbol{{L}}^{sim}_{o,j,k}$
for
$j \in \{1, \dots, N^{inc}_{o,k} \}$
and
$o \in \{-T, \dots, -1\}$
. The
$N^{rep}_{o,k}$
reported claims
$\boldsymbol{{L}}^{sim}_{o,i,k}$
(characterized by
$t^{rep}_{o,i,k} \le t^{sub}$
) are projected to the reduced random tuples
$\boldsymbol{{X}}_{o,i,k} \;:\!=\;(X_{1,o,i,k}, \dots, {X_{\ell}}_{,o,i,k}, \dots, X_{M,o,i,k})$
(a refined calibration approach that involves the incurred claims instead of the reported claims is described in Section 5.3.1). Following data slices
$\mathcal{X}_{\ell,o}^c$
containing the simulated random variables
${X_{\ell}}_{,o,i,k}$
for the feature
$\ell \in \{1, \dots, M \}$
in occurrence year
$o \in \{-T, \dots, -1 \}$
are extracted:(5.2)Respective data slices
\begin{equation} \mathcal{X}_{\ell,o}^c \;:\!=\; \left\{\left\{{X_{\ell}}_{,o,i,k}\right\}_{1 \le i \le N^{rep}_{o,k}}\right\}_{1 \le k \le K}\end{equation}
$\mathcal{X}_{\ell,o}^a$
and
$\mathcal{X}_{\ell}^p$
containing the aggregated random variables
${X_{\ell}}_{,o,k}$
and
${X_{\ell}}_{,k}$
can be extracted on an annual and a period level, respectively.
-
2nd step: A parametric distribution family
$f_{\ell}(x;\;\boldsymbol{\theta}_{\ell})$
is selected for each model feature
$\ell$
. Parametric probability distributions
$f_{\ell,o}^0(x)\;:\!=\;f_{\ell}(x;\; \boldsymbol{\theta}^{0}_{\ell,o})$
are fitted to the respective simulated distributions
$g_{\ell,o}(x)\;:\!=\;g(x \mid \mathcal{X}_{\ell,o})$
derived with (5.1) from the simulated sets
$\mathcal{X}_{\ell,o}$
. The parameters
$\boldsymbol{\theta}^{0}_{\ell,o} = (\vartheta^{0}_{\ell,o}, [\varphi^{0}_{\ell,o}, \varsigma^{0}_{\ell,o}, \varrho^{0}_{\ell,o}, \dots])$
are obtained with, for example, the method of moments (MM) fit or the maximum likelihood estimator (MLE) fit (see Example 6.1). -
3rd step: Conditional parameters
$\boldsymbol{\theta}_{\ell,o}(\boldsymbol{{c}}_{\ell}) = \left(\vartheta_{\ell,o}(\boldsymbol{{c}}_{\ell}), [\varphi^0_{\ell,o}, \varsigma^0_{\ell,o}, \varrho^0_{\ell,o}, \dots] \right)$
are linked to the calibration parameter
$ \boldsymbol{{c}}_{\ell}$
with the constraint
$\vartheta_{\ell,o}(\boldsymbol{{c}}_{\ell} = \textbf{0}) \overset{!}{=} \vartheta^{0}_{\ell,o}$
. The conditional probability distributions (5.3)derived for the occurrence years
\begin{equation} f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell}) \;:\!=\; f_{\ell}\left(x;\; \vartheta_{\ell,o}(\boldsymbol{{c}}_{\ell}), [\varphi^0_{\ell,o}, \varsigma^0_{\ell,o}, \varrho^0_{\ell,o}, \dots]\right)\end{equation}
$o \in \{-T, \dots, -1 \}$
are jointly representing the model feature
$\ell$
to be calibrated with the parameter
$\boldsymbol{{c}}_{\ell}$
. The conditional probability distributions
$f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell})$
are used as a proxy for determining the probabilities of the observations
${Y_{\ell}}_{,o,i}$
.
Bayes’ theorem is used to evaluate the conditional likelihood of
$\boldsymbol{{c}}_{\ell}$
given the prior distribution
$\pi(\boldsymbol{{c}}_{\ell})$
and the set
$\mathcal{Y}_{\ell}$
containing the observations, to derive the MAP estimate
$\boldsymbol{{c}}_{\ell, MAP}$
, and the posterior distribution
$p(\boldsymbol{{c}}_{\ell})$
.





































A straightforward approach is to calibrate the scale (or the location) of the distributions
 $f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell})$
with a scalar parameter
$f_{\ell,o}(x \mid \boldsymbol{{c}}_{\ell})$
with a scalar parameter
 ${c_{\ell}} \in \mathbb{R}$
. A two-dimensional calibration vector
${c_{\ell}} \in \mathbb{R}$
. A two-dimensional calibration vector
 $\boldsymbol{{c}}_{\ell} =({a_{\ell}}, {b_{\ell}}) \in \mathbb{R}^2$
is used in the case of a linear-trend calibration (see Remark 5.2). The T conditional annual distributions
$\boldsymbol{{c}}_{\ell} =({a_{\ell}}, {b_{\ell}}) \in \mathbb{R}^2$
is used in the case of a linear-trend calibration (see Remark 5.2). The T conditional annual distributions
 $f_{\ell,o}(x \mid {c_{\ell}}_{,o})$
are thus interlinked via
$f_{\ell,o}(x \mid {c_{\ell}}_{,o})$
are thus interlinked via
 ${c_{\ell}}_{,o}={c_{\ell}}$
in the case of a scale (or location) calibration and via
${c_{\ell}}_{,o}={c_{\ell}}$
in the case of a scale (or location) calibration and via
 ${c_{\ell}}_{,o}={a_{\ell}} + {b_{\ell}} \cdot (o-o_0)$
in the case of a linear-trend calibration (see Section 5.2.8).
${c_{\ell}}_{,o}={a_{\ell}} + {b_{\ell}} \cdot (o-o_0)$
in the case of a linear-trend calibration (see Section 5.2.8).
5.2.3. Calibration levels and iteration
A scale (or translate) calibration scalar
 ${c_{\ell}}$
can be derived from the set
${c_{\ell}}$
can be derived from the set
 $\mathcal{Y}_{\ell}^c$
containing all claim-level observations
$\mathcal{Y}_{\ell}^c$
containing all claim-level observations
 ${Y_{\ell}}_{, o,j}$
, or from the set
${Y_{\ell}}_{, o,j}$
, or from the set
 $\mathcal{Y}_{\ell}^a$
containing the observations
$\mathcal{Y}_{\ell}^a$
containing the observations
 ${Y_{\ell}}_{, o}$
aggregated on an annual level, or from the set
${Y_{\ell}}_{, o}$
aggregated on an annual level, or from the set
 $\mathcal{Y}_{\ell}^p$
containing the single observation
$\mathcal{Y}_{\ell}^p$
containing the single observation
 ${Y_{\ell}}$
aggregated on the period level. A trend calibration vector
${Y_{\ell}}$
aggregated on the period level. A trend calibration vector
 $\boldsymbol{{c}}_{\ell}=({a_{\ell}}, {b_{\ell}})$
can be derived either from
$\boldsymbol{{c}}_{\ell}=({a_{\ell}}, {b_{\ell}})$
can be derived either from
 $\mathcal{Y}_{\ell}^c$
or from
$\mathcal{Y}_{\ell}^c$
or from
 $\mathcal{Y}_{\ell}^a$
.
$\mathcal{Y}_{\ell}^a$
.
The generative model is supposed to accept the calibration tuple
 $\boldsymbol{{C}}^{(s)}$
and the simulation count
$\boldsymbol{{C}}^{(s)}$
and the simulation count
 $K^{(s+1)}$
as an input for the iteration
$K^{(s+1)}$
as an input for the iteration
 $s+1$
(with
$s+1$
(with
 $s \ge 0$
) and to provide the simulated set of sets
$s \ge 0$
) and to provide the simulated set of sets
 $\{ { \mathcal{S}_k^{sim} }^{(s+1)} \mid \boldsymbol{{C}}^{(s)} \}_{1 \leq k \leq K^{(s+1)}}$
(4.2) as an output. The calibration framework uses the derived sets
$\{ { \mathcal{S}_k^{sim} }^{(s+1)} \mid \boldsymbol{{C}}^{(s)} \}_{1 \leq k \leq K^{(s+1)}}$
(4.2) as an output. The calibration framework uses the derived sets
 ${\mathcal{X}_{\ell}}^{(s+1)}$
(5.2) containing the simulated reduced random variables and the set
${\mathcal{X}_{\ell}}^{(s+1)}$
(5.2) containing the simulated reduced random variables and the set
 $\mathcal{Y}_{\ell}$
containing the respective observations to derive the calibration parameters
$\mathcal{Y}_{\ell}$
containing the respective observations to derive the calibration parameters
 $\boldsymbol{{c}}_{\ell}^{(s+1)}$
for the model features
$\boldsymbol{{c}}_{\ell}^{(s+1)}$
for the model features
 $\ell \in \{ 1, \dots, M \} $
. The generative model is adjusted by feeding the calibration tuple
$\ell \in \{ 1, \dots, M \} $
. The generative model is adjusted by feeding the calibration tuple
 $\boldsymbol{{C}}^{(s+1)}$
back into the generative model where the calibration parameter
$\boldsymbol{{C}}^{(s+1)}$
back into the generative model where the calibration parameter
 $\boldsymbol{{c}}_{\ell}^{(s+1)}$
is applied to the generator(s) of the feature
$\boldsymbol{{c}}_{\ell}^{(s+1)}$
is applied to the generator(s) of the feature
 $\ell$
.
$\ell$
.
Remark 5.4. The generic iterative calibration framework can interact with the generative model via standardized interfaces. The generative model can thus be considered an independent module from the perspective of the calibration framework. The reverse is also the case; hence, the generic calibration framework can be implemented as a service that can be called by any exposure-based generative model capable of simulating claims for the observation period.
5.2.4. Link function
The calibration of the scale (or the location) of the annual probability distributions
 $f_{\kappa}(x \mid {c_{\ell}})$
with the scalar
$f_{\kappa}(x \mid {c_{\ell}})$
with the scalar
 ${c_{\ell}}$
is accomplished by combining a normal prior
${c_{\ell}}$
is accomplished by combining a normal prior
 $\pi_{\ell}({c_{\ell}})\;:\!=\;\mathcal{N}({c_{\ell}};\;0, \sigma_{{c_{\ell}}})$
with a link function
$\pi_{\ell}({c_{\ell}})\;:\!=\;\mathcal{N}({c_{\ell}};\;0, \sigma_{{c_{\ell}}})$
with a link function
 $\psi_{\ell}: ({c_{\ell}}, \vartheta^0_{\kappa}) \mapsto \vartheta_{\kappa}({c_{\ell}})$
that maps the set
$\psi_{\ell}: ({c_{\ell}}, \vartheta^0_{\kappa}) \mapsto \vartheta_{\kappa}({c_{\ell}})$
that maps the set
 $\{\vartheta^{0}_{\kappa}\}$
containing the prior parameters to the set
$\{\vartheta^{0}_{\kappa}\}$
containing the prior parameters to the set
 $\{\vartheta_{\kappa}({c_{\ell}})\}$
containing the adjusted parameters (the superscripts and subscripts indicated by
$\{\vartheta_{\kappa}({c_{\ell}})\}$
containing the adjusted parameters (the superscripts and subscripts indicated by
 $\kappa \in \{^c_{\ell,o},\; ^a_{\ell,o},\; ^p_{\ell}\} $
depend on the calibration level). The prior distributions of the annual parameters
$\kappa \in \{^c_{\ell,o},\; ^a_{\ell,o},\; ^p_{\ell}\} $
depend on the calibration level). The prior distributions of the annual parameters
 $\vartheta_{\kappa}$
are thus decomposed into a joint (normal) prior
$\vartheta_{\kappa}$
are thus decomposed into a joint (normal) prior
 $\pi_{\ell}({c_{\ell}})$
and annual link functions
$\pi_{\ell}({c_{\ell}})$
and annual link functions
 $\psi_{\kappa}({c_{\ell}})\;:\!=\;\psi_{\ell}({c_{\ell}}, \vartheta^0_{\kappa})$
. The reasons for this decomposition are the need to jointly calibrate the annual distributions
$\psi_{\kappa}({c_{\ell}})\;:\!=\;\psi_{\ell}({c_{\ell}}, \vartheta^0_{\kappa})$
. The reasons for this decomposition are the need to jointly calibrate the annual distributions
 $f_{\kappa}(x \mid {c_{\ell}})$
, the need to feed the calibration parameters
$f_{\kappa}(x \mid {c_{\ell}})$
, the need to feed the calibration parameters
 ${c_{\ell}}$
back into the generative model, and parsimony.
${c_{\ell}}$
back into the generative model, and parsimony.
The decomposition permits us to choose normal priors
 $\pi_{\ell}({c_{\ell}}) = \mathcal{N}({c_{\ell}};\; 0, \sigma_{{c_{\ell}}}^2)$
, provided that the link function
$\pi_{\ell}({c_{\ell}}) = \mathcal{N}({c_{\ell}};\; 0, \sigma_{{c_{\ell}}}^2)$
, provided that the link function
 $\psi_{\ell}$
adequately maps the range of validity
$\psi_{\ell}$
adequately maps the range of validity
 $\mathbb{R}$
of the calibration parameter
$\mathbb{R}$
of the calibration parameter
 ${c_{\ell}}$
to the range of validity of the respective model parameters
${c_{\ell}}$
to the range of validity of the respective model parameters
 $\vartheta_{\kappa}$
. Depending on the constraints on
$\vartheta_{\kappa}$
. Depending on the constraints on
 $\vartheta_{\kappa}$
, either a linear linking, an exponential linking, or a logistic (sigmoid) linking is applied (see examples in Section 6):
$\vartheta_{\kappa}$
, either a linear linking, an exponential linking, or a logistic (sigmoid) linking is applied (see examples in Section 6):
 \begin{equation} \begin{array}{l}\vartheta_{\kappa}(c) \;:\!=\; \psi_{\ell}(c,\vartheta^0_{\kappa}) \;:\!=\;\left\{ \begin{array}{l@{\quad}c@{\quad}l@{\quad}c@{\quad}l@{\quad}l@{\quad}l} \vartheta^0_{\kappa} + c & : & \textrm{linear} & \psi_{\ell} & : & \mathbb{R} \to \mathbb{R} & \\[5pt] \vartheta^0_{\kappa} \cdot e^c & : & \textrm{exponential} & \psi_{\ell} & : & \mathbb{R} \to \mathbb{R^+} & {\textrm{for all }} \vartheta^0_{\kappa} \in \mathbb{R^+} \\[5pt] \frac{\vartheta^0_{\kappa} \cdot e^c}{\vartheta^0_{\kappa} \cdot e^c + (1-\vartheta^0_{\kappa}) \cdot e^{-c}} & : & \textrm{logistic} & \psi_{\ell} & : & \mathbb{R} \to [0,1] & {\textrm{for all }} \vartheta^0_{\kappa} \in [0,1] \end{array}\right. \\ \end{array}\end{equation}
\begin{equation} \begin{array}{l}\vartheta_{\kappa}(c) \;:\!=\; \psi_{\ell}(c,\vartheta^0_{\kappa}) \;:\!=\;\left\{ \begin{array}{l@{\quad}c@{\quad}l@{\quad}c@{\quad}l@{\quad}l@{\quad}l} \vartheta^0_{\kappa} + c & : & \textrm{linear} & \psi_{\ell} & : & \mathbb{R} \to \mathbb{R} & \\[5pt] \vartheta^0_{\kappa} \cdot e^c & : & \textrm{exponential} & \psi_{\ell} & : & \mathbb{R} \to \mathbb{R^+} & {\textrm{for all }} \vartheta^0_{\kappa} \in \mathbb{R^+} \\[5pt] \frac{\vartheta^0_{\kappa} \cdot e^c}{\vartheta^0_{\kappa} \cdot e^c + (1-\vartheta^0_{\kappa}) \cdot e^{-c}} & : & \textrm{logistic} & \psi_{\ell} & : & \mathbb{R} \to [0,1] & {\textrm{for all }} \vartheta^0_{\kappa} \in [0,1] \end{array}\right. \\ \end{array}\end{equation}
5.2.5. Claim-level observations and Bayes
The MAP estimate
 ${c_{\ell}}^{c}_{,MAP} \;:\!=\; \mathop{\textrm{argmax}}\limits_{c \in \mathbb{R}} \Pr(c \mid \mathcal{Y}_{\ell}^c )$
derived from the set containing the claim-level (‘c’) observations
${c_{\ell}}^{c}_{,MAP} \;:\!=\; \mathop{\textrm{argmax}}\limits_{c \in \mathbb{R}} \Pr(c \mid \mathcal{Y}_{\ell}^c )$
derived from the set containing the claim-level (‘c’) observations
 $\mathcal{Y}_{\ell}^c$
is obtained by applying Bayes’ theorem and maximizing the log-likelihood function
$\mathcal{Y}_{\ell}^c$
is obtained by applying Bayes’ theorem and maximizing the log-likelihood function
 $\mathcal{L}^c(c)$
:
$\mathcal{L}^c(c)$
:
 \begin{equation*} \begin{array}{r@{\quad}c@{\quad}l}\Pr(c \mid \mathcal{Y}_{\ell}^c ) &= & \Pr( \mathcal{Y}_{\ell}^c \mid c ) \cdot \frac{\Pr(c)}{\Pr( \mathcal{Y}_{\ell}^c )} \propto \prod_{o,i} f^c_{\ell,o}({Y_{\ell}}_{,o,i}\mid c) \cdot \pi^c_{\ell}(c) \\[5pt] \Rightarrow \mathcal{L}^c_{\ell}(c) & = & \ln \left( \Pr \left(c \mid \mathcal{Y}_{\ell}^c \right) \right) = \textrm{const.} + \sum_{o,i} \ln \left( f^c_{\ell,o}({Y_{\ell}}_{,o,i}\mid c)\right) + \ln \left(\pi^c_{\ell}(c) \right) \\[5pt] \end{array}\end{equation*}
\begin{equation*} \begin{array}{r@{\quad}c@{\quad}l}\Pr(c \mid \mathcal{Y}_{\ell}^c ) &= & \Pr( \mathcal{Y}_{\ell}^c \mid c ) \cdot \frac{\Pr(c)}{\Pr( \mathcal{Y}_{\ell}^c )} \propto \prod_{o,i} f^c_{\ell,o}({Y_{\ell}}_{,o,i}\mid c) \cdot \pi^c_{\ell}(c) \\[5pt] \Rightarrow \mathcal{L}^c_{\ell}(c) & = & \ln \left( \Pr \left(c \mid \mathcal{Y}_{\ell}^c \right) \right) = \textrm{const.} + \sum_{o,i} \ln \left( f^c_{\ell,o}({Y_{\ell}}_{,o,i}\mid c)\right) + \ln \left(\pi^c_{\ell}(c) \right) \\[5pt] \end{array}\end{equation*}
where
 $f^c_{\ell,o}(x \mid c)$
is defined in (5.3) and the superscript ‘c’ indicates the calibration on a claim level. The MAP estimate
$f^c_{\ell,o}(x \mid c)$
is defined in (5.3) and the superscript ‘c’ indicates the calibration on a claim level. The MAP estimate
 ${c_{\ell}}^c_{,MAP}$
is derived from the condition
${c_{\ell}}^c_{,MAP}$
is derived from the condition
 $\partial \mathcal{L}^c_{\ell}(c) / \partial c \overset{!}{=} 0$
:
$\partial \mathcal{L}^c_{\ell}(c) / \partial c \overset{!}{=} 0$
:
 \begin{equation} \left. \sum_{o=-T}^{-1} \sum_{i=1}^{N^{rep}_{o}}\frac{\frac{\partial}{\partial c}f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c)}{ f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c)} \overset{!}{=} \frac{c}{\sigma_{{c_{\ell}}^c}^2} \; \right\vert_{c={c_{\ell}}^c_{,MAP}} \end{equation}
\begin{equation} \left. \sum_{o=-T}^{-1} \sum_{i=1}^{N^{rep}_{o}}\frac{\frac{\partial}{\partial c}f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c)}{ f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c)} \overset{!}{=} \frac{c}{\sigma_{{c_{\ell}}^c}^2} \; \right\vert_{c={c_{\ell}}^c_{,MAP}} \end{equation}
5.2.6. Annual-level observations and Bayes
The calibration of the model features can also be performed on an annual level (‘a’) with the observed random variables
 ${Y_{\ell}}_{,o}$
. The annual probability distributions
${Y_{\ell}}_{,o}$
. The annual probability distributions
 $f^a_{\ell,o}(x)$
are fitted to the simulated probability distributions
$f^a_{\ell,o}(x)$
are fitted to the simulated probability distributions
 $g^a_{\ell,o}(x)\;:\!=\;g(x \mid \mathcal{X}^a_{\ell,o})$
determined by the sets
$g^a_{\ell,o}(x)\;:\!=\;g(x \mid \mathcal{X}^a_{\ell,o})$
determined by the sets
 $\mathcal{X}^a_{\ell,o}\;:\!=\;\left\{ {X_{\ell}}_{,o,k} \right\}_{1 \le k \le K}$
. The MAP estimate
$\mathcal{X}^a_{\ell,o}\;:\!=\;\left\{ {X_{\ell}}_{,o,k} \right\}_{1 \le k \le K}$
. The MAP estimate
 ${c_{\ell}}^a_{,MAP}$
is derived from the condition
${c_{\ell}}^a_{,MAP}$
is derived from the condition
 $\partial \mathcal{L}^a_{\ell}(c) / \partial c \overset{!}{=} 0$
:
$\partial \mathcal{L}^a_{\ell}(c) / \partial c \overset{!}{=} 0$
:
 \begin{equation} \left. \sum_{o=-T}^{-1} \frac{\frac{\partial}{\partial c}f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c)}{ f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c)} \overset{!}{=} \frac{c}{\sigma_{{c_{\ell}}^a}^2} \; \right\vert_{c={c_{\ell}}^a_{,MAP}} \end{equation}
\begin{equation} \left. \sum_{o=-T}^{-1} \frac{\frac{\partial}{\partial c}f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c)}{ f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c)} \overset{!}{=} \frac{c}{\sigma_{{c_{\ell}}^a}^2} \; \right\vert_{c={c_{\ell}}^a_{,MAP}} \end{equation}
5.2.7. Period-level observations and Bayes
A third option is to calibrate the feature
 $\ell$
on an aggregated period level (‘p’) with the observed random variable
$\ell$
on an aggregated period level (‘p’) with the observed random variable
 ${Y_{\ell}}$
. The probability distribution
${Y_{\ell}}$
. The probability distribution
 $f^p_{\ell}(x)$
is fitted to the simulated distribution
$f^p_{\ell}(x)$
is fitted to the simulated distribution
 $g^p_{\ell}(x)\;:\!=\;g(x\mid \mathcal{X}^p_{\ell})$
determined by the set
$g^p_{\ell}(x)\;:\!=\;g(x\mid \mathcal{X}^p_{\ell})$
determined by the set
 $\mathcal{X}^p_{\ell}\;:\!=\;\left\{ {X_{\ell}}_{,k} \right\}_{1 \le k \le K}$
. The MAP estimate
$\mathcal{X}^p_{\ell}\;:\!=\;\left\{ {X_{\ell}}_{,k} \right\}_{1 \le k \le K}$
. The MAP estimate
 ${c_{\ell}}^p_{,MAP}$
is derived from the condition
${c_{\ell}}^p_{,MAP}$
is derived from the condition
 $\partial \mathcal{L}^p_{\ell}(c) / \partial c \overset{!}{=} 0$
:
$\partial \mathcal{L}^p_{\ell}(c) / \partial c \overset{!}{=} 0$
:
 \begin{equation} \left. \frac{\frac{\partial}{\partial c}f^p_{\ell}({Y_{\ell}} \mid c)}{ f^p_{\ell}({Y_{\ell}} \mid c)} \overset{!}{=} \frac{c}{\sigma_{{c_{\ell}}^p}^2} \; \right\vert_{c={c_{\ell}}^p_{,MAP}} \end{equation}
\begin{equation} \left. \frac{\frac{\partial}{\partial c}f^p_{\ell}({Y_{\ell}} \mid c)}{ f^p_{\ell}({Y_{\ell}} \mid c)} \overset{!}{=} \frac{c}{\sigma_{{c_{\ell}}^p}^2} \; \right\vert_{c={c_{\ell}}^p_{,MAP}} \end{equation}
5.2.8. Linear trend and Bayes
The approach derived for the calibration scalar
 ${c_{\ell}}$
(i.e.,
${c_{\ell}}$
(i.e.,
 ${c_{\ell}}_{,o} = {c_{\ell}}$
for all o) can be extended to a calibration vector
${c_{\ell}}_{,o} = {c_{\ell}}$
for all o) can be extended to a calibration vector
 $\boldsymbol{{c}}_{\ell}$
by postulating
$\boldsymbol{{c}}_{\ell}$
by postulating
 ${c_{\ell}}_{,o} = {a_{\ell}} + {b_{\ell}} \cdot(o-o_0)$
, that is,
${c_{\ell}}_{,o} = {a_{\ell}} + {b_{\ell}} \cdot(o-o_0)$
, that is,
 $\boldsymbol{{c}}_{\ell}=({a_{\ell}}, {b_{\ell}})$
. The two parameters
$\boldsymbol{{c}}_{\ell}=({a_{\ell}}, {b_{\ell}})$
. The two parameters
 ${a_{\ell}}$
and
${a_{\ell}}$
and
 ${b_{\ell}}$
are assumed to be independent with priors
${b_{\ell}}$
are assumed to be independent with priors
 $\pi_a({a_{\ell}}) = \mathcal{N}({a_{\ell}};\;0,\sigma_{{a_{\ell}}}^2)$
and
$\pi_a({a_{\ell}}) = \mathcal{N}({a_{\ell}};\;0,\sigma_{{a_{\ell}}}^2)$
and
 $\pi_b({b_{\ell}}) = \mathcal{N}({b_{\ell}};\;0,\sigma_{{b_{\ell}}}^2)$
.
$\pi_b({b_{\ell}}) = \mathcal{N}({b_{\ell}};\;0,\sigma_{{b_{\ell}}}^2)$
.
If calibrating a linear trend of feature
 $\ell$
on the claim level (indicated by the superscript ‘c’), following system of equations for the MAP estimates
$\ell$
on the claim level (indicated by the superscript ‘c’), following system of equations for the MAP estimates
 ${a_{\ell}}^c_{, MAP}$
and
${a_{\ell}}^c_{, MAP}$
and
 ${b_{\ell}}^c_{, MAP}$
is derived from the two conditions
${b_{\ell}}^c_{, MAP}$
is derived from the two conditions
 $\partial \mathcal{L}^c_{\ell}(c(o;\;a,b)) / \partial a \overset{!}{=} 0$
and
$\partial \mathcal{L}^c_{\ell}(c(o;\;a,b)) / \partial a \overset{!}{=} 0$
and
 $\partial \mathcal{L}^c_{\ell}(c(o;\;a,b)) / \partial b \overset{!}{=} 0$
:
$\partial \mathcal{L}^c_{\ell}(c(o;\;a,b)) / \partial b \overset{!}{=} 0$
:
 \begin{equation} \begin{array}{l}\left. \begin{array}{l@{\quad}c@{\quad}l} \sum_{o=-T}^{-1} \sum_{i=1}^{N^{rep}_{o}} \frac{\frac{\partial}{\partial c}f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))}{f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))} \cdot 1 & \overset{!}{=} & \frac{a}{\sigma_{{a_{\ell}}^c}^2} \\[5pt] \sum_{o=-T}^{-1} \sum_{i=1}^{N^{rep}_{o}} \frac{\frac{\partial}{\partial c}f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))}{f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))} \cdot (o-o_0) & \overset{!}{=} & \frac{b}{\sigma_{{b_{\ell}}^c}^2} \end{array}\;\right\vert_{(a,b)=({a_{\ell}}^c_{, MAP}, {b_{\ell}}^c_{, MAP})} \end{array}\end{equation}
\begin{equation} \begin{array}{l}\left. \begin{array}{l@{\quad}c@{\quad}l} \sum_{o=-T}^{-1} \sum_{i=1}^{N^{rep}_{o}} \frac{\frac{\partial}{\partial c}f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))}{f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))} \cdot 1 & \overset{!}{=} & \frac{a}{\sigma_{{a_{\ell}}^c}^2} \\[5pt] \sum_{o=-T}^{-1} \sum_{i=1}^{N^{rep}_{o}} \frac{\frac{\partial}{\partial c}f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))}{f^c_{\ell,o}({Y_{\ell}}_{,o,i} \mid c(o;\;a,b))} \cdot (o-o_0) & \overset{!}{=} & \frac{b}{\sigma_{{b_{\ell}}^c}^2} \end{array}\;\right\vert_{(a,b)=({a_{\ell}}^c_{, MAP}, {b_{\ell}}^c_{, MAP})} \end{array}\end{equation}
Respective trend parameters
 ${a_{\ell}}^a_{, MAP}$
and
${a_{\ell}}^a_{, MAP}$
and
 ${b_{\ell}}^a_{, MAP}$
(indicated by the superscript ‘a’) can also be derived from observations on an annual level:
${b_{\ell}}^a_{, MAP}$
(indicated by the superscript ‘a’) can also be derived from observations on an annual level:
 \begin{equation} \begin{array}{l}\left. \begin{array}{l@{\quad}c@{\quad}l} \sum_{o=-T}^{-1} \frac{\frac{\partial}{\partial c}f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))}{ f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))} \cdot 1 & \overset{!}{=} & \frac{a}{\sigma_{{a_{\ell}}^a}^2} \\[5pt] \sum_{o=-T}^{-1} \frac{\frac{\partial}{\partial c}f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))}{ f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))} \cdot (o-o_0) & \overset{!}{=} & \frac{b}{\sigma_{{b_{\ell}}^a}^2} \end{array}\;\right\vert_{(a,b)=({a_{\ell}}^a_{, MAP}, {b_{\ell}}^a_{, MAP})} \end{array}\end{equation}
\begin{equation} \begin{array}{l}\left. \begin{array}{l@{\quad}c@{\quad}l} \sum_{o=-T}^{-1} \frac{\frac{\partial}{\partial c}f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))}{ f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))} \cdot 1 & \overset{!}{=} & \frac{a}{\sigma_{{a_{\ell}}^a}^2} \\[5pt] \sum_{o=-T}^{-1} \frac{\frac{\partial}{\partial c}f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))}{ f^a_{\ell,o}({Y_{\ell}}_{,o} \mid c(o;\;a,b))} \cdot (o-o_0) & \overset{!}{=} & \frac{b}{\sigma_{{b_{\ell}}^a}^2} \end{array}\;\right\vert_{(a,b)=({a_{\ell}}^a_{, MAP}, {b_{\ell}}^a_{, MAP})} \end{array}\end{equation}
5.2.9. Smoothing
The simulated annual probability distributions
 $g_{\ell,o}(x)$
defined in (5.1) can be quite volatile unless a large number of simulated claim objects is generated. The resulting volatility of the fitted parametric distributions
$g_{\ell,o}(x)$
defined in (5.1) can be quite volatile unless a large number of simulated claim objects is generated. The resulting volatility of the fitted parametric distributions
 $f_{\ell}(x;\; \boldsymbol{\theta}^0_{\ell,o})$
can be reduced by replacing the parameters
$f_{\ell}(x;\; \boldsymbol{\theta}^0_{\ell,o})$
can be reduced by replacing the parameters
 $\boldsymbol{\theta}^0_{\ell,o}$
evaluated independently for each occurrence year o by smoothed parameters
$\boldsymbol{\theta}^0_{\ell,o}$
evaluated independently for each occurrence year o by smoothed parameters
 $\tilde{\boldsymbol{\theta}}_{\ell,o} \;:\!=\; (\tilde{\vartheta}_{\ell,o}, [\tilde{\varphi}_{\ell,o}, \tilde{\varsigma}_{\ell,o}, \tilde{\varrho}_{\ell,o}, \dots])$
. This can, for example, be accomplished by blending the parameters
$\tilde{\boldsymbol{\theta}}_{\ell,o} \;:\!=\; (\tilde{\vartheta}_{\ell,o}, [\tilde{\varphi}_{\ell,o}, \tilde{\varsigma}_{\ell,o}, \tilde{\varrho}_{\ell,o}, \dots])$
. This can, for example, be accomplished by blending the parameters
 $\boldsymbol{\theta}^0_{\ell,o}$
and the parameters
$\boldsymbol{\theta}^0_{\ell,o}$
and the parameters
 $\boldsymbol{\theta}^*_{\ell,o}$
, that is, by setting
$\boldsymbol{\theta}^*_{\ell,o}$
, that is, by setting
 $\tilde{\boldsymbol{\theta}}_{\ell,o} = diag (\alpha_{\ell,1}, \alpha_{\ell,2}, \dots) \times \boldsymbol{\theta}^0_{\ell,o} + diag (1-\alpha_{\ell,1}, 1-\alpha_{\ell,2}, \dots) \times \boldsymbol{\theta}^*_{\ell,o}$
where
$\tilde{\boldsymbol{\theta}}_{\ell,o} = diag (\alpha_{\ell,1}, \alpha_{\ell,2}, \dots) \times \boldsymbol{\theta}^0_{\ell,o} + diag (1-\alpha_{\ell,1}, 1-\alpha_{\ell,2}, \dots) \times \boldsymbol{\theta}^*_{\ell,o}$
where
 $\boldsymbol{\alpha}_{\ell} \;:\!=\; (\alpha_{\ell,1}, \alpha_{\ell,2}, \dots)$
is the vector containing the credibility weights to be applied to the components of
$\boldsymbol{\alpha}_{\ell} \;:\!=\; (\alpha_{\ell,1}, \alpha_{\ell,2}, \dots)$
is the vector containing the credibility weights to be applied to the components of
 $\boldsymbol{\theta}$
.
$\boldsymbol{\theta}$
.
The parameters
 $\boldsymbol{\theta}^0_{\ell,o}$
are obtained by independently fitting each distribution
$\boldsymbol{\theta}^0_{\ell,o}$
are obtained by independently fitting each distribution
 $f_{\ell}(x;\; \boldsymbol{\theta}^0_{\ell,o})$
to the respective simulated distribution
$f_{\ell}(x;\; \boldsymbol{\theta}^0_{\ell,o})$
to the respective simulated distribution
 $g_{\ell,o}(x)$
. The parameters
$g_{\ell,o}(x)$
. The parameters
 $\boldsymbol{\theta}^*_{\ell,o} = \boldsymbol{\theta}_{\ell}^*(o;\; \boldsymbol{\phi}_{\ell})$
are instead obtained by jointly fitting the set
$\boldsymbol{\theta}^*_{\ell,o} = \boldsymbol{\theta}_{\ell}^*(o;\; \boldsymbol{\phi}_{\ell})$
are instead obtained by jointly fitting the set
 $\{f_{\ell}(x;\; \boldsymbol{\theta}_{\ell}^*(o,\boldsymbol{\phi}_{\ell}))\}$
to the set
$\{f_{\ell}(x;\; \boldsymbol{\theta}_{\ell}^*(o,\boldsymbol{\phi}_{\ell}))\}$
to the set
 $\{g_{\ell,o}(x)\}$
with the help of the hyperparameters
$\{g_{\ell,o}(x)\}$
with the help of the hyperparameters
 $\boldsymbol{\phi}_{\ell} = (\varphi_{\ell,1}, [\varphi_{\ell,2}, \dots])$
.
$\boldsymbol{\phi}_{\ell} = (\varphi_{\ell,1}, [\varphi_{\ell,2}, \dots])$
.
Example 5.5. Discrete
 $\mathcal{P}\textit{anjer}$
class (see Appendix B in the Online Supplementary Material) with annually calibrated means
$\mathcal{P}\textit{anjer}$
class (see Appendix B in the Online Supplementary Material) with annually calibrated means
 $\lambda_o$
and a shared
$\lambda_o$
and a shared
 $f_P$
, that is,
$f_P$
, that is,
 $\boldsymbol{\alpha} =(\alpha_{\lambda}, \alpha_{f_P})=(1,0)$
:
$\boldsymbol{\alpha} =(\alpha_{\lambda}, \alpha_{f_P})=(1,0)$
:
 \begin{equation} \begin{array}{l@{\quad}r@{\quad}c@{\quad}l} & f_o(k) & \;:\!=\; & \mathcal{P}\textit{anjer}(k;\; \lambda_o, f_P) \\[5pt] \textit{with:} & \lambda_o & = &\mathbb{E}[N_o] \\[5pt] \textit{and:} & f_P & = & \frac{\sum_o \mathbb{V}[N_o]}{\sum_o \mathbb{E}[N_o]} \end{array}\end{equation}
\begin{equation} \begin{array}{l@{\quad}r@{\quad}c@{\quad}l} & f_o(k) & \;:\!=\; & \mathcal{P}\textit{anjer}(k;\; \lambda_o, f_P) \\[5pt] \textit{with:} & \lambda_o & = &\mathbb{E}[N_o] \\[5pt] \textit{and:} & f_P & = & \frac{\sum_o \mathbb{V}[N_o]}{\sum_o \mathbb{E}[N_o]} \end{array}\end{equation}
5.3. Calibration of interdependent features
The generative model is assumed to contain M partially dependent calibration parameters
 $\boldsymbol{{c}}_{\ell}$
, which are used to calibrate M distinctive features
$\boldsymbol{{c}}_{\ell}$
, which are used to calibrate M distinctive features
 $\ell$
within the generative model (depending on the feature to be calibrated,
$\ell$
within the generative model (depending on the feature to be calibrated,
 $\boldsymbol{{c}}_{\ell}$
is either a scalar or a vector).
$\boldsymbol{{c}}_{\ell}$
is either a scalar or a vector).
5.3.1. Decomposition of known interdependencies
The optimal approach is to decompose known interdependencies into independent features. The calibration of the variables
 $N_{o}^{inc}$
,
$N_{o}^{inc}$
,
 $\tau^{rep}_{o}$
, and
$\tau^{rep}_{o}$
, and
 $N_{o}^{rep}$
can, for example, be accomplished with two independent calibration parameters (an equivalent approach is applicable to the variables
$N_{o}^{rep}$
can, for example, be accomplished with two independent calibration parameters (an equivalent approach is applicable to the variables
 $I^*_{o,i}$
,
$I^*_{o,i}$
,
 $\tau^P_{o,i}$
, and
$\tau^P_{o,i}$
, and
 $P^*_{o,i}$
).
$P^*_{o,i}$
).
The count and the features of the IBNR claims are not known, that is, the annual counts
 $N_{o}^{inc}$
of the incurred claims and the reporting lags
$N_{o}^{inc}$
of the incurred claims and the reporting lags
 $\tau^{rep}_{o,j}$
of the IBNR claims (for which
$\tau^{rep}_{o,j}$
of the IBNR claims (for which
 $t^{rep}_{o,j} > t^{sub}$
) are not observed. These features are, however, modeled within the generative framework, that is, the counts
$t^{rep}_{o,j} > t^{sub}$
) are not observed. These features are, however, modeled within the generative framework, that is, the counts
 $N_{o,k}^{inc}$
and the reporting lags
$N_{o,k}^{inc}$
and the reporting lags
 $\tau_{o,i,k}^{rep}$
are accessible for all simulated claims.
$\tau_{o,i,k}^{rep}$
are accessible for all simulated claims.
The frequencies
 $\lambda_o^{rep} \;:\!=\; \mathbb{E}[N_o^{rep}] \approx \lambda_o^{inc} \cdot \rho_o(\tau=-o)$
of the claims reported for the occurrence years o depend on the frequencies
$\lambda_o^{rep} \;:\!=\; \mathbb{E}[N_o^{rep}] \approx \lambda_o^{inc} \cdot \rho_o(\tau=-o)$
of the claims reported for the occurrence years o depend on the frequencies
 $\lambda_o^{inc}\;:\!=\; \mathbb{E}[N_o^{inc}]$
of incurred claims and the reporting patterns
$\lambda_o^{inc}\;:\!=\; \mathbb{E}[N_o^{inc}]$
of incurred claims and the reporting patterns
 $\rho_o(\tau)$
evaluated at
$\rho_o(\tau)$
evaluated at
 $\tau = t^{sub} -t^{occ}_{o,j}\approx -o$
. The frequencies
$\tau = t^{sub} -t^{occ}_{o,j}\approx -o$
. The frequencies
 $\lambda_o^{inc}$
and the patterns
$\lambda_o^{inc}$
and the patterns
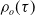 $\rho_o(\tau)$
are approximated by the simulated frequencies
$\rho_o(\tau)$
are approximated by the simulated frequencies
 $\hat{\lambda}_o^0$
and the simulated patterns
$\hat{\lambda}_o^0$
and the simulated patterns
 $\hat{\rho}_o(\tau)$
and considered independent, that is, they can be calibrated with respective scalar parameters
$\hat{\rho}_o(\tau)$
and considered independent, that is, they can be calibrated with respective scalar parameters
 $c_{\lambda}$
and
$c_{\lambda}$
and
 $c_{\rho}$
.
$c_{\rho}$
.
Parametric reporting patterns
 $\rho(\tau;\; \tau^0_o, [\dots])$
are fitted to the simulated reporting patterns
$\rho(\tau;\; \tau^0_o, [\dots])$
are fitted to the simulated reporting patterns
 $\hat{\rho}_o(\tau)$
. Conditional estimates
$\hat{\rho}_o(\tau)$
. Conditional estimates
 $\hat{\lambda}_o^{rep}(\boldsymbol{{c}})$
for the frequencies of reported claims given the calibration parameter
$\hat{\lambda}_o^{rep}(\boldsymbol{{c}})$
for the frequencies of reported claims given the calibration parameter
 $\boldsymbol{{c}} \;:\!=\; (c_{\lambda}, c_{\rho})$
are obtained as follows:
$\boldsymbol{{c}} \;:\!=\; (c_{\lambda}, c_{\rho})$
are obtained as follows:
 \begin{equation*} \hat{\lambda}_o^{rep}(\boldsymbol{{c}}) = \hat{\lambda}_o^0 \cdot e^{c_{\lambda}} \cdot \rho(\tau=-o;\; \tau^0_o \cdot e^{c_{\rho}},[\dots])\end{equation*}
\begin{equation*} \hat{\lambda}_o^{rep}(\boldsymbol{{c}}) = \hat{\lambda}_o^0 \cdot e^{c_{\lambda}} \cdot \rho(\tau=-o;\; \tau^0_o \cdot e^{c_{\rho}},[\dots])\end{equation*}
These frequencies are used as parameters in the discrete probability distributions
 $f_N(k;\; \hat{\lambda}^{rep}_o(\boldsymbol{{c}}), [\dots])$
used to evaluate the conditional likelihood of the observations
$f_N(k;\; \hat{\lambda}^{rep}_o(\boldsymbol{{c}}), [\dots])$
used to evaluate the conditional likelihood of the observations
 $N^{rep}_o$
given
$N^{rep}_o$
given
 $\boldsymbol{{c}}$
. The MAP estimate
$\boldsymbol{{c}}$
. The MAP estimate
 $\boldsymbol{{c}}_{MAP}\;:\!=\; \mathop{\textrm{argmax}}\limits_{\boldsymbol{{c}} \in \mathbb{R}^2} \Pr(\boldsymbol{{c}} \mid \{N^{rep}_o\}_{-T \leq o \leq -1})$
is obtained numerically by applying Bayes’ theorem in combination with independent normal priors
$\boldsymbol{{c}}_{MAP}\;:\!=\; \mathop{\textrm{argmax}}\limits_{\boldsymbol{{c}} \in \mathbb{R}^2} \Pr(\boldsymbol{{c}} \mid \{N^{rep}_o\}_{-T \leq o \leq -1})$
is obtained numerically by applying Bayes’ theorem in combination with independent normal priors
 $\pi_{\lambda}(c_{\lambda})$
and
$\pi_{\lambda}(c_{\lambda})$
and
 $\pi_{\rho}(c_{\rho})$
.
$\pi_{\rho}(c_{\rho})$
.
5.3.2. Multivariate normal approach MVN
One calibration approach is to generate a substantial number K of simulated variables
 $\boldsymbol{{X}}_k=(X_{1,k}, \dots, X_{M,k})$
, define
$\boldsymbol{{X}}_k=(X_{1,k}, \dots, X_{M,k})$
, define
 $\Xi_{i,k} \;:\!=\; X_{i,k}$
and
$\Xi_{i,k} \;:\!=\; X_{i,k}$
and
 $\Upsilon_i \;:\!=\; Y_i$
in the case of linearly linked components i, define
$\Upsilon_i \;:\!=\; Y_i$
in the case of linearly linked components i, define
 $\Xi_{j,k} \;:\!=\; \ln(X_{j,k})$
and
$\Xi_{j,k} \;:\!=\; \ln(X_{j,k})$
and
 $\Upsilon_j \;:\!=\; \ln(Y_j)$
in the case of exponentially linked components j, fit a multivariate normal (MVN) distribution
$\Upsilon_j \;:\!=\; \ln(Y_j)$
in the case of exponentially linked components j, fit a multivariate normal (MVN) distribution
 $\mathcal{N}(\boldsymbol{\xi};\; \boldsymbol{\mu}^0, \boldsymbol{\Sigma}^0)$
to the simulated set
$\mathcal{N}(\boldsymbol{\xi};\; \boldsymbol{\mu}^0, \boldsymbol{\Sigma}^0)$
to the simulated set
 $\left\{ \boldsymbol{\Xi}_k \right\}_{1 \le k \le K}$
, specify the prior
$\left\{ \boldsymbol{\Xi}_k \right\}_{1 \le k \le K}$
, specify the prior
 $\pi(\boldsymbol{\mu}^0)= \mathcal{N}(\boldsymbol{\mu}^0;\; \boldsymbol{\nu}^0, \boldsymbol{\Psi})$
, derive the posterior
$\pi(\boldsymbol{\mu}^0)= \mathcal{N}(\boldsymbol{\mu}^0;\; \boldsymbol{\nu}^0, \boldsymbol{\Psi})$
, derive the posterior
 $p(\boldsymbol{\mu}^0\mid \boldsymbol{\Upsilon})= \mathcal{N}(\boldsymbol{\mu}^0;\; \boldsymbol{\nu}^*, \boldsymbol{\Psi})$
, and obtain
$p(\boldsymbol{\mu}^0\mid \boldsymbol{\Upsilon})= \mathcal{N}(\boldsymbol{\mu}^0;\; \boldsymbol{\nu}^*, \boldsymbol{\Psi})$
, and obtain
 $\boldsymbol{{C}}_{MAP}= \boldsymbol{\nu}^* - \boldsymbol{\nu}^0$
(Lee, Reference Lee2012; Murphy, Reference Murphy2023). This approach does, however, rely on an explicit quantification of the prior means
$\boldsymbol{{C}}_{MAP}= \boldsymbol{\nu}^* - \boldsymbol{\nu}^0$
(Lee, Reference Lee2012; Murphy, Reference Murphy2023). This approach does, however, rely on an explicit quantification of the prior means
 $\boldsymbol{\nu}^0$
and the prior correlation matrix
$\boldsymbol{\nu}^0$
and the prior correlation matrix
 $\boldsymbol{\Psi}$
.
$\boldsymbol{\Psi}$
.
5.3.3. EM algorithm and Gibbs sampler
An alternative approach, which relies on the implicit specification of the correlations within the generative model, is to evaluate the calibration tuple
 $\boldsymbol{{C}}_{MAP}$
iteratively with the expectation-maximization (EM) algorithm (Lee, Reference Lee2012; Murphy, Reference Murphy2023). Preliminary estimates for the calibration parameters are used to generate marginal distributions, and Bayesian inference is used to update the parameters with the maximum likelihood values. The iterative process is initialized with the prior values
$\boldsymbol{{C}}_{MAP}$
iteratively with the expectation-maximization (EM) algorithm (Lee, Reference Lee2012; Murphy, Reference Murphy2023). Preliminary estimates for the calibration parameters are used to generate marginal distributions, and Bayesian inference is used to update the parameters with the maximum likelihood values. The iterative process is initialized with the prior values
 $\boldsymbol{{C}}^{(s=0)} =(\textbf{0},\dots,\textbf{0})$
. The parameter tuple
$\boldsymbol{{C}}^{(s=0)} =(\textbf{0},\dots,\textbf{0})$
. The parameter tuple
 $\boldsymbol{{C}}^{(s)}$
evaluated at step
$\boldsymbol{{C}}^{(s)}$
evaluated at step
 $s \ge 1$
with the EM algorithm is determined by the observations
$s \ge 1$
with the EM algorithm is determined by the observations
 $\{\boldsymbol{{Y}}\}$
and the simulations
$\{\boldsymbol{{Y}}\}$
and the simulations
 $\{\boldsymbol{{X}}^{(s)} \mid \boldsymbol{{C}}^{(s-1)} \}$
(see also Remark 5.3 and Section 5.2.3), that is, the process is governed by a Monte Carlo Markov chain (MCMC). The update of the parameter tuple
$\{\boldsymbol{{X}}^{(s)} \mid \boldsymbol{{C}}^{(s-1)} \}$
(see also Remark 5.3 and Section 5.2.3), that is, the process is governed by a Monte Carlo Markov chain (MCMC). The update of the parameter tuple
 $\boldsymbol{{C}}^{(s)}$
in step s can be done in several ways. In the case of relevant couplings, the basic Gibbs sampler is applied (Lee, Reference Lee2012; Murphy, Reference Murphy2023), where the iteration is run in cycles (with M steps per cycle), and where a single element
$\boldsymbol{{C}}^{(s)}$
in step s can be done in several ways. In the case of relevant couplings, the basic Gibbs sampler is applied (Lee, Reference Lee2012; Murphy, Reference Murphy2023), where the iteration is run in cycles (with M steps per cycle), and where a single element
 $\boldsymbol{{c}}_{\ell_i}$
is updated in an iteration step. Alternatively, a block Gibbs sampler might be applied where multiple or all parameters are updated in an iteration step.
$\boldsymbol{{c}}_{\ell_i}$
is updated in an iteration step. Alternatively, a block Gibbs sampler might be applied where multiple or all parameters are updated in an iteration step.
Finding a converging solution with the basic Gibbs sampler can involve a large number of iteration steps. It is thus computationally expensive (or even intractable), and paying the price only makes sense if the set containing the observational data ensures a robust solution. This condition is rarely fulfilled in the reinsurance rating process where the submission data comprises a small number (typically 10 to 100 per year) of medium and large partially developed claims. The intrinsic uncertainty in the observational data and the epistemic uncertainty in the generative model are thus significant (see Figures 6 and 7). These irreducible uncertainties translate into respective uncertainties in the parameter estimates. The calibration process aims to find a robust solution within these uncertainties and reflect the uncertainties in the posterior parameter distributions and the posterior predictive model.
5.3.4. Combined approach
A third option is to combine the two approaches. The variables
 $\boldsymbol{{Z}}$
are decomposed into weakly coupled components
$\boldsymbol{{Z}}$
are decomposed into weakly coupled components
 $Z_k$
and strongly coupled pairs
$Z_k$
and strongly coupled pairs
 $(Z_i, Z_j)$
. The MVN approach is applied to the sub-spaces in each iteration step of the EM algorithm.
$(Z_i, Z_j)$
. The MVN approach is applied to the sub-spaces in each iteration step of the EM algorithm.
5.4. Overall process and calibration of priors
The rating of reinsurance contracts is an integral part of the (annual) renewal process. Underwriters and pricing actuaries are then absorbed by the interaction of the reinsurer with its cedents, and they cannot calibrate the generative model for each incoming submission. However, the model calibration and the rating of the future covers with the calibrated model are two distinct processes that can be performed at separate times of the year. The calibration of the generative models can be performed outside of the renewal season by considering all information available at that time.
A differentiation is made between the initial setup, the initial calibration, subsequent updates of the setup, and calibration updates. The initial setup involves capturing the relevant market information, exposure profiles, insurance conditions, and claims experience for the reporting period and specifying the prior distributions (see Figure 2). The initial calibration is an interactive and iterative process performed by an expert.
The calibrated model is fed with the most recent exposure profiles (and other submission data) during the renewal process, and the model is used to rate the future contracts. A subsequent (periodic) recalibration can be performed after capturing any missing information from recent submission updates. This recalibration can either be performed (semi-) automatically in the case of minor changes in the underlying portfolio, or it is done analogously as the initial calibration in the case of significant changes in the underlying portfolio or if the generative model has been modified substantially.
A similar process can be implemented on a portfolio level to periodically update the prior assumptions, that is, with the help of a hierarchical model (see, e.g., Sections 3.6 and 3.7 in Murphy Reference Murphy2023). The reinsurer can use the set
 $\{ \boldsymbol{{C}}_{\iota} \}_{1 \le \iota \le N^{ced}}$
containing the calibration tuples
$\{ \boldsymbol{{C}}_{\iota} \}_{1 \le \iota \le N^{ced}}$
containing the calibration tuples
 $\boldsymbol{{C}}_{\iota}$
derived for the
$\boldsymbol{{C}}_{\iota}$
derived for the
 $N^{ced}$
cedents operating in the same market to update the hyperparameters used to specify the priors.
$N^{ced}$
cedents operating in the same market to update the hyperparameters used to specify the priors.
Table 3. Parameters and statistics for the generative process and the generative models shown in Figure 5.

6. Sample calibration
6.1. Calibration case study with a toy model
Example 6.1. The calibration of the frequencies
 $\lambda_o$
of the annual claim-counts distributions
$\lambda_o$
of the annual claim-counts distributions
 $N^{rep}_o \sim f_N(\lambda_o, {f_P}_{,o})$
with a scale parameter c can be performed either on an annual level or on a period level and a linear trend with the parameter
$N^{rep}_o \sim f_N(\lambda_o, {f_P}_{,o})$
with a scale parameter c can be performed either on an annual level or on a period level and a linear trend with the parameter
 $\boldsymbol{{c}}_{\ell}=({a_{\ell}},{b_{\ell}})$
can be calibrated on an annual level (the
$\boldsymbol{{c}}_{\ell}=({a_{\ell}},{b_{\ell}})$
can be calibrated on an annual level (the
 $\mathcal{P}\textit{anjer}$
factor
$\mathcal{P}\textit{anjer}$
factor
 $f_P$
is defined in Section 6.5.1 and in Appendix B). The calibration of the sample models specified in Table 3 is shown in Figure 5.
$f_P$
is defined in Section 6.5.1 and in Appendix B). The calibration of the sample models specified in Table 3 is shown in Figure 5.
The parameters and critical statistics for the generative process and the three generative models illustrated in Figure 5 for the discrete random variable
 $N_o\;:\!=\;N^{rep}_o$
are summarized in Table 3. The first line of each entry contains the model parameters and the expected statistics. The second line contains the statistics derived from the actual pmf (probability mass function) or the simulated pmf, respectively. The selected random variables listed at the bottom are used as input for the ‘toy model’ (see Appendix C.1 in the Online Supplementary Material for details).
$N_o\;:\!=\;N^{rep}_o$
are summarized in Table 3. The first line of each entry contains the model parameters and the expected statistics. The second line contains the statistics derived from the actual pmf (probability mass function) or the simulated pmf, respectively. The selected random variables listed at the bottom are used as input for the ‘toy model’ (see Appendix C.1 in the Online Supplementary Material for details).
The model used to emulate the generative process is shown in panel (a), and the initial generative model is shown in panel (b). The simulated annual and aggregate pmfs are fitted with
 ${\log}\mathcal{N}$
distributions. The scale calibration (see (A.1) in the Online Supplementary Material) based on aggregated period-level statistics is shown in panel (c), and the linear-trend calibration (see (A.3) in the Online Supplementary Material) based on annual statistics is shown in panel (d).
${\log}\mathcal{N}$
distributions. The scale calibration (see (A.1) in the Online Supplementary Material) based on aggregated period-level statistics is shown in panel (c), and the linear-trend calibration (see (A.3) in the Online Supplementary Material) based on annual statistics is shown in panel (d).
6.2. Calibration statistics
Additional insight is gained by running the calibration procedure multiple times and analyzing the resulting statistics. This is either done on a conditional basis, that is, by keeping the ‘observations’
 $\{N_o\}_{-T \leq o \leq -1}$
fixed as shown in Figure 6, or on an unconditional basis, that is, by drawing a new set of observations
$\{N_o\}_{-T \leq o \leq -1}$
fixed as shown in Figure 6, or on an unconditional basis, that is, by drawing a new set of observations
 $\{{N_o}^{(m)} \}_{-T \leq o \leq -1}$
in each calibration run m, as shown in Figure 7.
$\{{N_o}^{(m)} \}_{-T \leq o \leq -1}$
in each calibration run m, as shown in Figure 7.
The systematic bias observed in Figure 6 for the deviation statistics
 $F(\Delta X)$
stems from the different trend assumptions and stochastic processes specified in the underlying models. The calibration of the scale (determined by a and c) is more robust than the calibration of the trend (determined by
$F(\Delta X)$
stems from the different trend assumptions and stochastic processes specified in the underlying models. The calibration of the scale (determined by a and c) is more robust than the calibration of the trend (determined by
 $b^*$
); therefore, the bias and the uncertainty of the overall mean
$b^*$
); therefore, the bias and the uncertainty of the overall mean
 $\hat{\mu}$
are minor compared to the bias and uncertainty of the means at
$\hat{\mu}$
are minor compared to the bias and uncertainty of the means at
 $o=-T$
,
$o=-T$
,
 $o=-1$
, and
$o=-1$
, and
 $o=+1$
(determined by
$o=+1$
(determined by
 $b^*$
). The scale-only calibration (top panels) preserves the optimistic trend assumption; therefore, it leads to a positive bias for the calibrated mean at
$b^*$
). The scale-only calibration (top panels) preserves the optimistic trend assumption; therefore, it leads to a positive bias for the calibrated mean at
 $o=-T$
, a negative bias for the calibrated mean at
$o=-T$
, a negative bias for the calibrated mean at
 $o=-1$
, and a substantial negative bias for the projected mean at
$o=-1$
, and a substantial negative bias for the projected mean at
 $o=+1$
. The linear-trend calibration (bottom panels) overcompensates the underestimated trend in the initial model; hence, it leads to a (moderate) positive bias for the projected mean at
$o=+1$
. The linear-trend calibration (bottom panels) overcompensates the underestimated trend in the initial model; hence, it leads to a (moderate) positive bias for the projected mean at
 $o=+1$
.
$o=+1$
.
The variation in the unconditional case (Figure 7) increases by about one order of magnitude compared to the variation in the conditional case. However, the variation of the scale parameters a and c in the unconditional case is insignificant compared to the variation of the parameter
 $b^*$
. The scale-only calibration (top panels) thus leads to projections with a significant systematic bias but low uncertainty. In contrast, the linear-trend calibration (bottom panels) leads to projections with a small systematic bias but a significant uncertainty.
$b^*$
. The scale-only calibration (top panels) thus leads to projections with a significant systematic bias but low uncertainty. In contrast, the linear-trend calibration (bottom panels) leads to projections with a small systematic bias but a significant uncertainty.
6.3. Features of the calibration
The key features of the calibration process are presented in Figure 5. The annual pmfs (derived from the generative model) are represented by negative binomial distributions
 $f_o(k)\;:\!=\;\mathcal{NB}(k;\; r_o, p_o)$
. They can be adequately approximated by
$f_o(k)\;:\!=\;\mathcal{NB}(k;\; r_o, p_o)$
. They can be adequately approximated by
 ${\log}\mathcal{N}$
distributions if
${\log}\mathcal{N}$
distributions if
 $\Pr(N_o=0) \ll 1.0$
. The parameters
$\Pr(N_o=0) \ll 1.0$
. The parameters
 $r_o$
are assumed to increase with time, while the parameters
$r_o$
are assumed to increase with time, while the parameters
 $p_o = 1/f_P$
are kept constant (see (5.10) and Appendix B.3 in the Online Supplementary Material). The respective overall distribution of the average over the period is shown on the right.
$p_o = 1/f_P$
are kept constant (see (5.10) and Appendix B.3 in the Online Supplementary Material). The respective overall distribution of the average over the period is shown on the right.
The probability distributions underlying the generative process leading to the observations
 $\{N_o\}_{-T \leq o \leq -1}$
are not known. These observations are, instead, used to adjust the respective calibration parameter
$\{N_o\}_{-T \leq o \leq -1}$
are not known. These observations are, instead, used to adjust the respective calibration parameter
 $\boldsymbol{{c}}_{\ell}$
within the generative model. This is accomplished by fitting parametric distributions to the simulated distributions (see Section 6.6). The calibration of the scale (or the location) with a scalar
$\boldsymbol{{c}}_{\ell}$
within the generative model. This is accomplished by fitting parametric distributions to the simulated distributions (see Section 6.6). The calibration of the scale (or the location) with a scalar
 ${c_{\ell}}$
(i.e.,
${c_{\ell}}$
(i.e.,
 ${c_{\ell}}_{,o}={c_{\ell}}$
for all o) is performed with statistics on a claim level, on an annual level, or on a period level. The statistics on a claim level and on an annual level can also be used to calibrate a linear trend (i.e.,
${c_{\ell}}_{,o}={c_{\ell}}$
for all o) is performed with statistics on a claim level, on an annual level, or on a period level. The statistics on a claim level and on an annual level can also be used to calibrate a linear trend (i.e.,
 ${c_{\ell}}_{,o} ={a_{\ell}} + {b_{\ell}} \cdot(o-o_0)$
).
${c_{\ell}}_{,o} ={a_{\ell}} + {b_{\ell}} \cdot(o-o_0)$
).
Remark 6.2. The calibration procedure can be expanded to higher-dimensional vectors
 $\boldsymbol{{c}}_{\ell}$
. Given the interdependencies between parameters, the uncertainties, and the need to provide an adequate prior for each parameter, it is rarely possible to calibrate any feature beyond a linear trend.
$\boldsymbol{{c}}_{\ell}$
. Given the interdependencies between parameters, the uncertainties, and the need to provide an adequate prior for each parameter, it is rarely possible to calibrate any feature beyond a linear trend.
6.4. Continuous distributions
Most elements within the set of reduced random variables (see Section 4.3) are nonnegative, that is, they have a support
 $\mathbb{R^+}$
or
$\mathbb{R^+}$
or
 $\mathbb{Z^+}$
. The underlying modules within the generative model are, therefore, calibrated via an exponential linking (5.4). The incurred lag can, however, be positive or negative, that is, it has a support
$\mathbb{Z^+}$
. The underlying modules within the generative model are, therefore, calibrated via an exponential linking (5.4). The incurred lag can, however, be positive or negative, that is, it has a support
 $\mathbb{R}$
, and the underlying modules are calibrated via a linear linking.
$\mathbb{R}$
, and the underlying modules are calibrated via a linear linking.
In the case of continuous processes,
 ${\log}\mathcal{N}$
distributions are fitted to the simulated distributions in the exponential-linking case and
${\log}\mathcal{N}$
distributions are fitted to the simulated distributions in the exponential-linking case and
 $\mathcal{N}$
distributions are fitted to the simulated distributions in the linear-linking case. Combining these distributions with
$\mathcal{N}$
distributions are fitted to the simulated distributions in the linear-linking case. Combining these distributions with
 $\mathcal{N}$
priors for the calibration parameters and plugging the pdfs (probability density function) into (5.5), (5.6), (5.7), (5.8), and (5.9) leads to the MAP estimates for
$\mathcal{N}$
priors for the calibration parameters and plugging the pdfs (probability density function) into (5.5), (5.6), (5.7), (5.8), and (5.9) leads to the MAP estimates for
 $c^c_{MAP}, c^a_{MAP}, c^p_{MAP}$
and
$c^c_{MAP}, c^a_{MAP}, c^p_{MAP}$
and
 $(a^c_{MAP}, b^c_{MAP}), (a^a_{MAP}, b^a_{MAP})$
, respectively (see (A.1) and (A.3) in the Online Supplementary Material).
$(a^c_{MAP}, b^c_{MAP}), (a^a_{MAP}, b^a_{MAP})$
, respectively (see (A.1) and (A.3) in the Online Supplementary Material).
Remark 6.3. The conjugate prior distribution of a
 ${\log}\mathcal{N}$
(or
${\log}\mathcal{N}$
(or
 $\mathcal{N}$
) distribution with known parameter
$\mathcal{N}$
) distribution with known parameter
 $\sigma$
is a
$\sigma$
is a
 $\mathcal{N}$
distribution and the posterior predictive distribution is also a
$\mathcal{N}$
distribution and the posterior predictive distribution is also a
 ${\log}\mathcal{N}$
(or
${\log}\mathcal{N}$
(or
 $\mathcal{N}$
) distribution. The fitted
$\mathcal{N}$
) distribution. The fitted
 ${\log}\mathcal{N}$
(or
${\log}\mathcal{N}$
(or
 $\mathcal{N}$
) distributions are used as a proxy for calibration purposes; they are not used within the generative model. The posterior predictive
$\mathcal{N}$
) distributions are used as a proxy for calibration purposes; they are not used within the generative model. The posterior predictive
 ${\log}\mathcal{N}$
(or
${\log}\mathcal{N}$
(or
 $\mathcal{N}$
) distributions can thus not be fed back into the generative model; therefore, ‘scale’ (or ‘translate’) calibration parameters are used as a proxy.
$\mathcal{N}$
) distributions can thus not be fed back into the generative model; therefore, ‘scale’ (or ‘translate’) calibration parameters are used as a proxy.
6.5. Discrete: The
$\mathcal{P}\textit{anjer}$
class

6.5.1. Exponential linking
The three distribution families within the
 $\mathcal{P}\textit{anjer}$
class (Panjer, Reference Panjer1981; Sundt and Jewell, Reference Sundt and Jewell1981) are suitable to fit a broad variety of discrete processes (see Appendix B in the Online Supplementary Material). The class comprises the Poisson family
$\mathcal{P}\textit{anjer}$
class (Panjer, Reference Panjer1981; Sundt and Jewell, Reference Sundt and Jewell1981) are suitable to fit a broad variety of discrete processes (see Appendix B in the Online Supplementary Material). The class comprises the Poisson family
 $\mathcal{P}$
, the negative binomial family
$\mathcal{P}$
, the negative binomial family
 $\mathcal{NB}$
, and the binomial family
$\mathcal{NB}$
, and the binomial family
 $\mathcal{B}$
. The variance-over-mean ratio (Panjer factor)
$\mathcal{B}$
. The variance-over-mean ratio (Panjer factor)
 $f_P =\mathbb{V}[N] / \mathbb{E}[N]$
is used to discriminate between the three families:
$f_P =\mathbb{V}[N] / \mathbb{E}[N]$
is used to discriminate between the three families:
 $f_P=1$
for
$f_P=1$
for
 $\mathcal{P}$
,
$\mathcal{P}$
,
 $f_P>1$
for
$f_P>1$
for
 $\mathcal{NB}$
, and
$\mathcal{NB}$
, and
 $f_P < 1$
for
$f_P < 1$
for
 $\mathcal{B}$
.
$\mathcal{B}$
.
The calibration of the discrete process
 $N^{inc}_o$
,
$N^{inc}_o$
,
 $N^{rep}_o$
,
$N^{rep}_o$
,
 $N^{clo}_o$
,
$N^{clo}_o$
,
 $N^I_{o,i}$
, and
$N^I_{o,i}$
, and
 $N^P_{o,i}$
with support
$N^P_{o,i}$
with support
 $\mathbb{Z^+}$
is performed in an analogous way as the calibration of continuous processes with support
$\mathbb{Z^+}$
is performed in an analogous way as the calibration of continuous processes with support
 $\mathbb{R^+}$
. A parametric
$\mathbb{R^+}$
. A parametric
 $\mathcal{P}\textit{anjer}$
-class distribution is fitted to the respective simulated discrete distribution and used as a proxy when calibrating the underlying discrete process within the generative model. The calibration parameter
$\mathcal{P}\textit{anjer}$
-class distribution is fitted to the respective simulated discrete distribution and used as a proxy when calibrating the underlying discrete process within the generative model. The calibration parameter
 $\boldsymbol{{c}}_{\ell}$
with normal prior
$\boldsymbol{{c}}_{\ell}$
with normal prior
 $\pi_{\ell}(\boldsymbol{{c}}_{\ell})$
is linked to the frequency parameter (i.e.,
$\pi_{\ell}(\boldsymbol{{c}}_{\ell})$
is linked to the frequency parameter (i.e.,
 $\lambda$
for
$\lambda$
for
 $\mathcal{P}$
, n for
$\mathcal{P}$
, n for
 $\mathcal{B}$
, and r for
$\mathcal{B}$
, and r for
 $\mathcal{NB}$
) via an exponential linking. The
$\mathcal{NB}$
) via an exponential linking. The
 $\mathcal{N}$
distribution is not a conjugate prior of the
$\mathcal{N}$
distribution is not a conjugate prior of the
 $\mathcal{P}\textit{anjer}$
-class families, but the MAP estimate of the calibration parameters with a
$\mathcal{P}\textit{anjer}$
-class families, but the MAP estimate of the calibration parameters with a
 $\mathcal{N}$
prior can be found iteratively (see formulas in Table B.1 in the Online Supplementary Material).
$\mathcal{N}$
prior can be found iteratively (see formulas in Table B.1 in the Online Supplementary Material).
A discrete process can also be calibrated with a continuous distribution if the frequency is sufficiently large (see Appendix A.3 in the Online Supplementary Material). A gamma distribution
 $\mathcal{G}\textit{a}$
can, for example, approximate the
$\mathcal{G}\textit{a}$
can, for example, approximate the
 $\mathcal{P}\textit{anjer}$
-class distributions without the need to discriminate between the three families. Another alternative is to derive the calibration parameters with the help of a
$\mathcal{P}\textit{anjer}$
-class distributions without the need to discriminate between the three families. Another alternative is to derive the calibration parameters with the help of a
 ${\log}\mathcal{N}$
approximation (see Figure 5). A comparison of the calibration of discrete processes performed with several discrete and continuous distributions is shown in Table 5 and in Figure 8.
${\log}\mathcal{N}$
approximation (see Figure 5). A comparison of the calibration of discrete processes performed with several discrete and continuous distributions is shown in Table 5 and in Figure 8.

Figure 8. Fitting comparison. Representation of
 $L(c) = c /e^{c}$
and of
$L(c) = c /e^{c}$
and of
 $R_D(c) = R(c \mid N_o, \mu^0_o, f_P, \sigma_c)$
for various distributions D. The random variables
$R_D(c) = R(c \mid N_o, \mu^0_o, f_P, \sigma_c)$
for various distributions D. The random variables
 $N_o$
and
$N_o$
and
 $\mu^0_o$
are taken from the ‘toy model’ (see Table 3) and combined with
$\mu^0_o$
are taken from the ‘toy model’ (see Table 3) and combined with
 $f_P \in \{ 0.5, 0.8, 1.0, 1.2, 2.0 \}$
. The distribution D is selected depending on
$f_P \in \{ 0.5, 0.8, 1.0, 1.2, 2.0 \}$
. The distribution D is selected depending on
 $f_P$
:
$f_P$
:
 $D=\mathcal{P}$
if
$D=\mathcal{P}$
if
 $f_P=1$
,
$f_P=1$
,
 $D=\mathcal{NB}$
if
$D=\mathcal{NB}$
if
 $f_P>1$
, and
$f_P>1$
, and
 $D=\mathcal{B}$
if
$D=\mathcal{B}$
if
 $f_P <1$
(see Table B.1 in the Online Supplementary Material). The approximation
$f_P <1$
(see Table B.1 in the Online Supplementary Material). The approximation
 $D=\mathcal{G}\textit{a}$
(dotted lines) is evaluated for all selections of
$D=\mathcal{G}\textit{a}$
(dotted lines) is evaluated for all selections of
 $f_P$
. The diamonds depict the root
$f_P$
. The diamonds depict the root
 $c_{MAP}=-0.48$
evaluated with
$c_{MAP}=-0.48$
evaluated with
 $D={\log}\mathcal{N}$
(see (A.1) in the Online Supplementary Material). The top panels show L(c) and
$D={\log}\mathcal{N}$
(see (A.1) in the Online Supplementary Material). The top panels show L(c) and
 $R_D(c)$
for the wide range
$R_D(c)$
for the wide range
 $c \in [\!-\!5, +5]$
around the prior
$c \in [\!-\!5, +5]$
around the prior
 $c=0.0$
, and the bottom panels show the curves for the narrow range
$c=0.0$
, and the bottom panels show the curves for the narrow range
 $c \in [\!-\!0.6, -0.4]$
.
$c \in [\!-\!0.6, -0.4]$
.



6.5.2 Logistic linking
A generative model might also comprise processes involving a fixed support
 $\{ 0, \dots, n \}$
or processes involving a fixed threshold r for a discrete random variable N. Such features can be calibrated via a logistic linking of the calibration parameter
$\{ 0, \dots, n \}$
or processes involving a fixed threshold r for a discrete random variable N. Such features can be calibrated via a logistic linking of the calibration parameter
 ${c_{\ell}}$
to a probability parameter
${c_{\ell}}$
to a probability parameter
 $p_o \in [0,1]$
, for example,
$p_o \in [0,1]$
, for example,
 $N\sim \mathcal{B}(n,p_o({c_{\ell}}))$
or
$N\sim \mathcal{B}(n,p_o({c_{\ell}}))$
or
 $N\sim \mathcal{NB}(r,p_o({c_{\ell}}))$
. The respective equations to be fulfilled by the calibration parameter
$N\sim \mathcal{NB}(r,p_o({c_{\ell}}))$
. The respective equations to be fulfilled by the calibration parameter
 ${c_{\ell}}_{,MAP}$
via a logistic linking (5.4) to the annual probability parameters
${c_{\ell}}_{,MAP}$
via a logistic linking (5.4) to the annual probability parameters
 $p_o$
are listed in the two bottom rows of Table B.1 in the Online Supplementary Material.
$p_o$
are listed in the two bottom rows of Table B.1 in the Online Supplementary Material.
Table 4. Parameters used for the model comparison.

Table 5. Comparison of the calibration parameters derived on an annual and a period level with different approximations for the three model cases
 $\mathcal{NB}$
,
$\mathcal{NB}$
,
 $\mathcal{P}$
, and
$\mathcal{P}$
, and
 $\mathcal{B}$
.
$\mathcal{B}$
.

One
 $\mathcal{B}$
example (Bernoulli case) is a random indicator variable
$\mathcal{B}$
example (Bernoulli case) is a random indicator variable
 $\mathbb{1}_{EN}$
for ‘El Niño’ years (i.e.,
$\mathbb{1}_{EN}$
for ‘El Niño’ years (i.e.,
 $n=1$
). Another
$n=1$
). Another
 $\mathcal{B}$
example is an upper bound on the random count of payments per year, for example,
$\mathcal{B}$
example is an upper bound on the random count of payments per year, for example,
 $0 \le N^P_{o,i} \le n=12$
for all (o, i).
$0 \le N^P_{o,i} \le n=12$
for all (o, i).
A
 $\mathcal{NB}$
example is a hypothetical dual-trigger contract that covers the economic loss of
$\mathcal{NB}$
example is a hypothetical dual-trigger contract that covers the economic loss of
 $N_T = N_{TF} + N_{TT}$
claims stemming from TF events or TT events (i.e., the first trigger must be ‘True’ and the second trigger can be ‘False’ or ‘True’) as long as the count
$N_T = N_{TF} + N_{TT}$
claims stemming from TF events or TT events (i.e., the first trigger must be ‘True’ and the second trigger can be ‘False’ or ‘True’) as long as the count
 $N_{TT}$
of TT events does not exceed the fixed threshold
$N_{TT}$
of TT events does not exceed the fixed threshold
 $r \in \mathbb{R^+}$
:
$r \in \mathbb{R^+}$
:
 $N_{TF} \sim \mathcal{NB}(r,p)$
, and
$N_{TF} \sim \mathcal{NB}(r,p)$
, and
 $N_{TT} = \lfloor r \rfloor$
.
$N_{TT} = \lfloor r \rfloor$
.
6.6. Method comparison
The various calibration approaches briefly described above (see details in Appendices A and B in the Online Supplementary Material) are applied to the
 $\mathcal{NB}$
case (i.e.,
$\mathcal{NB}$
case (i.e.,
 $f_P > 1$
), the
$f_P > 1$
), the
 $\mathcal{P}$
case (i.e.,
$\mathcal{P}$
case (i.e.,
 $f_P \approx 1$
), and the
$f_P \approx 1$
), and the
 $\mathcal{B}$
case (i.e.,
$\mathcal{B}$
case (i.e.,
 $f_P < 1$
). The parameters used to generate the set
$f_P < 1$
). The parameters used to generate the set
 $\{N_o^{obs}\}$
containing the observations stemming from the generative process and the parameters used to generate the set
$\{N_o^{obs}\}$
containing the observations stemming from the generative process and the parameters used to generate the set
 $\{N_{o,k}^{sim}\}$
representing the generative model are listed in Table 4. The reference frequencies
$\{N_{o,k}^{sim}\}$
representing the generative model are listed in Table 4. The reference frequencies
 $\{ \lambda^{ref}_o \}$
for the occurrence year o are derived from
$\{ \lambda^{ref}_o \}$
for the occurrence year o are derived from
 $\lambda^{ref}_{-T}$
and
$\lambda^{ref}_{-T}$
and
 $\lambda^{ref}_{-1}$
via an exponential interpolation. The simulated frequencies
$\lambda^{ref}_{-1}$
via an exponential interpolation. The simulated frequencies
 $\lambda^{sim}_o \sim \mathcal{G}\textit{a}(\alpha_o, \beta)$
with
$\lambda^{sim}_o \sim \mathcal{G}\textit{a}(\alpha_o, \beta)$
with
 $\alpha_o = \lambda^{ref}_o \cdot \beta$
are used to simulate the K random variables
$\alpha_o = \lambda^{ref}_o \cdot \beta$
are used to simulate the K random variables
 $N_{o,k}^{sim} \sim \mathcal{P}\textit{anjer} (\lambda^{sim}_o, f_P)$
. The derived calibration parameters
$N_{o,k}^{sim} \sim \mathcal{P}\textit{anjer} (\lambda^{sim}_o, f_P)$
. The derived calibration parameters
 $c^a_{MAP}$
(annual level) and
$c^a_{MAP}$
(annual level) and
 $c^p_{MAP}$
(period level) obtained with the various approaches are compared in Table 5. Five simulations are run for each of the three cases
$c^p_{MAP}$
(period level) obtained with the various approaches are compared in Table 5. Five simulations are run for each of the three cases
 $f_P=1.5$
(
$f_P=1.5$
(
 $\mathcal{NB}$
case),
$\mathcal{NB}$
case),
 $f_P=1.0$
(
$f_P=1.0$
(
 $\mathcal{P}$
case), and
$\mathcal{P}$
case), and
 $f_P=0.6$
(
$f_P=0.6$
(
 $\mathcal{B}$
case), respectively. The case, the respective model Panjer factor
$\mathcal{B}$
case), respectively. The case, the respective model Panjer factor
 $f_P$
, and the calculated calibration parameter
$f_P$
, and the calculated calibration parameter
 $c^{mod}$
(the difference of the mean log frequencies
$c^{mod}$
(the difference of the mean log frequencies
 $\widehat{\ln{\lambda}^{ref}_{o}}$
) are indicated in column 1 for each of the three cases. The simulated Panjer factors
$\widehat{\ln{\lambda}^{ref}_{o}}$
) are indicated in column 1 for each of the three cases. The simulated Panjer factors
 ${f_P}^{sim}$
per run are shown in column 2.
${f_P}^{sim}$
per run are shown in column 2.
The respective calibration parameters
 $c^a_{MAP}$
and
$c^a_{MAP}$
and
 $c^p_{MAP}$
are shown in columns 3–11. The calibration parameters are only evaluated with the
$c^p_{MAP}$
are shown in columns 3–11. The calibration parameters are only evaluated with the
 $\mathcal{NB}$
approach when
$\mathcal{NB}$
approach when
 ${f_P}^{sim}>1$
, and with the
${f_P}^{sim}>1$
, and with the
 $\mathcal{B}$
approach when
$\mathcal{B}$
approach when
 ${f_P}^{sim}<1$
. The parameters derived with the
${f_P}^{sim}<1$
. The parameters derived with the
 $\mathcal{NB}$
approach in the
$\mathcal{NB}$
approach in the
 $\mathcal{NB}$
case, with the
$\mathcal{NB}$
case, with the
 $\mathcal{P}$
approach in the
$\mathcal{P}$
approach in the
 $\mathcal{P}$
case, and with the
$\mathcal{P}$
case, and with the
 $\mathcal{B}$
approach in the
$\mathcal{B}$
approach in the
 $\mathcal{B}$
case, are shown in bold (see Appendix C.2 in the Online Supplementary Material for details).
$\mathcal{B}$
case, are shown in bold (see Appendix C.2 in the Online Supplementary Material for details).
Using the
 $\mathcal{P}$
approximation (with
$\mathcal{P}$
approximation (with
 $c^a_{MAP}=c^p_{MAP}$
) as a reference indicates that the scale calibration parameters
$c^a_{MAP}=c^p_{MAP}$
) as a reference indicates that the scale calibration parameters
 $c^p_{MAP}$
derived from aggregate period statistics with the different approaches are remarkably close. The scale calibration parameters
$c^p_{MAP}$
derived from aggregate period statistics with the different approaches are remarkably close. The scale calibration parameters
 $c^a_{MAP}$
derived from annual statistics vary between the approaches, but the variations are not substantial.
$c^a_{MAP}$
derived from annual statistics vary between the approaches, but the variations are not substantial.
Hence, the model comparison indicates that a
 ${\log}\mathcal{N}$
approximation based on annual statistics might be used to derive linear-trend parameters
${\log}\mathcal{N}$
approximation based on annual statistics might be used to derive linear-trend parameters
 $a^a_{MAP}$
and
$a^a_{MAP}$
and
 $b^a_{MAP}$
with the help of (A.3) in the Online Supplementary Material. Attempting to derive these two parameters with other models, for example, the
$b^a_{MAP}$
with the help of (A.3) in the Online Supplementary Material. Attempting to derive these two parameters with other models, for example, the
 $\mathcal{G}\textit{a}$
family or the
$\mathcal{G}\textit{a}$
family or the
 $\mathcal{P}\textit{anjer}$
class yields more complex equations that must be solved numerically (see Table B.1 in the Online Supplementary Material).
$\mathcal{P}\textit{anjer}$
class yields more complex equations that must be solved numerically (see Table B.1 in the Online Supplementary Material).
6.7. Example of a complete calibration
An example of an iterative calibration of seven features is shown in Figures 9 and 10 (see Appendix C.3 in the Online Supplementary Material for details). A marginal linear-trend calibration is applied to the annual claim counts
 $N^{rep}_o$
, the average annual claims severities
$N^{rep}_o$
, the average annual claims severities
 $\hat{I}^*_o$
, the average annual lags
$\hat{I}^*_o$
, the average annual lags
 $\tau^{rep}_o$
,
$\tau^{rep}_o$
,
 $\tau^I_o$
,
$\tau^I_o$
,
 $\tau^P_o$
, and the average annual counts
$\tau^P_o$
, and the average annual counts
 $\hat{n}^I_o$
and
$\hat{n}^I_o$
and
 $\hat{n}^P_o$
. The distributions of the annual counts of closed claims
$\hat{n}^P_o$
. The distributions of the annual counts of closed claims
 $N^{clo}_o$
and the distributions of the annual average paid amounts
$N^{clo}_o$
and the distributions of the annual average paid amounts
 $\hat{P}^*_o$
are strongly dependent ‘test variables’ (they are monitored but not calibrated). The distributions drawn at
$\hat{P}^*_o$
are strongly dependent ‘test variables’ (they are monitored but not calibrated). The distributions drawn at
 $o=0$
show the respective aggregate distributions on a period level. The different linear-trend assumptions underlying the model used to emulate the generative process and the initial generative model, respectively, can be recognized in the pmfs and pdfs shown in Figure 9. The two models are sampled 200 times, and parametric distributions are fitted to the simulated marginal distributions.
$o=0$
show the respective aggregate distributions on a period level. The different linear-trend assumptions underlying the model used to emulate the generative process and the initial generative model, respectively, can be recognized in the pmfs and pdfs shown in Figure 9. The two models are sampled 200 times, and parametric distributions are fitted to the simulated marginal distributions.

Figure 9. Generative process and initial model. Temporal evolution of the probability distributions (shown at
 $o \in \{ -T, \dots, -1 \} $
with
$o \in \{ -T, \dots, -1 \} $
with
 $T = 12$
) and the aggregated distribution (shown at
$T = 12$
) and the aggregated distribution (shown at
 $o=0$
) of nine reduced variables. The underlying (hidden) pmfs (horizontal lines) and pdfs (continuous lines) of the generative process are drawn with thin lines. The pdfs of the underlying generative model are drawn with thicker lines, and the diamonds represent the ‘observations’ drawn from the generative process. Large offsets of the corresponding modes (large relative to the respective standard deviations) can be identified for the claims count
$o=0$
) of nine reduced variables. The underlying (hidden) pmfs (horizontal lines) and pdfs (continuous lines) of the generative process are drawn with thin lines. The pdfs of the underlying generative model are drawn with thicker lines, and the diamonds represent the ‘observations’ drawn from the generative process. Large offsets of the corresponding modes (large relative to the respective standard deviations) can be identified for the claims count
 $N^{rep}$
, the incurred amount
$N^{rep}$
, the incurred amount
 $\hat{I}^*$
, and the (derived) cumulative paid amount
$\hat{I}^*$
, and the (derived) cumulative paid amount
 $\hat{P}^*$
.
$\hat{P}^*$
.

Figure 10. Generative process and calibrated model. Same representation as in Figure 9. The linear-trend parameters within the generative model are calibrated in five iteration steps with seven marginal distributions. The residual offsets between the corresponding modes of the (hidden) true model and the calibrated generative model are minor compared to the standard deviations. Note: The count of closed claims
 $N^{clo}$
and the paid amount
$N^{clo}$
and the paid amount
 $\hat{P}^*$
are dependent ‘test variables’ that are monitored but not calibrated.
$\hat{P}^*$
are dependent ‘test variables’ that are monitored but not calibrated.
The calibration procedure is iterated five times after the initial sampling (iteration 0). The marginal linear-trend parameters
 ${a_{\ell}}^a_{,MAP}$
and
${a_{\ell}}^a_{,MAP}$
and
 ${b_{\ell}}^a_{,MAP}$
are evaluated in the first step of each iteration, the respective parameters within the generative model are adjusted in the second step, and the adjusted model is used to generate 200 new samples in the third step. A robust solution is obtained by reducing the prior parameters
${b_{\ell}}^a_{,MAP}$
are evaluated in the first step of each iteration, the respective parameters within the generative model are adjusted in the second step, and the adjusted model is used to generate 200 new samples in the third step. A robust solution is obtained by reducing the prior parameters
 $\sigma_{{a_{\ell}}^a}$
and
$\sigma_{{a_{\ell}}^a}$
and
 $\sigma_{{b_{\ell}}^a}$
after each iteration. The resulting marginal distributions derived from the calibrated model are shown in Figure 10. The residual offsets of corresponding modes are small relative to the respective standard deviations, that is, the highest density regions of corresponding distributions are overlapping. The calibrated generative model is thus well aligned with the (hidden) ‘true’ model used to emulate the generative process.
$\sigma_{{b_{\ell}}^a}$
after each iteration. The resulting marginal distributions derived from the calibrated model are shown in Figure 10. The residual offsets of corresponding modes are small relative to the respective standard deviations, that is, the highest density regions of corresponding distributions are overlapping. The calibrated generative model is thus well aligned with the (hidden) ‘true’ model used to emulate the generative process.
7. Conclusions
A generic framework that permits calibrating the relevant features within exposure-based generative models with the claims experience
 $\mathcal{Y}$
of a cedent has been introduced. Depending on the generative model, the calibration is accomplished by applying the maximum a posteriori (MAP) point estimates
$\mathcal{Y}$
of a cedent has been introduced. Depending on the generative model, the calibration is accomplished by applying the maximum a posteriori (MAP) point estimates
 $\boldsymbol{{C}}_{MAP}$
or by applying the posterior probability distribution
$\boldsymbol{{C}}_{MAP}$
or by applying the posterior probability distribution
 $Pr(\boldsymbol{{C}} \mid \mathcal{Y})$
.
$Pr(\boldsymbol{{C}} \mid \mathcal{Y})$
.
Generative models attempt to emulate all relevant features of the generative process underlying the claims experience of a cedent, that is, the simulated claims are represented in the same way as the observed claims in the submission data. The detailed features of the simulated high-dimensional claim objects are required for the rating process, but these objects cannot be directly used for calibration. The calibration is thus performed with low-dimensional reduced variables and simulated marginal probability distributions. Rating and calibration are two distinct processes performed with the same generative model; the two processes can, however, be performed at different points in time.
Standard experience-based rating approaches project the past claims experience to the future, and the incomplete claims are developed. In contrast, the integrated framework projects the exposure models to the past and attempts to replicate the characteristics of the claims experience. A calibrated generative model is, therefore, coherently reflecting all information available to the reinsurer. The calibrated model is projected to the cover period and used for rating, while the standard experience-based rating is obsolete.
The generic calibration framework interacts with the generative model via standardized interfaces, and it is applicable to all nonlife lines of business. In the case of short-tail business, it is used to calibrate the claims frequency and the claims severity. In the case of long-tail lines, it is used to calibrate the claims frequency, the claims severity, the reporting pattern, the incurred pattern, and the payment pattern.
The marginal probability distributions encountered in reinsurance ratings are assumed to be uni-modal and heavy-tailed. The calibration of such distributions with Bayesian inference is determined by the highest density region (HDR), and it only depends on relative probabilities. It is thus sufficient to adequately fit the simulated distributions in the HDR, and there is no need to normalize the potentials defining the shape of the distributions. Continuous potentials as, for example, defined by the normal (
 $\mathcal{N}$
) family, the log-normal (
$\mathcal{N}$
) family, the log-normal (
 ${\log}\mathcal{N}$
) family, or the gamma (
${\log}\mathcal{N}$
) family, or the gamma (
 $\mathcal{G}\textit{a}$
) family, can, therefore, be used to calibrate discrete processes if the frequencies are not too small. This is of particular interest when attempting to calibrate the linear trend of a feature.
$\mathcal{G}\textit{a}$
) family, can, therefore, be used to calibrate discrete processes if the frequencies are not too small. This is of particular interest when attempting to calibrate the linear trend of a feature.
Interdependencies between the calibration features, for example, the (unknown) count of incurred claims, the reporting lag, and the count of reported claims, depend on the characteristics of the underlying generative processes. Such dependencies are considered in the calibration by reflecting the characteristics within the generative model and by iterating the calibration procedure with an expectation-maximization (EM) algorithm.
The set of calibration parameters derived during a certain period for cedents operating in the same market can be used to update the hyperparameters used to specify the prior distributions in a subsequent period.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/asb.2024.17.
Data availability statement
Replication data and code can be found in GitHub: https://github.com/Steivan/GIRF.
Acknowledgments
The author thanks the editor and the referees for their constructive feedback.
Competing interests
The author declares none.














































































































 Open access
Open access