

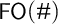
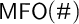
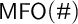
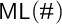

Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Fu, Xiaoxuan
and
Zhao, Zhiguang
2024.
Modal Logic with “Most”.
Studia Logica,
Fu, Xiaoxuan
and
Zhao, Zhiguang
2024.
Axiomatization of modal logic with counting.
Logic Journal of the IGPL,
Mayer, Thomas L.
2024.
Foundations of Information and Knowledge Systems.
Vol. 14589,
Issue. ,
p.
287.
Fu, Xiaoxuan
and
Zhao, Zhiguang
2025.
Artificial Intelligence Logic and Applications.
Vol. 2248,
Issue. ,
p.
3.
Fu, Xiaoxuan
and
Zhao, Zhiguang
2025.
Numerical expressive power of logical languages with cardinality comparison.
Journal of Logic and Computation,
Vol. 35,
Issue. 3,
Sauerland, Uli
Sugawara, Ayaka
and
Yatsushiro, Kazuko
2025.
Higher-Order Logical Reasoning in Preschool Children: Evidence from Intonation and Quantifier Scope.
Open Research Europe,
Vol. 5,
Issue. ,
p.
34.
Liang, Xiaolong
Wáng, Yì N.
and
Ågotnes, Thomas
2026.
Logic, Rationality, and Interaction.
Vol. 16010,
Issue. ,
p.
95.