


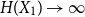

Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Fradelizi, Matthieu
Gavalakis, Lampros
and
Rapaport, Martin
2024.
Dimensional Discrete Entropy Power Inequalities for Log-Concave Random Vectors.
p.
3582.