



Policy Significance Statement
This study presents a robust approach for predicting future migration patterns in the European Union, specifically in forecasting asylum applications and irregular border crossings. We emphasise the importance of policymakers adopting robust migration forecasting when formulating responsive strategies. Through leveraging advanced analytics that enhance prediction accuracy, policymakers can more effectively allocate resources and address politically contentious issues in advance, thanks to enhanced preparedness. The policy implications advocate for embracing scientific advancements in anticipatory methods for establishing migration governance mechanisms, such as the relocation plans outlined in the EU New Pact on Migration and Asylum. The integration of data-driven insights into migration-related policymaking is paramount in a rapidly evolving global landscape.
1. Introduction
Every year, millions of people are forced to move from their homes due to different reasons that span from conflict, disasters of various nature, climate change, and others. In 2022, the number of people displaced worldwide was 108.4 million (including internally displaced), of which 5.4 million are asylum seekers.Footnote 1 Some forcibly displaced people, alongside with voluntary migrating ones, try to reach Europe in an unauthorised manner in the hope of creating a better future for themselves and their families. In 2022, around 330.000 irregular border crossings were detected at the EU’s external border, the highest number since 2016.Footnote 2 In the same year, almost 1 million asylum applications were lodged in the EU+ countries,Footnote 3 and an additional 4 million people fleeing the war in Ukraine benefited from temporary protection.Footnote 4 Some of these asylum applicants reached the EU via irregular border crossing; others via other means.
Understanding and anticipating volumes of people migrating to the EU is crucial to local, national, and supra-national authorities to better manage the challenges related to the policy response, for instance, in terms of reception capacity and integration (Marcucci and Verhulst, Reference Marcucci and Verhulst2023). However, migration as a field of study has always presented challenges even in documenting the contemporary and past processes. Among others, Bakewell (Reference Bakewell2008) attributed this to the so-called “sedentary bias,” namely, the fact that the statistical data collection for public purposes has been skewed towards monitoring the stable resident population and has not been sensitive enough to capture the variously mobile individuals.
Moreover, migration and its drivers are complex and very context-dependent features (Black et al. Reference Black, Bellagamba, Botta, Ceesay, Cissokho, Engeler, Lenoël, Oelgemöller, Riccio, Sakho, Somparé, Vitturini and Zingari2022), and forecasting the volume of people moving to a certain destination is therefore non-trivial (Sohst et al., Reference Sohst, Tjaden, de Valk and Melde2020). The datasets that can be used to forecast migration might not be available for specific countries, might not always have the desired temporal resolution or, even if they do, they might be published too late for effective use (Bijak and Czaika, Reference Bijak and Czaika2020; Sohst et al., Reference Sohst, Tjaden, de Valk and Melde2020).
The policy demand for predicting migration processes is rising. In the European Union, the shock tied to the perceived migration crisis of years 2015-16 led to the reworking of the policy framework (Pachocka and Caballero Vélez, Reference Pachocka and Caballero Vélezin press), and the policymakers have placed more emphasis on preparedness and anticipation. In this vein, the New Pact on Migration and Asylum, proposed by the European Commission in September 2020, contains a recommendation on an EU mechanism for preparedness and management of crises related to migration (the Migration Preparedness and Crisis Blueprint, EU, 2020/1366Footnote 5). The Council of the European Union finally adopted legislative acts that reform the entire European framework for asylum and migration management on May 14, 2024.Footnote 6 This should develop an early warning and forecasting system at the EU level to enhance preparedness, effective governance, and timely response to migration situations.Footnote 7
In Europe, the number of large research projects dedicated to anticipating migration flows has increased in response to the Horizon Europe calls such as ‘Secure societies - Protecting freedom and security of Europe and its citizens,’ as is the case of the ITFLOWS project, within whose framework tools to predict migratory flows were developed for humanitarian purposes. Another important project is Mignex. Aligning Migration Management and the Migration-Development Nexus funded under ‘SOCIETAL CHALLENGES - Europe in a Changing World - Inclusive, Innovative and Reflective Societies’ call. These projects address the growing policy demand for migration governance tools, although the calls are not explicitly centred around this objective.
In parallel, several initiatives demonstrate the increasing use of Machine Learning (ML) techniques to predict and manage irregular border crossings and asylum applications in Europe. For instance, Machine Learning algorithms have been used by the European Border Surveillance System (EUROSUR), the EU Entry/Exit System (EES), the SIS II (Schengen Information System), the Frontex Risk Analysis Network (FRAN), the Predictive Analytics for Security Information (PASI), and Sweden’s PREDICT Project.
Using machine learning for detecting irregular border crossings and asylum applications in the European Union offers several advantages, like the possibility to detect irregularities more accurately than traditional methods (i.e., better model performance in out-of-sample forecasts, Robinson and Dilkina, Reference Robinson and Dilkina2018; Sohst et al., Reference Sohst, Tjaden, de Valk and Melde2020; de Valk et al., Reference de Valk and Scholten2022) or to identify subtle patterns and anomalies and high-risk areas effectively (Robinson and Dilkina, Reference Robinson and Dilkina2018). Moreover, the analysis can be automatised, reducing time, resource allocation, and cost (e.g., by implementing streamlining processes) needed for manual inspection, therefore allowing focus on higher priority tasks.
In this paper, we focus on forecasting irregular border crossing and asylum applications. This is for two reasons: First, to pilot our model we needed to delimit the phenomenon to forecast. Second, irregular border crossings and asylum applications present more similar and pressing challenges in terms of policy response. We present a case study on forecasting irregular border crossings on the so-called Central Mediterranean Route and asylum applications in Italy by ensembling three different machine learning techniques. The approach taken in our exercise yields good results and promises the upscaling potential of forecasting migration for policy needs.
Theoretical and contextual framework of using Machine Learning systems
Predicting migration proves exceedingly challenging (Sohst et al., Reference Sohst, Tjaden, de Valk and Melde2020). The migration process operates within a complex framework, where causal elements interact in non-linear ways, greatly influenced by specific contexts (Van Hear et al., Reference Van Hear, Bakewell and Long2018). The array of potential driving forces is broad (de Haas et al., Reference de Haas, Czaika, Flahaux, Mahendra, Natter, Vezzoli and Villares-Varela2019; Czaika and Reinprecht, Reference Czaika and Reinprecht2020; Czaika and Reinprecht, Reference Czaika, Reinprecht and Scholten2022), and their impacts and interactions vary significantly across different migration streams. In certain scenarios, intense conflict or persecution may surprisingly yield a minimal migration flow, whereas, in other situations, seemingly minor social unrest can catalyse significant international displacements.
Migration drivers often operate under thresholds and feedback loops, wherein once initiated, movements between countries tend to set off self-reinforcing mechanisms, ultimately establishing migration systems (Carammia et al., Reference Carammia, Iacus and Wilkin2022). Because of the high uncertainty of the migration process, migration modelling results are complex to be addressed (Willekens, Reference Willekens2016; Bijak and Czaika, Reference Bijak and Czaika2020). Sudden occurrences like violent conflicts, economic downturns, or shifts in policies pose challenges for producing precise predictions. Additionally, the typically inadequate quality of data concerning migration and refugee movements can add a significant error in forecasting (Disney et al., Reference Disney, Wiśniowski, Forster, Smith and Bijak2015).
Some researchers have already attempted to provide a solution to this issue. For example, Carammia et al. (Reference Carammia, Iacus and Wilkin2022) developed a comprehensive system for forecasting asylum applications four weeks ahead based on adaptive models and a mix of traditional, operational, and innovative data. Nair et al., (Reference Nair, Madsen, Lassen, Baduk, Nagarajan, Mogensen, Novack, Curzon, Paraszczak, Urbak and Urbak2019) developed MM4SIGHT, a machine-learning system that enables annual forecasts of mixed-migration flows using more than 80 macroindicators. Napierała et al. (Reference Napierała, Hilton, Forster, Carammia and Bijak2022) developed an early warning system using frequent data (specifically, weekly and monthly) of asylum application registrations across various European countries. Drawing inspiration from statistical control theory (Bijak et al., Reference Bijak, Forster and Hilton2017), their model generates alerts when a predefined threshold in asylum application numbers is reached.
Information regarding migration, including its underlying causes, carries inherent uncertainty, posing challenges for migration modelling (Bijak and Czaika, Reference Bijak and Czaika2020; Sohst et al., Reference Sohst, Tjaden, de Valk and Melde2020). Despite advancements in official statistics gathering and ongoing endeavours to enhance data collection both at the European and global levels by entities like EUROSTAT, EUAA, KCMD, Frontex, UNHCR, and IOM, most data sets suffer from limitations in terms of their frequency, definitions, timeliness, and quality assurance (Singleton, Reference Singleton2016; Willekens, Reference Willekens2019). This constraint extends to data concerning migration drivers such as conflicts, human rights conditions, and economic factors, particularly in terms of their regularity, accuracy, and promptness, all of which are crucial for effective predictive analysis.
Machine Learning systems are often seen as black boxes that do not explain their predictions in a way that humans can understand (Rudin, Reference Rudin2019). This often generates mistrust, and it does not allow for actionable results. Explainable ML can strengthen people’s trust, increasing transparency and minimising the risk of bias or error, by allowing humans to understand the basis of their actions (COM (2018) 237 final). It offers the potential to provide stakeholders with insights into the model’s behaviour (Bhatt et al., Reference Bhatt, Xiang, Sharma, Weller, Taly, Jia, Ghosh, Puri, Moura and Eckersley2020). Moreover, trustworthy models should provide a measure of uncertainty to accompany their predictions to allow for well-informed decisions (Wickstrøm et al., Reference Wickstrøm, Kampffmeyer and Jenssen2020).
This article demonstrates the predictive capacity of several machine learning methods through quantification of uncertainty and model fit by combining Asylum applications, IBCs, and a number of covariates (described in Section 2.2). We produced predictions of asylum applications and Irregular Border Crossings (IBCs), respectively, for Italy and the Central Mediterranean Migratory Route.Footnote 8
Another important aspect of our work is that it relies on a relatively small set of predictors (e.g., food price inflation, foreign direct investment net inflows, etc.), carefully selected from migration literature, rather than on a massive collection of potential drivers. This makes the model easier to explain since the features that contribute to the outcome are generally well known and expected.
2. Materials and methods
In the following paragraphs, we detail the datasets and the methodology as the basis of our attempt to forecast irregular border crossings and asylum applications.
2.1. Source of data for IBCs and Asylum applications
IBCs and asylum applications are the two dependent variables considered in our study. They are publicly available online. Data on IBCs were downloaded from Frontex’s website.Footnote 9 These are updated monthly and represent the detections of IBCs from January 2009 until July 2023 (at the time of writing). They are disaggregated by different migratory routes as defined by FrontexFootnote 10, by the border type (either land or sea), and the nationality. In this work, we focused on the total detections on the Central Mediterranean Route, without distinguishing between different border types or nationalities.
Data on asylum applications were downloaded from EUROSTAT’s website.Footnote 11 Here, we focused on the total number of first-time applicants in Italy, regardless of their country of citizenship. Data are available from January 2008 until July 2023 (at the time of writing). No missing data are present in either dataset.
2.2 Defining a suite of covariates to predict Irregular Border Crossing and Asylum applications
Identifying covariates among the variables relevant to the migration processes has been part of a larger effort to create a library of drivers at the Joint Research Centre. Following an extensive literature review as well as available meta-analyses, we decided to follow with some modifications the typology of drivers elaborated by Czaika and Reinprecht (Reference Czaika and Reinprecht2020, Reference Czaika, Reinprecht and Scholten2022), based on a meta-analysis of 463 papers. They distinguish nine migration driver dimensions, composed of 24 migration-driving factors.
The dimensions were the following: demographic, economic (including labour market), environmental, human development, political-institutional, security, socio-cultural, supranational, and those tied to international development. We reviewed more than 100 indicators representing all dimensions of migration drivers that vary greatly in terms of frequency and timeliness of publishing updates. Between 10 to 20 indicators and composite indicators representing a given dimension have been identified during the review.
We followed two conditions in identifying the set of variables used to predict Irregular Border Crossings and Asylum applications: first, the variables had to be relevant for the migratory processes according to the literature. Second, they had to meet challenging technical criteria, when it comes to frequency, consistency, and availability over time and for key geographical areas (countries of origin). The real challenge was to identify variables meeting the technical criteria. It was especially difficult for countries with less developed monitoring practice. For example, labour market indicators are not available on a monthly basis for the majority of African countries. Some dimensions, such as the demographic dimension, are more structural and characterised by slow change, and indicators in these cases are updated only yearly.
We identified candidate variables in the dimension of economic drivers, namely inflation data, including the food price index and headline consumer price index. Another important variable that reflected the supranational ties was the foreign direct investment net inflows. We have also singled out instrumental variables that represented processes at the intersection of several dimensions such as monthly Food Price Inflation Estimates. Food Price Inflation reflects the condition of the economy, the human development in terms of food security, the economic condition of the population, as well as environmental phenomena that affect food availability and its prices, and as such is extremely valuable as a covariate for the countries for which it is available (the so-called fragile countries as defined by the World BankFootnote 12). Among the covariates included in the model that yielded good results, food price inflation estimates are published in a very timely manner, allowing for using it in predicting the flows in the following months. The full list of the covariates that we tested within our models is available in the supplementary material.
Apart from the above-mentioned covariates representing migration drivers, we used the IBCs as an additional covariate in the model to forecast first-time asylum applications. This can lead to better performances because IBCs and first-time asylum applications are related to each other. A basic intuition of this relationship is that a higher number of detections at the EU border is generally followed by a higher number of asylum applications in some EU Member States. The timing and magnitude of such relationship could vary from country to country, particularly considering that asylum applications also come from legal migrants, secondary movement, and air passengers (who are not part of the IBC dataset).
2.3 Selection of covariates
Choosing the optimal set of covariates is crucial for maximising a model’s predictive capacity. Including too few informative covariates can reduce the explanatory power, while incorporating too many can lead to overfitting, with the model learning not just the underlying pattern in the data but also the noise or random fluctuations. It happens especially by applying machine learning techniques such as Artificial Neural Networks (ANNs). In statistical modelling, selecting the best-performing covariates within a chosen modelling framework is a widely accepted practice (Murtaugh, Reference Murtaugh2009). To identify the most suitable combination of independent variables for predicting IBCs and Asylum applications, two different approaches were applied to the full set of covariates.
Although the initial number of variables we considered is rather small, it becomes larger since we disaggregated each one by country of origin and by different time lags. This led to around 100 covariates. Given the large number of covariates compared to the relatively limited number of observations in the dataset (169 monthly data both for IBCs and asylum applications), we employed an unsupervised technique based on distance correlation (Székely et al., Reference Székely, Rizzo and Bakirov2007) to remove redundant variables and avoid multicollinearity, which can lead to model specification issues. This approach aimed also to mitigate overfitting and significantly diminish the possibility of spurious correlations arising by chance. We applied distance correlation to identify a subset of covariates that exhibit low inter-correlation. This approach’s aim was to cherry-pick a group of up to 20 covariates, primarily uncorrelated with one another. To accomplish this, we employed the dist_corr function from the Mastrave modelling library (de Rigo, Reference de Rigo2012a) within the GNU Octave computing environment (Eaton et al., Reference Eaton, Bateman, Hauberg and Wehbring2019).
To identify the more suitable set of covariates for forecasting asylum applications in Italy and irregular border crossings along the Central Mediterranean route, we conducted a sensitivity analysis employing two different methods. In most cases, a jackknife approach (Tukey, Reference Tukey1958; Bosco et al., Reference Bosco, Watson, Game, Brooks, de Rigo, Qader, Greenhalgh, Nilsen, Ninneman, Wood and Bengtsson2019) was applied. Throughout this selection process, the entire set of factors is evaluated, and, at each step, the least impactful covariate is iteratively removed, enhancing the model’s performance. Jackknife techniques help prevent overfitting, maximising the potential for explanation. At the end of the covariate selection process, we used the metrics (RMSE) resulting from the last iteration of the jackknife approach to evaluate the most important variables (leave-one-covariate out, LOCO).
In applying the Random Forest technique for predicting IBCs on the Central Mediterranean route, we decided to apply a different methodology for conducting the sensitivity analysis. We discovered that the Permutation Feature Importance (PFI) was better performing than the aforementioned jackknife approach. The PFI is very similar to the LOCO in that both strategies rely on evaluating the effect of altering one variable at a time on the loss in the model explanatory power. The main difference is that PFI is more parsimonious in terms of computation resources since it requires no re-training of the model. On the contrary, it is based on the permutation (i.e., random shuffle with reintroduction) of each single variable at a time and evaluates the loss in model performance compared to the original dataset.
Feature importance measures like PFI and LOCO can be strongly misleading when features of a given data set are correlated. In the case of PFI, when features are collinear, shuffling creates uncommon or even impossible values (e.g., “a 2-meter tall 2-year-old child”). This is why we run PFI and jackknife only after a first round of variable selection using distance correlation, making sure no major autocorrelation is present in the remaining predictors by evaluating the variance inflation factor (VIF) of the remaining features (further information on this is available in the supplementary material).
2.4 Modelling architecture
In this study, we exploit machine-learning methods to produce forecasts, up to 6 months in the future, of IBCs and first-time asylum applications. The machine learning approaches we used are Artificial Neural Networks (ANNs), Gradient Boosted Decision Trees (GBDT), and Random Forest (RF).
All these ML techniques require the input data to be in matrix format. Therefore, to take into account how the past values of the covariates (i.e., lagged predictors) might influence the current values of our response variable(s), we had to transform them using a method called time delay embedding (Takens, Reference Takens, Rand and Young1981). In practice, from each variable vector, we built a matrix where each column is the representation of the original indicator with the time index shifted from t-1 to t-L. Table 1 shows an example of time delay embedding for a generic vector X of size Nx1 turned into a matrix of size NxL, where N is the number of observations and L represents the time lags from 1 to 6 months.
Table 1. Time delay embedding example for vector X of size Nx1 into a matrix of size NxL, where L is set to 6

The structure of our modelling approach heavily relies on the Semantic Array Programming paradigm (SemAP) as outlined in previous works (de Rigo, Reference de Rigo, Seppelt, Voinov, Lange and Bankamp2012b, Reference de Rigo2015; de Rigo et al., Reference de Rigo, Rodriguez-Aseretto, Bosco, Di Leo, San-Miguel-Ayanz, Hřebíček, Schimak, Kubásek and Rizzoli2013; Bosco et al., Reference Bosco, De Rigo, Dijkstra, Sander and Wasowski2013, Reference Bosco, Alegana, Bird, Pezzulo, Bengtsson, Sorichetta, Steele, Hornby, Ruktanonchai, Ruktanonchai, Wetter and Tatem2017, Reference Bosco, Watson, Game, Brooks, de Rigo, Qader, Greenhalgh, Nilsen, Ninneman, Wood and Bengtsson2019, Bosco and Sander, Reference Bosco and Sander2015). To address the complexity of modelling and the disparities among input data, parameters, and output, semantic checks were implemented on processed information. Additionally, key components of the model were modularised, aligning with the SemAP principles, which are largely supported by the Mastrave modelling library (de Rigo, Reference de Rigo, Seppelt, Voinov, Lange and Bankamp2012b, Reference de Rigo2015).
In the following sections, we provide a brief description of the three ML techniques we have used in this study (ANN, GBDT, and RF) and of the ensembling.
2.4.1 Artificial Neural networks
An Artificial Neural Network (ANN) is a data-transformation model generating outputs based on given input data. It is based on the structure of the human brain, learning and storing information within inter-neuron connection strengths, represented as synaptic weights (numerical parameters in their artificial form). A valuable theoretical finding pertains to a specific group of ANNs, namely feed-forward multilayer perceptron (McCulloch and Pitts, Reference McCulloch and Pitts1943). These ANNs possess the property of universal approximation, signifying that a well-constructed and trained ANN in this family is virtually able to reproduce any relationship between input covariates and the quantity to be modelled (Hornik et al., Reference Hornik, Stinchcombe and White1989; Kreinovich, Reference Kreinovich1991). Here we applied a feed-forward multilayer perceptron implemented in MATLAB language in GNU Octave. This model was created by exploiting the Neural network Package (Schmid, Reference Schmid2009) available in GNU Octave. To further increase model performance, a simplified version of the Selective Improvement by Evolutionary Variance Extinction (SIEVE) (de Rigo et al., Reference de Rigo, Castelletti, Rizzoli, Soncini-Sessa and Weber2005) was applied to the ANN.
2.4.2 Random Forest
Random Forest (RF) (Breiman, Reference Breiman2001) is a supervised machine learning technique based on an ensemble of independent decision trees and is designed to capture high non-linearities (if any) between a dependent variable and the covariates. In this study, we used the implementation of RF from the GNU R package “randomForest” (Liaw and Wiener, Reference Liaw and Wiener2002).
While using PFI for selecting the best predictors in the case of IBCs (see Section 2.3), we also performed hyperparameter tuning to select a set of optimal hyperparameters for the learning algorithm. As reported in Figure 1, for RF these are the number of trees to grow (ntree), the number of variables randomly sampled as candidates at each split (mtry), and the size of the sample to draw (sampsize). The number of trees was not set too high to prevent overfitting and to limit the interference of collinearity, which might still be present even after the prior variable selection is made with the distance correlation.
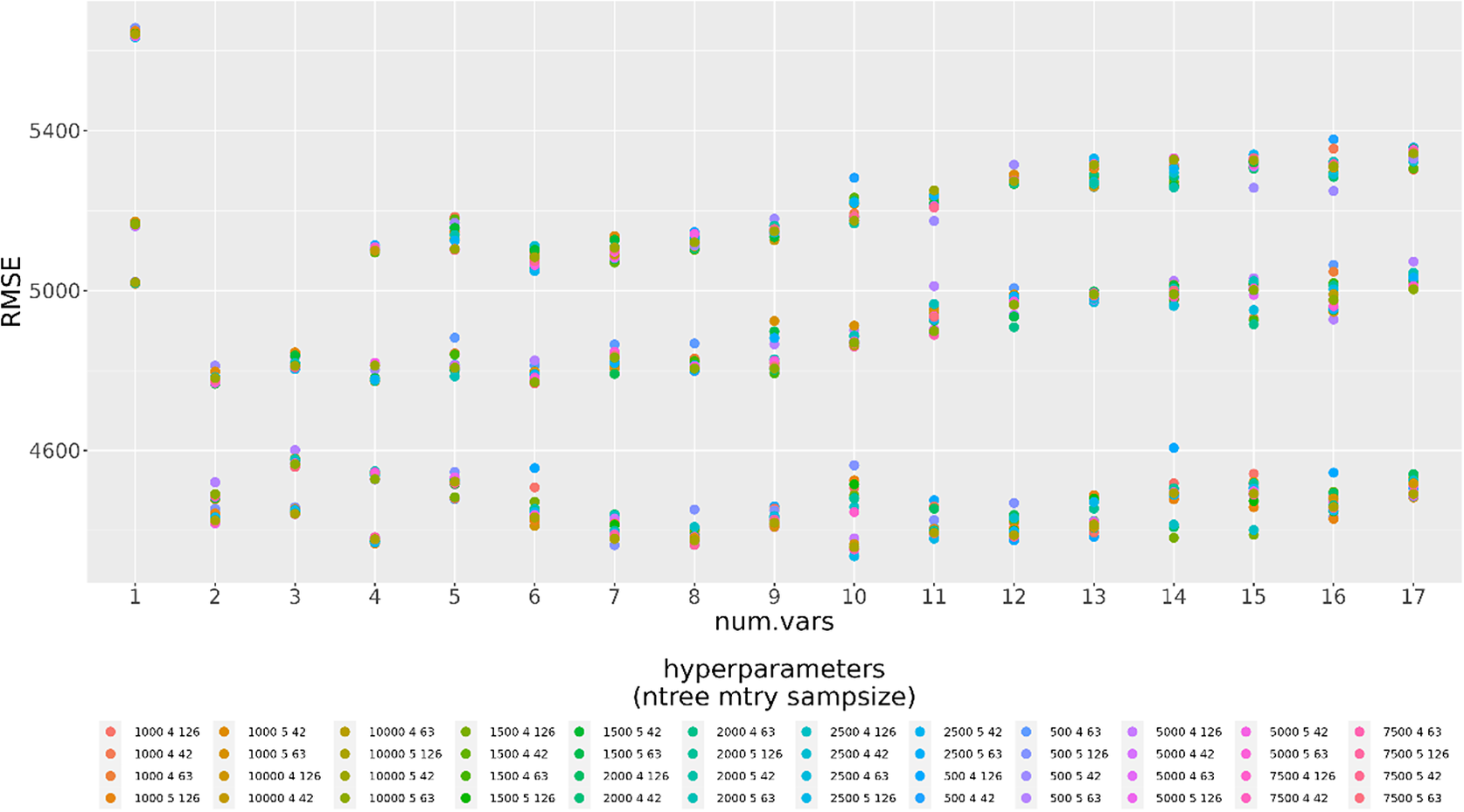
Figure 1. Plot showing the RMSE obtained with Random Forest using 1) a different number of variables (num.vars) ranging from 1 to 17 and 2) forty-eight different sets of optimal hyperparameters for the learning algorithm (ntree: number of trees to grow; mtry: number of variables randomly sampled as candidates at each split; sampsize: size of sample to draw).
Finally, we selected the combination of features and hyperparameters that scored the lowest RMSE on the OOB sample (see Figure 1) and we used these to build the final model.
For the prediction of asylum applications with RF, we used the same variable selection strategy highlighted for the other models (see Section 2.3), and we performed hyperparameter tuning with grid search (Bergstra et al., Reference Bergstra, Bardenet, Bengio and Kégl2011).
2.4.3 Extreme Gradient Boosting
Gradient Boosted Decision Trees (GBDT, Friedman, Reference Friedman2001) are a supervised machine learning technique based on (weak) decision trees, like RF. However, unlike RF, where the trees are grown in parallel and are independent from each other (bagging), in GBDT, trees are sequential (boosting), and each new tree is dependent on the previous one since it uses its residuals to optimise the split. Within our study, we applied Extreme Gradient Boosting (XGBoost, Chen and Guestrin, Reference Chen and Guestrin2016). Extreme Gradient Boosting stands out in the realm of gradient boosting due to its remarkable speed and performance. At its core, XGBoost employs an ensemble learning technique, specifically a boosting algorithm, to create a powerful predictive model. We used the implementation of XGBoost in R available in the “xgboost” package.Footnote 13
2.4.4 Ensembling
To improve the model prediction capacity, we proposed a robust ensemble approach to combine the results from the three ML models described in the previous sections. To exploit the strengths of all the different modelling techniques and training strategies we applied, we employed an ensemble technique based on stacked generalisation (Wolpert, Reference Wolpert1992). Stacking involves training a learning algorithm to integrate predictions from multiple other learning algorithms. Figure 2 summarises the overall modelling architecture.
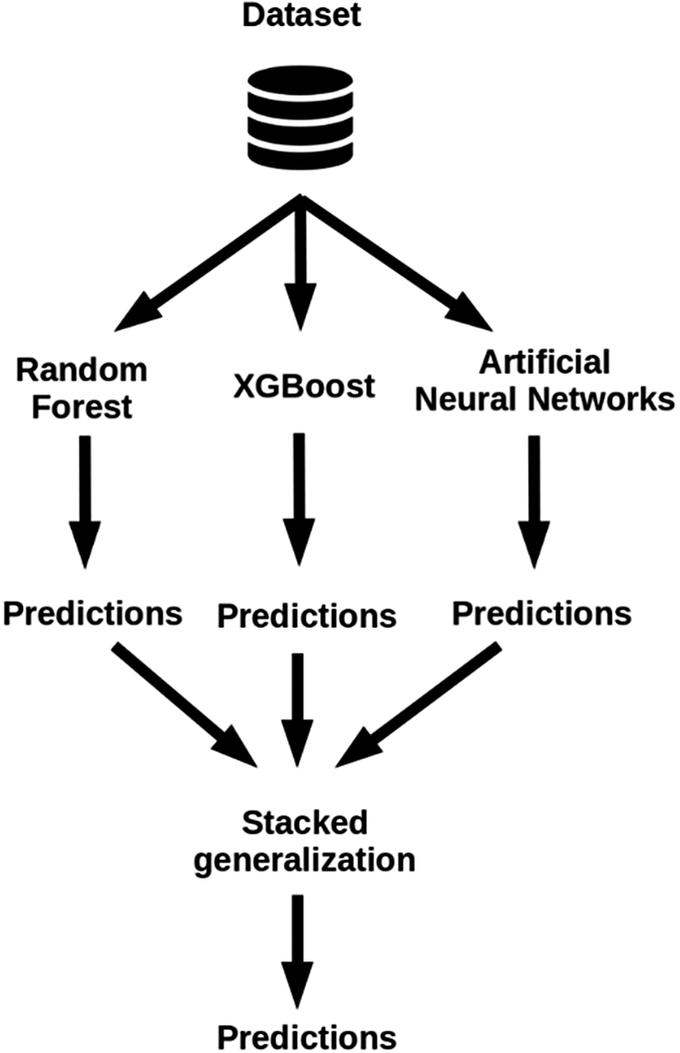
Figure 2. The flowchart reports the modelling architecture applied to forecast asylum applications in Italy and IBCs along the Central Mediterranean Route.
In summary, this ensemble approach constitutes a reproducible data transformation model (D-TM) applied to the outputs of the three models using a feed-forward artificial neural network based on the Levenberg-Marquardt algorithm (Moré, Reference Moré2006) for combining them. This method proves to be especially beneficial in poor data conditions, as it helps alleviate inaccuracies in local model performance by mitigating outlier predictions.
To further enhance the ensemble training’s performance, we used again the simplified version of the SIEVE methodology in the ANN. The output of this ensemble architecture consists of the best 100 networks surviving at the SIEVE method. The final result of this ensemble (our forecast) is represented by the median of the modelling outputs and the uncertainty by the interquartile range (IQR, see e.g., Barlow, Reference Barlow1993).
2.5 Models performance and validation
To maximise model performance, we split the data into training and validation (employing a 75-25 ratio). Because of the peculiar characteristics of the migratory phenomenon, with migration dynamics changing over time, the training and validation datasets should cover the same temporal interval in order to consider all the possible changes affecting migration (e.g., different nationalities of migrants in different time intervals). The dataset was divided into groups of 4 months, and in each of these groups, 75% of the data was randomly selected for training, and the remaining 25% was assigned to the validation set of data (more details can be found in the “Data Partitioning” section of the supplementary material).
Through repeated random sub-sampling cross-validation applied to the data set for model training, we identified the optimal model parameters for each of the architectures (tuning). To assess the model’s accuracy, which reflects the relationship between predicted and observed values, we computed both the root mean square error (RMSE) and the mean absolute error (MAE). While some experts recommend solely relying on MAE for comparing average model performance (Willmott and Matsuura, Reference Willmott and Matsuura2005), we opted to include RMSE in our evaluation due to its sensitivity in detecting occasional large predictive errors (Chai and Draxler, Reference Chai and Draxler2014).
We used the validation set to evaluate the performance of each model by calculating the MAE, RMSE, and the explained variance (expressed in proportional terms). The explained variance was obtained using the approach detailed by Bosco et al. (Reference Bosco, Alegana, Bird, Pezzulo, Bengtsson, Sorichetta, Steele, Hornby, Ruktanonchai, Ruktanonchai, Wetter and Tatem2017).
3. Results
The following sections document the performance of the modelling architecture we applied both in predicting asylum applications in Italy and irregular border crossings along the Central Mediterranean route. The performance is also compared to that of a trivial model that we used as a benchmark (the definition of the trivial model can be found in the supplementary material). Summary tables and example graphs are presented, with further results provided in the electronic supplementary material. The results highlight that relatively accurate predictions can be produced both for asylum applications in Italy and for IBCs over the Central Mediterranean Route.
All the applied machine learning techniques were able to extract the information present within the available covariates to predict the target variables over six months in the future. The most important covariates turned out to be the 6-month lagged values of the predicted indicator, the food price index, and food price inflation and, for asylum applications only, the six-month lagged IBCs value by route and nationality. For example, regarding asylum requests, the six-month lagged total number of asylum applications shows a correlation of 0.75, and the correlation of the six-month lagged IBCs related to migrants from Egypt and Nigeria is in the range of 0.44−0.53. Also, the lagged food price index of many different countries presents a good correlation with asylum applications (from 0.2 to 0.42).
However, for IBCs, we did not find such a high correlation between the dependent variable and available covariates. For example, the six-month lagged total number of IBCs shows a correlation of 0.35 only with IBCs, and the food price index and inflation food price do not overpass0.39 (for Syria) and 0.3 (for Cameroon and Tunisia), respectively.
3.1 Asylum applications
Table 2 shows the performance for all the applied models, with consistently high levels of explained variance—all with a proportion over 0.8 in validation—and generally low values of MAE, with the ensemble showing the best performance. Figure 3 shows the results for the modelling ensemble in validation. The model generally shows a good prediction capacity along the whole-time interval considered.
Table 2. Modelling results related to all the different models we applied to predict first-time asylum application in Italy. MAE and explained variance in training and validation were calculated for all the models we applied and compared with the same metrics calculated for a trivial model. Further information is available in the electronic supplementary material

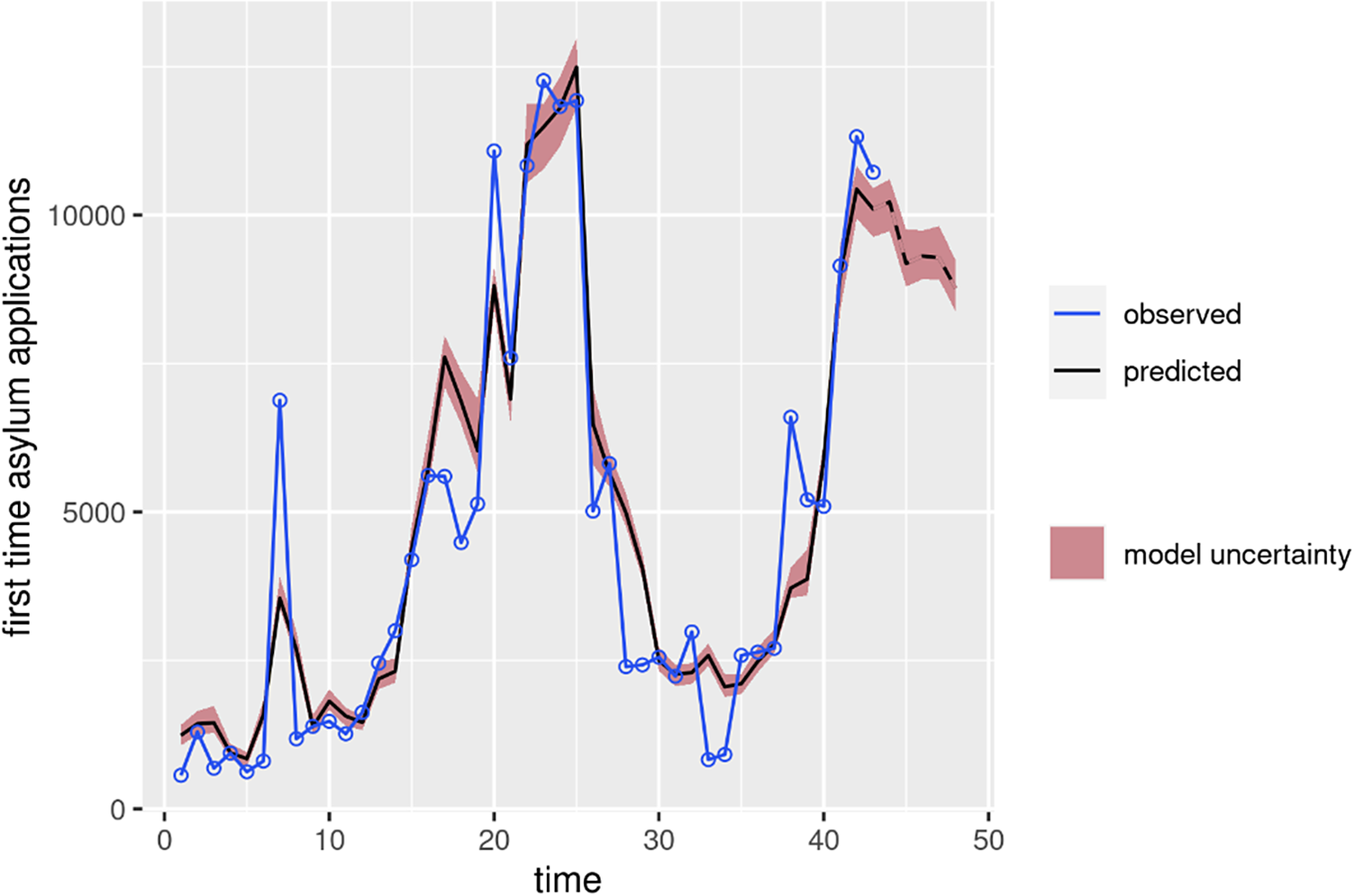
Figure 3. Results of the modelling ensemble to predict asylum applications in Italy (validation set of data). In blue are the observed values and in black are the modelling predictions. The dashed black line on the right represents the predictions beyond the last available observation (August to December 2023). In red is the model uncertainty.
Figure 4 shows the feature importance plot derived from the Random Forest model used to forecast asylum applications in Italy. This helps understand which are the most important variables in predicting the outcome. The unit of measure represents the loss in explained variance when permuting one variable at a time. In other words, it measures the impact on the model performance when a predictor gets shuffled (or is missing in the case of LOCO). Among the selected predictors, the historical values of asylum applications in Italy seem to be the most important one, with a loss of explained variance of 0.25. ANN and GBDT gave very similar results in terms of the importance of the covariates. We don’t show the feature importance plot for the final ensemble, as it would not make sense in terms of interpretability, since its input features are not the original selected covariates but the predictions from the three ensembled models (see Figure 2).
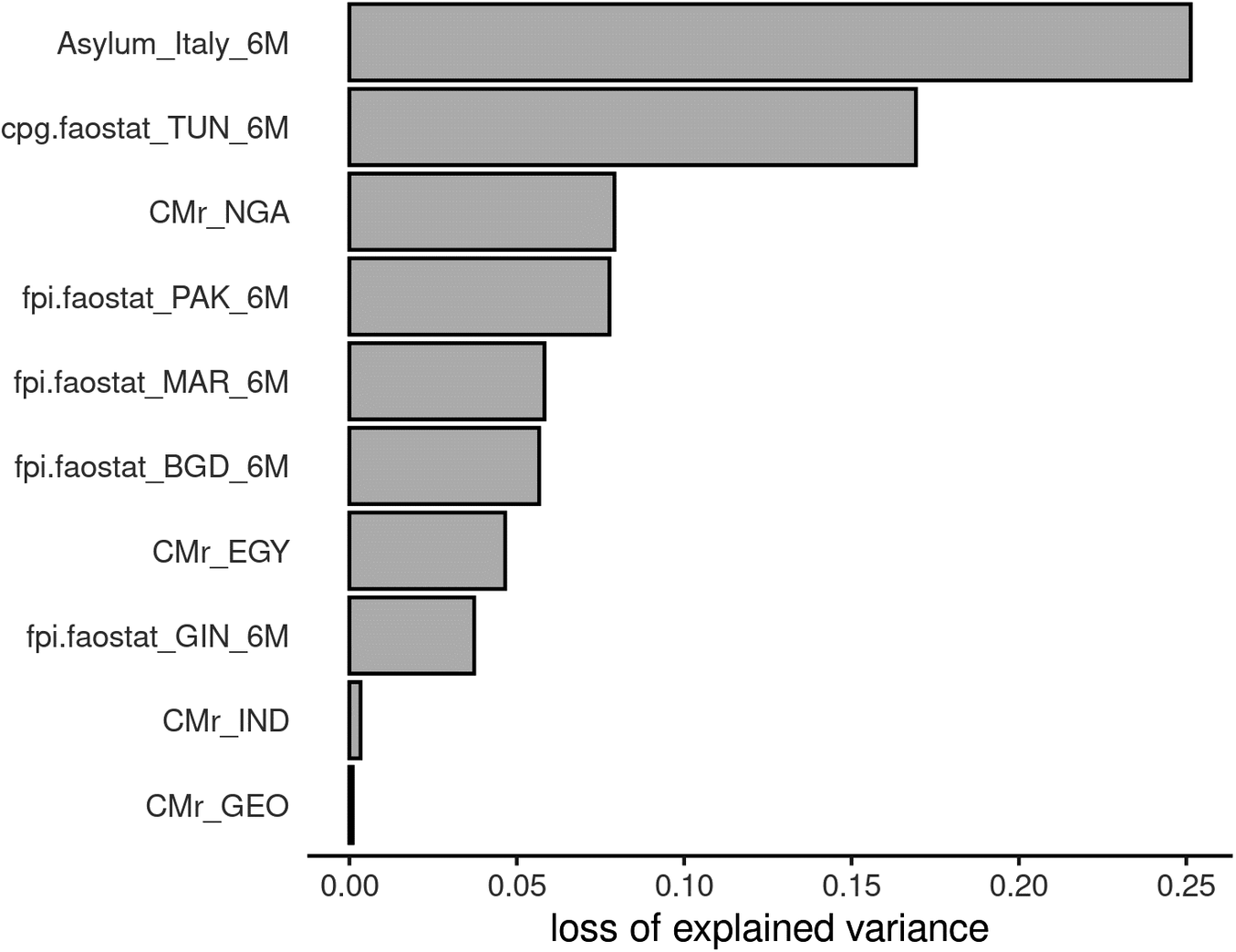
Figure 4. Feature Importance plot for the estimate of first-time asylum applications in Italy, related to the application of the Random Forest model (similar results were obtained for ANN and GBDT models). cpg.faostat: Consumer Price Index general by FAOSTAT. fpi.faostat: Food Price Index by FAOSTAT. 6M: 6-months lag. Suffixes are ISO 3 country codes.
3.2 Irregular Border Crossings
For the IBCs forecasting over the Central Mediterranean Route, the statistics produced for all the models are entailed in Table 3. The models present generally high levels of explained variance, all with a proportion over 0.74 in validation, with the ensemble showing again the best performance. Figure 5 shows the results for the modelling ensemble in validation. The model generally has a good prediction capacity during the whole period considered. A slightly higher uncertainty characterises the last months. The reasons behind this increased modelling uncertainty will be discussed in section 4.
Table 3. Modelling results in predicting Irregular Border Crossings along the Central Mediterranean Migratory Route. MAE and explained variance in training and validation were calculated for all the applied models and compared with the same metrics calculated for a trivial model. Further information is available in the electronic supplementary material

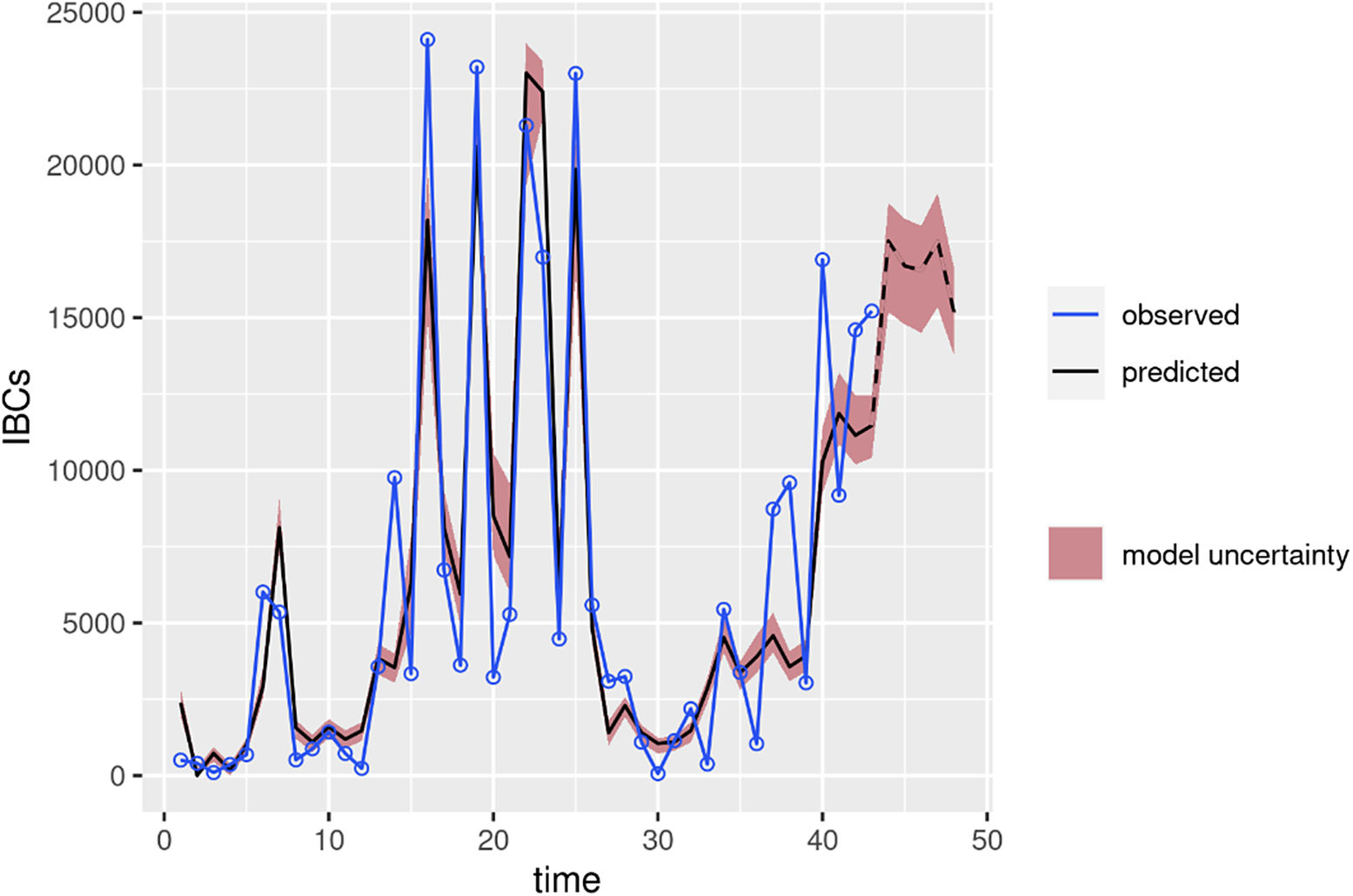
Figure 5. Results of the modelling ensemble to predict IBCs over the Central Mediterranean Route (validation set of data). In blue are the observed values, and in black are the predictions of the model. The dashed black line on the right represents the predictions beyond the last available observation (August to December 2023). In red is the model uncertainty.
The feature importance plot for irregular border crossings through the Central Mediterranean Migratory Route obtained for the RF algorithm is displayed in Figure 6. In general, we can clearly see that compared with the variable importance of asylum applications (Figure 4), the scores are lower, meaning that all predictors seem to provide a similar contribution to the final model. As in the case of asylum applications, the feature importance for ANN and GBDT is not shown since they were very similar to the one for RF.
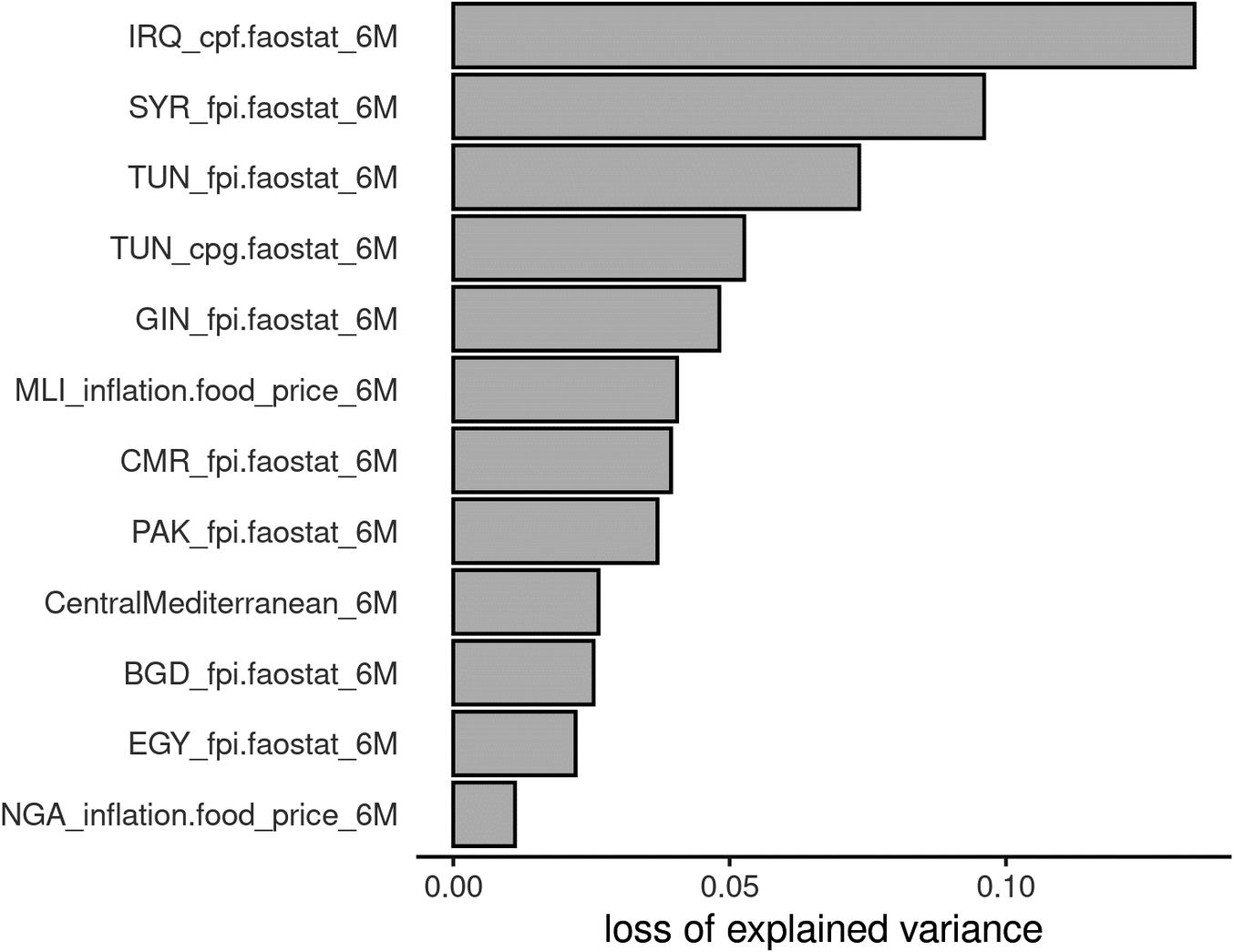
Figure 6. Example of a Feature Importance plot for the estimate of IBCs. It was obtained by applying PFI for the RF model (similar results were obtained for the ANN and GBDT models). cpg.faostat: Consumer Price Index general by FAOSTAT. fpi.faostat: Food Price Index by FAOSTAT. cpf.faostat: the FAOSTAT monthly Food Consumer Price Index. inflation.food_price: Monthly food price inflation estimates for fragile countries by Worldbank. 6M: 6-months lag. Prefixes are ISO 3 country codes.
4. Discussion
Because of the escalation of global displacement, with more than 100 million people forced to move from their homes for various factors (see Section 1), both irregular migration and asylum-seeking have gained prominence on the political agenda. Effectively addressing challenges tied to diverse migration streams necessitates governments’ preparedness for future flows. Yet, due to context-specific and limited data availability, forecasts remain a challenge.
This study adopts an approach that integrates data on occurrences, the dataset on socio-economic drivers in origin countries, instances of irregular border crossings along the Central Mediterranean Migratory Route, and asylum requests in Italy.
The datasets underwent analysis by a machine learning architecture, generating forecasts of migration flows up to six months in the future. These forecasts show the potential of the methodology but also reveal challenges in constructing consistently accurate predictions over time.
One of the challenges was the case of Tunisia, which faced very dynamic political changes in the first half of 2023. Already since the last quarter of 2022, Tunisia has replaced Libya as the main country of departures towards Italy. Although there was a decrease in May, associated with an increase in police raids in Sfax and other Tunisian towns along the coast that have been known to be heavily involved in smuggling activity, in July the arrivals achieved new highsFootnote 14.. This happened after a major political development in the form of the EU-Tunisia agreement (‘migration deal’) that was supposed to help curb the flows from Tunisia to the EU. Our models had some difficulties in predicting these waves of irregular border crossings because none of the predictors we exploited could explain the political reasons behind these events. The high uncertainty characterizing our results from April 2023 onwards is due to the difficulties of our models in predicting these unexpected fluctuations.
Another instance where our model struggles to make good predictions is the start of the Arab Spring. In 2011, anti-government protests, uprisings, and armed rebellions shook the Arab world, leading to a surge in irregular border crossings in the EU through the Central Mediterranean Route. This consisted of a shift of the regime of IBCs, during which the numbers went from a few hundred a month in 2010 to around 6000 in February 2011. The model was not able to predict the shock, most likely because the selected covariates did not have any signal of such abrupt change. After the first months of 2011, the model was then able to better understand the new emerging regime, and the following predictions got closer to the actual values.
The results presented here clearly highlight that producing regular forecasts for IBCs and asylum applications is a challenge. There are many obstacles, starting from forecasting unexpected environmental, security-related or political shocks, the lack of good quality input data and the difficulty in selecting and setting the most appropriate modelling architecture capable of exploiting short historical series of data. Despite that, both for IBCs and asylum prediction, the value of the proportion of variance explained by our ensemble modelling architecture was over 80%.
Several factors contribute to the variation in modelling performance. Primarily, this variation is driven by the amount of variability displayed by IBCs or asylum applications and by the extent to which they are associated with available covariates. When there is sparse or lacking information within these factors, it is no surprise that models struggle to accurately predict phenomena. Conversely, a stronger correlation yields more accurate predictions. For example, the correlation of the historical (six-month lagged) total number of asylum applications with asylum requests is 0.75 which decreases to a maximum of 0.53 (Egypt) when analysing the six-month lagged IBCs related to each considered nationality. For Irregular Border Crossings, we did not find such a high correlation with any of the available covariates (see Chapter 4).
Future work should, therefore, focus on a refinement of the methodology. This may, for example, include an additional set of covariates that could further improve the predictions, especially where the selected ones struggle to achieve good results or to pass to a mixed model where expert judgement could be used to feed the machine learning architecture.
Recent studies have included non-traditional datasets along with traditional ones to fortify the overall predictive capacity (Carammia et al., Reference Carammia, Iacus and Wilkin2022; Minora et al., Reference Minora, Bosco, Iacus, Grubanov-Boskovic, Sermi and Spyratos2022, Reference Minora, Iacus, Batista E Silva, Sermi and Spyratos2023; Boss et al., Reference Boss, Groeger, Heidland, Krueger and Zheng2023). The review of Bosco et al. (Reference Bosco, Grubanov-Boskovic, Iacus, Minora, Sermi and Spyratos2022) has shown that innovative data can offer great geographic and temporal granularity, a (near-) real-time availability, and extensive coverage suitable for more immediate international comparisons. For example, the Global Database of Events, Language, and Tone (GDELT) projectFootnote 15 has been used by the EUAA to build the Push Factor Index, a synthetic indicator related to the intensity of political events, social unrest, conflicts, economic events, and governance-related events (Melachrinos et al., Reference Melachrinos, Carammia and Wilkin2020). More recently, Carammia et al. (Reference Carammia, Iacus and Wilkin2022) included GDELT as a predictor for their machine learning model. Google TrendsFootnote 16 is another example of a non-traditional data source that was used along with other covariates to forecast future bilateral migration flows (Carammia et al., Reference Carammia, Iacus and Wilkin2022; Boss et al. Reference Boss, Groeger, Heidland, Krueger and Zheng2023). The European Media Monitor developed at the European Commission’s Joint Research Centre (JRC)Footnote 17 provides yet another source of rich and timely data reflecting the social developments globally. In addition, many socio-economic indicators, not captured by the suite of covariates we tested, and often available at aggregate levels such as administrative units, could be assessed in their ability to improve the accuracy of the models.
In this study, we focused on the total (aggregated) number of detections of IBCs and asylum applications. However, these data sources include disaggregated demographic information such as nationality, gender, and others. This information is often very valuable for policymakers and in our future research, we would investigate the feasibility of disaggregating our predictions by possibly producing a new set of covariates covering all the nationalities involved in the migratory flow.
To refine our methodology, we should also consider a different approach to the calculation of the modelling uncertainty. At present, the modelling uncertainty is only related to the modelling ensemble. All the ML techniques we applied are characterised by their uncertainty which is currently not considered within our ensembling methodology. Because the uncertainty of the ensemble is calculated using the outputs of the three ensembled models, and those models are rather close to each other in terms of predictions, the way we calculate the uncertainty makes the uncertainty range for the ensemble rather narrow. A further improvement could be to consider the uncertainty of each of the models while ensembling them.
Overall, our results demonstrate that short- and medium-term migration forecasting is a topic worth further exploration, particularly concerning improving its transparency, explainability, and accuracy.
5. Conclusions
In this paper, we have presented a modelling architecture designed to predict irregular border crossings along the Central Mediterranean Migratory Route and first-time asylum applications in Italy six months ahead. While we rely on publicly available data for our models, our overall approach can be classified as a non-traditional exploration-based method, as outlined in the taxonomy presented recently by the Big Data 4 Migration AllianceFootnote 18 (Marcucci and Verhulst, Reference Marcucci and Verhulst2023). This is due to the use of a state-of-the-art modelling architecture primarily based on machine learning techniques. The results indicate that our predictions are sufficiently accurate to be shared with policy- and decision-makers to plan and allocate resources. Their accuracy and temporal resolution (up to six months ahead) make them particularly valuable for planning purposes. Assessing future migration flows is crucial as unmanaged migration scenarios pose humanitarian, political, and social challenges for the mobile populations and in the receiving societies. Integrating forecasting into the policy cycle provides a robust tool for better governance of migration processes, enhancing preparedness, and addressing future challenges.
The novelty of our contribution lies mainly in the methodological approach we adopted to forecast migration flows: the use of the ensemble model combines the benefits of various Machine Learning techniques (ANN, GBDT, and RF) to further improve the performance of the predictions. Moreover, we try to explain the outcome of our models by highlighting which features were most important in producing the results and by providing the prediction intervals as a measure of uncertainty. This added value is key for policymakers who need to base their decisions on explainable evidence rather than on a black-box. Finally, the prediction intervals can also be as important as the central estimate in case the desired output needs to be in the form of a range of values (min-max).
The methodology presented here offers a robust approach to predict migrations, thereby improving policy measures. It is relevant on various policy levels: regional, to assess and adjust local capacity, and national, to allocate the funding to enhance preparedness. Finally, at the European level, to offer a robust basis for the DGs responsible for migration management and for negotiations between Member States on how to allocate responsibility for the foreseen migrations, for example, within the Voluntary Solidarity Mechanism for the relocation of asylum applicantsFootnote 19 and other relocation mechanisms envisaged in the New Pact on Migration and Asylum.Footnote 20
While we are aware of the inherent uncertainty tied to any anticipation effort (Bijak and Czaika, Reference Bijak and Czaika2020), we advocate for pursuing available evidence and state-of-the-art forecasting tools that offer the most robust basis for the preparation of policy measures to address future challenges. The modelling architecture presented in this paper offers exactly that and is one of the tools to implement to better integrate robust forecasting in the migration management policy cycle.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/dap.2024.48.
Data availability statement
The datasets necessary to support the findings of this article are available in the supplementary material.
Author contributions
C.B. drafted the manuscript. C.B. was responsible for the study design, analysis, and interpretation. M.T., U.M., and A.R. undertook data collection, assembly, and analyses and produced the datasets. C.B., U.M., and M.T. performed their technical validation. C.B. and U.M. developed the modelling architecture and developed the code for running the models. M.B. and A.R. followed the policy implications of the study. All the authors contributed to the interpretation and production of the final manuscript. All authors read and approved the final version of the manuscript.
Funding statement
None
Competing interest
None












 Open access
Open access
Comments
No Comments have been published for this article.